
Abstract
Sentiment analysis has emerged as a vital tool for gauging public opinion in today’s fast-paced digital environment. This study examines the use of advanced artificial intelligence techniques to analyze sentiments derived from Twitter, a leading platform for real-time social media engagement. By utilizing Twitter’s vast dataset, the research implements a comprehensive pre-processing pipeline that incorporates natural language processing (NLP) techniques such as tokenization, stop-word removal, and stemming to prepare the textual data for analysis. For feature representation, the study employs Bi-Directional Long Short-Term Memory (Bi-LSTM) networks, which are highly effective in identifying sequential patterns within text data. The extracted features are then input into a Logistic Regression model with optimized hyperparameters to classify sentiments as positive or negative. Experimental results highlight the efficacy of this integrated approach, achieving an impressive 81.8% precision, 83.4% recall, 82.5% F1-score, and 82.32% accuracy. These outcomes underscore the strength of combining Bi-LSTM and Logistic Regression for sentiment analysis, offering a robust framework for analyzing unstructured textual data in social media contexts. This approach demonstrates significant potential for enhancing sentiment classification tasks in the ever-evolving digital landscape.
Similar content being viewed by others
Introduction
Twitter data analysis has become a cornerstone for analyzing public feelings, trends, and opinions, because of the platform’s large user base and capacity to deliver real-time updates. With millions of tweets created every day, Twitter is a powerful resource for insights across numerous fields such as politics, marketing, and societal issues1. Sarcasm identification, on the other hand, presents a significant problem in sentiment prediction since sardonic statements frequently communicate meanings that differ from their literal interpretation. Misinterpreting sarcasm can influence sentiment analysis results, leading to incorrect conclusions2. Addressing sarcasm detection is crucial for accurate sentiment forecasts and deeper insights into user behavior on the platform3.
To address the complexity of sarcasm detection, researchers have increasingly used advanced artificial intelligence (AI) approaches such as machine learning (ML) and deep learning (DL)4,5. Traditionally, sarcasm detection depended mainly on manually created features that included sentiment-related information. While these strategies were somewhat effective, they necessitated a significant amount of manual effort. Deep learning techniques have transformed this discipline in recent years, reducing the need for human feature extraction and allowing models to discover detailed patterns within textual data automatically6.
Deep learning, which leverages artificial neural networks, offers an advanced approach to understanding text beyond its surface-level meaning. These models excel at identifying contextual nuances, including irony and sarcasm, enabling a deeper comprehension of a writer’s true intentions and emotions. The combination of text mining and deep learning techniques ensures that sentiment analysis systems can process information more effectively, capturing subtle cues and enhancing prediction accuracy7. Therefore, by incorporating DL, ML, and text mining techniques into sentiment prediction models, analysts can address the challenges posed by sarcasm and other complex linguistic elements. This integration ultimately improves the reliability of sentiment analysis, empowering businesses and researchers to derive actionable insights from social media data.
Building on the ideas discussed above, we suggested a hybrid framework for sentiment analysis leveraging Twitter data based on the Bi-directional Long Short-Term Memory (Bi-LSTM) network, Logistic Regression (LR), and GridSearchCV. To clarify the objectives of this study, the following research questions are formulated:
-
1.
How effectively can a hybrid model combining Bi-LSTM and Logistic Regression improve the accuracy of sentiment analysis on Twitter data?
-
2.
What are the key challenges in detecting sarcasm and sentiment polarity using deep learning techniques?
-
3.
How does the proposed approach compare with traditional machine learning methods in terms of precision, recall, and overall accuracy?
-
4.
Can the model generalize well across various topics and domains in real-time social media data?
Highlights of the study
The main contributions of the proposed approach are as follows:
-
1.
Improved Generalizability: Unlike methods that rely solely on deep learning, our hybrid approach ensures adaptability across varied Twitter datasets by leveraging Bi-LSTM’s ability to capture sequential dependencies and LR’s robustness in classification tasks.
-
2.
Enhanced Feature Integration: The architecture ensures effective utilization of text features extracted by Bi-LSTM, thereby reducing inefficiencies commonly observed in standalone models.
-
3.
Computational Efficiency and Interpretability: While deep learning models such as Bi-LSTM enhance performance, their black-box nature makes interpretation challenging. The inclusion of LR improves interpretability while maintaining computational efficiency, ensuring a balance between accuracy and resource consumption.
While previous studies have explored hybrid approaches combining deep learning and traditional machine learning models, our work introduces a novel combination of Bi-LSTM and LR with GridSearchCV for hyperparameter tuning. This unique integration optimizes both predictive accuracy and model interpretability. Furthermore, we provide an in-depth comparison with existing approaches, demonstrating the advantages of our method in terms of generalizability and computational efficiency across diverse Twitter datasets.
In the following sections, we review several notable works that focus on analyzing sentiment in Twitter data, highlighting their methodologies and contributions to the field.
Related works
Sentiment analysis on Twitter data has gained significant attention as it offers valuable insights into public opinions expressed on this dynamic and real-time platform. Researchers have explored various approaches to enhance the accuracy and efficiency of sentiment analysis. Below is an overview of some key works in this field:
Zhuojun Lyu8 introduced a Bi-directional Long Short-Term Memory (Bi-LSTM) model combined with an attention mechanism to enhance the accuracy of emotion detection in textual data, achieving a notable accuracy of 78.12%. Jiayi Tang9 presented a transformer-based model specifically designed to improve sentiment analysis on Twitter data, attaining an accuracy of 82.1%. Ang Jia Pheng et al.10 developed a Bi-LSTM-based network for sentiment analysis, achieving a precision rate of 81.79%. Ankit and Nabizath Saleena11 implemented an ensemble learning approach for sentiment analysis on Twitter data, reporting an accuracy of 74.67%.
Rhea Bharal and Vamsi Krishna12 proposed a hybrid model combining Convolutional Neural Networks (CNN) with Bi-LSTM, achieving a detection rate of 78.84%. Dhyan and Thakur13 introduced a MapReduce framework for sentiment analysis using a Twitter dataset, which delivered a classification accuracy of 75.5%. Meanwhile, Upadhyay et al.14 employed a machine learning approach using a Linear Support Vector Machine (Linear SVM) for sentiment analysis on social media platforms, achieving an accuracy of 81%. Ganesh Kumar et al.15 proposed a context-sensitive three-tier DL framework using a bi-directional gated recurrent unit (BiGRU) for multimodal sentiment analysis. Prakash and Vijay16 introduced a multi-aspect framework for sentiment analysis by leveraging latent Dirichlet al.location (LDA) and neural networks. All these methods are summarized in Table 1 with methodology and cons.
Research gaps
Despite the advancements in sentiment analysis, existing approaches still face several limitations. Many deep learning models, including Bi-LSTM, CNN, and transformer-based architectures, have achieved notable success in sentiment classification. However, they often lack generalizability across diverse Twitter datasets, as model performance is highly dependent on domain-specific data distributions8. Furthermore, some models struggle with feature integration, where extracted text representations may not be efficiently leveraged for classification tasks. Additionally, high computational costs associated with complex deep learning architectures hinder their widespread adoption for large-scale Twitter sentiment analysis9.
Several studies have attempted to mitigate these issues using hybrid models, but they often suffer from compatibility challenges, where different techniques fail to work cohesively, resulting in suboptimal performance. There remains a need for a hybrid framework that effectively balances model interpretability, computational efficiency, and classification performance, particularly in sarcasm detection. Therefore, this work presents a framework hybrid methodology to address existing challenges in sarcasm detection within Twitter sentiment analysis.
The following sections will discuss the methodologies employed, present the results of our experimental evaluation, and provide a detailed discussion of how our model outperforms existing techniques in terms of accuracy, efficiency, and generalization.
Materials and methods
Figure 1 illustrates the framework of the developed model, which consists of several key stages: the collection and pre-processing of data, followed by feature extraction, and ultimately classification through a hybrid mechanism. This framework outlines the sequential steps that are essential for processing and analyzing Twitter data. Initially, relevant materials are gathered and preprocessed to ensure the data is in an appropriate format for further analysis. Feature extraction then takes place, where key characteristics of the text are identified and processed. Finally, the hybrid mechanism, combining advanced methods such as LSTM and Logistic Regression optimized through GridSearchCV, is employed for effective sentiment classification.

Work-flow of the suggested approach.
Materials
The Sentiment14017 dataset is a widely recognized resource for sentiment analysis, developed by Stanford researchers in 2009. It contains 1.6 million tweets, each labeled to represent sentiment categories: positive (800,000 tweets), negative (800,000 tweets), and neutral (11,000 tweets). These tweets were collected using the Twitter API and annotated based on the presence of specific emoticons, serving as proxies for sentiment polarity. This work mainly focuses on the enhancement of sarcasm detection in sentiment analysis, which is primarily relevant to distinguishing between positive and negative sentiments rather than neutral statements. However, neutral tweets often contain vague or mixed sentiments, making them difficult to classify consistently. Many neutral tweets may have implicit sentiments that are not captured by emoticon-based labeling.
Data pre-processing
Data pre-processing is a vital step in Twitter-based sentiment analysis as it transforms raw, unstructured tweets into a clean and analyzable format. Tweets often contain noise such as URLs, mentions, hashtags, emojis, and slang, which can hinder the accuracy of sentiment classification if left unprocessed. Key pre-processing steps include removing irrelevant elements, standardizing text by converting it to lowercase and correcting misspellings, and handling special features like hashtags and emojis to extract meaningful information. Additionally, tokenization and stop-word removal streamline the data, reducing complexity and improving model performance. Here, initially, we are performing text normalization as follows:
-
Punctuation Removal: Eliminates unnecessary symbols like commas and periods that don’t affect sentiment.
-
Lowercasing: Converts all text to lowercase to treat words consistently regardless of case.
-
URL removal: Removes web addresses that don’t contribute to sentiment.
-
Numeric Numbers Removal: Eliminates numbers unless contextually important for sentiment.
-
Repeated Characters Removal: Normalizes exaggerated characters (e.g., “sooo” to “so”) to prevent overemphasis.
-
1.
Word Tokenization: Word tokenization is an essential step in sentiment analysis, as it breaks down text into individual words or tokens, which can then be analyzed for sentiment. The “word_tokenize” function from the NLTK (Natural Language Toolkit) library is widely used for tokenizing text in natural language processing tasks18, including sentiment analysis on Twitter data. This function splits the input text into words, punctuation, and special characters, making it easier to process and analyze the meaning behind the words.
In the context of Twitter data, where informal language, emojis, and hashtags are prevalent, tokenization helps separate these elements, allowing sentiment analysis models to focus on the words that convey sentiment. For example, the tweet “I love coding in Python! #Python #Coding” would be tokenized into individual words and symbols, preserving the structure and meaning of the text. By using this process, sentiment prediction models can more accurately determine sentiment from tweets, as tokenization ensures that the data is in a format suitable for further analysis.
-
2.
Stop Words Removal: Stop words, such as “is,” “the,” and “and,” are common words that typically do not carry significant meaning in sentiment analysis. Removing these words from Twitter data helps focus on more meaningful terms that influence sentiment, such as adjectives and verbs. This step reduces data noise, decreases computational complexity, and enhances the accuracy of prediction models by eliminating irrelevant information. Stop word removal ensures that the analysis concentrates on words that contribute directly to the sentiment expressed in the tweet19. This technique is essential in improving the effectiveness of sentiment analysis on noisy and unstructured Twitter data.
-
3.
Stemming and Lemmatization: Stemming and lemmatization are text normalization techniques that reduce words to their base or root forms, enhancing sentiment prediction accuracy. Stemming involves cutting off prefixes or suffixes to get the root form of a word, often resulting in incomplete or non-dictionary words (e.g., “running” becomes “run”). On the other hand, Lemmatization considers the word’s meaning and returns the base or dictionary form (e.g., “better” becomes “good”). In sentiment analysis, these techniques help group similar words, ensuring that variations of a word (e.g., “runs,” “running”) are treated as the same, improving model efficiency and consistency20.
Feature extraction
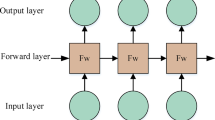
Feature extraction is a crucial step in sentiment analysis, involving the identification of essential elements within Twitter data (tweets) that contribute to accurate sentiment prediction. Key features include word frequencies, sentiment-laden words, and specific patterns such as hashtags and emoticons. For this study, we leveraged Bi-Directional Long Short-Term Memory (Bi-LSTM) to extract meaningful features. LSTMs are particularly effective in capturing long-term dependencies and contextual nuances within textual data. By extending this to a bidirectional framework, the model processes text both forward and backward, ensuring a holistic understanding of sentiment. This makes Bi-LSTM especially suitable for analyzing short, context-rich texts like tweets, where every word contributes to the sentiment conveyed. To achieve high accuracy in sentiment analysis tasks, the proposed architecture integrates tokenization, semantic embedding, sequential feature extraction, and overfitting prevention. The sequential steps involved in the network are as follows:
-
1.
Tokenizer and Sequences Preparation: The text data was first processed using a Tokenizer, which converts words into sequences of integers based on their frequency in the dataset. Each word is assigned a unique token, ensuring consistent representation. For this study, a vocabulary size of 10,000 was selected, considering word frequency as the criterion. Further, to enhance computational efficiency during both training and inference, tokenized sequences were padded to a uniform length. This ensures all input sequences are of equal length, making them suitable for batch processing. The maximum padding length was set to 100, as recommended in recent research.
-
2.
Embedding Layer: Here, an embedding layer was incorporated to map each token into a dense vector representation of fixed dimensions. This embedding captures the semantic relationships between words, enabling the model to understand the contextual meaning. The dimensionality of the embedding vectors was set to 128, providing a compact yet informative representation of the text.
-
3.
Bi-Directional LSTM Layer: To effectively capture contextual information, a Bi-Directional Long Short-Term Memory (Bi-LSTM) layer was used. This layer processes the input sequences in both forward and backward directions, allowing the model to learn dependencies from both preceding and succeeding words. Here, the Bi-LSTM layer was configured with 64 units, enabling it to extract temporal features and remember long-term dependencies. This design also helps address challenges like vanishing gradients, ensuring robust feature extraction.
-
4.
Dropout Layer: To prevent overfitting and improve the generalizability of the model, a dropout layer was employed. This layer randomly deactivates a fraction of neurons during training, thereby reducing reliance on specific neurons. A dropout rate of 25% was applied to the output of the Bi-LSTM layer, effectively mitigating overfitting while maintaining model performance.
-
5.
Dense Layer: Finally, a fully connected dense layer with a sigmoid activation function was added for sentiment classification. This layer predicts the sentiment of the input text as either positive or negative, based on the features extracted by the preceding layers.
Classification
In sentiment analysis, combining Bi-LSTM with Logistic Regression provides an effective approach for robust predictions. After using Bi-LSTM to extract features from Twitter data, these features are fed into a Logistic Regression (LR)21 model to classify sentiment (positive or negative). The extracted features capture the contextual and sequential dependencies in the text, while LR serves as a lightweight and interpretable classifier.
GridSearchCV22 is employed to optimize the hyperparameters of LR. It systematically tests various parameter combinations (e.g., regularization strength, solver types) to find the optimal settings that maximize classification accuracy. By leveraging GridSearchCV, the model ensures that Logistic Regression is fine-tuned for the features extracted by Bi-LSTM, improving performance and generalization on unseen data. In this work, we introduced 5-fold cross-validation to find the optimized parameters and they are represented in Table 2. This hybrid approach balances the deep learning capabilities of Bi-LSTM for feature extraction with the simplicity and speed of LR for classification, achieving efficient and accurate sentiment prediction on Twitter data.
Results and discussions
This section presents the experimental results of the proposed model, highlighting its performance compared to state-of-the-art methods. We comprehensively analyze the outcomes and demonstrate why our approach outperforms existing methodologies.
For sentiment analysis on Twitter data, we initially utilized a Bi-LSTM-based model applied to preprocessed tweets. The network automatically extracted meaningful features through multiple hidden layers and was trained using the backpropagation algorithm. The training process employed the binary cross-entropy loss function, with key parameters including a batch size of 256, 15 epochs, and the Adam optimizer. To mitigate potential overfitting, we introduced a learning rate scheduler, starting with an initial learning rate of 0.01. Subsequently, the extracted features were passed to a Logistic Regression (LR) classifier, which performed effective classification using hyperparameters specified in Table 1. All experiments were conducted by dividing the dataset into 80% for training and 20% for testing. To ensure a thorough evaluation of the model’s performance and reliability, we assessed it using various metrics, including precision, recall, F1-score, and accuracy, providing a comprehensive analysis.
Figure 2 illustrates the accuracy and loss curves of the proposed Bi-LSTM model. From these curves, it is evident that as the number of epochs increases, the loss decreases while accuracy improves. However, after approximately 5 epochs, both loss and accuracy stabilize, indicating that the network effectively extracts relevant features while minimizing overfitting. This behavior demonstrates that the proposed model predicts sentiments with reasonable accuracy, achieving an overall accuracy of 79%. To further validate this observation, the confusion matrix of the implemented architecture is presented in Fig. 3, providing additional support for the model’s performance.
While the implemented Bi-LSTM model delivers reasonably good performance, its effectiveness is slightly lower compared to existing models. To address this, we further processed the Bi-LSTM features by passing them through a dense layer and subsequently applying LR with the parameters specified in Table 1. Using this enhanced approach, we achieved performance metrics of 81.84% precision, 83.4% recall, 82.60% F1-score, and an accuracy of 82.42%. To substantiate these results, we provide the confusion matrix of the combined Bi-LSTM and LR model in Fig. 4, demonstrating its improved effectiveness. For a better understanding, both method’s results are accumulated in the Table 3.

Accuracy and loss curves of the proposed Bi-LSTM.
Table 3 compares the performance of two machine learning models on a classification task: the Bi-LSTM model and the Bi-LSTM model enhanced with GridSearchCV-based LR. All metrics—Recall, Precision, F1-Score, and Accuracy—show an improvement with the GridSearchCV-based LR approach. Specifically, the Bi-LSTM model achieves a recall of 79.70%, while the enhanced version improves this to 83.38%, indicating better detection of positive instances. Similarly, precision rises from 78.70% for the Bi-LSTM model to 81.84% for the Bi-LSTM with GridSearchCV-based LR, demonstrating better prediction accuracy for positive instances. The F1-Score, which balances precision and recall, also increases from 79.20 to 82.60%, reflecting a more balanced performance in classifying both positive and negative instances. Accuracy improves from 78.99% with the Bi-LSTM to 82.42% with the enhanced model, marking an overall improvement in correct classifications. These improvements across all metrics suggest that the integration of GridSearchCV-based LR with Bi-LSTM enhances the model’s ability to classify data accurately and efficiently, particularly in terms of handling both false positives and false negatives.

Confusion matrix of the Bi-LSTM model.

Confusion matrix of the Bi-LSTM- LR model.
Table 4 presents a comparison of the proposed model with the approaches discussed in the related work section, specifically in terms of accuracy. From this comparison, we observe that the suggested model outperforms the Bi-LSTM models presented in8,10,12,23 by more than 1% in accuracy. Additionally, when compared to the transformer-based model, our approach achieves an accuracy that is 0.32% higher. Overall, we conclude that our model (Bi-LSTM- Optimized LR) delivers significantly better performance than the state-of-the-art methods due to the following reasons:
-
1.
Bi-LSTM significantly captures context in both directions, improving sentiment analysis.
-
2.
The combination of Bi-LSTM and LR leverages the strengths of both deep learning and machine learning, outperforming other models.
-
3.
Optimized hyperparameters and a learning rate scheduler help minimize overfitting, ensuring better generalization.
Limitations of the proposed model
Despite the several advantages of the proposed model, however, still some limitations are observed during the implementation process:
-
1.
The lack of transparency in the Bi-LSTM layer poses challenges like sensitivity to noise. Hence, in the future techniques such as attention mechanisms, Shapley Additive explanations (SHAP, ) and Layer-Wise Relevance Propagation (LRP) will be introduced into our model to improve interpretability, making the model more suitable for real-world applications.
-
2.
Training Bi-LSTM on large-scale datasets is computationally expensive due to sequential processing, memory constraints, and large parameter space. Therefore, in the future, this problem can be resolved by introducing a Gated Recurrent Unit (GRU) or utilizing advanced architectures like transformer-based models.
-
3.
Sarcasm and irony degrade Bi-LSTM’s sentiment classification performance due to their implicit meaning, contextual dependence, and sentiment reversals. While traditional Bi-LSTMs struggle with sarcasm, integrating attention mechanisms, transformers (like BERT), sarcasm-aware features, and sentiment shift detection can significantly enhance performance.
Conclusion and future scope
In this study, we proposed a Bi-LSTM-based model for sentiment analysis on Twitter data, which effectively extracted meaningful features from preprocessed tweets. While the model demonstrated satisfactory performance, we further enhanced its effectiveness by integrating the Bi-LSTM features with a Logistic Regression (LR) classifier. This resulted in improved performance metrics, including 81.84% precision, 83.38% recall, 82.60% F1-score, and 82.42% accuracy. The combination of Bi-LSTM and LR outperformed the individual Bi-LSTM model, highlighting the potential of hybrid approaches in sentiment analysis. The results, validated by confusion matrices, show that the proposed model can predict sentiments more accurately than baseline models.
Future work could explore more advanced deep learning architectures, such as Transformer-based models, to improve feature extraction and classification accuracy. Additionally, extending the model to handle multi-class sentiment analysis and evaluating its performance on different datasets could provide valuable insights for broader applications.
Data availability
The data that support the findings of this study are openly available at https://www.kaggle.com/datasets/kazanova/sentiment140.
References
Mittal, A. & Patidar, S.. Sentiment analysis on twitter data: A survey. In Proceedings of the 7th International Conference on Computer and Communications Management (2019).
Wankhade, M., Kulkarni, C. & Annavarapu Chandra Sekhara Rao, and A survey on sentiment analysis methods, applications, and challenges. Artif. Intell. Rev. 55 (7), 5731–5780 (2022).
Farias, D. I. H. & Rosso, P. Irony, sarcasm, and sentiment analysis. Sentiment analysis in social networks. Morgan Kaufmann, 113–128 (2017).
Bansal, S. et al. Pt/ZnO and Pt/Few-Layer graphene/zno Schottky devices with al ohmic contacts using atlas simulation and machine learning. J. Sci. Adv. Mater. Devices, 9, 100798-1–100798-14 (2024).
Bansal, S. et al. Optoelectronic performance prediction of HgCdTe homojunction photodetector in long wave infrared spectral region using traditional simulations and machine learning models. Sci. Rep. 14, 28230 (2024).
Balaji, T. K. Chandra Sekhara Rao annavarapu, and Annushree bablani. Machine learning algorithms for social media analysis: A survey. Comput. Sci. Rev. 40, 100395 (2021).
Chatterjee, N., Aggarwal, T. & Maheshwari, R. Sarcasm detection using deep learning-based techniques. In Deep Learning-Based Approaches for Sentiment Analysis 237–258 (2020).
Lyu, Z. Enhancing emotion recognition in text data based on Bi-LSTM and attention approach. In 2024 2nd International Conference on Image, Algorithms and Artificial Intelligence (ICIAAI 2024) (Atlantis Press, 2024).
Tang, J. Leveraging transformer neural networks for enhanced sentiment analysis on online platform comments. In Proceedings of the 2023 4th International Conference on Machine Learning and Computer Application (2023).
Pheng, A. J., Pham, D. N. & Hoe, O. H.. Benchmarking Supervised Learning Models for Sentiment Analysis.
Saleena, N. An ensemble classification system for Twitter sentiment analysis. Procedia Comput. Sci. 132, 937–946 (2018).
Bharal, R. & Krishna, O. V. Social media sentiment analysis using CNN-BiLSTM. Int. J. Sci. Res. (IJSR). 10, 656–661 (2021).
Dhyani, S. & Thakur, G. S. Assorted model of sentiment using mapreduce framework. Int. J. Recent. Technol. Eng. 8(6) (2020).
Upadhyay, P. et al. Machine learning-based sentiment analysis for the social media platforms. In 2023 6th International Conference on Information Systems and Computer Networks (ISCON) (IEEE, 2023).
Paul, A. & Nayyar, A. A context-sensitive multi-tier deep learning framework for multimodal sentiment analysis. Multimedia Tools Appl. 83 (18), 54249–54278 (2024).
Jothi Prakash, V. & Arul Antran Vijay, S. A multi-aspect framework for explainable sentiment analysis. Pattern Recognit. Lett. 178, 122–129 (2024).
Go, A., Bhayani, R. & Huang, L. Twitter sentiment classification using distant supervision. In CS224N Project Report, Stanford, Vol. 1 12 (2009).
Bird, S., Klein, E. & Edward Loper. Natural Language Processing with Python: Analyzing Text with the Natural Language Toolkit ( O’Reilly Media, Inc., 2009).
Khan, M. & Srivastava, A. Sentiment analysis of Twitter data using machine learning techniques. Int. J. Eng. Manag. Res. 14 (1), 196–203 (2024).
Pant, V. K., Sharma, R. & Kundu, S. An overview of stemming and lemmatization techniques. In Advances in Networks, Intelligence and Computing 308–321.
Hosmer, D. W. Jr, Lemeshow, S. & Rodney, X. Sturdivant. Applied Logistic Regression (Wiley, 2013).
Pedregosa, F. et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 12, 2825–2830 (2011).
Bansal, S. Nature-inspired-based multi-objective hybrid algorithms to find near-OGRs for optical WDM systems and their comparison. In (ed. Hamou, R. M.) 175–211 (IGI Global Publisher, 2018). https://doi.org/10.4018/978-1-5225-3004-6.ch011
Acknowledgements
The authors acknowledge that the research Universiti Grant, Universiti Kebangsaan Malaysia, Geran Translasi: UKM-TR2024-10 conducting the research work. Moreover, this research acknowledges Princess Nourah bint Abdulrahman University Researchers Supporting Project number (PNURSP2025R10), Princess Nourah bint Abdulrahman University, Riyadh, Saudi Arabia.
Author information
Authors and Affiliations
Contributions
N. S. Jonnala, A. V. S. R.Teja, S. R. Rajeswari, S. Jakeer, made substantial contributions to design, analysis and characterization. A, Dheeraj, S. Bansal, S. Singh, K. Prakash, participated in the conception, application and critical revision of the article for important intellectual content. M. R. I. Faruque and K. S. A. Mugren provided necessary instructions for analytical expression, data analysis for practical use and critical revision of the article purposes.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Jonnala, N.S., Ram Teja, A.V.S., Rajeswari, S.R. et al. Leveraging hybrid model for accurate sentiment analysis of Twitter data. Sci Rep 15, 24438 (2025). https://doi.org/10.1038/s41598-025-09794-2
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-09794-2
