
Abstract
Malicious image tampering has gradually become another way to threaten social stability and personal safety. Timely detection and precise positioning can help reduce the occurrence of risks and improve the overall safety of society. Due to the limitations of highly targeted dataset training and low-level feature extraction efficiency, the generalization and actual performance of the recent tampered detection technology have not yet reached expectations. In this study, we propose a tampered image detection method based on RDS-YOLOv5 feature enhancement transformation. Firstly, a multi-channel feature enhancement fusion algorithm is proposed to enhance the tampering traces in tampered images. Then, an improved deep learning model named RDS-YOLOv5 is proposed for the recognition of tampered images, and a nonlinear loss metric of aspect ratio was introduced into the original SIOU loss function to better optimize the training process of the model. Finally, RDS-YOLOv5 is trained by combining the features of the original image and the enhancement image to improve the robustness of the detection model. A total of 6187 images containing three forms of tampering: splice, remove, and copy-move were used to comprehensively evaluate the proposed algorithm. In ablation test, compared with the original YOLOv5 model, RDS-YOLOv5 achieved a performance improvement of 6.46%, 5.13%, and 3.15% on F1-Score, mAP50 and mAP95, respectively. In comparative experiments, using SRIOU as the loss function significantly improved the model’s ability to search for the real tampered regions by 2.54%. And the RDS-YOLOv5 model trained by the fusion dataset further improved the comprehensive detection performance by about 1%.
Similar content being viewed by others

Introduction
As one of the important ways for human beings to perceive and understand the world, images have gradually been integrated into all aspects of our daily life. With the vigorous development of science and technology as well as people’s growing material and spiritual needs, a variety of image “beauty” software has also been favored by more and more people. People can easily and conveniently make various custom edits and modifications to the image to achieve their purpose and needs, but it also creates a lot of problems and troubles. The falsification of identity photo information, the tampering of receipt type images, and the malicious smearing and exaggerated rendering of real images have gradually become new means to endanger social security. Therefore, rapid and effective detection and localization of tampering regions in images is of crucial significance for the security and stable development of society.
Currently, there are three main types of image tampering forms: copy-move, remove, and splice. Generally speaking, these three operations will leave more or less traces of digital processing on the original image, which can be used as an effective basis for discrimination. However, for some exquisitely retouched images, due to the addition of image filtering, smoothing, light adjustment and other subsequent processing, it is difficult for ordinary people to distinguish such images, and even for professionals, it is often difficult to see through at a glance. This has prompted relevant scholars to try to use artificial intelligence technology to capture the traces of image tampering. Muhammad Hussain et al. proposed a multi-resolution Weber law descriptor based on the tampering detection method of copy-move images, which tries to extract features from the chromaticity components of the image to capture the relative information of different neighborhoods in the image, and then uses the support vector machine to classify it to obtain the final discriminant result1. Jiachen Yang et al. proposed a multi-scale self-texture attention generation network, which simulated the forgery process based on image generation from the perspective of image generation, and traced potential forgery traces and texture features. Finally, based on the loss function of the classification probability constraint, the generation and monitoring process of forgery traces can be directly corrected2. Shilpa Dua et al. proposed an image forgery detection technology based on image artifact coding analysis, which divides the JPEG compressed image into several non-overlapping blocks, and then performs an independent discrete cosine transformation on each block, generates the corresponding feature vectors through the evaluation and counting of the transformation coefficients, and then uses the support vector machine to realize the image discrimination3. Rani Susan Oommen et al. proposed a hybrid method based on Local Shape Dimension (LFD) and Singular Value Decomposition (SVD) to effectively detect and locate duplicate forgery regions in images. Firstly, the image is divided into fixed-size fast, the shape dimension of the local part is estimated, and then the image blocks are arranged into a B + tree based on the LFD value, and the image blocks in each fragment are compared with the singular value, so as to narrow the comparison range, effectively reduce the complexity of calculation and quickly screen the duplicate parts in the image4. Other tampering detection methods using wavelet transform, DCT features, and variant neural networks have also achieved certain results in their respective screening tasks5,6,7,8,9,10,11,12. However, most of the proposed methods are for specific types of images and data, and the relevant deep learning models are also inefficient at extracting features from the input original tampering images.
In this study, we first designed an image preprocessing algorithm based on multi-channel feature enhancement fusion for tampering images, which was used to enhance the features of the tampered regions in the tampered image, and amplify the tampering details in the tampered images from multiple perspectives such as light, texture, and transformation domain, so as to improve the feature extraction efficiency of the subsequent model. Then, we proposed an improved YOLOv5 model, which introduces the residual structure, the multi-branch dynamic kernel selection channel attention mechanism and the SPD convolution module on the basis of the original network structure, and optimizes the loss function of the model to further improve the fitting ability of the model. Finally, we combined the preprocessed enhanced image with the original tampered image for weight fusion as input to the improved model to achieve higher detection performance.
Methodology
Multi-channel feature enhancement fusion algorithm
For tampered images, although some images have obvious traces of modification, it is often difficult for the naked eye to detect the tampering parts of the retouched images. We all know that feature extraction is relatively abstract for deep learning models, but more significant features often mean faster fitting efficiency and stronger evaluation performance. Therefore, this paper chooses to perform multi-dimensional feature enhancement processing on the original tampered images, including simplified SRM filtering, edge detection, color gamut enhancement transformation, and frequency domain enhancement transformation, to capture the subtle traces left in the modification process. Then, the enhanced images of each dimension are fused in the form of channel combination to provide more significant input features for the subsequent deep learning model.
Simplified SRM filtering
The conventional SRM filter uses noise convolution to amplify the unique traces of the image in the noise space, so as to realize the mining and extraction of relevant features13. This module is often introduced into deep learning models as a precursor convolutional layer14. In this paper, the principle of the SRM filter is simplified, and the structure is modified so that it can be used independently of the model. The three filter weight matrices selected in this paper are shown in Fig. 1, and compared with the original SRM filter, the weight matrix in the middle position is adjusted to improve the noise distribution difference in different regions of the image and strengthen the contour characteristics of the noise image. Here, we perform a two-dimensional array convolution operation on the tampered image separately with three weight matrices, and reduce the dimensionality of the operation results to obtain the final simplified SRM filtered image through channel concatenation, as shown in Eq. 1.
Where \(\:{T}_{3\to\:1}\) represents compressing a three channel image into a single channel image, \(\:convolve2d\) represents two-dimensional array convolution operation, and \(\:Merge\) represents channel concatenation.

Weight matrices of simplified SRM filter.
Edge detection
In various modification operations of the image, the edges of the modified part often have more significant differences compared to the original image. For this reason, we use the Sober operator15 to perform edge detection in the horizontal and vertical directions of the tampered image, and then perform variable weight fusion on the results, as shown in Eq. 2 and Eq. 3. Among them, Eq. 3 introduces the idea of variable parameters into the original weighted fusion strategy, and assigns differentiated weights to the detection results in the horizontal and vertical directions according to the features of the tampered image, so as to obtain more significant edge detection results.
Where \(\:\vartheta\:\) is the variation factor, \(\:{W}_{x}\) and \(\:{W}_{y}\) are weight coefficients.
Color gamut enhancement transformations
Compared with RGB color space, HSV color space achieves a visual effect that is closer to human color perception by encapsulating color information16. Therefore, we chose to perform an enhancement transformation on the image in the HSV space to further explore the possible modification traces in the tampered image. The improved dual channel CLAHE algorithm17 is chosen as the enhancement method, that is, only the saturation and brightness channels in the HSV space are enhanced, and the original hue channels are retained, and then the three channels are merged to obtain the final color gamut enhancement transformation image, as shown in Eq. 4.
Where \(\:clipLimit\) represents the threshold of contrast, and \(\:tileGridSize\) represents the size of the image block.
Frequency domain enhancement transformations
Fourier transform has a wide range of applications in the fields of image filtering, compression, encoding, enhancement and restoration18. It mainly extracts and adjusts the frequency components of frequency domain images to achieve fine-tuning of spatial domain images. This article fine tunes the Fourier transform function based on the features of the tampered images, as shown in Eq. 5.
Where \(\:\mu\:\) represents the fine-tuning coefficient, and \(\:{channel}_{m}\) represents the channel for transformation.
Channel combinations
The enhanced images obtained by the above four methods are grayscale processed separately to realize the normalization of the channels. Then, the five enhanced single-channel images are divided into multiple sets of 3 + 2 in the way of permutation and combination. In each set, 3 single-channel images are fused first, and then with the other 2 single-channel images through dimensionality reduction. Finally, a comprehensive evaluation of the fusion effect of multiple sets (including texture, contrast, visual sensitivity, etc.) is conducted, and the best combination is selected as the final multi-channel fusion feature enhancement image, as shown in Eqs. 6–9.
Where \(\:ME\_Images\) represents the set of images obtained by the above four enhancement transformations, and \(\:{C}_{m}^{n}\) represents randomly selecting n elements from m elements.
Image forgery detection based on deep learning model
Framework of RDS-YOLOv5
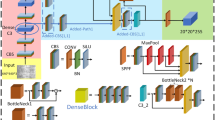
As the most classic one-stage model in the field of object detection, the YOLO series has undergone continuous improvement and innovation since it was proposed in 201519, and the YOLO5 object detection model born in 2020 has become a leader in the field of object detection20. YOLOv5 uses a lightweight network structure based on CSPDarknet53 to extract image features at different scales by stacking a series of convolutional layers and residual connections, resulting in faster speed, higher performance, smaller model size, and easier model training and deployment compared to other models. Based on the classical YOLO5 model, this paper makes a series of improvements, trying to introduce a multi-channel residual structure21on the basis of the lightweight (S-level) network to couple the feature maps of different layers, so as to improve the receptive field of the network through cross-layer, introduce a multi-branch dynamic kernel selection channel attention mechanism22to learn the weights of the feature map at different scales, balancing the learning weights between channels by selecting more suitable multi-branch features, and introduce SPD convolution23 to enhance the model’s attention to the spatial distribution of targets and better capture their subtle features, thereby improving the detection performance of the model for small objects and low-resolution images, so that it can obtain better detection results without increasing the training cost and network depth. We named the improved YOLOv5 model RDS-YOLOv5, as shown in Fig. 2.

Architecture of RDS-YOLOv5.
SRIOU loss function
IOU24is the most common loss function in the field of object detection, but in many complex scenarios, the basic IOU loss function cannot make the model achieve the best convergence effect, so it is necessary to consider the characteristics of the detection box in various scenarios to improve and optimize the loss function. Among the many improved loss functions, SIOU25 redefines the loss function through the integration of angle loss, distance loss and shape loss, which solves the problem that the traditional type of loss function has a slow convergence speed and does not consider the direction between the real box and the prediction box, making it more suitable for object detection tasks in complex scenarios. In this paper, on the basis of retaining the three loss metrics of SIOU, a nonlinear loss metric function of aspect ratio is added to further increase the difference of loss values between prediction boxes of different shapes and optimize the loss ratio between the prediction boxes and the real box with the same center point distance, thereby further improving the fitting ability of the model, as shown in Eq. 10.
Where \(\:(w,\:h)\) and \(\:{{(w}^{gt},\:\:h}^{gt})\) are the widths and heights of the prediction and real boxes, respectively, \(\:\theta\:\) is the scaling factor.
Then we combine it with the original loss function of SIOU to obtain an improved loss function, which we named SRIOU as shown in Eq. 11.
Where \(\:\alpha\:\) and \(\:\beta\:\) are weight coefficients, and \(\:2\text{*}\alpha\:+{\upbeta\:}=1\), \(\:\gamma\:\) is an exponential factor.
Fine-tuning the detection model based on image weighted fusion
To further improve the robustness of the tampered image detection model, we introduce the previously proposed multi-channel feature enhanced image to fine-tune the improved deep learning model. At the same time, in order to ensure that the trained model can still use the original tampered image as input, we proposed weighted fusion of the multi-channel feature enhancement transformed image and the original tampered image as the input to the model, as shown in Eq. 12.
Where \(\:\phi\:\) and \(\:\omega\:\) are weight coefficients, and \(\:\phi\:+\omega\:=1\).
Evaluation indices
The precision, recall, F1-Score, \(\:{mAP}_{50}\) and \(\:{mAP}_{50:5:95}\) were selected as the main evaluation indices for image tampering detection. Among them, precision is used to measure the proportion of tampered areas predicted by the model that are indeed tampered areas, reflecting the model’s ability to identify tampered areas. High precision means that the model can accurately identify the true tampered areas, reducing misjudgments. Recall is used to measure the proportion of areas correctly identified by the model among all truly tampered areas, reflecting the model’s ability to detect tampered areas. High recall means that the model can identify as many tampered areas as possible, avoiding missed detections. F1-Score combines the information of precision and recall, and is the harmonic mean of precision and recall. The higher the F1 Score, the better the model performs in terms of precision and recall, and the overall performance is better. \(\:{mAP}_{50}\) and \(\:{mAP}_{50:5:95}\) are the average precision values calculated at different thresholds. They are used to comprehensively evaluate the performance of the model under different detection difficulties. These two indices take into account the performance of the model at different categories and different confidence levels, providing a more comprehensive assessment. The formulas for the above five evaluation indices are shown in Eqs. 13–17.
Where \(\:K\) is the total number of classes, \(\:{AP}_{j}\) is the average precision of the j-th class, and \(\:{r}_{i}\) represents the recall value at the first interpolation of the precision interpolation segment.
Results and discussion
Data samples
Five groups of data samples were used as input to the deep learning model:
-
A)
A total of 564 high-quality, high-resolution samples from the NIST16 dataset26, including three tampering forms: splice, remove, and copy-move.
-
B)
A total of 100 pairs of medium-resolution samples from the Coverage dataset27, only including the tampering form of copy-move.
-
C)
A total of 220 high-quality, high-resolution samples from the Pawel korus-Realistic Tampering dataset28, including two tampering forms: splice and remove.
-
D)
A total of 5123 low-resolution samples from the CasiaV2.0 dataset29, including the tampering form of splice and copy-move.
-
E)
A total of 180 medium-resolution samples from the Columbia Uncompressed Image Splicing Detection dataset30, including the tampered form of splice.
All the samples in the five datasets were randomly divided into training sets, validation sets, and test sets at a ratio of 8:1:1.
Tampered image transformation based on multi-channel feature enhancement fusion
The multi-channel feature enhancement fusion algorithm proposed in this paper was used to perform multi-dimensional enhancement transformation on all images in the fusion dataset to obtain the feature enhancement transformation fusion dataset. The parameters of the proposed feature enhancement method were set empirically and are shown in Table 1. Some typical examples are shown in Fig. 3.

Multi-dimensional enhancement transformation result.
It can be seen that the tampered area in the transformed image has more significant differences in colour temperature and chromaticity compared with the normal area, the noise distribution has also changed, and the tampered area also has a more obvious sense of boundary with the normal area in the contour. It shows that the image feature enhancement algorithm proposed in this paper can effectively amplify the tampering traces in the tampered images, increase the feature difference, and be more conducive to subsequent recognition and detection.
Comparison with state-of-the-art models
Two general evaluation datasets (D, E) from the above five datasets were used to compare the results of the proposed algorithm with the existing advanced image tampering detection models, including C2RNet6, RRU-Net7, D-UNet8and Faster-RCNN + Edge detection9. The test results are shown in Table 2.
It can be seen from the comparative test results in Table 2, the evaluation results of the image tampering detection model proposed in this paper are significantly better than most of the existing advanced models on the two general datasets. Although the evaluation of Columbia dataset is slightly lower than D-UNet, this is mainly because all the data in Columbia dataset are tampering images of splice type, while D-UNet is mainly aimed at splice type and has poor generalization of other types of tampering images. Therefore, its effect on the CASIA2.0 dataset is not as good as that of the RDS-YOLOv5 model proposed in this paper. This indicates that the RDS-YOLOv5 model proposed in this paper not only has stronger tampering detection performance, but also has stronger generalization, which can be better applied to all kinds of tampering image detection tasks.
RDS-YOLOv5 ablation test
To verify the contribution of each improvement in the RDS-YOLOv5 model, we conducted ablation test. The above mixed dataset was used to train and evaluate the YOLOv5 model with various improved modules.

Changing indicator curves with increasing number of training epochs.

F1-Confidence Curves of the seven networks.

Comparison of the detection results derived using different networks.
As can be seen from the average results of 9-fold cross validation in Table 3, compared with the original YOLOv5 model, the introduction of various improvement modules can improve the performance of the model to varying degrees, among which the introduction of SPD convolution can effectively improve the model’s comprehensive screening ability of the forged region, the introduction of the residual module can effectively improve the model’s ability to correctly identify the forged region, and the introduction of the SK attention mechanism can effectively balance the constraints between the above two. Therefore, RDS-YOLOv5, which integrates the three mechanisms has achieved more considerable improvement in various indicators, and compared with the original YOLOv5 model, it has achieved 6.46%, 5.13% and 3.15% improvement on F1-Score, mAP50 and mAP95, respectively.
The average loss, precision, recall, \(\:{mAP}_{50}\) and \(\:{mAP}_{50:5:95}\) varying with the number of iteration epochs of the seven models are shown in Fig. 4. The loss curve of the training set shows a decreasing trend with the duration of training, while the loss curve of the validation set tends to stabilize at the end of training, proving that the models’ training has basically reached the optimal state. The peaks of the four evaluation curves show the same results as the data in Table 3, and the end of each curve is also close to stable, indicating that it has basically reached the optimal training node and there is no serious overfitting. Figure 5 shows the F1 confidence curve under different classification thresholds, and it can be seen that the RDS-YOLOv5 model proposed in this paper obtains the highest F1 score at the optimal threshold, and the curve representing the model was almost at the top of all curves at all thresholds, indicating that the model has the strongest discrimination accuracy.
Some typical examples of the detection results of the seven networks are shown in Fig. 6. It can be seen that compared with the original YOLOv5, the improved model with the introduction of each module has made different degrees of progress in the detection results. The RDS-YOLOv5 model, which combines all improved modules, not only effectively solves the false detection problem caused by the introduction of part of the modules, but also improves the model’s ability to detect small targets and further reduce the missed detection rate of the model. Therefore, the proposed RDS-YOLOv5 model further obtained results closer to the ground truth labels than the other compared networks for all kinds of tampered images.
SRIOU comparative test results
The proposed SRIOU loss function was compared with the existing classical loss functions (IOU, CIOU, EIOU31, SIOU, WIOU32). As can be seen from Table 4, compared with other types of classical loss functions, SIOU was significantly higher in precision, F1-Score, mAP50 and mAP95, indicating that the SIOU loss function with angle loss, distance loss and shape loss was more conducive to the convergence and fitting of the model in the image tampering detection task. Although the precision of the SRIOU proposed in this paper was slightly lower than that of SIOU, the recall, F1-Score, mAP50 and mAP95 were improved, indicating that the loss function with the introduction of aspect ratio nonlinear loss measure can further enhance the model’s ability to search for the forged regions. Although the precision is affected to a certain extent, the comprehensive performance is better improved.
Image forgery detection based on weighted fusion image
The original tampered image and the multi-channel feature enhancement image were fused with a weight of 9:1 as shown in Fig. 7. The large weight retains all the information in the original tampered image, while the small weight makes the fused image more specific in tampered features, thereby improving the detection sensitivity of the model to the tampered regions. The improved RDS-YOLOv5 was used to train and evaluate the fusion dataset, and the average results of 9-fold cross validation are shown in Table 5.

Typical examples of image fusion.
As can be seen from Fig. 7, the colour contrast of the tampered area in the fused image is sharper than that of the normal area, and the edge is also more prominent, indicating that the features of the tampered area have been significantly enhanced, which is more conducive to the detection of the model.
From Table 5, it can be seen that the improved RDS-YOLOv5 model trained with weighted fusion dataset further balanced the constraint relationship between recall and precision, and also showed further improvement in mAP50, and mAP95. This indicated that the fused image effectively enhanced the tampering features in the image, making the trained model had stronger tampering trace detection capabilities.

The curve of comprehensive loss with the number of training epochs.

The confusion matrices of the Mixed Dataset and the Fusion Dataset.

Comparison of the detection results derived using different datasets.
As can be seen from the loss curves in Fig. 8, the loss change trend of the model is basically the same when the two datasets are used for training. Although the final landing point of the two models is basically the same on the training set, the loss value near the endpoint of the model trained with the fusion dataset on the validation set is slightly lower than that of the model trained with the mixed dataset, indicating that the model trained with the fusion dataset enhanced by tampered features is more robust.
The confusion matrices of the mixed dataset and the fusion dataset trained using RDS-YOLOv5 are shown in Fig. 9. It can be seen that the model trained using the fusion dataset has further improved its detection ability for forged regions compared to the mixed dataset. The typical examples of the detection results in Fig. 10 also showed that compared with the mixed dataset, the model trained by the fusion dataset detected more forgery regions, and corrected some false detection regions. Although there were still some missed detections, the overall performance has been significantly improved.
Conclusion
Malicious image tampering often brings serious damage to social stability and personal value. Necessary detection and identification can not only effectively protect the legitimate rights and interests of the people, but also effectively maintain social fairness and justice. The existing image forgery detection methods are usually limited by specific data, and the extraction of tampered features is not sufficient, making it difficult to obtain satisfactory detection results. In this study, we propose an improved RDS-YOLOv5 network architecture, and realize the accurate identification and localization of the tampered region in the image by combining the features of the original image and the tampered region enhancement image.
Experimental results proved that: 1) The image feature enhancement algorithm can effectively amplify the tampering traces in the tampered image, increase the feature difference, and be more conducive to the identification and localization of the tampered area. 2) The RDS-YOLOv5 model, which integrates the residual structure, SPD convolution and SK attention mechanism, can effectively improve the detection ability of small targets in the image without increasing the training cost and network depth, reduce the false detection rate and missed detection rate of the model, thus obtain better detection results. 3) The loss function with the introduction of aspect ratio nonlinear loss measure can effectively improve the model's ability to search for the forged region, which is more conducive to the convergence and fitting of the model. 4) The fusion of the features of the original image and the tampered region enhancement image can further enhance the feature extraction ability of the model, optimize the discriminant criteria of the model, and effectively improve the robustness of the model.
Although the proposed method has certain advantages compared with the existing methods, and performs well on the five public datasets, there are still some shortcomings. Firstly, through the visual analysis of the detection results, it can be found that the model still has some missed judgments, and the detection results for images with relatively soft tampered target boundaries are poor. Secondly, due to the introduction of some noise factors into the input of the improved model, the detection results for tampered images that already contain a large amount of noise are also poor. Therefore, further research can be conducted from the following two aspects: 1) Multi-resolution batch training can be performed on the images in the dataset to further improve the robustness of the model. 2) The features of the multi-channel feature enhancement image can be extracted from more angles and the form of fusion can be optimized, so as to further improve the comprehensive feature extraction ability of the model from the input image.
Data availability
ALL the data that supports the findings of this study are available on the internet, and the relevant URL link has been placed in the supplementary file.
References
Hussain, M., Muhammad, G., Saleh, S. Q., Mirza, A. M. & Bebis, G. Copy-move image forgery detection using multi-resolution weber descriptors. Signal. Image Technol. Internet Based Syst. (SITIS). 395–401. https://doi.org/10.1109/SITIS.2012.64 (2012).
Yang, J. et al. Msta-net: Forgery detection by generating manipulation trace based on multi-scale self-texture attention. IEEE Trans. Circuits Syst. Video Technol. 32 (7), 4854–4866. https://doi.org/10.1109/tcsvt.2021.3133859 (2022).
Shilpa, D., Jyotsna, S. & Harish, P. Image forgery detection based on statistical features of block dct coefficients. Procedia Comput. Sci. 369–378. https://doi.org/10.1016/j.procs.2020.04.038 (2020).
Rani, O., Susan, Jayamohan, M. & Sruthy, S. Using fractal dimension and singular values for image forgery detection and localization. Procedia Technol. 24, 1452–1459. https://doi.org/10.1016/j.protcy.2016.05.176 (2016).
Gunjan, B. & Anand, J. S. Image forgery detection using feature based clustering in jpeg images. In: International Conference on Industrial and Information Systems (ICIIS), 1–5, (2014). https://doi.org/10.1109/iciinfs.2014.7036583
Xiao, B., Wei, Y., Bi, X., Li, W. & Ma, J. Image splicing forgery detection combining coarse to refined convolutional neural network and adaptive clustering. Inf. Sci. 511, 172–191. https://doi.org/10.1016/j.ins.2019.09.038 (2020).
Bi, X., Wei, Y., Xiao, B. & Li, W. RRU-Net: The ringed residual U-Net for image splicing forgery detection. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. Workshops (CVPRW). 30–39. https://doi.org/10.1109/CVPRW.2019.00010 (2019).
Liu, B. et al. D-UNet: A dual-encoder U-Net for image splicing forgery detection and localization. (2020). https://arxiv.org/pdf/2012.01821
Wei, X., Wu, Y., Dong, F., Zhang, J. & Sun, S. Developing an image manipulation detection algorithm based on edge detection and faster R-CNN. Symmetry. 11 (10), 1223. https://doi.org/10.3390/sym11101223 (2019).
Anastasia, N. K., Antonios, G., Nikolaos, T. & Charalampos, A. D. News authentication and tampered images: Evaluating the photo-truth impact through image verification algorithms. Heliyon. https://doi.org/10.1016/j.heliyon.2020.e05808 (2020).
Manaf, A. A., Mohammed, Amir, T., Hossein, Haider, S. & Ismael A robust detection and localization technique for copy-move forgery in digital images. J. King Saud Univ. - Comput. Inform. Sci. 449–461. https://doi.org/10.1016/j.jksuci.2022.12.014 (2023).
Zhongping, Z., Yixuan, Z., Zheng, Z. & Jiebo, L. Boundary-based image forgery detection by fast shallow cnn. In: International Conference on Pattern Recognition (ICPR), 2658–2663, (2018). https://doi.org/10.1109/icpr.2018.8545074
Zhou, P., Han, X., Morariu, V. I. & Davis, L. S. Learning rich features for image manipulation detection, pp. 1053–1106, (2018). https://doi.org/10.1109/cvpr.2018.00116
Qiuxu, L., Hongjiao, L. & Zheng, L. Image forgery localization based on fully convolutional network with noise feature. Multimedia Tools Appl. 81, 17919–17935. https://doi.org/10.1007/s11042-022-12758-7 (2022).
Heath, M. D., Sarkar, S., Sanocki, T. & Bowyer, K. W. A robust visual method for assessing the relative performance of edge-detection algorithms. IEEE Trans. Pattern Anal. Mach. Intell. 19 (12), 1338–1359. https://doi.org/10.1109/34.643893 (1997).
Giuliani, D. Metaheuristic algorithms applied to color image segmentation on hsv space. J. Imaging. 8 (1). https://doi.org/10.3390/jimaging8010006 (2022).
Loay, A. Kadom Contrast enhancement of infrared images using adaptive histogram equalization (ahe) with contrast limited adaptive histogram equalization (clahe). Iraqi J. Phys. 16 (37), 127–135. https://doi.org/10.30723/ijp.v16i37.84 (2018).
Ravishankar, C. & Sridevi, P. Fourier transform. Image Process. Acquisition Using Python. 29https://doi.org/10.1201/9780429243370-7 (2016).
Redmon, J., Divvala, S., Girshick, R. & Farhadi, A. You only look once: Unified, Real-Time object detection. Comput. Vis. Pattern Recognit. (CVPR). 779–788. https://doi.org/10.1109/CVPR.2016.91 (2016).
Wei, Q., Hu, X. & Hou, Q. Dynamic-YOLOv5: An improved aerial small object detector based on YOLOv5. Neural Networks Inform. Communication Eng. (NNICE). 679–683. https://doi.org/10.1109/nnice58320.2023.10105776 (2023).
He, K., Zhang, X., Ren, S. & Sun, J. Deep residual learning for image recognition. Conf. Comput. Vis. Pattern Recognit. (CVPR). 770–778. https://doi.org/10.1109/cvpr.2016.90 (2016).
Li, X., Wang, W., Hu, X. & Yang, J. Selective Kernel Networks. Conf. Comput. Vis. Pattern Recognit. (CVPR). 510–519. https://doi.org/10.1109/cvpr.2019.00060 (2019).
Raja, S. & Tie, L. No more strided convolutions or pooling:a New CNN Building Block for Low-Resolution images and small obiects. Comput. Vis. Pattern Recognit. (CVPR). https://doi.org/10.48550/arXiv.2208.03641 (2022).
Yu, J., Jiang, Y., Wang, Z., Cao, Z. & Huang, T. UnitBox: An advanced object detection network. ACM Int. Conf. Multimedia. 516–520. https://doi.org/10.1145/2964284.2967274 (2016).
Zhora, G. SIoU loss: More powerful learning for bounding Box Regression. Comput. Vis. Pattern Recognit. (CVPR). https://doi.org/10.48550/arXiv.2205.12740 (2022).
Nist nimble 2016. datasets, [online] Available: https://www.nist.gov/itl/iad/mig/nimble-challenge-2017-evaluationl
Wen, B. et al. COVERAGE -A novel database for copy-move forgery detection, International Conference on Image Processing (ICIP), pp. 161–165, (2016). https://doi.org/10.1109/icip.2016.7532339
Pawel korus-Realistic. Tampering dataset, [online] Available: https://pkorus.pl/downloads/dataset-realistic-tampering
Dong, J., Wang, W. & Tan, T. C. A. S. I. A. Image Tampering Detection Evaluation Database, China Summit and International Conference on Signal and Information Processing, pp. 422–426, (2013). https://doi.org/10.1109/chinasip.2013.6625374
Hsu, Y. & Chang, S. Detecting image splicing using geometry invariants and camera characteristics consistency. Int. Conf. Multimedia Expo. 549–552. https://doi.org/10.1109/icme.2006.262447 (2006).
Yi-Fan, Z. et al. Focal and efficient IOU loss for accurate bounding box regression, Neurocomputing, pp. 146–157, (2022). https://doi.org/10.1016/j.neucom.2022.07.042
Zanjia, T., Yuhang, C., Zewei, X. & Rong, Y. Wise-loU:Bounding Box Regression Loss with Dynamic Focusing Mechanism, Computer Vision and Pattern Recognition (CVPR), (2023). https://doi.org/10.48550/arXiv.2301.10051
Author information
Authors and Affiliations
Contributions
All authors contributed to the study conception and design. Requirement analysis and preliminary research were performed by WZH. Data collection and scheme formulation were carried out by LMD. Algorithm implementation, experimental verification and first draft of the manuscript were written by ZML, and all authors commented on previous versions of the manuscript. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Ethical approval and informed consent
All collected data are freely and publicly available on the internet. Neither personal nor private information is involved in this study.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Zhu, M., Li, M. & Wang, Z. Image tampering detection based on RDS-YOLOv5 feature enhancement transformation. Sci Rep 14, 26166 (2024). https://doi.org/10.1038/s41598-024-76388-9
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-024-76388-9
