
Abstract
The process of teaching and learning during the pandemic has been evolving globally, with many institutions transforming their approaches to enhance the teaching and learning experience. Despite the presence of improved frameworks due to the varied learning capabilities of students, it remains quite challenging to analyse individual characteristic features. Consequently, this research provides clear insights into the integration of the Personalised Learning Approach (PLA) to foster effective interaction with students. However, many existing methods suggest different techniques for evaluating learners in a hybrid mode, where obtaining clear data sets can be difficult. In the teaching and learning approach, if the defined data set from experts is clear, decisions regarding the learning characteristics of students can be made in a shorter period. In the proposed method the PLA framework categorizes learners into four engagement-based clusters using a three-dimensional sensor model and machine learning classifiers. A dual-controller mechanism (master-slave) dynamically adjusts communication intervals and optimizes video transmission, reducing latency and packet loss. The methodology is validated using MATLAB-based simulations with a dataset of 1,700–5,000 learners, analyzing throughput, delay, packet loss, and cost efficiency. The test results clearly demonstrate that the PLA outperforms the conventional method, not only with the parameters mentioned above but also in terms of cost-effectiveness using master and slave controllers.
Similar content being viewed by others

Introduction
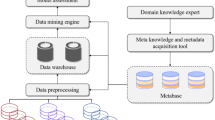
The current technology in the teaching process is primarily conducted in an offline manner, where all students visit a specific location for learning. Although offline teaching has a significant impact on the connectivity activities of the current generation, some learners wish to pursue their education in remote locations. However, the challenge associated with this approach is that a new type of integration and system model must be developed to ensure that the foundational learning is akin to face-to-face teaching methodologies. Additionally, the identification mechanism for each student should be designed to quickly identify slower learners. The aforementioned conditions must at least be measured equivalently with those learners engaged in offline education systems. Therefore, the proposed method of identification in this unique teaching and learning process involves an approach that enhances interaction using Machine Learning (ML) techniques. The prerequisites for this type of identification include sensors for collecting data from learners and an appropriate data transfer methodology for further processing. The block diagram of the proposed method is illustrated in Fig. 1.

Teaching learning procedure with observation rates.
From Fig. 1 it can be stated that the data inputs are directly given in the presence of sensors which is categorized for different working functionality. In most of the cases accelerometer sensors with three dimensional models is created with three axis model where different learners are identified with extraction set features. During this identification process more number of active learners will be present thus the entire data set is clustered using set of classifiers that divides the data in appropriate form. The output of clustered data is used for monitoring all the physical activities of learners where the observed changes are directly reported to both master and slave controllers using a wireless connected systems. These two controllers identify different data and categorizes learners based on their distinct functions. Once the learners are classified then data is pre-processed this learning rate is finally measured and described. Existing studies have extensively explored machine learning techniques for student classification and learning behavior analysis. Similarly, dual controller mechanisms have been widely applied in communication networks and optimization problems. However, their direct application to personalized learning environments remains relatively unexplored, particularly in a way that dynamically adjusts both learning content and student engagement strategies. In this study, we propose a Personalized Learning Approach (PLA) that uniquely integrates machine learning with a dual controller mechanism to provide real-time, adaptive learning pathways. Unlike prior approaches, PLA does not simply classify students into predefined categories; instead, it continuously refines its understanding of student progress using an iterative feedback mechanism. Additionally, our dual controller mechanism is not a direct adaptation from communication networks but is specifically designed to optimize real-time learning flow adjustments based on cognitive engagement metrics.
Literature survey
Most conventional methods in the teaching and learning process are implemented without optimisation, leading to poor outcomes. However, after analysing the unsuccessful paths, many academic establishments have transformed their teaching approaches using various tools that help students understand the subjects better. This section examines existing methods, and using the same information, the projected model will be updated. In1, the researchers allocated resources using a ML algorithm employed in remote locations. In this resource allocation process, a video will be integrated to monitor the quality of students, and a decision-making approach is utilised with frequency division networks. However, the significant drawback of the resource allocation process is that the same quality of framework is achieved even through preeminent reserved procedures. A fundamental outlook questioning using visual representation cases was made in2, where the knowledge development process is analysed with a Deep Learning (DL) application platform. Even with ground initialisation stages, the process fails to examine the importance of distinct network architectures when the performance of students is found to be poor. Additionally, with new DL algorithms, the same architecture can be applied for observation, even at diverse procedural stages.
To provide better observation cases for future evaluation techniques, regulations are made in all possible circumstances3 using ML algorithms. The regulations mentioned earlier provide better insights for big data integration, as the separation of learning types is processed in earlier stages to avoid cross-sectional impacts. However, a visual representation case for separated instances is not integrated with any framing measures, which is considered a disadvantage of this process. One significant concern in self-directed learning development is that the nature of the system must be well known to all students4 before implementing ML in this context. However, predicting the adaptability rate of different techniques before testing the nature of different systems is quite challenging. The application of non-deterministic techniques makes sudden changes in monitoring physical activity highly unlikely; thus, deterministic characteristics with multiple interaction stages are utilised. Furthermore, all ethical standards must be adhered to in the design of technology, as control techniques are essential for defining the roles in the teaching and learning process5. Such control techniques can provide quick solutions if ethical guidelines are not followed under certain circumstances.
To provide quick solutions to all problems in teaching and learning, a mathematical model is essential, where all formulations can be defined with certain lower-bound constraints6. Therefore, a mathematical model has been created based on ten underlying principles that provide good knowledge representation. Since differential equations are employed, the characteristics of the learning process will vary, thus affecting the intelligence of learners. To maintain a constant learning representative, a hybrid teaching model is preferred over statistical ones7, where solutions are provided to improve imminent classroom systems. For this category of hybrid teaching, datasets are collected from proficient learners; however, it is still challenging to incorporate the reference set with defined data. Instead of dataset integration, a score-based procedure is introduced, where valuation scores for each course are assessed at the end periods8. This type of scoring method will engage students in all learning activities, and the use of e-learning systems will also be extended. Additionally, the score will allow instructors to identify students with low engagement levels, and for such identification processes, ML algorithms will be implemented. Conversely, the mathematical model for score prediction has not been formulated mathematically, leading to confusion regarding the approach. In most learning processes, student interaction tends to be significantly lower concerning certain topics9, necessitating greater concentration in such cases. Consequently, the researchers have created a method consisting of a tenfold validation approach, processed with the Naïve Bayes model, showing a considerable increase in the learning capability of students. Nevertheless, in the current generation, a standalone Naïve Bayes model cannot be employed as it is integrated with ML models of a singular type. The importance of e-learning has risen during the pandemic as the learning process has been completely transformed, as suggested by cypher recognition models10. These recognition models integrate the use of artificial intelligence for the development of software and for the use of an electronic teaching board. The outcome of such integration is that all bibliophiles will be encouraged by observing individual characteristics. However, there is a certain drawback: large data sets cannot be integrated in the same procedure due to observed numerical changes. A review from recent years suggests the presence of three-dimensional structures that include a classification mechanism with a data-gathering approach11. The aforementioned mechanism will monitor the teaching feedback of all supporters using immersive gaming techniques. Therefore, much more active participation from learners will be achieved, thus overcoming the gap in the artificial intelligence models. Furthermore, the learning styles of students can also be monitored using ML algorithms, where parameters such as impetus and levels of concentration can be measured accurately12. This type of measurement will enhance student behaviour, thus increasing the success rate from lower values. Nonetheless, a high success rate cannot be achieved without constraints, even with predictive analysis. After understanding the learning process from the perspective of students, both audio and video processing systems are merged using reinforcement techniques13. Consequently, a remote learning experience can be realised in real-time environments by adhering to ethical standards. In14, researchers have provided an open view on solving networking problems during the teaching-learning process by enhancing the quality of education, even in the presence of fault management systems. Thus, all the aforementioned techniques are taken into consideration, and the drawbacks are addressed by formulating a system model in Sect. 2.
Research gap and motivation
Several studies have explored ML based frameworks to enhance e-learning experiences. However, most existing models lack real-time adaptability, leading to suboptimal classification of learners and inefficient resource allocation. Additionally, video-based hybrid learning requires structured control mechanisms to minimize communication delays and packet loss, yet current solutions do not adequately address these issues.
To bridge this gap, a Personalized Learning Approach (PLA) is proposed, integrating ML techniques with a structured master-slave controller system. This approach enhances learning engagement by categorizing students based on real-time data analysis and optimizing content delivery based on observed learning rates. The core contribution of this study is the development of a PLA framework that:
-
Automatically categorizes students into different learning groups based on cognitive and behavioural data.
-
Implements a master-slave controller mechanism to enhance communication efficiency and minimize packet loss.
-
Optimizes learning throughput by dynamically adjusting video-based instructional content according to student performance metrics.
To validate the effectiveness of the proposed approach, at initial state literature review is described before detailing the proposed methodology.
Proposed methodology
To address the limitations of existing hybrid learning models15, a PLA that integrates ML techniques with real-time monitoring and adaptive control mechanisms is designed where the functionalities such as categorization of learners dynamically based on cognitive and behavioral data, Optimization of hybrid learning interactions using a structured master-slave controller framework and enhancement of communication efficiency by minimizing packet loss, delay, and throughput fluctuations are performed. Additionally, to analyse the behaviour of students and to differentiate between them before and after the COVID situation, it is essential to implement an automated working model. Therefore, the proposed methodology focuses on implementing a framework using a Personalised Learning Approach (PLA) that identifies and categorises different students into various stage groups. For categorising the learners, the dataset is collected and integrated into the PLA for monitoring necessary parametric values. Moreover, no existing approaches have implemented two different controllers for securing the data, whereas the proposed method has introduced master and slave controllers for accurate sharing of data with other learners. Table 1 provides the comparison of key parameters between existing and proposed approach.
Objectives
The proposed work on teaching learning process focuses on multiple objective case studies that are listed as follows,
-
To incorporate a functionality model that automatically categorizes different characteristics of learners.
-
To implement a controlled operation using master and slave controllers using a set of communication interval periods.
-
To minimize the loss of packets and delay of representations during teaching learning process with high percentage of accomplished throughput.
All the objectives involve a set of parametric values such as to be monitored with video class set of representations.
Teaching learning: a system model of conception
In the past two years the effect of Corona Virus (COVID) has affected many people and as a cause of it education that is delivered to all students has been converted to online mode. However due to this many academicians have shifted their ideas and notations towards online developmental mode but the process of conception does not provide any effectiveness over study period.
Perception mechanism
The proposed system model combines two different contrivances such as cognitive and ML which is determined as perception mechanism that is mathematically formulated using Eq. (1).
Preliminary 1
Let us consider the rate of different learners in the order of various sense explorations as \(\:{\mathfrak{s}}_{1}+.+{\mathfrak{s}}_{i}\) where each cognitive actions will be recorded in accordance with same reactions. Hence in case of different actions it is necessary to explore the perceptions that must follow the condition as indicated in Eq. (2).
Lemma 1
For proving the possibility of relational conditions during the observation process the step process for each study periods are considered as \(\:{\mathfrak{l}}_{1}+.+{\mathfrak{l}}_{i}\). Therefore for each step it is necessary to provided high step of response by mapping the perception from each student by following equality principle as indicated in Eq. (3).
Aggregate knowledge
Equation (1) can be applied to all complex situations that involves differential mode where the information is observed with high focus of responsiveness. Thus aggregate knowledge terms can be framed using Eq. (4) as follows,
Preliminary 2
The variations in terms of knowledge must be observed by each academician in such a way the low knowledge is represented in significant way as \(\:{\mathfrak{V}}_{1}+.+{\mathfrak{V}}_{i}\). In this type of knowledge representations the response periods are observed where the understanding ability must be fulfilled by the following condition.
Lemma 2
In case of knowledge based conditions the functionality principle can be considered thus at each case it can be applied to individual students. Therefore for each changes in low knowledge it is the responsibility of academicians to check over the probabilities to higher levels as indicated in Eq. (6).
Equations (1) and (4) serve as the mathematical foundation that ensures the model’s adaptability and efficiency in real-world teaching applications. Equation (1) formulates the classification and adaptability of learners, ensuring that the system recognizes variations in learning behaviours where all key learning parameters are integrated thus dynamically adjusting the model response to individual learning paces. Additionally it enables real-time assessment of student engagement, providing a solid framework for intelligent adaptation in hybrid learning environments. Similarly Eq. (4) captures the essence of knowledge accumulation and progression, ensuring that learning materials are structured effectively over time. Also it defines how prior learning influences future knowledge acquisition, optimizing the transition between different difficulty levels in teaching. Therefore by utilizing mathematical aggregation models, the system ensures that students can seamlessly build upon existing concepts, fostering a deeper understanding.
Perception allocation
Equation (4) is applied in the case where the understanding ability is reduced for learners. Thus a limitation must be applied to transfer the perception to infinite cases which can be defined using Eq. (7) as follows,
Equation (7) is defined as maximum varying capacity of number of learners that are present in a particular section.
Distinctive intelligence
However even if number of learners are increased then the cognitive system can able to handle as it is expanded with unbounded expressions. In case if distinctive intelligence is measured then Eq. (8) will be implemented.
Preliminary 3
Let us consider various segments of representation units as \(\:{\mathfrak{g}}_{1}+.+{\mathfrak{g}}_{i}\) where the bouding units are changed in according to distinct orders \(\:{\mathfrak{i}}_{1}+.+{\mathfrak{i}}_{i}\). Hence for each bouding units the possibility of managing at each phase changes and it is observed with behavior of students by following the condition in Eq. (9).
Lemma 3
For proving the above mentioned changes the principle of segmentations are applied to each cognitive functions \(\:{\mathcal{C}}_{1}+.+{\mathcal{C}}_{i}\) thus the values nearly appraoches to different segements. Hence in this case the inbound expressions must be followed without allowing maximum changes as indicated in Eq. (10).
Learner inquisitiveness
With the introduction to bias terms inquisitiveness of all learners can be observed using Eq. (11) as follows,
Preliminary 4
The true learning rate of each users are considered from the available cognitive actions where in case of changing time periods it is necessary to add additional weighting units which can be considered as \(\:{AW}_{1}+.+{AW}_{i}\). As the weights are addded at each incorrect output states the following condition must be incorporated.
Lemma 4
The joint probability theorem that are used for adding weighting factors in separate orders can be considered for proving individual case factors in accordance with cognitive actions. Hence for appropriate determinations it is necessary to change each input pattern by following the criteria in Eq. (13).
Data cluster
All the observed data can be processed using cluster based technique for dividing two distinct data that are defined for slow and fast learner. This clustering data can be represented using Eq. (14) as follows,
Error rates
Equation (15) can be varied with two or three dimensional factors to avoid constant value desecrations therefore error of monitoring in teaching learning process will be reduced. Thus the minimization of error can be represented using Eq. (15) as follows,
All the three minimization objectives are integrated with ML algorithm as for testing process both supervised and unsupervised learning techniques have to be incorporated. This incorporation is described in Sect. 3.
Optimization of teaching learning process
Since ML provides great advantages such as time saving, manual customization, advances in analytical skills, understanding student perception and applicability for wide audience set with low data transfer approach it is chosen in teaching learning procedures25,26. This type of benefits will lead to a PLA thus makes the student to be more interactive with governesses where intent prediction can be made with distinct behavioral input patterns.
Configuration function
A separate path is selected for every individuals based on their configuration and exertion levels with high degree of relationship. Thus the configuration fitness function can be mathematically defined using Eq. (16) as follows,
Equation (16) is implemented using a comparative matrix of size 256\(\:\times\:\)256 because high recombination rate of data is possible with double match rounding periods.
Loss inhibition
To prevent loss in recombination rate a similarity measure is performed as data is divided in to clusters. Moreover in this stage two different data such as sensor and noise is combined with each other. Therefore minimization of loss can be framed as follows,
Dynamic speed
In Eq. (17) the presence of similarity index can be found by using binary variables 0,1 with conditions followed by weight factors. Even there is a high possibility that similarity index will be present due to varying speed dynamics therefore the teaching and learning speed index can be defined using Eq. (18) as follows,

Personalized learning.

Block representations of personalized learning approach.

Personalized learning algorithm for teaching learning process.
Information gain
Equation (18) is applied to control the entire system with intermediate speed as sufficient time must be provided for observation. In addition this time is given for improving the information gain using negative probability values which are stated in Eq. (19).
Quality indications
In the above mentioned Equation the reference gain will be associated with expected values and it will be compared. If the values are not changed then it is indicated as maximized gain where a quality descriptive process can be achieved. To achieve more quality in teaching learning process the flair depiction must be observed in correlation form which is represented in Eq. (20).
The step-by-step algorithmic determinations are provided and the block representations with flow chart for learning process are represented in Figs. 2 and 3. By integrating the system model objectives with ML consequences and benefits can be deliberated by designing a simulation setup using MATLAB which is discussed in the subsequent sections. Also the list of variables with relevant significance is provided in Table 2.
Student classification
As more number of data sets needs to be processed in machine learning model it is necessary to divide the learners based on various categories. Therefore in each category the learners will be separated based on distinct labels where control strategy can be improved as indicated in Eq. (21).
Equation (21) represents that the classification probability of each user will be much higher hence providing exact realizations in this case. Further instead of using all futuristic set the personalized learning approach can be used to reduced high dimensional cases without any loss of information.
Feature extraction
Since dimensionality is reduced to retain various information by learners it is necessary to represent extracted features by using individual projection sets. Hence a covariance representation is used in this case to extract the information without any complexity patterns thus making the learners to remain at adaptable state as indicated in Eq. (22).
In case of unidentifiable states individual bias representations can be added hence the probability of each learners remains within the threshold value of 1. Hence Eq. (22) is used to extract information only with respect to identifiable user state where complete unidentified states are removed from the learning systems.
Outcome exploration
This section analyses the controlling assessment case, using a training data set obtained directly from connoisseurs17. To evaluate the data set, a slave controller is utilised, employing a hierarchical framework with real-time simulations. Initially, the outcomes are predicted, and after several iterations, the value points are accurate and validated. For clearer observation points, learners are divided into four categories: category 1 has 52.5% of students registered, while category 2 has 61.2% registered. However, in categories 3 and 4, only a few learners have registered due to the high intervals and the absence of integrated audio systems. In the first two categories, frames are scheduled at equal intervals, and video processing systems are connected to both the slave and master controlling units. Further scenarios are conducted to demonstrate the efficiency of the proposed method in both classifications, and the importance of the considered scenarios is outlined in Table 3, along with the relevant simulation parameters in Table 4.
Scenario 1: Controlled communication intervals.
Scenario 2: Percentage of throughput in category 2.
Scenario 3: Percentage of delay in category 1 and 2.
Scenario 4: Loss of packets in category 1 and 2.
Scenario 5: Cost of master and slave controllers.
The real time data set that includes learning capabilities of various users are incorporated in the proposed method with a scaling factor of 1700 to 5000 learners. Further the sources are collected from video-based learning platforms therefore the activities such as student interactions, response times, and activity levels are tracked. Hence the characteristic representation includes sensor-based motion data (accelerometer readings), network traffic logs, video class duration, and throughput metrics. Therefore data is preprocessed to eliminate noise, normalize engagement scores, and categorize learners into four clusters such as highly active learners, moderately active learners, passive learners and inactive learners.
Discussions
To evaluate the effectiveness of the PLA, a series of simulations were conducted using MATLAB. The primary objectives of the experiment are as follows.
-
1.
Assess the accuracy of learner categorization using ML clustering techniques.
-
2.
Measure system performance metrics such as throughput, delay, and packet loss in a hybrid learning environment.
-
3.
Evaluate the effectiveness of the master-slave controller in optimizing video class scheduling.
-
4.
Compare PLA with existing hybrid learning models to demonstrate performance improvements.
The key performance improvements that are achieved in above mentioned scenarios are observed under various performance metrics and it illustrated in Table 5.
The various measurements under performance metrics simulates a video-based hybrid learning environment using MATLAB-based simulations this modeling real-time student interactions and network conditions. In the proposed method the PLA system is deployed with three key components and the functionality of components are listed in Table 6.
For the first four scenarios the simulation is processed using set of scheduled rules thus quality of scheduled periods are examined in the presence of high number of learners. After checking the maximum allocation all the non-linear approximations which are shown in the system model are integrated in simulation segment using MATLAB.
Scenario 1
In this scenario, the behaviour of users under controlled communication is established as a greater number of learners not adhering to the PLA guidelines. If users do not follow certain protocols, immediate control actions will be implemented, and a request will be made to modify their characteristic features. At the initial stage, users will be categorised from high priority to low priority based on their learning interests, with a separation point of 0.99 selected as the maximum tolerance limit. As the device is installed in the contraptions, it is essential to maintain correct limitations; otherwise, the entire process will result in failure. Even though the device is constructed with an adjustment failure rate, much care is taken in ensuring safety, thus introducing two controllers at intersection points. The simulated results are illustrated in Fig. 4 under mixed traffic conditions.
From Fig. 4, it can be observed that the total number of video classes varies from 10 to 50, and for each class, the control points are normalised. As previously mentioned, in the proposed method, a scheduler will remain ON until all video units are in capture mode. A variation period with the dataset is utilised, employing qualified educators in the design rule. The normalisation factor must be increased if the number of video classes expands, as small inaccuracies will be detected and corrected in the next stage. If the normalisation factor exceeds 1, a good control is established between interval periods; however, should it fall below 1, control cannot be maintained, adversely affecting the rate of learning. For example, the number of video classes over a seven-day period ranges from 10 to 50, with the normalisation factor measured for each created video class. In the proposed method, at the initial stage, the normalised video factor for the categorisation process surpasses 1, whereas the existing method7 fails to normalise the learning video to an appropriate factor. This issue persists in other cases as well; only after surpassing 40 classes does the existing model normalise in a suitable manner, thereby providing an exact normalisation factor of 1. Furthermore, in the final stage of the model, the normalised factor reaches 1.9, which is indicated as a constant value with good categorisation of learners.

Controlled communication with normalization factor.
Scenario 2
As a larger number of users is present in category 2, a higher number of video classes is needed in this case. If the number of users falls below 50%, then the intervals for video classes can be easily controlled by primary and secondary controllers. However, due to the overpopulation of users, it is necessary to analyse throughput with a constant factor. Therefore, by increasing the number of video classes, this constant factor is maintained at 1% for the number of users in category 2. Nevertheless, this constant factor cannot be altered, as it is directly linked with the number of users; thus, a separate group will be created, and users will be automatically connected to their respective data sets. This provides significant advantages to all learners, as PLA allows users to choose their content based on its identifiable importance. As a result of this scenario, throughput will be enhanced along with learning concentration, and the simulated results are plotted in Fig. 5.
From Fig. 5, it can be observed that the number of video classes varies from 10 to 400, with constant factors set at 0.1, 1, 2, 3, and 4. To calculate the throughput value, the constant factor will be multiplied by the previously determined state where control intervals are established. Therefore, the throughput of the proposed method is significantly higher than that of the existing method7 due to the absence of PLA procedures. This is clearly evident when the number of video classes is increased to 400, resulting in a throughput of 89,000 units, whereas for the existing method, it remains at 84,000 units. As the throughput rate of PLA exceeds 3%, it is recommended to increase the number of video classes for enhanced observation states.

Throughput with constant rate.
Scenario 3
This scenario examines PLA schedulers during delay periods, as some of the learning devices will be inactive for a time. In PLA, if learners are not present in any category, operation in an inactive state is permitted. However, if learners are present, zero state activity is not allowed. Furthermore, if a zero activity rate is present, throughput will be affected. To maintain zero delay in the process, a high-percentile delay analysis has been conducted. Delays can also occur due to the slow movement characteristics of users in both defined categories, which are not factored into the projected model, as learners are selected from a pre-defined data set. It is also noted that in categories 3 and 4, no learners exhibit slow movement characteristics, and thus these categories are neglected. Moreover, due to the unpredictable nature of wireless networks, zero delay is observed at the initial stage; however, once the wireless characteristics are recognised, the delay period is measured. If the measurements do not meet the enhanced characteristics, PLA category users will be shifted at a rate below 50%. The simulation results in Fig. 6 are plotted for both categories 1 and 2 users.

Period of delay.
From Fig. 6, it can be seen that for the first three classes, users in category 1 are selected, whereas for the next two classes, both category 1 and 2 users are preferred. For all five classes, there is an insignificant delay period, which is negligible. In contrast, the existing model provides a moderate delay rate that varies with time periods, and this delay is not present during negligible periods. It can be observed that when the number of users moves into the second category stage, the delay in wireless modes is significantly higher, as noted in7, measuring 0.32 s. In the same category, the PLA provides a much lower delay of 0.08 s. This demonstrates that as the number of video classes increases, it becomes possible to further reduce the delay period, with the PLA achieving zero delay at the end periods.
Scenario 4
In this scenario, the number of lost packets due to delays is continuously monitored, serving as a substitute for detecting voice loss. The proposed work employing PLA is structured so that only organised movement signals are permitted within the primary network (i.e. in category 1). In contrast, for category 2, non-movement signals are associated with a higher number of users, resulting in increased noise within the system. To align the equivalent loss rate with the packets present in the process, a scheduled timeframe is established where if any packet is lost, the preceding packet will be considered immediately. This management capability significantly prioritises weighted agents by preventing pseudo voice signals in the transmission process. Besides standard packet loss, the PLA also identifies burst packets that exhibit a similar voice mixing ratio. The predefined process clearly states that burst packets in the learning model will lead to significant interruptions and must be eliminated at early stages.
Figure 7 illustrates the loss rate of both standard and burst packets, categorised by video classes ranging from 10 to 50. For this video class, both categories 1 and 2 are characterised by a percentage exceeding 51%, with the packet loss rate for these categories observed to be below 0.09 when using PLA, whereas the existing method records a rate above 0.09, thereby reducing packet similarity with established formulations. Furthermore, the factors contributing to packet loss rate impact device quality, consequently diminishing lifespan and necessitating resending of lost packets. Additionally, it has been noted that the number of retransmitted learning and characteristic packets remains significantly lower within a defined percentage limit.

Number of packets lost.
Scenario 5
Since two different controllers are involved in the cost of installation, it is calculated and simulated in this scenario. Generally, there are two different approaches for installing the PLA in academic organisations: using a third party with pre-defined requirements, or making direct representations with programming code. The proposed method is based on direct representations, as third party requirements significantly increase the installation cost. Therefore, to avoid high costs, the PLA is installed using an uninterrupted power source, where an annual reduction of approximately 6000 dollars can be realised.
Figure 8 portrays the cost factor, presenting a cost analysis with respect to the number of unit installations, as some locations are left unoccupied. Consequently, cost analysis for empty spaces is not included, and the number of controllers is maintained at two in all cases. From the observed results, it is evident that due to the inclusion of empty space, the costs of existing units22 increase to 72,000 pounds, whereas for the projected method using PLA, it decreases to 67,000 dollars even with a high number of unit installations. This scenario demonstrates that PLA can be installed in the teaching and learning process, thus providing effective outcomes at a lower cost.

Cost of installation of master and slave units.
Overall comparative analysis of scenarios
The proposed personalized learning approach framework demonstrates significant improvements in student learning behaviour analysis and video transmission optimization compared to existing methods. The experimental results from four scenarios validate the effectiveness of personalized learning approach in multiple aspects as personalized learning approach effectively categorizes learners based on engagement levels and dynamically adjusts learning content delivery. Unlike traditional methods, personalized learning approach maintains a stable normalization factor for personalized content adaptation, ensuring better student retention. Hence with intelligent user grouping, personalized learning approach improves learning throughput by 3%, ensuring a more efficient content distribution for large student populations.
In addition, the video buffering delay is reduced as personalized learning approach minimizes content delivery delays from 0.32s22 to 0.08s (Proposed), ensuring seamless learning experiences. Subsequently lower packet loss rate is observed with personalized learning approach as packet loss is reduced below 0.09, compared to higher loss in traditional methods, improving video and voice quality. As a personalized learning approach reduces implementation costs therefore making it a scalable and economical solution for digital education.
Performance metrics
In this section, the performance metric is evaluated for the teaching and learning process after incorporating the learning rate with separate factorial considerations. In the proposed method, the performance metric is utilised to observe both master and slave configurations, as both act as controlling units in the entire process. Furthermore, both categories of studies are evaluated simultaneously over the same time period by using the following studies.
Case study 1: Robustness characteristics.
Case study 2: Convergence characteristics.
Case study 1: robustness characteristics
The robustness characteristics are observed to provide certain limitations regarding significant changes in the personalised learning process. Whenever changes occur, each individual can adapt to separate characteristic features, allowing for improvements at each stage. Moreover, to ensure safe operation in the teaching-learning process, it is necessary to conduct robustness measurements, where high-potential issues can be addressed in a timely manner. Thus, individual problems can be resolved if the system is highly robust to changing conditions, thereby avoiding prerequisite procedures in the data transmission process. Even unexpected situations in the measurement process can be effectively managed with robustness measurements to enhance confidence measures, which further improve the learning capabilities of students.
Figure 9 illustrates the comparative characteristics of robustness for the existing and proposed approaches. From Fig. 9, it is clear that robustness is reduced for the proposed approach compared to the existing method22. The primary reason for the reduction in robustness is that information gain has improved due to the preference for personalised learning techniques in the proposed method over the existing model. To verify the outcome of robustness characteristics, a total number of iterations considered are 10, 20, 30, 40, 50, 60, 70, 80, 90, and 100. For each iteration period, robustness is observed to be dynamic, with constant representations achieved in the early iterations of the proposed method compared to the existing approach. Consequently, the variation in robustness is limited to 5% and 17% in the proposed and existing methods respectively, effectively reducing losses in the proposed approach.

Robustness characteristics for changing iteration periods.
Case study 2: convergence characteristics
To achieve better and more effective solutions, convergence characteristics are evaluated; therefore, for all changing environments, adaptations can be made as necessary. Since different techniques are combined in a single device for the evaluation process, it is essential to observe convergence that is subject to less variable measurements. Moreover, for each student, individual knowledge representations can be improved if convergence is achieved in earlier cases, thus minimising the probability of change with respect to character. Additionally, characteristic changes and all distribution patterns are minimised, ensuring sustainability in the teaching and learning process without including any arbitrary separation of patterns. Conversely, inward movements in teaching and learning are assured if convergence is achieved during early periods, thus enabling transformations at the appropriate times.
Figure 10 compares the robustness of the existing and proposed approaches using only the best epoch periods. From Fig. 10, it is evident that the convergence rate of the personalised learning approach is higher compared to the existing method22. The main reason for the improvement in the convergence rate is that the personalised learning approach can adapt to certain changes, allowing common goal patterns to be achieved at earlier stages. To verify the outcome of the convergence characteristics, the best epoch is chosen in steps of 20, 40, 60, 80, and 100, where individual adaptation characteristics are assessed for each student during the observation periods. Consequently, the convergence in the proposed method is reached at early iterations, observed to be 1.4 and 1.1, after which constant rates are maintained. In contrast, the existing method achieves convergence rates of 0.9, 0.7, 0.5, and 0.3, indicating a lower rate without any constancy representations.

Comparison of convergence with best epoch periods.
The scalability and adaptability of PLA in large-scale online education scenarios can be effectively addressed by referencing both robustness and convergence characteristics. These properties ensure that the method can dynamically adjust to complex and changing environments at the same time maintaining stability and effectiveness. The robustness analysis demonstrates that personalized learning approach exhibits slightly reduced robustness to 5% compared to traditional models that provides 17% thus improved information gain which is considered as a key factor in personalized learning is achieved. Since robustness remains dynamic yet stable across 100 iterations, the system can adapt efficiently to increasing student numbers and fluctuating learning conditions. Also robustness ensures that even in unexpected scenarios such as network instability, content variability, or diverse student learning behaviours personalized learning approach maintains functional integrity, allowing it to scale without the need for frequent manual interventions. Conversely the higher convergence rate of personalized learning approach that leads to 0.9 s confirms that the system quickly adapts to new learning conditions, reducing delays in knowledge acquisition. Due to early-stage convergence the probability of drastic changes are minimized in student learning pathways, making it more resilient in large-scale deployments. Moreover the ability to achieve convergence faster and maintain it at a stable rate suggests that personalized learning approach can function effectively in real-time learning environments without excessive computational costs. As a result the combined robustness and convergence properties indicate that PLA can handle large-scale online learning platforms while ensuring personalized learning remains effective. Therefore the observed stability across iterations confirms that even with a high number of learners and varying teaching conditions, PLA remains sustainable and the proposed system adapts dynamically without requiring manual recalibration where it can be implemented in diverse hybrid teaching models without major modifications.
Conclusions
This paper provides a viable solution for enhancing the teaching-learning process in future generation systems. A particular impact is assessed with resource allocation systems where PLA is integrated into the decision-making approach. The failure rate of conventional methods is significantly higher due to poor handling mechanisms for video classes, as no precise optimisation algorithm is incorporated. Additionally, the audio system mechanism cannot adequately trace the varying quality of students, as wireless networks exhibit slow-defined characteristics. Furthermore, a scheduling scheme is introduced with user prioritisation sequences, and a visual representation of learners is implemented, thus avoiding conflicts between two individuals. To prevent confusion in the implementation systems, learner characteristics are divided into two categories, where users in category 2 will experience high occupancy. Given the necessity to develop and share knowledge, a distinct set of transmitters must be designed for separate learning institutions, resulting in high installation costs. However, the proposed method using PLA introduces two controllers that enable users to maintain an informative relationship with each other, thereby reducing implementation costs. By dynamically categorizing learners based on cognitive and behavioural data, PLA enhances engagement and learning effectiveness. The system’s adaptive scheduling mechanism ensures seamless video-based learning sessions, overcoming key challenges faced by conventional hybrid learning models. The findings indicates that PLA is a highly efficient and scalable solution for future hybrid education systems, providing improved personalization, real-time adaptability, and cost-effective deployment.
Future work
The work implemented on the teaching and learning process can be prolonged to enable learners to make their own decisions according to the different observed categories. Additionally, adaptive learning will be enhanced through automated design of a set of courses based on uniqueness characteristics.
Data availability
The data that support the findings of this study are available from the author Hariprasath Manoharan, upon reasonable request.
References
Comşa, I. S. et al. A machine learning resource allocation solution to improve video quality in remote education. IEEE Trans. Broadcast. 67, 664–684. https://doi.org/10.1109/TBC.2021.3068872 (2021).
Wang, L. & Yoon, K. J. Knowledge distillation and student-teacher learning for visual intelligence: a review and new outlooks. IEEE Trans. Pattern Anal. Mach. Intell. 14 https://doi.org/10.1109/TPAMI.2021.3055564 (2021).
Aslam, S. M., Jilani, A. K., Sultana, J. & Almutairi, L. Feature evaluation of emerging e-learning systems using machine learning: an extensive survey. IEEE Access. 9, 69573–69587. https://doi.org/10.1109/ACCESS.2021.3077663 (2021).
Webb, M. E. et al. Machine learning for human learners: opportunities, issues, tensions and threats. Educ. Technol. Res. Dev. 69, 2109–2130. https://doi.org/10.1007/s11423-020-09858-2 (2021).
Popenici, S. A. D. & Kerr, S. Exploring the impact of artificial intelligence on teaching and learning in higher education. Res. Pract. Technol. Enhanc Learn. 12 https://doi.org/10.1186/s41039-017-0062-8 (2017).
Fadul, J. A. Mathematical formulations of learning: based on ten learning principles. Int. J. Learn. Annu. Rev. 13, 139–152. https://doi.org/10.18848/1447-9494/cgp/v13i06/44910 (2006).
Liang, J. & Nie, Y. Abstract. https://doi.org/10.2174/1874061802006010 (2020).
Hussain, M., Zhu, W., Zhang, W. & Abidi, S. M. R. Student engagement predictions in an e-learning system and their impact on student course assessment scores. Comput. Intell. Neurosci. 2018 https://doi.org/10.1155/2018/6347186 (2018).
Morilla, R. C. et al. Application of machine learning algorithms in predicting the performance of students in mathematics in the modern world. Taran-Awan J. Educ. Res. Technol. Manag. 1, 49–57 (2020).
Jha, S. et al. A post-covid machine learning approach in teaching and learning methodology to alleviate drawbacks of the e-whiteboards. J. Appl. Sci. Eng. 25, 285–294. https://doi.org/10.6180/jase.202204_25(2).0014 (2022).
Zhai, X. et al. A review of artificial intelligence (AI) in education from 2010 to 2020. Complexity 2021 https://doi.org/10.1155/2021/8812542 (2021).
Halde, R. R. Application of machine learning algorithms for betterment in education system. Int. Conf. Autom. Control Dyn. Optim. Tech. 2016 https://doi.org/10.1109/ICACDOT.2016.7877759 (2017).
Balaji, S., Gopannagari, M., Sharma, S. & Rajgopal, P. Developing a machine learning algorithm to assess attention levels in ADHD students in a virtual learning setting using audio and video processing. Int. J. Recent. Technol. Eng. 10, 285–295. https://doi.org/10.35940/ijrte.a5965.0510121 (2021).
Chung, C. K. & Kato, Y. Zero-field vortex-induced hall effect and Polar Kerr effect in chiral p-wave superconductors near Kosterlitz-Thouless transition. J. Low Temp. Phys. 175, 359–364. https://doi.org/10.1007/s10909-013-0906-6 (2014).
Chen, X., Xie, H., Zou, D. & Hwang, G. J. Application and theory gaps during the rise of artificial intelligence in education. Comput. Educ. Artif. Intell. 1, 100002. https://doi.org/10.1016/j.caeai.2020.100002 (2020).
Hwang, G. J., Sung, H. Y., Chang, S. C. & Huang, X. C. A fuzzy expert system-based adaptive learning approach to improving students’ learning performances by considering affective and cognitive factors. Comput. Educ. Artif. Intell. 1, 100003. https://doi.org/10.1016/j.caeai.2020.100003 (2020).
Wang, R. & Shi, Z. Personalized online education learning strategies based on transfer learning emotion classification model. Secur. Commun. Netw. 2021 https://doi.org/10.1155/2021/5441631 (2021).
Aberbach, H. et al. A personalized learning approach based on learning speed. J. Comput. Sci. 17, 242–250. https://doi.org/10.3844/JCSSP.2021.242.250 (2021).
Aluvalu, R. K., Kulkarni, V. & Asif, M. Handling classrooms with students having heterogeneous learning abilities. J. Eng. Educ. Transform. 31, 36–41 (2017). http://www.journaleet.org/index.php/jeet/article/view/119557/82219
Aluvalu, R. University Bridge program: innovation at the grass roots of learning in higher education. J. Eng. Educ. Transform. 0, 0–5. https://doi.org/10.16920/jeet/2016/v0i0/85595 (2016).
Zhang, J. et al. Process monitoring for tower pumping units under variable operational conditions: from an integrated multitasking perspective. Control Eng. Pract. 156, 106229. https://doi.org/10.1016/j.conengprac.2024.106229 (2025).
Zhang, J. et al. A variational local weighted deep sub-domain adaptation network for remaining useful life prediction facing cross-domain condition. Reliab. Eng. Syst. Saf. 231, 108986. https://doi.org/10.1016/j.ress.2022.108986 (2023).
Fabian, K., Smith, S. & Taylor-Smith, E. Being in two places at the same time: a future for hybrid learning based on student preferences. TechTrends 68, 693–704. https://doi.org/10.1007/s11528-024-00974-x (2024).
Gudoniene, D. et al. Hybrid teaching and learning in higher education: A systematic literature review. Sustainability 17 (2), 756. https://doi.org/10.3390/su17020756 (2025).
Aluvalu, R. & Uma Maheswari, V. Pedagogies for blended TLP. J. Eng. Educ. Transform. 35, 93–96. https://doi.org/10.16920/jeet/2021/v35i0/167027 (2021).
Kandakatla, R. et al. Role of Indian higher education institutions towards Aatmanirbhar India: government policies and initiatives to promote entrepreneurship and innovation. 2021 world eng. Educ. Forum/Global eng. Deans Counc. WEEF/GEDC 2021, 8–14. https://doi.org/10.1109/WEEF/GEDC53299.2021.9657261 (2021).
Author information
Authors and Affiliations
Contributions
Data curation: Adil O. Khadidos and Alaa O. Khadidos; Writing original draft: Shitharth Selvarajan and Hariprasath Manoharan; Supervision: Adil O. Khadidos; Alaa O. Khadidos; Project administration: Adil O. Khadidos; Alaa O. Khadidos; Conceptualization: Shitharth Selvarajan and Hariprasath Manoharan; Methodology: Shitharth Selvarajan and Hariprasath Manoharan; Verification: Mohammad Alanazi and Fuhid Alanazi Validation: Mohammad Alanazi and Fuhid Alanazi; Visualization: Mohammad Alanazi and Fuhid Alanazi; Resources: Shitharth Selvarajan and Hariprasath Manoharan; Overall Review & Editing: Mohammad Alanazi and Fuhid AlanaziAll authors reviewed the final manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Khadidos, A.O., Manoharan, H., Khadidos, A.O. et al. Personalized learning in hybrid education. Sci Rep 15, 18176 (2025). https://doi.org/10.1038/s41598-025-03361-5
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-03361-5
