
Abstract
The quantity of cable conductors is a crucial parameter in cable manufacturing, and accurately detecting the number of conductors can effectively promote the digital transformation of the cable manufacturing industry. Challenges such as high density, adhesion, and knife mark interference in cable conductor images make intelligent detection of conductor quantity particularly difficult. To address these challenges, this study proposes the YOLO-cable model, which is an improvement made upon the YOLOv10 model. Specifically, the Focal loss function is introduced, the C2F structure in the backbone is optimized, the Focal NeXt module is added, and a multi-scale feature (MSF) module is incorporated in the Neck section. Comparative experiments with various YOLO series models demonstrate that the YOLO-cable model significantly outperformed the baseline YOLOv10s model as it achieves recall, mAP0.5, and mAP scores of 0.982, 0.994, and 0.952, respectively. Further visualization analysis shows that the overlap of YOLO-cable detection boxes with manually labeled samples reaches 90.9% in length and 95.7% in height, indicating high data consistency. The IOU threshold adopted by the model enables it to effectively filter out false detection, thus ensuring detection accuracy. In short, the proposed model excels in detecting the number of cable conductors, enhancing quality control in cable production. This study provides new insights and technical support for the application of deep learning in industrial inspections.
Similar content being viewed by others

Introduction
Cables, serving as the primary medium for transmitting signals and energy in power, communication, and industrial control systems, have their manufacturing quality directly impacting the stability and safety of these systems1,2,3. The cable core is a crucial component of cables, where the number of conductors serves as a key quality indicator, as illustrated in the cross-sectional view in Fig. 1. Digitally recording these core parameters can significantly enhance cable production quality4.
Current research efforts predominantly focus on defect detection during the usage of cables5. The existing methods for detecting cable cores largely rely on manual visual inspection or basic image processing algorithms, where samples are cut from the cable, and quality parameters are analyzed and recorded. Additionally, the traditional measurement of cable insulation structure parameters typically requires manual labor: conductors and insulation layers are extracted, cross-sectional slices are taken along the cable axis, and then observed using reading microscopes or projectors. This manual approach is not only time-consuming and labor-intensive but also susceptible to subjective biases, which can compromise the accuracy and consistency of inspection results. Consequently, adopting intelligent methods to detect the quantity of cable cores represents a promising direction for future development. Moreover, traditional morphological processing methods face difficulties in effectively addressing issues like knife marks and adhesion in cable conductors, complicating the accurate counting of high-precision cable conductors6,7.
In recent years, with the advancement of computer vision technology, an increasing number of researchers have begun applying deep learning methods to the field of industrial inspection8. Researchers commonly use deep learning to detect defects in PCB boards, material gaps, and other imperfections9,10. In smart manufacturing, defects detection using deep learning techniques11,12has become a growing trend. However, most current detection models are designed for sparse objects13, and detecting dense targets in industrial products remains one of the key challenges in machine vision technology14.
The YOLO (You Only Look Once) series models, as a widely used deep learning approach in object detection, have garnered significant attention from researchers due to their real-time performance and high accuracy15. These models have achieved notable success in various detection tasks16,17, such as dense pipe counting on construction sites18, pedestrian counting in public spaces19, and fruit counting in orchards20. The YOLOv10 model21, the latest in the YOLO series, significantly improves detection performance by enhancing the feature extraction network and incorporating multi-scale features. Despite these advancements, the YOLO models encounter challenges in detecting small objects such as those found in cable core images, which are characterized by dense arrangements and small sizes. Ji et al. highlight issues including insufficient detection accuracy and a limited ability to discern fine details in such scenarios22. To overcome these limitations, this paper introduces an improved YOLO-cable model, which optimizes the network structure and boosts multi-scale feature extraction to enhance the accuracy and robustness of detecting cable core quantities, offering an automated detection solution tailored for the cable manufacturing industry.

Schematic diagram of cable cross-section.
Material and method
Training environment
The training environment for the research was established using the Ubuntu 20.04 operating system, leveraging an NVIDIA GTX 4090 GPU for both training and testing. The primary software tools included Python 3.9, Pytorch 2.0, and OpenCV 4.1.
Dataset
The dataset for this study was acquired through a personal data collection process, which involved slicing cables and capturing images. The dataset preparation included data annotation and augmentation.
Data collection
Cable slices were obtained from the Shangwei Cable Factory in Wuwei City, Wuhu, Anhui Province, with cable parameters detailed in Table 1.
To enable future application of the model on mobile platforms (such as Android devices), data collection was performed using a smartphone, specifically a Xiaomi 13. Images were captured with the cable cross-section in a vertical orientation, and the camera was positioned 15–20 cm from the cable. The image parameters were set to RGB with a resolution of 3024*4032. An example of the collected data is shown in Fig. 2.

Example of original images.
Dataset creation
Images were annotated using the LabelImg software, with the annotation label designated as ‘core_s’. The dataset included 100 single-core cable images, annotated with 6,000 labels, and 100 three-core cable images, annotated with 14,400 labels, totaling 20,400 labels. To align with practical applications, data augmentation was performed involving random adjustments to brightness, noise, and saturation parameters, as detailed in Table 2.
Following augmentation, the total number of images increased to 1,000, and the total label count was 204,000. The images before and after data augmentation are shown in Fig. 3.

Data Augmentation Example.
The dataset was then split into a training set and a validation set in an 8:2 ratio, with an additional test set consisting of 40 images not used in the training process.
Cable core recognition model construction
YOLOv10 model
The YOLOv10, part of the Ultralytics project, represents a significant advancement in real-time object detection, achieving state-of-the-art performance while reducing computational overhead by eliminating Non-Maximum Suppression (NMS) and optimizing multiple model components. It employs a dual-assignment strategy for NMS-free training and adopts an efficiency-accuracy driven design strategy, delivering an excellent precision-latency trade-off. The basic framework of the YOLOv10 model is illustrated in Fig. 4.

Basic framework of YOLOv10 model.
Loss function improvement
YOLOv10 utilizes the Complete Intersection over Union (CIoU) to measure the loss between the predicted bounding boxes and the ground truth bounding boxes. The corresponding formulas are presented in Eqs. 1–3.
IoU represents the ratio of the intersection area to the union area between the predicted bounding box and the ground truth bounding box.
\(\rho (b,{b_{gt}})\) represents the Euclidean distance between the center points of the predicted bounding box and the ground truth bounding box.
c represents the diagonal length of the smallest enclosing box that contains both the predicted bounding box and the ground truth bounding box.
w and h represent the width and height of the bounding box, respectively.
\({w_{gt}}\)and \({h_{gt}}\) represent the width and height of the ground truth bounding box, respectively.
v is a parameter utilized to quantify the similarity of aspect ratios.
α is a weighting parameter used to balance the trade-off between distance and aspect ratio similarity.
In detecting the number of cable conductors, the negative samples (background class) are typically much more prevalent than the positive samples (object class). This imbalance can lead the model to neglect the minority class, i.e., the positive samples, during training, consequently reducing the model’s accuracy in detecting cable conductors. To mitigate this issue, it is crucial to adjust the model’s focus on both positive and negative samples can help mitigate this issue to some extent. Focal Loss23 addresses this by modifying the loss function to place greater emphasis on hard-to-classify samples (i.e., samples that are difficult to predict correctly), as described in Eqs. 4–6.
p denotes the predicted probability of the sample.
y represents the class labels (positive or negative samples).
α is a hyperparameter that balances the weights of positive and negative samples.
γ is a hyperparameter that adjusts the weight factor for the prediction probability of the actual class.
The cable conductor objects, characterized by attributes such as adhesion and density, lead to a significantly higher number of negative samples compared to positive samples in the dataset. Given these conditions, employing Focal Loss for computation is strategic.
Dense object detection module
Both CNN and Transformer networks adhere to a design principle that entails progressively reducing the spatial dimensions of feature maps to extract high-level semantic features for prediction24. However, many dense prediction tasks, such as detection and segmentation, necessitate multi-scale features to accommodate objects of varying sizes. The architecture of the Cascade Fusion Network (CFNet) has proven to significantly enhance performance in dense prediction tasks25. Within this architecture, ConvNeXt represents an advanced enhancement of traditional convolutional neural networks, such as ResNet. It maintains the core structure of CNNs but incorporates grouped convolutions (Depthwise Separable Convolutions) to decrease computational demands and parameter counts while preserving efficient feature extraction capabilities. Its performance is comparable to that of Vision Transformers.

Basic framework of the CFNet module.
The fundamental structure of the CFNet module is depicted in Fig. 5. Within CFNet, the blocks may consist of various modules, including ResNet bottleneck blocks, ConvNeXt blocks, or Swin Transformer blocks. The Focal Block incorporates both fine-grained local features and coarse-grained global features, facilitating more efficient extraction of features from dense objects. As a result, the Focal Block is employed as the feature fusion module. The primary composition of the Focal Block is illustrated in Fig. 6.

Focal block module.
In Fig. 6, D 7*7 denotes a 7*7 depthwise convolution, while 1*1 represents a 1*1 convolution, n stands for the number of output feature channels, rrefers to the dilation rate of the additional convolution, and GELU indicates the activation function25.
The YOLOv10 model persists in utilizing the C2F module for feature extraction following the convolutional layers. As a standard feature extraction module, the C2F provides a compromise between speed and efficiency. Nonetheless, its efficacy in managing dense object detection tasks could be enhanced. Consequently, the ConvNeXt and Focal Block have been amalgamated into the C2F module, resulting in the creation of the C2F_FocalNeXt module. The detailed architecture of this module is depicted in Fig. 7.

Structure of the C2F module and C2F_FocalNeXt module.
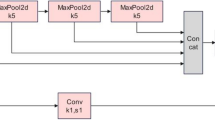
Multi-scale feature module
Dense objects frequently result in feature loss during the feature fusion phase. To improve the model’s capability to extract features, a Multi-Scale Feature (MSF) extraction module is constructed. The detailed structure of this module is depicted in Fig. 8.

Multi-scale feature extraction module.
C1, C2, and C3 represent large-scale, medium-scale, and small-scale feature maps, respectively. C1 is processed through adaptive max pooling and adaptive average pooling to resize it to the dimensions of C2, facilitating the extraction of diverse features and enhancing feature representation. C3 is upsampled via nearest-neighbor interpolation to align with the dimensions of C2. These three channels are then concatenated to form the Multi-Scale Feature (MSF) module, which extracts a variety of information from different scale feature maps.
In the Neck section, a straightforward Concat structure is initially used to merge feature maps from different stages of the network. To further enhance the model’s feature extraction capabilities, this Concat module is subsequently replaced with the MSF module.
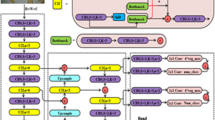
YOLO-cable model
Combine the above modules with the base YOLOv10 model to construct the optimized YOLOv10 model. The overall framework of the YOLO-cable model is shown in Fig. 9.

YOLO-cable network architecture diagram.
Evaluation metrics
Following other related works26,27, the evaluation is conducted using three metrics: Recall, mAP@0.5, and mAP@0.5:0.95. The calculation formulas for these metrics are provided in Eqs. 7–10.
Training hyperparameters
The training hyperparameters are detailed in Table 3.
Results
Model training results
Using the same hyperparameter settings, the YOLOv10 model was trained over 300 epochs. The overall training results for various metrics are shown in Fig. 10. The loss curve is observed to converge rapidly between 0 and 50 epochs and then stabilizes, exhibiting a more gradual convergence rate between 200 and 300 epochs.

Training results of YOLOv10 with different modules.
The training results for the mAP metric are illustrated in Fig. 11. The mAP value shows a rapid increase from 0 to 50 epochs, followed by a more gradual and stable growth between 200 and 300 epochs. After stabilization, the mAP value of YOLOv10-C2F_FocalNeXt_MSF (YOLO-cable) exceeds that of YOLOv10-C2F (YOLOv10s) and surpasses YOLOv10-C2F_FocalNeXt after 290 epochs.

The mAP training curves for YOLOv10 with different modules.
To evaluate the model’s performance, we trained four models: YOLOv5s, YOLOv6s, YOLOv8s, and YOLOv9c. The mAP training results are shown in Fig. 12. These results reveal that all models in the YOLO series achieve mAP@0.5 values above 0.95 and mAP@0.5:0.95 values above 0.92. Among these, the YOLOv9c model registers the highest mAP value. The YOLO-cable model ranks second in mAP@0.5 and third in mAP@0.5:0.95 in the comparative analysis.

The mAP training curves for various YOLO models.
Detection results visualization
Various models were utilized to evaluate images from a test set that did not participate in the training process. The test set included 20 images of single-core cables and 20 images of three-core cables. To enhance the visualization of detection outcomes, the line thickness of the detection boxes was minimized, and random-colored dots were placed at the center of each detection box. This approach helps to better identify issues such as false negatives and false positives. Some detection results are shown in Fig. 13.

Detection results of various models.
As shown in Fig. 13, the detection results are as follows:
(a) and (b) illustrate the detection results for single-core cables.
(c) and (d) depict the detection results for three-core cables.
In Fig. 13(a), YOLOv6s and YOLOv9c display false detections, whereas the other models achieve accurate detection. Figure 13(b) shows that all models experience missed detections at the same location. In Fig. 13(c), apart from the YOLOv6s model, the other models demonstrate varying degrees of missed or false detections. In Fig. 13(d), every model except YOLO-cable exhibits different levels of false detections.
Overall, the detection performance reveals that most models are capable of effectively identifying the number of conductors in single-core cables. However, some models exhibit noticeable missed or false detections when dealing with three-core cables. Compared to other models, the YOLO-cable model demonstrates the fewest detection errors in three-core cable images.
Analysis and discussion
Model comparison analysis
By examining the performance metrics of various models, such as YOLO-cable, this analysis aims to explore the variations in their effectiveness for cable conductor detection tasks. Table 4 displays crucial performance indicators for each model, including Recall, mAP, and the total number of model parameters.
YOLOv9c achieves a high recall rate of 0.981, showcasing its superior detection accuracy. However, YOLO-cable slightly surpasses this with a recall rate of 0.982, indicating robust detection capabilities combined with high precision. The models’ precision is evaluated using the mAP@0.5 and mAP@0.5:0.95 metrics, which assess performance under different IoU thresholds. YOLOv9c excels in these metrics, especially with an mAP@0.5:0.95 of 0.978, demonstrating its robustness across varying IoU conditions. YOLO-cable, while close with an mAP@0.5 of 0.994, has a slightly lower mAP@0.5:0.95 of 0.952 compared to YOLOv9c, indicating some performance decrement under stricter IoU conditions. In terms of model parameters, which reflect computational complexity and resource consumption, YOLOv9c has the highest count at 51.6 M, indicating greater complexity. YOLO-cable, with 18.3 M parameters, strikes a balance between YOLOv5s and YOLOv10s, offering high performance with reduced computational demand. FPS is crucial for assessing the model’s processing speed in practical applications. YOLOv10s leads with 140 FPS, while YOLO-cable follows at 119 FPS. Although slightly lower than YOLOv10s, YOLO-cable significantly outperforms YOLOv9c, which has only 82 FPS, showcasing a strong balance between speed and accuracy.
Overall, YOLO-cable exhibits a commendable balance of recall rate, mAP, and computational complexity. It maintains a high FPS with a relatively low parameter count, making it suitable for tasks requiring efficient real-time processing. However, the marginally lower mAP@0.5:0.95 suggests potential areas for optimization in handling more stringent IoU conditions.
Ablation study
The ablation study delineates the performance variations of the model before and after the integration of specific modules. This includes the baseline model C2F, the model enhanced with the Focal NeXt module (C2F + Focal NeXt), and the model further improved with the MSF module (C2F + Focal NeXt + MSF). Performance metrics such as Recall, Average Precision (mAP), Parameters (Param), and Frames Per Second (FPS) are utilized to evaluate the strengths and weaknesses of each configuration.
As shown in Table 5, the Recall for model M3 is the highest at 0.982, illustrating an improvement in detection capabilities with this configuration. In contrast, M1 has a Recall of 0.977, slightly lower than the other models, which suggests that the introduction of new modules has enhanced the baseline model’s detection ability.
The differences in mAP@0.5 and mAP@0.5:0.95 among the three configurations are slight, all exceeding 0.9. Specifically, M2 and M3 register an mAP@0.5 of 0.994, marginally higher than the baseline model’s 0.993, indicating that the Focal NeXt and MSF modules contribute to improved model precision.
The parameter count for the baseline model M1 stands at 16.6 M. With the addition of the Focal NeXt module, the parameter counts decreases to 15.5 M, likely due to the optimized design of the Focal NeXt module. However, with the subsequent incorporation of the MSF module, the parameter counts increases to 18.3 M, suggesting that while the module boosts detection performance, it also adds to the computational load.
The baseline model C2F achieves the highest FPS at 140. After incorporating the Focal NeXt module, FPS slightly drops to 129, reflecting a decrease in processing speed but still maintaining a high level. With the addition of the MSF module, FPS further reduces to 119, demonstrating that multi-scale feature fusion improves detection performance at the cost of reduced processing speed.
Analysis of the performance metrics across different model combinations reveals that M3 excels in both recall rate and average precision, notably achieving the highest recall rate of 0.982. However, this enhancement in detection accuracy comes with a decrease in processing speed, from 140 FPS to 119 FPS. In tasks like cable conductor detection, where accuracy is paramount over speed, the M3 combination emerges as a strong contender in this experiment. Future work will involve evaluating these models on embedded systems for a more comprehensive analysis.
Detection results analysis
Optimization of cable conductor count detection based on non-overlapping features
The YOLO-cable model’s test results, as visualized, frequently show false detections, especially in overlapping scenarios. Given that cable conductor cores typically do not overlap in cross-sectional cable images, this characteristic can be leveraged to filter out false detections.
To address this, a post-processing step was implemented where the IoU is calculated for pairs of detected bounding boxes. If the IoU exceeds a predetermined threshold, one of the overlapping boxes is filtered out.
As indicated in Table 6, employing the IoU threshold-based filtering method significantly mitigates the impact of false detections on the results, notably enhancing the accuracy of conductor count detection for three-core cables. Nevertheless, there are still occasional instances of false deletions. Future work will focus on further optimizing the filtering algorithm to minimize these occurrences.
Cable conductor detection box analysis
The dimensions of cable conductors are a critical parameter in assessing cable quality. By analyzing the length and width of the detection boxes, it is feasible to estimate the dimensions of cable conductors to a certain degree. Data from three-core cables were specifically chosen for generating density plots to compare the actual label dimensions with the predicted label dimensions.

Comparison of detection boxes with ground truth labels.
Figure 14 illustrates that the overlap of the width data from the detection boxes is 90.9%, while the height data overlap reaches 95.7%. This signifies a minimal variance in the dimensions of the detection boxes between the two methods, with very similar data distributions. The detection results align closely with the manually annotated data in the core areas.
In terms of dimensions, the relative errors in width and height of the detection boxes compared to manual annotations are 5.3% and 3.2%, respectively. This underscores a high level of consistency in the data, with comparable degrees of dispersion.
Therefore, the detection boxes generated by object detection methods can, to a certain extent, closely approximate manually annotated boxes. Both the width and height of these detection boxes maintain a high degree of accuracy relative to the ground truth labels, effectively mirroring the dimensions of cable conductors and providing essential technical support for subsequent size parameter detection of cable conductors.
YOLO-cable attention analysis
Heatmaps reveal the model’s focus on the objects, aiding researchers in understanding its operational nuances.
As shown in Fig. 15, the results of the cable conductor count detection and the corresponding heatmap are presented. The green dots in the detection results denote the centers of the detection boxes. The images demonstrate that the model generally performs effectively in detecting the number of cable conductors and accurately pinpointing their locations in most instances.

Visualization of YOLO-cable Heatmaps.
However, further analysis of the heatmaps in Fig. 15 indicates that the YOLO-cable model focuses more on areas with distinct contours. The model may pay insufficient attention to regions where cable conductors are closely bundled together, an issue particularly prominent in the detection results for three-core cables. The existing convolutional layers and attention mechanisms exhibit a bias towards areas with high contrast or clearly defined edges, which may lead to difficulties in distinguishing objects in low-contrast or complex backgrounds.
Given the relatively simple background environment in which the model excels, future efforts will be directed towards optimizing the model’s capacity to distinguish bundled objects. The objective is to achieve high-precision detection of cable conductors in more intricate environments.
Limitations and future work
Although the model demonstrated high accuracy in this experiment, heatmap visualizations identified potential shortcomings in processing unknown samples. Future research will explore the incorporation of more sophisticated modules for identifying bundled objects by designing more appropriate convolutional structures or integrating multi-scale feature fusion mechanisms. These enhancements aim to improve the model’s capability to distinguish bundled conductors.
Subsequent testing indicated that several models had difficulties recognizing certain conductor objects in some images, as depicted in Fig. 13(b). A likely cause is the dataset’s limited diversity, which may prevent the model from learning specific or similar features. Future work will concentrate on augmenting the dataset with a broader array of samples to mitigate this limitation.
To address the cable manufacturing industry’s demand for convenient quality inspection, forthcoming initiatives will focus on implementing the model in embedded systems to enhance its practical application.
Conclusion
This study introduces innovations in cable conductor detection, summarized as follows:
(1) We enhanced the YOLOv10 model to cater specifically to the unique features of cable cross-sectional conductor images, resulting in the high-precision YOLO-cable detection model optimized for accurately quantifying cable conductors.
(2) Leveraging the non-overlapping structure of cable conductors, an IoU threshold technique was applied to filter out redundant detection boxes, refining the model’s precision and strengthening its detection capabilities.
(3) The model’s high-precision detection provides essential technical support for detailed subsequent analyses of cable conductor dimensions.
(4) While effective, the model may require further optimization for detecting cable conductors under conditions of extreme bundling, enhancing its robustness in complex scenarios.
Data availability
The datasets used and/or analysed during the current study available from the corresponding author on reasonable request.
References
De Arizon, P. & Dommel, H. W. Computation of cable impedances based on subdivision of conductors. IEEE Trans. Power Delivery. 2 (1), 21–27 (1987).
Li, C. et al. Design and optimization of large size conductor for submarine cable. In 2017 4th IEEE International Conference on Engineering Technologies and Applied Sciences (ICETAS) (pp. 1–4). IEEE. (2017), November.
Simons, D. M. Cable geometry and the calculation of current-carrying capacity. Trans. Am. Inst. Electr. Eng. 42, 600–620 (1923).
Lenty, B., Kwiek, P. & Sioma, A. Quality control automation of electric cables using machine vision. In Photonics Applications in Astronomy, Communications, Industry, and High-Energy Physics Experiments 2018 (Vol. 10808, 236–244). SPIE. (2018), October.
Sharma, P., Saurav, S. & Singh, S. Object detection in power line infrastructure: a review of the challenges and solutions. Eng. Appl. Artif. Intell. 130, 107781 (2024).
Yu, A., Shan, L., Zhu, W., Jie, J. & Hou, B. A novel improved total variation algorithm for the elimination of scratch-type defects in high-voltage cable cross-sections. Plos One, 19(4), e0300260. (2024).
Zhang, X. & Yin, H. A monocular vision-based Framework for Power Cable Cross-section Measurement. Energies 12 (15), 3034 (2019).
Jia, Z., Wang, M. & Zhao, S. A review of deep learning-based approaches for defect detection in smart manufacturing. J. Opt. 53 (2), 1345–1351 (2024).
Ling, Q. & Isa, N. A. M. Printed circuit board defect detection methods based on image processing, machine learning and deep learning: a survey. IEEE Access. 11, 15921–15944 (2023).
Bhatt, P. M. et al. Image-based surface defect detection using deep learning: a review. J. Comput. Inf. Sci. Eng. 21 (4), 040801 (2021).
Wang, J., Fu, P. & Gao, R. X. Machine vision intelligence for product defect inspection based on deep learning and Hough transform. J. Manuf. Syst. 51, 52–60 (2019).
Yang, J. et al. Using deep learning to detect defects in manufacturing: a comprehensive survey and current challenges. Materials 13 (24), 5755 (2020).
Saberironaghi, A., Ren, J. & El-Gindy, M. Defect detection methods for industrial products using deep learning techniques: a review. Algorithms 16 (2), 95 (2023).
Wang, X., Jia, X., Jiang, C. & Jiang, S. A wafer surface defect detection method built on generic object detection network. Digit. Signal Proc. 130, 103718 (2022).
Hussain, M. & Khanam, R. In-depth review of yolov1 to yolov10 variants for enhanced photovoltaic defect detection. In Solar (Vol. 4, No. 3, 351–386). MDPI. (2024).
Cai, Y. et al. YOLOv4-5D: an effective and efficient object detector for autonomous driving. IEEE Trans. Instrum. Meas. 70, 1–13 (2021).
Wang, J., Chen, Y., Dong, Z. & Gao, M. Improved YOLOv5 network for real-time multi-scale traffic sign detection. Neural Comput. Appl. 35 (10), 7853–7865 (2023).
Li, Y. & Chen, J. Computer vision–based counting model for dense steel pipe on construction sites. J. Constr. Eng. Manag. 148 (1), 04021178 (2022).
Duraipandian, K., Padmanabhan, B. R. & Ranka, V. Designing a dynamic framework for people counting using YOLO-PC. In AIP Conference Proceedings (Vol. 2919, No. 1). AIP Publishing. (2024).
Neupane, C., Walsh, K. B., Goulart, R. & Koirala, A. Developing machine vision in Tree-Fruit Applications—Fruit Count, Fruit size and Branch Avoidance in Automated Harvesting. Sensors 24 (17), 5593 (2024).
Wang, A., Chen, H., Liu, L., Chen, K., Lin, Z., Han, J. & Ding, G. Yolov10: Real-time end-to-end object detection. http://arxiv.org/abs/2405.14458. (2024).
Ji, S. J., Ling, Q. H. & Han, F. An improved algorithm for small object detection based on YOLO v4 and multi-scale contextual information. Comput. Electr. Eng. 105, 108490 (2023).
Lin, T. Y., Goyal, P., Girshick, R., He, K. & Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE international conference on computer vision (pp. 2980–2988). (2017).
Han, K. et al. A survey on vision transformer. IEEE Trans. Pattern Anal. Mach. Intell. 45 (1), 87–110 (2022).
Shen, Z., Dai, Y. & Rao, Z. Cfnet: Cascade and fused cost volume for robust stereo matching. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 13906–13915). (2021).
Dai, Z., Yi, J., Zhang, Y., Zhou, B. & He, L. Fast and accurate cable detection using CNN. Appl. Intell. 50, 4688–4707 (2020).
Zhao, C., Shu, X., Yan, X., Zuo, X. & Zhu, F. RDD-YOLO: a modified YOLO for detection of steel surface defects. Measurement 214, 112776 (2023).
Author information
Authors and Affiliations
Contributions
Xiaoguang Xu: Supervision, Resources, Conceptualization, Funding acquisition; Jiale Ding: Data Curation, Software, Validation; Qi’an Ding: Conceptualization, Writing- Reviewing and Editing, Methodology, Software, Validation; Qikai Wang: Software, Validation; Yi Xun: Software, Validation.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Xu, X., Ding, J., Ding, Q. et al. A study on the detection of conductor quantity in cable cores based on YOLO-cable. Sci Rep 14, 31107 (2024). https://doi.org/10.1038/s41598-024-82323-9
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-024-82323-9
Keywords
This article is cited by
-
Lightweight obstacle detection for unmanned mining trucks in open-pit mines
Scientific Reports (2025)
