
Abstract
Current approaches for cardiac amyloidosis (CA) identification are time-consuming, labor-intensive, and present challenges in sensitivity and accuracy, leading to limited treatment efficacy and poor prognosis for patients. In this retrospective study, we aimed to leverage machine learning (ML) to create a diagnostic model for CA using data from routine blood tests. Our dataset included 6,563 patients with left ventricular hypertrophy, 261 of whom had been diagnosed with CA. We divided the dataset into training and testing cohorts, applying ML algorithms such as logistic regression, random forest, and XGBoost for automated learning and prediction. Our model’s diagnostic accuracy was then evaluated against CA biomarkers, specifically serum-free light chains (FLCs). The model’s interpretability was elucidated by visualizing the feature importance through the gain map. XGBoost outperformed both random forest and logistic regression in internal validation on the testing cohort, achieving an area under the curve (AUC) of 0.95 (95%CI: 0.92–0.97), sensitivity of 0.92 (95%CI: 0.86–0.98), specificity of 0.95 (95%CI: 0.94–0.97), and an F1 score of 0.89 (95%CI: 0.85–0.92). Its performance was also superior to the serum FLC-kappa and FLC-lambda combination (AUC of 0.88). Furthermore, XGBoost identified unique biomarker signatures indicative of multisystem dysfunction in CA patients, with significant changes in eGFR, FT3, cTnI, ANC, and NT-proBNP. This study develops a highly sensitive and accurate ML model for CA detection using routine clinical laboratory data, effectively streamlining diagnostic procedures, and providing valuable clinical insights and guiding future research into disease mechanisms.
Similar content being viewed by others


Introduction
Cardiac amyloidosis (CA) is a rapidly progressive form of cardiomyopathy with a poor prognosis, characterized by the deposition of insoluble misfolded proteins in the cardiomyocyte extracellular matrix1,2. Despite the availability of effective treatments for the primary forms of CA—chemotherapy for immunoglobulin light-chain (AL) and transthyretin stabilizers (tafamidis) for transthyretin (ATTR), which reduce cardiac-related sudden death and shorten hospital stays—patients with CA frequently go unrecognized or receive an advanced-stage diagnosis3,4, highlighting a significant gap in sensitive early detection5.
Over the past decade, machine learning (ML) predictive models have become crucial for early diagnosis research of rare diseases6,7,8. Models employing algorithms such as decision trees, logistic regression, random forests, and K-means clustering can automatically identify and categorize patients’ characteristics, thus achieving accurate identification, classification, and prognosis prediction. Each algorithm excels with specific data types. For example, logistic regression is favored for binary models; random forests adapt well to missing information or imbalanced datasets; and XGBoost is renowned for its efficiency, fast performance with large datasets, low hardware requirements, and robustness.
Leading teams worldwide have developed ML models for CA, leveraging data from electronic health records, radiomics, proteomics, and clinical laboratories. García9 and Stefano10 constructed prediction models for high-risk CA patients based on textual data, identifying 11 key warning signs such as “diabetes” and “bilateral carpal tunnel syndrome”. Nature Communication reported that a CNN model trained on medical claim texts achieved an accuracy of 0.87 in recognizing the ATTRwt-CA subtype in heart failure (HF) patients11. Bonderman and Schrutkad12 used Electrocardiogram (ECG) signals to extract abnormal electrocardiograph features of CA through CNNs, with subsequent validation studies at the Mayo Clinic confirming the AI-enhanced ECG model’s diagnostic performance and generalizability across different ages and genders13. Meanwhile, Circulation highlighted Zhang’s work on dual-branch CNN methods trained on Echocardiogram (ECHO) videos for automatic CA recognition and ejection fraction prediction from 23 viewing angles14, validated at the First Affiliated Hospital of Guangxi Medical University, outperforming manual ultrasonography by experts15. Building on this, Goto et al.16 proposed an ECG and ECHO serial AI model, showing that ECG pre-screening significantly enhances ECHO model performance. In the field of laboratory medicine, routine laboratory test data, reflective of the body’s functional status and widely used in clinical practice, offer a cost-effective alternative for CA model training. Agibetov et al.17 developed a CA-ML model trained on blood test values, that successfully differentiated AL and ATTR subtypes in HF patients, achieving 89.2% sensitivity and 78.2% specificity. However, the study’s limited sample size and its focus solely on biomarkers from HF patient cohorts may restrict its effectiveness in early-stage CA detection.
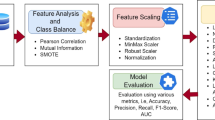
To address these limitations, our study introduces a ML-enhanced diagnostic tool that utilizes algorithms to analyze routine blood test data. Through feature visualization analysis and comparison with biomarkers, we demonstrate that this model can serve as a sensitive and timely auxiliary diagnostic tool. While it cannot replace a physician’s judgment, it provides a cost-effective method for early risk warning of CA. With future validation studies in multiple cohorts and centers, this approach will significantly reduce the rate of missed diagnoses and improve treatment outcomes for patients with CA, while also streamlining clinical workflows and informing future research directions in the field (Fig. 1).

Development and internal validation of a machine learning model for cardiac amyloidosis identification using routine blood tests.
Materials and methods
Study approval and participants
Research involving human subjects complied with all relevant national regulations and institutional policies and is in accordance with the tenets of the Helsinki Declaration (as revised in 2013) and has been approved by the Wuhan Asia Heart Hospital (Ethics Approval No. 2022-YXKY-P028). The need for informed consent was waived from the respective committee as the study is retrospective. This study retrospectively collected clinical information from 6,463 participants at the Wuhan Asia Heart Hospital between January 1, 2015, and December 31, 2022, including age, gender, and routine laboratory blood test results. All participants were categorized into the CA group and the non-CA LVH control, please see Fig. 2 for inclusion and exclusion criteria.
Data collection
Our dataset comprised results from 72 routine laboratory tests conducted during the hospitalization of enrolled patients. These laboratory tests encompassed 14 hematological tests, 42 biochemical tests, 8 coagulation tests, and 8 serology immunological tests. Hematological tests were measured using a hematology analyzer (Beckman Coulter DXH 800, America). For biochemical indicators, cardiac troponin I (cTnI) and immunological tests were detected on Beckman Coulter DXi 800; N-terminal pro-B-type natriuretic peptide (NT-proBNP) and procalcitonin (PCT) were detected on Cobas E 601 and BioMerieuxVIDAS 30, respectively; and other serum biochemical indexes were tested on an automatic chemical analyzer (Beckman coulter AU 5821, America). Coagulation tests were measured using an automatic coagulation analyzer (Werfen ACL-Top 700, America). Detailed information, including the abbreviation, units, equipment, and missing rates for each test item, can be found in the Supplementary Information (SI) Table S2.
Data preprocessing
The routine blood test data of participants was obtained from the hospital LIS platform, and only the initial results of each test were retained. Tests with missing values exceeding 60% were excluded during parameter selection to enhance model stability and reduce complexity. The threshold for moving missing values was set to 60% because we want to obtain as many real samples as possible, while retaining features were the common and meaningful indicators of laboratory examination data. The discarded tests, either infrequently used or requiring specialized expertise, were deemed irrelevant to our study. After excluding 27 tests, a total of 45 tests remained for further analysis. To ensure comprehensive data and minimize bias, missing values in any of the 45 tests were imputed with the mean value from the total sample of all participants.
For Tree-based models like XGboost and random forest, we used the obtained values directly as model features. While, for logistic regression, we normalized numerical features to mitigate the impact of varying value ranges. This normalization was done using the equation \(\:\frac{(\text{x}-\text{m}\text{i}\text{n})}{\text{m}\text{a}\text{x}-\text{m}\text{i}\text{n}}\).
Machine learning process
To prevent data leakage from highly similar tests, participants were manually and randomly divided into training and testing cohorts at a 9:1 ratio before starting the ML process, ensuring no overlap of target patients in both groups. The training cohort’s data was used to build logistic regression, random forest, and XGBoost models. The hyperparameters optimized through grid search included: for Logistic Regression, class_weight was set to 300; for Random Forest, max_depth was set to 6; and for XGBoost, settings were learning_rate = 0.121, gamma = 0.017, max_depth = 8, and min_child_weight = 1 (detailed in Supplementary Table S3). These configurations were then applied to the testing cohort data, which acted as an internal validation set across all models. In addition, 100 training/test splits were performed on the dataset to obtain each performance metric and their average while the hyperparameters were unchanged.
Given CA’s rarity and the resultant data imbalance, area under the curve (AUC) scores were chosen to evaluate model performance, alongside accuracy, sensitivity, specificity, positive predictive value (PPV), negative predictive value (NPV), and F1-score. The latter is calculated as the harmonic mean of recall rate and precision, with FN and TN denoting false negatives and true negatives, and FP and TP denoting false positives and true positives, respectively.
In the testing dataset, we compared the performance of CA models built with three algorithms. The most effective one was then used for gain map visualization analysis, focusing on key biomarker features. Subsequently, 21 CA patients and 21 controls were randomly selected to measure serum FLC-kappa and FLC-lambda levels using Diazyme Serum Free Light Chain Assay (USA) kit. The predictive performance of the model was evaluated in the same cohort, and sensitivity, specificity, and AUC were compared with FLC.

Flowchart of machine learning process. Footnotes: Laboratory routine blood tests data were used to develop a cohort of CA (n = 261) and non-CA controls (n = 6202). Features with more than 60% missing rate were excluded. The data were divided into 90% training and 10% testing cohorts. Three commonly used machine learning algorithms were employed to develop prediction models for CA. The performance of these models was then evaluated using metrics including sensitivity, specificity, and AUC and compared with the serum biomarker FLCs. A variable importance algorithm was employed to conduct feature selection, facilitating the identification of key biomarkers critical for distinguishing CA from controls. Furthermore, the researcher assessed the individual diagnostic performance of these biomarkers and conducted an inter-project correlation analysis to explore their relationships.
Statistical analysis
The statistical analysis was performed using Origin 2022 (OriginLab Corp., Massachusetts, USA) and StataMP-64.0 software (Stata Corp., Texas, USA). Quantitative data with a normal distribution were expressed as mean and standard deviation (x ± s) and analyzed using Mann-Whitney U test, and those with skewed distribution were expressed as median (interquartile range). A receiver operating characteristic (ROC) curve was plotted to calculate the AUC and all tests were performed as two-tailed tests, and p < 0.05 was considered statistically significant. The Pearson correlation coefficient (r) was analyzed using heat maps.
Results
Patient baseline characteristics
Supplementary Table S1 presents the clinical characteristics of the CA group and controls. Our findings indicate a significantly greater prevalence of males in the CA group (74.3%, 194 out of 261; χ2 = 48.64, p < 0.0001) and an older median age of 63 years compared to the controls, as illustrated in Fig. 3.

Demographic feature (gender and age) distributions for CA and control cases.
Performance of machine learning models
Figure 4A and Supplementary Table S1 reveal that the XGboost model outperforms other algorithms in CA prediction performance, with an accuracy of 1.00 in the training set and an AUC of 0.95 (95%CI: 0.92–0.97) in the test set, which exceeds the logistic regression (AUC 0.83; 95%CI: 0.77–0.88) and random forest (AUC 0.91; 95%CI: 0.88–0.94), with an accuracy of 0.95 (95%CI: 0.93–0.97), sensitivity of 0.92 (95%CI: 0.86–0.98), specificity of 0.95 (95%CI: 0.94–0.97), F1-score of 0.89 (95%CI: 0.85–0.92), PPV of 0.70 (95%CI: 0.60–0.79), and NPV of 0.99 (95%CI: 0.98-1.00), thereby, XGBoost was chosen for deeper investigation. The robustness of the model was proved to be reliable by the average of the performance metrics for 100 random splits of the dataset.
Supplementary Figure S1 confirmed that CA patients had higher concentrations of FLC-kappa and FLC-lambda than the non-amyloidosis-driven control group (p < 0.05). As shown in Fig. 4B and Supplementary Table S5, the AUC for detecting CA using FLC-kappa and FLC-lambda alone was 0.68 and 0.75, respectively, in cohorts of 21 individuals each in the CA and control groups. When combined, they approach an AUC of 0.88, yet still fell short of our ML model’s AUC of 1.00.

(A) ROC curve comparisons of CA detection across three ML models, each utilizing a unique algorithm. The AUC represents the classifier’s ability to distinguish between classes. (B) ROC curves for serum biomarkers FLC-kappa and FLC-lambda, and their combined diagnostic efficacy, and model prediction. Maximum AUC of 0.68 was observed at an FLC-kappa cutoff of 45.8 mg/L, while FLC-lambda reached a 0.75 AUC at a 70.5 mg/L cutoff. The AUC for combined diagnosis was 0.88, while the AUC of model prediction was 1.00.
Hematochemical features associated with CA
In the XGBoost-model, hematochemical features were ranked by importance, with higher Gain values signifying greater predictive capacity (Fig. 5). The top five indicators identified were eGFR, FT3, cTnI, ANC, and NT-proBNP, with detailed feature distribution seen in Supplementary Table S6. Subsequent statistical analysis revealed significant differences between CA patients and controls in the levels of the top 15 ranked features (p = 0.371), as depicted in violin plots (Fig. 6).
In the CA group, RBC and eGFR levels were lower than in the control group [RBC, 4.14 (3.70–4.64) 1012/L vs. 4.34 (4.04–4.79) 1012/L; eGFR, 73.00 (60.00–86.00) mL/min vs. 89.00 (77.00-101.00) mL/min]. Levels of cTnI and NT-proBNP were elevated in all enrolled patients compared to healthy individuals, with even higher levels observed in the CA group [cTnI 0.29 (0.11–1.68) ng/L; NT-proBNP 3709.00 (1112.00-6168.35) pg/mL]. Additionally, the CA patient group exhibited higher levels of liver damage markers [GGT 60.00 (29.00–87.00) U/L and ALT 22.80 (17.00-29.70) U/L, respectively] and compromised thyroid function (lower FT3 [2.87 (2.60–3.20) pg/mL] and upregulated TSH [3.64 (2.40–5.69) mIU/L]).
Furthermore, we closely examined the individual performance of the top 15 features extracted by XGBoost. Based on their AUC values, features were categorized into three groups: good (AUC > 0.80), moderate (0.70 ≤ AUC < 0.80), and poor (AUC < 0.70). As shown in Supplementary Fig. S2, FT3, eGFR, TSH, NT-proBNP, and GGT demonstrated moderate capability, with AUC values of 0.76, 0.74, 0.73, 0.72, and 0.70, respectively. However, the performance of the remaining features was poor, with all AUC values below 0.70.

Feature importance scores for the XGBoost algorithm using the routine blood test values. ANC, absolute neutrophils count; RBC, red blood cells; MCH, mean corpuscular he, moglobin; PDW, platelet distribution width; MCV, mean corpuscular volume; HGB, hemoglobin; RDW, erythrocyte distribution width; HCT, hematocrit; LYMPH#, lymphocytes count; MONO#, monocytes count; WBC, white blood cells; MCHC, mean corpuscular hemoglobin concentration; MPV, mean platelet volume; PLT, platelets; eGFR, estimated glomerular filtration rate; cTnI, cardiac troponin I; NT-proBNP, NT-proB-type natriuretic peptide; GGT, gamma glutamyl transferase; Glu, glucose; Chol, Cholesterol; ALT, alanine aminotransferase; K, potassium; Crea, creatinine; AST, aspartate aminotransferase; TG, triglyceride; UA, uric acid; ALb, albumin; TP, total protein; ALP, alkaline phosphatase; PCT, procalcitonin; LDH, lactate dehydrogenase; HDL-C, high density lipoprotein cholesterol; Na, sodium; DBIL, direct bilirubin; TBIL, total bilirubin; CL, Chlorine; Mg, magnesium; PT, prothrombin time; Fib, fibrinogen; APTT, activated partial thromboplastin time; FT3, free triiodothyronine; TSH, thyroid stimulating hormone; FT4, free thyroxine.

Violin plots depicting the distributions of the top 15 biomarkers in the CA group and controls. The blue and green areas correspond to patients with CA and the control cases, respectively. P values determined by the Mann-Whitney U test were used for group comparison. Significant differences are indicated with **** = p < 0.0001, ns = p > 0.05. ANC, absolute neutrophils count; ALT, alanine aminotransferase; Chol, Cholesterol; Glu, glucose; MCH, mean corpuscular hemoglobin; MCV, mean corpuscular volume; PDW, platelet distribution width; RBC, red blood cells; eGFR, estimated glomerular filtration rate; GGT, gamma glutamyl transferase; FT3, free triiodothyronine; NT-proBNP, NT-proB-type natriuretic peptide; TSH, thyroid stimulating hormone; cTnI, cardiac troponin I; PT, prothrombin time.
Correlation analysis between biomarkers in CA patients
To further reduce the complexity of the prediction model, Pearson’s correlation coefficient (r) between the 15 statistically significant biomarkers was analyzed using heat maps to avoid including variables with high correlations. Figure 7 shows a high correlation between MCH and MCV (r = 0.95). Correlations among the remaining variables were weak (absolute value of r < 0.70).

Pairwise correlations between the top 15 biomarkers. Yellow squares represent negative correlations, while green squares represent positive correlations. The magnitude of the correlation between features is indicated by the color gradient. ANC, absolute neutrophils count; ALT, alanine aminotransferase; Chol, Cholesterol; Glu, glucose; MCH, mean corpuscular hemoglobin; MCV, mean corpuscular volume; PDW, platelet distribution width; RBC, red blood cells; eGFR, estimated glomerular filtration rate; GGT, gamma glutamyl transferase; FT3, free triiodothyronine; NT-proBNP, NT-proB-type natriuretic peptide; TSH, thyroid stimulating hormone; cTnI, cardiac troponin I; PT, prothrombin time.
Discussion
With the rapid advancement of medical research, auxiliary diagnostic methods for CA have grown complex, imposing significant economic burdens on patients and increased workload for healthcare professionals. To address the sensitivity and timeliness challenges in detecting CA, leveraging the widespread accessibility and standardization of routine laboratory data is crucial. By integrating data mining techniques with prediction model development, a high-performance and well-interpreted screening platform can be created, enhancing accuracy and efficiency for early CA diagnosis.
In this study, we successfully developed and internally validated a sensitive ML model for CA identification using routine blood test parameters. The model uncovers a distinctive feature profile of multi-system dysfunction in CA patients, providing insights into disease progression mechanism and distinguishing CA from other heart conditions with similar symptoms. These promising outcomes emphasize the clinical implications of integrating the model into the medical information system, facilitating targeted inspections for high-risk patients, and improving early detection and treatment of CA.
ML models have gained prominence for their ability to predict diseases and classify phenotypes, as illustrated by their deployments in tuberculosis, stroke, tumors, precursor Alzheimer’s disease, and dementia18,19,20. However, the quality of these studies can vary, with differences in patient cohorts, sample sizes, and most importantly, data types. Our results indicated that XGBoost model outperformed all other algorithms with an impressive AUC of 0.95 (Table S4), minimizing unnecessary examinations for the non-amyloid-driven controls, as evidenced by a PPV of 0.70. XGBoost has demonstrated exceptional performance in constructing medical prediction models in tasks related to orthopedics, acute lymphoblastic leukemia, and heart disease classification21,22,23. In this work, the clinical laboratory data collected were inevitably influenced by disease progression and attending physicians, leading to notable missing and inconsistent data (Supplementary Table S2). Therefore, we attribute the superior performance of the XGBoost model to its exceptional data mining capabilities. It is important to note that the prevalence rate significantly affects the interpretation of model performance indicators, especially the NPV. As the prevalence decreased, the NPV increased. In our study, the prevalence of CA among patients with myocardial hypertrophy is approximately 4%, which is already significantly higher than the prevalence in the general population (one in one hundred thousand)24. Therefore, an NPV of 0.99 still demonstrates that the model can effectively rule out non-CA patients, reducing unnecessary, invasive, and costly follow-up examinations for this group of patients.
We then benchmarked the XGBoost model against ML models from the literature that were trained on different medical datasets. Our model had lower performance than those based on Cardiovascular Magnetic Resonance (CMR)25,26,27 and Whole Body Scintigraphy (WBS)28 data, likely due to those studies excluding non-amyloidosis heart diseases and concentrating on a highly suspected CA cohort, resulting in more precise models. On the other side, our model excelled over others using Electronic Medical Record (EMR) (sensitivity 87% and precision 87%)11,]29,30, ECG and ECHO records (67% sensitivity, 77% precision)16, demonstrating higher sensitivity (92%) and precision (84.5%). This underscores the importance of selecting the right clinical entry points for CA models to balance cost, time efficiency, and accuracy.
A crucial practical implication of this study is the identification of a distinctive feature pattern for CA patients from routine blood tests. Our analysis revealed that 14 out of the top 15 features showed significant differences between CA and control, indicating more pronounced cardiac, thyroid, liver, and renal damage in CA patients. This damage likely results from systemic amyloidosis causing tissue and organ structural abnormalities. Moreover, these changes are closely associated with multiple myeloma, with literature indicating over 50% of patients with this condition experience cardiac involvement. Although bone marrow biopsy results were not included, the observed anemia (lower RBC) and coagulation disorders (prolonged PT) in CA patients further support this connection. CA patients exhibited NT-proBNP levels twice that of controls, indicating severe heart failure and highlighting the common issue of delayed diagnosis until advanced stages. The study also underscores the need for comprehensive blood testing in all suspected cases in clinical practice, as relying solely on cTnI, or classical CA marker FLC, fails to accurately diagnose CA (Supplementary Figure S1). Additionally, no significant correlation was observed among the top 15 key biomarkers, suggesting the model’s robustness and stability.
Several limitations necessitate careful consideration when analyzing the outcomes of our study: (1) The significant imbalance between the CA cases and controls in our dataset, along with the possibility of undiagnosed CA cases within the control group, may impact the model’s performance; (2) Due to the limitation in the amount of patient data, we did not allocate an additional validation set for the model’s hyperparameter tuning comparison. Therefore, although we avoided information leakage from the test set, the current method carries the risk of overfitting to the training set; (3) Furthermore, in handling missing data, we chose to exclude features with more than 60% missing values to maintain data quality, a decision that led to the loss of a substantial amount of potentially useful information. Future research might consider more advanced statistical techniques, such as multiple imputation, to address missing data, potentially offering a more comprehensive data utilization and more robust conclusions.
In conclusion, our study successfully developed and validated an ML model that predicts CA with high sensitivity using routine blood test values. Compared to patients with LVH not driven by amyloidosis, the model identified unique patterns of multi-organ dysfunction biomarkers in CA patients, offering reliable scientific insights into its recognition patterns. Given the rarity of CA, ethical considerations, patient privacy, and the extensive time and resources required for long-term follow-up studies, our ability to fully simulate the early diagnostic process of CA in a real-world setting is constrained. Looking forward, it is imperative that future research aims to evaluate the model’s predictive performance within a larger and more diverse population, potentially across multiple centers. Future integration of our model into a hospital’s LIS could streamline CA diagnosis. Automatically alerting physicians when routine tests indicate high CA risk could facilitate timely follow-up exams without added patient or system burdens.
Data availability
The data presented in this study are available upon request from the corresponding author.
References
Wechalekar, A. D., Gillmore, J. D. & Hawkins, P. N. Systemic Amyloidosis Lancet 387, 2641–2654 (2016).
Ruberg, F. L., Grogan, M., Hanna, M., Kelly, J. W. & Maurer, M. S. Transthyretin amyloid cardiomyopathy: Jacc State-of-the-art review. J. Am. Coll. Cardiol. 73, 2872–2891 (2019).
Bloom, M. W. & Gorevic, P. D. Cardiac amyloidosis. Ann. Intern. Med. 176, ITC33–ITC48 (2023).
Merlini, G. et al. Systemic immunoglobulin light chain amyloidosis. Nat. Rev. Dis. Primers. 4, 38 (2018).
Maurer, M. S. et al. Tafamidis Treatment for patients with transthyretin amyloid cardiomyopathy. N Engl. J. Med. 379, 1007–1016 (2018).
Shah, N. D., Steyerberg, E. W. & Kent, D. M. Big Data and Predictive analytics: recalibrating expectations. Jama. 320, 27–28 (2018).
Meng, C., Pei, Y., Zou, Q. & Yuan, L. Dp-Aop: a novel svm-based antioxidant proteins identifier. Int. J. Biol. Macromol. 247, 125499 (2023).
Ren, X. et al. Machine learning reveals salivary glycopatterns as potential biomarkers for the diagnosis and prognosis of papillary thyroid Cancer. Int. J. Biol. Macromol. 215, 280–289 (2022).
García-García, E. et al. Real-World Data and Machine Learning to Predict Cardiac Amyloidosis. Int. J. Environ. Res. Public. Health 18, 908 (2021).
Di Stefano, V. et al. Machine learning for early diagnosis of Attrv Amyloidosis in non-endemic areas: a Multicenter Study from Italy. Brain Sci. 13, 805 (2023).
Huda, A. et al. A machine learning model for identifying patients at risk for wild-type transthyretin amyloid cardiomyopathy. Nat. Commun. 12, 2725 (2021).
Schrutka, L. et al. Machine learning-derived Electrocardiographic Algorithm for the detection of Cardiac Amyloidosis. Heart (British Cardiac Society). 108, 1137–1147 (2022).
Harmon, D. M. et al. Postdevelopment Performance and Validation of the Artificial Intelligence-enhanced electrocardiogram for detection of Cardiac Amyloidosis. Jacc: Adv. 2, 100612 (2023).
Zhang, J. et al. Fully automated Echocardiogram Interpretation in Clinical Practice. Circulation. 138, 1623–1635 (2018).
Zhang, X. et al. Deep learn-based computer-assisted Transthoracic Echocardiography: Approach to the diagnosis of Cardiac Amyloidosis. Int. J. Cardiovasc. Imaging. 39, 955–965 (2023).
Goto, S. et al. Artificial Intelligence-enabled fully automated detection of Cardiac Amyloidosis using electrocardiograms and echocardiograms. Nat. Commun. 12, 2726 (2021).
Agibetov, A. et al. Machine learning enables prediction of Cardiac Amyloidosis by Routine Laboratory parameters: a proof-of-Concept Study. J. Clin. Med. 9, 1334 (2020).
Battista, P., Salvatore, C., Berlingeri, M., Cerasa, A. & Castiglioni, I. Artificial Intelligence and Neuropsychological measures: the case of Alzheimer’s Disease. Neurosci. Biobehav Rev. 114, 211–228 (2020).
Painuli, D., Bhardwaj, S. & Köse, U. Recent Advancement in Cancer diagnosis using machine learning and deep learning techniques: a Comprehensive Review. Comput. Biol. Med. 146, 105580 (2022).
Stafie, C. S. et al. Exploring the Intersection of Artificial Intelligence and Clinical Healthcare: a multidisciplinary review. Diagnostics 13, 1995, (2023).
Li, S. & Zhang, X. Research on Orthopedic Auxiliary classification and prediction model based on Xgboost Algorithm. Neural Comput. Appl. 32, 1971–1979 (2020).
Ramaneswaran, S., Srinivasan, K., Vincent, P. & Chang, C. Y. Hybrid Inception V3 Xgboost Model for Acute Lymphoblastic Leukemia Classification. Comput. Math. Method Med. (2021). (2021).
Budholiya, K., Shrivastava, S. K. & Sharma, V. An optimized Xgboost based Diagnostic System for Effective Prediction of Heart Disease. J. King Saud Univ. - Comput. Inform. Sci. 34, 4514–4523 (2022).
Quock, T. P., Yan, T., Chang, E., Guthrie, S. & Broder, M. S. Epidemiology of Al Amyloidosis: a real-world study using us Claims Data. Blood Adv. 2, 1046–1053 (2018).
Jiang, S. et al. Differentiating between Cardiac Amyloidosis and hypertrophic cardiomyopathy on non-contrast cine-magnetic resonance images using machine learning-based Radiomics. Front. Cardiovasc. Med. 9, 1001269 (2022).
Satriano, A. et al. Neural-network-based diagnosis using 3-Dimensional Myocardial Architecture and Deformation: demonstration for the differentiation of hypertrophic cardiomyopathy. Front. Cardiovasc. Med. 7, 584727 (2020).
Eckstein, J. et al. A machine learning challenge: detection of Cardiac Amyloidosis based on bi-atrial and right ventricular strain and cardiac function. Diagnostics (Basel Switzerland). 12, 2693 (2022).
Delbarre, M. et al. Deep learning on bone scintigraphy to detect abnormal Cardiac Uptake at Risk of Cardiac Amyloidosis. JACC Cardiovasc. Imaging 16, 1878–1936 (2023).
Di Stefano, V. et al. Machine learning for early diagnosis of Attrv Amyloidosis in non-endemic areas: a Multicenter Study from Italy. Brain Sci. 13, 805 (2023).
Bruno, M. et al. Clinical characteristics and Health Care Resource Use of patients at risk for wild-type transthyretin amyloid cardiomyopathy identified by machine learning model. J. Manag Care Spec. Pharm. 29, 530–540 (2023).
Funding
This study was supported by High-level Talent Research Startup Funding of Hubei University of Chinese Medicine (grant number 100501070302); and Wuhan Clinical Medical Research Center for Cardiovascular Imaging Internal Fund (grant number CMRC202304).
Author information
Authors and Affiliations
Contributions
Y.P.: Conceptualization, Formal analysis, Writing - original draft. Q.F: Data curation, Funding acquisition. Y.L.: Data curation, Formal analysis. Y.L.: Methodology, Software. H.Y.: Writing - review & editing, Supervision. C.L.: Writing - original draft, Supervision, Project administration, Funding acquisition. All authors reviewed the manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Pan, Y., Fan, Q., Liang, Y. et al. A machine learning prediction model for Cardiac Amyloidosis using routine blood tests in patients with left ventricular hypertrophy. Sci Rep 14, 28644 (2024). https://doi.org/10.1038/s41598-024-77466-8
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-024-77466-8
