
Abstract
The Hybrid-Brain Computer Interface (BCI) has shown improved performance, especially in classifying multi-class data. Two non-invasive BCI modules are combined to achieve an improved classification which are Electroencephalogram (EEG) and functional Near Infra-red Spectroscopy (fNIRS). Classifying contralateral and ipsilateral motor movements is found challenging among the other mental activity signals. The current work focuses on the performance of deep learning methods like – Convolutional Neural Networks (CNN) and Bidirectional Long-Short term memory (Bi-LSTM) in classifying a four-class motor execution of Right Hand, Left Hand, Right Arm and Left Arm taken from the CORE dataset. The model performance was evaluated using metrics such as Accuracy, F1 – score, Precision, Recall, AUC and ROC curve. The CNN and Hybrid CNN models have resulted in 98.3% and 99% accuracy respectively.
Similar content being viewed by others
Introduction
Brain-Computer Interface (BCI) integrates the brain with different actuators using a computer. This captures the minds of various researchers to make it practically feasible. Several non-invasive brain-reading techniques like EEG, functional Magnetic Resonance Imaging (fMRI), and fNIRS are used commonly for this application1,2. Amongst most mental activities Motor Imagery (MI) is an interesting candidate for investigation and hence feature extraction and classification of MI signals have gained much importance3,4. Classification of Motor Imagery (MI) signals using EEG were commonly investigated using various machine learning algorithms5,6. Common machine learning classifiers like Tree classifiers, K-Nearest Neighbor (KNN), Linear Discriminant Analysis (LDA) and Support Vector Machines (SVM) have shown an accuracy of up to 95% for 2 class MI tasks7,8,9. Optimizations have also helped to improve the accuracy10. Furthermore, intelligent algorithms have also been investigated for single modalities for improving accuracy in two class classifications11. These improvements have led to multi-class classification of MI or MI with other mental activities like mental arithmetic12. Nevertheless, beyond the best techniques used for classification, a single modality has its own merits and demerits which introduces the use of Hybrid BCI that can be achieved by combining two modalities. This can complement each other’s limitations13. It was also found that the hybrid system showed improved performance for motor imagery hand clenching in terms of speed and force14. Such a system can also be applied for multi-class applications like four class classification of Alzheimer’s disease15, mental arithmetic, motor imagery, and motor executions, which are further converted into command signals to be used for clinical and non-clinical applications like quadcopter and wheelchair controls16,17. The initial limitations in hybrid BCI setup were overcome by upgrading the acquisition devices18.
Processing both motor imagery and motor execution tasks acquired from EEG and fNIRS modalities are seen in some of the recent work to investigate the performance of multi-class motor imagery and execution19,20. EEG is known to have a good temporal resolution while spatial resolution is good in fNIRS. However, fNIRS has a slow response due to hemodynamic activity. In addition, fNIRS is preferred to fMRI for being cost-effective and reducing acquisition complexity21,22. Hybrid BCI with EEG and fNIRS is a good combination for classifying motor imagery and motor tasks. Many feature extraction techniques and classifiers have been used to achieve good classification accuracy. Common machine learning classifiers that were employed for the classification of two-class motor imagery or motor tasks were also used initially with EEG or fNIRS modalities12,23. The same has been applied to Hybrid datasets either as a single model or a combination of 2 models or applying feature selections24,25. However, good accuracy could not be achieved since the complexity also increases with the number of modalities and the amount of data that has to be handled by the machine learning algorithms. Increasing dimensionality and computational cost can be handled better by deep neural networks26. A deep neural network was also used by fully connected layers, but achieved a lesser accuracy27,28. Aiming to increase the performance of machine learning algorithms for multi-class hybrid datasets, channel selection methods were employed before extracting features29,30,31. This additional pre-processing improved the machine learning model accuracy from approximately 92% to 98%32, however, this would compensate for the spatial information especially if the dataset is small. The performance of the models can also vary with the feature extraction methods. In order to preserve the spatial information, techniques like Common Spatial Pattern (CSP), Regularized Common Spatial Pattern (RCSP), and Principal Component Analysis (PCA)33,34were commonly employed33,34. Linear and non-linear features were also considered35,36,37to investigate the linear and non-linear relationship in the signals35,36,37. However, these feature extraction models along with machine learning classifiers have given a classification accuracy ranging from 92 to 98%. An increase in accuracy has always been met with complex methods. Channel selections can increase the accuracy but compensate for spatial information. Machine learning models without channel selection yield less than 98% accuracy. This reduction in accuracy is seen especially for multi-class classification of limb movements since their spatial distribution along the scalp is more adjacent which makes the classification more challenging. This challenge may be resolved by additional processing layers which can extract more complex features as in Deep Neural Networks (DNN)26. DNN and combinations of two DNN models – commonly called hybrid DNN have been used for single modality like EEG. The most common model is combining Convolutional Neural Network (CNN) and Recurrent Neural Network (RNN). This is because CNN can improve spatial features while RNN works well for temporal features. This combination can be used to improve spatio-temporal features38. However, it is seen that the deep learning models are not explicitly investigated for these hybrid BCI systems where spatio-temporal features co-exist.
The proposed work investigates a hybrid deep learning approach on a limited dataset for contralateral and ipsilateral limb movements to know if a good accuracy can be attained without compensating for the spatial information. The data would be more spatially localized signals which may lead to generalization and misclassification problems39,40. Since both hand movements are performed, the number of trials and the time taken to perform the task is also limited. The objectives of this study are – to classify ipsilateral (spatially localized)/contralateral (spatially distinct) hand movements and to investigate deep learning algorithms for improving classification accuracy with reduced pre-processing steps thereby reducing the computational load. The dataset used for this study consists of Motor Imagery (MI) and Motor Execution for the Right arm, Left arm, Right hand, and Left hand. Since the cortical locations for these movements lie adjacent to each other, it increases the chances of misclassification. The proposed Hybrid CNN model uses more filters to simplify the classification problem. The Hybrid CNN was developed and trained using Python Version 3.11. The paper is further divided into a methodology which consists of dataset description with its preparation, pre-processing, feature extraction and classification. The results and discussions section presents the performance comparisons with another proposed model. The comparison of the proposed model performance with previous works is also presented.
Methodology
Dataset description data augmentation and preprocessing
The overall work done is shown in Fig. 1. The dataset provided by Buccino et al.20 has a simultaneous recording of both EEG and fNIRS taken during motor execution. 15 healthy male subjects aged from 22 to 54 years participated in the experiment and were given 4 different upper limb tasks.

Block diagram of methodology.
The motor tasks assigned were flexion of Left/Right Arm/Hand. The acquisition system had 21 channels for EEG and 34 channels for fNIRS with a sampling frequency of 250 Hz and 10.42 Hz respectively. Each trial of tasks lasts for 12 s with 6 s of rest and 6 s of movement with 25 such trials for one class. The 6 s of movement performance is augmented for further processing.
Data Augmentation is done to increase the input data to the model since the dataset is limited. This was done using time-slicing and overlapping methods. The first second after the cue was skipped due to delay in hemodynamic response and the first second of rest was taken due to sustenance of the response. The time slicing was done for 3 s at three intervals as seen in Fig. 2. Data redundancy was also induced to increase the quantity of input data.

Schematic block diagram of data augmentation.
The EEG data was filtered in the mu (8–13 Hz) and beta band (13–30 Hz) for motor imagery and motor execution signals with a filter order of 5 due to its constant group delay and improved Signal-to-Noise Ratio. A Gaussian transformation was used for normalization as in Eq. (1)
The optical wavelengths acquired from fNIRS were converted to changes in optical densities showing oxygen concentration in blood using Modified Beer-Lambert Law (MBLL) at two wavelengths, W1 = 760 nm (red) and W2 = 850 nm (infrared). These were filtered from 0.01 Hz to 0.1 Hz to extract motor imagery and motor execution data.
Feature extraction
The common features used in previous studies are mean, peak, standard deviation, skewness kurtosis and slope indicators20,32. Spatial filtering is another common method of feature extraction which preserves the spatial information. This is done by using a variety of Common Spatial Pattern (CSP) algorithms which are more prominently used in two class problems. This was introduced as a feature extraction method by41. The objective of the algorithm is to maximize the ratio of variance of the two classes present in the signal.
Multi-class CSP
The four classes were converted into two-class problems – Right Hand/Left Hand and Right Arm/Left Arm. The CSP filters were derived for these two class problems by solving Rayleigh’s eigen value problem using Eq. (2),
where \({\Sigma }_{1}\) and \({\Sigma }_{2}\) denote the covariance matrix of classes 1 and 2 while b is the spatial filter that can be obtained by solving the generalized Eigenvalue decomposition. In this work, we have considered 2 filters for 4 classes hence, N = 8.
Thin-ICA CSP
In order to use CSP more effectively in four class, this is combined with Thin-ICA method which computes the second and fourth-order of statistics and extracts the independent components37. ICA belongs to the Blind Source Separation methods, which detect the source amongst many sources. This method can extract motor movement features given a proper initialization. CSP aids in giving the appropriate initialization for ICA to extract the independent components that belong to motor movements. The independent components to be extracted can be modified as required. Since this is applied only to EEG data, the binary problem is considered as Right hand, Left hand, Right Arm and Left arm. The EEG signal can be represented as x(t) with a linear equation Eq. (3)
where, \(A \epsilon {R}^{m \times n}\) is the mixing matrix, \(w(t) \epsilon {R}^{m}\) is the zero mean gaussian noise and \(s(t) \epsilon {R}^{n}\) is the independent source vector. The estimated output is given as in Eq. (4)
where U (U = WA) is considered as the orthogonal matrix, which was obtained after the pre-whitening process and z(t) represents the pre-whitened observations, which is given as \(z\left(t\right)=Us\left(t\right)+Wn\left(t\right) \epsilon {R}^{N}\)
Equation 5 gives the contrast function to estimate the second order and higher-order statistics,
where, N signifies the number of splits and P signifies the number of independent components to extract. Here we set N = 3 (three splits in data), P = 20 and T = {1,…..,6}(delays).
The underlying condition here is that the independent components that would be extracted should belong to Motor Imagery and motor execution tasks. This can be assured by using the CSP matrix to initialize the unmixing matrix in the Thin ICA algorithm. The EEG signals were then spatially filtered using the computed spatial filters. The Thin-ICA parameters were tuned, to get 8 and 20 independent components with splits = 3. The log variances of these filtered signals gave the features which were applied to train the classifier as in Eq. (6)
These extracted EEG features were input to Hybrid CNN for classification. However, optical densities for changes in hemoglobin concentration were fed to Hybrid CNN for feature extraction and classification.
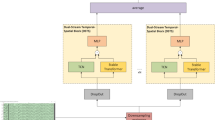
Hybrid-CNN with bidirectional long short-term memory (Bi-LSTM)
The Bi-LSTM model is a combination of forward and backward LSTM which is useful for collecting front and back information42. Sequence models can collect temporal information but lacks capability for collecting spatial information43. However, CNN had good performance for fNIRS since they are spatial features. Combining these two models can improve the extracting and classifying process for both temporal and spatial features of EEG and fNIRS. CNN is added as the first two layers since they can extract localized patterns and also reduce sequence length and this processed data is then sent to Bi-LSTM layers, which can send both positive and inverted sequence of data to be trained. Placing CNN first can extract spatio-temporal features in time series data, and also detect important information from various positions with a good accuracy. In addition, univariate data can be converted to multi-dimentional data, leading to multiple feature extraction from the dataset44.
The model architecture is given in Fig. 3. The architecture is called hybrid since the convolutional layers are included along with the Bi-LSTM layers. The input data (EEG and fNIRS) is prepared to be presented to the model. The EEG data is zero padded to match the columns of fNIRS. The input data was first passed into two layers (layer 1 and layer 2) of convolutional neural networks with 128 filters and a 1 × 3 kernel of filter coefficients. Rectified Linear Unit (ReLU)/Exponential Linear Unit (ELU) activation functions were experimented with appropriate dropouts along with Max/Average pooling. This was followed by the classifier – Bi-LSTM with , 128 and 64 filters (layer 3 and layer 4). Two dense layers were followed by Softmax activation for final classification. The model was run for 100 epochs and a fivefold cross-validation was performed.

Hybrid—CNN model architecture.
Results and discussion
The dataset used for the current study is taken from CORE dataset. This consists of EEG and fNIRS scalp recording taken simultaneously while performing Left Hand, Right Hand, Left Arm and Right Arm motor tasks. The concentration changes of oxygenated and deoxygenated blood are considered features for fNIRS which is taken from MBLL. Thin–ICA applied to EEG gives independent components as features for EEG data. However, feature extractions like CSP were not applied to fNIRS data since it led to over fitting as compared with raw HbO and HbR. Applying feature extractions to fNIRS reduced the effect of CNN, which also extracts patterns, leading to poor performance with 60% accuracy. The performance was significantly increased to 90% while the fNIRS data was presented as changes in optical densities of HbO and HbR using MBLL. The data pre-processing done for both EEG and fNIRS is band-pass filtering.
A 60:40 ratio is considered for splitting data for training and testing respectively. However, as seen in Fig. 4, the performance is poor in the Hybrid CNN model with an accuracy of 84.3.

Hybrid CNN Performance for original input data—Accuracy (Left), Confusion matrix (Right).
Since the batch size of the hybrid model is 200, and the input shape is (1054,1), for every epoch 20 batches were trained. The poor performance may be due to insufficient input data; therefore, a redundancy is created 3 times to increase the data size. Feature redundancy can improve performance even if some features are not learned or absent in an instance. A fivefold cross-validation was used. 60 batches were trained for each epoch. This shows an improved model performance as seen in Fig. 5 with an accuracy of 99% and loss of 0.045 using hybrid CNN model with max pooling and ReLU activation function. However, a 40% drop in accuracy for the data used without redundancy as seen in Fig. 4 since the amount of data for training is less while this is reduced to 10% when the training input is increased by introducing redundancy (as seen in Fig. 5). It is also seen that the generalization of training and testing is achieved as the number of epochs is increased. In Fig. 4, due to insufficient data, the test data is underfitting even after 200 epochs. This is improved by increasing the input data, the generalization is achieved at 100 epochs of training although there is initial overfitting due to similarities in data. The number of CNN, BiLSTM and dense layers were restricted to only two layers since complexity and execution time increases with layers.

Hybrid CNN Performance for original input data with redundancy – Accuracy (a), Confusion matrix (b) (ReLU activation with Max pooling) [class 0 – right hand, class 1 – left hand, class 2 – right arm, class 3 – left arm].
To ensure faster convergence, ELU activation was also experimented with both average and max pooling as in Fig. 6. It is observed that ELU activation provides a faster convergence than ReLU (shown in Fig. 5). This is because the number of negative values in the input data are more than the number of positive values and ELU provides a non-zero value to a negative input, which is unlike ReLU which gives zero output for negative values. Also, in order to get a smooth generalization, the zero masking was also done, since EEG data were zero-padded. The drop in around 20–30 epochs is continuously witnessed due to a drop in fold 2 and fold 4 of the five-fold cross-validation. This can be attributed to the zero values in the data or the shuffling of data during the fold separation in cross-validation and also due to the variations in the batch of data taken during the training. However, the stabilization occur as the upcoming epochs train a better combination of data. Nevertheless, it is observed that the drop is significantly reduced when zero-masking is done since it has further reduced the decrease in performance due to the zero-padding done. The max pooling along with ELU activation has given a smooth generalization curve. The test accuracy and loss were, 99.5% and 0.045 respectively. Some more conclusions can be drawn from the confusion matrix of Fig. 5b and 6c as seen in Table 1.

Performance of Hybrid CNN with ELU activation and zero masking for average pooling (a) and Max pooling (b), Confusion matrix of ELU activation with max pooling and zero masking [class 0 – right hand, class 1 – left hand, class 2 – right arm, class 3 – left arm] (c).
From the observations in Table 1, it can be seen that, true positives remain the same. However, the false positive and false negatives are greatly reduced while applying zero masking. It is also noted that, the true negatives are also slightly lower when zero masking is done. Hence it is clear, that the misclassifications are reduced especially on class 0 (right hand) and class 2 (right arm) on zero masking and the drop in the epoch is reduced as seen in Fig. 6b. This is important since both contralateral and ipsilateral movements are classified accurately.
The current model was compared with a 5-layer CNN model whose accuracy was 98% and Hybrid CNN which uses CNN and Bi-LSTM layers shows better accuracy of classification and better performance as compared with CNN as seen in Table 2. In addition to the accuracy, F1 score, Precision. Recall and AUC parameters prove that the Hybrid CNN model is extracting the spatio-temporal features more efficiently and classifying multi-class motor movement as seen in Fig. 7It can also be seen that the time taken to train one epoch is lower in the Hybrid CNN model. This is because the number of CNN layers and the number of filters used are comparatively lesser (only 2 layers) than using only CNN which used 5 CNN layers.

ROC curve for Hybrid CNN performance with redundancy.
Besides the 5-layer CNN model, the current work performs better than CNN + LSTM models which was experimented in our previous work. This also includes experimentation with lesser CNN layers and how 5-layer CNN was chosen45. Machine learning methods like LDA and SVM were also experimented for the same dataset and feature extraction methods, which gave lower accuracy46.
As seen in Fig. 8, the obtained accuracy of 99% is higher compared to the previous works on the classification, especially the classification of contralateral and ipsilateral limb movements, which in previous works gave 94%20and 98%32.

Comparison of accuracy with previous works.
Conclusion
The proposed work aims to address the challenging classification of contralateral and ipsilateral data which can be achieved by properly extracting spatial and temporal patterns. A deep learning model is developed to investigate this challenge by combining CNN and Bi-LSTM which can identify spatial patterns and temporal patterns respectively. The investigation shows that the Hybrid CNN model with 2 CNN and 2 Bidirectional LSTM layers showed better classification compared with CNN models alone. Also, zero padding the input data with ELU activation and Max pooling provided a smooth generalization of the model and a faster convergence. The achieved classification accuracy is 99% for the Hybrid CNN model with minimal pre-processing, feature extraction and 2 CNN layers to detect the complex patterns in the signal.
Data availability
The datasets analyzed during the current study are available in the figshare repository, https://figshare.com/search?q = EEG-fNIRS + hybrid + SMR + BCI + data.
References
Müller-Putz, G. et al. Towards noninvasive hybrid brain–computer interfaces: framework, practice, clinical application, and beyond. Proc. IEEE 103(6), 926–943 (2015).
Visani, E. et al. Hemodynamic and EEG time-courses during unilateral hand movement in patients with cortical myoclonus. An EEG-fMRI and EEG-TD-fNIRS study. Brain Topogr. 28, 915–925 (2015).
Khan, G. H., Hashmi, M. A., Awais, M. M., Khan N. A. & Ahmad, R. B. High Performance Multi-class Motor Imagery EEG Classification. In BIOSIGNALS, 149–155 (2020)
Ahn, M. & Jun, S. C. Performance variation in motor imagery brain–computer interface: a brief review. J. Neurosci. Method. 243, 103–110 (2015).
Páez-Amaro, R. T. et al. EEG motor imagery classification using machine learning techniques. Revista mexicana de física 68, 4. https://doi.org/10.31349/revmexfis.68.041102 (2022).
Isa, N. E. M., Amir, A., Ilyas, M. Z. & Razalli, M. S. Motor imagery classification in Brain computer interface (BCI) based on EEG signal by using machine learning technique. Bull. Electr. Eng. Inform. 8(1), 269–275 (2019).
Isa, N. E. M., Amir, A., Ilyas, M. Z. & Razalli, M. S. The performance analysis of K-nearest neighbors (K-NN) algorithm for motor imagery classification based on EEG signal. In MATEC web of conferences 1024 (2017).
Afrakhteh, S., Amirkhani, A., Mosavi, M. R. & Ayatollahi, A. Classification of two motor imagery based on EEG signals in brain computer interface systems using LDA, SVM and GMM methods. In 1st. International Conference on Application of Research in Sciences and Engineering (2016).
Narayan, Y. Motor-Imagery EEG Signals Classificationusing SVM, MLP and LDA Classifiers. Turkish J. Comput. Math. Educ. (TURCOMAT) 12(2), 3339–3344 (2021).
Ma, Y. et al. Classification of motor imagery EEG signals with support vector machines and particle swarm optimization. Comput. Math. Method. Med. 2016, 1 (2016).
Bhattacharyya, S., Khasnobish, A., Konar, A., Tibarewala, D. N. & Nagar, A. K. Performance analysis of left/right hand movement classification from EEG signal by intelligent algorithms. In 2011 IEEE Symposium on Computational Intelligence, Cognitive Algorithms, Mind, and Brain (CCMB), 1–8 (2011).
Jawad Khan, M., Hong, K.-S., Naseer, N. & Raheel Bhutta, M. A hybrid EEG-fNIRS Bel: motor imagery for EEG and mental arithmetic for fNIRS. In 14th International Conference on Control, Automation and Systems (ICCAS 2014), (2014).
Amiri, S., Fazel-Rezai, R. & Asadpour, V. A review of hybrid brain-computer interface systems. Adv. Hum. Comput. Interact. 2013, 1 (2013).
Yin, X. A hybrid BCI based on EEG and fNIRS signals improves the performance of decoding motor imagery of both force and speed of hand clenching _ enhanced reader. J. Neural Eng. https://doi.org/10.1088/1741-2560/12/3/036004 (2015).
Cicalese, P. A. et al. An EEG-fNIRS hybridization technique in the four-class classification of alzheimer’s disease. J. Neurosci. Method. 336, 108618. https://doi.org/10.1016/j.jneumeth.2020.108618 (2020).
Khan, M. J. & Hong, K. S. Hybrid EEG-FNIRS-based eight-command decoding for BCI: Application to quadcopter control. Front. Neurorobot https://doi.org/10.3389/fnbot.2017.00006 (2017).
Cao, L., Li, J., Ji, H. & Jiang, C. A hybrid brain computer interface system based on the neurophysiological protocol and brain-actuated switch for wheelchair control. J. Neurosci. Method. 229, 33–43 (2014).
Ahn, S. & Jun, S. C. Multi-modal integration of EEG-fNIRS for brain-computer interfaces – Current limitations and future directions. Front. Media S.A. https://doi.org/10.3389/fnhum.2017.00503 (2017).
Lachert, P. et al. Coupling of Oxy- and Deoxyhemoglobin concentrations with EEG rhythms during motor task. Sci. Rep. 7, 1. https://doi.org/10.1038/s41598-017-15770-2 (2017).
Buccino, A. P., Keles, H. O. & Omurtag, A. Hybrid EEG-fNIRS asynchronous brain-computer interface for multiple motor tasks. PLoS One 11, 1. https://doi.org/10.1371/journal.pone.0146610 (2016).
Liu, Z. et al. A systematic review on hybrid EEG/fNIRS in brain-computer interface. Biomed. Signal. Process. Control. 68, 102595. https://doi.org/10.1016/j.bspc.2021.102595 (2021).
Khan, M. J., Ghafoor, U. & Hong, K. S. Early detection of hemodynamic responses using EEG: A hybrid EEG-fNIRS study. Front. Hum. Neurosci. https://doi.org/10.3389/fnhum.2018.00479 (2018).
Diniz, S. et al. Online Classification of Motor Imagery Using EEG and fNIRS: A Hybrid Approach with Real Time Human-Computer Interaction http://www.springer.com/series/7899 (2020).
Alhudhaif, A. An effective classification framework for brain-computer interface system design based on combining of fNIRS and EEG signals. PeerJ Comput. Sci. 7, e537 (2021).
Hong, K.-S. & Khan, M. J. Hybrid brain–computer interface techniques for improved classification accuracy and increased number of commands: a review. Front. Neurorobot. 11, 35 (2017).
Chiarelli, A. M., Croce, P., Merla, A. & Zappasodi, F. Deep learning for hybrid EEG-fNIRS brain–computer interface: application to motor imagery classification. J. Neural. Eng. 15(3), 036028. https://doi.org/10.1088/1741-2552/aaaf82 (2018).
Zhang, Z. et al. A novel deep learning approach with data augmentation to classify motor imagery signals. IEEE Access. 7, 15945–15954 (2019).
Saadati, M., Nelson, J. & Ayaz, H. Multimodal fNIRS-EEG Classification Using Deep Learning Algorithms for Brain-Computer Interfaces Purposes 209–220 (Springer International Publishing, 2020).
Kwon, J., Shin, J. & Im, C. H. Toward a compact hybrid brain-computer interface (BCI): Performance evaluation of multi-class hybrid EEG-fNIRS BCIs with limited number of channels. PLoS One 15, 3. https://doi.org/10.1371/journal.pone.0230491 (2020).
Li, R., Potter, T., Huang, W. & Zhang, Y. Enhancing performance of a hybrid EEG-fNIRS system using channel selection and early temporal features. Front. Hum. Neurosci. https://doi.org/10.3389/fnhum.2017.00462 (2017).
Ge, S. et al. A brain-computer interface based on a few-channel EEG-fNIRS bimodal system. IEEE Access. 5, 208–218. https://doi.org/10.1109/ACCESS.2016.2637409 (2017).
Hasan, M. A. H., Khan, M. U. & Mishra, D. A computationally efficient method for hybrid EEG-fNIRS BCI based on the pearson correlation. Biomed. Res. Int. 2020(1), 13. https://doi.org/10.1155/2020/1838140 (2020).
Hong, K.-S., Khan, M. J. & Hong, M. J. Feature extraction and classification methods for hybrid fNIRS-EEG brain-computer interfaces. Front. Hum. Neurosci. 12, 246 (2018).
Wahid, M. F. & Tafreshi, R. Improved motor imagery classification using regularized common spatial pattern with majority voting strategy. IFAC-PapersOnLine 54(20), 226–231 (2021).
Maher, A. et al. Hybrid EEG-fNIRS brain-computer interface based on the non-linear features extraction and stacking ensemble learning. Biocybern. Biomed. Eng. 43(2), 463–475. https://doi.org/10.1016/j.bbe.2023.05.001 (2023).
Tao, Xu. et al. Motor imagery decoding enhancement based on hybrid EEG-fNIRS signals. IEEE Access. https://doi.org/10.1109/ACCESS.2022 (2017).
Thiyam, D. B., Cruces, S. & Rajkumar E.R. ThinICA-CSP algorithm for discrimination of multiclass motor imagery movements. In IEEE Region 10 Conference (TENCON) — Proceedings of the International Conferenc (2016).
Alzahab, N. A. et al. Hybrid deep learning (hDL)-based brain-computer interface (BCI) systems: A systematic review. Brain Sci. 11(1), 75. https://doi.org/10.3390/brainsci11010075 (2021).
Robinson, N. & Vinod, A. P. Noninvasive brain-computer interface: decoding arm movement kinematics and motor control. IEEE Syst. Man. Cybern. Mag. 2(4), 4–16. https://doi.org/10.1109/MSMC.2016.2576638 (2016).
Kowalski, M. & Gramfort, A. A priori par normes mixtes pour les problèmes inverses. Application à la localisation de sources en M/EEG. Traitement du signal 27(1), 53–78. https://doi.org/10.3166/ts.27.53-78 (2010).
Fukunaga, K. & Koontz, W. L. G. Application of the karhunen-loève expansion to feature selection and ordering. IEEE Trans. Comput. C–19(4), 311–318. https://doi.org/10.1109/T-C.1970.222918 (1970).
Yang, J., Huang, X., Wu, H. & Yang, X. EEG-based emotion classification based on bidirectional long short-term memory network. Procedia. Comput. Sci. 174, 491–504. https://doi.org/10.1016/j.procs.2020.06.117 (2020).
Omar, S. M., Kimwele, M., Olowolayemo, A. & Kaburu, D. M. Enhancing EEG signals classification using LSTM-CNN architecture. Eng. Rep. 6, 9. https://doi.org/10.1002/eng2.12827 (2024).
Matthew, J. M. & Mustafa, M. B. N. M. Enhancement of hybrid deep neural network using activation function for EEG based emotion recognition. Traitement du Signal 41(4), 1991–2002. https://doi.org/10.18280/ts.410428 (2024).
Shelishiyah, R. & Thiyam, D. B. Performance analysis of hybrid – BCI signals using CNN for motor movement classification. Traitement du Signal 41(4), 2143–2152. https://doi.org/10.18280/ts.410442 (2024).
Shelishiyah, R. & Beeta, T. D. A comparative performance study on the time intervals of hybrid brain-computer interface signals. SN Comput. Sci. 4(6), 771. https://doi.org/10.1007/s42979-023-02255-5 (2023).
Author information
Authors and Affiliations
Contributions
R. Shelishiyah contributed to the data pre-processing, feature extraction model development and manuscript preparation. Thiyam Deepa Beeta contributed to the data pre-processing, feature extraction and manuscript preparation Jehosheba Margaret M and N.M Masoodhu Banu contributed in model development.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Shelishiyah, R., Thiyam, D.B., Margaret, M.J. et al. A hybrid CNN model for classification of motor tasks obtained from hybrid BCI system. Sci Rep 15, 1360 (2025). https://doi.org/10.1038/s41598-024-84883-2
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-024-84883-2
Keywords
This article is cited by
-
Mixed precision quantization based on information entropy
Scientific Reports (2025)
