
Abstract
Human Immunodeficiency Virus (HIV) is a retrovirus that weakens the immune system, increasing vulnerability to infections and cancers. HIV spreads primarily via sharing needles, from mother to child during childbirth or breastfeeding, or unprotected sexual intercourse. Therefore, early diagnosis and treatment are crucial to prevent the disease progression of HIV to AIDS, which is associated with higher mortality. This study introduces a machine learning-based framework for the classification of HIV infections crucial for preventing the disease’s progression and transmission risk to improve long-term health outcomes. Firstly, the challenges posed by an imbalanced dataset is addressed, using the Synthetic Minority Over-sampling Technique (SMOTE) oversampling technique, which was chosen over two alternative methods based on its superior performance. Additionally, we enhance dataset quality by removing outliers using the interquartile range (IQR) method. A comprehensive two-step feature selection process is employed, resulting in a reduction from 22 original features to 12 critical variables. We evaluate five machine learning models, identifying the Random Forest Classifier (RFC) and Decision Tree Classifier (DTC) as the most effective, as they demonstrate higher classification performance compared to the other models. By integrating these models into a voting classifier, we achieve an overall accuracy of 89%, a precision of 90.84%, a recall of 87.63%, and a F1-score of 98.21%. The model undergoes validation on multiple external datasets with varying instance counts, reinforcing its robustness. Furthermore, an analysis focusing solely on CD4 and CD8 cell counts which are essential lab test data for HIV monitoring, demonstrates an accuracy of 87%, emphasizing the significance of these clinical features for the classification task. Moreover, these outcomes underscore the potential of combining machine learning techniques with critical clinical data to enhance the accuracy of HIV infection classification, ultimately contributing to improved patient management and treatment strategies. These findings also highlight the scalability of the approach, showing that it can be efficiently adapted for large-scale use across various healthcare environments, including those with limited resources, making it suitable for widespread deployment in both high- and low-resource settings.
Similar content being viewed by others

Introduction
Acquired Immune Deficiency Syndrome (HIV), caused by the Human Immunodeficiency Virus (HIV), continues to present a formidable global health crisis. HIV attacks the immune system, specifically targeting CD4 + T cells, which leads to immunodeficiency and exposes individuals to opportunistic infections and eventual mortality if untreated. Despite advancements in antiretroviral therapy (ART), HIV remains a public health challenge due to the high rates of new infections and insufficient global progress toward eradication1. The World Health Organization (WHO) estimates that 38.4 million people were living with HIV at the end of 2021, with a significant portion of these cases located in low- and middle-income countries2. The UNHIV “Fast-track” initiative set ambitious 95–95–95 targets to combat the HIV epidemic by 2030: 95% of people living with HIV knowing their status, 95% of diagnosed individuals receiving ART, and 95% of those on ART achieving viral suppression1,3.
The power of Machine learning (ML) in transforming various fields, especially healthcare, is becoming increasingly evident. Deep learning models, for example, are significantly enhancing medical diagnostics, demonstrated by their effectiveness in analyzing medical images for highly critical conditions like cardiac amyloidosis and neurological disorders, leading to improved accuracy and quicker diagnosis4,5. Beyond medical imaging, machine learning’s utility extends to optimizing processes in other health-related areas, such as enhancing the nutritional quality and sensory properties of food products6. Furthermore, advanced ML models are setting new benchmarks for early and accurate detection of diseases like cancer, showcasing their broad applicability and impact7. ML offers promising solutions in the fight against HIV/HIV. ML algorithms HIV to understand the patterns within challenging datasets, particularly useful for forecasting HIV infection risk and progression analysis8. To improve patient outcomes and reduce mortality rates, early detection and prediction of disease progression are critical9. With the ability to predict disease progression and identify those at the highest risk, ML could play a transformative role in efforts to control and eventually end the HIV/HIV epidemic. Despite the increasing use of ML in disease classification, several challenges remain. A persistent issue in HIV datasets is class imbalance, where the scarcity of HIV-positive cases skews classifiers toward majority classes (HIV-negative), compromising sensitivity, a critical metric for infectious disease detection. For instance, in HIV screening programs, imbalance ratios as severe as 5:100 are common due to the low incidence of new infections relative to the tested population, as observed in large-scale surveillance studies10. Additionally, medical datasets are often high-dimensional and noisy, making feature selection a critical challenge, as irrelevant features can degrade model performance and interpretability. Scalability is another concern, as models trained on small or region-specific datasets may not generalize well to larger, more diverse populations. Finally, the computational inefficiencies and need for extensive feature sets in real-world clinical settings hinder the integration of ML models into fast, cost-effective diagnostic workflows. Therefore, the impact of dataset size variation on model accuracy is a critical factor that needs to be addressed for robust performance in real-world applications.
To address the challenges, in this study, a ML-based approach is proposed to classify HIV infection utilizing effective augmentation and noise handling techniques. The initial dataset contained 50,000 instances, which was highly imbalanced. The dataset comprises two classes with HIV infected and non-infected class, where the data of infected class is given half of the non-infected class. To address this, we applied Synthetic Minority Over-sampling Technique (SMOTE), an oversampling method to balance the dataset11. SMOTE generates synthetic data points by interpolating between existing minority class samples, effectively balancing the dataset without simply duplicating instances. This approach enhances the model’s ability to learn decision boundaries for the minority class, improving its sensitivity to correctly classify HIV-infected instances while minimizing overfitting. In addition to data imbalance, the dataset contains outliers across all 22 features, with six features exhibiting a particularly high number of extreme outliers. Outliers in medical datasets can significantly distort statistical distributions and impair model performance by skewing decision boundaries. To address this, we employed the interquartile range (IQR) method, which is robust to non-Gaussian distributions often observed in healthcare data. The IQR method identifies outliers based on the spread of the middle 50% of the data, providing a more reliable approach for removing extreme values without excluding informative data points. This preprocessing step helps the model to generalize better, particularly when applied to external datasets with varying data distributions. Additionally, while all 22 features contain some outliers, six classes exhibit a significant number of large outliers, further complicating the classification task. These outliers can distort the learning process and hinder the model’s ability to generalize effectively. To address this issue, we employed outlier detection and removal using the interquartile range (IQR) method to eliminate unnecessary outliers. To further refine the dataset, we applied a two-stage feature selection process. First, Recursive Feature Elimination (RFE) was used, followed by feature ranking based on Median Absolute Deviation (MAD). This process revealed that 12 features significantly influenced the classification task, and thus, they were selected for further analysis. For the classification, we evaluated ten ML models: Random Forest Classifier (RFC), Decision Tree Classifier (DTC), Logistic Regression (LR), AdaBoost (AB), and K-Nearest Neighbor (KNN). The models were tested using the complete set of 22 features and the selected 12 features. Based on superior performance, RFC and DTC were chosen to form a voting classifier. This combined model achieved an accuracy of 89% in classifying HIV. To assess the model’s scalability, we validated its performance on four additional datasets containing similar features. These datasets included 2,139, 5,000, and 15,000 instances, respectively, and a merged dataset of 72,139 instances. The model consistently performed well across all datasets, achieving comparable results using both the full 22 features and the selected 12 features, demonstrating its robustness against feature redundancy and dataset variation. Moreover, this consistent performance across varying dataset sizes highlights the model’s adaptability to different data distributions. Additionally, the minimal performance gap between the full and reduced feature sets underscores its ability to extract relevant patterns without over-relying on redundant features.
Furthermore, an additional performance analysis is conducted using only laboratory test data, specifically CD4, CD4/20, CD8, CD8/20. The CD4 and CD8 cell counts are some key elements that are tested in laboratories and considered to be an integral component of monitoring HIV progression3,12,13. They are used to assess the degree of immunosuppression in HIV-positive individuals and guide treatment decisions. Notably, the model achieved an accuracy of 87%, just 2% lower than when using all 22 or 12 selected features, after testing these four lab test features alone (CD4, CD4/20, CD8, CD8/20). This highlights the significance of these lab test features in HIV classification. Overall, this study demonstrates the efficacy of the proposed voting classifier and emphasizes the importance of laboratory test data in HIV classification. Despite eliminating 18 features, the model maintained strong performance, reinforcing the relevance of CD4 and CD8 cell counts in the classification process. The major contributions of this study are as follows:
-
Data augmentation using SMOTE and outlier elimination with the IQR method to address class imbalance and improve data quality.
-
Presented a two-stage feature selection process using Recursive Feature Elimination (RFE) and Median Absolute Deviation (MAD) to identify the most influential features, enhancing model performance.
-
Development of a robust ML-based voting classifier combining Random Forest Classifier (RFC) and Decision Tree Classifier (DTC) models, achieving high classification accuracy.
-
Comprehensive performance evaluation on datasets of varying sizes to investigate the impact of dataset size on model accuracy and scalability.
-
Demonstration of the significance of laboratory test features (CD4, CD4/20, CD8, CD8/20) in HIV classification, achieving competitive performance with a minimal feature set, highlighting the model’s potential for practical clinical applications.
Moreover, this study explicitly investigates the impact of dataset size variation on model performance. By systematically evaluating ML models on datasets of different sizes this research provides valuable insights into how dataset characteristics influence HIV classification accuracy. The findings contribute to the ongoing effort to develop scalable, data-efficient ML models for real-world HIV diagnosis, emphasizing the importance of balanced datasets, robust preprocessing techniques, and key laboratory test features in achieving reliable HIV classification.
The rest of this paper is organized as follows: Sect. 2 reviews related works, Sect. 3 describes the dataset and preprocessing, Sect. 4 details the models, Sect. 5 presents experimental results, and Sect. 6 presents the discussion and limitations, and lastly Sect. 7 concludes with future directions.
Literature review
The utilization of machine learning techniques in research on AIDS has been investigated in diverse contexts, especially in the realms of mortality prediction, disease progression, and associated health complications. Sara Domínguez-Rodríguez et al.14 conducted a comparative analysis of seven algorithms aimed at predicting one-year mortality and clinical progression to AIDS among a cohort of infants diagnosed with HIV in South Africa and Mozambique. The Random Forest (RF) algorithm was identified as the most effective performer, achieving an accuracy of 82.8%, a sensitivity rate of 78%, and an area under the curve (AUC) of 0.73. This algorithm demonstrated superior sensitivity and specificity relative to its counterparts. In a related study, G.B. Silva Júnior et al.15 investigated the occurrence of acute kidney injury (AKI) in patients with AIDS, utilizing the RIFLE classification system to forecast clinical outcomes. Their findings indicated that AKI was present in 37% of the studied population, with patients categorized into various risk levels, thereby underscoring the significance of predictive modeling in assessing clinical outcomes associated with AIDS. Bankole Olatosi et al.16 conducted an investigation into the utilization of linked integrated health data pertaining to individuals living with HIV (PLWH) for the purpose of predicting future HIV care status. Their study demonstrated that a Bayesian Network model yielded superior performance metrics, achieving an F1 score of 0.87 and an Area Under the Curve (AUC) of 0.94, alongside commendable precision and recall values. Furthermore, Huaxin Pang et al.17 incorporated deep learning methodologies by introducing an attention mechanism that allocates varying weights to different symptomatic features. This framework exhibited consistent enhancements over conventional approaches, thereby reinforcing the significance of feature weighting in augmenting model efficacy for AIDS classification. Additional relevant research has explored diverse dimensions of AIDS diagnosis and prognosis. Yvonne A.L. Lim et al.18 investigated the presence of Cryptosporidium oocysts and Giardia cysts in fecal specimens collected from HIV/AIDS patients. Their study employed small subunit (SSU) sequencing techniques, successfully identifying the species Cryptosporidium parvum in 64% of the analyzed samples. This investigation underscores the interplay between AIDS and other co-infectious diseases in the context of disease advancement. In a computationally oriented study, You-Shyang Chen et al.19 employed a hybrid rough set classifier to analyze the factors that influence adherence to Highly Active Antiretroviral Therapy (HAART). The integration of both linear and nonlinear feature selection methodologies yielded enhanced classification outcomes, thereby demonstrating the potential of hybrid models to augment research findings in the context of acquired immunodeficiency syndrome (AIDS). Furthermore, Paulo E Rauber et al.20 underscored the significance of dimensionality reduction techniques within predictive modeling, advocating for projection-based visual analytics to improve classification effectiveness. Their research laid the groundwork for the application of low-dimensional mappings to refine feature selection processes and enhance classification accuracy. Moreover, the use of deep learning models was further investigated by Margaret C. Steiner et al.21, who determined that convolutional neural networks (CNNs) emerged as the most effective architecture for the identification of drug resistance mutations (DRMs), thereby highlighting the importance of biologically relevant features in optimizing model performance. V. Mageshwari et al.22 explored AIDS-related discussions on Twitter, achieving high accuracy (94.65%) and sensitivity (94.56%) in tweet identification. Their methodology showed the relevance of social media data in AIDS-related research, particularly for monitoring public health trends. Kuifang Du et al.23 developed a deep learning system to detect AIDS-related conditions from ultra-wide-field (UWF) fundus images, achieving impressive AUC scores across multiple clinical datasets. Their work highlights the potential of computer vision in enhancing AIDS diagnosis through medical imaging. Yufeng Zhao et al.24 examined a dataset where AIDS patients were characterized by a list of symptoms and labeled with Traditional Chinese Medicine (TCM) syndromes. Their model achieved an average precision of 0.7736 and recall of 0.7111, showcasing the integration of alternative medical approaches in AIDS research. In addition to machine learning approaches for AIDS classification, various studies have explored optimization techniques and adaptive AI strategies that enhance predictive accuracy and computational efficiency in healthcare and beyond. El-Sayed M. El-Kenawy et al.25 have discussed various hybrid optimization strategies in healthcare AI, integrating metaheuristic algorithms to enhance diagnostic accuracy and decision-making efficiency. These approaches, including hybrid swarm-based and evolutionary methods, optimize medical image analysis, disease prediction, and patient outcome assessment by balancing exploration and exploitation in search spaces. The findings highlight significant improvements over traditional models, demonstrating the potential of hybrid techniques in advancing intelligent healthcare solutions. Mona Ahmed Yassen et al.26 have explored advancements in scalable machine learning, focusing on adaptive models that efficiently process dynamic datasets in renewable energy forecasting. Their study integrates deep learning and hybrid optimization techniques to enhance prediction accuracy while addressing challenges like data volatility and computational complexity. The findings underscore the effectiveness of AI-driven frameworks in managing large-scale, evolving datasets for sustainable energy solutions. El-Sayed M. El-Kenawy27 et al. have examined resilient modeling frameworks designed to function effectively under fluctuating resource constraints, emphasizing adaptive AI-driven strategies for healthcare forecasting. Their work integrates machine learning with metaheuristic optimization to enhance predictive accuracy while ensuring computational efficiency in environments with limited data availability. The study highlights the necessity of scalable, interpretable models that maintain robustness despite variations in resource allocation. While these studies focus on optimization techniques and adaptive AI strategies in diverse domains, their insights into hybrid models, computational efficiency, and predictive accuracy provide a broader perspective on enhancing machine learning applications, including in medical diagnostics like HIV classification. In the pursuit of improving classification tasks like HIV diagnosis, leveraging cutting-edge artificial intelligence (AI) techniques is crucial for improving diagnostic accuracy and understanding complex disease patterns. Aiesha Mahmoud Ibrahim et al.28 explored the potential of AI methods for early diagnosis of Parkinson’s disease (PD), reviewing various deep learning and machine learning techniques that enhance prediction accuracy by processing large datasets. Similarly, Ali Mahmoud Ali et al.29 proposed an advanced feature selection method using Cat Swarm Optimization (CSO) and Support Vector Machines (SVM), achieving a significant 100% accuracy in cancer subtype classification, which greatly outperforms existing models and contributes to the interpretability of cancer research. In addition, another work by Ali Mahmoud Ali et al.30 focused on reviewing AI applications in omics data analysis, highlighting the challenges and solutions for preprocessing, dataset validation, and model testing, thus offering invaluable insights for future applications in omics-based disease classification.
This study distinguishes itself from the presented literature in several key aspects. Unlike prior works that broadly investigate AIDS-related predictions such as mortality or disease progression, our research specifically focuses on HIV classification, directly addressing the diagnostic challenge. Furthermore, our approach emphasizes rigorous data preprocessing with SMOTE and IQR to handle class imbalance and outliers, alongside feature selection techniques are not explicitly detailed in reviewed studies. Notably, we developed and validated a robust voting classifier, and uniquely investigated the impact of dataset size on model scalability, offering insights into model performance across varying data volumes. Finally, a crucial differentiator is our emphasis on the clinical relevance of readily available lab features (CD4, CD8), demonstrating strong classification performance with these minimal features and highlighting the potential for practical clinical application, a focus less pronounced in the existing literature. Therefore, this study provides a unique and clinically relevant approach to HIV classification, distinct from the broader predictive modeling trends prevalent in the current literature.
Methodology
The principal methodology employed in this research encompasses several critical phases, advancing from gathering data to assessing the model. The stages are elaborated upon in Fig. 1.

The illustration of proposed methodology of this study.
The methodology of this study begins with a dataset comprising 2,100 patient records and 22 attributes, containing 50,000 attributes. To address class imbalance, the SMOTE is applied, generating synthetic samples for the minority class to create a well-balanced dataset, ensuring that the classification model does not become biased toward the majority class. Following this, outlier removal is performed to eliminate any extreme values that could distort model training, thereby enhancing the reliability and integrity of the dataset. To standardize feature scales and improve model convergence, Min-Max Scaling is employed for data normalization. Next, feature selection is conducted using two robust techniques including, RFE and MAD. Based on these methods, 12 of the most significant features are chosen for the final classification process. To build a high-performing model, ten machine learning classifiers are initially evaluated. Among these, RFC and DTC demonstrate the highest accuracy, making them the most suitable candidates for further optimization. Given their strong individual performance, a Voting Classifier is designed using a hard voting strategy, which aggregates predictions from both classifiers to improve overall classification accuracy and robustness. The performance of the proposed Voting Classifier is evaluated in multiple ways. First, it is tested using both the original 22-feature dataset and the refined 12-feature subset to assess the impact of feature selection on classification performance. Furthermore, to investigate the model’s scalability and robustness, experiments are conducted using datasets of varying sizes, specifically 2,139, 5,000, 15,000, 50,000, and 72,139 data points. These evaluations demonstrate that the Voting Classifier maintains consistent performance across different dataset sizes, proving its reliability in handling large-scale data. Additionally, to explore the model’s effectiveness in clinical settings, classification is performed using only four key clinical lab test features: CD80, CD820, CD40, and CD420. Despite the significant reduction in input features, the Voting Classifier continues to exhibit stable and reliable classification performance. This result underscores the model’s ability to function effectively even with minimal but crucial medical indicators, highlighting its potential applicability in resource-constrained healthcare environments for HIV classification.
Dataset description
The dataset utilized in this investigation comprises healthcare statistics and categorical data about 2,139 patients diagnosed with acquired immunodeficiency syndrome (AIDS), initially released in 199631. The dataset was created by the AIDS Clinical Trials Group (ACTG) of the National Institute of Allergy and Infectious Diseases (NIAID). Additionally, the General Research Center units funded by the National Center for Research Resources contributed to the creation and maintenance of this dataset. The dataset includes 34,494 instances of non-infected patients and 15,506 instances of infected patients. It includes demographic and clinical information such as age, weight, gender, race, treatment types, laboratory results, and behavioral aspects, including a history of intravenous drug use and homosexual conduct. The data is sourced from the AIDS Clinical Trials Group and funded by NIAID and the National Center for Research Resources. It contains no missing values and has not undergone any preprocessing. The dataset reflects medical history elements, including hemophilia and previous antiretroviral treatments. Furthermore, it incorporates variables related to treatment, identifying whether the patients received particular medications, such as Zidovudine (ZDV), Didanosine (ddI), or Zalcitabine (Zal), along with specifications of the treatment group to which they were assigned. Laboratory results, specifically CD4 and CD8 lymphocyte counts, are documented at baseline and after 20 weeks. Additional information about the attributes provided in Table 1.
Performance status is measured through the Karnofsky scale, which ranges from 0 to 100. Additionally, the dataset includes information on time-to-failure or censoring alongside a binary classification indicating whether patients were infected with AIDS. This extensive array of variables affords a comprehensive understanding of the patients’ clinical profiles and treatment responses, facilitating detailed analysis and classification.
Feature explanation
The dataset encompasses various attributes that are crucial for predicting HIV infection. Age and weight serve as fundamental baseline measurements, where age can significantly affect disease progression and treatment efficacy, while weight is measured in kilograms at baseline, as weight loss can be an indicator of disease progression. Gender is categorized as female ‘0’ or male ‘1’, as it may influence disease susceptibility and progression, while race is classified as White ‘0’ or non-white ‘1’, accounting for potential genetic or socioeconomic factors that might impact disease outcomes. The dataset documents several risk factors, such as hemophilia, marking its presence ‘1’ or absence ‘0’ as a known risk factor for HIV transmission. The dataset records the homosexual activity as yes ‘1’ or no ‘0’, a known risk factor, and notes the history of intravenous drug use as yes ‘1’ or no ‘0’, another significant factor in HIV transmission. The treatment regimen (trt) indicates specific protocols, ranging from ZDV only ‘0’ to various combinations of antiretroviral medications. The ‘oprior’ and ‘preanti’ variables capture previous antiretroviral therapy exposure, providing valuable information on prior treatment history. Antiretroviral history is categorized as naive or experienced, with stratification based on the duration of prior therapy, offering insights into potential treatment responses and resistance patterns. These treatment-related features are essential for understanding patient history and predicting potential outcomes. CD4 and CD8 T-lymphocytes play crucial roles in the immune system and are key markers for HIV/HIV progression and treatment efficacy. The dataset captures these values at two critical timepoints.
CD4 T-cell counts (cd40 and cd420)
CD4 + T-cells, also known as T-helper cells, are the primary targets of HIV infection32. These cells coordinate the immune response by stimulating other immune cells to fight infection. The dataset tracks CD4 counts at baseline (cd40) and after 20 weeks of treatment (cd420). Normal CD4 counts in healthy adults range from 500 to 1,500 cells/mm³33. In HIV-positive individuals, CD4 counts typically decline over time, with counts below 200 cells/mm³ indicating HIV34. The baseline measurement (cd40) provides crucial information about the patient’s immune status at the start of treatment and is a strong predictor of disease progression. The 20-week follow-up measurement (cd420) is particularly valuable as it indicates the patient’s response to antiretroviral therapy. An increase in CD4 count from baseline to 20 weeks suggests treatment effectiveness, while a continued decline may indicate treatment failure or resistance35. The rate of CD4 count change between these two timepoints (cd40 to cd420) can also predict clinical outcomes and inform treatment decisions.
CD8 T-cell counts (cd80 and cd820)
CD8 + T-cells, or cytotoxic T-lymphocytes, are immune cells that identify and destroy virus-infected cells36. Unlike CD4 cells, CD8 cells typically increase during HIV infection as the immune system attempts to control the virus. The dataset includes CD8 counts at baseline (cd80) and after 20 weeks (cd820). Normal CD8 counts range from 150 to 1,000 cells/mm³37, but in HIV infection, they often become elevated, sometimes exceeding 1,500 cells/mm³38. The baseline CD8 count (cd80) provides information about the initial immune activation state, while the 20-week measurement (cd820) helps track changes in immune response. The CD8 response is complex; while these cells are crucial for controlling HIV replication, persistently elevated CD8 counts can indicate chronic immune activation, which is associated with faster disease progression39. The ratio of CD4 to CD8 cells (calculated from cd40:cd80 and cd420:cd820) is another valuable metric, with a lower ratio generally indicating more advanced disease.
Data preprocessing
The data preprocessing phase involved multiple critical steps to prepare the dataset for effective modeling. To understand the class balance, we first examined the dataset for the distribution of the target variable ‘infected’, distributed in two classes 0 and 1. Additionally, we checked for duplicate records and discovered no duplicate entries in the dataset. The code also implicitly verified that there were no null values in the dataset, as subsequent operations proceeded without any null value handling, indicating a complete dataset with no missing values.
SMOTE (Synthetic minority Over-sampling Technique)
To address the class imbalance issue in the target variable ‘infected,’ we applied the SMOTE technique. SMOTE works by generating synthetic samples for the minority class instead of merely duplicating existing samples. It creates new instances by selecting a data point from the minority class and generating synthetic samples along the line joining that point to its nearest neighbors40. This process helps to balance the dataset by increasing the representation of the minority class, thus preventing the model from being biased toward the majority class. By applying SMOTE, we ensured that both the infected and non-infected classes were equally represented, which significantly improved the model’s ability to learn and predict effectively. After applying SMOTE, the number of instances in the infected class was increased to 34,494, adding an additional 18,988 samples (See Fig. 2). As a result, the overall dataset after augmentation consists of 68,988 instances. This balanced dataset ensures equal representation of both classes, improving the model’s ability to learn from both outcomes.

Comparison of infected and non-infected sample counts before and after data augmentation.
Outlier elimination
Then, we moved on to identify and address outliers in the dataset. Figure 2 illustrates the initial visualization of the data distribution using box plots. Using the Interquartile Range (IQR) method, features with significant spread (IQR > 2) were identified, which included all 22 features.
As visualized in Fig. 3, our feature distributions revealed significant outliers, particularly in ‘time’, ‘cd40’, ‘cd420’, ‘cd80’, and ‘cd820’, with orange dots scattered far beyond the main blue box in the higher value range. These outliers, especially in the ‘cd’ markers, reflect extreme concentrations of immune cell surface proteins in HIV infection and pose a risk to the reliability and generalizability of our model. IQR-based outlier removal generally enhances predictive accuracy in medical classification tasks by reducing overfitting to anomalies41,42. So, we used an IQR-based outlier handling method, which effectively filters out noise while preserving valid biological extremes, ensuring that our classifier focuses on the core, clinically meaningful trends in HIV biomarkers.

Distribution of features before outlier treatment.
To handle these outliers, we applied a Quantile Transformer with normal distribution output, transforming the data and capping extreme values. The Quantile Transformer maps the original data to a normal distribution, which both reduces the influence of extreme values and makes the data more amenable to models that assume a Gaussian input. This approach is particularly advantageous when the data do not follow a standard normal distribution and when robust performance in the presence of outliers is desired. The transformation process involved calculating the 25th and 75th percentiles for each feature and defining upper and lower limits as 1.5 times the IQR beyond these percentiles. We capped values outside these limits to prevent outliers from disproportionately influencing the model. The effectiveness of this outlier treatment can be observed in Fig. 4. The post-processing visualization demonstrates a more normalized distribution of values across all features, with significantly reduced outlier presence and more consistent value ranges.

Distribution of features after outlier treatment.
After comparing Figs. 3 and 4, the impact of outlier management is clearly visible. In Fig. 3, numerous orange dots representing outliers are scattered far beyond the box plot whiskers. However, in Fig. 4, these distant orange dots have significantly diminished and are now concentrated much closer to, or within, the box plot whiskers. This demonstrates IQR’s effectiveness in identifying and managing extreme data points. Overall, the application of IQR has led to a more refined dataset representation for the HIV infection classification task, where the data points are now more concentrated within the typical ranges defined by the box plots. This indicates a reduction in the influence of outliers, ensuring a more consistent and reliable dataset for training the machine learning model.
After treating outliers, we performed feature selection using two methods: Recursive Feature Elimination (RFE) with Logistic Regression and Mean Absolute Difference (MAD) scoring. Based on these analyses, we reduced the dataset from 22 to 13 features by eliminating less significant predictors like ‘hemo’, ‘drugs’, ‘oprior’, ‘z30’, ‘gender’, ‘str2’, ‘strat’, ‘symptom’, ‘treat’, and ‘offtrt’. Finally, we applied MinMaxScaler to normalize all features to a range between 0 and 1, ensuring a consistent scale across all predictors for optimal model performance.
Feature selection
This study utilized two feature selection methods: Recursive Feature Elimination (RFE) and Feature Ranking based on Median Absolute Deviation (MAD). RFE identifies complex relationships between features by recursively eliminating the least significant ones, ensuring model-driven feature ranking. However, it is sensitive to outliers. To address this, we applied MAD, which is robust to extreme values, ensuring stable feature selection. MAD is outlier-resistant which is crucial in medical datasets where noisy or extreme values can distort statistical measures, ensuring that important features are not overlooked. This two-step approach ensures that both global feature relevance and local feature variability are considered, offering a more comprehensive and reliable feature selection process compared to using either method alone or other conventional techniques like correlation-based or variance threshold methods.
While alternative feature selection methods such as LASSO and PCA are commonly used, they have certain limitations in this context. LASSO tends to eliminate correlated features, which is problematic in medical datasets where multiple biomarkers may be jointly informative43. PCA transforms features into principal components, reducing interpretability, a crucial factor in clinical decision-making44. In contrast, RFE captures complex feature relationships, while MAD ensures robustness to outliers, making their combination particularly suitable for medical datasets. Prior studies45,46,47 have also demonstrated the effectiveness of RFE and MAD in similar tasks, reinforcing our choice.
Recursive feature elimination (RFE)
RFE is a wrapper-based feature selection method that works with any machine learning model capable of assigning importance to each feature, typically models like decision trees, support vector machines (SVMs), and linear regression models. RFE functions based on backward feature elimination, whereby it iteratively constructs models and discards the least significant features following the feature weights (or coefficients) determined by the model48. This approach is especially advantageous in high-dimensional datasets, wherein irrelevant or redundant features may adversely affect model efficacy, extend computation duration, and result in overfitting. Figure 5 illustrates the results of RFE in this dataset.

Illustration of RFE ranking.
Based on the RFE ranking chart shown in Fig. 5, we can select features with a ranking of 10 or higher as influential for the classification task. Firstly, by observing the highest RFE ranking achieved by any feature, like ‘cd820’ and ‘cd80’, is equal and slightly above 20, represents the upper limit of feature importance in this context. Secondly, a significant number of features exhibit RFE rankings between 15 and 20, as seen with features like ‘cd420’, ‘cd40’, ‘preanti’, and others in the top half of the chart. This concentration in the upper range suggests a set of features with moderate to high influence. Choosing a threshold of 10 allows us to effectively capture a substantial portion of these moderately to highly ranked features. By setting this cutoff, we prioritize and retain top 12 features including, ‘cd820’, ‘cd80’, ‘cd420’, ‘cd40’, ‘preanti’, ‘karnof’, ‘drugs’, ‘homo’, ‘wtkg’, ‘age’, ‘trt’, and ‘time’, all of which clearly surpass the ranking of 10. Conversely, features falling below this threshold, such as ‘race’, ‘gender’, and ‘hemo’, exhibit considerably lower RFE rankings, indicating their relatively diminished importance or weaker contribution to the model’s performance. Therefore, a threshold of 10 serves as a reasonable and visually informed cut-off to select a set of features demonstrably more influential based on their RFE ranking values in the provided Fig. 5.
Feature ranking with median absolute deviation (MAD)
MAD is a statistical metric employed to assess the average divergence of data points from the arithmetic mean of a dataset. This measure indicates the dispersion or variability present within a particular feature. MAD is frequently employed for unsupervised feature selection, wherein the objective is to prioritize features based on their variability or significance within the dataset, devoid of utilizing labeled outcomes49. Features that exhibit elevated levels of variability are generally indicative of increased informational content and are likely to exert a more pronounced influence on model performance. The mathematical formation can be used as,
Where \(\:{x}_{i}\:\)is an individual data point, \(\:{x}^{{\prime\:}}\) is the mean of the feature, and n is the total number of observations. Figure 6 shows the results of MAD in this dataset.

Feature ranking according to MAD analysis.
As depicted in Fig. 6, MAD scores indicate that preanti and time variables exhibit the greatest variability. This observation implies a substantial capacity for these variables to elucidate significant distinctions within the dataset. Conversely, features exhibiting low MAD scores may offer limited informational value; however, their removal must be approached cautiously to prevent the inadvertent exclusion of potentially beneficial features. Therefore, we selected top six features as, there is a discernible drop in MAD score after the sixth feature, ‘cd80’, as visually evident in the Fig. 6.
In this two-step feature selection process, RFE first identified 12 important features, while MAD then pinpointed the six most impactful ones: preanti, time, cd420, cd40, cd820, and cd80. These top MAD features are also present within the 12 features selected by RFE, which strongly validates their significance in the classification task. MAD highlights features with the most substantial individual predictive power, complementing RFE’s model-centric feature ranking. This overlap strengthens confidence in these six features as highly relevant for classification. The convergence of both RFE and MAD on these features provides a robust and well-justified final feature set. Thus, we selected 12 features from RFE to capture a broader range of relevant variables, while the six features identified by MAD, including four key clinical lab test data, were highlighted for their strong individual predictive power and significant relevance to HIV classification.
Normalization with minmaxscaler
Lastly, to enhance the model’s performance, we used MinMaxScaler to normalize all features in the dataset to a consistent scale between 0 and 1. Normalization is crucial because it ensures that each feature contributes equally to the model’s predictions, preventing certain features from dominating due to their larger magnitudes. The MinMaxScaler works by subtracting the minimum value of each feature and then dividing by the range of that feature.This technique transforms all features into a uniform range, making it easier for the model to converge during training and leading to better overall performance.
Model
For the classification task of this study, we utilized ten machine learning models. The selection of these models was driven by their diverse strengths, each contributing to the robustness and scalability of the classification task. Tree-based models like RFC, DTC, GB, LightGBM, and XGBoost are well-suited for handling complex, non-linear relationships and interactions within the data. These models excel in capturing intricate patterns and are less sensitive to noisy data, making them highly effective for large datasets and real-world applications. Their ensemble nature (in RFC, GB, and XGBoost) further enhances their robustness, as combining multiple weak learners reduces overfitting and increases generalization. On the other hand, models like LR and NB are linear and probabilistic, respectively, offering simplicity and interpretability, which is valuable for understanding feature importance and making decisions in settings where transparency is critical. MLP and KNN bring flexibility in capturing both linear and non-linear relationships, with MLP being effective for more complex datasets due to its deep learning nature. Each model’s ability to handle different data structures and learn from them efficiently makes them widely adopted for classification tasks, particularly in large-scale applications where scalability and computational efficiency are paramount. Upon conducting a comprehensive evaluation of the performance of five distinct machine learning models, it became apparent that the RFC and DTC consistently exhibited superior accuracy. This noteworthy performance underscores their efficacy in identifying and capturing the underlying patterns within the dataset. Acknowledging the complementary strengths inherent in both RFC and DTC, we opted to employ an ensemble approach that integrates the predictions of these models. Subsequently, we developed a Voting Classifier as our proposed model. This ensemble methodology not only harnesses the individual strengths of the RFC and DTC but also significantly enhances the overall robustness and accuracy of the classification task.
Random forest classifier (RFC)
The primary goal of RFC is to enhance the accuracy and robustness of decision trees by reducing overfitting, which is a common problem with single decision trees50. RFC generates numerous decision trees utilizing random subsets of the training dataset. Each individual tree is constructed from a distinct bootstrap sample; consequently, certain instances may be replicated while others may be excluded entirely. This methodology is referred to as bagging, or Bootstrap Aggregating. In order to enhance randomness and diversity within the tree ensembles, the Random Forest Classifier (RFC) utilizes a random subset of features when determining the optimal split at each node, rather than evaluating all available features. This methodological approach aids in minimizing the correlation among the individual trees and consequently enhances the overall performance of the model. RFC generates an extensive array of decision trees (denoted as T1, T2, ., Tn) by employing bootstrapped samples derived from the training dataset51,52. Each individual tree undergoes training in isolation, utilizing a randomly chosen subset of the data alongside a randomly selected subset of features51. The final prediction of the RFC is made by majority voting across all the trees can be presented as Eq. 2:
In this equation \(\:x\) is the input feature vector. Additionally, this algorithm provides an understanding of the significance of features, which is determined by the reduction in Gini impurity (or the enhancement of information gain) resulting from the splits that incorporate the feature across all decision trees.
Decision tree classifier (DTC)
The Decision Tree Classifier constitutes a fundamental algorithm within machine learning, applicable to classification and regression objectives53. This algorithm operates by partitioning the input space into distinct regions predicated on feature values, thereby facilitating decision-making through a hierarchical, tree-like framework. A significant benefit of decision trees lies in their interpretability. The configuration of a decision tree can be graphically represented, facilitating comprehension of the decision-making process based on various features53. This level of interpretability is especially pertinent in fields where transparency is paramount, such as healthcare and finance.
DTC uses measures like Gini impurity or entropy to decide how to split the data at each node. These measures assess how mixed or pure a dataset is at a given split, influencing the tree’s ability to classify data efficiently. Gini Impurity: It quantifies the likelihood of incorrectly classifying a randomly chosen element if it were labeled according to the class distribution in a subset. The Gini impurity is computed as:
here \(\:{p}_{i}^{2}\) is the proportion of class i in dataset D. A lower Gini impurity value indicates that a node contains more homogeneous class distributions, meaning less uncertainty in classification54.
Entropy measures the amount of uncertainty or disorder within a dataset. The equation of entropy can be represented as,
A high entropy value signifies more disorder, meaning the data contains a mix of multiple classes, while an entropy of zero indicates a perfectly pure subset55. Decision trees aim to reduce entropy by maximizing information gain, which is the difference in entropy before and after a split.
In the context of classification, the prediction is derived by navigating through the decision tree from the root node to a terminal node56, guided by the feature values of the input.
DTCs are extensively applied across diverse domains, such as medical diagnostics, financial modeling, and customer segmentation, attributed to their user-friendly nature and proficiency in managing both categorical and continuous data.
Logistic regression (LR)
Logistic Regression constitutes a statistical framework predominantly employed for the resolution of binary classification challenges57. It was initially posited in the early twentieth century and has since established itself as a cornerstone methodology within the realms of statistics and machine learning. In contrast to conventional linear regression, which forecasts continuous variables, logistic regression estimates the likelihood that a particular observation is associated with a designated categorical class. This is achieved by employing the logistic function, which transforms the predicted values into a probability scale ranging from 0 to 158. The logistic function, commonly referred to as the sigmoid function, provides a transformation for any real number, constraining its output to the interval [0, 1]. This function can be represented as:
Where, \(\:Y\) is the dependent variable,\(\:\:X\) is the feature vector, and \(\:{\beta\:}_{n}\) are the coefficients to be learned. Logistic regression is extensively employed across various disciplines59, including the medical field for the diagnostic classification of diseases, marketing for forecasting consumer response, and the social sciences for the evaluation of binary outcome variables.
AdaBoost (AB)
The fundamental concept underlying AdaBoost is the integration of numerous weak classifiers, typically in the form of decision stumps, to formulate a singular, robust classifier. A weak learner is characterized as a classifier that exhibits performance marginally superior to random chance60. The fundamental concept underlying AdaBoost is the integration of numerous weak classifiers, typically in the form of decision stumps, to formulate a singular, robust classifier. A weak learner is characterized as a classifier that exhibits performance marginally superior to random chance. The weight for each sample is updated based on the misclassification error. This can be represented as:
Where, \(\:{\in\:}_{t\:}\) is the weighted error of the weak learner. While boosting methods can be prone to overfitting, AdaBoost is relatively robust when used with simple classifiers, especially when the number of iterations is carefully controlled.
K-Nearest neighbors (KNN)
KNN is one of the simplest and most intuitive machine learning algorithms. It is a non-parametric method, meaning it does not make any assumptions about the underlying data distribution61. The K-Nearest Neighbors algorithm employs various metrics, including Euclidean distance, to ascertain the proximity between data points.
where \(\:{x}_{i}\) and \(\:{x}_{j}\:\)are feature vectors for the points being compared. he choice of distance metric (e.g., Euclidean, Manhattan, Minkowski) can affect the performance of KNN62. Euclidean distance is commonly used, but other metrics can be more appropriate for certain types of data. The k-Nearest Neighbors algorithm exhibits a pronounced sensitivity to the scale of the dataset. Consequently, it is frequently imperative to either standardize or normalize the feature variables to ensure that each attribute has an equitable influence on the computation of distance metrics.
Proposed model explanation
The Voting Classifier constitutes an ensemble learning methodology that integrates various models to enhance the aggregate efficacy of classification initiatives63. This approach is especially proficient when disparate models discern distinct patterns within the dataset.
Voting Mechanism: In the context of a voting classifier, multiple foundational classifiers, such as the Random Forest Classifier and Decision Tree Classifier, are trained autonomously on an identical dataset. During the prediction phase, each classifier casts a vote for a particular class label, with the ultimate decision being ascertained through either the predominant class (hard voting) or the mean of the predicted probabilities (soft voting)64.
Hard Voting: The equation for soft voting is represented as Eq. 8
Soft Voting: The equation for soft voting is represented as Eq. 9
where p (\(\:c\left|x\right)\) is the predicted probability of class C for instance X. The efficacy of the voting classifier is predominantly contingent upon the heterogeneity of the constituent classifiers65. The amalgamation of various models facilitates the ensemble in capitalizing on their distinct advantages while mitigating their inherent limitations. By averaging the predictions from multiple models, the voting classifier can reduce the risk of overfitting to the training data, making it more robust to variations in the input. Ensemble methods, specifically voting classifiers, are extensively employed across a multitude of fields such as image classification, text classification, and medical diagnostic processes, owing to their capacity to attain superior accuracy in comparison to solitary predictive models.
Due to the superior performance of RFC and DTC model over other ML models in the classification task, they were selected for the voting classifier model. The DTC is a simple yet powerful model that captures decision boundaries effectively and works well on datasets with non-linear relationships. However, it is susceptible to overfitting when the dataset is noisy or lacks sufficient training samples66. In contrast, the RFC is an ensemble model that reduces overfitting by averaging multiple decision trees, thus improving the overall model’s stability and generalization ability67. This characteristic makes RFC more robust and less prone to errors compared to individual decision trees. In the Voting Classifier, the complementary nature of RFC and DTC enhances the ensemble’s performance. The DTC’s ability to make quick, decisive predictions is balanced by RFC’s aggregated decision-making process, which mitigates the risk of overfitting. The voting classifier handles feature interactions differently, with DTCs modeling deep specific interactions and RFCs capturing broader patterns across features. By averaging the predictions, the ensemble approach reduces the model’s variance and improves its ability to generalize across different subsets of the dataset. This combined approach leverages both the sharp decision boundaries of DTCs and the smoother boundaries of RFCs, potentially improving performance on complex datasets and making it particularly effective for this task.
Model configurations and hyperparameters
In this study, we evaluated ten different machine learning models for the classification task, including RFC, DTC, GB, LightGBM, XGBoost, MLP, NB, LR, AB, and KNN. For the RFC, we set the number of estimators to 100 and used the Gini impurity criterion, with no maximum depth restriction to allow the model to grow until the stopping criteria are met. In the case of the DTC, we employed the default settings, as the model’s hyperparameters such as criterion and depth were sufficient for achieving good results in preliminary tests. For GB, we used a learning rate of 0.1, a maximum depth of 3, and 100 estimators to balance model performance and training time. Similarly, LightGBM was configured with a learning rate of 0.1, and the number of leaves was set to 31, optimizing for speed and accuracy in large datasets. The XGBoost model was configured with a learning rate of 0.1, 100 estimators, and a maximum depth of 3 to capture nonlinear relationships without overfitting. For the MLP, the hidden layer size was set to 100, with ReLU activation and the Adam optimizer to enable efficient training. NB was used with its default Gaussian distribution, as this approach is simple and effective for certain classification problems. Logistic Regression was configured with the ‘lbfgs’ solver and a maximum iteration of 100 to ensure convergence during optimization. AdaBoost was implemented using a base DTC with 50 estimators and a learning rate of 1.0. Lastly, the KNN model was set with 5 neighbors and used the Minkowski distance metric to evaluate proximity between data points.
For our proposed model, we employed a Voting Classifier, combining the RFC and DTC models with hard voting. This method aggregates the predictions of both models by selecting the class that receives the majority vote, which helps improve robustness by reducing the risk of overfitting or bias toward any one model. The selection of RFC and DTC was based on their complementary learning mechanisms, enabling the ensemble to capture various aspects of the dataset. The hard voting mechanism enhances generalization, making the model more scalable and suitable for practical applications. This combination of diverse machine learning models ensures a comprehensive and balanced approach between model interpretability and scalability, which is critical for real-world deployment.
Result analysis
For proposed approach ten ML models were evaluated with several performances metrices. The RFC, DTC, LR, AB, KNN are best ML models. In first experiment all 22 features were evaluated and then selected 12 features. the dataset has 50,000 instances. The selected performance metrices are (Test Accuracy, Sensitivity, Precision, Specificity, Recall. MCC, NPV, FPR, FDR, FNR, F1 Score) derived. The F1 score is the most significant of utilizing the models. The excellent test accuracy (89%) and AUC (94%) of our voting classifier which is built utilizing two best models RFC (86.49%) and DTC (79.97%). The classifier provides validation accuracies close to the highest accuracy in both Accuracy and AUC.
Evaluation of class imbalance mitigation techniques
In this section, we evaluate various techniques employed to address class imbalance in our dataset, comparing their impact on classification accuracy. The methods assessed include SMOTE, Random Over-sampling, and Adaptive Synthetic Sampling (ADASYN). The performance of these techniques is compared against the baseline model without any class imbalance mitigation.
The results presented in Table 2 indicate that applying SMOTE outperforms other evaluated methods in mitigating class imbalance, achieving an accuracy of 89.00%. In contrast, the baseline model without any mitigation achieved an accuracy of 84.69%, highlighting the negative impact of class imbalance on model performance. Random Over-sampling, which involves duplicating minority class instances68, resulted in an accuracy of 86.49%. This method improves performance compared to the baseline but is less effective than SMOTE. Similarly, ADASYN, which generates synthetic samples based on the feature space of minority class instances69, achieved an accuracy of 85.55%. While it offers some improvement over the baseline, it does not surpass the performance of SMOTE. These findings suggest that SMOTE is the most effective technique among those evaluated for addressing class imbalance in our dataset. Its ability to generate synthetic samples that enhance the representation of the minority class contributes to improved model performance. In contrast, methods like Random Over-sampling and ADASYN, while beneficial, do not provide the same level of improvement, possibly due to their propensity to introduce noise or overfitting by duplicating or inadequately generating minority class samples. Therefore, based on our analysis, SMOTE is recommended as the preferred method for addressing class imbalance in similar classification tasks.
The performance analysis of ten ML models
Table 3 presents the test accuracies of ten ML methods for HIV classification, comparing performance with a dataset containing 22 features and a reduced dataset with the top 12 selected features.
The RFC achieved the best accuracy, improving slightly from 86.16% with 22 features to 86.49% with 12 features. The DTC experienced a minor decline, decreasing from 80.14 to 79.97% after feature reduction. Both LR and AB showed decreases in accuracy, with LR falling from 65.05 to 62.97% and AB decreasing from 66 to 64%. The KNN model maintained a stable accuracy of 66%, indicating that the reduction in the number of features did not impact its performance. The GB model showed a slight improvement from 60.57 to 60.63%, while LightGBM experienced a minimal decline from 60.50 to 60.41%. XGBoost remained relatively stable, increasing marginally from 59.19 to 59.24%. Notably, the MLP model benefited from feature reduction, improving from 62.98 to 64.60%. Similarly, the NB model saw a significant accuracy boost, rising from 61.36 to 64.58%. Overall, the impact of feature reduction on model performance was mixed across the different models.
The variation in performance after feature reduction can be attributed to differences in how each model processes information. RFC is an ensemble learning method, benefits from feature selection by reducing redundancy and noise, leading to a slight improvement in accuracy. DTC builds hierarchical splits, is relatively robust to feature reduction but can experience minor accuracy drops when key discriminative features are removed. GB, LightGBM, and XGBoost remained stable or slightly improved since they inherently prioritize important features, making them less sensitive to feature reduction. MLP benefited from a smaller feature set, as removing redundant features reduced noise and improved learning efficiency. NB showed a significant boost because feature reduction eliminated redundant attributes, enhancing its probability estimations. Boosting models and deep learning models can perform well with both large and small feature sets, while probabilistic models like NB benefit from fewer, more relevant features. In contrast, models relying on feature-rich representations, such as LR and AB, experience performance declines when critical features are removed. LR and AB, both of which rely on linear decision boundaries, tend to perform better with a higher number of relevant features, as reducing features may remove critical information needed for effective classification. KNN, a distance-based algorithm, is less affected by feature reduction when the removed features are not highly informative, resulting in stable accuracy. Thus, models that prioritize important features, like RFC, boosting models, and MLP, adapt well to feature reduction, while probabilistic models (NB) benefit from removing redundancy. In contrast, linear models (LR, AB) and DTC model may decline if key features are lost, highlighting the need for careful feature selection.
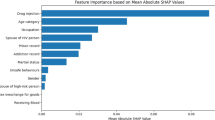
Feature importance analysis of HIV classification using tree-based models and linear models
The Fig. 7 presents a comparative analysis of feature importance for an HIV classification task, as determined by various machine learning algorithms. It showcases the relative importance assigned to different clinical features by DTC, RFC, GB, XGBoost, LightGBM, and LR models.

Feature importance comparison for HIV classification using tree-based models and linear model.
A consistent trend across tree-based methods reveals features such as ‘preanti’, ‘cd420’, ‘cd40’, ‘time’, and ‘wtkg’ as notably important, suggesting their significant predictive power in distinguishing HIV status. However, the emphasis and ranking of these features vary somewhat between models; for instance, ‘preanti’ is particularly prominent in Gradient Boosting, while ‘cd40’ and ‘time’ are highly emphasized by LightGBM. Interestingly, LR also highlights ‘cd420’, ‘preanti’, and ‘cd40’ as important, aligning with the tree-based model findings and reinforcing the relevance of these clinical markers in HIV classification. The summary table (See Table 4) consolidates this information, presenting the average feature importance scores numerically.
Table 4 summarizes the average feature importance scores from tree-based models alongside the feature weights from Logistic Regression (LR), providing a clear picture of which factors contribute most to HIV classification. Among the tree-based models, cd40 stands out with the highest importance score (88.2819), followed closely by time (85.8808) and cd420 (81.5046). These features likely play a crucial role in distinguishing HIV status. Other notable features, including cd80 (72.6612), wtkg (69.8646), and cd820 (62.0620), suggest that immune markers and weight significantly impact classification. Preanti (55.0111) and age (49.4478) also rank relatively high, emphasizing the role of prior antiretroviral treatment and age in predicting outcomes. In contrast, trt (20.0318), karnof (6.4203), homo (5.0173), and race (4.6167) show much lower importance, indicating they contribute less to the model’s decision-making. Interestingly, LR highlights similar key features, with cd420 (0.3205), preanti (0.2463), and cd40 (0.2242) receiving the highest weights, aligning well with the tree-based findings. Time (0.1726) and wtkg (0.0776) remain important across both methods, reinforcing their relevance in HIV classification. Unlike tree-based models, LR assigns slightly more weight to trt (0.0903) and race (0.0392), suggesting these factors may still have some predictive value in a linear setting. Features such as cd820 (0.0231), age (0.0155), and cd80 (0.0103) hold minor influence in both approaches. Overall, this comparison highlights the consistency of key predictors, particularly cd40, cd420, preanti, and time, across different modeling techniques, further confirming their significance in HIV classification.
Confusion matrix analysis of top five ML models with different feature sets
The confusion matrices for the top five machine learning models, including RFC, DTC, LR, AB, and KNN, are presented. These models were evaluated based on their classification accuracy when trained and tested on both the full set of 22 features and the reduced set of 12 features. These five models exhibited the highest performance in classifying HIV, demonstrating their ability to handle both the complete and reduced feature sets effectively. These matrices visually represent the model’s classification abilities, highlighting true positives, false positives, and false negatives.
Figure 8 shows the confusion matrices for RFC, indicating robust performance across both feature sets. Figure 9 illustrates the confusion matrices for DTC, which reveals a slight decline in classification accuracy with the reduced feature set. Figure 10 presents the confusion matrices for LR, highlighting a noticeable decrease in true positives when using 12 features. Figure 11 depicts the confusion matrices for AB, reflecting changes in misclassification patterns between the two feature sets. Finally, Fig. 12 shows the confusion matrices for KNN, which maintains consistent performance regardless of the number of features used.

The confusion matrices of RFC with 22 features and with 12 features respectively.

The confusion matrices of DTC with 22 features and with 12 features respectively.

The confusion matrices of LR with 22 features and with 12 features respectively.

The confusion matrices of AB with 22 features and with 12 features respectively.

The confusion matrices of KNN with 22 features and with 12 features respectively.
Proposed classifier’s performance analysis
The performance of the five machine learning models was evaluated based on classification accuracy, which measures the proportion of correctly classified instances. Both the RFC and DTC achieved the highest accuracy scores with both the full set of 22 features and the reduced 12 features. While RFC outperformed DTC, the latter still showed promising results. In contrast, other models demonstrated significantly lower performance. Due to their strong classification accuracy, RFC and DTC were selected for the voting classification ensemble. This choice was made because of their consistent ability to distinguish between classes effectively. These models were identified as the most effective for improving overall classification performance. So, a voting classifier is built utilizing RFC and DTC models which achieves the highest accuracy for the classification task. The confusion matrix and ROC curves for the proposed classifier is given in Figs. 13 and 14.

Confusion matric and ROC curve with 22 features.

Confusion matric and ROC curve with selected 12 features.
Figures 13 and 14 represents the confusion matrix and ROC curve of the proposed model for 22 features and 12 features respectively. In the confusion matrix, Class 0 represents non-infected patients and class 1 represents infected patients. Receiver Operating Characteristic (ROC) Curve, which plots the True Positive Rate (y-axis) against the False Positive Rate (x-axis) at diverse threshold settings for a binary classifier. The ROC curve evaluates the trade-off between sensitivity (True Positive Rate) and specificity (1 - False Positive Rate). In this situation, the curve is close to the pinnacle left corner, indicating that the classifier has an excellent balance of excessive sensitivity and specificity. The Area Under the ROC Curve (AUC-ROC) is stated as 0.94 (for both cases) The 95% confidence interval (0.9357–0.9475) indicates that if the experiment were repeated multiple times, the AUC would fall within this range 95% of the time. This confirms the statistical reliability of the results, suggesting that the model consistently distinguishes between classes with high accuracy. The narrow confidence interval further highlights the model’s stability and minimal performance variability. Notable that, the model gives similar performance with all features and selected features. This indicates the efficiency of the feature selection. After feature selection, we dropped 10 features, which did not cause any accuracy gain or loss. This indicates that, the model’s performance has near to no effect on the dropped features.
The model’s performance with selected features is further analyzed through statistical analysis. Table 5 shows the statistical evaluations.
The model’s comprehensive performance across various metrics, including Accuracy, Sensitivity, Precision, Specificity, MCC, Recall, NPV, FPR, FDR, and FNR, is detailed in Table 5. These results, derived from the confusion matrix values and provide a thorough evaluation. According to Table 5, the model demonstrates strong predictive capabilities, achieving an overall accuracy of 89%. Sensitivity and Precision are recorded at 87.63% and 90.84%, respectively. The model’s specificity stands at 90.42%, reflecting its ability to accurately identify true negatives. Additionally, it exhibits FPR of 9.58%, FDR of 9.16%, NPV of 87.08%, and FNR of 12.37%. The model’s low FPR of 9.58% ensures minimal misclassification of negative cases, reducing unnecessary medical interventions. Its FNR of 12.37% remains within an acceptable range, demonstrating strong sensitivity in detecting positive cases. The high MCC of 77.99% confirms the model’s balanced and reliable performance, particularly in handling class imbalances. These metrics collectively highlight the model’s robustness, minimizing errors while ensuring accurate and trustworthy predictions. Finally, the F1 Score, which represents the harmonic mean of Precision and Recall, is an impressive 98.21%. These high scores indicate the model’s robustness and balanced performance across various evaluation criteria, effectively capturing the trade-offs between Sensitivity, Precision, and error rates.
Moreover, in our classification study, the Voting Classifier achieved an F1-score of 98.21%, demonstrating a strong balance between precision and recall. The AUC-ROC of 0.94 indicates excellent discriminative ability in distinguishing HIV-positive and negative cases. Additionally, the Gini Index of 0.88 reinforces the robustness of the ensemble model’s predictive performance. These results confirm the effectiveness and reliability of our Voting Classifier for HIV classification task.
Model’s performance on five different datasets
The proposed model was evaluated on five different datasets with varying sizes, ranging from 2139 to 72,139 instances. Importantly, no changes were made to the model’s architecture or hyperparameters across the evaluation process of these datasets. The model consistently demonstrated high performance, with only minor fluctuations in accuracy across different dataset sizes. The dataset used in this study, contained four csv files containing same features but different in size and values. All datasets were obtained from the same healthcare institution, representing different patient cohorts. For model training, we used the largest dataset, consisting of 50,000 instances. To evaluate model performance across varying data volumes, we selected three additional datasets containing 2,139, 5,000, and 15,000 instances. Although sourced from the same institution, these datasets encompass diverse patient demographics and clinical contexts, providing a comprehensive assessment of model robustness. We generated an additional dataset of 72,139 data, merging all the given datasets. The proposed model’s performance on each dataset is showed in Table 6. Table 6 presents the accuracy and ROC curve values for three scenarios: using all 22 features, using the selected 12 features, and using features generated from laboratory test data.
For the dataset with 2139 instances, the model achieves an accuracy of 95% with all features and 98% with the selected 12 features. The accuracy drops slightly to 96% when utilizing lab test-generated features. In the 5000 instances dataset, the model’s accuracy is 87% with all features and remains the same with the selected 12 features, but it drops to 85% with lab test features. The 15,000 instances dataset also shows a consistent accuracy of 88% with all features and the selected 12 features, while it decreases to 86% with lab test data. For the dataset with 50,000 instances, the model achieves an accuracy of 89% across all feature sets, whereas in the 72,139 instances merged dataset, the accuracy remains at 89% for both the full feature set and the selected 12 features but drops to 87% with lab test features. The model’s performance across all five datasets, using both the full set of 22 features and the reduced set of 12 features, does not significantly outperform its performance with only the laboratory test data. Despite the laboratory test data consisting of just four features, the model shows only a 2% decrease in accuracy compared to the larger feature sets. The model’s performance using only CD4/CD8-related features remains competitive compared to models with all features, as shown in Table 6. The high accuracy (e.g., 96% for 2139 samples) and AUC values (99%) indicate that CD4 and CD8 counts alone provide strong discriminatory power. This supports the clinical significance of these features, as they directly relate to immune function and HIV progression. For the 5k dataset, the model with all features and the one using only CD4/CD8 features both achieved 87% accuracy and 94% AUC, suggesting that additional features provided no significant benefit. While utilizing 15k dataset, the performance remained consistent, with 88% accuracy and 93% AUC for both models, further demonstrating that CD4/CD8 features contribute the most critical information for classification. On the other hand, for 50k dataset, the model using all features achieved 89% accuracy and 94% AUC, while the CD4/CD8-only model had a very similar performance (88% accuracy and 93% AUC), again reinforcing that these immune features are sufficient for strong classification. For the largest dataset (72,139 samples, merged data), a small drop was observed when using only CD4/CD8 features (87% accuracy, 92% AUC) compared to the full-feature model (89% accuracy, 94% AUC). This suggests that while CD4/CD8 counts are highly informative, some additional features might provide minor refinements in classification for large-scale data. These results collectively highlight that CD4/CD8 cell counts and their ratio are not just relevant but are among the most significant features for classification. The minimal performance drops across datasets when excluding other features underscores their predictive value, demonstrating that immune system dysregulation captured by these markers is a key determinant in classification accuracy. The minimal drop in accuracy demonstrates that these lab features are highly informative and critical for the model’s overall performance.
The model demonstrated consistent performance across external datasets of varying sizes, as shown in Table 6. No significant challenges were encountered during validation, with the model maintaining high accuracy and AUC scores across all datasets. Its robustness to different dataset sizes suggests effective generalization without requiring adjustments to the architecture or hyperparameters. This stability indicates that the model is well-regularized, ensuring reliable performance without overfitting. To provide a visual representation of the Voting Classifier’s performance, Fig. 15 illustrates the model’s accuracy across varying dataset sizes under different feature configurations.

Performance comparison of the proposed voting classifier across different dataset sizes.
Scalability of the voting classifier
The Fig. 16 illustrates the scalability and deployment characteristics of our voting classifier model by showcasing the training and inference times against varying dataset sizes (2k, 5k, 15k, 50k, and 72k data points). All experiments were performed on a system equipped with an Intel Core i5-8400 processor, 16GB RAM, and an NVIDIA GeForce GTX 1660 GPU, offering adequate computational capacity for deep learning tasks. The system also utilized a 256GB DDR4 SSD, ensuring efficient data storage and retrieval.

Voting classifier performance—training and inference times vs. dataset size.
As depicted, the training time exhibits a sublinear increase with dataset size, rising from approximately 0.3 s at 2k to 1.6 s at 15k, and further to 6.8 s at 50k, culminating at 8.6 s for 72k. This trend underscores the model’s ability to efficiently handle larger datasets, indicating strong scalability. In contrast, the inference time remains consistently low, fluctuating between 0.02 and 0.4 s across all dataset sizes, demonstrating the model’s rapid prediction capabilities and suitability for real-time applications. This minimal inference time, even with substantial dataset growth, highlights the model’s deployability potential. However, a potential negative impact lies in the increasing training time for very large datasets, which could pose a challenge in scenarios requiring frequent model updates or retraining. Nonetheless, the overall trend of manageable training times and consistently low inference times suggests that our voting classifier model is both scalable and deployable, making it a viable solution for various classification tasks.
A distribution of prediction errors is also analyzed to assess the model’s reliability. The results are illustrated in Fig. 17.

Distribution of prediction errors for varying dataset sizes in the voting classifier.
The Fig. 17 depicts the distribution of prediction errors for our voting classifier model across different dataset sizes (2k, 5k, 15k, 50k, and 72k). The x-axis represents the error, ranging from − 1.0 to 1.0, while the y-axis indicates the frequency of these errors. As observed, the error distributions for all dataset sizes are centered around zero, indicating a general tendency for the model to make accurate predictions. However, the spread of the distributions varies significantly. For smaller datasets (2k and 5k), the error distributions are broader, with a higher frequency of errors at the extreme ends (-1.0 and 1.0), suggesting that the model’s predictions are less consistent with limited data. As the dataset size increases (15k, 50k, and 72k), the distributions become narrower and more concentrated around zero, reflecting improved prediction accuracy and consistency. Notably, the 72k dataset exhibits the narrowest distribution, with the highest peak near zero and the lowest frequency of extreme errors, signifying the model’s enhanced performance with larger datasets. This trend underscores the importance of data volume in achieving robust and accurate predictions with our voting classifier model. The reduced error spread with larger datasets indicates that the model benefits from increased data diversity, leading to more stable and reliable predictions. This analysis highlights the model’s ability to leverage larger datasets for improved performance, demonstrating its effectiveness in handling varying data volumes.
Proposed model’s performance comparison with prior studies
In this section, we compared the performance of our proposed model against existing studies, highlighting its effectiveness in predictive accuracy and robustness. By incorporating a voting classifier that synergizes the strengths of both the RFC and DTC, our approach addresses class imbalance and enhances prediction reliability. This comparative analysis shown in Table 7 sets the stage for demonstrating how our methodology advances the state-of-the-art in HIV-related classification tasks.
Table 7 summarizes key performance metrics, including Accuracy, AUC, and F1 score, from various studies. Notably, while previous research reports accuracies ranging from 82.8 to 87.1% and AUC values mostly in the 0.73–0.94 range, our proposed model achieves a superior accuracy of 89% with an equivalent AUC of 0.94 and an outstanding F1 score of 98.21%. This performance improvement underscores the robustness of our ensemble strategy over traditional models, providing compelling evidence of its enhanced predictive capabilities and overall effectiveness compared to earlier studies.
Discussion and limitations
This study highlights the efficacy of combining data preprocessing, feature selection, and ensemble learning techniques for classifying AIDS. The incorporation of SMOTE for addressing class imbalance and advanced feature selection methods notably contributed to improving model performance. In real-world implementations, the proposed Voting Classifier, given its strong performance and stability, can be seamlessly integrated into existing diagnostic workflows in clinical settings. This can be achieved by embedding the model into hospital information systems (HIS) or electronic health records (EHR) platforms, allowing automated pre-screening for HIV using routine lab test results. Additionally, mobile health (mHealth) applications can leverage the model to provide rapid, on-the-go diagnostics, particularly in resource-limited settings where access to specialists is scarce. These applications can facilitate early detection and prompt intervention, significantly improving patient outcomes. From an economic standpoint, the scalability of the model ensures cost-effective implementation, as machine learning-based solutions require minimal infrastructure once deployed. The reduction in reliance on extensive, costly laboratory tests, while maintaining diagnostic accuracy, a result in substantial cost savings for healthcare providers, particularly in low-income regions. Furthermore, our study demonstrates that the classifier maintains robust performance across varying dataset sizes, indicating strong generalizability. This adaptability suggests that the model can be fine-tuned for diagnosing other infectious diseases by training on different datasets, including tuberculosis, hepatitis, or COVID-19, thereby enhancing its broader utility. Moreover, the ability to maintain high accuracy with only four key clinical lab features demonstrates its feasibility for use in diverse healthcare settings, including regions with limited diagnostic capabilities. By addressing these aspects, our research underscores the transformative potential of machine learning in enhancing diagnostic precision, reducing healthcare costs, and broadening accessibility to reliable medical classification models.
While the study demonstrates the effectiveness of the Voting Classifier, it is important to acknowledge certain limitations that may impact its broader applicability. As demonstrated in Table 6, our results demonstrate the strong predictive power of CD4 and CD8 cell counts in our classification model. However, there are several implications, limitations, and potential biases associated with relying predominantly on these features. The reliance on CD4 and CD8 cell counts as primary features in the classification model highlights their predictive potential in assessing immune function, particularly in resource-constrained settings where streamlined, cost-effective diagnostics are critical73. This approach could facilitate the development of rapid point-of-care testing systems, improving accessibility in underserved regions. However, CD4/CD8 counts alone do not fully represent the complex interplay of immune responses, as various immune cells, cytokines, and signaling pathways contribute to disease progression74. The predictive utility of these markers may vary across different disease stages, with early or subclinical conditions potentially remaining undetected. Additionally, comorbidities such as autoimmune disorders or immunosuppressive treatments could independently alter CD4/CD8 counts, confounding the model’s performance. Demographic variations in CD4/CD8 reference ranges across age, sex, and ethnicity may introduce biases if not adequately represented in the training data. Furthermore, the model does not account for temporal fluctuations in CD4/CD8 counts or inconsistencies in measurement methods across clinical laboratories, which could impact real-world performance. Addressing these limitations requires validating the model across diverse populations, incorporating longitudinal data, and integrating additional biomarkers to improve robustness and generalizability.
Besides CD features, if we can integrate more clinical features, the diagnostic accuracy of HIV classification may improve. Viral load plays a critical role in HIV progression, as higher levels correlate with lower CD4 counts and increased immune activation75. Inflammatory markers like IL-6, TNF-α, and CRP provide insights into immune system activation, which can refine classification models. Expanding the dataset to include CD38, HLA-DR, and β2-microglobulin could enhance predictive performance by capturing immune system turnover and activation. Hematological parameters such as absolute lymphocyte count, neutrophil-to-lymphocyte ratio, and platelet-to-lymphocyte ratio could indicate systemic inflammation 74. These features, combined with CD4 and CD8 counts, can provide a more comprehensive view of disease progression. Another key limitation is the reliance on a single dataset for model evaluation. Though the results show promise, the generalizability of the Voting Classifier to different datasets or demographic groups remains uncertain. Additionally, it is important to acknowledge that the dataset used in our study is from 1996, which is quite old, it remains valuable for understanding the foundational patterns and trends in HIV diagnosis. However, despite its age, it continues to be a useful reference for understanding historical trends in the disease. Moving forward, our focus will be on utilizing more recent, private datasets collected from hospitals, which will allow us to develop a more reliable detection system and ensure that our model is applicable to current HIV diagnostic practices. Future research should consider validating the model on diverse and larger datasets, particularly those representing various geographical regions and patient profiles, to assess its robustness and versatility. Another limitation pertains to the model’s reliance on traditional machine learning algorithms, which may not fully capture the complex patterns in medical data. Incorporating advanced deep learning techniques, such as CNNs, could potentially improve the model’s performance further, especially in detecting subtle patterns. Furthermore, the interpretability of the model could be enhanced by integrating explainable AI approaches, which would facilitate clinical adoption by ensuring transparency in decision-making. Lastly, while feature selection reduced computational costs, the generalizability of the model may still be affected by smaller or imbalanced datasets, which could hinder its performance in real-world applications.
Therefore, In the future, we aim to address these challenges and further enhance the robustness and applicability of our model in future research. One promising direction is the development of hybrid machine learning models that combine deep learning techniques with traditional classifiers. Integrating Convolutional Neural Networks (CNNs) with tree-based classifiers can enhance feature extraction and decision-making, particularly in complex medical datasets. Furthermore, incorporating ensemble techniques, including boosting methods like XGBoost and LightGBM alongside the existing Voting Classifier, has the potential to refine model performance and scalability. These hybrid models are expected to improve predictive accuracy and robustness for medical classification tasks. Optimizing computational efficiency through model quantization and knowledge distillation will make the model suitable for real-time deployment in mobile health applications and clinical settings. Additionally, cross-domain validation with datasets from other medical conditions will assess the model’s adaptability and generalizability across diverse populations and healthcare systems. By pursuing these future directions, we aim to further improve machine learning models’ accuracy, scalability, and real-world applicability, ultimately advancing diagnostic efficiency and improving patient outcomes in healthcare settings.
Conclusions
This research introduces a robust machine learning methodology for classifying AIDS, utilizing sophisticated techniques in data preprocessing, feature selection, and ensemble modeling. The application of SMOTE to mitigate class imbalance, coupled with the use of Recursive Feature Elimination and Median Absolute Deviation for feature selection, significantly enhanced the model’s predictive accuracy. The RFC and DTC were assessed, with the ensemble Voting Classifier emerging as the most effective model. The main contributions of this study are the application of data balancing and feature selection techniques to enhance the performance of machine learning models, especially in healthcare settings with imbalanced datasets. Additionally, this work highlights the potential of ensemble learning methods, demonstrating the ability of the Voting Classifier to achieve superior classification results, making it a promising tool for medical diagnosis, particularly for conditions like AIDS.
From a practical perspective, the proposed ensemble Voting Classifier offers a scalable solution for automating AIDS diagnosis, particularly in resource-constrained healthcare settings. The model’s robustness to varying dataset sizes makes it suitable for deployment in both small clinics and large hospitals. Furthermore, the integration of feature selection techniques reduces computational costs, making the model highly efficient for real-time applications. These practical benefits suggest that the framework could be a valuable tool in enhancing diagnostic capabilities in healthcare, improving the speed and accuracy of AIDS detection.
However, small, or medium-sized datasets may limit the model’s generalization performance. Future studies could overcome this by collecting larger datasets with more samples of infected patients and selecting the most discriminative features to improve the model’s capability in detecting AIDS more effectively. Nevertheless, the model’s performance was evaluated on a single dataset, and external validation using diverse datasets from different populations is necessary to ensure its generalizability across various demographic groups. In addition, future research could explore advanced deep learning architectures, such as convolutional neural networks or hybrid models, to improve predictive performance further. Incorporating explainable AI techniques could enhance the model’s interpretability, making it more transparent and reliable for clinical decision-making.
The findings of this study underscore the potential benefits of integrating data balancing methodologies with feature selection and ensemble learning to augment the accuracy and dependability of classification models in medical research, particularly for conditions characterized by imbalanced datasets such as AIDS. Moreover, the proposed framework provides a strong foundation for future research focused on enhancing diagnostic systems and supporting clinical decision-making.
Data availability
The datasets generated and/or analysed during the current study are available in the AIDS Virus Infection Prediction repository at https://www.kaggle.com/datasets/aadarshvelu/aids-virus-infection-prediction/data.
References
Fieggen, J., Smith, E., Arora, L. & Segal, B. The role of machine learning in HIV risk prediction. Front. Reproductive Health 4, (2022).
Tu, W. et al. Machine learning models reveal neurocognitive impairment type and prevalence are associated with distinct variables in HIV/AIDS. J. Neurovirol. 26, 41–51 (2020).
Seboka, B. T., Yehualashet, D. E. & Tesfa, G. A. Artificial intelligence and machine learning based prediction of viral load and CD4 status of people living with HIV (PLWH) on Anti-Retroviral treatment in Gedeo zone public hospitals. Int. J. Gen. Med. 16, 435–451 (2023).
Maman, A., Pacal, I. & Bati, F. Can deep learning effectively diagnose cardiac amyloidosis with 99mTc-PYP scintigraphy? J. Radioanal Nucl. Chem. 334, 1033–1048 (2025).
Bayram, B., Kunduracioglu, I., Ince, S. & Pacal, I. A systematic review of deep learning in MRI-based cerebral vascular occlusion-based brain diseases. Neuroscience vol. 568 76–94 Preprint at (2025). https://doi.org/10.1016/j.neuroscience.2025.01.020
Yıkmış, S. et al. Optimization of bioactive compounds and sensory quality in thermosonicated black Carrot juice: A study using response surface methodology, gradient boosting, and fuzzy logic. Food Chem. X 25, (2025).
Ozdemir, B. & Pacal, I. An innovative deep learning framework for skin cancer detection employing ConvNeXtV2 and focal self-attention mechanisms. Results Eng. 25, (2025).
Saha, R., Malviya, L., Jadhav, A. & Dangi, R. Early stage HIV diagnosis using optimized ensemble learning technique. Biomed. Signal. Process. Control 89, (2024).
Li, Y. et al. The predictive accuracy of machine learning for the risk of death in HIV patients: a systematic review and meta-analysis. BMC Infectious Diseases vol. 24 Preprint at (2024). https://doi.org/10.1186/s12879-024-09368-z
Delaney, K. P. et al. Evaluation of the performance characteristics of 6 rapid HIV antibody tests. Clin. Infect. Dis. 52, 257–263 (2011).
Chawla, N. V., Bowyer, K. W., Hall, L. O. & Kegelmeyer, W. P. SMOTE: synthetic minority Over-Sampling technique. J. Artif. Intell. Res. 16 (2002).
Singh, Y., Narsai, N. & Mars, M. Applying machine learning to predict patient-specific current CD 4 cell count in order to determine the progression of human immunodeficiency virus (HIV) infection. Afr. J. Biotechnol. 12, 3724–3730 (2013).
Alehegn, M. Application of machine learning and deep learning for the prediction of HIV/AIDS. HIV AIDS Rev. 21, 17–23 (2022).
Rodriguez, S. D. et al. Machine learning outperformed logistic regression classification even with limit sample size: A model to predict pediatric HIV mortality and clinical progression to AIDS. PLoS One 17, (2022).
Júnior Silva, G. B. et al. Acute kidney injury in AIDS: frequency, RIFLE classification and outcome. Braz. J. Med. Biol. Res. 43, 1102–1108 (2010).
Olatosi, B. et al. Application of machine-learning techniques in classification of HIV medical care status for people living with HIV in South Carolina. AIDS 35, S19–S28 (2021).
Pang, H. et al. Effective attention-based network for syndrome differentiation of AIDS. BMC Med. Inf. Decis. Mak. 20, (2020).
Lim, Y. A. L. et al. First genetic classification of Cryptosporidium and giardia from HIV/AIDS patients in Malaysia. Infect. Genet. Evol. 11, 968–974 (2011).
Chen, Y. S. A comprehensive identification-evidence based alternative for HIV/AIDS treatment with HAART in the healthcare industries. Comput. Methods Programs Biomed. 131, 111–126 (2016).
Rauber, P. E., Falcaõ, A. X. & Telea, A. C. Projections as visual aids for classification system design. Inf. Vis. 17, 282–305 (2018).
Steiner, M. C., Gibson, K. M. & Crandall, K. A. Drug resistance prediction using deep learning techniques on HIV-1 sequence data. Viruses 12, (2020).
Mageshwari, V. & Aroquiaraj, I. L. A novel technique for identification and classification of HIV/AIDS related social media data using LD-KMEANS and DBN-LSTM. Multimed Tools Appl. https://doi.org/10.1007/s11042-024-19283-9 (2024).
Du, K. et al. Deep learning system for screening AIDS-related cytomegalovirus retinitis with ultra-wide-field fundus images. Heliyon 10, (2024).
Zhao, Y. et al. A novel classification method for syndrome differentiation of patients with AIDS. Evidence-based Complementary and Alternative Medicine (2015). (2015).
El-kenawy, E. S. M. et al. Greylag Goose optimization: Nature-inspired optimization algorithm. Expert Syst. Appl. 238, (2024).
Abdel-Fattah, Ismail, M. G. A., Kenawy, I., El, E. S. M., Moustafa, H. & admin,, , & E.-D. An AI-Based system for predicting renewable energy power output using advanced optimization algorithms. J. Artif. Intell. Metaheuristics. 8, 01–08 (2024).
El-Sayed, E., Eid, M. M. & Abualigah, L. Machine learning in public health forecasting and monitoring the Zika virus. Metaheuristic Optim. Rev. 1, 01–11 (2024).
Mahmoud Ibrahim, A., Abed Mohammed, M. A. & Comprehensive Review on advancements in artificial intelligence approaches and future perspectives for early diagnosis of Parkinson’s disease. Int. J. Math. Stat. Comput. Sci. 2, 173–182 (2024).
Ali, A. M. & Mohammed, M. A. Optimized Cancer subtype classification and clustering using Cat swarm optimization and support vector machine approach for Multi-Omics data. J. Soft Comput. Data Min. 5, 223–244 (2024).
Ali, A. M. & Mohammed, M. A. A comprehensive review of artificial intelligence approaches in omics data processing: evaluating progress and challenges. Int. J. Math. Stat. Comput. Sci. 2, 114–167 (2023).
Hammer, S. & Katzenstein, D. Dataset. https://www.kaggle.com/datasets/aadarshvelu/aids-virus-infection-prediction/data
Govindaraj, S. et al. CD4 + T cells in HIV: A friend or a foe?? Front. Immunol. 14, (2023).
Maciej et al. Recommendations on public health strategies for sexually transmitted infections in China. Uniwersytet Śląski. 7, 343–354 (2024).
Parekh, N., Westerman, L., … L. V.-L. and point-of & 2023, undefined. Human immunodeficiency virus (HIV) infectionsQ1BMC Medicine; H-Index: 155 SJR: Q1 CORE: NA CCF: NA ABDC:NA FT50: NA. books.google.comB Parekh, L Westerman, L Vojnov, C YangLaboratory and point-of-care diagnostic testing for sexually, 2023•books.google.com.
Gebremedhin, Q. Q., Aynalem, R., Adem, M., Reports, M. & Adem, M. 0. 9NAABS Nas.,D. G.-S. & undefined. Dolutegravir based therapy showed CD4 + T cell count recovery and viral load suppression among ART naïve people living with HIV AIDS: a pilot evaluationQ1Scientific Reports; H-Index: 242 SJR: Q1 CORE: NA CCF: NA ABDC: NA FT50: NA 1Scientific Reports; H-Index: 242 VHB: NA FNEGE: NA CoNRS: NA HCERE: NA BFI: 1 AJG: NA +. nature.comT Gebremedhin, M Aynalem, M Adem D Geremew, Y Aleka, A KiflieScientific Reports, 2024•nature.com. (2024).
immunology, Q. Q. 4. 163NAABS Nat. in immunologyY S.-T. in & undefined. Factors contributing to the potency of CD8 + T cellsQ1Trends in immunology; H-Index: 236 SJR: Q1 CORE: NA CCF: NA ABDC: NA FT50: NA 2Trends in immunology; H-Index: 236 VHB: NA FNEGE: NA CoNRS: NA HCERE: NA BFI: 2 AJG: NA +. cell.comY SykulevTrends in immunology, 2023•cell.com. (2023).
Meintjes, G., Bekker, L. G. & Wood, R. Clinical features and management of HIV/AIDS in adults. Manson’s Trop. Dis. Fourth Ed. 110–133. https://doi.org/10.1016/B978-0-7020-7959-7.00015-4 (2023).
Xiaoyan, X. & Sato, M. K. Quality of life and related factors among people living with HIV in China. J. Nurs. Healthc. Chronic Illn. 3, 513–520 (2011).
Guedes, Q. Q. 1. 14NAABS Nav. D. S., Viruses, W. C.-S.- & undefined. Thymic exhaustion and increased immune activation are the main mechanisms involved in impaired immunological recovery of HIV-positive patients under Q1Viruses; H-Index: 101 SJR: Q1 CORE: NA CCF: NA ABDC: NA FT50: NA. mdpi.comMC Dos Santos Guedes, WHV Carvalho-Silva, JL Andrade-Santos, MCA Brelaz-de-CastroViruses, 2023•mdpi.com. (2023).
Blagus, R. & Lusa, L. SMOTE for High-Dimensional Class-Imbalanced Data. vol. 14 (2013). http://www.biomedcentral.com/1471-2105/14/106
Lee, J. S., Paintsil, E., Gopalakrishnan, V. & Ghebremichael, M. A comparison of machine learning techniques for classification of HIV patients with antiretroviral therapy-induced mitochondrial toxicity from those without mitochondrial toxicity. BMC Med. Res. Methodol. 19, (2019).
Ramadhan, N. G. & Adiwijaya, Maharani, W. Akbar Gozali, A. Chronic diseases prediction using machine learning with data preprocessing handling: A critical review. IEEE Access. 12, 80698–80730 (2024).
Wang, S., Nan, B., Rosset, S. & Zhu, J. Random Lasso. Annals Appl. Stat. 5, 468–485 (2011).
Pechenizkiy, M., Tsymbal, A. & Puuronen, S. PCA-Based Feature Transformation for Classification: Issues in Medical Diagnostics. (2004).
Yang, M. et al. Establishing a prediction model of severe acute mountain sickness using machine learning of support vector machine recursive feature elimination. Sci. Rep. 13, (2023).
Johannes, M. et al. Integration of pathway knowledge into a reweighted recursive feature elimination approach for risk stratification of cancer patients. Bioinformatics 26, 2136–2144 (2010).
Gong, X., Shen, L. & Lu, T. Refining training samples using median absolute deviation for supervised classification of remote sensing images. J. Indian Soc. Remote Sens. 47, 647–659 (2019).
Alshanbari, H. M. et al. Prediction and Classification of COVID-19 Admissions to Intensive Care Units (ICU) Using Weighted Radial Kernel SVM Coupled with Recursive Feature Elimination (RFE). Life 12, (2022).
Al-Hadeethi, H., Abdulla, S., Diykh, M., Deo, R. C. & Green, J. H. Adaptive boost LS-SVM classification approach for time-series signal classification in epileptic seizure diagnosis applications. Expert Syst. Appl. 161, 113676 (2020).
Mathew, D. T. E. An Improvised Random Forest Model for Breast Cancer Classification. NeuroQuantology 20, 713–722 (2022).
De, A. & Chowdhury, A. S. DTI based Alzheimer’s disease classification with rank modulated fusion of CNNs and random forest. Expert Syst. Appl. 169, (2021).
Farombi, O., Farombi, O. E., Adetunji, A. B. & Ajala, F. A. DEVELOPMENT OF RFC, SVC AND GAUSSIAN NB CLASSIFIER MODELS FOR DISEASE PREDICTION IN MACHINE LEARNING. https://www.researchgate.net/publication/382495280
Grethlein, D. & Kandadai, V. Classification of Drivers with HIV-Associated Neurocognitive Disorders Using Virtual Driving Test Performance Data. (2023).
Jiang, L., Zhang, B., Ni, Q., Sun, X. & Dong, P. Prediction of SNP sequences via Gini impurity based gradient boosting method. IEEE Access. 7, 12647–12657 (2019).
Huang, C. Y., Chen, Y. A., Hwang, I. S. & Wu, R. M. Improving Dual-Task control with a Posture-Second strategy in Early-Stage Parkinson disease. Arch. Phys. Med. Rehabil. 99, 1540–1546e2 (2018).
Onah, E. et al. Prediction of HIV-1 protease cleavage site from octapeptide sequence information using selected classifiers and hybrid descriptors. BMC Bioinform. 23, (2022).
Etowa, J., Hannan, J., Etowa, E. B., Babatunde, S. & Phillips, J. C. Determinants of infant feeding practices among black mothers living with HIV: a multinomial logistic regression analysis. BMC Public. Health 21, (2021).
Joshi, R. D. & Dhakal, C. K. Predicting type 2 diabetes using logistic regression and machine learning approaches. Int. J. Environ. Res. Public. Health 18, (2021).
Khandezamin, Z., Naderan, M. & Rashti, M. J. Detection and classification of breast cancer using logistic regression feature selection and GMDH classifier. J. Biomed. Inf. 111, (2020).
Belete, D. M. & Huchaiah, M. D. Performance Evaluation of Classification Models for HIV/AIDS Dataset. in Data Management, Analytics and Innovation: Proceedings of ICDMAI 2021, Volume 1 109–125Springer, (2021).
Alotaibi, A. S. Hybrid model based on relieff algorithm and K-Nearest neighbor for Erythemato-Squamous diseases forecasting. Arab. J. Sci. Eng. 47, 1299–1307 (2022).
Pal, O. K. Skin Disease Classification: A Comparative Analysis of K-Nearest Neighbors (KNN) and Random Forest Algorithm. in International Conference on Electronics, Communications and Information Technology (ICECIT) 1–5 (2021). (2021). https://doi.org/10.1109/ICECIT54077.2021.9641120
Fili, M. et al. A classification algorithm based on dynamic ensemble selection to predict mutational patterns of the envelope protein in HIV-infected patients. Algorithms Mol. Biology 18, (2023).
Belete, D. M. & H, M. D. Classification of Binary Class HIV/AIDS Test Results Using Ensemble Learning Models. in International Conference on Decision Aid Sciences and Application (DASA) 1240–1247 (2020). (2020). https://doi.org/10.1109/DASA51403.2020.9317082
Osamor, V. C. & Okezie, A. F. Enhancing the weighted voting ensemble algorithm for tuberculosis predictive diagnosis. Sci. Rep. 11, 14806 (2021).
Leiva, R. G., Anta, A. F., Mancuso, V. & Casari, P. A novel hyperparameter-free approach to decision tree construction that avoids overfitting by design. IEEE Access. 7, 99978–99987 (2019).
Raza, A., Rustam, F., Ur Rehman Siddiqui, H., de la Torre Diez, I. & Ashraf, I. Predicting microbe organisms using data of living micro forms of life and hybrid microbes classifier. PLoS One 18, (2023).
Yang, C., Fridgeirsson, E. A., Kors, J. A., Reps, J. M. & Rijnbeek, P. R. Impact of random oversampling and random undersampling on the performance of prediction models developed using observational health data. J. Big Data 11, (2024).
Park, H. & Kim, H. AR-ADASYN: angle radius-adaptive synthetic data generation approach for imbalanced learning. Stat. Comput. 34, 166 (2024).
Lin, Y. H. et al. Application of Machine Learning Algorithms in Predicting HIV Infection among Men who Have Sex with Men: Model Development and Validation.
Paul, R. H. et al. Machine-learning classification of neurocognitive performance in children with perinatal HIV initiating de Novo antiretroviral therapy. AIDS 34, (2020).
Li, Y., Tian, Y., Qin, Z. & Yan, A. Classification of HIV-1 protease inhibitors by machine learning methods. ACS Omega. 3, 15837–15849 (2018).
Kagendi, N. & Mwau, M. A. Machine learning approach to predict HIV viral load hotspots in Kenya using Real-World data. Health Data Sci. 3, (2023).
Turk, G. et al. Biomarkers of progression after HIV acute/early infection: Nothing compares to CD4 + T-cell count? Viruses 10, (2018).
Farooq, S. A. et al. Revealing HIV viral load patterns using unsupervised machine learning and cluster summarization. F1000Res 7, 1144 (2018).
Author information
Authors and Affiliations
Contributions
Q.S. (Qian Sui) contributed to the conceptualization and design of the study, conducted data analysis, and drafted the manuscript. G.L. (Gaoxu Li) participated in data collection, performed statistical analysis, and contributed to the revision of the manuscript. Y.P. (Yaqi Peng) assisted in data validation and manuscript editing. J.Z. (Jiasheng Zhang) was responsible for data interpretation and provided critical revisions for important intellectual content. Y.Z. (Yibo Zhang) supervised the study, contributed to project administration, and reviewed the manuscript for final approval. R.Z. (Riyang Zhao) coordinated the revision process, contributed to methodological refinement, and critically reviewed the manuscript. All authors read and approved the final manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Sui, Q., Li, G., Peng, Y. et al. Scalable and robust machine learning framework for HIV classification using clinical and laboratory data. Sci Rep 15, 18727 (2025). https://doi.org/10.1038/s41598-025-00085-4
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-025-00085-4
