
Abstract
Given the limited capacity to accurately determine the necessity for intubation in intensive care unit settings, this study aimed to develop and externally validate an interpretable machine learning model capable of predicting the need for intubation among ICU patients. Seven widely used machine learning (ML) algorithms were employed to construct the prediction models. Adult patients from the Medical Information Mart for Intensive Care IV database who stayed in the ICU for longer than 24 h were included in the development and internal validation. The model was subsequently externally validated using the eICU-CRD database. In addition, the SHapley Additive exPlanations method was employed to interpret the influence of individual parameters on the predictions made by the model. A total of 11,988 patients were included in the final cohort for this study. The CatBoost model demonstrated the best performance (AUC: 0.881). In the external validation set, the efficacy of our model was also confirmed (AUC: 0.750), which suggests robust generalization capabilities. The Glasgow Coma Scale (GCS), body mass index (BMI), arterial partial pressure of oxygen (PaO2), respiratory rate (RR) and length of stay (LOS) before ICU were the top 5 features of the CatBoost model with the greatest impact. We developed an externally validated CatBoost model that accurately predicts the need for intubation in ICU patients within 24 to 96 h of admission, facilitating clinical decision-making and has the potential to improve patient outcomes. The prediction model utilizes readily obtainable monitoring parameters and integrates the SHAP method to enhance interpretability, providing clinicians with clear insights into the factors influencing predictions.
Similar content being viewed by others

Background
The mechanical ventilation through an endotracheal tube is a life-saving, invasive intervention designed to support or replace spontaneous respiration for patients experiencing acute respiratory distress1,2. Critically ill patients often require tracheal intubation3,4,5, and between 38 and 88% of patients admitted to critical care units require intratracheal intubation and mechanical ventilation6,7. A total of 10-15% of intubated ICU patients experience hypoxia, 18% experience cardiovascular instability, and 2% experience cardiac arrest8,9. In addition, the first-pass success rate of tracheal intubation in the critically ill is often < 80%, with up to 20% of tracheal intubations taking more than two attempts, while multiple intubation attempts are associated with a higher risk of adverse outcomes10. The incidence of peri-intubation adverse events is further elevated in patients with anticipated difficult airways11. Moreover, the worse physiological reserve of ICU patients significantly contributes to increased risks of profound peri-intubation hypoxemia, hypotension, arrhythmia, cardiac arrest, and death12.
Despite the high stakes involved13,14,15, the timing of tracheal intubation in the ICU has historically lacked rigorous research support. The optimal timing for intubation, early versus late16,17, remains a subject of controversy, resulting in considerable variability in clinical intubation practices18. Thus, there is an urgent need for objective and standardized methods to determine the appropriate timing and patient selection for intubation in order to reduce long-term complications and mortality rates among ICU patients19,20,21.
As a subfield of artificial intelligence, machine learning is a methodology that enables computers to identify patterns and classify data by utilizing historical or existing data to train models, thereby facilitating predictions about outcomes22. Machine learning has been applied in various healthcare domains, including gastroenterology, pulmonology, neurology, cardiology, emergency medicine, and critical care medicine22,23,24,25,26,27,28,29. As electronic healthcare record (EHR) data sets grow in size and complexity, predictive models based on machine learning can enhance patient safety and improve outcomes while controlling costs30,31,32,33.
While the field of medicine is increasingly leveraging the potential of machine learning, a key challenge in applying ML models to healthcare remains their interpretability30. Although algorithms such as logistic regression and decision trees offer a high degree of transparency, many commonly used machine learning algorithms face significant interpretability challenges, commonly referred to as the ‘black box’ problem34. To address the interpretability challenge, Lundberg and Lee proposed SHAP (Shapley Additive exPlanations), a model-agnostic method based on Shapley values from cooperative game theory, which offers insights into individual predictions for kernel-based and tree-based models alike35. SHAP’s capacity to attribute each feature’s contribution to a model’s prediction has proven valuable in medical applications, including early-stage prognostic predictions for sepsis23 and mortality prediction for gastrointestinal bleeding in intensive care units22. Despite these developments, to our knowledge, SHAP has not yet been explored in the context of intubation prediction, presenting an opportunity for further investigation.
Therefore, the objective of our study was to develop and validate a machine learning model based on clinical features for the early prediction of tracheal intubation in critically ill patients. The most effective model was selected for external validation and its interpretation was performed using the SHAP method.
Methods
Source of data
The data utilized for model development were obtained from the MIMIC-IV36 database at Beth Israel Deaconess Medical Center, which houses comprehensive and high-quality data on patients admitted to ICUs between 2008 and 2019. Deidentified data were contained in MIMIC-IV, including admissions, discharges, diagnoses, monitoring data and laboratory results.
The external validation data were obtained from the eICU Collaborative Research Database (eICU-CRD37), a multicenter database comprising deidentified health data associated with over 200,000 ICU admissions in the United States between 2014 and 2015. Both databases are released under the Health Insurance Portability and Accountability Act (HIPAA) safe harbor provision, which eliminates the need for additional ethical approval. The data extraction was performed by one author (Xiangjie Duan, CITI record number: 42039823) who obtained access to both databases. This study was reported in accordance with the recommendations of the Transparent Reporting of a Multivariable Prediction Model for Individual Prognosis or Diagnosis statement (TRIPOD, additional file 2)38.
Selection of participants and outcome definition
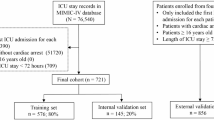
We enrolled all patients aged 18 and above in the MIMIC-IV database who were not mechanically ventilated invasively prior to ICU admission. For patients with multiple hospital admissions, we only included data from their first ICU stay and initial hospitalization. Patients were excluded if (1) they stayed in the ICU for less than 24 h, (2) intubation was initiated before hour 24 of ICU admission, or (3) extubated before consecutive 24 h of their first invasive mechanical ventilation39,40. Additionally, patients without blood gas measurements were also excluded since the previous studies have demonstrated that pulse oximetry was not reliable indicators at low oxygen saturation levels (a common sign of endotracheal intubation), especially in critically ill patients compared with healthy volunteers41. And caution should be exercised when interpreting these results compared to invasive tests such as blood gas analysis42. In the eICU-CRD validation cohort, all eligible patients who did not meet any exclusion criteria described above were included.
The outcome of the present study was defined as the requirement for endotracheal intubation within 24 to 96 h following admission to the ICU. For prediction purpose, we set an initial prediction time window beyond 24 h for the following reasons. Firstly, as physician shifts are often 12–24 h, it is crucial to establish a prediction time window after this period, which facilitates the replacement physician in gaining a more comprehensive understanding of the patients’ potential need of intubation. Secondly, research has indicated that during the initial 24 h of ICU admission, patients often exhibit erratic fluctuations in their physiological and biochemical indicators43,44. Consequently, newly admitted ICU patients received heightened attention from the healthcare team compared to those already admitted, and we have extended the earliest prediction time beyond 24 h to optimize the allocation of medical resources, including ventilators and nursing teams. Additionally, certain indicators such as APACHE score can only be accurately measured after spending at least 24 h in the ICU.
Variable collection
In the MIMIC-IV cohort, data were extracted from hours 4 to 24 after ICU admission, including 5 categories of variables: (a) demographic characteristics; (b) other static information (e.g., length of stay before ICU admission, length of stay in the ICU before intubation); (c) vital signs; (d) laboratory data (e.g., blood analysis, blood gas, liver function, renal function, electrolyte, etc.) and (e) clinical scores (e.g., SOFA, GCS, etc.) were calculated and included as predictors. The detailed descriptions of all predictive variables are listed in Supplementary Table 1 (additional file 1). These variables were selected to develop a model grounded in vital signs, routine laboratory tests commonly performed in the ICU, and standard interventions, ensuring broad applicability across diverse ICU settings without imposing additional burden.
Model building
The dataset from MIMIC-IV was randomly split into three distinct sets with a ratio of 7:1:2. This allocation resulted in 8,391 samples designated for training the prediction models. An internal validation set that comprises 1,199 samples was reserved for feature selection and model simplification. Additionally, a hold-out test set of 2,398 samples was allocated to independently assess the model’s performance. The dataset obtained from eICU-CRD was utilized to assess the generalizability of the prediction model, serving as the external validation set.
Prior to model training, we conducted a preliminary analysis of the dataset to identify features with more than 50% missing data, which were subsequently excluded from the analysis. To handle the missing values, we employed K-nearest neighbours imputation within the training, internal validation, and test sets separately to avoid data leakage. We employed a range of techniques including SMOTE, Random oversampling, Random undersampling, Tomek links and the combination of SMOTE and ENN using the Python library imbalanced-learn package in order to address the class imbalance problem in the dataset. To construct prediction classifiers, we employed seven machine learning algorithms, namely CatBoost (Categorical Boosting), LightGBM (Light Gradient Boosting Machine), XGBoost (eXtreme Gradient Boosting), RF (random forest), LR (Logistic Regression), SVM (Support Vector Machine) and NB (Naïve Bayes). Detailed descriptions of each algorithm can be found in Supplementary Table 2 (additional file 1).
We employed ten-fold cross-validation within the training dataset for Bayesian optimization in the hyperparameter tuning process. This process involved partitioning the training dataset into 10 folds, where one fold was designated as the inner validation set and the remaining 9 folds were utilized for inner training purposes. The hyperparameter configuration yielding the highest average performance across all cross-validation folds was selected.
Model performance evaluation
We used six commonly used evaluation indices to evaluate the overall model performance, namely, accuracy, area under the receiver operating characteristic curve (AUC), sensitivity, specificity, F1 score and matthews correlation coefficient (MCC). These evaluation indices were commonly reported in the evaluation of classification problems with ML. For each metric, we conducted 1000 resamples to calculate the 95% confidence intervals (CIs). Each resample was drawn with a sample size equivalent to that of our test set to ensure the accuracy and representativeness of the confidence intervals. The metrics were defined as follows:
The metric definitions employed in this study encompassed the following abbreviations: TP (true positives), TN (true negatives), FP (false positives), and FN (false negatives). Sensitivity, also referred to as the true positive rate (TPR = TP / (TP + FN)), was defined as the proportion of intubated patients correctly identified. Specificity, also known as the true negative rate (TNR = TN / (TN + FP)), denoted the fraction of non-intubated patients correctly identified.
Model interpretation
We employed the SHAP framework, a game theory-based approach that provides consistent and accurate calculations of feature contributions to any machine learning model’s prediction, for interpreting our ML model. This framework assigns an importance value (SHAP value) to each feature in order to explain the prediction of individual observations and summarize their overall contribution. Moreover, it effectively captures feature interactions, including cases where a specific value may either increase or decrease risk (e.g., a heart rate of 130 can be considered protective for a child but detrimental for a geriatric patient). Additionally, the SHAP values allow for the interpretation of each observation within the dataset.
Statistical analysis
The baseline characteristics were compared between the intubation group and the non-intubation group. Categorical variables were presented as frequencies or proportions and compared using either the chi-square test or Fisher’s exact test. Continuous variables were reported as mean ± standard deviation (SD) along with median and 95% confidence interval (CI), as well as first quartile (Q1) and third quartile (Q3). Student’s t-test was employed for normally distributed continuous variables, while the Mann-Whitney U test was used for skewed distribution. Statistical significance was defined as a two-sided p-value < 0.05.
Results
Demographic characteristics
Among the 76,943 patients included in the MIMIC-IV database, a final cohort of 11,988 adult patients was selected for this study. The schematic representation of the patient screening process is illustrated in Fig. 1.

The schematic representation of the patient screening process.
Baseline characteristics, including demographics, laboratory values, and clinical parameters, between eligible participants with and without intubation are summarized in Supplementary Table 3 (additional file 1). The mean age, BMI and sex were not significantly different. Patients in the non-intubated group had a lower respiratory rate and higher GCS score than intubated patients.
Model development and simplification
A total of 51 variables were collected within the first 24 h after admission to the ICU, excluding 10 variables with more than 50% missing data. We developed seven machine learning binary classifiers for predicting intubation risk in ICU patients, including CatBoost, LightGBM, XGBoost, RF, LR, SVM and NB. Among these algorithms, Naïve Bayes exhibited the poorest performance while CatBoost demonstrated the best performance. As shown in Table 1, the CatBoost model displayed relatively superior fit with an area under the curve (AUC) of 0.881 in the test cohort compared to other ML models (AUC: LightGBM: 0.873; XGBoost: 0.871; RF: 0.824; SVM: 0.813; LR: 0.813; NB: 0.768). Additional model evaluation indices are also presented in Table 1.The CatBoost model was therefore selected for further prediction analysis in this study. Figure 2a illustrates receiver operating characteristic (ROC) curves for these models on a held-out test set. The performance of different sampling methods using CatBoost was presented in Supplementary Table 4 (additional file 1) and the confusion matrix of the CatBoost model was shown in supplementary Fig. 1 (additional file 1). Moreover, the final hyperparameters setting of CatBoost model was shown in the Supplementary Table 5 (additional file 1). As shown in the Fig. 2b, the CatBoost model demonstrated improved calibration after applying isotonic regression, with a Brier score of 0.043, which implies that the predicted probabilities are more aligned with the actual outcomes.

ROC curve and calibration curve of the prediction models. (a) The ROC curve of the predictive models on the test set. (b) The calibration plot of the prediction models.
In most cases, an ensemble model incorporating a larger number of variables yeilds more precise predictions compared to a model with fewer variables. Nevertheless, it is more economically viable and efficient to attain comparable or identical enhancements by utilizing prominent features, thereby offering advantages to clinical practice. To identify the number of variables needed for the machine learning model to achieve an equivalent predictive capability as observed when employing all 41 variables, we assessed the fluctuation of the area under the curve (AUC) in relation to the inclusion of varying numbers of variables in the models in the internal validation set. Firstly, the variables were ranked by arranging them in descending order of importance. Subsequently, the model was retrained with an increasing number of variables. As depicted in Fig. 3a, there is a gradual decrease in classification error rate as the number of variables increases. However, beyond five features, the AUC value remains relatively stable and removing additional features leads to a decline in AUC. Importantly, adding more features does not increase the AUC. The significance scores of the top five variables are illustrated in Fig. 3b. While the CatBoost model utilizing all available variables achieved an impressive AUC of 0.88, a slightly lower AUC of 0.86 was obtained for the simplified model comprising only these selected five key features (Fig. 3c). This suggests that employing an ensemble model with these essential features is both feasible and practical. Consequently, we adopted Catboost with these top five important features as our final model selection criteria, which included Glasgow coma scale, body mass index, arterial partial pressure of oxygen, respiratory rate, length of stay before ICU admission.

Model performance evaluation. Comparison between the full and simplified CatBoost models was conducted. The full model was developed using all available features, while the simplified model was derived based on key features selected by the recursive feature elimination algorithm. (a) AUC of the CatBoost model with varying numbers of variables was evaluated. (b) Feature importance in CatBoost with 5 variables was analyzed. (c) Receiver operating characteristic curves (ROCs) were compared between the full and simplified models. (d) Validation of our model’s performance in the eICU-CRD database involved different cohorts divided by ICU type. eICU represented all types of ICUs in the eICU-CRD database, Med-Surg referred to medicine-surgery ICUs, MICU indicated medicine ICUs, and SICU denoted surgery ICUs.
External validation and explanation of the simplified model
The model was externally validated against the eICU dataset (baseline characteristics of the external validation set was shown in Supplementary Table 6 ( additional file 1), yielding an AUC score of 0.75, which suggests a robust generalization capability. Additionally, a detailed subgroup analysis was carried out across various ICU types within the eICU dataset. Notably, the model excelled in the medical ICU, achieving an AUC of 0.82, indicating its superior performance in this specific setting (Fig. 3d).
Subsequently, the SHAP method was employed to obtain a comprehensive explanation for our cohorts. We computed the feature importance using the SHAP value for the simplified CatBoost model, which exhibited excellent discriminatory ability in the validation cohort and demonstrated suitability for clinical practice. Figure 4 provides an overview of how factors positively or negatively affect the simplified CatBoost model.

SHAP value impact on model output. Illustrates the relationship between feature values and their corresponding SHAP values in Catboost with 5 features. In this figure, red points represent relatively higher numerical feature values, while blue points correspond to relatively lower ones. Grey points represent the missing values. The horizontal axis denotes the assigned SHAP value for patients belonging to each category based on this particular feature. A positive SHAP value signifies an increased risk of intubation, whereas a negative value implies a decreased risk. Features were ranked according to the sum of absolute SHAP values across all samples analyzed. Notably, GCS (Glasgow Coma Scale) emerges as the most influential predictor for intubation in our final model, where a lower GCS score indicates a higher risk of intubation.
Furthermore, we utilized the SHAP method to acquire explanations for individual patients. To further investigate feature contributions on specific individuals and explore clinical applications of our final model, we randomly selected two patients from the validation cohort. Fig. 5 visually interprets the simplified CatBoost model’s findings. A detailed discussion regarding the clinical significance of these results will be provided.

SHAP explanation force plot for 2 patients from the held-out validation set of the ML model. The SHAP force plot can be utilized to visually represent the Shapley value for each feature as a force, which either positively contributes (positive value) or negatively impacts (negative value) the prediction from its baseline. The SHAP values indicate the predictive relevance of individual patients’ features and their respective contributions to intubation prediction. If the bold-faced number, representing the probabilistic predicted values f(x), is positive, it indicates that intubation is required for the patient; conversely, if it is negative, intubation may not be necessary. The f(x) represents the log odds ratio of each observation. Red features (on the left) signify an increased risk while blue features suggest a decreased risk. The length of arrows aids in visualizing the magnitude of effect on prediction; longer arrows indicating larger effects. LOS before ICU refers to length of stay prior to ICU admission; RR denotes respiratory rate; PaO2 stands for arterial partial pressure of oxygen; GCS refers to Glasgow coma scale; BMI denotes body mass index.
Model application
The simplified intubation prediction model, developed by the CatBoost algorithm, was implemented into a python-based online web application framework for utilization by clinicians (https://dmj163-app-intubation-app-udioou.streamlit.app/). Figure 6 illustrates an example of utilizing our tool.

An example of the web-based tool. A user needs to enter the average value measured during the patient’s ICU admission between 4 and 24 h and click the “predict” button. The probability of invasive mechanical ventilation within 24–96 h after ICU admission assessed by the model will be shown to the user.
Discussion
Currently, ML algorithms have emerged as a potent tool for predicting the need for intubation in hospitalized patients, particularly in ICU settings45,46. Arvind et al.44 developed a random forest model that achieved an AUC of 0.83 for predicting intubation within 72 h following a 24-hour sampling window for COVID-19 patients admitted to hospitals. Another study by Shashikumar et al.39 introduced a highly effective deep learning tool adaptable to both COVID-19 and general hospital populations in two large urban academic health centers; all validation models exhibited AUC values exceeding 0.88. Although their models achieved excellent performance, they required significantly more predictive parameters than standard approaches. An excessive number of parameters in prediction models can be costly to collect and inefficient for frontline physicians’ use, especially when many rely on laboratory tests that may not be readily available upon admission. Siu47 et al. also developed a random forest model, which had an AUC of 0.86, using the MIMIC database. However, their model may not be trusted enough for clinicians to use due to the “black box phenomenon”, as mentioned previously. As far as we know, our model was the first to apply the SHAP method in predicting ICU patients’ need for intubation to interpret the predication of each observation, which made clinicians comprehend how a prediction was given. Furthermore, our simplified model attained an AUC of 0.860 using only five easily accessible parameters, and it exhibited robust performance in an external validation cohort.
Meanwhile, our study also demonstrated that the CatBoost model outperformed logistic regression in accurately predicting intubation among ICU patients. We identified several significant variables associated with the need for intubation in ICU patients. The variable importance analysis revealed that the Glasgow Coma Scale (GCS), body mass index (BMI), arterial partial pressure of oxygen (PaO2), respiratory rate (RR) and length of stay (LOS) before ICU were the most influential input parameters contributing to the predicted risk of intubation in ICU patients.
The GCS score is widely recognized as a standard assessment tool for evaluating impaired consciousness and coma in critically ill trauma and non-trauma patients, aiding predictions of neurological outcomes such as complications, impaired recovery, and mortality. Siu et al.39 further confirmed its association with intubation risk. Consistently, our current study found that the GCS score carried the highest weight within the CatBoost model, indicating its utmost significance as a predictor for determining intubation necessity among ICU admitted patients.
Furthermore, our investigation revealed a close relationship between body mass index and intubation likelihood in ICU patients. This finding aligns with previous studies highlighting BMI’s pivotal role as a predictor within machine learning algorithms for intubation prediction44. Additionally, both PaO2 and RR emerged as important factors influencing intubation prediction accuracy in ICU patients—a consistent observation supported by prior research findings34,39,44,47,48.
Despite the success of various algorithms in this domain, a crucial determinant for physicians to adopt ML model predictions for clinical decision making lies in their ability to comprehend the underlying reasoning behind these predictions. Therefore, it is imperative to elucidate the factors contributing to an ML model’s prediction and enable physicians to understand why a specific prediction aligns with optimal patient care. To the best of our knowledge, our study is the first to apply the SHAP algorithm within the CatBoost model to develop an interpretable model for predicting intubation in ICU patients, achieving exceptional predictive performance. Figure 5 presents the SHAP explanation force plot that illuminates how the prediction model informs clinical decision support. Although SHAP does not completely resolve the black box issue, for clinicians (in other words, non-experts in computer science), using the SHAP algorithm can help enhance their trust in the model and improve their understanding of its predictions, thereby assisting them in making better clinical decisions regarding intubation.
The following are two randomly selected examples from the validation dataset, illustrating how the application of the SHAP method aids ICU physicians in interpreting model predictions. The SHAP baseline value is 0.01.
Patient 1 (Fig. 5a) is a 56-year-old female with a Charlson Comorbidity Index of 6, while her other laboratory indicators fall within normal ranges. The model yields a SHAP value of 1.71, corresponding to a predicted intubation probability of 84.8%. The primary factors contributing to this prediction include her overweight status, low blood oxygen saturation, and low GCS score. A review of the patient’s outcomes confirms that she underwent intubation within 24 to 96 h of ICU admission. This accurately predicted outcome highlights the importance of interpretability in machine learning models, fostering trust among healthcare providers.
Patient 2 (Fig. 5b) is a 77-year-old male with a Charlson Comorbidity Index of 11, indicating a substantial burden of comorbidities. His laboratory results reveal a red blood cell count of 3.07 × 10^12/L, suggesting severe anemia and reduced oxygen-carrying capacity. The model assigns a SHAP value of -0.05, resulting in a predicted intubation probability of 49%. This intermediate probability suggests that clinicians should closely monitor the patient’s condition to ensure timely provision of advanced respiratory support if his respiratory status deteriorates.
Our findings are important for several reasons. First, we developed and externally validated an interpretable ML model that predicts the need for tracheal intubation using commonly accessible clinical variables. The model demenstrated robust external validation performance, with an AUC of up to 0.82 in the MICU of the eICU-CRD database, thereby ensuring the reliability of the study. Moreover, such findings have the potential to reduce adverse outcomes and mortality rates in ICU patients associated with delayed intubation, while also minimizing the risk of related complications by preventing unnecessary intubations. Additionally, they can enhance the efficiency of ICU equipment (e.g., ventilators) utilization and optimize the use of medical human resources, ultimately contributing to a reduction in the overall disease burden. Second, we showed high predictive value, which proved that modern machine learning models performed better by leveraging the complex interactions in the clinical data than classical statistical analyses (e.g., logic regression). Third, a simplified model based on five selected variables was developed. According to the simplified model, an online web tool was also published. By entering the values of five variables, the prediction result based on our model will be shown to the user. Under the condition of ensuring accuracy, it achieved practicality as much as possible, which facilitated clinicians’ use in clinical practice.
However, certain limitations were identified in the present study. Firstly, our study adopted a retrospective modeling approach which prevented us from establishing a causal relationship between features and outcomes. The occurrence of intubation in the dataset may not accurately reflect the true needs of the patients. Retrospective studies and data-driven studies rely on previously collected data, which may come from electronic health records, public database, clinical trials, medical billing, patient-reported outcomes, or other health-related information. We generally lacked direct control over the data collection process and, consequently, must accept the data in its existing state to some extent. Secondly, in the model development process, we assumed that the clinical decision to intubate, as recorded in the data, is the best available proxy for the true need for intubation at the time of assessment. This assumption aligns with the practical application of our model, where the goal is to support clinical decision-making rather than to second-guess decisions made retrospectively. Another concern is the low proportion of positive samples which may lead to high-risk false positives. Although the proportion of positive samples is relatively low, this accurately reflects real-world scenarios. To address this issue, we have employed random undersampling during model training to balance the class distribution. However, the moderate F1 score and Matthews Correlation Coefficient indicates a moderate level of correlation between the predicted and actual classifications and suggests that while the model exhibits some degree of predictive accuracy, it is not as robust as we would ideally desire. Additionally, the highest AUC value achieved by our model suggests room for improvement in terms of its reliability and predictive power. This is an important limitation as it indicates that the model may not consistently perform at the desired level across all scenarios. Lastly, it is worth noting that our data was obtained from a publicly available database and did not include some state-of-the-art parameters such as the ROX index and enough samples about the oxygen support before intubation; hence we may have overlooked potential variables in model building. We are currently conducting a prospective cohort study in the ICU of University-Town Hospital of Chongqing Medical University and the eICU of Chao-yang Hospital of Capital Medical University to improve the model by incorporating more comprehensive variables related to intubation prediction. This will allow us to optimize the model’s performance by enhancing its training on a larger and more diverse patient set.
Conclusions
We developed a CatBoost prediction model that has undergone external validation and demonstrates superior performance in predicting the need for intubation in critically ill patients within 24 to 96 h of ICU admission. Notably, this model relies exclusively on easily obtainable parameters that are routinely captured during patient monitoring. Furthermore, by incorporating the SHAP method, our model enhances interpretability and offers clinicians valuable insights into the underlying factors influencing patient outcomes.
Data availability
MIMIC-IV database https://physionet.org/content/mimiciv/2.2/eICU Collaborative Research Database (eICU-CRD) https://www.physionet.org/content/eicu-crd/2.0/.
Abbreviations
- ML:
-
Machine learning
- SHAP:
-
SHapley Additive exPlanations
- GCS:
-
Glasgow coma scale
- BMI:
-
Body mass index
- PaO2 :
-
Arterial partial pressure of oxygen
- RR:
-
Respiratory rate
- LOS before ICU:
-
Length of stay before ICU admission
- EHR:
-
Electronic healthcare record
- MIMIC:
-
Medical Information Mart for Intensive Care
- CatBoost:
-
Categorical boosting, LightGBM: Light gradient boosting machine
- XGBoost:
-
eXtreme gradient boosting
- RF:
-
Random forest
- LR:
-
Logistic regression
- SVM:
-
Support vector machine
- NB:
-
Naïve Bayes
- AUC:
-
Area under the receiver operating characteristic curve
- CI:
-
Confidence intervals
- TP:
-
True positives
- TN:
-
True negative
- FP:
-
False positive
- FN:
-
False negative
- TPR:
-
True positive rate
- TNR:
-
True negative rate
- SD:
-
Standard deviation
- Q1:
-
First quartile
- Q3:
-
Third quartile
- ICD:
-
International classification of diseases
- ROC:
-
Receiver operating characteristic
References
Jia, Y. et al. Prediction of weaning from mechanical ventilation using convolutional neural networks. Artif. Intell. Med. 117, 102087 (2021).
Cattin, L. et al. Airways management in SARS-COV-2 acute respiratory failure: A prospective observational multi-center study. Med. Intensiva. 47 (3), 131–139 (2023).
De Jong, A. & Jaber, J. B. Intubation in the ICU: We could improve our practice. Crit. Care. 18 (2), 209 (2014).
Jaber, S. et al. An intervention to decrease complications related to endotracheal intubation in the intensive care unit: A prospective, multiple-center study. Intensive Care Med. 36 (2), 248–255 (2010).
Jaber, S. et al. Clinical practice and risk factors for immediate complications of endotracheal intubation in the intensive care unit: A prospective, multiple-center study. Crit. Care Med. 34 (9), 2355–2361 (2006).
Ahmad, I. et al. A prospective, observational, cohort study of airway management of patients with COVID-19 by specialist tracheal intubation teams. Can. J. Anaesth. 68 (2), 196–203 (2021).
Gholinataj Jelodar, M. et al. Analyzing trends in demographic, laboratory, imaging, and clinical outcomes of ICU-hospitalized COVID-19 patients.Can. J. Infect. Dis. Med. Microbiol. 3081660 (2023).
Downing, J. et al. Prevalence of peri-intubation major adverse events among critically ill patients: A systematic review and meta analysis. Am. J. Emerg. Med. 71, 200–216 (2023).
Cook, T. M. et al. Consensus guidelines for managing the airway in patients with COVID-19: Guidelines from the difficult airway society, the association of anaesthetists the intensive care society, the faculty of intensive care medicine and the royal college of anaesthetists. Anaesthesia. 75 (6), 785–799 (2020).
Jang, W. et al. Introduction of infection prevention tracheal intubation protocol during the covid-19 pandemic is not associated with first-pass success rates of endotracheal intubation in the emergency department: A before-and-after comparative study. J. Pers. Med., 13 (6) (2023).
Ahmad, I. et al. Difficult Airway Society guidelines for awake tracheal intubation (ATI) in adults. Anaesthesia. 75 (4), 509–528 (2020).
Higgs, A. et al. Guidelines for the management of tracheal intubation in critically ill adults. Br. J. Anaesth. 120 (2), 323–352 (2018).
Russotto, V. et al. Tracheal intubation in the critically ill patient. Eur. J. Anaesthesiol. 39 (5), 463–472 (2022).
Russotto, V. et al. Intubation practices and adverse Peri-intubation events in critically ill patients from 29 countries. JAMA. 325 (12), 1164–1172 (2021).
Heffner, A. C. et al. Incidence and factors associated with cardiac arrest complicating emergency airway management. Resuscitation. 84 (11), 1500–1504 (2013).
Manrique, S. et al. Timing of intubation and ICU mortality in COVID-19 patients: A retrospective analysis of 4198 critically ill patients during the first and second waves. BMC Anesthesiol. 23 (1), 140 (2023).
Farhadi, N. et al. Deciding when to intubate a COVID-19 patient. Anesth. Pain Med. 12 (3), e123350 (2022).
Seitz, K. P., Gandotra, S. & Casey, J. D. Emergency tracheal intubation: A procedure in need of better evidence. Am. J. Respir Crit. Care Med. 206 (4), 370–371 (2022).
Levin, S. et al. Machine-learning-based electronic triage more accurately differentiates patients with respect to clinical outcomes compared with the emergency severity index. Ann. Emerg. Med. 71 (5), 565–574 e2 (2018).
Ken, J., Goh, M. C. C., Cheong, E. H., Kalimuddin, S. & Wen, S. D. Ghee C. P., Kian S. C., Salahudeen H. M., Rapid progression to acute respiratory distress syndrome: Review of current understanding of critical illness from COVID-19 infection. Ann. Acad. Med. Singap. 49 (3), 108–118 (2020).
Biddison, L. D. et al. Ethical considerations: Care of the critically ill and injured during pandemics and disasters: CHEST consensus statement. Chest. 146 (4 Suppl), e145S–55S (2014).
Deshmukh, F. & Merchant, S. S. Explainable machine learning model for predicting GI bleed mortality in the intensive care unit. Am. J. Gastroenterol. 115 (10), 1657–1668 (2020).
Hu, C. et al. Interpretable machine learning for early prediction of prognosis in sepsis: A discovery and validation study. Infect. Dis. Ther. 11 (3), 1117–1132 (2022).
Li, C. et al. Machine learning based early mortality prediction in the emergency department. Int. J. Med. Inf. 155, 104570 (2021).
Fahmy, A. S. et al. Machine learning for predicting heart failure progression in hypertrophic cardiomyopathy. Front. Cardiovasc. Med. 8, 647857 (2021).
Yao, D. F., Chi, W. L. & Khishe, M. Parkinson’s disease and cleft lip and palate of pathological speech diagnosis using deep convolutional neural networks evolved by IPWOA. Appl. Acoust. 199, 13 (2022).
Liu, H. et al. A few-shot learning approach for covid-19 diagnosis using quasi-configured topological spaces. J. Artif. Intell. Soft Comput. Res. 14 (1), 77–95 (2023).
Chen, F., Yang, C. Y. & Khishe, M. Diagnose Parkinson?s disease and cleft lip and palate using deep convolutional neural networks evolved by IP-based chimp optimization algorithm. Biomed. Signal Process. Control. 77, 14 (2022).
Cai, C. et al. Improved deep convolutional neural networks using chimp optimization algorithm for Covid19 diagnosis from the X-ray images. Expert Syst. Appl. 213, 119206 (2023).
Hilton, C. B. et al. Personalized predictions of patient outcomes during and after hospitalization using artificial intelligence. NPJ Digit. Med. 3, 51 (2020).
Liang, H. et al. Evaluation and accurate diagnoses of pediatric diseases using artificial intelligence. Nat. Med. 25 (3), 433–438 (2019).
Woodman, R. J. et al. Use of multiprognostic index domain scores, clinical data, and machine learning to improve 12-month mortality risk prediction in older hospitalized patients: prospective cohort study. J. Med. Internet Res. 23 (6), e26139 (2021).
Goldstein, B. A., Navar, A. M. & Carter, R. E. Moving beyond regression techniques in cardiovascular risk prediction: applying machine learning to address analytic challenges. Eur. Heart J. 38 (23), 1805–1814 (2017).
The Lancet Respiratory. Opening the black box of machine learning. Lancet Respir Med. 6 (11), 801 (2018).
Lundberg, S. M. et al. From local explanations to global understanding with explainable AI for trees. Nat. Mach. Intell. 2 (1), 56–67 (2020).
Goldberger, A. L. et al. PhysioBank, PhysioToolkit, and PhysioNet: Components of a new research resource for complex physiologic signals. Circulation. 101 (23), E215–E220 (2000).
Pollard, T. J. et al. The eICU Collaborative Research Database, a freely available multi-center database for critical care research. Sci. Data. 5, 180178 (2018).
Collins, G. S. et al. Transparent reporting of a multivariable prediction model for Individual Prognosis or Diagnosis (TRIPOD): The TRIPOD statement. J. Clin. Epidemiol. 68 (2), 134–143 (2015).
Shashikumar, S. P. et al. Development and prospective validation of a deep learning algorithm for predicting need for mechanical ventilation. Chest. 159 (6), 2264–2273 (2021).
Simonis, F. D. et al. Effect of a low vs intermediate tidal volume strategy on ventilator-free days in intensive care unit patients without ARDS. Jama, 320(18). (2018).
Tobin, M. J., Laghi, F. & Jubran, A. Why COVID-19 silent hypoxemia is baffling to physicians. Am. J. Respir. Crit Care Med. 202 (3), 356–360 (2020).
Dhont, S. et al. The pathophysiology of ‘happy’ hypoxemia in COVID-19. Respir. Res., 21 (1). (2020).
Ding, X. F. et al. Predictive model for acute respiratory distress syndrome events in ICU patients in China using machine learning algorithms: A secondary analysis of a cohort study. J. Transl Med. 17 (1), 326 (2019).
Arvind, V. et al. Development of a machine learning algorithm to predict intubation among hospitalized patients with COVID-19. J. Crit. Care. 62, 25–30 (2021).
Venturini, M. et al. Predicting time-to-intubation after critical care admission using machine learning and cured fraction information. Artif. Intell. Med. 150, 102817 (2024).
Ustebay, S. et al. A comparison of machine learning algorithms in predicting COVID-19 prognostics. Intern. Emerg. Med. 18 (1), 229–239 (2023).
Siu, B. M. K. et al. Predicting the need for intubation in the first 24 h after critical care admission using machine learning approaches. Sci. Rep. 10 (1), 20931 (2020).
Hur, K. et al. Factors associated with intubation and prolonged intubation in hospitalized patients with COVID-19. Otolaryngol. Head Neck Surg. 163 (1), 170–178 (2020).
Acknowledgements
Not applicable.
Funding
This work was supported by the Natural Science Foundation of Chongqing [grant number cstc2020jcyj-msxmX0254], the Chongqing Municipal Public Health Bureau of Chongqing People’s Municipal Government [grant number 2022MSXM006] and the Chongqing Medical University [grant number CYS21248].
Author information
Authors and Affiliations
Contributions
JL* contributed to project administration and visualization and was a major contributor in writing the original draft and editing the manuscript. XD* contributed to data acquisition and management and screened data to meet our study’s inclusion and exclusion criteria. MD* contributed to data management, model development and validation, and visualization and was a major contributor in the review of the manuscript. YJ contributed mainly to funding acquisition and the review of the manuscript.WM contributed to the investigation and review of the manuscript. LM contributed to the investigation and review of the manuscript. GL was the corresponding author of the study and contributed to the conceptualization, supervision, funding acquisition and review of the manuscript.* JL, XD and MD contributed equally to this work.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Ethics approval and consent to participate
Not applicable.
Consent for publication
Not applicable.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Electronic Supplementary Material
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Liu, J., Duan, X., Duan, M. et al. Development and external validation of an interpretable machine learning model for the prediction of intubation in the intensive care unit. Sci Rep 14, 27174 (2024). https://doi.org/10.1038/s41598-024-77798-5
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-024-77798-5
