
Abstract
Retinopathy of prematurity (ROP) is a significant cause of childhood blindness. Many healthcare institutions face a shortage of well-trained ophthalmologists for conducting screenings. Hence, we have developed the Deep Learning Infant Fundus Quality Feedback System (DLIF-QFS) to assess the overall quality of infant retinal photographs and detect common operational errors to support ROP screening and diagnosis. Our DLIF-QFS has been developed and rigorously validated using datasets comprising 13,372 images. In terms of overall quality classification, the DLIF-QFS demonstrated remarkable performance. The area under the curve (AUC) values for discriminating poor quality, adequate quality, and excellent quality images in the external validation dataset were 0.802, 0.691, and 0.926, respectively. For most classification tasks related to identifying issues in adequate and poor quality images, the AUC values consistently exceeded 0.8. In expert diagnostic tests, the DLIF-QFS improved accuracy and enhanced consistency. Its capability to identify the causes of poor image quality, enhance image quality and assist clinicians in improving diagnostic efficiency makes it a valuable tool for advancing ROP diagnosis.
Similar content being viewed by others

Introduction
Ophthalmology is a highly image-centric specialty, with fundus photography being the most common imaging modality1. Physicians use fundus photography to assess patients for conditions such as diabetic retinopathy, age-related macular degeneration, and retinopathy of prematurity, making it a crucial diagnostic tool2. This image-centric nature of ophthalmology positions it at the forefront of innovation in the realm of deep learning (DL) diagnostic systems. There are extensive literature and research dedicated to the utilization of fundus photography in pediatric ophthalmic diseases3,4, as well as exploring the potential and effectiveness of DL algorithms in the analysis of fundus images5,6,7.
Retinopathy of prematurity (ROP) represents a significant global cause of childhood blindness, and its prevalence is rising, largely attributed to the increasing number of premature births. The incidence of ROP varies markedly depending on the gestational age and birth weight of the neonate. Notably, infants born prior to 32 weeks of gestation and weighing less than 1500 g face the highest susceptibility to ROP, with an incidence ranging from 30 to 70%8. In contrast, infants born between 32 and 36 weeks of gestation have a comparatively lower risk, with an incidence ranging between 5% and 10%. The classification of ROP is based on a five-stage system depending on the condition’s severity9. The prognosis for infants with ROP depends on the severity of the disease and the timeliness of intervention. Infants who receive early treatment for ROP generally have better outcomes, emphasizing the crucial role of timely detection and intervention in preventing permanent vision loss. However, screening and treating ROP in premature infants present significant challenges, primarily due to a shortage of adequately trained ophthalmologists or neonatologists in many healthcare settings, which often leads to delays in diagnosis and treatment. To address these challenges, it is essential to implement telemedicine10 and other computer-based image analysis applications for ROP screening and diagnosis11,12.
The first authorized autonomous artificial intelligence (AI) diagnostic system in the medical field, IDx-DR, has been developed specifically for automated diabetic retinopathy screening using fundus photography13. However, a significant challenge that both traditional medical processes and AI diagnostic systems face is issues associated with image quality. Poor image quality not only renders fundus photography ineffective for diagnosis but can also lead to incorrect treatment decisions, potentially resulting in permanent vision loss. The quality of fundus photographs depends on various factors, including the operator’s skill, patient cooperation, the presence of refractive media opacity, and hardware characteristics14,15. Infants and children are usually less cooperative than adults, and the operation of hardware is more complex, demanding a higher level of operator proficiency. As a result, image quality issues are more pronounced in infant subjects compared to adults. For instance, a comprehensive study involving an adult retinal image database found that over 25% of the images were of insufficient quality for accurate medical diagnosis16. For infant fundus screening, this issue is even more prevalent. One study showed that only 50.8% of fundus photographs obtained during routine ROP screening examinations met the criteria for acceptable quality17. To address the issue of image quality, many efforts have been made by previous researchers. In the past, the most common strategy was to manually exclude poor quality images, but this placed an additional burden on already overburdened medical practitioners. Recently, several deep learning systems (DLS) have emerged, designed to autonomously evaluate the quality of fundus images, thereby alleviating the workload of medical professionals to some extent. To assess the quality of retinal images, DL models, particularly Convolutional Neural Networks (CNNs), are frequently employed to automatically discern quality attributes such as image clarity, contrast, brightness, field of view completeness, and the presence of imaging artifacts. In numerous investigations, these deep learning techniques have demonstrated their efficacy in effectively distinguishing between high quality and low quality retinal images18,19,20,21,22. CNNs can automatically extract latent features from input images without requiring manually designed feature engineering, thereby eliminating the dependency on human intervention inherent in traditional methods. This enables CNNs to outperform traditional machine learning approaches in image quality assessment tasks, particularly for evaluating color fundus images23. In recent years, deep learning applications across diverse datasets have further enhanced assessment accuracy and generalization capabilities through techniques such as multi-task learning and transfer learning24,25.
Previous research in the field of fundus image quality assessment has primarily focused on using deep learning models for post-processing classification tasks. For instance, Zago et al.26 proposed a CNN pre-trained on non-medical images to extract general image features, which achieved an impressive AUC of 0.9998 and 0.9856 in inter-database experiments. Similarly, Zapata et al.27 introduced an innovative CNN architecture referred to as CNN-1, achieving an AUC of 0.947 and an accuracy of 91.8%. Abramovich et al.28 introduced a fundus image quality scale along with a DL model capable of estimating the quality of fundus images based on this new scale. When evaluated as a binary classification model on the public DRIMDB database, used as an external test set, the model showed an accuracy of 99%. The effectiveness of deep learning in medical image quality assessment stems from its automated feature extraction capabilities and high robustness. Unlike traditional methods that rely on manually defined features, deep learning automatically learns optimal features through end-to-end training, significantly reducing dependence on expert experience. Deep learning models demonstrate superior performance in quality classification tasks, exhibiting strong generalization ability to accommodate device discrepancies and variations in imaging conditions. Their multi-task frameworks and attention mechanisms facilitate the identification of complex anomalies, thereby enhancing diagnostic reliability23,26,29.
While these efforts have shown promising results in automated quality evaluation, they mainly focus on classifying images as good or bad after acquisition. This approach can lead to the exclusion of all images from a patient, resulting in incomplete evaluations. Currently, there is no system capable of identifying specific operational errors (such as defective camera contact) and providing real-time feedback to photographers during the imaging process, particularly in neonatal eye screening. In the case of infant fundus exams, the commonly used RetCam, a contact wide-angle fundus camera, presents challenges, even for skilled operators, including difficulties with lens contact, focus, and pupil dilation3,30. Here, we developed a DLIF-QFS to address the significant challenges in infant fundus photography, particularly the poor image quality caused by the difficulties of infant cooperation and the complexities of the specialized equipment. The current state of fundus screening for ROP is hindered by inconsistent image quality, which directly impacts the accuracy and reliability of diagnoses. DLIF-QFS is capable of real-time detection of common operational errors in infant fundus photography. The system aims to provide immediate feedback to photographers to correct issues such as focus, lighting, and alignment during the imaging process. By addressing these issues at the point of capture, the DLIF-QFS aims to improve image quality, enhance diagnostic efficiency, and ultimately support better clinical outcomes in ROP screening.
Methods
Fundus images dataset
A total of 11,900 infant fundus images from Qilu Hospital of Shandong University were used to train and evaluate the models. To validate the applicability of our proposed DLIF-QFS in real-world scenarios, an additional set of 1,472 images was randomly collected from the Women and Children’s Healthcare Hospital of Linyi. These data were obtained between January 2017 and December 2019 using RetCam fundus photography (Clarity Medical Systems, Inc, Pleasanton, CA) and included infants who underwent fundus screening with mydriasis. All privacy information was removed, and all images were deidentified before transfer to the researchers. This study was approved by the Institutional Review Boards of Zhongshan Ophthalmic Center (ZOC) and conducted according to the Declaration of Helsinki. Informed consent was waived as it involved retrospective analysis of de-identified data, with no patient intervention, privacy risk, or commercial interest, in accordance with Article 39 of the 2016 ethical review guidelines and all methods were performed in accordance with the relevant guidelines and regulations.
Criteria of image quality and capturing issues
As shown in Fig. 1, image quality and the cause of quality issues were evaluated. Image quality was assessed as follows:

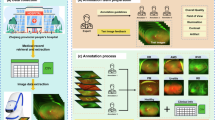
Illustration of the proposed algorithmic pipeline. A deep learning system was developed to assess the overall quality of infant retinal photographs and detect common operational errors. The classification included image quality categories such as excellent, adequate, and poor. Within adequate and poor quality, sub-categories were formed, including “defective contact of camera”, “out of focus” and “inadequate pupil dilatation”. Lower image quality diminishes the capacity to extract patient information effectively.
-
1.
Excellent quality refers to images without noticeable problems in image quality, and all targeted retinopathy lesions were gradable.
-
2.
Adequate quality refers to images with noticeable problems in image quality, but all targeted retinopathy lesions could be gradable.
-
3.
Poor quality refers to images with severe issues in image quality, and targeted retinopathy lesions were ungradable.
After discussions with three retinal ophthalmologists, each possessing over five years of experience in diagnosing infant ocular diseases, a consensus was established regarding the factors affecting image quality in RetCam captures. The mechanism and classification criteria for capturing issues are summarized as follows:
-
1.
Defective camera contact: This refers to issues arising from inadequate contact between the camera and the infants’ eyes during image capture. The mechanism is attributed to the small and unsteady nature of infant eyes, erratic eye movements, infant discomfort, and operator technique. The classification criteria encompass the presence of bright circular spots (accompanied by bubbles in the gel), overexposed and blurred images, or bright glare spots (resulting from partial lens contact with the cornea). Furthermore, it includes images with an overall yellowish and blurry appearance due to inadequate lens-to-cornea contact resulting from the small palpebral fissure.
-
2.
Out of Focus: This denotes images lacking sharpness and clarity due to improper camera focus on the infants’ eyes. The mechanism involves factors such as incorrect camera settings, inappropriate camera-to-eye distance, or issues with the autofocus mechanism. Classification criteria included assessing the sharpness of critical features such as blood vessels or the optic disc. Images that were below a certain threshold of sharpness were categorized as out of focus.
-
3.
Inadequate pupil dilatation: This refers to cases where the infants’ pupils were not sufficiently dilated, impeding the visibility of the fundus. The mechanism involves limitations on both the quantity and quality of light entering the retina, resulting in diminished visibility of fundus details. Additionally, the camera may necessitate increased gain or extended exposure time to capture the image, potentially introducing more noise into the image. Classification criteria include the presence of a central black shadow, peripheral gray non-illuminated areas, and a crescent-shaped iris reflection in the periphery.
The workflow of image annotation
First, all images were classified into three categories: excellent quality, adequate quality, and poor quality. In addition, the adequate and poor quality images were further divided into three categories according to operational factors: “defective contact of camera”, “out of focus”, and “inadequate pupil dilatation”. Three retina experts, each with a minimum of five years experience in infant fundus image capture and analysis, independently annotated all unclassified images. Annotation criteria were established only when all three experts unanimously agreed. Any images that generated controversy or uncertainty were referred to a senior retina expert with over twenty years of clinical experience for a final classification. Subsequently, the model’s performance in assessing overall image quality and capturing issues was compared to these annotation criteria.
Image preprocessing and model development
To facilitate deep learning model training, several image preprocessing steps were implemented. For instance, fundus images were standardized and resized to 512 × 512 pixels, with pixel values normalized to a range of 0 to 1. Data augmentation techniques, including random rotation, cropping, and flipping, were also applied to expand the training dataset and enhance model robustness.
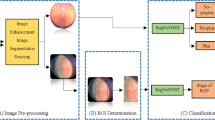
To effectively discriminate the quality of infant fundus images and automatically assess the factors influencing image quality in Retcam captures (i.e., defective camera contact, out of focus, and inadequate pupil dilation), we developed a deep convolutional neural network model with a cascaded architecture as our quality feedback system. The system’s development and evaluation workflow is illustrated in Fig. 2. Overall, the system comprises two interconnected stage sub-models. In the first stage, a deep CNN model primarily focuses on the early differentiation of the quality of infant fundus images. Specifically, this model classifies all images into three categories: “excellent quality”, “adequate quality” and “poor quality.” The second stage of the system features two distinct deep CNN models: the “adequate quality assess network” and the “poor quality assess network”. For fundus images classified as “adequate quality” in the first stage, the adequate quality assessment network further evaluates them, categorizing them into one of three sub-categories, namely, “defective camera contact”, “out of focus” or “inadequate pupil dilation”. Similarly, for images categorized as “poor quality” in the first stage, the poor quality assessment network assesses them into one of the same three sub-categories mentioned above. Thus, the task of automatically assessing fundus image quality can be performed in a multi-stage approach using this cascaded deep learning system architecture, yielding more dependable classification results compared to conventional one-stage models.

The workflow for developing and evaluating deep learning-based image quality feedback system based on fundus images. The internal dataset comprised 11,900 infant fundus images from Qilu Hospital of Shandong University (QLH), used for model training and evaluation. The external dataset consisted of 1,472 images from the Women and Children’s Healthcare Hospital of Linyi (LYH), randomly selected for model validation.
All three deep CNN models in these two stages underwent separate training using Inception_v3, which is currently one of the state-of-the-art CNN models. Figure 1 illustrates the Inception module group, which is the core innovation of Inception_v3. To train the first stage model, all the fundus images in the training dataset were labeled as “excellent quality,” “adequate quality,” or “poor quality,” respectively. Regarding the two models in the second stage, the training dataset’s “adequate quality” images were further categorized into the three sub-categories and used to train the “adequate quality assess network.” Similarly, the “poor quality” images in the training dataset were also further categorized in the same manner to train the “poor quality assess network.” All three models derived from the above training procedures constituted the final cascaded system and underwent evaluation using the fundus images in the testing dataset. The detailed settings for implementing the models are as follows. Firstly, transfer learning was employed from the pre-trained Inception_v3 to enhance model effectiveness. Secondly, given the imbalance in the number of images across different classes, the focal loss function was utilized as the loss function for all three models using an alpha parameter of 0.5 in the focal loss function. Lastly, Adam was selected as the optimizer for training Inception_v3, with 50 epochs, a batch size of 48, a learning rate of 0.003, and a learning rate decay factor of 0.99.
Validation of diagnostic accuracy and consistency
In the external validation results, we selected 200 images from each of the “excellent quality,” “adequate quality,” and “poor quality” categories. Among these, approximately 15% represented cases of ROP, 15% exhibited newborn retinal hemorrhage, and the remaining 70% were classified as normal images. Three retina experts, Dr. Li, Dr. Wang, and Dr. Xu, with two, five, and ten years of experience in infants’ fundus image capture and analysis, independently assessed these sets of anonymized images. We recorded and analyzed their diagnosis times, accuracy, and the level of agreement among the three experts.
Statistical analysis
The Kendall’s W test was used to analyze the consistency of diagnosis among three experts, with a higher Kendall’s coefficient indicating a stronger level of consistency in diagnosis.
Results
Characteristics of the datasets
The internal dataset comprised a total of 11,900 images collected from 1,192 subjects, which were utilized for both the development and validation of the DLIF-QFS. Additionally, an external dataset consisting of 1,472 images from 152 subjects was employed for further validation of the DLIF-QFS. A summary of the dataset details is shown in Table 1. Of note, the external dataset contained 22 missing patient records, which were excluded from the study analysis.
Performance of DL strategies in the internal validation dataset
Three DL algorithms (EfficientNet, ResNet50, and Inception V3) were used to develop models for image quality classification. The results in Table 2 revealed that the best algorithm is Inception V3. Given the imbalanced sample sizes in each category, we further explored the impact of data augmentation strategies on model performance. As shown in Table 3, the sample-balancing strategy of Inception V3 outperformed other configurations in each task.
For the classification of overall image quality, the system successfully differentiated poor quality images from both adequate and excellent quality images, achieving an AUC of 0.931. The system also displayed an F1 score of 0.765, a recall of 0.770, and a precision of 0.760 in this task. Similarly, when distinguishing adequate quality images from poor and excellent quality images, the system attained an AUC of 0.910, with an F1 score of 0.752, a recall of 0.798, and a precision of 0.710. In the classification of excellent quality images against poor and adequate quality images, the system achieved an AUC of 0.948, exhibited an F1 score of 0.897, a recall of 0.870, and a precision of 0.926.
In the classification of capturing issues within adequate quality images, the system effectively discriminated “defective contact” from “out of focus” or “inadequate pupil dilation” images with an AUC of 0.869, an F1 score of 0.724, recall of 0.648, and precision of 0.820. It also distinguished “out of focus” images from those with “defective contact” or “inadequate pupil dilation” with an AUC of 0.849, an F1 score of 0.622, a recall of 0.669, and a precision of 0.582. Additionally, it successfully identified “inadequate pupil dilation” images from those with “defective contact” or “out of focus” with an AUC of 0.915, an F1 score of 0.762, a recall of 0.829, and a precision of 0.705.
In the classification of capturing issues within poor quality images, the system effectively distinguished images with “defective contact” from those with “out of focus” or “inadequate pupil dilation” with an AUC of 0.999, an F1 score of 0.964, a recall of 1.000, and a precision of 0.931. It also successfully discriminated “out of focus” images from those with “defective contact” or “inadequate pupil dilation” with an AUC of 0.966, an F1 score of 0.824, a recall of 0.875, and a precision of 0.778. Additionally, it effectively identified “inadequate pupil dilation” images from those with “defective contact” or “out of focus” with an AUC of 0.965, an F1 score of 0.783, a recall of 0.692, and a precision of 0.900. These performance indicators of the DL strategies are presented in Tables 3 and 4, and 5.
Performance of DL strategies in the internal test dataset
In Fig. 3, we present the ROC curve and confusion matrices for the internal test dataset. Regarding overall quality classification, the AUC values for distinguishing poor quality, adequate quality, and excellent quality images were 0.873, 0.854, and 0.904, respectively. In the classification of capturing issues within adequate quality images, the AUC values for differentiating images with “defective contact”, “out of focus” and “inadequate pupil dilation” were 0.872, 0.848, and 0.859, respectively. For capturing issues within poor quality images, the AUC values for distinguishing images with “defective contact”, “out of focus” and “inadequate pupil dilation” were 0.900, 0.906, and 0.934, respectively.

Receiver operating characteristic (ROC) curve and confusion matrices for discerning overall image quality and capturing issues in the internal test set. (A,D) ROC curve and confusion matrix for discerning poor, adequate and excellent quality images. (B,E) ROC curve and confusion matrix for discerning the causes of adequate quality. (C,F) ROC curve and confusion matrix for discerning the causes of poor quality. (DC: Defective contact; OF: Out of focus; IPD: Inadequate pupil dilatation).
Performance of DL strategies in the external validation dataset
In the external test dataset, Inception V3 with the sample-balanced strategy still showed the best performance. Figure 4 shows the ROC curve and confusion matrices. For overall quality classification, the AUC values for distinguishing poor quality, adequate quality, and excellent quality images were 0.802, 0.691, and 0.926, respectively. In the classification of capturing issues within adequate quality images, the AUC values for differentiating images with “defective contact”, “out of focus” and “inadequate pupil dilation” were 0.838, 0.749, and 0.851, respectively. For capturing issues within poor quality images, the AUC values for distinguishing images with “defective contact”, “out of focus” and “inadequate pupil dilation” were 0.801, 0.773, and 0.860, respectively.

Receiver operating characteristic (ROC) curve and confusion matrices for discerning overall image quality and capturing issues in the external validation set. (A,D) ROC curve and confusion matrix for discerning poor, adequate and excellent quality images. (B,E) ROC curve and confusion matrix for discerning the causes of adequate quality. (C,F) ROC curve and confusion matrix for discerning the causes of poor quality. (DC: Defective contact; OF: Out of focus; IPD: Inadequate pupil dilatation).
Performance of DL strategies in auxiliary diagnosis
Figure 5 shows the confusion matrices for auxiliary diagnosis on infant fundus images. Diagnosis quality assessment was conducted on images of excellent quality. The three experts, ranked by experience in descending order, were found to require 5 min, 6 min and 8 min to complete the diagnosis and showed a diagnostic accuracy rate of 98%, 97% and 95%, respectively. The Kendall’s W coefficient for the diagnosis results of the three experts was 0.953 (P < 0.001), indicating a strong level of consistency.

Confusion matrices for diagnosis on infant fundus images. (A,D,G) Confusion matrix for diagnosis on excellent, adequate and poor quality images by retina expert with ten years of experience. (B,E,H) Confusion matrix for diagnosis on excellent, adequate and poor quality images by retina expert with five years of experience. (C,F,I) Confusion matrix for diagnosis on excellent, adequate and poor quality images by retina expert with two years of experience. (ROP: Retinopathy of prematurity; RH: Retinal hemorrhage).
The three experts took 6 min, 7 min, and 11 min to complete the diagnosis on images of adequate quality and showed a diagnostic accuracy rate of 93%, 91%, and 83%, respectively. The Kendall’s W coefficient for the diagnosis results of the three experts was 0.854 (P < 0.001), indicating a strong level of consistency.
For images of poor quality, the three experts took 8 min, 10 min and 15 min to complete the diagnosis and showed a diagnostic accuracy rate of 87%, 82% and 61%, respectively. The Kendall’s W coefficient for the diagnosis results of the three experts was 0.639 (P < 0.001), indicating a moderate level of consistency. Three participating clinicians stated that DLIF-QFS streamlined the diagnostic process, reduced diagnostic difficulty, and significantly enhanced screening efficiency.
Discussion
This study aimed to develop a DLIF-QFS for assessing both the overall quality and capturing issues in images. The performance of the DLIF-QFS was evaluated across different institutions. Our findings demonstrate that the DLIF-QFS can accurately classify the overall quality (poor, adequate, and excellent) and identify capturing issues (“defective contact,” “out of focus,” and “inadequate pupil dilation”) in the images. The DLIF-QFS exhibits excellent performance in the classification of infant fundus image quality.
Significant efficacy was achieved using the three prominent DL algorithms, namely EfficientNet, ResNet50 and Inception V3, for image quality classification. Among these algorithms, Inception V3, in combination with a sample balancing strategy, demonstrated the most compelling results. In both the internal validation and test datasets, the system exhibited strong performance in overall image quality classification, effectively distinguishing between poor, adequate and excellent quality images. Moreover, the F1 scores, recall and precision highlighted the system’s ability to balance between sensitivity and precision in classification tasks, which is crucial for ensuring reliable performance in real-world scenarios, as misclassifying images could potentially result in overlooked diagnoses or unnecessary treatment. The system also excelled in identifying specific capturing issues in both adequate and poor quality images, accurately distinguishing “defective contact”, “out of focus” and “inadequate pupil dilation”. When tested on the external validation dataset, Inception V3 with a sample balancing strategy maintained a notable level of classification proficiency for real-world applications. As shown in Table 6, the macro-AUCs and micro-AUCs for most quality and capturing issues classification tasks exceeded 0.8, demonstrating the DLIF-QFS’s efficacy and robustness beyond controlled conditions. However, there was a slight decrease in performance compared to the internal test dataset, likely due to differences in data distribution between the external validation dataset and the internal training dataset, resulting in a distribution shift that affected the model’s external performance. Notably, there were no significant statistical differences in demographic characteristics (e.g., gestational age, birth weight distribution) between the external and internal datasets. In the future, domain adaptation techniques, such as incorporating adversarial loss functions, could be used to align different data distributions and enhance the model’s generalization across multi-center datasets. However, compared to publicly available databases, our external validation dataset better represents real-world scenarios. To address this, strategies like data preprocessing, domain adaptation, label calibration, and multi-source data training can improve model performance on validation datasets. To validate DLIF-QFS’s real-world utility, we used it for image diagnosis. The results showed that DLIF-QFS significantly enhanced the efficiency, accuracy, and diagnostic consistency among three doctors. By filtering out poor quality images, DLIF-QFS not only saved time and resources but also reduced the risk of incorrect diagnoses, preventing both over and undertreatment. The trade-off between time and accuracy is an important issue in the clinical application of DLIF-QFS. It requires continuous optimization of the model’s performance, with regular adjustments and iterations based on feedback from doctors in real-world practice. Future studies could introduce more clinical data to further analyze the optimal balance between time and accuracy for DLIF-QFS.
Our DLIF-QFS holds significant potential for application in various clinical scenarios. Firstly, it can enhance the development and implementation of AI diagnostic systems. During development, DLIF-QFS automatically filters out poor quality images, reducing the risk of experts’ incorrect annotations due to quality issues and thereby improving dataset quality. In clinical applications, DLIF-QFS manages image quality in real-world settings akin to the development phase, resulting in enhanced generalizability for AI diagnostic systems. Secondly, DLIF-QFS has the potential to enhance the efficiency of telemedicine diagnostics. By automatically excluding average and poor quality images, which often confuse experts, DLIF-QFS streamlines the diagnostic process. Additionally, it provides real-time feedback to photographers for image recapture, along with precise information about the quality issues for targeted corrections. This feature can be particularly beneficial in training programs, where new or less experienced infant fundus photographers can use the system to receive instant feedback on their image quality. By guiding them in real time, DLIF-QFS helps novice photographers understand and correct common issues such as focus, lighting, or alignment. Over time, this continuous feedback loop can accelerate their learning process, improve their technical skills, and reduce the likelihood of poor-quality images being captured. DLIF-QFS can deploy lightweight models on fundus cameras or mobile devices to enable real-time quality assessment. It also incorporates hardware-triggered logic to enforce image reacquisition when the quality score is too low, preventing invalid data collection. Additionally, it can be integrated into existing telemedicine systems, providing real-time quality feedback for uploaded fundus images via API. Notably, for poor quality images with no potential for improvement through recapture, DLIF-QFS raises suspicions of obscured refractive media, prompting further ophthalmological examination for these patients.
Numerous studies have aimed to establish fundus image quality classifiers, but few have focused specifically on infant fundus images despite the distinct nature of infant fundus imaging devices. To our knowledge, Coyner et al. have developed the only other infant fundus image classifier based on CNN, achieving an AUC of 0.965 for discerning acceptable quality images in routine ROP screenings with a test set of 2109 images17. Compared to the previous study, our study had several unique characteristics. Firstly, no previous study has addressed the identification of capturing issues, which frequently arise in infant fundus screening due to the cooperation of infants and the unique operability of specialized equipment. Our DLIF-QFS effectively identifies these capturing issues, aiding photographers in making precise adjustments based on the identified issues and ultimately obtaining higher quality images. This feature also has educational benefits for inexperienced photographers. Secondly, to enhance image quality classification performance, our datasets for DLIF-QFS development and validation were considerably larger than those in the previous study. Additionally, we conducted rigorous external validation, while the previous study adopted a mixed-data approach from multiple centers. Thus, our strategy provides a more representative assessment in real-world settings.
In this study, we aimed to enhance the performance of the DL model by implementing a sample-balanced strategy with Inception V3. As indicated in Table 2, the sample-balanced strategy notably improved the DL model’s performance. It is a common challenge in medical AI research to encounter data imbalances among groups, such as having significantly fewer patients with rare diseases compared to healthy controls, which can significantly affect AI model performance, as the models may tend to predict new subjects belonging to a group with the larger dataset, thereby inflating accuracy. Our sample-balanced strategy was beneficial in improving the performance and generalizability of DL models in such scenarios.
There are still some limitations that should be highlighted in our study. First, there is still a potential for improvement in the DLIF-QFS accuracy, given that fundus images can exhibit multiple capturing issues simultaneously, making it challenging to fully differentiate each issue. A potential solution could be to configure the model to provide probability estimates for individual capturing issues. In a multi-label classification setting, instead of using softmax as the activation function in the output layer, sigmoid is applied to independently activate each node. This allows the model to output the probability of each class label being 1 rather than forcing a single-class prediction. Additionally, the binary cross-entropy loss function is used, enabling the model to iteratively minimize the entropy between the predicted outputs and the ground truth labels during training. To further enhance performance, ensemble learning methods such as bagging, boosting, or stacking can be applied. By leveraging multi-label classification strategies and ensemble techniques, the model can more accurately assess multiple capturing issues simultaneously, improving its reliability in real-world applications. Secondly, although DLIF-QFS’s performance underwent validation across diverse institutions, all were located in China. Further research is imperative to assess its performance in international settings. The performance of the system may be affected by geographic and demographic differences. The methods used for capturing fundus images, equipment operating standards, and even patients’ eye physiology can vary significantly between countries and regions, which may lead to differences in the manifestation of capture issues. These factors could impact the system’s adaptability in different environments. When deploying our model in other countries or regions, it may be necessary to make adjustments and optimizations based on geographic or cultural differences. To address these potential challenges, we plan to enhance the system by incorporating data from multiple centers and regions in future studies, which will improve the model’s generalization ability. Additionally, domain adaptation techniques will be explored to help the system better adapt to variations in demographic characteristics and image capture conditions. Lastly, exploring the cost-effectiveness of DLIF-QFS in real-world applications necessitates further investigation.
In summary, DLIF-QFS accurately discerns overall image quality and captures issues in both internal and external test datasets. The utilization of Inception V3 combined with a sample balancing strategy outperformed alternative models across all tasks. Taken together, DLIF-QFS may contribute significantly to the development and implementation of AI diagnostic systems by maintaining consistent image quality and can assist in the education of novice infant fundus photographers.
Data availability
The datasets used and/or analyzed during the current study are available from the corresponding author on reasonable request.
References
Dubey, S., Jain, K. & Fredrick, T. N. Quality assurance in ophthalmic imaging. Indian J. Ophthalmol. 67(8), 1279–1287. https://doi.org/10.4103/ijo.IJO_1959_18 (2019).
Jelinek, H.F., Cree, M.J. Automated Image Detection of Retinal Pathology CRC Press, Boca Raton (2010)
Chiang, M. F. et al. Telemedical retinopathy of prematurity diagnosis: accuracy, reliability, and image quality. Arch. Ophthalmol. 125(11), 1531–1538. https://doi.org/10.1001/archopht.125.11.1531 (2007).
Scott, K. E. et al. Telemedical diagnosis of retinopathy of prematurity intraphysician agreement between ophthalmoscopic examination and image-based interpretation. Ophthalmology 115(7), 1222-1228.e3. https://doi.org/10.1016/j.ophtha.2007.09.006 (2008).
Coyner, A. S. et al. External Validation of a Retinopathy of Prematurity Screening Model Using Artificial Intelligence in 3 Low- and Middle-Income Populations. JAMA ophthalmology 140(8), 791–798. https://doi.org/10.1001/jamaophthalmol.2022.2135 (2022).
Wang, J. et al. Automated Explainable Multidimensional Deep Learning Platform of Retinal Images for Retinopathy of Prematurity Screening. JAMA network open vol. 4,5 e218758. 3 May. 2021, https://doi.org/10.1001/jamanetworkopen.2021.8758
Taylor, S. et al. Monitoring Disease Progression With a Quantitative Severity Scale for Retinopathy of Prematurity Using Deep Learning. JAMA ophthalmology 137(9), 1022–1028. https://doi.org/10.1001/jamaophthalmol.2019.2433 (2019).
Hellström, A., Smith, L. E. & Dammann, O. Retinopathy of prematurity. Lancet 382(9902), 1445–1457. https://doi.org/10.1016/S0140-6736(13)60178-6 (2013).
Chiang, M. F. et al. International Classification of Retinopathy of Prematurity. Third Edition. Ophthalmology 128(10), e51–e68. https://doi.org/10.1016/j.ophtha.2021.05.031 (2021).
Quinn, G. E. et al. Validity of a telemedicine system for the evaluation of acute-phase retinopathy of prematurity. JAMA ophthalmology 132(10), 1178–1184. https://doi.org/10.1001/jamaophthalmol.2014.1604 (2014).
Campbell, J. P. et al. Expert Diagnosis of Plus Disease in Retinopathy of Prematurity From Computer-Based Image Analysis. JAMA ophthalmology 134(6), 651–657. https://doi.org/10.1001/jamaophthalmol.2016.0611 (2016).
Kalpathy-Cramer, J. et al. Plus Disease in Retinopathy of Prematurity: Improving Diagnosis by Ranking Disease Severity and Using Quantitative Image Analysis. Ophthalmology 123(11), 2345–2351. https://doi.org/10.1016/j.ophtha.2016.07.020 (2016).
Grzybowski, A. et al. Artificial intelligence for diabetic retinopathy screening: a review. Eye 34(3), 451–460. https://doi.org/10.1038/s41433-019-0566-0 (2020).
Peli, E. & Peli, T. Restoration of retinal images obtained through cataracts. IEEE Trans. Med. Imaging 8(4), 401–406. https://doi.org/10.1109/42.41493 (1989).
Hershey, M. S. Maximizing quality in ophthalmic digital imaging. J. Ophthalmic Photogr. 31, 32–39 (2009).
MacGillivray, T. J. et al. Suitability of UK Biobank Retinal Images for Automatic Analysis of Morphometric Properties of the Vasculature. PLoS ONE 10(5), e0127914. https://doi.org/10.1371/journal.pone.0127914 (2015).
Coyner, A. S. et al. Automated Fundus Image Quality Assessment in Retinopathy of Prematurity Using Deep Convolutional Neural Networks. Ophthalmology. Retina 3(5), 444–450. https://doi.org/10.1016/j.oret.2019.01.015 (2019).
Guo, T. et al. Learning for retinal image quality assessment with label regularization. Comput. Methods Programs Biomed. 228, 107238. https://doi.org/10.1016/j.cmpb.2022.107238 (2023).
Chalakkal, R. J., Abdulla, W. H. & Thulaseedharan, S. S. Quality and content analysis of fundus images using deep learning. Comput. Biol. Med. 108, 317–331. https://doi.org/10.1016/j.compbiomed.2019.03.019 (2019).
König, M. et al. Quality assessment of colour fundus and fluorescein angiography images using deep learning. Br. J. Ophthalmol. https://doi.org/10.1136/bjo-2022-321963 (2022).
Saha, S. K., Fernando, B., Cuadros, J., Xiao, D. & Kanagasingam, Y. Automated Quality Assessment of Colour Fundus Images for Diabetic Retinopathy Screening in Telemedicine. J. Digit. Imaging 31(6), 869–878. https://doi.org/10.1007/s10278-018-0084-9 (2018).
Lyu, X., Jajal, P., Tahir, M. Z. & Zhang, S. Fractal dimension of retinal vasculature as an image quality metric for automated fundus image analysis systems. Sci. Rep. 12(1), 11868. https://doi.org/10.1038/s41598-022-16089-3 (2022).
Schmidhuber, J. Deep learning in neural networks: an overview. Neural Netw. 61, 85–117. https://doi.org/10.1016/j.neunet.2014.09.003 (2015).
Yu, F. et al. Image quality classification for DR screening using deep learning. Annu Int Conf IEEE Eng Med Biol Soc. 2017, 664–667. https://doi.org/10.1109/EMBC.2017.8036912 (2017).
Saha, S. K., Fernando, B., Cuadros, J., Xiao, D. & Kanagasingam, Y. Automated Quality Assessment of Colour Fundus Images for Diabetic Retinopathy Screening in Telemedicine. J Digit Imaging. 31(6), 869–878. https://doi.org/10.1007/s10278-018-0084-9 (2018).
Zago, G. T., Andreão, R. V., Dorizzi, B. & Teatini Salles, E. O. Retinal image quality assessment using deep learning. Comput. Biol. Med. 103, 64–70. https://doi.org/10.1016/j.compbiomed.2018.10.004 (2018).
Zapata, M. A. et al. Artificial Intelligence to Identify Retinal Fundus Images, Quality Validation, Laterality Evaluation, Macular Degeneration, and Suspected Glaucoma. Clin. Ophthalmol. 14, 419–429. https://doi.org/10.2147/OPTH.S235751 (2020).
Abramovich, O. et al. FundusQ-Net: A regression quality assessment deep learning algorithm for fundus images quality grading. Comput. Methods Programs Biomed. 239, 107522. https://doi.org/10.1016/j.cmpb.2023.107522 (2023).
Shen, Y. et al. Domain-invariant interpretable fundus image quality assessment. Med Image Anal. 61, 101654. https://doi.org/10.1016/j.media.2020.101654 (2020).
Wu, C., Petersen, R. A. & VanderVeen, D. K. RetCam imaging for retinopathy of prematurity screening. J. AAPOS 10(2), 107–111. https://doi.org/10.1016/j.jaapos.2005.11.019 (2006).
Funding
This work was partially supported by Natural Science Foundation of Shandong Province (ZR202111120236), the Undergraduate Higher Education Teaching Quality and Teaching Reform Engineering Project of Guangdong Province (2022, No. 489), the Educational Research Project of the 14th Five-Year Plan for National Higher Education of Traditional Chinese Medicine in 2023 (Project No. YB-23-13), the Social Science Project of Guangzhou University of Chinese Medicine (Grant No. 2021SKYB01), the Opening Project of Guangdong Province Key Laboratory of Big Data Analysis and Processing at Sun Yat-sen University (Grant No. 202202), and the National Natural Science Foundation of China (82174527).
Author information
Authors and Affiliations
Contributions
Author contributions: (1)Conceptualization: Li, Y.; (2)Data curation: Wang, H.L., Xu, F.B., Wang, W.J. and Song, B.X.; (3)Formal analysis: Li, L.H., Wang, W.J. and Li, S.Q.; (4)Investigation: Yang, X.Y., Jian, T.Z.; (5)Methodology: Li, Y., Liu, S.P. and Xu, F.B.; (6)Project administration: Wang, H.L. and Li, L.H.; (7)Resources: li, Z.W. and Yang, X.Y.; (8)Software: Liu, S.P. and Li, S.Q.; (9)Validation: Liu, S.P., Xu, F.B., Wang, W.J., li, Z.W. and Song, B.X.; (10)Writing: Wang, H.L. and Li, L.H. and Li, Y. All authors have read and agreed to the published version of the manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Wang, H., Li, L., Wang, W. et al. Development and validation of a deep learning image quality feedback system for infant fundus photography. Sci Rep 15, 26852 (2025). https://doi.org/10.1038/s41598-025-10859-5
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-10859-5
Keywords
This article is cited by
-
Diagnostic Accuracy of Pediatrician-performed Digital Retinal Imaging with 3nethra neo for ROP Screening: Correspondence
Indian Journal of Pediatrics (2025)
