
Abstract
To address the challenges of high parameter volume, insufficient detection accuracy, and high false positive rates in traditional insulator target detection algorithms, this paper proposes a lightweight detection algorithm based on an enhanced YOLOX framework. First, Depthwise Separable Convolutions (DWConv) are employed to replace traditional convolutions, simplifying the model structure and reducing parameter count. Second, the Spatial Pyramid Pooling Fast-N (SPPF-N) module is introduced to substitute the traditional SPP module, and the last CSPLayer is removed, further compressing parameters while improving detection speed. Meanwhile, an Enhanced Convolutional Block Attention Module (E-CBAM) is embedded between the backbone and neck networks to significantly enhance feature extraction capabilities, overcoming the performance limitations of lightweight networks. Additionally, Coordinate Attention (CA) is integrated into the detection head to improve the precision of small target detection. Finally, the σWIoU loss function replaces the traditional IoU to accelerate convergence and optimize overall performance. Experiments show that compared to the original YOLOX, the proposed algorithm reduces parameters by 53.41% to 4.164 M and computational load to 12.975G, with mAP increased by 1.3%, detection accuracy reaching 98.81%, and recall achieving 100%. This algorithm balances high precision with lightweight design, meeting mobile deployment requirements and providing an efficient and reliable solution for insulator detection.
Similar content being viewed by others
Introduction
In recent years, China’s power system has maintained a commendable record of safe and stable operation, distinguishing itself as the only ultra-large power system globally that has not experienced a large-scale blackout. Despite this achievement, the security challenges facing the power system remain significant, with the potential for widespread power outages still a pressing concern. Regular maintenance and inspection of power grid equipment are crucial for ensuring the stability and reliability of the power system. Statistics indicate that over 80% of power system failures can be attributed to insulator defects1. Insulators, which are exposed to harsh external environments for extended periods, are susceptible to various factors such as lightning strikes, material degradation, pollution, and environmental stressors. These factors can lead to critical faults, including self-explosion, flashover, and pollution-induced flashover, which in turn can cause line paralysis and extensive blackouts, significantly impacting power supply stability. Traditional manual inspections of these vital components are not only time-consuming and labor-intensive but also inefficient and pose substantial safety risks to personnel. The need for advanced, automated inspection technologies is therefore paramount to enhance the efficiency, accuracy, and safety of maintenance operations, thereby reinforcing the overall resilience of the power system.
Leveraging the significant advancements in deep learning, especially in image classification and object detection, research on insulator detection has concentrated on two key areas. First, enhancing detection accuracy by optimizing model architecture to improve nonlinear expression capabilities. Second, accelerating detection speed through model compression and lightweighting, effectively reducing the number of parameters and computational complexity. These approaches aim to achieve both high precision and efficient performance in insulator detection systems.
In the pursuit of enhancing detection accuracy, notable contributions have been made by several researchers. He Y2 advanced the Faster R-CNN3 method, significantly improving small target detection accuracy through fine-tuning the Region Proposal Network (RPN) and Region of Interest (RoI) pooling layer, implementing a multi-scale feature map generation mechanism, and augmenting the training dataset with image transformation techniques. Yang Lina4 integrated DenseNet into the DarkNet53 backbone of YOLOv35, promoting the reuse and fusion of feature information to effectively address overlapping occlusions in complex backgrounds, thus achieving precise recognition and localization of insulators. Cheng6 developed an insulator defect detection algorithm based on DETR, mitigating DETR’s training difficulty and enhancing small target detection through transfer learning and an improved loss function. Li7 introduced the HRD-YOLOX algorithm, tailored for insulator recognition and defect detection using the YOLOX8 network. This approach incorporates a Hybrid Attention Module (HAM) with CSP (Cross Stage Partial connections) to reduce interference from complex backgrounds in insulator images. It replaces the PANet structure with an R-BiFPN (Refined Bidirectional Feature Pyramid Network) for enhanced feature fusion and adds an improved regularization module within the BiFPN convolutional layers to prevent overfitting and boost inference speed. While these methods have markedly improved detection accuracy, they still present substantial parameter volumes and computational complexities, posing significant challenges for deployment on edge devices due to the stringent requirements of such platforms.
In the context of enhancing detection speed, several researchers have introduced innovative approaches to streamline model architectures and reduce computational complexity. He M9 simplified the feature pyramid layers and shared convolutional layers of the Region Proposal Network using a hybrid deep dilated convolutional network. This approach effectively reduces the model’s parameter volume while preserving robust feature extraction capabilities, thus accelerating detection speeds. Deng10 developed a lightweight object detection network by refining YOLOv3 with CSPNet and GhostNet, creating a new backbone called ML-Darknet. This design achieves gradient diversion and significantly boosts detection speed without compromising accuracy. Han Gujing11 enhanced Tiny-YOLOv412 by integrating self-attention mechanisms and ECA-Net, resulting in a lightweight object detection algorithm that dramatically reduces the complexity of the original YOLOv4 while maintaining performance. Li1313 proposed an improved lightweight model based on YOLOv514 incorporating MobileNet-V3 modules into the YOLOv5 backbone and introducing a shuffle attention mechanism. The original PAN + FPN feature fusion structure was replaced with a weighted bidirectional pyramid structure (BiFPN), optimizing network performance and enhancing generalization capability through streamlined architecture. Sun15 introduced a lightweight model based on ShuffleNetv2-YOLOv3, utilizing ShuffleNetv216 as the backbone for YOLOv3. This configuration increases detection speed but comes at the cost of some detection accuracy. While these methods have successfully minimized the model’s parameter volume and computational demands, their performance in insulator detection and overall generalization remains an area for further improvement.
Through the analysis of existing research methods, it is clear that current algorithms face challenges in achieving an optimal balance between detection accuracy, speed, and model parameter volume, making them less suitable for deployment on mobile terminal devices such as drones. To address these issues, this paper proposes an improved lightweight insulator target detection algorithm based on YOLOX, designed to meet stringent detection accuracy requirements while also optimizing for speed and parameter efficiency.
The main contributions of this work include the following aspects: (1) Replacing standard convolutions with Depthwise Separable Convolutions (DWConv)17 to significantly reduce the model’s parameter volume without sacrificing performance. (2) Upgrading the Spatial Pyramid Pooling (SPP) module in the backbone network to the Spatial Pyramid Pooling Fast-N (SPPF-N) module and removing the last CSPLayer module, thereby increasing detection speed and further reducing the parameter count. (3) Introducing an Enhanced Convolutional Block Attention Module (E-CBAM) between the backbone and neck networks to bolster feature extraction capabilities, addressing the inherent limitations of lightweight neural networks in this area. (4) Incorporating Coordinate Attention (CA)18 into the small target detection head to enhance local feature extraction and improve the detection accuracy of small insulators. (5) The proposed σWIoU loss function is used to replace the original loss function, which accelerates model convergence and enhances overall network performance. These enhancements aim to deliver a robust solution that not only maintains high detection accuracy but also meets the critical demands of real-time operation and efficient deployment on mobile terminals such as drones.
YOLOX network
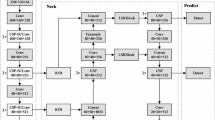
YOLOX adopts an anchor-free mechanism, eliminating the traditional anchor box design and thereby simplifying the input processing workflow. At the input stage, it employs adaptive image resizing, mosaic data augmentation19, and mixup data augmentation20. Adaptive image resizing uniformly adjusts all images to a 640 × 640 size, streamlining inference speed. Mosaic data augmentation enhances data diversity by generating new training samples through the random processing and concatenation of four images. Mixup data augmentation further enriches the data distribution and mitigates overfitting risks by blending two images according to a weighted average. The backbone network of YOLOX comprises modules such as Focus, Conv2D_BN_SiLU, CSPLayer, and SPPBottleneck. The Conv2D_BN_SiLU module integrates convolution with batch normalization and SiLU activation, ensuring efficient feature extraction. The CSPLayer leverages residual structures and convolutional operations for robust feature fusion, enhancing both feature richness and model stability. The SPPBottleneck utilizes spatial pyramid pooling to fuse multi-scale features, strengthening the model’s capability to detect objects across various sizes. For feature aggregation, the neck network adopts a Path Aggregation Network (PANet) structure, which combines low-level location information with high-level semantic details via bidirectional feature fusion, thus improving multi-scale object detection. The detection head features a decoupled design that separates classification from regression tasks, preventing mutual interference and boosting overall detection performance. Figure 1. provides a visual representation of the YOLOX network architecture.

YOLOX network structure.
Improved YOLOX network
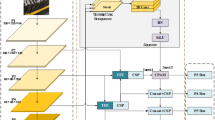
Aiming at the image characteristics of transmission line insulators, this paper proposes an improved lightweight YOLOX-based insulator target detection algorithm. The network model is shown in Fig. 2.,to reduce the parameter count and improve the model’s detection speed, this paper employs the lightweight module DWConv in the backbone, neck, and head networks. This module significantly reduces the model’s parameter volume. An E-CBAM Module, proposed in this paper, is introduced between the backbone and neck networks to enhance the model’s feature extraction capabilities and address the limitations of lightweight networks. Additionally, the proposed SPPF-N module is added after the backbone network, and the last layer of CSPLayer is removed to enhance the capability for multi-scale target detection while reducing the parameter count and computational speed. The CA mechanism is integrated into the front end of the small-target detection head to further improve the detection accuracy of the algorithm for small insulators. Finally, the proposed σWIoU loss function replaces the original IOU aim to accelerate model convergence and enhance overall network performance.

Improved YOLOX Network Structure.
SPPF-N: lightweight Spatial pyramid pooling
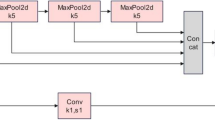
In the task of insulator target detection, insulator images exhibit different scales, which can make it difficult for the model to capture detailed information when processing these targets. Handling feature maps of varying scales increases computational complexity and slows down the model’s detection speed. To address this, this paper introduces and improves upon the SPPF module. The improved SPPF module is named SPPF-N, and its structure is shown in Fig. 3. SPPF is an enhanced version of the SPP structure, replacing the parallel structure with a series connection to avoid potential feature fragmentation caused by parallel pooling. This makes it more robust in power inspection tasks involving complex backgrounds. In this paper, a channel-wise Batch Normalization (BN) layer is added to the output end of the ConvBNSiLU in SPPF, which effectively reduces the weight of less significant features. Additionally, sparse weight penalties are applied to the attention modules, maintaining model performance while improving computational efficiency. As a result, SPPF-N accelerates the inference speed of the network model while simultaneously integrating local and global features, enriching the expressive power of feature maps, and thereby enhancing detection accuracy and overall performance.

SPPF-N module schematic.
Backbone network optimization
In the backbone feature network of the YOLOX model, the last two layers incorporate the SPP and CSPLayer designs, with the SPP module notably expanding the network’s receptive field and facilitating multi-scale information exchange by processing input feature maps of arbitrary sizes into fixed-size feature vectors. However, this effectiveness comes at a cost, as the SPP module requires performing three parallel pooling operations with different-sized convolutional kernels on the input feature map and concatenating these results, leading to a significant increase in model parameters and computational complexity.
To streamline the model and accelerate inference, we introduce the SPPF-N module to replace the original SPP module. The SPPF-N optimizes the pooling operation, reducing redundant calculations and effectively lowering computational complexity while enhancing model efficiency during inference. Furthermore, to further lighten the model’s burden without compromising detection accuracy, we have opted to remove the CSPLayer from the final layer of the backbone network.
Feature augmentation module
This paper conducts a series of experiments based on the YOLOX algorithm and finds that, in multi-scale transmission scenarios, the original feature extraction network has significant shortcomings in capturing the contour information of insulators, particularly exhibiting notable missed detections for small-scale or occluded insulators. To address this, this study proposes an attention-guided feature enhancement strategy to improve the model’s ability to handle targets of varying scales while reducing the parameter count and enhancing detection speed. Specifically, an improved CBAM21 module is introduced as a feature optimization layer between the backbone network and the feature pyramid. The improved CBAM module is named the E-CBAM module, and its structure is shown in Fig. 4. The E-CBAM module is an enhanced version of the CBAM architecture, replacing the original channel attention mechanism with the Efficient Channel Attention (ECA) module22 and integrating it with the Spatial Attention Module (SAM)23. The ECA module introduces a local interaction mechanism, avoiding potential information loss caused by channel compression in CBAM, thereby more effectively preserving the correlation between key channels. Additionally, it eliminates the need for fully connected layers, significantly reducing the parameter count and computational overhead, thus enhancing the model’s lightweight nature and operational speed. In insulator detection scenarios, where real-time performance and accuracy are equally critical, the improved E-CBAM module not only maintains or even enhances feature extraction capabilities but also improves the model’s responsiveness and robustness to targets in complex backgrounds.

structure of E-CBAM and its sub-modules.
In E-CBAM, the input feature map \(\:Z\in\:{R}^{H\times\:W\times\:C}\)is processed through the ECA module to construct the channel attention map \(\:{M}_{C}\in\:{R}^{1\times\:1\times\:C}\) and through the SAM to construct the spatial attention map \(\:{M}_{s}\in\:{R}^{H\times\:W\times\:1}\). The overall structure of the convolutional attention mechanism is shown in Fig. a, and the implementation process is described by Eqs. (1) and (2).
In the E-CBAM, Z represents the input feature map, \(\:{M}_{C}\) represents the efficient channel attention weights, \(\:{M}_{S}\) represents the spatial attention weights, \(\:Z^{\prime\:}\) represents the feature signal after channel attention weight calculation, and \(\:{Z}^{{\prime}{\prime\:}}\) represents the final output of E-CBAM.
The structure of the ECA module is shown in Fig. b. First, a Global Average Pooling (GAP) layer is used to reduce each channel of the input feature map to a scalar, capturing the global information of the channel, as shown in Eq. (3).
where \(\:y\) represents the global feature, and \(\:{\:x}_{i}\) represents the \(\:i\)-th feature map with input size \(\:H\:\text{x}\:W\). Secondly, a one-dimensional convolutional layer performs a linear transformation on the feature vector output by the GAP, learning the interaction weights between different channels, thus capturing the dependencies among channels, as shown in Eq. (4).
where \(\:\sigma\:\) represents the Sigmoid activation function, and \(\:w\:\)represents the channel weights. Finally, the channel weight vector is multiplied element-wise with the input feature map along the channel dimension, resulting in a feature map with channel attention, where each channel’s feature is assigned a different importance, enabling the differentiation and extraction of important features. To improve local interaction efficiency, the values are adaptively determined by mapping in the channel dimension, thereby optimizing the feature extraction process, as shown in Eq. (5).
where \(\:\gamma\:\) and \(\:b\:\)are adjustment parameters, set to 2 and 1 respectively, and \(\:K\:\)is the kernel size, with \(\:{\left|F\right|}_{odd}\) odd representing the nearest odd number to F.
The structure of the SAM is shown in Fig. c. The SAM complements the ECA module by focusing on the position of information. The input signal passes through both a MaxPooling layer and an AveragePooling layer to generate two sets of feature signals. These two sets of feature signals are concatenated to form the SAM \(\:{M}_{s}\in\:{R}^{H\times\:W\times\:1}\). The spatial attention mechanism is shown in Eq. (6).
In the formula: \(\:\sigma\:\:\)denotes the sigmoid function, and \(\:{f}^{n\times\:n}\) represents the convolution operation with a filter size of \(\:n\times\:n\).
The E-CBAM module enhances the model’s computational efficiency and deployment flexibility while avoiding information loss caused by dimensionality reduction in the CBAM module. It fully preserves the fine-grained features of insulators, improving the sensitivity to small targets.
Channel attention mechanism
In the insulator object detection task, where some targets are small and prone to feature information loss due to background factors during YOLOX’s feature fusion, this paper proposes integrating the CA mechanism into the small target detection head to enhance local feature representation. This improvement allows the network model to more accurately locate and identify key information in images. Unlike traditional attention mechanisms such as Squeeze-and-Excitation Networks (SE) 24and CBAM, the CA attention mechanism is a novel module specifically designed for channel attention, integrating positional information into channel information to capture directional and positional details while extracting features.
As illustrated in Fig. 5, the process begins with global average pooling of the input feature map along both vertical and horizontal directions. The feature information from these directions is then merged back into the feature map to enrich its representation. Following this, the enhanced feature map undergoes division and convolution along the horizontal and vertical directions. The two resulting parts of the feature map precisely pinpoint the rows and columns of the target objects of interest, thereby improving the accuracy and robustness of small target detection.

CA mechanism module.
Improvement of the loss function
The loss function of the YOLOX algorithm consists of three parts: classification loss, confidence loss, and regression loss. For the insulator dataset of transmission lines used in this paper, the algorithm’s built-in classification loss and confidence loss functions perform relatively well. However, the accuracy of bounding box regression predictions is relatively low, leaving room for improvement. In this paper, the improved WIoUv125 loss function is used to replace the original IoU loss function. The improved WIoUv1 loss function is denoted as \(\:\sigma\)WIoU. The WIoUv1 loss function introduces a center distance penalty mechanism based on the original IoU loss function. Its core idea is to incorporate the distance between the center of the prior box and the target center as a penalty term while calculating the overlap degree between the prior box and the ground truth box, thereby encouraging more accurate bounding box positioning. The calculation formula for the WIoUv1 loss function is as follows:
\(\:{L}_{IoU}\) is the IoU loss function, \(\:{R}_{WIoU}\) represents the normalized distance between the centers of the ground truth box and the predicted box. where (\(\:{W}_{g},{\:H}_{g}\)) represent the width and height of the optimal bounding box, (\(\:{x}_{gt}\),\(\:{y}_{gt}\)) and (\(\:x\), \(\:y\)) represent the coordinates of the center points of the ground truth box and the predicted box, respectively. The symbol ∗ indicates that the value is detached from the computation graph, meaning that gradients will not be computed with respect to this value during backpropagation. The parameters used in the WIoUv1 loss function are shown in Fig. 6.

WIOU loss calculation diagram.
The WIoUv1 loss function handles offsets in the\(\:\:x/y\) directions symmetrically when processing objects. Given that images of insulators on transmission lines are often long and narrow, this symmetry in how WIoUv1 penalizes shifts in the center of targets results in a weakened penalty for such displacements. Consequently, the model exhibits an imbalance in sensitivity to horizontal or vertical shifts, leading to a decrease in positioning accuracy. To address this issue, this paper proposes a new loss function, σWIOU, based on WIoUv1. The σWIOU introduces asymmetric penalty factors \(\alpha\) and\(\:\:\beta\:\). These parameters \(\alpha\) and\(\:\:\:\beta\:\) are adjustable weights for errors in the \(\:x\) and \(\:y\) directions, respectively. By adjusting these parameters, it is possible to compensate for the imbalance in aspect ratios of detected targets, enhancing the precision of different detection boxes and the robustness of the model. Specifically, the asymmetric penalty factors \(\alpha\) and\(\:\:\beta\:\) can be adaptively adjusted according to the aspect ratio of the target image, as shown in Eq. (9) and Eq. (10). Parameter \(\alpha\) is introduced into the calculation along the x-axis, while \(\:\beta\:\) is used for the y-axis calculation. This approach leads to a new normalized distance R_σWIoU between the center points of the target box and the predicted box, as expressed in Eq. (11). σWIoU enables the model to pay more attention to the imbalance in the aspect ratio of targets, thereby improving the model’s detection performance. The improved loss function is shown in Eq. (12).
Experiments and results analysis
Dataset
This paper focuses on the object detection of insulator images, constructing an image dataset through aerial photography by drones, collecting a total of 600 valid insulator photos. To enhance model robustness and prevent overfitting given the relatively small dataset size, a combination of mosaic and mixup data augmentation methods is employed for data enhancement. Specifically, four images are randomly selected from the training dataset, and a base image twice the feature map size and filled with a specific color is created. A point within this base image is randomly determined as the origin of coordinates. The four selected images are then randomly scaled and arranged according to predefined rules within the base image, clipped using the coordinate origin as the boundary to ensure the synthesized image fits within the base image’s limits. Label information from the original four images is accurately mapped onto the newly generated mosaic image based on label mapping relationships. Insulators in the images are labeled using specialized software, and the dataset is divided into training, validation, and test sets in an 8:1:1 ratio to achieve optimal training outcomes.
Experimental environment and parameter settings
The experimental environment is based on the PyTorch deep learning framework, operating on a Windows 11 system. The network model is constructed using the Python language, leveraging CUDA version 11.0 and cuDNN version 7.6.5 for optimized performance. Specific additional configurations are detailed in Table 1.
During the training process, the input image size is set to 640 × 640, with an initial learning rate of 0.01 to prevent poor convergence and ensure efficient training speed. The training is configured for 200 iterations, using a batch size of 4. Model parameters are updated via the SGD (Stochastic Gradient Descent) optimizer. The specific parameter configurations for the experimental training phase are detailed in Table 2.
Evaluation metrics
To quantitatively evaluate the performance of the proposed algorithm for insulator object detection, this paper employs mAP (mean Average Precision) as the assessment metric. mAP is calculated as the average of the AP values across all target categories, with each AP value representing the area under the Precision-Recall (PR) curve. A larger area under the curve indicates higher precision. The formula for this evaluation is expressed as follows:
where TP represents the number of true positive samples correctly predicted by the model, FP denotes the number of false positive samples incorrectly predicted, and FN indicates the number of false negative samples missed by the model. N signifies the total number of sample categories.
Loss function comparison experiment
To verify the superiority of the proposed loss function, we conducted a comparison experiment using several mainstream loss functions, altering only the loss function while keeping all other training parameters constant. The experimental results are presented in Table 3.
From the experimental results, it can be concluded that replacing YOLOX’s loss function with Complete-IoU (CIoU), Distance-IoU (DIoU)26, Generalized-IoU (GIoU)27, and Efficient-IoU (EIoU)28 led to increases in precision AP by 1.91%, 2.25%, 2.3%, and 2.46%, respectively, yet their mAP exhibited varying degrees of decrease. In contrast, substituting the loss function with WIoU resulted in a precision AP increase of 2.47% and an mAP improvement of 0.85%, achieving an mAP of 97.01% with an FPS boost of 2.36. This clearly demonstrates that the WIoU loss function adopted in this paper effectively enhances the overall performance of the detection algorithm. Therefore, based on the WIoU loss function, this paper proposes an improved loss function, σWIOU, to address the issue of weakened center offset penalty when handling targets with imbalanced aspect ratios.
Ablation experiments
To validate the effectiveness of each proposed module, an ablation study based on improvements to the YOLOX algorithm was designed, with the experimental setup detailed in Table 4 and results presented in Table 5. Experiment 1 utilizes the original YOLOX model, achieving an mAP of 96.16%, precision of 91.45%, recall of 96.00%, and FPS of 76.94. Experiments 2 through 9 progressively incorporate different modules into the YOLOX model, Experiment 10 represents the algorithm model incorporating all the proposed improvements. From Experiments 1 and 2, it can be observed that replacing basic convolutions with DWConv resulted in a lightweight model with parameters reduced to 5.343 M and computational complexity lowered to 13.914G FLOPs, though at the expense of some performance metrics. From Experiments 3 and 4, it is evident that, compared to the original SPPF module, the proposed SPPF-N structure showed no significant changes in parameter count, computational load, or FPS, while achieving a 0.42% improvement in mAP, validating the effectiveness of the proposed SPPF-N structure. Experiment 5 added the CA mechanism to the small target detection head, significantly improving detection accuracy with minimal parameter increase. Comparing Experiments 6 and 7, the proposed E-CBAM module showed no noticeable changes in recall rate, parameter count, computational load, or FPS, but achieved a 0.58% improvement in precision and a 0.49% increase in mAP, demonstrating the effectiveness of the E-CBAM module. From Experiments 8 and 9, it can be seen that, compared to the original WIoU loss function, the proposed σWIoU loss function showed no significant changes in recall rate, parameter count, or computational load, but achieved a 3.43% improvement in precision and a 0.16% increase in mAP, validating the effectiveness of the σWIoU loss function. When comparing Experiment 10 with other algorithms, it is clear that the proposed algorithm achieves the smallest parameter count and computational load while attaining the highest mAP of 97.46%, demonstrating the best overall performance. Compared to the unimproved version, the proposed algorithm improves precision by 7.36%, recall rate by 4%, and mAP by 1.3%, while reducing the parameter count and computational load by 4.774 M and 13.782G, respectively, and increasing FPS by 13.43.
Through these experiments, the impact of each module on the overall performance of the proposed algorithm model can be systematically evaluated, validating the effectiveness of all the proposed improvements.
Comparison experiment
This paper conducts comparison experiments using YOLOv3, YOLOv5 s, SSD, Faster-RCNN, YOLOX, YOLOv4-tiny, YOLOv7-Tiny, YOLOv8-n, YOLO11 s and the improved YOLOX algorithm models, with results shown in Table 6. The mAP value of the proposed algorithm reaches 97.46%, marking improvements over YOLOv3, YOLOv5 s, SSD, YOLOX, YOLOv4-Tiny, YOLOv7-Tiny, YOLOv8-n and YOLO11 s by 6.63%, 5.63%, 21.16%, 1.3%, 6.84%, 4.72%,0.6%,3.86% respectively. Recall rates are enhanced by 27.68%, 26%, 41.92%, 3%, 19%, 9.43%, 3%, 9.2% compared to these models. Relative to Faster-RCNN, the mAP is only 1.14% lower. However, the Faster-RCNN model parameters boasts 136.68 M, 33 times more than the proposed algorithm, hindering deployment on mobile terminals like drones. In terms of parameter count, the improved YOLOX algorithm model is smaller than YOLOv3, YOLOv5 s, SSD, Faster-RCNN, YOLOv4-tiny, YOLOv7-Tiny, and YOLO11 s, with respective reductions of 57.786 M, 42.886 M, 19.446 M, 132.516 M, 1.706 M, 2.063 M, and 5.236 M, though it is slightly higher than YOLOv8-n. In terms of FPS, the improved YOLOX algorithm model outperforms YOLOv3, YOLOv5 s, SSD, and YOLOX, achieving respective values of 18.082, 24.659, 26.6, 43.116, and 34.29 FPS. However, it falls short compared to lightweight models such as YOLOv4-Tiny, YOLOv7-Tiny, YOLOv8-n, and YOLO11 s. Nevertheless, the proposed algorithm model demonstrates superior performance in terms of mAP compared to these lightweight models.
Comprehensive analysis reveals that the improved algorithm excels in detection precision and model lightweighting. Compared to the original YOLOX, the number of parameters is reduced to 4.164 M, a decrease of 53.41%, while precision improves by 7.36%, recall rate by 4%, and mAP by 1.3%. As depicted in Fig. 7, the improved YOLOX algorithm converges at the fastest speed, achieving notably superior detection accuracy over YOLOv3, YOLOv5 s, SSD, YOLOv4-Tiny, YOLOv7-Tiny, YOLOv8-n and YOLO11 s second only to the Faster-RCNN algorithm model, yet with significantly fewer parameters, making it highly suitable for efficient deployment.

The mAP chart from the comparative experiment.
To intuitively analyze the detection performance of the proposed improved algorithm, three groups of insulators in different environmental backgrounds were selected for object detection, with comparative results shown in Table 7. Image A, featuring a complex background with 4 insulators including one partially obscured by a tower, saw successful detection of all insulators by the proposed algorithm, YOLOX, Faster-RCNN, YOLOv7-Tiny and YOLO11 s; however, other algorithms had varying degrees of missed detections. Notably, Faster-RCNN misidentified a soil mound beside the river as an insulator, while YOLOX experienced repeated detections on the partially obscured insulator.
In Image B, containing 3 insulators where one is partially obscured by a tower and the other two are larger targets, only the proposed algorithm, Faster-RCNN and YOLO11 s detected all three targets, whereas other models failed to detect the partially obscured insulator. For Image C, which includes 6 insulators—3 small targets, two partially obscured by a tower, and one at the image edge. only the proposed algorithm successfully detected all six insulators. Other network models exhibited varying degrees of missed and false detections, with YOLOv8-n failing to correctly identify two partially obscured insulators and YOLO11 s failing to correctly identify one partially obscured insulator. Additionally, Faster-RCNN not only failed to fully detect all insulators but also encountered issues with false and repeated detections.
In summary, the proposed algorithm excels in complex backgrounds and occlusion scenarios, effectively avoiding missed and false detections, particularly demonstrating superior performance in detecting small and partially obscured targets, making it highly reliable for challenging inspection environments.
Conclusions
To address the challenges of low detection accuracy, redundant parameters, and high false positive rates in insulator detection under complex transmission line backgrounds, a lightweight YOLOX-based object detection algorithm is proposed. Compared to the original model, the algorithm reduces parameters by 53.41% to 4.164 M and computational load to 12.975G, while achieving 98.81% detection accuracy, 97.46% mAP, and 100% recall rate. Its parameter count is significantly lower than existing models, making it suitable for mobile terminal deployment. Although FPS is slightly lower than algorithms like YOLOv7-tiny and YOLOv8-n, it outperforms them in mAP, recall rate, and detection accuracy, with parameter efficiency superior to YOLOv7-tiny and comparable to YOLOv8-n. Future work will focus on optimizing the model architecture to enhance FPS, further reduce parameters and computational complexity, improve edge device applicability, and promote practical deployment.
Data availability
The data generated during and/or analyzed during the current study are available from the corresponding author on reasonable request.
References
1. Zhai Y J, Wang D, et al. Fault detection of insulator based on saliency and adaptive morphology[J]. Multimedia Tools and Applications, 2016, 76(9): 12051–12064.
2. He Y. Improved Faster R-CNN Based on Multi-Scale Module for Detecting Weak Ground Targets in Remote Sensing Images[J]. International Journal of High Speed Electronics and Systems, 2024: 2540042.
3. Ren SHQ, He K M,Girshick R, et al. Faster R-CNN: Towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(6): 1137–1149.
4. Yang L, Chen G, Ci W. Multiclass objects detection algorithm using DarkNet-53 and DenseNet for intelligent vehicles[J]. EURASIP Journal on Advances in Signal Processing, 2023, 2023(1): 85.
5. Deng L, Li H, Liu H, et al. A lightweight YOLOv3 algorithm used for safety helmet detection[J]. Scientific reports, 2022, 12(1): 10981.
6. Cheng Y, Liu D M. An image-based deep learning approach with improved DETR for power line insulator defect detection[J]. Journal of Sensors, 2022, 2022: 6703864.
7. Y. Li, D. Feng, Q. Zhang and S. Li, HRD-YOLOX Based Insulator Identification and Defect Detection Method for Transmission Lines[J]. IEEE Access, 2024, 12:22649–22661,
8. S. Wang, G. Xu, Q. Song, Z. Yang and Y. Xue, A UAV Object Detection Algorithm Based on Improved YOLOX. [C]// 2022 5th International Conference on Intelligent Robotics and Control Engineering (IRCE), Tianjin, China, 2022: 98–102
9. He M, He K ,Huang Q, et al. Lightweight mask R-CNN for instance segmentation and particle physical property analysis in multiphase flow[J].Powder Technology,2025,449:120366–120366.
10. Deng L, Li H, Liu H, et al. A lightweight YOLOv3 algorithm used for safety helmet detection[J]. Scientific reports, 2022, 12(1): 10981.
11. Gujing H ,Min H ,Feng Z, et al. Insulator detection and damage identification based on improved lightweight YOLOv4 network[J].Energy Reports,2021,7(S7):187–197.
12. Gezgin H, Alkan R M .Traffic sign detection and recognition based on MMS data using YOLOv4-Tiny algorithm[J].Neural Computing and Applications, 2024, 36(33):20633–20651.
13. J. Li, H. Pei and Y. Peng. Detection of insulator defects in lightweight networks based on YOLO-V5s [C]// 2024 5th International Conference on Computer Engineering and Application (ICCEA), Hangzhou, China, 2024: 23–28
14. Han Y, Wang L, Wang Y ,et al. Intelligent Small Sample Defect Detection of Concrete Surface Using Novel Deep Learning Integrating Improved YOLOv5[J]. IEEE/CAA Journal of Automatica Sinica, 2024(2):11.
15. Sun S, Han L, Wei J ,et al.ShuffleNetv2-YOLOv3: a real-time recognition method of static sign language based on a lightweight network[J].Signal, Image and Video Processing, 2023:1–9.
16. Fan ZM, Hu W, Guo H, et al. Hardware and Algorithm Co-optimization for Pointwise Convolution and Channel Shuffle in ShuffleNet V2 [C]// 2021 IEEE International Conference on Systems, Man, and Cybernetics (SMC). Melbourne: IEEE, 2021: 3212–3217.
17. Park M, Hwang S, Cho H. BiRD: Bi-directional Input Reuse Dataflow for Enhancing Depthwise Convolution Performance on Systolic Arrays[J]. IEEE Transactions on Computers, 2024.
18. Yi S, Li J, Liu X, et al. CCAFFMNet: Dual-spectral semantic segmentation network with channel-coordinate attention feature fusion module[J]. Neurocomputing, 2022, 482: 236–251.
19. Su M S, Hwang W L, Cheng K Y. Analysis on multiresolution mosaic images[J]. IEEE Transactions on Image Processing, 2004, 13(7): 952–959.
20. Shin W, Kahng H, Kim S B. Mixup-based classification of mixed-type defect patterns in wafer bin maps[J].Computers & Industrial Engineering, 2022, 167:107996-.
21. Chen L, Yao H, Fu J, et al. The classification and localization of crack using lightweight convolutional neural network with CBAM[J]. Engineering Structures, 2023, 275: 115291.
22. Wang J, Wu X .A deep learning refinement strategy based on efficient channel attention for atrial fibrillation and atrial flutter signals identification[J].Applied Soft Computing, 2022.
23. Wang J, Xiao H, Chen L ,et al. Integrating Weighted Feature Fusion and the Spatial Attention Module with Convolutional Neural Networks for Automatic Aircraft Detection from SAR Images[J].Remote Sensing, 2021, 13:910.
24. Jie,Shen, Samuel, et al. Squeeze-and-Excitation Networks.[J].IEEE transactions on pattern analysis and machine intelligence, 2019.
25. Cho Y J. Weighted Intersection over Union (wIoU) for evaluating image segmentation[J]. Pattern Recognition Letters, 2024, 185: 101–107.
26. Dong C, Duoqian M. Control distance IoU and control distance IoU loss for better bounding box regression[J]. Pattern Recognition, 2023, 137: 109256.
27. Liu X, Hu J, Wang H, et al. Gaussian-IoU loss: Better learning for bounding box regression on PCB component detection[J]. Expert Systems with Applications, 2022, 190: 116178.
28. Zhang Y F, Ren W, Zhang Z, et al. Focal and efficient IOU loss for accurate bounding box regression[J]. Neurocomputing, 2022, 506: 146–157.
Author information
Authors and Affiliations
Contributions
Bing Zeng: Methodology. Wei Hua: Experiment implementation, Writing the original manuscript. Wenhua Zhang, Dezhi Li: Experiment assistance, Reviewing the manuscript. Zhihao Zhou, Hao Wan: Visualization of experimental data. Zihan Jin, Yuchong Chen: Manuscript review and editing. Yunmin Xie, Tangbing Li: Validation, Formal analysis. Shixun Fu, Jianglei Li, Shenli Wang: Dataset provision.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Zeng, B., Hua, W., Li, D. et al. Lightweight insulator target detection algorithm based on improved YOLOX. Sci Rep 15, 19241 (2025). https://doi.org/10.1038/s41598-025-04023-2
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-025-04023-2
