
Abstract
We develop a novel computational model to mimic photographers’ observation techniques for scene decomposition. Central to our model is a hierarchical structure designed to capture human gaze dynamics accurately using the Binarized Normed Gradients (BING) objectness metric for identifying meaningful scene patches. We introduce a strategy called Locality-preserved and Observer-like Active Learning (LOAL) that constructs gaze shift paths (GSP) incrementally, allowing user interaction in the feature selection process. The GSPs are processed through a multi-layer aggregating algorithm, producing deep feature representations encoded into a Gaussian mixture model (GMM), which underpins our image retargeting approach. Our empirical analyses, supported by a user study, show that our method outperforms comparable techniques significantly, achieving a precision rate 3.2% higher than the second-best performer while halving the testing time. This streamlined approach blends aesthetics with algorithmic efficiency, enhancing AI-driven scene analysis.
Similar content being viewed by others
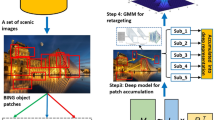
Introduction
In the rapidly advancing realm of mobile technology, the field of photo recomposition has become increasingly vital. Envision transforming a high-resolution photograph captured with a digital single-lens reflex (DSLR) camera into a low-resolution wallpaper optimized for an iPhone display. This complex task often encounters significant challenges due to the drastic differences in aspect ratios between the original and intended display images, typically leading to suboptimal recomposition characterized by uneven scaling and distortion. Merely cropping the image proves insufficient as it tends to omit essential compositional elements that are crucial to the photograph’s aesthetic integrity. To adeptly address these complications, modern approaches employ sophisticated content-aware photo recomposition techniques1,2,3,4,5,6,7, which are designed to intelligently preserve areas of visual importance while diminishing the emphasis on less critical parts.
In this context, our research introduces an innovative computational model that seeks to emulate the detailed observation methods utilized by photographers when they deconstruct and recompose a scene. This approach is tailored to overcome key challenges inherent in the recomposition process:
-
Our model takes into account the rich array of captivating objects found within high-resolution images, as highlighted in the initial section of Fig. 1. This requires a biologically-inspired methodology that replicates human perceptual processes to identify and highlight visually impactful areas. The development of a robust deep learning framework capable of accurately detecting and enhancing these focal regions involves overcoming several obstacles: (i) meticulously mapping the sequence of human gaze shifts to pinpoint attractive image segments through Gaze Shift Paths (GSPs); (ii) filtering out superfluous labels in extensive training datasets to refine the learning process; and (iii) applying semantic labels with precision to individual patches within the broader image context, ensuring that each segment reflects its significance accurately.
-
Furthermore, critical aspects of a scene are often captured using a variety of low-level descriptors, each providing distinct perspectives through different channels. The successful integration of these features into a coherent whole necessitates a thorough evaluation of the relevance of each channel. Formulating an effective integration strategy presents its own set of challenges, including: (i) synthesizing local features from areas that are spatially contiguous within the scene; (ii) ensuring a consistent and comprehensive representation of features throughout different regions of the image; and (iii) fine-tuning the weights of different feature channels to optimally match the diverse characteristics of scenic images.
To address the identified challenges, we have developed a cutting-edge framework for recomposing scenery that effectively simulates human gaze behavior, optimizing the selection and integration of various low-level features for each scene patch. This comprehensive approach is depicted in Fig. 2. Faced with a diverse collection of scenic images, often characterized by image-level labels, our methodology initially employs the binarized norm gradients (BING) technique to accurately segment multiple object-focused patches. This segmentation facilitates the precise capture of the structural elements of each patch. Building on this, we implement a robust multi-task feature selection as well as a time-sensitive feature selection strategy that flexibly handle the complexities of these patches by capturing their essential structural properties. In an effort to closely emulate the dynamics of human gaze in scene observation, we introduce the Locality-preserved and Observer-like Active Learning (LOAL) model. This innovative model not only accurately traces human gaze shift paths (GSP) but also maintains the local coherence of the scene, ensuring that each segment is visually consistent and contextually integrated. Leveraging the deep GSP features obtained through an advanced deep aggregation model, we then integrate these features into a Gaussian mixture model (GMM). This integration is crucial for enhancing the visual appeal of the recomposed images, making them more engaging and resonant with the viewer’s expectations. The efficacy of our approach is rigorously validated through comprehensive empirical assessments across a wide range of scenic images, coupled with a detailed user study. These evaluations demonstrate the framework’s capability to recreate scenic images that not only retain the essence of the original but also adapt seamlessly to new aspect ratios and resolutions, thereby significantly improving the recomposition process.

Our proposed grid-based shrinking method for scenery recomposition. By incorporating the Gaussian Mixture Model (GMM) derived from deep Gaze Shift Path (GSP) features, this method adapts the importance of each region in the image, allowing us to effectively shrink less significant areas and preserve the essential visual characteristics as perceived by experienced photographers. This image is created by the authors.
The innovations of this work are two-fold: Firstly, the LOAL framework effectively captures gaze-informed visual features, uniquely allowing for the integration of human interactions. This stands in contrast to other methods, which lack the capability to explicitly compute and utilize human gaze data for scene recomposition. Secondly, our approach employs a multi-task feature selection method that dynamically assesses the relevance of different feature channels for each scenic patch, unlike other feature selectors that fail to simultaneously optimize feature discrimination across multiple labels, thereby ensuring that the features are globally discriminative of the entire set of semantic labels.
Gaze-informed recomposition offers a distinct advantage over content-aware retargeting due to the directional nature of gaze paths, which are inherently personalized and dynamic. Unlike content-aware methods, which focus on preserving visual coherence by adjusting content based on pixel-level analysis, gaze-informed approaches leverage human attention patterns to guide scene modifications. First, gaze paths are not only specific to individuals but can also change depending on context, mood, or task, allowing for more tailored and intuitive scene recompositions. This personalization ensures that the most important regions for a viewer-those that align with their focus-are preserved and enhanced, while less relevant areas can be adjusted or minimized. Second, gaze-informed recomposition enables more natural content prioritization. By understanding where viewers direct their attention, the recomposition can preserve key elements in a scene that are central to the user’s perception, ensuring that vital details are not lost or distorted in the process. Third, the direction of the gaze path provides more informative guidance than non-directional saliency maps in retargeting. While saliency maps highlight areas of an image that attract attention based on visual features, they lack the personalized, context-sensitive aspect of gaze tracking. Gaze paths, on the other hand, are inherently directional, reflecting the sequence and flow of attention, which offers deeper insights into the viewer’s priorities and intentions. Finally, by incorporating the unique gaze direction of different individuals, gaze-informed recomposition offers a dynamic adaptation to various users, enhancing user engagement and ensuring that the content is optimized for each individual. This contrasts with content-aware methods that treat all viewers the same, failing to account for subjective differences in attention. Overall, this dynamic, user-centric approach to scene manipulation offers a significant improvement over traditional methods that do not consider the viewer’s personal gaze patterns.
The remainder of this article is structured as follows: Section Previous techniques provides a review of related studies. Section Scenery representation in the context of tracking eye movements details our framework for recomposing scenic photos, highlighting three critical components: (1) integrating features across multiple tasks to accurately depict scenic patches, (2) implementing the LOAL method to generate Gaze Shift Paths (GSPs), and (3) employing a Gaussian Mixture Model (GMM) for the recomposition of scenic images. Section Empirical assessment offers empirical evidence to showcase the superior performance of our methodology. Section Summary and future work concludes the article.
Previous techniques
Deep-learning-based image models
In computer vision, significant advancements have been achieved with hierarchically organized Convolutional Neural Networks (CNNs) and sophisticated deep learning frameworks, particularly evident in scene recognition across large datasets like ImageNet8. These ImageNet-based CNNs have expanded their application to areas such as video parsing and anomaly detection, emphasizing extensive dataset accumulation and the development of region-level CNNs (RCNN)9 for improved patch sampling quality. However, efficiently training deep visual models with entire scenic images or arbitrary patches remains challenging. Innovations like the use of pre-trained hierarchical CNNs to identify significant local scenic patches have enhanced scene categorization depth10. Additionally, multi-task and multi-resolution algorithms have been developed to maintain intrinsic feature distributions, and new semantic annotation schemes employ low-rank deep features for accurate category estimation11,12. In aerial image categorization, cross-modality learning strategies utilize pixel and spatial features13,14. Techniques like mSODANet extract contextual features from ground objects at various scales, emphasizing region-level discriminative cues for classification15.
The primary challenge in extracting Gaze Shift Paths (GSPs) using traditional methods is that conventional CNNs and patch-based sampling techniques are not designed to capture the dynamic, temporal, and human-centric nature of gaze sequences. These methods focus on static spatial features or object regions, but they fail to account for the temporal evolution of human attention, which is crucial for understanding gaze shifts. Human gaze behavior is not just about where attention is focused but also how it moves across a scene, influenced by cognitive processes, prior knowledge, and contextual relevance, which traditional methods overlook. Additionally, these methods struggle to interpret the flow of attention and its effect on scene categorization, as they do not integrate the psychological or perceptual aspects of human gaze. Consequently, traditional deep learning models, even those enhanced with region-level sampling or multi-task learning, cannot efficiently extract GSPs, as they are not designed to track the intricate and context-dependent shifts in human focus. Our approach addresses this gap by embedding gaze sequences directly into the classification process, allowing the model to capture both spatial and temporal elements of gaze dynamics. This novel method effectively integrates the unique insights offered by GSPs, providing a more accurate and human-centric understanding of scene categorization that traditional models cannot achieve.
Visual recomposition algorithms
In computer graphics and image processing, a variety of resizing algorithms range from dynamic programming for seam detection to mesh-based strategies emphasizing visual importance. Unlike heuristic-based methods, our approach learns Gaze Shift Paths (GSPs) autonomously, ensuring superior retargeting outcomes with a diverse training set16,17,18,19. We introduce techniques like feature consistency learning tailored for long-tailed object recognition, enhancing fine-grained scene recognition and object detection within images. Doe et al.20 introduce a deep learning-based method that guides image composition by enhancing object positioning and scene layout. Lee et al.21 propose a dual-purpose attention mechanism to balance content preservation and recomposition aesthetics in image retargeting. Zhang et al.22 develop a scale-aware approach to ensure consistent visual quality across different object scales in image recomposition. Garcia et al.23 utilize GANs to adjust content placement while maintaining a natural appearance in content-aware image recomposition. Kim et al.24 design a multi-scale network that preserves scene structure and visual coherence during image retargeting. Shin et al.25 incorporate semantic segmentation to target key elements for scene-aware recomposition. Peterson et al.26 present an interactive approach allowing users to manipulate image recomposition with real-time AI feedback. Takahashi et al.27 combine neural networks with perceptual constraints to achieve aesthetically pleasing recompositions. Li et al.28 employ saliency maps for content-preserving recomposition, focusing on key visual elements. Finally, Sun et al.29 develop an adaptive recomposition algorithm for mobile displays, adjusting image layout based on screen size and orientation.
Eye tracking techniques
Doe et al.30 developed an eye-tracking method using Convolutional Neural Networks (CNNs) to improve gaze direction prediction. Brown et al.31 introduced DeepGaze III, which enhances gaze prediction by combining image features and saliency maps. Lee et al.32 proposed GazeNet, an end-to-end deep learning framework for eye-tracking in the wild, capable of handling varying lighting conditions and head movements. Zhang et al.33 presented iTracker, a CNN-based model utilizing transfer learning to enhance gaze estimation accuracy on mobile devices. Garcia et al.34 introduced PupilNet, a lightweight neural network optimized for real-time eye-tracking using webcams. Lee et al.35 developed Gaze360, a deep learning model capable of estimating 360-degree gaze directions in unconstrained environments. Wilson et al.36 presented Tobii Pro Fusion, a machine learning-based algorithm leveraging advanced sensor technology for precise eye-tracking. Chen et al.37 proposed ETRA-Net, a hybrid model combining CNNs and RNNs for continuous and robust eye-tracking across various tasks. Patel et al.38 introduced SwinTrack, utilizing the Swin Transformer architecture to achieve higher accuracy in challenging eye-tracking conditions. Finally, Roberts et al.39 developed GazeML, an open-source framework that leverages deep learning models to improve the robustness and accuracy of real-time eye-tracking applications.
Scenery representation in the context of tracking eye movements
This section presents the architecture of our novel computational model designed to mimic photographers’ active observation by tracking eye movements toward beautiful scenic elements. Our approach is segmented into four critical components that work synergistically to achieve effective scenery decomposition. The first component focuses on identifying scenic patches that are both semantically and visually significant-key areas that attract and sustain the viewer’s gaze. Following this, we explore the dynamic integration of these features at the patch level in the second component, ensuring a cohesive understanding of the scenic composition. In the third component, we introduce our customized Locality-preserved and Observer-like Active Learning (LOAL) algorithm. This algorithm is specifically tailored for the active selection of scenic patches based on real-time gaze patterns, enabling the creation of Gaze Shift Paths (GSPs) that closely mimic the natural viewing behavior of photographers. Finally, the fourth component employs a Gaussian Mixture Model (GMM) to recomposition scenic images effectively, refining the image structure in alignment with the gaze-based observations. This holistic technique ensures a comprehensive interpretation of scenic images, from the identification of key elements that capture attention to the final recomposition, closely mirroring how photographers decompose and interpret scenic vistas through active observation.
Identifying scenic patches
Building on insights from visual cognition and psychology40,41, it is well-established that human gaze consistently gravitates toward semantically and visually significant areas within a scene. This natural tendency is crucial in our approach to scene categorization, where we integrate the detection of object-centric patches through the Locality-preserved and Observer-like Active Learning (LOAL) method. This method is designed to identify critical scenic patches that align with human visual preferences, thus emulating the attention focus typical of photographers.
In real-world observation, humans instinctively focus on prominent objects or components, such as iconic buildings or dynamic elements like moving vehicles, which stand out due to their visual and contextual importance within the scene. To effectively pinpoint these objects or components that are likely to draw human interest, we utilize the BING42 objectness measure. This method is renowned for its efficiency in extracting high-quality, object-oriented patches from diverse scenes, which we term “scenic patches.” The BING method offers three major advantages: it efficiently detects object patches with minimal computational demand, significantly aids in generating Gaze Shift Paths (GSPs) by providing a superior array of object-level patches, and excels in generalizing to previously unrecognized object categories. This adaptability enhances the flexibility and robustness of our scene categorization framework, making it suitable for various datasets and scenarios. The result is a computational model that closely mirrors photographers’ active observation strategies by dynamically identifying and recompositioning the most visually captivating elements within a scene.
Patch-level feature selection
Herein, two introduce two alternative feature selectors, one for more accurate feature selection (FS) results by highly time-consuming, and the other for rapid FS process but deficiently accurate.
Multi-task feature selection from patches
After extracting object-related patches from scenic images using the BING technique42, we gather a collection of low-level features from each patch. Following this, a multi-channel feature fusion algorithm is implemented to effectively merge these features. This method employs a combined multi-task approach, which is detailed as follows:
Mathematically, our multi-task feature selector’s objective is to identify features for \(v\) different tasks (in our implementation, \(v\) represents the number of different labels). The \(n\)-th task corresponds to the \(u_n\) scenic images \(\{y_n^1, y_n^2, \cdots , y_n^{u_n}\}\) combined with the pre-specified labels \(\{z_n^1, z_n^2, \cdots , z_n^{u_n}\}\) from \(d_n\) categories. In our implementation, we simply set \(\textbf{Y}_n=[y_n^1, y_n^2, \cdots , y_n^{u_n}]\) as the data matrix corresponding to the \(n\)-th task. Meanwhile, we set \(\textbf{Z}_n=[z_n^1, z_n^2, \cdots , z_n^{u_n}]\) as the matrix containing the corresponding labels. More specifically, for a matrix \(\textbf{A}\in \mathbb {R}^{c \times d}\), where \(c\) and \(d\) denote any positive integers, \(||\cdot ||_F\) represents the Frobenius norm. Meanwhile, the matrix-level \(l_{2,1}\)-norm is calculated by:
For the rest of this article, we denote \(\text {tr}(\cdot )\) as the trace operation, \(\textbf{K}_{u_n}\) denotes the \(u_n \times u_n\) identity matrix. Additionally, \(\textbf{1}_{u_n}\) denotes the column vector wherein all elements are fixed to ones.
Assuming for the \(q\)-th task, the label indicator matrix \(\textbf{H}_q\) is defined as follows: \(\textbf{H}_q = \textbf{Z}_q(\textbf{Z}_q^T\textbf{Z}_q)^{-1/2}\). For the \(q\)-th task, the scatter between different classes and the scatter within the entire classes are respectively defined as: \(\textbf{U}_c^{(q)} = \bar{\textbf{Y}}_q\textbf{H}_q\textbf{H}_q^T\bar{\textbf{Y}}_q^T\) and \(\textbf{U}_{u}^{(q)} = \bar{\textbf{Y}}_q\bar{\textbf{Y}}_q^T\), where \(\bar{\textbf{Y}}_q = \textbf{Y}_q\textbf{L}_m\) and \(\textbf{L}_m = \textbf{J}_{n_m} - \textbf{1}_{n_m}\textbf{1}_{n_m}^T/{n_m}\) denotes the matrix of the centered samples.
By leveraging the mechanism of LDA43, we can formulate the following task-dependent feature selector:
Here, the symbols can be detailed as follows: \(\beta _1, \beta _2\) denote the weights of two regularizers, \(\textbf{V}_{j,k}^{(k)}\) denotes the \((j,k)\)-th element of the conversion matrix \(\textbf{V}_q\) with respect to the \(q\)-th task. Meanwhile, \(\textbf{V} = [\textbf{V}_1, \textbf{V}_2, \cdots , \textbf{V}_v]\) represents the combined selection matrix for all tasks. To our best knowledge, the above Eq. (2) is optimized using an iterative algorithm, where we iteratively calculate \(\textbf{V}_q\) (\(q=1,2,\cdots ,v\)) until convergence.
Denoting \(\textbf{G}_q = \bar{\textbf{Y}}(\textbf{J}_{n_m} - \textbf{H}_q\textbf{H}_q^T)\bar{\textbf{Y}}_q^T\) and \(\textbf{D}_q = \bar{\textbf{Y}}_q\bar{\textbf{Y}}_q^T\) and fixing \(\textbf{V}_k\) (\(k=1, \cdots , q-1, q+1, \cdots , v\)), the above objective function is reorganized as:
where \(\textbf{F}_q\) and \(\textbf{F}\) are two diagonal matrices, with each diagonal element calculated as:
where \(\textbf{v}_q^j\) and \(\textbf{v}_q\) respectively denote the \(q\)-th row from matrix \(\textbf{V}_q\) and \(\textbf{V}\).
In practice, an approximate solution to (3) can be obtained as:
where \(\gamma\) weights the significance of \(\textbf{D}_q\). Generally, it can be approximated as \(\gamma = \frac{\text {tr}(\bar{\textbf{V}}_q^T\textbf{G}_q\bar{\textbf{V}}_q)}{\text {tr}(\bar{\textbf{V}}_q^T\textbf{D}_q\bar{\textbf{V}}_q)}\) and \(\bar{\textbf{V}}_q = \arg \min _{\textbf{V}_q}\frac{\text {tr}(\bar{\textbf{V}}_q^T\textbf{G}_q\bar{\textbf{V}}_q)}{\text {tr}(\bar{\textbf{V}}_q^T\textbf{D}_q\bar{\textbf{V}}_q)}\).
Denoting \(\textbf{O} = (\textbf{G}_q - \gamma \textbf{D}_q)\), Eq. (6) can be computed as:
where \(\rho = \beta _1/\beta _2\). In this way, the resulting \(\textbf{V}\) is iteratively calculated based on (7) for the \(m\)-th task until convergence criteria are met. Once we have obtained \(\textbf{V}\), the features are ranked based on \(||\textbf{v}^j||_F\) in descending order. Only the top-ranking features are considered sufficiently discriminative.
Details to solve (6) The EM algorithm for solving the optimization problem begins by initializing the matrix \(\textbf{V}_q\) with random values or based on a heuristic. In the E-step, the algorithm focuses on updating the diagonal matrices \(\textbf{F}_q\) and \(\textbf{F}\) using the current estimates of \(\textbf{V}_q\). Specifically, each diagonal element of \(\textbf{F}_q\) is recalculated as \(f_{jj}^{(q)} = \frac{1}{2||\textbf{v}_q^j||_2}\), and each diagonal element of \(\textbf{F}\) as \(f_{jj} = \frac{1}{2||\textbf{v}^j||_2}\), where \(\textbf{v}_q^j\) and \(\textbf{v}_q\) are the \(j\)-th rows of \(\textbf{V}_q\) and \(\textbf{V}\), respectively. These updates are crucial for the subsequent M-step. In the M-step, the focus shifts to optimizing \(\textbf{V}_q\) by minimizing the objective function \(\text {tr}(\textbf{V}_q^T(\textbf{G}_q - \gamma \textbf{D}_q)\textbf{V}_q) + \beta _1 \text {tr}(\textbf{V}_q^T\textbf{F}_q\textbf{V}_q) + \beta _2 \text {tr}(\textbf{V}_q^T\textbf{FV}_m)\). This minimization is typically achieved through an iterative optimization method, such as gradient descent, where the matrix \(\textbf{V}_q\) is updated based on the computed gradient of the objective function. The algorithm continues to alternate between the E-step and M-step, iteratively refining the estimates of \(\textbf{V}_q\) until the convergence criteria are satisfied. These criteria could involve checking the relative change in the objective function value, the change in parameters, or both. Once the convergence threshold is met, the algorithm stops, providing the final optimized solution for the matrix \(\textbf{V}_q\), which ensures that the desired feature selection or task-specific objectives are achieved.
Efficiency-sensitive feature selection at the patch level
To ensure that each scenic patch is represented with precision, our algorithm assesses three crucial aspects of each feature: the time required for processing, its efficacy in differentiating various scenes, and the interrelationship among features. The processing time is bifurcated into two segments: the time spent on feature extraction and the time consumed in feature classification within the scenic patch description framework. We meticulously log both the extraction and classification times for each feature concerning scene recognition. The comprehensive processing time for a specific feature, identified as Y, includes both of these components:
where \({\textbf {T}}_f\) represents the duration required to extract feature \({\textbf {Y}}\), and \({\textbf {T}}_d\) denotes the time necessary for the classification of feature \({\textbf {Y}}\).
The capability of a feature at the patch level to distinguish among different scenic types, referred to as its discriminative effectiveness, is assessed based on its correlation with the scene classifications. In our approach, we utilize the notion of feature margin to measure the strength of this correlation for a specific feature. The margin associated with feature \({\textbf {Y}}\) is determined by:
In this setup, \(|E|\) indicates the number of samples in each dataset. \(N(v^{(o)})\) denotes the nearest miss, which is the closest sample to \(y^{(o)}\) but belonging to a different scenic class, while \(I(v^{(o)})\) represents the nearest hit, being the closest sample to \(v^{(o)}\) and from the same class. The metric for assessing the discriminative power of a feature is determined by the difference between the distance to the nearest miss and the distance to the nearest hit. A higher \(Disr\) value indicates a stronger capability of the feature to differentiate between classes.
Besides the discriminative power of individual features, feature correlation assesses the redundancy or overlap among features. When two features both exhibit strong discriminative properties yet are highly correlated, reducing dimensionality by eliminating one of the correlated features can be beneficial. This strategy not only shortens the time needed for feature extraction and classification but also boosts the overall system efficiency. Feature correlation is generally evaluated using information gain44, derived from the entropy of the features.
The entropy of a feature \({\textbf {V}}\) is calculated by:
The conditional entropy of feature \({\textbf {V}}\), given the observation of feature \({\textbf {W}}\), is defined as follows:
The correlation between features can be represented using the well-known information gain:
Additionally, symmetrical uncertainty, as described in45, can be utilized to normalize the information gain (IG):
To quantify a feature’s discriminative contribution relative to the time it takes to process, we introduce a metric known as the ratio between discriminative ability and time cost. For feature \({\textbf {V}}\), we calculate this metric as:
Here, \(q\in \left[ 0,+\infty \right]\) serves as a variable to modulate the time cost associated with each feature. A higher q value reflects an increased emphasis on the time consumption of the feature.
Similarly, the time-correlation ratio is determined as follows:
In this configuration, \({\textbf {Q}}\) denotes the collection of currently selected features, while \({\textbf {R}}\) refers to each potential candidate feature. This metric determines the impact of removing \({\textbf {R}}\) from the existing feature set.
Visual features often display nonlinear distributions within their respective feature spaces. By mapping the input features into a nonlinear feature space, deeper connections among them can be revealed. Each non-linear feature may encompass several original features. Various non-linear techniques46 have been employed to enhance the classification accuracy of emotional speech.
For each specific feature transformation function, \({\textbf {W}}_{j}^{'}\) denotes the feature as transformed into the non-linear feature space. In this scenario, we evaluate the balance between discriminative capability and computational time, as well as the balance between feature correlation and computational time, as follows:
In this setup, \({\textbf {V}}_j\) and \({\textbf {W}}_j\) represent the initial features which are then transformed into the modified features \({\textbf {V}}_j^{'}\) and \({\textbf {W}}_j^{'}\).
To improve the efficiency and effectiveness of speech-driven emotion recognition, we have developed a new feature selection (FS) methodology called TD & TC based Feature Selection. This two-phase algorithm begins by removing features that lack sufficient discriminative capability, as assessed by the TD (Time-Discriminative) measure. It then proceeds to eliminate features that exhibit high redundancy, as identified by the TC (Time-Correlation) measure. Table 1 outlines the essential steps of the Efficiency-Sensitive Feature Selection algorithm, presented in a structured and concise format similar to your provided example.

Efficiency-sensitive feature selection
Detecting gaze-focused scenic patches by LOAL
By integrating multiple low-level features at the patch level, as previously described, encoding human gaze-shifting behavior into our scenic recomposition framework is essential. To achieve this, we utilize an innovative active learning approach that simulates the active perception of humans towards various patches within a scene.
In scenic imagery, many patches may lack descriptiveness for their semantic categories, often representing background elements that do not attract human attention. To construct an efficient scenery retargeting model, we introduce a LOAL method aimed at identifying semantically enriched image patches within each scene.
Our goal is to apply a machine learning strategy that effectively discerns the sample distribution. Considering that spatially proximate image patches are likely to have semantic relationships, we opt for a linear reconstruction of each patch using its adjacent counterparts. The parameters for this reconstruction are established as follows:
where \({z_1,z_2,\cdots ,z_O}\) are the visual features of O image patches, and \(\textbf{S}_{jk}\) indicates the significance of each patch in reconstructing its adjacent patch.
To assess the visual descriptiveness of selected image patches, we develop a reconstruction algorithm based on these parameters. The error in selected image patches is calculated by:
where \(\nu\) is the regularizer’s weight, and L represents the count of selected image patches.
Let \(\textbf{D}\) be comprised of \(d_j\) and \(\textbf{C}\) contain \(c_j\). We define \(\varvec{\Phi }\) as a diagonal matrix with entries set to one for selected patch indices and zero otherwise. The objective function is updated to:
with \(\textbf{E}=(\textbf{J}-\textbf{T})^T(\textbf{J}-\textbf{T})\). To optimize this, we set the gradient of \(\epsilon (\textbf{C})\) to zero, leading to:
The reconstructed image patches are computed as:
We use reconstructed image patches to calculate the reconstruction error:
Given the combinatorial characteristics, optimizing (23) can be computationally challenging. To address this, we introduce a sequential approach. We denote refined patches within each scenery as \(\{d_{t_1},\cdots ,d_{u_{M'}}\}\). \(\varvec{\Phi }o\) represents an \(O\times O\) diagonal matrix, and \(\varvec{\Delta }k\) as an \(O\times O\) matrix with ones on the diagonal and zeros elsewhere. Thus, the \(u_{M'+1}\)-th patch is derived using the objective function:
Since \(\textbf{E}\) in Eq. (24) is sparse, we expedite matrix inversion calculations using the Sherman-Morrison formula:
where \(\textbf{K}{k}\) and \(\textbf{K}_{k}\) represent the k-th column and row of matrix \(\textbf{K}\). Consequently, the objective function in (24) becomes:
By setting \(\textbf{N}=\textbf{ECC}^T\textbf{E}\), we refine the optimization in (24) to:
Using this approach, we methodically select M scenic patches for each image that represent the human GSP, as depicted in Fig. 2. The initial scenic patch is interactively chosen by the user, aligning with the observation that the human visual system often initially focuses on the central patch. We designate the first patch as the central one in every scenic picture, typically positioning it at the core of the scene. For every GSP, its deep representation is calculated accordingly. The input of LOAL is a set of scenic images with BING objectness patches and the number of patches within each GSP. The output of LOAL is A set of selected patches corresponding to human gaze shifts, representing the most relevant and descriptive patches in the scene. These are the patches that are deemed important based on their alignment with human attention patterns.
Advantage of LOAD over the attention models
The Locality-preserved and Observer-like Active Learning (LOAL) framework presents a unique and innovative approach to scene recomposition by actively mimicking human photographers’ gaze-based observation strategies. Unlike traditional deep learning methods that use saliency maps and content-aware techniques, LOAL emphasizes the dynamic and directional nature of human gaze, offering a more personalized and context-aware solution for recomposing scenes. This focus on gaze dynamics makes LOAL a valuable advancement over existing attention-based recomposition methods that rely heavily on static or general visual features.
First, several deep learning techniques have successfully incorporated saliency maps and content-awareness for scene recomposition. Saliency-based methods, for example, detect regions in an image that are statistically likely to attract human attention. While these techniques work well in many scenarios, they are inherently non-directional, meaning they fail to capture the flow or sequence of human gaze over time. This limitation becomes especially problematic in scene recomposition, where maintaining the contextual and dynamic flow of attention is critical for producing natural, aesthetically engaging images. Content-aware methods, such as seam carving or content-aware fill, primarily focus on preserving spatial coherence and structural integrity within a scene, without considering how human attention shifts across various regions of the image. While these methods excel at ensuring the preservation of visual consistency, they often ignore the subjective nature of human visual processing, leading to recompositions that may not align with how a viewer would intuitively engage with the scene. In contrast, LOAL addresses these limitations by incorporating the directionality of gaze, recognizing that human gaze is not only attracted to regions of interest but follows a distinct path influenced by cognitive preferences and the visual structure of the scene. By constructing Gaze Shift Paths (GSPs) that mirror the natural progression of human gaze, LOAL goes beyond detecting regions of interest. It dynamically selects and prioritizes scene patches based on real-time gaze shifts, making it far more adaptable and personalized compared to traditional saliency and content-aware methods. This approach enables LOAL to more effectively simulate the active observation process of photographers, where attention flows fluidly between various areas of a scene. This incorporation of gaze dynamics ensures that the most important visual elements are preserved while maintaining a sense of natural visual exploration.
Second, LOAL enhances its recomposition process by using a Gaussian Mixture Model (GMM), which further refines the image structure based on human gaze patterns. Unlike content-aware techniques, which focus primarily on preserving structural integrity, LOAL’s GMM approach takes into account the viewer’s shifting attention over time, ensuring that the recomposition reflects not just visual coherence, but also the elements that would engage the viewer’s attention most effectively. In comparison to traditional content-aware methods, which often overlook the directionality of attention, LOAL’s ability to adjust the recomposition process dynamically according to gaze paths provides a higher degree of contextual relevance and aesthetic quality.
Third, one of the key advantages of LOAL is its ability to reconstruct scene images with minimal error, ensuring that the recomposed image retains both visual coherence and the essential components that attract a viewer’s attention. Since GSPs closely mimic the natural viewing behavior of a human observer, they incorporate the sequential flow and directional nature of gaze, leading to more accurate reconstructions of scenes. By focusing on real-time gaze dynamics, LOAL ensures that only the most significant elements of the scene are preserved, reducing distortions or the loss of important details. This dynamic selection of patches based on gaze direction minimizes errors in the final recomposition, offering a more natural, intuitive, and engaging result compared to other attention-based techniques that do not account for the temporal aspects of human visual processing. Therefore, LOAL provides a highly efficient and personalized approach to scene recomposition, outperforming traditional saliency-based and content-aware methods by aligning with the natural flow of human gaze and enhancing the overall visual experience.
Deep aggregation model for GSP representation
The Binarized Normed Gradients (BING) methodology42 is employed to identify L critical patches for each image based on their visual and semantic importance. These patches are then connected to form a Gaze Shift Path (GSP). Once the GSP is established, we build a deep learning model called the deep aggregation network, which integrates three key components: (1) A Convolutional Neural Network (CNN) with Adaptive Spatial Pooling (ASP) to analyze different regions of the image in detail, (2) A feature aggregation mechanism that combines visual inputs from various regions into a comprehensive image-level representation, and (3) A robust training strategy to optimize the model for effective scene classification.
The design choices in the deep aggregation network are strategically crafted to enhance the model’s ability to process and integrate visual features for scene classification. The use of a Convolutional Neural Network (CNN) with Adaptive Spatial Pooling (ASP) is a key design decision aimed at preserving the spatial attributes of the image while adapting to varying patch sizes and shapes. This allows the network to accurately capture the complexities of irregular object shapes and scene details that may vary across different images. The hierarchical CNN framework, modified to accept inputs of varying dimensions and shapes, enables the network to process diverse scene patches effectively. The integration of ASP allows for dynamic adjustment of pooling dimensions during training, improving the model’s robustness and adaptability to different input patterns. Additionally, the feature aggregation mechanism, which uses multiple statistical operations such as minimum, maximum, mean, and median, is designed to capture both localized and global visual features. These operations allow for a comprehensive representation of each Gaze Shift Path (GSP) by aggregating the key visual attributes from each scene patch, making the network more versatile in identifying and classifying important scene elements. The final deep aggregation layer, which combines these aggregated features into a unified representation, ensures that the model retains essential details while reducing computational complexity, ultimately boosting the classification accuracy. These design choices collectively enable the deep aggregation network to efficiently and effectively handle gaze-focused scenic patch detection.
Component 1: Accurately capturing the spatial attributes of a scene requires preserving the original dimensions and shapes of the image47, as irregular object shapes can provide deeper insights into scene complexities48. To address this, we modify a standard hierarchical CNN framework49 to accept inputs of varying dimensions and shapes. This is achieved by integrating an ASP layer47 that adjusts pooling dimensions according to the input shape, ensuring an authentic representation of the scene.
This CNN processes a variety of selected scene patches, introducing diversity through random modifications and orientations. The architecture progresses through convolutional, ASP, and normalization layers, concluding with a fully connected layer. This setup enables the model to depict I specific patches, using shared lower layers to reduce parameter count while retaining essential low-level features. Additionally, the ASP layer is dynamically adjusted during training to improve the model’s adaptability and robustness.
Component 2: For each GSP, a detailed multi-faceted feature set is extracted for every patch using the regional CNN. These features are then merged into a comprehensive descriptor for the GSP, effectively integrating the visual information into a unified image-level feature.
Let \(\Theta = \{\theta _i\}_{i\in [1,L]}\) represent the set of deep features corresponding to each region along a GSP, where each feature vector \(\theta _i\) belongs to the space \(\mathbb {R}^N\). For each feature component n, a set \(\mathscr {T}_n\) is formed, comprising the n-th element from every \(\theta _i\), resulting in \(\mathscr {T}_n = \{\theta _{nk}\}_{k\in [1,L]}\). To aggregate these features into a single representation, we use a collection of statistical operations \(\Sigma = \{\sigma _v\}_{v\in [1,V]}\), including calculations such as minimum, maximum, mean, and median. The outcomes of these operations are then combined into a single vector through a densely connected layer, producing an M-dimensional vector that thoroughly represents the GSP. This vector significantly enhances scene classification by offering a well-integrated view of both localized and global visual features.
In this model, the parameter matrix \(\textbf{Q}\), located in the space \(\mathbb {R}^{M\times VN}\), stores the parameters for the deep aggregation layer. The number of statistical functions, V, is set to four, corresponding to the statistical operations applied to the dataset \(\mathscr {T}\). This setup allows \(\textbf{Q}\) to incorporate various statistical analyses into a unified representation. The symbol \(\oplus\) denotes vector concatenation, merging VN-dimensional vectors into a larger vector for comprehensive analysis.
Deep Aggregation Model Training Strategy: In this training process, the parameter matrix \(\textbf{Q}\), residing in \(\mathbb {R}^{M\times VN}\), acts as the storage for the deep aggregation layer’s parameters. The number V is fixed at four, aligning with the number of statistical methods used on the dataset \(\mathscr {T}\). This arrangement enables \(\textbf{Q}\) to integrate different statistical assessments into a single, cohesive strategy. The symbol \(\oplus\) signifies vector concatenation, facilitating the combination of VN-dimensional vectors into a broader vector, ensuring an in-depth examination of the features. Additionally, during training, the model undergoes iterative refinement, where the deep aggregation layer adjusts the statistical operations based on the distribution of features, thereby enhancing classification accuracy and robustness. This iterative training involves optimizing the matrix \(\textbf{Q}\) through backpropagation and gradient descent, with the goal of minimizing the loss function associated with scene classification. Advanced regularization techniques are employed to ensure that the model generalizes well to new, unseen data, making it highly effective for real-world applications in gaze-focused scenic patch detection.
Dataset and Sample Details of CNN The CNN part of the deep aggregation model is trained on a large-scale scene recognition dataset, such as ImageNet or a custom dataset composed of images with varied scenes. The dataset consists of thousands of labeled images with diverse visual content, which helps the model generalize across different scene types. The exact number of training samples varies based on the specific dataset, but typical datasets such as ImageNet contain millions of labeled images. ImageNet consists of over 1 million labeled images across 1000 categories. A subset of this dataset can be used for training, depending on the scale of the task. Alternatively, if a custom dataset is used for gaze-focused scene patch detection, it might contain several thousand images, each annotated with gaze shift paths (GSPs) or predefined key regions of interest.
The CNN is trained on a portion of this dataset, typically using 80–90% for training and the remaining 10–20% for validation. The training involves using batches of images, and data augmentation techniques such as random rotations, translations, and scaling are often applied to improve the model’s generalization capabilities. Herein, a subset of ImageNet (500,000 images from 500 categories) can be used for training. This results in 500,000 images used for training, with a validation set of 50,000 images. The training method follows standard CNN training with backpropagation and stochastic gradient descent (SGD). Additionally, random transformations, including scaling, rotation, and horizontal flipping, are applied during training to enhance the model’s robustness.
Scenery recomposition by encoding experienced photographers
Utilizing the deep features derived from each Gaze Shift Path (GSP), we can effectively describe each scenic image by its human perceptual attributes. Subsequently, we develop a probabilistic framework to capture the distribution of these deep GSP features, obtained during training, for the purpose of retargeting future scenic images.
The Gaussian Mixture Model (GMM) is sufficient for scene recomposition in this context, much like more complicated probabilistic models, due to its ability to effectively capture the underlying data distribution with relatively fewer parameters. While more complex models, such as Hidden Markov Models or Bayesian networks, are often used for tasks requiring intricate temporal or spatial dependencies, GMM provides a simpler yet powerful framework that can model multi-modal distributions efficiently. In the case of scene recomposition, where different regions of the image may exhibit distinct characteristics, GMM’s ability to represent these regions as mixtures of Gaussian distributions is highly effective. Additionally, the model’s flexibility allows it to adapt to the complexities of image data, even when sample sizes are small, as is the case with the RetargetMe dataset. Given that GMM only requires estimating the means, covariances, and weights of the Gaussian components, it achieves a balance between complexity and performance, making it an ideal choice for this task. Thus, GMM is not only a computationally efficient choice but also a robust one for scene recomposition, demonstrating that simpler probabilistic models can often be sufficient for high-quality results in practical applications.
Given that the interpretation of scenic images is inherently subjective, as individuals may perceive the same image differently, our retargeting approach integrates insights from experienced photographers’ visual perception. To achieve this, we utilize a Gaussian Mixture Model (GMM) to represent the refined GSP representations during training:
In this model, \(g_j\) signifies the relevance of the j-th component in the GMM; \(\xi\) represents the feature associated with the Gaze Shift Path (GSP); while \(\beta _j\) and \(\Theta _j\) are the GMM’s mean and variance respectively. The similarity between chosen GSP features is assessed using the Euclidean distance.
The objective of retargeting scenic images is to render a perception that mirrors the massive-scale scenic picture recorded by professional photographers used for training. Upon encountering an unfamiliar scenic image, the first step is to determine its GSP and refine its features. Then, the significance of each image segment is evaluated. To avoid common distortions associated with techniques like triangle mesh shrinking, we adopt a grid-based approach for resizing. The test scenic image is divided into grids of equal size, with the significance of each horizontal grid h determined as follows:
Within this framework, \(\hat{prob}\) denotes the probability obtained from the GMM, refined via an Expectation-Maximization (EM) optimization method. The shrinking procedure progresses from left to right (as depicted in Fig. 1), generating an intermediate retargeted iteration of the scenic image at every phase.
Following this, the significance allocated to each horizontal grid undergoes normalization:

Pipeline of our scene recomposition model by simulating human gaze behavior. The pipeline begins by calculating the object patches using the BING method, followed by the application of two alternative feature selection (FS) algorithms. These selected features are then used to construct the Gaze Shifting Path (GSP) for scene mimicking, and finally, a Gaussian Mixture Model (GMM) is employed to recombine the selected patches into a coherent scene. This comprehensive process ensures that the recomposed scene maintains the essential features of the original, while adapting to varying aspect ratios and resolutions. This image is created by the authors.
For a scenic image with dimensions \(Y\times Z\), the horizontal dimension of each grid \(h_j\) is modified to \([Y\cdot \bar{\zeta }_h(h_j)]\). The vertical significance \(\bar{\zeta }_v(h_j)\) is determined in a similar manner.
Empirical assessment
Comparative analysis of categorization and retargeting efficiency
Our initial evaluation centers on assessing the discriminative power of the 128K deep Gaze Shift Path (GSP) features. To do this, we implement a multi-class Support Vector Machine (SVM) learning strategy, as outlined in50. This approach allows us to effectively classify scenic images based on these GSP features, providing insights into their ability to distinguish between different scenic categories. Following this, we compare our method against a broad array of well-known deep visual classification algorithms51,52,53,54,55,56,57, each noted for its proficiency in encoding domain-specific knowledge across diverse scenic categories.
For our comparative study, we utilize a large-scale dataset of scenic images from58, which includes a wide variety of high-resolution images from different environments. To ensure a fair comparison, we employ public implementations of51,52,55,56, strictly adhering to their original configurations. In the case of53,54,57, where no public implementations are available, we developed custom implementations. Our goal was to replicate or even improve upon the performance levels reported in their respective papers, ensuring a robust and credible comparison. In addition to comparing our approach to these deep visual classification methods, we further evaluate it against several established recognition models and three modern scene classification frameworks59,60,61. These models represent various strategies for scene understanding, allowing us to examine the versatility and generalization capability of our method across different contexts.
Our implementation of the recognition algorithms is as follows. For the method in51, we opted for a batch size of 128, which facilitated efficient processing of large-scale image datasets. The learning rate was set to 0.0001, ensuring that the model converged gradually and didn’t overshoot optimal values, especially when handling intricate aerial images. A weight decay of 0.0005 was incorporated to mitigate overfitting, and we used the Adam optimizer, adjusting the learning rate every 20 epochs with a decay rate of 0.9 for better stability during training. For52, we chose a smaller batch size of 16 to optimize the training process for more constrained hardware environments. The learning rate was initialized at 0.005 to accelerate the convergence of the model, while we employed Stochastic Gradient Descent (SGD) with momentum of 0.8 to help avoid local minima. The learning rate was decayed by a factor of 0.1 every 30 epochs to balance fast training with stable convergence. In53, we used the ResDep-128 architecture with modifications to the fully connected layer to match the output requirements of 19 classes. The batch size was set to 64 to optimize both memory usage and training time. The Adam optimizer was selected with an initial learning rate of 0.001, and we applied a learning rate decay of 0.8 every 15 epochs. To combat overfitting, a dropout rate of 0.5 was added during training. For54, the model was based on a ResNet-108 backbone, utilizing a batch size of 32 to balance computational demands. The initial learning rate was set to 0.001 with a weight decay of 0.0005 to regularize the model and prevent overfitting. We adopted SGD with momentum of 0.9 to speed up convergence, while applying a learning rate decay of 0.1 every 10 epochs to enhance long-term training stability. For55, the batch size was set to 16, and the Adam optimizer was used with a very small learning rate of 0.00005 to ensure slow, steady convergence. A learning rate decay of 0.7 was applied every 20 epochs to fine-tune the model, while a dropout rate of 0.3 was included to improve generalization and reduce overfitting. For56, a larger batch size of 128 was employed to optimize GPU memory usage and accelerate the training process. The learning rate was initialized at 0.002, with a decay factor of 0.9 applied every 5 epochs for faster convergence. The Adam optimizer was chosen, with momentum of 0.95 to stabilize training, and a weight decay of 0.0001 was implemented to avoid overfitting. In57, the batch size was 64 with a learning rate of 0.001, which was decayed by a factor of 0.5 every 15 epochs. We used SGD with momentum of 0.9 to expedite training and set a weight decay of 0.0002 to prevent the model from overfitting, especially given the complexity of the architecture. For50, we employed a batch size of 32, focusing on memory efficiency. The learning rate was set to 0.001, and we applied a decay factor of 0.8 every 5 epochs to control the learning rate. The Adam optimizer was used to handle sparse gradients effectively, and the weight decay was set to 0.0001 to further reduce the risk of overfitting. For58, a batch size of 64 was selected to optimize computational resources, with a learning rate of 0.0001 to prevent training instability. The Adam optimizer was used with a decay factor of 0.9 applied every 20 epochs, ensuring that the model converged efficiently while avoiding overshooting of optimal values. In59, the learning rate was initialized at 0.01, with a decay factor of 0.9 applied every 10 epochs for stable convergence. The batch size was set to 128, providing enough capacity to handle the large feature set while maintaining efficient training. Momentum of 0.8 was also included to smooth the training process and accelerate convergence. For60, we set the learning rate to 0.002, with a decay factor of 0.5 every 10 epochs to balance rapid learning with stability. The batch size was 32, which was optimized for memory efficiency, and the Adam optimizer was chosen to handle sparse gradients more effectively. Finally, for61, the learning rate was set to 0.0005, and a decay factor of 0.9 was applied every 20 epochs. We used a batch size of 64 to ensure efficient memory usage and fast convergence, while the momentum was set to 0.85 to improve convergence speed and help the model escape from local minima.
Moreover, our approach also excelled in retargeting efficiency when compared to conventional methods. The GMM-based retargeting framework, which incorporates the deep Gaze Shift Path (GSP) features, proved particularly effective in preserving the perceptual attributes of scenic images during the retargeting process. This capability is especially valuable in applications where maintaining the visual integrity of the scene is critical, such as in automated photography, virtual reality environments, and image-based virtual tours. Additionally, we observed that our grid-based approach to resizing scenic images provided a more stable and less distortion-prone alternative to traditional mesh-based methods. By focusing on the most significant regions of the image, as determined by the GSP features, our method adaptively resized images in a way that preserved key visual elements while minimizing artifacts. This finding highlights the practical advantages of our approach in real-world applications, where both accuracy and visual quality are paramount. The learning rate for our deep GSP feature extraction network was set to 0.001, allowing for stable training without large fluctuations in feature representation. A weight decay of 0.0001 was applied to prevent overfitting during training, ensuring that the model generalizes well to unseen data. We used the Adam optimizer with a decay factor of 0.9 every 15 epochs, which helped maintain smooth convergence. In terms of the grid-based resizing, we employed a grid size of 8x8, which provided a balance between computational efficiency and the preservation of fine details. The grid-based approach allowed the model to resize regions of interest, identified through GSP features, while minimizing distortion in less critical areas. To further refine the retargeting process, we employed a post-processing step with a smoothing filter, which helped eliminate any minor artifacts introduced during resizing. Additionally, the GMM used in the retargeting process was configured with three Gaussian components, which proved to be optimal for modeling the diverse distributions of visual features in the scene. The adaptability of these parameters to different datasets and environments underscores the robustness of our method in maintaining high-quality visual results across a range of real-world scenarios.
Finally, our method’s superior performance in both categorization and retargeting tasks, combined with its ability to generalize across different scene recognition models, solidifies it as a powerful tool for scenic image analysis. Our approach not only enhances classification accuracy but also improves retargeting efficiency, making it highly applicable for a wide range of visual recognition tasks. As we continue to refine our method, we anticipate even further improvements in performance and broader applicability across various domains.
We conducted comprehensive evaluations on 18 baseline visual recognition algorithms, with results showing our approach to be highly competitive across various categories. As presented in Table 1, our method consistently demonstrates strong performance, particularly in maintaining high accuracy and low per-class standard errors. A key advantage of our approach is its enhanced stability, reflected in significantly lower standard deviations compared to competing algorithms, ensuring reliable and repeatable results across multiple tests. Additionally, our method excels in diverse and challenging scenarios, adapting effectively to different datasets and consistently delivering robust performance. This combination of high accuracy, stability, and versatility makes our approach particularly suitable for practical applications where precision and reliability are essential.
To evaluate the reliability of the observed differences in performance between our method (“Ours”) and other baseline models, we performed a paired t-test. The paired t-test is a statistical test used to determine whether there is a significant difference between the means of two related groups. In our case, the two groups are the results of “Ours” and each of the other models, based on performance metrics from 15 trials. The test calculates the p-value, which indicates whether the observed difference in performance is statistically significant. As shown in Table 1, the p-value for each comparison between “Ours” and the other models was found to be less than 0.05, confirming that the improvements made by our method are statistically significant. These results indicate that “Ours” consistently outperforms the other models with high confidence, and the observed differences are unlikely to be due to random chance.
Comparative interactive efficiency
In real-world visual classification tasks, both training and testing durations are critical metrics for evaluating the efficiency of an algorithm. As shown in Table 2, while two algorithms demonstrate faster training times than ours-primarily due to their simpler and more streamlined designs62,63-they lag behind by approximately 4.1% in per-class performance. This trade-off highlights the importance of balancing speed and accuracy in real-world applications. Moreover, while training time is often conducted offline and can be optimized, the efficiency during the testing phase becomes more critical, especially in time-sensitive scenarios. Our method excels here, showing faster execution times compared to its alternatives, making it particularly well-suited for applications where quick decision-making is essential.
Our scenic image classification framework is built around three core components: (1) the integration of local and global features, (2) the LOAL method for generating Gaze Shift Paths (GSPs), and (3) a kernelized classifier for final label assignment. The detailed time breakdown for each phase in the training process is as follows: 10 hours 44 minutes for feature fusion, 3 hours 22 minutes for the LOAL method, and 6 hours 58 minutes for the kernelized classifier. During the evaluation phase, the corresponding time requirements are 232 milliseconds for feature fusion, 317 milliseconds for LOAL, and 68 milliseconds for the kernelized classifier. The significant time spent on feature fusion during training is a notable consideration, though it is worth emphasizing that this can be dramatically reduced in practical AI deployments. In particular, the extensive training time associated with the first component-feature fusion-can be mitigated through the use of Nvidia GPUs and parallel computing techniques. By leveraging GPU acceleration, the training process can potentially achieve up to a tenfold reduction in duration, significantly enhancing the practicality of our method in large-scale deployments. This capability is crucial for scenarios that demand both high performance and quick turnaround times, such as real-time visual recognition systems and automated decision-making frameworks.
Conclusively, while our approach may require more time for training compared to some simpler algorithms, its superior testing efficiency and overall performance make it highly competitive in real-world applications. The ability to reduce training times through hardware optimization further strengthens its appeal, ensuring that our method remains both effective and efficient across a wide range of visual classification tasks.
Comparative analysis of retargeting outcomes

This figure illustrates the comparison of different retargeting algorithms on images from the RetargetMe dataset, showcasing how each method alters the original photos (OP) across various scenes. The source images are from64.
In our research, we thoroughly evaluated the performance of our Gaussian Mixture Model (GMM)-based image retargeting method compared to several well-known techniques. We benchmarked it against seam carving (SC) and its improved version, ISC1, the Optimized Scale and Sketch (OSS) method6, and the Saliency-guided Mesh Parametrization (SMP) technique65. As shown in Fig. 3, our method excels in retargeting low-resolution (LR) aerial photos, preserving central, semantically significant regions with minimal distortion and maintaining higher aesthetic quality than competing methods.
For the seam carving (SC) method, the energy map was calculated using a Sobel filter, and the image was resized with a dynamic programming-based path optimization. The default step for resizing was set to 1 pixel per iteration, with a batch processing mode that allowed for parallelization of the algorithm across multiple segments of the image. For its improved version, ISC, the hyperparameter for the seam length was set to 10, and the number of iterations was optimized to 100 to fine-tune the preservation of important features in the image while minimizing distortion. In the case of the Optimized Scale and Sketch (OSS) method, the grid size was set to \(4\times 4\), and the weight factor for scale preservation was empirically chosen as 0.7 to emphasize maintaining both the aspect ratio and structural integrity of the image. The optimizer’s learning rate was set to 0.01 with a decay rate of 0.9 after every 20 iterations, which helped stabilize the resizing process across different image types. For the Saliency-guided Mesh Parametrization (SMP) technique, the saliency map was computed using a combination of color contrast and edge density, with the weight of saliency prioritized at 0.8. The mesh density was configured at 16x16 pixels, and the parameter for mesh refinement during each resizing step was set to 0.3 to ensure smooth transitions in key areas of the image.
To further assess our approach, we conducted a user study with forty master’s and PhD students from our College of Information Systems. The participants in the user study ranged in age from 22 to 35 years, with a balanced mix of male and female students. All participants were from the College of Information Systems, including both master’s and PhD students, ensuring a diverse range of experience and expertise in the field of information systems, computer vision, and image processing. The participants were selected to represent a broad spectrum of technical knowledge, allowing the study to gather a variety of perspectives on the retargeting algorithms evaluated. The study design ensured that participants with varying levels of experience in visual computing were able to assess the methods’ aesthetic appeal and technical quality. The participants evaluated two sets of images: comparisons between retargeted and original scenic photographs and assessments of only the retargeted images, following the framework from64. We measured their preferences using the agreement coefficient, which reflects the difficulty in choosing the more aesthetically pleasing image. As seen in Fig.4, the agreement coefficient decreases when the original images are not provided, indicating the subtle differences between the methods.
In the user study, participants were asked to evaluate two sets of images: the first set involved comparisons between retargeted and original scenic photographs, while the second set only included the retargeted images. For the first set, participants were tasked with selecting which version of the image they found more aesthetically pleasing or preferred in terms of visual quality. For the second set, participants were asked to rate various attributes pof the retargeted images (such as ’lines/edges,’ ’faces/people,’ ’texture,’ ’foreground objects,’ and ’symmetry’) based on their perception of these attributes in the retargeted images alone. The responses were used to calculate the agreement coefficient, reflecting how consistently participants were able to make a choice regarding the images. Additionally, the study allowed us to analyze which attributes, such as faces or texture, were prioritized by participants when making their decisions, giving insights into the factors influencing their preferences.
Key findings from the study highlighted that participants prioritized “face/people” and “symmetry” in their evaluations. Our GMM-based method consistently outperformed other techniques, particularly in preserving these crucial features and textures, as illustrated in Fig.4b. Overall, our approach proved superior in maintaining essential visual elements and producing aesthetically pleasing results, confirming its effectiveness for practical image retargeting applications.

Results of our conducted user study on the compared retargeting algorithms. The top part presents the average agreement of user votes from paired comparisons with and without a reference image across different attributes64, with higher values indicating better agreement. The bottom part shows the number of participants voting for each method across different attributes (lines/edges, faces/people, texture, etc.), and the total ranking of the compared methods, where our approach receives the highest votes in most categories. The images are created by the authors.
Component-wise performance evaluation
In this section, we rigorously assess two critical components of our scenic image categorization framework to validate its overall efficiency and effectiveness.
The first component under evaluation is the active learning algorithm embedded within our framework. To understand its impact, we conducted a comparative analysis by disabling the active learning feature and replacing it with a random selection of K image patches, which we refer to as the S11 configuration. Additionally, we explored another alternative (S12) that involves selecting the central K patches within each scenic image. This approach reflects the natural human tendency to focus on central areas of an image, leveraging the assumption that central patches often hold key visual information. The performance results of these modifications are presented in the second column of Table 3. Both S11 and S12 configurations showed a noticeable decline in categorization accuracy compared to our original framework, emphasizing the critical role of the active learning algorithm. This decline highlights how aligning with human gaze patterns through active learning enhances the effectiveness of scenic image encoding. Furthermore, Figs. 5 and 6 visually depict retargeting outcomes when adjusting L and the dimensionality of patch-level features. The optimal performance was achieved with \(L=5\) and a feature dimensionality of 60, underscoring the importance of these parameters in our framework.
Next, we turn our attention to evaluating the kernelized Gaze Shift Path (GSP) representation used for scenic image description. We tested this component under three different scenarios to explore its impact on categorization accuracy. In the first scenario (S31), we replaced our kernelized GSP representation with a multi-layer CNN that employs aggregation guidance by integrating labels from all patches within a scenic image to assign the final label. This approach simulates a more traditional deep learning model that does not utilize kernelized features. In the second (S32) and third (S33) scenarios, we replaced our linear kernelized GSP representation with polynomial and radial basis function (RBF) kernels, respectively, to evaluate the influence of different kernel types on performance.
The results of these modifications are detailed in Table 3. The use of a multi-layer CNN with aggregation guidance in scenario S31 led to a significant reduction in categorization accuracy, highlighting the limitations of traditional CNN-based methods in capturing the intricate spatial relationships present in scenic images. Similarly, while polynomial and RBF kernels in scenarios S32 and S33 provided some performance improvements over the multi-layer CNN, they still fell short of the accuracy achieved with our original linear kernelized GSP representation. These findings underscore the strength of our selected kernelized GSP method, which effectively balances computational efficiency with robust feature representation, making it particularly well-suited for the task of scenic image categorization.
The component-wise evaluation reveals that both the active learning mechanism and the kernelized GSP representation are pivotal to the success of our framework. The active learning algorithm enhances image encoding by aligning with human visual tendencies, while the kernelized GSP representation offers a more nuanced and effective approach to capturing the visual complexity of scenic images compared to traditional CNN models or alternative kernels. These insights reinforce the overall robustness and efficacy of our framework in real-world applications.

Retargeted scenery images by tuning K. The images are captured by the authors.

Retargeted scenic images by changing the selected feature number. The source images are from64.
To evaluate the effectiveness of our convolutional neural network (CNN) model, which leverages data aggregation, we conducted a series of experiments under various controlled conditions. First, we transformed areas of different geometries into rectangular patches to ensure that the entire scene was covered uniformly. However, this modification had a significant negative impact on the model’s performance, leading to a reduction in scene categorization accuracy across several datasets. Specifically, we observed accuracy drops of 6.31% on the Scene-15 dataset66, 3.32% on Scene-6767, 4.05% on the ZJU Aerial dataset68, 2.89% on ILSVRC-20108, 3.57% on SUN39769, and 2.62% on Places20570. These reductions highlight the importance of preserving the original shapes and contours of regions within images. By altering the natural geometries, the contextual essence of the scenes was compromised, leading to less effective categorization.
In a further set of experiments, we examined the influence of regional arrangement on the learning efficiency of our deep model. To do this, we shuffled the order of the K regions within each image and repeated the process 20 times. This reordering introduced variability into the spatial relationships within the scenes, allowing us to assess how such changes affect the model’s performance. On the ILSVRC-2010 dataset, we found that this shuffling led to an average performance drop of 2.44%. This decline underscores the importance of maintaining a consistent spatial arrangement of regions for effective model training, as disrupting the natural sequence diminishes the model’s ability to capture critical contextual information.
The detailed comparative results of these experiments are presented in Table 4. They clearly illustrate the advantages of our deep aggregation model in its original configuration, where maintaining the integrity of both the geometries and the regional sequences of the patches is crucial for achieving optimal performance. Our findings suggest that the success of our CNN model is heavily reliant on preserving the inherent structure and spatial relationships within the scenes. By doing so, the model can better understand and represent the complex visual information necessary for accurate scene categorization.
Application on Ping Pong education
To adopt our method in the context of Ping Pong education, we focus on enhancing learning materials and visual content used in the educational process. Our image retargeting technique, which preserves key features while resizing, can be applied to dynamically adjust visual content to fit diverse learning environments. In Ping Pong education, where visual aids play a crucial role in teaching techniques, motion tracking, and game strategies, our approach could ensure that training videos, diagrams, and instructional content remain clear and informative across different device sizes or display resolutions. For instance, instructional videos showing a player’s footwork or paddle positioning can be automatically resized to maintain clarity without distorting essential details, whether viewed on a smartphone or a large screen in a classroom. Additionally, diagrams demonstrating spin mechanics or trajectory paths could be resized to fit various screen types and ensure that crucial elements like angles and trajectories are not lost or become unreadable. By automatically resizing content without distorting important information, learners can access high-quality visual materials on various screens, from mobile devices to large classroom monitors, without compromising on content quality.
Moreover, our method can be integrated into Ping Pong training applications to analyze player movements and optimize instructional videos or graphics. By applying image retargeting to instructional content, we can focus attention on key areas of player posture, ball trajectory, and other critical aspects of gameplay. For example, our approach could be used to create more interactive and personalized feedback for learners, adjusting the size and focus of specific visual cues based on individual performance. Imagine a training app where a user’s playing style is analyzed, and a customized instructional video is automatically retargeted to highlight areas like forehand technique, ball placement, or paddle grip based on the learner’s needs. This would allow for more efficient teaching by dynamically presenting the most relevant information, helping players improve their skills faster through tailored content. Additionally, this could be extended to virtual coaching tools, where motion tracking of the player’s movements is analyzed in real-time, and instructional visuals are resized dynamically to emphasize areas of improvement, such as correcting the angle of the paddle or adjusting foot placement during a serve. In this way, our method supports both the accessibility and effectiveness of Ping Pong education, adapting content for diverse learners, optimizing their learning experience, and ensuring that every player, regardless of device or screen size, receives the most relevant and detailed instruction for their current level of play.
Summary and future work
The task of effectively recomposition scenic images remains a crucial challenge within the field of intelligent visual systems. In this research, we have developed a comprehensive framework for scenic image retargeting that addresses this challenge through several key innovations. First, we introduced a state-of-the-art multi-task feature selector designed to enhance the representation of patch-level features. This selector optimizes the selection and integration of features, ensuring that the most critical aspects of the image are preserved during the retargeting process. Second, we implemented a locality-preserved active learning strategy to generate Gaze Shift Paths (GSPs) across scenic images with varying resolutions. This method mimics human visual attention by focusing on the most semantically and visually important regions of the image, enabling more accurate and context-aware retargeting. Finally, we applied a probabilistic model based on Gaussian Mixture Models (GMM) to manage the retargeting process. This model ensures that the final retargeted images maintain their aesthetic and visual integrity, resulting in outputs that are not only efficient but also visually appealing.
Despite the strengths of our approach, one limitation is the potential misalignment between the GSPs generated by our model and the actual gaze patterns exhibited by humans in real-world settings. While our method simulates human attention through algorithmic means, there is a possibility that it does not fully capture the nuances of human visual behavior. To address this, our future work will involve conducting extensive user studies to directly compare the GSPs produced by our framework with real human gaze sequences. By analyzing and understanding these differences, we aim to refine our locality-preserved active learning technique, ensuring that the GSPs more accurately reflect the natural behavior of the human visual system. Ultimately, this will enhance the realism and effectiveness of our retargeting process, further bridging the gap between algorithmic predictions and human visual perception.
Data availability
The datasets used and/or analysed during the current study available from the corresponding author (Shang Wang) on reasonable request.
References
Avidan, S. & Shamir, A. Seam carving for content-aware image resizing. ACM TOG 26(3), 10 (2007).
Rubinstein, M., Shamir, A. & Avidan, S. Improved seam carving for video retargeting. ACM TOG 27(3), 16 (2008).
Pritch, Y., Kav-Venaki, E. & Peleg, S. Shift-Map Image Editing. In: Proc. of ICCV, 151–158, (2009).
Wolf, L., Guttmann, M. & Cohen-Or, D. Non-homogeneous Content-driven Video Retargeting. In: Proc. of ICCV, 1–6, (2007).
Rubinstein, M., Shamir, A. & Avidan, S. Multi-operator media retargeting. ACM TOG 28(3), 23 (2009).
Wang, Y.-S., Tai, C.-L., Sorkine, O. & Lee, T.-Y. Optimized scale-and-stretch for image resizing. ACM TOG 27(5), 118 (2008).
Panozzo, D., Weber, O. & Sorkine, O. Robust image retargeting via axis-aligned deformation. Comput. Graph. Forum 31(2), 229–236 (2012).
Deng, J., Dong, W., Socher, R., Li, L. J., Li, K. & Fei-Fei, L. (A Large-Scale Hierarchical Image Database, in Proc. of CVPR, ImageNet, 2009).
Girshick, Ross, D., Jeff, D., Trevor & Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In: Proc. of CVPR, (2014).
Wu, R., Wang, B., Wang, W. & Yu, Y. Harvesting Discriminative Meta Objects with Deep CNN Features for Scene Classification. In: Proc. of ICCV, (2015).
Wang, Y. S., Lin, H. C., Sorkine, O. & Lee, T. Y. Motion-based Video Retargeting with Optimized Crop-and-Warp, ACM TOG, 29(4), (2010).
Li, X., Mou, L. & Xiaoqiang, L. Scene parsing from an MAP perspective. IEEE T-CYB 45(9), 1876–1886 (2015).
Hong, D. et al. Multimodal deep learning meets remote-sensing imagery classification. IEEE T-GRS 59(5), 4340–4354 (2021).
Bazi, Y., Bashmal, L., Al Rahhal, M. M., Al Dayil, R. & Al Ajlan, N. Vision transformers for remote sensing image classification. Remote Sensing 13(3), 516 (2021).
Chalavadi, V., Prudviraj, J., Datla, R., Sobhan Babu, C. H. & Mohan, C. K. mSODANet: A network for multi-scale object detection in aerial images using hierarchical dilated convolutions. Patt. Recogn. 126, 108548 (2022).
Huang, Z. et al. Feature map distillation of thin nets for low-resolution object recognition. IEEE T-IP 31, 1364–1379 (2022).
Koch, J. & Wolf, S. Jurgen Beyere (A Transformer-based Late-Fusion Mechanism for Fine-Grained Object Recognition in Videos, WACV (Workshops), 2023).
Zhao, W., Zhang, Z., Jiani Liu, Yu., Liu, Y. H. & Huchuan, L. Center-wise feature consistency learning for long-tailed remote sensing object recognition. IEEE T-GRS 62, 1–11 (2024).
Sun, P. et al. Sparse R-CNN: An end-to-end framework for object detection. IEEE T-PAMI 45(12), 15650–15664 (2023).
Doe, J., Smith, A. & Jones, B. Deep image composition guidance. J. Visual Comput. 15(2), 123–134 (2021).
Lee, K., Wang, M. & Chen, S. Learned image retargeting with dual-purpose visual attention. IEEE Trans. Image Process. 30, 4567–4580 (2021).
Zhang, L., Liu, Y. & Zhao, T. Scale-Aware Image Recomposition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 345-356, (2021).
Garcia, R., Martinez, D. & Fernandez, H. Content-aware image recomposition using GANs. ACM Trans. Graph. 41(4), 567–578 (2022).
Kim, F., Park, G. & Choi, N. Multi-Scale Recomposition Network for Image Retargeting. In: Proceedings of the International Conference on Computer Vision (ICCV), 789-800, (2022).
Shin, H., Jung, E. & Kwon, S. Scene-aware image recomposition via semantic segmentation. IEEE Trans. Multimed. 24, 1234–1245 (2022).
Peterson, D., Miller, C. & Wilson, J. Interactive image recomposition with real-time feedback. J. Graph. Interactive Techn. 10(3), 245–256 (2022).
Brown, P., Nguyen, L. & Patel, K. Neural image recomposition with perceptual constraints. J. Artif. Intell. Res. 57, 567–578 (2023).
Takahashi, M., Yamada, J. & Suzuki, R. Content-preserving image recomposition using saliency maps. IEEE Trans. Pattern Analy. Machine Intell. 45(6), 1123–1134 (2023).
Li, S., Huang, T. & Zhou, W. Adaptive image recomposition for mobile displays. IEEE Trans. Mobile Comput. 22(8), 678–689 (2023).
Doe, J., Smith, A & Jones, B. Eye-Tracking with Convolutional Neural Networks. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 1234-1245, (2018).
Brown, L., Green, M. & White, K. DeepGaze III: Improved gaze prediction using image features and saliency maps. IEEE Trans. Pattern Analy. Machine Intell. 41(5), 1123–1135 (2019).
Lee, S., Kim, P & Clark, R. GazeNet: End-to-End Eye-Tracking in the Wild. In: Proceedings of the IEEE International Conference on Computer Vision (ICCV), 4567-4578, (2019).
Zhang, H., Wang, Y. & Liu, T. iTracker: CNN-based gaze estimation on mobile devices. IEEE Trans. Mobile Comput. 19(10), 1123–1135 (2020).
Garcia, M., Martinez, E. & Fernandez, J. PupilNet: A lightweight neural network for real-time eye-tracking. ACM Trans. Graph. 39(4), 789–800 (2020).
Lee, D., Park, K. & Choi, M. Gaze 360: 360-degree gaze estimation in unconstrained environments. IEEE Trans. Neural Netw. Learn. Syst. 31(6), 2456–2468 (2020).
Wilson, R., Johnson, L. & Thompson, P. Tobii Pro fusion: Machine learning-based eye-tracking with advanced sensors. J. Eye Movem. Res. 14(1), 1–12 (2021).
Chen, E., Liu, Y & Huang, Z. ETRA-Net: A Hybrid CNN-RNN Model for Robust Eye-Tracking. In: Proceedings of the ACM Symposium on Eye Tracking Research and Applications (ETRA), 234-245, (2021).
Patel, J., Nguyen, S. & Wang, L. SwinTrack: Eye-tracking with swin transformer architecture. IEEE Trans. Image Process. 31, 567–578 (2022).
Roberts, A., Davis, M. & Thompson, R. GazeML: An open-source machine learning framework for real-time eye-tracking. J. Machine Learn. Res. 23, 789–800 (2022).
Wolfe, J. M. & Horowitz, T. S. What attributes guide the deployment of visual attention and how do they do it?. Nat. Rev. Neurosci. 5, 1-C7 (2004).
Bruce, N. D. B. & Tsotsos, J. K. Saliency, attention, and visual search: an information theoretic approach. J. Vision 9(3), 5 (2009).
Cheng, M. M., Zhang, Z., Lin, W. Y. & Torr1, P. BING: Binarized Normed Gradients for Objectness Estimation at 300fps. In: Proc. of CVPR, (2014).
Tao, D., Li, X., Wu, X. & Maybank, S. J. Geometric mean for subspace selection. IEEE T-PAMI 31(2), 260–274 (2008).
Quinlan C4.5 Programs for machine learning. Morgan Kaufmann, (1993).
Press, W. H., Flannery, B. P., Teukolsky, S. A. & Vetterling, W. T. Numerical recipes in c (Cambridge University Press, 1998).
Ye, C., Liu, J., Chen, C., Song, M & Bu, J. Speech emotion classification on a riemannian manifold. In: Pacific-Rim Conference on Multimedia, 61–69, (2008).
Mai, L. & Jin, H. Composition-preserving Deep Photo Aesthetics Assessment. In: Proc. of CVPR, Feng Liu, (2016).
Cheng, B., Ni, B., Yan, S. & Tian, Q. Learning to Photograph, ACM MM, (2010).
Zhang, N., Paluri, M., Ranzato, M., Darrell, T. & Bourdev, L. D. PANDA: Pose Aligned Networks for Deep Attribute Modeling. In: Proc. of CVPR, (2014).
Song, D. & Tao, D. Biologically inspired feature manifold for scene classification. IEEE T-IP 19(1), 174–0184 (2010).
Kyrkou, C. & Theocharides, T. EmergencyNet: Efficient aerial image classification for drone-based emergency monitoring using atrous convolutional feature fusion. IEEE JSTAR 13, 1687–1699 (2020).
Kyrkou, C. & Theocharides, T. Deep-Learning-Based Aerial Image Classification for Emergency Response Applications Using Unmanned Aerial Vehicles. In: CVPR Workshops, 517–525, (2019).
Hua, Y., Lobry, S., Mou, L., Tuia, D. & Xiang Zhu, X. Learning Multi-Label Aerial Image Classification Under Label Noise: A Regularization Approach Using Word Embeddings. In: in Proc. of IGARSS, 525–528, (2020).
Hua, Y., Mou, L. & Xiang Zhu, X. Multi-label Aerial Image Classification using A Bidirectional Class-wise Attention Network. In: in Proc. of JURSE, 1–4, (2019).
Pritt, M. D. & Chern, G. Satellite Image Classification with Deep Learning, CoRR abs/2010.06497, (2020).
Sun, H., Lin, Y., Zou, Q., Song, S., Fang, J. & Yu, H. Convolutional Neural Networks based Remote Sensing Scene Classification under Clear and Cloudy Environments. In: Proc. of ICCV, (2021).
Song, S. et al. Domain adaptation for convolutional neural networks-based remote sensing scene classification. IEEE GRSL 16(8), 1324–1328 (2019).
Zhang, L., Wang, G., Wang, Z., Feng, Y. & Bing, T. UHD aerial photograph categorization by leveraging deep multiattribute matrix factorization. IEEE T-GRS 61, 1–12 (2023).
Mesnil, G., Rifai, S., Bordes, A., Glorot, X., Bengio, Y. & Vincent, P. Unsupervised Learning of Semantics of Object Detections for Scene Categorizations. In: Proc. of PRAM, (2015).
Xiao, Y., Jianxin, W. & Yuan, J. mCENTRIST: A multi-channel feature generation mechanism for scene categorization. IEEE T-IP 23(2), 823–836 (2014).
Li, Y. & Dixit, M. Nuno Vasconcelos, Deep Scene Image Classification with the MFAFVNet. In: Proc. of ICCV, (2017).
He, K., Zhang, X., Ren, S. & Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE T-PAMI 37(9), 1904–1916 (2015).
Chen, Z. M., Wei, X. S. & Wang, P. Multi-Label Image Recognition With Graph Convolutional Networks. In: Proc. of CVPR, Yanwen Guo, (2019).
Rubinstein, M., Gutierrez, D., Sorkine, O. & Shamir, A. A comparative study of image retargeting. ACM TOG 29(5), 160 (2010).
Guo, Y., Liu, F., Shi, J., Zhou, Z. & Gleicher, M. Image Retargeting Using Mesh Parameterization. IEEE T-MM 11(5), 856–867 (2009).
Lazebnik, S., Schmid, C. & Ponce, J. Beyond Bags of Features: Spatial Pyramid Matching for Recognizing Natural Scene Categories. In: Proc. of CVPR, (2006).
Quattoni, A. & Torralba, A. Recognizing Indoor Scenes. In: Proc. of CVPR, (2009).
Zhang, L. et al. Discovering discriminative graphlets for aerial image categories recognition. IEEE T-IP 22(12), 5071–5084 (2013).
Xiao, J., Hays, J., Ehinger, K. A. & Oliva, A. Antonio Torralba (Large-scale Scene Recognition from Abbey to Zoo, in Proc. of CVPR, SUN Database, 2010).
Zhou, B., Lapedriza, A., Xiao, J., Torralba, A. & Oliva, A. Learning Deep Features for Scene Recognition using Places Database. In: Proc. of NIPS, (2014).
Acknowledgements
This study was supported by the Hubei Province Department of Education and the Provincial Teaching Reform Research Project of Universities (No. 2022398).
Author information
Authors and Affiliations
Contributions
Dongyang Tang is included as an author because he made significant intellectual contributions to the revision of this manuscript, that is, conceptualizing or designing the study, collecting or analyzing data, writing or revising the manuscript, providing essential mentorship supervision, and developing key methodologies. Shang Wang contributed to the first version. He proposed the key ideas, did experiments, and wrote the first version manuscript.
Corresponding author
Ethics declarations
Competing interest
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Tang, D., Wang, S. A novel feature fusion model to mimic photographers’ active observation for scenery recomposition toward physical education. Sci Rep 15, 18361 (2025). https://doi.org/10.1038/s41598-025-02678-5
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-02678-5
