
Abstract
This study presents an innovative air quality prediction framework that integrates factor analysis with deep learning models for precise prediction of original variables. Using data from Beijing’s Tiantan station, factor analysis was applied to reduce dimensionality. We embed the factor score matrix into the Transformer model which leveraged self-attention to capture long-term dependencies, marking a significant advancement over traditional LSTM methods. Our hybrid framework outperforms these methods and surpasses models like Transformer, N-BEATS, and Informer combined with principal component and factor analysis. Residual analysis and \({R}^{2}\) evaluation confirmed superior accuracy and stability, with the maximum likelihood factor analysis Transformer model achieving an MSE of 0.1619 and \({R}^{2}\) of 0.8520 for factor 1, and an MSE of 0.0476 and \({R}^{2}\) of 0.9563 for factor 2. Additionally, we introduced a cutting-edge CNN-BILSTM-ATTENTION model with discrete wavelet transform, which optimizes predictive performance by extracting local features, capturing temporal dependencies, and enhancing key time steps. Its MSE was 0.0405, with \({R}^{2}\) values all above 0.94, demonstrating exceptional performance. This study emphasizes the groundbreaking integration of factor analysis with deep learning, transforming causal relationships into conditions for predictive models. Future plans include optimizing factor extraction, exploring external data sources, and developing more efficient deep learning architectures.
Similar content being viewed by others

Introduction
Air quality prediction plays a crucial role in modern society’s environmental governance and public health management. With the acceleration of urbanization, air pollution has become increasingly severe, directly impacting residents’ quality of life and health levels. Accurate air quality prediction can help governments and the public take timely and effective measures to mitigate the harm caused by air pollution, and provide scientific support for the formulation and implementation of environmental policies. In recent years, with the rapid development of data science and deep learning technologies, significant progress has been made in air quality prediction models. However, when facing high-dimensional complex data and non-linear trends of pollution changes, traditional prediction methods are still inadequate, especially in capturing long-term time dependencies and extracting potential associative features. To address these issues, this study proposes an innovative air quality prediction framework aimed at improving the accuracy and stability of prediction models by combining factor analysis with deep learning techniques. In terms of research methodology, factor analysis was applied to reduce the dimensionality of the air quality data from the Tian Tan station in Beijing, extracting the main factors and reducing the data’s dimensionality, providing a simplified and efficient data structure for subsequent modeling. Then, during the time series prediction phase, we introduced the Transformer model based on the self-attention mechanism, using factor scores as input, fully leveraging its advantages in capturing long-term time dependencies and modeling sequential data. Additionally, the CNN-BILSTM-ATTENTION hybrid deep learning architecture, combined with wavelet transform, further enhanced the model’s performance. The fundamental purpose of this study is to look into the effectiveness of the combined factor analysis and deep learning prediction frameworks in forecasting air quality. We believe that this new hybrid modeling method may effectively solve the shortcomings of standard models when dealing with vast volumes of data, complex changes in pollutants, and time-related aspects. This should result in better and more efficient predictions. This research aims to provide a novel methodological framework for air quality analysis and prediction, as well as scientific support for environmental governance and policy formation, thereby serving as a reference for air quality monitoring and management in similar settings.
This paper first proposes an innovative deep learning prediction approach based on factor analysis. Initially, factor analysis is conducted on the data, revealing that two interpretable factors can be extracted. Factor 1 explains four original variables, while Factor 2 explains two original variables. Subsequently, we integrate factor analysis with the Transformer model for the overall prediction of factors. A series of comparative studies are then carried out, contrasting this integrated approach with other advanced baselines, including a baseline combined with principal component analysis, as well as predictions from two different factor analysis methods. The results indicate that the factor analysis using the maximum likelihood method combined with the Transformer model stands out in performance, making it suitable as a model for overall factor prediction. Next, we employ discrete wavelet transform to decompose the output of the maximum likelihood factor analysis combined with the Transformer model into multiple scales. These decomposed components serve as feature inputs for the CNN-BILSTM-ATTENTION model. By constructing this model, we conduct localized and specific predictions for the original variables explained by the two factors respectively. In summary, the research logic of this paper follows a holistic-to-local approach.
Related work
Time series analysis has extensive applications across various fields. For instance, Fahman Saeed and Sultan Aldera1 proposed an adaptive renewable energy forecasting method based on PCA-Transformer. This approach leverages the advantages of Principal Component Analysis and the Transformer model, significantly enhancing the accuracy of renewable energy output forecasting by using PCA for dimensionality reduction and Transformers for capturing long-term dependencies in time series data. The study demonstrated that this method excels in handling complex renewable energy datasets, dynamically adjusting the model structure to accommodate varying data complexity and scale, thereby improving prediction efficiency and reliability.
In a 2022 study, Wan et al.2 introduced a model that integrates Convolutional Neural Networks, Long Short-Term Memory networks, and attention mechanisms for short-term power load forecasting. The model extracts high-dimensional features through one-dimensional CNN layers, captures temporal dependencies within time series using LSTM layers, and incorporates an attention mechanism to optimize the weights of LSTM outputs, enhancing the impact of critical information. Experimental results indicated that this model outperformed traditional LSTM models in predicting the power load of two thermal power plant units, improving prediction accuracy by 7.3% and 5.7%, respectively. This research highlights the effectiveness of incorporating attention mechanisms into power load forecasting, providing a more efficient solution for energy management.
In another 2022 study, Zhao et al.3 proposed a convolutional neural network combining wavelet transform and attention mechanisms for image classification. The model employs discrete wavelet transform to decompose feature maps into low-frequency and high-frequency components, storing the structural information of basic objects and detailed features or noise, respectively. Attention mechanisms are then applied to capture detailed information.
In recent years, deep learning has significantly advanced meteorological prediction, particularly in handling nonlinear spatiotemporal data. Gong et al.4 proposed a CNN-LSTM hybrid model that uses CNN for spatial feature extraction and LSTM for temporal dependencies, achieving high accuracy in historical temperature prediction with MAE optimization, supporting agriculture and energy management. Similarly, Shen et al.5 designed a multi-scale CNN-LSTM-Attention model that incorporates attention mechanisms to focus on key features, achieving an MSE of 1.98 and RMSE of 0.81 in temperature prediction for eastern China, validating the effectiveness of multi-scale feature fusion.
In air quality prediction, Bekkar et al.6 explored a CNN-LSTM hybrid model, integrating spatiotemporal features such as PM2.5 data from adjacent stations and meteorological variables, achieving superior performance in hourly PM2.5 prediction in Beijing compared to traditional models. This work provided methodological references for subsequent studies like Kumar’s multi-view model.
For severe convective weather forecasting, Zhang et al.7 developed the CNN-BILSTM-AM model, combining bidirectional LSTM and attention mechanisms, using ERA5 data to predict precipitation 0–6 h in advance. This model outperformed traditional numerical models like WRF and highlighted the importance of total precipitable water (PWAT) and convective available potential energy (CAPE). In extreme weather event prediction, Alijoyo et al.8 proposed a hybrid CNN-BILSTM model optimized with a genetic algorithm and fruit fly optimizer (FFO), achieving a 99.4% accuracy in cyclone intensity prediction, significantly outperforming existing methods such as VGG-16.
Multi-step forecasting and data decomposition methods have further enhanced model stability. Coutinho et al.9 compared SD-CNN-LSTM and EEMD-CNN-LSTM, finding SD-CNN-LSTM better for single-step forecasts and EEMD-CNN-LSTM more stable for long-term forecasts, with error metrics significantly lower than undecomposed models. For multivariate meteorological data, Bai et al.10 proposed a hybrid model combining CNN-BILSTM with Random Forest, achieving MAE and MSE reductions of 35.6% and 57.5%, respectively, in temperature prediction for Changsha.
In pollutant prediction, Kumar and Kumar11 proposed MvS CNN-BILSTM, reducing RMSE by 3.8–7.1% in PM2.5 prediction. Park et al.12 used CNN with dynamic climate data (KPOPS) for monthly PM2.5 prediction in Seoul, while Yin and Sun13 combined CEEMD-DWT decomposition with BILSTM-InceptionV3-Transformer, reducing MAE by 57.41% in wind power prediction.
Although current research has made breakthroughs in model architecture optimization and multi source data fusion, it has not sufficiently explored dimensionality—reduction prediction tasks. Lv et al.14 used factor analysis to select key indicators in wastewater treatment, improving the accuracy of machine learning predictions. However, no study in meteorological prediction has combined factor analysis with deep learning models. This gap limits model efficiency and generalization in high dimensional meteorological data. Future research should urgently explore integrating factor analysis with deep learning models to unlock more prediction potential.
Dataset overview
We adopted a dataset called “Beijing Multi-Site Air-Quality Data Set” from Kaggle, which covers air quality monitoring data for the Tiantan station in Beijing, spanning from March 1, 2013, to February 28, 2017. This dataset includes hourly pollutant concentration records from multiple national-controlled air quality monitoring stations. The data was sourced from the Beijing Environmental Monitoring Center and was cross-referenced with recent meteorological station data provided by the China Meteorological Administration to ensure completeness and accuracy. The selection of these air quality features is based on the availability of sensors. Due to advancements in modern environmental monitoring technology, many sensors can measure the concentration of pollutants and meteorological conditions in the air in real-time and with accuracy. Therefore, pollutants such as PM2.5, PM10, SO2, NO2, CO, and O3, as well as meteorological data like temperature, pressure, dew point, and wind speed, can all be obtained through existing sensors. They together provide a solid data foundation for precise air quality prediction.
Research methodology
Data preprocessing and visualization
Data cleaning
To ensure the integrity of the time series data and address issues of missing values, we used the column-wise mean value imputation method. By filling in missing values with the column mean, the bias caused by missing data can be reduced, as this method assumes that the missing values are random and similar to the mean of other observations. At the same time, after filling in the missing values, the integrity of the dataset is maintained, which helps the model utilize all available information during training.
Standardization
During the data preprocessing phase, in order to eliminate discrepancies in the dimensionality of the various variables and enhance the numerical stability of the data, we applied Z-score standardization to all variables. The mathematical expression for Z-score standardization is as follows:
\({Z}_{i}\) represents the standardized data value, \({X}_{i}\) denotes the original data value, \(\mu\) and \(\sigma\) correspond to the mean and standard deviation of the variable. Z-score standardization ensures that different variables are optimized on the same scale during model training, thereby enhancing the learning efficiency and predictive accuracy of the model.
Data visualization
To intuitively understand the distribution characteristics of various air pollutant indicators and meteorological factors, we conducted a visualization analysis of the standardized data. Violin plots were generated to illustrate the probability density distribution of each variable. These plots combine the statistical information of box plots with kernel density estimation, providing a more comprehensive representation of the data distribution. Figure 1 shows the distribution of air pollutant and meteorological variables using violin plots.

Violin plots of air pollutant and meteorological variables.
From the Visualization Results, it can be observed that the distribution of PM2.5 and PM10 particles is relatively wide, indicating significant concentration variations and the potential presence of extreme values. The distribution of NO2 and CO is more concentrated, with relatively smaller concentration variations. SO2 has a narrower distribution, reflecting lower variability. The distribution of O3 is relatively concentrated, showing smaller variability.
Correlation Analysis
We subsequently calculated the correlation matrix and visualized it using a heatmap to intuitively present the correlations between variables. Figure 2 presents the heatmap of the correlation matrix for air quality variables.

Heatmap of correlation matrix for air quality variables.
The results indicate that there is a strong correlation between PM2.5, PM10, NO2, and CO, suggesting that they may be driven by the same latent factor.
Framework overview
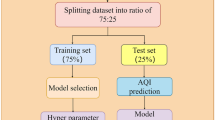
Figure 3 illustrates the overall flowchart of the air quality prediction framework.

Overall flowchart of the air quality prediction framework.
Factor analysis
Factor analysis applicability analysis
Next, we conducted an applicability test on the air quality data to ensure that it meets the basic assumptions and requirements for factor analysis. For this purpose, we used the KMO test and Bartlett’s sphericity test. The formula for calculating the KMO test is as follows:
\({r}_{ij}\) represents the simple correlation coefficient between variable \(i\) and \(j\), and \({a}_{ij}\) represents their partial correlation coefficient.
The formula for calculating Bartlett’s test statistic is:
\(N\) is the total sample size, \(k\) is the number of groups, \({S}_{i}\) is the sample variance of group \(i\), \({N}_{i}\) is the sample size of group \(i\), and \(S\) is the weighted average variance.
This statistic follows a chi-square distribution with \(k-1\) degrees of freedom.
Through computation, the KMO value is 0.6799, which exceeds the minimum applicability threshold of 0.6 for factor analysis. The p-value for Bartlett’s sphericity test is 0.0, which is significantly less than 0.05, indicating significant correlations among the variables and confirming the suitability for conducting factor analysis.
Factor analysis models
The factor analysis model assumes that the observed variables are generated by linear transformations of latent factors with error terms. The model can be expressed as follows:
\(\Lambda\) is the factor loading matrix, describing the influence of the factors on the observed variables. \(\epsilon\) denotes the error term, and \(z\) represents the factors, which are assumed to be independent of the errors.
We estimated the parameters of the factor analysis model using the maximum likelihood method and Principal Component Method. The maximum likelihood method formula is as follows:
Since factor \(z\) is latent variable, we employed the Expectation–Maximization algorithm for estimation15.
The Principal Component Method is a commonly used approach that determines factor loadings by calculating the eigenvalues and eigenvectors of the data’s covariance or correlation matrix. First, solve for the eigenvalues \({\lambda }_{i}\) and corresponding eigenvectors \({e}_{i}\) of the correlation matrix \(R\) of the observed variables. Then, select the eigenvectors corresponding to the \(k\) largest eigenvalues as the initial estimate of the factor loading matrix \(L\), The formulas are presented as follows:
where \(\Lambda\) is a diagonal matrix containing the square roots of the selected Eigen values.
To enhance the interpretability of the factors, orthogonal rotation is typically performed.
Orthogonal rotation is a transformation method aimed at adjusting the factor structure so that each variable’s loading on a particular factor tends to be extreme, thereby improving the interpretability of the factors. The most common orthogonal rotation method is Varimax Rotation, which seeks to maximize the variance of the factor loadings, resulting in each factor having high loadings on a few variables and low loadings on others.
Let the rotation matrix be \(R\). The rotated factor loading matrix \(L^{{\prime }}\) is given by:
\(R\) is an orthogonal matrix satisfying the condition \({R}^{T}R=I\).
The rotation matrix \(R\) is adjusted through iterative optimization methods, such as the Kaiser criterion, to make the rotated factor loading matrix sparser.
Finally, the factor scores are computed as:
there by completing the process of factor analysis.
The communalities of the variables were computed as follows:
\({h}_{i}^{2}\) denotes the communality of variable \(i\), \(m\) is the number of factors.
In order to determine the number of factors to be utilized in subsequent predictive modeling, we calculated the variance contribution of the four factors. Tables 1 and 2 show the factor loading matrices from maximum likelihood and principal component methods to determine the number of factors for predictive modeling. The results are as follows:
As can be seen from the results in Tables 1 and 2, given that the cumulative variance contribution of the first two factors exceeds 0.7, while the variance contributions of the third and fourth factors are too low, we decided to exclude the latter two factors in order to extract the key features and facilitate subsequent interpretation.
The results indicate that TEMP has a communality close to 1, suggesting that its variance is almost entirely explained by the extracted factors, In terms of explained variance, Factor 1 and Factor 2 account for variances of 3.515 and 1.944, respectively, highlighting Factor 1’s dominant role in the data structure.
After iteration, we obtained the factor loading matrix. For the sake of convenient exposition, we have selected the factor loading matrix and factor score matrix derived from the maximum likelihood method of factor analysis. Table 3 presents the factor loading matrix.
The factor loadings indicate that Factor 1 has a strong loading on PM2.5, PM10, NO2, and CO, all exceeding 0.7, suggesting that these pollutants may share a common source, such as traffic emissions or industrial pollution. Factor 2 has strong loadings on TEMP and DEWP, indicating its relationship with temperature-related meteorological factors.
We calculated the factor score matrix using the maximum likelihood regression method, expressed by the following formula:
\(F\) is the factor score matrix, \(\Lambda\) is the factor loading matrix, \(\Psi\) is the error covariance matrix, and \(X\) is the standardized observation data matrix. Table 4 shows the factor scores matrix.
Factor analysis combined with transformer models
Combining two factor analysis methods with transformer models
After the aforementioned analysis, we have identified two factors encompassing six original variables. Our subsequent research focuses on prediction based on dimensionality reduction through factor analysis. We embed the factor scores as features into a Transformer-based time series prediction model to enhance predictive performance. The calculation formula is as follows:
\(Q\), \(K\), and \(V\) represent the query matrix, key matrix, and value matrix, respectively, and \({d}_{k}\) is the dimension of the key. The multi-head attention mechanism applies self-attention multiple times, which can be expressed as:
Each head’s computation is identical to standard attention, and the results are linearly transformed via \({W}^{O}\). The Transformer effectively captures nonlinear patterns and long-term dependencies in time series data through this mechanism. We serialize the factor scores into an input matrix:
\({f}_{t,1}\) and \({f}_{t,2}\) represent the scores of Factor 1 and Factor 2 at time step \(t\) respectively. The target matrix is defined as:
We aim to use the factor scores at time \(t\) to predict the trend of factor changes at the next time step \(t+1\). The optimization objective of the model is to minimize the mean squared error, with the loss function defined as:
\({y}_{i}\) is the true value, and \({\widehat{y}}_{i}\) is the model’s predicted value.
We optimized the hyper-parameters of the Transformer model through grid search combined with tenfold cross-validation. We used the same cross-validation protocol. All tests in this study were conducted with the same processing to identify the optimal hyper-parameters. The results are shown in Table 5.
We optimized the hyper-parameters of the Transformer model through grid search combined with tenfold cross-validation. The best hyper-parameter combination was found to be: the number of attention heads is 2, the key dimension is 32, the number of units in the dense layer is 64, and the learning rate is 0.001. This combination performs excellently on multiple metrics, including MSE, RMSE, and \({R}^{2}\).
Tables 6, 7, 8 and 9 present the architecture and hyper-parameter tables of the prediction models combining two factor analysis methods with the Transformer.
Comparative study with two advanced baselines
Then we incorporated the factor scores derived from the maximum likelihood factor analysis into two advanced forecasting models, N-Beats and Informer, and compared their prediction results with those of our model. Tables 10, 11, 12 and 13 are the architecture tables and hyper-parameter tables of the prediction models that combine Maximum Likelihood Factor Analysis with N-Beats and Informer models.
Principal component analysis comparative experiments
To further compare our models, we then applied Principal Component Analysis to the dataset, and the results are as follows:
As shown in Table 14, the first two principal components account for more than 70% of the variance, which is generally considered a reasonable way to simplify the data since they retain most of the information. Therefore, we extracted the two main components to reduce the dimensionality of the data while preserving its primary information. The extracted principal component feature matrix was then used to construct time series forecasting models. We input these principal component feature matrices into Informer and N-Beats, respectively. Tables 15, 16, 17 and 18 present the architecture tables and hyper-parameter settings for the prediction models that integrate Principal Component Analysis with N-Beats and Informer models, respectively.
Model robustness assessment
To further validate the robustness of our model and ensure the rigor of our comparative study, we tested our approach on additional datasets.
In the predictive analysis conducted on the “Shunyi” dataset, we compared four models: Maximum Likelihood Factor Analysis combined with the Transformer model, PCA combined with the Transformer model, Maximum Likelihood Factor Analysis combined with the N-Beats model, and Maximum Likelihood Factor Analysis combined with the Informer model.
In order to compare the performance of different models at their optimal states, we employed grid search to identify new optimal hyper-parameters and retrained the models.
The following tables present the hyper-parameters of the relevant models. Tables 19, 20, 21, 22, 23, 24, 25 and 26 present the architecture and hyper-parameter tables for four different models.
Discrete wavelet transform
To further enhance prediction accuracy and feature extraction capabilities, we introduced DiscreteWavelet Transform to decompose the Transformer model’s output into multiple scales, thereby providing richer feature inputs for subsequent prediction models16. DWT recursively decomposes signals using a set of orthogonal wavelet bases, simultaneously capturing high-frequency details and low-frequency trends in time series data, thus more comprehensively characterizing data variation patterns. In this study, we employed the Daubechies wavelet basis function to decompose the Transformer model’s output, enabling the model to extract features from multiple scale levels. Assuming the Transformer model’s output is a time series, the DWT process can be expressed as:
\({A}_{K}\) is the approximation component at level \(k\), reflecting the long-term trend of the data, \({D}_{K},{D}_{K-1},\dots ,{D}_{1}\) is the detail component at different scales, capturing short-term fluctuations. In the specific computation process, DWT uses filter banks and down sampling operations, mathematically expressed as:
Through recursive computation, we obtain feature representations at different scales. To integrate DWT with the Transformer, we first use the Transformer to extract high-dimensional feature representations of the time series data, with its output denoted as \(H\in {\mathbb{R}}^{N\times d}\), \(d\) is the feature dimension. Then, we perform DWT decomposition on each feature channel, transforming it into multiple scale components of low and high frequencies:
The resulting components \({A}_{i,K}\) and \({D}_{i,K},{D}_{i,K-1},\dots ,{D}_{i,1}\) can serve as inputs to the subsequent CNN-BILSTM-ATTENTION mechanismmodel17, thereby enhancing the model’s ability to learn features at different time scales. This multi-scale feature extraction method not only effectively reduces data dimensionality and improves computational efficiency but also captures local details while preserving global trends, providing more precise factor analysis for air quality prediction.
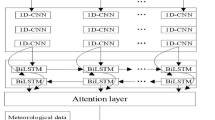
CNN-BILSTM-ATTENTION model
Relationship between transformer prediction and CNN-BILSTM-ATTENTION
The Transformer model’s self-attention mechanism captures long-term dependencies in time series data, effectively filtering noise, smoothing the data, and reducing overfitting risks. Simultaneously, the combination of DWT with the CNN-BILSTM-ATTENTION model based on the Transformer model yields more accurate prediction results18. The Transformer excels in global dependency modeling, while the CNN-BILSTM-ATTENTION model is suitable for predicting local features and dynamic changes. Their combination createsa synergistic effect, jointly enhancing prediction performance. In this study, we have chosen to employ both the Transformer model and the CNN-BILSTM-ATTENTION model, rather than opting for more complex deep learning models. This decision was made after careful consideration. The focus of our research lies in the integration of factor analysis with forecasting, tightly combining statistical methods with deep learning to explore the concept of dimensionality reduction in predictions, rather than merely pursuing the complexity of the model. The versatility of the model is an important factor in our considerations. We aimed to select a model that performs well across a variety of tasks, thereby reducing the complexity of parameter tuning across different datasets and tasks. The Transformer model has demonstrated robustness in handling sequential data and has shown strong performance in a range of forecasting tasks, aligning well with our research objectives.
CNN-BILSTM-ATTENTION model architecture
We propose an innovative hybrid deep learning architecture that integrates the aforementioned wavelet transform, convolutional neural network, bidirectional long short-term memory network, and attention mechanism into a CNN-BILSTM-ATTENTION model19. The core innovation of this architecture lies in its use of wavelet transform for multi-scale feature extraction of input data, followed by further local feature extraction through convolutional neural networks, and the capture of long-term dependencies in time series data through bidirectional LSTM and attention mechanisms. We utilized a grid search combined with cross-validation to identify the optimal hyper-parameters for the model. Table 27 describes the architecture of the CNN-BILSTM-ATTENTION model.
The convolutional neural network extracts local features by sliding convolutional kernels over the input data. We use a three-layer convolutional network, with each layer’s kernel size set to 2. The convolution operation is expressed as:
\(x\) is the input data, \(w\) is the convolutional kernel weight, \(b\) is the bias term, and \(k\) is the kernel size. Through convolution operations, we extract local features from the input data and reduce feature dimensionality via pooling layers.
The bidirectional LSTM captures both forward and backward temporal dependencies. We employ a two-layer bidirectional LSTM, with 100 and 50 units in each layer, respectively
\({f}_{t}\),\({i}_{t}\), and \({o}_{t}\) represent the forget gate, input gate, and output gate, respectively, \({C}_{t}\) is the cell state, and \({h}_{t}\) is the hidden state.
The attention mechanism automatically learns the importance of different time steps, expressed as:
\({\alpha }_{t}\) is the attention weight, \({h}_{t}\) is the hidden state of the LSTM, \({s}_{t-1}\) is the context vector from the previous time step, \(v\), \({W}_{h}\) and \({W}_{s}\) are learnable parameters.
Training strategy
We implemented an early stopping20 callback function, where training automatically halts if the validation loss does not show significant improvement over 7 consecutive epochs. This effectively prevents overfitting and saves training time.
Results
Two factor analysis methods with transformer models results
Predictive results
The factor scores derived from the principal component method of factor analysis and the maximum likelihood method of factor analysis were respectively embedded into the Transformer model to conduct predictions on the test set. Subsequently, a comparative analysis was performed with the traditional LSTM model. Figures 4 and 5 illustrate the predictive outcomes of the two models pertaining to Factor 1 and Factor 2.

Transformer model prediction results for Factor 1 and Factor 2 (PC).

Transformer model prediction results for Factor 1 and Factor 2 (ML).
In the principal component method of factor analysis, the \({R}^{2}\) values for Factor 1 and Factor 2 are 0.8835 and 0.9233, respectively. In contrast, the \({R}^{2}\) values for Factor 1 and Factor 2 obtained from the maximum likelihood method of factor analysis are 0.8511 and 0.9532, respectively. These results indicate that the Transformer model effectively captured the fluctuation trends in the data.
Prediction residual plot
Figures 6 and 7 present the residual plots for the predictions of Factor 1 and Factor 2.

Residual plots for Factor 1 and Factor 2 predictions (PC).

Residual plots for Factor 1 and Factor 2 predictions (ML).
The predictions for Factor 1 performed well in regions with significant data fluctuations, particularly in capturing peaks and troughs accurately. The residuals were mainly concentrated within the range of [− 1, 1], indicating minimal prediction errors. The predictions for Factor 2 were even more superior, precisely capturing the intense fluctuations in the data. Compared to the traditional LSTM model, the Transformer exhibited smaller deviations at certain peaks and troughs, further validating its advantage in modeling complex time series data.
Specifically, for the maximum likelihood factor analysis Transformer, the mean squared error for factor 1 was 0.1619, with an \({R}^{2}\) of 0.8520; for factor 2, the MSE was 0.0476, the \({R}^{2}\) was 0.9563, and the 95% confidence interval was (0.0433, 0.0918). The principal component analysis factor analysis Transformer model performed slightly less well, with an MSE of 0.1668 and an \({R}^{2}\) of 0.8447 for factor 1, and a 95% confidence interval of (− 0.0055, 0.0389); for factor 2, the MSE was 0.0905, the \({R}^{2}\) was 0.9256, and the 95% confidence interval was (0.0825, 0.1319).
Histogram of residual distribution
Next, we plotted the residual distribution of the factor analysis model based on the maximum likelihood method, as shown in the Figure below:
From the Fig. 8, both Factor 1 and Factor 2 residuals are approximately normally distributed, indicating random and unbiased model errors. For Factor 1, residuals cluster near 0 in a symmetrical distribution with gradually decreasing frequencies on both sides, showing no obvious skewness or outliers. This means the model has high accuracy and stability in predicting Factor 1, with small and evenly distributed errors and no systematic bias. Similarly, Factor 2 residuals are centered around 0 with good symmetry.

Residual distribution histogram.
In summary, the maximum likelihood factor analysis method combined with the Transformer model demonstrates superior performance in predicting Factor 2, with a higher \({R}^{2}\), lower MSE, and narrower confidence interval. For Factor 1, the differences between the two methods are relatively minor, but the maximum likelihood method still holds a slight edge in terms of MSE and \({R}^{2}\). Therefore, considering the overall performance, the maximum likelihood factor analysis method combined with the Transformer model exhibits greater capability in capturing the fluctuation trends in the data and is thus the preferred choice.
We have conducted an analysis of this result. In terms of data characteristics, the maximum likelihood method, which takes into account the probability distribution of the data, may exhibit greater robustness against noise or outliers in the data. Regarding model complexity, the maximum likelihood method typically generates more complex models. In contrast, the principal component method usually produces simpler models, which in some cases may be less precise than those generated by the maximum likelihood method.
Prediction accuracy in random time intervals
We further evaluated the predictive performance of the Transformer model through visualization analysis. Specifically, we divided the data into groups every ten hours and plotted two-dimensional graphs to illustrate the relationship between the actual and predicted values, as shown in the Fig. 9.

Transformer model performance visualization.
Figure 9 displays the model’s prediction results across different time periods, where blue points represent the actual values and red points indicate the predicted values. To enhance representativeness, we implemented a random function to randomly select six time periods from each factor for presentation. The results demonstrate that the model’s prediction errors are relatively small within these selected time periods, with the lowest error rate being 2.93% and the highest error rate being 5.08%. This indicates that the model achieves high prediction accuracy during these periods. Through this visualization method, we are able to gain a more comprehensive understanding of the model’s predictive capability and error distribution.
Based on these evaluation metrics, we can conclude that the proposed method exhibits good generalization ability and robustness when dealing with complex datasets. These results suggest that the constructed Transformer model is capable of stably capturing patterns in the data during cross-validation and achieving efficient predictions based on factor analysis.
Comparison with two baseline predictions
The prediction results of these models are evaluated and illustrated in Figs. 10 and 11.

Comprehensive model prediction evaluation (N-beats).

Comprehensive model prediction evaluation (informer).
For the N-Beats model, like Fig. 10, for Factor 1, the model’s MSE is 0.1912, the RMSE is 0.4373, and the Coefficient of Determination \({R}^{2}\) reaches 0.8220, with a 95% confidence interval of (− 0.0746, − 0.0382). These metrics indicate that although the model has achieved a relatively good fit for predicting Factor 1, the negative values in the 95% confidence interval suggest instability in the model’s predictions. For Factor 2, the model’s MSE is 0.1616, RMSE is 0.4020, \({R}^{2}\) is 0.8671, and the 95% confidence interval is (− 0.0248, 0.0314). The prediction results for Factor 2 show a higher \({R}^{2}\) value, indicating a better fit for this factor.However, despite these metrics demonstrating the N-Beats model’s capability in predicting Factors 1 and 2, compared to the Maximum Likelihood Factor Analysis combined with the Transformer model, the predictive performance of the N-Beats model is not as ideal.
Figure 11 presents the predictive outcomes of the Informer model. For Factor 1, the Transformer model demonstrated a slightly better performance than the Informer model. The Transformer model achieved a MSE of 0.1619 and \({R}^{2}\) of 0.8520, with a 95% confidence interval of (− 0.0124, 0.0305), indicating relatively stable performance. In contrast, the Informer model had an MSE of 0.1694, \({R}^{2}\) of 0.8423, and a 95% confidence interval of (− 0.0017, 0.0420). These results suggest that although the two models performed similarly, the Transformer model had a slight edge in terms of predictive accuracy and stability.
When predicting Factor 2, the Transformer model significantly outperformed the Informer model. The Transformer model recorded an MSE of 0.0476 and \({R}^{2}\) of 0.9563, with a 95% confidence interval of (0.0433, 0.0918), whereas the Informer model had an MSE of 0.0688, \({R}^{2}\) of 0.9434, and a 95% confidence interval of (0.1641, 0.2118).
Our visualization analysis of the prediction plots further supported the statistical results. For Factor 1, both models showed a reasonable alignment between predicted and actual values, with the Transformer model’s predictions clustering more closely around the actual values. For Factor 2, the Transformer model’s predictions were even closer to the actual values, especially in areas where data fluctuations were more pronounced.
The similarity in results between these two models may stem from their core mechanisms, such as the use of self-attention mechanisms to process sequential data. This similarity allows them to achieve comparable predictive outcomes in certain tasks.
Principal component analysis comparative experiments results
The predictive results are presented as follows:
Figures 12 and 13 present the predictive outcomes of PCA combined with the N-Beats and Informer models.

Prediction results of principal component analysis (N-beats).

Prediction results of principal component analysis (informer).
For PC1, the N-Beats model shows a significant improvement in performance, with MSE of 0.4717, RMSE of 0.6868, and \({R}^{2}\) of 0.8946. The 95% confidence interval is (− 0.0949, − 0.0054). The 95% confidence interval is narrower than in previous results, suggesting an increase in the stability of the predictions. For PC2, the N-Beats model also demonstrates better performance, with MSE of 0.6030, RMSE of 0.7765, \({R}^{2 }\) of 0.7668, and a 95% confidence interval of (0.1616, 0.2315), showing reasonable reliability in the predictions.
The Informer model performs slightly better than the N-Beats model for PC1, with MSE of 0.6291, RMSE of 0.8594, and \({R}^{2}\) of 0.8594. The 95% confidence interval is (− 0.2884, − 0.2061), indicating relative stability, but there is still room for improvement. For PC2, the Informer model’s performance is less satisfactory, with MSE of 0.7215, RMSE of 0.7209, and \({R}^{2}\) of 0.7209, although the 95% confidence interval of (0.2159, 0.2731) suggests some level of reliability.
Visualizations of the PC1 and PC2 predictions show that the N-Beats model has reduced the discrepancies between predicted and actual values, demonstrating a better ability to capture data fluctuations. The Informer model, while slightly better in some aspects, still does not cluster predictions closely around the true values, indicating limited predictive power.
The results indicate that both the N-Beats and Informer models have room for improvement when dealing with PCA-derived data. However, it is worth noting that PCA, which focuses on maximizing data variance, may not always provide clear interpretative meaning. Factor analysis aims to uncover latent factors behind observed variables, which are usually more interpretable. Using these interpretable factor scores for prediction is more effective than PCA combined with a Transformer model in predictive tasks. Although PCA can be a useful tool, it is not as effective as factor analysis combined with a Transformer model.
Model robustness test results
Figure 14 shows the prediction results of the “Shunyi” dataset:



Comparison test results on the “Shunyi” dataset.
Below is the comparative performance table of various models on the “Shunyi” dataset. MLFA means Maximum Likelihood Factor Analysis, PCFA means Principal Component Factor Analysis. Table 28 displays the prediction results for the four models.
Based on our comparative analysis of various models on the “Shunyi” dataset, it has been demonstrated that the Maximum Likelihood Factor Analysis combined with the Transformer model and the Maximum Likelihood Factor Analysis combined with the Informer model both exhibit significant predictive accuracy and robustness, significantly outperforming the other two models. When predicting Factor 1, the Maximum Likelihood Factor Analysis with the Transformer model achieved MSE of 0.1652 and \({R}^{2}\) value of 0.8231, with a 95% confidence interval of (− 0.0115, 0.0348), indicating low prediction error and high stability. For Factor 2, the model showed even more exceptional performance, with MSE of 0.0441, \({R}^{2}\) of 0.9597, and a 95% confidence interval of (0.0003, 0.0464), further confirming that the model’s predictions for Factor 2 were not only more accurate but also highly stable and reliable.
The Maximum Likelihood Factor Analysis combined with the Informer model also showed high reliability, especially in predicting Factor 2, with \({R}^{2}\) value of 0.9433, MSE of 0.2600, RMSE of 0.5099, and a 95% confidence interval of (0.0806, 0.1149). However, when predicting Factor 1, the Maximum Likelihood Factor Analysis with the Informer model had \({R}^{2}\) value of 0.8408, MSE of 0.2867, RMSE of 0.5354, and a 95% confidence interval of (− 0.1679, − 0.0275), indicating slightly lower performance compared to the Maximum Likelihood Factor Analysis with the Transformer model for this factor.
The Maximum Likelihood Factor Analysis combined with the N-Beats model performed well in predicting Factor 2, achieving \({R}^{2}\) value of 0.8932, MSE of 0.1616, RMSE of 0.4021, and a 95% confidence interval of (− 0.0247, 0.0313). However, its performance in predicting Factor 1 was slightly inferior, with \({R}^{2}\) value of 0.7852, MSE of 0.1912, RMSE of 0.4373, and a 95% confidence interval of (− 0.0746, − 0.0381).
On the other hand, the Principal Component Factor Analysis combined with the Transformer model showed better predictive performance for PC 2, with \({R}^{2}\) value of 0.9474, MSE of 0.2579, RMSE of 0.5079, and a 95% confidence interval of (− 0.1256, − 0.0563), but its performance in predicting PC 1 was not as strong as the other models, with \({R}^{2}\) value of 0.8198, MSE of 0.6977, RMSE of 0.8353, and a 95% confidence interval of (− 0.0618, 0.0279).
The Maximum Likelihood Factor Analysis combined with the Transformer model performs exceptionally well in both Factor 1 and Factor 2, closely competing with the Maximum Likelihood Factor Analysis combined with the Informer model. Although it slightly lags behind the Informer model in terms of \({R}^{2}\) value, it surpasses in convergence speed and MSE, and significantly outperforms the Principal Component Factor Analysis with Transformer and Maximum Likelihood Factor Analysis with N-Beats models.
In summary, the combination model of Maximum Likelihood Factor Analysis and the Transformer model consistently excels on other datasets, maintaining low prediction errors and high stability. It is still a highly competitive choice for the time—series prediction tasks of the two factors assessed in this study.
CNN-BILSTM-ATTENTION model results
Predictive results
We plotted the final prediction results and residual graphs for the six original variables explained by the two factors to visually demonstrate the model’s predictive performance. Figure 15 shows the prediction results of the CNN-BILSTM-ATTENTION model for the original variables:


Prediction results for original variables.
The prediction plots illustrate the comparison between predicted and actual values. In most cases, the predicted values closely align with the actual values, indicating the model’s strong predictive performance. The \({R}^{2}\) values are all close to 1, further demonstrating the model’s high accuracy.
Residual distribution of original variable predictions
Figure 16 presents the residual plots for the predictions of the original variables:

Residual plots for original variable predictions.
The residual plots display the differences between predicted and actual values. The vast majority of residuals are concentrated near zero, suggesting that the model’s prediction errors are minimal.
Prediction accuracy in random time intervals
Then we plotted the comparison charts of the actual and predicted values over time for these six original variables. As before, we divided each 10-h period into a group and set a random function to randomly select 1 image for each variable for display, Fig. 17 shows the result:

Time-specific prediction plots of the original variables.
Error rate results
We also generated an error rate table using a random function, as shown below:
Table 29 further substantiates the accuracy and stability of our model.
Performance evaluation
We employed MSE and RMSE metrics to evaluate the model’s performance. On the test set, the model achieved MSE of 0.06184 and RMSE of 0.2486, indicating that the model possesses high predictive precision.
Reasons for selecting the model architecture
In this study, we have chosen to employ both the Transformer model and the CNN-BILSTM-ATTENTION model, rather than opting for more complex deep learning models. This decision was made after careful consideration. The focus of our research lies in the integration of factor analysis with forecasting, tightly combining statistical methods with deep learning to explore the concept of dimensionality reduction in predictions, rather than merely pursuing the complexity of the model. The versatility of the model is an important factor in our considerations. We aimed to select a model that performs well across a variety of tasks, thereby reducing the complexity of parameter tuning across different datasets and tasks. The Transformer model has demonstrated robustness in handling sequential data and has shown strong performance in a range of forecasting tasks, aligning well with our research objectives.
Summary
In this study, we successfully integrated factor analysis with deep learning to propose an innovative framework for air quality prediction. By employing factor analysis for dimensionality reduction and feature extraction, we enhanced the model’s interpretability and prediction accuracy. Experimental results demonstrate that this framework excels in capturing long-term dependencies in time series and improving prediction stability. Future research directions include optimizing factor extraction methods and exploring external data sources to enhance the comprehensiveness of predictions. Additionally, we plan to investigate more efficient deep learning architectures to further optimize time-series modeling capabilities and enhance the model’s practical applicability. These efforts aim to provide more reliable solutions for air quality prediction and related fields. By combining factor analysis with deep learning models, our research offers new perspectives and methods for predicting complex environmental data.
Computational resources for model training
The model was trained on a computer equipped with an NVIDIA V100 GPU, which has 16 GB of VRAM, and the system memory is 32 GB. After data preprocessing and hyperparameter tuning, the model completed training in 2–3 h.
Data source
The data utilized in this research were sourced from the Beijing Multi-Site Air-Quality Data Set available on Kaggle (https://www.kaggle.com/datasets/sid321axn/beijing-multisite-airquality-data-set?select=PRSA_Data_Tiantan_20130301-20170228.csv).
Data availability
The data used in this study are sourced from the "Beijing Multi-Site Air-Quality Data Set," which is available on Kaggle. This dataset was originally published by Zhang et al. (2017) in the Proceedings of the Royal Society A. The download URL for the dataset is: https://www.kaggle.com/datasets/sid321axn/beijing-multisite-airquality-data-set?select=PRSA_Data_Tiantan_20130301-20170228.csv.
References
Saeed, F. & Aldera, S. Adaptive renewable energy forecasting utilizing a data driven PCA transformer architecture. IEEE Access 12, 109269–109280 (2024).
Wan, A., Chang, Q., Al-Bukhaiti, K. & He, J. Short-term power load forecasting for combined heat and power using CNN-LSTM enhanced by attention mechanism. Energy 2852, 128274 (2022).
Zhao, X., Huang, P. & Shu, X. Wavelet-attention CNN for image classification. Multimed. Syst. 28, 915–924 (2022).
Gong, Y., Zhang, Y., Wang, F., & Lee, C. H. Deep learning for weather forecasting: A CNN-LSTM hybrid model for predicting historical temperature data. arXiv:2410.14963 (2024).
Shen, J., Wu, W., & Xu, Q. Accurate prediction of temperature indicators in eastern china using a multi-scale CNN-LSTM-ATTENTION model. arXiv:2412.07997 (2024).
Bekkar, A., Hssina, B., Douzi, S. & Douzi, K. Air-pollution prediction in smart city, deep learning approach. J. Big Data 8, 1–21 (2021).
Zhang, J., Yin, M., Wang, P. & Gao, Z. A method based on deep learning for severe convective weather forecast: CNN-BILSTM-AM (version 1.0). Atmosphere 15(10), 1229 (2024).
Alijoyo, F. A. et al. Advanced hybrid CNN-BILSTM model augmented with GA and FFO for enhanced cyclone intensity forecasting. Alex. Eng. J. 92, 346–357 (2024).
Coutinho, E. R. et al. Multi-step forecasting of meteorological time series using CNN-LSTM with decomposition methods. Water Resour. Manage. 39, 3173–3198 (2025).
Bai, X., Zhang, L., Feng, Y., Yan, H. & Mi, Q. Multivariate temperature prediction model based on CNN-BILSTM and random forest. J. Supercomput. 81(1), 162 (2025).
Kumar, S. & Kumar, V. Multi-view stacked CNN-BILSTM (MvS CNN-BILSTM) for urban PM2.5 concentration prediction of India’s polluted cities. J. Clean. Prod. 444, 141259 (2024).
Park, I., Ho, C. H., Kim, J., Kim, J. H. & Jun, S. Y. Development of a monthly PM2.5 forecast model for Seoul, Korea, based on the dynamic climate forecast and a convolutional neural network algorithm. Atmospheric Res. 309, 107576 (2024).
Yin, L. & Sun, Y. BILSTM-InceptionV3-Transformer-fully-connected model for short-term wind power forecasting. Energy Convers. Manage. 321, 119094 (2024).
Lv, J. et al. Enhancing effluent quality prediction in wastewater treatment plants through the integration of factor analysis and machine learning. Biores. Technol. 393, 130008 (2024).
Peterson, R. A. A meta-analysis of variance accounted for and factor loadings in exploratory factor analysis. Mark. Lett. 11, 261–275 (2000).
Hou, Y., Zheng, F. & Shao, Y. The multi-timescale climate change and its impact on runoff based on cross-wavelet transformation. J. Water Resour. Res. 5, 564–571 (2016).
Luan, Y., & Lin, S. Research on text classification based on CNN and LSTM. In 2019 IEEE international conference on artificial intelligence and computer applications (ICAICA) 352–355 (IEEE, 2019).
Siami-Namini, S., Tavakoli, N., & Namin, A. S. The performance of LSTM and BILSTM in forecasting time series. In 2019 IEEE International Conference on Big Data (Big Data) 3285–3292 (IEEE, 2019).
Yang, Y. et al. A study on water quality prediction by a hybrid CNN–LSTM model with attention mechanism. Environ. Sci. Pollut. Res. 28(39), 55129–55139 (2021).
Anam, M. K., Defit, S., Haviluddin, H., Efrizoni, L. & Firdaus, M. B. Early stop on CNN–LSTM development to improve classification performance. J. Appl. Data Sci. 5(3), 11751188 (2024).
Author information
Authors and Affiliations
Contributions
L. was the principal contributor to the study. L. conceived and implemented the innovative idea of integrating factor analysis with the Transformer model and the CNN-BILSTM-ATTENTION architecture, including the integration of discrete wavelet transform with the Transformer model. H. made significant contributions to data collection and provided valuable suggestions for model improvement. He also played an important role in the writing of the paper, particularly in the factor analysis section, where H.'s contributions were outstanding. Both authors reviewed and approved the final version of the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Liu, S., Hu, Y. Air quality prediction based on factor analysis combined with Transformer and CNN-BILSTM-ATTENTION models. Sci Rep 15, 20014 (2025). https://doi.org/10.1038/s41598-025-03780-4
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-03780-4
