
Abstract
Machine-learning disease classification models have the potential to support diagnosis of various diseases. Pairing classification models with synthetic image generation may overcome barriers to developing classification models and permit their use in numerous contexts. Using 10 images of penises with human papilloma virus (HPV)-related disease, we trained a denoising diffusion probabilistic model. Combined with text-to-image generation, we produced 630 synthetic images, of which 500 were deemed plausible by expert clinicians. We used those images to train a Vision Transformer model. We assessed the model’s performance on clinical images of HPV-related disease (n = 70), diseases other than HPV (n = 70), and non-diseased images (n = 70), calculating recall, precision, F1-score, and Area Under the Receiver Operating Characteristics Curve (AUC). The model correctly classified 64 of 70 images of HPV-related disease, with a recall of 91.4% (95% CI 82.3%-96.8%). The precision of the model for HPV-related disease was 95.5% (95% CI 87.5%-99.1%), and the F1-score was 93.4%. The AUC for HPV-related disease was 0.99 (95% CI 0.98-1.0). Overall, the HPV-related disease classification model demonstrated excellent performance on clinical images, which was trained exclusively using synthetic images.
Similar content being viewed by others

Introduction
Machine-learning models for disease classification have the potential to support the diagnosis of various diseases. Such models have been used to support radiographic assessment of different pathologies1, data-monitoring to classify patients with type 1 diabetes2, and clinical identification of cutaneous diseases3. However, the algorithms are dependent on large clinical image databases encompassing a diverse range of pathology, which are not available for many diseases, and can be difficult to access due to patient privacy protections. Further, the establishment of such databases is time- and resource-intensive, limiting the potential applications of machine-learning diagnostic models. To offset the need for large datasets of clinical images for any given disease, some have explored synthetic image generation from non-image inputs using machine-learning models – the converse of image classification. The potential applications of such a synergistic pairing of image generation and image classification models are numerous. During the outbreak of a new cutaneous disease, similar to the 2022 mpox outbreak4, when timely diagnosis is essential to limit the spread of infection, dependency on clinical image databases to support machine-learning models may limit utility.
The traditional method for image generation is known as generative adversarial networks (GAN)5. GANs have numerous limitations, however, including a lack of image diversity and dependence on large datasets, which have limited their value in medical contexts6,7. A novel approach to image generation, known as diffusion probabilistic modeling, has had much more success than GANs8,9, which, with additional improvements, can reverse the diffusion process, effectively transforming image ‘noise’, or uninterpretable pixels, into coherent imagery10. Recent advances have led to improved denoising of diffusion probabilistic models11, further augmenting the quality of synthetic image generation. One study applied denoising diffusion probabilistic modeling to a dataset of magnetic resonance and computed tomography images, and demonstrated robust, diverse, and high-quality production of 3-dimensional images, as evaluated by expert radiologists12. That study then used the images generated to train an existing breast image segmentation model, resulting in improved model performance12.
We aimed to further enhance denoising diffusion probabilistic modeling, adding text-to-image generation and train a Vision Transformer model for disease classification using entirely synthetic, generated images. We selected genital warts, caused by human papilloma virus (HPV) infection, as a use case. HPV-related disease is highly stigmatized13 for which visual diagnosis is a core component. Further, HPV-related diseases are common, with an estimated 10% lifetime cumulative incidence14. A disease classification model for genital warts has the potential to support the diagnosis of this highly prevalent and morbid disease.
Methods
Synthetic image generation
We curated an clinical image dataset of 10 penises with HPV-related disease sourced from a mobile platform we previously described15. Two expert clinicians reviewed each image to confirm representation of HPV-related disease. We paired those images with descriptive text files to link subject class (e.g., genital warts) with text prompt descriptors (e.g., “cauliflower shape”). We then applied class-specific prior-preservation loss to encourage generation of diverse images per class, as has been described previously16. We also used a bounding box to shift the generative model’s focus to the HPV-related lesions, rather than the entire genital area, as we found the broader focus resulted in inaccurate rendering of the genital area during model piloting.
We inputted those synthetic images into a diffusion probabilistic model using stable diffusion to create coherent structured images from random image noise. We further enhanced that model with an existing personalized text-to-image model known as DreamBooth17, which permitted generation of customizable synthetic content based on text descriptions. To do so, we used a U-net architecture model to classify pixels as either background or subject image18, as well as a text encoder training as a part of the DreamBooth software. The U-net learning rate (or model change in response to estimated error each time the weights are updated) was fixed at 2e−6, while the text encoder learning rate was set at 4e−7 with training steps set at 350 to balance learning with overfitting.
We then used text to specify a range of HPV-related disease presentations as well as multiple variations on the same pathology to generate images representing the complete disease spectrum. The Fig. 1 shows examples of text inputs and image output.
To determine clinical plausibility, expert clinicians assessed each image. All images were reviewed first by one physician (a general practitioner with expertise in dermatologic conditions). The physician categorized each image as either clinically plausible or not. A further random sample of 20 images (10 categorized as clinically plausible and 10 categorized as clinically implausible) were sent to a second clinician, a professor of dermatology, for a blinded second review. We used the resulting synthetic images deemed plausible to train the classification model. Supplemental Fig. 1 in the Appendix shows examples of images deemed implausible.
Disease classification model
We used a Vision Transformer model for learning on the synthetic images19. Such models deconstruct images into segments, and analyze each segment individually to make a final determination about whether or not the disease is present. We used the Vision Transformer Base-Patch 16–224 (Google Brain, United States), which processes images in 16 × 16 pixel patches and is optimized for an input size of 224 × 224 pixels. We used the cross-entropy loss function to train the classifier; the cross-entropy loss function measures model performance by comparing the predicted class probability with the actual class labels, and uses the output to guide optimization. No further image segmentation training was required as all synthetic images were produced with labels of disease characteristics, on which the Vision Transformer model relied.
We evaluated the addition of two commonly used image optimizers to reduce information losses, which function via augmentation of neural network attributes (e.g., weights, learning rate, etc.): Adam optimizer (Adaptive Moment Estimation)20, and Root Mean Squared Propagation image optimizer21. We set the epochs at 50 for that comparison. Subsequently, we serially evaluated model epochs (number of times the model works through the entire training set) between 50 and 200 at intervals of 50. After determining the optimal epochs, we evaluated model learning rates between 1e−2 and 1e−5. We used the average F1-score (see below) as the outcome metric for each of those comparisons22. For all model optimizations, we used a subset of images from the training dataset.
We trained that model exclusively on the 500 synthetic images of HPV-related disease, as well as 500 images of non-diseased penises and 500 images of other penile pathology (herpes simplex virus (HSV) (n = 150), primary syphilis (n = 150), penile cancer (n = 140), penile eczema (n = 30), and penile psoriasis (n = 30)). All clinical images were submitted by clinicians, including experts in infectious diseases, sexually transmitted diseases, dermatology, or family practice with a special interest in sexually transmitted diseases from six countries (India, Sri Lanka, Singapore, Australia, The United States, and The United Kingdom).
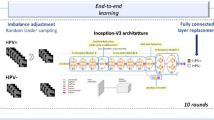
For further fine tuning of the model, we conducted a validation step using 50 images previously not seen by the model in each class (HPV-related disease, non-HPV-related disease, and non-diseased images). The 50 images of other pathology included 20 of HSV infection, 10 of primary syphilis, 10 of penile cancer, 5 of penile eczema, and 5 of penile psoriasis. We took several steps to guard against overfitting during training. First, we aimed to ensure a diverse sample set using text-to-image prompts. Second, we employed early stopping, whereby training stops when loss ceases to improve in the validation dataset after a set number of epochs. Finally, we maintained a separate validation dataset. Figure 2 shows the overall model architecture.
Assessment of model performance
We assessed the performance of the model on an additional dataset of clinical images. We used 70 clinical images of HPV-diseased penises, 70 of diseases other than HPV (HSV (n = 30), primary syphilis (n-20), penile cancer (n = 10), penile eczema (n = 5), and penile psoriasis (n = 5)), and 70 non-diseased images. All images were submitted by expert clinicians. We then assessed the performance of the classification model against all 210 images, calculating recall (or sensitivity), precision (or positive predictive value), specificity, and F1-score22, as well as overall accuracy of the model, which we defined as the average F1-score across each disease class. Equations for each outcome metric are shown below.
We graphed the performance of the model via a Receiver Operating Characteristic curve using TensorFlow Version 2.8.0 (TensorFlow, United States). We used TensorFlow to calculate the Area Under the Curve (AUC) for multiclass classifications, which compared the performance of the model for each class (e.g., HPV-related disease images) against the combination of all other classes (i.e., HPV-unrelated disease images combined with non-diseased images). We therefore calculated the AUC of the model for each classification. As a sensitivity analysis, we developed additional validation datasets via bootstrap resampling of the initial dataset over 1,000 iterations, and recalculated the AUC for each classification. We report the average AUC and 95% confidence intervals (CI) across all 1,000 iterations.
Ethical considerations
All methods were carried out in accordance with the relevant guidelines and regulations, which included the reporting guidelines for prognostic and diagnostic machine learning modeling studies23. Informed consent was obtained from all subjects who submitted clinical images through the mobile platform prior to use. All experimental protocols for this study were approved by the National University of Singapore institutional review board. The analysis of de-identified data was deemed non-human subjects’ research by the Massachusetts General Brigham institutional review board.
Equations
Results
The denoising diffusion probabilistic model produced 630 synthetic images. Of those, 500 were deemed plausible by the first expert reviewer. A blinded, second expert reviewer agreed with the plausibility determination of all 20 randomly selected images (10 plausible, 10 implausible).
Table 1 shows the results of model optimization. Between the two image optimizers, we selected Root Mean Squared Propagation image optimizer given trend towards improved accuracy. Using that optimizer, epochs of 150 appeared to perform optimally, with a learning rate of 1e−4. Supplemental Fig. 2 in the Appendix shows the learning curves for both the training and validation datasets, which indicate successful mitigation of overfitting.
The model correctly classified 64 of 70 HPV-related disease images, with a recall (or sensitivity) of 91.4% (94% CI 82.3% – 96.8%). The precision (or positive predictive value) of the model for HPV-related disease was 95.5% (95% CI 87.5% − 99.1%), and the F1-score was 93.4%. Table 2 shows the distribution of images and model assignment. Figure 3 shows the Receiver Operating Characteristics curve of the model performance for each class; the AUC of the model for images of HPV-related disease was 0.99 (95% CI 0.98-1.0%), with similar AUCs for images of HPV-unrelated disease (0.96; 95% CI 0.93–0.99) and non-diseased images (AUC 0.99; 95% CI 0.98-1.0). The performance of the model was stable across all 1,000 bootstrap iterations for all three classifications: average HPV-related disease AUC 0.99 (95% CI 0.98-1.0), average HPV-unrelated disease AUC 0.96 (95% CI 0.91–0.99), and average non-diseased AUC 0.99 (95% CI 0.96-1.0).
The model incorrectly classified six images of genital warts, one as non-diseased and five as other non-HPV-related pathology. The model also incorrectly identified one image of HSV infection as HPV-related disease, and two images of penile cancer as HPV-related disease, as well as one image of HSV infection, one image of penile psoriasis, and one image of penile eczema as non-diseased. Figure 4 shows the misclassified images. Supplemental Fig. 3 in the Appendix shows additional examples of images correctly classified.
Discussion
We developed a machine-learning disease classification model for external penile warts that was trained exclusively on synthetically generated images using a combination of denoising diffusion probabilistic and of text-to-image models. That model demonstrated excellent performance against a validation dataset of a range of clinical images. The described approach pairing synthetic image generation and disease classification has numerous possible extensions, including improved support for visually classifying known diseases as well as quickly developing classification models for new and emerging diseases. Additionally, with further development and evaluation, the specific model produced has the potential to support HPV-related disease diagnosis, particularly in areas with limited access to specialists.
Recent work has explored similar pairing of synthetic image generation and downstream classification. Schaudt et al. evaluated five different image generation models for abnormal chest radiograph images and assessed performance on a subsequent classification task, reporting accuracies ranging from 73 to 81%24. Notably, that study used intentionally simple text inputs to isolate the impact of image augmentation after generation, which may have impacted overall performance of the classification model24. Another study used a GAN model to produce synthetic images of retinal blood vessels and successfully trained classification models for retinal pathology, which showed an AUC above 97%25. However, that dataset required training on nearly 3,500 clinical images. Using denoising diffusion probabilistic modeling with more elaborate text inputs permitted training with only 10 clinical images, and resulted in an AUC above 93%.
Our HPV-related disease classification model has many possible applications. Incorporation of the model into a mobile platform can facilitate at-home disease classification, possibly overcoming fear of stigma that restrict healthcare seeking behavior26,27. Use in low-resource settings can support access to specialized sexual health services27. Given the inherent connectivity of mobile platform-based diagnoses, such tools can also support case identification and public health surveillance.
Potential impacts of the overall approach – combining synthetic image generation to rapidly train a classification model on a limited initial dataset – are broad. In the context of an outbreak of a new or emerging disease, initial image repositories are often non-existent. Creation of such datasets is labor and time-intensive, limiting any possible utility of machine-learning models to support diagnosis. Our approach overcomes that barrier, permitting the development and deployment of models with minimal initial data input.
Medical image repositories are also difficult to establish because of patient privacy protections. Synthetic images are not subject to the same restrictions. Other areas of medicine that can benefit from such an approach include the incorporation of machine-learning to support radiographic evaluation of two-dimensional images (e.g., chest radiographs) or 3-dimensional images (e.g., computed tomography and magnet resonance images)1, and even clinical dentistry28. Thus, the current successful pairing of synthetic image generation and disease classification represents a significant advance, opening the door for many other applications of machine-learning models into healthcare.
Limitations
Our study had several limitations. First, the model was assessed on a relatively small sample of clinical images, limiting the precision of our findings. Second, while the model maintained classification integrity against several distinct disease states, there remain additional pathologies that can mimic genital warts (e.g., molluscum contagiosum, condyloma lata of secondary syphilis, etc.), and thus potentially attenuate model performance. Subsequent work should aim to refine the model via including additional diseases in model training, evaluating the differences in model performance by skin tone, image quality, and type of image used, and aim to refine the synthetic image generation in order to reduce the number of implausible images produced. Reducing the number of implausible images produced will be additionally helpful for improving the usefulness of the approach described. As we did not have data on the reasons for classifying an image as implausible, such should be the subject of future work.
Further, the performance of the model was assessed on submitted clinical images with a balanced distribution of diseases. Additional methods of evaluating model accuracy will be important to understand model performance and possible utility; the model could be compared, for example, against expert physician classification of such images, blinded to the diagnosis. Additionally, the model could be assessed against molecular diagnostic testing (e.g., polymerase chain reaction of lesion swabs). Future work could also develop alternative image generation methods for comparison in order to identify the optimal strategy. Real-world evaluation will support evaluation among populations with varying disease prevalence, as well as further evaluate if the range of HPV-related disease images sufficiently captured the diversity clinical presentations. Therefore, further evaluation in a real-world setting is warranted. However, given the potential impact of pairing image generation with classification model training, however, we feel those limitations do not diminish the importance of our findings.
Conclusion
We paired denoising diffusion probabilistic modeling with a text-to-image model to produce synthetic images based on minimal initial training, which we used to train a downstream disease classification model without any further augmentation. That model demonstrated excellent performance for classifying images of penile pathology. The potential applications of this successful synergistic pairing are numerous.

Examples of input text and output images from text-to-image generation.

Schematic showing model architecture pairing text-to-image inputs with denoising diffusion probabilistic modeling to generate synthetic images of HPV-related disease used to train a vision transformer classification model. Legend for Fig. 2: The figure shows the overall structure of the HPV-related disease classification model. Text-to-image inputs paired with a denoising diffusion probabilistic model generated synthetic images across a range of presentations. All generated images were then reviewed by an expert physician, and improbable synthetic images were removed. The remaining synthetic images were used as inputs in a vision transformer classification model along with clinical images of other similar diseases and non-diseased images.

Receiver operating characteristics curve for HPV-related disease classification model trained exclusively on synthetic images. Legend for Figure 3: The figure shows the receiver operating characteristics curve for the machine-learning HPV-related disease classification model, plotting model sensitivity against 1 minus the specificity.

Images incorrectly classified by the machine-learning model. Legend for Fig. 4: The figure shows six images misclassified by the machine-learning HPV classification model, one image of genital herpes incorrectly classified as HPV-related disease, two images of penile cancer incorrectly classified as HPV-related disease, and one image of penile eczema, penile psoriasis, and genital HSV incorrectly classified as non-diseased.
Data availability
All data supporting this manuscript are available upon reasonable request of the corresponding authors.
References
Habehh, H. & Gohel, S. Machine learning in healthcare. Curr. Genomics. 22 (4), 291–300 (2021).
Woldaregay, A. Z. et al. Data-Driven blood glucose pattern classification and anomalies detection: machine-learning applications in type 1 diabetes. J. Med. Internet Res. 21 (5), e11030 (2019).
Esteva, A. et al. Dermatologist-level classification of skin cancer with deep neural networks. Nature. 542 (7639), 115–118 (2017).
Chadaga, K. et al. Application of Artificial Intelligence techniques for Monkeypox: a systematic review. Diagnostics (Basel) 2023 Feb 21; 13(5): 824.
Kwon, G., Han, C. & Kim, D. Generation of 3D Brain MRI Using Auto-Encoding Generative Adversarial Networks (2019). Preprint available at: https://arxiv.org/abs/1908.02498. Accessed 13 Feb 2024.
Thanh-Tung, H. & Tran, T. On Catastrophic Forgetting and Mode Collapse in Generative Adversarial Networks. in 2020 International Joint Conferenceon Neural Networks (IJCNN) 1–10. (2020).
Li, X. et al. When medical images meet generative adversarial network: recent development and research opportunities. Discover Artif. Intell.1 (1), 5 (2021).
Rombach, R., Blattmann, A., Lorenz, D., Esser, P. & Ommer, B. High-Resolution Image Synthesis with Latent Diffusion Models. (2022). https://arxiv.org/abs/2112.10752 Accessed 13 Feb 2024.
Muller-Franzes, G. et al. A multimodal comparison of latent denoising diffusion probabilistic models and generative adversarial networks for medical image synthesis. Sci. Rep. 13 (1), 12098 (2023).
Nichol, A. & Dhariwal, P. Improved Denoising Diffusion Probabilistic Models. (2021). https://arxiv.org/abs/2102.09672 Accessed 13 Feb 2024.
Ho, J., Jain, A. & Abbeel, P. Denoising Diffusion Probabilistic Models. in Advances in Neural Information Processing Systems vol. 33 6840–6851 (Curran Associates, Inc., 2020). https://arxiv.org/abs/2006.11239 Accessed 13 Feb 2024.
Khader, F. et al. Denoising diffusion probabilistic models for 3D medical image generation. Sci. Rep. 13 (1), 7303 (2023).
Cunningham, S. D., Kerrigan, D. L., Jennings, J. M. & Ellen, J. M. Relationships between perceived STD-related stigma, STD-related shame and STD screening among a household sample of adolescents. Perspect. Sex. Reprod. Health. 41 (4), 225–230 (2009).
Kjaer, S. K. et al. The burden of genital warts: a study of nearly 70,000 women from the general female population in the 4 nordic countries. J. Infect. Dis. 196 (10), 1447–1454 (2007).
Allan-Blitz, L-T., Ambepitiya, S., Tirupathi, R. & Klausner, J. D. The development and performance of a machine-learning based mobile platform for visually determining the etiology of 5 Penile diseases. Mayo Clin. Proc. Digit. Health. 2(2), 280-8 (2024).
Kaleta, J., Dall’Alba, D., Plotka, S. & Korzeniowski, P. Minimal data requirement for realistic endoscopic image generation with stable diffusion. Int. J. Comput. Assist. Radiol. Surg. 19 (3), 531–539 (2024).
Ruiz, N. et al. Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation. (2023). https://arxiv.org/abs/2208.12242 Accessed 28 Feb 2024.
Ronneberger, O., Fischer, P., Brox, T. & U-Net Convolutional Networks for Biomedical Image Segmentation. arXiv 2015. (2023). https://arxiv.org/abs/1505.04597v1 Accessed 28 Nov.
Dosovitskiy, A. et al. Houlsby, N. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. (2021). https://arxiv.org/abs/2010.11929 Accessed 28 Feb 2024.
Kingma, D., Ba, J. Adam: A Method for Stochastic Optimization Availablet at: (2024). https://arxiv.org/abs/1412.6980 Accessed 6 Mar 2017.
Reddy, S., Reddy, K. T. & Kumari, V. Optimization of deep learning using various optimizers, loss functions and dropout. Int. J. Innov. Technol. Explor. Eng. 8 (2S), 272–279 (2018).
Dalianis, H. Evaluation Metrics and Evaluation. Clinical Text Mining: Secondary Use of Electronic Patient Records 45–53 (Springer International Publishing, 2018).
Klement, W. & El Emam, K. Consolidated Reporting Guidelines for Prognostic and Diagnostic Machine Learning modeling studies: development and validation. J. Med. Internet Res. 25, e48763 (2023).
Schaudt, D. et al. A Critical Assessment of Generative Models for Synthetic Data Augmentation on Limited Pneumonia X-ray Data. Bioeng. (Basel) 2023. 10(12): 1421.
Coyner, A. S. et al. Synthetic Medical images for robust, privacy-preserving training of Artificial Intelligence: application to Retinopathy of Prematurity diagnosis. Ophthalmol. Sci. 2 (2), 100126 (2022).
Tilson, E. C. et al. Barriers to asymptomatic screening and other STD services for adolescents and young adults: focus group discussions. BMC Public. Health. 4, 21 (2004).
Newton-Levinson, A., Leichliter, J. S. & Chandra-Mouli, V. Sexually Transmitted Infection Services for Adolescents and youth in low- and Middle-Income countries: perceived and experienced barriers to Accessing Care. J. Adolesc. Health. 59 (1), 7–16 (2016).
Surlari, Z. et al. Current Progress and challenges of using Artificial Intelligence in Clinical Dentistry-A Narrative Review. J. Clin. Med. 2023 Nov 28; 12(23): 7378
Acknowledgements
A startup, HeHealth has raised funding from institutional investors and angel investors, and would like to specifically acknowledge Plug and Play Tech Center as well as ARKRAY Corporate Venture Capital.
Author information
Authors and Affiliations
Contributions
L.AB., S.A., Y.K. and J.D.K designed the study. L.AB., S.A., J.P., and Y.K curated and analyzed data. L.AB. prepared all tables and figures and wrote the first draft of the manuscript. C.A.R. and J.D.K provided study oversight. All authors reviewed the manuscript and contributed to revisions.
Corresponding authors
Ethics declarations
Competing interests
LAB and JDK received consulting fees from HeHealth Inc. SA and JP are employees of HeHealth Inc. YK is the CEO of HeHealth Inc. CAR has no relevant conflicts of interest.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Allan-Blitz, LT., Ambepitiya, S., Prathapa, J. et al. Synergistic pairing of synthetic image generation with disease classification modeling permits rapid digital classification tool development. Sci Rep 14, 25632 (2024). https://doi.org/10.1038/s41598-024-77565-6
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-024-77565-6
