
Abstract
Quantum computing leverages unitary matrices to perform reversible computations while preserving probability norms. However, many real-world applications involve non-unitary sparse matrices, posing a challenge for quantum implementation. This paper introduces a novel method for transforming a class of non-unitary sparse binary matrices into higher-dimensional permutation matrices, ensuring unitarity. Our approach is efficient in both space and time, ensuring practical applicability to large-scale problems. We demonstrate the utility of this transformation in constructing quantum gates and apply the method to model quantum finite state machines (QFSMs) derived from classical deterministic finite automata (DFAs). This work offers a practical pathway for integrating non-unitary transformations into quantum systems, with implications for the many applications that are based on sparse, non-unitary matrices. The significance of this work for automata theory and quantum computation is outlined.
Similar content being viewed by others

Introduction
Quantum computing has the potential to revolutionize a wide range of scientific fields, including cryptography, drug discovery, climate modeling, finance, and artificial intelligence. Unlike classical computing, which relies on binary bits, quantum computing uses qubits, which can exist in superposition, allowing them to represent multiple states simultaneously. This unique property enables quantum computers to perform complex computations at exceptional speeds compared to classical computers.
Unitary matrices are crucial in quantum computing, where quantum gates are represented as unitary operators acting on qubits. Unitary matrices preserve two key properties of quantum systems: reversibility and probability conservation. In quantum mechanics, the evolution of a system must be reversible to ensure that no information is lost over time1. Additionally, the sum of probabilities for all possible states of a quantum system must always equal 1(the norm of any quantum state is 1). These properties are embedded in unitary matrices, whose structure ensures that quantum gates can be inverted, and that the quantum state’s total probability remains unchanged throughout the computation process. This preservation is achieved by unitary transformations as unitary matrices preserve the norm of vectors representing quantum states.
The motivation for this work can be found in non-Hermitian quantum Physics which is rooted in the observation that Hermiticity is a sufficient (not necessary) condition for real eigenvalues. Recently, there have been many research papers published on this topic highlighting theory and applications. The works presented in2,3 are based on the parity-time-symmetric (PT-symmetric) Hamiltonian theory. PT-symmetric Hamiltonians do not guarantee the evolution operator is unitary. References4,5,6 are based on open system formalism. In this case, a closed quantum system interacts with the environment. The significance of non-Hermitian or open system time evolution is that it can be non-unitary. Hence from the perspective of quantum computation, representation of non-unitary matrices as quantum circuits is necessary.
The duality computer, introduced in7, is a theoretical model that extends the conventional quantum computer by allowing wave functions to coherently split and recombine along multiple paths. In this framework, a multi-dubit (duality bit) system propagates along two spatially identical paths. When these sub-waves recombine at the Quantum Wave Combiner (QWC), they interfere constructively because their spatial modes remain in phase. If only a single path is used, the duality computer effectively reduces to a standard quantum computer. This architectural extension provides additional flexibility in manipulating quantum information and lays the foundation for new algorithmic strategies.
An algorithm named LCU (linear combination of unitaries) algorithm is developed based on a duality computer to synthesize a quantum circuit. The LCU algorithm expresses a non-unitary matrix A as the linear combination of unitary matrices. The resulting circuit is equivalent to embedding the matrix A as the principal block of a higher dimensional unitary matrix U = \(\left(\begin{array}{cc}A& B\\ C& D\end{array}\right)\). Zheng8 applies the LCU algorithm to simulate a single qubit non-unitary operator. A quantum circuit with two qubits is demonstrated using the LCU algorithm where the \(2\times 2\) non-unitary matrix is decomposed as a linear combination of Pauli matrices. All these works suggest that non-unitary operations and embedding them into quantum circuits are necessary to synthesize quantum systems. In our work, the non-unitary matrix A is assumed to be sparse and binary.
Despite these advances, many practical systems such as those arising from Partial Differential Equations (PDEs) involve non-unitary boundary conditions due to errors, noise, or model approximations9,10. PDEs are foundational in modeling real-world phenomena, and quantum computing offers the potential to reduce the cost of solving them. However, to leverage quantum algorithms for such applications, efficient conversion of non-unitary matrices into unitary forms is essential.
Our proposed approach provides a structurally simple and resource-efficient alternative for a special class of non-unitary matrices. Specifically, we address non unitary sparse binary matrices with norms greater than one and show how they can be embedded into higher-dimensional permutation matrices, which are naturally unitary.
-
1.
Our main contribution in this paper is the introduction of a novel method for converting non-unitary sparse binary matrices with a norm greater than one into higher-dimensional unitary matrices. Specifically, we focus on transforming \(n\times n\) square matrices that have atmost n nonzero entries, with each row containing no more than one nonzero element, into higher-dimensional permutation matrices. To the best of our knowledge, no prior work addresses this specific class of transformations.
-
2.
An important advantage of our method is that the resulting permutation matrices are not only unitary but also allow for efficient quantum gate construction. Each permutation can be decomposed into a sequence of transpositions, which can be implemented as a series of SWAP or CNOT operations acting on binary encodings of the indices. This facilitates direct synthesis of permutation-based unitaries into hardware-efficient quantum circuits.
-
3.
As an application, we demonstrate the implementation of a Quantum Finite State Machine (QFSM) where the initial transformation matrix is non-unitary. Our results provide an effective solution to this challenge, ensuring the preservation of unitary properties essential for quantum computations.
Related works
Our work aims to construct permutation matrices from a certain class of non-unitary matrices. With that focus, we review related work. In11 Robert M. Gingrich and Colin P. Williams, addressed the problem of computing non-unitary operators probabilistically and presented a method to convert a non-unitary matrix to a unitary matrix. They construct the quantum circuit for the operation \(\rho { } \to { }\frac{{M\rho M^{\dag } }}{{tr\left( {M\rho M^{\dag } } \right)}}\) where M is non-unitary and \(\rho\) a density matrix and \(\dag\) is the complex conjugate transpose. The method presented first converts the non-unitary matrix M into a high dimensional unitary matrix by padding zeros. The unitary matrix U is obtained by the transformation \(U = { }e^{{i\varepsilon \left[ {\begin{array}{*{20}c} 0 & { - iN} \\ {iN^{\dag } } & 0 \\ \end{array} } \right]}}\). The computation introduces an ancilla qubit and approximates the computation as \(\rho^{\prime} = U\left( {\left| {1 > < 1} \right| \otimes \rho } \right)M^{\dag }\). However, the most significant drawback is its non-deterministic nature. The success probability depends on the norm of the operator, often requiring multiple repetitions that increase circuit depth and error accumulation. Additionally, constructing the required higher-dimensional unitary embedding incurs gate overhead and may disturb the quantum state upon failure. These factors limit the scalability and efficiency of the approach, especially for large systems or complex operators.
Childs and Wiebe12 introduced the LCU method. In this approach, a non-unitary matrix is expressed as a weighted sum of unitary operators: \(A=\sum_{i}{a}_{i}{U}_{i}\), where each \({U}_{i}\) is a unitary (e.g., a Pauli string). The LCU framework constructs a quantum circuit that uses ancilla qubits to encode the coefficients \({a}_{i}\), performs controlled-unitary operations, and applies oblivious amplification (OAA) to boost the success probability of the correct evolution. This method provides a powerful, general-purpose way to simulate time evolution \({e}^{-iHt}\) where \(t\) is time evaluation and \(H\) is Hermitian matrix. But, since it is probabilistic and requires ancilla-driven controlled operations and post-selection or amplitude amplification, which introduces additional circuit depth and ancilla overhead. In contrast, our proposed method, enabling deterministic and low-depth circuit implementations without probabilistic post-selection. This offers a resource-efficient and hardware-friendly alternative for representing non-unitary operations within a fully unitary framework.
Lin13 proposed a block encoding method. This approach embeds a general matrix (which may not be unitary) into a higher-dimensional unitary matrix, enabling quantum algorithms to process non-unitary matrices through additional quantum operations. This technique has been foundational in quantum algorithms for efficiently representing complex matrices. Given a matrix A, which may not be unitary, block encoding allows constructing a unitary matrix U such that A is a submatrix of U. Formally, we express U = \(\left(\begin{array}{cc}A& B\\ C& D\end{array}\right)\) In this approach, A represents the original matrix, while B, C, and D are selected to ensure that U is unitary. This transformation allows quantum algorithms to handle non-unitary matrices by simulating unitary operations within a higher-dimensional space. While the size of U increases linearly, the method relies on singular value decomposition method, which has a computational complexity of \(O({n}^{3})\). In contrast, our proposed method delivers significant improvements in both computational efficiency and practical implementation as described later.
In14, George Cybenko addresses the challenge of simplifying complex quantum computations into sequences of elementary quantum operations. Re et al.6 demonstrates any general unitary operation can be represented as a sequence of elementary quantum gates. The paper also discusses the importance of maintaining specific properties, like unitarity and control, during the decomposition process. The work also raises questions about the efficiency and feasibility of implementing these reductions in practice, particularly regarding the exponential number of operations required as the number of qubit increases, which remains a significant challenge in the field of quantum computing.
Planat et al.15 in the section “From permutations to quantum gates”, establish a link between classical permutation matrices and quantum gates. Permutation matrices, which rearrange elements by placing 1 s in specific positions and 0 s elsewhere, can describe certain quantum gates, especially the Controlled-NOT (CNOT) gate. The authors introduce a particular subset of these matrices, termed “magic” permutation matrices, which have 1 s on the main diagonal. These matrices correspond to essential quantum gates, such as the Pauli X gate, the CNOT gate, and the Toffoli gate, which are foundational in constructing multi-qubit quantum gates and generating quantum states like stabilizer states and “magic” states. However, this paper focuses only on a limited group of permutation matrices, those that correspond directly to these specific quantum gates. It does not extend the analysis to the general class of permutation matrices, nor does it explore the broader applicability of permutation matrices in quantum gate design.
Weber16 provides several examples of quantum permutation matrices, illustrating how these matrices can arise from combinations of classical operations but with quantum behavior embedded. One of the key examples discussed involves Pauli matrices combined with unitary transformations, generating a quantum permutation matrix from their tensor products. The study of quantum permutation matrices extends to their application in quantum isomorphisms of graphs, which allows quantum analogs of graph isomorphisms. These quantum isomorphisms provide a broader symmetry framework for graph structures in quantum settings, indicating that quantum symmetries can go beyond classical permutations.
One application of our work in constructing permutation matrices from non-unitary matrices can be seen in the domain of quantum automata. Similar to the work on Quantum Automata and Quantum Grammars by Moore and Crutchfield17, where unitary matrices are used to model quantum versions of classical computational structures like finite state machines and pushdown automata, our approach provides a method for handling non-unitary matrices. In their models, unitary matrices were connected to alphabets and grammar symbols, which are applied during state transitions in Hilbert space.
In this article, we present a method to convert non-unitary sparse binary matrices into permutation matrices, enabling their use in quantum implementations of finite state machine (QFSM) models with initial non-unitary transformation matrices. Our approach offers a practical solution for integrating non-unitary transformations within a quantum framework and provides a pathway for mapping permutation matrices to quantum gates.
Another key contribution of our work is the ability to map the resulting permutation matrices directly to quantum gate sequences. Each permutation is decomposed into a series of transpositions, which can be implemented using a small set of hardware-efficient gates such as CNOT and SWAP. This decomposition allows for the systematic construction of low-depth quantum circuits, making our method highly suitable for noisy intermediate-scale quantum (NISQ) devices.
Our work offers a novel solution to the challenge of maintaining unitary properties essential for quantum computation when starting from non-unitary matrices. Our method produces a unitary matrix of size \(np \times np\), significantly reducing resource requirements compared to other approaches. Additionally, our method enables effective handling of non-unitary matrices within quantum systems, specifically in QFSM models, where unitary matrices are associated with alphabets and grammar symbols that facilitate state transitions in a Hilbert space.
Proposed method for sparse to permutation matrix conversion
In this section we outline our proposed approach to create a permutation matrix from a non-unitary sparse binary matrix. The class of matrices we consider are sparse binary matrices that have at most one nonzero entry in a row. Our method is presented via the two propositions stated below.
Proposition 1
Let \(T \epsilon {R}^{n \times n}\) matrix with entries \({T}_{ij}= \left\{\begin{array}{c}0; 1 \le j\le n-1\\ 1; j=0\end{array}\right\}\). Then there is a permutation matrix \(M \epsilon { R}^{m\times m}\) where \(m={n}^{2}\times {n}^{2}\) such that \(M= \left[\begin{array}{ccc}{M}_{00}& \cdots & {M}_{0(n-1)}\\ \vdots & \ddots & \vdots \\ {M}_{\left(n-1\right)0}& \cdots & {M}_{(n-1)(n-1)}\end{array}\right]\) and \(T= \sum_{i=0}^{n-1}{M}_{01}\) where \({M}_{kl} is \; a \; n\times n\) block matrices.
Proof
Given \(T\), construct a matrix \(A\) of dimension \(m={n}^{2}\times {n}^{2}\) using tensor product \(A\) = \({I}_{n \times n}\) ⊗ \({T}_{n \times n}\) where \(I\) is the identiy matrix. Observe that \(A\) is a diagonal block matrix with every diagonal block being T. Also, only the first column of \(T\) is nonzero with all elements 1. So, we can split \(A\) into \(m \times \text{m}\) matrices \({A}_{t}\) such that \(A= \sum_{t=0}^{m-1} {A}_{t}\), where all elements of \({A}_{t}\) are 0’s except the element \({A}_{t}\left[t, k\right], where \; k=n \times \text{floor }\left(\frac{t}{n}\right)\). Apply mod m column permutation on each \({A}_{t}\) to move the 1’s into distinct columns. Let \(M=\) \({A}_{0}\) + \(\sum_{t=1}^{n-1} {A}_{t}\text{ P}\left(0,\text{ nt}+0\right)+\) \(\sum_{t=1}^{\text{n}} {\text{A}}_{t}\text{ P}(\text{n}, \left(\text{nt}+1\right)\text{ mod m}\) …. + \(\sum_{t=1}^{n} {\text{A}}_{t}\text{P}\left(\text{m}-\text{n}\right),(\left(\text{m}-\text{n}\right)\text{t}+\left(\text{n}-1\right)\text{m mod m}\), where \(P\upepsilon\) \({R}^{m\times m}\) is a permutation matrix. \(M\) is a permutation matrix as each column and row has exactly one nonzero entry which is 1 by construction and is unitary. Hence, we can represent \(M\) as an \(m \times \text{m}\) block matrix with block size of n and having exactly one nonzero element. Also, for the first row of the block matrix the nonzero entries are \({M}_{0l}\left[l,0\right]=1\) where the first row of blocks is \({M}_{0l}, 0\le l \le n-1\).
Furthermore, each step of the construction of M is well defined and hence given a final \({n}^{2}\times {n}^{2}\) permutation matrix, we can determine the initial \(n\times n\) matrix. If all entries of column \(k\) rather than column 0 are 1’s, then we can apply the permutations \(P\left(k,nt+k\right), P(n+k, nt+k+1)\) etc. to construct the matrix M. Thus, we can extend Proposition 1 to any matrix T with all columns but one are zeros and the nonzero column is \({\left[\begin{array}{cccc}1& 1& \dots ,& 1\end{array}\right]}^{T}\).
Properties of M
-
1.
The matrix \(M\) is an \({n}^{2}\times {n}^{2}\) block matrix, represented as follows:
\(M= \left[\begin{array}{ccc}{M}_{00}& \cdots & {M}_{0(n-1)}\\ \vdots & \ddots & \vdots \\ {M}_{\left(n-1\right)0}& \cdots & {M}_{(n-1)(n-1)}\end{array}\right]\), where each \({M}_{\text{k}l}, 0\le \text{k},l \le n-1\) is an \(n\times n\) matrix. Each block \({M}_{\text{k}l}\) contains exactly one nonzero entry, located at position \(\left[x,y\right]\), with \({M}_{\text{k}l}\left[x,y\right]=1\). For a fixed \(k\) ,if \(l=k\) then \(x=0\) and \(y=k\), if \(l=k+1\) , then \(x=1\) and \(y=k\) and so on. If \(l=n\), it is reset to \(l=0\) and the process continue until \(l=k-1\). So, in the overall matrix, the first \(n\) rows each have exactly one nonzero entry positioned at columns \(0,n,2n\dots ,\) respectively. Matrix M is obtained by first taking the tensor product of the matrix \(T\) with identity matrix, creating a block diagonal matrix \(A\) with diagonal blocks equal to \(T\). Then, columns in \(A\) are permuted in such a way that only one row in each \(n\)-row block is shifted per permutation. As a result, each \(n\) -row block of \(M\) corresponds to a column-permuted version of \(T\), with distinct permutations applied across blocks.
$$\sum_{0}^{n-1}{M}_{0l}=T$$ -
2.
Hence if v is an n-dimensional vector then \((\sum_{0}^{n-1}{M}_{0l})v=Tv\). The matrices \(\sum_{0}^{n-1}{M}_{kl}\) are column permutations of \(T\) starting with the first column.
-
3.
Let v be an n-dimensional vector and \(\overrightarrow{1}= {[1, 1, \cdots ,1]}^{T}\) be the n-dimensional vector with all 1’s. Then \(M{ }\left( {\vec{1} \otimes v} \right) = { }\left[ {\left( {\mathop \sum \limits_{0}^{n - 1} M_{0l} ,{ }\mathop \sum \limits_{0}^{n - 1} M_{1l} ,{ } \cdots ,\mathop \sum \limits_{0}^{n - 1} M_{{\left( {n - 1} \right)l}} } \right)v} \right]{ }^{T}\).
-
4.
From the above properties, \(Tv\) constitutes the first n elements of \(M{ }\left( {\vec{1} \otimes v} \right)\).
Example 1
To illustrate the construction described above, we provide an example demonstrating how to derive a unitary matrix from a non-unitary sparse binary matrix. Consider a matrix \(T\) of dimensions \(2\times 2\) In this matrix, exactly 2 entries are 1’s, all of which are in the first column, while the remaining entries are 0.
Given \(n=2\) and \(T=\left[\begin{array}{cc}1& 0\\ 1& 0\end{array}\right]\) by applying Proposition 1, we get:
Step 1 compute \(A = I_{n \times n} \otimes { }T_{n \times n}\) which gives
Step 2 Compute the individual matrices \({A}_{i }s\)
Step 3 Compute \({A}_{i }P\)’s
Step 4 Finally, Build the matrix M
The general case
In the previous section, we presented and demonstrated a method for constructing a unitary matrix from a non-unitary sparse binary matrix, where all non-zero entries are confined to the first column. In this section, we extend our discussion to the general case of an \(n \times n\) sparse binary matrix that contains at most \(n\) non-zero entries. These non-zero entries are distributed such that some columns contain only zeros, while others contain more than one non-zero entry. The method for constructing a unitary matrix in this context is outlined in the following proposition.
Proposition 2
Let \(T \epsilon R^{{n \times n}}\) be a \(n\times n\) matrix in which every row has exactly one nonzero element, with entries \({T}_{ij}\in \left\{0, 1\right\}.\) The matrix \(T\) has exactly \(n\) entries are 1’s and some of its columns consist entirely of zero entries. Then there is a permutation matrix \(M \epsilon { R}^{m\times m}\) where \(m=np \text{and}\) \(p\) is the maximum number of nonzero elements in any column of \(T\) . Further, \(M\) is structured as a block matrix:\(\left[\begin{array}{ccc}{M}_{00}& \cdots & {M}_{0(p-1)}\\ \vdots & \ddots & \vdots \\ {M}_{\left(p-1\right)0}& \cdots & {M}_{(p-1)(p-1)}\end{array}\right]\) where each \({M}_{kl}\) is an \(n\times n\) block matrix. Additionally, we can express \(T= \sum_{i=0}^{p-1}{M}_{0i}\).
Proof
We will prove the statement by constructing the matrix \(M\) based on the given matrix \(T\) as follows:
Let \(T\) be a \(n\times n\) binary matrix with q nonzero columns and let p = maximum number of nonzero entries in a column of \(T\). We construct \(n\times n\) matrices \({T}_{0}, {T}_{1}\dots ,{T}_{q-1}\) , where each \({T}_{j},\) has only one nonzero column. Specifically:
-
The nonzero column of \({T}_{0}\) is corresponds to the first nonzero column of \(T\)
-
The nonzero column of \({T}_{1}\) is corresponds to the second nonzero column of \(T\) and so on.
Then, we can express \(T\) as sum of these matrices: \(T= \sum_{i=0}^{q-1}{T}_{i}\).
\(\text{For each }i=0 \cdots q-1\), construct the \(np\times np\) matrix \(A_{i} = { }I \otimes T_{i} ,\) where \(I\) is the \(p\times p\) identity matrix. Since T contains exactly one nonzero element in each row, every distinct pair \({T}_{i}\) and \({T}_{j}\) will have the property that if one row of one matrix is nonzero, the corresponding row in the other will be zero, then \({A}_{i}\) block diagonal matrix equal to \(\left[\begin{array}{ccc}{T}_{i}& \cdots & 0\\ \vdots & \ddots & \vdots \\ 0& \cdots & {T}_{i}\end{array}\right]\). If \(l\) is the first nonzero column of \({A}_{i}\), then the other nonzero columns are \(n+l, 2n+l, ...\left(p-1\right)n+l\) Each nonzero segment of the nonzero column occurs in the diagonal blocks. We follow the method used in the proof of ‘Proposition 1’ to express \({A}_{i}\) as the sum of m matrices. Let \({A}_{i}^{j}\) be the matrix whose \({j}^{th}\) row is a copy of the matrix \({A}_{i}\) and other rows are zeros. Viewed as a block matrix, all blocks are 0 matrices except the one enclosing the \({j}^{th}\) row which has exactly one nonzero element. Each \({A}_{i}^{j}\) has exactly one nonzero element in one of the columns \(l, n+l, 2n+l, ...\left(p-1\right)n+l\) in one of the diagonal blocks. Then \({A}_{i}= \sum_{j=0}^{m-1}{A}_{i}^{j}\). Nonzero columns of \({A}_{i}^{j}\) may be the same if \({A}_{i}\) has more than one nonzero element in a column. We use column permutations to align nonzero element of \({A}_{i}^{j}\) so that no two matrices have nonzero elements in the same column. For the elements in column l (those are in the first diagonal block), use the permutations \(P(l, ns+s+1)\) where \(s=0,\dots ,n-1\). For elements of column \(nr+l,\text{ where} r=1,\dots p-1\) (those are in the \({r}^{th}\) diagonal block), use permutations \(P(nr+l, \left(nr+l+ns+r\right) mod m\). The relative positions of the nonzero elements in the column from the first are given by s. Let \({B}_{i}^{j}\) denote \({A}_{i}^{j}\) following the outlined permutation. Let \({B}_{i}= \sum_{j=0}^{m-1}{B}_{i}^{j}\). Then \({B}_{i}\) has at most one nonzero element (which is 1) in each row and column. Also, by construction for any pair \({B}_{i}\) and \({B}_{j}\) there is no nonzero intersection of elements. Let \(M= \sum_{i=0}^{q-1}{B}_{i}\). Since T has exactly n elements, M has exactly m = np elements and no row or column contains more than one nonzero element. So, \(M\) is a permutation matrix. If we represent \(M\) as a \(p\times p\) block matrix, \(M= \left[\begin{array}{ccc}{M}_{00}& \cdots & {M}_{0(p-1)}\\ \vdots & \ddots & \vdots \\ {M}_{\left(p-1\right)0}& \cdots & {M}_{(p-1)(p-1)}\end{array}\right]\) and each \({B}_{i}\) as block matrices, \({B}_{i}= \left[\begin{array}{ccc}{B}_{i}^{00}& \cdots & {B}_{i}^{0(p-1)}\\ \vdots & \ddots & \vdots \\ {B}_{i}^{\left(p-1\right)0}& \cdots & {B}_{i}^{(p-1)(p-1)}\end{array}\right]\), then \({M}_{0j}= \sum_{i=0}^{p-1}{B}_{i}^{0j}\) is an n-by-n matrix. Hence \(T= \sum_{i=0}^{p-1}{M}_{0i}\).
Example 2
To illustrate the construction described above, we provide an example demonstrating how to derive a unitary matrix from a sparse binary matrix. Consider a matrix \(T\) of dimensions \(4\times 4\) In this matrix, exactly 4 entries are 1’s, some columns are entirely composed of zero entries.
Given \(T=\left[\begin{array}{cccc}1& 0& 0& 0\\ 0& 0& 1& 0\\ 1& 0& 0& 0\\ 0& 0& 1& 0\end{array}\right]\), we aim to construct a permutation matrix \(M\) by applying.
Proposition 2
where p \(=2\). The steps are as follows:
Step 1 Express \(T\) as the sum of matrices with isolated nonzero columns, \(T= \sum_{i=0}^{q-1}{T}_{i}\)
Since \(T\) has two nonzero columns with two 1 s each, we write \(T\) as a sum: \(T={T}_{0}+{T}_{1}\)= T0 + T1 where
Step 2 Construct matrices \(A_{i} = I \otimes T_{i} ,\) for each \(T_{i}\)
Step 3 Decompose each \({A}_{i}\) into matrices \({A}_{i}^{j}\) with only one 1 per matrix.
For each \({A}_{i}\) separate it as a sum of matrices \({A}_{i}^{j}\), each containing at most one 1 \({A}_{0}\):
where each \({A}_{0}^{j}\) has one nonzero entry. For example:
Step 4 Apply column permutations to ensure unique positions.
For each \({A}_{0}^{j}\) apply column permutations (as in Proposition 1) to avoid overlaps among nonzero entries. Let the resulting matrices be \({B}_{0}^{j}\)
\({B}_{0}^{0}=\left[\begin{array}{cccccccc}1& 0& 0& 0& 0& 0& 0& 0\\ 0& 0& 0& 0& 0& 0& 0& 0\\ 0& 0& 0& 0& 0& 0& 0& 0\\ 0& 0& 0& 0& 0& 0& 0& 0\\ 0& 0& 0& 0& 0& 0& 0& 0\\ 0& 0& 0& 0& 0& 0& 0& 0\\ 0& 0& 0& 0& 0& 0& 0& 0\\ 0& 0& 0& 0& 0& 0& 0& 0\end{array}\right] {B}_{0}^{1}=\left[\begin{array}{cccccccc}0& 0& 0& 0& 0& 0& 0& 0\\ 0& 0& 0& 0& 0& 0& 0& 0\\ 0& 0& 0& 0& 1& 0& 0& 0\\ 0& 0& 0& 0& 0& 0& 0& 0\\ 0& 0& 0& 0& 0& 0& 0& 0\\ 0& 0& 0& 0& 0& 0& 0& 0\\ 0& 0& 0& 0& 0& 0& 0& 0\\ 0& 0& 0& 0& 0& 0& 0& 0\end{array}\right] {B}_{0}^{2}=\left[\begin{array}{cccccccc}0& 0& 0& 0& 0& 0& 0& 0\\ 0& 0& 0& 0& 0& 0& 0& 0\\ 0& 0& 0& 0& 0& 0& 0& 0\\ 0& 0& 0& 0& 0& 0& 0& 0\\ 0& 1& 0& 0& 0& 0& 0& 0\\ 0& 0& 0& 0& 0& 0& 0& 0\\ 0& 0& 0& 0& 0& 0& 0& 0\\ 0& 0& 0& 0& 0& 0& 0& 0\end{array}\right] {B}_{0}^{3}=\left[\begin{array}{cccccccc}0& 0& 0& 0& 0& 0& 0& 0\\ 0& 0& 0& 0& 0& 0& 0& 0\\ 0& 0& 0& 0& 0& 0& 0& 0\\ 0& 0& 0& 0& 0& 0& 0& 0\\ 0& 0& 0& 0& 0& 0& 0& 0\\ 0& 0& 0& 0& 0& 0& 0& 0\\ 0& 0& 0& 0& 0& 1& 0& 0\\ 0& 0& 0& 0& 0& 0& 0& 0\end{array}\right]\)
Step 5 Combine all \({B}_{0 }^{j}\) to form \({B}_{0}\)
Likewise from \(T\) 1 we construct \({B}_{1}=\left[\begin{array}{cccccccc}0& 0& 0& 0& 0& 0& 0& 0\\ 0& 0& 1& 0& 0& 0& 0& 0\\ 0& 0& 0& 0& 0& 0& 0& 0\\ 0& 0& 0& 0& 0& 0& 1& 0\\ 0& 0& 0& 0& 0& 0& 0& 0\\ 0& 0& 0& 1& 0& 0& 0& 0\\ 0& 0& 0& 0& 0& 0& 0& 0\\ 0& 0& 0& 0& 0& 0& 0& 1\end{array}\right]\)
Step 6 Finally construct \(M \; as \; the \; sum \; of \; {B}_{i}\)
M = B0 + B1.
M = \(\left[\begin{array}{cccccccc}1& 0& 0& 0& 0& 0& 0& 0\\ 0& 0& 1& 0& 0& 0& 0& 0\\ 0& 0& 0& 0& 1& 0& 0& 0\\ 0& 0& 0& 0& 0& 0& 1& 0\\ 0& 1& 0& 0& 0& 0& 0& 0\\ 0& 0& 0& 1& 0& 0& 0& 0\\ 0& 0& 0& 0& 0& 1& 0& 0\\ 0& 0& 0& 0& 0& 0& 0& 1\end{array}\right]\)
Space complexity
The total space complexity for constructing the matrix \(M\) is \(O(np)\) where n is the dimension of the given sparse matrix \(T\), \(p\le n\) is the maximum number of nonzero entries in any column of \(T\).
Time complexity
For a given sparse binary matrix of dimension \(n\), constructing the corresponding permutation matrix requires \({n}^{2}\) assignments. This results in a time complexity of \(O({n}^{2})\), reflecting the computational effort needed to complete the transformation efficiently.
Comparison of methods
Our proposed method, with a space complexity of \(O(np)\) and a time complexity of \(O({n}^{2})\), demonstrates efficient scaling for sparse matrices. Here, n is the matrix dimension, p is the maximum number of nonzero entries in any column, ensuring practical applicability to large-scale problems. This contrasts with the method by Gingrich and Williams in11, which constructs a unitary matrix through probabilistic computations and computational overhead unsuitable for large-scale systems. Similarly, the block encoding method in13 embeds a non-unitary matrix into a higher-dimensional unitary matrix using singular value decomposition, with a space complexity that is linear in the size of the output matrix but a time complexity of \(({n}^{3})\) , limiting scalability due to the computationally expensive decomposition. While the latter methods are versatile and can handle general non-unitary matrices, their resource demands make them impractical for many applications. In comparison, our method not only ensures unitary transformation but also reduces the time complexity, making it particularly advantageous for sparse matrices and applications requiring efficient quantum computations. Table 1 shows the comparison between the proposed methods with other methods.
Permutation matrices to gates
From the previous section, we conclude that any non-unitary sparse binary matrix with exactly \(n\) nonzero entries (where \(n\) is the size of the matrix) can be transformed into a permutation matrix, which is inherently unitary. Though permutation matrices are unitary, their practical implementations are restricted to a particular set of quantum gates. In this section, we demonstrate how to decompose any permutation into a product of elementary quantum gates.
Observation on permutations matrices
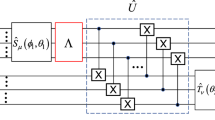
In18, the system model defines a parameterized quantum circuit as a sequence of unitary operations acting on an input state, expressed as:
This structure underlies many variational quantum algorithms, where each \({U}_{i}({\uptheta }_{i})\) represents a layer or gate applied sequentially to the quantum register. Our method aligns naturally with this model because the permutation matrices constructed from sparse binary matrices can be directly translated into such unitary operations, with each permutation corresponding to a swap gate or CNOT gate.
Let \({a}_{1,} {a}_{2,}\dots {a}_{n,}\) represent an ordered sequence. Consider a permutation \({P}_{(i,j),}\) which swaps the elements at positions \(i\) and \(j\). The permutation \({P}_{(i,j)}\) can be expressed as a product of transpositions of neighboring elements as follows
Each of these adjacent transpositions corresponds to a hardware-efficient gate, such as a Swap or CNOT, and fits directly into the layered structure in Eq. (1). Moreover, these permutation operations can be interpreted as unitaries derived from Hermitian generators, using the exponential form:
where \({P}_{i}\) is a Hermitian matrix representing a basic transposition, and \({\uptheta }_{i}\) is a tunable parameter. This provides a formal mapping from permutation logic to the standard unitary framework used in quantum circuits.
An additional advantage of our approach is its exploitation of Hamming distance: any permutation of binary strings can be decomposed into transpositions between strings that differ by a Hamming distance of 1. This means the overall permutation matrix can be realized as a sequence of minimal bit-flip operations, further reducing circuit depth and enhancing efficiency for NISQ devices19.
In summary, by embedding non sparse binary matrices into structured permutation matrices and decomposing them into transpositions with minimal Hamming distance, we enable an efficient realization of non-unitary operations in the unitary model of Eq. (1).
Transposition to quantum gates
We construct quantum gates to implement transpositions represented by the matrices whose rows as binary integers differ by 1 in hamming distance. Since a transposition with a Hamming distance of 1 involves swapping two elements that differ in only one bit, it can be realized using a controlled quantum operation that acts conditionally based on that bit.
It is well known that any permutation can be expressed as a product of such transpositions; hence we can systematically construct a sequence of quantum gates to realize any desired permutation gate. This approach allows for the decomposition of any arbitrary permutation matrix into a series of elementary gates that operate on transpositions, thereby enabling efficient implementation in quantum circuits.
We start with a given \({2}^{n} \times {2}^{n}\) permutation matrix. First, we analyze the matrix to identify the indices that have been swapped by the permutation. This can be achieved by comparing the rows and columns of the permutation matrix to determine which positions map to each other.
Once the swapped indices are identified, we construct quantum gates to implement these swaps. For each swap, we check if the indices differ by a Hamming distance of 1. If they do, the corresponding transposition can be directly realized using a single gate designed for Hamming distance 1 swaps. If the Hamming distance is greater than 1, we decompose the swap into a sequence of transpositions with neighboring elements (i.e., intermediate swaps with Hamming distance 1), as shown in the earlier observation.
By repeating this process for all swaps in the permutation matrix, we construct a sequence of quantum gates that faithfully implements the given \({2}^{n} \times {2}^{n}\) permutation matrix. This method ensures a systematic and efficient translation of any permutation matrix into a quantum circuit.
The method is implemented in Python 3 using Qiskit, and the pseudo code listings are provided in the “Supplementary Materials”). At a high level, the method involves the following steps:
-
1.
Preprocessing the matrix to identify the swapped elements and the corresponding qubit controls.
-
2.
Checking the Hamming distance between the binary representations of the indices.
-
If the Hamming distance is 1, a direct multi-controlled- X (MCX) gate is inserted.
-
If greater than 1, the permutation matrix is factorized into simpler transpositions.
-
-
3.
Recursive construction of the circuit until the full permutation is realized.
This method guarantees that any \({2}^{n} \times {2}^{n}\) transposition matrix can be translated into a corresponding \(n\)-qubit quantum circuit through a systematic construction of controlled gates.
Illustrative example
We demonstrate the method with a simple example transposition matrix:
\(M=\) \(\left[\begin{array}{cccccccc}1& 0& 0& 0& 0& 0& 0& 0\\ 0& 1& 0& 0& 0& 0& 0& 0\\ 0& 0& 1& 0& 0& 0& 0& 0\\ 0& 0& 0& 1& 0& 0& 0& 0\\ 0& 0& 0& 0& 0& 1& 0& 0\\ 0& 0& 0& 0& 1& 0& 0& 0\\ 0& 0& 0& 0& 0& 0& 1& 0\\ 0& 0& 0& 0& 0& 0& 0& 1\end{array}\right]\) is a transposition between states 4 and 5 (with indexing from \(0\) to \(n-1\)).
The binary indices of the states are: \({bin}_{s1}=100\) and \({bin}_{s2}=101\). The Hamming distance between \({bin}_{s1}\) and \({bin}_{s2}\) is 1. Therefore, the swap can be implemented using a multi-controlled X (MCX) gate with controls on Qubit 0 and Qubit 1, and the target on Qubit 2. Negative control handling is required for Qubit 1, as it is initially 0 in both \({bin}_{s1}\) and \({bin}_{s2}\). The resulting quantum circuit is shown in Fig. 1. Quantum circuit for transposition M. The circuit uses controls on qubits \(q[0]\) (positive control) and \(q[1]\) (negative control, created by add X gate before and after the controls) to apply an X (NOT) gate on the target qubit \(q[2]\). The negative control ensures that the gate is triggered when \(q[1]\) is in the \(\left| 0 \right. \rangle\).

Quantum circuit for transposition M.
Applications
Sparse binary matrices have extensive real-world applications due to their efficiency in representing large, structured, and often sparse datasets. Examples include representations of social networks, web graphs, telecommunication networks, finite state machines, and so on. These matrix representations in general are not unitary. However, within the quantum system, operations are unitary matrices. So, to make use of these representations nonunitary-to-unitary transformations are necessary. To demonstrate the application of our method, we consider classical deterministic finite state automata (DFA). DFA is a computational model with a wide range of applications including compiler design, text processing and pattern matching. We show how a quantum finite state system can be built from a classically defined DFA.
In the theory of computation, DFAs are powerful models that recognize languages by processing input symbols and transitioning deterministically between states. Traditionally, a deterministic finite state automaton is defined as a five tuple M = (K, Σ, Δ, s, F), where: K is a finite set of states, Σ (the alphabet) is a finite set of symbols, s ∈ K is the initial state, F ⊆ K is the set of accepting or final states, and Δ is the transition function. Δ is a function from K × Σ to K. DFAs consist of a finite set of states, a transition function defined as a mapping from the current state and input symbol to the next state, and a set of final or accepting states that define the acceptance condition of the automaton. Adapting DFAs for quantum systems bridges classical automata with quantum algorithms, laying the foundation for advanced quantum computational models and enhancing our ability to tackle probabilistic or complex-pattern languages.
To translate a classical DFA into a quantum framework, DFA states can be encoded as binary vectors in Hilbert space. Transitions are then represented by unitary matrices that transform the quantum state vector. Hence, DFA transitions can be realized as quantum gates. By associating unitary matrices to input symbols, the quantum DFA processes input strings by applying the associated unitary matrices/quantum gates, representing each input symbol in sequence. The system’s final state vector after processing the string indicates whether the input is accepted.
Figure 2 DFA over \(\Sigma = \{\text{a},\text{ b}\}\) recognizes the language L, illustrates a two-state deterministic finite automaton (DFA) over the alphabet \(\Sigma = \{\text{a},\text{ b}\}\) designed to recognize the language \(L = \left\{ {w {\text{|w}}\;{\text{is}}\;{\text{a}}\;{\text{string}}\;{\text{of}}\;{\text{a'}} {\text{s}}\;{\text{and}}\;{\text{b'}} {\text{s}}\;{\text{ending}}\;{\text{in}}\;{\text{b}}} \right\}\). The start state \({q}_{0}\) is shown as a single-bordered circle, while the accepting (final) state \({q}_{1}\) is indicated by a double-bordered circle. There is a self-loop on \({q}_{0}\) for input \(a\), allowing the automaton to remain at \({q}_{0}\) upon reading \(a\),. Two horizontal transitions connect the states: An upper arrow labeled \(a,b\) sends the automaton from \({q}_{1} to {q}_{0}\) on reading either \(a\) or \(b\). A lower arrow labeled \(b\) sends the automaton back from \({q}_{0} to {q}_{1}\) when a \(b\) is read.

DFA over \(\Sigma = \{\text{a},\text{ b}\}\) recognizes the language L.
To illustrate the application in a quantum-inspired framework, we represent the DFA states \({q}_{0}\) and \({q}_{1}\) as two-dimensional column vectors: \({q}_{0}=\left[\begin{array}{c}1\\ 0\end{array}\right]\), \({q}_{1}=\left[\begin{array}{c}0\\ 1\end{array}\right]\), The input symbols \(a\) and \(b\) are represented as \(a=\left[\begin{array}{cc}1& 0\\ 1& 0\end{array}\right],\text{ and b}= \left[\begin{array}{cc}0& 1\\ 1& 0\end{array}\right].\) A state transition upon reading an input symbol is defined as a matrix–vector multiplication: \({v}^{T}={u}^{T}A\), where u represents the current state, v represents the next state, and A represents the current input symbol either \(a\) or \(b\).
To realize the method outlined in this paper, complete the list of steps to construct quantum state transition symbol ‘a’ equivalent to the classical state transition \({v}^{T}={u}^{T}A\) as shown below:
-
1.
Input preparation.
$${\text{U}} = \left[ {\begin{array}{*{20}c} 0 \\ 1 \\ \end{array} } \right],\quad \hat{u} = e_{0} \otimes {\text{u}},\;where{ }\;e_{0} = { }\left[ {1{ }0} \right]^{T} ,{ }\;\hat{u} = \left[ {\begin{array}{*{20}c} 0 \\ 1 \\ 0 \\ 0 \\ \end{array} } \right]$$ -
2.
Construct unitary matrix M from the given ‘a’ (steps shown in proposition 1).
$$M=\left[\begin{array}{cccc}1& 0& 0& 0\\ 0& 0& 1& 0\\ 0& 0& 0& 1\\ 0& 1& 0& 0\end{array}\right]$$ -
3.
State transition with the unitary matrix.
$$\begin{aligned} \hat{v}^{T} = & \hat{u}^{T} M \\ = & \left[ {\begin{array}{*{20}c} 0 & 1 & 0 & 0 \\ \end{array} } \right]\left[ {\begin{array}{*{20}c} 1 & 0 & 0 & 0 \\ 0 & 0 & 1 & 0 \\ 0 & 0 & 0 & 1 \\ 0 & 1 & 0 & 0 \\ \end{array} } \right] \\ = & \left[ {\begin{array}{*{20}c} 0 & 0 & 1 & 0 \\ \end{array} } \right] \\ \end{aligned}$$The state vector obtained here is a permutation of the actual vector. The permutation is realized by the permutations performed to construct the unitary matrix. Affected permutation needs to be reversed.
-
4.
Reverse the effect of permutations (affected permutation is columns 1 and 3).
$$\hat{v}^{T} = \left[ {\begin{array}{*{20}c} 1 & 0 & 0 & 0 \\ \end{array} } \right] = \left[ {\begin{array}{*{20}c} 1 & 0 \\ \end{array} } \right]^{T} { } \otimes \left[ {\begin{array}{*{20}c} 1 \\ 0 \\ \end{array} } \right] = e_{0} \otimes v$$Thus \({\widehat{v}}^{T}= {\widehat{u}}^{T}M\) is equivalent to \({v}^{T} = {u}^{T}T\).
-
5.
Convert this M into Quantum gate.
-
5.1.
Express M as the product of Transposition.
Cycles in M [1, 1–3] so M can be expressed as:
$$M={P}_{0}\left[\text{1,3}\right]. {P}_{1}\left[\text{1,2}\right]$$ -
5.2
Convert the index into binary.
$$M= {P}_{0}\left[\text{01,11}\right].{P}_{1}\left[\text{01,10}\right]$$In \({P}_{1}\) Haming distance between 01 and 10 is not equal to one so we need to decompose it further,
$${P}_{1}= {P}_{10}\left[\text{01,11}\right]. {P}_{11}[\text{11,10}] {P}_{12}\left[\text{01,11}\right]$$$$\begin{aligned} M = & P_{0} \left[ {{\text{01,11}}} \right].P_{{10}} \left[ {{\text{01,11}}} \right].P_{{11}} [{\text{11,10}}]P_{{12}} \left[ {{\text{01,11}}} \right] \\ = & P_{{11}} [{\text{11,10}}]P_{{12}} \left[ {{\text{01,11}}} \right] \\ \end{aligned}$$ -
5.3.
\({P}_{11}\) represent by a CNOT with control on qubit 1 and target on qubit 0.
-
5.4.
\({P}_{12}\) represent by a CNOT with control on qubit 0 and target on qubit 1.
-
5.1.
Figure 3 Quantum circuit implementing the DFA symbol \(a=\left[\begin{array}{cc}1& 0\\ 1& 0\end{array}\right]\). The circuit applies a two-qubit controlled-X (CNOT-like) operation, followed by a measurement in the computational (Z) basis on q [0]. The measurement outcome is recorded into the classical register c [0], indicated by the downward dashed arrow from the measurement box to the classical bit.

Quantum circuit for DFA symbol a.
This arrow signifies the transfer of information from the quantum state to a classical bit, allowing the result to be processed classically after measurement.
Though DFA operations are irreversible, each transition deterministically moves from one state to another without storing information about prior states. However, in quantum computing, unitary matrices (the primary transition operators) are inherently reversible. This seemingly contradictory behavior occurs because the DFA transition matrix is embedded into a larger unitary matrix.
Moreover, in gate-model quantum neural networks (QNNs), the ability to embed sparse structures into unitary matrices is also highly valuable. Training QNNs often encounters challenges like barren plateaus and slow convergence, which are exacerbated by dense or poorly structured parameterizations. The results in20 highlight the importance of initialization strategies that maintain structure while supporting trainability. Our method allows for the construction of permutation-based unitary matrices from sparse binary inputs. These can serve as lightweight and expressive layers in QNNs, facilitating both better optimization during training and improved generalization performance. This aligns well with current trends in designing noise-resilient and resource-efficient machine learning models.
Our method also extends to quantum networking applications. In emerging quantum internet infrastructures, sparse matrices frequently model the distribution of entanglement, routing paths, or connectivity graphs between network nodes. As discussed in21,22, unitary transformations are required to preserve entanglement during distributed operations while minimizing communication overhead. By embedding sparse binary matrices into structured unitary permutation matrices, our method offers an efficient tool for implementing routing protocols, optimizing quantum channel usage, and supporting scalable quantum network architecture.
Conclusions
This work presents an efficient and scalable method for converting non-unitary sparse binary square matrices into unitary matrices, enabling their application in quantum computational frameworks. The proposed approach addresses a significant bottleneck in embedding non-unitary transformations into quantum systems. The proposed approach is significantly less complex than previously proposed methods. Furthermore, a method to translate permutation matrices into quantum circuits is outlined, providing a practical pathway for implementation. The application of this method in quantum finite state machines demonstrates its potential to bridge classical automata with quantum algorithms. While this study focuses on square matrices, future work will explore the embedding of rectangular matrices into unitary matrices and their integration into diverse quantum computing paradigms.
Data availability
All data generated or analyzed during this study are included in this published article.
References
Nielsen, M. A. & Chuang, I. L. Quantum Computation and Quantum Information (Cambridge University Press, 2010).
Bender, C. M. & Boettcher, S. Real spectra in non-Hermitian Hamiltonians having P T symmetry. Phys. Rev. Lett. 80(24), 5243 (1998).
Zheng, C., Hao, L. & Long, G. L. Observation of a fast evolution in a parity-time-symmetric system. Philos. Trans. R. Soc. A Math. Phys. Eng. Sci. 371(1989), 20120053 (2013).
Breuer, H. P. & Petruccione, F. The Theory of Open Quantum Systems (OUP Oxford, 2002).
Hu, Z., Xia, R. & Kais, S. A quantum algorithm for evolving open quantum dynamics on quantum computing devices. Sci. Rep. 10(1), 3301 (2020).
Del Re, L., Rost, B., Kemper, A. F. & Freericks, J. K. Driven-dissipative quantum mechanics on a lattice: Simulating a fermionic reservoir on a quantum computer. Phys. Rev. B 102(12), 125112 (2020).
Gui-Lu, L. General quantum interference principle and dualitycomputer. Commun. Theor. Phys. 45(5), 825 (2006).
Zheng, C. Universal quantum simulation of single qubit nonunitary operators using duality quantum algorithm. Sci. Rep. 11(1), 3960 (2021).
Krantz, P. et al. A quantum engineer’s guide to superconducting qubits. Appl. Phys. Rev. https://doi.org/10.1063/1.5089550 (2019).
Sato, Y., Kondo, R., Koide, S., Takamatsu, H. & Imoto, N. Variational quantum algorithm based on the minimum potential energy for solving the Poisson equation. Phys. Rev. A 104(5), 052409 (2021).
Gingrich, R. M. & Williams, C. P. Non-unitary probabilistic quantum computing. In Proceedings of the Winter International Symposium on Information and Communication Technologies (WISICT ‘04). Trinity College Dublin 1–6 (2004).
Childs, A. M. & Wiebe, N. Hamiltonian simulation using linear combinations of unitary operations. arXiv preprint arXiv:1202.5822 (2012).
Lin, L. Lecture Notes on Quantum Algorithms for Scientific computing. quant-ph (2022).
Cybenko, G. Reducing quantum computations to elementary unitary operations. Comput. Sci. Eng. 3(2), 27–32. https://doi.org/10.1109/5992.908999 (2001).
Planat, M. & Haq, R. U. The magic of universal quantum computing with permutations. Adv. Math. Phys. 2017, 1–9. https://doi.org/10.1155/2017/5287862 (2017).
Weber, M. Quantum permutation matrices. Complex Anal. Oper. Theory 17, 37. https://doi.org/10.1007/s11785-023-01335-x (2023).
Moore, C. & Crutchfield, J. P. Quantum automata and quantum grammars. Theor. Comput. Sci. 237(1–2), 275–306. https://doi.org/10.1016/S0304-3975(98)00191-1 (2000).
Gyongyosi, L. & Imre, S. Circuit depth reduction for gate-model quantum computers. Sci. Rep. 10(1), 11229 (2020).
Gyongyosi, L. & Imre, S. Scalable distributed gate-model quantum computers. Sci. Rep. 11(1), 5172 (2021).
Gyongyosi, L. & Imre, S. Training optimization for gate-model quantum neural networks. Sci. Rep. 9(1), 12679 (2019).
Gyongyosi, L. & Imre, S. Advances in the quantum internet. Commun. ACM 65(8), 52–63 (2022).
Gyongyosi, L., Imre, S. & Nguyen, H. V. A survey on quantum channel capacities. IEEE Commun. Surv. Tutor. 20(2), 1149–1205 (2018).
Author information
Authors and Affiliations
Contributions
K.K. conception and design of the research, article writing; V.P. Algorithm design and article reviewing; K.G. research supervision, study design, article writing; J.P research supervision, article revising; All authors have read and approved the final manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Karuppasamy, K., Puram, V., George, K.M. et al. Quantum circuits from non-unitary sparse binary matrices. Sci Rep 15, 22502 (2025). https://doi.org/10.1038/s41598-025-03424-7
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-03424-7
