
Abstract
Architectural photography style transfer, a task in computer vision, employs deep learning algorithms to transform the style of architectural photograph while preserving key structure and content. Existing algorithms face challenges due to the intricate details of buildings, including diverse shapes, lines, and textures. Moreover, considerations for artistic effects in architectural photography style transfer, such as lighting, shadows, and atmosphere, require high-quality image generation algorithms. However, current algorithms often struggle to address these complexities, leading to loss or blurring of details and less realistic images. To overcome these challenges, this paper proposes a Photorealistic Attention Style Transfer Network. The proposed approach utilizes a semantic segmentation model to accurately segment the input image into foreground and background components for independent style transfer. Subsequently, the transferred images are refined by focusing on intricate building parts using the coordinate attention mechanism. Additionally, the network incorporates loss functions to capture light, shadow, and colors in stylish images, ensuring realism while maintaining aesthetic appeal. Through comparative experiments, the proposed network shows better performance in terms of image fidelity and overall aesthetics, and the SSIM and PSNR indices are also better than the current mainstream methods.
Similar content being viewed by others

Introduction
Architectural photography image style transfer is a technique within computer vision and image processing that enables the transfer of visual styles from one architectural photograph to another while preserving the content and structure of the source image. In the architectural design field, this technique can be used to preview the way a building will look under different artistic styles, helping designers to better understand and evaluate design schemes. Moreover, in the advertising and marketing field, it can provide attractive promotional materials for architectural or real estate projects, effectively attracting the attention of potential customers. Finally, in urban planning, injecting stylistic elements into the development process can ensure a fresh perspective and help improve the cultural identity of the urban landscape.
Architectural image style transfer presents unique challenges compared to general image style transfer due to the structural and geometric complexity inherent in architectural images, such as building lines, contours, and windows. Traditional methods1,2 are not directly applicable to architectural images. Moreover, they are difficult to handle well this complexity and can result in the loss of building-specific structures during the style-transfer process. In addition, the visual effect of architectural photographic images is affected by several factors such as shooting angle, lighting, and the surrounding environment. Therefore, traditional methods are not yet able to meet the unique color and lighting requirements of architectural images. Thus, to better align with the intricacies of architectural photography, it is imperative to apply specially designed or tailored style transfer algorithms. These algorithms need to consider factors, such as structure, texture, color, lighting, and spatial relationships, within architectural images to realize a more precise and accurate style transfer for architectural photography images. While current methods3,4,5 have made progress in the conversion of image textures and colors, the preservation of semantic information remains inadequate. In this paper, we aim to enhance the visual representation of architectural images through innovative image style transfer techniques, with the goal of improving upon the shortcomings of traditional image style transfer methods.
To address the aforementioned issues while ensuring the image’s structural integrity and retaining the photographic texture of the original image, this paper proposes a novel approach, known as Photorealistic Attention Style Transfer Network (PASTN). Grounded in a Generative Adversarial Networks (GANs)6 framework, PASTN employs a dilated ResNet507 and a Pyramid Pooling Module (PPM)8 for accurate segmentation of architectural background and style images. This segmentation step allows for the extraction of background and foreground elements from both architectural and style images. Subsequently, these processed images are fed into PASTN to generate new architectural photography images.
Upon segmentation, the foreground and background images undergo feature extraction in the style and text encoders of the network, respectively. The style encoder employs convolutional kernels of various sizes to extract features from input images, which are then fused to obtain a detailed style feature mapping. Meanwhile, the content encoder utilizes the Coordinate Attention (CA) mechanism9 to improve the representation of different features within the image. Finally, the resulting feature mapping maps are decoded to achieve the desired style transfer.
Additionally, a loss function is integrated into the network to accurately capture the color aesthetics of buildings against diverse backgrounds and infuse vibrancy into the style-shifted images while enhancing their photographic quality; thus, a loss function has been incorporated into the network to quantify these features.
In summary, our main contributions are the following:
-
1.
A novel and effective PASTN technique specifically designed for architectural photography photos is proposed, capable of independently separating the foreground and background parts. This network incorporates an innovative coordinate attention mechanism that preserves key image elements, ensuring that critical information is maintained throughout the style transfer process.
-
2.
A balanced loss function is introduced to effectively preserve the semantic information of the photographs while facilitating the transformation of both texture and color. This carefully designed loss function imbues the generated image with an artistic essence, all while upholding the authenticity of the photographic prints.
Related work
Generating adversarial networks
Early style transfer algorithms10,11,12 relied on a single static style model, constraining their adaptability to diverse styles. These algorithms often lacked perceptual quality, struggled to generate high-quality images, and encountered difficulties in maintaining the structural integrity of content while applying stylistic effects. The introduction of GANs, a deep learning framework comprising generators and discriminators, has revolutionized the field of image style transfer. GAN-based image style transfer methods enable end-to-end training, enhancing image quality, flexibility, and adaptability by adjusting input conditions for different style transfers.
In 2017, Goodfellow et al. introduced the Wasserstein Generative Adversarial Network (WGAN)13 to address issues such as gradient vanishing by employing the Wasserstein distance as a loss function, enhancing therefore the training stability compared to traditional GAN architectures. Despite this method, complex data distributions could still lead to pattern collapse. Thus, Miyato et al. proposed the Spectrally Normalized GAN (SNGAN)14, enhancing training stability by introducing spectral normalization, mitigating issues of gradient explosion, or vanishing. However, its applicability was limited across various GAN architectures due to the required additional computation per weight layer, potentially leading to slower training. Subsequently, Wu et al. introduced the Gradient Normalized Generative Adversarial Network (GNGAN)15, applicable to different GAN architectures. This algorithm imposes gradient paradigm constraints on the discriminator, improving its capability and solving the instability problem residing in GAN training. However, its effectiveness in enhancing image quality was limited. Furthermore, Radford et al. proposed the Deep Convolutional Inverse Network (DCGAN)16 by constructing generators and discriminators using CNNs and employing the Adam optimization algorithm, significantly enhancing image quality. Nevertheless, this technique only optimized the GAN’s network structure and did not completely resolve the issue of unstable GAN training. Consequently, to generate higher resolution images and address unstable GAN training, this paper proposes an improved network structure by introducing the Attention Mechanism (AM). This approach enhances GAN performance and application scope, dealing with the limitations of existing methods.
Photographic image style transfer
Image Style Transfer has found wide applications across various fields. Artists leverage this technique to infuse diverse painting styles into their works, while users use it to apply artistic nuances to their photos. Moreover, it finds extensive use in film and game production, design, and advertising, among other fields. To better meet people’s demands for image authenticity and visual appeal, by bridging the generated images closer to the semblance of real photographs, image style transfer techniques are now extended to photographic images. For instance, in 2017, Luan et al. proposed a Deep Learning (DL) method for photographic style transfer17. Although capable of handling various image contents while faithfully transferring reference styles, the quality of image generation is not high, and the spatial structure of architectural images is not clear. Moreover, in 2019, Qu et al. made a pioneering attempt to address real-world modeling challenges using a non-local representation scheme18. This approach enhanced the model’s ability to capture global information in images, resulting in achieving photo-realistic stylization. Nevertheless, the adoption of non-local representation also brings an increase in the computational complexity of the model, consequently hampering its efficiency in practical applications. In 2020, Xu et al. introduced a deep paradigm coloring architecture inspired by effective feature extraction and blending19. Despite its innovative approach, the network generated images with uneven color distribution. Furthermore, Anokhin presented a High-resolution Daytime Transformation (HiDT) model20, capable of re-rendering the same scene under varying lighting conditions. Yet, the proposed model does not integrate the translation and augmentation networks into a unified, end-to-end trained model. Added to that, An et al. proposed an automatic network pruning framework for realistic stylization, designed in a teacher-student co-learning approach21. This model achieved a noticeable speed-up while maintaining almost as-is stylization. It also exhibited sensitivity to the selection of hyper-parameters, posing challenges in the optimization process. Moving to 2022, Chen et al. addressed the realistic style transformation of architectural photographs from different periods22, offering a novel approach. However, the proposed method grappled with pre-segmentation processing, leading to less stable quality images.
To enhance image quality without affecting model complexity, PASTN technique is proposed in this work. PASTN incorporates the lightweight CA attention mechanism, enabling seamless integration into various architectures without yielding unnecessary complexity. This attention mechanism improves the neural network’s capacity to capture inter-channel information, enabling a more focused emphasis on critical feature channels. Moreover, this enhancement in expressiveness results in clearer image generation, effectively balancing image quality and model efficiency.
Attention mechanisms
In 2014, the Seq2Seq model23 was introduced, revolutionizing machine translation with its impressive performance. However, adequately capturing input information poses challenges, particularly when handling lengthy sentences. To tackle this issue, Bahdanau et al. proposed the attention mechanism24. By integrating learnable weights, this mechanism enables the model to dynamically adjust attention across different parts of the input data, thereby enhancing flexibility and overall performance. In tasks like image generation and style transfer, the attention mechanism proves invaluable, allowing the model to focus on specific image regions, thereby capturing local details and style nuances more effectively.
Moreover, in 2018, Woo et al. proposed Convolutional Block Attention Module (CBAM)25 as a simple and effective feed-forward Convolutional Neural Network (CNN) attention module. While this module introduces a large-scale convolutional kernel for extracting spatial features, it overlooks the long-range dependency problem. Moreover, the Squeeze-and-Excitation Network (SENet)26 introduced a novel channel attention mechanism but the dimensionality reduction operation used by SENet negatively impacts channel attention prediction, and acquiring dependencies is inefficient and unnecessary. Building on this, in 2019 Wang et al. proposed an Efficient Channel Attention (ECA) module27 for CNNs, which avoids dimensionality reduction and efficiently achieves cross-channel interaction. However, the ECA mechanism is typically global, weighting the entire channel without considering the spatial relationships between different locations. This oversight may result in local spatial correlations not being adequately captured for a particular task.
In response to these challenges, in 2021, Hou proposed Coordinate Attention (CA) for Efficient Mobile Network Design. This attention mechanism not only considers channel information but also orientation-related position information. Moreover, it is flexible and lightweight enough to be seamlessly integrated into the core of lightweight network module. Additionally, in 2024 a new feedforward Dual Rank-1 Tensor Attention Module (DRTAM) was proposed28, which is more suitable for large networks.
Considering the characteristics of attention mechanisms, we opt to utilize the CA attention mechanism in our network. Its flexibility and adaptability enhance the model’s generalization ability, and it can be combined with various models to improve feature sensing and extraction performance.
Methods
The existing techniques employed for image style migration in architectural photography encounter challenges when dealing with intricate building structures, making it difficult to accurately capture and convey these distinctive features. Furthermore, conventional image style migration methods often overlook the subtle visual effects crucial for photographic excellence, neglecting considerations for the influence of diverse lighting conditions, shadows, and varying camera angles on the images.
Therefore, this paper proposes a novel approach, the Photorealistic Attention Style Transfer Network (PASTN), aimed at addressing current challenges in style-shifting methods to produce high-quality architectural photographic images. The network generates realistic images with consistent architectural geometry from photographic viewpoints, utilizing reference style images. The training for architectural photographs is conducted in two stages within the proposed network: foreground training and background training.
Foreground training focuses on generalizing the geometrical structure of the building, while background training encompasses other elements beyond the building. The primary objective is to preserve the architectural structural characteristics while enabling the network to comprehend the impact of varied sky styles, including lighting effects, colors, temperatures, and photographic angles.
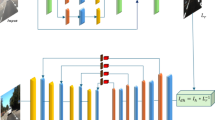
As illustrated in Fig. 1, the network comprises three key main: the style encoder, content encoder, and decoder. In the style encoder, two distinct convolution modules design are used to extract features from the input foreground and background images, generating feature mapping maps of different receptive fields. After fusion and a series of operations, the feature mapping map containing style features is outputted. In the content encoder, two-branch structure are employed to perform feature extraction operations on both the style image and the target image to be migrated. The coordinate attention mechanism is then applied to improve the correlation of features across different directions. In this process, a priori feature mapping map is generated to validate the model’s feature extraction capability. Finally, the resulting graph is fed into the shared residual block to obtain a feature mapping map representing the content of the building image. The decoder is responsible for feeding the feature mapping map obtained from the encoder into the residual block. Subsequently, it restores the original size of the image through successive up-sampling and implements the style transfer operation to produce the final image through convolution operation.
In summary, the network utilizes a style encoder to extract style features, a content encoder to manage the geometric features of the building, and a decoder to optimize the final image effect. Through this approach, essential architectural details are faithfully preserved, and the network adapts to subtle changes in lighting and style, resulting in highly realistic and aesthetically pleasing architectural images.

Photorealistic attention style transfer network structure (the input images are sourced from the public database provided by Chen et al.22, which can download from the website (https://github.com/hkust-vgd/architectural_style_transfer ), the output image was generated by using our proposed PASTN technique, and the figure was drawn by the first author XZ.
Style encoder
During the extraction of style features, the size of the perceptual field plays a crucial role. A larger perceptual field enables capturing comprehensive information about the entire image, but it may result in the loss of finer details concerning the object. Conversely, a smaller perceptual field focuses on specific details but may overlook the broader global context of the image. To address this challenge, we adopt a Visual Geometry Group (VGG)-like full convolutional network architecture in the style encoder. This architecture efficiently handles input images of varying sizes and generates outputs with corresponding dimensions, eliminating the need for additional preprocessing or adjustments.
The structure of the style encoder, depicted in Fig. 2, comprises two distinct convolution modules: the initial convolutional processing \(\:{X}_{init\_conv}\) and preliminary convolutional processing \(\:{X}_{intermediate\_conv}\), applied to the input image to obtain intermediate feature mapping maps. The expression for both convolutions are defined in Eqs. (1) and (2) where W represents the initial convolution kernel, and b denotes the bias. The intermediate feature mapping maps are unified through a channel stitching operation involving different convolution processes. Subsequently, a series of convolution operations, including down-sampling convolution and global average pooling, are performed, yielding a style-encoded feature mapping map with a specified number of style-encoded feature channels. The channel stitching operation effectively fuses information from different scales while preserving individual features. This method enhances the expression of the input image’s style features and ensures the extraction of both the image’s global information and the object’s detailed features during the feature extraction process.
Multiple down-sampling operations and stacked convolution blocks progressively augment the number of channels and diminish the spatial resolution of the feature mapping map. This design facilitates the capture of image features at different scales, enabling the style encoder to comprehend the semantic information and details of the input image more comprehensively. Lastly, the style encoder conducts a pooling operation on the feature mapping map using a global average pooling layer, thereby reducing the spatial dimension of the feature mapping map to 1 × 1. This operation effectively extracts the overall contextual information of the entire image, aiding in the capture of the image’s overall stylistic features.

Style encoder structure.
Content encoder
The specific structure of the content encoder is depicted in Fig. 3. As illustrated, the content encoder adopts a two-branch architecture, featuring two encoders labelled A and B, each equipped with its independent convolutional layer and residual block. This design enables the content encoder to capture different aspects or features of the input data, thereby providing richer information for subsequent processing. Connecting the two encoders is a shared residual block, which receives the output of either Encoder A or Encoder B and processes it accordingly. By incorporating the shared residual block, both encoders can share a portion of the feature representation, facilitating cross-encoder information transfer and learning. Additionally, we employ a 7 × 7 convolution in the encoder to extract more global features.

Content encoder structure.
To capture the correlation between different spatial locations in building images and facilitate the network’s focus on image regions with crucial details, the paper integrates the CA attention mechanism into the encoder. The CA attention mechanism is a novel and efficient technique designed to enable mobile networks to operate efficiently within limited computational resources. It allows mobile networks to concentrate on larger regions while avoiding significant computational overhead by incorporating location information into the channel attention.
Attentional blocks efficiently capture long-term interactions and precise positional information through two critical transformations, as denoted in Eqs. (3) and (4). These transformations aggregate features along distinct spatial directions, thereby generating direction-aware feature mapping maps. When processing input x, pooling kernels of spatial extents (H, 1) and (1, W) are applied to encode channel c along the horizontal and vertical coordinates, respectively. This strategic approach enables the attentional blocks to focus on specific spatial regions, ensuring that detailed positional information is accurately retained.
The CA attention mechanism, depicted in Fig. 4, starts by averaging pooling the input feature mapping maps, which have a shape of C×H×W, channel by channel. Each channel is then encoded using pooling kernels of (H, 1) and (1, W) along the X and Y axis directions, respectively, resulting in feature mapping maps with shapes of C×H×1 and C×1×W. Subsequently, the feature mapping maps extracted above undergo a stitching operation in spatial dimensions, as illustrated in Eq. (5).
where\(\:\:{z}^{h}\) and \(\:{z}_{w}\) are spliced to generate the feature map of the shape. Moreover, the \(\:{F}_{1}\) convolutional transform function, based on 1 × 1 convolution, and the nonlinear activation function are then processed to generate the intermediate feature mapping maps \(\:f\text{ϵ}{\mathbb{R}}^{\frac{C}{r}\times\:1\times\:\left(W+H\right)}\), where r is used to control the block reduction rate. After splitting f into two tensors \(\:{f}^{h}\in\:{\mathbb{R}}^{\frac{C}{r}\times\:H\times\:1}\) and \(\:{f}^{w}\in\:{\mathbb{R}}^{\frac{C}{r}\times\:1\times\:W}\) regarding spatial dimensionality, the 1 × 1 convolution is then employed to perform the dimensionality ascending operation, respectively. Being combined with the sigmoid activation function, it generated the final attention vectors \(\:{g}^{h}\in\:{\mathbb{R}}^{C\times\:H\times\:1}\) and \(\:{g}^{w}\in\:{\mathbb{R}}^{C\times\:1\times\:W}\). Therefore, the final output formula can be expressed as denoted in Eq. (8).
The incorporation of the CA mechanism enhances the network’s ability to capture extensive connections within a single channel while preserving precise positional information. This unique capability empowers the network to accurately identify objects, thereby enhancing the overall architectural imagery. By integrating CA attention, architectural photographs undergo a transformation into captivating artistic compositions. This transformation amplifies the visual impact of the image, accentuating the intricate details of the building, intensifying the richness of colors, and elevating the overall ambiance. Careful selection of an appropriate art style is paramount to preserving the nuances of the architectural photograph, particularly given the abundance of fine textures, intricate structures, and bold lines often found in architectural photography. Such details play a pivotal role in conveying the character and elegance of a building, infusing architectural photography with distinct styles and profound emotions inspired by nature.
After feature extraction, the network conducts multiple down-sampling operations on the feature mapping maps to obtain feature mapping maps with reduced resolution. These down-sampling operations are performed in a variable manner, with the degree of down-sampling controlled by adjusting parameters of the convolutional layer, such as the convolutional kernel size and step size. This flexible down-sampling strategy enables the network to adapt more efficiently to input data of different scales and complexities, making it particularly suitable for architectural photography style transfer.

CA attention mechanism structure diagram.
Decoder
In the decoding process, the network leverages residual structures and up-sampling operations to efficiently decode the feature mapping maps generated by the encoder. The decoding process is illustrated in Fig. 5. By integrating residual structures, the network mitigates issues related to gradient vanishing and explosion during neural network training, thereby enhancing the model’s generalization and learning capabilities. This architecture facilitates smooth gradient propagation and amplifies the model’s ability to represent intricate data. While the feature mapping maps derived from the encoder contain crucial image features, they may lack diversity. The incorporation of residual structures in the decoder rectifies this limitation, resulting in a more nuanced feature representation within the generated image. Subsequently, up-sampling and convolution operations are employed interchangeably, enhancing the correlation among neighboring image features. As a result, the image produced by the decoder closely resembles a real-life scene, exhibiting heightened expressiveness and realism. This strategic fusion of residual structures, up-sampling, and convolution operations not only address concerns related to gradient propagation but also comprehensively captures image features, thereby enhancing the model’s proficiency in understanding and expressing the inherent diversity of images.

Decoder structure.
Loss function
To attain superior style transfer effects, various types of loss functions are judiciously applied in the paper.
L1 Loss can be used to measure the difference between the generated image and the target one, yielding in more similar images. The L1 Loss is calculated as depicted in Eq. (11). Equations (9) and (10) are the derivation of Eq. (11), where N represents the number of pixels in the image, \(\:{x}_{i}\) is the i-th pixel value in the generated image, and \(\:{y}_{i}\) denotes the i-th pixel value in the target image. Applying L1 Loss to architectural image style transfer helps in generating more detailed and accurate results. This is mainly due to L1 Loss that encourages the minimization of the absolute difference between the generated image and the target one. As a result, the target style preserves better the details.
Luminance Gradient Loss is a loss function that measures the difference in luminance gradient between the generated image and the target one. It helps ensuring that the generated image is similar in luminance to the target one in such a way that the luminance characteristics of the target style are better preserved during the style transfer process. The \(\:{L}_{gradient}\) expression can be expressed as Eq. (12):
where \(\:{L}_{gradient}\) renders the network more concerned about preserving the luminance variations and the details of the target image to produce more realistic and naturalistic style transfer results. Moreover, N represents the number of pixels in the image number, \(\:{x}_{i}\) is the luminance gradient of the i-th pixel value in the generated image, \(\:{y}_{i}\:\)denotes the luminance gradient of the i-th pixel value in the target image, and, finally, ∇ indicates the luminance gradient operation.
Luminance KL Scatter Loss is a loss function applied to measure the difference in luminance distribution between the generated image and the target one. It aims to ensure that the generated image is similar to the target image in terms of luminance distribution. Equation (13) is the definition of entropy, and Eq. (14) represents the loss of luminance KL.
where \(\:L\left(P,\lambda\:\right)\) is the Lagrangian function, P(i) represents the probability of the i-th luminance value in the luminance distribution of the target image, Q(i) denotes the probability of the i-th luminance value in the luminance distribution of the generated image, and\(\:\:{\sum\:}_{i}\) indicates the summing up all the luminance values. Using Luminance KL Loss, the luminance characteristics of the target style can be better preserved during the style transfer process. This helps bringing the resulting image closer to the target one in terms of luminance, producing therefore more realistic and natural architectural photography style transfer results. Both Luminance Gradient Loss and Luminance KL Loss help in preserving the luminance characteristics of the target style in architectural photography style transfer; however, they model and measure the luminance characteristics from different perspectives, ensuring that the network fits the photographic sense of light and achieving better results.
Results
In this section, the dataset used for training is first introduced, followed by the baseline and evaluation metrics. Then, quantitative and qualitative comparisons are analyzed. In addition, results from ablation studies will serve to validate the proposed methodology.
Dataset
The proposed system was trained with 21,291 high-resolution exterior building photographs, using the dataset provided by Chen et al.22. These training photos consists of 16,908 unpaired photos of field landmarks and 4,383 frames extracted from 110 time-lapse videos representing outdoor scenes.
Implementation details
The model was deployed using the pytorch framework with a total of 200,000 iterations trained. Moreover, Adam was selected as the optimizer and \(\:{\beta\:}_{1}\:\)was set to 0.9, \(\:\epsilon\:\) was set to 1e-7. The initial learning rate was set to 0.0001, and a step decay was chosen with a step size of 10,000. In addition, a segmentation network is used to segment the image between foreground and background and the resulting image is send to the network for training. For inference, the shortest edge was adjusted to 256 pixels or 512 pixels to generate transmission results. All models were trained using a 256 × 256 resolution on NVIDIA GeForce RTX 3090 Ti GPU. The inference time of the model is 8.476 s, which includes the time for loading the model, preprocessing the data and generating the image.
Results and comparison
Figure 6 shows the results of Photorealistic Attention Style Transfer Network. The architectural photographic images are generated by inputting style images and content images. The results of the artistic pictures presented in the figure show that the proposed method allows the shape, structure and finer detail features of the building to be preserved. In addition, the style features are efficiently transferred in the network, achieving a balance of composition and colour scheme and enhancing the visual appeal of the image.

Results of photorealistic attention style transfer network (the content images and style images are sourced from the public database provided by Chen et al.22, which can download from the website (https://github.com/hkust-vgd/architectural_style_transfer), the remaining images was generated by using our proposed PASTN technique.
Referring to Fig. 7, we qualitatively compare the proposed method to four state-of-the-art style transfer methods, namely, AST22, QuantArt30, CCPL31, and DPS17. These methods were selected for comparison as they all preserve the structure of the building and, unlikely to the artistic abstraction of general style transfer, the generated images are realistic and in line with the characteristics of architectural photography. In more detail, AST, proposed in 2022, is a neural style transfer method for architectural photography, which posed the problem of realistic style transfer of architectural photographs at different times, and generated dramatic architectural photography building images. However, referring to Fig. 7 where a white box is highlighted, situations, such as background distortion in (a) and overexposure of the picture in (b), occur, and these challenges can be remedied by the method proposed in this paper. As for QuantArt, it enables high visual fidelity stylization; however, it is too abstract and does not have the realism of a photographic photograph. Moreover, CCPL is a generalized style transfer method capable of jointly performing art style, photo-realism, and video style conversion. The images it generates retain the characteristics of the buildings, nevertheless color alterations are not obvious, lacking the aesthetics of a photographic photograph, and the style transfer effect is insufficient. Finally, DPS is the first method proposed for photo-realistic style transformation. It uses the VGG network, which is less sensitive to some texture details of the generated image; therefore, the output images are not good in aesthetics and resolution.

Comparison experimental results graph (the content images and style images are sourced from the public database provided by Chen et al.22, which can download from the website (https://github.com/hkust-vgd/architectural_style_transfer), the remaining images was generated by using the cited models and our proposed PASTN model.
To further enhance the validity of the experiments, the resultant images were quantitatively analysed using structural similarity (SSIM)32, peak signal-to-noise ratio (PSNR)33, and sparse representation-based image quality evaluation metric (SRQE)34 in the comparison and ablation experiments.
Equation (15) represents the SSIM expression where x and y represent two images, \(\:{\mu\:}_{x}\) and \(\:{\mu\:}_{y}\) denote their means, \(\:{\sigma\:}_{x}^{2}\) and \(\:{\sigma\:}_{y}^{2}\) represent their variances, \(\:{\sigma\:}_{xy}\) is their covariance, and \(\:{K}_{1}\)\(\:,\:{K}_{2}\:\)are two constants used to avoid a zero denominator. Moreover, the PSNR expression is represented in Eq. (17) where b denotes the number of bits in the image, generally taken as 8, and the Mean Square Error (MSE) between image I and image J, where m and n represents the number of pixels in the image.
SRQE breaks down the quality assessment of arbitrarily stylised migrated images into three key factors: content retention (CP), stylistic similarity (SR), and overall visual effect (OV). CP looks at the extent to which a stylised image retains the structural information of the original content image.SR evaluates how well a stylised image mimics the stylistic features of a stylised image. OV is a composite metric that It considers both content retention and stylistic similarity to provide an assessment of the overall quality of an arbitrarily stylised migrated image.
Equation (18) is the quality fraction \(\:{Q}_{content}\:\)of content retention (CP), defined by merging sparse feature similarity across all scales or octaves. Where \(\:Z\:\)and \(\:O\) respectively denote the number of scales and octaves.
The quality fraction \(\:{Q}_{style}\)of style similarity (SR) is defined by merging the sparse feature similarity of all layers, which is calculated in Eq. (19), where \(\:L\:\)denotes the number of layers.
The quality fraction \(\:{Q}_{overall}\) of the overall visual effect (OV), is calculated by combining \(\:{Q}_{content}\) and \(\:{Q}_{style}\), as shown in Eq. (20). In this equation, \(\:{w}_{1\:}\)and \(\:{w}_{2}\:\)are the parameters used to adjust the relative importance of the two components, \(\:{w}_{1\:}\)=0.7 and \(\:{w}_{2}\)=0.3.
Based on the results in Table 1, it can be seen that to the evaluation metrics of SSIM and PSNR, our proposed method is significantly better than other methods. This finding suggests that the proposed method not only preserves the structural features of the original image, but also generates images with higher quality.
Compared to other networks, PASTN possesses a higher score on CP evaluation metric, which also indicates that the proposed network better preserves the content features in the image during the style migration process and exhibits a more detailed building outline. From the SR scores, the proposed method does not pursue maximum stylisation when mimicking the stylistic features of stylised images but chooses to appropriately reduce the degree of stylisation. This is because the original intention of our network design is to ensure the structural integrity of the image while preserving the photographic texture of the original image. In order to reflect the authenticity of the generated images, the method in this paper adjusts the stylisation migration to an optimal state to avoid over-stylisation.
OV, as a score calculated based on CP and SR, can visually reflect the quality of the generated images. It is straightforward to see in the table that our network can generate higher quality images.
Although, our method scores lower than CCPL on all three quality scores evaluated by SRQE. but the images generated by CCPL are not applicable to some specific scenes. Especially in the stylistic migration of architectural photographic images, the CCPL-generated images are not stylised to the expected extent, despite their high similarity to the original images. It can be clearly observed in Fig. 7 that CCPL produces colour homogenisation during the stylisation process and is unable to migrate other vibrant colours in the styled image, further confirming that CCPL is not applicable to our application scenarios.
Considering the performance of the above evaluation metrics, we can conclude that our proposed method achieves the best results overall. This conclusion is not only based on quantitative evaluation metrics, but also takes into account the specific needs of images in real application scenarios. Our method achieves effective and moderate style migration while maintaining the authenticity and structural integrity of architectural photographic images, which meets our expectations for high-quality style migration.
Ablation experiment
To validate the effectiveness of each component of our approach, we conducted a comprehensive ablation study yielding the below variables, illustrated in Table 2.
\({\mathcal{L}_{{\varvec{total}}}}\): Our overall network structure, including the introduced attention mechanism CA and loss function.
w/o\({\mathcal{L}_{{\varvec{loss}}+{\varvec{CA}}}}\): The network structure without the incorporation of the attention mechanism CA and the loss function.
w/o\({\mathcal{L}_{{\varvec{loss}}}}\): The network without the addition of the loss function.
Referring to Fig. 8, simply constructing the network structure results in artefacts as shown by the mark in (c). To enable the network to capture detailed features more accurately, we introduced the CA attention mechanism, which enables the model to accurately capture detailed features and apply style-specific information from the stylised source image. After the introduction of CA, the image quality is improved, but it is not stable enough and prone to the situation highlighted in (d). To increase the stability of the training process, the model is prevented from overfitting the training data, further balance the style and content, improve the quality of the generated images, and ensure that the generated images are consistent regarding the content. Finally, the paper provides a quantitative analysis of each component to fully demonstrate the effectiveness of each step.

Graph of ablation experiment results (the input images and style reference images are sourced from the public database provided by Chen et al.22, which can download from the website (https://github.com/hkust-vgd/architectural_style_transfer), the remaining images was generated by using our proposed PASTN model and its variants.
Conclusion
In this paper, an innovative Photorealistic Attention Style Transfer Network is introduced, pushing the boundaries of architectural photography style transfer. Challenges related to detailing and realism in generated images have been successfully addressed using advanced attention mechanisms and meticulously designing loss functions. The seamless integration of various photographic styles has been also demonstrated, resulting in captivating architectural photography. While the network architecture consists of three distinct components and necessitates separate training for foreground and background images. This complexity complicates the training process and requires significant computational resources as well as potentially constraining its practical applicability. Moving forward, collaboration with fellow researchers will be pursued to enhance efficiency and expand the practical utility of style migration in architectural photography. Moreover, we plan to develop interactive tools and interfaces, allowing architects and photographers to increase flexibility and control the overall process.
Data availability
The datasets used and analyzed during the current study are available from the corresponding author on reasonable request.
References
Gatys, L. A., Ecker, A. S. & Bethge, M. Image style transfer using convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2414–2423 (IEEE, 2016).
Johnson, J., Alahi, A. & Li, F. Perceptual losses for real-time style transfer and super-resolution. In Proceedings of the 14th European Conference on Computer Vision (ECCV), 694–711 (Springer, 2016).
An, J., Li, T., Huang, H., Ma, J. & Luo, J. Is bigger always better? An empirical study on efficient architectures for style transfer and beyond. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 4073–4083 (IEEE, 2023).
Gunawan, A., Kim, S. Y., Sim, H., Lee, J. H. & Kim, M. Modernizing Old Photos Using Multiple References via Photorealistic Style Transfer. In Proceedings of the IEEE /CVF Conference on Computer Vision and Pattern Recognition (CVPR), 12460–12469 (IEEE, 2023).
Bae, K., Kim, H. I., Kwon, Y. & Moon, J. Unsupervised Bidirectional Style Transfer Network using Local Feature Transform Module. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 740–749 (IEEE, 2023).
Creswell, A. et al. Generative adversarial networks: an overview. IEEE Signal. Process. Mag. 35 (1), 53–65 (2018).
He, K., Zhang, X., Ren, S. & Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 770–778 (IEEE, 2016).
Yu, B., Yang, L. & Chen, F. Semantic segmentation for high spatial resolution remote sensing images based on convolution neural network and pyramid pooling module. IEEE J. Select Top. Appl. Earth Obs Remote Sens. 11 (9), 3252–3261 (2018).
Hou, Q., Zhou, D. & Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 13713–13722 (IEEE, 2021).
Jing, Y. et al. Neural style transfer: a review. IEEE Trans. Vis. Comput. Graph. 26 (11), 3365–3385 (2019).
Singh, A. et al. Neural style transfer: a critical review. IEEE Access. 9, 131583–131613 (2021).
An, J. et al. IEEE,. Artflow: Unbiased image style transfer via reversible neural flows. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 862–871 (IEEE, 2021).
Arjovsky, M., Chintala, S. & Bottou, L. Wasserstein generative adversarial networks. In Proceedings of the 34th International Conference on Machine Learning (ICML), 214–223 (PMLR, 2017).
Miyato, T., Kataoka, T., Koyama, M. & Yoshida, Y. Spectral normalization for generative adversarial networks. In 6th International Conference on Learning Representations (ICLR), 1–26 (OpenReview.net, 2018).
Wu, Y. L., Shuai, H. H., Tam, Z. R. & Chiu, H. Y. Gradient normalization for generative adversarial networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 6373–6382 (IEEE, 2021).
Radford, A., Metz, L. & Chintala, S. Unsupervised representation learning with deep convolutional generative adversarial networks. Preprint at (2015). https://arxiv.org/abs/1511.06434.
Luan, F., Paris, S., Shechtman, E. & Bala, K. Deep photo style transfer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 6997–7005 (IEEE, 2017).
Qu, Y., Shao, Z. & Qi, H. Non-local representation based mutual affine-transfer network for photorealistic stylization. IEEE Trans. Pattern Anal. 44 (10), 7046–7061 (2021).
Xu, Z., Wang, T., Fang, F., Sheng, Y. & Zhang, G. Stylization-based architecture for fast deep exemplar colorization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 9363–9372 (IEEE, 2020).
Anokhin, I. et al. IEEE,. High-resolution daytime translation without domain labels. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 7488–7497 (IEEE 2020).
An, J., Xiong, H., Huan, J. & Luo, J. Ultrafast photorealistic style transfer via neural architecture search. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), 10443–10450 (AAAI, 2020).
Chen, Y., Vu, T. A., Shum, K. C., Yeung, S. K. & Hua, B. S. Time-of-Day Neural Style Transfer for Architectural Photographs. In IEEE International Conference on Computational Photography (ICCP), 1–12 (IEEE, 2022).
Sutskever, I., Vinyals, O. & Le, Q. V. Sequence to sequence learning with neural networks. Preprint at (2014). https://arxiv.org/abs/1409.3215.
Bahdanau, D., Cho, K. & Bengio, Y. Neural machine translation by jointly learning to align and translate. In 3rd International Conference on Learning Representations (ICLR), 1–15 (2015).
Woo, S., Park, J., Lee, J. Y., & Kweon, I. S. CBAM: Convolutional block attention module. In Proceedings of the 15th European Conference on Computer Vision (ECCV), 3–19 (Springer, 2018).
Hu, J., Shen, L. & Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 7132–7141 (IEEE, 2018).
Wang, Q. et al. ECA-Net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 11534–11542 (IEEE, 2020).
Lin, B. et al. Dual Rank-1 Tensor Attention Module for Convolutional Neural Networks. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 3880–3884 (IEEE, 2024).
Shi, J., Tao, X., Xu, L. & Jia, J. Break ames room illusion: depth from general single images. ACM T Graphic. 34 (6), 1–11 (2015).
Huang, S. et al. Quantizing image style transfer towards high visual fidelity. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 5947–5956 (IEEE, 2023).
Wu, Z., Zhu, Z., Du, J., & Bai, X. CCPL: Contrastive coherence preserving loss for versatile style transfer. In Proceedings of the 17th European Conference on Computer Vision (ECCV), 189–206 (Springer, 2022).
Zhou, W. Image quality assessment: from error measurement to structural similarity. IEEE T Image Process. 13, 600–613 (2004).
Kapur, J. N., Sahoo, P. K. & Wong, A. K. A new method for gray-level picture thresholding using the entropy of the histogram. Comput. Vis. Graphic Image Process. 29 (3), 273–285 (1985).
Chen, H., Shao, F. & Chai, X. Quality evaluation of arbitrary style transfer: subjective study and objective metric. IEEE Trans. Circuits Syst. Video Technol. 33 (7), 3055–3070 (2022).
Acknowledgements
This research was supported in part by the Scientific Research Fund of Hunan Provincial Education Department (22A0502, 23C0228, and 23C0240), the National Natural Science Foundation of China (61772179), the Hunan Provincial Natural Science Foundation of China (2019JJ40005, 2023JJ50095), the 14th Five-Year Plan Key Disciplines and Application-oriented Special Disciplines of Hunan Province (Xiangjiaotong [2022] 351), and the Science and Technology Plan Project of Hunan Province (2016TP1020).
Author information
Authors and Affiliations
Contributions
X.Z. and M.L. conceived the idea and proposed the method. X.Z. and M.Y. wrote the code and conducted the experiments. X.Z wrote the manuscript. M.L. and H.Z revised the manuscript. All authors reviewed the manuscript and approved of the final version.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Zhu, X., Lin, M., Yi, M. et al. Photorealistic attention style transfer network for architectural photography photos. Sci Rep 14, 29584 (2024). https://doi.org/10.1038/s41598-024-81249-6
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-024-81249-6
This article is cited by
-
Design and experimental research of on device style transfer models for mobile environments
Scientific Reports (2025)
