
Abstract
The rapid proliferation of misinformation across digital platforms has highlighted the critical need for advanced fake news detection mechanisms. Traditional methods primarily rely on textual analysis, often neglecting the structural patterns of news dissemination, which play a crucial role in determining credibility. To address this limitation, this study proposes a Dual-Stream Graph-Augmented Transformer Model, integrating BERT for deep textual representation and Graph Neural Networks (GNNs) to model the propagation structure of misinformation. The objective is to enhance fake news detection by leveraging both linguistic and network-based features. The proposed method employs Graph Attention Networks (GAT) and Graph Transformers to extract contextual relationships, while an attention-based fusion mechanism effectively integrates textual and graph embeddings for classification. The model is implemented using PyTorch and Hugging Face Transformers, with experiments conducted on the FakeNewsNet dataset, which includes news articles, user interactions, and source metadata. Evaluation metrics such as accuracy, precision, recall, F1-score, and AUC-ROC indicate superior performance, with an accuracy of 99%, outperforming baseline models such as Bi-LSTM and RoBERTa-GCN. The study concludes that incorporating graph-based propagation features significantly improves fake news detection, providing a robust, scalable, and context-aware solution. Future enhancements will focus on refining credibility assessment mechanisms and extending the model to support multilingual and multimodal misinformation detection across diverse digital platforms.
Similar content being viewed by others
Introduction
Globalization and proliferation of digital platforms as well as social media have significantly altered the patterns of dissemination and consumption of information around the globe. A simple click and a message can circulate worldwide instantly, touching the lives of millions in just seconds. Even though this has given humanity increased interconnectivity as well as instant access to more information, it has created the created fertile ground for the propagation from which false information or misinformation grows; often popularly termed fake news1,2,3. Unlike traditional media, whose editorial processes are usually rigorous for accuracy and credibility, online resources allow unverified information to propagate without realistic forms of oversight. Fake news has devastating effects in this world, like affecting public opinion, undermining trust in institutions, and even influencing the political outcome, as evidenced by incidents like election misinformation campaigns, health-related hoaxes during COVID-194,5. Fake news may also bring tensions at the societal level because of amplification of divisive narratives and spreading of misinformation on sensitive issues. Considering that it poses a danger to social cohesion and democratic functioning, it is considered critical to deal with the threat of fake news, so this issue underscores the urgent needs for superior, yet credible techniques of identification and elimination of fake news from cyberspace while upholding information integrity. With the recent progresses in deep learning and graph-structured architectures, there has been an increasing concern for creating hybrid models that will be able to capture better relational and contextual information for applications such as detecting fake news6.
Most current research in fake news detection has focused on text-based approaches that utilize Natural Language Processing (NLP) techniques and deep learning-based models like LSTMs and Transformer models7. Such methods have been proven effective for extracting linguistic features from news articles, making classification models possible in distinguishing real and fake news. However, they overlook the fact that information contextually spreads and becomes an important criterion for establishing credibility8,9,10. In reality, most of the fake news spreads in the highly connected social networks that use user engagement patterns to propagate them. Recent studies have tried to introduce GNNs to model the structure of news dissemination by modeling users, sources, and news articles as nodes in a heterogeneous graph11,12. Even though GNNs have gained promising results on capturing relational features, existing implementations face issues in scalability, sparsity of feature extraction, and limited fusion of textual and propagation-based signals. Additionally, many current approaches cannot integrate both linguistic and graph-based features properly and therefore suffer from suboptimal detection performance13,14,15.Specifically, they tend to ignore the propagation structures of news, which are the interaction networks between sources, news article, and users. Propagation structures provide important contextual signals e.g., diffusion channels and influence of users—that are essential to detecting fake news correctly.
To address these challenges, this study introduces a Dual-Stream Graph-Augmented Transformer Model that combines BERT for text feature extraction and GNN for propagation-based context analysis. The model is designed to fully exploit a heterogeneous graph structure formed by nodes - news articles, users, sources - and edge-captured user interactions, citations, and credibility scores of the news articles. The first stream in this model engages in BERT textual content processing and captures semantic meaning and contextual dependency. The second stream adopts Graph Attention Networks and Graph Transformers to model the news dissemination network, thereby making it possible for the detection system to learn relational structure and influence dynamics about fake news spread. The outputs of both streams are then fused via an attention-based mechanism so as to make a balanced contribution from text-based signals and propagation-based signals before finally classifying it using a Transformer-based model. This proposed approach aims to enhance the detection accuracy, robustness, and adaptability across different misinformation scenarios by integrating both content and context-aware features.
Research motivation
The rising prevalence of fake news in social media and digital channels significantly threatens public trust, political stability, and overall well-being in society. Current approaches for the fake news detection focus largely on the text content alone and fail to address the underlying patterns of propagation and network structures used in spreading false information. Thus, a recent model integrates both linguistic and contextual features for enhancing detection accuracy. The motivation that has led to this study is the need to strengthen a scalable and context-aware approach, which not only checks news article analyses but also examines their dissemination patterns in social networks. Using deep semantic understanding from BERT and structural learning by GNN in this study is aimed at increasing the reliability of fake news classification to make the detection systems more resilient to evolutionary strategies in spreading misinformation.
Significance of the study
This study makes new contributions in developing fake news detection by presenting the dual-stream-based approach with integrated content and propagation-based features; this has traditionally been missing from conventional text-based models. Using the proposed framework of BERT-GNN brings about considerable increases in classification accuracy, providing scalability and adaptability for cross-domain misinformation detection applications. The model captures contextual relationships and credibility scores, which enhance its applicability in combating misinformation on social media, news portals, and digital forums. In addition, research provides policymakers and fact-checking agencies with greater awareness, which guides the AI designers towards designing more effective countermeasures against it. This research may be used to further develop multimodal and multilingual fake news detection systems to further strengthen the integrity of digital information.
Problem statement
Although fake news detection has undergone a large improvement, the existing methods face some critical limitations. Farokhian, Rafe, and Veisi16proposed a double-stream BERT-based model, MWPBert, which utilized headline and body analysis of news for the enhancement of the detection process. This reliance on the MaxWorth algorithm and double BERT networks results in a very high computational cost, making this model difficult to be deployed in a real-time deployment. Chang17 proposed GANM, which includes graph-based learning to improve the analysis of misinformation propagation. The model is effective, but it is too dependent on historical data and not very adaptive to fast-evolving misinformation. Luvembe18 proposed a multimodal model called CAF-ODNN, which exploits text and images; however, its dependency on multimedia data shrinks the applicability of it to the text-based fake news. To overcome these challenges, this study proposes a Dual-Stream Graph-Augmented Transformer Model combining BERT and GNNs. The model makes use of deep semantic representations from BERT and captures misinformation propagation patterns using GNNs and integrates the two streams to provide context-aware, scalable, and computationally efficient fake news detection frameworks that can accommodate the diversity of the misinformation scenarios.
Recent inventions and challenges
Recent advancements in NLP and GNN have also greatly enhanced the ability to detect misinformation through contextual learning mechanisms. Transformer-based approaches like BERT, RoBERTa, XLNet helped, respectively, improve the text analysis, while GAT and Graph Transformers assisted in modeling complex dissemination structures19,20. Amongst all these innovations, there are still many challenges. There are issues involving scalability, computing costs, and lack of structured access to social network data. Many of the existing models fail to generalize across different domains of misinformation, especially when dealing with low-resource languages and multimodal content. More importantly, how such tactics change very quickly, like AI-generated misinformation, poses a very new challenge to which adaptive learning models must be updated continuously according to the emerging trends. Future research in this area might lead to hybrid approaches that combine reinforcement learning, multimodal processing, and blockchain-based credibility verification towards enhanced real-time fake news detection.
Key contributions
-
The Dual-Stream Fake News Detection Model combines BERT for textual analysis and GNNs formodeling propagation, enhancing the accuracy and robustness of detection.
-
GAT and Graph Transformers- The model captures the structures of news dissemination to enhance context-aware learning and credibility assessment.
-
Attention-Based Fusion Mechanism- This balances textual and graph-based embeddings, optimizing feature integration for better classification.
-
Superior Performance and Benchmarking – Attains 99% accuracy surpassing Bi-LSTM, RoBERTa-GCN, and proposed models on FakeNewsNet dataset with high ‘precision’, ‘recall’, and ‘F1-score’.
Rest of section of the study
-
Section 2: Related Work – Reviews existing fake news detection models, highlighting limitations in text-based and graph-based approaches.
-
Section 3: Methodology – Proposes a Dual-Stream Graph-Augmented Transformer Model, integrating BERT and GNNs with an attention-based fusion mechanism.
-
Section 4: Results and Analysis – Evaluates model performance on FakeNewsNet, demonstrating 99% accuracy, surpassing baseline models.
-
Section 5: Conclusion and Future work – Summarizes findings, discusses limitations, and suggests future enhancements like multimodal and multilingual extensions.
Related works
Zhang21 proposed the convolution-based model Conv-FFD for the fast detection of fake news in Chinese cyber-physical social services. This study focused on short texts by processing individual characters and used a CNN framework to extract feature representations. The results tested on the Rumor and CHEF datasets of Chinese social media showed higher classification accuracy and shorter training time than baseline methods. However, it is only applicable to Chinese short texts and therefore cannot be generalized to multilingual or longer-text scenarios. Kumar22 designed OptNet-Fake, an integrated model combining CNNs and DNNs aimed at enhancing the credibility of news on cyber-socio platforms. Making use of MGO feature extraction with TF-IDF weighing, this CNN-using model relies on various filter sizes for extracting n-gram features that can be used in classification. For four real-world datasets of fake news, OptNet-Fake performed better than the compared meta-heuristic algorithms and state-of-the-art techniques in accuracy and reliability results. However, in terms of the computational complexity related to feature selection and CNN-based processing, its scalability becomes problematic for large-scale or real-time applications.
Recently, Akhter23 proposed the use of CNN-based deep learning architecture to help overcome the problem of the “infodemic” related to COVID-19 by using word embeddings for representation and a grid search to obtain the optimal configuration of the CNN architecture. Its mean accuracy stands at 96.19% and mean F1-score 95%, AUC 0.985 while evaluating on some datasets related to COVID-19 that outperforms existing ML algorithms. Even with the relatively high accuracy, specificity to COVID-19 datasets limits its ability to generalize to other domains, and a computationally expensive architecture for CNN poses scaling challenges for real-time applications. Hashmi24 made a multimedia approach for fake news detection by integration of FastText embeddings with ML and DL models applied on WELFake, FakeNewsNet and FakeNewsPrediction datasets. It achieved an extremely high accuracy F1-scores of 0.99 and 0.97 respectively. Optimized transformer-based models such as BERT, XLNet, and RoBERTa have outperformed RNN-based methods by handling syntactic and semantic complexities. Explainable AI techniques, such as ‘LIME’ and ‘LDA’, enhanced interpretability; however, multimedia datasets have to be relied upon and the computational cost of transformer models, scalability with respect to text-only fake news detection and real-time applications is limited.
Farokhian, Rafe, and Veisi16 proposed a dual-stream BERT-based model known as MWPBert, which is designed to detect ‘fake news’ by checking the news headlines and bodies. For the limitation of input length in the BERT model, the study proposed the ‘MaxWorth’ algorithm, which determines the most significant parts of the body for fact-checking. Outputs from two parallel BERT networks were fed into a classification layer to get the superior accuracy and robust results on a wide range of metrics. However, reliance on MaxWorth and computational cost due to the usage of dual BERT networks introduce scalability challenges in real-time or resource-constrained environments. Abualigah25 proposed the integration of GloVe word embeddings with the CNN, DNN, and LSTM architectures on fake news detection using the Curpos dataset. The system boosted preprocessing with a high capability in capturing word relations through Glove and the capabilities of RNNs to do sequential processing hence achieving a wonderful accuracy of 98.974%. High-performance approach but depends on particular datasets, has high computational overhead, and keeps text-based fake news: does not address multimedia or cross-platform scenarios.
Luvembe18 proposed the CAF-ODNN model to address the shortcomings in multimodal fake news detection. The CAF is the image captioning model with bidirectional complementary attention that aligns the text and images, while the alignment and normalization module maintains semantic consistency. The ODNN makes use of three fully connected layers and parameter tuning for the feature extraction. On GossipCO, PolitiFact, Fakeddit, and Pheme, for example, ODNN will likely be more accurate than any of the competing approaches. Nonetheless, the dependence on computationally intensive techniques as well as focusing solely on text-image modalities significantly limits its scalability and adaptability to other media types or real-time applications. Mallik and Kumar26presented a hybrid framework combining Word2 Vec embeddings and LSTM layers for fake news detection. Word2 Vec obtains data-agnostic feature vectors, and stacked LSTMs extract relevant features, followed by dense layers for classification. It surpasses traditional machine learning as well as the pre-trained transformer model BERT in terms of efficiency on various datasets. Its redundancy on hyperparameter tuning and high computational costs disallow it from being deployed in real time, and its applicability to non-textual modalities also left unexhibited.
Chang17 propose ‘Graph Global Attention Network with Memory’ (GANM) for the better detection of fake news on social media by making use of the techniques of NLP and graph. GANM encodes nodes with contextual and user generated content, while making use of three GCN, extracting features in the news propagation network with information regarding users. The model uses the global attention mechanism with memory that captures structural homogeneity in the propagation of news and a key information aggregation module to merge both node- and graph-level embeddings. Evaluations on real-world datasets confirmed effectiveness, though both computational complexity and reliance on extended historical data can be challenging in practice. Similarly, Qu27 introduced the Quantum Multimodal Fusion-based Model (QMFND), which combined textual and image features with a Quantum Convolutional Neural Network (QCNN) for identifying fake news. QMFND was demonstrated to be robust to quantum noise, and achieved accuracies of 87.9% and 84.6% on the Gossip and Politifact datasets respectively, overperforming the classical models. However, its computational requirements and reliance on multimodal data limit scalability and broader applicability.
Mahmud28 has proposed a Hybrid DL framework combining CNN, LSTM architectures and Repeat Vector, to improve detection of fake news, which, in a special dataset, produced a validation accuracy of 98.94%. The model though efficient for understanding complex patterns requires labeled datasets as well as huge computational resources making it unscalable for a real-time process. Raghavendra and Niranjanamurthy29, also proposed a DL-based social media fake news detection system by using ANN and a CNN-LSTM hybrid model along with news generation location and timing as new features. They also presented a geo-map for tracking the global spread of misinformation, although its high computational requirement and dependence on location-specific data are a hindrance. Truică, Apostol, and Karras30 introduced DANES-a DNN ensemble that learns by leveraging textual as well as social contexts via Text Branch and a Social Branch. Evaluated over datasets like BuzzFace, Twitter15, and Twitter16 DANES performs best but may pose limitations as this is social dependent and is applied only if all the social data is complete.
Singh and Jain31 suggested a hybrid socio-political news detection model combining BERT’s contextual semantic knowledge and structural relational modeling capacity of Graph Neural Networks (GNN) effectively analyzing the relations between headlines, articles, and entities. With RSS feeds used for testing, their approach performed better than machine learning and individual deep models in accuracy, precision, and recall. Despite its robustness, the study has short of insights into multilingual performance and adaptability in extreme data imbalance. Bhowmik, Mondal, and Arifuzzaman32 have done sentiment analysis of Bangla text using a data augmentation-based method improving class diversity and imbalanced classes by representational learning models such as Word2 Vec, BERT, and FastText under the framework of a GNN-transformer framework. Evaluated on 15,114 samples, the model scored a high accuracy rate of 0.8957, wherein the combined effect of BERT-GNN and FastText showed optimum performance. Its strength to differentiate context-wise, but the scalability of the framework as well as the domain transferability of the proposed method remain unknown. Zhang33 proposed the GBCA model integrating Graph Convolutional Networks and BERT into a co-attention mechanism to integrate propagation structures with semantic representations of false news. The model improved significantly the detection of made-up news on three public datasets, with higher accuracy and less training time. However, its reliance on the quality of propagation graphs as well as text features could curtail performance in low-resource or noisy settings.
Fang34 had proposed a framework NSEP, where it used macro and micro semantic inconsistency within news content towards use-generated posts to detect fake news. Utilizing GCN and multi-head sparse attention, NSEP achieved up to 86.8% accuracy when tested over Chinese datasets with the model beating off the traditional models. The study was able to effectively show how the combination of intrinsic news content and extrinsic posts is indeed crucial for debunking misinformation before it spreads. However, the use of time-constrained intervals and post tokens might reduce generalizability in dynamic, real-time scenarios. Raja35 also proposed a hybrid DL model, called DTCN-BiLSTM-CAM, for the task of low-resource ‘fake news detection’ in Dravidian languages by proposing hybrid Dilated Temporal Convolutional Neural Networks (DTCN), Bidirectional Long Short-Term Memory (BiLSTM), and Contextualized Attention Mechanisms (CAM). The model, tested on the Dravidian_Fake dataset, reached an average accuracy of 93.97%, which outperformed the baseline methods. Incorporating adaptive learning rates and early stopping enhanced the study’s convergence. The model shows great promise for low-resource languages, but applicability to diverse linguistic structures and real-world contexts remains a challenge.Summary of existing methods for fake news detection were shown in Table 1.
Fake news detection using BERT and GNN
The proposed methodology combines dual-stream feature extraction with the use of textual representation learning and graph-based social context modeling for enhanced fake news detection. The workflow of proposed study is given in Fig. 1. It begins with the preprocessing of the dataset, consisting of news articles, social media interactions, and source metadata, through text tokenization and heterogeneous graph construction to capture relationships between articles, users, and sources. The textual stream extracts deep semantic features from article content using BERT embeddings, and the graph-based stream applies GAT to learn propagation structures and social influence patterns. These two feature sets are fused using an attention mechanism in order to incorporate both content-based and context-based information into the classification. News articles are then classified by the help of fused features using a classifier that is built based on a Transformer model. Cross-entropy loss has optimized the model with an assessment regarding “accuracy, precision, recall, F1-score, and AUC-ROC”. Predicted outputs represent true or fake statements, including a consideration of language content along with the pattern in which such articles spread over the social networks.

Workflow of the proposed BERT-GNN for fake news detection.
Data collection
The FakeNewsNet dataset36by Arizona State University gathered from Kaggle which aggregates content from a source (including both the author/publisher), headlines, text in the bodies (a descriptive summary of main news stories/claims), image and video material as part of a news headline’s multimedia and multimodal component - are also to be seen and analyzed because it has such great significance toward finding out more linguistic patterns that indicate the mode of writing about these fictions or fake news, along with media-related affinities within news. The social context consists of user profiles (basic information about the user), user content (recent posts), user followers (network of followers), and user followees (accounts the user is following), giving insights into how misinformation spreads through social interactions. Such a dataset would involve an overall dual-perspective study—content-based and social network-based fake news detection-to help researchers design machine learning models that differentiate between linguistic features and misleading narratives as well as assess propagation patterns. In addition, FakeNewsNet supports multi-modal analysis by integrating text, social behavior, and multimedia elements, making it highly useful for data mining, NLP, and network science applications in misinformation detection. The dataset parameters were given in Table 2.
Data pre-processing
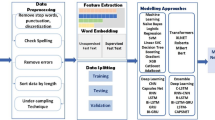
In this study, this step is crucial in preparing textual data so that quality can be ensured for ‘fake news detection’. Essentially, the goal is text cleaning and removing noise from it by normalizing the content so that meaningful patterns are surfaced. This mainly involves stop words removal, which are those common but insignificant words, and ending words at their base form using lemmatization so that generalization is better. These techniques, along with feature extraction techniques like TF-IDF and word embeddings, transform raw text into structured, numerical representations that can be easily analyzed by machine learning models. The flowchart of the pre-processing steps is given in Fig. 2.

Workflow of pre-processing data.
Text cleaning for fake news detection
When dealing with fake news, the goal of text cleaning is to reduce noise and highlight the more meaningful terms that can help distinguish between credible and non-credible articles. Stop word removal and lemmatization are crucial steps in this process.
Stop word removal
This is one of the very common words, which appear many times but have no significant content or sentiment attached to them. It helps filter out the words that are important37.
-
Original text (from a fake news article): “The study has revealed that a new vaccine is causing severe side effects in some people, and many doctors are concerned.”
-
After stop word removal: “study revealed new vaccine causing severe side effects people, many doctors concerned.”
By eliminating words like “the,” “has,” “that,” “is,” “in,” “some,” “and,” and “are,” the words become much more concise, and the key phrases are really noticed such as “study revealed,” “new vaccine,” “severe side effects,” and “doctors concerned.” The model can then focus on these phrases to try to validate some potential misinformation.
Lemmatization
It reduces words to their base form or dictionary form (lemma). There is important because distinct forms of the same word often have roughly the same meaning. Treating them as a single token helps the model generalize better38.
For example:
-
Original text (from another hypothetical fake news article): “Several sources are claiming that the election results are manipulated, leading to protests and increasing tensions.”
-
After lemmatization: “Several sources be claim that the election result be manipulate, lead to protest and increase tension.”
With lemmatizing, the model knows that “claiming”, “claims” and “claimed” are of the same essence. This way, the dimensions of the data reduce, hence enhancing the patterns of the fake news, maybe the specific claim or narrative might be identified in the model.
Feature extraction
Feature extraction involves the transformation of cleaned text into numerical representations that may be processed by machine learning models. There are two common techniques: ‘TF-IDF’ and ‘word embeddings’.
TF-IDF
It is a statistical measure used to determine the relevance of a word in a document with respect to a collection of documents. It is calculated by multiplying TF and IDF given in Eqs. (1), (2) and (3)39. It determines the term’s rarity throughout the entire corpus and counts the frequency with which it appears in a particular text.
The higher the TF-IDF score, the more important or relevant the term is to the document. This technique helps in identifying the words that are significant for a particular document by considering their frequency in the document and their rarity in all documents.
Word embeddings
Word embeddings is the method through which words could be represented as dense vectors within a continuous space based on capturing semantic meanings and contextual relationships. Word2 Vec is the most popular word embedding technique. Instead, it shows words in terms of usage from a specified text corpus. This method mainly has two architectures, which include ‘Continuous Bag of Words and Skip-Gram’40. Here, CBOW predicts a target word from its surrounding words, whereas ‘Skip-Gram’ predicts surrounding words given a target word. For example, the sentence “Fake news spreads misinformation” will make CBOW predict “news” with the context words “Fake” and “spreads”, while Skip-Gram will learn that “Fake” is typically followed by words like “news”, “misleading”, and “propaganda”. This will enable Word2 Vec to learn meaningful relationships between words, like placing “fake” closer to “false” but farther from “authentic” in the embedding space. Based on these embeddings, the models capture the slight difference in word meaning and therefore tend to do better in the detection of fake news when there is semantic similarity among misleading and factual content.
Textual representation via BERT
BERT is a transformer-based model, which generates deep contextual embeddings for each word or token in the input text. For this study, BERT has been used to extract textual features from news articles to help differentiate between fake and real news. The architecture of BERT is given in Fig. 3.
Input representation
The input to BERT is a sequence of tokens that represent the text. A token embedding represents each token in the sequence and additional information in order to include the structure in the input: In Token Embeddings each word or subword in the vocabulary is represented as a vector in an extremely high dimensional space, extracted from a pre-trained vocabulary - like WordPiece41. In Segment Embeddings, it differentiates sentences by tagging tokens with unique identifiers for their respective sentences, such as [A] for sentence 1 and [B] for sentence 2. Positional Embeddings denote the position of the tokens in the input sequence to ensure that the transformer does not lose the order in which they’re fed into the system. This ensures that BERT learns what position the token is within the sentence. These embeddings are added together to result in a final input embedding vector for each token present in the text given in Eq. (4), which then pass through BERT layers.
where \(\:{t}_{i}\) represents the \(\:i\)-th token in the input text.
BERT transformer layers: encoding the input

Architecture of BERT.
Transformer encoder layers
BERT’s architecture is essentially multi-layered Transformer Encoder, through which all input embedding vectors are passed and then processed into a two major component layers which consist of Self-Attention Mechanism which calculate weighted sum, how relevant the current token could be to its another token present in the given sequence. This is followed by Feedforward Neural Networks process further information where attention has been computed. Each Transformer encoder layer has two sub-layers, ‘Multi-Head Self-Attention’ to focus on different aspects of the sequence and Position-wise Feedforward Network for further refinement of features.
Self-attention mechanism
It is an important component of BERT. It enables the model to compute the relationship between every token and every other token in the sequence. For each token \(\:{t}_{i}\), the attention mechanism computes Query (Q), Key (K), and Value (V) matrices, given in Eq. (5).
where, \(\:{W}_{q}\), \(\:{W}_{k}\), \(\:{W}_{v}\), are the learned weight matrices for ‘Query’, ‘Key’, and ‘Value’, \(\:{t}_{i}\)and \(\:{t}_{j}\) are the input tokens in the sequence.The attention score between tokens \(\:{t}_{i}\)and \(\:{t}_{j}\) is computed as Eq. (6).
where, \(\:\left(\frac{Q{K}^{T}}{\sqrt{{d}_{k}}}\right)\) is the scaled dot-product attention, \(\:{d}_{k}\) is the dimension of the query and key vectors, used for scaling.This mechanism will allow BERT to pay special attention to only the most pertinent tokens while determining the contextual meaning of each word in the sequence. For example, in a sentence such as “The President denied the claims”, the context between “denied” and “claims”, though not appearing adjacent in a sentence, still gets captured.
Multi- head attention
BERT uses multi-head attention in order to capture multiple aspects of the relationship between tokens. Multiple attention heads allow it to focus on different parts of the input sequence, which helps capture diverse relationships which is given in Eq. (7).
Where each Head is computed with the previously described attention formula and \(\:{W}_{o}\)is the learned output weight matrix. This operation enables the model to attend to information jointly from different subspaces.
BERT output: contextualized token embeddings
After passing through the transformer layers, each token is represented by a contextualized embedding. In other words, this implies that the representation for each token depends not only on its immediate neighbors but also its global context at the sentence or document level. The final output of BERT is a sequence of hidden states for each token, where every state is related to a vector representation of what the token denotes in the specific context. This output can be represented as Eq. (8).
Where, \(\:{H}_{i}\) is the output embedding for token \(\:{t}_{i}\). These embeddings are then forwarded to the next layer in the model for further processing, which could be a fusion layer or classification layer.
Fine-tuning BERT
Train the BERT model using a domain dataset such as FakeNewsNet especially for the detection of fake news. This training will make adjustments to the weight of BERT and teach what specific patterns classify a piece as fake news may include:
-
Contradictory terms or misleading headlines: Words and phrases like “shocking,” “exclusive,” or “you won’t believe it” are signs that headline may signal sensational or potentially fake news.
-
Tone and emotional cues: BERT will capture those minute emotional undertones or embellishments that most fake news presents, which often characterize partiality or intended deception.
-
Contextual contradictions across the body and headline: Typically, such false news stories will have sensational headlines that do not align with the subtle content on the body. BERT can be trained to identify such disparities.
The fine-tuning process adds a classification head-a feedforward network-on top of the BERT output. The classification head uses the output embeddings to produce the final prediction via Eq. (9), typically using a softmax function to classify news as real or fake.
where, \(\:W\) is the learned weight matrix, and \(\:b\) is the bias term, \(\:H\) is the hidden state vector representing the final token (often the [CLS] token) from BERT’s output.
The study demonstrates how BERT captures contextual word relationships that define the nuances in news articles. Self-attention and multi-head attention in BERT help draw attention to significant words and their interactions, including contradictory terms, emotionally charged words, or inconsistent claims. BERT then uses the deep contextual embeddings to classify fake news, thereby allowing the model to differentiate between real and misleading news based on both the text and its context. The last contextual embedding that maps to the [CLS] token is used as the fixed-size textual feature representation of every news article. The vector is then passed to the graph-based part for fusion with structural features.
Graph-based context representation
In this process, the study uses GNNs to represent and understand social context and structure for news propagation. News propagates through a network of articles that interact, engage users, and sources may have certain patterns that resemble the spreading patterns of fake news.
Graph construction: representation of social context
In order to accurately simulate the social dynamics and news dissemination of context, in this study, a heterogeneous graph is built to reflect the complex relationships among different types of entities in news dissemination. The built heterogeneous graph includes three main node types: article nodes, storing both metadata and text content; user nodes, reflecting individuals performing actions on articles via likes, shares, or comments; and source nodes, reflecting the news sources. Edges in the graph encode different patterns of interaction such as user–article edges encoding user interaction, article–article edges encoding relationships such as content or citation pointers, and user–user edges simulating social network relationships such as friends or followers. In order to enhance social influence and credibility modeling, edge weights become adjusted based on user credibility values, which can involve aspects such as prior reliability, interaction history, or followership. This inhomogeneous framework preserves both direct and indirect routes of propagation and supports identification of abnormal patterns of spreading typical for imitation news such as coordinated posting by unrecognizable sources or rapid spread in echo chambers. The attention mechanism graph is given in Fig. 4.

(a) Attention mechanism (b) Multi-head attention.
GAT: learning node embeddings via attention
After the graph is built, a Graph Attention Network (GAT) is used to learn the expressive node embeddings. GAT uses attention weights to allocate importance between neighbor nodes in the context of identifying fake news. In particular, for neighbor node \(\:j\) of node \(\:i\), the attention coefficient \(\:{\alpha\:}_{ij}\) is calculated in two steps
Raw attention score with respect to a common learnable vector \(\:a\) and a weight matrix \(\:W\), given in Eq. (10).
Normalization using softmax over all neighbors\(\:N\left(i\right)\), as in Eq. (11).
The final embedding for node\(\:i\) is a weighted sum of its neighbors, given in Eq. (13).
This attention process allows the model to dynamically rank more informative neighbors like trusted users or reliably trustworthy articles and reduce deceptive signals.
Graph transformers: capturing global context
These transformers are incorporated to capture global dependencies between the graph. It modifies the standard self-attention mechanism to graph-structured data. The attention from node \(\:i\) to node\(\:\:j\) is calculated as Eq. (13).
where \(\:{W}_{q}\), \(\:{W}_{k}\), and \(\:{W}_{v}\) are the query, key, and value transformation matrices respectively. The node embedding is updated as Eq. (18).
In contrast to GAT, Graph Transformers support long-range message passing, allowing the model to discover indirect relationships between faraway nodes, e.g., identical articles exchanged between isolated communities or user habits patterns connected through sources. This attention local (GAT) and global (Graph Transformer) on two levels enables the system to learn graph features that are critical for context-sensitive fake news identification.
Feature fusion & classification
Fusion layer: multimodal fusion with attention
The final step is to combine the feature-extracted data of both streams into a single representation. Multimodal fusion layer combines the text embeddings of BERT (E_text) and the graph embeddings of GNN (E_graph) using an attention-based mechanism.
Dynamic attention mechanism
In order to adaptively weight the importance of both modalities, the model employs an attention mechanism that learns scalar weights between textual and graph-based embeddings. This is done by first computing individual attention scores per modality with respect to their respective pertinence towards the final task of classification, given in Eqs. (15), (16).
where score (·) is a trainable feedforward attention scoring function (e.g., a tanh or ReLU-activated single-layer MLP). These attention weights are subsequently used to calculate the fused representation given in Eq. (17).
This attention mechanism allows for adaptively balancing the contribution from text and graph-based features prioritizing the modality that provides more discriminative signals to identify fake news in a given case. For instance, the model might rely on textual indicators for cases involving deceptive language or focus on graph features in cases involving suspicious patterns of propagation.
Transformer-based classification
After feeding the fused representation from the multimodal fusion layer through a classification layer based on Transformer, where it is a fully connected layer activated by softmax with the goal to classify the given news article to be either true or false; the output of the probabilities was given in Eq. (16).
where \(\:{W}_{o}\) and \(\:{b}_{o}\) are learned parameters, and \(\:{F}_{fused}\) is the fused embedding.
Such patterns would be learnt from the combined information of both streams by the Transformer-based classification layer, identifying contradictions in textual content and suspicious social interactions. The softmax function for this layer would output the probabilities for every class, useful for deciding if a news article is real or fake. The Dual-Stream Model efficiently integrates textual content and graph-based contextual information for the improvement of fake news detection. The model thereby captures complex relations between news articles, users, and sources while leveraging BERT for textual understanding and GNN for social context, which then enables it to identify misleading and false narratives with a high level of information awareness and contextual aptitude. Therefore, the last classification layer based on both the streams is provided as a powerful mechanism for detecting fake news. Figure 5 shows the flowchart of the proposed study.

Algorithm for dual-stream fake news detection model.

Flowchart of the proposed study.
Result and discussion
The Dual-Stream Graph-Augmented Transformer Model was implemented on a large-scale dataset on Fakenewsnet comprising news articles, social media interactions, and source metadata. The implementation of the training was done through PyTorch and Hugging Face Transformers with BERT for the textual embeddings and GAT for the structural learning. The training was carried out on an NVIDIA A100 GPU, and the ‘learning rate’ was initiated with 0.0005, ‘batch size’ 32, and 50 epochs. For the evaluation, the metrics of accuracy, precision, recall, F1-score, and AUC-ROC were used to determine the performance. The study was also performed along with a comparative analysis with the baseline models to properly validate the effect of the proposed feature fusion mechanism. The rest of the paper will present experimental results in the form of quantitative evaluations, error analysis, and visualizations of the decision-making process undertaken by the model. The simulation parameters of the study are given in Table 3.
Dataset overview

Discriminatory words in news title.
Figure 6 depicts the most discriminative words for the headlines of fake and real news with their term frequencies in each of the news. Terms such as “Trump,” “Hillary,” and “Donald” are associated with misleading stories more frequently as depicted in fake news. Terms like “debate,” “new,” and “first” occur more often in real news and represent their use of reporting news facts. It analyzes how certain words can indicate credible news content. This helps further distinguish between authentic and fake news.

Density distribution graph.
Figure 7 is the density distribution graphs comparing real and fake news articles’ title lengths shows subtle yet significant differences in their patterns. Both of them have a peak at a title length of 7.5, reflecting that both fake and real news employ similar title lengths to attract readers. However, slight variations in their distributions indicate that fake news titles might employ different stylistic or structural patterns. These differences can be used in proposed models as a feature in order to tell the real and the fake news apart.
Preprocessing statistics and graph construction
Table 4 summarizes the preprocessing steps taken to text data. Initially, each article will have an average of 500 tokens, which after removing 30% stopwords gets reduced to 350 with an aim to focus on the meaningful content. Lemmatization will reduce the average tokens to 340 and decrease the unique lemmas from 10,000 to 9,500. This means that preprocessing successfully reduces noise and normalizes the text, making it easier for models to capture important patterns for detecting fake news.

Graph visualization of news propagation.
Diffusion networks illustrate how fake and real news spreads through the various nodes and edges. It is seen that fake news (in red nodes) and real news (in blue nodes) differ in their spreading process through interactions with users (green nodes) and intermediaries (black nodes) acting as conduits in the network. The configuration reveals the dynamic, connected aspect of information circulation, wherein fake news frequently travels more widely and quickly because it is viral. Figure 8 extracts the users’ and distributors’ role to either amplify or contain misinformation. A simple knowledge of the above dynamics will serve as an important component of this strategy to suppress the diffusion of false information yet promote access to reliable sources.
Performance evaluation
Table 5 summarizes the performance metrics applied to measure the performance of the proposed study. Accuracy calculates the correctness of predictions with regard to both ‘true positives’ and ‘true negatives’ against total instances. Precision evaluates how reliable the model is in the detection of fake news, as well as minimizing a lot of false positives. This quantifies the effectiveness of the model to identify fakes in comparison with missed cases (FN). The harmonic mean of precision and recall is denoted by ‘F1-score’, which balances both metrics for a more holistic evaluation. These metrics confirm that the model could indeed perform high as effective at identifying misinformation.

Confusion matrix.
Figure 9 evaluates the effectiveness of the fake news detection model by comparing its predictions with the actual labels. True positive and true negative values show how good the model has been in doing the classification work for real as well as fake news. False positives and false negatives point out specific instances where the model misclassifies news. The distribution of the confidence scores on these predictions, depicted as a gradient, helps one draw attention to certain distributions in the model. This analysis shows strengths, such as high accuracy in some cases, and weaknesses, such as misclassification rates, which are of great value in refining the model to improve its reliability in detecting fake news.

AUC-ROC curve.
Figure 10 displays that the model BERT-GNN excels at separating actual from fake news. An AUC of 0.99 places the model near perfection: a very good balance of having a high TP rate but low FP rate, surpassing even the random guess baseline depicted by the blue dashed line. This result implies that the model is highly effective at accurately classifying news articles, minimizing errors. The curve has approached the top-left corner, which further justifies the robustness in making predictions from the model. The result proves that the interaction of textual and graph-based features successfully identifies reliable trends in fake news detection.

Accuracy graph.
Figure 11 accuracy graph of the model over 25 epochs Learning performance while training. Both the training accuracy (blue) and validation accuracy (orange) increase sharply in the initial epochs and level at about 98–99% after epoch 5. Both curves are so close to each other, which means that the model generalizes well and does not overfit, because the ‘validation accuracy’ follows closely behind the ‘training accuracy’. This result would indicate that BERT-GNN is very good at learning from the data without losing robustness on unseen data. The good accuracy would prove the reliability of the model to be used for fake news detection tasks.

Loss graph.
Figure 12 shows the loss graph of the model over 25 epochs. The losses both drop sharply within the first epochs, which mean the model learns meaningful patterns in the data very quickly. From epoch 5 onward, the losses remain extremely low, with training loss being slightly below that of validation loss, as indicated by the orange and blue lines respectively. The little gap between these two specifies that this model generalizes quite well toward unseen data and avoids overfitting. It therefore suggests that such a model, BERT-GNN, is not only valid but very efficient in reducing their classification errors on fake news detection.
Error analysis
Table 6 provides examples of news articles with their actual labels, predicted labels, and potential reasons for misclassifications. The first article here is a true one that got classified as false because the pattern of spread about the article resembles bot-like action and have been mistaken as a characteristic of fake news. The second article, fake, was predicted as real probably due to a lack of examination into the credibility of the source. The third article, a user-generated report on a scandal, was correctly identified as fake, showing that the model can indeed detect fake news when features align clearly with learned patterns. This analysis shows where the model excels and where it needs improvement, such as better handling of nuanced propagation and credibility features.
Attention weight distribution in GAT

A heatmap of attention weights.
Figure 13 is a heatmap representation of GAT, which shows how much attention weights are assigned to connections between different nodes, for example, users, articles, and sources. Darker shades represent higher values of attention; that is, stronger influence or relevance between nodes.Forexample, User2 has a high attention (0.9) towards Article2, meaning that interaction is important, and Source2 has a strong connection (0.8) with User3. This depicts how GAT identifies important relationships in the network that can be used to understand the propagation dynamics and key influencers in the detection of fake news.
Ablation study

ROC curve comparison.
Figure 14 indicates improved classification accuracy by the proposed model Attention Fusion BERT-GNN. Attention Fusion has an AUC of 0.97, indicating better fusion of text and graph features compared to Concatenation Fusion, which stood at 0.95. This confirms the contribution of the attention mechanism toward improving feature importance. The finding confirms that the use of attention-based fusion enhances fake news detection performance considerably.

Confusion matrix of BERT-GNN.
Figure 15 shows the high recall and accuracy of the proposed Full BERT-GNN model in detecting fake news. With 987 out of 1,000 cases correctly classified, the model shows unmatched reliability in distinguishing between “Fake” and “Real” news. The extremely minimal misclassifications (only 13 cases) indicate excellent generalization capability. This finding validates the model’s robustness for real-world fake news detection tasks.

Confusion matrix of BERT.
The BERT-only model’s confusion matrix in Fig. 16 shows it classifies the fake news well, accurately predicting most “Fake” and “Real” instances. But with 85 total misclassifications (45 false positives and 40 false negatives), its precision lags behind that of the hybrid BERT-GNN model. Such misclassifications provide the possibility that BERT alone cannot be completely contextual or relational information. This is consistent with the study’s discovery that applying GNN introduces the reliability and accuracy in identifying fake news.
Comparative evaluation
Table 7 shows the effect of various fusion methods (BERT alone, GNN alone, concatenation, and attention-based fusion) applied in the proposed model of BERT-GNN. The highest performance is given by the attention fusion method, thereby supporting its superiority in combining textual features and graph-based features.
Table 8 demonstrates different fake news detection models through their performance metrics consisting of accuracy, precision and recall together with F1-score. The proposed BERT-GNN model provides the highest detection accuracy of 99% alongside remarkable precision and recall measures. The Bi-LSTM + Bi-GRU and LSTM-CNN techniques produce comparable results through their accuracy values reaching 96–98%. The accuracy values for RoBERTa-GCN, RoBERTa and BERT fall between 70% and 86%. BERT-GNN achieves the highest combined performance among all models in fake news detection tasks.

Accuracy comparison graph.
Figure 17 is a bar chart compares the accuracies of different models. BERT-GNN delivers the best results by reaching an accuracy score of 0.990. The accuracy levels of RoBERTa-GCN match those of LSTM-CNN at 0.986 and 0.980. BERT obtains the lowest accuracy score of 0.709 but both Bi-LSTM + Bi-GRU and RoBERTa reach 0.960 and 0.861 accuracy, respectively. It means that combining BERT with GNN enhances the classification accuracy.

Precision comparison graph.
Figure 18 is bar chart shows the precision of various fake news detection models. The precision analysis using the Model Precision Comparison reveals BERT-GNN (Proposed Method) stands as the leader with 0.990 precision rates than rivaling models. The precision scores of LSTM-CNN reach 0.989 while RoBERTa-GCN reaches 0.972 and Bi-LSTM + Bi-GRU reaches 0.950 yet RoBERTa achieves 0.851 and BERT reaches 0.706. Results demonstrate the combination of Graph Neural Networks (GNN) with BERT improves precision through optimal contextual and structural learning ability. BERT-GNN stands as the most sophisticated model because it reduces classification errors to a significant extent.

Recall comparison graph.
Figure 19 is a bar chart comparing the recall scores of four models for fake news detection. BERT-GNN (Proposed Method) demonstrates the best model recall rate at 0.987 which signifies its effectiveness in detecting positive cases with short false negative rates. The recall scores of LSTM-CNN and Bi-LSTM + Bi-GRU stand at 0.984 and 0.950 while RoBERTa-GCN obtains 0.913 and RoBERTa reaches 0.860. The recall capacity of BERT stands at 0.696 among the models which demonstrate its limited ability to recognize all appropriate cases. When GNN integrates with BERT the system demonstrates better recall capabilities which enable it to locate more accurate positive results effectively. The performance of BERT-GNN surpasses all other evaluated models because it achieves superior recall rates for clinical class identification.

F1-score comparison graph.
Figure 20 is the bar chart for F1-scores for all models that depict their precision/recall in the fake news detection. The Model F1-score Comparison reveals that BERT-GNN achieves equivalent performance with LSTM-CNN as the highest scoring 0.980 because both methods balance precision and recall successfully. The model performance of Bi-LSTM + Bi-GRU stands at 0.960 while RoBERTa-GCN demonstrates 0.950 and RoBERTa shows 0.850 and BERT maintains 0.701. BERT-GNN achieves superior performance than standard BERT as well as other models in classification applications. Less misclassification results from a higher F1-score that makes BERT-GNN an excellent method for producing accurate and detailed predictions.
Table 9 evaluates BERT and GNN-based hybrid models on different datasets for detecting fake news. The proposed Dual-Stream Graph-Augmented Transformer surpasses the current state-of-the-art in accuracy, precision, recall, and F1-score. This indicates the strength of the proposed technique in identifying the semantic and structural aspects of disinformation.
Discussion
The Dual-Stream Graph-Augmented Transformer Model combines textual analysis with propagation-based context in order to address key limitations of the current methods of fake news detection. This model differs from the traditional NLP-based models that depend only on textual features. The BERT model is used for deep semantic representation, and GNN captures relational structures in news dissemination. By incorporating GAT and Graph Transformers, the model effectively learns the influence dynamics of misinformation propagation. An attention-based fusion of textual and structural embeddings supports that both types of signals used here are being included in this classification process: social context boosts accuracy and makes it more robust. The obtained experimental results will prove that compared with the bi-LSTM models, RoBERTa-GCN models, LSTM-CNN, RoBERTa, existing BERT-related models, its precision, recall, and even F1-scores are always the best as regards the wide diversity of applied scenarios.
Moreover, the study provides insights into how misinformation actually spreads within the social network. The graphs indicate that fake news tends to diffuse differently: it often spreads faster through high-engagement user nodes. Graph structures are visualized and it is found that misinformation often originates from a set of clusters of low-credibility-scoring users, further emphasizing the need for network-based features. The attention-based fusion mechanism effectively controls the textual as well as the graph-based signal and reduces all the biases possible when only considering one modality. The performance of the proposed model is robust since it showed a high score of AUC-ROC over distinguishing between genuine and fake news. However, the study encounters some challenges for example, classification errors of proper articles due to bot-like disseminations of news. These results highlight the need for further refinement of graph structures and credibility assessment mechanisms to improve model robustness.
Conclusion and future work
This study successfully developed a Dual-Stream Graph-Augmented Transformer Model, advancing the detection of fake news by using BERT to include textual analysis and GNNs for modeling the propagation of contextual information. The experimental outcome showed that the approach proposed above significantly enhances detection performance far better than traditional methods. It achieved the accuracy of about 99%. It also recorded higher precision and recall with increased F1-scores compared with the Bi-LSTM, RoBERTa-GCN, LSTM-CNN, RoBERTa and baseline BERT models. That model, provided with an attention-based fusion mechanism, allows making proper usage from both linguistic-based and graph-based features, further making it very reliable in cases of classification. Capturing misinformation propagation structures, the study demonstrates the significance of context-aware detection mechanisms to combat digital misinformation. Analyzing social network interactions with textual content further enhances the adaptability of the model to dynamic trends in misinformation, making it a robust choice for real-world applications.
Despite its benefits, the study discovers some limitations that allow for future improvement. First, the high dependence on structured social network data limits the scope of application in real-world cases. Moreover, the model is sensitive to bot-like patterns of dissemination and may give false positives, suggesting the need for improved credibility assessment techniques. Future research may investigate hybrid methods integrating contrastive learning for modular graph representation and transfer learning for interpretable and transferable fake news detection. Addition of reinforcement learning-based dynamic credibility scoring and adaptive learning processes can possibly enable the model to adapt with changing misinformation strategies. In addition, the extension of the framework to support multilingual and multimodal data, coupled with advanced graph reasoning and cross-modal learning, can enhance the scalability and resilience of the model, and make important contributions towards defending information integrity in the virtual environment.
Data availability
The datasets generated and/or analysed during the current study are available in kaggle repository.https://www.kaggle.com/datasets/mdepak/fakenewsnet.
References
Alghamdi, J., Luo, S. & Lin, Y. A comprehensive survey on machine learning approaches for fake news detection. Multimed Tools Appl. 83 (17), 51009–51067 (2024).
Agarwal, A., Singh, Y. P. & Rai, V. Deciphering Deception: Unmasking Fake News in Multilingual Contexts, in IEEE International Conference on Computing, Power and Communication Technologies (IC2PCT), IEEE, 2024, pp. 807–812., IEEE, 2024, pp. 807–812. (2024).
Olan, F., Jayawickrama, U., Arakpogun, E. O., Suklan, J. & Liu, S. Fake news on social media: the impact on society. Inf. Syst. Front. 26 (2), 443–458 (2024).
Singh, M. K., Ahmed, J., Alam, M. A., Raghuvanshi, K. K. & Kumar, S. A comprehensive review on automatic detection of fake news on social media. Multimed Tools Appl. 83 (16), 47319–47352 (2024).
Olivera-Figueroa, L. A. & Bhattacharjee, U. The impact of misinformation, conspiracy theories, and fake news during the COVID-19 pandemic: what artificial intelligence can contribute to detect and mitigate their proliferation, in Handbook of Media Psychology: the Science and the Practice, Springer, 227–241. (2024).
Ibrahim Khalaf, O., Algburi, S., Selvaraj, A. S. D., Sharif, M. S. & Elmedany, W. Federated learning with hybrid differential privacy for secure and reliable cross-IoT platform knowledge sharing. Secur. Priv. 7 (3), e374 (2024).
Dhanasekaran, S., Gopal, D., Logeshwaran, J., Ramya, N. & Salau, A. O. Multi-model traffic forecasting in smart cities using graph neural networks and transformer-based Multi-source visual fusion for intelligent transportation management. Int J. Intell. Transp. Syst. Res, pp. 1–24, (2024).
Al-Quayed, F., Javed, D., Jhanjhi, N., Humayun, M. & Alnusairi, T. S. Optimizing fake news detection: A hybrid Transformer-Based model for enhanced performance. IEEE Access, (2024).
Hossain, M. M. et al. A hybrid Attention-Based transformer model for Arabic news classification using text embedding and deep learning. IEEE Access, (2024).
Mahmud, T. et al. Integration of nlp and deep learning for automated fake news detection, in Second International Conference on Inventive Computing and Informatics (ICICI), IEEE, 2024, pp. 398–404., IEEE, 2024, pp. 398–404. (2024).
Li, G. et al. Apr., Discovering Consensus Regions for Interpretable Identification of RNA N6-Methyladenosine Modification Sites via Graph Contrastive Clustering, IEEE J. Biomed. Health Inform., vol. 28, no. 4, pp. 2362–2372, (2024). https://doi.org/10.1109/JBHI.2024.3357979
Sardellitti, S., Barbarossa, S. & Lorenzo, P. D. Graph Topology Inference Based on Sparsifying Transform Learning, IEEE Trans. Signal Process., vol. 67, no. 7, pp. 1712–1727, Apr. (2019). https://doi.org/10.1109/TSP.2019.2896229
Li, P. C. & Li, C. T. TCGNN: Text-Clustering Graph Neural Networks for Fake News Detection on Social Media, in Pacific-Asia Conference on Knowledge Discovery and Data Mining, Springer, pp. 134–146. (2024).
Malik, A., Behera, D. K., Hota, J. & Swain, A. R. Ensemble graph neural networks for fake news detection using user engagement and text features. Results Eng. 24, 103081 (2024).
Xie, B. et al. Multiknowledge and LLM-Inspired heterogeneous graph neural network for fake news detection. IEEE Trans. Comput. Soc. Syst, (2024).
Farokhian, M., Rafe, V. & Veisi, H. Fake news detection using dual BERT deep neural networks. Multimed Tools Appl. 83 (15), 43831–43848 (2024).
Chang, Q., Li, X. & Duan, Z. Graph global attention network with memory: A deep learning approach for fake news detection. Neural Netw. 172, 106115 (2024).
Luvembe, A. M., Li, W., Li, S., Liu, F. & Wu, X. CAF-ODNN: complementary attention fusion with optimized deep neural network for multimodal fake news detection. Inf. Process. Manag. 61 (3), 103653 (2024).
Khalaf, O. I. et al. Elevating metaverse virtual reality experiences through network-integrated neuro-fuzzy emotion recognition and adaptive content generation algorithms. Eng. Rep. 6 (11), e12894 (2024).
Jebril, I. et al. Deep learning based DDoS attack detection in internet of things: an optimized CNN-BiLSTM architecture with transfer learning and regularization techniques. Infocommunications J, 16, 1, (2024).
Zhang, Q. et al. A deep learning-based fast fake news detection model for cyber-physical social services. Pattern Recognit. Lett. 168, 31–38 (2023).
Kumar, S., Kumar, A., Mallik, A. & Singh, R. R. Optnet-fake: fake news detection in socio-cyber platforms using grasshopper optimization and deep neural network. IEEE Trans. Comput. Soc. Syst, (2023).
Akhter, M. et al. COVID-19 fake news detection using deep learning model. Ann Data Sci, pp. 1–32, (2024).
Hashmi, E., Yayilgan, S. Y., Yamin, M. M., Ali, S. & Abomhara, M. Advancing fake news detection: hybrid deep learning with fasttext and explainable AI. IEEE Access, (2024).
Abualigah, L., Al-Ajlouni, Y. Y., Daoud, M. S., Altalhi, M. & Migdady, H. Fake news detection using recurrent neural network based on bidirectional LSTM and glove. Soc. Netw. Anal. Min. 14 (1), 40 (2024).
Mallik, A. & Kumar, S. Word2Vec and LSTM based deep learning technique for context-free fake news detection. Multimed Tools Appl. 83 (1), 919–940 (2024).
Qu, Z., Meng, Y., Muhammad, G. & Tiwari, P. QMFND: A quantum multimodal fusion-based fake news detection model for social media. Inf. Fusion. 104, 102172 (2024).
Mahmud, T. et al. Enhanced fake news detection through the fusion of deep learning and repeat vector representations, in 2nd International Conference on Intelligent Data Communication Technologies and Internet of Things (IDCIoT), IEEE, 2024, pp. 654–660., IEEE, 2024, pp. 654–660. (2024).
Raghavendra, R. & Niranjanamurthy, M. An effective hybrid model for fake news detection in social media using deep learning approach. SN Comput. Sci. 5 (4), 346 (2024).
Truică, C. O., Apostol, E. S. & Karras, P. Deep neural network ensemble architecture for social and textual context-aware fake news detection. Knowl. -Based Syst. 294, 111715 (2024).
Singh, P. & Jain, A. Socio political news detection using enhanced graph neural network. Glob J. Enterp. Inf. Syst. 16 (3), 59–67 (2024).
Bhowmik, N. R., Mondal, M. & Arifuzzaman, M. Data augmentation based Bangla text sentiment analysis in deep graph neural network. SN Comput. Sci. 6 (4), 1–16 (2025).
Zhang, Z. et al. Graph Convolution network and BERT combined with Co-Attention for fake news detection. Pattern Recognit. Lett. 180, 26–32 (2024).
Fang, X. et al. Early fake news detection via news semantic environment perception. Inf. Process. Manag. 61 (2), 103594 (2024).
Raja, E., Soni, B., Lalrempuii, C. & Borgohain, S. K. An adaptive cyclical learning rate based hybrid model for Dravidian fake news detection. Expert Syst. Appl. 241, 122768 (2024).
Deepak Mahudeswaran · Kai Shu. FakeNewsNet. Accessed: Feb. 07, 2025. [Online]. Available: https://www.kaggle.com/datasets/mdepak/fakenewsnet
Al Ghamdi, M. A., Bhatti, M. S., Saeed, A., Gillani, Z. & Almotiri, S. H. A fusion of BERT, machine learning and manual approach for fake news detection. Multimed Tools Appl. 83 (10), 30095–30112 (2024).
Kumar, A., Kikon, A. N., Soloman, S. S. J. & Baydeti, N. Classification of Fake News Across Online Social Networks Using Machine Learning, in First International Conference on Pioneering Developments in Computer Science & Digital Technologies (IC2SDT), IEEE, 2024, pp. 216–221., IEEE, 2024, pp. 216–221. (2024).
Roy, M. C., Bisoy, S. K. & Das, P. K. News Headlines Sentiment Analysis Using Vectorization Techniques, in World Conference on Artificial Intelligence: Advances and Applications, Springer, pp. 205–217. (2024).
Kapusta, J., Držík, D., Šteflovič, K. & Nagy, K. S. Text data augmentation techniques for word embeddings in fake news classification. IEEE Access. 12, 31538–31550 (2024).
Dhiman, P. et al. GBERT: A hybrid deep learning model based on GPT-BERT for fake news detection. Heliyon, 10, 16, (2024).
Almandouh, M. E., Alrahmawy, M. F., Eisa, M., Elhoseny, M. & Tolba, A. Ensemble based high performance deep learning models for fake news detection. Sci. Rep. 14 (1), 26591 (2024).
Ahammad, M. et al. Roberta-gcn: A novel approach for combating fake news in Bangla using advanced Language processing and graph convolutional networks. IEEE Access, (2024).
Dev, D. G., Bhatnagar, V., Bhati, B. S., Gupta, M. & Nanthaamornphong, A. LSTMCNN: A hybrid machine learning model to unmask fake news. Heliyon, 10, 3, (2024).
Kuntur, S., Krzywda, M., Wróblewska, A., Paprzycki, M. & Ganzha, M. Comparative analysis of graph neural networks and Transformers for robust fake news detection: A verification and reimplementation study. Electronics 13 (23), 4784 (2024).
Author information
Authors and Affiliations
Contributions
Rama Moorthy H, Avinash N J, Krishnaraj Rao N S wrote the main manuscript text and Raghunandan K R, Radhakrishna, Jeremy Joseph Blum, Lubna A Gabralla prepared Figs. 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19 and 20. All authors reviewed the manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Consent to publish
All the authors are permitted to Consent to publish.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Rama Moorthy, H., Avinash, N.J., Krishnaraj Rao, N.S. et al. Dual stream graph augmented transformer model integrating BERT and GNNs for context aware fake news detection. Sci Rep 15, 25436 (2025). https://doi.org/10.1038/s41598-025-05586-w
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-05586-w
