
Abstract
In recent years, the detection of non-ferrous metals in end-of-life vehicles (ELVs) has become essential for improving recycling in the circular economy. Traditional methods struggle with accurate detection due to the variety of metals and challenging industrial environments. This study proposes a Hybrid-YOLOv5-based algorithm for efficiently detecting copper, aluminum, and stainless steel in ELVs. The goal is to enhance detection accuracy and computational efficiency in metal sorting. By integrating the Coarse-to-Fine (C2F) module, Squeeze-and-Excitation (SE) module, and MobileNetV3 backbone, we significantly improve performance and speed. On a dataset of 2,500 infrared images, Hybrid-YOLOv5 achieves 84.2% mAP@0.5 and 60 FPS inference speed, outperforming YOLOv3, YOLOv5, YOLOv7, and YOLOv11 by 22.2%, 12.4%, 11.1%, and 36.2% in mAP@0.5, respectively. This work provides an efficient solution for industrial metal sorting and intelligent recycling in the circular economy.
Similar content being viewed by others

Introduction
The disposal of end-of-life vehicles (ELVs), including buses, cars, and trucks, represents a critical environmental and resource management issue1. In China, the Ministry of Commerce reported that approximately 2.3 million ELVs were processed in 2019, reflecting an annual growth rate of 15.3% and an increase of 16.8% compared to 2018, in 2024, the number of scrapped vehicles recovered nationwide reached 8.46 million, marking a substantial 64% increase compared to the previous year2,3.Li et al. estimated the critical metal stock and recycling potential in China’s automobile industry showed that China’s passenger vehicle ownership will reach 547.5 million to 623.8 million by 20504.
This rising volume of ELVs presents both challenges and opportunities. On one hand, their complex structures, which include ferrous and non-ferrous metals, plastics, and composites, make efficient recycling difficult5. On the other hand, ELVs contain significant quantities of valuable materials, In a typical end-of-life vehicle (ELV) with a mass of 1050 kg, the mass of critical or precious metals can reach up to 50 kg. Steel, aluminum, copper, glass, and plastics make up the majority of the vehicle’s mass, with iron (Fe), aluminum (Al), and copper (Cu) accounting for over 90% of the vehicle’s metal content6.
Traditional recycling methods, such as manual or semi-automated sorting, are labor-intensive, inefficient, and error-prone, especially when dealing with large-scale and mixed-material waste streams7. Given the complexity of ELV material compositions8, traditional approaches are insufficient, driving the need for intelligent detection systems capable of addressing these challenges9. Automated object detection systems have shown potential in improving recycling efficiency by accurately identifying and classifying recyclable materials10,1112,13.
Among recent advances, object detection algorithms such as Faster R-CNN, SSD, and YOLO have demonstrated promising results in industrial applications. YOLOv5, in particular, has gained attention for its balance between detection accuracy, inference speed, and computational efficiency. Its lightweight structure and scalability make it suitable for real-time detection in resource-constrained industrial environments14,15,16,17,18,19. However, its performance in detecting small, mixed, or occluded non-ferrous metal components in complex recycling scenarios still requires further optimization.
To address these challenges, this study proposes a novel Hybrid-YOLOv5 algorithm for the detection of non-ferrous metals, specifically copper, aluminum, and stainless steel, in ELVs. The Hybrid-YOLOv5 model improves detection accuracy and computational efficiency by integrating MobileNetV3, Squeeze-and-Excitation (SE) modules, and a Coarse-to-Fine (C2 F) module. This solution is designed to overcome key challenges in recycling, such as small particle identification, mixed material separation, and real-time processing in resource-constrained environments.
The experimental setup provides stable lighting and temperature conditions to evaluate the algorithm’s performance, though it does not fully replicate complex industrial environments (e.g., dust, vibration). The results of this study contribute to intelligent recycling technologies by offering an efficient and scalable solution for resource recovery, supporting global sustainability goals and promoting the circular economy. The key contributions of this work include:
A dataset of 2,500 infrared images of ELVs containing non-ferrous metals.
Integration of MobileNetV3, SE, and C2 F modules into YOLOv5 for enhanced detection performance.
Development of the Hybrid-YOLOv5 model, improving detection accuracy, computational efficiency, and real-time performance.
A performance comparison with traditional YOLO models, demonstrating significant improvements in detection accuracy and inference speed.
The remainder of the article is structured as follows: Sect. Contribution of the SE module reviews the current metal sorting technologies in resource recovery; Sect. Effect of integrated optimization details the methodology and technical improvements applied to the Hybrid-YOLOv5 model; Sect. Effect of integrated optimization presents the experimental results and component analysis; Sect. 5 discusses the practical and academic implications, as well as future research directions; Sect. 6 concludes the study and outlines future prospects.
To address these challenges, this study proposes a novel Hybrid-YOLOv5 algorithm for the detection of non-ferrous metals, specifically copper, aluminum, and stainless steel, in ELVs. The Hybrid-YOLOv5 model improves detection accuracy and computational efficiency by integrating MobileNetV3, Squeeze-and-Excitation (SE) modules, and a Coarse-to-Fine (C2 F) module. This solution is designed to overcome key challenges in recycling, such as small particle identification, mixed material separation, and real-time processing in resource-constrained environments.
The experimental setup provides stable lighting and temperature conditions to evaluate the algorithm’s performance, though it does not fully replicate complex industrial environments (e.g., dust, vibration). The results of this study contribute to intelligent recycling technologies by offering an efficient and scalable solution for resource recovery, supporting global sustainability goals and promoting the circular economy. The key contributions of this work include:
A dataset of 2,500 infrared images of ELVs containing non-ferrous metals.
Integration of MobileNetV3, SE, and C2 F modules into YOLOv5 for enhanced detection performance.
Development of the Hybrid-YOLOv5 model, improving detection accuracy, computational efficiency, and real-time performance.
A performance comparison with traditional YOLO models, demonstrating significant improvements in detection accuracy and inference speed.
The remainder of the article is structured as follows: Sect. Contribution of the SE module reviews the current metal sorting technologies in resource recovery; Sect. Contribution of MobileNetv3 details the methodology and technical improvements applied to the Hybrid-YOLOv5 model; Sect. Effect of integrated optimization presents the experimental results and component analysis; Sect. 5 discusses the practical and academic implications, as well as future research directions; Sect. 6 concludes the study and outlines future prospects.
Related work
Physical separation technology
Recent advancements in non-ferrous metal sorting technologies have significantly improved resource recovery. Physical sorting technologies, such as eddy current sorting, magnetic separation, liquid media sorting, and wind sorting, are widely used due to their low cost and simplicity20,21. Eddy current sorting22,23,24, for example, demonstrates high separation efficiency (85–95%) for medium-sized non-ferrous metals like aluminum and copper, but struggles with complex shapes, fine particles, or low-conductivity metals like zinc and stainless steel. Magnetic separation excels at removing ferromagnetic impurities with high purity but cannot identify non-magnetic metals. Liquid media sorting25,26,27 efficiently separates metals with large density differences, such as aluminum and copper, but faces challenges related to pollution and processing costs. Wind sorting28,29, while effective for lightweight metals, struggles with close-density metals and lacks precision.
Despite the practicality of these methods, they are limited in terms of separation accuracy in complex scenarios, such as small particles, irregular shapes, or metals with similar densities. These limitations highlight the need for combining physical separation techniques with optical detection or intelligent sorting methods to achieve high-precision separation.
Optical and spectral sorting technology
Optical and spectroscopic sorting technologies30 use the optical properties of metals, such as color and spectral absorption, to achieve high-precision separation. Laser-induced breakdown spectroscopy (LIBS)31,32,33 utilizes a high-energy laser to analyze metal components through plasma spectral data, offering over 95% identification accuracy in controlled environments. However, its high cost (approximately $500,000/unit) limits its industrial application. X-ray sorting technology34,35,36 can separate high-density metals like copper and lead with over 90% accuracy, but it is expensive and slow, with a sorting speed of about 1 ton per hour. Spectral and color sorting37,38,39, typically used for preliminary screening of metals like aluminum and copper, has lower operating costs but is less effective for metals with surface coatings, dirt, or complex shapes, and its accuracy typically ranges from 75 to 85%.
While optical and spectroscopic methods offer high-precision sorting, their high costs and sensitivity to environmental and material conditions limit their large-scale industrial application, highlighting the need for more cost-effective and adaptable sorting methods.
Smart sorting technology
Intelligent sorting technology40,41 combines machine vision and artificial intelligence to achieve high-precision metal sorting. Machine vision sorting42,43,44,45 uses industrial cameras to acquire images of metals and extract features for sorting, performing well for metals with regular shapes or distinct color differences, with efficiency up to 80–90%. However, it is sensitive to lighting conditions and surface variations. Deep learning-based sorting46,47,48, using algorithms like YOLO and ResNet, automatically extracts features from large datasets and achieves over 95% sorting accuracy in complex scenarios, such as for aluminum, copper, and stainless steel. It also significantly improves the recognition of small-particle metals (< 5 mm), with accuracy up to 85–90%. However, it requires large datasets and high computational complexity, which affects real-time performance.
In our study, although only 2,500 infrared images were used, the optimization of the Hybrid-YOLOv5 algorithm, combined with the lightweight MobileNetV3 and SE modules, enabled efficient and accurate non-ferrous metal detection on a relatively small dataset. This demonstrates that effective metal sorting can be achieved through algorithm optimization rather than relying on large amounts of data.
Materials and methods
Data acquisition system
Infrared imaging plays a vital role in revealing the distinct thermal properties of non-ferrous metals, which are critical for their accurate identification and classification during the recycling process. The dataset used in this study consists of 2,500 infrared images of non-ferrous metals sourced from end-of-life vehicles. However, there are some limitations to consider. The samples were collected from a single local scrap car factory, which may not fully capture the variety of non-ferrous metals found in other regions or industrial settings. Furthermore, the dataset is imbalanced, with 1,000 samples each of copper and aluminum, but only 500 samples of stainless steel. This imbalance could potentially lead to biased detection performance, which may affect the broader applicability of the findings. To address these limitations, future work will focus on incorporating a more diverse and representative dataset.
Images were captured at three temperatures (50 °C, 150 °C, and 200 °C) using the FOTRIC 626 CH infrared imager. While these controlled temperature variations were chosen to ensure a consistent evaluation of the algorithm’s performance, it is important to note that real industrial environments may exhibit a wider range of temperature fluctuations, as well as other factors such as humidity, dust, and mechanical vibrations, which could influence detection accuracy. Future work will explore the algorithm’s robustness under these more variable conditions, providing a better understanding of its applicability in real-world industrial settings.
All images were manually labeled using LabelImg software to annotate the bounding boxes of different metal types. The imager was securely mounted above the heating platform (see Fig. 1) to ensure a consistent and repeatable setup. Once a stable temperature was reached, the imager’s proprietary software was used to capture the infraredimages (see Fig. 2).

Image capture device.

Image capture software.
Data acquisition
The materials used in this experiment were sourced from a scrap car factory, including crushed copper, aluminum, and stainless steel. These materials exhibit complex compositions, uneven granularity, and surface oxidation and contamination. Their infraredand visible light images are shown in Fig. 3. The dataset was split into training, validation, and test sets in a 7:2:1 ratio(This commonly used split ratio ensures a sufficient amount of data for training while reserving adequate samples for validation and testing to reliably evaluate the model’s performance. Similar split ratios have been widely adopted in other studies.), with 1,750 training images, 500 validation images, and 250 test images49,50. All metals in the images were manually labeled using LabelImg, and the annotations were stored in TXT format.

Visible and infrared imaging of non-ferrous metal shreds.
Algorithm development environment and software
The experiments in this study were performed using uniform computer equipment. Detailed specifications for the specific environmental configuration can be found in Table 1.
Detection of non-ferrous metals based on the hybrid-YOLOv5
Overall technical route
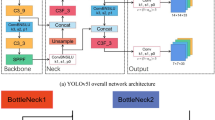
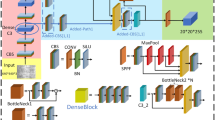
To ensure reliable detection of non-ferrous metals, the technical approach is illustrated in Fig. 4. This study introduces a hybrid-YOLOv5 algorithm aimed at robust metal classification. Several modifications were made to the YOLOv5 backbone network to enhance performance. Specifically, the C3 module was replaced with a C2 F module for better feature integration. Additionally, a Squeeze-and-Excitation (SE) module was incorporated at the input layer to improve channel-wise feature recalibration. Furthermore, the conventional convolutional layers in the backbone were replaced with MobileNet V3 layers, optimizing both feature extraction and computational efficiency. These improvements are intended to significantly enhance the overall effectiveness of the network.

Hybrid-YOLOv5 network architecture.
YOLOv5 network architecture
As a core framework of the hybrid-YOLOv5, YOLOv5 is a prominent variant in the YOLO series, recognized for its strong performance in addressing various object detection tasks. The network architecture of YOLOv5 consists of four main components: Input, Backbone, Neck, and Detection Head. The Input module handles data pre-processing, including size adaptation, data augmentation, and adaptive anchor calculation. The Backbone employs CSPDarknet for initial feature extraction, incorporating modules such as CBS, SPPF, and C3. The Neck further enhances feature extraction by utilizing Feature Pyramid Network (FPN) and Path Aggregation Network (PANet) to integrate feature information across different scales. The Detection Head generates three feature vectors of different sizes to predict target location, category, and confidence levels for detecting objects of varying sizes.
Building on the inspiration of YOLOv5, the hybrid-YOLOv5 proposed in this study introduces significant architectural improvements which enhances performance and efficiency.Specifically, the coarse-to-fine (C2 F) module employs a multi-stage feature extraction strategy, which starts with an initial global feature analysis and enhances the feature representation through gradual refinement to improve the detection accuracy. This hierarchical refinement approach can effectively improve the performance of small target detection while optimizing the utilization of computational resources. In addition, the compression and excitation (SE) module enhances the model’s sensitivity to critical information by dynamically calibrating the feature importance between channels, thereby achieving higher detection performance in complex visual tasks without significantly increasing the computational overhead. To further enhance the feature extraction capability and accelerate the inference speed, this study replaces the convolutional layer (Conv) of the CSPDarknet53 backbone network in YOLOv5 with MobileNetV3, which enables the model to be lightweight and efficient while maintaining a high detection accuracy.The design of MobileNetV3, such as the depth-separable convolution, is particularly suitable for real-time application scenarios The design of MobileNetV3, such as depth-separable convolution, is especially suitable for real-time application scenarios. Table 2 compares the original YOLOv5 and the improved Hybrid-YOLOv5, highlighting the architectural improvements and their corresponding motivations and performance gains.
Adding SE_block (Squeeze-and-Excitation blocks) to YOLOv5
This study presents an enhanced YOLOv5 object detection framework that integrates the Squeeze-and-Excitation (SE) module to improve the model’s feature representation capacity. The SE module serves as an efficient attention mechanism, dynamically recalibrating feature channels by learning inter-channel dependencies. This process increases the network’s sensitivity to critical features while suppressing less important ones, thereby strengthening the model’s representational capabilities.
In our implementation, the SE module is conFig.d as a distinct network component, referred to as SE_Block, as illustrated in Fig. 5. This component is integrated into YOLOv5’s convolutional blocks, forming a new module called ConvBlockWithSE. ConvBlockWithSE combines traditional convolution operations with SE module-enhanced feature activations, enabling the network to perform channel-wise feature recalibration immediately after convolution operations.

SE_Block structure.
Specifically, the SEBlock first applies global average pooling to the input feature map, generating statistical attributes that capture the global distribution of each channel. These attributes are then passed through a network composed of two fully connected layers, which, through adaptive learning, produce recalibration weights for each channel. Finally, after being processed by a sigmoid activation function, the recalibration weights are used to scale the original feature map, enabling adaptive feature recalibration, as illustrated in Fig. 6.

SE_Block operation process diagram.
.
The strategy for replacing the convolutional layers in the backbone network
As shown in Fig. 7, the replacement strategy for MobileNetV3’s convolutional layers with YOLOv5-compatible structures enhances both efficiency and detection performance.When replacing the convolutional layers in the MobileNetV3 backbone with a structure compatible with YOLOv5, it is crucial to implement a systematic and innovative approach. First, a thorough comparison between the MobileNetV3 and YOLOv5 architectures is necessary, particularly because MobileNetV3 employs depthwise separable convolutions to enhance computational efficiency, while YOLOv5 uses traditional convolutions to achieve high-performance object detection. Based on this comparison, a hybrid replacement strategy can be developed, retaining depthwise separable convolutions in layers with lower computational demands and applying traditional convolutions in feature-rich layers to improve detection accuracy. Furthermore, MobileNetV3’s inverted residual blocks and Squeeze-and-Excitation (SE) modules can be incorporated into the redesigned backbone network to enhance feature extraction and dynamically adjust feature map weights. It is also essential to adjust convolution types and parameters, such as kernel size, stride, and padding, to ensure consistency with YOLOv5’s detection head. Each layer should be replaced gradually, tested, and validated to optimize performance. Finally, fine-tuning and training techniques—such as learning rate adjustments, data augmentation, and transfer learning—are necessary to ensure the new architecture maintains the lightweight nature of MobileNetV3 while delivering exceptional performance in object detection tasks.

SE_Block operation process diagram.
Loss function improvement
Accurate bounding box prediction is critical to the performance of object detection models. This study introduces an advanced loss function, Complete Intersection over Union (CIOU) Loss, which extends the Distance Intersection over Union (DIOU) Loss by incorporating an aspect ratio term. This term ensures the predicted bounding box’s aspect ratio aligns with the ground truth, thereby improving localization accuracy. Additionally, we propose a weighted loss strategy that differentiates between small, medium, and large objects to address the varying challenges associated with detecting objects of different sizes51. The formula for calculating CIOU loss is as follows:
In the formula, the range of CIOU loss values is between 0 and 1, where 0 represents perfect overlap between the predicted and true bounding boxes, and 1 indicates no overlap.
IOU (Intersection over Union) is the ratio of the overlapping area between the predicted bounding box and the true bounding box to the area of their union. Given a predicted bounding box B and a true bounding box B_gt, IOU is calculated as follows:
Distance Intersection over Union (DIOU) loss function:
where \({\rho ^2}{\text{ }}(b,{b_{gt}})\) denotes the Euclidean distance between the center points of the predicted box b and the true box \({b_{gt}}\), and c is the length of the diagonal of the smallest enclosing box covering the two boxes.
Aspect ratio consistency term \((\upsilon )\) and the weight parameter \((\alpha )\):
where, \({\omega _{gt}}\) and \({h_{gt}}\) are the width and height of the true box, \(\omega\) and h are the width and height of the predicted box. The parameter \(\alpha\) is designed to make the influence of the aspect ratio term proportional to the inconsistency of IOU.CIOU Loss:
Furthermore, this study proposes a feature-scale weight strategy to weight the losses computed for bounding boxes of different scales with different weights:
Weighted Loss:
where, \({\lambda _{small}}\), \({\lambda _{medium}}\) and \({\lambda _{l\arg e}}\) are loss weight coefficients for small, medium, and large-sized bounding boxes respectively. In the experiments, these weight coefficients were set to specific values (for example, small size weight of 4.0, medium size weight of 1.0, and large size weight of 0.4) to tune the detection performance for targets of different sizes.
The proposed CIOU Loss not only accounts for overlap and center distance between the predicted and ground truth boxes, as DIOU Loss does, but also introduces an aspect ratio term. This term penalizes discrepancies in aspect ratio, enabling the model to predict bounding boxes that more closely match the ground truth in shape. To prioritize the detection of smaller objects, which are typically more challenging, we assign different weights to the loss calculations across various feature scales. Specifically, weights of 4.0, 1.0, and 0.4 are applied to small, medium, and large object scales, respectively.
In our experiments, CIOU Loss is applied to several benchmark datasets with varied feature scale weights to find the optimal balance for each dataset. The loss for each predicted bounding box is computed as 1 − CIOU1 − CIOU, incentivizing the network to maximize the CIOU score. Additionally, the confidence loss is determined by the CIOU score of the anchor, reflecting the probability of an object’s presence within the bounding box.
The proposed CIOU Loss function, which comprehensively accounts for overlap, distance, and aspect ratio, combined with a feature-scale weighted strategy, provides an effective solution to the bounding box regression problem in object detection tasks. Future work will explore the adaptability of this loss function across different network architectures and larger, more complex datasets.
Evaluation metrics
Model evaluation in this experiment involved the use of commonly employed metrics: average precision (AP), mean average precision (mAP), precision (P), recall (R), and F1. AP represents the average precision for a specific target category, while mAP represents the average precision across all categories. The evaluation of the model’s detection accuracy in this study utilized mAP and F1, while the model’s detection speed was assessed using frames per second (FPS).
To determine the successful prediction of a target, the intersection over union (IOU) was calculated between the predicted frame and the actual labeled frame. A target was considered successfully predicted if the IOU was greater than or equal to 0.5, and incorrectly predicted if the IOU was less than 0.5. TP denotes the detection of a target with the same portion as the positive sample (labeled strawberry target), FP indicates the detection of a target with the portion of the negative sample (unlabeled background), FN indicates the failure to detect a target with the positive sample, and TN indicates the failure to detect a target with the negative sample. P represents the proportion of correctly predicted positive samples out of the samples identified as positive, while R represents the proportion of correctly predicted positive samples out of all actual positive samples. F1 is a composite evaluation metric combining P and R. The formulas for these metrics are provided below.
where N is the number of categories(N = 2).
Results and discussion
Choosing the best model for detecting non-ferrous metals in automotive scrap involves balancing model complexity, data availability, and computational resources. Given the diversity of the dataset, although multi-layer deep learning models can capture complex patterns, they are not always efficient due to potential overfitting issues, especially when data is limited. This task requires careful consideration of the trade-off between model complexity and available computational resources. It served as a test of the validity and supremacy of the proposed Hybrid-YOLOv5 algorithm.
In this study, we selected YOLOv3, YOLOv5, YOLOv7, and YOLOv11 for comparison with the primary goal of demonstrating the technological evolution and optimization process of the YOLO series models. The rationale for choosing these versions is based on their representation of different stages of development in the YOLO framework. YOLOv3 provides a baseline with early innovations, YOLOv5 has become widely adopted in practice due to its speed and accuracy balance, YOLOv7 offers precision improvements, especially for small object detection, and YOLOv11 incorporates state-of-the-art performance optimizations. These versions were selected to effectively showcase the progression in accuracy, speed, and detection capabilities, while avoiding unnecessary complexity that might arise from including newer versions such as YOLOv8, which may introduce significant changes not directly comparable with the previous versions.
Results of detection algorithms
In this experiment, state-of-the-art models, including YOLOv3, YOLOv5, YOLOv7, and YOLOv11, were selected as comparison algorithms. All algorithms were trained using their default parameters, with the number of epochs set to 100 and a batch size of 4. The detection results are presented in Table 3, while Fig. 8 visually illustrates the differences among these algorithms.

Performance comparison of different algorithms.
By comprehensively comparing and analyzing the performance results of the YOLO family of variants, the proposed Hybrid-YOLOv5 algorithm demonstrates significant advantages in several key metrics. Precision reaches 72.3%, and mAP@0.5 is as high as 84.2%, which is significantly better than the other comparative algorithms, sufficiently proving its superiority in detection accuracy. Although its F1-score is 75.9%, slightly lower than the original YOLOv5’s 76.1%, this difference is due to the trade-off between Precision and Recall. Hybrid-YOLOv5 improves Recall to 79.9% while maintaining robust Precision, enabling better detection of small and complex objects, which is critical in real-world industrial applications.
In contrast, YOLOv11, despite its superior performance in Recall (84.7%) and inference speed (102 FPS), has a significantly lower Precision (38.8%) and mAP@0.5 (61.8%), indicating a higher false alarm rate, which is difficult to meet the demands of high-precision industrial sorting tasks. While YOLOv5 and YOLOv7 are relatively balanced in terms of Precision, Recall and mAP (e.g., 74.9% for mAP@0.5 in YOLOv5 and 75.8% in YOLOv7), they are still inferior to our proposed algorithms in terms of detection robustness in complex scenes and adaptability to small targets. By introducing MobileNetV3 lightweight backbone network, SE module and C2 F module, our algorithm not only achieves a good balance between precision and recall, but also significantly improves the detection of small targets and complex textures, while maintaining the inference speed at 60 FPS, which is sufficient to meet the demand of industrial real-time sorting.
To evaluate the model’s performance in complex real-world applications, we focus on two key metrics: mAP@0.5:0.95 and inference time. By analyzing YOLOv3, YOLOv5, YOLOv7, YOLOv11, and our proposed Hybrid-YOLOv5, we observe a substantial improvement in detection accuracy. Specifically, the mAP50-95 values of these models are 36.0%, 44.3%, 46.0%, 47.3%, and 54.7%, respectively, indicating continuous performance enhancement.
Regarding inference time, YOLOv3 takes 5.2 ms, while YOLOv11 achieves the fastest speed at 2.7 ms. In contrast, YOLOv5 and YOLOv7 have longer inference times of 21.5 ms and 23.4 ms, respectively. Although the inference time for Hybrid-YOLOv5 increases slightly to 15.2 ms, the significant accuracy gain demonstrates that the trade-off between inference time and accuracy is justified. This highlights our algorithm’s ability to effectively balance speed and accuracy, underlining its effectiveness.
Ablation experiment results of proposed model
In order to verify the performance of the Hybrid-YOLOv5 model proposed in this paper, ablation experiments were conducted under the same dataset conditions. The experiments compare the C2 F module, the SE module, and different model combinations using MobileNetv3 as the feature extraction backbone network, and the results are shown in Table 4.
Contribution of the C2 F module
The introduction of the C2 F module improves the model’s Precision (P), Recall (R), F1 score and mAP_0.5 by 0.6%, 4.4%, 2.2% and 3.4%, respectively. This result indicates that the C2 F module has a significant effect in optimizing feature extraction and fusion, and can effectively improve the detection performance. In addition, the C2 F module slightly reduces the inference time from 21.5 ms to 21.2 ms and improves the FPS from 43 to 44. Although the reduction in inference time and the improvement in FPS are relatively small, these improvements demonstrate the potential of the C2 F module in optimizing the model structure and reducing the computational overhead. This lightweight design is especially valuable in resource-constrained or real-time detection scenarios. Theoretically, the C2 F module reduces redundant computations through an efficient feature fusion mechanism while maintaining or even improving the expressive power of the model.
Contribution of the SE module
After the introduction of the SE module, the mAP_0.5 of the model is improved from 74.6 to 78.1%, and the F1 score is also improved to 77.3%. The experimental results show that the SE module can effectively improve the performance of the classification task by adaptively enhancing the useful features and suppressing the irrelevant features, and the accuracy improvement is especially significant for the non-ferrous metal classification task. However, the introduction of the SE module also brings additional computational overhead, which increases the FLOPs to 48.4 G. Despite the increase in computational complexity, this overhead is acceptable in high-precision demand scenarios compared to the significant performance improvement. From a theoretical perspective, the SE module strengthens the model’s focus on the target category by assigning weights in the feature channels, which improves the model’s feature representation and classification effect. This feature is especially important in complex classification tasks.
Contribution of MobileNetv3
After using MobileNetv3 as the feature extraction backbone network, the inference time of the model was significantly reduced from 21.5 ms to 15.4 ms, and the FPS was improved from 43 to 60, while maintaining a high mAP_0.5 (74.4%). This shows that MobileNetv3, through its lightweight architecture, effectively reduces the complexity of the model while maintaining good performance in classification and detection tasks. This substantial efficiency improvement provides a significant advantage for the model in real-time demanding tasks.
Effect of integrated optimization
By integrating the C2 F module, the SE module, and the MobileNetv3 backbone network, the model achieves optimal performance, with the mAP_0.5 improved to 84.2%, the F1 score of 75.9%, the inference time further reduced to 15.2 ms, and the FPS improved to 60. This demonstrates that multi-strategy fusion significantly enhances the model in terms of classification accuracy, detection efficiency, and resource adaptability performance. Notably, while the F1 score slightly decreases from 76.1 to 75.9% for the benchmark YOLOv5 model, mAP_0.5 significantly improves from 74.9 to 84.2%. This trade-off is mainly attributed to the optimization of small target detection and the improvement in mAP, which may have led to some impact on the balance between Precision and Recall.
Implications of the work
This study proposes a novel Hybrid-YOLOv5 algorithm for efficient and accurate detection of non-ferrous metals in end-of-life vehicles, offering several significant practical and academic implications.
Practical implications
The Hybrid-YOLOv5 algorithm demonstrates considerable improvements in detection accuracy and computational efficiency for metal sorting in the recycling industry. The inclusion of Coarse-to-Fine (C2 F) and Squeeze-and-Excitation (SE) modules, alongside the MobileNetV3 backbone network, allows the model to detect small, mixed, or occluded metal objects in real-time, which is a common challenge in industrial environments. This makes the algorithm highly applicable to smart recycling technologies, offering a scalable and efficient solution for metal sorting in end-of-life vehicles. By enhancing the efficiency of recycling processes, this work contributes to resource conservation and supports the circular economy, ensuring that valuable metals like copper, aluminum, and stainless steel are more effectively recovered.
Academic implications
This research makes a notable contribution to the field of object detection and deep learning by proposing a lightweight, efficient algorithm tailored for real-time industrial applications. The successful integration of advanced techniques like MobileNetV3, SE modules, and C2 F introduces new methods for improving detection accuracy while reducing computational load. These innovations provide insights into how deep learning models can be adapted for resource-constrained environments. This study also sets the stage for future academic exploration in intelligent sorting and recycling technologies, particularly in challenging industrial settings.
Future research directions
Despite the strong performance of Hybrid-YOLOv5, several areas remain open for exploration:
-
1.
Data Diversity and Real-World Verification: Future research will focus on collecting more diverse data from real industrial environments to further test and validate the algorithm’s robustness under various environmental conditions (e.g., extreme lighting, dust, vibration).
-
2.
Expanding Applicability: The algorithm could be adapted for use in other industrial fields, such as e-waste sorting or rare metal recovery, extending its applicability beyond end-of-life vehicles.
-
3.
Introducing New Evaluation Metrics: More comprehensive evaluation metrics will be introduced, such as energy consumption, false detection rate, and missed detection rate, to better assess the algorithm’s performance in real-world applications.
-
4.
Optimizing Computational Efficiency: Future studies could explore further optimizations in the algorithm’s architecture, such as model compression and pruning, to improve its computational efficiency and adaptability across a wider range of industrial scenarios.
-
5.
Developing More Lightweight Algorithms: As industry demands evolve, the development of even more lightweight and deployable detection algorithms will be critical to the wider application of smart recycling technology, enabling deployment in more varied and challenging environments.
Conclusion
In summary, the proposed Hybrid-YOLOv5 algorithm provides a highly efficient and accurate solution for detecting non-ferrous metals in end-of-life vehicles, contributing to improving metal sorting processes in the recycling industry. The integration of MobileNetV3, SE modules, and the C2 F module has enhanced the detection accuracy, computational efficiency, and real-time performance of the algorithm. However, further considerations are needed for deploying this model in real-world, non-controlled environments. Specifically, challenges related to energy efficiency and real-time adaptability in dynamic, non-ideal conditions must be addressed for broader applicability. This work not only advances intelligent recycling technologies but also contributes to the circular economy by promoting better resource recovery. Future work will focus on optimizing the algorithm for deployment in more diverse industrial settings, improving its robustness and energy efficiency, and ensuring its real-time adaptability to a wider range of operational environments.
Data availability
All data generated or analysed during this study are included in this published article.
References
Molla, A. H. et al. A. E-waste and end-of-life vehicles management and circular economy initiatives in Romania. Sci. Rep. 13 (1), 4169 (2023).
Wang, J. et al. Institutional, technology, and policies of end-of-life vehicle recycling industry and its indication on the circular economy-comparative analysis between China and Japan. Front. Sustain. 2, 645843 (2021).
Yuxi, J. In the national recycling of scrapped motor vehicles reached 8.46 million, an increase of 64%.Preprint at (2024). https://baijiahao.baidu.com/s?id=1820671730353617794&wfr=spider&for=pc(2025).
Li, Y., Liu, Y., Huang, S., Sun, L. & Ju, Y. Estimation of critical metal stock and recycling potential in China’s automobile industry. Front. Environ. Sci. 10, 937541 (2022).
Soo, V. K. Life Cycle Impact of Different Joining Decisions on Vehicle Recycling (2018).
Arnold, M., Pohjalainen, E., Steger, S., Kaerger, W. & Welink, J. H. Economic viability of extracting high value metals from end of life vehicles. Sustainability 13 (4), 1902 (2021).
Zeng, X. et al. Current status and future perspective of waste printed circuit boards recycling. Procedia Environ. Sci. 16, 590–597 (2012).
Santini, A. et al. End-of-Life vehicles management: Italian material and energy recovery efficiency. Waste Manage. 31 (3), 489–494 (2011).
Karagoz, S., Aydin, N. & Simic, V. End-of-life vehicle management: A comprehensive review. J. Mater. Cycles Waste Manage. 22, 416–442 (2020).
Choi, J., Lim, B. & Yoo, Y. Advancing plastic waste classification and recycling efficiency: integrating image sensors and deep learning algorithms. Appl. Sci. 13 (18), 10224 (2023).
Ahmed, M. I. B. et al. Youldash, M. Deep learning approach to recyclable products classification: towards sustainable waste management. Sustainability 15 (14), 11138 (2023).
Sayem, F. R. et al. A. Enhancing waste sorting and recycling efficiency: robust deep learning-based approach for classification and detection. Neural Comput. Appl. 37, 4567–4583. https://doi.org/10.1007/s00521-024-10855-2 (2025).
Islam, M. S. B. et al. ECCDN-Net: A deep learning-based technique for efficient organic and recyclable waste classification. Waste Manage. 193, 363–375 (2025).
Mukhopadhyay, A., Biswas, P., Agarwal, A. & Mukherjee, I. Performance comparison of different cnn models for indian road dataset.In Proceedings of the 3rd International Conference on Graphics and Signal Processing. (pp. 29–33). (2019).
Sultana, F., Sufian, A. & Dutta, P. A review of object detection models based on convolutional neural network. In: Intelligent Computing: Image Process. Based Applications, Vol. 1157 (eds Mandal, J. & Banerjee, S.) (Springer, Singapore, 2020). https://doi.org/10.1007/978-981-15-4288-6_1.
Srivastava, S. et al. Comparative analysis of deep learning image detection algorithms. J. Big Data. 8 (1), 66 (2021).
Mukhopadhyay, A. & Biswas, P. Advancements in Deep-Learning-Based object detection in challenging environments. Wireless World Res. Trends Magazine, 1–6 (2024).
Mukhopadhyay, A., Br, H., Gaikwad, P. T., Mukherjee, I. & Biswas, P. I-rod: an ensemble of CNNs for object detection in unconstrained road scenarios. Signal. Image Video Process. 19 (1), 3 (2024).
Malhotra, P. & Garg, E. Object Detection Techniques: A Comparison. Paper presented at the 2020 7th International Conference on Smart Structures and Systems (ICSSS) (2020).
Brooks, L. Evaluating Identification and Sorting Technologies for Improved Ferrous and Non-Ferrous Recycling (Rochester Institute of Technology, 2021).
Brooks, L., Gaustad, G., Gesing, A., Mortvedt, T. & Freire, F. Ferrous and non-ferrous recycling: challenges and potential technology solutions. Waste Manage. 85, 519–528 (2019).
Smith, Y. R., Nagel, J. R. & Rajamani, R. K. Eddy current separation for recovery of non-ferrous metallic particles: A comprehensive review. Miner. Eng. 133, 149–159 (2019).
Luo, X., He, K., Zhang, Y., He, P. & Zhang, Y. A review of intelligent ore sorting technology and equipment development. Int. J. Min. Metall. Mater. 29 (9), 1647–1655 (2022).
Kaya, M. Recovery of metals and nonmetals from electronic waste by physical and chemical recycling processes. Waste Manage. 57, 64–90 (2016).
Gaustad, G., Olivetti, E. & Kirchain, R. Improving aluminum recycling: A survey of sorting and impurity removal technologies. Resour. Conserv. Recycl. 58, 79–87 (2012).
Sarvar, M., Salarirad, M. M. & Shabani, M. A. Characterization and mechanical separation of metals from computer printed circuit boards (PCBs) based on mineral processing methods. Waste Manage. 45, 246–257 (2015).
Curtolo, D. C., Xiong, N., Friedrich, S. & Friedrich, B. High-and ultra-high-purity aluminum, a review on technical production methodologies. Metals 11 (9), 1407 (2021).
Castaldo, R. et al. Critical factors for the recycling of different end-of-life materials: wood wastes, automotive shredded residues, and dismantled wind turbine blades. Polymers 11 (10), 1604 (2019).
Gundupalli, S. P., Hait, S. & Thakur, A. A review on automated sorting of source-separated municipal solid waste for recycling. Waste Manage. 60, 56–74 (2017).
Maier, G., Gruna, R., Längle, T. & Beyerer, J. A survey of the state of the Art in sensor-based sorting technology and research. In: IEEE Access 12, 6473–6493. https://doi.org/10.1109/ACCESS.2024.3350987 (2024).
Hahn, D. W. & Omenetto, N. Laser-induced breakdown spectroscopy (LIBS), part II: review of instrumental and methodological approaches to material analysis and applications to different fields. Appl. Spectrosc. 66 (4), 347–419 (2012).
Zhang, Y., Zhang, T. & Li, H. Application of laser-induced breakdown spectroscopy (LIBS) in environmental monitoring. Spectrochimica Acta Part. B: At. Spectrosc. 181, 106218 (2021).
Swedish, I. & Kimab, S. Compact industrial LIBS systems can assist aluminum recycling(2014).
Mesina, M., De Jong, T. & Dalmijn, W. Automatic sorting of scrap metals with a combined electromagnetic and dual energy X-ray transmission sensor. Int. J. Miner. Process. 82 (4), 222–232 (2007).
Xiong, T., Ye, W. & Xu, X. Combination of dual-energy X-ray transmission and variable gas-ejection for the in-line automatic sorting of many types of scrap in one measurement. Appl. Sci. 11 (10), 4349 (2021).
Qin, G. et al. Current Status and Prospects of Mineral Sorting Technology Research at Home and Abroad. Paper presented at the E3S Web of Conferences(2024).
Lindsey, D. T., Brown, A. M., Violette, A. N., Lange, R. & Deshpande, P. S. Color sorting and color term evolution. Color. Res. Application. 49 (3), 318–338 (2024).
Modise, E. G., Zungeru, A. M., Mtengi, B. & Ude, A. U. Sensor-based ore sorting—A review of current use of electromagnetic spectrum in sorting. IEEE Access. 10, 112307–112326 (2022).
Henry, T. & Jie, F. Design and construction of color sensor based optical sorting machine. Paper presented at the 5th International Conference on Instrumentation, Control, and Automation (ICA) (2017). (2017).
Adhithya, S. & Kathirvelan, J. Development of Computer Vision Based Aluminium Scrap Sorting Using Real Time Metal Scrap Dataset. Paper presented at the 4th International Conference on Sustainable Expert Systems (ICSES)(2024). (2024).
Zhao, G., Chang, F., Chen, J. & Si, G. Research and prospect of underground intelligent coal gangue sorting technology: A review. Miner. Eng. 215, 108818 (2024).
Cui, X. et al. A General Overview of Intelligent Sorting System Based on Machine Vision. Paper presented at the 2023 35th Chinese Control and Decision Conference (CCDC) (2023).
Rathoure, A. K. Revolutionizing waste management with advancements in sorting and processing technologies. In Municipal Solid Waste Manage. Recycling Technologies, 387–406 (2024).
Fan, B. et al. Instance segmentation algorithm for sorting dismantling components of end-of-life vehicles. Eng. Appl. Artif. Intell. 133, 108318 (2024).
Lu, W. & Chen, J. Computer vision for solid waste sorting: A critical review of academic research. Waste Manage. 142, 29–43 (2022).
Diaz Romero, D. J. Artificial Intelligence Techniques for Enhanced Sorting (2023).
Ziouzios, D., Baras, N., Balafas, V., Dasygenis, M. & Stimoniaris, A. Intelligent and real-time detection and classification algorithm for recycled materials using convolutional neural networks. Recycling 7 (1), 9 (2022).
Ali, M. L. & Zhang, Z. The YOLO framework: A comprehensive review of evolution, applications, and benchmarks in object detection. Computers 13 (12), 336 (2024).
Nguyen, Q. H., Ly, H. B., Ho, L. S., Al-Ansari, N., Le, H. V., Tran, V. Q., … Pham,B. T. Influence of data splitting on performance of machine learning models in prediction of shear strength of soil. Mathematical Problems in Engineering,2021(1), 4832864(2021).
Vrigazova, B. The proportion for splitting data into training and test set for the bootstrap in classification problems. Bus. Syst. Research: Int. J. Soc. Adv. Innov. Res. Econ. 12 (1), 228–242 (2021).
Zhang, W. et al. YOLOv5-RF: a deep learning method for tailings pond identification in high-resolution remote sensing images based on improved loss function. Big Earth Data, 9(1), 100–126. https://doi.org/10.1080/20964471.2024.2436230 (2024).
Funding
This research was funded by the National Natural Science Foundation of China, Grant Number: 52065034 and 52205374.The Fundamental Research Funds for the Central Universities of China, Grant Number: N2303002.The Special Basic Cooperative Research Programs of Yunnan Provincial Undergraduate Universities Association (No. 202101BA070001-157), Yunnan Fundamental Research Projects (No. 202301 AT070052) and Frontier Research Team of Kunming University 2023,Yunnan Province College Students’Innovation and Entrepreneurship Project (202411393014 and 202411393010).
Author information
Authors and Affiliations
Contributions
Author Contributions: Conceptualization, Y.J. (Youdong Jia); methodology, Y.J. (Youdong Jia); data curation, X.L. (Xinzhi Li), R.Y. (Rui Yang), Z.Z. (Ziyue Zhu), Y.Z. (Yuanxin Zhang); writing—original draft preparation, Y.J.;writing—review and editing, Y.J.and J.Z.(Jiaxing Zeng); supervision, Y.Z.(Yuhang Zhang), S.Y(Sibo Yao) and Z.L.(Zhengfang Li); project administration, Y.J. All authors have read and agreed to the published version of the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Jia, Y., Zhang, Y., Yang, R. et al. Hybrid-YOLOv5 for object detection of non-ferrous metals in end-of-life vehicles. Sci Rep 15, 23170 (2025). https://doi.org/10.1038/s41598-025-02683-8
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-02683-8
