
Abstract
Vision transformers have garnered substantial attention and attained impressive performance in image super-resolution tasks. Nevertheless, these networks face challenges associated with attention complexity and the effective capture of intricate, fine-grained details within images. These hurdles impede the efficient and scalable deployment of transformer models for image super-resolution tasks in real-world applications. In this paper, we present a novel vision transformer called Scattering Vision Transformer for Super-Resolution (SVTSR) to tackle these challenges. SVTSR integrates a spectrally scattering network to efficiently capture intricate image details. It addresses the invertibility problem commonly encountered in down-sampling operations by separating low-frequency and high-frequency components. Additionally, SVTSR introduces a novel spectral gating network that utilizes Einstein multiplication for token and channel mixing, effectively reducing complexity. Extensive experiments show the effectiveness of the proposed vision transformer for image super-resolution tasks. Our comprehensive methodology not only outperforms state-of-the-art methods in terms of the PSNR and SSIM metrics but, more significantly, entails a reduction in model parameters exceeding tenfold when compared to the baseline model. As shown in Fig. 1, the substantial decrease of parameter amount proves highly advantageous for the deployment and practical application of super-resolution models. Code is available at https://github.com/LiangJiabaoY/SVTSR.git.
Similar content being viewed by others


Introduction
Single image super-resolution (SISR) constitutes a longstanding challenge within the domains of computer vision and image processing. Its primary objective resides in the reconstruction of a high-resolution image based on a provided low-resolution input. Since deep learning has been successfully applied to the SR task1, numerous methods based on the convolutional neural network (CNN)2,3,4,5,6,7,8,9 have been proposed and almost dominate this field in the past few years. Nevertheless, owing to the parameter-dependent receptive field scaling and content-independent local interactions of convolutions employed, the CNN is constrained in its ability to capture long-range dependencies10.
To overcome this constraint, several Transformer-based image super-resolution (SR) networks10,11,12,13 have been introduced, aiming to model long-range dependencies and enhance SR performance. For instance, the Image Processing Transformer (IPT)11 was intentionally pre-trained on the ImageNet14 dataset to thoroughly exploit the capabilities of the Transformer architecture, thereby attaining optimal performance in image SR. SwinIR10 was proposed, leveraging the Swin Transformer architecture15, with the primary aim of substantially enhancing SR performance. In addition, HAT13 was proposed based on SwinIR10 delving deeper into the potential of the Transformer architecture and achieved state-of-the-art results on the image SR task.
Despite the performance improvements achieved by these Transformer-based methods in image SR tasks, they still encounter certain challenges. One of the challenges faced by Transformers in the field of image SR is the escalating computational complexity of the self-attention module with the increase in sequence length or image resolution. Furthermore, with the augmentation of image resolution or sequence length, there is a corresponding increase in model size, the quantity of floating-point operations per second (FLOPS), and the inference time of the model. These factors necessitate meticulous consideration and resolution to ensure the efficient and scalable deployment of image SR Transformer models in real-world applications. In addressing the challenges, we have embarked on exploratory investigations. Our objective is to identify an approach that, while ensuring the performance of image SR models, concurrently reduces the computational complexity and parameter amount of the model. This pursuit aims to propel the deployment and practical application of image SR models.
Recently, Scattering Vision Transformer has shown great promise in image classification and instance segmentation tasks with a significant reduction in a number of parameters and FLOPS. On the one hand, it uses a spectral scattering network to address the attention complexity and Dual-time Complex Wavelet Transforms (DTCWT) to capture the fine-grained information using spectral decomposition into low-frequency and high-frequency components of an image. On the other hand, it uses attention layers that focus on extracting semantic features and addressing long-range dependencies present in the image. A Hybrid Attention Transformer is proposed for SR tasks that combines self-attention, channel attention and an overlapping cross-attention to activate more pixels for better reconstruction13.
In this paper, we propose a Scattering Vision Transformer for Super-Resolution, namely SVTSR. SVTSR consists of three modules: shallow feature extraction, deep feature extraction and image reconstruction. Diverging from the conventional approach, to mitigate the computational complexity and reduce the parameter amount of the model, we introduced a scatter layer in the deep feature extraction component, concurrently reducing the number of RHAG (residual hybrid attention groups) layers. Ultimately, our SR model surpassed the baseline in terms of PSNR and SSIM metrics on classic SR datasets such as Set516 and Set1417, achieving satisfied results. Moreover, the model exhibited a reduction in parameter amount by over tenfold compared to the baseline.
Overall, the main contributions of our work are as follows:
-
We introduce an invertible spectral network based on DTCWT transformation into vision transformers for image SR tasks to decompose image features into low-frequency and high-frequency features;
-
We design a novel vision transformer for image super-resolution tasks;
-
Detailed performance analysis shows that our method achieves state-of-the-art performance. In addition, the model’s parameter count reduces by more than tenfold compared to the baseline model;
Related work
Vision transformer
Recently, Transformer18 has attracted the attention of computer vision community due to its success in the field of natural language processing. A series of Transformer-based methods15,19,20,21,22,23,24,25,26,27,28,29,30,31 have been developed for high-level vision tasks, including image classification15,20,25,32,33,34,35, object detection15,30,36,37,38, segmentation28,34,39,40, etc. Despite the demonstrated superiority of the vision Transformer in modeling long-range dependencies20,41, numerous studies have highlighted the potential of convolution to enhance the visual representation of Transformer22,24,31,42,43. Because of its outstanding performance, the Transformer has also been implemented for tasks related to low-level vision10,11,12,13,44,45,46,47,48. Specifically, IPT11 devises a ViT-style network and incorporates multi-task pre-training for image processing purposes. SwinIR10introduces an image restoration Transformer model inspired by15. VRT45presents Transformer-based architectures for video restoration tasks. EDT12 incorporates a self-attention mechanism and a strategy of pre-training across multiple related tasks. HAT13 integrates self-attention, channel attention, and a novel overlapping cross-attention mechanism to activate a greater number of pixels, thereby enhancing the quality of reconstruction and further advancing the state-of-the-art in SR. Although Transformer-based methods in the field of super-resolution have made significant progress in performance metrics such as PSNR and SSIM, challenges still exist in terms of model computational complexity and parameter quantity, which hinders the practical deployment and application of super-resolution models. We use spectral transform block based on an invertibility spectral network instead of the standard self-attention network and reduce the number of transformer layers, thus achieving a reduction in model computational complexity and number of model parameters while maintaining model performance metrics (Fig. 1).

PSNR results compared to the total number of parameters of classical methods for image super-resolution (\(\times 4\)) on the Set5 dataset.
Frequency learning
Numerous studies have been conducted focusing on the frequency domain in low-level restoration tasks49,50,51,52,53,54. Several methodologies50,51,52 were examined for decomposing features into distinct frequency bands using a multi-branch CNN to enhance the level of detail. Typically, the omni-frequency region-adaptive network51 employed a multi-branch CNN to segregate diverse frequency components and enhance these attributes using the proposed frequency enhancement unit. Frequency-specific convolutional neural networks52 segregated the input images into three sub-frequency clusters and conducted training for the convolutional neural network individually for each sub-frequency cluster. The ultimate SR image was synthesized by amalgamating the multi-SR images generated from various networks. Moreover, the frequency aggregation network50 extracted distinct frequencies from the low resolution (LR) image and forwarded them individually to a channel attention-grouped residual dense network to produce corresponding features. Next, these residual dense features are adaptively aggregated to reconstruct the high resolution (HR) image with improved details and textures. Other approaches49,53,54 converted images into the frequency domain. For instance, D349 devises a dual-domain restoration network to eliminate artifacts present in compressed images. The wavelet-based dual recursive network54 was introduced to decompose the LR image into a sequence of wavelet coefficients and predict the corresponding sequence of HR wavelet coefficients using networks, thereby generating the final HR image. SwinFIR53 extends SwinIR10 through the substitution of fast Fourier convolution, aiming to investigate the image-wide receptive field to enhance the SR performance. Our method introduces a DTCWT-based STB block to decompose image features into low frequency and high frequency features.

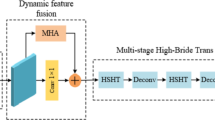
The overall architecture of SVTSR and the structure of STB and RHAG.
Method
Network architecture
As shown in Fig. 2, SVTSR consists of three modules: shallow feature extraction, deep feature extraction and high quality (HQ) image reconstruction module. The architecture design is widely used in previous works8,10,13.
Shallow feature extraction
Given a low-quality (LQ) input \(I_{LQ} \in R^{H\times W\times C_{in} }\) (H, W and are the image height, \(C_{in}\) width and input channel number, respectively), we use a \(3\times 3\) convolutional layer \(H_{CONV} (\cdot )\) to extract shallow feature \(F_{0} = R^{H\times W\times C}\) as
where C is the feature channel number. The convolution layer is good at early visual processing, leading to more stable optimization and better results42. It also provides a simple way to map the input image space to a higher dimensional feature space.
Deep feature extraction
we extract deep feature \(F_{DF} \in R^{H\times W\times C }\) from \(F_{0}\) as
where \(H_{DF} (\cdot )\) is the deep feature extraction module and it contains K layers, comprising m Spectral Transform blocks (STB) and (K - m) residual hybrid attention groups (RHAG), where K denotes the network’s depth, and one \(3\times 3\) convolution layer \(H_{CONV3}\). More specifically, intermediate features \(F_{1},F_{2},...,F_{m},F_{m+1},...,F_{K}\) and the output deep feature \(F_{DF}\) are extracted block by block as
where \(H_{STB} (\cdot )\) denotes the i-th STB, \(H_{RHAG} (\cdot )\) denotes the j-th RHAG and \(H_{CONV}\) is the last convolutional layer. The Spectral Transform block (STB), being invertible, adeptly capture both the global and the fine-grain information in the image effectively via low-pass and high-pass filters, while residual hybrid attention group (RHAG) focus on extracting semantic features and addressing long-range dependencies present in the image. The STB structure is described in detail in Sect. 3.2. Applying a convolutional layer at the end of feature extraction can incorporate the inductive bias of the convolution operation into the Transformer-based network, providing a more robust foundation for subsequently aggregating shallow and deep features.
High quality image reconstruction
We reconstruct the high-quality image \(I_{SR}\) by aggregating shallow and deep features as
where \(H_{IR} (\cdot )\)is the function of the HQ image reconstruction module. The pixel-shuffle method55 is adopted to up-sample the fused feature.
Loss function
We optimize the parameters of SVTSR by minimizing the L1 pixel loss as
where \(I_{IR}\) is obtained by taking \(I_{LQ}\) as the input of SVTSR, and \(I_{HQ}\)is the corresponding ground-truth HQ image.
Spectral transform block (STB)
Overview of DTCWT
Discrete Wavelet Transform (DWT) substitutes the infinite oscillating sinusoidal functions with a collection of locally oscillating basis functions, commonly referred to as wavelets56,57. A wavelet is formed by combining a low pass scaling function \(\phi (t)\) with a shifted version of a band-pass wavelet function, denoted as \(\psi (t)\). Mathematically, it can be represented as follows:
Where c(n) represents the scaling coefficients, and d(j,n) represents the wavelet coefficients. These coefficients are calculated through the inner product of the scaling function \(\phi (t)\) and the wavelet function \(\psi (t)\) with input x(t).
The Discrete Wavelet Transform (DWT) encounters the following challenges: oscillations, shift variance, aliasing, and a deficiency in directionality. One solution to address the above problems involves employing the Complex Wavelet Transform (CWT), which utilizes complex-valued scaling and wavelet functions. The DTCWT tackles the challenges encountered by the CWT. The DT-CWT57,58,59 closely approaches mirroring the desirable characteristics of the Fourier transform, such as a smooth, non-oscillating magnitude, nearly shift-invariant magnitude with a simple near-linear phase encoding of signal shifts, significantly reduced aliasing, and improved directional selectivity of wavelets in higher dimensions. This facilitates the detection of edges and orientational features within images. The wavelet transformation consists of six orientations: \(15^{\circ } ?45^{\circ }?75^{\circ }?105^{\circ }?135^{\circ }\) and \(165^{\circ }\). The dual-tree CWT utilizes two real DWTs: the first DWT produces the real part of the transform, while the second DWT produces the imaginary part. The two real DWTs utilize distinct sets of filters, which are collaboratively designed to provide an approximation of the overall complex wavelet transform and meet the perfect reconstruction (PR) criteria. Let \(h_{0} (n),h_{1} (n)\) represent the low-pass and high-pass filter pair in the upper band, while \(g_{0} (n),g_{1} (n)\) represent the same for the lower band. Two real wavelets, denoted as \(\psi _{h} (t)\) and \(\psi _{g} (t)\), are linked with each of the two real wavelet transforms. The complex wavelet \(\psi _{h} (t):=\psi _{h} (t)+ \psi _{g} (t)\)can be approximated using the Half-Sample Delay condition60, where \(\psi _{h} (t)\) is approximately the Hilbert transform of \(\psi _{g} (t)\) like
Similarly, we can define \(\psi _{g} (t),\phi _{g} (t)\), and \(g_{1} (n)\). As the filters are real, implementing DTCWT does not necessitate complex arithmetic. In 1D, it is merely two times more expansive because the total output data rate is precisely twice the input data rate. It is also straightforward to invert since the two separate DWTs can be inverted. Comparing DTCWT with the Fourier Transform, obtaining the low pass and high pass components of an image is challenging with the Fourier Transform, and it is less invertible (Loss is high when performing Fourier and inverse Fourier transforms) compared to DTCWT. Moreover, it cannot address time and frequency simultaneously.
The structure of STB
Figure 2 illustrates the distinct components of the STB Structure in detail. The Spectral Transform Block consists of three components: Spectral Transformation, Spectral Gating Network, and Spectral Channel and Token Mixing.
Spectral transformation
The input image I undergoes shallow feature extraction to acquire feature \(F_{0} \in R^{C\times H\times W}\) , with a spatial resolution of \(H\times W\) and C channels. To further extract the features of \(F_{0}\), we input \(F_{0}\) into a sequence of transformer layers. Instead of the standard self-attention network, we utilize a spectral transform based on an invertible spectral network. This enables us to capture both fine-grained and global information in the image. The fine-grain information comprises texture, patterns, and small features encoded by the high-frequency components of the spectral transform. The global information includes overall brightness, contrast, edges, and contours encoded by the low-frequency components of the spectral transform. Given feature \(F_{0} \in R^{C\times H\times W}\), we employ spectral transform using DTCWT61, as discussed in Sect. 3.2.1, to obtain the corresponding frequency representations \(X_{F}\) by \(X_{F} = F_{spectral} (F_{0} )\). The frequency domain transformation \(X_{F}\) yields two components: one low-frequency component, i.e., the scaling component \(X_{\phi }\), and one high-frequency component, i.e., the wavelet component \(X_{\psi }\). The simplified formulation for the real component of \(F_{DTCWT} (\cdot )\) is as follows:
M denotes resolution, and k denotes directional selectivity. Similarly, we compute the transformation for the imaginary component of \(F_{DTCWT} (\cdot )\).
Spectral gating network
We introduce a technique called Spectral Gating Network (SGN) to extract spectral features from both low and high-frequency components of the scattering transform. Figure 2 illustrates the structure of the method. We employ learnable weight parameters to blend each frequency component, employing distinct blending methods for low and high frequencies. For the low-frequency component \(X_{\phi } \in R^{C\times H\times W}\), we utilize the Tensor Blending Method (TBM), a novel technique. TBM combines \(X_{\phi }\) with \(W_{\phi }\) through element-wise tensor multiplication, also recognized as the Hadamard tensor product.
where \((X_{\phi },W_{\phi } )\in R^{C\times H\times W}\), and \(M_{\phi } \in R^{C\times H\times W}\), \(W_{\phi }\) having same dimension as in \(X_{\phi }\). \(M_{\phi }\) represents the low-frequency image representation, capturing the global information of the image. Acquiring effective features in the high-frequency components \(X_{\phi } \in R^{k\times C\times H\times W\times 2}\) poses a significant challenge due to their complex-valued nature and ’k’ times more dimensions compared to the low-frequency components. Hence, applying the Tensor Blending Method to the high-frequency components \(X_{\psi }\) would amplify the parameter count by 2k times and escalate the computational cost (GFLOPS), where k denotes directional selectivity, and the factor of 2 denotes the complex value comprising real and imaginary parts. To tackle this challenge, we introduce a novel approach called the Einstein Blending Method (EBM) to efficiently and effectively blend the high-frequency components \(X_{\psi }\) with the learnable weight parameters \(W_{\psi }\) within the Spectral Gating Network proposed in this paper. By employing EBM, we can capture fine-grain details in the image, including texture, patterns, and small features. To perform EBM, we initially reshape a tensor A from \(R^{H\times W\times C}\) to \(R^{H\times W\times C_{b} \times C_{d} }\), where \(C= C_{b} \times C_{d}\), and \(b>> d\). We then define a weight matrix of size \(W_{\psi _{c} } \in R^{C_{b}\times C_{d} \times C_{d} }\). We then conduct Einstein multiplication between A and W along the last two dimensions, resulting in a blended feature tensor \(Y\in R^{H\times W\times C_{b}\times C_{d} }\). The formula for EBM is:
Spectral channel and token mixing
We execute EBM in the channel dimension of the high-frequency component, termed Spectral Channel Mixing, and subsequently in the token dimension of the high-frequency component, referred to as Spectral Token Mixing. To perform EBM in the channel dimension, we first reshape the high frequency component \(X_{\psi }\) from \(R^{2\times k\times H\times W\times C}\) to \(R^{2\times k\times H\times W\times C_{b}\times C_{d} }\), where \(C= C_{b} \times C_{d}\), and \(b>>d\). We then define a weight matrix of size \(W_{\psi _{c} } \in R^{C_{b}\times C_{d}\times C_{d} }\). We then conduct Einstein multiplication between \(X_{\psi }\) and W along the last two dimensions, yielding a blended feature tensor \(S_{\psi _{c} } \in R^{2\times k\times H\times W\times C_{b}\times C_{d} }\). The formula for EBM in Channel mixing is:
To perform EBM in the Token dimension, we first reshape the high frequency component \(S_{\psi _{c} }\) from \(R^{2\times k\times H\times W\times C}\) to \(R^{2\times k\times C\times W\times H}\), where \(H=W\). We then define a weight matrix of size \(W_{\psi _{t} } \in R^{W\times H\times H}\). We then execute Einstein multiplication between \(X_{\psi }\) and W along the last two dimensions, producing a blended feature tensor \(S_{\psi _{t} } \in R^{2\times k\times C\times W\times H}\). The formula for EBM in Token mixing is:
where \(\otimes\) represents an Einstein multiplication, the bias terms \(b_{\psi _{c} } \in R^{C_{b} \times C_{d} }\), \(b_{\psi _{t} } \in R^{H \times H }\). Now, the total number of weight parameters in the high-frequency gating network is \((C_{b} \times C_{d}\times C_{d} )+ (W\times H\times H)\) instead of \((C\times H\times W\times k\times 2)\) where \(C>>H\) and bias is \((C_{b}\times C_{d} )+ (H\times W)\). This decreases the number of parameters and multiplications during high-frequency gating operations in an image. We utilize the standard torch package62 for performing Einstein multiplication. Ultimately, we execute inverse spectral transform using both low-frequency and high-frequency representations to revert the spectral domain back to the physical domain.

Visual quality comparisons of \(\times 4\) image SR on Set14, BSDS100 and Manga109 test datasets.
Experiments
Experimental setup
Like the HAT13work, we use DF2K (DIV2K7+ Flicker2K63) dataset as the training dataset. The model is trained on four NVIDIA GeForce GTX 1080 Ti blocks. For the structure of SVTSR, the STB number and RHAG number are both set to 3. The channel number is set to 96. Both (S)W-MSA and OCA are configured with an attention head number of 6 and a window size of 16. Five benchmark datasets, specifically Set516, Set1417, BSD10064, Urban10065, and Manga10966, are employed to assess the methodologies. To evaluate the effectiveness of the proposed method, we utilize PSNR, SSIM, model size and parameters as the metrics.
Quantitative results
Table 1illustrates the quantitative indicators (PSNR and SSIM) comparison between our approach and the state-of-the-art methods, including CNN-based approaches (EDSR7, RCAN8, SAN2, IGNN61, HAN67, NLSN68, RCAN-it69) and Transformer-based SR methods (SwinIR10, EDT12, HAT13). As shown in Table 1, our SVTSR achieves the best performance on all five benchmark datasets. Concretely, SVTSR surpasses HAT by 0.07dB-0.12dB on Set14 and 0.06dB-0.13dB on BSD100. At the same time, it can be seen from Table 2 that the biggest advantage of our method is that the number of parameters of the model is only 2.3M-2.5M, and the size of the model is only 21.16MB-22.56MB, which is much lower than the baseline HAT 20.6-20.80M and 161.27–162.40MB. These data show that the size and number of parameters of our model decreased significantly while keeping PSNR and SSIM metrics slightly above SOTA. All these results show the effectiveness of our method.
Qualitative results
We present several challenging examples for visual comparison (at \(\times\)4 magnification) across three test datasets in Fig. 3, including “MukoukizuNoChonbo” in Manga109, “210088” in BSDS100, “monarch” in Set14. The SVTSR successfully recovered clear image texture information. Conversely, all the other approaches exhibit severe blurry effects. Similar behaviors are also observable in “MukoukizuNoChonbo” within Manga109. During the process of character recovery, SVTSR achieves notably clearer textures compared to other methods. The visual outcomes additionally illustrate the superiority of our approach.
Ablation study
STB employs a spectral network to partition the signal into low-frequency and high-frequency components. We utilize a gating operator to acquire effective learnable features for spectral decomposition. The gating operator involves the multiplication of the weight parameter in both high and low frequencies. We have performed experiments employing both tensor and Einstein mixing techniques. Tensor mixing operates as a straightforward multiplication operator, whereas Einstein mixing employs an Einstein matrix multiplication operator. Observationally, in low-frequency components, Tensor mixing exhibits superior performance compared to Einstein mixing. As demonstrated in Table-3, we begin with \(STB_{TTTT}\), incorporating tensor mixing in both high and low-frequency components. We observe that it may not achieve optimal performance. Subsequently, we reverse the approach and employ Einstein mixing in both low and high-frequency components, however, this also does not yield optimal performance. Subsequently, we devised the alternative method \(STB_{TTEE}\), which utilizes tensor mixing in low frequency and Einstein mixing in high frequency. In the high-frequency domain, further decomposition involves token and channel mixing, while in the low-frequency domain, we simply apply tensor multiplication, given its representation as an energy or amplitude component.
Conclusion
In this paper, we present a novel vision transformer model, SVTSR, for SISR tasks. We introduce an invertible spectral network founded on DTCWT transformation into vision transformers designed for image SR tasks to partition image features into low-frequency and high-frequency components. Extensive experiments show the effectiveness of the proposed model. Our method not only outperforms SOTA method in PSNR and SSIM indexes, but also has significant advantages over other methods in model size and number of parameters.
Data availability
The datasets generated and/or analysed during the current study are available in the [https://github.com/LiangJiabaoY/SVTSR.git] repository.
References
Dong, C., Loy, C. C., He, K., Tang, X. Learning a deep convolutional network for image super-resolution. In Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part IV 13, Springer, pp. 184–199 (2014)
Dai, T., Cai, J., Zhang, Y., Xia, S.-T., Zhang, L. Second-order attention network for single image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 11065–11074 (2019)
Dong, C., Loy, C.C., Tang, X. Accelerating the super-resolution convolutional neural network. In Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11-14, 2016, Proceedings, Part II 14, Springer, pp. 391–407 (2016)
Dong, C., Loy, C. C., He, K. & Tang, X. Image super-resolution using deep convolutional networks. IEEE Trans. Pattern Anal. Mach. Intell. 38(2), 295–307 (2015).
Kong, X., Zhao, H., Qiao, Y., Dong, C. Classsr: A general framework to accelerate super-resolution networks by data characteristic. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 12016–12025 (2021)
Li, Z., Liu, Y., Chen, X., Cai, H., Gu, J., Qiao, Y., Dong, C.: Blueprint separable residual network for efficient image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 833–843 (2022)
Lim, B., Son, S., Kim, H., Nah, S., Mu Lee K. Enhanced deep residual networks for single image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, pp. 136–144 (2017)
Zhang, Y., Li, K., Li, K., Wang, L., Zhong, B., Fu, Y. Image super-resolution using very deep residual channel attention networks. In Proceedings of the European Conference on Computer Vision (ECCV), pp. 286–301 (2018)
Zhang, Y., Tian, Y., Kong, Y., Zhong, B., Fu, Y. Residual dense network for image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 2472–2481 (2018)
Liang, J., Cao, J., Sun, G., Zhang, K., Van Gool, L., Timofte, R. Swinir: Image restoration using swin transformer. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 1833–1844 (2021)
Chen, H., Wang, Y., Guo, T., Xu, C., Deng, Y., Liu, Z., Ma, S., Xu, C., Xu, C., Gao, W. Pre-trained image processing transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 12299–12310 (2021)
Li, W., Lu, X., Qian, S., Lu, J., Zhang, X., Jia, J. On efficient transformer-based image pre-training for low-level vision, arXiv preprint arXiv:2112.10175 (2021).
Chen, X., Wang, X., Zhou, J., Qiao, Y., Dong, C. Activating more pixels in image super-resolution transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 22367–22377 (2023)
Deng, J. et al. IEEE conference on computer vision and pattern recognition. IEEE 2009, 248–255 (2009).
Liu, Z., Lin, Y., Cao, Y., Hu, H., Wei, Y., Zhang, Z., Lin, S., Guo, B., Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 10012–10022 (2021)
Bevilacqua, M., Roumy, A., Guillemot, C., Alberi-Morel, M. L. Low-complexity single-image super-resolution based on nonnegative neighbor embedding (2012).
Zeyde, R., Elad, M., Protter, M. On single image scale-up using sparse-representations. In Curves and Surfaces: 7th International Conference, Avignon, France, June 24–30, 2010, Revised Selected Papers 7, Springer, pp. 711–730 (2012)
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, Ł., Polosukhin, I. Attention is all you need, Advances in neural information processing systems 30 (2017).
Patel, K., Bur, A.M., Li, F., Wang, G. Aggregating global features into local vision transformer. In 2022 26th International Conference on Pattern Recognition (ICPR), IEEE, pp. 1141–1147 (2022)
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S. An image is worth 16x16 words: Transformers for image recognition at scale, arXiv preprint arXiv:2010.11929 (2020).
Dong, X., Bao, J., Chen, D., Zhang, W., Yu, N., Yuan, L., Chen, D., Guo, B. Cswin transformer: A general vision transformer backbone with cross-shaped windows. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 12124–12134 (2022)
Wu, H., Xiao, B., Codella, N., Liu, M., Dai, X., Yuan, L., Zhang, L. Cvt: Introducing convolutions to vision transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 22–31 (2021)
Yu, Q. et al. Glance-and-gaze vision transformer. Advances in Neural Information Processing Systems 34, 12992–13003 (2021).
Yuan, K., Guo, S., Liu, Z., Zhou, A., Yu, F., Wu, W. Incorporating convolution designs into visual transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 579–588 (2021)
Li, Y., Zhang, K., Cao, J., Timofte, R., Van Gool, L. LocalViT: Bringing locality to vision transformers, arXiv preprint arXiv:2104.05707.(2021)
Tu, Z., Talebi, H., Zhang, H., Yang, F., Milanfar, P., Bovik, A., Li, Y. Maxvit: Multi-axis vision transformer. In European Conference on Computer Vision, Springer, pp. 459–479 (2022)
Wu, S., Wu, T., Tan, H., Guo, G. Pale transformer: A general vision transformer backbone with pale-shaped attention. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 36, pp. 2731–2739 (2022)
Wang, W., Xie, E., Li, X., Fan, D.-P., Song, K., Liang, D., Lu, T., Luo, P., Shao, L. Pyramid vision transformer: A versatile backbone for dense prediction without convolutions. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 568–578 (2021)
Huang, Z., Ben, Y., Luo, G., Cheng, P., Yu, G., Fu, B. Shuffle transformer: Rethinking spatial shuffle for vision transformer, arXiv preprint arXiv:2106.03650 (2021).
Chu, X. et al. Twins: Revisiting the design of spatial attention in vision transformers. Adv. Neural Inf. Process. Syst. 34, 9355–9366 (2021).
Li, K., Wang, Y., Zhang, J., Gao, P., Song, G., Liu, Y., Li, H., Qiao, Y. Uniformer: Unifying convolution and self-attention for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. (2023).
Vaswani, A., Ramachandran, P., Srinivas, A., Parmar, N., Hechtman, B., Shlens, J. Scaling local self-attention for parameter efficient visual backbones. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 12894–12904 (2021)
Ramachandran, P., Parmar, N., Vaswani, A., Bello, I., Levskaya, A., Shlens, J. Stand-alone self-attention in vision models, Advances in neural information processing systems 32 (2019).
Wu, B., Xu, C., Dai, X., Wan, A., Zhang, P., Yan, Z., Tomizuka, M., Gonzalez, J., Keutzer, K., Vajda, P. Visual transformers: Token-based image representation and processing for computer vision, arXiv preprint arXiv:2006.03677 (2020).
Liu, Y., Sun, G., Qiu, Y., Zhang, L., Chhatkuli, A., Van Gool, L. Transformer in convolutional neural networks, arXiv preprint arXiv:2106.03180 3 (2021).
Carion, N., Massa, F., Synnaeve, G., Usunier, N., Kirillov, A., Zagoruyko, S. End-to-end object detection with transformers. In European Conference on Computer Vision, Springer, pp. 213–229 (2020)
Liu, L. et al. Deep learning for generic object detection: A survey. Int. J. Comput.Vis. 128, 261–318 (2020).
Touvron, H., Cord, M., Douze, M., Massa, F., Sablayrolles, A., Jégou, H. Training data-efficient image transformers & distillation through attention. In International Conference on Machine Learning, PMLR, pp. 10347–10357 (2021)
Huang, G. et al. Glance and focus networks for dynamic visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 45(4), 4605–4621 (2022).
Cao, H., Wang, Y., Chen, J., Jiang, D., Zhang, X., Tian, Q., Wang, M. Swin-unet: Unet-like pure transformer for medical image segmentation. In European Conference on Computer Vision, Springer, pp. 205–218 (2022)
Raghu, M., Unterthiner, T., Kornblith, S., Zhang, C. & Dosovitskiy, A. Do vision transformers see like convolutional neural networks?. Adv. Neural Inf. Process. Syst. 34, 12116–12128 (2021).
Xiao, T. et al. Early convolutions help transformers see better. Adv. Neural Inf. Process. Syst. 34, 30392–30400 (2021).
Yuan, Y. et al. Hrformer: High-resolution vision transformer for dense predict. Adv. Neural Inf. Process. Syst. 34, 7281–7293 (2021).
Cao, J., Li, Y., Zhang, K., Van Gool, L. Video super-resolution transformer, arXiv preprint arXiv:2106.06847 (2021).
Liang, J., Cao, J., Fan, Y., Zhang, K., Ranjan, R., Li, Y., Timofte, R., Van Gool, L. Vrt: A video restoration transformer, IEEE Trans. Image Process. (2024).
Tu, Z. et al. Multi-axis mlp for image processing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 5769–5780 (2022).
Wang, Z., Cun, X., Bao, J., Zhou, W., Liu, J., Li, H. Uformer: A general u-shaped transformer for image restoration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 17683–17693 (2022)
Zamir, S.W., Arora, A., Khan, S., Hayat, M., Khan, F.S., Yang, M.-H. Restormer: Efficient transformer for high-resolution image restoration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 5728–5739 (2022)
Wang, Z., Liu, D., Chang, S., Ling, Q., Yang, Y. & Huang, T.S. D3: Deep dual-domain based fast restoration of JPEG-compressed images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 2764–2772 (2016).
Pang, Y., Li, X., Jin, X., Wu, Y., Liu, J., Liu, S., Chen, Z. Fan: Frequency aggregation network for real image super-resolution. In Computer Vision–ECCV 2020 Workshops: Glasgow, UK, August 23–28, Proceedings, Part III 16, Springer, 2020, pp. 468–483 (2020).
Li, X., Jin, X., Yu, T., Sun, S., Pang, Y., Zhang, Z., Chen, Z. Learning omni-frequency region-adaptive representations for real image super-resolution. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 35, pp. 1975–1983 (2021)
Baek, S., & Lee, C. Single image super-resolution using frequency-dependent convolutional neural networks. In 2020 IEEE International Conference on Industrial Technology (ICIT), IEEE, pp. 692–695 (2020)
Zhang, D., Huang, F., Liu, S., Wang, X., Jin, Z. Swinfir: Revisiting the swinir with fast fourier convolution and improved training for image super-resolution, arXiv preprint arXiv:2208.11247 (2022).
Xin, J. et al. Wavelet-based dual recursive network for image super-resolution. IEEE Trans. Neural Netw. Learn. Syst. 33(2), 707–720 (2020).
Shi, W., Caballero, J., Huszár, F., Totz, J., Aitken, A.P., Bishop, R., Rueckert, D., & Wang, Z. Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 1874–1883 (2016)
Selesnick, I., Baraniuk, R. & Kingsbury, N. The dual-tree complex wavelet transform-a coherent framework for multiscale signal and image processing (IEEE Signal Process, Mag, 2005).
Kingsbury, N. Complex wavelets for shift invariant analysis and filtering of signals. Appl. Comput. Harmonic Anal. 10(3), 234–253 (2001).
Kingsbury, N. Image processing with complex wavelets. Philos.Trans. R. Soc. Lond. Ser. A: Math. Phys. Eng. Sci. 357(1760), 2543–2560 (1999).
Kingsbury, N.G. The dual-tree complex wavelet transform: A new technique for shift invariance and directional filters. In IEEE Digital Signal Processing Workshop, Vol. 86, Citeseer, pp. 120–131 (1998)
Selesnick, I. W. Hilbert transform pairs of wavelet bases. IEEE Signal Process. Lett. 8(6), 170–173 (2001).
Zhou, S., Zhang, J., Zuo, W. & Loy, C. C. Cross-scale internal graph neural network for image super-resolution. Adv. Neural Inf. Process. Syst. 33, 3499–3509 (2020).
Rogozhnikov, A. Einops: Clear and reliable tensor manipulations with einstein-like notation. In International Conference on Learning Representations (2021).
Timofte, R. et al. challenge on single image super-resolution: Methods and results. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops 2017, 114–125 (2017).
Martin, D., Fowlkes, C., Tal, D., & Malik, J. A database of human segmented natural images and its application to evaluating segmentation algorithms and measuring ecological statistics. In Proceedings Eighth IEEE International Conference on Computer Vision. ICCV 2001, Vol. 2, IEEE, pp. 416–423 (2001)
Huang, J.-B., Singh, A., Ahuja, N. Single image super-resolution from transformed self-exemplars. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 5197–5206 (2015)
Matsui, Y. et al. Sketch-based manga retrieval using manga109 dataset. Multimedia Tools Appl. 76, 21811–21838 (2017).
Niu, B., Wen, W., Ren, W., Zhang, X., Yang, L., Wang, S., Zhang, K., Cao, X., Shen, H. Single image super-resolution via a holistic attention network. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XII 16, Springer, pp. 191–207 (2020)
Mei, Y., Fan, Y., & Zhou, Y. Image super-resolution with non-local sparse attention. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 3517–3526 (2021)
Lin, Z., Garg, P., Banerjee, A., Magid, S.A., Sun, D., Zhang, Y., Van Gool, L., Wei, D., & Pfister, H. Revisiting rcan: Improved training for image super-resolution, arXiv preprint arXiv:2201.11279 (2022).
Acknowledgements
This work was supported by the National Natural Science Foundation of China [grant number 61903274] and the Natural Science Foundation of Tianjin [grant number 23YDTPJC00500].
Author information
Authors and Affiliations
Contributions
Jiabao Liang contributed the innovative ideas, wrote the code, conducted the experiments, and authored the original paper. Yutao Jin assisted in writing the code. Xiaoyan Chen provided experimental resources, managed project progress, and reviewed the paper. Haotian Huang helped with data processing. Yue Deng conducted the literature review.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Liang, J., Jin, Y., Chen, X. et al. SVTSR: image super-resolution using scattering vision transformer. Sci Rep 14, 31770 (2024). https://doi.org/10.1038/s41598-024-82650-x
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-024-82650-x
Keywords
This article is cited by
-
Efficient progressive training with granularity cross for image super-resolution
Scientific Reports (2025)
