
Abstract
Image fusion is generally utilized for retrieving significant data from a set of input images to provide useful informative data. Image fusion enhances the applicability and quality of data. Hence, the analysis of multimodal image fusion is a new to the research topic, which is designed by combining the images of multimodal into single image in order to preserveexact details. On the other hand, the existing approaches face challenges in the precise interpretation of source images, and also it have only captured local information without considering the wide range of information. To consider these weaknesses, a multimodal image fusion model is planned to develop according to the multi-resolution transform along with the optimization strategy. At first, the images are effectively analyzed from standard public datasets and further, the images given into the Optimized Dual-Tree Complex Wavelet Transform (ODTCWT) to acquire low frequency and high frequency coefficients. Here, certain parameters in DTCWT get tuned with the hybridized heuristic strategy with the Probability of Fitness-based Honey Badger Squirrel Search Optimization (PF-HBSSO) to enhance the decomposition quality. Then, the fusion of high-frequency coefficients is performed using adaptive weighted average fusion technique, whereas the weights are optimized using PF-HBSSOto achieve the optimal fused results. Similarly, the low-frequency coefficients are combined by average fusion. Finally, the fused images undergo image reconstruction using the inverse ODTCWT. The experimental evaluation of the designed multimodal image fusion illustratessuperioritythat distinguishes this work from others.
Similar content being viewed by others
Introduction
Image fusion is a recently emerging concept owing to the amplifying requirements of diverse image processing applications especially in medical-aided diagnosis, video surveillance, remote sensing, and so on1. Image fusion is rapidly growing with various imaging sensors and the accessibility of a huge range of imaging techniqueslikeComputed Tomography (CT), and Magnetic Resonance Images (MRI), etc. It has explored the healthcare community for efficient decision-making and treatment to patients2. In addition, the major goal of image fusion also considers various factors like the fused image should be reliable and robust, inconsistencies or artifacts have to be eliminated, and salient information in any of the inputs must not be eradicated2. On the other hand, the major issues of image fusion research are similarity across modalities as data formation can be statistically uncorrelated and completely different, the efficient feature illustration of every modality and image noise, etc.3. In addition to these requirements in real-time applications, image fusion-guided disease prognosis and diagnosis have been formulated to assist medical professionals in decision-making as there is a restriction on human interpretation of clinical images owing to their subjectivity4. The major reason of multimodal clinical image fusion is to get the information with superior quality by combining the complementary information from various source images5.
Image fusion can be performed in various ways including multi-focus, multi-temporal, multi-modal, and multi-view fusion techniques6. Among these approaches, multi-modal image fusion is more essential, and it is carried out on images gathered by different sensors. Moreover, it is more helpful in getting precise results, especially in the medical field7. Generally, multi-modal image fusion combines both complementary and supplementary information of source images8.The multimodal image fusion results in final fused images that is free from redundant and random information. It minimizes the storage space, and stores one final fused image instead of storing two individual images9. The amalgamation of two different modalities results in precise localization or detection of abnormalities.The fundamental features of multi-modal image fusion are listed here. It reduces the uncertainty as the joint information from various sensors minimizes the vagueness related to the decision or sensing process10. The temporal and spatial coverage is extended for better performance. Fusion requires condensed representations to give complete information on images11. Multi-modal image fusion increases the system efficiency by reducing the redundancy in different measurements. It enhances reliability and reduces noise12.
Generally, image fusion is conducted via different approaches like transform domain as well as spatial domain methods. The consideration of high pass filtering, Intensity and Hue Saturation (IHS), Brovey method etc., are performed in the spatial domain methods. Thus, there is a need of adopting transform domain approaches come into the picture. Some popular transforms used for image fusion process include Contourlet (CT)13, Curvelet (CVT)14, Stationary Wavelet (SWT)12, Discrete Wavelet (DWT)11, DTCWT15, and Non-Subsampled Contourlet Transform (NSCT)16. While estimating with spatial domain methods, transform domain techniques get higher efficiency in terms of image fusion.On the other hand, a reliable, accurate, and appropriate image fusion approach is needed for several classes of images in diverse domains that must be simply interpretable for getting superior image fusion performance17. Some challenges are inexpensive computation time, uncontrollable acquisition conditions, and errors found in fusing the images. Thus, there is a need of suggesting an innovative multi-modal image fusion approach with the integration of two medical images by adopting transform domain techniques.
The innovationssuggested in this paper are listed here.
-
To recommend a new Multimodal Image Fusion with intelligent approaches like ODTCWT and adaptive weighted average fusion strategy along with the suggestion of hybrid nature-inspired approaches for performing medical image fusion for better localization of abnormalities and disease diagnosis through the gathered images.
-
To propose a novel ODTCWT and adaptive weighted average fusion strategy for efficient image fusion using a new hybrid nature-inspired algorithm termed PF-HBSSO for obtaining the salient information from the input images and formulates the objective as the maximization of fusion mutual information.
-
To implement the PF-HBSSO algorithm by the combination of Honey Badger Algorithm (HBA) as well as Squirrel Search Algorithm (SSA) for recommending ODTCWT by optimizing the filter coefficients and weights for adaptive weighted average fusion model for increasing the convergence rate that aids in maximizing the fused image quality.
Followed by introduction, the forthcoming section is shown.Part II specifiesthe discussion on existing works. Part III recommends an innovativemodel for multimodal image fusion. Part IV specifies the generation of low and high frequency coefficientsusingODTCWT. Part V derives the fusion of high frequency and low frequency by heuristic algorithm. Part VI estimates the results and Part VII completes this paper.
Study on existing works
Literature review
Research work based on deep learning models
In 2021, Zuoet al.18 has presented a new automated multi-modal medical image fusion strategy using classifier-based feature synthesis with a deep multi-fusion scheme. They have used a pre-trained autoencoder to analyze the fusion strategy by multi-cascade fusion decoder and a feature classifier. The public datasets were used for analyzing the image fusion results. TheParameter-Adaptive Pulse Coupled Neural Network (PAPCNN)was used in thelow and high-frequency coefficients. This image fusion was especially used for classifying brain diseases via the final fused images.
In 2022, Sun et al.19 have suggested a new deep MFNet using LiDAR data and multimodal VHR aerial images for performing medical image fusion. The multimodal learning and attention strategy was utilized for adaptively fusing the intramodal and intermodal features. A multilevel feature fusion module, pyramid dilation blocks, and a multimodal fusion strategy were implemented. This proposed network has adopted the adaptive fusion of multimodal features, enhanced the effects of global-to-local contextual fusion, and improved the receptive field. Moreover, this network was optimized using a multiscale supervision training strategy. The ablation studies and simulation outcomes have supreme performance of the recommended MFNet.
In 2021, Fu et al.20 have proposed a novel multimodal biomedical image fusion approach through deep Convolutional Neural Network (CNN) and rolling guidance filter”. The VGG model was applied for enhancing the image details and edges. Here, the rolling guidance filter was intended for extracting the detail and base images. Here, the fusion was done on both perceptual, detail, and base images with three diverse fusion methods. They have then chosen the image decomposition constraints by simulation for getting the suitable structure and texture images. In addition, the normalization operation was used to the perceptual images to eradicate noise and feature variations. Finally, it has shown the superior fusion outcomes and achieved better performance in terms of various objective measures.
In 2022, Goyal et al.21 have collected the images from standard sources, where NSCT was used for extracting the features. Next, a Siamese Convolutional Neural Network (sCNN) was applied for getting the significant features by weighted fusion. In order to eradicate noise, a new method has beenenhanced rate. Finally, the combination of NSCT + sCNN + FOTGV strategies has helped in enhancing the image fusion and also exhibited higher performance on both quantitative and visual analysis.
In 2022, Venkatesan and Ragupathyan22 have suggested a medical image fusion approach for fusing both MRI and CT images for recommending a healthcare model. To get both spectral and spatial domain features, the hybrid technique by integrating Deep Neural Network and DWT was suggested for getting more accuracy rate while estimating with traditional approaches. The performance enhancement was noticed in terms of standard deviation and average entropy for the designed DWT-CNN fusion approach compared with other wavelet transform methods. The superior efficiency on image fusion was noticed and has achieved considerable fusion performance rate.
In 2018, Bernal et al.23 have suggested a supervised deep multimodal fusion model for automated human activity and egocentric action recognition to monitor and assist patients. This model has collected video data using body-mounted or egocentric camera and motion data gathered with wearable sensors. The performance was estimated on multimodal public dataset and has analyzed the efficiency. They have used CNN-LSTM architecture for performing the multimodal fusion to get the results regarding automated human activity and egocentric action recognition.
Research work based on machine learning algorithms
In 2021, Duan et al.24 have recommended a new regional medical multimodal image fusion by adopting Genetic Algorithm (GA)-derived optimized approach. A weighted averaging technique was recommended for averaging the images of the source clinical images. Next, a fast Linear Spectral Clustering (LSC) superpixel technique was used for getting the homogenous regions and preserved the detailed information of images, which has segmented the average images and obtained the superpixel labels. The most significant regions were chosen and produced a decision map. The efficiency of the designed fusion approach was estimated via various experimental evaluations. Finally, the performance estimation on GA-based image fusion has shown the superiority on final fused images over others.
Research work based on image processing techniques
In 2022, Kong et al.25 have implemented a new medical image fusion approach via Side Window Filtering (SWF) and Gradient Domain-Guided Filter Random Walk (GDGFRW) in the Framelet Transform (FT) domain. Initially, FT was used on standard multimodal images for getting the residual and approximate illustrations. Then, a new GDGFRW was used for integrating the superiority of GD and GFRW that has built for interpreting the sub-bands, and the fusion was done by SWF. Next, inverse FT was performed for getting the residual models have fused images. The performance were addressed the fusion issues and outperformed the recent representative ones regarding objective estimation and subjective visual efficiency.
Comparative analysis of the existing techniques and proposed model
In 2023, Zhang et al.26 have implemented the novel fusion approach using Infrared-To-Visible Object Mapping (IVOMFuse) for extracting the target region from the infrared image. Further, the Expectation–Maximization (EM) has evolved to tune the probabilities in the target region. The fused image was attained by combining PCA and average fusion strategy. Hence, the final validation was attained by considering the TNO, CVC14, and RoadScene to get the final outcomes. In 2022, Zhou et al.27 have suggested the differential image registration model termed as robust image fusion to assist thermal anomaly detection (Re2FAD). The fusion strategy has been effectively done to enhance the accuracy. In 2023, Gu et al.28 have implemented the improved end-to-end image fusion approach (FSGAN) model to enhance the image fusion approach. Here, the auxiliary network has been extracted to enhance performance with diverse experiments.
Due to the heterogeneous nature, the multimodal image fusion is challenging in accordance of misalignment and non-linear relationships between the input data26. Also, the decomposition based methods are not highly preferred in the fusion model27. However, there is a complexity of discovering better multimodal images with fusion quality estimation in the suggested image fusion approaches28.To eradicate the drawbacks in the existing techniques, an effective deep learning method is implemented in the multimodal image fusion model. By considering the decomposition model, the multimodal image fusion gets enhanced by analyzing the texture details and smoothen the layers. It has the ability to maximize image quality to detect the performance effectively. The diverse implementation outcome is done whereas the recommended framework ensures to get better reliable outcomes.
Problem specification
In multimodal image fusion, it is very challenging to perform the multi-scale analysis that intends to analyze the feature maps extracted using shearlet domain. The analysis of the strengths and weakness of the existing models is given in Table 1. LSC and GA24 are very efficient in both the objective evaluation and visual effects in the segmentation of medical images. However, when increasing the region count, the fusion efficiency may get reduced and increase the running time in the image fusion. PAPCNN18 provides accurate and detailed information present in the fusion results. On the other hand, it does not completely utilize the fusion layer and decoding layer, which is observed through the quantification evaluations. Deep MFNet19 attains better performance regarding the visualization and quantification when considering the quantitative and qualitative evaluations. Yet, it does not consider the multi-scale decomposition for encoding and decoding to get performance enhancement. VGG network20 ensures the final fused images through the combination of three informative images like fused base image, detail image as well as perceptual image. Still, it has provided the results with increased color distortion and fusion noise without considering the fusion quality. sCNN21 are trained with the concatenated features for considering huge significance.But, it is time-consuming and cannot perform region-based medical image fusion. DWT-CNN22 is efficient on capturing the high-level association among the modalities and obtains the feature descriptors from the spatiotemporal regions. Yet, it may fail on preserving the shift-invariance. GDGFRW25 has an ability to understand the temporal patterns of behavior over data modalities, which have been hidden through the overriding of individual modality. Still, it is unable to perform multi-focus image fusion. RNN23 has efficiently utilized the location and hand presence as their significant cues for automatically classifying the images. Yet, it does not support the practical, feedback and in-device inference in the fusion. Hence, it is important to develop an enhanced multimodal image fusion model with superior optimization strategy.
An intelligent model for multimodal image fusion
Collection of dataset
This multimodal image fusion approach gathers medical images for performing the fusion, which helps in healthcare systems regarding better treatment planning and decision making.It is available from https://www.med.harvard.edu/aanlib/home.htm. The proposed model considers the images of MRI and Single Photon/Positron Emission Computed Tomography (SPECT/PET). The resolution of theimageis taken as 256 × 256. In total, the 66 images are considered for the evaluation. The gathered images are known as \(C_{a}\), where \(a = 1,2,3, \cdots ,A\), and the final number of obtained images is denoted as \(A\).The sample images of MRI and SPECT/PET are visualized in Fig. 1.

Sample images in terms of MRI and SPECT/PET.
Proposed multimodal image fusion model
Imaging technology in the healthcare applications need a huge amount of information that helps to provide the additional requirement for medical image fusion. It is further split into single-modal and multimodal image fusion. Various researchers are focused on designing multi-modal image fusion with several complications in the information offered uisng single-modal fusion. The multimodal image fusion comprises both physiological and anatomical data, which makes disease detection easier. Various modalities in the medical field are SPECT, PET, MRI, CT, etc. It has offered medical information regarding the human body’s structural properties such as soft tissue, etc. Different imaging approaches preserve diverse characteristics regarding the similar part. Hence, the reason for image fusion is to get a superior perceived experience, fusion quality, and contrast. The better image fusion results must require to follow the below constraints like avoiding bad states like noise and misregistration from the images. In classical approaches, the issues presented in the fusion effects are enhanced but not addressed effectively including feature information extraction and color distortion. Thus, there is a need to utilize innovative and intelligent approaches for medical image fusion that remains a major complication in this research area. Finally, it is concluded that there is a huge requirement for medical image fusion with multimodal medical images for getting better functional and structural information about the same part and thus, the fused images will be high-quality information preserved images.Consequently,the multimodal image fusion model is designed with intelligent approaches in this paper, which promotes medical image fusion. The visual representation ofdevelopedmodel is depicted in Fig. 2.

Architectural representation of multimodal image fusion with developed framework.
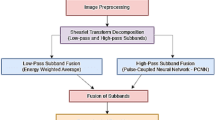
A new multimodal image fusion approach is recommended here, especially for the medical fieldwith the help of multi-resolution transform with the optimization strategy. Firstly, the source medical images are collected from benchmark sources. The next process is to decompose both images using the ODTCWTto acquire the frequency coefficient of low and high. Here, the filter coefficients of DTCWT are tuned using recommended PF-HBSSO algorithm.The decomposition helps in distinguishing the frequencies from the images to get the texture as well as smooth layer. The individual processing of both frequency parts helps in better preservation of images. Next, the fusion of high-frequency coefficients is performed bythe adaptive weighted average fusion technique, where the weights are optimized using the same PF-HBSSO algorithmto achieve the optimal fused results. Consequently, the low-frequency coefficients are fused usingstandard average fusion technique. At last, the fused image is retained using inverse ODTCWT to maximize thefused mutual information and ensure the quality of fused images.
Generating low and high “frequency coefficients” by optimized dual-tree complex wavelet transform
Optimization concept by PF-HBSSO
In this proposed multimodal image fusion approach, a new heuristic algorithm is recommended with the adoption of two recently familiar algorithms like SSA29 and HBA30. Here, the suggested model uses this new PF-HBSSO algorithm for maximizing the performance of image fusion regarding maximization of fused mutual information. PF-HBSSO algorithm optimizes the frequency coefficientsin DT-CWT and also the weights used for weighted average fusion for fusing the high frequency coefficients. This innovation increases the efficiency of the designed model while estimating with other approaches, which is detailed in result section. Here, HBA is chosen for performance enhancement owing to their vast range of features like skill towards sustaining the swapping among exploitation and exploration phases, good diversity, convergence speed, and provides statistical significanceto handle complex optimization problems, and utilization of the dynamic search schemes. Conversely, it faces complications in handling the local optima solutions. Henceforth, a SSA is adopted into this mechanism for giving better performance owing to their higher efficiency, capability towards producing the better solutions at faster manner even for critical and high dimensional optimization problems.
A new PF-HBSSO algorithm is recommended in this paper by modifying the random parameter \(b\) used in HBA technique, where this random parameter \(b\) is assigned in the range of [0, 1] in conventional HBA. On the other hand, this sameparameter \(b\) is implemented in this PF-HBSSO by taking the probability of fitness-based solutions as shown in Eq. (1).
Here, the \(P\) determines the number of population and \(\alpha\) is specified as the capability of the individuals to reach food (\(\alpha\) ≥ 1) as given in traditional HBA. Moreover, in this recommended PF-HBSSO,\(\alpha\) is found by determininghow many number of fitness is less than mean fitness, which results in getting the better reach of optimal solutions at higher convergence rate.
Consequently, this new parameter \(b\) is used for updating the solutions from either HBA or SSA with the following conditions. If \(b < 0.5\) is verified, then the solution updating is carried out via digging phase of HBA or else the solution updating is performed using SSA. Here, the solution updating in SSA is carried out via formulating the case 1 with the condition of total flying squirrels. Hence, it produces higher convergence rate and free from local optimal with superior outcomes, which increases the efficiency of image fusion.
Initially, the population of search individual is created based on HBA, as derived in Eq. (2).
The \(j^{th}\) position of honey badger is specified in Eq. (4). In Eq. (2), a random number with limit of [0, 1] is specified as \(b_{1}\), the upper and lower bounds of search range istermed as \(u_{j}\) and \(l_{j}\) and the \(j^{th}\) position of individual referring candidate solution is derived as \(z_{j}\).
The size of the population is shown as \(P\). In the next stage,the parameter \(b\) is implemented by Eq. (1) and verifies \(b < 0.5\). Then, the solution updating is started with HBA while satisfying the \(b < 0.5\).
HBA has two phases for updating their solutions, which aredigging phase and honey phase. But, PF-HBSSO algorithm only formulates the digging as well as honey phase is replaced by SSA.
The digging phase is executed while honey badger performs in Cardioid shape as shown in Eq. (5).The position is updated by evaluating digging as well as the honey phase.Here, the position is updated by the several movement patterns that help to sort better solution during the optimization problem. The updated position is generally suited for the global optimization in which it maximizes or minimizes the multivariate function to find out the optimal solution. It helps to set the desired and reliable outcomes. The position update mechanism helps to avoid from the premature convergence to maximize the algorithms efficiency and effectiveness.
The variables \(b_{2}\),\(b_{2}\),\(b_{4}\),\(b_{5}\),\(b_{6}\) and \(b_{7}\) is denoted as random numbers with a specific interval of [0, 1].Also,the global prey position is denoted as \(z_{prey}\), the flag utilized for modifying the search direction is mentioned as \(D\), and also the term \(It\) specifies the smell intensity, distance among the individual and prey is known as \(h_{j}\), the concentration strength is specified as \(CS\), density factor is termed as \(\delta\) and the constant term is derived as \(G\), where the maximum number of iterations denotes the \(i_{\max }\) and iteration number is specified as \(i\).
Then, the proposed PF-HBSSO verifies the \(b < 0.5\) factor, if it is not satisfied then; the solutions are executed by formulating the case 1 of SSA with the condition of total flying squirrels.
The location of the search individuals is updated while they move from the acorn treesto hickory nut tree as derived in Eq. (11).
In the afore mentioned equations, the constant terms are correspondingly derived as \(\chi\),\(o\),\(y_{G}\),\(e\),\(sr\),\(Cr_{ll}\) and \(Cr_{dd}\), the and the lift force is represented by \(X\), \(Q\) specifies the drag force, and the gliding angle is known as \(\tan \left( \phi \right)\), random gliding distance is indicated by \(r_{G}\), the random function \(v_{1}\) is computed at the interval of \(\left[ {0,1} \right]\) and the gliding constant is derived by \(K_{C}\) and the position of search individual that reached hickory nut tree is shown as \(z_{hit}^{i}\), the position of search individual in acorn tree is derived as \(z_{act}^{i}\). Moreover, the predator presence probability \(\rho_{dg}\) is the essential role in updating position of individuals.
Finally, the search individuals are updated and the optimal solutions are attained for enhancing the efficiency of image fusion. Here, the new parameter updating for integrating two familiar algorithms gives the better efficiency and it is exhibited in results.
The pseudo-code of PF-HBSSOisshown in Algorithm 1.

Algorithm 1: PF-HBSSO
The hybrid heuristic algorithms exhibit better significance in recent days and thus, this paper also recommend one hybrid algorithm to increase efficiency of image fusion.The applications of the suggested PF-HBSSO model are solving unimodal, multimodal, and multi-dimensional optimization problems, system control, machine design and engineering planning. The flowchart of the designed PF-HBSSO is visualized in Fig. 3.

Flowchart of the designed PF-HBSSO algorithm.
Optimized DT-CWT-based image decomposition
In the recommended model, the decomposition of both MRI and SPECT/PET is done using ODT-CWT, where a newly recommended PF-HBSSO optimizes the filter coefficients of DTCWT for getting the better fusion effects that promotes the medical diagnosis approach.The gathered images \(C_{a}\) are given to ODT-CWT, where the decomposition of images is done via ODT-CWT for getting low frequency and high frequency coefficients.
DT-CWT31 is the most eminent approach used in image fusion approaches, where the masks are used for extracting the information from the decomposed structure. It is the extended version of DWT, which is processed by executing two parallel trees. It is useful in eradicating the aliasing effects and achieved shift invariance.It helps reveal the visual sensitivity, which comprises of real and complex coefficients. The gathered images \(C_{a}\) are given to ODT-CWT for getting frequencies of low \(L\) and high \(H\) in Eq. (16).
Here, the fusion rules for high and low frequency coefficients are correspondingly known as \(\phi_{H}\), and \(\phi_{L}\), which are optimized by PF-HBSSO algorithm.
Finally,ODT-CWT offers ideal reconstruction over the traditional wavelet transform for getting better multimodal image fusion approach for medical images, which will be explained in upcoming sections.The gathered images \(C_{a}\) are given to ODT-CWT, where decomposition of images is done via ODT-CWT for getting low and high frequency.
The framework of ODT-CWT for image decomposition using recommended PF-HBSSO algorithm is expressed in Fig. 4.

Illustration of ODT-CWT for image decomposition using recommended PF-HBSSO algorithm
High frequency and low frequency image fusion by proposed heuristic algorithm
Developed objective model
The implemented multimodal image fusion approach aims to improve the performance rate with the help of PF-HBSSO algorithm. Here, the PF-HBSSO algorithm is used for optimizing the frequency coefficients in DT-CWT and also the weights used for the weighted average fusion method for fusing the high frequency coefficients. This model considers the major goal as the maximization of fused mutual information as equated in Eq. (19).
Here, the high and low frequency coefficientsare optimized using PF-HBSSO algorithm and the weights used for the weighted average fusion method is represented as \(W_{1} ,W_{2}\) that is also optimized by PF-HBSSO algorithm. The range of \(\phi_{H}\),\(\phi_{L}\) are assigned among [-20, 20] and \(W_{1} ,W_{2}\) are assigned among the range of [0, 1]. The optimal tuning of frequency coefficients results in better image decomposition whereas the weight optimization in weighted average fusion increases performance of high frequency fusion method. Term \(FMI\) represents fused mutual information. The fused mutual information is determined among the fused image and the source image as derived here.
In the aforementioned equations, the joint histogram among source and fused images are correspondingly specified as \(gt_{{GA_{igjg} }}\), and \(gt_{{FA_{igjg} }}\), the column and row size of the image are correspondingly known as \(Qs\) and \(Ys\), and the normalized histogram of the source image 1 \(Fi\), source image 2 \(Ai\), and fused image \(Bi\) are specified accordingly.The higher mutual information value represents the superior quality of fused images.
High frequency optimization by adaptive weighted average fusion
The recommended model gets the high frequency coefficients of two different imaging modalities using ODT-CWT.It is fused using adaptive weighted average fusion strategy. This scheme is modeled in Eq. (23).
Here, the fused images are known as \(HBi\), the weights utilized for fusing the high frequency coefficients of images are correspondingly specified as \(W_{1}\) and \(W_{2}\), where the range of weights is assigned byPF-HBSSO algorithm in the range of [0, 1], the high frequency coefficients of two source images are given as \(Fi_{H}\) and \(Bi_{H}\), where the weights \(W_{1}\) and \(W_{2}\) are optimized using PF-HBSSO algorithm.The high frequency coefficients are fused via this recommended adaptive weighted average fusion scheme, which is carried out via optimizing the weights utilized for the fusion process.High frequency coefficients are fused for specifying the edge information to increase the image fusion quality. There is a need of maintaining the superiority of frequency information in the images for increasing the better contrast in the final fused images.
Finally, the final high frequency coefficients of two source images is attained as \(HBi\), which is further given to the reconstruction process to get final fused images. The sample representation of adaptive weighted average fusion for fusing the high frequency images is given in Fig. 5.

Fusion process of high frequency by adaptive weighted fusionmodel.
Low frequency optimization by average fusion
In this suggested image fusion model, the average fusion is performed on low frequency coefficients of two source images, which is used for storing the local information in terms of increasing the image fusion. This process is derived in Eq. (24).
The average fusion method is performed via taking the averaging among two different modal source images. Averaging is the simplest technique in implementation, where the average of entire pixels from the input low-frequency coefficients of medical images is considered as the intensity of the output pixel. The averaging operation is useful in reducing the bad information and enhancing the good information from the images by taking a mean image. Although this approach is not eminent in image fusion, it is helpful in fusing the low-frequency coefficients.The final fused low frequency of two source images is attained as \(LBi\). In Fig. 6, it represents the averaging fusion-based low frequency source image model.

Fusion process of low frequency by adaptive weighted fusion model.
Image reconstruction by inverse ODT-CWT
In this designed multimodal image fusion approach, the final fused images are attained using inverse ODT-CWT from both MRI and SPECT/PET images, which is derived in Eq. (25).
Here, the final fused images \(Fu_{a}\) are attained using inverse ODT-CWT via fusing both low frequency fused images \(LBi\) and high frequency fused images \(HBi\). At last, the final fused images are attained via the image reconstruction stage and ensured its higher quality regarding the maximization of fused mutual information.
Experimental analysis
Validation setting
There commended multimodal image fusion framework was implemented in MATLAB 2020a, with different quantitative measures. Some techniques like Dragon Algorithm (DA)32, Grey Wolf Optimizer (GWO)33, HBA30, SSA29, and traditional transform approaches such as PCA34, DWT35, IHS36, DCT37, CWT38, NSCT39 and DT-CWT28. The experimentation was done via measures like number of population as 10, chromosome length as 82, and the maximum Iteration was considered as 10.The recent methods like Spatial-Frequency Information Integration Network (SFINet)40, Channel Attention dual adversarial Balancing network (CABnet)41, DUSMIF42 and Dense-ResNet43 are compared using the developed model.
Validation metrics
-
(a)
SSIM: The SSIM measure helps to evaluate the local patterns of different pixel intensities. It is formulated in Eq. (26).
$$\begin{gathered} SSIM\left( {RC_{a} ,Fu_{a} } \right) = \hfill \\ \frac{{\left( {2\mu_{{RC_{a} }} \mu_{{Fu_{a} }} + Vn_{1} } \right)\left( {2\sigma_{{RC_{a} Fu_{a} }} + Vn_{2} } \right)}}{{\left( {\mu_{{RC_{a} }}^{2} + \mu_{{Fu_{a} }}^{2} + Vn_{1} } \right)\left( {\sigma_{{RC_{a} }}^{2} + \sigma_{{Fu_{a} }}^{2} + Vn_{2} } \right)}} \hfill \\ \end{gathered}$$(26)Here, the constants are represented as \(Vn_{1}\) and \(Vn_{2}\), it is measured among two images \(\left( {RC_{a} ,Fu_{a} } \right)\), and the average of \(Fu_{a}\) is termed as \(\mu_{{Fu_{a} }}\),and the average of \(RC_{a}\) is termed as \(\mu_{{RC_{a} }}\). The covariance of \(RC_{a}\) and \(Fu_{a}\) is termed as \(\sigma_{{RC_{a} Fu_{a} }}\) and the variance of \(RC_{a}\) and \(Fu_{a}\) are termed as \(\sigma_{{RC_{a} }}\) and \(\sigma_{{Fu_{a} }}\), respectively.
-
(b)
BRISQUE: The non-referenced image \(Fu_{a}\) is calculated using score = Brisque (\(Fu_{a}\)).
-
(c)
Entropy: It is used to measure the information content of a fused image. The high entropy value indicates the fused image has rich information content and given in Eq. (27).
$$Ent = - \sum\limits_{ig = 0}^{Ng} {hh_{{Fu_{a} }} } \left( {ig} \right)\log_{2} hh_{{Fu_{a} }} \left( {ig} \right)$$(27)Here, the term \(hh_{{Fu_{a} }}\) is specified as the probability of the gray level of fused image.
-
(d)
PSNR: The PSNR is expressed in Eq. (28).
$$PSNR = 20\log_{10} \left( {\frac{{Ng^{2} }}{{RMSE^{2} }}} \right)$$(28)Here, the number of gray levels is denoted as \(Ng\).
-
(e)
RMSE: It is formulated in Eq. (29).
$$RMSE = \sqrt {\frac{1}{Ys \times Qs}\sum\limits_{ig = 1}^{Ys} {\sum\limits_{jg = 1}^{Qs} {\left( {RC_{a} \left( {ig,jg} \right) - Fu_{a} \left( {ig,jg} \right)} \right)^{2} } } }$$(29)Here, \(RC_{a}\) is the reference image,\(Fu_{a}\) is the fused image and the intensity values of the reference and fused imageare accordingly represented as \(RC_{a} \left( {ig,jg} \right)\) and \(Fu_{a} \left( {ig,jg} \right)\).
-
(f)
Standard Deviation: It is used for measuring the fusion performance, where the larger standard deviation results show better fusion results. The STD is described in Eq. (30).
$$STD = \left( {\frac{1}{Ys \times Qs}\sum\limits_{ig = 1}^{Ys} {\sum\limits_{jg = 1}^{Qs} {\left( {Fu_{a} \left( {ig,jg} \right) - \hat{\mu }} \right)^{2} } } } \right)^{\frac{1}{2}}$$(30)In Eq. (30), the mean value of the image is given as \(\hat{\mu }\).
Experimental images
Some of the resultant images attained using different techniques and proposed model are shown in Fig. 7.The recent image fusion techniques like Unified and Unsupervised end-to-end image fusion network (U2Fusion)37, Information Gate Network for multimodal medical image fusion (IGNFusion)38 and Fast, Lightweight Image Fusion Network (FLFuse-Net) are compared in the image fusion model. This resultant analysis helps the developed model show effective outcomes.

Resultantimages attained using the existing method and proposed model.
Estimation over heuristic approaches
The effectiveness of the achieved fused images isanalyzed over various techniques as given in Fig. 8. From the evaluation, it is clearly shown that the designed model has exhibited its higher performance over traditional approaches. For example, while comparing with the recent heuristic algorithms, the recommended ODT-CWT-based PF-HBSSO algorithm specifies superior effectiveness over traditional methods.


Efficiency analysis on designed model over heuristic approaches for (a) Fused mutual information, (b) Standard deviation, (c) Entropy, (d) Brisque, (e) SSIM, (f) PSNR, (g) RMSE and (h) SNR.
Estimation over transform approaches
The effectiveness of the designed image fusion model is estimated over traditional transform domain approaches as listed in Fig. 9. The final fused images are compared over conventional approaches using standard statistical measures to illustrate the efficiency of the multi-modal image fusion approach.


Efficiency analysis on designed model over transform domain approaches for (a) Fused mutual information, (b) Standard deviation, (c) Entropy, (d) Brisque, (e) SSIM, (f) PSNR, (g) RMSE and (h) SNR.
Comparative estimationof image fusion over heuristic algorithms
The comparative estimation of the designed image fusion over various optimization algorithms is given in terms of various performance metrics from Tables 2, 3, 4, 5, 67, 8 and 9. The investigation clearly exhibited superior performance over both positive measures and error measures. The positive measures show the superior performance regarding image fusion quality whereas the negative measures specify the performance enhancement by getting lower error rates in image fusion. Hence, the designed model exhibit better performance and thus, it is more applicable for medical applications.
Comparative estimation on image fusion over transform algorithms
The comparative analysis on the designed image fusion approach over various transform approaches for various performance metrics are given from Tables 10, 11, 12, 13, 14, 15, 16 and 17. By analyzing the values, the designed fusion model exhibits the better performance and clearly shows the superiority over the traditional methods.
Comparative analysis of the developed model with recent methods
The comparative analysis of the developed model is done using the recent methods in the multimodal image fusion approach shown in Table 18. This table analysis is performed by analyzing the entropy measure that helps to show the potential outcome in the designed framework. The recent methods like SFINet, CABnet, DUSMIF, and Dense-ResNet model is compared with different images. In this experimental evaluation, the developed PF-HBSSO-DT-CWT model shows 29.2, 29.13, 26.25, and 30.9% decreased than SFINet, CABnet, DUSMIF, and Dense-ResNet in terms of validating the image 6. The analysis of performance evaluation shows the developed model shows lower entropy value. Thus, it ensures to reduce the dimensionality problem that occur between the data points. Commonly, the developed model used to evaluate better data quality outcomes to make the possible predictions in the multimodal image fusion approach.
Conclusion
A multimodal image fusion model wasrecommendedin this paper via heuristic derived transform approaches. Initially, the medical source images wereacquired from the standard public datasets, and further, decomposed was done using the ODTCWT to acquire low frequency and high frequency coefficients. Here, frequency coefficients in DTCWT were tuned with the PF-HBSSO to enhance the better fusion quality. Then, the fusion of high-frequency coefficients was performed with the adaptive weighted average fusion technique, where the weights were optimized using the same PF-HBSSO algorithm to achieve the optimal fused results. Similarly, the low-frequency coefficients were fused by average fusion. Finally, the fused images were given to inverse ODTCWT for image reconstruction. The experiments have demonstrated that the recommended multimodal image fusion method has illustrated superior efficiency than the conventional image fusion approaches. For example, the SNR of the designed PF-HBSSO-DTCWT has achieved higher rate while estimating with traditional approaches for image 8, which was 35.2, 36.5, 72.9, 27.7, 51.6, 53, and 51% maximized than PCA, DWT, IHS, DCT, CWT, NSCT, and DT-CWT. However, the proposed model has to be improved in future in terms of statistical analysis to eradicate the performance overlap with the traditional heuristic algorithms.
Data availability
The data underlying this article are available in https://www.med.harvard.edu/aanlib/home.htm.
References
Gao, X. W. & Hui, R. A deep learning based approach to classification of CT brain images. SAI Computing Conference (SAI). (2016)
Yang, H., Sun, J. Li, H., Wang, L. & Xu, Z. Deep fusion net for multi-atlas segmentation: Application to cardiac mr images.MICCAI 2016: Medical Image Computing and Computer-Assisted Intervention. pp 521–528. (2016)
Nie, D., Zhang, H., Adeli, E., Liu, L. & Shen, D. 3D deep learning for multi-modal imaging-guided survival time prediction of brain tumor patients. MICCAI 2016: Medical Image Computing and Computer-Assisted Intervention. pp 521–528. (2016)
James, A. P. & Dasarathy, B. V. Medical image fusion: A survey of the state of the art. Inform. Fusion. 19, 4–19 (2014).
Li, S., Kang, X., Fang, L., Hu, J. & Yin, H. Pixel-level image fusion: A survey of the state of the art. Inform. Fusion. 33, 100–112 (2017).
James, A. P. & Dasarathy, B. A review of feature and data fusion with medical images. Computer Vision and Pattern Recognition. (2015)
Mangai, U. G., Samanta, S., Das, S. & Chowdhury, P. R. A survey of decision fusion and feature fusion strategies for pattern classification. IETE Tech. Rev. 27(4), 293–307 (2010).
Hermessi, H., Mourali, O. & Zagrouba, E. Convolutional neural network-based multimodal image fusion via similarity learning in the shearlet domain. Neural Comput. Appl. 30, 2029–2045 (2018).
Yang, Y. et al. Multimodal medical image fusion based on fuzzy discrimination with structural patch decomposition. IEEE J. Biomed. Health Inform. 23(4), 1647–1660 (2019).
Gómez-Chova, L., Tuia, D., Moser, G. & Camps-Valls, G. Multimodal classification of remote sensing images: A review and future directions. Proc. IEEE 103(9), 1560–1584 (2015).
Ioannidou, S. & Karathanassi, V. Investigation of the dual-tree complex and shift-invariant discrete wavelet transforms on quickbird image fusion. IEEE Geosci. Remote Sens. Lett. 4(1), 166–170 (2007).
Jiang, Q., Jin, X., Lee, S. & Yao, S. A novel multi-focus image fusion method based on stationary wavelet transform and local features of fuzzy sets. IEEE Access 5, 20286–20302 (2017).
Bhateja, V., Patel, H., Krishn, A., Sahu, A. & Lay-Ekuakille, A. Multimodal medical image sensor fusion framework using cascade of wavelet and contourlet transform domains. IEEE Sens. J. 15(12), 6783–6790 (2015).
Madheswari, K., Venkateswaran, N. & Sowmiya, V. Visible and thermal image fusion using curvelet transform and brain storm optimization. 2016 IEEE Region 10 Conference (TENCON). pp 2826–2829. (2016)
Tao, J. Li, S. & Yang, B. Multimodal image fusion algorithm using dual-tree complex wavelet transform and particle swarm optimization. Communications in Computer and Information Science. vol 93, pp 296–303. (2010)
Kumari, D. & Agwekar, A. Survey paper on image fusion using hybrid non-subsampled contourlet transform and neural network. International Conference on Intelligent Computing and Control Systems (ICICCS). pp 1564–1568. (2021)
Zheng, S., Shi, W.-Z., Liu, J., Zhu, G.-X. & Tian, J.-W. Multisource image fusion method using support value transform. IEEE Trans. Image Process. 16(7), 1831–1839 (2007).
Zuo, Q., Zhang, J. & Yang, Y. DMC-Fusion: Deep multi-cascade fusion with classifier-based feature synthesis for medical multi-modal images. IEEE J. Biomed. Health Inform. 25(9), 3438–3449 (2021).
Sun, Y., Fu, Z., Sun, C., Hu, Y. & Zhang, S. Deep multimodal fusion network for semantic segmentation using remote sensing image and LiDAR data. IEEE Trans. Geosci. Remote Sens. 60, 1–18 (2022).
Fu, J., Li, W., Ouyang, A. & He, B. Multimodal biomedical image fusion method via rolling guidance filter and deep convolutional neural networks. Optik. 237, 166726 (2021).
Goyal, S., Singh, V., Rani, A. & Yadav, N. Multimodal image fusion and denoising in NSCT domain using CNN and FOTGV. Biomed. Signal Process. Control. 71, 103214 (2022).
Venkatesan, B. & Ragupathy, U. S. Integrated fusion framework using hybrid domain and deep neural network for multimodal medical images. Multidimens. Syst. Signal Process. 33(3), 819–834 (2022).
Bernal, E. A. et al. Deep temporal multimodal fusion for medical procedure monitoring using wearable sensors. IEEE Trans. Multimed. 20(1), 107–118 (2018).
Duan, J. et al. A novel GA-based optimized approach for regional multimodal medical image fusion with superpixel segmentation. IEEE Access 9, 96353–96366 (2021).
Kong, W. et al. Multimodal medical image fusion using gradient domain guided filter random walk and side window filtering in framelet domain. Inform. Sci. 585, 418–440 (2022).
Zhang, X., Liu, G., Huang, L., Ren, Q. & Bavirisetti, D. P. IVOMFuse: An image fusion method based on infrared-to-visible object mapping. Dig. Signal Process. 137, 104032 (2023).
Zhou, X. et al. Re2FAD: A differential image registration and robust image fusion method framework for power thermal anomaly detection. Optik. 259, 168817 (2022).
Gu, X. et al. Infrared-visible synthetic data from game engine for image fusion improvement. IEEE Trans. Games. 16, 291–302 (2023).
Jain, M., Singh, V. & Rani, A. A novel nature-inspired algorithm for optimization: Squirrel search algorithm. Swarm Evol. Comput. 44, 148–175 (2019).
Hashim, F. A., Houssein, E. H., Hussain, K., Mabrouk, M. S. & Al-Atabany, W. Honey Badger algorithm: New metaheuristic algorithm for solving optimization problems. Math. Comput. Simul. 192, 84–110 (2022).
Aghamaleki, J. A. & Ghorbani, A. Image fusion using dual tree discrete wavelet transform and weights optimization. Vis. Comput. 39(3), 1181–1191 (2023).
Jafari, M. & Chaleshtari, M. H. B. Using dragonfly algorithm for optimization of orthotropic infinite plates with a quasi-triangular cut-out. Euro. J. Mech. A/Solids 66, 1–14 (2017).
Mirjalili, S., Mirjalili, S. M. & Lewis, A. Grey wolf optimizer. Adv. Eng. Softw. 69, 46–61 (2014).
Qian, J. et al. Structured illumination microscopy based on principal component analysis. ELight. 3(1), 4 (2023).
Trivedi, G. & Sanghavi, R. Fusesharp: A multi-image focus fusion method using discrete wavelet transform and unsharp masking. J. Appl. Math. Inform. 41(5), 1115–1128 (2023).
Hussein, Y. D., Makkey, Y. M. & Abdelrahman, A. S. Hybrid fusion approach for Alzheimer’s disease progression employing IHS and wavelet transform. Menoufia J. Electron. Eng. Res. 33(1), 17–23 (2024).
Xu, H., Ma, J., Jiang, J., Guo, X. & Ling, H. U2Fusion: A unified unsupervised image fusion network. IEEE Trans. Pattern Anal. Mach. Intell. 44(1), 502–518 (2020).
Wang, C., Nie, R., Cao, J., Wang, X. & Zhang, Y. IGNFusion: An unsupervised information gate network for multimodal medical image fusion. IEEE J. Select. Top. Signal Process. 16(4), 854–868 (2022).
Zhou, M., Huang, J., Yan, K., Hong, D., Jia, X., Chanussot, J., & Li, C. A general spatial-frequency learning framework for multimodal image fusion. IEEE Transactions on Pattern Analysis and Machine Intelligence. (2024).
Sun, Le., Tang, M. & Muhammad, G. CABnet: A channel attention dual adversarial balancing network for multimodal image fusion. Image Vis. Comput. 147, 105065 (2024).
Lin, C., Chen, Y., Feng, S. & Huang, M. A multibranch and multiscale neural network based on semantic perception for multimodal medical image fusion. Sci. Rep. 14(1), 17609 (2024).
Ghosh, T. & Jayanthi, N. An efficient Dense-Resnet for multimodal image fusion using medical image. Multimed. Tools Appl. 2024(83), 68181–68208 (2024).
Long, Y., Jia, H., Zhong, Y., Jiang, Y. & Jia, Y. RXDNFuse: A aggregated residual dense network for infrared and visible image fusion. Inform. Fusion 69, 128–141 (2021).
Acknowledgements
I would like to express my very great appreciation to the co-authors of this manuscript for their valuable and constructive suggestions during the planning and development of this research work.
Funding
This research did not receive any specific funding.
Author information
Authors and Affiliations
Contributions
J.R. and R.N. designed the model, computational framework and carried out the implementation. Jampani Ravi performed the calculations and wrote the manuscript with all the inputs. J.R. and R.N. discussed the results and contributed to the final manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Ethical approval
Not Applicable.
Informed consent
Not Applicable.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Ravi, J., Narmadha, R. Optimized dual-tree complex wavelet transform aided multimodal image fusion with adaptive weighted average fusion strategy. Sci Rep 14, 30246 (2024). https://doi.org/10.1038/s41598-024-81594-6
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-024-81594-6
