
Abstract
Deep neural networks are used to accurately detect, estimate, and predict human body poses in images or videos through deep learning-based human pose estimation. However, traditional multi-person pose estimation methods face challenges due to partial occlusions and overlaps between multiple human bodies and body parts. To address these issues, we propose EE-YOLOv8, a human pose estimation network based on the YOLOv8 framework, which integrates Efficient Multi-scale Receptive Field (EMRF) and Expanded Feature Pyramid Network (EFPN). First, the EMRF module is employed to further enhance the model’s feature representation capability. Second, the EFPN optimizes cross-level information exchange and improves multi-scale data integration. Finally, Wise-IoU replaces the traditional Intersection over Union (IoU) to improve detection accuracy through precise overlap measurement between predicted and ground-truth bounding boxes. We evaluate EE-YOLOv8 on the MS COCO 2017 dataset. Compared to YOLOv8-Pose, EE-YOLOv8 achieves an AP of 89.0% at an IoU threshold of 0.5 (an improvement of 3.3%) and an AP of 65.6% over the IoU range of 0.5–0.95 (an improvement of 5.8%). Therefore, EE-YOLOv8 achieves the highest accuracy while maintaining the lowest parameter count and computational complexity among all analyzed algorithms. These results demonstrate that EE-YOLOv8 exhibits superior competitiveness compared to other mainstream methods.
Similar content being viewed by others

Introduction
Human Pose Estimation (HPE), also known as human keypoint detection, is one of the core tasks in the field of computer vision. Its technical objective is to achieve precise quantitative descriptions of human skeletal joints and their topological connections through image/video data analysis. A typical human skeletal model usually includes 17 keypoints, covering the head (nose tip, eyes), torso (neck, shoulders, hips), and limbs (elbows, wrists, knees, ankles), among other landmarks. These keypoints are connected through a directed graph structure to represent joint relationships1. The core challenge of this technology lies in overcoming complex environmental factors such as lighting variations, occlusions, and diverse poses, while achieving a balance between sub-pixel localization accuracy and real-time processing efficiency.
With the advancement of deep learning and sensor technologies, human pose estimation has evolved into a multi-modal (RGB/RGB-D/thermal imaging) and multi-view (monocular/multi-view/panoramic) technical system. Its application scenarios demonstrate cross-disciplinary penetration:
-
(1)
Intelligent human–computer interaction: Through real-time gesture recognition and full-body motion capture, virtual avatars are driven to achieve natural interaction. Typical applications include 6DoF pose tracking in VR devices like Meta Quest Pro, and ADAS safety strategy optimization in vehicle systems based on driver posture (head orientation, hand position)2. Additionally, by integrating facial keypoint models and eye-tracking, non-contact control interfaces are developed for patients with motor disabilities3.
-
(2)
Sports and health management: In competitive sports, high-speed camera arrays are used to capture athletes’ 3D motion trajectories, quantifying joint angle change rates to optimize technical movements4. In clinical settings, wearable sensors are combined with visual pose estimation to quantitatively assess gait parameters in Parkinson’s disease (e.g., step length asymmetry, trunk tilt angle). RGB camera-based fall detection systems are also employed for remote monitoring of elderly individuals living alone5,6.
-
(3)
Intelligent security surveillance: Leveraging temporal pose analysis, abnormal behaviors in public spaces (e.g., sudden increases in limb acceleration to identify fights, abnormal torso tilt angles to detect climbing) can be detected with significantly improved response times compared to traditional methods7. Pose estimation algorithms are also used to generate heatmaps of passenger flow density in airport hubs, enabling high-precision crowd flow statistics8.
-
(4)
Digital entertainment innovation: Virtual fitting systems for human models are developed, where keypoint-driven cloth physics simulation ensures high accuracy in online try-ons, reshaping the consumer experience9.
-
(5)
Industrial safety monitoring: By analyzing workers’ postures (e.g., spinal curvature angle, upper limb movement frequency), ergonomic risk indices are assessed to optimize production line design10. In power inspections, infrared imaging is combined with pose estimation to detect violations, enhancing safety in high-risk tasks11.
In recent years, deep learning-based human pose estimation methods have become mainstream12, generally categorized into top-down and bottom-up approaches. In single-person scenarios, the top-down method focuses on detailed analysis of individual human instances, identifies and locates keypoints more precisely, and achieves higher accuracy. Therefore, it typically outperforms in single-person pose estimation. However, in crowded multi-person scenarios, top-down methods suffer from performance degradation due to missed or false human body detections13. Moreover, the top-down approach first detects humans and subsequently predicts keypoints within each bounding box. Consequently, the top-down method incurs high computational overhead, particularly when processing high-resolution images or videos. In contrast, the bottom-up method detects all human keypoints across the entire image and assigns them to distinct instances via geometric relationships. Thus, it is more suitable for crowded multi-person scenarios. Unlike top-down methods, bottom-up approaches do not detect human instances separately; instead, they directly identify and associate keypoints across the entire image. As a result, they achieve higher computational efficiency and relatively lower overhead. However, bottom-up methods exhibit lower detection accuracy compared to top-down approaches, particularly for small human instances in images, which may result in missed keypoints or misalignment14.
YOLO is an efficient object detection framework that has also been applied to human pose estimation. The YOLO-based human pose estimation method combines object detection and keypoint detection techniques. As an end-to-end architecture, YOLO offers advantages such as high detection speed, real-time performance, and ease of deployment. Therefore, we have chosen YOLOv8 as our foundational model.
To address the limitations of top-down approaches, particularly their lower precision, we introduce improvements in multi-scale keypoint information extraction, feature fusion, and sample focus regulation. To this end, we propose EE-YOLOv8, a human pose estimation network based on the YOLOv8 framework. The main contributions of EE-YOLOv8 are as follows:
-
(1)
An Efficient Multi-scale Attention (EMA) mechanism is added in the Efficient Multi-scale Receptive Field (EMRF) module to enhances the attention on human-related features in images, the representation ability and generalization performance.
-
(2)
An Expanded Feature Pyramid Network (EFPN) is proposed to replace the original Path Aggregation Network (PAN) of neck to optimize information exchange between different levels better, and to enhance data fusion at different scales.
-
(3)
In order to improve the convergence speed, the robustness and accuracy of the model, Wise-IoU is used as to calculate the bounding box loss. So, the complex scenes with overlapping objects of different sizes and aspect ratios can be handled more accurately especially for low-quality examples.
The remainder of this paper is organized as follows. In the related work section, several mainstream human pose estimation methods are described. In the method section, the EE-YOLOv8 model, critical modules, and network structure are introduced. In the experiment section, the experiments on MS COCO 2017 dataset are conducted to evaluate and analyze the performance of the EE-YOLOv8 model. Finally, a summative conclusion is drawn in the conclusion section.
Related work
The top-down pose estimation method
The top-down pose estimation method first detects the entire person and then determines the position of each joint15. Since the human body is much larger than individual joints, it is relatively easier to detect. As a result, top-down methods generally achieve a higher recall rate. Additionally, by detecting the full-body region, spatial alignment allows for the extraction of intermediate contextual information, which helps in accurately locating keypoints.
SimpleBaseline16 is a benchmark method for human pose estimation. It extracts features using convolutional neural networks (CNNs) and predicts keypoint heatmaps via a simple upsampling network. Despite its simplicity, this method has demonstrated strong performance across multiple human pose estimation benchmarks.
HRNet17 is a neural network architecture designed for human pose estimation. By maintaining a high-resolution representation and gradually fusing multi-scale information, it achieves high prediction precision. However, it suffers from high computational costs, difficult training, and poor transferability.
ViT-Pose18 applies Vision Transformer to pose estimation, formulating the task as a sequence-to-sequence prediction problem. It leverages the self-attention mechanism to capture global dependencies among image patches. While ViT-Pose achieves high accuracy in human pose estimation, it has a large number of parameters, incurs high computational costs, and lacks lightweight adaptability.
The bottom-up pose estimation method
Firstly, the bottom-up pose estimation method detects the keypoints of a person’s joints and then connects them to form the complete pose using graph-based algorithms or conditional random fields (CRF)19. Compared to top-down methods, bottom-up methods are usually faster during inference and are more suitable for multi-person scenarios.
OpenPose20 is a deep learning-based human pose estimation algorithm that accurately detects and estimates keypoints and pose information from images or videos. It employs a dual-branch architecture, where one branch generates keypoint heatmaps to represent the probability distribution of various body keypoints in an image, while the other branch predicts Part Affinity Fields (PAFs)—two-dimensional vectors that model relationships between joints. This dual-branch design enables the model to effectively detect and associate body keypoints, thereby accurately estimating complete human poses.
HigherHRNet21 enhances HRNet by introducing a multi-level feature fusion mechanism. By maintaining high-resolution features and integrating multi-scale information, HigherHRNet captures fine-grained details and complex poses more accurately, thereby improving both the accuracy and robustness of multi-person pose estimation.
DEKR22 decouples keypoint position regression from keypoint association modeling, treating them as separate tasks. This approach allows it to predict keypoint locations and relationships more effectively. Additionally, it adopts a separate feature extraction and fusion strategy to better capture multi-scale features.
However, while bottom-up methods detect all keypoints directly from the entire image, their improved efficiency comes at the cost of reduced accuracy, particularly for small or occluded body parts23.
Pose estimation method based on YOLO
YOLO is an efficient object detection framework and is also used in human pose estimation. The human post estimation method based on YOLO is a combination of object detection and keypoint detection24. The end-to-end design is one of YOLO’s key contributions, it integrates target detection and human posture estimation into a single model. Normally, in the traditional human pose estimation methods, there are two stages: human detection and key point localization. YOLO directly outputs the position and keypoint information of the target by a single forward propagation, simplifies the process, and significantly improves the overall efficiency25.
Furthermore, in YOLO, a bottom-up path based on the feature pyramid and a path aggregation network are added to integrate low-level features and high-level features better26. In YOLO-Rlepose27, the Swin Transformer is introduced. By integrating Swin Transformer branches, YOLO-Rlepose enhances its ability to capture global context and enrich feature representations. However, the introduce-tion of Transformer results in the inevitable increase of computational cost. In RTMO28, a dynamic coordinate classifier and a customized loss function are proposed to learn the heat map by representing keypoint with dual one-dimensional heat map to in YOLO structure. So, the incompatibility among coordinate classification and intensive prediction models is solved, and the efficiency was improved.
Methods
YOLOv8
YOLOv8 is a major update to YOLOv5. It currently supports the tasks, such as image classification, object detection and instance segmentation29. the core features and major improvements of YOLOv8 can be summarized as follows:
-
(1)
A state-of-the-art (SOTA) model is introduced, including P5 640 and P6 1280 resolution object detection networks and instance segmentation models on basis of YOLACT, is provided.
-
(2)
The backbone network and neck part refer to the design concept of YOLOv7 ELAN. The C3 structure of YOLOv5 is replaced with a C2f structure with richer gradient flow30, and the number of channels for different scale models is adjusted. The models have different set of parameters, and the performance of models is greatly improved.
-
(3)
Compared to YOLOv5, the head architecture has undergone significant changes replacing it with the current mainstream decoupling head structure, separating the classification and detection heads, and also changing from anchor-based to anchor-free.
-
(4)
In terms of loss calculation, the Task-aligned Assistant positive sample allocation strategy was adopted, and Distribution Focal Loss (DFL) was introduced. The data augmentation part of the training introduces the operation of disabling Mosaic augmentation in the last 10 epochs of YOLOX, which can effectively improve accuracy.
EE-YOLOv8
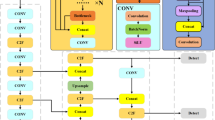
A human pose estimation network based on YOLOv8 framework with Efficient Multi-scale Receptive Field (EMRF) and Expanded Feature Pyramid Network (EFPN), EE-YOLOv8, is proposed in this paper. Specifically, the improvements are done in the three aspects: the capability of feature representation, information exchange between levels, the human contour localization and keypoint recognition. The structure of EE-YOLOv8 is shown in Fig. 1.

EE-YOLOv8 framework.
In the backbone network, the original C2f module is replaced with an EMRF module. By the introduced EMA mechanism and the combination of different scale features, the limitations of single scale methods have been overcome to improve the feature representation ability of the model, and to predict and classify better.
In the neck, an EFPN structure, replacing the original PAN structure, is proposed to deal with the information exchange between levels. This structure stacks data of multiple levels together, and fuses the multi-level feature information efficiently and comprehensively.
Wise-IoU, as a bounding box regression loss, includes a dynamic non monotonic mechanism, and designs a reasonable gradient gain allocation. Wise-IoU focuses more on ordinary quality samples to improve the generalization ability and overall performance of the network model. So, Wise-IoU is used in EE-YOLOv8 to reduce the occurrence of large or harmful gradients in extreme samples.
The design focus of EE-YOLOv8 structure is to balance the parameter quantity and recognition accuracy. That is, the goal of EE-YOLOv8 is to achieve better performance with fewer parameters. Therefore, a more accurate and powerful solutions for the diversity and complexity of real-world scenarios can be provided by these innovative designs in this paper.
Efficient multi‑scale receptive field module
The EMRF module is integrated into the backbone of the model to understand objects of different sizes or resolutions of images better, and to improve the accuracy of subsequent regression and classification tasks. In computer vision tasks, the features of different scales are crucial for understanding different parts of an image. Small scale features, such as edges and textures, help capturing detailed information; large-scale features, such as the overall shape and position of objects, help capturing global information. The traditional C2f module enhances object detection performance through cross-stage feature extraction. However, in complex pose estimation tasks, it lacks adaptive attention capabilities for multi-scale human keypoints. Specifically, in human keypoint tasks, the complexity of human poses is reflected in the scale variations of different body parts. Human keypoints can vary due to factors such as body size, posture, and camera distance. Multi-scale methods can simultaneously capture local details (e.g., joint positions) and global structures (e.g., body posture), effectively adapting to different body sizes and poses, and addressing various changes in different scenarios. Additionally, multi-scale methods reduce the impact of occlusion on key-point localization by integrating feature information from different scales in the image, thereby further minimizing noise interference and enhancing the model’s robustness. Therefore, the EMRF module is proposed to take place of the original C2f module of the backbone (shown in Fig. 2). By combining features of different scales, the limitations of single scale methods are overcome to improve the overall performance of the model.

EMRF module network structure.
The traditional multi-scale processing methods, such as pyramid method and multi-scale feature fusion etc., process the same image at different scales to capture features of different sizes and resolutions in the image. Although these methods can effectively improve the accuracy and robustness of image processing, they often require additional computational resources and parameters. EMA (Efficient Multi Scale Attention) (shown in Fig. 3) is a novel attention module31. It is designed to enhance the feature representation capabilities of deep convolutional neural networks in computer vision tasks, such as image classification and object detection. It proposes a novel cross-space learning approach and designs a multi-scale parallel sub-network to establish both short-term and long-term dependencies. Additionally, a general method is considered, which reshapes part of the channel dimensions into the batch dimension to avoid a form of dimensionality reduction through conventional convolutions. In the keypoint estimation task, we leverage multiple parallel branches with EMA to capture feature information at different scales. The large-scale branch rapidly locates keypoint regions, while the medium and small-scale branches progressively refine the positions. By weighting predictions from different scales, more accurate localization is ultimately achieved. Furthermore, the parallel processing of multiple branches optimizes computational efficiency compared to traditional methods.

EMA module network structure.
The calculation process of the EMA structure is described as follows:
where, reshape is to reshape the tensor, \(\:{X}_{h}\) and \(\:{X}_{W}\) are used to process feature information along the height and width dimensions, Cat is to \(\:{X}_{h}\) and \(\:{X}_{w}\) along the dimension, and matmul is the product of inputs and weights, Re_weight is to reweight the input features.
The calculation process of the EMRF structure is described as follows:
where, split represents segmentation along the channel dimension, Cat represents the connection of the channel dimension, and Conv indicates convolution.
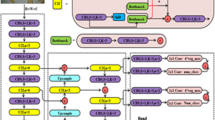
Expanded feature pyramid network
In the original YOLOv8 architecture, Path Aggregation Network (PAN)32, an improved feature pyramid structure, is used to enhance the traditional feature pyramid network (FPN)33. PAN adds a bottom-up path enhancement while retaining the top-down path of FPN. It is a deep learning model architecture for object detection and image segmentation. It constructs feature maps with a pyramid shape to process objects of different scales, and improves the detection capability of the model at different scales. The core idea of PAN is to fuse the P3, P4 and P5 feature levels by top-down and bottom-up paths, and to simultaneously focus on semantic information at different levels.
By the hierarchical fusion, the perception ability of model to targets with different scales is improved, and the accuracy of object detection is enhanced. However, the simple three-layer fusion cannot fully utilize the pyramid structure. The Expanded Feature Pyramid Network (EFPN) on the basis of PAN is proposed to further explore semantic information and enhance feature propagation in this paper (shown in Fig. 4).

Neck structure.

Differences between PAN and EFPN in terms of structure.
The fusion with a three-layer hierarchical structure is used by PAN to perceive targets of different scales. However, there are fewer down-samplings compared with the original input image, much feature information is still missed.
The P2 layer has not undergone deep convolutional processing. There are more local and detailed information in the P2 layer, and the detection of more object details and small-sized features can be achieved in the human target localization. At the same time, we find that multiple fusions between levels can make the feature information extracted by the shallow network be weighted and fused with the information extracted from the deep network for multiple times, which strengthens the information exchange between the shallow features and the deep features, thereby enhancing the propagation of features. The more up-sampled results and the same size feature maps, generated by bottom-up, are fused by expanding the horizontal connections of model, adding the top-down and bottom-up paths, the more effective the information transmission and integration is, and the better the different input changes and complex scenes can be adapted.
Therefore, in the designed EFPN structure, the P2, the expanded horizontal connections, both top-down and bottom-up paths, are combined to form a feature pyramid with more scales, and fuse more feature levels (shown in Fig. 5).
In the first top-down path, semantic information is passed from the high-level feature map to the low-level feature map:
where, \(\:{P}_{ij}\)represents the j-th layer feature map of the i-th top-down path. Upsample denotes upsampling the resolution of the high-level feature map to align with that of the low-level feature map. Cat indicates concatenating the upsampled feature map with the low-level feature map along the channel dimension.
In the first bottom-up path, detailed information is passed from the low-level feature map to the high-level feature map:
where, \(\:{N}_{ij}\) represents the j-th layer feature map of the i-th bottom-up path. Downsample denotes downsampling the resolution of the low-level feature map to align with that of the high-level feature map.
The final output multi-scale feature map is:
Bounding box regression loss function of dynamic focusing mechanism
The loss function is crucial for improving the performance of the model. The traditional loss function only considers the overlap between the predicted box and the true box, without taking into account the region between the two, which may result in bias in evaluating the results. Wise-IoU has introduced a new bounding box regression (BBR) loss function34, whose core principle is to enhance target localization performance by introducing a dynamic non monotonic focusing mechanism.
Firstly, in the original YOLOv8 network structure, the height and width gradients in the CIoU loss function are a pair of opposite numbers, which cannot increase or decrease simultaneously. It is unreasonable. Secondly, there are low-quality data samples, such as other background noise, the inconsistent aspect ratios etc., in dataset. The factors further exacerbate the negative effects of the training, and have a negative impact on the experiment. In Wise-IoU, the model is more sensitive to the geometric information by the additional weights, and the detection accuracy is improved. Therefore, the original CIoU is replaced with Wise-IoU in this paper.
Wise-IoU v1
There inevitably are low-quality samples in training data and geometric factors, such as distance and aspect ratio, the punishment for low-quality samples is exacerbated, and the generalization performance of the model is reduced. Therefore, a distance attention, based on distance metrics, is constructed for Wise-IoU v1, which has a two-layer attention mechanism, as shown in Eqs. (1) and (2).
where, \(\:{W}_{g}\), \(\:{H}_{g}\)are the size of the smallest bounding box. To prevent \(\:{\mathcal{R}}_{WIoU}\) to generate the gradients, which hinder convergence, \(\:{W}_{g}\), \(\:{H}_{g}\) are separated from the computed graph (superscript * indicates this operation).
Wise-IoU v2
Wise-IoU v2 refers to the method of focus loss, and adds monotonic focus constraints on the basis of Wise-IoU v1. So, the model can focus on difficult samples, and improve classification performance. However, during the training process of the model, the gradient gain decreases when \(\:{\mathcal{L}}_{IoU}\) decreases, the convergence speed of the later stages of training is slower. Therefore, the average value of \(\:{\mathcal{L}}_{IoU}\) is introduced as the normalization factor, as shown in Eq. (3).
Although the monotonic mechanism of Wise-IoU v2 improves stability, its strict constraints may limit the model’s adaptability to complex scenarios (such as occlusion targets and multi-scale targets). To this end, Wise-IoU v3 proposes dynamic non-monotonic focusing to further balance flexibility and stability.
Wise-IoU v3
The outliers are defined to reflect the quality of anchor boxes. The smaller the outlier, the higher the quality of the anchor box. So, a small gradient gain is assigned to concentrate BBR on a regular quality anchor box.
In addition, a smaller gradient gain is specified for anchor boxes with high outliers to effectively prevent the large harmful gradients of low-quality examples. So, a non-monotonic focusing coefficient β is constructed for Wise-IoU v1. When the β is constant, the gradient gain is the highest, and Wise-IoU v3 has dynamic non monotonicity. The gradient gain distribution strategy can be dynamically adjusted for improve the performance of Wise-IoU v3, as shown in Eqs. (4) and (5).
Wise-IoU v3 realizes the fine control of samples of different qualities through the outlier perception mechanism, especially in small target and occlusion scenes, which is significantly better than the previous two versions.
Experiment
Datasets and experimental settings
The performance analysis of EE-YOLOv8 is conducted on MS COCO 2017. The MS COCO 2017 data-set is a widely used large-scale computer vision dataset, in which the publicly available human keypoint dataset has been widely applied in the field of human pose estimation. The dataset contains over 200,000 images and 250,000 human instances labeled with 17 key points.
The experimental environment configuration of this paper is shown in Table 1. The PyTorch version 1.13.1 + cu117 deep learning framework, and CUDA 12.0 Hardware Acceleration Tool are used, with an Intel(R) Core (TM) (TM) i5-13600KF CPU, 64GB memory, NVIDIA GeForce GTX 4090 graphics card, and Windows 11 operating system; the software programming environment was Python 3.9.
Specifically, the model is trained for 500 epochs to ensure comprehensive learning. The learning rate is 0.01 to balance convergence speed and accuracy, the momentum is 0.9, the weight decay of optimizer is 0.0005, batch size is 16, and the other training parameters is set to the default values of YOLOv8 network. Furthermore, a stochastic gradient descent (SGD) optimizer is used to effectively update model parameters for processing large-scale datasets. It calculates the gradient of mini-batch samples, gradually updates the model parameters, and minimizes the value of the loss function, providing good stability and generalization performance in model training.
Evaluate metrics
The precision (P), recall (R), average precision (AP), and parameter count are used as the main evaluation criteria.
where, TP is the number of the correctly predicted positive samples, which reflects the model performance of detecting positive samples correctly; FN represents the number of positive samples that were incorrectly predicted as negative, which reflects the model performance of detecting positive samples erroneously; FP represents the number of negative samples that were incorrectly predicted as positive samples, which reflects the model performance of detecting negative samples erroneously; AP metrics are further divided into AP50 and AP50-95. AP50 represents the average accuracy at 50% IoU, while AP50-95 represents the average accuracy across different IoU values (ranging from 50 to 95 in steps of 5, such as 50, 55, 60, 65, 70, 75, 80, 85, 90, and 95).
Experimental results
The experiments are conducted on the MS COCO 2017 dataset, and the performance of EE-YOLOv8 is compared with the classical and state-of-art human pose detection methods, such as HighHRNet, DEKR, YOLO-Pose, RTMO, etc. (shown in Table 2). It can be seen indicate that the parameter number of EE-YOLOv8 is the lowest of all, and AP50 of EE-YOLOv8 is only a little lower than that of YOLO-Pose24 and YOLOv5m6-Rlepose27, whose parameter number are almost twice that of EE-YOLOv8. Therefore, EE-YOLOv8 can acquire high accuracy with the lowest parameters.
Ablation experiments
A series of experiments are conducted to evaluate the impact of different components on network performance on the basis of YOLOv8-Pose. Wise-IoU, EMRF, and EFPN are sequentially added; and then all three components are added simultaneously. AP50, AP50-95, and AR are used as indicators to evaluate the modified models (as shown in Table 3).
Wise-IoU adopts a dynamic non monotonic focusing mechanism, which mitigates the negative impact of low-quality data samples on training and improving experimental speed and accuracy by changing the gradient gain through the variation of dispersion. From Table 2, it can be seen that no additional parameters are added with the introduction of Wise-IoU. From Table 3, it can be seen, after the CIoU is replaced by Wise-IoU, the AP50 and AP50-95 are improved. However, the improvement is not very obvious. From further experiments, it can be seen, the train epoch reduced from 100 to 90 for AP50 = 80 by Wise-IoU. Therefore, the main function of Wise-IoU is to accelerate the convergence speed of the model.
After introducing EMRF, both AP50 and AP50-95 are further improved, though the improvement is also modest. EFPN, the main innovation of this paper. After the network structure is replaced with EFPN, the performance of the model was significantly improved. Especially, comparing YOLOv8 + EFPN withYOLOv8m-Pose, the AP50-95 is 5.1% higher, and the robustness is improved. The combination of EFPN with EMRF results in significant improvements in AP50 and AP50-95, and the combination with Wise-IoU yields even greater improvements. Thus, the importance of EFPN is clearly demonstrated.
Finally, compared with the YOLOv8-Pose, the impact of the combination of three components is analyzed. Of EE-YOLOv8, AP50 increases 3.3%, AP50-95 increases 5.8%, AR increases 3.8%, and the performance of human pose estimation tasks was significantly improved. Therefore, the combination of Wise-IoU, EMRF, and EFPN components plays a crucial role in human pose estimation tasks.
Characteristic pyramid structure ablation experiment
EFPN is integrated into the YOLOv8-Pose model, and compared with three other state-of-art network structures: PAN, BiFPN, and GFPN. By the designed EFPN, the feature information can be better integrated to improve the performance and robustness of human keypoint detection tasks. In Table 4, it can be seen that EFPN has the highest AP50, AP50-95 and AR, which are 88.1, 64.9 and 83.4 respectively. So, EFPN outperforms other network structures.
Loss function ablation experiment
To verify the impact of different loss functions on the model, an experimental analysis of CIoU, DIoU, SIoU, and Wise-IoU on the basis of YOLOv8-Pose is conducted. As shown in Table 5, the model replaced with the Wise-IoU loss function outperforms other loss functions in both AP50 and AP50-95 metrics, which are 86.0 and 59.9 respectively. This indicates that Wise-IoU more accurately handles complex scenes with overlapping objects of different sizes and aspect ratios.
Visual analytics
Figure 6 shows single-person and multi-person scenes, along with a visual comparison between the benchmark models YOLOv8-Pose and the EE-YOLOv8 methods. The positions that cannot be correctly recognized are highlighted by yellow circles. In single person scenes, the recognition ratio of the two methods is roughly the same. However, in multi person scenes, there are many missed or false detections of YOLOv8-Pose, the accuracy should be improved further. The EE-YOLOv8 outperforms multi person scenarios, its recognition accuracy is higher and its keypoint information is more precise.

Comparison of test results.
Conclusion
In this article, a human pose estimation network based on YOLOv8 framework with Efficient Multi-scale Receptive Field (EMRF) and Expanded Feature Pyramid Network (EFPN), EE-YOLOv8, is proposed in this paper. Firstly, EMRF module is used to enhance the feature representation capability of the model further. Secondly, EFPN is designed to optimize information exchange between levels more efficiently, and to enhance data integration at different scales. Finally, the IoU is instead of Wise-IoU to improve the detection accuracy of the model by measuring the overlap between the predicted bounding box and the real bounding box more accurately.
Experimental results on the MS COCO 2017 dataset demonstrate that EE-YOLOv8 achieves an AP50 of 89.0% and an AP50-95 of 65.6%, which are 3.3% higher than those of YOLOv8-Pose. Therefore, compared with YOLOv8-Pose, the EE-YOLOv8 can achieve much higher accuracy at the cost of almost half parameters, it outperforms much better.
Although EE-YOLOv8 performs well on the MS COCO 2017 dataset, the performance is evaluated on a single dataset, which may introduce potential biases. Furthermore, in some complex scenarios, it is found that EE-YOLOv8 does not perform well when handling abnormal poses or occluded parts. So, some further work should be done to analyze the performance of model on other datasets, and to find out the way to deal with abnormal poses or occluded parts further.
Data availability
The datasets used and/or analysed during the current study available from the corresponding author on reasonable request. The datasets and images used in this paper are all publicly available datasets. Here are the links to the publicly available datasets: https://cocodataset.org/#download.
References
Liu, Z. et al. Deep dual consecutive network for human pose estimation. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 525–534 (2021).
Korkalo, O. Systems and methods for multiple-view and depth-based people tracking and human–computer interaction. (2024).
Andrushchenko, M. et al. Hand movement disorders tracking by smartphone based on computer vision methods. Informatyka Automatyka Pomiary W Gospodarce I Ochronie Środowiska. 14, 5–10 (2024).
Edriss, S. et al. The role of emergent technologies in the dynamic and kinematic assessment of human movement in sport and clinical applications. Appl. Sci. 14 (3), 1012 (2024).
Alazeb, A. et al. Effective gait abnormality detection in parkinson patients for multi-sensors surveillance system. IEEE Access. (2024).
Zhang, W. et al. Wearable sensor-based quantitative gait analysis in Parkinson’s disease patients with different motor subtypes. NPJ Digit. Med. 7 (1), 169 (2024).
Wastupranata, L. M., Kong, S. G. & Wang, L. Deep learning for abnormal human behavior detection in surveillance videos—A survey. Electronics. 13 (13), 2579 (2024).
Lee, H. et al. Real-time human group detection and clustering in crowded environments using enhanced multi-object tracking. IEEE Access. (2024).
Lee, H., Xu, Y. & Porterfield, A. Consumers’ adoption of AR-based virtual fitting rooms: from the perspective of theory of interactive media effects. J. Fashion Mark. Manag. Int. J. 25 (1), 45–62 (2021).
Shahabadkar, K. Embodied Posture Analysis for Industry Operator Safety Enhancements. (Swinburne, 2024).
Tian, Y., Li, N. & Mao, B. Video behavior detection based on optimized alphapose in electricity facility management. In IEEE/WIC/ACM International Conference on Web Intelligence and Intelligent Agent Technology, 364–367 (2021).
Zheng, C. et al. Deep learning-based human pose estimation: A survey. ACM Comput. Surveys. 56 (1), 1–37 (2023).
Cheng, Y., Wang, B. & Tan, R. T. Dual networks based 3d multi-person pose estimation from monocular video. IEEE Trans. Pattern Anal. Mach. Intell. 45 (2), 1636–1651 (2022).
Dong, C., Tang, Y. & Zhang, L. HDA-pose: a real-time 2D human pose estimation method based on modified YOLOv8. Signal. Image Video Process. 1–17 (2024).
Ke, L. et al. DetPoseNet: improving multi-person pose estimation via coarse-pose filtering. IEEE Trans. Image Process. 31, 2782–2795 (2022).
Xiao, B., Wu & Wei, Y. Simple baselines for human pose estimation and tracking. In Proceedings of the European Conference on Computer Vision (ECCV) (2018).
Sun, K. et al. Deep high-resolution representation learning for human pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 5693–5703. (2019).
Xu, Y. et al. Vitpose: simple vision transformer baselines for human pose estimation. Adv. Neural. Inf. Process. Syst. 35, 38571–38584 (2022).
Cheng, Y. et al. Bottom-up 2D pose estimation via dual anatomical centers for small-scale persons. Pattern Recogn. 139, 109403 (2023).
Cao, Z. et al. Realtime multi-person 2d pose estimation using part affinity fields. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 7291–7299 (2017).
Cheng, B. et al. Higherhrnet: Scale-aware representation learning for bottom-up human pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 5386–5395 (2020).
Geng, Z. et al. Bottom-up human pose estimation via disentangled keypoint regression. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 14676–14686 (2021).
Wu, J. & Lee, H. J. Optimizing offset-regression by relay point for bottom-up human pose estimation. Appl. Intell. 53 (24), 30535–30551 (2023).
Ding, J. et al. Research on human posture estimation algorithm based on YOLO-Pose. Sensors. 24 (10), 3036 (2024).
Tang, X. F. & Zhao, S. The application prospects of robot pose Estimation technology: exploring new directions based on YOLOv8-ApexNet. Front. Neurorobot. 18, 1374385 (2024).
Shi, H. et al. Detection and recognition of digital instrument in substation using improved YOLO-v3. Signal. Image Video Process. 17 (6), 2971–2979 (2023).
Jiang, Y. et al. YOLO-Rlepose: improved YOLO based on Swin transformer and Rle-Oks loss for multi-person pose estimation. Electronics. 13 (3), 563 (2024).
Lu, P. et al. RTMO: towards high-performance one-stage real-time multi-person pose estimation. Arxiv 2023. arxiv preprint arxiv:2312.07526.
Hussain, M. YOLO-v1 to YOLO-v8, the rise of YOLO and its complementary nature toward digital manufacturing and industrial defect detection. Machines. 11 (7), 677 (2023).
Zhu, J. et al. YOLOv8-C2f-Faster-EMA: an improved underwater trash detection model based on YOLOv8. Sensors. 24 (8), 2483 (2024).
Ouyang, D. et al. Efficient multi-scale attention module with cross-spatial learning. In ICASSP 2023–2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 1–5 (IEEE, 2023).
Liu, S. et al. Path aggregation network for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 8759–8768 (2018).
Lin, T. Y. et al. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2117–2125 (2017).
Tong, Z. et al. Wise-IoU: bounding box regression loss with dynamic focusing mechanism. Arxiv Preprint Arxiv :230110051 (2023).
Funding
This work was supported by the Huzhou Normal University scientific research start-up fund, and National Natural Science Foundation of China under Grant No. 62473278.
Author information
Authors and Affiliations
Contributions
Each author contributed to this article. W.C. and H.X. wrote the manuscript and did the performance analysis. S.C., Y.M., and L.W. supervised this study.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Cai, S., Xu, H., Cai, W. et al. A human pose estimation network based on YOLOv8 framework with efficient multi-scale receptive field and expanded feature pyramid network. Sci Rep 15, 15284 (2025). https://doi.org/10.1038/s41598-025-00259-0
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-00259-0
