
Abstract
Deep language models (DLMs) have exhibited remarkable language understanding and generation capabilities, prompting researchers to explore the similarities between their internal mechanisms and human language cognitive processing. This study investigated the representational similarity (RS) between the abstractive summarization (ABS) models and the human brain and its correlation to the performance of ABS tasks. Specifically, representational similarity analysis (RSA) was used to measure the similarity between the representational patterns (RPs) of the BART, PEGASUS, and T5 models’ hidden layers and the human brain’s language RPs under different spatiotemporal conditions. Layer-wise ablation manipulation, including attention ablation and noise addition was employed to examine the hidden layers’ effect on model performance. The results demonstrate that as the depth of hidden layers increases, the models’ text encoding becomes increasingly similar to the human brain’s language RPs. Manipulating deeper layers leads to more substantial decline in summarization performance compared to shallower layers, highlighting the crucial role of deeper layers in integrating essential information. Notably, the study confirms the hypothesis that the hidden layers exhibiting higher similarity to human brain activity play a more critical role in model performance, with their correlations reaching statistical significance even after controlling for perplexity. These findings deepen our understanding of the cognitive mechanisms underlying language representations in DLMs and their neural correlates, potentially providing insights for optimizing and improving language models by aligning them with the human brain’s language-processing mechanisms.
Similar content being viewed by others
Introduction
A key goal of Natural Language Processing (NLP) is to enable machines to understand and generate language like humans. Recent advances in Deep Learning (DL) techniques have led to remarkable progress in Deep Language Models (DLMs) across various NLP tasks, with these models demonstrating language understanding and generation capabilities comparable to those of humans1,2. This phenomenon has prompted researchers to investigate the similarities and differences between the internal mechanisms of DLMs and human language cognitive processing, attempting to explain the connection between Artificial Intelligence(AI) and biological intelligence in language processing3,4,5. DLMs have provided a new computational framework for studying the cognitive neural mechanisms of human language understanding5,6,7, while drawing on knowledge from cognitive neuroscience has also offered new perspectives for optimizing and improving DLMs8,9,10.
Numerous studies have demonstrated that DLMs exhibit similarities in Language Representation (LR) to the human brain and can, to a certain extent, explain the brain’s activation patterns in response to language11,12,13. Pioneering research has found that Transformer-based DLMs (such as GPT and BERT) can predict functional Magnetic Resonance Imaging (fMRI) and Electrocorticography (ECoG) activation in language-related human brain regions within a noise tolerance range, substantially outperforming traditional Recurrent Neural Network (RNN) models14.15 discovered that a model’s performance on the next-word prediction task is highly correlated with its ability to explain brain activation. This finding suggests that the human brain may primarily rely on a predictive coding mechanism to understand language, continuously predicting the likely upcoming words during the comprehension process16,17. Recent empirical studies have provided further support for this theory. Research18 has provided strong evidence for hierarchical predictive processing in natural language understanding. Brain responses to words were found to be modulated by predictions at multiple levels, from phonemes to meaning, supporting theories of hierarchical predictive coding in language processing. Additional investigations demonstrated that enhancing language model activations with long-range predictions improved their mapping to brain responses, revealing a hierarchical organization of language predictions in the cortex. Frontoparietal cortices were shown to predict higher-level, longer-range, and more contextual representations compared to temporal cortices, emphasizing the importance of context in language understanding19.Expanding on these findings, researchers have delved deeper into the intrinsic connection between the internal representations of DLMs and human brain language processing. In terms of semantic representation,5,6,20 found that the contextual word embeddings of DLMs like GPT-2 can capture the geometric structure of activation in the human brain’s language areas (such as the left Inferior Frontal Gyrus, IFG), outperforming traditional static word embeddings (like GloVe). This result indicates that DLMs have learned context-dependent lexical semantic representations similar to the human brain’s.
Regarding factors influencing similarity,21 discovered that the activation similarity between GPT-2 and the human brain in semantic-related brain regions (such as the left temporal lobe) increases with a person’s level of semantic understanding, and this similarity is most evident in the deeper layers of the model22. DLMs exhibit hierarchical representation characteristics, with shallow layers of models like BERT encoding surface information, middle layers encoding syntactic features, and deep layers integrating long-distance, high-level global semantics23. When using DLMs to predict human brain activation, it was found that different layers of different models have varying predictive abilities for human brain language processing. For example, in GPT-2, the long-distance dependency representations in the middle layers best predict human language understanding, while the short-distance attention in the shallow layers best predicts speech encoding24; in BERT, the middle layers perform best in predicting human brain activation10. These studies have uncovered the close connection between the internal mechanisms of DLMs and human language understanding, offering valuable insights for further investigating their similarities.
While many current studies focus on investigating the factors contributing to the similarities between DLMs and the human brain, few have explored how the degree of such similarity relates to model performance. Some research has found that the higher the similarity between language models and the human brain, the better their performance on various benchmarks12. However, other studies have indicated that this correlation has limited predictive power for model performance. For example,14 discovered that a model’s neural fit (brain score) only significantly correlates with its performance on the next-word prediction task. Furthermore, current research on the internal mechanisms of DLMs mainly focuses on elemental semantic composition at the lexical or sentence level. In contrast, exploration of discourse comprehension mechanisms is relatively insufficient25,26. Contextual information is crucial for language understanding27,28, yet existing studies have not fully considered the impact of context on model LR. The task of Abstractive Summarization (ABS) provides an ideal research scenario for investigating the discourse comprehension mechanisms of DLMs. Automatic text summarization, which extracts critical knowledge from vast amounts of information, alleviates information overload29. It has broad application prospects and research value30,31. Compared to other NLP tasks, the ABS task places higher demands on a model’s language understanding ability, as it requires deep encoding and integration of the semantics of an entire text. This task primarily employs encoder-decoder architecture models, such as BART32, PEGASUS33 as well as T534,35, which can be scaled up to Large Language Models (LLMs) with sufficient parameters36. The encoder is responsible for hierarchical semantic encoding of the original text, while the decoder generates text summaries based on the encoded information. Considering the encoder’s crucial role in semantic understanding and integration, exploring the neural correlates of the ABS model’s encoder can help reveal the cognitive mechanisms of the human brain in understanding and integrating discourse semantics.
Regarding the ABS task and models, this study raises two pressing questions. First, the roles of different layers of ABS models in discourse semantic understanding and the Representational Patterns (RPs) of syntactic and semantic information remain unclear. Research has found that the human brain processes semantics and syntax with different spatiotemporal characteristics37, and the two exhibit partially overlapping distributed representations in the human brain38,39. Consequently, we aim to investigate the following question: What roles do the different layers of the ABS model’s encoder play in integrating discourse semantics, and how are grammatical and semantic information represented within these layers? Exploring the model’s RPs can help us understand ABS models’ hierarchical language encoding mechanisms and their neural basis. Second, the correlation between the similarity of ABS models to human brain LRs and their task performance merits further investigation. Language is a unique, high-level cognitive function of humans, and the human brain has evolved highly complex and efficient language processing mechanisms over a long period. Therefore, the closer a DLM is to the human brain in structure and function, the stronger its language understanding and generation capabilities may be. So, for the more complex ABS task, can the degree of similarity between the model and human brain representations also predict the quality of its generated summaries?
Based on the above analysis of the relationship between DLMs and human brain language processing, we hypothesize that, in the context of the ABS task, the hidden layers of the model that exhibit a higher degree of Representational Similarity (RS) to the human brain’s activation patterns may play a more critical role in the model’s performance on this task. To test this hypothesis, we designed an experiment involving human participants and employed two methods: Representational Similarity Analysis (RSA) and layer-wise ablation. This study used the ABS models PEGASUS and BART as the research objects to investigate the similarity between their encoder hidden layer representations and those of the human brain (i.e., neural similarity) and the contribution of each layer to the summarization task. RSA can reveal the similarity of representational structures between systems (such as DLMs and the human brain) by calculating the correlation between their response patterns to the same set of inputs, overcoming differences in representational forms13,40,41. Many different stimuli are input into the target system to compute representational structure, i.e., the geometric properties of the representational space. The activity patterns evoked by each stimulus are measured, and the similarity of responses between all stimulus pairs is calculated. This process quantifies the system’s representational structure. Layer-wise ablation, on the other hand, removes the model’s learned attention layer by layer, examining the contribution of each layer to the ABS task by intervening with the model’s internal representations10,42.
Specifically, the N400, a negative-going Event-Related Potential (ERP) component peaking around 400 ms post-stimulus onset, is a neural signature of semantic processing43. In contrast, the P600, a positive-going ERP component peaking around 600 ms, is associated with syntactic processing and integration44. This study first calculated the similarity between the model’s hidden layer representations and human brain representations under different spatiotemporal conditions. It aimed to reveal the model’s hierarchical language processing mechanism and potential neural correlates. We defined four spatiotemporal conditions: Full time window (using the complete time window and all channels), Early window (using the time window and electrode positions typically associated with the N400 component), Late window (using the time window and electrode positions typically associated with the P600 component) and Baseline (using a pre-stimulus time window and all channels as a control). Then, we performed layer-wise attention ablation and noise addition on each layer, and evaluate the resulting changes in summary quality to investigate the role of each layer in integrating semantics and grasping the text’s overall meaning. Finally, this study connects the RS of each hidden layer of the model to the human brain and its impact on model performance, attempting to test the hypothesis we proposed. Figure 1 illustrates the overall research framework.

Schematic diagram of the research framework.
Through a series of experiments and analyses, this study makes the following contributions:
-
1.
This study employed RSA to compare LRs in DLMs and the human brain. Results showed increasing similarity with model depth, reaching statistical significance, indicating DLMs’ ability to acquire brain-like LRs. Control experiments revealed the crucial role of model training in this process.
-
2.
The layer manipulation experiment reveals that each encoder layer contributes to the ABS task to a different extent. Ablating the attention mechanism or adding noise in deeper hidden layers leads to a more substantial decline in summarization performance, indicating that deeper layers play a more crucial role in integrating critical information from the original text and understanding its comprehensive theme.
-
3.
This study reveals a significant correlation between hidden layers’ similarity to human brain activity patterns and their impact on model summarization performance. Examining BART, PEGASUS, and T5 models, we found this correlation consistent across diverse spatiotemporal brain activity conditions and layer manipulation methods. The correlation’s persistence after controlling for perplexity further supports our findings’ robustness.
These findings deepen the understanding of the internal working mechanisms of DLMs. They provide valuable insights for optimizing and improving DLMs from a brain-inspired perspective.
Methods
EEG signal acquisition and processing
Experimental design
Fifteen healthy adult participants were recruited for this study, of which 13 were effective, including nine males and four females, with a mean age of 24.31 ± 2.72 years. All participants were right-handed, had normal or corrected-to-normal vision, and had no neurological or psychiatric disorders history. All participants provided written informed consent prior to their participation in the study.
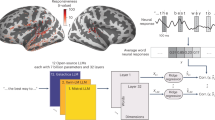
The BEATs system45 was utilized to collect 28-channel EEG signals, as shown in Fig. 3b. The electrodes were placed in an elastic cap according to the standard positions of the international 10-20 system. The 28 electrodes used for recording EEG signals are highlighted in yellow. Based on the research46, the electrodes sensitive to the N400 ERP component include Cz, C3, C4, CP1, CP2, Pz, P3, and P4, marked with blue borders in Fig. 3b. The time window sensitive to the N400 component was set to 250-450ms. According to the study47, the channels sensitive to the P600 ERP component include C3, Cz, C4, P3, Pz, and P4, marked with red borders in Fig. 3b. The time window sensitive to the P600 component was set to 500-800ms. Throughout the recording process, the sampling rate was set to 250Hz, and the impedance of each electrode was maintained below 10 K\(\Omega\) to ensure signal quality.
The experimental program was written using PsychoPy (version 2022.2.5)48,49, requiring participants to read a text that appeared word by word continuously. The reading materials were selected from 8 articles in the Factuality Evaluation Benchmark (FRANK) dataset50, containing 62 sentences and 1427 words. We present the details of the selected materials in Supplementary Table S1 in the appendix.
Before the experiment, all participants were required to read and voluntarily sign an informed consent form. The experiment was conducted in a soundproof laboratory, with participants seated approximately 60cm from the computer screen. They were required to maintain a horizontal gaze and minimize head movements. The procedure of the EEG signal acquisition experiment is shown in Fig. 2.

Procedure of the EEG experiment.
First, participants fixated on a central fixation point (a cross) presented on the screen for 5000ms to record baseline EEG signals. Subsequently, participants read articles presented word by word, with each word appearing in the center of the screen for 1500ms, during which the EEG signals were recorded. Finally, after each article was played, participants were required to answer three judgment questions related to the content to ensure they were focused on the reading task. To ensure data quality, only participants who achieved an accuracy rate exceeding 50% for all questions were included in the analysis. After answering the questions, participants had a 2-minute break to avoid potential fatigue effects before starting the experiment with the following article.
Data processing
A series of preprocessing steps were performed to remove noise and artifacts from the EEG signals, including filtering, segmentation, baseline correction, artifact removal, and re-referencing. First, the continuous EEG data were bandpass filtered between 0.5Hz and 30Hz to remove low-frequency drift and high-frequency noise. Then, based on the 1459 tokens obtained by PEGASUS’s tokenizer, the continuous data were segmented into discrete time windows. Tokens derived from the same word shared the EEG signals recorded during the presentation of that word. The duration of the EEG signal segment corresponding to each token was 1700ms, including 1500ms of EEG signals during each event (word presentation) and 200ms of EEG signals preceding the event. To avoid signal drift, we performed baseline correction by subtracting the average potential of the 200ms preceding each event from the entire epoch. Next, we identified noisy or faulty channels through visual inspection of the raw EEG data, focusing on channels exhibiting persistent high-frequency noise, flat lines, or excessive artifacts. Then, bad channels were repaired using spherical spline interpolation, and Independent Component Analysis (ICA) was employed to remove artifacts such as eye movements and muscle activity. Finally, a whole-brain re-referencing approach, which means using the mean voltage across all electrodes as the reference, was performed to obtain EEG signals relative to the global average potential. We used Python 3.7.9 and SPSS version 26 for EEG data processing and statistical analysis.
Experiments on ABS models
This experiment explores the intrinsic mechanisms of discourse comprehension in ABS models. Given the crucial role of the encoder in text comprehension within the model and the focus of EEG experiments primarily on human language comprehension rather than generation, this study centers on analyzing the characteristics of the encoder. The study utilizes three prevalent DLMs that have been fine-tuned for ABS tasks: BART, PEGASUS, and T535. Specifically, the BART-large model is fine-tuned on the CNN/DM dataset51, while the PEGASUS-large model on the XSum dataset52, and the T5-large model on a combined XSum-CNN/DM dataset. CNN/DM and XSum are benchmark datasets used for training and evaluating ABS models, containing news articles paired with human-written summaries. Each model, featuring distinct architectures and varying numbers of layers, is fine-tuned on different datasets, enhancing the robustness of the experimental findings.
Take the PEGASUS-large model as an instance, the encoder consists of 16 hidden layers, each generating a unique representation of the input discourse text. To analyze the impact of the attention mechanism in different hidden layers of the encoder on the model’s performance, we designed an experiment to remove the attention in each layer individually. This approach eliminates the influence of the learned attention in a specific encoder layer while keeping the parameters of the other layers fixed, allowing us to observe its contribution to the model’s performance. The attention is calculated as shown in Equation 153, where \({d}_k\) is the dimension of the keys, \(Q=X{W}^Q\) is the query matrix, \(K=X{W}^K\) is the key matrix, and \(V=X{W}^V\) is the value matrix.
X represents the input to the layer, and \({W}^Q\), \({W}^K\), \({W}^V\) are pre-trained parameter matrices. The uniformization of the attention mechanism is achieved by modifying the matrices \({W}^Q\), \({W}^K\), and \({W}^V\) to ensure that the attention produces equal probabilities for the values in matrix V, thereby eliminating the influence of the layer’s attention on matrix V10. Specifically, the \({W}^Q\) and \({W}^K\) matrices are set to zero matrices, and the \({W}^V\) matrix is set to an identity matrix. This modification allows for removing the learned attention effect of the layer during model propagation, facilitating the analysis of the contribution of the encoder’s layer to the model’s performance. In subsequent sections, we refer to the method of setting attention to a uniform distribution as attention ablation. Additionally, we employ another approach to influence model performance called noise addition. This method involves introducing random perturbations drawn from a Gaussian distribution to the weight matrices of each encoder layer, allowing us to examine the impact of controlled noise on model performance.
To assess the impact of layer manipulation on model performance in the ABS task, we employ two different layer-wise manipulations on the BART, PEGASUS, and T5 models: attention ablation and noise addition. We then generate summaries using these manipulated models on the complete test set. The quality of these summaries, which reflects the models’ performance on the ABS task, is assessed using three variants of Rouge (Recall-Oriented Understudy for Gisting Evaluation): Rouge1, Rouge2, and RougeL. These metrics evaluate the overlap between generated and reference summaries at different levels. Rouge1 measures word-level overlap by calculating the ratio of words in the reference summary that appear in the generated summary. Rouge2 assesses the overlap of consecutive word pairs (bigrams) between the generated and reference summaries. RougeL evaluates the sequence similarity based on the longest common subsequence, capturing the overall structural similarity. This comprehensive evaluation allows us to assess summary quality regarding individual words, phrase structures, and overall content alignment. By applying these metrics to summaries generated after manipulating each encoder layer, we can quantify the impact of attention mechanisms and noise introduction on the models’ ABS capabilities.
Representational similarity analysis
Due to the substantial differences in how language is represented in artificial neural network models and the human brain, directly comparing the correspondence between the two at the word or token level is challenging. Therefore, this study employed the RSA method to compare the activation patterns of models and the human brain in response to input text, i.e., the geometric structure of the representational space. The overall process of RSA is shown in Fig. 3.

Schematic of representational similarity analysis.
For the activation patterns of the model, the cosine similarity was used to calculate the pairwise similarity between the feature vectors corresponding to all tokens in each hidden layer of the encoder, yielding an n \(\times\) n similarity matrix, as shown in Fig. 3a (n is the total number of tokens after the tokenizer processes the text; in the example shown, n = 5). This matrix characterizes the representational structure of the input text within the model. Specifically, the Representational Similarity Matrix (RSM) \({\textbf{M}}_{ij}^l\) of the hidden layer can be represented as Equation 2, where \({\textbf{h}}_i^l\) represents the feature vector of the i-th token in the l-th hidden layer, and n is the total number of tokens.
Regarding the activation patterns of the human brain, the EEG signals corresponding to each token were similarly represented as a vector and calculated as follows. The EEG experiment recorded the participants’ electrical signals of the human brain while they read all the tokens. After aligning each token with its corresponding word, each token corresponded to the 1500ms EEG signal from the appearance to the disappearance of the word. Given that the sampling rate of the EEG signals was 250Hz, each token had 375 sampling points within the 1500ms time window, accumulating 10500 data points (375 \(\times\) 28) across the 28 electrodes. By concatenating the signals from the 28 electrodes, each token corresponded to a 10500-dimensional EEG feature vector. Similar to the model, the similarity of all token pairs in the EEG feature space was computed, and an n \(\times\) n similarity matrix was generated for each participant, as shown in Fig. 3b (n = 5 in the example, the EEG signal placed at the right of each word (\(e_i\)) represents the concatenation of all electrode data for that word), reflecting the representational structure of the human brain during language processing.
We established four spatiotemporal conditions for EEG signals in language comprehension. The condition of Full time window uses the complete time window and all electrodes, providing a comprehensive view of brain activity during language processing. Early window and Late window conditions employ time windows and electrode locations associated with the N400 and P600 components, respectively, capturing brain activity in these specific spatiotemporal windows. Finally, Baseline condition (control group) uses the time window from -200 to 0 ms before stimulus onset and all electrodes as a comparison baseline. Traditional ERP components inspire these conditions; we posit that EEG signals under these conditions may contain information relatively sensitive to human brain semantic (Early window) or syntactic (Late window) processing. However, we do not assume a direct, exclusive mapping between these components and specific linguistic processes. The selection of these conditions primarily aims to observe brain activity patterns during language processing from multiple perspectives, thereby enabling the examination of RS across different spatiotemporal windows. The composition of the EEG vectors under the four conditions is shown in Table 1.
The similarity matrix \({\textbf{B}}_{ij}^{k,t}\) of the human brain’s representation of text can be represented as Equation 3, where \({\textbf{e}}_i^{k,t}\) represents the EEG vector recorded for the k-th participant while reading the i-th token, based on the representation type t, which can be overall representation, semantic representation, or syntactic representation.
Using the n\(\times\)n RSM, this study characterizes the language comprehension process of the model and the human brain in a unified manner. Based on these RSMs, we calculate the correlation between them to investigate the RS between different hidden layers of the model and the brain’s overall, semantic-specific, and syntactic-specific representations. The Spearman rank correlation coefficient was used to calculate the correlation between the RSMs of the model and the human brain, yielding the RSA score:
In Equation 4, \(r_i^l\) and \(r_i^{k,t}\) represent the ranks of the upper (lower) triangular part (excluding the diagonal) of \({\textbf{S}}_{ij}^l\) and \({\textbf{B}}_{ij}^{k,t}\), respectively, when sorted by similarity values. \({{\overline{r}}}^l\) and \({{\overline{r}}}^{k,t}\) are the corresponding average ranks. Since the similarity matrix is symmetric about the diagonal and the values on the diagonal are always 1, the Spearman rank correlation coefficient calculation is based on the upper triangular part of the matrix, excluding the diagonal elements, as shown in Fig. 3c. Furthermore, this study first calculates the correlation between each participant’s EEG RSM and the RSM of each hidden model layer. Then, it averages the correlations across participants to record the correlation between the representation of that hidden layer and the human brain.
Experimental results
RS between human brain and models
To systematically investigate the RPs across the human brain and DLMs, we first conducted comprehensive visualization analyses of their RSMs using rank-based correlation heatmaps. Figure 4 presents these matrices, where color intensity denotes the strength of RS: darker red indicates more substantial similarity and darker blue indicates weaker similarity. We constructed these heatmaps based on rank ordering rather than absolute values to align with our subsequent Spearman rank correlation analyses.

Visualization of RSMs.
Visual analyses of these matrices revealed distinct architectural features in the representational spaces. A characteristic cross-shaped pattern emerged consistently across the human brain and model RSMs, indicating systematic similarities in specific RPs. In human brain RSMs (excluding baseline conditions), the core of the cross-pattern is localized in the lower-left quadrant of the heatmaps. Notably, BART’s RSMs demonstrated remarkable architectural convergence with human brain RPs, resembling this characteristic lower-left positioning of the cross-pattern core. In contrast, PEGASUS and T5 initially exhibited divergent organizational principles, with their cross-pattern cores predominantly concentrated in the upper-right quadrant. This difference aligns with our later findings that BART achieved higher performance in the RSA.
Figure 5 illustrates the relationship between the degree of RS (RSA scores) of the hidden layers in BART, PEGASUS, and T5 models and human brain activation during language processing. The error bars represent the standard error (SE), serving as uncertainty estimators and provide a visual representation of data dispersion. For each model, we calculated seven sets of RSA scores: Full time, Early, Late window and Baseline from Table 1, and three control groups for the former three. We randomly initialized the model parameters in the control groups and processed the same text input as the standard ABS models. Then, we calculated the RSA scores between these models and human brain RPs. The control group results, represented by thin lines without markers in Fig. 5, help demonstrate the effect of language model training and fine-tuning on representational capabilities.

RSA scores between each hidden layer of the DLMs and the human brain.
While RSA’s effect sizes (correlation coefficients) appear relatively small, we suggest they are meaningful and interpretable for several reasons. First, our visualization analysis of the RSMs reveals systematic similarities in RPs between the human brain and DLM representations, particularly the characteristic cross-shaped structures in blue. These geometric configuration matches substantiate the meaningful relationships underlying the low correlation coefficients. Second, given the scale of our RSMs (\(1459\times 1459\)), the actual sample size for correlation computation reaches the order of one million, making even small effect sizes statistically reliable at such large scales54. Finally, the core strength of RSA lies in capturing the overall geometric structure of representational spaces rather than superficial linear relationships. Therefore, despite modest effect sizes, RSA effectively reveals the fundamental similarities in information encoding patterns between human brains and DLMs.
We employed the Jonckheere–Terpstra test to assess the presence of a statistically significant monotonic trend in the seven sets of RSA scores for each model as the number of layers increased. This statistical analysis was performed using SPSS (version 26), and the results are recorded in Table 2. The sign of Z indicates the trend direction, with positive and negative values representing increasing and decreasing trends. The p-value < 0.05 indicates statistical significance.
For the three experimental groups (Full time, Early and Late window), the Jonckheere–Terpstra test revealed that the PEGASUS and T5 models exhibited a statistically significant monotonic increase in RSA scores as the number of layers deepened (Z> 0, p < 0.05). The BART model showed a statistically significant monotonic increase in RSA scores for Full time and Early window (Z > 0, p < 0.05), but for Late window, the increasing trend did not reach statistical significance (Z = 1.643, p = 0.100). Theses findings indicate that the neural networks of DLMs progressively learn LRs that more closely resemble those of the human brain. Through successive layers of abstraction and integration, these deep neural networks encode text in a way that increasingly parallels human cognitive processes. This evolution may be attributed to the models’ shift from extracting superficial lexical features to integrating complex semantic information, aligning more closely with the mechanisms of human language comprehension23.
For the four control groups, the Jonckheere–Terpstra test showed no statistically significant monotonic trend in RSA scores as the layers deepened for the BART and PEGASUS models under Baseline. The T5 model exhibited a statistically significant monotonic increase (Z = 3.413, p = 0.001). Still, Fig. 5 reveals that its RSA scores were close to 0 with minimal fluctuation compared to other groups, indicating no apparent learning effect or similarity to human brain representations despite statistical significance. For the randomly initialized control groups (Control (rand.init., Full time, Early and Late)), the BART model showed a statistically significant monotonic decrease in RSA scores (Z < 0, p < 0.05), while the PEGASUS and T5 models showed no significant trend. This finding suggests that without specific training, deepening layers in DLMs leads to either decreased (BART) or unchanged (PEGASUS and T5) similarity between the model’s hierarchical representations and human brain representations, underscoring the importance of appropriate training for learning brain-like representations.
We conducted Friedman tests to determine if there were differences among the RSA scores of the three experimental groups (Full time, Early and Late window) for each model. The results revealed statistically significant differences for all models: BART (\(\chi ^2(2)\) = 22.17, p < 0.001), PEGASUS (\(\chi ^2(2)\) = 12.88, p = 0.002), and T5 (\(\chi ^2(2)\) = 48.00, p < 0.001).
Subsequently, we performed post hoc analysis using Wilcoxon signed-rank tests with a Bonferroni correction for multiple comparisons. This statistical analysis was also performed using SPSS (version 26). For the BART model, there were statistically significant differences in RSA scores between all conditions: Full time (Mdn = 0.0326) and Early window (Mdn = 0.0199) (p = 0.002), Full time and Late window (Mdn = 0.0226) (p = 0.002), and Early and Late window (p = 0.005). For the PEGASUS model, post hoc analysis revealed no statistically significant difference in RSA scores between Full time (Mdn = 0.0391) and Early window (Mdn = 0.0397) (p = 0.196). However, there were statistically significant differences between Full time and Late window (Mdn = 0.0238) (p = 0.013) and between Early and Late window (p = 0.001). Finally, for the T5 model, there were statistically significant differences in RSA scores between Full time window (Mdn = -0.0024 and Early window (Mdn = 0.0024) (p < 0.001), between Full time and Late window(Mdn = -0.0061) (p < 0.001), and between Early and Late window (p < 0.001).
The results revealed distinct processing patterns across language models for various spatiotemporal windows of linguistic information. BART exhibited the highest similarity to human brain activity in comprehensive information processing (Full time window), followed by the P600-associated window (Late window), and lastly, the N400-associated window (Early window). This finding possibly indicates that BART excels in capturing overall language processing and potentially syntax-related information. PEGASUS demonstrated similar processing for comprehensive and N400-associated information but diverged significantly in the P600-associated window. This pattern may indicate consistent handling of general and potentially semantic-related information, with a distinct approach to syntax-related information. T5 showed the highest similarity in the N400-associated window, followed by the comprehensive condition, and lowest in the P600-associated window. This finding suggests that T5’s processing patterns align more closely with human brain activity in spatiotemporal windows associated with the N400 component. These disparities likely reflect the architecture, pretraining methods, and task adaptability differences of DLMs. For instance, BART’s sequence-to-sequence pretraining may enhance structural information processing, while PEGASUS’s summarization-focused design may prioritize semantic information. The findings provide insights into how various language models process different components of human language comprehension.
We also employed Wilcoxon signed-rank tests to determine whether significant differences existed between each model’s three experimental conditions and their respective control conditions. The results are presented in Table 3. A positive Z-score indicates that the experimental condition surpassed the control condition. At the same time, a p-value < 0.05 denotes a statistically significant difference between the two.
The results demonstrate that all experimental conditions for each model exceeded their corresponding control conditions (Z > 0), with the majority achieving statistical significance (p < 0.05). This finding suggests that trained language models can acquire LRs more akin to those of the human brain and, in most cases, significantly differentiate between language processing states (Full time, Early and Late window) and baseline states (Baseline). These findings underscore the crucial role of model training in attaining brain-like LRs.
The RSA score comparisons that do not reach statistical significance include the PEGASUS model’s Late window vs. Baseline, the T5 model’s Full time window vs. Control (rand.init., Full), and Early window vs. Baseline. As illustrated in Fig. 5, in the shallower layers of each model, the experimental conditions’ RSA scores are lower than those of the control conditions. However, as the layer depth increases, the experimental conditions’ RSA scores consistently surpass those of the control conditions from a particular layer onwards. This phenomenon indicates that as the network deepens, the model progressively learns representations that better distinguish between language processing and baseline states. Baseline, serving as the baseline before stimulus presentation, represents a non-specific language processing state. As the layer depth increases, the models’ similarity to language processing-related conditions (Full time, Early and Late window) increases, while the difference from the baseline condition becomes more apparent, suggesting that the models are learning features similar to human brain language processing. Concurrently, this phenomenon indicates that the effects of training are more pronounced in the deeper layers of the model, emphasizing that more profound layers of network structures play a more critical role in capturing the LRs of the human brain.
Finally, we conducted two additional exploratory analyses. First, we performed an RSA across different encoder layers of the 3 DLMs. Specifically, we calculated the RSA scores between each pair of encoder layers for BART, PEGASUS, and T5 models. We generated three heatmap matrices based on these RSA scores, as illustrated in Supplementary Fig. S1. Supplementary Fig. S1a and Fig. S1c correspond to the inter-layer similarities between BART-PEGASUS, BART-T5, and PEGASUS-T5. We normalized the matrices to a square format to facilitate a comparison between models with different numbers of layers. This visualization approach revealed several interesting trends. For BART and PEGASUS, the RS between hidden layers initially increased with depth but decreased in the deeper layers. The representational similarity between BART and T5 hidden layers showed an increasing trend as the layer depth increased. Conversely, the RS between PEGASUS and T5 hidden layers exhibited a decreasing trend with increasing layer depth. These findings offer valuable insights that could inform future comparative analyses of representational patterns across different models.
We performed two exploratory RSA-based analyses to comprehensively interpret the experimental results.
In the first analysis, we calculated the RSA scores between each pair of encoder layers across the BART, PEGASUS, and T5 models. We visualized these scores as three heatmap matrices in Supplementary Fig. S1, normalizing them to a square format to facilitate comparison between models with different numbers of layers. The visualization revealed extensive regions of similarity (depicted in blue), indicating potential convergence in RPs across these DLMs. Notably, PEGASUS and T5 demonstrate higher inter-model RS than their respective similarities with BART, consistent with the visualization patterns observed in Figure 4. Furthermore, our analysis revealed significant correlations between the deeper hidden layers of all three DLMs and human brain activity patterns. These results support the Platonic Representation Hypothesis55, which suggests that, given adequate training data and model capacity, neural networks naturally converge toward a common statistical representation of reality.
In the second analysis, we calculated the correlation between the RSMs obtained under three conditions for each participant and then averaged the results across all participants. The results reveal a Spearman correlation of 0.439 between Full time and Early window, 0.466 between Full time and Late window, and 0.273 between Early and Late window. All 13 participants demonstrate statistically significant correlations (p < 0.05) across the three comparisons. These findings indicate high correlations among the RPs of EEG under the three conditions, notably higher than the RSA scores between human brain activity and DLMs. We posit that this outcome is reasonable. Firstly, it relates to the construction method of the EEG vectors. Full time window effectively encompasses all the information from Early and Late window, including time durations and electrode locations. Moreover, Early and Late window partially overlap, sharing specific EEG electrodes and being temporally separated by only 50ms. This inherent interconnection in the data structure may contribute to the high similarity between conditions. Secondly, this analysis compares different RPs within the same neural system (the human brain). In contrast, we compare patterns between two independent systems when we conduct RSA between human brain activity and DLMs. Therefore, it is reasonable that RSA scores across different EEG conditions are higher than those between brain activity and models. This reasoning also applies to the observation that inter-layer RSA scores within DLMs are higher than those between brain activity and DLMs, as all three DLMs are fundamentally based on the Transformer architecture, and we have extracted representations from their encoder layers. Lastly, previous research41 analyzing the RS between human EEG signals and model embeddings has reported RSA scores (correlation coefficients) on the order of \(10^{-2}\). To some extent, this finding supports the notion that this magnitude of correlation between human brain activity and model representations is indeed meaningful and valid.
Impact of layer manipulation on model performance
Tables 4, 5 and 6 present the Rouge metrics for three DLMs after conducting layer-wise attention ablation or noise addition, reflecting the models’ performance on the ABS task. The notation “w/o” indicates that no manipulation was applied to any encoder layer, while “all” signifies that all encoder layers were processed. The bolded values represent the Rouge scores that showed the greatest performance decline after attention ablation or noise addition. Perplexity is a control variable for the correlation analysis in the following subsection. In language model evaluation, a lower perplexity score indicates that the model is better at predicting the text.
Figure 6 graphically demonstrates the impact of ablating attention and noise addition at each layer on the ABS task, with negative numbers indicating performance improvements. This subsection primarily describes experimental results to lay the groundwork for analysis in the following subsection. For BART, attention ablation in any encoder layer decreases all Rouge metrics, most significantly in the final layer. Noise introduction causes the most significant decline at layer 11. Interestingly, layer 4 shows slight increases in Rouge1 and RougeL. From layer 3 onwards, attention ablation degrades performance in PEGASUS, with deeper layers having a more significant impact. The 11th layer’s ablation most significantly reduces Rouge1 and Rouge2. The 14th layer’s uniform attention distribution causes the most significant RougeL decrease. Noise introduction from layer 8 onwards reduces all Rouge metrics, peaking at the final layer. For T5, performance degradation due to attention ablation begins at layer 13. Earlier layers show performance fluctuations, with some improving all Rouge metrics. From layers 13 to 24, performance consistently declines, maximally at layer 20. Noise introduction generally decreases all Rouge metrics (except RougeL in the lower seven layers), with peak drops at layers 16 (Rouge1) and 22 (Rouge2 and RougeL).

Impact of layer-wise attention ablation and noise addition on ABS task performance.
Notably, the changes in Rouges for the PEGASUS and T5 models are considerably more minor than those observed in the BART model, suggesting that the increased number of layers in PEGASUS and T5 enhances performance stability. However, this does not imply that more layers invariably leads to better performance. For instance, after setting the attention of layer 9 in the T5 model to a uniform distribution, a considerable performance improvement was observed. This suggests that the attention mechanism in this layer may have previously interfered with the effective extraction and integration of crucial information, indicating that not every hidden layer positively contributes to the task of ABS.
Correlation between RS and model performance
This subsection presents the experimental results based on a correlation analysis conducted to test the research hypothesis using data from the previous two subsections. Figure 7 and Supplementary Fig. S2 and Fig. S3 illustrate the correlation between model performance (Rouge1/2/L) decline and the RSA scores of each encoder hidden layer for the three ABS models. Each subplot represents the results of correlation analysis under a specific experimental condition of RSA. Specifically, each subplot contains two sets of regression lines and corresponding scatter plots: solid lines with solid scatter points represent the effects of attention ablation (setting each layer’s attention to a uniform distribution). In contrast, dashed lines with diamond scatter points depict the effects of adding noise to each layer. Both sets of regression lines share the same x-axis (RSA scores) but utilize different y-axis. The left y-axis corresponds to the former, representing the performance decline due to attention ablation (Rouge1/2/L decline (a)). The right y-axis corresponds to the latter, indicating the performance decline from noise addition (Rouge1/2/L decline (n)). For example, with its 12 encoder layers, the BART model is represented by 24 data points: 12 circle points for attention ablation and 12 diamond points for noise addition, each corresponding to a specific layer. The shaded areas surrounding each regression line represent the 95% confidence intervals (95%CI). the Spearman correlation coefficients presented in this subsection were calculated using Python 3.7.9. The ‘r’ value in the figure represents the Spearman correlation coefficient, and ‘p’ denotes the significance level of the correlation, with a p-value < 0.05 signifying a statistically significant correlation. To better focus on the main findings of our study, we have opted to include only the figures and tables related to Rouge1 in the main text. The Supplementary Fig. S2 and Fig. S3 and tables showing results for Rouge2 and RougeL can be found in the Appendix.
Figure 7 demonstrates that for the three DLMs, the RSA scores calculated under three conditions show a significant positive correlation (p < 0.05) with the model performance decline (Rouge1) caused by two types of encoder layer operations. Similar results are observed for Rouge2 and RougeL in Supplementary Fig. S2 and Fig. S3. In other words, hidden layers with LRs more closely aligned to the human brain exhibit more pronounced model performance deterioration when manipulated. This finding supports our hypothesis that the hidden layers of the model that exhibit a higher degree of RS to the human brain’s activation patterns may play a more critical role in the model’s performance on the ABS task.

Correlation between RSA scores and Rouge1 declines in BART, PEGASUS, and T5 models.
To enhance the preciseness of our findings, we used approximate non-parametric partial correlation analysis to control for perplexity’s influence. We first calculated Spearman correlations among Rouge, RSA, and perplexity. To remove perplexity’s impact, we computed partial correlations between Rouge and RSA using linear regression to estimate perplexity’s effect, then calculated residuals. Finally, we determined Spearman correlations between these residuals, yielding partial correlation coefficients. This method excluded potential confounding effects from perplexity, allowing for a more accurate assessment of relationships between variables.
Table 7 presents the results of partial correlation analysis for Rouge1 scores. The study reveals that, even when controlling for perplexity, the RSA scores maintain a significant positive correlation (p < 0.05) with the performance decline caused by two types of encoder layer operations across all three experimental conditions for the three DLMs. Supplementary Table S2 and Table S3 show essentially consistent results for Rouge2 and RougeL, except the positive correlation between RSA scores and Rouge2 decline for the T5 model in Full time window narrowly missed statistical significance (p = 0.051). These findings unveil a deep structure-function relationship that transcends the models’ general language understanding capabilities while emphasizing the crucial role of specific neural network layers in the ABS task. These layers may perform functions analogous to the human brain in language compression and key information extraction processes.
Notably, this correlation persists across different model architectures (BART, PEGASUS, T5), various conditions of human brain LR (Full time, Early and Late window), different perturbation methods (attention ablation, noise injection), and multiple performance metrics (Rouge1, 2, L). This consistency and robustness suggest the possible existence of universal neural computational principles independent of specific model implementations.
To comprehensively evaluate model performance, we invite five native speakers to manually score summaries generated by BART and PEGASUS models. We randomly select ten articles from the test set to assess the model summaries after attention ablation. The evaluation metrics include informativeness, readability, and factual consistency, with scores ranging from 1 to 5, where higher scores indicate better performance. Detailed evaluation criteria are presented in Supplementary Table S4. We do not evaluate the T5 model, as it generates 25 summaries per article, which could lead to evaluator fatigue and introduce errors. We calculate the correlation between the three metrics of model summaries and the RSA scores of affected hidden layers and the human brain, with results shown in Table 8 (BART) and Table 9 (PEGASUS). For BART, the three metrics show negative correlations with RSA scores under all three conditions, although these correlations do not reach statistical significance. This result suggests that model performance tends to decline when hidden layers more similar to human brain representations are disrupted. PEGASUS exhibits identical trends in Full time and Early window, while in Late window, RSA scores are only moderately negatively correlated with readability.
Overall, the manual evaluation results align with the trends observed in Rouge evaluations (Rouge uses decreased values in evaluation, hence the positive correlation). Although the correlations in the manual assessment do not reach significant levels, they also support our hypothesis: hidden layers with representations similar to human brain language patterns play a crucial role in summarization tasks.
Discussion
This study proposes a central hypothesis: the hidden layers of a Deep Language Model (DLM) that exhibit a higher degree of Representational Similarity (RS) to the human brain’s activation patterns may play a more critical role in the model’s performance. We employed EEG experiments and Representational Similarity Analysis (RSA) to systematically investigate the similarity between the Language Representations (LRs) of hidden layers in Abstractive Summarization (ABS) models and human language understanding processes to validate this hypothesis. We further explored the correlation between this brain-model similarity and model performance through layer-wise attention ablation and noise addition. The experimental results consistently supported our hypothesis across diverse testing conditions, demonstrating robust evidence for our claim.
Through the RSA of three representative ABS models, we derived several findings that hold significant implications for understanding the internal LR mechanisms of DLMs and their relationship to human language cognition. We observed a notable trend: as the model layers deepened, the similarity between encoder layers and human brain language processing generally showed an upward trend, reaching statistical significance (p < 0.05) under most experimental conditions. However, this finding differs from some previous studies. For instance, research56 found that the 9th layer (out of 12) of GPT-2 was most similar to human brain activity. At the same time10, it was discovered that the middle layers (6 or 7 out of 12) of the BERT model showed the highest similarity to human brain activity. This apparent discrepancy reflects several issues worthy of in-depth exploration. Firstly, although our experimental results show a statistically significant monotonic increase in RSA scores between the model and the human brain as layer depth increases, this does not preclude the possibility of local fluctuations in intermediate hidden layers. For example, under Full time window, the BART model showed a temporary decrease starting from the 6th layer, and the difference in RSA scores between the 6th layer and the 12th (final) layer was insignificant (p = 0.385). Focusing on individual layer comparisons rather than the overall trend might lead to different conclusions. Secondly, our study employed an encoder-decoder model fine-tuned on the ABS task to analogize the complete process of human language understanding and generation. In contrast, GPT-2 and BERT use decoder-only and encoder-only architectures, respectively. This task-specific architectural difference may result in different representation learning patterns. Moreover, the ABS task demands more robust semantic integration and information compression capabilities from the model, potentially driving deeper networks to form high-level LRs more akin to the human brain. Lastly, control experiments using randomly initialized models indicate that the pre-training and fine-tuning processes play a crucial role in shaping the model’s representational characteristics. This finding underscores the importance of task-specific training in molding internal model representations. Thus, specific fine-tuning for the ABS task may alter the LRs of DLMs, causing deeper networks to focus more on language feature extraction relevant to the ABS task. Our findings help to reveal the complex interplay between DLM architecture, task-specific training, and models’ similarity to human brain language processing. This study underscores the importance of considering these factors when comparing DLMs to human cognition, providing a foundation for future research in developing more human-like language models.
The core findings of this study reveal that hidden layers in DLMs with higher similarity to human brain LRs have a more significant impact on model performance. This correlation demonstrates remarkable robustness across multiple dimensions: various DLM types (BART, PEGASUS, T5), different human brain LR conditions (Full time, Early and Late window), diverse layer manipulation methods (attention ablation, noise addition), and persists even after controlling for perplexity. The consistency and robustness of these findings warrant in-depth discussion from multiple perspectives. From the architectural standpoint of DLMs, although BART, PEGASUS, and T5 models differ in the number of hidden layers, training objectives, and fine-tuning datasets, they all share the encoder-decoder Transformer architecture as a common foundation. The shared underlying structure may preserve similar information processing mechanisms and representation learning patterns, potentially as a critical factor in the observed cross-model similarities. Considering the human brain LR conditions, while Full time, Early and Late window focus on different time windows and electrode locations, they likely capture partially overlapping language processing information. This spatiotemporal overlap in neural signals may contribute to the consistency across conditions. Moreover, DLMs may simultaneously learn LRs corresponding to multiple stages of brain processing, enabling them to exhibit similarities with human brain patterns across different conditions. From the perspective of layer-wise operations, layers with LRs more closely aligned to human brain language patterns may perform specific functions crucial to the ABS task, such as high-level semantic integration or contextual understanding. Consequently, whether through attention ablation or noise addition, directly impacting the model’s ability to process critical linguistic information leads to significant performance degradation. Regarding the control variable, perplexity primarily reflects a model’s general language modeling capability. However, the ABS task requires not only basic language comprehension but also the ability to extract and compress critical information. LRs in DLMs similar to those in the human brain may excel at this advanced information processing and abstraction, which is not fully captured by the perplexity metric. These findings highlight a crucial link between the neural representations in DLMs and human brain language processing, suggesting that the brain-like layers are also critical for high-level language tasks. This convergence, robust across model architectures and experimental conditions, implies that DLMs may be capturing fundamental aspects of human language processing.
Throughout our research process, we have identified several limitations in the current study, which provide directions for future research. Firstly, this study did not conduct an in-depth comparative analysis of the experimental results among the three DLMs. Our research design selected BART, PEGASUS, and T5 models, which vary in type, hidden layer count, and fine-tuning dataset, to enhance the consistency and robustness of our hypotheses across diverse model types. However, this approach limited our ability to isolate the effects of individual factors. Future research could adopt more rigorous variable control strategies to investigate these factors independently. For example, comparing BART and PEGASUS models with identical layer counts and fine-tuning datasets could isolate the influence of model type. Similarly, examining T5 variants that differ only in parameter count while keeping other conditions constant could focus on the impact of model scale on performance. These targeted comparisons would provide more nuanced insights into the specific contributions of each factor to the observed effects. Secondly, this study primarily focused on the overall trends of RSA scores across different experimental conditions without delving into changes at the individual hidden layer level. Therefore, future experiments could be designed to cross-validate RSA scores with findings from other interpretability research methods, such as probing tasks or feature visualization, to understand the model’s internal representations better. Furthermore, although we set three EEG signal conditions, this approach still faces challenges separating semantic and syntactic representations within EEG signals. However, studies18,19,56 have, in turn, provided approaches for separating syntactic and semantic representations in GPT-2 (decoder-only). Future research could attempt to adapt and transfer this method to encoder architectures, enabling separation and analysis of syntactic and semantic representations within encoder layers. Lastly, the recent emergence of decoder-only open-source Large Language Models (LLMs), such as LLaMA57, Vicuna58, and Mistral59, has captured significant attention from academia and industry. Despite lacking explicit encoder structures, these models demonstrate remarkable language understanding capabilities and show potential for application in ABS tasks. Future research could explore the relationships between these LLMs and human language cognition. Specifically, comparative analyses could focus on aspects such as parameter scale, pre-training strategies, and performance on downstream tasks. Such investigations could provide valuable insights into the similarities and differences between these advanced AI models and human language processing, potentially bridging the gap between artificial and biological approaches to language understanding.
Conclusion
This study investigated the similarity between the deep language models’ encoder hidden layer representations and human brain activity during language processing using EEG-based experiments and representational similarity analysis. Subsequently, we employed a hierarchical manipulation approach to analyze the correlation between this brain-model similarity and model performance. Our core hypothesis was verified: the hidden layers of a model that exhibit a higher degree of representational similarity to the human brain’s activation patterns play a more critical role in the model’s performance on the abstractive summarization task. This correlation manifested and attained statistical significance across various experimental conditions. These conditions encompassed diverse deep language model types (BART, PEGASUS, T5), multiple spatiotemporal windows representing distinct phases of human language representation, various hierarchical manipulation techniques including attention ablation and noise addition, and an array of model performance evaluation metrics (Rouge1, Rouge2, RougeL). Notably, this correlation persisted even after accounting for the confounding influence of perplexity on model performance. The heterogeneity of these experimental conditions bolsters the robustness and validity of our conclusions, yielding profound insights into the alignment between deep language models and human language processing mechanisms.
Data availability
The EEG data and model hidden states are available at https://drive.google.com/drive/folders/1-C_e_HqdS6MIf1gGVehG7DW6B0MQguco?usp=sharing.
Code availability
The code for RSA (with data), layer manipulation, and correlation computation (with data) are also available at https://drive.google.com/drive/folders/1-C_e_HqdS6MIf1gGVehG7DW6B0MQguco?usp=sharing.
References
Chang, Y. et al. A survey on evaluation of large language models. ACM Trans. Intell. Syst. Technol. 15, 1–45. https://doi.org/10.1145/3641289 (2024).
Zhao, W. X. et al. A survey of large language models, https://doi.org/10.48550/arXiv.2303.18223 (2023). arXiv: 2303.18223.
Antonello, R., Vaidya, A. & Huth, A. Scaling laws for language encoding models in fmri, in Oh, A. et al. (eds.) Advances in Neural Information Processing Systems, vol. 36 21895–21907 (2023).
Arana, S., Pesnot Lerousseau, J. & Hagoort, P. Deep learning models to study sentence comprehension in the human brain. Lang. Cognit. Neurosci.. https://doi.org/10.1080/23273798.2023.2198245 (2023).
Goldstein, A. et al. Alignment of brain embeddings and artificial contextual embeddings in natural language points to common geometric patterns. Nat. Commun.. https://doi.org/10.1038/s41467-024-46631-y (2024).
Goldstein, A. et al. Thinking ahead: spontaneous prediction in context as a keystone of language in humans and machines. bioRxiv[SPACE]https://doi.org/10.1101/2020.12.02.403477 (2021).
Goldstein, A. et al. Shared computational principles for language processing in humans and deep language models. Nat. Neurosci. 25, 369–380. https://doi.org/10.1038/s41593-022-01026-4 (2022).
Ding, X., Chen, B., Du, L., Qin, B. & Liu, T. CogBERT: Cognition-guided pre-trained language models, in Calzolari, N. et al. (eds.) Proceedings of the 29th International Conference on Computational Linguistics 3210–3225 (International Committee on Computational Linguistics, 2022).
Hollenstein, N. et al. Decoding eeg brain activity for multi-modal natural language processing. Front. Hum. Neurosci.. https://doi.org/10.3389/fnhum.2021.659410 (2021).
Toneva, M. & Wehbe, L. Interpreting and improving natural-language processing (in machines) with natural language-processing (in the brain), in Wallach, H. et al. (eds.) Advances in Neural Information Processing Systems, vol. 32 (2019).
Hale, J. T. et al. Neurocomputational models of language processing. Annu. Rev. Linguist. 8, 427–446. https://doi.org/10.1146/annurev-linguistics-051421-020803 (2022).
Mischler, G., Li, Y. A., Bickel, S., Mehta, A. D. & Mesgarani, N. Contextual feature extraction hierarchies converge in large language models and the brain, https://doi.org/10.48550/arXiv.2401.17671. arXiv: 2401.17671 (2024).
Wingfield, C. et al. On the similarities of representations in artificial and brain neural networks for speech recognition. Front. Comput. Neurosci. . https://doi.org/10.3389/fncom.2022.1057439 (2022).
Schrimpf, M. et al. The neural architecture of language: Integrative modeling converges on predictive processing. Proc. Natl. Acad. Sci.. https://doi.org/10.1073/pnas.2105646118 (2021).
Hosseini, E. A. et al. Artificial neural network language models predict human brain responses to language even after a developmentally realistic amount of training. Neurobiol. Lang. 5, 43–63. https://doi.org/10.1162/nol_a_00137 (2024).
Barthel, M., Tomasello, R. & Liu, M. Conditionals in context: Brain signatures of prediction in discourse processing. Cognition 242, 105635. https://doi.org/10.1016/j.cognition.2023.105635 (2024).
Nour Eddine, S., Brothers, T., Wang, L., Spratling, M. & Kuperberg, G. R. A predictive coding model of the n400. Cognition 246, 105755. https://doi.org/10.1016/j.cognition.2024.105755 (2024).
Heilbron, M., Armeni, K., Schoffelen, J.-M., Hagoort, P. & de Lange, F. P. A hierarchy of linguistic predictions during natural language comprehension. Proc. Natl. Acad. Sci. 119, https://doi.org/10.1073/pnas.2201968119 (2022).
Caucheteux, C., Gramfort, A. & King, J.-R. Evidence of a predictive coding hierarchy in the human brain listening to speech. Nat. Hum. Behav. 7, 430–441. https://doi.org/10.1038/s41562-022-01516-2 (2023).
Goldstein, A. et al. Correspondence between the layered structure of deep language models and temporal structure of natural language processing in the human brain. bioRxiv[SPACE]https://doi.org/10.1101/2022.07.11.499562 (2022).
Caucheteux, C. & King, J.-R. Brains and algorithms partially converge in natural language processing. Commun. Biol. 5, https://doi.org/10.1038/s42003-022-03036-1 (2022).
Caucheteux, C., Gramfort, A. & King, J.-R. Long-range and hierarchical language predictions in brains and algorithms, https://doi.org/10.48550/arXiv.2111.14232. arXiv:2111.14232. (2021)
Jawahar, G., Sagot, B. & Seddah, D. What does bert learn about the structure of language? in Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, https://doi.org/10.18653/v1/p19-1356 (2019).
Caucheteux, C., Gramfort, A. & King, J.-R. Deep language algorithms predict semantic comprehension from brain activity. Sci. Rep. 12, https://doi.org/10.1038/s41598-022-20460-9 (2022).
Golan, T., Siegelman, M., Kriegeskorte, N. & Baldassano, C. Testing the limits of natural language models for predicting human language judgements. Nat. Mach. Intell. 5, 952–964. https://doi.org/10.1038/s42256-023-00718-1 (2023).
Sun, K. & Wang, R. Computational sentence-level metrics predicting human sentence comprehension, https://doi.org/10.48550/arXiv.2403.15822. arXiv: 2403.15822 (2024).
Deniz, F., Tseng, C., Wehbe, L., Dupré la Tour, T. & Gallant, J. L. Semantic representations during language comprehension are affected by context. J. Neurosci. 43, 3144–3158. https://doi.org/10.1523/jneurosci.2459-21.2023 (2023).
Yang, S., Feng, D., Liu, Y. & Li, D. Distant context aware text generation from abstract meaning representation. Appl. Intell. 52, 1672–1685. https://doi.org/10.1007/s10489-021-02431-1 (2021).
Wang, T. et al. A study of extractive summarization of long documents incorporating local topic and hierarchical information. Sci. Rep. 14, https://doi.org/10.1038/s41598-024-60779-z (2024).
Zhang, M., Zhou, G., Yu, W., Huang, N. & Liu, W. A comprehensive survey of abstractive text summarization based on deep learning. Comput. Intell. Neurosci. 1–21, 2022. https://doi.org/10.1155/2022/7132226 (2022).
Huang, Y. et al. Abstractive document summarization via multi-template decoding. Appl. Intell. 52, 9650–9663. https://doi.org/10.1007/s10489-021-02607-9 (2022).
Lewis, M. et al. Bart: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension, in Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, https://doi.org/10.18653/v1/2020.acl-main.703 (2020).
Zhang, J., Zhao, Y., Saleh, M. & Liu, P. PEGASUS: Pre-training with extracted gap-sentences for abstractive summarization, in III, H. D. & Singh, A. (eds.) Proceedings of the 37th International Conference on Machine Learning, vol. 119 of Proceedings of Machine Learning Research, 11328–11339 (2020).
Raffel, C. et al. Exploring the limits of transfer learning with a unified text-to-text transformer. J. Mach. Learn. Res. 21, 1–67 (2020).
Goodwin, T., Savery, M. & Demner-Fushman, D. Flight of the pegasus? comparing transformers on few-shot and zero-shot multi-document abstractive summarization, in Proceedings of the 28th International Conference on Computational Linguistics, https://doi.org/10.18653/v1/2020.coling-main.494 (International Committee on Computational Linguistics, 2020).
Chung, H. W. et al. Scaling instruction-finetuned language models. J. Mach. Learn. Res. 25, 1–53 (2024).
Friederici, A. D., Opitz, B. & von Cramon, D. Y. Segregating semantic and syntactic aspects of processing in the human brain: an fmri investigation of different word types. Cereb. Cortex 10, 698–705. https://doi.org/10.1093/cercor/10.7.698 (2000).
Pasquiou, A., Lakretz, Y., Thirion, B. & Pallier, C. Information-restricted neural language models reveal different brain regions’ sensitivity to semantics, syntax, and context. Neurobiol. Lang. 4, 611–636. https://doi.org/10.1162/nol_a_00125 (2023).
Reddy, A. J. & Wehbe, L. Can fmri reveal the representation of syntactic structure in the brain? In Ranzato, M., Beygelzimer, A., Dauphin, Y., Liang, P. & Vaughan, J. W. (eds.) Advances in Neural Information Processing Systems, vol. 34 9843–9856 (2021).
Karamolegkou, A., Abdou, M. & Søgaard, A. Mapping brains with language models: A survey, in Findings of the Association for Computational Linguistics: ACL 2023, https://doi.org/10.18653/v1/2023.findings-acl.618 (2023).
He, T., Boudewyn, M. A., Kiat, J. E., Sagae, K. & Luck, S. J. Neural correlates of word representation vectors in natural language processing models: Evidence from representational similarity analysis of event-related brain potentials. Psychophysiology. https://doi.org/10.1111/psyp.13976 (2022).
OOTA, S., Gupta, M. & Toneva, M. Joint processing of linguistic properties in brains and language models, in Oh, A. et al. (eds.) Advances in Neural Information Processing Systems, vol. 36 18001–18014 (2023).
Kutas, M. & Hillyard, S. A. Reading senseless sentences: Brain potentials reflect semantic incongruity. Science 207, 203–205. https://doi.org/10.1126/science.7350657 (1980).
Osterhout, L. & Holcomb, P. J. Event-related brain potentials elicited by syntactic anomaly. J. Mem. Lang. 31, 785–806. https://doi.org/10.1016/0749-596x(92)90039-z (1992).
Zou, B. et al. Beats: An open-source, high-precision, multi-channel eeg acquisition tool system. IEEE Trans. Biomed. Circuits Syst. 16, 1287–1298. https://doi.org/10.1109/tbcas.2022.3230500 (2022).
Dimigen, O., Sommer, W., Hohlfeld, A., Jacobs, A. M. & Kliegl, R. Coregistration of eye movements and eeg in natural reading: Analyses and review. J. Exp. Psychol. Gen. 140, 552–572. https://doi.org/10.1037/a0023885 (2011).
Coderre, E. L. & Cohn, N. Individual differences in the neural dynamics of visual narrative comprehension: The effects of proficiency and age of acquisition. Psychon. Bull. Rev. 31, 89–103. https://doi.org/10.3758/s13423-023-02334-x (2023).
Peirce, J. et al. Psychopy2: Experiments in behavior made easy. Behav. Res. Methods 51, 195–203. https://doi.org/10.3758/s13428-018-01193-y (2019).
Peirce, J. W. Psychopy-psychophysics software in python. J. Neurosci. Methods 162, 8–13. https://doi.org/10.1016/j.jneumeth.2006.11.017 (2007).
Pagnoni, A., Balachandran, V. & Tsvetkov, Y. Understanding factuality in abstractive summarization with frank: A benchmark for factuality metrics, in Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, https://doi.org/10.18653/v1/2021.naacl-main.383 (2021).
Hermann, K. M. et al. Teaching machines to read and comprehend, in Cortes, C., Lawrence, N., Lee, D., Sugiyama, M. & Garnett, R. (eds.) Advances in Neural Information Processing Systems, vol. 28 (Curran Associates, Inc., 2015).
Narayan, S., Cohen, S. B. & Lapata, M. Don’t give me the details, just the summary! topic-aware convolutional neural networks for extreme summarization, in Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, https://doi.org/10.18653/v1/d18-1206 (Association for Computational Linguistics, 2018).
Vaswani, A. et al. Attention is all you need, in Guyon, I. et al. (eds.) Advances in Neural Information Processing Systems, vol. 30 (2017).
Funder, D. C. & Ozer, D. J,. Evaluating effect size in psychological research: Sense and nonsense. Adv. Methods Pract. Psychol. Sci. 2, 156–168. https://doi.org/10.1177/2515245919847202 (2019).
Huh, M., Cheung, B., Wang, T. & Isola, P. The platonic representation hypothesis, https://doi.org/10.48550/arXiv.2405.07987, arXiv: 2405.07987. (2024)
Caucheteux, C., Gramfort, A. & King, J.-R. Disentangling syntax and semantics in the brain with deep networks, in Meila, M. & Zhang, T. (eds.) Proceedings of the 38th International Conference on Machine Learning, vol. 139 of Proceedings of Machine Learning Research, 1336–1348 (PMLR, 2021).
Touvron, H. et al. Llama: Open and efficient foundation language models, https://doi.org/10.48550/arXiv.2302.13971. arXiv: 2302.13971 (2023).
Chiang, W.-L. et al. Vicuna: An Open-Source Chatbot Impressing gpt-4 with 90%* Chatgpt Quality (2023).
Jiang, A. Q. et al. Mistral 7b, https://doi.org/10.48550/arXiv.2310.06825 (2023). arXiv: 2310.06825.
Acknowledgements
We are immensely grateful to the Beijing University of Posts and Telecommunications students who participated in this work and provided us with their invaluable support.
Funding
This research was funded by National Natural Science Foundation of China (NSFC) [grant number 62176024]; and BUPT innovation and entrepreneurship support program [grant number 2024-YC-A126]; and Engineering Research Center of Information Networks, Ministry of Education.
Author information
Authors and Affiliations
Contributions
Conceptualization, L.L. and L.Z.; methodology, Z.Z. and S.G.; validation, Z.Z. and Y.Z.; formal analysis, Z.Z., S.G., W.Z. and Y.L.; investigation, Z.Z. and S.G.; resources, L.L.; data curation, Z.Z. and Y.L.; writing-original draft preparation, Z.Z. and S.G.; writing-review & editing, Z.Z., S.G., W.Z., L.L. and L.Z.; visualization, Z.Z.; supervision, L.L., L.Z. and Y.Z.; project administration, L.L.; funding acquisition, L.L.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Ethical approval declarations
The study was conducted according to the guidelines of the Declaration of Helsinki and approved by the Ethics Committee of the Beijing University of Posts and Telecommunications (Ethic approval code: 202302003).
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Zhang, Z., Guo, S., Zhou, W. et al. Brain-model neural similarity reveals abstractive summarization performance. Sci Rep 15, 370 (2025). https://doi.org/10.1038/s41598-024-84530-w
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-024-84530-w
