
Abstract
Accurate diagnosis and severity estimation of gastrointestinal tract (GT) lesions are crucial for patient care and effective treatment plan decisions. Traditional methods for diagnosing lesions face challenges in accurately estimating severity due to requiring interpretable biomarkers, inter-observer variability, and overlapping lesions. Moreover, existing deep-learning models treat lesion classification and severity estimation as separate tasks, complicating diagnosis. To address these gaps, we propose a deep multi-task learning framework that aims to improve accuracy by simultaneously addressing classification and severity estimation. The proposed framework is designed in three stages utilizing four multi-class GT datasets. The first stage involves multi-scale feature representation using the convolutional vision transformer (CViT) blocks. The CViT with enhanced multi-head attention employs a deep multi-task learning approach extracting shared features in a unified manner. In the second stage, the extracted features are combined with the features from the first stage. In a subsequent stage, task-specific enhanced multi-head attentions are applied to the concatenated features to facilitate efficient learning between global and local information features. Our approach enhances fine-grained image features by incorporating semantic image features and focusing on representation subspace. Extensive experimental results demonstrate significant performance, validating the proposed model’s effectiveness across various datasets in lesion diagnosis and severity estimation.
Similar content being viewed by others

Introduction
The gastrointestinal tract (GT) is susceptible to various disorders ranging from minor annoyances, including abdominal pain, difficulty swallowing, and bleeding1 to lethal diseases2. For example, GT cancers contribute to around 3.5 million new cases worldwide each year, leading to a combined mortality rate of 63% and 2.2 million annual deaths3. These cancers make up 26% of cancer incidences and account for 35% of global cancer-related deaths. Colorectal cancer, ranked as the third most common cancer worldwide, constitutes nearly 10% of all cancer diagnoses and ranks as the second leading cause of cancer-related deaths, imposing a significant financial burden on individuals and healthcare systems4. In 2018, 4.8 million new cases and 3.4 million deaths were associated with GT cancers, including colorectal, stomach, and esophagus. Predictions indicate a 58% increase in cases and a 73% rise in deaths by 2040, primarily attributed to endoscopic errors2,5,6. The challenge lies in accurately differentiating lesion types and severity levels, particularly in the early stages, due to limited view, inter-observer variability, and overlapping conditions experts are prone to overlook. On the other hand, early detection of lesions can significantly improve outcomes, minimize the need for invasive treatments, and provide a high recovery rate of 90%2.
Gastrointestinal endoscopy (GIE) is an advanced optical imaging technique that utilizes flexible optical fibers to guide light into the GT. The system uses image sensors to capture reflections from the mucosa within the tract, seamlessly converting them into electronic signals. These signals undergo a meticulous process of amplification, filtering, and digitization, culminating in the enhancement of endoscopic image quality and the production of detailed visualizations of the digestive tract mucosa7. Clinically, GIE is the primary method for lesion detection, followed by biopsy confirmation and appropriate treatment. Minimally invasive surgical techniques like endoscopic submucosal dissection, laparoscopic rectal resection, and endoscopic mucosal resection are commonly employed for malignancies8. Accurate and unbiased classification of lesions is pivotal for early diagnosis and patient treatment9 Thus, an automatic GT lesion diagnosis and severity estimation is needed to improve clinical precision and interpretability.
Subsequently, the advancement of accurate methods for diagnosis is needed to help clinicians make effective decisions and guide suitable treatments in practical settings10. Endoscopy is widely acknowledged as the preferred method for examining lesions, but operational variability hinders endoscopy’s effectiveness. Endoscopic procedures are recognized as the gold standard for the abnormality’s diagnosis11 and provide a clear view of internal organs, tissues, and cavities, making it easy to precisely identify lesions1. Identifying lesions in complex backgrounds, such as those associated with ulcerative colitis or near folds and flexures, is difficult during conventional endoscopy. Thus, diagnosing diseases using endoscopy in the GT remains complex due to the system’s intricate nature and the severity of potential lesions that heavily rely on visual inspection through clinical screening, endoscopy, or histopathological examinations2,12. GT disorders, encompassing a spectrum from inflammatory conditions to neoplastic lesions, are currently formidable challenges for healthcare professionals, underscoring the need for precise and efficient diagnostic solutions.
Exiting methods faced challenges, including early lesion detection, identifying precancerous lesions, subtle and flat lesions, varied disorders, and lesions in a complex location13. Moreover, the classification of diseases alone does not confirm the accurate estimation of severity levels for critical care planning1. Estimating the severity of diseases and implementing treat-to-target strategies are crucial in quantifying the extent of diseases, ranging from mild to severe. The severity of the lesions is typically graded on a scale from mild to severe, with each grade indicating the extent of damage or inflammation present in the affected area12. The current severity assessment procedure has focused on assessing disease activity at a specific moment, utilizing diverse tools. Medical experts often use the severity index to guide treatment decisions and evaluate the progression of diseases during endoscopic examinations to address each patient’s specific needs and prevent further complications by assessing the severity of lesions. Ulcerative colitis endoscopic index of severity and the standard endoscopic esophagitis severity index scoring are commonly used grading systems to evaluate the severity of the lesion. The severity of each factor is graded on a scale of 0 to 3, with higher scores indicating more severe inflammation. It generally provides a standardized and objective method for classifying the severity based on findings, allowing for consistent assessment and comparison of patients with this condition14. On the other hand, effective care provision depends on precisely evaluating disease severity and considering longitudinal variables for a comprehensive understanding15.
The diagnosis and severity estimation of lesions using deep learning (DL) face significant challenges despite its potential. A lightweight transformer-based model, FLATer16was proposed for diagnosing diseases in endoscopic images, integrating a residual block, a ViT module, and a spatial attention block to focus on local and global features. However, existing DL models often focus on single tasks and struggle to integrate diverse information crucial for accurate diagnosis in GT images, which vary widely in appearance and complexity17,18. Besides, conventional diagnostic methods are subjective and inconsistent and exacerbated by limited and unbalanced datasets that are essential for model training3. Recent studies like CrossViT19 and MedViT20 demonstrate the efficacy of transformer-based architectures in handling large-scale image datasets, emphasizing their adaptability and robustness. Yet, their complexity and computational overhead become significant drawbacks.
Further, fine-grained approaches have shown promising results in object detection21,22. Wu et al.23 proposed convolutions into the ViT architecture to combine the Transformers with the s of CNNs for image recognition tasks. Residual Networks (ResNet)24 was introduced, employing residual connections to address the degradation problem in training deep neural networks. This approach enables the training of exceptionally deep models, leading to better performance in image recognition tasks. The previous studies highlight the importance of CNNs like attention-guided convolutional neural networks (AG-CNN)18 and transformer-based approaches in a single task. They have shown limited accuracy on small imbalanced complex GT lesions, which bottleneck the GT lesion diagnosis. Despite advancements in diagnostic systems, the simultaneous classification and severity estimation of GT lesions remains fragmented across distinct models, limiting clinical utility and scalability. This study proposes a novel deep multi-task learning (MTL) framework called the deep computer-aided method for lesion diagnosis (GTCAD) to optimize both tasks within a single, unified model and enhance diagnostic accuracy across diverse real-world datasets.
The main contributions of this study are described as follows.
-
We propose GTCAD, a novel unified deep MTL framework that concurrently addresses GT lesion classification and severity estimation through shared representations. This approach substantially improves performance on complex, class-imbalanced datasets by leveraging a single model to optimize both tasks.
-
We integrate the CViT with an Enhanced Multi-head Attention (EMA) mechanism, which augments feature representation and interpretability. This integration facilitates improved diagnostic accuracy and provides fine-grained visualizations of key regions contributing to lesion diagnosis and severity estimation, thereby enriching model transparency.
-
Extensive validation across multiple public and private datasets demonstrates that GTCAD outperforms state-of-the-art models, offering superior performance, robustness, and efficiency in lesion classification and severity estimation.
The subsequent sections of the study are organized as a method that describes the proposed method used in GT lesion diagnosis and severity estimation. The third section describes the experiments that present datasets, implementation details, evaluation metrics, and result analysis. Section four presents a discussion of the key findings. The section presents the conclusion of the proposed method.
Methods
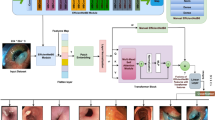
In this work, we propose a deep MTL framework to improve accuracy by simultaneously addressing classification and severity estimation, designed in three stages. The first stage involves inputting multi-scale feature representation to the convolutional token embeddings, which utilizes the ResNet50 backbone network as a convolution with overlapping patches. To maximize the strengths of CNNs and transformers, we introduced CViT for shared feature extraction for the model, which comprises an encoder and decoder. In the second stage, the extracted deep features from the pre-trained MTL model are combined with the features from the first stage. Then, convolutional projection is applied in a depth-wise separable operation. In a subsequent stage, task-specific EMA are applied to the concatenated features to facilitate efficient learning between global and local information features. Finally, a fully connected (FC) task-specific head is applied to the classification of the last stage output to predict the lesion and its severity.
By integrating MTL, GTCAD simultaneously performs two critical tasks: identifying lesions and estimating their severity within a unified DL framework, as shown in Fig. 1. We also introduced EMA for the MTL to enhance diagnostic accuracy and efficiency in analyzing endoscopic images, offering significant improvements over existing methods. Different from the conventional attention formulation, in our case, the original semantic image feature is included, and the information from various representation subspaces is focused, which enhances the representation of fine-grained image features and supports the MTL for lesion identification and severity estimation. The learned attention enhances the image features with the enhanced multi-head self-attention approaches to superior performance. The details of the proposed framework are described as follows.
The GTCAD
The GTCAD consists of three steps, including preprocessing, training, fine-tuning, and evaluation, each step of which is detailed below.
Step 1. Preprocessing. For GT endoscopy images and videos collected from public and private sources, some image frames were generated from GT-labeled videos in a standard fixed time frame to solve the class imbalance. Furthermore, we employed standard data augmentation techniques to address the class imbalance and improve generalization, including horizontal and vertical flipping, random rotation (± 15°), cropping, zooming (10–15%), and color jittering. All the images were resized in three categories (224 \(\:\times\:\) 224, 384 \(\:\times\:\) 384, and 512 \(\:\times\:\) 512). 224 \(\:\times\:\) 224 input size utilized as default. The pixel values of the images are normalized and expressed as Eq. (1).
where \(\:\mathcal{x}\) represents the original pixel value. \(\:\mu\:\) is the mean of all pixel values in the dataset, \(\:\sigma\:\) is the standard deviation (SD) of all pixel values in the dataset, and \(\:{\mathcal{x}}^{{\prime\:}}\) is the normalized pixel value.
Step 2. Training: Giving an image \(\:{X\in\:\mathbb{R}}^{\text{{\rm\:H}}\times\:\mathcal{W}\times\:\complement\:}\), where \(\:H,\) \(\:W,\complement\:\) are the height, width, and number of channels, respectively, then split into a sequence of flattened two-dimensional square patches \(\:{X\in\:\mathbb{R}}^{N\times\:\left({P}^{2.}C\right)}\), where \(\:P\) is the side length of a patch, and \(\:N=HW/{P}^{2}\), is the total number of patches. In this setup, all trainable parameters, including the backbone, class-specific queries, and the class-agnostic vector, undergo end-to-end training for lesion classification, as shown in Fig. 1(a). The \(\:N\) transformer encoders produce superior features for the task, and the classification block involves five layers, including batch normalization and a SoftMax layer. These patches undergo a series of merging stages, resulting in a final patch size of 32 × 32. The transformer encoder blocks \(\:N\) consist of repeated layers with multi-head attention and FC feedforward network. Thus, the input feature X is projected into three projection matrices: queries, keys, and values, which are obtained through learned weight matrices (i.e., \(\:{W}^{q},{W}^{k},{W}^{v}\)), which is formulated in Eqs. (2)-(5).
After the convolutional projection, we obtain the enhanced and intermediate tensor of \(\:{Q}_{q},\:{K}_{k},\) and \(\:{V}_{v}\) by adding the original input feature \(\:X\). This maintains the original semantic image features, and the model collectively focuses on information from various representation subspaces, enhancing interpretability and overall performance25. Then, the attention value for the learnable query \(\:{Q}_{q}\) and \(\:{K}_{k}\) with the amplification of the inner product with the given image, \(\:X\) is defined as d.

The deep MTL framework of the proposed method. (a) Demonstrates MTL for GT lesion diagnosis and severity estimation in a unified manner by using the backbone network, ResNet50, and CViT for feature extraction \(\:{F}_{i}\). \(\:{F}_{i}\) fused to the next stage, and the weight is shared with each task to enhance model interpretability. (b) Fused output utilized by EMA to get attention heads for each task. This demonstrates convolutionally projected queries \(\:\left(Q,K,V\right)\). After applying SoftMax to normalize attention scores, the outputs of all heads are concatenated and transformed. The final multi-head output represents a combined representation that captures diverse patterns and relationships within image patches and tokens across multiple attention heads.
where is \(\:{A}_{t}^{h}\) used to compute attention heads and \(\:\sqrt{d}\) is used to normalize the inner product. The learned attention enhances the image features with the multi-head self-attention approaches, which is superior performance. This is formulated by concatenation of each single head defined as follows:
Therefore, the proposed module consists of an enhanced multi-head cross-attention \(\:{M}_{h}\) learning with MLP blocks. In addition, the LayerNorm and residual connections are applied, which is expressed in Eq. (7).
where \(\:MLP\) is Multi-layer Perceptron, \(\:LN\) is Layer Normalization, and \(\:\stackrel{-}{X}\) output features. In this way, our proposed method effectively learns image features at each stage and creates a unified feature representation for GT lesion classification and severity estimation.
Step 3. Fine-Tuning and evaluation. We applied the ViT-based model for the initial stage of our model, which is with a patch size of 16 × 16. To improve the performance of the GTCAD, which was initially trained from scratch, we used pre-trained weight. The training of our model was initialized from scratch and with pre-trained weights26. DETR-ResNet-50 weight model is used to stack a transformer encoder on the feature extractor, employing attention to enhance feature representations27. After implementing weight from the pre-trained model, the proposed model can improve even when trained on a complex multimodal dataset. Recognized metrics, including accuracy, precision, and F1 score, were implemented to evaluate the model’s performance based on the tasks. Depending on the evaluation results, further fine-tuning or adjustments to the model were performed to improve performance. This could involve tweaking hyperparameters, training for additional epochs, and transfer learning.
Loss function
In a deep MTL framework, different loss functions are computed and merged. The effect of each loss function on the overall loss can be adjusted using different weights. Cross-entropy (CE) loss functions are utilized for lesion classification and severity estimation. This study employed loss functions to quantify the errors generated in the training and validation phases. Considering the diverse class numbers in each stage, using an appropriate loss function, such as CE loss, effectively computed the loss for each model. The calculation of the loss \(\:\left({l}_{i}\right)\) involves the implementation of the cross-entropy loss function expressed in Eq. (8)
where \(\:n\) represents the number of samples, \(\:m\) denotes the number of label classes, \(\:{y}_{jc=\text{{\rm\:I}}(j=c)}\) is the indicator function yielding either 0 or 1, and \(\:{p}_{jc}\) signifies the probability that sample \(\:j\) pertains to class \(\:c\). The total loss of our model is articulated as in (9) a weighted sum encompassing the three losses:
Furthermore, the categorical cross-entropy functions were applied to estimate lesion and severity in MTL. The results obtained from each output are stored for cross-entropy loss computation, and the two loss values are then merged into a single loss value28. Equations (10)-(11) shows the categorical CE, while Eq. (12) demonstrates that the merged loss value is achieved by adding the three values with equal weight.
where, \(\:log\) represents the natural algorithm, \(\:S\) values are predicted probabilities, \(\:{y}_{i}\:\) (i is j or k) is the class indicator, and \(\:\theta\:\) denotes an activation function. \(\:{\lambda\:}_{1}\:\)and \(\:{\lambda\:}_{2}\) are hyperparameters of lesion loss \(\:{L}_{Loss}\) and severity loss \(\:{S}_{loss}\).
Experiments
Experimental dataset
The experimental datasets were collected from public and private (hospital) sources. Figure 2 shows the classes in the image and videos, including esophagitis, ulcerative colitis, and colorectal cancer. The details are described as follows:
-
(1)
HyperKvasir: HyperKvasir3 is the largest multi-class video and image dataset of the GT. The information is collected during colonoscopy and gastro procedures at Bærum Hospital in Norway, with some labeling performed by skilled gastrointestinal endoscopists. The dataset contains a total of 10,662 labeled images from 23 classes, 1000 segmented images, 99,417 unlabeled images, and 374 videos (30 classes), which represents different findings obtained from the upper and lower GT with high pixel dimensions including 571 \(\:\times\:\) 530, 1221 \(\:\times\:\) 1012, and 1349 \(\:\times\:\) 1071.
-
(2)
GastroVision: The dataset consists of multi-class endoscopy images with key anatomical landmarks, pathological abnormalities, and normal findings within the GT. Gastrovision5 encompasses 27 classes and includes 8,000 images obtained from the upper and lower GT. Most images were captured through white light imaging. At the same time, a small number were acquired using Narrow Band Imaging, with varying high pixel dimensions such as 576 \(\:\times\:\) 720, 1280 \(\:\times\:\) 1048, and 1920 \(\:\times\:\) 1072.
-
(3)
Labeled Images for Ulcerative Colitis (LIMUC): A total of 11,276 images were collected from 564 patients and 1043 colonoscopy procedures for ulcerative colitis at the Department of Gastroenterology in Marmara University School of Medicine between December 2011 and July 2019. Three experienced gastroenterologists reviewed, labeled, and graded all images according to the Mayo Endoscopic Score. The grades were Mayo 0 (54.14%), Mayo 1 (27.70%), Mayo 2 (11.2%), and Mayo 3 (7.67%) were found in 352 \(\:\times\:\) 288 sizes12.
-
(4)
Lab (hospital): We utilized a dataset comprising 2690 GT images from 617 patients collected at the Digestive Endoscopy Center, West China Hospital of Sichuan University, China. Medical experts labeled and confirmed all lesions. The original images were captured at a size of 384 × 384 pixels. Approval for collecting and utilizing the datasets was granted by the Institutional Review Ethics Committee of the University of Electronic Science and Technology of China (UESTC) and the Ethics Committee on Biomedical Research at West China Hospital of Sichuan University. Before data collection, informed consent forms were signed by all patients. The study adhered to institutional guidelines, following the ethics outlined in the 1964 Helsinki Declaration and its subsequent amendments or equivalent ethical standards29.
The GT endoscopy images were color images in joint photographic group (jpg) format. Original datasets are split into training, validation, and testing before preprocessing and augmentation. After preprocessing, sixty thousand from thirty-two classes (10 of the classes were with severe cases) were implemented. Additional images were generated from videos and augmented similarly to29 to improve class imbalance and make the model robust. The summary of the dataset, as depicted in Table 1, was split into training, validation, and test (70%), validation (15%), and test sets (15%) before preprocessing. Some lesion image datasets, such as ulcerative colitis (UC), are with sub-classes. Moreover, sample lesion findings are demonstrated in Fig. 2.
Implementation details and evaluation metrics
Training and Inference: For the training and inference stages, we resize the dimensions of all to 224 \(\:\times\:\) 224. The models are implemented by Python 3.11.5 and Pytorch 2.1.2 on NVIDIA A100 80 GB PCIe GPU ubuntu 20.04.1 LTS server. The backbone network follows ViT architecture pre-trained models that have been implemented. In addition, performance improved with fine-tunes pretrained ResNet50 26. The main experiments were conducted utilizing both the baseline setup (L = 4, H = 8, D = 384, P = 16) and GTCAD (L = 12, H = 8, D = 512, P = 16), where L, H, D, P denote the number of layers, the number of heads, the embedding dimension, and the patch size, respectively. Additional key hypermeters are presented in Table 2 The accuracy, precision, recall, and F1 scores were implemented to assess the model’s performance. Equations 9–12 depict that the primary metrics were closely monitored throughout the training process, demonstrating consistently promising performance, even on validation. Accuracy, a widely used metric in MTL performance, was highlighted.

Sample upper and lower GT endoscopy images with different findings3,5. The figure indicates the upper and lower tract (organs) with lesions or findings (pathological findings, anatomical landmarks, therapeutic interventions, and quality of mucosal views). The figures in the rectangular box, which contain findings of pathological landmarks, anatomical landmarks, therapeutic interventions, and quality of mucosal views, demonstrate sample images with lesion and severity.
The accuracy, precision, recall, and F1 scores were implemented to assess the model’s performance. Equations (13)-(16) depict that the primary metrics were closely monitored throughout the training process, demonstrating consistently promising performance, even on validation. A multi-task evaluation widely utilized the mean with SD of accuracy, precession, Recall, and F1 score.
where \(\:TP\), \(\:FP\), \(\:TN\), and \(\:FN\) represent true positives, false positives, true negatives, and false negatives, respectively.
Experimental results
In this work, the comparison describes the experimental performance of the proposed method with baseline and existing works. ViT-based model is used as the baseline. To validate the performance of the GTCAD, we compared it with recent related works. Thus, CrossViT19ViTfSCD30MedViT20FLATer16CST31and AG-CNN18 are used to compare the proposed method, GTCAD.
The comparison results on the test sets are depicted in Table 3. The baseline method shows good classification performance in accuracy (0.939 ± 0.062), precision (0.952 ± 0.124), recall (0.925 ± 0.120), and F1 score (0.936 ± 0.161), signifying a reasonable predictive capacity. Comparably, other related works demonstrated promising results. However, there’s a potential enhancement for the related works, especially in accurately identifying true negatives and reducing false negatives. The proposed method demonstrates promising performance, reflecting robust predictive capabilities and highlighting a well-balanced lesion diagnosis and severity-level estimation encompassing precision and recall. The GTCAD demonstrated significant performance compared to existing works.
The accuracy is a strong indicator of the model’s overall performance. In the context of medical image analysis, particularly for GT lesions, such high accuracy (0.965 ± 0.041) achieved by GTCAD is significant as it suggests reliable detection and classification. Precision of (0.960 ± 0.102) and recall of (0.952 ± 0.104) are substantial. Precision indicates that 96% of the identified positive cases or lesions are true positives, and recall indicates that the model successfully identifies 95.2% of all actual positive cases. Compared to related works, precision and recall for lesion diagnosis typically range between 90% and 95%. The proposed model’s performance exceeds these ranges, reflecting robust lesion diagnosis and severity estimation capabilities. The F1 score, the mean of precision and recall, is (0.958 ± 0.153).
Furthermore, a paired t-test was conducted to assess the accuracy difference between the Baseline method and the proposed GTCAD framework, yielding a t-statistic of 2.28 and a p-value of 0.0299, below the 0.05 significance threshold. This result substantiates the rejection of the null hypothesis, demonstrating that GTCAD significantly outperforms the Baseline. The 95% confidence intervals further reinforce this, with the Baseline accuracy ranging from 91.6 to 96.2% and GTCAD’s accuracy ranging from 95.5 to 98.5%. The proposed method enhances diagnostic performance by integrating lesion classification and severity estimation within a unified MTL model. This approach, along with EMA for focused learning and CViT for advanced feature representation, addresses the Baseline’s limitations, mitigates class imbalance, and improves interpretability via attention maps, leading to superior accuracy, robustness, and interpretability performance.
Visualization analysis
Similar to the class activation map32 used in CNN architecture, we conduct an attentional visualization of patch-level images to diagnose lesions. In particular, by utilizing the attention head maps of the model, we identify lesions or ROI. Visually emphasizing these regions can assist healthcare providers in pinpointing potential lesions more accurately, enhancing interpretability by establishing correlations between learned image features and endoscopic features. Figure 3 demonstrates attention heads of the different performances of each model. The qualitative performance results of the proposed method are compared with existing related methods, which show areas with higher attention weights and indicate where the model is focusing more, like GTCAD. Comparing attention maps of lesion diagnosis across layers reveals how the model’s focus evolves from local to global context, as shown in Fig. 4.

Visualization of the GT lesion diagnosis results of the GTCAD and existing methods. The 1st column represents original images with a complicated GT lesion, and the 2nd to 7th columns represent attention heads (head zero to seven). From 1st row to 8th row represents Baseline, CrossViT19ViTfSCD30MedViT20FLATer16CST31AG-CNN18and GTCAD (ours). As we can see, the proposed model can accurately diagnose and visualize lesions regardless of their size.

Experimental sample multi-head attention maps (8 heads). Visualization of the lesion diagnosis results of the proposed method. The 1st column represents the input (original), and the 2nd column to the 8th column represents the generated attention head, respectively. As we can see, the proposed model can accurately localize and detect lesions on GT regardless of their size.
Learning curve analysis
To assess model convergence and generalization, we plotted training and validation curves for accuracy and loss across 100 epochs. The proposed GTCAD showed stable convergence with minimal overfitting, as indicated by the consistent gap between training and validation loss. The validation accuracy curve plateaued early, confirming adequate early stopping and generalization. These curves are shown in Fig. 5.
The results demonstrate the model’s performance across training and testing phases, as shown by the loss and accuracy trends. The training loss consistently outperforms the testing loss, with both decreasing over time, indicating effective model learning. However, the higher testing loss than the training loss suggests that the model faces challenges in generalizing to unseen data. Similarly, the accuracy metrics show a steady increase in both the training and testing phases, with the training accuracy consistently surpassing the testing accuracy. This discrepancy indicates potential overfitting, where the model fits the training data more closely than the test data. Nevertheless, overall loss reduction and accuracy improvement suggest positive model development.

Proposed method training performance on test sets. (a) Shows the accuracy of training and testing results along with the epoch. (b) Demonstrates loss history of training and testing with epoch.
Table 4; Fig. 6 show that the GTCAD demonstrated significant performance at the class-specific level. The model improves the accuracy, precision, recall, and F1 score for each class label. This indicates model learnability in a unified manner.

Proposed model lesion diagnosis and severity estimation performance over class labels. (a) Accuracy, (b) Precision, (c) Recall, and (d) F1 score.
Computational complexity and efficiency
DL has revolutionized disease diagnosis and severity estimation, offering better accuracy and the ability to handle complex, multimodal data. However, these benefits come with significant computational complexity and efficiency challenges. The number of implemented parameters mainly determines the computational efficiency of the DL models. The computational complexity and performance of the GTCAD compared with the baseline and existing related works are depicted in Fig. 7. The Baseline model serves as a reference point, featuring 34.6 million parameters and presenting a relatively light architecture compared to more advanced models. An attention-guided CNN model18 showed commendable performance despite having fewer parameters than the baseline. Moving to deeper architectures, GTCAD, ResNet50 backboned surpasses the baseline in a few parameters, contributing to a more complex model. The additional layers enhance its representative capacity, potentially capturing intricate patterns in the data.
CrossViT19 goes even more profound; the parameters to facilitate learning more intricate features and representation are particularly beneficial for more complex tasks. Further deeper parameters result in an even larger parameter count, which is suitable for highly complex tasks but poses a risk of overfitting on smaller datasets. The ViT-based ResNet50 combines aspects of both ViT and ResNet, striking a balance with a moderate parameter count. This suggests a fusion of ResNet’s depth and attention mechanisms. Generally, the number of parameters influences the trade-off between model complexity and the risk of overfitting. Deeper models like CST and MedViT, while having higher complexity, may face limitations and take long FLOPs. The proposed method, which demonstrated significant performance and lower parameters, emerges as a promising choice in this study.
Table 5 outlines the hyperparameter configurations across various models, highlighting key parameters such as batch size, learning rate, optimizer type, number of layers, embedding dimensions, and patch size. Commonly used optimizers include AdamW and Adam, with learning rates ranging from 1e-4 to 1e-3. The activation function is predominantly ReLU, though GeLU is used in some models. Batch sizes vary from 8 to 32, with 16 being the most frequent, and a dropout rate of 0.1 is consistently applied. Layer depths range from 12 to 24, and embedding dimensions span 192 to 768. 16 × 16 is the standard patch size, with CrossViT employing multi-scale patches. Attention heads range from 8 to 16, and training epochs vary from 50 to 300. These configurations optimize model performance, balancing efficiency and capacity across different tasks, including baseline models like ViT and CrossViT and the proposed GTCAD framework, which adapts well to various datasets.

Comparisons of computational complexity and efficiency.
Ablation studies
We conduct ablation studies to examine the effectiveness of the proposed method. We begin by comparing various fusion approaches and analyzing the influences of different parameters and floating-point operations (FLOPS) in architectural design. These parameters encompass patch sizes, channel width and depth, and attention heads. In the end, we confirm the capability of the proposed method to collaborate with other contemporary approaches, leading to improved accuracy.
Effects of the number of attention heads
To address the effects of attention heads, we further evaluate them with the GT dataset. In the given attention heads of 4, 8, and 16, the mean accuracies are 0.926 ± 0.061, 0.956 ± 0.041, and 0.948 ± 0.421, respectively. Thus, attention heads of 8 achieved optimal results. We compare the attention maps of the proposed method to the saliency map using ResNet-50. In the case of GTCAD, this occurs via the multi-head cross-attention activated by distinct queries. Each attention map emphasizes areas where there is a resemblance between the candidate class and the test image. The performance variation in the proposed model with varying heads of attention can be attributed to how attention mechanisms operate in transformer models. In the context of ViT, attention heads refer to other parts of the model, focusing on specific lesions of the input data. Each attention head captures different patterns or features in the data, and combining these heads contributes to the model’s overall performance.
The model performance results indicate that the proposed method achieved different accuracies when using other numbers of attention heads (4, 8, and 16). This implies the model’s effectiveness in grasping and utilizing information from various input sections changes with the number of attention heads. A higher number of attention heads improves the model’s capability to capture a long range of patterns and relationships within the data with additional computational cost. However, this also adds complexity to the model, and more attention heads may not always lead to better performance, as it might introduce noise or redundancy. Besides, the dataset used for training and evaluation plays a crucial role. Certain datasets may benefit from more attention heads, while others may not. Thus, the variation in accuracy with different attention heads may reflect the model’s adaptability to various aspects of the data and architectures, as shown in Fig. 8.
Model performance under single-task
Task-specific experiments were conducted to evaluate model performance. In this experiment, lesion classification and severity estimation tasks were conducted separately. In the first task, the lesion classification performed better with accuracy (0.979), precision (0.976), recall (0.994), and F1 score (0.985) than the severity estimation, as shown in Table 6. The model may classify lesions better but perform lower results in severity level estimation. Overall, these metrics suggest that the model performs exceptionally well in classifying lesions and providing accurate, reliable, and balanced predictions, which are critical in endoscopy imaging and diagnosis. To improve the performance of the severity estimation, in our proposed model, further classification weight is shared for lesion severity estimation.

Sample visualization of GT lesion attention heads (4 heads). The first column represents sample lesions and columns 2nd to 5th represent the results of attention heads (head zero to head three) of the proposed method.
Training model with and/without pre-trained weight
We also conducted an extensive ablation study on the effect of pre-trained weight on the proposed model. The intensive experiments achieved different results (i.e., with pre-trained weight = 96.5 and without pre-trained weight model = 93.97). Pretraining a model on a large dataset, potentially in a related domain, has significant advantages in the context of lesion classification and severity-level estimation. Pretrained weights provide a solid foundation for fine-tuning, allowing the model to converge faster and achieve better results. The use of the ViT-based model validates effectiveness in capturing complex hierarchical features in images, and the pre-trained weights likely encompass general image features that are beneficial for understanding various aspects of lesions. This enhances the model’s ability to differentiate between lesion classes and quantify severity levels.
The pre-trained model’s capacity to generalize across diverse images, including those relevant to lesion classification, is advantageous. This generalization capability improves accuracy on previously unseen data, which is particularly important when dealing with class-imbalanced complex endoscopy images. Training a DL model from scratch on a limited dataset may lead to overfitting or underfitting, where the model memorizes training data rather than learning valuable patterns. Pretraining addresses this issue by providing a broader understanding of visual features, reducing the risk of overfitting during fine-tuning. Additionally, pretraining enables the model to leverage knowledge from a larger dataset, enhancing data efficiency during the fine-tuning phase. This proves especially beneficial in the medical imaging domain, where datasets may be limited in size. In summary, pre-trained weights serve as valuable initialization for the GTCAD model, offering improved accuracy by leveraging knowledge from diverse data and facilitating faster convergence during task-specific fine-tuning.
Comparison of class-wise severity analysis
Severity analysis of the disease is vital for early treatment and management. In this work, we performed severity estimation for the selected sample class labels. Figure 9 demonstrates the proposed model performance results of each evaluation metric across severity labels. The model shows significant accuracy in classifying all severity levels. Recall and F1 score achieve relatively low esophagitis level estimation.

Comparison of proposed framework performance over class-wise severity.
Effects of EMA and CViT in maximizing model performance
The performance comparison of different model variants reveals the critical impact of each module on the overall predictive performance. As shown in Table 7, the Without EMA variant demonstrates solid results, achieving a high accuracy and F1 score, but the inclusion of EMA provides significant improvements in model regularization and generalization, particularly by reducing overfitting. Removing the CViT module results in a noticeable performance drop across all metrics, highlighting the importance of CViT in capturing complex spatial and contextual dependencies within the data, directly impacting the model’s classification capabilities. In contrast, the Full GTCAD model, which integrates both EMA and CViT, outperforms all other variants, achieving the highest accuracy, precision, recall, and F1 score. This indicates a synergistic effect between EMA’s regularization benefits and CViT’s advanced feature extraction capabilities, leading to an optimal balance between precision and recall. The results show that combining both modules maximize model performance for complex classification tasks.
As presented in Fig. 10, the ROC curve analysis reveals superior model performance in discriminating between positive and negative instances across multiple classifier variants. The classifiers for eso_severe, uc_severe, and uc_moderate demonstrate significant performance, achieving an AUC of 1.00, indicative of flawless predictive accuracy with no false positives or false negatives. These models exhibit an exceptional ability to identify the correct class across all instances. In contrast, the models for other sub-classes exhibit AUC values of 0.99 and 0.98, suggesting that while their performance is slightly low, they still maintain high sensitivity and specificity. Importantly, all models’ ROC curves are situated well above the diagonal, indicating that each model significantly outperforms random classification. Collectively, these results underscore the robustness and efficacy of the classifiers, with only marginal differences in performance, suggesting that the models exhibit highly reliable classification capabilities.

ROC curves for classifiers across various sub-categories demonstrates GTCAD performance. AUC values are provided to highlight the effectiveness of each classifier in distinguishing between classes.
Furthermore, qualitative results were validated using different visualization techniques, including t-distributed stochastic neighbor embedding (tSNE), as shown in Fig. 11. The proposed model demonstrated the successful identification of each severity label significantly. Due to the relatedness of the lesions, the proposed model was challenged to identify a few severity levels.

A tSNE visualization of GT lesions diagnosis. (a) shows baseline performance results, and (b) shows the performance results of the GTCAD on the test dataset.
Failure case analysis
In the traditional approach, lesions are detected hard-to-reach in a complex setting. In this work, some cases failed during training and testing. The cases might be because flattened lesions and subtle images make the model difficult to learn features, lesions in varied GT disorders, and lesions in challenging locations. This probability of case failures is checked with radiologists. Besides, the similarity of lesions presence also hinders the model performance. The limitations and failure cases of the GTCAD approach in lesion classification and severity-level estimation in GT images might include the following factors. Firstly, the CViT architecture developed for classification tasks may struggle with the spatial complexity of GT endoscopy images, which often exhibit subtle features that are not effectively captured by ViT’s attention mechanisms focused on global features. Secondly, GT images require an understanding of sequential dependencies and contextual information. Finally, the pre-trained weights were trained on natural and other objects that might affect transfer learning.
In contrast, ViT models process images independently, potentially hindering their ability to learn temporal relationships or contextual information within sequences. Thirdly, ViT models, pre-trained on large-scale image datasets, may not generalize well to the specific diversity and complexity of GT images, especially if fine-tuning lacks sufficient annotated datasets. Finally, the proposed GTCAD model, though a deep neural network, may lack interpretability in clinical settings, impacting its adoption for medical applications. Addressing these challenges may require the development of domain-specific model architectures, meticulous dataset curation, and a heightened focus on interpretability in clinical contexts.
Discussion
In this study, we proposed a deep MTL framework to enhance the accuracy of GT lesion diagnosis and severity estimation simultaneously in complex multimodal datasets. GTCAD employed the CViT with EMA in a unified manner to improve the model performance. Employing multiple stages for MTL led to the design of the preprocessed dataset’s distribution to align with the stage-wise approach. CNNs-based and transformer-based models require substantial amounts of data, and their predictive performance is closely linked to the scale and quality of labeled data. Obtaining large-scale, quality-labeled medical images becomes challenging33 due to image annotation’s time-consuming and knowledge-intensive nature, especially in an emerging medical imaging technique unfamiliar to most medical experts. The scarcity of labeled images inevitably affects the training and validation of DL-based CAD models34 for lesion diagnosis. However, after distribution, imbalances in the number of training samples across some classes became evident in the dataset. To avoid class imbalance, we generated additional frames from labeled videos and applied data augmentation for those without labeled videos before the datasets split. Overfitting and underfitting issues were addressed to improve the performance of the model during training and validation. Based on the learning curves, the proposed model monitored the changes in training and testing accuracy and losses over time. All models, including GTCAD, were trained and validated using their respective datasets. Besides, the selected parameters performed well with the proposed method, even without an optimal hyperparameter tuning approach. However, not all achieved full convergence, and the results showed that all models had learned progressively and in a stable manner.
Previously, there has been a significant increase in the size and complexity of models, leading to heightened research efforts focused on improving model interpretability35. Lesion interpretability is crucial for establishing trust in a model’s predictions, understanding its rationale, gaining insights into its internal mechanisms, and identifying the specific input features for accurate predictions36. This study explores interpretation by extracting and visualizing the key regions of interest in input images that contribute to a model’s predictions. The method is designed for end-to-end training using the popular CNNs and ViT-based architecture. Specifically, the study applies the ViT-based model as a baseline for lesion classification in the context of clinical interpretability. Visualizing learned features and attention scores in the proposed model enhances accuracy and contributes valuable insights to disease diagnosis, significantly improving patient care and treatment decisions.
The key challenges of lesion diagnosis and severity-level estimations mainly depend on qualitative analysis, which lacks treatment effectiveness and results in low recovery rate and accuracy10. Conventional lesion grading methods use endoscopic evaluation indexes12,14. Similarly, in37 study, automatic diagnosis systems was proposed for non-invasive diagnosis based on extreme learning machines that primarily focus on a single task. Moreover, we employed a threshold to estimate the severity level of the lesion, which scores into mild, moderate, and severe. This enhanced the interpretability of the diagnosis because most experienced medical experts labeled and graded lesions based on disease appearance and distribution on the images, agreeing with inter-variability. Visually grading lesions based on appearance is insufficient to classify them into mild, moderate, or severe12. In this work, we experimented with severity level estimation threshold by computing the severity of the lesion on images. GT lesions are classified into normal and abnormal (lesions). Then, those lesions with some severity stages were classified into severity levels. One of the key approaches in GTCAD is to enhance interpretability among the features of severity levels. The model feedforward to classify each subclass specifically. The lesion is the distribution of disease or lesion on the specific image in each class. Further, the computed scores ranged from zero to one, representing mild, moderate, and severe levels by defining level zero (score 0) as health or no lesion but suspected. Severity level 1 categorized the score fall between less than 10% as intermittent or occasional symptoms with slight changes (labeled as mild), and 10 − 50% were labeled as more persistent symptoms with moderate pain or discomfort (labeled as moderate). Finally, a score higher than 50% is defined as severe and persistent symptoms, substantial weight loss, and malnutrition, which may need surgical intervention (labeled as severe).
In our evaluation, we examine the model’s identification of salient features, those regions crucial for subsequent processing in later model blocks by presenting EMA mechanism. In contrast, what’s commonly referred to as an attention map in prior work27 is computed for a token, typically the output token in ViT38by recursively tracing the token’s compatibility with other tokens back to the input layer. This results in different maps for various class tokens39each conditioned on a specific token. These maps can be interpreted as highlighting input regions most relevant to producing the given class token. In this work, we note that the compatibility used for this visualization is a component of the overall attention score. Attention maps generated through this method don’t align with our objective, which is to pinpoint the salient input regions and the focus of attention during the bottom-up signal flow in inference mode. These high attention score regions influence the visual signal through the residual connection, prompting us to assess the performance of the attention module in experiments. Furthermore, incorporating later temporal attention, as proposed by40could enhance our framework by learning sequential lesion progression, especially in video endoscopy. Future work will explore integrating temporal context modeling for improved severity trend prediction and dynamic lesion tracking across frames.
Additionally, using non-overlapping images in this study poses challenges for modeling feature interactions, addressed by global self-attention and a subsequent cross-attention module to fuse multi-scale features. The model’s training process involves three stages: pre-training with endoscopy images, fine-tuning the pre-trained ViT-based model through optimization, and utilizing the trained model weights for the final stage. One of the unique parts of the GTCAD is demonstrating the optimization of transformer model performance through leveraging a low-level dataset derived from a robust backbone network trained on a vast, well-vetted dataset in a unified way. Utilizing this backbone network, trained on extensive data, helps subsequent models employed for classification and severity-level estimation tasks mitigate the risk of overfitting, even when dealing with a smaller set of labeled cases. This strategy notably enhances the network’s ability to generalize findings. The innovative utilization of class-specific information from image and video datasets allows for clinical interpretation and severity analysis. Comparing these metrics with the SOTA models in the area, the GTCAD performance appears to be competitive. The high precision suggests a low rate of false positives, demonstrating the model’s ability to identify positive instances correctly. The recall, capturing a significant proportion of true positives, further emphasizes the model’s effectiveness in recognizing relevant patterns. When assessing the GTCAD against the existing related works, it crucially considers the task’s specific context and requirements. Additionally, computational efficiency, interpretability, and generalizability should be regarded as an overall assessment of the model’s overall capabilities compared to existing SOTA approaches.
The GTCAD demonstrates a significant performance in addressing challenges associated with diagnosing and assessing disease severity. Designed explicitly for diagnosing lesions, the model utilizes a multi-class, multimodal dataset for training and testing. Experimental results demonstrate successful evaluations across diverse types and stages of lesions demonstrate its adaptability, which is assessed through comparisons within the specific dataset, multimodal datasets, and a diverse array of SOTA methods. Moreover, fine-tuning on a multimodal dataset reflects thoughtful efforts to enhance performance under varied conditions, emphasizing the model’s adaptability. Quantitative and qualitative performance metrics offer insights into the model’s robustness. Also, senior physicians participated to verify the clinical significance of the model’s lesion diagnosis and the severity levels it determined. This collaboration aimed to validate the accuracy and relevance of the healthcare-related information provided by the model in assessing lesions. Successful integration into clinical workflows and increased confidence among healthcare professionals accentuate the practical application of the model in practical scenarios. Typically, this makes the proposed method interpretable and adaptable. Thus, the GTCAD method exhibits significance across multimodal datasets and the transferability of architecture, interpretability, collaboration with medical professionals, and various scenarios.
Conclusion
In this work, we proposed a deep MTL framework for the diagnosis and severity estimation of lesions in endoscopy images. Specifically, we integrate lesion classification and severity estimation within a unified CViT architecture, addressing the complexity and variability in lesion diagnosis by enhancing the interpretability and visualization performance of the MTL model leveraging EMA. The intensive experimental results exhibit that the multi-task model outperforms single-task models, achieving higher accuracy and robustness across diverse lesion types and severities on unseen test sets. This multi-tasking capability not only enhances diagnostic precision but also provides valuable insights, which is crucial for determining appropriate treatment strategies. The implementation of such advanced CAD methods in clinical settings could significantly improve diagnostic workflows, reduce the burden, and lead to better patient outcomes. Future work could be integrating more efficient multi-scale models for complex multimodal tasks, including 2D and 3D medical image segmentation, self-supervised learning, and video detection.
Data availability
The datasets analyzed in this study can be publicly accessible at the following links 1. hyper-kvasir data is available at https://datasets.simula.no/hyper-kvasir, 2. Gastrovision data is available at https://osf.io/gvx3q, 3. Labeled Images for Ulcerative Colitis data are available at https://zenodo.org/records/5827695#.ZF-92OzMJqs, and 4. The lab (hospital) dataset is available upon request of the corresponding author.
References
Guo, H., Somayajula, S. A., Hosseini, R. & Xie, P. Improving image classification of Gastrointestinal endoscopy using curriculum self-supervised learning. Sci Rep 14, (2024).
Arnold, M. et al. Global burden of 5 major types of Gastrointestinal Cancer. Gastroenterology 159, 335–349e15 (2020).
Borgli, H. et al. HyperKvasir, a comprehensive multi-class image and video dataset for Gastrointestinal endoscopy. Sci Data 7, (2020).
Chen, Y., Chen, T. & Fang, J. Y. Burden of Gastrointestinal cancers in China from 1990 to 2019 and projection through 2029. Cancer Lett 560, (2023).
Jha, D. et al. GastroVision: A Multi-class Endoscopy Image Dataset for Computer Aided Gastrointestinal Disease Detection. (2023).
Namikawa, K. et al. Utilizing artificial intelligence in endoscopy: a clinician’s guide. Expert Review of Gastroenterology and Hepatology 689–706 Preprint at (2020). https://doi.org/10.1080/17474124.2020.1779058
Kim, J., Faruque, A., Kim, H., Kim, S., Hwang, J. Y. & E. & Multimodal endoscopic system based on multispectral and photometric stereo imaging and analysis. Biomed. Opt. Express. 10, 2289 (2019).
Zhang, K. et al. BFE-Net: bilateral fusion enhanced network for Gastrointestinal polyp segmentation. Biomed. Opt. Express. 15, 2977 (2024).
Nastase, I. N. A., Moldovanu, S., Biswas, K. C. & Moraru, L. Role of inter- and extra-lesion tissue, transfer learning, and fine-tuning in the robust classification of breast lesions. Sci. Rep. 14, 22754 (2024).
Yang, P., Chen, W. & Qiu, H. M. M. G. C. N. Multi-modal multi-view graph convolutional networks for cancer prognosis prediction. Comput Methods Programs Biomed 257, (2024).
Jha, D. et al. A comprehensive analysis of classification methods in Gastrointestinal endoscopy imaging. Med Image Anal 70, (2021).
Polat, G. et al. Improving the Computer-Aided Estimation of ulcerative colitis severity according to Mayo endoscopic score by using Regression-Based deep learning. Inflamm. Bowel Dis. 29, 1431–1439 (2023).
Klang, E., Sourosh, A., Nadkarni, G. N., Sharif, K. & Lahat, A. Deep learning and gastric cancer: systematic review of AI-Assisted endoscopy. Diagnostics 13, 1–22 (2023).
Pagnini, C. et al. Mayo endoscopic score and ulcerative colitis endoscopic index are equally effective for endoscopic activity evaluation in ulcerative colitis patients in a real life setting. Gastroenterol. Insights. 12, 217–224 (2021).
Pabla, B. S. & Schwartz, D. A. Assessing Severity of Disease in Patients with Ulcerative Colitis. Gastroenterology Clinics of North America vol. 49 671–688 Preprint at (2020). https://doi.org/10.1016/j.gtc.2020.08.003
Wu, S. et al. High-Speed and Accurate Diagnosis of Gastrointestinal Disease: Learning on Endoscopy Images Using Lightweight Transformer with Local Feature Attention. Bioengineering 10, (2023).
Huang, S. C. et al. Self-supervised learning for medical image classification: a systematic review and implementation guidelines. npj Digital Medicine vol. 6 Preprint at (2023). https://doi.org/10.1038/s41746-023-00811-0
Lonseko, Z. M. et al. Gastrointestinal disease classification in endoscopic images using Attention-Guided convolutional neural networks. Appl. Sci. 11, 11136 (2021).
Chen, C. F., Fan, Q., Panda, R. & CrossViT Cross-Attention Multi-Scale Vision Transformer for Image Classification. (2021).
Manzari, O. N. et al. A robust vision transformer for generalized medical image classification. Comput. Biol. Med. 157, 106791 (2023).
Carion, N. et al. Springer,. End-to-end object detection with transformers. in European conference on computer vision 213–229 (2020).
Paul, D. et al. A Simple Interpretable Transformer for Fine-Grained Image Classification and Analysis. (2023).
Wu, H. et al. CvT: Introducing Convolutions to Vision Transformers. in Proceedings of the IEEE International Conference on Computer Vision 22–31 (2021). https://doi.org/10.1109/ICCV48922.2021.00009
He, K., Zhang, X., Ren, S. & Sun J. Deep Residual Learning for Image Recognition. (2015).
Vaswani, A. et al. Attention Is All You Need. (2017).
Carion, N. et al. End-to-End Object Detection with Transformers. https://github.com/facebookresearch/detr
Dosovitskiy, A. et al. An Image Is Worth 16x16 Words (Transformers for Image Recognition at Scale, 2020).
Keceli, A. S., Kaya, A., Catal, C. & Tekinerdogan, B. Deep learning-based multi-task prediction system for plant disease and species detection. Ecol. Inf. 69, 101679 (2022).
Lonseko, Z. M. et al. Early esophagus cancer segmentation from Gastrointestinal endoscopic images based on U-Net + + model. Journal Electron. Sci. Technology 21, (2023).
Yang, G., Luo, S. & Greer, P. A. Novel vision transformer model for skin Cancer classification. Neural Process. Lett. 55, 9335–9351 (2023).
Sui, D. et al. CST: A Multitask Learning Framework for Colorectal Cancer Region Mining Based on Transformer. Biomed Res Int (2021). (2021).
Zhou, B., Khosla, A., Lapedriza, A., Oliva, A. & Torralba, A. Learning Deep Features for Discriminative Localization. (2015).
Zhu, Z., Liu, Y., Yuan, C. A., Qin, X. & Yang, F. A diffusion model multi-scale feature fusion network for imbalanced medical image classification research. Comput Methods Programs Biomed 256, (2024).
Wang, Q., Chen, K., Dou, W. & Ma, Y. Cross-Attention based Multi-Resolution feature fusion model for Self-Supervised cervical OCT image classification. IEEE/ACM Trans. Comput. Biol. Bioinform. 20, 2541–2554 (2023).
Panayides, A. S. et al. AI in medical imaging informatics: current challenges and future directions. IEEE J. Biomed. Health Inf. 24, 1837–1857 (2020).
Zhao, S. et al. An interpretable model based on graph learning for diagnosis of Parkinson’s disease with voice-related EEG. NPJ Digit. Med 7, (2024).
Cai, J., Chen, T., Qi, Y., Liu, S. & Chen, R. Fibrosis and inflammatory activity diagnosis of chronic hepatitis C based on extreme learning machine. Sci. Rep. 15, 11 (2025).
Umamaheswari, T. & Babu, Y. M. M. ViT-MAENB7: an innovative breast cancer diagnosis model from 3D mammograms using advanced segmentation and classification process. Comput Methods Programs Biomed 257, (2024).
Mehrani, P. & Tsotsos, J. K. Self-attention in vision Transformers performs perceptual grouping, not attention. Front Comput. Sci 5, (2023).
Cai, J. et al. Developing deep LSTMs with later Temporal attention for predicting COVID-19 severity, clinical outcome, and antibody level by screening serological indicators over time. IEEE J. Biomed. Health Inf. 28, 4204–4215 (2024).
Acknowledgements
This study is supported by the National Natural Science Foundation, No. 62271127 and 61872405, the Medico-Engineering Cooperation Funds from the University of Electronic Science and Technology of China and West China Hospital of Sichuan University, No. ZYGX2022YGRH011 and HXDZ22005, Sichuan Natural Science Foundation, No. 23NSFSC0627.
Author information
Authors and Affiliations
Contributions
Conceptualization: Z.M.L., and N.R.; methodology: Z.M.L, and N.R.; Software: Z.M.L., D.H., and K.Z.; Validation: Z.M.L., and T.G.; Formal analysis: Z.M.L., and K.Z.; Investigation: Visualization: Z.M.L., D.H., and K.Z.; Writing- Original draft preparation: Z.M.L., and H.H.H.; Review & Editing: Z.M.L, D.H., H.H.H, and N.R.; Data curation: D.H., H.H.H., and T.G.; Resources: T.G., and J.Y.; Investigation: Z.M.L., and J.Y.; Supervision: N.R.; Project administration: N.R. All the authors reviewed the manuscript and agreed to be published.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Lonseko, Z.M., Hu, D., Zhang, K. et al. Deep multi-task learning framework for gastrointestinal lesion-aided diagnosis and severity estimation. Sci Rep 15, 25827 (2025). https://doi.org/10.1038/s41598-025-09587-7
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-025-09587-7
