
Abstract
Driven by the growing challenges of global climate change and the urgent need to meet Sustainable Development Goals (SDGs), the green transformation of the economy has become a global consensus, with enterprises playing a crucial role. Using data from China’s A-share listed companies between 2010 and 2022, this paper examines the impact of big data advancements on corporate green development through the construction of a quasi-natural experiment. Specifically, the “National Big Data Comprehensive Pilot Zone” is used as a policy intervention to explore the causal effects of big data on corporate green practices. The findings indicate that the implementation of the big data pilot policy has fostered the adoption of more sustainable business practices, particularly in the eastern and central regions, as well as among large-scale enterprises. These positive effects are primarily driven by improved resource allocation and the reduction of agency costs. Based on these findings, the paper proposes a series of policy recommendations aimed at accelerating the green transition of the economy, offering valuable insights for policymakers and researchers.
Similar content being viewed by others

Introduction
As global awareness of environmental challenges grows and the emphasis on sustainable development intensifies, the greening of the economy has emerged as a dominant global trend. Central to this transition is the green development of enterprises, which plays a crucial role in achieving sustainable development goals (SDGs)1. In support of this transformation, the international community has introduced stringent environmental regulations and sustainable development standards, with initiatives such as the European Union’s Green Deal serving as key examples. These measures are designed to reduce carbon emissions, improve resource efficiency, and foster synergies between economic growth and environmental protection. As a result, enterprises are increasingly required to integrate green principles into their strategies, operations, and management practices, shifting from traditional models toward green, low-carbon, and sustainable development pathways in alignment with the global momentum toward green growth.
China has proactively embraced the global trend of integrating ecological protection with economic development by embedding these principles into its national strategic framework to foster comprehensive green development. According to the latest development plan issued by the central government, innovation-driven growth, especially in the fields of ecological science and technology, has been identified as a primary objective of economic progress. This offers both strategic direction and policy support for the green transformation at the enterprise level. The 2023 government report emphasizes the urgent need for a nationwide green transition, focusing on improving energy efficiency, reducing emissions, enhancing environmental protection, and fostering a conducive policy environment for the development of green corporations.
As the world’s second-largest economy and a leading developing country, China has committed to achieving peak carbon emissions and carbon neutrality. This ambitious goal involves restructuring industrial sectors, increasing investment in clean energy and environmental protection industries, and encouraging enterprises to adopt green technologies and processes to drive industrial upgrading2.
To foster the integration of the digital economy with the real economy and guide the transition to low-carbon development, China launched a pilot project on big data in regions such as Guizhou in 2016. The initiative aims to position data as a new production factor, promoting the development of the big data industry. By enhancing the efficient circulation of resources, this policy seeks to achieve the dual objectives of environmental protection and economic growth through the application of big data technologies.
While existing literature has extensively examined the relationship between green sustainability and the digital economy, it has largely recognized the critical role of big data in advancing environmentally friendly development3. However, gaps remain in understanding the causal relationships and mechanisms through which digital transformation specifically facilitates green development at the enterprise level.
To further examine the relationship between big data advancements and corporate green behavior, this paper employs the entropy method to scientifically evaluate enterprise green development. By conducting a quasi-natural experiment, the study provides a robust basis for the government to design policies that facilitate enterprise green transformation. The research offers significant contributions in three key areas:
-
(1)
Development of a Multi-Dimensional Evaluation Framework: Building on existing literature, this study constructs a multi-dimensional green development indicator system to comprehensively assess the green development levels of enterprises. This approach addresses the limitations of single-indicator evaluations and establishes a holistic reference framework for future research.
-
(2)
Micro-Level Analysis of Policy Impacts: This study examines the impact of big data policies on the green development of enterprises at the micro level, offering a fresh perspective for assessing policy effectiveness. By conducting a thorough analysis of enterprise-level data, the research reveals how big data policies influence corporate decision-making and operational strategies. These insights provide valuable guidance for refining policies and optimizing corporate practices to be better aligned with green development goals.
-
(3)
Exploration of Mechanisms and Heterogeneous Impacts: This paper delves into the internal mechanisms and heterogeneous effects of big data policies in fostering enterprise greening, offering theoretical support for the formulation of targeted and effective green policies. The findings not only guide enterprises in adopting green strategies but also equip the government with differentiated policy recommendations. This dual contribution enhances the overall effectiveness of policy implementation, fosters corporate green development, and has far-reaching implications for achieving long-term, sustainable economic growth.
This study investigates the impact of big data pilot policies on the green development of enterprises, with a particular focus on the mechanisms through which these policies enhance resource allocation efficiency and reduce agency costs. Additionally, it examines the differential effects of these policies across regions and enterprises of varying scales. By providing a theoretical foundation and practical insights, the research aims to guide the effective application of big data in promoting green development within businesses, promote their green transformation, and offer valuable support for the formulation of government policies.
Figure 1 shows the working methods and workflow of this study in a brief way.

Workflow of the study.
Literature review
Research on the impact of big data
Big data technology has emerged as a key driver of enterprise development. Existing research primarily focuses on the impact of big data on enterprise performance and innovation4. Some studies argue that the core value of big data applications lies in the collection, processing, and analysis of vast amounts of information, with data itself serving as a valuable resource capable of generating competitive advantages5. The rapid advancement and widespread adoption of big data have led to transformative changes in areas such as enterprise management, customer interactions, and business models6. Moreover, big data has the potential to unlock significant financial value7, and the ability to effectively analyze such data can have a substantial positive impact on corporate performance8.
Research on the impact of corporate green development
The green transition has become a critical global development priority, centered on achieving the coordinated advancement of economic growth and environmental sustainability9. Against the backdrop of deepening global industrial restructuring, many countries have adopted industrial green transformation as a key strategy to enhance industrial competitiveness. Enterprises, as direct producers, play a pivotal role in this process10. Proactive corporate green initiatives address stakeholder demands, including supply chain security, product sustainability, public health concerns, and sustainable government governance. Such actions are not only vital for ensuring long-term corporate viability11 but also serve as a prerequisite for transitioning from high-speed growth to high-quality economic development12. Furthermore, big data significantly influences corporate competitive advantages by driving green innovation activities13.
Research on the impact of big data on the corporate green development
Many existing studies have established that digital technologies such as big data can have a positive impact on green and sustainable development aspects. For example, it is argued that big data policies can scale up data and promote venture capital, talent, and technology in pilot cities, thereby supporting sustainable urban development14. Digital technologies such as artificial intelligence and blockchain play an important role in the production systems of businesses, thus supporting their sustainable development15 and positively impacting all SDGs by improving social and environmental sustainability16.
In the digital economy of the 21st century, the deep integration of digital technology and the real economy not only affects the production and operation mode of enterprises, but also becomes a facilitator of service-oriented transformation and a driving force for sustainable development17. From the perspective of enterprises, green innovation is the driving force of enterprise green transformation18, and big data can help enterprises overcome technological challenges, which reduces the burden of R&D financial constraints19. The reduction in the cost and risk of enterprise innovation might accelerate the R&D process of green technology, improve the efficiency and level of green innovation20, and have a significant impact on enterprise green process innovation21. Big data technology can affect the competitive advantage of enterprises by influencing their green innovation activities13. At the same time, big data can also provide green technical support for enterprise pollutant management22 by helping enterprises to obtain environmental pollution data1, and renewing the traditional production mode as well as governance mode of enterprises2.
As evident from existing literature, research on the impact of digital technologies such as big data on corporate green development, as well as the underlying mechanisms, urgently needs to be enriched and expanded.
Theoretical analysis and hypotheses proposal
Amidst the swift expansion of big data technology, in 2016, China launched a national-scale initiative for a comprehensive big data pilot zone, henceforth denoted as the “Policy”. The primary goal of the “Policy” is to position the development of big data technology as a key driver for high-quality economic growth and economic structure upgrading. At the same time, it also emphasizes the importance of ecological environmental protection to facilitate a shift towards a sustainable economic model, thereby enhancing the efficiency of resource distribution.
Big data progress refers to the continuous development of big data technologies and their applications. In this process, big data can help companies discover new sustainable materials, energy-efficient technologies, or eco-friendly production processes, facilitating the evolution and breakthrough of eco-friendly products23. In addition, advances in big data technology have improved internal knowledge management and external knowledge exchange within the corporate structure. Companies can streamline their internal R&D assets and accelerate the development of eco-friendly technologies by leveraging data analytics24. At the same time, big data enables companies to identify and participate in external eco-innovation networks and resources, such as environmental research organizations and government assistance programs, thereby improving their ability to sustainably innovate25. With big data, manufacturing organizations can improve the scope and efficiency of searching and processing relevant information. Data mining and analytics can help optimize business processes by enabling manufacturing firms to achieve smarter management and decision-making, which facilitates investment in areas such as cleaner production and green technology transformation26. In addition, digital technologies such as big data can help financial providers, such as banks, to strengthen the monitoring of capital flows and reduce the possibility of “greenwashing"27, which promotes the substantial green development of enterprises. Based on the above analysis, hypothesis 1 is proposed as follows.
Hypothesis 1
The development of big data drive enterprises to green transformation.
The development of big data enables various economic activities of enterprises to be recorded as information data, which are integrated and then transmitted in the form of big data. Big data accelerates enterprise information transmission by providing more detailed information in data disclosure, and by reducing the information acquisition cost significantly28. Meanwhile, while improving the transparency of enterprise internal information, big data also reduces the information asymmetry between stakeholders and enterprises, inhibits the opportunistic behavior of insiders, and as a result, reduces the cost of governance29. Reduced agency cost means more efficient utilization of corporate funds, allowing the enterprises to invest more resources in green technology R&D and application to promote green development. In summary, this paper proposes hypothesis 2:
Hypothesis 2
The development of big data promotes corporate green growth by reducing the cost of corporate agency.
Enterprises can utilize big data to process and analyze information in capital allocation, accurately collect and systematically analyze information from all aspects of raw material procurement3. This could reduce the cost of searching and transmitting, and could also verify information products30, pointing to better capital allocation. With the strong analytical ability of big data, corporate executives can guide the company to respond more effectively to adjustments in the external environment and adjust the corporate capital allocation strategy in a more rational way31. Therefore, big data helps to better adapt the company’s situation to the external situation, solve the problems of biased capital allocation decisions and unclear direction of capital allocation due to information errors, and improve the risk-bearing capacity of capital allocation, and thereby improves the efficiency of capital allocation32. The improvement of capital allocation efficiency will also bring positive economic benefits to enterprises33, which is conducive to guiding more funds to green projects and promoting green technological innovation, thus lowering the volatility and credit risk of the company, and improving the value of the company and its emission performance34; at the same time, it can also improve total factor productivity and promote the upgrading of industrial structure. And all the changes are pointing to a multifaceted positive impact on the green development of enterprises. In summary, this paper proposes hypothesis 3:
Hypothesis 3
The development of big data promotes corporate green growth by improving the efficiency of resource allocation.
Data and method
Methodology
To evaluate the impact of China’s big data initiatives on corporate green development, a difference-in-differences (DID) model is applied. The DID approach assumes that the policy is exogenous and its implementation is randomized, unaffected by individual choices. For instance, the establishment of the National Big Data Comprehensive Pilot Zone may have been influenced by factors such as geographic location or other uncontrollable elements, rather than the areas themselves possessing higher green development potential. By calculating the difference in outcomes between the treatment and control groups both before and after the policy implementation, and then taking the difference between these two differences, the DID model estimates the causal effect. In this paper, we construct a quasi-natural experiment using the establishment of the National Comprehensive Big Data Pilot Zone as a policy shock. The policy was started in February 2016, when Guizhou Province was designated as the pilot city for the zone’s development, with a subsequent approval in October for additional cities, encompassing Inner Mongolia, Shanghai, the Beijing-Tianjin-Hebei city cluster, Chongqing, the Pearl River Delta city cluster, Shenyang, and Henan, and the regions above are marked as big data pilot areas. According to the policy, this paper identifies 2016 as the policy implementation year, utilizing listed companies from the pilot regions as the experimental group and those from non-pilot regions as the control group. The specific model is set as follows.
where \(\:{EGDI}_{i,t}\) is the corporate green development index, where i denotes firms, and t denotes years; \(\:{DID}_{i,t}\:\)is a dummy variable for policy shocks, where it takes the value 1 if the company belongs to a national-level comprehensive big data pilot area in 2016 or later, and 0 if a corporate belongs to the control group. \(\:{\alpha\:}_{1}\) is the coefficient of most interest, which denotes the net effect of the Policy on the green development of the firms; \(\:{Controls}_{i,t}\) is a set of control variables; \(\:{\alpha\:}_{0}\) is a constant term;\(\:{\:\lambda\:}_{i}\) controls for firm individual fixed effects, and\(\:{\:\phi\:}_{t}\:\)controls for time fixed effects; \(\:{\epsilon\:}_{i,t}\) is a randomized disturbance term.
In this paper, the DID model is used to assess policy effects, so after performing the baseline regression analysis, a parallel trend test is conducted to verify the applicability of the model. Nonetheless, we recognize that there are limitations in the causal effects analysis, particularly in terms of other policy disturbances that may have existed during the same period. To address this potential problem, we included a placebo test in the robustness test section and excluded municipalities and other cities that may have been affected by other policies as a way of mitigating the potential impact of these disturbances on the findings.
Variable calculation
-
(1)
Independent variables.
Policy shocks usually refer to the impact of policies taken by the government on entities such as businesses and individuals. The comprehensive pilot zone of big data optimizes the green allocation of resource elements by fully releasing the empowering effect of data elements, and accelerates the green and sustainable development of enterprises. Therefore, this paper takes the pilot policy of national-level Big Data Comprehensive Pilot Zones as an exogenous shock, the explanatory variable in this paper is defined as the big data pilot policy (DID), which is constructed by calculating the product of the dummy variable of the pilot area and the time of policy implementation. Specifically, the value is 1 if the city where the enterprise is located is recognized as a national-level comprehensive big data pilot area and the city is selected as a big data pilot city in 2016 or later; otherwise, the value is 0.
-
(2)
Dependent variable.
The explanatory variable of this paper is Enterprise Green Development (EGDI). The 2015 United Nations Sustainable Development Summit officially adopted 17 SDGs. The SDGs aim to completely solve the development problems in the three dimensions of society, economy and environment in an integrated way from 2015 to 2030, and shift to the path of sustainable development, which is formed by the composite of three subsystems: economy, society and ecology35. “Green development” is not only an extension of “sustainable development” but also a theoretical innovation in the context of sustainable development in China. Therefore, this paper focuses on the manufacturing industry and endeavors to establish an overall green development assessment framework covering economic returns, social values and ecological advantages36. Specific indicators were selected and calculated as shown in Table 1.
To gauge the extent of corporate green advancement, this study employs the entropy weight technique to determine the overall green development index. The entropy weight is the parameter that describes the differences in the evaluation objectives. The lower the entropy value, the more information is provided, and the higher the weight.
The first step is data normalization, in formula (2), \(\:{x}_{ij}\:\)represents a positive indicator, in formula (3), \(\:{x}_{ij}\:\)represents a negative indicator. And the detailed method is listed as follows:
where \(\:{x}_{ij}\:\)is the value of the jth indicator of the ith enterprise (\(\:i=1,\cdots\:,\text{n};\:j=1,\ldots\:,\text{m}\)). The data are standardized to eliminate the effect of the scale.
Then the entropy value is calculated to reflect the uncertainty of the information. The formula for calculating the entropy value is listed as follows:
Here, k is a constant, k = 1/ln(n) > 0, and \(\:{e}_{j}\ge\:0\). \(\:{e}_{j}\:\)denotes the first j entropy value of the jth attribute, and\(\:\:{\:p}_{ij}\:\:\)is the weight of the ith evaluation object on the jth attribute. Subsequently, we need to calculate the coefficient of variation for each attribute to measure its contribution to the decision. The formula for calculating the coefficient of variation is as follows:
\(\:\:{d}_{j}\:\)denotes the first jth attribute’s coefficient of variation, and the larger its value, the more important the attribute’s role in decision making.
Finally, we determine the weight of each attribute based on the coefficient of variation, and the formula for calculating the weight is as follows:
Here, \(\:{w}_{j}\) denotes the first j weight of the jth attribute, \(\:m\) is the total number of attributes.
Based on the weight of each attribute, we can calculate the composite score by using the following formula, this step is the key of the entropy method because it combines the weight of each attribute with the corresponding attribute value in order to arrive at the final evaluation result:
Control variables
Based on the literature related to green development, the control variables control the factors affecting the green development of enterprises, and this paper controls the following characteristic variables at the company level: company size (size), net profit rate on total assets (ROA), asset-liability ratio (LEV), equity concentration (Concentration_H), attention by research reports (Report), and whether the board of directors has overseas background (Oversea). Table 2 lists the definitions of the main variables in this paper.
Data preparation
For observational data, the list of pilot cities of national-level Big Data Comprehensive Pilot Zones comes from the announcement of the Ministry of Industry and Information Technology (MIIT). The research object of this paper is Chinese A-share listed companies from 2010 to 2022, and the data of corporate green development indicators and other corporate characteristics are from the China Stock Market Accounting Research (CSMAR). In this paper, we process the sample data as follows: (1) Samples of financial companies are deleted; (2) Samples with serious missing data for core variables are dropped; (3) Samples labelled as ST and *ST companies are dropped; And (4) Variables are winsorized at the 1% level to mitigate the impact of extreme values on the regression results.
Table 3 provides the descriptive statistics of the variables involved in this study. The time span of the samples 2010–2022, 2461 enterprise samples with a total of 17,218 observation units are applied in estimation.
Data analysis
Figure 2 shows the green development of enterprises between 2010 and 2022. The aggregate green development trajectory of listed companies has been ascending. Notably, following the initiation of the “Policy” across various cities in 2016, there has been a significant enhancement in the green development of the listed companies. Between 2010 and 2022, despite the overall moderate green development, numerous enterprises have achieved significantly higher green development levels compared to the average. The outliers indicate that the green development of enterprises is to some extent unbalanced. After the pilot project of “Policy”, enterprises have witnessed a marked escalation in their green development. Additionally, the distribution of data creation has become more concentrated, signifying a trend towards equilibrium in the eco-progress of China’s A-listed companies.

Enterprise green development index 2010–2022.
Figure 3 illustrates that the median level of green development in non-state-owned enterprises (non-SOEs) is generally lower than that in state-owned enterprises (SOEs), which may reflect disparities in resource allocation, policy execution, and market responses. Non-SOEs tend to adopt more focused and efficient strategies for green transformation, resulting in a more concentrated data distribution with fewer extreme values. In contrast, the presence of more extreme data points suggests the existence of significant internal disparities in green development levels within SOEs. This variation may present challenges during the transition process, such as uneven resource distribution and inconsistent policy implementation.

2010–2022 Green development of SOEs and non-SOEs.
Empirical analysis: benchmark regression
Table 4 presents the results of the benchmark regression analysis, which examines the effects of the policy on EGDI. In column (1), the regression outcomes include both firm and time fixed effects. The robustness of these results is further confirmed in column (2), which incorporates a range of control variables. This regression approach clusters standard errors at the industry level, which helps mitigate potential biases arising from industry-specific characteristics. The findings highlight the significant positive impact of the establishment of the National big data comprehensive pilot zone on promoting corporate green development, thereby providing empirical support for hypothesis 1.
Robustness testing
Parallel trend test
In this paper, the event analysis method is adopted to construct the corresponding analytical model, and the mathematical formula is detailed in Eq. (9):
where \(\:{policy}_{i,t+k}^{k}\:\)denotes a dummy variable for a given year before and after the construction of the comprehensive pilot zone for big data. If it is a treatment group, it is set to 1 in year t+k ≥ 2016, and is set to 0 in the rest of the years; if it is a control group, it is set to 0 in all cases. \(\:{\alpha\:}_{k}\:\)is the coefficient of interest in this paper, which indicates that the parallel trend hypothesis is valid if \(\:{\alpha\:}_{k}\) is not significant in the period k < 0.
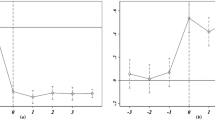
In this study, the year of the launch of the Big Data Integrated Pilot Zone was selected as the baseline point in time. The analysis presented in Fig. 4 indicates that prior to the establishment of the Pilot Zone, there was no statistically significant difference in the level of green development between the treatment group and the control group. This result provides strong evidence supporting the validity of the parallel trend hypothesis. As a result, the parallel trend hypothesis is confirmed, and the application of the Difference-in-Differences model is substantiated.
However, our observations reveal that, three years after the implementation of the big data policy, its initially significant impact began to diminish gradually. This attenuation may be attributed to shifts in the market environment and the emergence of new challenges faced by enterprises during their development. These factors may have interfered with the long-term effectiveness of the big data policy.
Despite the short-term weakening of the policy’s effect, we contend that the long-term impact of big data on the green development of enterprises remains fundamentally sustainable. The data-driven decision-making model and the enhanced capacity for resource optimization introduced by big data technologies, once integrated into organizational practices, are likely to exert a lasting influence on enterprise operations and management strategies. Even three years post-implementation, enterprises can continue to leverage the data and insights accumulated earlier to refine production processes and optimize supply chain management, thereby advancing more sustainable green development objectives.

Parallel trend test.
Placebo test
This study constructs “pseudo-policy” dummy variables by randomly assigning cities and policy implementation years. First, 123 firms are randomly selected from the sample pool as new treatment units, and the remaining firms assigned to the control group. Second, a hypothetical policy implementation year is randomly allocated to each city within the treatment groups. Finally, pseudo-policy dummy variables are created based on these hypothetical scenarios, and regression analyses are conducted. This randomized simulation estimation is repeated 500 times.
Figure 5 illustrates the kernel density distribution of the coefficients derived from the random samples. The results show that the vast majority of the estimates are tightly clustered around zero, indicating that the regression findings reflect the true positive effect of big data on enhancing firms’ green performance, rather than being a random occurrence. This supports the robustness of the baseline conclusions.

Placebo test.
Considering a certain time lag
Considering that the effects of policy may not be immediately apparent following the policy shock, time variables for the green development index at t-1 and t-2 are used to test the robustness of the results. The findings in Table 5 show that the regression coefficients for the one-period lag in column (1) and the two-period lag in column (2) are both positive and statistically significant, suggesting that the research conclusions are robust.
Excluding special samples
This study excludes specific cities, such as Shanghai, Beijing, Chongqing, and Tianjin, where the level of economic development and digital infrastructure may have had an impact on the establishment of the Comprehensive big data pilot zone and its greening, and subsequently conducts a re-benchmarked regression analysis. The corresponding regression results are described in Table 5, column (3), which indicated the robustness of the findings.
Excluding other policy disturbances
This paper uses the establishment of the “National Big Data Comprehensive Pilot Zone” as an exogenous shock to measure the impact of big data on the green development of enterprises. Since the implementation of other policies may also promote green development, which could lead to systematic bias in baseline estimates, this study further addresses this issue. In addition to including the dummy variables for the “Broadband China” pilot policy (Bcpolicy) and the “Smart City” pilot policy (Scpolicy) in the baseline model, it also incorporates two additional dummy variables for the “Action Plan of Air Pollution Prevention and Control” policy (Appolicy) and the “Low Carbon Pilot” policy (Lcpolicy). This approach helps more comprehensively exclude the potential interference from other policies on the green development of enterprises. If a city is selected as a pilot city for the “Broadband China” program, Bcpolicy is set to 1 for the year in which the city is chosen as a pilot and subsequent years. Similarly, for cities participating in the Smart City pilot, implementing the “Action Plan of Air Pollution Prevention and Control” policy, and those implementing the “Low Carbon Pilot” policy, the variable setting follows the same structure as for Bcpolicy. The corresponding regression results are shown in columns (4) to (7) of Table 5. These results indicate that, even after excluding the impact of other policy interventions, the Big Data Comprehensive Pilot Zone policy still has a positive and significant impact on the green development of enterprises.
PSM-DID model
This study employs a staged matching method for propensity score matching to assess the impact of the Big Data Pilot Policy on the green development of enterprises. The matching process is based on variables such as company size, ROA (Return on Assets), LEV (Leverage Ratio), ownership concentration, media attention from research reports, and the overseas backgrounds of directors, supervisors, and senior managers. Using the nearest neighbor matching method, a control group was identified for the enterprises located in the Big Data pilot areas, resulting in a matched dataset. Additionally, city samples were matched by year to create a panel dataset. After conducting a balance test and analyzing the matching effect, the accuracy of the matching process was confirmed. Regression analysis using a multi-time-point DID method reveals that the policy has a robust positive impact on the green development of enterprises. The DID coefficient is significantly positive and consistent with the baseline regression results. More detailed descriptions for the tests could be found in the Appendix.
Mechanism analysis
Based on the hypotheses proposed in this paper, the channels of agency cost and operational capabilities are selected for testing24. In Eq. (10), the explanatory variables represent the mediating variables, which tests the linkage between the mediating factors and the primary explanatory variables.
Agency costs
Agency theory posits that corporate executives may obscure allowance expenses by categorizing them under operating costs, such as advertising, selling, and administrative expenses, thereby increasing agency costs37. In China, due to the underdeveloped audit market, executives can easily conceal self-serving and unethical behaviors through administrative and selling expenses, as audit independence in reviewing annual reports is not sufficiently guaranteed38. In light of previous studies39,40, this paper adopts the operating expense ratio (AC1) and administrative expense ratio (AC2) as proxy variables for agency costs, measured by the ratios of operating expenses and administrative expenses to main business revenues, respectively. Higher values of these ratios are indicative of higher agency costs. The results presented in Table 6 demonstrate that big data can play a role in improving supervision and governance, thereby reducing enterprise agency costs. Consequently, this paper argues that agency costs partially mediate the effect of the big data pilot policy on the green development of enterprises, thus supporting Hypothesis 2. As big data continues to evolve, firms are able to monitor management behavior in real-time, effectively reducing monitoring costs. Furthermore, in the context of innovation and R&D investments, agency costs primarily arise from conflicts between shareholders and management over investment direction and resource allocation. The application of big data can streamline the decision-making process, mitigate such conflicts, and enhance the efficiency of R&D investment, thereby promoting the sustainable development of enterprises.
Capital allocation efficiency
Drawing on related studies, this paper adopts Richardson’s41 approach to assess the capital allocation efficiency of firms by estimating the optimal level of investment for each firm in the current year. This approach enables the identification of overinvestment or underinvestment based on the efficiency of capital allocation.
where \(\:{Invest}_{t}\) is the fixed asset investment is the original cost of fixed assets, which is calculated as a proportion of total assets at the beginning of the period;\(\:\:{Growth}_{u,t-1\:}\)is the growth rate of the firm i’s main business revenue;\(\:{\:\:Roa}_{i,t-1}\) is the return on assets, which is calculated as net profit divided by average total assets; \(\:{Lev}_{i,t-1}\) is the return on total assets;\(\:\:{Age}_{i,t-1}\) is the age of the firm; \(\:{Size}_{i,t-1}\) is the size of the firm’s total assets, which is represented by the natural logarithm of asset totals; \(\:{Invest}_{i,t-1}\) is the firm’s fixed asset investment in the year t-1, which is calculated as a proportion of total assets at the beginning of the period. When the value of the residuals exceeds 0, this indicates the existence of overinvestment phenomenon; conversely, if the value of the residuals is lower than 0, it indicates that the enterprise is not investing sufficiently. In this paper, we utilize the absolute value of the residuals as a measure of inefficient investment, where a larger value reflects a lower investment efficiency.
The results, as presented in Table 6, particularly in paragraphs (3), indicate that the coefficients are significantly negative, suggesting that the big data pilot policy has effectively mitigated inefficient investments and improved the capital allocation efficiency of firms. Capital allocation efficiency is a critical indicator of a firm’s investment decision-making and resource management capabilities41. The integration of big data technology enables firms to more accurately evaluate investment opportunities and risks, thereby optimizing capital allocation and minimizing ineffective investments. Furthermore, big data enhances informational transparency, thereby improving decision-making quality and enabling management to formulate more scientifically grounded investment strategies32. This informational advantage allows firms to allocate resources more rationally during their green transformation, reduce resource waste, and improve capital utilization efficiency. Additionally, big data facilitates synergistic cooperation among firms, improving capital allocation efficiency across the entire industrial chain33, reducing investment costs, strengthening green competitiveness, and supporting the sustainable development of the industry. Therefore, this paper posits that capital allocation efficiency mediates the impact of the big data pilot policy on the green development of firms, thus supporting Hypothesis 3.
Heterogeneity analysis
Analysis of regional heterogeneity
Differences in natural endowments, historical context, economic structure, and stages of development across regions can lead to varying responses to the same policy. Accordingly, this study categorizes cities into the eastern, central, and western regions based on geographic location. As shown in Table 7, entries (1) to (3), the DID coefficients are significantly positive in both the eastern and western regions, while the central region shows no significant impact. This disparity can be attributed to the more advanced economic development in the eastern region, where enterprises are better capitalized, enabling substantial investments in big data technologies to promote green development. In contrast, the central region has long been dominated by heavy industries, such as energy and chemical sectors, which constitute a large portion of the total industrial output. These industries generate significant environmental pressures, complicating the green transformation process. Consequently, enterprises in the central region face substantial challenges in altering deeply entrenched production models and addressing the current issues of high pollution and energy consumption. As a result, big data technologies have a relatively limited impact on green development in this region. Although the western region has a lower level of economic development, it benefits from favorable policy incentives, such as investment-attracting measures and improved infrastructure, which create conducive conditions for the application of big data in promoting green development.
Heterogeneity in firm size
Heterogeneity in enterprise size is pivotal for understanding how firms of varying scales adapt to market changes and policy adjustments. In this study, consistent with previous research42, firms with more than 2000 employees are classified as large enterprises, while those with 2000 or fewer employees are classified as small and medium-sized enterprises (SMEs). The findings of this analysis, presented in columns (4) to (5) of Table 7, demonstrate that the influence of big data on the green development of large enterprises is markedly stronger than that on small and medium-sized enterprises. This discrepancy arises because large enterprises typically possess more resources and capital, enabling them to invest in green technologies and clean energy initiatives. In contrast, SMEs are often confronted with greater challenges related to funding and technological innovation. SMEs face significant barriers to securing external financing, which restricts their capacity to invest in big data technologies43. Furthermore, they may lack the technical expertise necessary to fully leverage big data. Additionally, SMEs often lack the specialized talent in data management and analytics needed to unlock the full potential of Big Data44. For instance, many SMEs lack specialized data analysts and data scientists capable of extracting valuable insights from large datasets, which undermines their decision-making and innovation in green transformation, thereby hindering their potential for green development.
Conclusion and research prospects
Many existing studies have pointed out the positive impact of big data technologies on sustainable development in other national and domain contexts, and the findings of this paper are similar to those of some other areas. For example, big data and predictive analytics technologies have been shown to improve social and environmental sustainability in manufacturing organizations in India45. Big data technologies can help and improve the sustainability performance of organizations in selected MENA countries46. Big data analytics capabilities can positively impact the sustainability performance of selected manufacturing organizations in Malaysia47. Against the backdrop of the “National Big Data Comprehensive Pilot Zone”, which is regarded as a quasi-natural experimental setting, this paper delves into the impact of big data on corporate green development by analyzing the panel data of Chinese A-share listed companies from 2010 to 2022. The empirical findings reveal several key insights:
Firstly, following the establishment of the pilot zone, the green development level of enterprises in the treatment group significantly improved, indicating that the big data pilot policy has a positive effect on promoting corporate green development.
Secondly, the research highlights that big data offers a practical avenue for enhancing the green development of enterprises by reducing agency costs and improving resource allocation efficiency, thereby fostering the adoption of sustainable business practices.
Finally, regarding regional differences, the influence of big data on corporate green development is most pronounced in the eastern and western regions, while its impact is relatively weaker in the central region. In terms of differences among enterprise types, the effect of big data on green development is more significant in large enterprises and non-state-owned enterprises.
Based on the above analysis, this paper puts forward the following policy recommendations:
-
(1)
Adopt strategies that are tailored to local conditions. The eastern region should deepen the integration of big data and green finance to expand financing channels; The central region should leverage its manufacturing advantage to optimize production through big data and enhance resource efficiency; The western region should take advantage of its policy advantages to attract investment, strengthen infrastructure construction, and cultivate new drivers of green development.
-
(2)
Support SMEs and promote cooperation between large and SMEs. Large enterprises should be encouraged to invest in green innovation of big data and set industry standards, while small and medium-sized enterprises need government support to lower the barriers to big data application.
-
(3)
Formulate long-term green development strategies. The government should promote cooperation between environmental protection, industrial and information technology sectors, and establish a unified data sharing platform and regulatory system, ensuring a long-term and effective implementation of policies.
Limitations
This paper reveals the impact of big data policies on corporate green development and provides insights for related fields. However, the study is limited by the data source mainly based on China’s A-share companies, which fails to cover various types of enterprises comprehensively. Future studies should broaden the data scope to include more types of enterprises and industries to enhance the generalizability of the results. Meanwhile, the impact of individual differences among enterprises on policy response and green development has not been fully considered, and dynamic factors should be included in subsequent studies to more realistically reflect the heterogeneity of enterprises.
Data availability
The datasets used and/or analysed during the current study available from the corresponding author on reasonable request.
References
Li, Z. & Wang, J. The dynamic impact of digital economy on carbon emission reduction: evidence City-level empirical data in China. J. Clean. Prod. 351, 131570 (2022).
Li, Y., Zheng, L., Xie, C. & Fang, J. Big data development and enterprise ESG performance: empirical evidence from China. Int. Rev. Econ. Finance. 93, 742–755 (2024).
Wu, K., Liu, S., Zhu, M. & Qu, Y. The impact of digital transformation on resource mismatch of Chinese listed companies. Sci. Rep. 14, 9011 (2024).
Ghasemaghaei, M. Calic g.assessing the impact of big data on firm innovation performance: big data is not always better data. J. Bus. Res. 108, 147–162 (2020).
Horng, J. S., Liu, C. H., Chou, S. F., Yu, T. Y. & Hu, D. C. Role of big data capabilities in enhancing competitive advantage and performance in the hospitality sector: Knowledge-based dynamic capabilities view. J. Hosp. Tour. Manag. 51, 22–38 (2022).
Raguseo, E. Big data technologies: an empirical investigation on their adoption, benefits and risks for companies. Int. J. Inf. Manag. 38, 187–195 (2018).
Chen, D. Q., Preston, D. S. & Swink, M. How the use of big data analytics affects value creation in supply chain management. J. Manag. Inform. Syst. 32, 4–39 (2015).
Yasmin, M., Tatoglu, E., Kilic, H. S., Zaim, S. & Delen, D. Big data analytics capabilities and firm performance: an integrated MCDM approach. J. Bus. Res. 114, 1–15 (2020).
Cheba, K., Bąk, I., Szopik-Depczyńska, K. & Ioppolo, G. Dir. Green. Transformation Eur. Union Ctries. Ecol. Indic. 136, 108601 (2022).
Fu, H., Zheng, C. & Yang, P. Digital inclusive finance and green transformation of manufacturing enterprises: empirical analysis based on the dual perspectives of demand and supply. Technol. Forecast. Soc. Chang. 200, 123152 (2024).
Lăzăroiu, G., Ionescu, L., Andronie, M. & Dijmărescu, I. Sustainability management and performance in the urban corporate economy: a systematic literature review. Sustainability. 12, (2020).
Li, J. & Li, Y. Digitalization, green transformation, and the high-quality development of Chinese tourism enterprises. Finance Res. Lett. 66, 105588 (2024).
El-Kassar, A. N. & Singh, S. K. Green innovation and organizational performance: the influence of big data and the moderating role of management commitment and HR practices. Technol. Forecast. Soc. Chang. 144, 483–498 (2019).
Wu, T., Xu, W. & Kung, C. The impact of data elements on urban sustainable development: evidence from the big data policy in China. Technol. Soc. 81, 102800 (2025).
Vinuesa, R. et al. Fuso Nerini, F. The role of artificial intelligence in achieving the sustainable development goals. Nat. Commun. 11, 233 (2022).
Varriale, V., Cammarano, A., Michelino, F. & Caputo, M. The role of digital technologies in production systems for achieving sustainable development goals. Sustain. Prod. Consum. 47, 87–104 (2024).
Luo, S. & Liu, J. Enterprise service-oriented transformation and sustainable development driven by digital technology. Sci. Rep. 14, 10047 (2024).
Miao, Z. & Zhao, G. Configurational paths to the green transformation of Chinese manufacturing enterprises: a TOE framework based on the FsQCA and NCA approaches. Sci. Rep. 13, 19181 (2023).
Liu, F., Liu, G., Wang, X. & Feng, Y. Whether the construction of digital government alleviate resource curse? Empirical evidence from Chinese cities. Resour. Policy. 90, 104811 (2024).
Feng, Y., Gao, Y., Hu, S., Sun, M. & Zhang, C. How does digitalization affect the green transformation of enterprises registered in China’s resource-based cities? Further analysis on the mechanism and heterogeneity. J. Environ. Manage. 365, 121560 (2024).
Tian, H., Li, Y. & Zhang, Y. Digital and intelligent empowerment: can big data capability drive green process innovation of manufacturing enterprises? J. Clean. Prod. 377, 134261 (2022).
Kwon, O., Lee, N. & Shin, B. Data quality management, data usage experience and acquisition intention of big data analytics. Int. J. Inf. Manag. 34, 387–394 (2014).
Yu, E. & Luu, B. International variations in ESG disclosure—Do cross-listed companies care more? Int. Rev. Financial Anal. 75, 101731 (2021).
Kim, J., Yang, I., Yang, T. & Koveos, P. The impact of R&D intensity, financial constraints, and dividend payout policy on firm value. Finance Res. Lett. 40, 101802 (2021).
Yan, Y., Xu, X. & Lai, J. Does Confucian culture influence corporate R&D investment? Evidence from Chinese private firms. Finance Res. Lett. 40, 101719 (2021).
Cockburn, I. M. Henderson Rebecca & Stern Scott. The Impact of Artificial Intelligence on Innovation. (2018).
Xing, C., Zhang, Y. & Tripe, D. Green credit policy and corporate access to bank loans in China: the role of environmental disclosure and green innovation. Int. Rev. Financial Anal. 77, 101838 (2021).
Zhang, H. & Enterprise, E. S. G. Information disclosure quality and stock market Performance——Based on the perspective of double agency cost. J. Capital Univ. Econ. Business(in Chinese). 25, 73–88 (2023).
Li, Z., Xie, B., Chen, X. & Fu, Q. Corporate digital transformation, governance shifts and executive pay-performance sensitivity. Int. Rev. Financial Anal. 92, 103060 (2024).
Chen, R., Ghoul, E., Guedhami, S., Wang, H. & O. & Do state and foreign ownership affect investment efficiency? Evidence from privatizations. J. Corp. Finance. 42, 408–421 (2017).
Zhai, H., Yang, M. & Chan, K. C. Does digital transformation enhance a firm’s performance? Evidence from China. Technol. Soc. 68, 101841 (2022).
Li, C., Liu, J., Liu, Y. & Wang, X. Can digitalization empowerment improve the efficiency of corporate capital allocation? —Evidence from China. J. Econ. Anal. Policy. 80, 1794–1810 (2023).
Lv, X., Zhao, B., Cheng, D. & Xia, C. Patent strategies in the digital revolution: how businesses use digital technology patents to optimize resource allocation efficiency. Finance Res. Lett. 67, 105835 (2024).
Liu, L. Green innovation, firm performance, and risk mitigation: evidence from the USA. Environ. Dev. Sustain. 26, 24009–24030 (2024).
Islam, H. Nexus of economic, social, and environmental factors on sustainable development goals: the moderating role of technological advancement and green innovation. Innov. Green. Dev. 4, 100183 (2025).
Ding, H. & Cheng, Q. Digital innovation, entrepreneurship and green development of manufacturing enterprises. Sci. Res. Manage. (in Chinese). 45, 84–97 (2024).
Zhang, L., Zhang, Z., Jia, M. & Ren, Y. A tiger with wings: CEO–board surname ties and agency costs. J. Bus. Res. 118, 271–285 (2020).
Du, X. What’s in a surname?? The effect of Auditor-CEO surname? sharing on financial misstatement. J. Bus. Ethics. 158, 849–874 (2019).
He, W. & Luo, J. Agency problems in firms with an even number of directors: evidence from China. J. Bank. Financ. 93, 139–150 (2018).
Du, X. Does religion matter to Owner-Manager agency costs?? Evidence from China. J. Bus. Ethics. 118, 319–347 (2013).
Richardson, S. Over-investment of free cash flow. Rev. Acc. Stud. 11, 159–189 (2006).
Deng, F., Yang, G. & Ren, Z. R&D subsidies and technological innovation of digital enterprises: empirical evidence based on digital economy industry. Ind. Econ. Res. (in Chinese) 27–41 (2021).
Liu, F. et al. Whether the construction of digital government alleviate resource curse? Empirical evidence from Chinese cities. Resour. Policy. 90, 104811 (2024).
Zhang, L. et al. A tiger with wings: CEO–board surname ties and agency costs[J]. J. Bus. Res. 118, 271–285 (2020).
Dubey, R. et al. Can big data and predictive analytics improve social and environmental sustainability? Technol. Forecast. Soc. Chang. 144, 534–545 (2019).
Singh, S. & El-Kassar, A. Role of big data analytics in developing sustainable capabilities. J. Clean. Prod. 213, 1264–1273 (2019).
Cheng, J., Singh, M., Zhang, H., Wang, S. & Y & The impact of business intelligence, big data analytics capability, and green knowledge management on sustainability. J. Clean. Prod. 429, 139410 (2023).
Acknowledgements
Thanks to the National Natural Science Foundation of China (No. 72364035), Yunnan Fundamental Research Projects (No. 202301AT070421) and Foundation of Yunnan University of Finance and Economics (No. 2023D07). And we are very thankful to the editor and anonymous reviewers for their helpful input.
Funding
The paper is supported by National Natural Science Foundation of China (No. 72364035), Yunnan Fundamental Research Projects (No. 202301AT070421) and Foundation of Yunnan University of Finance and Economics (No. 2023D07).
Author information
Authors and Affiliations
Contributions
Conceptualization, Supervision: [Y.W.]; Software and Formal analysis: [Y.L.], [Z.T.]; Methodology, Data Curation: [Y.W.], [Y.L.]; Writing editing: [Z.T.], [Z.R.]; Writing – original draft: [Z.R.], [T.G.]. All authors reviewed the manuscript, and agreed to the published version of the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Wang, Y., Li, Y., Ruan, Z. et al. Empirical evidence and role mechanisms of big data enabling corporate green development. Sci Rep 15, 18476 (2025). https://doi.org/10.1038/s41598-025-03207-0
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-03207-0
Keywords
This article is cited by
-
Data assetization and corporate green technology innovation: a dual perspective of information and resources
Management System Engineering (2026)
