
Abstract
Traditional manual sorting has problems such as low efficiency, low automation level and increased costs, which are difficult to meet the sorting challenges brought by the rapid development of logistics industry. In addition, it is difficult for existing parcel box detection algorithms to strike a balance between identification efficiency, identification accuracy and deployment cost. In this paper, we propose a 3D localization algorithm for rectangular packaging boxes based on deep learning, and design a lightweight parcel box detection model, the Efficient Object detection Network (EODNet). Linear attention mechanism is used in the backbone of the model to achieve efficient feature selection with low-cost computing resources. The high-low layer feature fusion structure and C2f-GhostCondConv are designed on the neck of the model to achieve the selective fusion of input features at different levels with small parameter number and computational amount. The effectiveness of the model improvement strategy and the universality of the detection model were verified on the packing box data set and the public data set. Moreover, the proposed algorithm achieved high accuracy in the parcel box size prediction experiment with an average error of less than 3.7% and took less than 10 ms.
Similar content being viewed by others


Introduction
The vigorous development of the e-commerce industry has brought significant challenges to the sorting work of the logistics industry. The traditional manual sorting has problems such as inefficiency and rising labor costs, and it is difficult to meet the growing demand for parcel sorting in the logistics industry1. Compared with manual sorting, logistics enterprises at this stage are more inclined to adopt semi-automated and fully automated express package sorting schemes, and related researches are gradually emerging, mainly involving mechanical structure, control system and recognition algorithm and other fields2. Among them, the identification of parcel box information is the primary task of sorting in the logistics industry, and is one of the prerequisites for the efficient operation of the sorting system. The identification of package information mainly includes the three-dimensional size determination of the package, the three-dimensional position posture determination and the barcode information recognition, etc. As the basic attribute of the package, the package information provides the necessary information assistance for the machine capture of the package in the logistics industry, the determination of the transportation mode, the determination of the storage area and the correction of the transportation position. Therefore, package information recognition based on vision has important research value for logistics industry.
Manual measurement is vulnerable to interference from human factors, resulting in unstable measurement accuracy and efficiency. At present, laser measurement methods have requirements for the working environment (such as air dust and conveyor belt speed), and the cost is relatively high, which limits their popularization. This paper mainly carries out three-dimensional positioning of the parcel box when loading the parcel box, aiming to solve the high-speed identification problem of the three-dimensional size of the parcel box in the intelligent logistics sorting system.
The main contributions of this paper are as follows:
-
1.
This paper proposes a visual detection algorithm for three-dimensional positioning of parcel box for high-speed sorting system, which restores three-dimensional information of parcel box by collecting two-dimensional image information of parcel box. Based on the proposed algorithm, a lightweight parcel box Detection model, the Efficient Object Detection Network (EODNet), was designed. The model realized high speed and accurate parcel box identification with a small number of parameters and computational cost.
-
2.
In order to reduce the number of parameters and computational complexity of the model and improve the multi-scale feature extraction capability of the model, this paper designs an efficient feature extraction network: ES-ViT as the backbone of the model.
-
3.
We design a new neck structure to achieve selective fusion of features of different levels and adaptive convolution processing of input of different features. This structure includes a fusion module for features of different scales: Channel Weight Screening Module (CWS) and feature fusion module with efficient convolution operation: C2f-GCC.
-
4.
In order to verify the universality of the proposed model and the effectiveness of the model improvement strategy, we selected a large number of data sets to test the model, and compared with other target detection models, our model has the best detection performance in the parcel box dataset.
Related work
Deep learning based detection models have greatly promoted the application of visual technology in real-life logistics scenarios in the past few years.
In the parcel inspection task, Zhang et al.3 designed a lightweight deep learning network EPYOLO to detect small targets and overlapping express packages. Zhang et al.4 designed a lightweight SFN-YOLOv8 model based on YOLOv8 for defect detection of express packages. Qi et al.5 constructed a package recognition system based on ResNet and DenseNet, which has strong robustness and can meet the requirements of autonomous package retrieval for robotic arms. Zhu et al.6 designed a prohibited item packaging detection system based on YOLO, which can efficiently identify and detect prohibited items, and has a good detection effect on overlapping and obstructed prohibited items. Chen et al.7 proposed a hybrid model called Parcels-DNet that efficiently captures the characteristics of parcel deformation and penetration damage, and that the model can be deployed in resource-constrained scenarios such as mobile or embedded devices.
In addition to parcel inspection tasks, researchers have also focused on parcel tracking tasks. Wu et al.8 used an improved network model based on Faster R-CNN to identify and track express packages. Liu et al.9 proposed a multi-target tracking algorithm based on improved YOLOv5 and DeepSORT, which can accurately track express packages and has good real-time performance. Ren et al.10 used the Mask R-CNN model to segment the package in two-dimensional instances to determine its contour, and then performs accurate filtering and fitting on the three-dimensional point cloud data of the package surface to obtain the three-dimensional data of the package. Finally, the robot arm is combined to grasp and classify the package. Kim et al.11 used YOLOv5 model to realize rapid detection and location estimation of parcel boxes. Li et al.12 used the multi-source vision sensor Kinect to collect image information, and combines the minimum boundary rectangle algorithm and background subtraction to achieve non-contact and uninterrupted parcel box volume measurement, and the relative error is less than 5%. Arpenti et al.13 used the depth convolutional model to conduct semantic segmentation of objects on the shelf to obtain the approximate position of objects, and calculated the position information of goods by combining the depth information collected by the RGB-D camera. Ladplee et al.14 designed a rectangular parcel box volume measurement system based on a single liDAR depth camera, which realized the measurement of the three-dimensional size of the parcel box, and the average measurement time was 1.01 s. Dai et al.15 proposed a package positioning algorithm, which combines traditional vision with artificial intelligence vision to achieve the detection and position correction of packages. Lu et al.16 Combined the traditional visual processing methods with the enhanced lightweight YOLOv5 object detection algorithm to achieve high-speed and high-precision package positioning.
Based on the above research work, we can draw some conclusions: 1. Deep learning based visual inspection methods have a significant impact on improving the performance of logistics sorting systems; 2. There are few size measurement techniques for rectangular packaging boxes, and existing measurement solutions have problems such as high hardware costs, low model detection accuracy, multiple model parameters, large computational complexity, and low recognition speed. Based on this, this article proposes a three-dimensional size positioning algorithm for parcel boxes based on a lightweight detection model, which achieves a good balance between recognition accuracy, recognition speed, and equipment cost.
Methods
As shown in Fig. 1, when the worker places the parcel box on the sorting table against the side of the right angle frame, three industrial cameras simultaneously record the position and attitude of the parcel box at the moment. Camera 1 will capture the top view of the parcel box, camera 2 will capture the front view of the parcel box, and camera 3 will capture the rear view of the parcel box. In the three views containing the parcel box, the deviation angle between the parcel box and the camera is 0°, that is, there is no positional deviation of the parcel box in the picture. In this paper, the three-dimensional size of the parcel box can be restored by acquiring the data of the three directions of the parcel box.

Algorithm framework for three-dimensional size recognition of parcel boxes.
Before the operation of the logistics conveyor belt, a square object is used as a standard part, and the proportion between the size of the parcel box in the picture and its actual size. It is assumed that the rear view of the standard object collected in camera 3 is the input data. Since the standard parts are close to the rear wall (reference object), and there is no deviation angle between the standard object and the camera direction, the ratio \(r\) between the pixels of the standard parts in the picture and the real size of the standard parts can be directly obtained. Assuming that the position of the parcel box and the standard part is similar, the real length \(L_{R}\), width \(W_{R}\) and height \(H_{R}\) of the parcel box are calculated as follows:
where \(r\) represents the proportional relationship between the standard part length pixel size \(l_{P}\) and the real standard part length \(l_{R}\), \(R_{LW}\) is the length–width ratio of the parcel box in the image, \(R_{LH}\) is the length-height ratio of the parcel box in the image.
After inputting the original parcel box image into the Efficient and Spatial Vision Transformer(ES-ViT), the parcel box feature map can be obtained. In the neck, the Efficient Channel Weight Filtering Module (ECWS) is used to fuse features from different levels, and finally output recognition results through the detection head of the model.
Model structure
Backbone
Compared with the single CNN structure of mainstream models (such as Faster R-CNN, SSD and YOLO, etc.), the global attention mechanism of Vision Transformer model can effectively capture the global information of the image and avoid the loss of target feature information as the number of network layers increases. In this paper, ES-ViT(as shown in Fig. 2) is designed as the backbone of a parcel box 3D positioning detection model, which will meet the needs of intelligent logistics in reality from the aspects of parameter quantity, computation amount and accuracy. In the middle and high levels of the network, different combinations of MBConv, EfficientViT17, Spatial Pyramid Pooling Fast Module (SPPF) were used to output a total of 4 feature maps of different scales.

ES-ViT structure.
In order to improve the efficiency of the model in feature extraction of parcel boxes, the EfficientViT module in the middle and higher layers of the backbone introduces a nonlinear function ReLU in the self-attention mechanism. Specifically, given the input \(x \in R^{N \times f}\), the generalized form of the attention \(Attention\left( {Q,K,V} \right)\) mechanism can be written as:
where \(Q = xW_{Q}\), \(K = xW_{K}\), \(V = xW_{V}\). Note that the attention function can be described as mapping a query and a set of key-value pairs to an output, where the query, keys, values, and output are all vectors. \(W_{Q} /W_{K} /W_{V} \in R^{N \times d} (N \gg d)\), both \(W_{Q}\), \(W_{K}\), and \(W_{V}\) are learnable linear projection matrices. And after being initialized with certain values, \(W_{Q}\), \(W_{K}\), and \(W_{V}\) undergo continuous changes during network training. \(Attention\left( {Q,K,V} \right)_{i}\) is row i of matrix \(Attention\left( {Q,K,V} \right)\), and \(Sim\left( {Q,K} \right)\) is the similarity function.
In the EfficientViT module, the ReLU based linear attention mechanism was selected as the similarity function, as shown in formula (4). Using the correlation of matrix multiplication, formula (4) can be rewritten step by step, as shown in formula (5). When we do calculations, we only need to compute \((\sum\nolimits_{j = 1}^{N} {ReLU(K_{j} )^{T} V_{j} } ) \in R^{d \times d}\) and \((\sum\nolimits_{j = 1}^{N} {ReLU(K_{j} )^{T} } ) \in R^{1 \times d}\) once, and we can reuse them for every query. Compared with the attention mechanism based on softmax function, the computational complexity of the linear attention mechanism based on ReLU is reduced from \(o(N^{2} )\) to \(o(N)(Softmax(Q_{i} ,K_{j} ) \in R^{N \times N} ,ReLU(Q_{i} ) \in R^{N \times d} )\), and the ReLU function consumes less computing resources than the softmax function, and is more friendly to the hardware equipment of the real intelligent logistics center.
Deep convolution is used after each FFN layer in the EfficientViT module to enhance the ReLU-based linear attention and improve the model’s attention to local information in space. Using group convolution within the module to reduce the overall computational overhead of information aggregation can further enhance the efficiency of parcel box feature extraction.
In order to improve the feature extraction capability of the model in this paper, SPPF module is added to the end of backbone to further improve the efficiency of the model in extracting package feature information in complex industrial environment. Due to the existence of multi-scale spatial containers in SPPF, compared with single-scale sliding window pooling, the model can process spatial feature information of different sizes, avoiding the unbalanced spatial feature information of packages in pictures caused by cropping and warping (as shown in Fig. 3), and improving the quality of model training and the recognition accuracy of packages.

(a) The image has been cropped. (b) The image has been warped.
Neck
In order to improve the model’s attention to input data, we use the channel attention mechanism (as shown in Fig. 4) at the connection between backbone and neck in the network structure, so that the network can more accurately handle the relationship between parcel box features and dynamically adjust the attention distribution. The channel attention mechanism in this paper first performs average pooling and maximum pooling on the parcel box feature map \(F_{in} \in R^{H \times W \times C}\)(where H is the height of the feature map, W is the width of the feature map, and C is the number of channels), respectively, to reduce the dimension of the feature map, eliminate redundant data, and reduce parameters and computation amount. Then, the two pooling results are directly combined, and the sigmoid activation function is used to calculate the weight of each channel in the feature map, that is, \(F_{W} \in R^{1 \times 1 \times C}\), and finally, the channel attention mechanism adds a convolution to modify the number of output channels.

Channel Weight Screening Module (CWS).
The model needs to process information from high and low networks in order to better classify and locate parcel boxes. In the FPN structure of the current mainstream models, the upsampling method is adopted to adjust the feature map. This method is based on human prior knowledge and uses a fixed interpolation method, making it difficult to adjust according to the characteristics of the task. In the neck of the network structure proposed in this article, we opt for transposed convolution instead of traditional upsampling. During the training of the parcel box detection model, the parameters of the convolution kernel are updated gradually according to the gradient change of the loss function, which aims to minimize the error between the predicted value and the true value of the parcel box, and then adjust and optimize the upsampling strategy of the model. In addition, we add a channel attention mechanism in the feature fusion part of neck, so that the model can dynamically adjust the weight of the feature map and improve the parcel box detection performance of the model.
The feature fusion process of different scales is shown in formulas (6) and (7). Given input \(F_{h} \in R^{H \times W \times C}\) of a high-level feature and input \(F_{l} \in R^{{H_{1} \times W_{1} \times C}}\) of a low-level feature, a transposed convolution T-Conv (kernel size = 3, stride = 2, padding = 1) is used to expand the high-level feature \(F_{h}\) to get \(F^{\prime}_{h} \in R^{{H_{1} \times W_{1} \times C}}\). The extended high-level feature \(F^{\prime}_{h}\) is converted into the corresponding attention weight after CA module to filter the low-level feature. Finally, the filtered feature and the extended high-level feature are fused again to get \(F_{O} \in R^{{H_{1} \times W_{1} \times C}}\).
At the end of feature fusion, we add a C2f module to improve the efficiency of the model for parcel box feature fusion (as shown in Fig. 5). Two improvements are made to the C2f module to improve the efficiency of the convolution operation.

C2f-GhostCondConv structure.
The output of a convolutional layer in a neural network can be divided into multiple feature maps according to the number of channels, and there are similar multiple groups of feature maps. In Ghost Module18, one of the similar feature maps in a group is set as Intrinsic feature map, and the rest are Ghost feature maps. The remaining Ghost feature maps can be generated through linear transformations of the Intrinsic feature maps. Given an input \(F_{in} \in R^{h \times w \times c}\), the convolutional filters \(f_{C} \in R^{k \times k \times c \times n}\) of the layer are divided into groups \(s\) on average, and one group of convolutional filters (\(f_{i} \in R^{k \times k \times c \times m} ,m = {n \mathord{\left/ {\vphantom {n s}} \right. \kern-0pt} s}\)) is taken to perform ordinary convolution operations to obtain \(m\) intrinsic feature maps. A group of \(m\) intrinsic feature maps are taken each time for linear transformation. In order to calculate unity and reduce resource consumption, \(m\) Ghost feature maps of the group can be calculated using the same linear transformation. Finally, \(m\) Intrinsic feature maps and \((n - m)\) Ghost feature maps are combined to obtain the final output \(F_{out} \in R^{h1 \times w1 \times n}\). Assuming that the size of all convolution cores is \(k \times k\), the acceleration ratio \(r_{S}\) and compression ratio \(r_{C}\) of the convolution of Ghost Module are theoretically used to calculate the following formula:
where \(s \ll c\).
We selectd dynamic convolution to improve the operation of each convolution \(f \in R^{k \times k \times n}\) in C2f module, so as to enlarge the capacity of the convolution layer and reduce the computation as much as possible. The parameters of the convolution kernel can be obtained by formula (10). In conventional convolution, a convolution kernel determined by the same parameter is used for all input samples, while in the CondConv19 layer, the parameters of a convolution kernel are calculated for each input sample before the convolution operation, the effect is equivalent to a linear combination of \(n\) planar convolution [as shown in formula (12)], so that different convolution is used for different input samples. With the increase of \(n\), the CondConv layer can increase the capacity of the CondConv layer with only a small increase in inference cost, and each CondConv convolution kernel can be applied to different positions of the image only once.
By improving the neck feature fusion and convolution operation of some modules, the generalization ability and inference speed of the model are improved.
Head
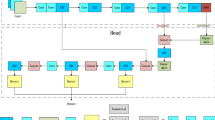
In the real logistics scenario, our parcel box detection model needs to meet the low power consumption of computing power, real-time detection of targets and easy deployment. Based on this, the detection head of YOLOv8 is selected as the detection head of the model in this paper. The specific structure is shown in Fig. 6. CIoU20 loss and Distribution Focal Loss(DFL)21 calculations are shown in formulas (13)–(14) and (15)–(16).
where \(A\) represents the area occupied by the prediction box, \(B\) represents the area occupied by the ground truth box, \(b\) is the coordinate of the center point of the prediction box, \(b^{gt}\) is the coordinate of the center point of the ground truth box, \(w\) is the width of the prediction box, \(w^{gt}\) is the width of the ground truth box, \(h\) is the height of the prediction box, \(h^{gt}\) is the height of the ground truth box, \(c\) represents the diagonal distance of the smallest rectangular area that can simultaneously contain both the prediction box and the ground truth box, \(\rho ( \bullet )\) stands for Euclidean distance.
where \(y_{i}\) and \(y_{i + 1}\) are the two labels closest to the label, \(y_{i} \le y \le y_{i + 1}\), \(S_{i}\) and \(S_{i + 1}\) are the probabilities of predicting labels for label \({y}_{i}\) and \(y_{i + 1}\), respectively.

Detect head structure.
Experiments
Datasets and experiments platform
Parcel box dataset: In order to verify the effectiveness of the parcel box 3D positioning detection algorithm proposed in this paper, we use the real-time images of parcel boxes collected by the image acquisition structure in 3.1 (as shown in Fig. 7) to sort out the real and effective data set. In this study, we sorted out a total of 2916 real-time images of parcel boxes as the total sample of the experiment. These live images are taken by the on-site industrial camera MV-CA003-20GC, and the image resolution is \(672 \times 512\). In order to show the effect of model training and verification, we used the open-source labeling tool labelimg to objectively produce the pictures into three dataset formats, including YOLO, COCO and VOC, and randomly divided the total training data set (training set and verification set) and test set according to the ratio of \(3:1\).

Parcel box dataset.
Traffic Signs Detection dataset22: This dataset mainly collected a total of 4969 samples in 15 categories including red light, green light, stop and speed limit, and the resolution of the picture was \(416 \times 416\). This dataset was used to verify the effectiveness of the model improvement, with 3530 images used for model training, 801 images used for model validation, and 638 images used for model testing.
African Wildlife dataset23: This dataset mainly displays images of four types of animals commonly found in nature reserves in South Africa with a resolution of \(128 \times 86 \sim 4288 \times 3000\). To verify the effectiveness of the model improvement in this paper, 1203 images were used as the training set, 150 images as the validation set, and 151 images as the test set.
Pascal VOC dataset24: Created by the Computer Vision Group at the University of Oxford, this dataset is widely used in computer vision tasks such as object detection, image segmentation, and image classification. The dataset contains 20 common object categories such as people, cars, planes and dogs. In this paper, the dataset was used to verify the universality of the model in other visual tasks. A total of 16,551 pictures from Pascal VOC 2007-trainval and Pascal VOC 2012-trainval were selected for model training. A total of 4952 pictures from Pascal VOC 2007-test were selected as the test set of the model.
In order to ensure the fairness of the experiments, all experiments are conducted on the same server for training and reasoning processes. Table 1 shows the configuration of the experimental environment.
Model measurement criteria
Since the object detection model studied in this paper will be applied to the real logistics center for real-time three-dimensional parcel box positioning, the detection accuracy, model size and reasoning speed are important evaluation criteria. In this experiment, Precision(P), recall(R), F1 and mAP50 are selected as the evaluation indexes of model accuracy, and their calculation is as follows :
In ablation experiments, according to the definition in TIDE25, localization error, duplicate detection error, background error and False Positive are used to intuitively reflect the error between the prediction box and the real box of the 3D positioning model. Under the assumption that the prediction box and the real box have the same category and the overlap degree of IOU26 is greater than the set threshold t, we choose the one with the highest overlap degree as True Positive, and the rest as False Positive. Therefore, the above four errors can be defined as:
-
localization error \(E_{loc}\): The prediction frame classification is correct, but the location is incorrect.
-
duplicate detection error \(E_{dupe}\): The category of prediction boxes is correct and the overlap is greater than t, but a prediction box with a higher score matches the true box.
-
background error \(E_{bkg}\): Checks the background as the foreground.
-
False Positive error \(E_{FP}\): indicates a location error, background confusion, or repeated detection.
Ablation experiments
In this paper, open-source datasets and parcel box dataset were selected to conduct ablation experiments on the model, so as to ensure that the improved strategies in this paper are valid and effective in improving the model detection performance.
In the ablation experiment of open-source datasets, this paper selected Traffic Signs Detection dataset and African Wildlife dataset as the datasets to verify that the improvement strategy proposed in this paper has the same improvement effect on different data. The results are shown in Tables 2 and 3. According to the experimental results, it can be seen that the detection performance of the model is improved when using ES-ViT and C2f-GCC modules. The improvement strategy proposed in this paper is effective for different types of datasets.
In this paper, two groups of ablation experiments, network structure improvement and loss function improvement, were carried out respectively when using the parcel box dataset.
According to the results in Tables 4 and 5, it can be seen that the detection performance of the model is improved when using ES-ViT and C2f-GCC modules. The positioning error, duplicate detection error, and background error of the model are all reduced. The experimental results indicate that the improvement strategy proposed in this paper is effective.
We recorded the packet detection performance of models with different improvement strategies at different confidence levels, as shown in Fig. 8a–c, as well as the training process before and after model improvement, as shown in Fig. 8d–f.

Performance of the model in the parcel box dataset.
In order to verify that the loss function selected in this paper can meet the parcel detection task of the real intelligent logistics center, we tried to combine various loss functions and recorded relevant experimental information, and the experimental results are shown in Table 6. The experiment shows that in the parcel box dataset, the loss function selected in this paper demonstrates high precision detection performance and can meet the task of parcel box detection.
Considering that different loss functions may affect the quality of the model prediction box, TIDE index is also used to evaluate the error between the model prediction box and the ground truth box under different loss functions (as shown in Table 7). The experiment shows that when BCELoss and CIoU are used in the detection header of the model in this paper, the model produces high-quality predicted bounding boxes for parcel box, low probability of repeated detection and background confusion, and the comprehensive detection accuracy of the model is the highest.
Based on the experimental outcomes derived from the aforementioned distinct datasets, it is evident that the model proposed in this paper achieves relatively high values in terms of detection precision, recall, and mAP for the target. This indicates that the model exhibits strong classification capability for the target. Furthermore, under the TIDE index, the quality of the model’s predicted bounding boxes for the target is superior, demonstrating its excellent positioning ability. To sum up, the model in this paper may be applicable to the tasks of target classification and localization.
We recorded the detection performance of the model under different IoU thresholds, and the results are presented in Table 8. The model exhibits a relatively high overall detection accuracy across various IoU thresholds, with the fluctuation of accuracy values controlled within approximately 1%, indicating that the model’s detection performance is relatively stable.
In addition, in order to verify that the network structure of the proposed model can achieve a balance between detection performance and model lightweighting in parcel box detection tasks, this paper conducts two additional groups of comparison experiments on the neck and backbone of the model respectively. In order to control experimental variables, only part of the network structure in each group is selected for comparison experiments. At the same time, the lightweight structure commonly used in the field of target detection is replaced.
According to the results in Tables 9 and 10, it can be seen that the backbone and neck networks designed in this paper have achieved a good balance between structural lightweighting and detection accuracy.
Model comparison experiment
In order to verify the balance between the detection performance and model lightweighting of the packaging detection model designed in this article in the detection task, commonly used models in the field of object detection were selected for comparison in the packaging detection experiment. The experimental results are shown in Table 11. The model in this paper has the smallest number of parameters and file size, and the detection accuracy of the model is the highest. In addition, the inference results of some models were also recorded, as shown in the Fig. 9.

Inference results of different models on parcel box dataset.
Comparison experiment of parcel box size prediction
We select 450 images from the parcel test dataset to sort out 150 parcel information of different sizes, and selects a common model in the field of object detection for experiment. The experimental results are shown in Table 12. Our model has the best overall performance in terms of parcel box size prediction error, and the four errors are relatively low, showing high-precision detection performance and meeting the task of parcel box detection.
In addition, we compared our proposed method with some existing methods with smaller model sizes on the PASCAL VOC 2007 test dataset. As shown in Table 13, our model has the best detection performance, with mAP and mAP50-95 reaching 78.4% and 44.6%, respectively. The model has good universality.
Conclusions
In this paper, a vision algorithm based on deep learning is proposed to recognize the three-dimensional size of the rectangular parcel box on the sorting table of intelligent logistics system. The algorithm achieves a good balance between recognition efficiency, recognition accuracy, algorithm universality and deployment cost.
According to the requirements of the parcel box detection task in this article, a deep learning based end-to-end object detection model for parcel box recognition is designed. This paper introduces innovations of varying degrees in the backbone and neck sections of the model’s network structure and uses multiple datasets to sequentially verify the effectiveness of the improved strategy, the effectiveness of the localization algorithm, and the universality of the detection model. In the backbone of the model, we use EfficientViT and SPPF modules to improve the model’s focus on target parcel boxes with fewer parameters and computational costs, and efficiently process parcel box features of different scales. In the neck part of the model, we design a high-low layer feature fusion structure CWS, and use C2f-GCC module to improve the convolution operation efficiency and reduce the number of parameters and computation. The results of the ablation experiment indicate that the improvement strategy proposed in this paper can improve the detection performance of the model on different domain datasets and reduce the error of the model’s prediction box. In the comparison experiment of parcel box detection and parcel box size prediction error with other object detection models, our designed model performed the best in terms of parameter quantity, model volume, inference speed, and detection accuracy. Although the comprehensive index of our model is the best in the experiment in this paper, there is still a large room for improvement in GFLOPs and the number of model parameters. Therefore, in the future work, we will focus on the network structure, computational complexity and inference speed of the model to design a general model suitable for parcel box detection in the field of logistics.
Data availability
The data gathered in the experimental work of this study, supporting the findings of this work are available from the corresponding author upon reasonable request.
References
Qu, Y., Zhao, N. & Zhang, H. Digital twin technology of human-machine integration in cross-belt sorting system. Chin. J. Mech. Eng. 37(1), 33 (2024).
Zou, B. et al. Robotic sorting systems: Performance estimation and operating policies analysis. Transp. Sci. 55(6), 1430–1455 (2021).
Zhang, G. et al. A global lightweight deep learning model for express package detection. J. Intell. Fuzzy Syst. 45(6), 12013–12025 (2023).
Zhang, Z. & Chang, X. Express packaging defects detection model based on YOLOv8. In Fourth International Conference on Image Processing and Intelligent Control (IPIC 2024). SPIE, 13250, 726–730 (2024).
Qi, W. & Sun, X. The study on recognition and detection of express package grabbing based on machine vision. Acad. J. Sci. Technol. 9(1), 198–203 (2024).
Zhu, H., Gao, B., Qiao, L. et al. Design of a visual detection method for prohibited item packages detection based on the YOLO model. In 2024 4th Asia-Pacific Conference on Communications Technology and Computer Science (ACCTCS), 220–225. (IEEE, 2024).
Chen, Z., Du, C., Huang, X. et al. Deformation and penetration hybrid detection-net for parcels inspection in industrial supply chain. In ICASSP 2024–2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 5815–5819 (IEEE, 2024).
Wu, C., Duan, X. & Ning, T. Express parcel detection based on improved fast-er regions with CNN features. J. Intell. Fuzzy Syst. (Preprint), 1–16.
Liu, Q., Wu, J., Yin, L. et al.: Real-time detection and tracking of express parcels based on improved YOLOv5+ DeepSORT. In International Conference on Intelligent Robotics and Applications, 3–14. (Springer Nature Singapore, 2023).
Ren, C. et al. Visual sorting of express packages based on the multi-dimensional fusion method under complex logistics sorting. Entropy 25(2), 298 (2023).
Kim, M. & Kim, Y. Parcel classification and positioning of intelligent parcel storage system based on YOLOv5. Appl. Sci. 13(1), 437 (2023).
Li, L., Zhuang, X., Chen, L., et al. An adapted vision measurement method for package volume based on Kinect. In 2017 13th International Conference on Natural Computation, Fuzzy Systems and Knowledge Discovery (ICNC-FSKD), 918–922 (IEEE, 2017).
Arpenti, P. et al. RGB-D recognition and localization of cases for robotic depalletizing in supermarkets. IEEE Robot. Autom. Lett. 5(4), 6233–6238 (2020).
Ladplee, N., Pimpin, A., Srituravanich, W., et al. Volumetric measurement of rectangular parcel box using LiDar depth camera for dimensioning and 3D bin packing applications. In 2022 IEEE International Conference on Consumer Electronics-Asia (ICCE-Asia), 1–4 (IEEE, 2022).
Dai, N. et al. Research on the algorithm of position correction for high-speed moving express packages based on traditional vision and AI vision. Sensors 24(3), 892 (2024).
Lu, Z., Dai, N., Hu, X., Xu, K. & Yuan, Y. Research on high-speed classification and location algorithm for logistics parcels based on a monocular camera. Sci. Rep. 14(1), 15901 (2024).
Cai, H., Li, J., Hu, M. et al. Efficientvit: Lightweight multi-scale attention for high-resolution dense prediction. In Proceedings of the IEEE/CVF International Conference on Computer Vision, 17302–17313 (2023).
Han, K., Wang, Y., Tian, Q, et al. Ghostnet: More features from cheap operations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 1580–1589 (2020).
Yang, B., Bender, G., Le, Q. V. et al. Condconv: Conditionally parameterized convolutions for efficient inference. In Advances in Neural Information Processing Systems, 32 (2019).
Zheng, Z., Wang, P., Liu, W. et al. Distance-IoU loss: Faster and better learning for bounding box regression. In Proceedings of the AAAI Conference on Artificial Intelligence 34(07), 12993–13000 (2020).
Li, X. et al. Generalized focal loss: Learning qualified and distributed bounding boxes for dense object detection. Adv. Neural. Inf. Process. Syst. 33, 21002–21012 (2020).
Traffic Signs Detection. Self-Driving Cars Dataset. https://universe.roboflow.com/selfdriving-car-qtywx/self-driving-cars-lfjou.
African Wildlife Dataset. https://www.kaggle.com/biancaferreira/datasets.
Everingham, M. et al. The pascal visual object classes (voc) challenge. Int. J. Comput. Vis. 88, 303–338 (2010).
Bolya, D., Foley, S., Hays, J. et al. Tide: A general toolbox for identifying object detection errors. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part III 16, 558–573. (Springer International Publishing, 2020).
Yu, J., Jiang, Y., Wang, Z. et al. Unitbox: An advanced object detection network. In Proceedings of the 24th ACM International Conference on Multimedia, 516–520 (2016).
Lin, T. Y., Goyal, P., Girshick, R. et al. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, 2980–2988 (2017).
Zhang, H., Wang, Y., Dayoub, F. et al. Varifocalnet: An iou-aware dense object detector. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 8514–8523(2021).
Gevorgyan, Z. SIoU loss: More powerful learning for bounding box regression. arxiv preprint arXiv:2205.12740(2022).
Liu, X., Peng, H., Zheng, N. et al. Efficientvit: Memory efficient vision transformer with cascaded group attention. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 14420–14430(2023).
Cai, Y., Zhou, Y., Han, Q., et al. Reversible column networks. arXiv preprint arXiv:2212.11696 (2022).
Wang, A., Chen, H., Lin, Z. et al. Repvit: Revisiting mobile CNN from vit perspective. arXiv preprint arXiv:2307.09283(2023).
Howard, A., Sandler, M., Chu, G. et al. Searching for mobilenetv3. In Proceedings of the IEEE/CVF International Conference on Computer Vision, 1314–1324 (2019).
Wang, W., Xie, E., Li, X., et al. Pyramid vision transformer: A versatile backbone for dense prediction without convolutions. In Proceedings of the IEEE/CVF International Conference on Computer Vision, 568–578 (2021).
Bochkovskiy, A., Wang, C. Y. & Liao, H. Y. M. Yolov4: Optimal speed and accuracy of object detection. arXiv preprint arXiv:2004.10934(2020).
He, K., Zhang, X., Ren, S. et al. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 770–778 (2016).
Ding, X., Zhang, X., Ma, N. et al. Repvgg: Making vgg-style convnets great again. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 13733–13742 (2021).
Tan, M., Le, Q.: Efficientnet: Rethinking model scaling for convolutional neural networks. In International Conference on Machine Learning, PMLR, 6105–6114 (2019).
Kang, M. et al. ASF-YOLO: A novel YOLO model with attentional scale sequence fusion for cell instance segmentation. Image Vis. Comput. 147, 105057 (2024).
Li, H., Li, J., Wei, H. et al. Slim-neck by GSConv: A better design paradigm of detector architectures for autonomous vehicles. arXiv preprint arXiv:2206.02424 (2022).
Yang, G., Lei, J., Zhu, Z. et al. AFPN: Asymptotic feature pyramid network for object detection. In 2023 IEEE International Conference on Systems, Man, and Cybernetics (SMC), 2184–2189 (IEEE, 2023).
Tan, M., Pang, R., Le, Q. V.: Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 10781–10790 (2020).
Li, C., Li, L., Jiang, H. et al. YOLOv6: A single-stage object detection framework for industrial applications. arXiv preprint arXiv:2209.02976 (2022).
Lin, T. Y., Dollár, P., Girshick, R. et al. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2117–2125 (2017).
Wang, C. Y., Bochkovskiy, A., Liao, H. Y. M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 7464–7475(2023).
Tian, Z., Shen, C., Chen, H. et al. FCOS: Fully convolutional one-stage object detection. arXiv 2019. arXiv preprint arXiv:1904.01355 (2019).
Cai, Z. & Vasconcelos, N. Cascade R-CNN: Delving into high quality object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 6154–6162 (2018).
Chen, Z., Yang, C., Li, Q. et al. Disentangle your dense object detector. In Proceedings of the 29th ACM International Conference on Multimedia, 4939–4948 (2021).
Zhao, Y., Lv, W., Xu, S. et al.: Detrs beat yolos on real-time object detection. arXiv preprint arXiv:2304.08069 (2023).
Zhang, S., Chi, C., Yao, Y. et al.: Bridging the gap between anchor-based and anchor-free detection via adaptive training sample selection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 9759–9768 (2020).
Zhou, X., Wang, D. & Krähenbühl, P.: Objects as points. arXiv preprint arXiv:1904.07850 (2019).
Sandler, M., Howard, A., Zhu, M. et al.: Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 4510–4520 (2018).
Ganesh, P., Chen, Y., Yang, Y. et al.: YOLO-ReT: Towards high accuracy real-time object detection on edge GPUs. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 3267–3277 (2022).
Wang, R. J., Li, X. & Ling, C. X.: Pelee: A real-time object detection system on mobile devices. In Advances in Neural Information Processing Systems, 31 (2018).
Huang, X., Wang, X., Lv, W. et al.: PP-YOLOv2: A practical object detector. arXiv preprint arXiv:2104.10419 (2021).
Shen, Z. et al. Object detection from scratch with deep supervision. IEEE Trans. Pattern Anal. Mach. Intell. 42(2), 398–412 (2019).
Ge, Z., Liu, S., Wang, F. et al. Yolox: Exceeding yolo series in 2021. arXiv preprint arXiv:2107.08430 (2021).
Zhong, X. et al. Scpnet: self-constrained parallelism network for keypoint-based lightweight object detection. J. Vis. Commun. Image Represent. 90, 103719 (2023).
Wang, G. et al. Negative deterministic information-based multiple instance learning for weakly supervised object detection and segmentation. IEEE Trans. Neural Netw. Learn. Syst. 36, 6188–6202 (2024).
Zhang, H., Xu, C. & Zhang, S.: Inner-iou: More effective intersection over union loss with auxiliary bounding box. arXiv preprint arXiv:2311.02877 (2023).
Li, Y., Li, J., Lin, W. et al.: Tiny-DSOD: Lightweight object detection for resource-restricted usages. arXiv preprint arXiv:1807.11013 (2018).
Zhu, Y. et al. Uncertainty-aware graph-guided weakly supervised object detection. IEEE Trans. Circuits Syst. Video Technol. 33, 3257–3269 (2022).
Funding
This research was funded by The Science and Technology Program of Zhejiang Province, China (No. 2022C01202, No. 2022C01065), the Zhejiang Sci-Tech University Research Start-up Fund, China (No. 23242083-Y), and The Research Project of the Zhejiang Provincial Department of Education (Y202455953).
Author information
Authors and Affiliations
Contributions
N.D. and J.C. wrote the main manuscript text; N.D. edited the manuscript; K.X., X.H. and Y.Y. verifed the methodology; X.H. and Y.Y. contributed to funding acquisition. All authors reviewed the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Dai, N., Chen, J., Hu, X. et al. Research on dimension measurement algorithm for parcel boxes in high-speed sorting system. Sci Rep 15, 21980 (2025). https://doi.org/10.1038/s41598-025-07730-y
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-025-07730-y
