
Abstract
This paper introduces 3D-QTRNet, a novel quantum-inspired neural network for volumetric medical image segmentation. Unlike conventional CNNs, which suffer from slow convergence and high complexity, and QINNs, which are limited to grayscale segmentation, our approach leverages qutrit encoding and tensor ring decomposition. These techniques improve segmentation accuracy, optimize memory usage, and accelerate model convergence. The proposed model demonstrates superior performance on the BRATS19 and Spleen datasets, outperforming state-of-the-art CNN and quantum models in terms of Dice similarity and segmentation precision. This work bridges the gap between quantum computing and medical imaging, offering a scalable solution for real-world applications.
Similar content being viewed by others
Introduction
Volumetric Segmentation of Medical Images1 is in trends from the recent few years in the field of Medical Research and Health Care. It involves dividing a 3D Medical Image into distinct regions based on characteristics like intensity, texture or shape. This is a vital function of the model as it helps in rationalizing the structures, organs, tissues as well as other details that are abnormal in the images. But the process of Manually segmenting volumetric images is quite challenging and demanding for large databases and it needs expertise which can’t be available in all cases and even if they are available there is no assurance that the results will be free from mistakes. For that, automated image segmentation techniques were introduced to minimize human intervention and reducing errors. Region Based Segmentation Edge Based Segmentation are the traditional methods used in medical image segmentation, but these methods are not efficient in providing full accuracy due to their complexity and they are also sensitive to noise.
With recent advancements in Deep Learning, traditional techniques are introduced in integration with Deep Learning Models for higher accuracy. Supervised CNN2 was introduced and achieved high accuracy in 2D image segmentation3 but due the limitation that it segments the images in slice by slice manner, which limits the processing of the segmented images, With some minor changes 2D-CNNs4 are introduced to overcome the limitation of the classical CNNs, 2D-CNNs are able to segment the image in 2D slices, which directly increases their accuracy but it are only limited to 2D data and can’t capture 3D information present in the volumetric data, So 3D-CNNs5were introduced that outperforms on limitations of 2D-CNNs with comparatively high convergence and are able to segment the images and to provide a 3D view. It is highly capable of extracting extensive features from the volumetric 3D images and segmenting them more accurately. Researchers developed specialized architectures and training methodologies to handle the various challenges which are proposed by 3D volumetric data such as the problem of memory consumption and complexity of the data, it have 3D convolution and pooling layers to analyze complex patterns across multiple frames and have improved efficiency and performance over the 2D CNNs, but 3D-CNNs also suffer with various limitations, such as lack of interpret ability, problem of vanishing gradients and over fitting with slow convergence.
Currently Quantum Inspired Networks6 (QINNs) have been introduced and its simply integration of Deep Learning Models and Quantum Computing which overcomes the limitations of traditional Networks, it adds faster information processing and solve complex problems in volumetric segmentation with expert-level accuracy. Researchers started to explore and develop new quantum neuron models, which directly enhance the power of traditional networks. New and advanced quantum inspired algorithms are introduced, which increases efficiency through quantum back-propagation algorithms and quantum encoding algorithms7, which gives the model more resources, uses qubits to represent the data in multiple states simultaneously due to the superposition property of qubits, and use weight vectors to represent the relationships between the different layers of the model, Quantum gates are used to manipulate qubits to extract information from them, and are used in the training process of the QINNs. However, QINNs suffer from slow convergence, mainly because they utilize a complex quantum back-propagation algorithm in training’s of their model, and also due to the use of fixed activation axes. QINN models are limited to gray-scale image segmentation. With recent advancements in technology, optimized QINNs are going to be introduced.
The proposed model, is tailored and tested on the given benchmark datasets such as the BRATS 2019 dataset namely the (Multi modal Brain Tumor Image Segmentation)8 and the Spleen dataset.
The BRATS19 dataset8 mainly consists of the MRI volumes of brain focusing on brain tumor images. It totally includes 315 MRI volumes with 240 volumes of high-grade gliomas and also 75 volumes of low-grade Gliomas with multiple modalities including the T1-weighted, T1-weighted with contrast-enhanced, T2-weighted and FLAIR images with a resolution of 240 × 240 pixels per slice. Whereas the Spleen dataset mainly consists of 61 CT Scans 41 for training and 20 for testing of the patients undergoing chemotherapy treatment for liver. Each of the CT Scan volume contains variable number of slices of 512 × 512 resolutions.
The scope of the proposed model is helping in extending domain of semantic segmentation for volumetric medical data, mainly focusing on voxel-wise processing and analysis of complex data which helps in providing expert level accuracy in comparison to the traditional models. The models architecture comprises of the following layers: first input layer, secondly the intermediate or the hidden layer and at last output layer which is connected through III order neighborhood-oriented design to gather complex relationship between the voxels. By incorporating the quantum inspired techniques and the cross mutation tensor ring decomposition, the model aims to enhance the convergence and segmentation accuracy. Proposed model addresses main challenges such as slow convergence, gradient instability and lack of interpret-ability faced by classical networks and aim to accelerate the segmentation process with high precision and reduces the problem of distorted segments.
The model includes qutrit encoding, cross mutated tensor ring decomposition voxelwise information processing These techniques enable the model to process high-dimensional data efficiently, which is helpful for feature extraction the weight vectors are represented using tensor ring representation structure the input neurons that have pixel information are portrayed as qutrits as well as the quantum gates are utilized to express their inter-connected weights, which are used to manipulate qutrits the 3d-QTR Net model is centered on counter-propagation which is bi-directional for more rapid convergence, Adaptive hyper-parameters are linked with gray scale image segmentation and information sensitive to voxel is demonstrated in quantum form The proposed model demonstrates superior performance compared to traditional models, showcasing its potential for advancement in segmentation tasks The primary contributions of this purposed model are highlighted below:
(1) In this work, the authors has come up with a qutrit inspired self-supervised pixel-wise cross-mutated tensor ring network for segmentation of volumetric data.
(2) To overcome correlation and the entanglements between model parameters, a cross mutated tensor ring structure is used for regularization of data, which helps in gathering more complex relationship information from data.
(3) For faster convergence bi-directional counter propagation is used.
(4) Qutrit’s extra states allow the quantum model in encoding the quantum neurons with higher dimensions and offer better representation which enables faster counter propagation between these states.
(5) An adaptive voxel-wise Q-sigmoid (Vox-QSig)9 activation function is used.
(6) In this work we used a advanced 3rd order S shaped neighborhood neuron architecture for pixel-wise handling of three dimensional image data.
The arrangement of the next sections is structured as follows: overall review of deep learning and quantum based segmentation methods with overview of challenges faced by them is showcased in “Prior literature review”. “Quantum computing and it’s fundamentals” describes main fundamentals of quantum computing and introduces the architecture of the QTR-Net, in “The architecture”. Experimental analysis, which includes dataset experimental setups and outcomes, is provided in “Experimental analysis” the advantages and the shortcoming’s of the author’s model is presented in Section VI. At last, the results and the conclusion are provided in “Conclusion”.
Prior literature review
In this section we will trace the development from the beginnings of volumetric image segmentation1 to the changes it has undergone. This section is divided into three main topics: traditional methods for volumetric medical image segmentation and their limitations, advancements in deep learning models and integration with traditional models, integration of deep learning models and quantum computing.
Originally, image segmentation was performed manually by humans. This task requires an expert to continuously monitor the work until the segmentation is complete, which is very time-consuming if the data set is very large. To minimize errors and human intervention, automated methods are therefore proposed, such as region-based segmentation. In this method, the images are segmented based on the features of a region and each region is classified differently. In the second method, edge-based segmentation, the segmentation is proposed based on the edges of the different regions and these are classified.
In recent years, deep learning has made various advances, and then traditional deep learning models, which are a combined version of both traditional models and deep learning models, and deeply supervised Convolutional Neural Networks (CNN)2, which have higher segmentation accuracy, but segment the images in slice by slice manner, which limits the processing of the segmented images, with some minor modifications, we then proposed 2D CNNs4that can segment the images into 2D slices, which helps in faster processing of the data but still lags behind in many factors as we are not able to utilize the 3D features of MRI and CT scans, hence a powerful model was introduced, the 3D CNNs5 that are able to segment the images and provide a 3D view and help in understanding. It is highly capable of extracting extensive features from the volumetric 3D images and segmenting them more accurately, but suffers from slow convergence10, that distorts the image segments and makes it difficult to distinguish features such as shape, size and location, and as the feature levels are increased it starts to suffers with vanishing gradient problem.
Currently, quantum-inspired neural networks (QINNs) as an integrated idea is in trends, which adds faster information processing to the capabilities of conventional neural networks. QINNs11 have gained acceptance in solving complex problems in volumetric image segmentation with expert-level accuracy. It has addressed all the challenges that were presented by the earlier models by employing quantum inspired algorithms that help in presenting simplicity of the model along with enhanced convergence rate, along with introducing the abstraction of learning processes as implemented in quantum computers. High computing costs, error rates in quantum processes, and a lack of quantum hardware are some of the obstacles to scaling quantum-inspired models for practical implementation. The scalability of existing hybrid quantum-classical systems is hindered by energy consumption, memory constraints, and noisy qubits. For real-world applications, developments in error correction methods and quantum computers are essential6. It provides more capability to the model, encoding the data in qubits leads to encoding in several states at once because of the superposition of qubits, weight vectors that represent the connections of one layer to another layer in the model, quantum gates for manipulations on qubits to get information out of them, and in the training process of the quantum inspired model named QNN in Fig. 3. However, QINNs suffer from slow convergence10, mainly due to the complex quantum back propagation algorithm12 used to train the model, and due to the use of fixed activation axes, QINN models are limited to gray scale image segmentation. To overcome the traditional models, new models have recently been developed.
Despite the great success of newly developed models, the motivation for the proposed 3D quantum-inspired self supervised tensor mesh is as follows:
(1) Additional efforts are required to optimize the hyperparameters of the conventional neural networks for deep learning.
(2) The inability of conventional CNN models to capture complex patterns and structures within images for accurate segmentation.
(3) The major drawbacks of the QINN models include slow convergence and the employment of fixed activation functions that restrict the usage of these models only up to the segmentation of gray-scale image data.
(4) QINN models characterized by high complexity and low interpret ability resulted in low accuracy of volumetric image segmentation.
Addressing them authors have offered a Tensor Shallow Neural Network architecture inspired by quantum which is self supervised for the segmenting volumes of medical data for overcoming problems associated with complex 3D CNNs.
Quantum computing and it’s fundamentals
The fundamental idea of quantum computing offers the features such as superposition, decoherence, coherence and quantum entanglement which helps in implementation of quantum algorithms13. Early classical systems are based on binary logic, Now most of the quantum systems are based on multiple levels. States of these systems are called as qudits (d-level system).
(a) Qubits and qutrits.
The latest quantum d-level system can be represented as combination of d basis states.
Here, every coefficient represents the likelihood that the system will be in the matching basis state. When we use s = 2, it’s the traditional quantum two-state system, which is described as a qubit
Here, the authors used a three-level quantum system with s = 3. Three states described as states 0〉,1〉 and 2〉are used for every qutrit. The superposition of all three states constitutes the pure state of a qutrit, which is represented as:
(b) Quantum Operations.
To execute qutrit quantum computation, we mainly require the set of unitary operations and perform measurements. GellMann14 observable are used, it naturally generalizes the qubit Pauli operations and it describes a measurement on qutrits.
here \(\:\theta\:={e}^{j\frac{2{\Pi\:}}{d}}\) represents dth root of unity. Here X and Z generalized Pauli group performs shifting of one state to the next and multiplies the states with a phase. To create superposition in the states Hadamard gate is used on qutrits.
The observables we are going to measure are the GellMann14 observable. there are 3 × 3 × 3 for one candidate voxel hermitian observables which we generalize qubit Pauli group.

Initialize neighboring qutrits neurons and there corresponding central qutrit neuron.
The architecture
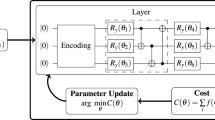
Here a 3D qutrit based model which is shown in Fig. 1, self-supervised with a tensor ring network is suggested to perform automatic pixel based segmentation of the medial data. The three-dimensional QTRNet architecture consists of three layers of volumetric qutrit neurons arranged throughout the architecture layers. The volumetric input (H x W x D) is first normalized using the min - max normalization before transforming into qutrits as:

3D Qutrit Model. For all Central quantum neurons, which is in the middle of all neighboring qutrits, It form the S neighborhood-oriented architecture with inter-layer connections, Information from volumetric data is mapped to qutrits with the help of angle encoding. The weights interconnected between input and the hidden or the intermediate layers are represented as \(\:\mid\:Op{t}_{b,a}^{lyr,dpt}>\), then for the output between hidden layer and the output layer is represented as \(\:\mid\:Op{t}_{a,c}^{lyr,dpt}>\),similarly for the output and the intermediate layer \(\:\mid\:Op{t}_{c,a}^{lyr,dpt}>\) at a layer lyr with depth dpt. Then the interconnected weights are transformed in quantum formalism with rotation gates with as rotational angle, which is determined by utilizing the fuzzy relative difference15of intensities between central pixel and neighbor hood pixels in the S shaped architecture with quantum neurons inside a \(\:3\text{*}3\text{*}3\) structured voxel, here there are multiple such blocks of S-connected neighborhood neurons so fuzzy15 intensities form all the blocks are taken through the outcome of there respective central qutrit neuron L1,L2,L3.Ln.
Then propagated through the three-dimensional input qutrit layer to subsequent intermediate layer and output layer of the architecture and then processing takes place in S-structured voxels. Inter layer connections between the layers is formed using a 3rd order S-connected pixel wise neighborhood architecture.
Here the spatial feature from the qutrit neurons as neighborhood pixels are extracted and transmitted as inputs which are guided by a voxel multilevel sigmoid function (Vox-Sig)9 and the accumulation at the next layer’s candidate central neuron with slope as λ and activation as ϑ.
here \(\:{\kappa\:}_{\varphi\:}\) is described as the multi-response exhibited by S shaped III order neighbor hood voxels and it is expressed as:
here the \(\:{\beta\:}_{\varphi\:},{\beta\:}_{\varphi\:-1}\) are the \(\:\varphi\:th,\varphi\:-1\) response outcomes of the neighborhood architecture and the \(\:{\chi\:}_{s}\) is the contribution of the gray-scale pixels, which is defined as:
Then the information by voxels is counter propagated by the output layer and transmitted to the intermediate layer for further processing of the data. Qutrit based neurons from every layer and then reassigned through transformation gate, the weights between the layers are being mapped by Phased Hadamard gates which are described as:
the quantum fuzzy thresholding16 is employed to ascertain how the information is propagating both forward and backward between layers by self-organizing weight matrices. Now the product between the quantum states
and quantum weights
is given as:
where \(\:{\tau\:}_{d}\) and \(\:{H}_{d}\) are transformation and Hadamard gate.
The dimensions are reduced using the tensor ring decomposition17 which is one of the best data compression techniques which enhances the representation of weight matrices, the loss function applied in the architecture is expressed in terms of weight matrices’ root mean squared error. with the depth as dt in a given uth epoch which is determined by the phase angles specified and with the help of all these components, the whole 3D-QTRNet model is designed for volumetric segmentation.

Propagating Relationships in Qutrit Model with Cross-Mutated Tensor Ring Network.
Experimental analysis
A. Dataset descriptions
In this proposed 3D QTR-NET all the experiments have been performed using the Multi modal brain tumor segmentation dataset8) and the Spleen dataset. The dataset mainly consists 315 MRI volumes. Each pf the volumes mainly consists of 155 slices having a resolution 240 × 240 along with the original ground truth (mask labels) as well as 4 distinct MRI modalities t1, having FLAIR, t1 with enhanced contrast (t1-ce) and t2. Three primary classes of annotation are applied to the segmented labels: non-enhancing tumor region, tumor-enhancing tumor region, and tumor core (TC). The Decathlon Medical Segmentation is a free for all challenge mainly for testing of various ML algorithms generally utilized for tasks involving segmentation. The segmentation of the Spleen images is a task of MSD which mainly consists of 61 CT scans: 41 for training and 20 for the purpose of testing the individuals getting liver chemotherapy. A varied number of slices with 512 × 512 resolutions are present in each CT Scan volume.
B. Experimental setup
In this given work, experiments were conducted by employing 3D QTR-Net on MR brain images taken from the BRATS8 of size 240 × 240 and the Spleen dataset of size 512 × 512 with super computer with GPU integration. The proposed 3D-QTR-Net architecture is implemented using multi-class levels of the voxel sigmoid activation function9. The main steepness varied between the ranges from 0.24 to 0.25, with the learning rate of 0.001 and the S = 26 (3 × 3 × 3) neighborhood pixels providing optimal performance. Mainly to identify a whole tumor, the image segments are then resized in order to correspond with the mask’s dimensions, with result 1 showcasing the tumor region and result 0 showcasing the background. Dice Similarity: A standard assessment technique is used to evaluate segmented images voxel-to-voxel in comparison with the original image mask. Each of the 2D pixels is then predicted as true positive, true negative, false positive, and false negative. The goodness measure (predictive positive value) (PPV), accuracy (AC), dice similarity (DS), and sensitivity (SS) are used to evaluate results.
Here we are looking at the metrics used to evaluate the results provided by the models it comprises of the following:
-
True Positive (TP): The condition when the actual result is 1(True) and the model truly predicts it to be 1(True).
-
True Negative (TN): The condition when the actual result is 0(False) and the model truly predicts it to be 0(False).
-
False Positive (FP): The condition when the actual result is 0(False) and the model truly predicts it to be 1(True).
-
False Negative (FN): The condition when the actual result is 1(True) and the model truly predicts it to be 0(False).
-
Precision: It is the measure of positively true predictions out of all positive predictions. It’s the ratio of true positives to sum of true positives and false positives.
-Accuracy: It is a measure of instances that are classified correctly to total instances and is calculated as the ratio correct predictions to total predictions.
-Recall (Sensitivity): Recall, also known as sensitivity. measures the proportion of predictions which are truly positive out of total positive predictions in the dataset. It’s simply ratio of true positives to the sum of true positives and false negatives.
-Specificity: It mainly measures of the ratio of true negative prediction over all the actual negative instances. It can be calculated by taking the ratio of true negatives to addition of false positive and true negative values.
-Dice Similarity Coefficient (F1 Score): It is frequently used to compare the similarity of predicted image and segmentation masks in tasks such as segmentation. It mainly tries to measure the overlap between two image masks which are mostly the predicted image and the segmentation mask (ground truth). It is the ratio of twice the intersection of the two sets to the sum of the cardinalities of the sets, with 1 indicating perfect overlap and 0 indicating no overlap.
C. Experimental results
In this configuration, the experiments are conducted, and the outcomes are reported with numerical analysis utilizing all these models 3D-QTRNet, DRINet18, 3D-UNet19,3DQNet6, and VoxResNet20 using the Spleen and BraTS2021 datasets shown in Fig. 2. The provided Tables 1, 2, 3, 4 and 5 presents complete Spleen segmentation and also in the Fig. 5. This proves that the proposed model, 3D-QTRNet, performs optimally for spleen segmentation of CT volumes using the activation method guided by the 26 neighboring voxel intensities over following evaluation matrices: (AC, PV, SS, DC)21,22,23.

Results on the BraTS2021 dataset.
Table 5 provides us the quantitative results which are obtained by using the proposed 3D-QTRNet, DRINet18, 3D-UNet19,3D-QNet6, and VoxResNet20 on evaluating the AC, DS, SS and PV on all modalities if the BraTS dataset.
It has been observed that the proposed model, 3D-QTRNet, outperforms the convolutional models (DRINet18, 3D-QNet6, 3D-UNet19, and VoxResNet20) in the prediction of the complete brain tumor. 3D-QTRNet is experimented on classical systems; as higher quantum computing tasks such as Q-parallelism13 and many more are not yet been fully explored. Comparing the developed quantum model to the classical CNN models, requires fewer trainable parameters.
Conclusion
The 3D qutrit inspired network is fully self-supervised and it’s architecture comprises of a S-connected neighbour hood topology for processing the voxel to voxel information in segmentation of brain tumor volumes (MR) and the Spleen CT volumes are showcased in above sections (Figs. 3, 4, 5). In order to display the efficiency of proposed 3D-QTRNet model it is validated against the BraTS-2021 and the Spleen dataset (Fig. 4) which promotes automatic segmentation of volumetric images well in comparison to other recent cutting-edge techniques. The proposed model is capable of being used immediately in any application, whereas the other models for deep learning encounter various challenges. However, the model is unable to yield extremely optimal outcomes in the segmentation of multi-level data due to hardware limitations and the undiscovered domain of quantum computing. The authors are working in extend and up-scale the 3D-QTRNet model to yield more optimal segmentation outcomes.

Training and validation loss with dice coeff value for BraTS dataset.

Results on the spleen dataset.

Validation loss with dice coeff value for spleen dataset.
Data availability
The datasets used in the current study can be download from below link. https://www.kaggle.com/datasets/balraj98/modelnet40-princeton-3d-object-dataset https://github.com/ierolsen/Brain-Tumor-Segmentation-BraTS-2019 https://www.kaggle.com/code/shivamb/3d-convolutions-understanding-use-case.
References
Suetens, P. Fundamentals of Medical Imaging (Cambridge University Press, 2017).
Kshatri, S. S. & Singh, D. Convolutional neural network in medical image analysis: A review. Arch. Comput. Methods Eng. 30 (4), 2793–2810 (2023).
Huang, M. et al. Brain tumor segmentation based on local independent projection-based classification. IEEE Trans. Biomed. Eng. 61 (10), 2633–2645 (2014).
Salehi, A. W. et al. A study of Cnn and transfer learning in medical imaging: advantages, challenges, future scope. Sustainability 15 (7), 5930 (2023).
Niyas, S., Pawan, S., Kumar, M. A. & Rajan, J. Medical image segmentation with 3d convolutional neural networks: A survey. Neurocomputing 493, 397–413 (2022).
Konar, D., Bhattacharyya, S., Gandhi, T. K., Panigrahi, B. K. & Jiang, R. 3-d quantum-inspired self-supervised tensor network for volumetric segmentation of medical images. IEEE Trans. Neural Networks Learn. Syst. (2023).
Simoes, R. D. M., Huber, P., Meier, N. & Smailov, N. Experimental evaluation of quantum machine learning algorithms. IEEE Access. 11, 6197–6208 (2023).
Menze, B. H. et al. The multimodal brain tumor image segmentation benchmark (brats). IEEE Trans. Med. Imaging 34(10), 1993–2024 (2015).
Konar, D., Bhattacharyya, S., Gandhi, T. K., Panigrahi, B. K. & Jiang, R. 3D quantum-inspired network with q-voxsigmod for volumetric segmentation of brain mr images. Authorea Preprints (2023).
Ghosh, A., Pal, N. & Pal, S. Self-organization for object extraction using a multilayer neural network and fuzziness measures. IEEE Trans. Fuzzy Syst. 1 (1), 54 (1993).
Menneer, T. & Narayanan, A. Quantum-inspired neural networks. In Proceedings of the Neural Information Processing Systems. Vol. 95. 27–30 (1995).
Abbas, A. et al. On quantum backpropagation, information reuse, and cheating measurement collapse. Adv. Neural. Inf. Process. Syst. 36 (2024).
Chuang, I. L. & Yamamoto, Y. Simple quantum computer. Phys. Rev. A. 52 (5), 3489 (1995).
Valtinos, T., Mandilara, A. & Syvridis, D. The gell-mann feature map of qutrits and its applications in classification tasks. In Quantum Computing, Communication, and Simulation IV. Vol. 12911. 229–247. (SPIE, 2024).
Singh, S. K., Abolghasemi, V. & Anisi, M. H. Fuzzy logic with deep learning for detection of skin cancer. Appl. Sci. 13 (15), 8927 (2023).
Wahid, F. F. et al. A novel fuzzy-based thresholding approach for blood vessel segmentation from fundus image. J. Adv. Inform. Technol. 14 (2), 185–192 (2023).
Sedighin, F. Tensor methods in biomedical image analysis. J. Med. Signals Sens. 14 (6), 16 (2024).
Chen, L. et al. Drinet for medical image segmentation. IEEE Trans. Med. Imaging. 37 (11), 2453–2462 (2018).
Çiçek, O., Abdulkadir, A., Lienkamp, S. S., Brox, T. & Ronneberger, O. 3d u-net: Learning dense volumetric segmentation from sparse annotation. In Medical Image Computing and Computer-Assisted Intervention – MICCAI (2016).
Chen, H., Dou, Q., Yu, L., Qin, J. & Heng, P. A. Voxresnet: deep Voxelwise residual networks for brain segmentation from 3d Mr images. NeuroImage 170, 446–455 (2018). segmenting the Brain.
Umirzakova, S., Muksimova, S., Mardieva, S., Sultanov Baxtiyarovich, M. & Cho, Y. I. MIRA-CAP: Memory-Integrated Retrieval-Augmented captioning for State-of-the-Art image and video captioning. Sensors 24 (24), 8013 (2024).
Muksimova, S., Umirzakova, S., Baltayev, J. & Cho, Y. I. Multi-Modal fusion and longitudinal analysis for Alzheimer’s disease classification using deep learning. Diagnostics 15 (6), 717 (2025).
Abdusalomov, A. et al. Accessible AI diagnostics and lightweight brain tumor detection on medical edge devices. Bioengineering 12 (1), 62 (2025).
Acknowledgements
The authors would like to acknowledge the support of Princess Nourah bint Abdulrahman University Researchers Supporting Project number (PNURSP2025R435), Princess Nourah bint Abdulrahman University, Riyadh, Saudi Arabia.
Funding
This research was funded by Princess Nourah bint Abdulrahman University Researchers Supporting Project number (PNURSP2025R435), Princess Nourah bint Abdulrahman University, Riyadh, Saudi Arabia.
Author information
Authors and Affiliations
Contributions
Pratishtha Verma, Dr. Sambit, Dr. Shukla, Harish Kumar both wrote the manuscript. Dr. Deema, Prof. Osamah Ibrahim Khalaf , Prof. Ala Alzoubi, Dr. Basma, Prof. Diaa Salama, Dr. Kushwaha, Dr. Singh did the complete conceptualization of the method. Harish, Sambit and Dr. Dhirendra made the figures and wrote algorithm. All authors reviewed the manuscript as last.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Verma, P., Kumar, H., Shukla, D.K. et al. V3DQutrit a volumetric medical image segmentation based on 3D qutrit optimized modified tensor ring model. Sci Rep 15, 15785 (2025). https://doi.org/10.1038/s41598-025-00537-x
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-00537-x
