
Abstract
This paper presents a novel framework for implementing the k-NN algorithm, designed to enhance its accuracy in contexts with sparse data. The framework addresses limitations in the algorithm’s training process by optimizing data structures. It employs composite datasets generated from the initial data using a data-driven fuzzy Analytic Hierarchy Process weighting scheme. This approach is designed to enhance the informational content in the initial datasets, thus reducing the entropy and implementation uncertainty. The framework was evaluated using 75 publicly available datasets and 3 generated datasets, demonstrating significant accuracy improvements across various k-parameter values. The findings were rigorously generalized using non-parametric hypothesis tests; while the resulting sensitivity was assessed by applying different distance metrics. By enhancing informational content, the composite data structures contribute to both accuracy improvements and scalability, particularly in data-sparse contexts. This relationship underscores the critical role of entropy in enhancing the performance of explainable machine learning algorithms, providing a valuable and interpretable tool for transforming data structures in sparse data environments.
Similar content being viewed by others

Introduction
Data sparsity presents an interesting challenge within the context of data analytics. In particular, it refers to situations where the available data is insufficient, incomplete, or scattered, and it often results when the data to be processed either has significant amount of missing values or when the volume of data is quite short. The sparsity can be due to various reasons, including the newness of the data domain, challenges in data collection, or inherent characteristics of the subject being studied. Sparse data poses unique challenges for forecasting and analysis, as traditional models may not perform adequately with the limited information available. Arguably, all these challenges affect the quality and reliability of analyses and predictions made by the k-NN algorithm, especially in data sparsity contexts. This issue has a proven impact on many practical applications, such as Recommender Systems, where it is referred to as the cold start problem, in Data-Driven Medical Decision Support Systems, in Sensors-Aided Network Tracking Systems, Fin-Tech algorithms and in research applications such as Bio-informatics, Neuroscience, Natural Language Processing, Image Processing and other applications1.
The k-NN (k-Nearest Neighbors) algorithm stands out for its intuitiveness and the interpretability of its results, reinforcing its suitability for various problem-solving scenarios. This algorithm is based on supervised learning techniques, allowing user interaction in forming training structures and selecting implementation parameter values, making it conducive for informed decision-making in data sparsity context2. However, the k-NN algorithm faces notable limitations. One significant issue is its poor performance with high-dimensional data. As the feature numbers increase, the k-NN algorithm is more likely to encounter irrelevant or redundant features, leading to higher computational costs and reduced accuracy3. Additionally, the k-NN algorithm is highly sensitive to outliers, which can significantly affect distance measurements between samples, thereby impacting the selection of nearest neighbors. Even clusters of outliers can distort these distances, influencing neighbor selection. These limitations, particularly within the context of data sparsity, greatly hinder the algorithm’s efficiency in several practical applications. Based on this analysis the following research questions (RQ) are deemed relevant:
-
RQ1: How does integrating data-driven weighting mechanisms affect the accuracy of the k-NN algorithm, especially in sparse data environments?
-
RQ2:How sensitive is the k-NN algorithm to the distance metric selection, when applied to composite data structures?
This paper proposes an innovative framework to enhance the k-NN algorithm’s accuracy by addressing specific limitations. We introduce a novel data structure incorporating composite variables, combining original independent variables with their correlation-based weights to the target variable, building upon previous work4. These weights are calculated using the fuzzy Analytic Hierarchy Process (AHP), a multi-criteria method extended by fuzzy set theory. Unlike traditional methods, our approach utilizes a progressive statistical evaluation of each dataset for weight determination. This method retains essential dataset information and enhances the k-NN algorithm by forming neighborhoods with more accurate and less biased distances. By reducing information entropy, it ensures that the data structure preserves critical information, leading to faster and more precise neighbor detection, regardless of k value or metric used, as evidenced by extensive statistical experiments. The framework’s generalizability is evaluated using 75 publicly available and 3 generated datasets, focusing on Classification Accuracy (CA) improvement. Additionally, our framework significantly reduces training time. We further assess the generalizability through a sensitivity analysis, calculating algorithm’s accuracy before and after the framework implementation across a range of k values. Our analysis provides empirical validation and a robust examination of the framework’s practical application, generalizability, and effectiveness.
The remainder of the paper is structured as follows: we first review the relevant literature on integrated k-NN and AHP approaches. We then present findings on the optimal k value for accuracy, comparing the resulting accuracy for various distance metrics and assessing the generalizability with non-parametric tests. Lastly, we discuss the results, training times, and provide the implementation details of the framework to ensure its reproducibility.
Related work
In this section, we review studies where the AHP method enhances the k-NN algorithm by incorporating feature weight mechanisms. In5, the authors use AHP to calculate subjective feature weights from customer demand analysis data and the Entropy Weighting Method (EWM) to determine objective weights. The k-NN algorithm sorts database items based on similarity. Similarly, in6 the authors apply AHP for weight assignment in case indexing and retrieval, using domain knowledge from multiple experts. Their results show that the AHP-weighted k-NN outperforms the traditional k-NN in CA. Another interesting approach is presented in7 in which the authors use AHP to determine feature importance and apply these weights in the k-NN model. Their approach is based on expert knowledge extraction, similar to previous studies. They also use K-fold cross-validation for training and evaluation, aligning with our procedure. Also, the authors in8 examine methods like Support Vector Machine (SVM) and the k-NN in landslide susceptibility modeling using expert-driven multi-criteria analysis. AHP is applied to weight input parameters, and the resulting patterns train both the SVM and the k-NN algorithm. Their SVM-based model outperforms other models. Moreover, the authors in9 combine the AHP with data mining classification techniques, using AHP to rank factors affecting traffic accidents based on expert knowledge. Various classification techniques, including the k-NN, are then applied, with the k-NN-based models outperforming others. Also, research10 proposes a synergistic framework to assess the efficiency of different ML methods, including k-NN, based on the examination of different criteria, a process supported by the incorporation of autism field experts. The AHP method is applied to rank the compared ML methods in a structured manner. Our research builds upon feature weighting mechanisms to create composite data structures of lower entropy, presenting significant differences with this research.
Extending beyond previous approaches, research in11 proposes an AHP-based weighting mechanism to enhance the accuracy of the k-NN classifier, in the acoustic insulation domain. Similarly, in12 the authors use an AHP-driven method to calculate the weights of ten different flash-flood predictors which then serve as inputs in both kNN-AHP and KS-AHP models, based on which the Flash-Flood Potential Index (FFPI) is determined, with the k-NN-AHP method to outperform the KS-AHP. While the above approaches share similarities with our research, the main difference is that in both cases a limited range of criteria was applied, predefined based on empirical evidence or expert knowledge. The idea of exploring the Granger causality to create data-driven weighting mechanisms in the domain of pattern recognition, is also presented in13. In this approach, the authors establish two criteria and use the Granger causality method to determine the preferences between them. They then apply the AHP to calculate the weights of different factors influencing these two criteria. Using these weights, they propose a weighted distance function for the k-NN classifier, which shows strong performance on high-dimensional face and handwriting recognition datasets. Methodologically, this work is similar to ours, with key technical differences. For instance, we used a correlation method instead of Granger causality, and we evaluated a much larger number of datasets (78 compared to their 15) to generalize our findings. Lastly, the synergistic potential of the AHP and k-NN methods in the field of cross-border qualitative evaluation of experts’ skills, is studied in14. In this approach the AHP method is used to qualitatively assess various skills and the k-NN algorithm is applied to calculate the weights of those skills. In this manner, the study establishes an assessment framework, tailored to industry-specific needs. Technically, this approach is quite different from ours, since it applies the k-NN for weights calculation and the AHP for qualities identification.
Delving into the technical details of the above works, we manage to classify them into four (4) broader thematic areas based on the purpose of AHP application, which include: (a) two-layered weighting mechanisms, (b) expert-driven weighting mechanisms, (c) application of AHP for ranking purposes; and (d) development of novel distance functions for the k-NN algorithm. Such an analysis makes clear that our framework presents several distinct differences from the located works. In Table 1 we summarize the main similarities and differences between our work and the previous works presented above.
To summarize, it is worth noting that while the synergistic potential of the AHP and k-NN algorithms is pivotal in addressing a wide spectrum of problems, the research is limited when it comes to combinations that focus on data-driven weighting mechanisms, especially development of composite datasets. The unique combination of fuzzy AHP and the k-NN, presents a novel pathway in forming appropriate data structures and reducing entropy, which significantly enhances the accuracy of the ML techniques. Also, our method was carefully designed to avoid discrepancies associated with expert knowledge modeling and assessment. To this end, the proposed framework, relying upon a data-driven approach, marks a valuable advancement in the field, emphasizing reliability, scalability, and accuracy.
Evaluation of the proposed framework
The contribution of the proposed framework is demonstrated by a comparative analysis of the accuracy achieved before and after its implementation, applied to both the initial and composite datasets. In the following sections, we present the results of these comparative assessments and evaluate the generalizability of the findings through hypothesis testing. Additionally, we conduct a sensitivity analysis to determine how variations in the algorithm’s parameters influence the outcomes.
Comparison assessments using open datasets
Following the strategy detailed in the “Methods” section, we selected 75 publicly available datasets to evaluate the proposed framework. The implementation of the framework resulted in the creation of composite datasets. We applied the k-NN algorithm to both the initial and composite datasets and compared the results using the CA metric. The Euclidean distance metric was used due to its widespread applicability in the k-NN evaluations. Also, we strategically choose to evaluate a wide range of k values to specify the optimally-fitted value. Specifically, we assessed values ranging from 1 to the maximum feasible k value for each dataset. After implementing the algorithm for such a wide range, we identify that for certain k values the k-NN reaches a plateau, meaning that from this point above changes in k values do not affect the achieved accuracy. Having completed these computations, we specify the k value leading to the best accuracy, based on the application in the initial datasets. As a next step, we calculate the accuracy obtained when the algorithm is applied in each composite dataset, by considering the same k value as calculated for the corresponding initial dataset.
A noteworthy implementation detail is that we do not fix the percentage split between training and test datasets. Instead, we employ the K-fold cross-validation technique (K equals to 5). Cross-validation ensures that each model does not merely memorize the training data but learns to generalize the information contained within it. This is crucial for validating the performance of unexplored data and markedly ensures the reliability of the training process. As a result, this technique streamlines the training process and enhances the algorithm’s adaptability in situations where only limited data is available. This is particularly beneficial in contexts characterized by data sparsity, as it allows for effective learning even with fewer data points. Furthermore, the cross-validation technique contributes to the conclusion that the proposed framework does not lead to model over-fitting and, thus, can be reliably generalized15. The differences, based on the Euclidean distance metric, are presented in Fig. 1.

Classification accuracy based on optimal k in each dataset.
The Euclidean-specific results highlight the contribution of the proposed framework. Notable improvements are observed for the vast majority (95%) of the datasets assessed. Conversely, the proposed framework appears to cause a slight reduction in accuracy achieved in four datasets. Upon deeper analysis of these datasets, it was found that the local maximum is reached at larger values of k for the composite datasets compared to the initial datasets. This indicates that selecting k based on the initial datasets likely prevents achieving the maximum possible accuracy for the corresponding composite datasets. Consequently, the actual improvements are likely higher than those presented above, and the reductions in accuracy in the four datasets are attributable to the existence of a local maximum in the initial forms. Further examination confirms that once a local maximum is reached in both the initial and composite forms, the accuracy is precisely equal.
To better interpret the above results, we classify the improvements obtained based on the optimally-fitted k in the initial datasets. Specifically, we consider three classes, presenting improvements less than 5%, within the range of 5% and 15% and higher than 15%, respectively. We observed an improvement of 5% to 15% in 80% of the datasets, which is significant given that the basic k-NN algorithm already produces high accuracy. Additionally, in 20% of the datasets, the improvement exceeded 15%.
It is also worth-noting that 51 of the aforementioned datasets (68%) are related to binary classification problems (classification into two sub-classes), while the remainder datasets pertain to classification problems with three or more classes. This observation leads us to two important insights. First, it’s clear that the majority of research on classification problems concentrates on binary classifications. This implies that improvements in this area could significantly benefit both practitioners and researchers working within this specific subset of classification. Second, it is commended that the overall rates of accuracy improvement significantly differ when considering only binary datasets. In these cases, improvements of up to 5% account for about 35% of the datasets, while improvements ranging from 5% to 15% account for 31.5%.
Another key finding from the analysis concerns the effect of the framework on accuracy improvement relative to the accuracy levels achieved in the initial datasets. The findings indicate that for initial accuracy values below 80%, the improvements achieved are significantly greater compared to cases where the initial accuracy exceeds 80%. Notably, when the initial accuracy is below 50%, the effect is even more pronounced. This leads to the conclusion that the framework’s impact is stronger in cases where the initial accuracy ranges from medium to low levels. This finding suggests that the framework significantly reduces the entropy within the data, facilitating faster and more effective training of the algorithm to accurately reflect the underlying patterns in data structures.
Overall the comparative analysis demonstrates that the proposed framework significantly enhances the accuracy of the k-NN algorithm, particularly for binary classification problems and cases with high misclassification rates due to large information entropy. Also, in many cases the framework effectively shifts the optimal k values to higher levels, indicating improved generalization and reduced over-fitting. These results highlight the framework’s effectiveness in addressing key challenges in data sparsity context, thereby significantly improving the k-NN performance, especially in initial deployment phases16.
Inferential statistics and reasoning
Acknowledging that the analyzed datasets represent only a subset of the total population of datasets with sparse characteristics, as defined in the “Methods” section, we employ inferential statistical methods to generalize the findings to the entire population. To validate our research hypothesis, we carried out the following test:
By applying Hypothesis Test 1, we compare the mean accuracy of the algorithm when applied to the initial and composite form of the datasets. If the null hypothesis can not be rejected, it indicates that the framework does not substantially improve the efficiency of the overall population of datasets. Conversely, if the alternative hypothesis can not be rejected, it suggests that the proposed framework significantly enhances the accuracy of the entire population.
As illustrated in Fig. 2, the two variables do not follow the normal distribution. The first, representing the “CA initial” variable, is negatively skewed, as depicted in the leftmost part of the figure. The distribution of the “CA composite” variable, while is also negatively skewed, presents higher peak on the rightmost side. Based on these observations, we determine that a non-parametric test should be applied to test the above hypothesis. In this paper, the Wilcoxon Signed Rank (WSR) test is selected. This test is considered an extension of the t-test for scenarios where the compared variables do not follow a normal distribution. Implementing the test at a 99% confidence interval leads to the rejection of the null hypothesis (\(H_0\)). In simpler terms, this means that we can be 99% confident that the proposed framework will improve accuracy for any dataset with sparse features.

Density diagrams for the CA initial (leftmost part) and CA composite variables (rightmost part).
Sensitivity analysis
As extensively discussed in the literature, there is no universally granted method for determining the value of k, which is the main parameter influencing the effectiveness of the algorithm. Typically, k is calculated using empirical rules and heuristics. A common approach is to set k equal to the square root of the number of data entries. However, this approach is not universal, as in many cases, the maximum accuracy is achieved with different, usually smaller, values of k17. On the other hand, setting k equal to relatively small values, has been related to over-fitting phenomena, which underpines the model’s generalizability18. Based on the above restrictions, the optimal pathway is to consider a wide range of values, starting from 1 and extending to the maximum feasible value of k where accuracy plateaus, meaning it does not change with further increases in k, similarily to what is observed in previous works19.
Considering the issues mentioned above, in this section we thoroughly examine a reliable range of k values, ranging from the value 1 up to maximum feasible value. By applying all the above values and considering two different distance metrics, i.e. Manhattan and Chebyshev, we focus on investigating whether the choice of a different distance metric affects the previously observed impact of the framework on improving algorithm’s CA.
Methodologically, for each selected value of k, the values of “CA initial” and “CA composite” are calculated in each dataset, by utilizing three different distance metrics. Using these values, the average values for “CA initial” and “CA composite” in each dataset are also computed. Thus, three new samples are created, for which a hypothesis test similar to the one previously presented is conducted. We select the calculation of the average value as the primary technique for sensitivity analysis with the goal of ensuring the algorithm’s overall superiority across the entire range of k values for the commonly used distance metrics. This approach also tests the likelihood that the previous assessment was falsely positive, possibly due to any local maxima or minima exhibited by the algorithm in the initial datasets. Using the mean values of the variables “CA initial” and “CA composite” a new hypothesis test is implemented to validate the following assumptions:
The hypothesis test is conducted three times, regarding the distance metrics selected, using the WSR method, because the mean values of the two variables, in each of the metrics, do not follow a normal distribution, as shown in Fig. 3. In particular, the violin diagrams combine aspects of a box plot and a density plot to provide a richer display of the underlying data distribution. Applying this test at a 99% significance level, and in comparison to the previous test, we conclude that the null hypothesis (\(H_0\)) should be rejected in all of the three cases, meaning that the average value of the “CA composite” variable is greater than the average value of the “CA initial” variable, and this difference is statistically significant at the 99% level. Importantly, this conclusion is verified for all of the three distance metrics, leading to the important conclusion that the proposed framework significantly contributes to accuracy enhancements regardless of the selected distance metric.

Violin plots using three distance metrics.
Comparison assessments using generated datasets
Aiming at enhancing the reliability of the results discussed above, we extend our analysis beyond the computations made for the set of the retrieved datasets. Specifically, in this subsection the performance of the algorithm is tested on entirely new datasets. To ascertain this argument and in order to ensure that these datasets have not previously applied in any other classification tasks in the related literature, we decide to craft them from scratch, using data generating functions. Technically, we first use the random sampling function to generate the data. Secondly, we restrict the function to generate datasets according to the specifications described earlier. Thirdly, we restrict the generator function according to missing values, specifically commanding that such values must be generated randomly and they must not exceed the 10% of total values per feature. Lastly, but most importantly, we generate three entirely new datasets, which differ in terms of average correlation index (as per Pearson) between the independent variables and the target variable. Regarding the last restriction, we examine the following scenarios:
-
1.
an under-correlated dataset scenario, in which the average correlation index is lower than 0.35
-
2.
a semi-correlated dataset scenario, in which the average correlation index yields values between the values 0.35 and 0.65; and
-
3.
an inter-correlated dataset scenario, in which the average correlation index excels the 0.65 value threshold.
For each generated dataset, we use our framework to create the corresponding composite datasets. We apply the k-NN algorithm to both the original and composite datasets, comparing the results obtained. To align with the computations presented earlier, we calculate both the best accuracy, using the optimally-fitted k, and the mean accuracy achieved, considering the different distance metrics (Euclidean, Manhattan, Chebyshev). The results are presented in Table 2, consistent with the conclusions made for the open datasets, thus validating the contribution of our framework.
Assessing framework’s ability to optimize algorithm’s interpretability and time-related metrics
Complementing the framework’s contribution to accuracy improvement, we focus on assessing two more aspects, namely the interpretability and the training time required. This procedure is designed to reflect a more holistic approach regarding the improvements driven by the application of the proposed framework.
Regarding the contribution on the interpetability improvement, it is noted that there is no one-way approach to calculate this metric. To the best of our knowledge, several approaches were proposed in the related literature to quantify the interpretability of different models20. Since the k-NN algorithm is embedded in the explainable ML techniques, we solely focus on interpretability metrics proposed for such approaches21,22. Therefore, based on the literature, we conclude that the number of variables is in most cases negatively related to the algorithms’ accuracy. This is perfectly aligned with our approach, in which we calculate the weights of each variable in the composite dataset by considering only the variables whose weights constitute the 90%. Following such a procedure, we ascertain that variables standing as noise in the training phase, are excluded. To quantify the contribution on the interpretability enhancement, we calculate the ratio of the number of variables in each initial dataset to the number of variables in the corresponding composite dataset. This metric is crafted in the light of the related literature suggestions, as described above. Summary statistics prove that in 65% of cases at least 35% of noisy variables were excluded, while in 25% of the initial datasets, at least 20% of noisy variables were excluded. These findings suggest that the proposed framework also significantly contributes to the algorithm’s interpretability enhancement.
Apart from the interpretability metric, we comparatively assess the training time required before and after the application of the proposed framework. To do so, we run several computations, considering a wide range of k, as described earlier, to specify the optimally-fitted k for each initial dataset. After that, we run the algorithm in both the initial and the composite dataset and we specify the required training and test times. By analyzing the obtained results, we conclude that in approximately 90% of cases, both training time and test times are improved. Specifically, improvements of 42.76 ms, 36.89 ms and 44.73 ms were facilitated regarding the mean training times, when the Euclidean, Manhattan and Chebyshev metrics were applied. The computations were carried out on a computer equipped with an Intel Core i7-8750H processor and 16 GB of RAM. Synthesising the above information, we infer that the proposed framework provides a really promising pathway towards the k-NN algorithm’s optimization, in different instances, including interpretability and required training time, especially in data sparsity contexts.
Discussion and conclusions
In this paper, we present and evaluate an implementation framework for the k-NN algorithm that significantly enhances its accuracy in contexts of data sparsity, therefore addressing the issue of information entropy. The framework focuses on configuring data structures to facilitate the algorithm’s training process, mitigating limitations encountered with insufficient training data. Composite datasets are created by leveraging the initial data, with each variable multiplied by a weighting coefficient calculated using the fuzzy-AHP method, independent of expert knowledge extraction. This approach reduces information entropy and ensures the preservation of critical information, while differentiating our framework from previous methods that often rely on hybrid models or complex mathematical techniques for calculating the k parameter. The framework was rigorously evaluated on 75 publicly available and 3 generated datasets. Accuracy was measured before and after applying the framework using three different distance metrics and various k values, ranging from 1 to higher values where accuracy plateaus. The results have demonstrated significant accuracy enhancements. Inferential techniques have generalized these findings to a broader population of similar datasets. Fairly strict non-parametric hypothesis tests (alpha = 99%) confirmed the reliable generalizability of these results.
Our study’s comparison with similar research provides valuable insights. However, direct comparisons are complicated by the distinctive dataset characteristics in previous works. For instance,7 achieved a maximum accuracy of 95.68% with an optimal k-value of 7, marking a 4.6% improvement over the standard k-NN algorithm. Similarly,6 showed that a hybrid k-NN model surpassed the traditional k-NN by approximately 21.5% in accurately retrieving bankruptcy cases. The authors in5 reported a 3.9% increase in case matching similarity for their hybrid model compared to the conventional unweighted k-NN. It is worth-noting that our framework also demonstrates significant enhancements. Specifically, we observed improvements ranging from 5% to 15% across 80% of the datasets, while, in 20% of the datasets, we noted improvements exceeding 15%, when the Euclidean metric is applied. These findings underscore the efficacy of our proposed framework which can be reliably extended to the application of Manhattan and Chebyshev metrics, as well.
This advancement in the k-NN application could provide added value in various fields, overcoming limitations imposed by data sparcity and enhancing the algorithm’s usability in practical, real-world situations. For example, in healthcare, particularly in diagnostics, the framework can enhance the accuracy of identifying rare diseases, where patient data is typically scarce and incomplete. This could lead to quicker, more accurate diagnoses and, consequently, more effective treatment plans. In the finance sector, especially in fraud detection, the framework’s ability to accurately identify fraudulent activities in vast datasets with relatively few instances of fraud can be of significant value. In the field of manufacturing, particularly in predictive maintenance, the framework’s improved accuracy in sparse data scenarios can also be of significant value. Accurately predicting equipment failures with limited historical failure data, can significantly reduce downtime and maintenance costs. Finally, in cybersecurity, where new and unique threats constantly emerge, the framework’s enhanced ability to detect threats with limited examples can bolster the security of systems against evolving cyber threats. These applications highlight the versatility and impact of the framework in addressing real-world challenges across diverse domains, especially in data sparsity contexts.
In the pursuit of advancing ML towards models that not only perform with high accuracy but also embody the principles of transparency and interpretability, our study contributes significantly to the broader discourse on interpretable ML (IML). By enhancing the performance of the k-NN algorithm through the integration of fuzzy AHP, we underscore the essential role of interpretability in AI, particularly in sectors where decision-making processes require both precision and clarity. This approach mirrors the wider effort in IML to blend simplicity with robust performance, by exemplifying the potential of hybrid models in achieving a harmonious balance between interpretability and computational efficacy, thus setting a precedent for future research in hybrid approaches within IML.
Ultimately, our methodological approach, outlines a novel pathway for delivering complex classification tasks in data sparsity contexts not just by applying the k-NN algorithm but potentially other models, embedded in the IML class, seeking to improve performance without compromising on explainability. This innovative approach could significantly influence the development of transparent, user-friendly ML applications, thereby aligning with the goals of Explainable AI (XAI). XAI aims to demystify the decision-making processes of AI systems, ensuring they are understandable to humans, which is crucial for ethical AI development and deployment. Through our research, we not only address a specific challenge in data analytics but also contribute to the overarching objectives of XAI by demonstrating that it is possible to enhance the accuracy of ML models in data-sparse conditions while maintaining, if not enhancing, their interpretability. This synergy between performance and transparency is vital for the continued trust and integration of AI technologies in sensitive and impactful areas of human activity.
As concluding remarks, while the retrieval of 75 datasets for this study is extensive, it represents only a subset of all the potential datasets for classification tasks. This necessitated non-parametric tests to generalize findings, given the impracticality of comparing accuracy across infinite similar datasets. Future studies should provide mathematical evidence of the proposed framework’s advantages, particularly focusing on its learning function. The framework was evaluated primarily in scenarios with limited training data, as it was designed to reduce information entropy in data sparsity contexts. This limitation affects its generalizability. Expanding research to include larger or intercorrelated datasets, time series data, or simulations could broaden its applicability and enhance the implementation of explainable ML techniques. Regarding weight assignment for composite variables, the fuzzy-AHP method was employed. Further research could explore alternative techniques and comparative evaluations to determine the most effective approach for different datasets. Additionally, developing new hybrid methods that integrate fuzzy forms of other multi-criteria decision-making techniques with the k-NN and other explainable algorithms could prove beneficial. Given the limited data, K-Fold cross-validation was used to optimize training. Future studies might consider other data allocation techniques, such as bootstrapping, stratified sampling, and systematic sampling, to optimize model performance and robustness. Exploring these methods can provide insights into addressing information entropy and improving model accuracy. Finally, conducting real-world case studies in sectors like healthcare, finance, and cybersecurity can validate the framework’s practical utility and contribute to its refinement and enhancement.
Methods
To ascertain the contribution of the proposed framework towards enhancing the accuracy of the k-NN algorithm, a comprehensive methodology is designed and employed. As depicted in Fig. 4, this methodology is comprised of several distinct steps. Initially, the objective of this paper is clarified. Based on this objective, appropriate criteria are designed, the fulfilment of which leads to the identification of datasets with sparse features. Subsequently, the proposed framework is developed and the k-NN algorithm is applied to the initial datasets and those resulting from the application of the proposed framework, referred to as composite datasets. Hence, the accuracy of the algorithm is computed by utilizing a wide range of k values for both the initial and composite datasets, facilitating a comparative assessment. To provide further elucidation of the proposed framework, inferential statistics are employed, aiming to generalize the results obtained during the comparative assessment. Last, to ascertain the overall robustness of the algorithm, a sensitivity analysis is carried out. These computational experiments aim to demonstrate that the superiority of the algorithm is not contingently based on local characteristics or the selection of a specific distance metric but is reliably generalizable. It is worth noting that our methodology is fully transparent and reproducible. In particular, for the interested reader to better interpret the procedure followed to create the composite variables and support the reproducibility of our research, we provide the pseudo-code within Supplementary file I, in which we detail the mathematical foundations of each step followed to create the composite datasets. We also provide the relevant code for the interested reader to create and compute the composite data set(s) at https://github.com/panagiotisgian/Fuzzy-AHP-based-composite-variables/tree/main. Having both the initial and composite dataset, the k-NN algorithm can be easily applied to retrieve the results of both approaches (please see Supplementary file II to locate the datasets used in the analysis).

Research methodology.
Technically, the comparison assessment is implemented using some publicly available datasets retrieved from online repositories, namely Kaggle, UCI ML repository and OpenML. The selection of such datasets promotes the transparency of the proposed framework, while posing a reliable response to improve decision-making in several challenging problems. Since the objective of this paper is centered around the data sparsity problem in classification tasks, the following context-specific criteria are designed and implemented to retrieve the datasets:
-
1.
The total number of records for each variable should not exceed 1000.
-
2.
The variables should not have the typical characteristics of time series, as classification in these cases requires special techniques and limits the ability to generalise effectiveness findings.
-
3.
The proportion of missing values should be relatively small (< 10%), given the limited size of the datasets.
-
4.
The variables should not be derived by simulation models, because in these cases there is a risk of overlapping between two or more variables, which significantly reduces the reliability of the proposed framework.
Applying the above criteria, 75 datasets were eventually selected to evaluate the proposed methodology. As mentioned earlier, the contribution of the framework is tested based on the improvement of the CA metric. Detailed descriptions of the techniques applied for the development of the proposed framework are provided in the following sections. The whole set of computations presented earlier, is based on the composite structures resulted from this methodology. Latly, to facilitate the evaluation and enable direct comparison of our proposed framework with other datasets, we calculated certain statistical properties of the selected datasets. In particular, we measured kurtosis, skewness, and the average Pearson correlation index between descriptive variables and the target variable. Our initial analysis showed that the skewness of variables across all datasets falls within the range of [− 25, 25], kurtosis values start at − 2 and can go higher, and the average Pearson correlation index ranges from 0.04 to 0.714.
Development of the framework
The framework’s development is based on integrating the correlation level found in each dataset with the fuzzy-AHP method. This method is applied to transform the correlation level into a weighting coefficient, that results in the creation of composite variables, preserving all the information from the initial datasets, while simultaneously enhancing the algorithm’s accuracy in a reliable manner. To the best of our knowledge, there is limited research that deals with the algorithm’s accuracy improvement without focusing on the modification of its learning function. Thus, the minimal complexity and an increased level of reliability are considered the main advantages of our proposed framework. In the sequence, we provide a detailed description of the techniques applied and the assumptions made for developing the framework. In Fig. 5, we present the implementation phases of the proposed framework.

The proposed framework.
In the first phase, the target variable is identified and information about classes, such as the number and the frequencies of different observations, is stated. Additionally, as part of the first phase, a statistical analysis in each of the datasets is carried out to determine certain measures such as skewness, kurtosis, % missing values per variable; and
the Pearson correlation index between the target variable and each of the independent variables.
At this point, it should be noted that the term independent variables refers to all variables contained in the initial dataset, except for the target variable. In addition, the absolute values of the correlation index (as per Pearson) are selected to calculate the significance of each variable. This is in accordance with our focus on assessing the extent to which each variable affects the algorithm’s classification result for each data entry.
In the second phase, the primary objective is the deployment of the pairwise comparison matrix, which is the fundamental component to implement the fuzzy-AHP method. Our proposal differs in terms of deploying this matrix from previous approaches, since the majority of studies is based on experts’ judgements, which is in contrast to our approach, thus providing an innovative aspect to our proposed framework23,24.
Specifically, we build upon a data-driven approach to calculate the pairwise comparison matrix, which is significantly contrasting to judgemental approaches. Designing and implementing such an approach, we focus both on reducing the subjectivity of the weights’ calculation process, which serves as one of the main limitations of the typical fuzzy-AHP method25; and on constructing a weighting tool to facilitate several datasets encompassing different domains.
To apply the proposed data-driven fuzzy form of the AHP method, we first determine the relative importance of each variable. To do so we identify the maximum and minimum absolute values of the correlation index, retrieved in the previous phase. We have chosen the 9-point Likert scale to express relative importance, where a value of 1 represents minimal importance and a value of 9 represents maximum importance. Based on this scale, we divide the range obtained by subtracting the maximum with the minimum value, into 9 equal width intervals. Following this procedure, each interval is assigned a value from 1 to 9, which represents the relative importance. As a final step, each variable is placed in an interval according to the absolute Pearson correlation index value it has received. Thus, the relative importance of each variable is derived.
In particular, with the calculated minimum and maximum absolute values of the correlation index, we can reach the width of each interval following Equation 3:
Having calculated the step for each interval, we then specify the 9 individual intervals and, thus, the relative importance for each variable, as presented in the following range:
The role of the intervals presented above is pivotal for the implementation of the proposed framework. Having calculated the s parameter, we use the above-mentioned range to create nine intervals of same width; and then we examine in which of these intervals the absolute Pearson index of each independent variable is embedded to. By applying this procedure we determine the importance of each independent variable. Specifically, following the intervals defined earlier, each variable is assigned a relative importance value ranging from 1 to 9, depending on its correlation level with the target variable. The described procedure for calculating the importance ensures that in each dataset, at least one variable will be assigned a relative importance value of 1 and another one a 9. This design aligns with the method’s scalability, ensuring an appropriate expression of “how much a variable, compared to others in the dataset, affects the final classification outcome.” For instance, consider a variable with an absolute Pearson index of 0.7. The relative importance assigned to this variable should differ depending on whether the maximum Pearson value in the dataset is 0.75 or 0.95. Such feature scaling makes the proposed framework flexible and applicable across various datasets.
To better interpret the independent variables’ relative importance calculation procedure, we consider a short paradigm. In this paradigm, we consider a dataset consisting of three independent variables and one more variable which serves as the target variable. For this dataset, we calculate the Pearson indexes between each independent variable and the target variable; and we result that the absolute values of Pearson equal to 0.33, 0.67 and 0.49, respectively. Applying the first equation, we observe that the s parameter equals to 0.04 for this dataset. Thus, we need to create nine different intervals in which each variable will be classified regarding its absolute Pearson value. Based on the classification on a specific interval, we determine the relative importance of each variable. In this example, we have calculated that the s-parameter’s value equals to 0.04, thus the corresponding intervals are: [0.33, 0.37], [0.37, 0.41], [0.41, 0.45], [0.45, 0.49], [0.49, 0.53], [0.53, 0.57], [0.57, 0.61], [0.61, 0.65], [0.65, 0.69]. The above intervals are matched with a relative importance ranging from 1 to 9. Since the first variable’s absolute Pearson equals to 0.33, it is classified in the first interval, receiving relative importance that equals to 1. In this manner, the second variable receives relative importance equal to 9; and the third receives 4, respectively.
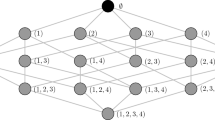
The deployment of the pairwise comparison matrix is delivered following an iterative procedure, as depicted in Fig. 6. The number of iterations equals to the number of independent variables in each dataset (n) that means that the matrix is diagonal, consisting of n columns and n rows. In simpler terms, if a dataset consists of five (5) independent variables, the matrix should be consisting of 5 rows and 5 columns. It should also be noted that the elements on the matrix’s diagonal are equal to 1, representing equal relative importance when comparing the same variables. The values in the first column match those calculated in the previous phase. We suggest arranging the variables in the matrix in ascending order so that the first value is always set to 1. This coincides with the value in the first cell of the pairwise comparison matrix, which is also filled with 1s. Finally, to complete the first row of the matrix, we reverse the values from the first column.

The iterative procedure to fill the pairwise comparison matrix.
The second column of the matrix is filled in by comparing the value in the second cell of the first column with all the other values of the first column. For example, the third cell in the second column will be obtained by comparing the value in cell 3 with the value in cell 2 in the first column. The comparison of the cells is finalized by subtracting these two values and obtaining the difference (d), which is used to fill in the second column according to Equation 4. Note that x is the importance of each variable, according to the first column of the matrix, and y is the importance of the variable being compared at each iteration.
This iterative procedure is repeated until all the columns of the pairwise comparison matrix are filled. After calculating the values for each column, it is suggested to reverse these values to fill in the corresponding rows. This procedure results in the deployment of the primary component of the fuzzy-AHP technique, significantly different than the original. Once the matrix is deployed, the next step involves applying the logic of fuzzy sets of triangular numbers, as the fuzzy AHP method is based on them. This implementation leads to the calculation of a fuzzy set for each variable, indicating its weight. This set is transformed again into discrete numbers by applying the CoA (Center of the triangular Area). Thus, the fuzzy weights of each variable are converted into discrete numbers26. To finalize the procedure, the weights are normalized. The purpose of this normalization is to enhance the weights of variables that contribute to increasing efficiency, while simultaneously reducing the noise likely introduced by variables that do not significantly contribute to the classification outcome. The idea behind this normalisation technique comes as an extension of the method’s adoptability and consistency techniques proposed in several related works23. To elaborate on the normalization technique, in the composite dataset, only the variables whose weights constitute 90% of the total are considered, starting from the highest to the lowest. Furthermore, the weights to be processed are appropriately incremented to sum up to 1, in order to meet the completeness criterion of the applied fuzzy-AHP technique. Subsequently, the variables that undergo the aforementioned procedure are multiplied by their corresponding weights. Following this process, the composite dataset is deployed.
Data availability
The authors confirm that all data used in this research is publicly available and has been retrieved from the following repositories: Kaggle, the UCI ML Repository, and OpenML. Access links to these datasets are listed in the Supplementary file II. Additionally, the data derived from the analyses presented in this paper will be made publicly available at the time of publication.
Change history
15 November 2024
A Correction to this paper has been published: https://doi.org/10.1038/s41598-024-79198-1
References
Engelke, S. & Ivanovs, J. Sparse structures for multivariate extremes. Annu. Rev. Stat. Appl. 8, 241–270. https://doi.org/10.1146/annurev-statistics-040620-041554 (2021).
Zhang, S., Cheng, D., Deng, Z., Zong, M. & Deng, X. A novel knn algorithm with data-driven k parameter computation. Pattern Recogn. Lett. 109, 44–54. https://doi.org/10.1016/j.patrec.2017.09.036 (2018). Special Issue on Pattern Discovery from Multi-Source Data (PDMSD).
Ali, M. et al. Semantic-k-nn algorithm: An enhanced version of traditional k-nn algorithm. Expert Syst. Appl. 151, 113374. https://doi.org/10.1016/j.eswa.2020.113374 (2020).
Giannopoulos, P. G., Dasaklis, T. K., Maragkoudakis, E. G. & Chondrokoukis, G. P. Enhancing k-nn algorithm’s efficiency using fuzzy ahp-based composite variables. In 2023 14th International Conference on Information, Intelligence, Systems & Applications (IISA), 1–4, https://doi.org/10.1109/IISA59645.2023.10345895 (2023).
Zhang, J. et al. Research on the Intelligent Design of Office Chair Patterns. Appl. Sci. (Switzerland) 12. https://doi.org/10.3390/app12042124 (2022).
Park, C.-S. & Han, I. A case-based reasoning with the feature weights derived by analytic hierarchy process for bankruptcy prediction. Expert Syst. Appl. 23, 255–264. https://doi.org/10.1016/S0957-4174(02)00045-3 (2002).
Lan, J., Bu, X., Meng, Y. & Li, Y. Sound insulation mechanism and prediction of membrane-type acoustic metamaterial with multi-state anti-resonances by weighted-kNN. Appl. Phys. Express 16. https://doi.org/10.35848/1882-0786/acf184 (2023).
Marjanović, M., Bajat, B. & Kovačević, M. Landslide susceptibility assessment with machine learning algorithms. In International Conference on Intelligent Networking and Collaborative Systems, INCoS 273–278, 2009. https://doi.org/10.1109/INCOS.2009.25 (2009).
Gustian, D., Armand, A., Wati, M. & Setiawan, F. Analytical Hierarchy Proccess with Data Mining Classification to Reduce Traffic Accident Level. In 5th International Conference on Computing Engineering and Design, ICCED 2019, https://doi.org/10.1109/ICCED46541.2019.9161133 (2019).
Jassim, M. M. et al. Multi-criteria decision making for machine learning algorithms using ahp-vikor techniques: Case study adult autism diagnosis. 574 – 578. https://doi.org/10.1109/IICETA54559.2022.9888273 (2022).
Sun, Y. The prediction and analysis of acoustic metamaterial based on machine learning. Int. J. Artif. Intell. Tools 31. https://doi.org/10.1142/S0218213022400036 (2022).
Costache, R. et al. Flash-flood susceptibility assessment using multi-criteria decision making and machine learning supported by remote sensing and gis techniques. Rem. Sens. 12, https://doi.org/10.3390/RS12010106 (2020).
Bhattacharya, G., Ghosh, K. & Chowdhury, A. S. Granger causality driven ahp for feature weighted knn. Pattern Recogn. 66, 425–436. https://doi.org/10.1016/j.patcog.2017.01.018 (2017).
Wei, W. Application of feature weighted knn classification algorithm in cross-border e-commerce talent training. Lect. Notes Data Eng. Commun. Technol. 138, 1047–1052. https://doi.org/10.1007/978-3-031-05484-6_142 (2022).
Xu, Y. & Goodacre, R. On splitting training and validation set: A comparative study of cross-validation, bootstrap and systematic sampling for estimating the generalization performance of supervised learning. J. Anal. Test. 2, 249–262 (2018).
Nasiri, M., Minaei, B. & Sharifi, Z. Adjusting data sparsity problem using linear algebra and machine learning algorithm. Appl. Soft Comput. 61, 1153–1159. https://doi.org/10.1016/j.asoc.2017.05.042 (2017).
Hassanat, A. Two-point-based binary search trees for accelerating big data classification using knn. PLoS ONE 13 (2018).
Molnar, C., Casalicchio, G. & Bischl, B. Interpretable machine learning – a brief history, state-of-the-art and challenges. In ECML PKDD 2020 Workshops, 417–431 (Springer International Publishing, Cham, 2020).
Giannopoulos, P., Kournetas, G. & Karacapilidis, N. On the integration of machine learning algorithms and operations research techniques in the development of a hybrid recommender system. Intelligent Decision Technologies 497–510, https://doi.org/10.3233/IDT-200217 (2021).
Li, X. et al. Interpretable deep learning: interpretation, interpretability, trustworthiness, and beyond. Knowl. Inf. Syst. 64, 3197–3234. https://doi.org/10.1007/s10115-022-01756-8 (2022).
Khan, U., Pao, W., Pilario, K. E. & Sallih, N. Flow regime classification using various dimensionality reduction methods and automl. Eng. Anal. Boundary Elem. 163, 161–174. https://doi.org/10.1016/j.enganabound.2024.03.006 (2024).
Khalil, M., AlSayed, A., Liu, Y. & Vanrolleghem, P. A. Machine learning for modeling n2o emissions from wastewater treatment plants: Aligning model performance, complexity, and interpretability. Water Res. 245, 120667. https://doi.org/10.1016/j.watres.2023.120667 (2023).
Liu, Y., Eckert, C. M. & Earl, C. A review of fuzzy ahp methods for decision-making with subjective judgements. Expert Syst. Appl. 161. https://doi.org/10.1016/j.eswa.2020.113738 (2020).
Aboutorab, H., Saberi, M., Asadabadi, M. R., Hussain, O. & Chang, E. Zbwm: The z-number extension of best worst method and its application for supplier development. Expert Syst. Appl. 107, 115–125. https://doi.org/10.1016/j.eswa.2018.04.015 (2018).
Cengiz, L. D. & Ercanoglu, M. A novel data-driven approach to pairwise comparisons in AHP using fuzzy relations and matrices for landslide susceptibility assessments. Environ. Earth Sci. 81, 222. https://doi.org/10.1007/s12665-022-10312-0 (2022).
Soltani, A. & Marandi, I. Hospital site selection using two-stage fuzzy multi-criteria decision making process. J. Urban Environ. Eng. 5, 32–43. https://doi.org/10.4090/juee.2011.v5n1.032043 (2011).
Acknowledgements
This work has been partly supported by the University of Piraeus Research Centre. In addition, this work has been partly supported by the Hellenic Open University and the European Commission, under the NextGeneration-EU program (YP1TA 0555681).
Author information
Authors and Affiliations
Contributions
P. G. G.: Conceptualization, Methodology, Writing Original Draft, Data Curation, Formal Analysis; T. K. D.: Conceptualization, Methodology, Visualization, Supervision; N. P. R.: Methodology, Formal Analysis, Supervision
Corresponding author
Ethics declarations
Competing interests
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Ethical and informed consent for data used
We used publicly available datasets and there are no ethical concerns.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
The original online version of this Article was revised: The original version of this Article contained an error in the order of the Figures. Full information regarding the corrections made can be found in the correction for this Article.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Giannopoulos, P.G., Dasaklis, T.K. & Rachaniotis, N. Development and evaluation of a novel framework to enhance k-NN algorithm’s accuracy in data sparsity contexts. Sci Rep 14, 25036 (2024). https://doi.org/10.1038/s41598-024-76909-6
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-024-76909-6
