
Abstract
This paper exhibits a proportional-type robust current controller for permanent magnet synchronous motors (PMSMs), incorporating the variable bandwidth technique driven by the proposed online auto-tuner and the disturbance observer (DOB) as the subsystems. There are two contributions: (a) the proposed online auto-tuner implements the variable bandwidth for the closed-loop system to boost the transient current tracking performance and (b) the combination of proportional-type feedback controller and DOB eliminates the requirement of the integral action, ensuring the steady-state error rejection property. Moreover, it is proved that the resultant feedback system recovers the target current tracking performance without steady-state errors. The experimental study is conducted to verify the efficacy of the proposed controller using a 700-W prototype PMSM.
Similar content being viewed by others

Introduction
The permanent magnet synchronous motor (PMSM) has been considered a promising solution to induction motors (IMs) and DC motors due to their high efficiency and simple structure. These advantages have widened their applications such as tension controls, electric power steering (EPS), home appliances, electric vehicles, and so on1,2,3,4,5.
The torque control is essential for speed and position control system, which can be implemented by the classical direct torque control (DTC) technique. Recently, the rotational coordinate transform based current control scheme has been adopted for the torque control due to its high performance and low current ripple, which is called the vector control technique. In the resulting rotational d-q frame, a simple proportional–integral (PI) regulator has been used to regulate the d-q frame current errors. Their PI gains were tuned through a trial-and-error process and frequency domain analysis technique, called the Bode and Nyquist methods6,7, for a fixed operating point. For wide-range operating range, an extra online gain selector has to be embedded in the control algorithm8. To overcome this limitation, the feedback-linearization (FL) method was applied, which is composed of the PI regulator and a feed-forward compensation for the disturbance from the back EMF effect9,10,11. The PMSM parameter dependent PI gains and feed-forward compensator force the closed-loop dynamics to be a low-pass filter (LPF) with a desired bandwidth via a pole-zero cancellation. To guarantee the desired closed-loop performance, the on-line or off-line parameter identification (ID) algorithms must be combined with the FL controller12,13,14,15. The parameter dependency problem can be alleviated by the sliding mode control method in Ref.16. This scheme requires a conservative lower and upper bounds of the PMSM parameters for the discontinuous sign-function gain and feed-forward compensator, which could produce an excessive control signal. A novel model predictive control (MPC) technique was proposed with a significant reduced computational complexity, compared with classical MPC methods17,18. The closed-loop optimality and control input feasibility can be guaranteed with additional ID algorithms like to the FL controller. It was reported that the disturbance observe (DOB) can be used as an effective solution to construct the feed-forward compensator while eliminating the steady-state errors19,20. Recently, the DOB based current controller was systematically developed for PMSMs with a rigorous closed-loop stability and property analysis21. These surveyed techniques assign the fixed bandwidth to the closed-loop system by their well-tuned control gains. The magnified control gains could improve the transient performance but result in an efficiency degradation in steady-state operations.
Unlike the literature mentioned above, this study devises a novel variable bandwidth-based proportional-type current controller subject to the constraints;
-
(C1) an fixed a high-level of current feedback gain to ensure the desired outer loop bandwidth for speed and position loops;
-
(C2) the requirement of the integral actions for the control loop involving the additional anti-windup mechanisms to ensure the steady-state error rejection;
-
(C3) the true PMSM parameter dependence of the controller to secure the desired closed-loop stability and performance.
The proposed technique considering these constraints makes the following major contributions:
-
1.
The proposed auto-tuner continuously updates the feedback gain according to the simple rule in the analytic form to find the desired closed-loop bandwidth for the transient and steady-state operations, resulting in improved current tracking performance and lowered current ripple level (for (C1)).
-
2.
The proportional-type current controller employs the reduced-order DOB as a subsystem as a replacement of the integrator to simplify the resultant feedback system structure by removing the requirement of the additional anti-windup mechanisms, so that it ensures the performance recovery property (for (C2) and (C3)).
Moreover, practical advantages are shown by providing convincing experimental data using a 700-W prototype PMSM dynamo system.
Current and speed dynamics of PMSMs
In accordance with result9, the PMSM current dynamics are described in the rotational d-q frame as
where \(i_x(t)\), \(u_x\), \(x=d,q\), denote the current (in A) and voltage (in V) represented in the rational d-q frame, respectively. The electrical speed is defined as \(\omega _r(t):= P\omega (t)\) with P and \(\omega (t)\) being the pole-pair numbers and rotor speed in rad/s, which is used to transform the reference frame into the rational d-q frame. The inductance values in this frame are given as \(L_x\), \(x=d,q\), (in H) and the stator resistance and flux are represented as \(R_s\) (in \(\Omega\)) and \(\lambda _{PM}\) (in Wb), respectively.
The PMSM mechanical speed dynamics is related to the d-q frame current as
with the load torque \(T_L(t)\) and electrical torque \(T_e(i_d(t),i_q(t))\) defined as
where J and B represent the inertia and viscous damping constants, respectively, and \(\Delta L_{dq}:= L_d - L_q\). Note that the PMSM speed acts as the internal dynamics in the current control mode. Fortunately, it is proved that any stabilizing current controller stabilizes the internal dynamics coming from the PMSM speed. See21 for details. Thus, this study focuses on developing the current tracking controller without internal dynamics analysis.
The next section designs an advanced current control algorithm under the practical assumptions:
-
(A1) The nominal PMSM parameter values, \(L_{x,0}\), \(x=d,q\), \(R_{s,0}\), \(\lambda _{PM,0}\), are available, but their variations are unknown. e.g., \(L_x = L_{x,0} + \Delta L_x\), \(R_s = R_{s,0} + \Delta R_s\), and \(\lambda _{PM} = \lambda _{PM,0} + \Delta \lambda _{PM}\) with unknown variations \(\Delta L_x\), \(\Delta R_s\), and \(\Delta \lambda _{PM}\).
-
(A2) The d-q frame current \(i_x(t)\), \(x=d,q\), and mechanical speed \(\omega (t)\) are available for feedback using the shut resistors and rotary encoder.
Design of proposed proportional-type robust current controller
Control objective
This subsection introduces the variables as \(I_{x,b}^*(s) = \mathcal {L}\{i_{x,b}^*(t)\}\) and \(I_{x,ref}(s) = \mathcal {L}\{i_{x,ref}(t)\}\) as the Laplace transforms of desired current response \(i_x^*(t)\) and its reference \(i_{x,ref}(t)\), which defines the transfer function as the base feedback system performance:
with its realization given by
for given desired bandwidth \(\omega _{cc}\) (in rad/s, \(f_{cc} = \frac{\omega _{cc}}{2\pi }\) Hz) determining the current tracking performance and ripple level in the transient and steady-state operations.
To secure both the transient and steady-state behaviors of the feedback system, this work modifies the base desired system (5) such that \(i_x^*(t) = i_{x,b}^*(t)\bigg |_{\omega _{cc} = \hat{\omega }_{cc}}\) resulting in the time-varying system
for a variable bandwidth \(\hat{\omega }_{cc}(t)\) with property \(\hat{\omega }_{cc}(t) \ge \omega _{cc}\), \(\forall t\), and initial condition \(\hat{\omega }_{cc}(0) = \omega _{cc}\), which is driven by the proposed auto-tuner presented in “Proposed controller” section. This modification constitutes the control objective given by
exponentially (named the performance recovery) to assign variable bandwidth to the resultant feedback system. The controller including the update logic for \(\hat{\omega }_{cc}(t)\) is designed in “Proposed controller” and “Feedback system analysis results” sections presents the closed-loop system analysis results.
Proposed controller
Open-loop system derivation
Using the notations of (A1) in “Current and speed dynamics of PMSMs” section, the system of (1) and (2) gives an equivalent form given by
with unknown lumped disturbance defined as
which results in the open-loop system for \({\textbf {u}}_{dq}(t) \mapsto {\textbf {i}}_{dq}(t)\):
where \({\textbf {L}}_{dq,0}:= \left[ \begin{array}{cc} L_{d,0} & 0 \\ 0 & L_{q,0} \end{array}\right]\), \({\textbf {i}}_{dq}(t):= \left[ \begin{array}{cc} i_d(t) \\ i_q(t) \end{array}\right]\), \({\textbf {u}}_{dq}:= \left[ \begin{array}{cc} u_d(t) \\ u_q(t) \end{array}\right]\), \({\textbf {q}}_0 (\omega _r(t),{\textbf {i}}_{dq}(t)):= \left[ \begin{array}{cc} L_{q,0}i_q(t) \\ -(L_{d,0}i_d(t) + \lambda _{PM}) \end{array}\right] \omega _r(t)\), \({\textbf {d}}(t):= \left[ \begin{array}{cc} d_d(t) \\ d_q(t) \end{array}\right]\), and \(\Vert \dot{{\textbf {d}}}(t)\Vert \le \bar{d}\), \(\forall t \ge 0\).
Implementation of proposed controller
This subsection defines the error \(\tilde{{\textbf {i}}}_{dq}(t):= {\textbf {i}}_{dq,ref}(t) - {\textbf {i}}_{dq}(t)\) for given reference \({\textbf {i}}_{dq,ref}(t):= \left[ \begin{array}{cc} i_{d,ref}(t) \\ i_{q,ref}(t) \end{array}\right]\), which constructs the proposed current controller to stabilize the open-loop system (10) by the rule given by
where the proposed online auto-tuner drives the time-varying feedback gain \(\hat{\omega }_{cc}(t)\) along the system given by
involving the design parameters \(\gamma _{at} > 0\) and \(\rho _{at} > 0\) where \(\tilde{\omega }_{cc}(t):= \hat{\omega }_{cc}(0) - \hat{\omega }_{cc}(t)\) (\(=\omega _{cc} - \hat{\omega }_{cc}(t)\)), \(\forall t \ge 0\). The disturbance estimate \(\hat{{\textbf {d}}}(t)\) is governed by the reduced-order DOB:
with the DOB gain \(l > 0\). It should be noticed that the reduced DOB of (13) and (14) is derived by referencing the design technique in Ref.20.
The substitution of (11) and (12) to (10) forms the closed-loop current error dynamics as
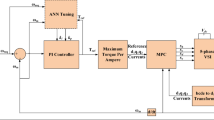
where \({\textbf {e}}_d(t):= {\textbf {d}}(t) - \hat{{\textbf {d}}}(t)\), \(\forall t \ge 0\), which is used for “Feedback system analysis results” section to prove the control objective (7) and closed-loop stability. The configuration of resultant feedback system is shown in Fig. 1.

Proposed auto-tuner-based current controller structure.
Feedback system analysis results
This section proves that the proposed solution of (11)–(14) guarantees the control objective (7) and exponential current error convergence \(\lim _{t\rightarrow \infty } {\textbf {i}}_{dq}(t) = {\textbf {i}}_{dq,ref}(t)\) through further analysis of the closed-loop dynamics (15) incorporating the subsystem dynamics of (12), (13), and (14). To this end, “Reduced-order DOB analysis results” section begins with the analysis of the reduced-order DOB of (13) and (14).
Reduced-order DOB analysis results
The reduced-order DOB of (13) and (14) does not explicitly show the disturbance estimation tendency for \(\hat{{\textbf {d}}}(t)\), which is clarified in Lemma 1.
Lemma 1
The reduced-order DOB of (13) and (14) guarantees that
Proof
The time derivative of (14) adopting (13) gives
where the open-loop system (10) showing \({\textbf {d}} = {\textbf {L}}_{dq,0}\dot{{\textbf {i}}}_{dq} + R_{s,0} {\textbf {i}}_{dq} - {\textbf {q}}_0 - {\textbf {u}}_{dq}\) validates the last equation above; completes the proof. \(\square\)
Remark 1
The result (16) of Lemma 1 derives the system for \({\textbf {e}}_d = {\textbf {d}} - \hat{{\textbf {d}}}\) satisfying
which shows \(\dot{V}_{e_d}\) for \(V_{e_d}:= \frac{1}{2}\Vert {\textbf {e}}_d\Vert ^2\) such that
for any \(l > 0\) such that \(\frac{2\bar{d}}{l}\approx 0\); used for the remaining analysis.
Online auto-tuner analysis results
The proposed online auto-tuner (12) updating the variable bandwidth \(\hat{\omega }_{cc}(t)\) has a lower bound of its initial bandwidth \(\omega _{cc}\), which helps to prove the closed-loop properties in Theorems 1 and 2. See Lemma 2 for details.
Lemma 2
The proposed online auto-tuner (12) renders the variable bandwidth \(\hat{\omega }_{cc}(t)\) to satisfy the inequality
Proof
The system (12) can be written as
whose lower bound can be found by integrating both side:
which verifies the result of this lemma. \(\square\)
Control loop analysis results
This subsection ends the feedback system analysis tasks by proving the design objective (7), exponential current error convergence \(\lim _{t\rightarrow \infty } {\textbf {i}}_{dq}(t) = {\textbf {i}}_{dq,ref}(t)\), and offset-free property using the results (18) and (19) obtained from “Reduced-order DOB analysis results” and “Online auto-tuner analysis results” sections. Theorem 1 begins with the proof of the design objective (7).
Theorem 1
The proposed feedback system shown in Fig. 1 guarantees
exponentially for \({\textbf {i}}_{dq}^*(t):= \left[ \begin{array}{cc} i_d^*(t) \\ i_q^*(t) \end{array}\right]\) satisfying
(e.g., accomplishment of the control objective (7)) for any \(\frac{2\bar{d}}{l}\approx 0\).
Proof
The deviation \(\varvec{\epsilon }:= {\textbf {i}}_{dq}^* - {\textbf {i}}_{dq}\) gives the system along (22) and (20):
which makes \(V_\epsilon := \frac{1}{2}\Vert \varvec{\epsilon }\Vert ^2 + \kappa _{e_d}V_{e_d}\) with \(\kappa _{e_d} > 0\) to be
using the results (18) and (19) and fact \({\textbf {x}}^T {\textbf {y}} \le \frac{\epsilon }{2}\Vert {\textbf {x}}\Vert ^2 + \frac{1}{2\epsilon }\Vert {\textbf {y}}\Vert ^2\), \(\forall {\textbf {x}}\), \({\textbf {y}} \in \mathbb {R}^n\), \(\forall \epsilon > 0\) (Young’s inequality). Then, the selection \(\kappa _{e_d} = \frac{1}{l}\big (\frac{\Vert {\textbf {L}}_{dq,0}^{-1}\Vert ^2}{\omega _{cc}} + 1\big )\) concludes
where \(\alpha _e:= \min \big \{\omega _{cc}, \frac{1}{\kappa _{e_d}}\big \}~(>0)\); completing the proof. \(\square\)
Theorem 2 proves the exponential current error convergence \(\lim _{t\rightarrow \infty } {\textbf {i}}_{dq}(t) = {\textbf {i}}_{dq,ref}(t)\) using the result (18) obtained in “Reduced-order DOB analysis results” section. Before proceeding with the formal analysis, rewrite the closed-loop system (15) with the online auto-tuner (12) as
where \({\textbf {w}}(t):= \dot{{\textbf {i}}}_{dq,ref}(t)\) and \(\Vert {\textbf {w}}(t)\Vert \le \bar{w}\), \(\forall t \ge 0\), which is used for a basis to prove the result of Theorem 2
Theorem 2
The proposed feedback system shown in Fig. 1 guarantees
exponentially for any design parameters \(\gamma _{at} > 0\) and \(\rho _{at} > 0\) of the auto-tuner resulting in \(\frac{2\bar{w}}{\hat{\omega }_{cc}(t)}\approx 0\).
Proof
The closed-loop trajectories (22) and (23) yield \(\dot{V}\) for \(V:= \frac{1}{2}\Vert \tilde{{\textbf {i}}}_{dq}\Vert ^2 + \frac{1}{4\gamma _{at}}\tilde{\omega }_{cc}^2 + \beta _{e_d}V_{e_d}\) with \(\beta _{e_d} > 0\) as
where the result (18) and Young’s inequality justify the inequality above. Then the selection \(\beta _{e_d} = \frac{1}{l}\bigg (\frac{2\Vert {\textbf {L}}_{dq,0}^{-1}\Vert ^2}{\omega _{cc}} + 1\bigg )\) concludes
where \(\alpha := \min \big \{\frac{\omega _{cc}}{2}, 2\rho _{at}\gamma _{at}, \frac{1}{\beta _{e_d}}\big \} >0\) subject to the variable bandwidth \(\hat{\omega }_{cc}\) (\(\ge \omega _{cc}\), \(\forall t \ge 0\), by Lemma 2) satisfying \(\frac{2\bar{w}}{\hat{\omega }_{cc}}\approx 0\); completing the proof. \(\square\)
The closed-loop system could suffer from a steady-state error because the proposed controller includes the proportional component of current tracking error. However, the reduced-order DOB of (13) and (14) contributes the steady-state error rejection property to the closed-loop system without current tracking error integrators, which is investigated in Theorem 3.
Theorem 3
The proposed feedback system shown in Fig. 1 guarantees
for any steady-state, where \(\lim _{t\rightarrow \infty } {\textbf {i}}_{dq}(t) = {\textbf {i}}_{dq}(\infty )\) and \(\lim _{t\rightarrow \infty } {\textbf {i}}_{dq,ref}(t) = {\textbf {i}}_{dq,ref}(\infty )\).
Proof
The closed-loop system of (22) and (17) results in the static relationships such that
which completes the proof since the combination of (29) and (28) implies \(\tilde{{\textbf {i}}}_{dq}(\infty ) = {\textbf {0}}\). \(\square\)
Experimental results
This section provides the experimental data to convince the practical merits of the proposed controller and adopts the FL controller for comparison study. The Texas Instruments (TI) DSP28335 implemented the control algorithms under pulse-width modulation (PWM) periods 0.1 ms synchronized to the analog-to-digital conversion and control interrupts. The TI DRV8302-HC-C2-KIT was used as the three-phase inverter with the DC voltage level \(V_{dc} = 15\) V. Figure 2 depicts the hardware setup. A 700 W prototype PMSM was used for this experiment where the rated current and speed are 30 A and 3000 rpm, respectively. The PMSM parameters are given by \(R_s = 0.0315~\Omega\), \(L_d = 0.126\) mH, \(L_q = 0.34\) mH, \(\lambda _{PM} = 0.0109\) Wb, \(P = 3\), \(J = 0.000341\) kg\(\cdot\)m2, \(B = 0.001\) Nm/rad/s. It was assumed that the nominal PMSM parameters were given to be not equal to their true values to taking the model-plant mismatches into account, whose values were selected as \(R_{s,0} = 0.7R_s\), \(L_{d,0} = 0.8L_d\), \(L_{q,0} = 0.5L_q\), \(\lambda _{PM,0} = 0.7\lambda _{PM}\).

Hardware setup.
For the proposed controller, the bandwidth update algorithm (12) was set to be initiated from its initial bandwidth \(f_{cc} = 30\) Hz for \(\omega _{cc} = 2\pi f_{cc} = 188.49\) rad/s. The rest of design parameters were chosen as \(\gamma _{at} = 10\times 10^3\), \(\rho _{at} = 50/\gamma _{at}\), and \(l = 1885\). The FL controller (presented in Ref.9) given by
is used for comparison with the bandwidth \(\omega _{cc}\), which is the same as the initial bandwidth of the proposed controller. Note that the FL controller results in the closed-loop transfer function \(\frac{I_x(s)}{I_{x,ref}(s)} = \frac{\omega _{cc}}{s + \omega _{cc}}\), \(x=d,q,\) \(\forall s \in \mathbb {C}\), through a pole-zero cancellation, if \(R_s = R_{s,0}\), \(L_{d} = L_{d,0}\), \(L_q = L_{q,0}\), and \(\lambda _{PM} = \lambda _{PM,0}\), i.e., there are no plant-model mismatches.
Pulse reference tracking test under constant speed load
The first experiment verified the q-frame current tracking performance for a pulse-wave reference with \(i_{d,ref} = 0\). This experiment was repeated for three speed loads of \(\omega _{rpm} = 500\), 1000, and 2000 rpm. The resulting d-q frame current responses are shown in Fig. 3, which observes that the proposed technique considerably enhances the robustness of the feedback system by effectively attenuating the performance degradation from model-plant mismatches and operating mode changes due to the improved feedback system structure including the online auto-tuner and DOBs. Figure 4 presents the corresponding DOB and bandwidth responses.

d-q frame current tracking performance comparisons for pulse-wave reference under three speed loads \(\omega _{rpm} = 500\), 1000, and 1500 rpm.

DOB and bandwidth responses for pulse-wave reference tracking test under speed load \(\omega _{rpm} = 2000\) rpm.
Sinusoidal reference tracking test under sinusoidal speed load
This subsection demonstrates the improvement of frequency response characteristics by the proposed technique under the same setting as the first experiment. To this end, the speed load was set to in a biased sinusoidal form as \(\omega _{rpm} = 1200 + 70 \sin (2\pi 10 t)\), \(\forall t \ge 0\), and three kinds of references were applied to the feedback system such that \(i_{q,ref}(t) = 15 + 10 \sin (2\pi f t)\) A, \(f=20,~40,~60\) Hz. The upper side of Fig. 5 shows the resulting closed-loop current responses, which implies that the proposed technique considerably enhances the frequency response characteristics (e.g., the reductions of magnitude distortion and phase delay) of the feedback system by boosting the bandwidth, accordingly, despite a severe operating mode change. The lower side of Fig. 5 shows the corresponding bandwidth behaviors.

q-frame current tracking performance comparison result and variable bandwidth behaviors under sinusoidal speed load and sinusoidal references with three kinds of bandwidths, 20, 40, 60 Hz.
Current regulation test under sinusoidal speed load
In the third experiment, the q-frame current regulation performance was investigated for \(i_{q,ref}(t) = 20\) A under the time-varying speed load \(\omega _{rpm} = 1200 + 70 \sin (2\pi 10 t)\), \(\forall t \ge 0\). As can be seen from Fig. 6, the proposed controller makes the current oscillation smaller about three-times than the FL controller through effective cooperation by the subsystems, such as DOB and online auto-tuner, which leads to a considerable torque ripple reduction resulting in an improved ride comfort for the electrical vehicle applications.

q-frame current regulation performance comparison under sinusoidal speed load.
Numerical performance comparison result
This subsection concludes this section by presenting the numerical comparison result for the closed-loop performances demonstrated in “Pulse reference tracking test under constant speed load” to “Current regulation test under sinusoidal speed load” sections using the metric function defined as \(f_{RMS}:= \sqrt{\int _0^\infty |i_{q,ref}(t) - i_q(t)|^2 + |i_{d,ref}(t) - i_d(t)|^2 dt}\). Here, additional comparison result was included in this numerical performance evaluation using the PI controller tuned for the bandwidth \(f_{cc} = 30\) Hz (\(\omega _{cc} = 2\pi 30\) rad/s) under the constant speed load \(\omega _{rpm} = 500\) rpm. Figure 7 tabulates the numerical performance comparison result showing a 39% performance improvement by the proposed technique. From this experimental evidence, the useful properties proven in “Feedback system analysis results” section were experimentally confirmed, and the proposed technique could be qualified as a promising solution for actual industrial systems, such as home appliances, electric vehicles, and so on.

Numerical performance comparison result.
Conclusions
A robust current control technique was suggested for PMSMs, which includes the online auto-tuner and DOBs with closed-loop analysis. The beneficial closed-loop properties obtained by the auto-tuner and DOBs were proven theoretically and experimentally verified by convincing experimental data. Especially, the proposed auto-tuner played a crucial role in improving the current tracking performance and frequency response characteristics in the experimental study by increasing and restoring the closed-loop bandwidth accordingly. In future work, a combination of DOBs and integrators will be devised to secure improved closed-loop robustness with a closed-loop performance optimization process through the order-reduction technique.
Data availability
The datasets used and/or analysed during the current study available from the corresponding author on reasonable request.
References
Luo, M. et al. Full-order adaptive sliding mode control with extended state observer for high-speed PMSM speed regulation. Sci. Rep. 13, 6200 (2023).
Zhang, B. et al. Fuzzy PID control of permanent magnet synchronous motor electric steering engine by improved beetle antennae search algorithm. Sci. Rep. 14, 2898 (2024).
Cao, W. et al. Optimization of x-axis servo drive performance using PSO fuzzy control technique for double-axis dicing saw. Sci. Rep. 13, 20719 (2023).
Liu, X. et al. Research on permanent magnet synchronous motor algorithm based on linear nonlinear switching self-disturbance rejection control. Sci. Rep. 13, 20133 (2023).
Kim, S.-K. et al. Current sensorless position-tracking control with angular acceleration error observers for hybrid-type stepping motors. Sci. Rep. 12, 14993 (2022).
Andeescu, G.-D. et al. Combined flux observer with signal injection enhancement for wide speed range sensorless direct torque control of IPMSM drives. IEEE Trans. Energy Convers. 23, 393–402 (2008).
Tang, L., Zhong, L., Rahman, M. & Hu, Y. A novel direct torque control for interior permanent-magnet synchronous machine drive with low ripple in torque and flux—A speed-senseroless approach. IEEE Trans. Ind. Appl. 39, 1748–1756 (2003).
Matausek, M. R., Jeftenic, B. I., Miljkovic, D. M. & Bebic, M. Z. Gain scheduling control of DC motor drive with field weakening. IEEE Trans. Ind. Electron. 43, 153–162 (1996).
Sul, S.-K. Control of Electric Machine Drive Systems Vol. 88 (Wiley, 2011).
Kwon, Y.-C., Kim, S. & Sul, S.-K. Voltage feedback current control scheme for improved transient performance of permanent magnet synchronous machine drives. IEEE Trans. Ind. Electron. 59, 3373–3382 (2012).
Kwon, Y.-C., Kim, S. & Sul, S.-K. Six-step operation of PMSM with instantaneous current control. IEEE Trans. Ind. Appl. 50, 2614–2625 (2014).
Srilakshmi, K. et al. Development of renewable energy fed three-level hybrid active filter for ev charging station load using jaya grey wolf optimization. Sci. Rep. 14, 4429 (2024).
Wu, X. et al. Adaptive suspension state estimation based on immakf on variable vehicle speed, road roughness grade and sprung mass condition. Sci. Rep. 14, 1740 (2024).
Mejia, J. et al. Adaptive filter with Riemannian manifold constraint. Sci. Rep. 13, 9014 (2023).
Tian, Y. et al. Application of a long short-term memory neural network algorithm fused with Kalman filter in UWB indoor positioning. Sci. Rep. 14, 1925 (2024).
Jezernik, K., Korelic, J. & Horvat, R. PMSM sliding mode FPGA-based control for torque ripple reduction. IEEE Trans. Power Electron. 28, 3549–3556 (2013).
Geyer, T., Papafotieu, G. & Morari, M. Model predictive direct torque control-part I: Concept, algorithm and analysis. IEEE Trans. Ind. Electron. 56, 1894–1905 (2009).
Papafotieu, G., Kley, J., Papdopoulous, K., Bohren, P. & Morari, M. Model predictive direct torque control-part II: Implementation and experimental evaluation. IEEE Trans. Ind. Electron. 56, 1906–1915 (2009).
Chen, W.-H., Ballance, D., Gawthrop, P. & O’Reilly, J. A nonlinear disturbance observer for robotic manipulators. IEEE Trans. Ind. Electron. 47, 932–938 (2000).
Son, Y. I., Kim, I. H., Choi, D. S. & Shim, H. Robust cascade control of electric motor drives using dual reduced-order PI observer. IEEE Trans. Ind. Electron. 62, 3672–3682 (2015).
Kim, S.-K. Proportional-type performance recovery current tracking control algorithm for permanent magnet synchronous motor. IET Electric Power Appl. 12, 332–338 (2018).
Acknowledgements
This work was supported by Korea Institute of Planning and Evaluation for Technology in Food, Agriculture, Forestry(IPET) through Eco-friendly Power Source Application Agricultural Machinery Technology Development Program, funded by Ministry of Agriculture, Food and Rural Affairs(MAFRA)(322047-5).
Author information
Authors and Affiliations
Contributions
Software, validation, formal analysis, investigation, and writing-original draft preparation, Y. Kim; Writing-review and editing, data curation, validation, and visualization, H. Choi and J. Park; Supervision, project administration, and funding acquisition, S.-K Kim and Y. Kim; Conceptualization and methodology, S.-K. Kim; resources. All authors have read, reviewed, and agreed to the published version of the manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Choi, H., Park, J.K., Kim, SK. et al. Proportional-type robust current controller under variable bandwidth technique for permanent magnet synchronous motors. Sci Rep 14, 28985 (2024). https://doi.org/10.1038/s41598-024-77701-2
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-024-77701-2
