
Abstract
The human brain is a dynamic system that is constantly learning. It employs a combination of various learning strategies to facilitate complex learning processes. However, implementing biological learning mechanisms into Spiking Neural Networks (SNNs) remains challenging; thus, most SNNs are trained with only a single learning strategy such as spike timing dependent plasticity (STDP). Moreover, conventional neural networks are first trained on one dataset and subsequently evaluated on unseen data. In this traditional approach, the weights and structure of the model remain fixed once the training step concludes. In this research, we aim to modify this traditional approach and hypothesize that adding short-term plasticity (STP) to a trained SNN enables the model to learn post-training without changing synaptic weights. In particular, by combining triplet STDP for long-term learning during initial training and STP for short-term learning after training (post-training), we employ multiple learning rules to enhance the biological plausibility and computational abilities of SNNs. In this way, two unsupervised learning pipelines are designed for image classification as a proof of concept, in which the dynamic synapse model, driven by neurotransmitter release and synaptic strength, is integrated into the trained network. The proposed method outperforms traditional training by achieving higher classification accuracy and a faster convergence rate. Consequently, our results show that the concept of post-training learning can be realized by incorporating STP in SNNs. Future studies should extend this concept to other challenges and explore its applicability to new datasets.
Similar content being viewed by others


Introduction
Spiking neural networks (SNNs) are third-generation artificial neural networks (ANNs) that use more biologically-inspired neurons. They are rich in spatiotemporal neuronal dynamics and try to simulate the intricate information processing observed in the human brain1,2. This brain-like processing is achieved by combining dimensions including frequency, time, and phase, as well as event-driven processing, spike-based information encoding, and localized learning principles communicating through discrete spikes3.
Unsupervised learning in SNNs often utilizes synaptic plasticity mechanisms which refer to the ability of synapses to modify their strength or efficacy4. This alteration in strength can be either an increase or a decrease and is influenced by various factors such as neural activity and neurotransmitter release. It is believed that the internal mechanisms of synaptic plasticity shape cognitive processes such as learning4. However, connecting synaptic plasticity interactions to human learning can be difficult and has been a longstanding question in computational neuroscience5,6.
Plasticity involves processes that occur at various time scales. Short-term synaptic plasticity (STP) occurs within milliseconds to minutes, while alterations over tens of minutes or longer, are regarded as long-term synaptic plasticity7,8. One form of long-term plasticity is spike-timing-dependent plasticity (STDP). STDP is an unsupervised learning technique used in SNNs that adjusts the synaptic weights based on the relative timing of pre- and post-synaptic spikes. The conventional form of this approach is inspired by one of the numerous physiological forms of STDP in the brain4. Utilizing STDP in SNNs as an unsupervised learning approach has shown promising results in different tasks, including image classification9,10.
Recent studies have demonstrated the diverse applications of STP in both SNNs and non-spiking models8,11,12,13. Compared to networks with static connections, a network with STP shows greater dynamism and enables more effective information processing14. The training approaches for SNNs can be categorized into three groups: Supervised Learning, which involves gradient descent and spike backpropagation15. Unsupervised Learning, utilizing local learning rules at the synapse, such as STDP. Reinforcement Learning, which relies on reward or error signals through reward-modulated plasticity16,17,18,19,20,21. However, despite being prevalent in cortical synapses, STP is not commonly integrated into these training schemes. One reason may be that most studies19,20,21,22,23,27 offer limited possibilities for the customization of dynamics. This restriction may hinder complex modifications to synaptic dynamics or simulation parameters. Consequently, the intricate mathematical analysis and practical training issues involved in SNNs pose challenges hindering the effective utilization of STP for machine learning tasks.
SNNs typically follow a predetermined and controlled training process, which commonly consists of two phases: training and evaluation. The training phase involves adjusting the weights and biases of the network based on the input and output spike patterns, utilizing a learning algorithm like STDP19. Current SNN models evaluate all samples based on the learned synaptic weights in the training phase without exploiting the model’s capacity to adjust to new observations. This approach does not conform to the principles of human learning22,23. Conversely, the brain continuously adapts in structure and function through plasticity in response to learning and experience. Plasticity enables the brain to form new pathways between neurons to learn as well as to compensate for damage or injury24. Additionally, the brain combines various learning methods. Understanding the integration of these different learning mechanisms can provide insights for developing more efficient artificial intelligence systems inspired by the brain’s computational principles25,26. To address these aspects, we hypothesize a novel concept titled “Post-training learning”, suggesting that the end of training in SNNs does not have to signify the end of learning. After the training phase, the network can continue to learn in response to new samples without adjusting its synaptic weights.
Unlike traditional ANNs, spiking neuron models and their communication are time- dependent, making neuronal behavior reliant on input timing. This intrinsically temporal representation in SNNs enables the post-training integration of time-dependent components or features into a trained model. To the best of our knowledge, this aspect of SNNs is missing from previous SNN learning studies1,15,16,17,18,19. In the present study, we integrate STP into a trained SNN by incorporating a new rule into the synapse model subsequent to its initial training phase. In this way, the network can learn new features from previously unseen data without changing its structure containing prior knowledge. As a proof of concept, we propose two unsupervised pipelines for training of a multilayer leaky-integrate-and-fire-based SNN (LIF-SNN). These pipelines utilize an identical network architecture, combining STDP as the training phase with STP as the post-training phase for further learning even after the training phase. In addition, we introduce a synapse model that updates excitatory synapse conductance based on the amount of neurotransmitter release and the synaptic weight as inspired by STP. To test the effectiveness of the proposed pipelines and to avoid the complexities of tuning, we limit the sample size to 1000 images and evaluate our approach on four subgroups of samples from two benchmark datasets: MNIST27 and EMNIST28. The subgroups consist of two sets of unaltered images from each dataset and two sets of the same images with added Gaussian noise. Our choice of dataset was motivated by the need for better quantification of the STP’s effect on learning dynamics. Thus, we selected benchmark datasets such as MNIST, which is widely used across numerous studies. We employ the noisy datasets to analyze input noise effects and test the robustness of our approach. Our findings reveal that increasing the biological plausibility of SNNs through multiple learning rules in the form of STDP and STP will indeed enhance the model’s performance. Moreover, the proposed pipelines will enable the network to continue learning even after training, without any alterations in synaptic weights, while taking advantage of the new information from previously unseen data.
The following section explains the methods, including the neuron and synapse model, network architecture, and training and learning strategies. Section “Results and discussion” contains the simulation results. Finally, section “Conclusion” concludes and discusses future work.
Method
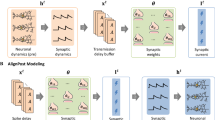
This study introduces a novel “Post-training learning” concept to enhance synaptic plasticity in a LIF-SNN model. In this regard, we integrate STP into a network trained with the Triplet STDP rule, applying it after the training phase by exploiting the time-variable properties of spikes in SNN simulation. As shown in Fig. 1, three unsupervised learning pipelines are considered. Pipeline 0 represents the conventional approach, and pipelines 1 and 2 include the novel post-training learning methods. The proposed pipelines are divided into three phases: training, post-training learning, and evaluation. In all pipelines the network is fully trained with Triplet STDP accompanied by synaptic weight changes (training phase). In the post-training learning phase, we incorporate the proposed STP (described in section “Short-term learning (STP) as the post-training learning rule”) into the synapses of the LIF-SNN (taken from Diehl et al.9). The difference between pipelines 1 and 2 is an additional step called “Update labeling”. Adding STP, as a new feature, into the trained SNN changes the inherent neuron dynamics of the model after labeling. Consequently, updating the labels assigned to each neuron after adding STP is necessary. This step is included in pipeline 2. These pipelines are designed to explore how the model performance is affected by the post-training learning approach compared to the traditional pipeline and how the STP mechanism can modify the dynamics of spiking neurons after STDP training.

An overview of the proposed approach. Each pipeline is shown with its specific order of processing. The training process is depicted in the training phase (on the left). All images are converted to Poisson spike trains before being fed into the network. Furthermore, weight and neuron membrane threshold matrices are adjusted. In the “Labeling” step, each output (excitatory) neuron is assigned to one class based on its highest response to all classes. In pipeline 0, the model is evaluated on unseen data after the training phase. On the right side, in the evaluation phase, a set of previously unseen images are fed to the network. Then, the network proceeds to classify these test images as represented by the “pattern recognition” step. Pipelines 1 and 2 differ from pipeline 0 (conventional approach) in that they include a new phase of learning based on STP and modification of excitatory synaptic conductance in their post-training phase. These pipelines also differ in how they update the labeling of the classifying neurons after introducing STP into their trained models. In pipeline 1, labeling only occurs after training is completed before adding STP to the model. In contrast, in pipeline 2, in addition to the same labeling step as the other pipelines (to calculate the training accuracy), labeling is also updated after introducing STP.
To simulate the SNN, we use the Python programming language and the BRIAN2 simulator29. All simulations are conducted on an Intel(R) Core (TM) i5-7400 CPU @ 3.00 GHz. In this section, we will first outline the model of an individual neuron and synapse, then explain the employed network topology and the learning mechanisms. Subsequently, we will discuss the training and classification procedure for four datasets consisting of two noise-free and two noisy sets of images.
Neuron model
In our model, the dynamics of excitatory and inhibitory neurons are described by a leaky integrate-and-fire (LIF) model, a one-dimensional spiking neuron model with low computational cost30. The membrane potential \(\:V\) of a neuron is defined by the following equation (Eq),
where \(\:{E}_{rest}\) is the resting membrane potential, \(\:{E}_{exc}\) and \(\:{E}_{inh}\) denote the excitatory and inhibitory reversal potentials, \(\:{g}_{e}\) and \(\:{g}_{i}\) are the conductances of excitatory and inhibitory synapses, respectively. The term \(\:\tau\:\:\) is defined as the membrane time constant and is greater for excitatory neurons, as observed in biology. After a neuron surpasses the threshold value\(\:\:{V}_{thr}\), an action potential is initiated. The neuron then goes through a refractory period \(\:{\tau\:}_{ref}\) before returning to its resting potential. Table 1 summarizes the values of the neuron parameters used in this work.
Synapse model
The most frequently observed type of synapses in the brain are chemical synapses. These synapses do not physically connect neurons. Instead, when an electrical signal is generated in the pre-synaptic cell, neurotransmitters are released into a small gap between the neurons called the synaptic cleft. The neurotransmitters then diffuse across this gap and change the post-synaptic membrane’s permeability. As a result, the membrane voltage may undergo either a positive or negative change31. Depending on each pipeline, we utilize two types of conductance-based chemical synapses: static synapses originating from excitatory and inhibitory neurons, described in this section, and novel dynamic synapses from input neurons, introduced in this study.
When a pre-synaptic spike arrives at the synapse, the synapse conductance changes instantaneously according to the synaptic weight, which quantifies the strength of the connection and the amplitude of the post-synaptic response (Eqs. 2, 3).
\(\:{w}_{ei}\) and \(\:{w}_{ie}\) indicate synaptic weights originating from excitatory to inhibitory and inhibitory to excitatory neurons, respectively, and are fixed values in the pipelines (Table 1). Then, the conductance is decaying exponentially (Eqs. 4, 5). The dynamics of the conductance \(\:{g}_{e}\) and \(\:{g}_{i}\) are described as follows:
where \(\:{\tau\:}_{e}\) (2 ms) and \(\:{\tau\:}_{i}\) (1 ms) are the excitatory and inhibitory post-synaptic potential time constant.
Network topology
In this work, the baseline SNN is a hierarchical structure derived from the work of Diehl and Cook9 (Fig. 2a). This network comprises an initial input layer and excitatory and inhibitory layers. The excitatory and inhibitory layers have the same number of neurons. The pixel values for the different patterns in the images are represented by the input layer (m x p dimensions). m and p represent the number of pixels in the rows and columns of the images (m = 28, p = 28). A conversion process transforms each pixel value into a spike train that follows a Poisson distribution. The rate of the spike train is directly proportional to the intensity value of the respective pixel. These spike trains, lasting 350 ms, are fed as inputs into the network.
Neurons in the input layer are connected to all neurons in the excitatory layer, forming a fully connected connectivity pattern. Considering n excitatory neurons, the total number of weighted excitatory connections from the input layer is m × p × n. These weights are then trained to classify a specific input pattern. The connections from the excitatory layer to the inhibitory layer are one-to-one. When an excitatory neuron fires, it concurrently triggers firing in the corresponding inhibitory neuron. All inhibitory neurons establish connections with every excitatory neuron in the network except for the one they are directly connected to. This arrangement of connections allows for lateral inhibition, facilitating competitive learning. This mechanism limits the concurrent firing of multiple excitatory neurons. Alongside lateral inhibition, the model also integrates a homeostasis mechanism32. Homeostasis is an adaptive membrane threshold mechanism in which the firing threshold of each excitatory neuron is controlled to prevent excessive activity. The membrane threshold of each excitatory neuron is determined by \(\:{V}_{thr}+\theta\:\), where \(\:{V}_{thr}\) is the predefined threshold and \(\:\theta\:\) increases incrementally every time the neuron fires, then decays exponentially over time32. The threshold gradually increases if a neuron is excessively active in a short period, requiring stronger input for subsequent spikes. Consequently, homeostasis helps maintain an equal firing rate among neurons, preventing individual neurons from dominating the neural response.

(a) An overview of the baseline SNN, network connections, and synaptic conductance update rules for different synapses in the proposed pipelines. The neuron populations are shown as a grey-filled circle. In this network, the images (28 × 28 pixels) are fed to the input layer (28 × 28 neurons) for 350 ms with a 150 ms time interval. The input layer consists of 784 neurons, fully connected to an image with 28 × 28 pixels. Each pixel in the input image corresponds to a neuron in the input layer. Every neuron in the input layer connects to all 400 excitatory neurons in the excitatory layer. Each excitatory neuron is coupled to exactly one inhibitory neuron in the inhibitory layer. Inhibitory neurons connect back to the excitatory layer with a lateral inhibition connection pattern. Excitatory neurons are also classifying neurons. When an action potential from a pre-synaptic inhibitory neuron occurs, inhibitory synapses will increase the inhibitory conductance in the post-synaptic cell by \(\:{w}_{ie}\). Similarly, when spiking occurs in pre-synaptic excitatory neurons, the excitatory conductance will increase by \(\:{w}_{ei}\). In the post-training phase, when input neurons spike, the excitatory conductance of excitatory synapses will increase by \(\:w+kw{r}_{s\:\:}\). (b) Neurotransmitter release (\(\:{r}_{s\:\:})\) in the synaptic cleft based on the TM model. This mechanism is used in synapses originating from the input layer during the post-training learning phase.
Learning strategies
This study aims to enhance the biological plausibility of learning mechanisms by employing a novel approach combining long-term and short-term learning rules. To this end, we introduce a new concept called post-training learning. This method consists of two phases: first, long-term plasticity during the training phase, where synaptic weights are adjusted using Triplet STDP (or another STDP variant); second, adding short-term plasticity (using the Tsodyks and Markram (TM)33,34 model) to the trained network after the training phase, which does not affect synaptic weights.
Long-term learning (Triplet STDP) as the main training rule
STDP is an unsupervised learning mechanism that follows the Hebbian learning rule. It regulates the adjustment of synaptic weights based on the temporal sequence of pre- and post-synaptic spikes35. When the pre-synaptic spike precedes the post-synaptic spike, the synaptic weight is strengthened, leading to long-term potentiation (LTP). Conversely, if the order of spike arrivals is reversed, it causes a reduction in the synaptic weight, resulting in long-term depression (LTD). STDP is a biologically plausible learning method, capturing the temporal evolution of synaptic weights through the interaction of pre- and post-synaptic spike pairs. However, pair-based STDP models cannot explain the influence of the repetition frequency in spike pairs. Furthermore, these STDP models fail to replicate triplet and quadruplet experiments7. The Triplet STDP mechanism formulated in36 assumes a triplet interaction focusing on three spike groups. These groups consist of one pre-synaptic and two post-synaptic spikes.
According to previous research, the triplet STDP rule in a network size of 400 excitatory neurons exhibits a higher performance level9. Therefore, we have selected this as the base learning mechanism for long-term learning in our pipelines during the training phase. The dynamics of the synaptic weights can be implemented using three localized variables: \(\:{a}_{pre}\), \(\:{a}_{post1}\) and \(\:{a}_{post2}\) which represent “traces” of pre- and two post-synaptic activity patterns governed by differential equations. This approach is analogous to pair-based rules and attempts to improve the simulation speed37. In contrast to the rules based on spike pairs, every spike emitted by the post-synaptic neuron contributes to a fast trace \(\:{a}_{post1}\) and a slow trace \(\:{a}_{post2}\:\)at the synapse, where \(\:{\tau\:}_{post1}\)< \(\:{\tau\:}_{post2}\) :
when a pre-synaptic neuron fires, the pre-synaptic trace is reset to 1 (Eq. 10); otherwise, \(\:{a}_{pre}\:\)decays exponentially (Eq. 6). When a pre-synaptic spike occurs, weight alterations are proportional to the value of the fast post-synaptic trace\(\:{\:a}_{post1}\) according to Eq. (9).
Similarly, when a post-synaptic spike occurs, the two post-synaptic traces are reset to 1 (Eqs. 12, 13), and LTP is induced by a triplet effect. When a post-synaptic spike occurs, weight change is induced proportional to both the trace \(\:{a}_{pre}\:\)and the slow post-synaptic trace \(\:{a}_{post2}\) due to previous pre-synaptic spikes (Eq. 11). The value of \(\:{a}_{post2}\) is first used in the weight update before it resets to 1 due to the post-synaptic spike:
\(\:{lr}_{pre}\), \(\:{lr}_{post\:}\) are the learning rates (0.0001 and 0.01 for pre- and -post-synaptic events, respectively), and determine the learning speed.
Short-term learning (STP) as the post-training learning rule
In pipelines 1 and 2, once training is finished, STP is enabled in the trained network without any further changes to the weights. We introduce this as an additional phase termed post-training learning. As the synaptic strength can change rapidly, the resulting response can fluctuate. Based on the pre-synaptic activity, this response can either decrease (synaptic depression) or increase (synaptic facilitation) the synaptic strength at short time scales33,34, which defines the so-called dynamic synapses. This type of synapse is the most common in the brain. Utilizing detailed biophysical models is essential in understanding the processes that drive synaptic plasticity. However, phenomenological models are generally more manageable and less computationally demanding when describing synaptic changes without referring to specific mechanisms. As a result, these models are highly valuable in analytical and simulation studies. In this context, we employ the TM model based on the phenomenological description of neocortical synapses exhibiting STP33,34. Based on this model, the process of synaptic neurotransmitter release can be represented by multiplying two variables \(\:{u}_{s}\) and \(\:{x}_{s}\) (Eqs. 14,15). Here, \(\:{u}_{s}\) is an approximation of the neurotransmitter resources that are available to be released by the \(\:{Ca}^{2+}\) influx, and \(\:{x}_{s}\) represents the proportion of all available neurotransmitters that will be released31,33,38. This process is illustrated in Fig. 2b. Between action potentials, \(\:{u}_{s}\) decays to 0 at the rate of \(\:{{\Omega\:}}_{f}\) (Eq. 14) while\(\:\:{x}_{s}\) recovers to 1 at the rate of \(\:\:{{\Omega\:}}_{d}\) (Eq. 15), i.e.
When an action potential arrives, it causes calcium to enter the pre-synaptic terminal. This calcium influx transfers a specific fraction (\(\:{U}_{0}\)) of the neurotransmitter resources that were not available for release \(\:\left(1-{u}_{s}\right)\) into a state where they can be readily released (\(\:{u}_{s}\)). Afterward, a portion (\(\:{u}_{s}\)) of the total neurotransmitter resources (\(\:{x}_{s}\)) is discharged as \(\:{r}_{s}\), resulting in a decrease of \(\:{x}_{s}\) by the same amount (Eq. 18); that is,
The release of neurotransmitters at synapses (\(\:{r}_{s}\)) changes with each action potential. Therefore, this amount is not the same for all connections. This alteration is influenced by the previous synaptic activities, determined by the values of the synaptic state variables \(\:{u}_{s}\) and \(\:{x}_{s}\:\)at the time of the action potential. When a pre-synaptic action potential arrives, excitatory synapses originating from the input neurons will increase the excitatory conductance within the post-synaptic cell (excitatory neurons) (Fig. 2a). Thus, we propose a new excitatory conductance update rule based on biological evidence that shows synaptic stochasticity4,7. This rule is applied whenever a pre-synaptic action potential occurs and consists of two components: one driven by Triplet STDP leading to long-term plasticity (w), and the other representing STP, an additive short-term component \(\:kw{r}_{s}\) resulting in learning and forgetting in the short-term, as follows,
Equation (19) is applied to the synapses connecting the input neurons to excitatory neurons after the training phase is complete. The parameter k in Eq. (19) indicates a scaling factor for STP strength; w represents the long-term synaptic weights, which in turn are the trained weights obtained during the training phase in our pipelines and remain fixed during the evaluation process. Synapses preserve image features within the long-term weights (w). In addition, they remember recent features on a short-term scale (through\(\:\:kw{r}_{s}\)). The traditional method (pipeline 0), on the other hand, employs uniform plasticity parameters across all synapses during the evaluation phase. The release of neurotransmitters from the pre-synaptic neurons affects the dynamics of the post-synaptic terminals, resulting in modulations of synaptic transmission. The utilized synapse parameters are shown in Table 1.
Training and evaluation
To assess the performance of the proposed pipelines, we utilize four subsets of images (1000 samples) from both noisy and noiseless datasets. These samples include images from the MNIST (mono channel images of digits 0–9)27 and alphabet letters randomly selected from 10 classes of the EMNIST dataset (the 10 classes include E, I, l, W, q, Q, u, s, b, g28, each class with the same number of samples. Noisy images are created by adding Gaussian noise (with a mean of 1 and a standard deviation of 1.5) to the same images of the MNIST and EMNIST datasets. All subgroups share the same image size (28 × 28 pixels), data format, and train-evaluation ratio. In each dataset, images from all classes are shuffled. Finally, images are split into sets of training (80%) and evaluation (20%). The classes are evenly distributed within the training and evaluation sets, ensuring a balanced representation.
During training, images are presented to the network. A time interval of 150 ms is applied between two consecutive images to enable the network to attain a stable state. In all pipelines, the training process is done on the whole training set, followed by the labeling step. The synaptic weights from input to excitatory neurons are updated using Triplet STDP in all pipelines (described in section “Long-term learning (Triplet STDP) as the main training rule”). Neurons’ membrane threshold matrices are updated based on the homeostasis mechanism (described in section Network topology). If the sum of spikes in the second layer is less than 5 in 350 ms, the maximum input firing rate will increase by 32 Hz, and the sample will be shown again for another 350 ms until at least five spikes are generated. After the training phase is done, the learning rate is set to zero, fixing the synaptic weight and neuron’s membrane threshold values. Given that the pipelines operate in an unsupervised manner; a label is assigned to each classifying (output) neuron during the labeling step. These assignments are determined by a neuron’s highest average response to a class with respect to the number of times the image in the training set is presented.
Next, based on the assigned labels, the accuracy of the training classification is calculated. Labeling is necessary to obtain the training accuracy for all pipelines and the evaluation accuracy for pipelines 0 and 1 After completing the training phase in all pipelines, the weight corresponding to each synapse remains fixed. In pipelines 1 and 2 (Fig. 1), the proposed STP (described in sectiion “Short-term learning (STP) as the post-training learning rule”) is added to all synapses originating from input to excitatory neurons. By adding STP into the synapses, neurotransmitter signaling can change the neurons’ inherent dynamics. Because the labeling step is applied before adding STP, the effect of STP is not seen in this step. This point motivated us to incorporate the impact of the neurons’ inherent dynamics into an “Update labeling” step on the whole training set in pipeline 2. “Update labeling” involves the reassignment of labels to the output neurons based on the highest average response to a class after adding STP. This step is performed on the whole training set. As a result, for pipeline 2, the STP can influence the firing rate of neurons once after the training phase on the training set and again on the evaluation set during the evaluation phase (Fig. 1). Therefore, during evaluation in pipelines 1 and 2, in addition to the long-term learning (\(\:w\)), the model’s performance is also influenced by the temporally evolving synaptic efficacy in response to images (STP). This effect results from neurotransmitter release dynamics, which varies across different synapses (total number of synapses from input to excitatory neurons is 313600).
Finally, the unseen evaluation set is given to the trained SNN. After the evaluation phase is complete, the response of the neurons assigned to specific classes is utilized to evaluate the accuracy. The predicted output is determined by calculating the average firing rate of each neuron for each class and selecting the class with the highest average firing rate as the predicted output.
Results and discussion
In SNNs, during the training phase, the strength of synapses changes in response to each sample in the training set, leading to the adjustment of synaptic weights. Once the training is completed, i.e., during the evaluation phase, the synaptic weights are fixed for all samples. Such an approach does not align with the biological processes of human learning22,23. We hypothesize that incorporating multiple biologically inspired learning rules, namely STDP and STP, can enhance learning in SNNs. To investigate this, we propose two novel learning pipelines for SNNs and evaluate them on four 10-class balanced subsets, each containing 1,000 samples (800 for training and 200 for evaluation), including noisy and noise-free samples. The goal is to assess how post-training learning improves performance with limited training data. Hence, we limit the training set to 800 images. Training is conducted for 15 epochs, a duration chosen based on the network’s convergence to near-steady accuracies, exhibiting fluctuations within stable ranges. The accuracy results during the evaluation phase for each epoch in every pipeline are presented in Fig. 3. Different degree factor (k) values (described in section “Short-term learning (STP) as the post-training learning rule”, Eq. 19) are investigated for pipelines 1 and 2 separately. Since we aim to show the impact of the post-training learning using the proposed STP, we consider a limited discrete range of 1 to 10.5 at 0.5 intervals of k for the evaluation phase. The presented results are based on the highest accuracy achieved for the corresponding k in each pipeline. Thus, the best-performing k might not be the same for the evaluation phase in pipelines 1 and 2. The training phase is the same for all pipelines, and each approach differs only in the post-training phase.
Depending on the value of the degree parameter k, performance varies, indicating stochastic variations in the amount of neurotransmitter release when the pre-synaptic neuron spikes, as strongly supported by biological evidence4,7. The degree factor k corresponding to the highest accuracies is 10.5, 10, 9, and 8.5 for pipeline 1, and 8, 10, 10.5, and 10 for pipeline 2 across the MNIST, EMNIST, noisy MNIST, and noisy EMNIST datasets, respectively. Figure 3 clearly shows the accuracy improvement of the proposed pipelines 1 and 2 compared to the traditional pipeline (pipeline 0 with no post-training learning) across all epochs and datasets. These results demonstrate that our approach improves learning without requiring additional training while maintaining robustness against input noise. Moreover, Fig. 3 reveals that post-training learning accelerates the network’s convergence rate, necessitating fewer training epochs. This is implied by the accuracies for pipelines 1 and 2 being consistently above pipeline 0. For example, in all datasets, accuracy at the first epoch increases by almost 15% in pipeline 2 compared to pipeline 0. During the initial stages of training, the knowledge acquired by the network through long-term plasticity may be insufficient, resulting in weaker performance. However, by introducing a short-term learning rule into the trained SNN, learning performance can rapidly grow, particularly at the beginning of training iterations. Overall, pipeline 2 demonstrates higher accuracies than pipelines 0 and 1. The greater accuracies of pipeline 2 over pipeline 1 highlight the significance of the “Update Labeling” step. Nevertheless, pipeline 1 consistently outperforms pipeline 0, showing the positive effects of Post-training learning.

Evaluation accuracy per epoch across 15 training iterations for all pipelines on MNIST and EMNIST (noisy and noise-free). The evaluation sets include 200 samples. An illustrative sample from each dataset is displayed in the lower right corner of each plot for reference. The networks trained using the proposed pipelines achieve higher accuracy than the traditional approach (pipeline 0) across all four datasets. Notably, pipeline 2 outperforms the others by having greater average and final accuracy in 15 epochs. The higher accuracies of pipeline 2 reveal the positive effect of STP and the “Update labeling” step over pipelines 0 and 1.
Table 2 summarizes the classification results across different values of k and the simulation times corresponding to one epoch. The simulation time involves the training, testing, and “Update labeling” duration, which varies for each pipeline. The table shows that the simulation time is approximately three minutes higher in pipeline 1 compared to pipeline 0. Indeed, the baseline method updates the excitatory conductance of synapses from input to excitatory neurons based on a single static value, while the proposed pipelines employ a time-varying parameter alongside this fixed value. Moreover, the simulation time for pipeline 2 exceeds that of pipeline 1. This increase is due to the additional “Update labeling” step, as the number of excitatory and inhibitory neurons and synapses remains constant at 800 and 313,600, respectively. The added complexity requires more significant computational resources, increasing overall simulation time.
Pipeline 2 exhibits substantially higher accuracies across all datasets compared to pipeline 0 even with only 800 training samples and 200 samples during the post-training phase, suggesting that the proposed concept can be practical. Improvements in the evaluation accuracies vary between approximately 5.5% (MNIST) to 17% (Noisy MNIST) and are present across all datasets for pipeline 2. For pipeline 1, these values change between approximately 2.5% (MNIST) and 8.5% (Noisy MNIST). From this table, it is evident that in all datasets, pipeline 2 outperforms both the traditional pipeline 0 and pipeline 1.
The most notable improvement in classification is in the noisy MNIST dataset, where pipeline 0 achieves 58% accuracy, whereas pipeline 2 achieves 75% accuracy. It is noteworthy that our aim was not to attain the best accuracy but to examine how the concept of multiple learning rules, specifically post-training learning, can enhance performance compared to using a single-rule learning approach. Table 2 also reveals that when noise is added to the input images, accuracy drops 22.5% and 6% for pipeline 0, 17%, and 7% for pipeline 1, and 11%, and 4% for pipeline 2 in the MNIST and EMNIST datasets, respectively. This indicates that the network trained and evaluated with pipeline 2 is significantly more robust to input noise, especially in the MNIST images, as the decrease in performance is halved in pipeline 2 compared to pipeline 0. Furthermore, we conducted experiments to compare the performance and computational properties of learning when STP is incorporated during the training phase versus after training over 15 epochs. The results demonstrate that joint Triplet STDP and STP training significantly improve performance over the approach that uses only the Triplet STDP for training (pipeline 0) across all datasets. This improvement, however, comes at the cost of much higher computation times approximately double those of the baseline approach (126–128 min) (supplementary information, Table S1).
In Fig. 4, we provide an illustrative example of the impact of “Update labeling” on the distribution of neurons per label for pipeline 2. Bar plots display the number of neurons assigned to each class for the best results (shown in Table 2) across the MNIST and EMNIST datasets. These results demonstrate a noticeable difference between the pre- and post-update labeling phases, emphasizing the significance of integrating STP into our methodology.

The number of neurons per label after the “Labeling” and “Update labeling” steps for pipeline 2, based on the best results from the MNIST and EMNIST datasets.
In order to gain a deeper understanding of the impact of STP on the dynamics of the excitatory layer in a trained SNN, spike counts per image are analyzed before “Update labeling” across the entire training set (Fig. 5). In pipeline 0 (green lines), as each neuron solely reacts to a minor subset of input images, the responses are quite sparse, leading to a small number of spikes generated per image. Interestingly, upon the addition of STP to the network, as depicted in Fig. 5, the number of active neurons per image approximately doubles or even triples in some cases compared to the baseline model. In all four datasets, the number of spiking neurons per image peaks at around 10 and 30 for all images in pipelines 0 and 2, respectively. This increase occurs as STP regulates synaptic transmissions based on the timing of pre-synaptic action potentials, leading to changes in temporal neural dynamics. Consequently, this requires more sophisticated computations, keeping a trade-off between computational complexity and performance. These findings suggest that, in pipeline 2, more information may be encoded in the excitatory neurons following the incorporation of STP.

The number of spiking excitatory neurons (active neurons) per image on the training set for each dataset with and without STP. The network trained with pipeline 2 has greater neural activity than pipeline 0, as the number of spikes for each training image is significantly higher for pipeline 2. The peak number of spikes in pipeline 0 is around 10, while this number is around 30 for pipeline 2.

Confusion matrices of each pipeline based on the best performances. (a) MNIST, (b) Noisy MNIST, (c) EMNIS, (d) Noisy EMNIST. Horizontal and vertical axes correspond to the original labels and the labels predicted by the proposed pipelines, respectively. Across all datasets, in pipelines 1 and 2, more classes have a lower or equal false positive rate than the conventional approach. The proposed pipelines outperformed the traditional method by having higher values on the main diagonal.
Confusion matrices (Fig. 6) are also provided to further examine the performance of the proposed methods based on the best results from the evaluation sets. The distribution of predictions in Fig. 6 reveals that for the proposed pipelines, the number of classes with a lower or equal false positive rate is greater or equal compared to the conventional approach. For example, pipeline 2 has equal or lower false positives for all classes except for “1” and “5” in MNIST. This yields higher or similar precision values in the proposed pipelines for most of the classes. From the values on the diagonal elements of the matrices in Fig. 6, we can see that, although pipeline 1 surpasses pipeline 0 overall and the number of correctly recognized classes is higher than pipeline 0, it produces slightly worse predictions for some classes (classes “1”, “4” and “5” in the MNIST, “w” in EMNIST, “3” in Noisy MNIST or “E” and “l” in Noisy EMNIST). By comparing pipelines 0, 1, and 2 on the diagonal elements of the matrices, we can see that our approach can recognize most patterns better than the conventional method. In summary, while pipelines 1 and 2 surpass pipeline 0 overall, they do not do so uniformly, though the differences are negligible.

Raster plots of the spiking events (dots) on 400 excitatory neurons during the evaluation phase based on the best results within 15 training epochs. Horizontal and vertical axes correspond to the time of the spikes and the classifying neuron indices, respectively. Pipelines 1 and 2 only differ in one extra step during their evaluation, which does not impact their internal neural behavior; thus, their responses to the inputs are the same when the factor k is the same for both pipelines. Across all datasets, synaptic facilitation driven by STP leads to a slight increase in firing frequency and network activity over time in the proposed pipelines compared to pipeline 0. This is evidenced by the higher density of dots in the plots for pipelines 1 and 2, corresponding to more spikes for each neuron while the evaluation set is presented to the network.
Furthermore, raster plots are utilized (as shown in Fig. 7) to examine how post-training learning can impact the dynamics of excitatory neurons (classifying neurons) during the evaluation phase. Across all datasets, synaptic facilitation driven by STP leads to increased firing frequency and network activity over time in the proposed pipelines compared to pipeline 0. Additionally, there is a more significant number of excitatory neurons firing synchronously. Since the difference between pipelines 1 and 2 is the addition of the “Update labeling” step, these outcomes are the same for both pipelines, as the added step in pipeline 2 has no impact on the activity of the excitatory neurons. Therefore, they are depicted with the same color. These heightened rates of synchronized firing may encode information and perform computations, contributing to improved learning. Figure 7 indicates that for the noiseless MNIST and EMNIST datasets, pipeline 0 has a longer horizontal axis compared to the others. If the sum of spike counts of the excitatory neurons in the second layer is not more than five within the duration of image presentation (350 ms), the maximum input firing rate will increase by 32 Hz to stimulate the excitatory population (as described previously in section “Training and evaluation”), followed by presenting the image to the network again. We repeat this procedure until the sum of spike counts exceeds five, resulting in a longer presentation time for all images. However, the proposed pipelines 1 and 2 require fewer attempts to present the same image to the network to reach the necessary number of spikes. In contrast, this behavior is not observed in the noisy datasets. In these datasets, noise in the inputs can make the neurons fire more than the minimum threshold of five, avoiding the repeat presentation of the images.
We also assess the network’s capacity to capture temporal dynamics by comparing the number of active neurons (spiking neurons) during the evaluation phase per input sample. As apparent in Fig. 8, there are distinct differences between pipeline 0 and pipelines 1 and 2. The figure indicates that the number of neurons involved in processing when responding to a new sample during evaluation is significantly higher in pipelines 1 and 2. In other words, the number of silent neurons decreases. This is indicated by the larger number of spiking neurons for pipelines 1 and 2 compared to pipeline 0. Moreover, we studied the neural activity of the network based on each neuron’s contribution score (NCS)39 (see Supplementary Information). NCS corresponds to the sum of previous spikes’ temporal spike contribution scores (TSCS).

The number of active excitatory neurons during the evaluation phase per sample. The horizontal and vertical axes correspond to the indices of images presented to the network during the evaluation phase and the number of active neurons firing to a new sample, respectively. The total number of samples in the evaluation set is 200. Pipelines 1 and 2 have the same outcome of increasing the number of active neurons. The only difference is one step (Update labeling), which does not affect the network behavior. As a result, we considered a single plot to represent the effect of both pipelines on the network. In all four datasets, neurons in pipelines 1 and 2 produced more spikes during the evaluation phase.
A high spiking frequency of a neuron yields higher TSCS values, while the same number of spikes over a more extended period produces lower values. Here, we compute an NCS score for each neuron based on the network’s activity in the evaluation phase. The more a neuron spikes in a short period, the higher the NCS. Figure 9 shows the NCS values for all 400 excitatory neurons of pipelines 0, 1, and 2 during the evaluation phase across the four datasets. The figure shows apparent dark spots in pipeline 0’s heatmap compared to pipelines 1 and 2. This pattern suggests that neurons in pipelines 1 and 2 contribute more uniformly to the prediction process. In other words, in pipelines 1 and 2, more neurons make meaningful contributions to the network. Specifically, in the Noisy MNIST dataset, while more dark spots are present in pipeline 0, it also exhibits more bright spots, indicating that a few neurons compensate for the lack of activity of other neurons. In pipelines 1 and 2, however, more neurons are active, and almost the entire network shares the neural activity during the evaluation. The same applies to the other three datasets, especially MNIST and EMNIST. In these two datasets, not only all 400 neurons are actively participating in the evaluation phase in pipelines 1 and 2, but more neurons also have higher NCS values as indicated by the higher number of bright spots in their heatmaps compared to pipeline 0.
The results depicted in Figs. 7 and 8, and 9 suggest that given a network with 400 excitatory neurons, the traditional learning approach fails to fully utilize the network’s potential. This is evident since pipeline 0 displayed subdued neural and spike activity during the evaluation phase (Figs. 7 and 8), with only a subset of neurons contributing to this phase (Fig. 9). This was not the case for pipelines 1 and 2. In both pipelines, higher neural activity was observed (Figs. 7 and 8), and more neurons participated in the evaluation phase (Fig. 9). These results suggest that post-training learning enables the network to use more of its computational potential, which in turn leads to better performance (Table 2). On the other hand, the sparse activity of Pipeline 0 (Figs. 5 and 8), characterized by a smaller number of active neurons and synapses, may have lower energy consumption compared to the proposed pipelines when implemented in hardware. However, the increased spike counts remain relatively low. Additionally, since STP only affects synaptic facilitation, the energy cost of synaptic transmission may increase energy consumption by more neurotransmitter release and potentially more frequent spiking when increasing synaptic strength. These dynamics are consistent with the processes that occur in the brain40,41. While there are always trade-offs when attempting to improve performance, our approach does so by enhancing the network’s behavior and making it more biologically plausible.

The neural contribution score (NCS) for all excitatory neurons during the evaluation phase for the four datasets in pipelines 0, 1, and 2. The horizontal and vertical axes correspond to the neuron indices and time points (50 time points) during the evaluation phase. The time points are considered with 2200 ms intervals, and the color of the heatmap depicts the NCS value. The brighter the color, the higher the value. The neural activity of pipelines 1 and 2 are the same when the factor k is the same for both pipelines. Pipelines 1 and 2 demonstrate higher and more uniformly distributed NCS values for all neurons and all datasets. In pipeline 0, the network is essentially a subset of the 400 included neurons, as some neurons have no contribution in the evaluation phase.
In our work, while lateral connections contribute to network stabilization, they are not explicitly designed to counteract STP-induced fluctuations in spike rate. Indeed, they serve to enforce competition and prevent runaway excitation. In the baseline SNN, lateral inhibition can lead to sparse firing activity of neurons due to different neuronal parameters of excitatory and inhibitory neurons (shorter refractory period and decay time constant and smaller firing threshold for inhibitory neurons). However, in the proposed pipelines, the excitatory conductance of synapses from input to excitatory neurons is strengthened after adding STP, which operates on much shorter time scales than lateral inhibition. This can accelerate the excitatory synaptic responses during ongoing activity, allowing excitation to dominate at a short time scale (much smaller than the inhibitory neurons), making the excitatory neurons faster to reach the spiking threshold than inhibitory neurons. As a result, STP enables more neurons to become active (as shown in Figs. 7 and 8, and 9), leading to increased network-wide firing.
In addition to examining the pipelines across four datasets, two traditional deep ANN models are tested on the same data. The outcome of these benchmarks is shown in Table 3 within 15 epochs. These networks include: (1) A Convolutional Neural Network (CNN) model with 2 two-dimensional convolution layers with 16 and 32 kernels (kernel size of 3 and 6, respectively), a 4 by 4 max pooling layer, a dense layer with 16 neurons, and ReLu activation function for all hidden layers; (2) A Recurrent Neural Network (RNN) model with a single RNN layer, fully-connected with output fed back as input, with 256 units. We intentionally chose simple architectures for these benchmark networks to provide a fair comparison to our conceptual network, as this study aims not to attain the highest possible performances but to introduce the concept of post-training learning.
From Table 3, it is evident that the CNN model achieved the highest accuracy across all datasets. This performance is notable given that the SNN used in pipeline 2 consists of just 800 neurons, while the CNN uses approximately 25,754 neurons. Pipeline 2’s accuracy is close to the RNN model, with only minor differences for various datasets. Furthermore, traditional ANN models rely on supervised learning and require labeled datasets. In contrast, the pipelines proposed in this work utilize unsupervised learning methods. Moreover, our approach follows local learning rules, whereas ANNs typically require global learning rules. Local learning rules also facilitate the parallelization of SNN computations, enabling implementations on field-programmable gate arrays (FPGAs) to leverage this parallelization for real-time operation. Additionally, CNNs and RNNs consume significantly more energy due to their dense and continuous activation patterns, as well as their high computational loads, such as matrix multiplications for CNNs and recurrent computations for RNNs while operating for less than a few minutes. Conversely, SNNs are far more energy-efficient as they exploit sparse activity and event-driven computation41.
Conclusion
This study primarily aims to enhance the biological plausibility of learning mechanisms by introducing new pipelines focusing on these aspects: (1) Utilizing multiple synaptic learning rules for pattern recognition rather than relying on a single rule. (2) Learning is not stopped after the training phase. (3) Using different types of synapses within the SNN, where the synaptic efficacy is not strictly dependent on weight changes but also on short-term modulation through STP. (4) The reciprocal influence of long-term and short-term plasticity within the brain. We suggested an unsupervised approach by combining long-term learning (Triplet STDP) as the main training rule and short-term learning (STP) as the post-training learning rule added to the trained network after the training phase, which does not affect synaptic weights. Our results show that combining STDP and STP during training and after training will significantly enhance the network performance, modulates neuronal responses over time, and enhances the biological plausibility of SNN training algorithms. This improves the network’s ability to solve pattern recognition tasks. In this way, we showed that the proposed pipelines increased the final accuracy of the models and significantly improved the convergence rate of learning, requiring fewer training iterations. We also demonstrated that the networks trained and evaluated with our proposed pipelines were more robust to input noise.
This research provides valuable insights into the interplay between long-term and short-term synaptic plasticity mechanisms. Our findings revealed that the traditional training method does not utilize all the inherent potential of the SNN. Conversely, the proposed combination of SDTP and STP exhibited a relatively uniform increase of neural activity in the network during the model evaluation. This increase implies that post-training learning takes advantage of the available computing power of the SNN more efficiently. However, this ability comes at the cost of higher energy consumption due to increased spike rates and neurotransmitter release. The selection of the optimal value for the k factor limits the current study. The dynamic nature and complexity of SNNs make finding an optimal value of k challenging. Additionally, it is essential to have a SNN with neural and synaptic dynamics. This facilitates control over the network and fosters the integration of biological-based learning paradigms, including STDP and STP.
In the future, we plan to investigate new training methods based on Triplet STDP and its various configurations in combination with STP. While our work shows that the concept of post-training learning does, in fact, enhance the model’s performance, additional work is needed to match this SNN model to other problems and datasets. Finally, our key idea behind this approach has inspired the addition of other components, such as astrocytes, to a trained model to examine the impact of such components on the efficiency and robustness of the network against noise and impairment.
Data availability
The MNIST/EMINST datasets, which were used in this study, are publicly available and can be accessed at the following link: http://yann.lecun.com/exdb/mnist, https://www.nist.gov/itl/products-and-services/emnist-dataset. The code related to this study is available from the following link: https://github.com/Research-lab-KUMS/SNN_TripletSTDP_STP.
References
Taherkhani, A. et al. A review of learning in biologically plausible spiking neural networks. Neural Netw. 122, 253–272 (2020).
Parvizi-Fard, A., Amiri, M., Kumar, D., Iskarous, M. M. & Thakor, N. V. A functional spiking neuronal network for tactile sensing pathway to process edge orientation. Sci. Rep. 11, 1320 (2021).
Davidson, S. & Furber, S. B. Comparison of artificial and spiking neural networks on digital hardware. Front. NeuroSci. 15, 4523 (2021).
Mansvelder, H. D., Verhoog, M. B. & Goriounova, N. A. Synaptic plasticity in human cortical circuits: cellular mechanisms of learning and memory in the human brain? Curr. Opin. Neurobiol. 54, 186–193 (2019).
Pogodin, R. & Latham, P. Kernelized information bottleneck leads to biologically plausible 3-factor hebbian learning in deep networks. Adv. Neural. Inf. Process. Syst. 33, 7296–7307 (2020).
Sarwat, S. G., Moraitis, T., Wright, C. D. & Bhaskaran, H. Chalcogenide optomemristors for multi-factor neuromorphic computation. Nat. Commun. 13, 2247 (2022).
Morrison, A., Diesmann, M. & Gerstner, W. Phenomenological models of synaptic plasticity based on Spike timing. Biol. Cybern. 98, 459–478 (2008).
Moraitis, T., Sebastian, A. & Eleftheriou, E. Optimality of Short-Term Synaptic Plasticity in Modelling Certain Dynamic Environments (2021). http://arxiv.org/abs/2009.06808.
Diehl, P. & Cook, M. Unsupervised learning of digit recognition using spike-timing-dependent plasticity. Front. Comput. Neurosci. 9, 1456 (2015).
Jin, Y., Zhang, W. & Li, P. Hybrid macro/micro level backpropagation for training deep spiking neural networks. In Advances in Neural Information Processing Systems vol. 31 (Curran Associates, Inc., 2018).
Kozachkov, L. et al. Robust and brain-like working memory through short-term synaptic plasticity. PLoS Comput. Biol. 18, e1010776 (2022).
Moraitis, T., Sebastian, A. & Eleftheriou, E. The role of Short-Term plasticity in neuromorphic learning: learning from the timing of Rate-Varying events with fatiguing Spike-Timing-Dependent plasticity. IEEE Nanotechnol. Mag. 12, 45–53 (2018).
Rodriguez, H. G., Guo, Q. & Moraitis, T. Short-term plasticity neurons learning to learn and forget. In Proceedings of the 39th International Conference on Machine Learning 18704–18722 (PMLR, 2022).
Tsodyks, M. & Wu, S. Short-term synaptic plasticity. Scholarpedia 8, 3153 (2013).
Wang, X., Lin, X. & Dang, X. Supervised learning in spiking neural networks: a review of algorithms and evaluations. Neural Netw. 125, 258–280 (2020).
Javanshir, A., Nguyen, T. T., Mahmud, M. A. P. & Kouzani, A. Z. Advancements in algorithms and neuromorphic hardware for spiking neural networks. Neural Comput. 34, 1289–1328 (2022).
Lobo, J. L., Ser, D., Bifet, J., Kasabov, N. & A. & Spiking neural networks and online learning: an overview and perspectives. Neural Netw. 121, 88–100 (2020).
Roy, K., Jaiswal, A. & Panda, P. Towards spike-based machine intelligence with neuromorphic computing. Nature 575, 607–617 (2019).
Tavanaei, A., Ghodrati, M., Kheradpisheh, S. R., Masquelier, T. & Maida, A. Deep learning in spiking neural networks. Neural Netw. 111, 47–63 (2019).
Yi, Z. et al. Learning rules in spiking neural networks: a survey. Neurocomputing 531, 163–179 (2023).
Yamazaki, K., Vo-Ho, V. K., Bulsara, D. & Le, N. Spiking neural networks and their applications: a review. Brain Sci. 12, 863 (2022).
Fang, W. et al. Incorporating Learnable Membrane Time Constant to Enhance Learning of Spiking Neural Networks 2661–2671 (Springer, 2021).
Tang, L., Hu, J., Yu, H., Liu, S. & Chu, J. Learning spiking neural network from easy to hard task. in 3rd International Conference on Digital Society and Intelligent Systems (DSInS) 207–212 (IEEE, 2023). https://doi.org/10.1109/DSInS60115.2023.10455649.
Hole, K. J. & Ahmad, S. A thousand brains: toward biologically constrained AI. SN Appl. Sci. 3, 743 (2021).
Khamassi, M. Adaptive coordination of multiple learning strategies in brains and robots. In Theory and Practice of Natural Computing (eds. Martín-Vide, C., Vega-Rodríguez, M. A. & Yang, M.-S.) 3–22 (Springer International Publishing, 2020). https://doi.org/10.1007/978-3-030-63000-3_1.
O’Keefe, J. & Nadel, L. Précis of O’Keefe & Nadel’s the hippocampus as a cognitive map. Behav. Brain Sci. 2, 487–494 (1979).
LeCun, Y., Cortes, C. & Burges Chris. MNIST handwritten digit database (1998). http://yann.lecun.com/exdb/mnist/.
Cohen, G., Afshar, S., Tapson, J. & van Schaik, A. EMNIST: An Extension of MNIST to Handwritten Letters (2017). http://arxiv.org/abs/1702.05373.
Stimberg, M., Brette, R. & Goodman, D. F. Brian 2, an intuitive and efficient neural simulator. eLife 8, e47314 (2023).
Dayan, P. & Abbott, L. F. Theoretical Neuroscience: Computational and Mathematical Modeling of Neural Systems (Massachusetts Institute of Technology, 2001).
Stimberg, M., Goodman, D. F. M., Brette, R. & Pittà, M. D. Modeling neuron–Glia interactions with the Brian 2 simulator. In Computational Glioscience 471–505 (Springer, 2019). https://doi.org/10.1007/978-3-030-00817-8_18.
Zhang, W. & Linden, D. J. The other side of the engram: experience-driven changes in neuronal intrinsic excitability. Nat. Rev. Neurosci. 4, 885–900 (2003).
Tsodyks, M. Course 7—activity-dependent transmission in neocortical synapses. in Les Houches, vol. 80 (eds. Chow, C. C. et al.) 245–265 (Elsevier, 2005).
Tsodyks, M., Pawelzik, K. & Markram, H. Neural networks with dynamic synapses. Neural Comput. 10, 821–835 (1998).
Phenomenological models of synaptic plasticity based on spike timing. https://link.springer.com/article/10.1007/s00422-008-0233-1 (2023).
Pfister, J. P. & Gerstner, W. Triplets of spikes in a model of Spike Timing-Dependent plasticity. J. Neurosci. 26, 9673–9682 (2006).
Morrison, A., Aertsen, A. & Diesmann, M. Spike-timing-dependent plasticity in balanced random networks. Neural Comput. 19, 1437–1467 (2007).
Fuhrmann, G., Segev, I., Markram, H. & Tsodyks, M. Coding of temporal information by activity-dependent synapses. J. Neurophysiol. 87, 140–148 (2002).
Kim, Y. & Panda, P. Visual explanations from spiking neural networks using inter-spike intervals. Sci. Rep. 11, 19037 (2021).
DiNuzzo, M. & Giove, F. Activity-dependent energy budget for neocortical signaling: effect of short-term synaptic plasticity on the energy expended by spiking and synaptic activity. J. Neurosci. Res. 90, 2094–2102 (2012).
Sorbaro, M., Liu, Q., Bortone, M. & Sheik, S. Optimizing the energy consumption of spiking neural networks for neuromorphic applications. Front. Neurosci. 14, 1456 (2020).
Acknowledgements
The authors would like to thank the esteemed reviewers for their insightful and helpful comments. Funding for this work was provided by the Human Frontier Science Program grant RGP0045/2022.
Author information
Authors and Affiliations
Contributions
R. N: Formal analysis, Methodology, Software, Writing – original draft, review & editing. A.R: Software, Methodology, Writing – review & editing. M. Amiri: Conceptualization, Methodology, Writing – review & editing. H.P: Conceptualization, Writing – review & editing.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Naderi, R., Rezaei, A., Amiri, M. et al. Unsupervised post-training learning in spiking neural networks. Sci Rep 15, 17647 (2025). https://doi.org/10.1038/s41598-025-01749-x
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-01749-x
