
Abstract
Accurate system reliability estimation facilitates engineers and statisticians in optimizing resource allocation within industrial and technological applications. In the field of statistical modeling for system reliability metrics, ranked set sampling (RSS) designs have been confirmed as effective alternatives to simple random sampling (SRS). In this study, we mainly focus on investigating the performance of different sampling designs, including SRS, RSS and extreme ranked set sampling (ERSS), on estimating stress-strength reliability when stress and strength are two independent random variables following power Lindley (PL) distributions under both uncensored and right-censored data. To obtain the parameter estimates of the PL distributions, the maximum likelihood (ML) method is used. Monte Carlo simulations considering perfect and imperfect ranking with uncensored data and perfect ranking with right-censored data show that RSS and ERSS provide more precise ML estimates of system reliability, R, compared to SRS under different sample sizes and parameter settings. Finally, applications to two datasets also illustrate the advantage of our proposed methodologies, which are conducive to enhanced precision in critical systems, cost-efficient resource allocation, adaptability to real-world data challenges.
Similar content being viewed by others
Introduction
In mechanical engineering, stress-strength (S-S) reliability models serve as a cornerstone for quantifying the failure probability of structural components under stochastic loading conditions. These models mathematically characterize system reliability through the relationship \(R=P(X<Y)\), where X (stress variable) and Y (strength variable) are random variables representing intrinsic material resistance and external operational loads, respectively. The failure mechanism arises when transient stress exceeds instantaneous strength, a phenomenon critical to predicting component lifespan and structural integrity. The S-S reliability models have become pivotal analytical tools in modern reliability engineering, particularly for lifetime testing scenarios where X and Y represent the failure times of dual-component systems (e.g., redundant circuits in avionics or parallel hydraulic actuators in heavy machinery). These models enable the probabilistic prediction of sequential failure events through the indicator R, which quantifies the likelihood of one component (strength Y) outperforming another (stress X) under operational loads. Let Y be the strength of a system subject to the stress X, then \(R=P(X<Y)\) can be seen as a measure of system performance. If the stress surpasses the strength, i.e., \(X>Y\), the system breaks down; otherwise, the system is still working.
Over several decades, the estimation of the system reliability in the S-S model has caused widespread concern. Researchers focused on the estimation of R when X and Y are two random variables from Normal1, Burr2, Generalized Exponential3, Weibull4, Generalized Pareto5, Lindley6, Power Lindley7, Generalized Lindley type 5 distributions8, separately. In a word, the above literature mainly considers the estimation of the system reliability under the assumption that X and Y are two simple random samples from certain distributions. Actually, collecting the information in the samples regarding the variable of interest is usually time-consuming and expensive. Therefore, some efficient sampling designs may be more suitable than the traditional simple random sampling (SRS) in terms of measuring system reliability.
Ranked set sampling (RSS) proposed by McIntyre9 has been confirmed as a more efficient sampling method compared to SRS and extended to various improved versions, such as extreme ranked set sampling (ERSS)10, median ranked set sampling (MRSS)11, double ranked set sampling (DRSS)12, imperfect Z ranked set sampling (IZRSS)13 and so on. In fact, the RSS methods have been applied in reliability testing in mission-critical systems, software reliability validation, and quality control in manufacturing processes within reliability engineering. Compared to SRS, the RSS methods have the following strengths. The RSS methods demonstrate superior statistical efficiency compared to SRS by leveraging auxiliary ranking information to reduce variability and improve estimation accuracy, particularly for population mean estimation. The methods achieves higher precision with smaller sample sizes by strategically selecting extreme or balanced subsets, which enhances regression coefficient estimation efficiency in linear models. These advantages make RSS particularly effective for symmetric distributions and nonparametric inference.
Recently, estimating R based on ranked set sampling designs for different distributions has aroused much attention. Studies have considered the estimation for R based on RSS when X and Y are two independent random variables from Exponential14, Weibull15, Lindley16, Exponentiated Pareto17, Inverse Lomax18, Burr Type X19, Inverted Topp-Leone20, Generalized Inverted Exponential21, Generalized Exponential22, Unit Gompertz23,24, Inverted Kumaraswamy25,26 distributions, respectively. Up to now, the Power-Lindley (PL) distribution was not considered in the S-S model based on RSS designs. Actually, PL distribution plays a critical role in system reliability estimation due to its enhanced flexibility in modeling lifetime data and failure patterns, particularly in scenarios involving censored or interval-truncated observations common in reliability engineering. By extending the classical Lindley distribution with an additional shape parameter, the PL distribution provides improved adaptability to asymmetric and multimodal failure datasets, enabling more accurate reliability predictions under diverse operational conditions. Consequently, it is imperative to incorporate the PL distribution into the estimation of R in the S-S model based on ranked set sampling methodologies.
Besides, right-censored data are common in actual life because some measurements are usually below the limit of detection. In recent years, some research has been focused on the estimation of reliability in the context of right-censored data. Krishna and Kumar27 considered the estimation of reliability under the assumption of one parameter Lindley distribution with progressively type II right-censored data. Later, Krishna and Kumar28 suggested the Generalized Inverted Exponential distribution as the lifetime model to estimate reliability based on type II progressively right-censored sampling scheme. Jia29 proposed the nonlinear method and transformation-based least-squares methods to obtain the estimates of reliability when X and Y are two independent random variables from Weibull distributions based on right-censored data. Although scholars have achieved notable progress in system reliability estimation under right-censored data, they predominantly focus on simple sampling method such as SRS and neglect the importance of RSS methods.
Therefore, this paper mainly focuses on the estimation of R in the S-S model based on ranked set sampling designs for the PL distribution with uncensored and right-censored data. To our knowledge, no one has investigated this problem so far. The purpose of this paper is to estimate system reliability R based on SRS, RSS and ERSS under the assumption that stress and strength are independent random variables from the PL distributions with uncensored and right-censored data. Potential applications of this study include enhancing reliability estimation accuracy in multi-component systems under both uncensored and right-censored failure data scenarios, and optimizing industrial quality control protocols through efficient lifetime testing frameworks. We first obtain the ML estimates based on SRS, RSS and ERSS for the PL distribution. Then Monte Carlo simulations considering perfect and imperfect ranking with uncensored data and perfect ranking with right-censored data, are carried out to evaluate the performance on the estimation of reliability based on different sampling designs for the PL distributions. Finally, applications to two real datasets are used to illustrate the effectiveness of our proposed methodologies. Simulation studies and empirical analyses demonstrate that RSS and ERSS designs outperform SRS in estimating system reliability R. The proposed methodologies achieve enhanced precision across both perfect and imperfect ranking scenarios with uncensored data, while maintaining their superiority in right-censored data under perfect ranking conditions.
The remaining contents of this paper are organized as follows. In Section 1, we introduce the RSS and ERSS methods briefly. The system reliability for the PL distribution is given in Section 2. And in Section 3, we present the ML estimates based on SRS, RSS and ERSS under perfect and imperfect ranking with uncensored data and perfect ranking with right-censored data. The Monte Carlo study is arranged in Section 4 to compare the performance of SRS, RSS and ERSS on the estimation of reliability under various cases. In Section 5, we present two real data applications. Finally, some conclusions are drawn in Section 6.
Ranked set sampling designs
In this section, the brief introductions of RSS and ERSS are made.
Ranked set sampling
The classical RSS scheme can be described as follows:
Step 1: Collect a random sample of size \(k^2\) from a certain population and then divide it randomly into k sets of size k.
Step 2: Rank the units of the k sets from the smallest to the largest without measuring them.
Step 3: Measure just the ith smallest ranked unit from the ith set, for \(i=1,2,\cdots ,k\).
Step 4: Steps 1-3 are repeated m times to obtain a RSS sample of size \(n=mk\).
Here, k and m denote the ranked set size and times of cycle, separately. For the sake of brevity, let \(x_{i,j}\) be the ranked unit in position i from set i in jth cycle, then the RSS sample can be denoted by \(\left\{ x_{i,j},i=1,2,\cdots ,k,j=1,2,\cdots ,m\right\}\). If there is no errors in the process of ranking, the probability density function (pdf) of \(x_{i,j}\)9,30 can be written as
where \(f_X(\cdot )\) and \(F_X(\cdot )\) represent the pdf and cumulative density function (cdf) of the population. Besides, the probability of imperfect ranking increases when the set size k is large.
Extreme ranked set sampling
To reduce the impact of imperfect ranking, Samawi, Ahmed and Abu-Dayyeh10 proposed ERSS, which measures the extreme units in sets. The ERSS scheme can be described as follows:
Step 1: Collect a random sample of size \(k^2\) from a certain population and then divide it randomly into k sets of size k.
Step 2: Rank the units of the k sets from the smallest to the largest without measuring them.
Step 3: If k is odd, measure the smallest units from the first \(\frac{k-1}{2}\) sets, the median unit from the \(\frac{k+1}{2}\) set, and the largest units from the last \(\frac{k-1}{2}\) sets. If k is even, measure the smallest units from the first \(\frac{k}{2}\) sets and the largest units from the last \(\frac{k}{2}\) sets.
Step 4: Steps 1-3 are repeated m times to obtain a ERSS sample of size \(n=mk\).
Let \(x_{s,t,v}\) be the sth smallest unit in the tth set at vth cycle, then the ERSS sample can be denoted as
otherwise,
For any element of the ERSS sample, its pdf can also be easily obtained by Eq. (1).
System reliability for the power Lindely distribution
Ghitany, Al-Mutairi, and Al-Enezi31 proposed the PL distribution and discussed its important properties. Due to its flexible characteristic, it has been widely used in various areas7,32,33,34. Therefore, in this paper, we discuss the estimation of system reliability based on different sampling designs with uncensored and right-censored data when both stress and strength are random variables from different PL distributions.
The pdf and cdf of PL distribution are written as follows
and
where \(\alpha\) and \(\theta\) denote the scale and shape parameters, respectively. If a random variable X follows the PL distribution with the scale papameter \(\alpha\) and the shape paramter \(\theta\), then it can be denoted by \(X\sim PL(\alpha ,\theta )\).
Consider stress X and strength Y be two independent random variables from \(PL(\alpha _1,\theta _1)\) and \(PL(\alpha _2,\theta _2)\), individually. Then the system reliability for the distributions can be obtained as follows
where we use the transformation \(u=y^{\alpha _2}\). It should be noted that the closed form expression of \(\delta (\alpha _1,\theta _1,\alpha _2,\theta _2)\) cannot be obtained owing to the unavailability of the solution of the integral in Eq. (4). So we compute the system reliability through the free statistical software R.
ML estimates of R based on different sampling designs with uncensored and right-censored data
In this section, we present the ML estimates based on three sampling methods for the PL distribution with uncensored and right-censored data.
ML estimates of R with uncensored data
Estimation of R based on SRS
Consider \(\left\{ x_i,i=1,2,\cdots ,n_x\right\}\) and \(\left\{ y_j,j=1,2,\cdots ,n_y\right\}\) to be two independent SRS samples from \(PL(\alpha _1,\theta _1)\) and \(PL(\alpha _2,\theta _2)\), separately. Then the log-likelihood function can be written as
The likelihood equations can be obtained by taking the derivatives of the log-likelihood with respect to the unknown parameters. The numerical method is used to obtain the solutions of the equations, which can be seen as the ML estimates of the unknown parameters of interest. According to the invariance property of the ML estimates, we can easily get the ML estimate of reliability based on SRS, denoted by \(\hat{R}_{SRS}\), namely \(\hat{R}_{SRS}=\delta (\hat{\alpha }_1,\hat{\theta }_1,\hat{\alpha }_2,\hat{\theta }_2)\), where \(\hat{\alpha }_1\), \(\hat{\theta }_1\), \(\hat{\alpha }_2\) and \(\hat{\theta }_2\) are the ML estimates of the unknown parameters based on SRS.
Estimation of R based on RSS
Consider \(\left\{ x_{i,j},i=1,2,\cdots ,k_x,j=1,2,\cdots ,m_x\right\}\) and \(\left\{ y_{i,j},i=1,2,\cdots ,k_y,j=1,2,\cdots ,m_y\right\}\) to be two independent RSS samples from \(PL(\alpha _1,\theta _1)\) and \(PL(\alpha _2,\theta _2)\), separately. Here, the sample sizes \(n_x=k_x m_x\) and \(n_y=k_y m_y\), where \(k_x\) and \(k_y\) denote the set sizes and \(m_x\) and \(m_y\) represent the times of cycles, individually.
According to Eq. (1), the log-likelihood function for the RSS samples is written as follows
where \(f_x(\cdot )\) and \(F_x (\cdot )\) are the pdf and cdf of \(PL(\alpha _1,\theta _1)\), \(f_y(\cdot )\) and \(F_y(\cdot )\) are the pdf and cdf of \(PL(\alpha _2,\theta _2)\), \(f_{i:{k_x},x}(\cdot )\) and \(f_{i:{k_y},y}(\cdot )\) are the pdfs of the ith smallest unit in the random samples with sizes \(k_x\) and \(k_y\) from \(PL(\alpha _1,\theta _1)\) and \(PL(\alpha _2,\theta _2)\), respectively.
Then we can obtain the ML estimates of \(\alpha _1\), \(\theta _1\), \(\alpha _2\) and \(\theta _2\) by taking the derivatives with the unknown paramters and solving the likelihood equations. Finally, the estimator of R based on RSS, namely \(\hat{R}_{RSS}\), can be obtained by incorporating the ML estimates of parameters into Eq. (4).
Estimation of R based on ERSS
Consider the ERSS sample of stress X to be \(\bigcup _{j=1}^{m_x} ((\bigcup _{i=1}^{\frac{k_x-1}{2}}x_{1,i,j})\bigcup x_{\frac{k_x+1}{2},\frac{k_x+1}{2},j}\bigcup (\bigcup _{i=\frac{k_x+3}{2}}^{k_x}x_{k_x,i,j}))\) if \(k_x\) is odd, otherwise, \(\bigcup _{j=1}^{m_x} ((\bigcup _{i=1}^{\frac{k_x}{2}}x_{1,i,j})\bigcup (\bigcup _{i=\frac{k_x+2}{2}}^{k_x}x_{k_x,i,j}))\). Additionally, the ERSS sample of strength Y is defined in a similar form as that of stress X.
If \(k_x\) is odd, then the log-likelihood function of the ERSS sample for X is
otherwise,
The log-likelihood function of the ERSS sample for Y, \(L_{ERSS,Y}\), also has a similar representation. Since the ERSS samples of X and Y are independent, then the joint log-likelihood function \(L_{ERSS}=L_{ERSS,X}+L_{ERSS,Y}\). Therefore, the ML estimate of R based on ERSS, namely \(\hat{R}_{ERSS}\), can be obtained in the same way.
ML estimates of R with righted-censored data
In this subsection, we mainly discuss the ML estimates of R in the S-S model with righted-censored data under various sampling designs. Firstly, the joint log-likelihood function based on SRS with right-censored data can be written as
where \(\delta _{i}=0\) when \(x_{i}\) is a right-censored observation, otherwise, \(\delta _{i}=1\). And \(\delta _{j}\) is also defined in a similar manner. Then we present the joint log-likelihood function based on RSS with right-censored data, which is given by
where \(\zeta _{i,j}=0\) when \(x_{i,j}\) is a right-censored observation, otherwise, \(\zeta _{i,j}=1\). \(f_{i:{k_x},x}(\cdot )\) and \(F_{i:{k_x},x}(\cdot )\) denote the pdf and cdf of the ith order statistic of the random sample with size \(k_x\) drawn from \(PL(\alpha _1,\theta _1)\), respectively. \(\eta _{i,j}\) and \(F_{i:{k_y},y}(\cdot )\) are defined in a similar manner as above. For simplicity, the joint log-likelihood function based on ERSS with right-censored data is not presented. The estimates of the parameters which maximize the log-likelihood function are also obtained through numerical optimization in computing softwares. Then, we can calculate the estimator of R with right-censored data using Eq. (4).
It should be stated that we use the Optim function in R software to obtain all ML estimates of parameters based on different sampling designs under various cases in this paper. Then all estimators of reliability are obtained according to Eq. (4).
Monte Carlo simulation
In this section, the extensive Monte Carlo simulations are carried out to observe the efficiency of the ML estimates of R based on SRS, RSS and ERSS under perfect and imperfect ranking with uncensored data and perfect ranking with righted-censored data. The mean, bias and mean squares error (MSE) criteria for evaluating the performance of the ML estimates of reliability are given as follows,
where R is the true reliability. Here M denotes the number of the simulation, which is set to 10000. Additionally, we also calculate the relative efficiencies (REs) of the estimates of reliability, which are written as follows
It is obvious that the estimator in the denominator is superior to that in the numerator if \(RE>1\).
Besides, for both RSS and ERSS, the following simulations are conducted with various ranked set sizes and number of cycles. For set sizes, \((k_x,k_y)=(2,2),(2,3),(3,3),(3,4),(4,4)\) and (4, 5) are assumed. The times of cycles are all taken as 10. Therefore, the sample sizes are takn to be \((n_x,n_y)=(20,20),(20,30),(30,30),(30,40),(40,40)\) and (40, 50). It should be stated that the paramter vectors \((\alpha _1,\theta _1,\alpha _2,\theta _2)=(0.5,1,0.5,1),(0.5,1,1,2)\) and (1, 2, 0.5, 1) are consided. Consequently, the true values of reliability corresponding to the above parameter settings can be computed as 0.5, 0.3313 and 0.6687, separately.
Perfect ranking with uncensored data
For simplicity, Table 1 presents the estimated results of the reliability based on different sampling designs, including means, biases, MSEs, and REs. It is evident from Table 1 that three sampling designs provide accurate estimates in all cases according to the mean and bias criterion. Besides, the MSE values tend to decrease with the increase of \(n_x\) and \(n_y\), which indicates that the ML method with a larger sample size produces a more precise estimator. It should also be noted that all \(RE_1\) and \(RE_2\) values are greater than 1, which confirms that the ML estimates of R based on RSS and ERSS are more efficient than the counterparts based on SRS for each of all cases.
In addition, we can observe that the \(RE_1\) values are larger than the \(RE_2\) values in most cases, indicating that RSS provides more precise estimators of R compared to ERSS when both stress and strength are independent random variables from PL distributions.
Imperfect ranking with uncensored data
The above simulations are conducted under the assumption of perfect ranking. It cannot be neglected that there are some judgment ranking errors caused by some subjective factors in the ranking process, especially for large set sizes. So, in this section, the performance of SRS, RSS and ERSS on the estimation of R under imperfect ranking is also investigated via Monte Carlo simulations. It should be stated that ranking error creates no impact on the ML estimates based on SRS for all given cases.
Up to now, there are many models to simulate data with imperfect ranking, such as the fraction of neighbors model and the concomitant variable model35,36,37. Here the concomitant variable model of Dell and Clutter35 is used to generate data with imperfect ranking. First of all, the SRS samples of X and Y with sizes \(k_x^2 m_x\) and \(k_y^2 m_y\), denoted by \(x_{i,i,j}\) \((i=1,2,\cdots ,k_x,j=1,2,\cdots ,m_x)\) and \(y_{i,i,j}\) \((i=1,2,\cdots ,k_y,j=1,2,\cdots ,m_y)\), are generated from \(PL(\alpha _1,\theta _1)\) and \(PL(\alpha _2,\theta _2)\), respectively. Then the independent random errors \(\epsilon _{1,i,i,j}\) \((i=1,2,\cdots ,k_x,j=1,2,\cdots ,m_x)\) and \(\epsilon _{2,i,i,j}\) \((i=1,2,\cdots ,k_y,j=1,2,\cdots ,m_y)\) with the same sizes \(n_x\) and \(n_y\) are drawn from \(N(0,\sigma ^2)\). Next, compute \(x_{i,i,j}^*=x_{i,i,j}+\epsilon _{1,i,i,j}\) \((i=1,2,\cdots ,k_x,j=1,2,\cdots ,m_x)\) and \(y_{i,i,j}^*=y_{i,i,j}+\epsilon _{2,i,i,j}\) \((i=1,2,\cdots ,k_y,j=1,2,\cdots ,m_y)\), then sort them from the smallest to the largest without any certain measurement. The corresponding values of \(x_{i,i,j}\) and \(x_{i,i,j}\) can be called the concomitants of \(x_{i,i,j}^*\) and \(x_{i,i,j}^*\). According to the sampling procedures of RSS and ERSS, we can use the concmitants to obtain the RSS and ERSS samples with imperfect ranking. Finally, the obtained RSS and ERSS samples are used to calculate the ML estimates of R under imperfect ranking.
Furthermore, \(\sigma\) controls the quality of imperfect ranking. When \(\sigma =0\), then the concomitant variable model becomes a perfect ranking model. when \(\sigma\) increases, the quality of ranking tends to decrease and the ranking error becomes more serious. In addition, \(\sigma\) is set to 0, 0.25, 0.5, 0.75 and 1 in the simulation study.
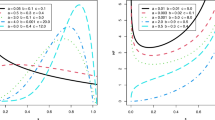
Figures 1, 2, 3 display the MSEs of the ML estimates based on various sampling designs under several levels \(\sigma\) of imperfect ranking. As expected, it is obvious that the MSEs based on RSS and ERSS gradually increase with the raise of \(\sigma\), which points to the fact that the estimators based on RSS-based designs become less efficient when the ranking error becomes more serious. However, the ML estimates based on ranking set samplings are still more effective than competitors based on SRS for each of parameter settings and levels of imperfect ranking. Besides, the estimates based on RSS are superior to the estimates based on ERSS in most cases.

MSEs of the ML estimates based on different sampling designs for \((\alpha _1,\theta _1,\alpha _2,\theta _2)=(0.5,1,0.5,1)\) under different levels \(\sigma\) of imperfect ranking.

MSEs of the ML estimates based on different sampling designs for \((\alpha _1,\theta _1,\alpha _2,\theta _2)=(0.5,1,1,2)\) under different levels \(\sigma\) of imperfect ranking.

MSEs of the ML estimates based on different sampling designs for \((\alpha _1,\theta _1,\alpha _2,\theta _2)=(1,2,0.5,1)\) under different levels \(\sigma\) of imperfect ranking.
Perfect ranking with righted-censored data
Actually, in survival data, the event time of interest is not always entirely recorded due to a series of subjective and objective factors. In this section, we mainly investigate the performance of SRS, RSS and ERSS on estimation of reliability with righted-censored data via simulations. For convenience, we assume that there is no error in the ranking process. Here we use the method of Taconeli and Giolo38 to simulate the righted-censored samples with censorship percentage p, where p is taken as 0.05, 0.1, 0.15, 0.2, 0.25, 0.3, 0.35, 0.4, 0.45 and 0.5. The number of righted-censored observations gradually increases with the raise of p.
Figures 4, 5, 6 display the MSEs based on three sampling designs under perfect ranking with righted-censored data for four parameter settings. From the four figures, we can observe that RSS and ERSS produce lower MSE values than SRS for each of censorship percentages. And gradual increases in the MSE values for three sampling designs can be seen for all parameter settings and set sizes as the percentage of censorship increases.

Estimated MSEs of the ML estimates based on different sampling designs for \((\alpha _1,\theta _1,\alpha _2,\theta _2)=(0.5,1,0.5,1)\) under different censorship percentages p.

Estimated MSEs of the ML estimates based on different sampling designs for \((\alpha _1,\theta _1,\alpha _2,\theta _2)=(0.5,1,1,2)\) under different censorship percentages p.

Estimated MSEs of the ML estimates based on different sampling designs for \((\alpha _1,\theta _1,\alpha _2,\theta _2)=(1,2,0.5,1)\) under different censorship percentages p.
Finally, it is obvious that the traditional RSS design usually produces the most accurate estimates. Therefore, RSS can be considered as the suggested design to estimate system reliability of the righted-censored stress and strength data from the PL distributions under perfect ranking.
Applications to real data sets
In this section, we firstly use the homeostasis model assessment (HOMA) index in the insulin resistance data39 to illustrate the effectiveness of our proposed procedure. The HOMA index for the healthy controls, denoted by X, contains 52 observations and the HOMA index for breast cancer patients, denoted by Y, contains 64 observations. Notably, the data set has been used by Akgul et al.40 to compare the insulin resistance of healthy individuals and patients using a stress-strength model based on ranked sampling designs for the generalized inverse Lindley distributions.
Before evaluating the performance of SRS, RSS, and ERSS on the estimation of reliability for the real data set, we use the PL distribution to fit the X and Y observations, respectively. The estimated results are presented in Table 2, which contains the estimates of parameters, the log-likelihood function and the p-values of the Kolmogorov-Simirnov (KS) tests. And the nonparametric plots of the datasets are given in Fig. 7.

The nonparametric plots of the HOMA index datasets.
We can see from Table 2 that the p-values of the KS tests for X and Y are greater than 0.05, which shows that the PL distribution provides good empirical fits to the X and Y data. Besides, we can calculate the estimate of R based on the estimated parameters as 0.6698.
The following simulations under various situations are conducted to assess the performance of three sampling designs on estimation of R when stress X and strength Y are two independent random variables from the PL(1.2894, 0.8092) and PL(0.8243, 0.6058) distributions, respectively.
With respect to the RSS and ERSS samples, the set sizes are taken to be \((k_x,k_y)=(4,4)\). And the number of cycles \((m_x,m_y)=(6,9)\) are considered. Therefore, the sample sizes of the RSS and ERSS samples are \((n_x,n_y)=(24,36)\). Apparently, the sizes of the SRS samples for X and Y are also set to 24 and 36, respectively. The Monte Carlo simulations are also repeated 10000 times to obtain the ML estimates based on each sampling design under perfect and imperfect ranking with uncensored data, and perfect ranking with right-censored data. Here \(\sigma\) which controls the quality of imperfect ranking is also set to 0.25, 0.5, 0.75 and 1. Besides, the percentage of censorship p is also taken as 0.05, 0.1, 0.15, 0.2, 0.25, 0.3, 0.35, 0.4, 0.45 and 0.5.
Table 3 presents the estimated results of the ML estimates based on three sampling designs under perfect and imperfect ranking, including average estimate (AE), bias and mean square error (MSE). And the corresponding results of the ML estimates under perfect ranking with uncensored and righted-censored data are reported in Table 4. According to Tables 3 and 4, all sampling designs produce the ML estimates close to 0.6698. Besides, gradual decreases in the MSEs of RSS and ERSS can be observed as \(\sigma\) decreases. Furthermore, the estimators for all sampling designs deviate more from the true value as p increases. More importantly, we can observe that the MSE values of RSS and ERSS are usually lower than that of SRS for each of all considered cases, which shows that RSS and ERSS provide more efficient estimators of reliability compared to SRS for the real data set.
Then we use the PL distribution to fit two datasets41 on failure stresses of single carbon fibers of lengths 20 mm and 50 mm, denoted by X and Y, respectively. Table 5 presents the estimated results. Figure 8 shows the nonparametric plots of the datasets.

The nonparametric plots of the failure stresses of single carbon fibers of lengths 20 mm and 50 mm.
We can see from Table 5 that the p-values of the KS tests for X and Y are much greater than 0.05, which shows that the PL distribution provides accurate empirical fits to the X and Y data. According to the estimated parameters in Table 5, the estimate of R for the two datasets can be obtained, which is 0.3739.
Next, we conduct simulation 10000 times under various cases to assess the performance of several sampling designs on estimation of R when stress X and strength Y are two independent random variables from the PL(3.8678, 0.0497) and PL(4.2212, 0.0521) distributions, respectively. Table 6 presents the estimated results of the ML estimates based on three sampling designs under perfect and imperfect ranking. And the corresponding results of the ML estimates under perfect ranking with uncensored and righted-censored data are reported in Table 7.
We can see from Table 6 that all ML estimates of R are close to 0.3739. The increases in the MSEs of SRS, RSS and ERSS can be obviously observed as \(\sigma\) increases. In Table 7, the ML estimates of R under three sampling designs deviates significantly from 0.3739 when p is large. More importantly, the MSE values of RSS and ERSS are much lower than that of SRS for any considered cases, which also shows that the RSS and ERSS produce more accurate estimates of reliability R than SRS for these datasets.
Conclusion
This study proposes a ranked sampling-based stress-strength reliability model, where the stress variable X and strength variable Y follow independent PL distributions. We systematically evaluate the comparative performance of SRS, RSS, and ERSS through Monte Carlo experiments and two real datasets under three conditions: (i) perfect ranking with uncensored data, (ii) imperfect ranking with uncensored data, (iii) perfect ranking with right-censored data. Finally, we find that the ML estimates based on RSS and ERSS are superior to the competitors based on SRS for all considered scenarios.
In fact, our study also has certain limitations. First of all, this paper focuses solely on system reliability estimation based on various ranked set sampling methods under right-censoring scenarios. However, in actual life, collected data often involves left-censoring and interval-censoring due to various subjective and objective factors. How to derive system reliability based on ranked set sampling methods under these censoring mechanisms remains a significant challenge. Besides, we neglect the the presence of the fuzziness in our proposed stress-strength model. Actually, The Bayesian estimation of system reliability based on ranked set sampling methods under such scenarios also remains a critical research topic. We leave these for future research.
Data availability
All data generated or analysed during this study are included in this published article.
Change history
28 July 2025
The original online version of this Article was revised: The original online version of this Article was revised: In the original version of this Article the authors were incorrectly affiliated.
References
Downton, F. The estimation of pr (y< x) in the normal case. Technometrics 15, 551–558. https://doi.org/10.1080/00401706.1973.10489081 (1973).
Awad, A. M. & Gharraf, M. K. Estimation of p (y< x) in the burr case: A comparative study. Communications in Statistics-Simulation and Computation 15, 389–403. https://doi.org/10.1080/03610918608812514 (1986).
Kundu, D. & Gupta, R. D. Estimation of p [y< x] for generalized exponential distribution. Metrika 61, 291–308. https://doi.org/10.1007/s001840400345 (2005).
Kundu, D. & Gupta, R. D. Estimation of p [y< x] for weibull distributions. IEEE Trans. Reliab. 55, 270–280. https://doi.org/10.1109/TR.2006.874918 (2006).
Rezaei, S., Tahmasbi, R. & Mahmoodi, M. Estimation of p [y< x] for generalized pareto distribution. Journal of Statistical Planning and Inference 140, 480–494. https://doi.org/10.1016/j.jspi.2009.07.024 (2010).
Al-Mutairi, D., Ghitany, M. & Kundu, D. Inferences on stress-strength reliability from lindley distributions. Communications in Statistics-Theory and Methods 42, 1443–1463. https://doi.org/10.1080/03610926.2011.563011 (2013).
Ghitany, M. E., Al-Mutairi, D. K. & Aboukhamseen, S. M. Estimation of the reliability of a stress-strength system from power lindley distributions. Communications in Statistics-Simulation and Computation 44, 118–136. https://doi.org/10.1080/03610918.2013.767910 (2015).
Rezaei, A., Sharafi, M., Behboodian, J. & Zamani, A. Inferences on stress-strength parameter based on gld5 distribution. Communications in Statistics-Simulation and Computation 47, 1251–1263. https://doi.org/10.1080/03610918.2017.1309666 (2018).
McIntyre, G. A method for unbiased selective sampling, using ranked sets. Australian journal of agricultural research 3, 385–390. https://doi.org/10.1071/AR9520385 (1952).
Samawi, H. M., Ahmed, M. S. & Abu-Dayyeh, W. Estimating the population mean using extreme ranked set sampling. Biometrical Journal 38, 577–586. https://doi.org/10.1002/bimj.4710380506 (1996).
Muttlak, H. A. Median ranked set sampling. Journal of Applied Statistical Science 6, 245–255 (1997).
Al-Saleh, M. F. & Al-Kadiri, M. A. Double-ranked set sampling. Statistics & Probability Letters 48, 205–212. https://doi.org/10.1016/S0167-7152(99)00206-0 (2000).
Al-Omari, A. I. & Almanjahie, I. M. New improved ranked set sampling designs with an application to real data. Computers, Materials and Continua 67, 1503–1522. https://doi.org/10.1016/j.matcom.2011.07.005 (2021).
Muttlak, H. A., Abu-Dayyeh, W., Saleh, M. & Al-Sawi, E. Estimating p (x< y) using ranked set sampling in case of the exponential distribution. Communications in Statistics-Theory and Methods 39, 1855–1868. https://doi.org/10.1080/03610920902912976 (2010).
Akgül, F. G. & Şenoğlu, B. Estimation of p (x< y) using ranked set sampling for the weibull distribution. Quality Technology & Quantitative Management 14, 296–309. https://doi.org/10.1080/16843703.2016.1226590 (2017).
Akgül, F. G., Acıtaş, Ş & Şenoğlu, B. Inferences on stress-strength reliability based on ranked set sampling data in case of lindley distribution. Journal of Statistical Computation and Simulation 88, 3018–3032. https://doi.org/10.1080/00949655.2018.1498095 (2018).
Al-Omari, A. I., Almanjahie, I. M., Hassan, A. S. & Nagy, H. F. Estimation of the stress-strength reliability for exponentiated pareto distribution using median and ranked set sampling methods. CMC-Computers, Materials and Continua 64, 835–857, https://doi.org/10.32604/cmc.2020.10944 (2020).
Al-Omari, A. I., Hassan, A. S., Alotaibi, N., Shrahili, M. & Nagy, H. F. Reliability estimation of inverse lomax distribution using extreme ranked set sampling. Advances in Mathematical Physics 1, 4599872. https://doi.org/10.1155/2021/4599872 (2021).
Akgül, F. G. & Şenoğlu, B. Inferences for stress-strength reliability of burr type x distributions based on ranked set sampling. Communications in Statistics-Simulation and Computation 51, 3324–3340. https://doi.org/10.1080/03610918.2020.1711949 (2022).
Yousef, M. M., Hassan, A. S., Al-Nefaie, A. H., Almetwally, E. M. & Almongy, H. M. Stress strength modeling using median-ranked set sampling: Estimation, simulation, and application. Mathematics 10, 3122. https://doi.org/10.3390/math1017312 (2023).
Heba, N. A. G. Y. & Hassan, A. Estimation in multicomponent stress strength for generalized inverted exponential distribution based on ranked set sampling. Gazi University Journal of Science 35, 314–331, https://doi.org/10.35378/gujs.760469 (2022).
Sadeghpour, A., Salehi, M. & Nezakati, A. Estimation of the stress-strength reliability using lower record ranked set sampling scheme under the generalized exponential distribution. Journal of Statistical Computation and Simulation 90, 51–74. https://doi.org/10.1080/00949655.2019.1672694 (2020).
Alsadat, N., Hassan, A. S., Elgarhy, M., Chesneau, C. & Mohamed, R. E. Efficient stress strength reliability estimate of the unit gompertz distribution using ranked set sampling. Symmetry 15, 1121. https://doi.org/10.3390/sym15051121 (2023).
Hassan, A. S., Almanjahie, I. M., Al-Omari, A. I., Alzoubi, L. & Nagy, H. F. Efficient stress strength reliability estimate of the unit gompertz distribution using ranked set sampling. Mathematics 11, 318. https://doi.org/10.3390/sym15051121 (2023).
Hassan, A. S. & Atia, S. A. Statistical inference and data analysis for inverted kumaraswamy distribution based on maximum ranked set sampling with unequal samples. Scientific Reports 14, 25450. https://doi.org/10.1038/s41598-024-74468-4 (2024).
Hassan, A. S., Alsadat, N., Elgarhy, M., Ahmad, H. & Nagy, H. F. On estimating multi stress strength reliability for inverted kumaraswamy under ranked set sampling with application in engineering. Journal of Nonlinear Mathematical Physics 31, 30. https://doi.org/10.1007/s44198-024-00196-y (2024).
Krishna, H. & Kumar, K. Reliability estimation in lindley distribution with progressively type ii right censored sample. Mathematics and Computers in Simulation 82, 281–294. https://doi.org/10.1016/j.matcom.2011.07.005 (2011).
Krishna, H. & Kumar, K. Reliability estimation in generalized inverted exponential distribution with progressively type ii censored sample. Journal of Statistical Computation and Simulation 83, 1007–1019. https://doi.org/10.1080/00949655.2011.647027 (2013).
Jia, X. A comparison of different least-squares methods for reliability of weibull distribution based on right censored data. Journal of Statistical Computation and Simulation 91, 976–999. https://doi.org/10.1080/00949655.2020.1839466 (2021).
Takahasi K, W. K. On unbiased estimates of the population mean based on the sample stratified by means of ordering. Annals of the institute of statistical mathematics 20, 1–31, https://doi.org/10.1007/bf02911622 (1968).
Ghitany, M. E., Al-Mutairi, D. K., Balakrishnan, N. & Al-Enezi, L. Power lindley distribution and associated inference. Computational Statistics & Data Analysis 64, 20–33. https://doi.org/10.1016/j.csda.2013.02.026 (2013).
Barco, K. V. P., Mazucheli, J. & Janeiro, V. The inverse power lindley distribution. Communications in Statistics-Simulation and Computation 46, 6308–6323. https://doi.org/10.1080/03610918.2016.1202274 (2017).
Sharma, V. K., Singh, S. K. & Singh, U. Classical and bayesian methods of estimation for power lindley distribution with application to waiting time data. Communications for Statistical Applications and Methods 24, 193–209. https://doi.org/10.5351/CSAM.2017.24.3.193 (2017).
Dey, S., Saha, M., Maiti, S. S. & Jun, C.-H. Bootstrap confidence intervals of generalized process capability index cpyk for lindley and power lindley distributions. Communications in Statistics-Simulation and Computation 47, 249–262. https://doi.org/10.1080/03610918.2017.1280166 (2018).
Dell, T. & Clutter, J. Ranked set sampling theory with order statistics background. Biometrics 545–555, https://doi.org/10.2307/2556166 (1972).
Frey, J. C. New imperfect rankings models for ranked set sampling. Journal of Statistical planning and Inference 137, 1433–1445. https://doi.org/10.1016/j.jspi.2006.02.013 (2007).
Vock, M. & Balakrishnan, N. A jonckheere-terpstra-type test for perfect ranking in balanced ranked set sampling. Journal of Statistical Planning and Inference 141, 624–630. https://doi.org/10.1016/j.jspi.2010.07.005 (2011).
Taconeli, C. A. & Giolo, S. R. Maximum likelihood estimation based on ranked set sampling designs for two extensions of the lindley distribution with uncensored and right-censored data. Computational Statistics 35, 1827–1851. https://doi.org/10.1007/s00180-020-00984-2 (2020).
Patrício, M. et al. Using resistin, glucose, age and bmi to predict the presence of breast cancer. BMC cancer 18, 29–36. https://doi.org/10.1186/s12885-017-3877-1 (2018).
Akgul, F. G., Yu, K. & Senoglu, B. Estimation of the system reliability for generalized inverse lindley distribution based on different sampling designs. Communications in Statistics-Theory and Methods 50, 1532–1546. https://doi.org/10.1080/03610926.2019.1705977 (2021).
Bader, M. G. & Priest, A. M. Statistical aspects of fibre and bundle strength in hybrid composites. Progress in Science and Engineering of Composites 1129–1136, https://doi.org/10.1016/j.matcom.2011.07.005 (1982).
Acknowledgements
This work was supported by Research Initiation Project for Young Teacher of Zhejiang Normal University (No. YS304222943) and 2023 National Project Cultivation Special Program for Universities in Zhejiang Province (No. YS343023932).
Author information
Authors and Affiliations
Contributions
All authors contributed equally to this paper.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Wu, Z., Xiang, L. Efficiency of ranked set sampling designs in power Lindley system reliability estimation with uncensored and right-censored data. Sci Rep 15, 22759 (2025). https://doi.org/10.1038/s41598-025-09136-2
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-09136-2
