
Abstract
Pedestrians, as vulnerable road users (VRUs), lack effective protective measures in traffic accidents, making them highly susceptible to injuries. Accurate prediction of pedestrian behavior is crucial for road safety, traffic management systems, advanced driver-assistance systems (ADAS), and autonomous vehicle development. Against this backdrop, this paper proposes a pedestrian group crossing intention prediction model that integrates spatiotemporal features to enhance the accuracy of pedestrian behavior prediction in autonomous driving scenarios. The model combines spatiotemporal features, including pedestrian pose key points, 2D positional trajectories, and group information. Experimental results on the JAADbeh and JAADall datasets demonstrate that the proposed model achieves superior performance in terms of accuracy, precision, and F1-Score. Notably, on the complex and large-scale JAADall dataset, the model achieves an accuracy of 0.82, highlighting its robustness. Furthermore, the findings reveal that incorporating pedestrian group information improves prediction accuracy, especially in group pedestrian scenarios, where this feature significantly enhances detection performance. This study provides a reliable pedestrian intention prediction framework for autonomous driving and intelligent transportation systems, while also laying a foundation for future exploration of diverse non-visual features and complex scenarios.
Similar content being viewed by others
Introduction
With the continuous advancement of autonomous driving technology, autonomous vehicles (AVs) are expected to enhance traffic efficiency, safety, and mobility for all users within the next decade or two, particularly benefiting the elderly and individuals with disabilities1,2. Once commercialized and widely deployed, AVs will share road space with traditional vehicles, non-motorized vehicles, and pedestrians in mixed traffic environments. In such settings, pedestrians, as one of the most vulnerable road users, will need to interact with both conventional vehicles and AVs, potentially leading to uncertainties in pedestrian behavior or unsafe situations. Predicting pedestrian crossing intentions has thus become a critical algorithm to ensure pedestrian safety. This algorithm analyzes pedestrian behavior and environmental information to predict whether a pedestrian intends to cross the road. It is built upon foundational technologies such as pedestrian detection and tracking, combined with higher-level video analysis techniques. Pedestrian crossing intention recognition provides AVs with crucial information, enabling them to understand pedestrian intentions and make appropriate decisions. This capability allows AVs to respond more intelligently to complex traffic scenarios, ensuring pedestrian safety while maintaining smooth traffic flow.
Pedestrians groups
In urban environments, interactions between multiple pedestrians and AVs are increasingly common, particularly when a group of people cross the street together. In today’s traffic environment, which is still dominated by non- AVs, pedestrians depend on this social information when making crossing decisions. For instance, Faria et al.3. observed that individuals tend to accelerate their crossing speed when they see others crossing directly in front of them. Furthermore, imitation behavior also plays a crucial role in pedestrian decision-making. Pedestrians tend to mimic the actions of those around them when deciding whether to comply with traffic rules4. Non-compliant group behavior can further encourage others to follow suit5. Social influence guides pedestrians to conform to the behavior of those around them, meaning that when assessing crossing situations, their decisions often align with social norms or group standards4.
Spatiotemporal features
Spatiotemporal features refer to the distribution characteristics of pedestrian behavior across temporal and spatial dimensions, which are essential for understanding pedestrian crossing interactions. These features encompass two main aspects: temporal and spatial characteristics. Temporal features capture the time-related distribution of pedestrian crossing behavior, including crossing intervals, crossing speed, and dwell time6. Spatial features describe the spatial distribution of pedestrian behavior, such as crossing locations, movement trajectories, and interaction distances between pedestrians7. To address the prediction of pedestrian intention in urban traffic environments, Khaled et al. proposed a real-time prediction framework that leverages spatiotemporal image sequences captured by monocular RGB cameras to better forecast pedestrian actions8. Utilizing this rich information, researchers developed an end-to-end fully convolutional long short-term memory networks (LSTM) encoder designed to model pedestrian flows within a crowd9. This approach effectively reduces tracking interruptions caused by issues such as long-distance tracking failures, trajectory discontinuities, or severe occlusions, significantly minimizing pedestrian ID switching incidents10.
Pedestrian intention prediction algorithm
Currently, algorithms based on pedestrian motion features are the mainstream approach for predicting pedestrian crossing intentions. These algorithms analyze pedestrian movement patterns to predict future trajectories, thereby determining crossing intentions. For instance, an algorithm employing Gaussian process dynamics models and probabilistic hierarchical trajectory matching predicts pedestrian paths using enhanced features extracted from dense optical flow, enabling the identification of crossing intentions11. Another approach combines the extended Kalman filter algorithm with dynamic models to predict pedestrian movement paths, providing detailed forecasts for four typical pedestrian motion types: crossing, standing, walking, and bending12. Additionally, research integrating inverse reinforcement learning with bidirectional recurrent neural networks (RNNs) has achieved high-precision trajectory predictions, with an average displacement error of fewer than five pixels13.
With the development of intelligent transportation systems, pedestrian crossing intention prediction has become a critical research direction for improving traffic safety. Traditional methods rely on hand-crafted features, but their performance is often limited in complex scenarios. Deep learning, particularly convolutional neural networks (CNNs) and LSTM, has demonstrated remarkable capabilities in image feature extraction and temporal sequence modeling. This paper proposes a pedestrian group crossing intention prediction model that integrates spatiotemporal features. The model effectively combines spatial and temporal characteristics to achieve accurate intention prediction.
Related work
Pedestrian group research
In transportation research, the analysis of pedestrian group behavior has become increasingly important, particularly in understanding collective crossing behavior and its impact on traffic flow. Moussaïd et al.14 observed 1,500 pedestrian groups in natural environments and found that the arrangement of group members changes with surrounding density. In low-density environments, groups often walk side by side to facilitate communication, while in medium-density scenarios, they tend to adopt a V-shaped formation, with the central member slightly trailing behind the side members. Gorrini et al.15 studied the behavior of groups of two, three, and four individuals within a sample of 1,600 pedestrians in low-density environments. Their results indicate that as group size increases, collective walking speed decreases. Pairs tend to walk side by side with lower dispersion, trios frequently adopt a V-shaped formation, and groups of four often split into smaller sub-structures, such as two pairs or a trio combined with a single individual. These group patterns suggest that even in low-density environments, larger groups maintain certain social boundaries, with common formations including side-by-side, V-shaped, and leader-follower arrangements16. These formations significantly influence pedestrian walking decisions and spatial distribution. Furthermore, even when walking in groups, individuals maintain reasonable distances from one another to avoid collisions17.
Research on human pose estimation
In recent years, significant progress has been made in 2D human pose estimation based on monocular vision. Prediction models built using deep convolutional neural networks have demonstrated the ability to recognize the intentions of vulnerable road users18. To further explore pedestrian group movement, Zaki19 proposed a trajectory-based group dynamics prediction method, which identifies pedestrian groups through spatio-temporal proximity and motion consistency, and analyzes their behaviors using trajectory features to reveal movement patterns in urban environments., Perdoch20 simulated the movement of robots working in groups to model the leader-follower concept observed in pedestrian group walking. Moreover, methods combining 2D human pose estimation with graph convolutional networks have shown advantages in predicting pedestrian crossing intentions, particularly in complex urban road environments. A model called “Pedestrian Graph” achieved state-of-the-art performance on the Joint Attention in Autonomous Driving (JAAD) dataset21.
Pedestrian crossing intention recognition can be considered a subtask of pedestrian action recognition. However, due to the diversity and complexity of pedestrian feature data, applying pedestrian crossing action recognition to video remains a challenging problem22. Current action recognition methods can be categorized into three main types: RGB video stream methods23, optical flow methods24, and skeleton modeling methods25. Among these, skeleton modeling predicts actions by estimating human poses, offering low dependency on environmental conditions and robustness to environmental changes. RNNs and CNNs are the most commonly used models in this domain. RNNs, capable of capturing action variations across temporal frames, include typical architectures such as bi-RNNs26, Deep-LSTMs27, feature fusion models, and attention-based models28. Skeleton-based pedestrian crossing action recognition usually begins with detecting the skeletal keypoints of the human body29. In addition, deep learning techniques have been applied to estimate pedestrian head pose and full-body orientation, utilizing supervised deep convolutional network models for prediction30. Another approach, RU-LSTM, predicts pedestrian crossing intentions by analyzing interactions among pedestrians, the surrounding environment, and other vehicles, leveraging multiple cues to enhance accuracy31.
Pedestrian crossing intentions are influenced by various factors, including pedestrian movement patterns, interactions with other road users, and individual characteristics. Observing pedestrian walking trajectories, patterns, and speeds can effectively predict future behaviors. For example, the use of fisheye monocular cameras has overcome blind spots in standard cameras, demonstrating excellent performance in pedestrian trajectory prediction32. Additionally, unsupervised learning methods can generate pedestrian trajectory intentions for multi-pedestrian tracking and rank the optimal trajectories using probabilistic approaches33. Some methods optimize trajectory prediction by analyzing irregular movement patterns34, while others employ graph convolutional networks to generate pedestrian crossing prediction graphs, enhancing performance by integrating multiple features35.
Another approach for human activity recognition is using pose estimation. 2D Human Pose Estimation (2D-HPE) is a fundamental problem in computer vision that involves detecting and localizing 2D keypoints from images or videos. With the gradual development of deep learning, 2D-HPE has achieved remarkable progress through the use of CNNs. A widely used method, OpenPose36, is a real-time multi-person pose detection technique that employs Part Affinity Fields (PAFs) to associate body parts with individuals in an image. CPN (Cascade Pyramid Network)37 introduced a two-stage framework: a global network for locating relatively simple keypoints and a refinement network designed to handle occluded and challenging keypoints. HRNet (High-Resolution Network)38 emphasizes that high-resolution features are crucial for position-sensitive vision tasks. Consequently, HRNet maintains high-resolution representations throughout the entire process of 2D human pose estimation.
Overall, significant progress has been made in the fields of pedestrian group behavior, crossing intention, and pedestrian behavior prediction based on 2D human pose estimation. Research indicates that group formations and interaction patterns with the environment have profound effects on traffic flow, while advancements in action recognition and pose estimation technologies provide powerful tools for pedestrian intention prediction. Additionally, the quality and balance of datasets are critical for the effective training and evaluation of predictive models.
Research methodology
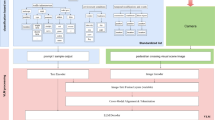
This paper proposes an innovative method that integrates CNN and LSTM networks to predict pedestrian crossing intentions by fusing spatiotemporal features. As illustrated in Fig. 1, the method extracts multiple features from the dataset and employs a CNN module to capture the spatial information from images. Simultaneously, the LSTM module models the temporal dependencies across video frames.
During the feature fusion stage, the spatial features extracted by the CNN and the temporal features captured by the LSTM are combined to enhance the model’s understanding of pedestrian behavior patterns. Finally, the fused features are analyzed by a classification network, which outputs the pedestrian’s crossing intention.

Pedestrian intention recognition process.
Feature extraction
In pedestrian crossing intention prediction research, the extraction and analysis of spatiotemporal features are critical to model performance. This study extracts five key spatiotemporal features: pedestrian groups, pedestrian 2D position trajectories, local context, global context, and pose keypoints. These features describe pedestrian behavior from multiple dimensions, including group interactions, motion trajectories, proximal environment, overall external factors, and individual posture, thereby constructing a comprehensive framework for intention prediction.
Pedestrian pose keypoints
Keypoints, also known as joints, are points of interest in an image. In this context, these points of interest represent joint positions such as shoulders, elbows, ankles, and more. The keypoints themselves provide spatial information based on their positions in the image, while their variations across multiple frames represent temporal information. Over time, predicted keypoints deliver spatiotemporal data that can be used to calculate a pedestrian’s trajectory and speed. This information is utilized to predict a pedestrian’s intention to cross the street.
In this study, a pre-trained OpenPose36 model is used to extract pedestrian keypoints. OpenPose is an open-source library for pose estimation widely applied in computer vision tasks, especially in human pose estimation, facial expression analysis, and hand gesture recognition. OpenPose can detect and analyze human keypoints in images and videos in real-time, including head, shoulders, elbows, wrists, hips, knees, and ankles. It also supports multi-person pose estimation, detecting multiple subjects in a single image or video and providing detailed skeletal keypoint information for each individual. Figure 2 illustrates the human pose keypoints extracted by the OpenPose model.

Human pose keypoints.
This study extracts pedestrian pose keypoints \(\:Pi={\{p}_{i}^{t-m},{p}_{i}^{t-m+1},\dots\:,{p}_{i}^{t},\dots\:,{p}_{i}^{t+m-1},{p}_{i}^{t+m}\}\), where \(\:p\) represents the 2D coordinates of 18 pose joints, specifically:\(\:{p}_{i}^{t-m}=\{{x}_{i0}^{t-m},{y}_{i0}^{t-m},{x}_{i1}^{t-m}\), \(\:{y}_{i1}^{t-m}\),…, \(\:,{x}_{i17}^{t-m}\), \(\:{y}_{i17}^{t-m}\}\), Here, \(\:i\) represents the pedestrian ID, \(\:t\) denotes the time step, and \(\:m\) is a constant at a given time step.
Pedestrian groups
Based on observations from the JAAD dataset, pedestrians often tend to cross the street as part of a group. If one member of the group begins walking to cross the street, another member of the group will spontaneously follow suit (as shown in Fig. 3). A small group of pedestrians can be defined as individuals interacting with one another, where such interaction may be indicated by their proximity, body posture, gaze, or active engagement through conversation. These small groups form while walking or waiting on the sidewalk and continue to exist as a unit when crossing the street. It should be pointed out that the pedestrian group studied in this paper is defined as individuals who are spatially close, that is, individuals without social relationships.

Illustration of pedestrian groups crossing the street.
This study defines the number of other pedestrians surrounding a given pedestrian as \(\:Ni={\{n}_{i}^{t-m},{n}_{i}^{t-m+1},\dots\:,{n}_{i}^{t},\dots\:,{n}_{i}^{t+m-1},{n}_{i}^{t+m}\}\) Here, \(\:i\) represents the pedestrian ID, \(\:t\) denotes the time step, and \(\:m\) is a constant at a given time step. In the study by Hübner et al.39, pedestrians within a 2-meter radius are considered to have a sense of group affiliation. Based on this concept, the number of pedestrians in this study is defined as follows: First, all other pedestrians within a 2-meter radius of the target pedestrian are identified. Next, for each of these identified pedestrians, a new 2-meter radius is constructed to determine whether additional pedestrians are present within the defined area. This process continues recursively until no further pedestrians are detected (as shown in Fig. 4). The final pedestrian count is defined as the total number of pedestrians surrounding the target individual. It is important to note that this method is applicable only to streets and intersections with relatively low pedestrian traffic.

Schematic diagram of pedestrian group.
Pedestrian 2D position trajectory
In this study, the pedestrian’s visual features and 2D position trajectories are extracted using the YoloV5-DeepSort model. As shown in Fig. 5, the pedestrian’s local context\(\:Ei={\{e}_{i}^{t-m},{e}_{i}^{t-m+1},\dots\:,{e}_{i}^{t},\dots\:,{e}_{i}^{t+m-1},{e}_{i}^{t+m}\}\) is composed of a sequence of RGB image patches of size [224, 224] pixels surrounding the target pedestrian, while the pedestrian’s 2D position trajectory \(\:Li={\{l}_{i}^{t-m},{l}_{i}^{t-m+1},\dots\:,{l}_{i}^{t},\dots\:,{l}_{i}^{t+m-1},{l}_{i}^{t+m}\}\) is composed of the bounding box coordinates of the target pedestrian, specifically:\(\:{l}_{i}^{t-m}=\{{x}_{ti}^{t-m},{y}_{ti}^{t-m},{x}_{bi}^{t-m}\),\(\:{y}_{bi}^{t-m}\)}, Here, \(\:{x}_{ti}^{t-m},{y}_{ti}^{t-m}\) represent the coordinates of the top-left corner of the bounding box, while \(\:{x}_{bi}^{t-m}\), \(\:{y}_{bi}^{t-m}\) denote the coordinates of the bottom-right corner. In this equation, \(\:i\) represents the pedestrian ID, \(\:t\) denotes the time step, and \(\:m\) is a constant at a given time step.

Pedestrian visual features and 2D position trajectories.
Road environment features
The road environment is a critical factor influencing pedestrian crossing decisions, reflected in the structural characteristics of the road, the behavioral patterns of other road users, and the dynamic interactions between road users. These factors collectively shape pedestrians’ judgments and decisions about whether to cross at a given moment. In this study, we use the DeepLabV3Plus40 model to automate the extraction of road environment features. By leveraging semantic segmentation, this model accurately identifies key elements such as roads, vehicles, and pedestrians, providing fine-grained environmental information for pedestrian crossing intention prediction. As shown in Fig. 6, this study selects road, street, pedestrian, and vehicle features as the global context \(\:C=\{{c}^{t-m},{c}^{t-m+1},\dots\:,{c}^{t},\dots\:,{c}^{t+m-1},{c}^{t+m}\}\) As part of the visual feature input, the semantic segmentation of all input frames is resized to [224,224] pixels, consistent with the visual features of the pedestrians.

Road environment features.
Model overview
The overall model framework is shown in Fig. 7, consisting of the CNN module, RNN module, attention mechanism, and feature fusion method.

Model architecture.
In this study, the VGG19 model is selected as the CNN module. VGG19 is a deep convolutional neural network model42, which has shown excellent performance in image classification and feature extraction tasks. We use the pre-trained weights based on the ImageNet dataset43 and convert the classifier part of VGG19 (vgg19.classifier) into a Sequential model, removing the final layer to serve as the new classifier. Additionally, the parameters of the 16 convolutional layers in VGG19 are frozen, meaning they do not participate in the model’s training and optimization. This is a common technique used in transfer learning to retain the features of the pre-trained model while avoiding excessive computation and optimization of the pre-trained parameters during the training of the new model.
In this study, a LSTM network is selected as the RNN module. LSTM is a special type of RNN that effectively handles and forgets long-term dependencies, making it particularly suited for processing and predicting sequential data. In this study, the size of the LSTM hidden layer is set to 256. The calculation formulas for LSTM are presented in Eqs. (1)–(5).
where \(\:{f}_{t}\), \(\:{i}_{t}\), \(\:{o}_{t}\), and \(\:{c}_{t}\) represent the actions for the forget, input, output and cell state gates at time \(\:t\) respectively. Furthermore, \(\:{W}_{f}\), \(\:{W}_{i}\), \(\:{W}_{o}\), \(\:{W}_{c}\), \(\:{b}_{f}\), \(\:{b}_{i}\), \(\:{b}_{o}\), \(\:{b}_{c}\) are the weight matrices and variable biases of the four gates mentioned above. In addition, \(\:{x}_{t}\) and \(\:{h}_{t}\) are input and final output at time \(\:t\) of the memory cell.
The attention module is used to dynamically adjust the weights of different parts of the input data, enhancing the model’s ability to focus on important information. The attention mechanism is widely applied in the field of deep learning, especially in tasks related to Natural Language Processing (NLP) and Computer Vision (CV). The sequence features (e.g., the output of an RNN-based encoder) are represented as hidden states \(h~ = ~\left\{ {h_{1}, h_{2} ,...,h_{i} } \right\}\). The attention weights are computed as follows Eq. (6):
where \(\:score({h}_{i},{h}_{s})\)= \(\:{{h}_{i}}^{T}{W}_{s}{h}_{s}\) and \(\:{W}_{s}\) is a weight matrix. This attention weight captures the relationship between the current hidden state \(\:{h}_{i}\) and the previous source hidden state \(\:{h}_{s}\), and the softmax function is applied to obtain the attention weights.
This study adopts a hybrid approach to fuse different inputs, as shown in Fig. 7, categorizing the features into visual and non-visual features. The non-visual feature fusion integrates three elements: bounding boxes, pose keypoints, and pedestrian groups. These features are hierarchically fused based on their complexity. In the process depicted in Fig. 7a, sequential pedestrian pose keypoints \(\:Pi\) are input into an LSTM encoder. The output of the first stage, along with the pedestrian’s 2D position trajectory \(\:Li\), is then fed into a new LSTM encoder. Subsequently, the output of the second stage is combined with the pedestrian group \(\:Ni\) and input into the final LSTM encoder. Finally, the output of the last encoder passes through the attention module to obtain the final non-visual feature vector \(\:{A}_{i-nv}\). The visual feature fusion integrates two elements: local context (the magnified pedestrian appearance around the bounding box) and global context (semantic segmentation of important objects in the entire scene). As shown in Fig. 7b, local context \(\:Ei\) is extracted using the CNN module, followed by temporal features extracted from the LSTM module. The global context \(\:C\) is extracted in the same way as the local context \(\:Ei\). These two features are then input into the attention module, generating the final visual feature vector \(\:{A}_{i-v}\).Finally, the non-visual feature vector \(\:{A}_{i-nv}\) and the visual feature vector \(\:{A}_{i-v}\) are fed into an attention module, followed by a fully connected (FC) layer to complete the prediction as follows Eq. (7):
Data collection and analysis
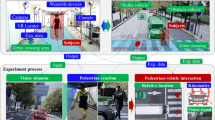
This study utilizes the Joint Attention in Autonomous Driving (JAAD) dataset41, which comprises 346 videos, each lasting 5–10 s, recorded using cameras mounted on vehicles. The videos are captured at a resolution of 1920 × 1080 and a frame rate of 30 fps. The dataset includes ground truth annotations of pedestrian bounding boxes and behavioral labels describing the current state of each pedestrian. The dataset consists of two subsets: JAAD Behavior Data (JAADbeh) and JAAD All Data (JAADall). JAADbeh contains pedestrians either crossing the road (495 samples) or about to cross the road (191 samples). JAADall includes additional pedestrians performing non-crossing actions (2,100 samples). Furthermore, we created a custom dataset of urban road driving scenarios, which includes pedestrian bounding box annotations and pedestrian group information, as shown in Fig. 8. In the figure, green boxes represent annotated pedestrian bounding boxes, while red boxes indicate pedestrian group information. This dataset was collected from selected urban roads in Zhangdian District, Zibo, China. It consists of 78 videos, each lasting between 15 and 25 s, captured using an action camera mounted on a vehicle. The videos were recorded at a resolution of 1920 × 1080 and a frame rate of 60 fps.

Custom urban road driving dataset.
This study incorporates pedestrian groups into non-visual features to investigate whether detecting the intention to cross the road of one member of a group enhances the detection of another member’s crossing intention. To explore this phenomenon, this study first employs YOLOv5-DeepSort to track and classify pedestrian groups in the JAAD dataset. Across 346 videos totaling 82,032 frames, 2,786 unique pedestrians were recorded. Table 1 presents the distribution of detected pedestrian groups in the JAAD dataset.
Data analysis revealed that 38.45% of the frames contained only one pedestrian, while 57.52% of the frames included two or more pedestrians. Based on these observations, pedestrian groups were categorized into four types: single pedestrians, pairs, trios, and groups of four or more. Subsequently, the proposed model was used to train and detect these four categories of pedestrian groups separately. To ensure that the datasets for these four categories have the same scale, we use stratified random sampling (stratified according to category proportions to maintain the distribution consistency between the training and test sets, preventing class imbalance caused by random splitting) to reduce each dataset to 10,000 frames.
Results and discussion
In the experiments, the proposed model was compared with the following baseline methods: SingleRNN44, SF-GRU45, and PCPA46. Building upon these baselines, the proposed model incorporates pedestrian group factors into the prediction of pedestrian crossing intention, aiming to explore the impact of group dynamics on pedestrian crossing behavior. This study employed a dropout rate of 0.5 in the attention module, an L2 regularization of 0.001 in the fully connected (FC) layer, a binary cross-entropy loss function, and the Adam optimizer with a learning rate of 6 × 10− 4. The training process included 40 epochs with a batch size of 8, and a StepLR learning rate adjustment strategy was applied, reducing the learning rate by a factor of 10 every 5 epochs.
Table 2 presents the results of the proposed model on the JAADbeh dataset, compared with the singlernn, SF-GRU, and PCPA models. The proposed model demonstrated superior performance in terms of accuracy, precision, and F1-Score. F1-Score, which considers both precision and recall, serves as a crucial evaluation metric. It is the harmonic mean of precision and recall, providing a comprehensive assessment of a classification model’s performance. A higher F1-Score indicates better model performance. Notably, the proposed model achieved an approximate 3% improvement in F1-Score.
Table 3 presents the results on the JAADall dataset, which includes all video sequences and associated annotations from the JAAD dataset. JAADall covers a broader range of scenarios and behaviors, featuring a larger dataset size and greater scene diversity, encompassing various traffic and environmental conditions. The proposed model demonstrated strong performance in terms of accuracy, AUC, precision, and F1-Score. Similar to the results on the JAADbeh dataset, the proposed model achieved notable performance across the three evaluation metrics: accuracy, precision, and F1-Score.
By comparing the results in Tables 2 and 3, it can be observed that the proposed model outperforms other models on both the JAADbeh and JAADall datasets. This finding indicates that the proposed method demonstrates significant advantages across all evaluation metrics, further validating its effectiveness and reliability in predicting pedestrian crossing intentions.
In addition to the direct comparison with other models mentioned above, this study also compares different fusion schemes for non-visual features, as shown in Fig. 9. Three approaches for non-visual feature fusion are considered. Unlike the hierarchical fusion proposed in this study, scheme (a) inputs the three non-visual features separately into the LSTM encoder, followed by the attention module. Scheme (b) inputs the three non-visual features together into the LSTM encoder, followed by the attention module. Scheme (c) inputs the three non-visual features separately into the LSTM encoder, then into the attention module separately, and finally fuses them with the visual features.

Non-visual feature fusion schemes.
Tables 4 and 5 present a comparison between the proposed model and the three different fusion scheme models on the JAADbeh and JAADall datasets, respectively. The models of the different fusion schemes are denoted as Mode(a), Mode(b), and Mode(c). It can be observed that the proposed model demonstrates a significant advantage over the three other fusion scheme models. Furthermore, on the JAADall dataset, all four evaluation metrics show good performance, indicating that the proposed model performs well on a larger dataset with higher scene diversity.
In addition, this study also investigates the impact of pedestrian group features on model performance. To this end, two models were trained: one that includes pedestrian group features and another that does not, while keeping other input features and network structures consistent. As shown in Fig. 10, under the same number of training epochs using the JAAD dataset, the proposed model that considers pedestrian group features exhibits significantly higher accuracy compared to the model that does not include these features. As the number of pedestrians in the group increases, the model’s prediction accuracy improves regardless of whether pedestrian group features are considered.

Prediction accuracy of pedestrian crossing intention for different pedestrian groups in two trained models.

Pedestrian crossing intention prediction in two trained models.
Furthermore, this study conducts validation on both the JAADall dataset and the custom urban road dataset. As shown in Fig. 11 (where the red box indicates a pedestrian crossing the street and the green box indicates a pedestrian not crossing), at time \(\:T\), when both models recognize the first pedestrian crossing the street, the model incorporating pedestrian group features consistently identifies subsequent pedestrians faster than the model that does not incorporate such features. The results indicate that when one pedestrian in the group begins crossing the street, the other pedestrians typically follow closely behind. Meanwhile, compared to an individual pedestrian, the likelihood of a pedestrian group crossing the street in the presence of vehicle pressure significantly increases. A single pedestrian may abandon crossing due to pressure, whereas the formation of a pedestrian group helps reduce the pressure felt by individuals, thereby enhancing the crossing intention of the entire group.
The above results further validate the important role of pedestrian group features, as part of the non-visual features, in predicting pedestrian crossing intention. By integrating pedestrian group information, the model is able to more accurately capture the influence of group dynamics on individual behavior, thereby improving both prediction accuracy and robustness.
Conclusion
This study proposes a novel method for predicting pedestrian crossing intentions based on the fusion of spatiotemporal features. The method utilizes CNN and LSTM modules to extract visual and non-visual features, respectively, and employs an attention mechanism for feature fusion, enabling the prediction of pedestrian intentions. The model treats pedestrian groups as a key non-visual feature and uses a hierarchical mixed fusion strategy for combining non-visual features. The main findings of the study are summarized as follows.
-
(1)
The evaluation results on the JAADbeh and JAADall datasets show that the proposed model performs well in comparison with other pedestrian crossing intention prediction algorithms, achieving good results in accuracy, precision, and F1-Score. To further validate the effectiveness of the hierarchical fusion strategy, a comparison of different non-visual feature fusion schemes was conducted. The results demonstrate that the proposed model consistently outperforms the three other fusion strategies, particularly in the JAADall dataset, which features a larger data size and greater scene diversity. All four evaluation metrics show strong performance. This indicates that the model proposed in this study has good robustness and adaptability when dealing with more complex scenarios and larger datasets.
-
(2)
This study introduces pedestrian group features into non-visual features to explore whether the prediction of crossing intentions for other group members can be improved when one member of the group begins crossing first. To this end, two models were trained: one that includes pedestrian group features and another that does not, while keeping other input features and network structures consistent. The results show that as the size of the pedestrian group increases, the prediction accuracy of the model improves, regardless of whether pedestrian group features are considered. Furthermore, validation on the JAAD and custom urban road dataset indicates that the model incorporating pedestrian group features consistently outperforms the model without these features in terms of recognition speed at subsequent time steps. This suggests that when one pedestrian in the group begins crossing, other pedestrians typically follow closely behind. Moreover, compared to individual pedestrians, pedestrian groups exhibit a higher tendency to cross in the presence of vehicle pressure. A single pedestrian may abandon crossing due to pressure, but when pedestrians form a group, the pressure experienced by individuals is alleviated, thereby enhancing the overall crossing intention of the group.
In practical applications, the proposed model is expected to provide effective pedestrian intention prediction for autonomous driving systems and intelligent traffic management, enhancing the system’s decision-making capabilities in complex dynamic environments. By incorporating pedestrian group features into the crossing intention prediction model, traffic systems can better recognize the crossing behavior of pedestrian groups, thereby reducing accidents and improving road safety. Future research could further explore the impact of other non-visual features, such as pedestrian status, on crossing intention prediction. Another potential direction is to expand the model’s adaptability to handle a wider range of traffic scenarios, such as pedestrian intention prediction in nighttime or adverse weather conditions. Additionally, research could focus on improving the computational efficiency of the model under real-time conditions to ensure its practical effectiveness and response speed in real-world traffic environments.
Data availability
The datasets generated and analysed during the current study are available from the corresponding author on reasonable request.
References
Fagnant, D. J. & Kockelman, K. Preparing a Nation for autonomous vehicles: opportunities, barriers and policy recommendations. Transpo. Res.. Part. A: Policy Pract. 77, 167–181 https://doi.org/10.1016/j.tra.2015.04.003 (2015).
Milakis, D., van Arem, B. & van Wee, B. Policy and society related implications of automated driving: A review of literature and directions for future research. J. Intell. Transp. Syst. 21, 324–348. https://doi.org/10.1080/15472450.2017.1291351 (2017).
Faria, J. J., Krause, S. & Krause, J. Collective behavior in road crossing pedestrians: The role of social information. Behav. Ecol. 21, 1236–1242. https://doi.org/10.1093/beheco/arq141 (2010).
Yagil, D. Beliefs, motives and situational factors related to pedestrians’ self-reported behavior at signal-controlled crossings. Transp. Res. Part. F: Traffic Psychol. Behav. 3, 1–13. https://doi.org/10.1016/s1369-8478(00)00004-8 (2000).
Shiwakoti, N., Tay, R. & Stasinopoulos, P. Exploring jaywalking at intersections. Australasian Transp. Res. Forum (2017). https://australasiantransportresearchforum.org.au/wp-content/uploads/2022/03/ATRF2017_047.pdf.
Brosseau, M., Zangenehpour, S., Saunier, N. & Miranda-Moreno, L. The impact of waiting time and other factors on dangerous pedestrian crossings and violations at signalized intersections: A case study in Montreal. Transp. Res. Part. F: Traffic Psychol. Behav. 21, 159–172. https://doi.org/10.1016/j.trf.2013.09.010 (2013).
Kuşkapan, E., Sahraei, M. A., Çodur, M. K. & Çodur, M. Y. Pedestrian safety at signalized intersections: Spatial and machine learning approaches. J. Transp. Health. 24, 101322. https://doi.org/10.1016/j.jth.2021.101322 (2022).
Saleh, K., Hossny, M. & Nahavandi, S. Spatio-temporal densenet for real-time intent prediction of pedestrians in urban traffic environments. Neurocomputing 386, 317–324. https://doi.org/10.1016/j.neucom.2019.12.091 (2020).
Chen, K. et al. Pedestrian behavior prediction model with a convolutional LSTM encoder–decoder. Phys. A: Stat. Mech. Its Appl. 560, 125132. https://doi.org/10.1016/j.physa.2020.125132 (2020).
Cao, J., Zhang, J., Li, B., Gao, L. & An, J. A long-memory pedestrian target tracking algorithm incorporating Spatiotemporal trajectory feature enhancement model. Digit. Signal Proc. 135, 103929. https://doi.org/10.1016/j.dsp.2023.103929 (2023).
Keller, C. G. & Gavrila, D. M. Will the pedestrian cross? A study on pedestrian path prediction. IEEE Trans. Intell. Transp. Syst. 15, 494–506. https://doi.org/10.1109/tits.2013.2280766 (2014).
Schneider, N. & Gavrila, D. M. Pedestrian path prediction with recursive bayesian filters: A comparative study. Lect. Notes Comput. Sci. 174-183 https://doi.org/10.1007/978-3-642-40602-7_18 (2013).
Saleh, K., Hossny, M. & Nahavandi, S. Long-Term recurrent predictive model for intent prediction of pedestrians via inverse reinforcement learning. Digit. Image Computing: Techniques Appl. (DICTA) 1–8 https://doi.org/10.1109/dicta.2018.8615854 (2018)..
Moussaïd, M., Perozo, N., Garnier, S., Helbing, D. & Theraulaz, G. The walking behaviour of pedestrian social groups and its impact on crowd dynamics. PLoS ONE 5, 10047. https://doi.org/10.1371/journal.pone.0010047 (2010).
Gorrini, A., Bandini, S. & Vizzari, G. Empirical investigation on pedestrian crowd dynamics and grouping. Traffic Granul. Flow. 13, 83–91. https://doi.org/10.1007/978-3-319-10629-8_10 (2014).
Repiso, E., Zanlungo, F., Kanda, T., Garrell, A. & Sanfeliu, A. People’s V-Formation and Side-by-Side Model Adapted to Accompany Groups of People by Social Robots. IEEE/RSJ Int. Conf. Intell. Robots Syst. (IROS) 2082–2088. https://doi.org/10.1109/iros40897.2019.8968601(2019 (2019).
Everett, M., Chen, Y. F. & How, J. P. Collision avoidance in pedestrian-rich environments with deep reinforcement learning. IEEE Access. 9, 10357–10377. https://doi.org/10.1109/access.2021.3050338 (2021).
Fang, Z. & Lopez, A. M. Intention recognition of pedestrians and cyclists by 2d pose estimation. IEEE Trans. Intell. Transp. Syst. 21, 4773–4783. https://doi.org/10.1109/tits.2019.2946642 (2020).
Zaki, M. H. & Sayed, T. Automated analysis of pedestrian group behavior in urban settings. IEEE Trans. Intell. Transp. Syst. 19, 1880–1889. https://doi.org/10.1109/tits.2017.2747516 (2018).
Perdoch, M. et al. Leader tracking for a walking logistics robot. IEEE/RSJ Int. Conf. Intell. Robots Syst. (IROS) 2994–3001. https://doi.org/10.1109/iros.2015.7353790(2015).
Cadena, P. R. G., Yang, M., Qian, Y. & Wang, C. Pedestrian graph: Pedestrian crossing prediction based on 2D pose estimation and graph convolutional networks. IEEE/RSJ Int. Conf. Intell. Robots Syst. (IROS). https://doi.org/10.1109/itsc.2019.8917118 (2019).
Gesnouin, J., Pechberti, S., Bresson, G., Stanciulescu, B. & Moutarde, F. Predicting intentions of pedestrians from 2D skeletal pose sequences with a representation-focused multi-branch deep learning network. Algorithms 13, 331. https://doi.org/10.3390/a13120331 (2020).
Donahue, J. et al. Long-term recurrent convolutional networks for visual recognition and description. in IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2625–2634https://doi.org/10.1109/cvpr.2015.7298878 (2015).
Zhang, B., Wang, L., Wang, Z., Qiao, Y. & Wang, H. Real-time action recognition with enhanced motion vector CNNs. in IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2718–2726. https://doi.org/10.1109/cvpr.2016.297 (2016).
Vemulapalli, R., Arrate, F. & Chellappa, R. Human action recognition by representing 3D skeletons as points in a lie group. in IEEE Conference on Computer Vision and Pattern Recognition (CVPR). https://doi.org/10.1109/cvpr.2014.82(2014).
Du, Y., Wang, W., Wang, L. & Hierarchical recurrent neural network for skeleton based action recognition. in IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 1110–1118. https://doi.org/10.1109/cvpr.2015.7298714(2015).
Shahroudy, A., Liu, J., Ng, T. T., Wang, G. N. T. U. & RGB + D: A Large scale dataset for 3D human activity analysis. in IEEE Conference on Computer Vision and Pattern Recognition (CVPR). https://doi.org/10.1109/cvpr.2016.115 (2016).
Song, S., Lan, C., Xing, J., Zeng, W. & Liu, J. An End-to-End Spatio-Temporal Attention Model for Human Action Recognition from Skeleton Data. arXiv. (2016). https://doi.org/10.48550/ARXIV.1611.06067.
Cao, Z., Simon, T., Wei, S. E. & Sheikh, Y. Realtime multi-person 2D pose estimation using part affinity fields. IEEE Conference on Computer Vision and Pattern Recognition (CVPR)1302–1310. https://doi.org/10.1109/cvpr.2017.143 (2017).
Raza, M., Chen, Z., Rehman, S. U., Wang, P. & Bao, P. Appearance based pedestrians’ head pose and body orientation Estimation using deep learning. Neurocomputing 272, 647–659. https://doi.org/10.1016/j.neucom.2017.07.029(2018.
Osman, N., Cancelli, E., Camporese, G., Coscia, P. & Ballan, L. Early pedestrian intent prediction via features estimation. IEEE International Conference on Image Processing (ICIP) 3446–3450. https://doi.org/10.1109/icip46576.2022.9897636 (2022).
Yang, L., Hu, G., Song, Y., Li, G. & Xie, L. Intelligent video analysis: A pedestrian trajectory extraction method for the whole indoor space without blind areas. Comput. Vis. Image Underst. 196, 102968. https://doi.org/10.1016/j.cviu.2020.102968 (2020).
Chen, W. et al. Multimodal pedestrian trajectory prediction using probabilistic proposal network. IEEE Trans. Circuits Syst. Video Technol. 33, 2877–2891. https://doi.org/10.1109/tcsvt.2022.3229694 (2023).
Yan, X. et al. Global temporal attention optimization for human trajectory prediction. in IEEE International Conference on Systems, Man, and Cybernetics (SMC). 184–189. https://doi.org/10.1109/smc53654.2022.9945387 (2022).
Cadena, P. R. G., Qian, Y., Wang, C. & Yang, M. Pedestrian graph +: A fast pedestrian crossing prediction model based on graph convolutional networks. IEEE Trans. Intell. Transp. Syst. 23, 21050–21061. https://doi.org/10.1109/tits.2022.3173537 (2022).
Cao, Z. et al. Realtime multi-person 2D pose estimation using part affinity fields. IEEE Trans. Pattern Anal. Mach. Intell. 43, 172–186. https://doi.org/10.1109/tpami.2019.2929257 (2021).
Chen, Y. et al. Cascaded Pyramid Network for Multi-Person Pose Estimation. arXiv. (2017). https://doi.org/10.48550/ARXIV.1711.07319.
Sun, K., Xiao, B., Liu, D. & Wang, J. Deep High-Resolution representation learning for human pose Estimation. ArXiv https://doi.org/10.48550/ARXIV.1902.09212 (2019).
Hübner, M., Baude, M. & Bengler, K. Pedestrian groups matter: Unraveling their impact on pedestrian crossings when interacting with an automated vehicle. in 2024 IEEE Intelligent Vehicles Symposium (IV) 69–76. (IEEE, 2024). https://doi.org/10.1109/iv55156.2024.10588543.
Chen, L. C., Zhu, Y., Papandreou, G., Schroff, F. & Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. ArXiv https://doi.org/10.48550/ARXIV.1802.02611.
Rasouli, A., Kotseruba, I. & Tsotsos, J. K. Agreeing to cross: how drivers and pedestrians communicate. 2017 IEEE Intell. Veh. Symp. (IV). https://doi.org/10.1109/ivs.2017.7995730 (2017).
Simonyan, K. & Zisserman, A. Very deep convolutional networks for Large-Scale image recognition. ArXiv (2014). https://doi.org/10.48550/ARXIV.1409.1556.
Deng, J. et al. &. ImageNet: A large-scale hierarchical image database. in IEEE Conference on Computer Vision and Pattern Recognition (CVPR). https://doi.org/10.1109/cvpr.2009.5206848(2009).
Kotseruba, I., Rasouli, A. & Tsotsos, J. K. Do they want to cross? Understanding pedestrian intention for behavior prediction. in 2020 IEEE Intelligent Vehicles Symposium (IV) 1688–1693. https://doi.org/10.1109/iv47402.2020.9304591 (2020).
Rasouli, A., Kotseruba, I. & Tsotsos, J. K. Pedestrian action anticipation using contextual feature fusion in stacked RNNs. ArXiv https://doi.org/10.48550/ARXIV.2005.06582 (2020).
Kotseruba, I., Rasouli, A. & Tsotsos, J. K. Benchmark for evaluating pedestrian action prediction. in IEEE Winter Conference on Applications of Computer Vision (WACV) (IEEE, 2021). https://doi.org/10.1109/wacv48630.2021.00130.
Funding
This research was supported by the Shandong Provincial University Discipline Talent Introduction and Training Program: Intelligent Connected Vehicle Technology Research and Innovation Team (grant number 2021SLG08), the Natural Science Foundation of Shandong Province (grant number ZR2024MG014), the National Natural Science Foundation of China (grant number 52272343), and the Undergraduate Education Reform of Shandong Province (grant numbers Z2023178 and M2022179).
Author information
Authors and Affiliations
Contributions
H.Z.: Data curation, Software, Writing—original draft. Y.G.: Conceptualization, Methodology, Writing—original draft. F.W.: Formal analysis, Investigation, Writing—review & editing. D.G.: Formal analysis, Writing—review & editing. Q.L.: Writing—review & editing, Validation. J.P.: Validation, Resources.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Zou, H., Guo, Y., Wei, F. et al. A pedestrian group crossing intention prediction model integrating spatiotemporal features. Sci Rep 15, 20675 (2025). https://doi.org/10.1038/s41598-025-05128-4
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-025-05128-4
