
Abstract
Given that the decision tree C4.5 algorithm has outstanding performance in prediction accuracy on medical datasets and is highly interpretable, this paper carries out an optimization study on the selection of hyperparameters of the algorithm in order to achieve fast and accurate optimization of the algorithm model. The decision tree models are first constructed by taking different values of hyperparameters, and then the performance of each model is evaluated, and then the evaluated data are associated and integrated with the character metadata of the dataset. Three evaluation values of accuracy, AUC and F1-measure and 293 basic data sets were used to build a meta-database of hyperparameter M optimization required by the study. And then the range of values of C4.5 algorithm hyperparameters corresponding to the different character datasets are recommended through the modeling learning. The results show that for more than 65% of the data sets, there is no need to tune the hyperparameter M, which can avoid the waste of time caused by unnecessary tuning. The accuracy rate of the hyperparameter optimization value judgment model obtained in this study can reach more than 80%. The test and evaluation results verify the feasibility of the optimized hyperparameter value recommendation, which provides an important basis for the fast tuning and optimization of the C4.5 algorithm parameters.
Similar content being viewed by others
Introduction
How can parameters be adjusted quickly to optimize the model after determining which algorithm to use? Although default parameter settings are available in most commercial software, just as the applicability of an algorithm fluctuates with the characteristics of the dataset, the default parameters are not applicable on all datasets. Therefore, for some data sets, it is necessary to adjust the parameters so as to achieve further model optimization. However, the adjustment and optimization of parameters often consume a lot of time in the modeling process, so how to achieve fast tuning of parameters is an important direction worthy of research and attention.
Generally speaking, the goals of data mining can be divided into description and prediction1. Descriptive data mining attempts to discover some implicit and previously unknown knowledge, which can provide theoretical support for future decision making. Unsupervised machine learning problems are a typical class of descriptive data mining tasks, such as frequent pattern mining, finding interesting associations and correlations in data, outlier analysis, and evolutionary analysis. Predictive data mining attempts to find a model or function to be used to predict unknown characteristics or outcomes of a given objective based on a dataset with currently known characteristics. Supervised machine learning problems are a typical class of predictive data mining tasks such as regression and classification. There is no clear dividing line between descriptive and predictive data mining. In some data mining tasks, descriptive and predictive data mining can be interchanged, and in some cases interesting patterns found by descriptive data mining can also be used for prediction. Vice versa, an easy-to-understand predictive model may have interesting patterns that are obvious and thus descriptive, such as a decision tree model.
Since the concept of data mining was introduced, various data mining algorithms have emerged in an endless stream. According to the different objectives of data mining tasks, it can be divided into four categories: classification, numerical prediction, clustering and association rules.
Classification, as one of the most important techniques in data mining, has a wide range of applications and many algorithms have been proposed so far. The so-called classification is a technology that constructs a classifier according to the feature attributes of a data set and uses the knowledge learned by the classifier to make category discrimination and prediction for samples of unknown categories2. The construction process of classifier is generally divided into two stages: training and test. In the training phase, the classifier learns the features of the training data set to produce a specific description or model of the current data set for each category. In the test stage, the test data is classified by using the description or model of various categories obtained in the training stage, and the classification accuracy of the classifier is tested.
According to the learning characteristics of each algorithm, classification algorithms can be divided into the following four categories: classification algorithms based on neural networks; classification algorithms based on Bayes; tree-based classification algorithms and other statistics-based classification algorithms. Logistic regression3, discriminant analysis4 and nearest neighbor algorithm5 have been widely used in many fields as classical statistical methods. In recent years, on the basis of statistical theories, support vector machines (SVM) have developed vigorously, showing their unique advantages in solving small-sample, nonlinear and high-dimensional pattern recognition problems6, and have attracted the attention and promotion of scholars in many fields. In addition, rough set theory7, fuzzy set theory8, genetic algorithm9 and ensemble learning method10 are introduced into the classification task.
Decision tree algorithms represented by Iterative Dichotomiser 3 (ID3)11, C4.5, Classification and Regression Tree (CART)12 and Chi-squared Automatic Interaction Detection (CHAID)13 are the most popular tree-based classification algorithms at present. Compared with other classification algorithms, they have the advantages of easy to understand the generated rules, faster learning speed and higher classification accuracy. However, they are prone to overfitting the data in the process of decision tree training, so they have necessary to carry out reasonable pruning to ensure the generalization of the model.
When a certain model or algorithm is determined, it usually needs to go through a series of parameter settings and adjustments to get relatively better results. In 2006, Ali and Smith conducted a comparative study on which kernel function should be selected for different characteristic datasets in 112 classification datasets within the UCI database14. They used 29 dataset characteristic metrics similar to those used in the STATLOG15, and set five kernel functions of support vector machines for learning classification respectively. The classification accuracy was used as the evaluation method, and the C4.5 algorithm16 was used to generate mapping rules. In 2015, Biondi and Prati introduced transfer learning into the parameter setting study of support vector machines17. Each algorithm has more or less parameters that need to be set and adjusted, such as the minimum sample number of decision leaf nodes, the initial weight of the neural network, the number of hidden layers, the number of clustering categories, and the confidence and support degree of association rules. Therefore, how to select and optimize parameter more efficiently is still a problem that needs our continued attention.
Faced with an independent new data set, the applicability of different algorithms and the applicability of default parameters is unknown due to its own characteristics. So, how to make model selection and hyperparameter optimization to ensure the successful application of data mining algorithms on independent new data sets? There are currently sub-communities of machine learning focused on solving the problem of parameter optimization, and they have demonstrated great success in many applications. However, the cost of hyperparameter optimization is still prohibitive for some algorithms with high computational cost of optimization.
The C4.5 decision tree can be applied in various fields and discovers knowledge for human understanding. However, different problems typically require different parameter settings. Rule of thumb or trial-and error methods are generally utilized to determine parameter settings. However, these methods may result in poor parameter settings and unsatisfactory results. John proposed a method for using cross-validation as the objective function in an exhaustive search for the best value of the M parameter, he tried all values from l to 10, 12, 15, 20, 25 and every tenth value from 30 to 10018. Lin et al. proposed a novel scatter search-based approach (SS + DT) to acquire optimal parameter settings and to select the beneficial subset of features that result in better classification results. For evaluating the model created by the DT, the most commonly used metric is the classification accuracy rate. Therefore, the classification accuracy rate was adopted as the objective function in this study19. Aaboub et al. investigated the efficacy of six decision tree methods that are based on a variety of node splitting metrics, results demonstrate that the traditional ID3 and CART approaches perform better than the other methods20. Most studies focused on tree construction and rule generation. However, they did not consider parameter settings or the establishment of empirical rules.
In this paper, we focus on the empirical knowledge of medical data set analysis mining. According to the knowledge base constructed by the previous research21, it can be found that the decision tree C4.5 algorithm performs well on most medical data sets. Given that decision tree algorithm inherently possesses excellent interpretability, this paper studies the hyperparameter selection optimization of the C4.5 algorithm. This paper is devoted to finding and establishing mappings between different characteristic datasets and applicable hyperparameters, so as to further lay a theoretical foundation of parameter selection optimization for subsequent practical research on different medical datasets.
In this paper, the important hyperparameter M of C4.5 algorithm is studied by using 5-fold cross-validation and traversal optimization method. Then, the optimal value of hyperparameter M is associated and learned with the quantitative characteristics of the dataset, and the judgment model of the recommended value of hyperparameter M on different characteristic datasets is obtained, thus realizing the rapid parameter adjustment and optimization based on the characteristics of the dataset.
Methods
Overall research program
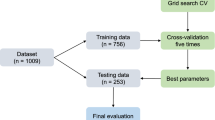
The C4.5 algorithm parameter selection and optimization study can be divided into three parts according to the module flow: construction of a meta-database for selection and optimization of C4.5 algorithm parameters, the generation of the mapping rule set for the optimized values of the C4.5 algorithm hyperparameters, and the evaluation and optimization of the mapping rule set. As shown in Fig. 1.

Research Process Illustration.
The base data sets in this paper are from the public available database, the UCI database, that is, the 293 data sets included in the study in the literature21. The metadata for C4.5 algorithm hyperparameter selection optimization mainly includes the optimal hyperparameter value data under different performance evaluation indexes in the process of C4.5 algorithm hyperparameter selection and adjustment. The quantitative characteristics of data set has been studied and calculated in previous studies. The performance of different hyperparameter values on each data set are calculated, sorted and evaluated to obtain the performance evaluation data of each hyperparameter value.
Based on the metadata base for hyperparameter optimization and selection of the C4.5 algorithm, preliminary statistics and analysis were carried out. Then, cross-validation method combined with a variety of classical data mining algorithms was used to learn the knowledge of the above meta data sets after data preprocessing. Thus, mapping rule sets of C4.5 hyperparameters applicable to different characteristic data sets were obtained.
The hyperparameter optimized value mapping rule set of C4.5 algorithm generated above is evaluated from the aspects of accuracy, generalization and ease of use. According to the evaluation results, the generated mapping rule set is optimized.
C4.5 algorithm parameter optimization
Overview and selection of adjustable parameters
The parameters of the algorithm include hyperparameters and parameters obtained by training. In machine learning algorithms, hyperparameters are parameters whose values can be set before starting the learning process, which can define higher-level concepts such as the complexity of the model. In general, different models can be obtained by adjusting hyperparameters and training, and the model with the best evaluation results will be selected to optimize on the specific data set, so as to improve the performance of learning. This paper selects the RWEKA package in programming language or software tool R, which is easy for medical staff to learn and adopt, to study and analyze the hyperparameters of the existing mature and active C4.5 algorithm. The following 12 hyperparameters are involved:
(1) U: Use unpruned tree, the parameter value can be set to the logical value “true” or “false”.
(2) O: Not fold the tree, the parameter value can be set to the logical value “true” or “false”.
(3) C: Set the confidence threshold of pruning, the default value is 0.25.
(4) M: Set the minimum sample number of each leaf node, the default value is 2.
(5) R: Use the error reduction method to prune, the parameter value can be set to the logical value “true” or “false”.
(6) N: Set the number of pruning folds used to reduce error, where one fold is used as a pruning set, the other folds are used to build the decision tree, the default value is 3.
(7) B: Only use binary splitting, the parameter value can be set to the logical value “true” or “false”.
(8) S: Not perform the subtree lifting operation when pruning, the parameter value can be set to the logical value “true” or “false”.
(9) L: The data is not cleaned, after the decision tree is built. The parameter value can be set to the logical value “true” or “false”.
(10) A: Using Laplace smooth prediction probability, the parameter value can be set to the logical value “true” or “false”.
(11) J: For numerical variables do not use the minimum description length to correct the information gain, the parameter value can be set to the logical value “true” or “false”.
(12) Q: The seed used to randomize the data when using error reduction pruning, the default value is 1.
By analyzing the function of the above 12 hyperparameters and combining with the research purpose of this paper, we mainly optimize the two hyperparameters C and M to achieve model optimization.
Among preliminary test, pruning confidence C was set as 0.05, 0.10, 0.15, 0.20, 0.25, 0.30, 0.35, 0.40, 0.45 and 0.50, respectively, and multiple modeling and evaluation were conducted on multiple datasets. The results showed that the adjustment of hyperparameter C, that is, pruning confidence, had no significant impact on model evaluation results. Therefore, the focus of parameter optimization in this paper is the adjustment of hyperparameter M.
Parameter optimization and performance evaluation
For the minimum sample number allowed by each leaf node of the decision tree, that is, the hyperparameter M of the C4.5 algorithm, this paper takes 1 as the step size, and then takes the value from 1 to 100 for traversal optimization. In order to reduce random errors as much as possible, 5-fold cross-validation is used in the modeling process to reduce the possible impact on the prediction results when randomly dividing the training set and test set. In 5-fold cross-validation, the original data set is randomly divided into 5 sub data sets with the same size. Among the five sub data sets, one is retained as validation data for testing the model, and the remaining 5 − 1 sub data sets are used as training data. The cross-validation process is repeated five times, and each of the five sub data sets is used to validate the model only once. Then, an estimate results of the model can be obtained by averaging the results of the five validations. The advantage of the K-fold cross-validation method over the randomly divided training set and test set is that all samples are used for training and validation, and each sample is used for validation only once.
Accuracy is a measure of the overall prediction accuracy of the model and is obtained by the sample size that was correctly predicted dividing by the overall sample size. In general, the higher the accuracy, the better the classification model. However, for non-balanced data sets, the accuracy does not reflect the model prediction ability of a relatively small classification. In practical applications, we often need to consider the sensitivity, specificity and accuracy comprehensively according to the specific situation. For example, in situations such as disease surveillance and anti-spam, we often need to improve sensitivity while maintaining accuracy. Therefore, we used both area under curve (AUC) and F-measure values to evaluate the model prediction results. ROC curve is a comprehensive index reflecting sensitivity and specificity, reflecting the relationship between sensitivity and specificity. The AUC value is the area of the lower part of the ROC curve. In general, the AUC value is between 0.5 and 1.0, and the larger the AUC value, the higher the accuracy of the model prediction. F-Measure is a weighted harmonic average of precision and recall, which is often used to evaluate the merits of classification models. In this paper, the commonly used F1-Measure value is used for evaluation. In general, the larger the F1-measure value, the better the model. When F1 is higher, the prediction model is more effective. For each hyperparameter M value, the accuracy, AUC and F-measure value of the corresponding model prediction result are calculated, so as to realize the evaluation of the sensitivity, specificity and other aspects of the model.
C4.5 algorithm hyperparameter M optimization
The hyperparameter selection and optimization knowledge base of C4.5 algorithm is the learning and induction of performance evaluation data of different values of hyperparameter M on each base data set, and the calculation and collection of model performance metadata corresponding to different values of C4.5 algorithm hyperparameter M is its cornerstone.
The value of the C4.5 algorithm hyperparameter M is set to 1 to 100 with the step of 1, and the 5-fold cross-validation is used to build a decision tree prediction model on each UCI data subset included in the study, so as to carry out traversal optimization of the C4.5 algorithm hyperparameter M in the range of 1-100. The accuracy, AUC and F1-measure of the corresponding classification prediction model constructed by 100 different values of the C4.5 algorithm hyperparameter M were calculated respectively to evaluate the model prediction performance. After sorting out the above evaluation results, three evaluation results corresponding to 100 different values of C4.5 algorithm hyperparameter M on each data set are obtained, so as to further analyze and determine the optimal value of C4.5 algorithm hyperparameter M.
Take the “Arrhythmia” dataset as an example. The dataset shared by Altay Guvenir is the data that has been used to distinguish the presence or absence of Arrhythmia and what kind of arrhythmia it is. It includes the data of the patient who has no arrhythmia and 15 kinds of arrhythmias. That is, the goal of this dataset is to diagnose whether or not arrhythmia is present and the type of arrhythmia, which can be converted into multiple classification tasks. The database contains 279 attribute variables, of which 206 are continuous variables and the rest are discrete variables, including a series of relevant examination indicators such as age, gender, height, weight, and the output value of each ECG channel.
The three evaluation results corresponding to 100 different values of C4.5 algorithm hyperparameter M on the “Arrhythmia” dataset are listed in Table 1 for comparison.
It can be seen from Table 1 that when the hyperparameter M is set to 4, the accuracy of the model is the highest, 74.0476%. When M is 8, the AUC value of the model is the highest, which is 0.7285. When M is 7, the F1-measure value of this model is the highest, 0.4431. Considering the accuracy, AUC and F1-measure, the optimal value of hyperparameter M can be obtained as 8.
Like the above data set, the accuracy, AUC and F1-measure of the corresponding classification prediction model constructed by the remaining 291 UCI data subsets included in the study were calculated when the C4.5 algorithm hyperparameter M took 100 different values respectively.
An exploratory analysis is performed on the C4.5 algorithm hyperparameter M selection meta-database, aiming to derive preliminary findings that inform parameter value selection and optimization. Through the above exploratory analysis, we have a preliminary understanding of the selection of the algorithm hyperparameter M. In order to further discover the hidden feature knowledge in the selection of the algorithm hyperparameter M, this study uses stepwise regression and C4.5 decision tree to build models for learning, so as to find the features or rules that need to be further analyzed and discussed in the previous exploratory statistical analysis.
Results
The selection meta database of the C4.5 algorithm hyperparameter M
In the process of calculation and collation, it is found that on some data sets, when the C4.5 algorithm hyperparameter M is adjusted in the range of 1-100, the performance of the corresponding prediction model changes slightly. In the “Adult” dataset shown in Figs. 2 and 3, the value changes of the three evaluation indicators are all within 3%.

Model prediction accuracy corresponding to different values of hyperparameter M on the “Adult” dataset.
As can be seen from Fig. 2, as the value of hyperparameter M changes from 1 to 100, the prediction accuracy of the constructed corresponding model generally presents a downward trend, but generally maintains within the range of 85.1-85.9%, with a small fluctuation range.

Model AUC and F1-measure corresponding to different values of hyperparameter M on the “Adult” dataset.
As can be seen from Fig. 3, as the value of the hyperparameter M changes from 1 to 100, the AUC and F1-measure value of the constructed corresponding model generally show a stable state, with a slight downward trend. The AUC value is generally maintained in the range of 0.87–0.90, and the F1-measure value is in the range of 0.78–0.81, and both the fluctuation range is small.
Based on the above findings, the following rules are formulated in this paper for comparative analysis, and the optimized values of hyperparameter M on each data set are transformed. The specific rule formulated is that if the value of the hyperparameter M is the default value 2, and the difference between the values of the three evaluation indicators of the corresponding model and the maximum values of the three evaluation indicators is less than 4%, the default value 2 is considered to be the appropriate value without further optimization. If the default value of the hyperparameter M is 2, and the difference between the value of the three evaluation indicators of the corresponding model and the maximum value of the three evaluation indicators is greater than 4%, then the three groups of indicators corresponding to the maximum value of any of the three evaluation indicators are compared, and the M value corresponding to the group in which the three evaluation indicators are relatively large is selected as its optimization value.
The optimization M value obtained by synthesizing three evaluation indicators on each dataset was sorted and summarized, and then matched and integrated with the quantitative data of the dataset characteristics constructed in previous studies. In addition, a new dataset characteristic “sample number of minimum category” was added. The meta-database of C4.5 algorithm hyperparameter M is constructed, laying the data foundation for analyzing parameter value optimization and selection.
The knowledge base of C4.5 algorithm hyperparameter M selection
Among 293 UCI data subsets included in the study, 13 mixed variable datasets and 2 continuous variable datasets failed to complete the traversal optimization of C4.5 hyperparameter M due to hardware limitations. The optimized value of hyperparameter M is discretized, and the frequency statistical results are shown in Table 2.
As can be seen in Table 2, when hyperparameter M was set as default value 2, there are 67 decision trees constructed on mixed variable datasets, 25 on discrete variable datasets, and 137 on continuous variable datasets reach the optimal performance. According to the analysis of Tables 2 and 65% of the mixed variable data sets can achieve better prediction results when the default value 2 of the C4.5 algorithm hyperparameter M is adopted, 73% of the discrete variable data sets and 87% of the continuous variable data sets can adopt the default setting of parameter M when constructing the decision tree model.
Through the above exploratory analysis, we have a preliminary understanding of the selection of the algorithm hyperparameter M. In order to further discover the hidden feature knowledge in the selection of the algorithm hyperparameter M, this study uses stepwise regression and C4.5 decision tree to build models for learning, so as to find the features or rules that need to be further analyzed and discussed in the previous exploratory statistical analysis.
Stepwise regression model
The optimized value meta-data of the discretized C4.5 algorithm hyperparameter M was studied and analyzed. With “optimized M value " as the target variable and the 26 quantization characteristics of data sets as attribute variables, the stepwise regression model was constructed to obtain the data set characteristics related to the optimized hyperparameter M value on the three kinds of datasets, mixed variable, discrete variable and continuous variable data sets, respectively. See Table 3 for details. The corresponding expression for determining the recommended hyperparameter M optimization value is shown in Formulas (1) to (3). The coefficients of stepwise regression refer to the regression coefficients corresponding to each independent variable when it is retained in the model during the stepwise regression analysis process. The coefficients of stepwise regression (a, b, c in Formulas (1) to (3)) reflect the degree and direction of the influence of independent variables on the dependent variable.
The expression for judging the recommended hyperparameter M value on the mixed variable data sets is Formula (1), and the coefficients corresponding to each recommended value are shown in Table 4.
The quantization characteristics value of the data set is substituted into Formula (1), and the M value corresponding to the maximum value of the calculated result is the recommended M value of the data set.
The expression for judging the recommended value of hyperparameter M on the discrete variable data sets is Formula (2), and the coefficients corresponding to each recommended value are shown in Table 5.
The quantization characteristics value of the data set is substituted into Formula (2), and the M value corresponding to the maximum value of the calculated result is the recommended M value of the data set.
The expression for judging the recommended value of hyperparameter M on the continuous variable data sets is Formula (3), and the coefficients corresponding to each recommended value are shown in Table 6.
The quantization characteristics value of the data set is substituted into Formula (3), and the M value corresponding to the maximum value of the calculated result is the recommended M value of the data set.
Decision tree model
With “optimized M value " as the target variable and the 26 quantization characteristics of data sets as attribute variables, the C4.5 algorithm decision tree model was constructed, and the obtained decision tree for determining the optimal value of hyperparameter M is shown in Figs. 4, 5 and 6.

Decision tree judgment model for recommended value of hyperparameter M - mixed variable data sets.

Decision tree judgment model for recommended value of hyperparameter M - discrete variable data sets.

Decision tree judgment model for recommended value of hyperparameter M - continuous variable data sets.
Take the leftmost branch in Fig. 4 as an example. Suppose we have a mixed variable data set, where the value of E_C is 0.85 and the value of N is 70. Then substitute them into the decision tree to obtain the final recommended M value is 5.
Discussion
This paper studies mapping rules for the selection and optimization of hyperparameters when C4.5 algorithm is applied to different characteristics data sets. On the one hand, it is helpful to select applicable hyperparameter values more quickly and reasonably, and on the other hand, it provides theoretical data support for subsequent research or improvement of data mining methods applicable to various characteristic data sets. Since there are many data mining algorithms, and there are multiple programming languages and platforms that can realize these algorithms, the research goal of this paper is to establish the hyperparameter optimization value mapping rule set of C4.5 algorithm to further improve the algorithm applicability knowledge base, and focus on serving the medical research field where most researchers have no engineering background. Therefore, this study selects programming languages or software tools that are relatively easy for medical staff to learn and adopt to conduct hyperparameter research and analysis on the existing mature and active C4.5 algorithm package.
By combining the results of exploratory analysis of the above three types of data sets and the results of stepwise regression and decision tree modeling learning after evaluation, the following knowledge of the recommended value of hyperparameter M based on prediction accuracy evaluation can be obtained:
(1) On more than 65% of data sets, C4.5 algorithm can build a classification prediction model without further optimization by using default parameter settings.
(2) To determine whether the C4.5 algorithm hyperparameter M needs to be optimized for a certain research data set, the quantization characteristics of the relevant data set can be consulted and calculated according to the types of variables covered by the data set and Table 3 of this paper. Then, by substituting the data set characteristics into the decision tree model as shown in Fig. 4 or Fig. 6, the recommended value range of the hyperparameter M of the mixed variable dataset or continuous variable data set can be determined. The discrete variable data set can be calculated according to the corresponding coefficients in Formula (2) and Table 5 to obtain the appropriate optimal value of hyperparameter M.
To verify the effectiveness of the proposed SS + DT approach, 23 datasets from the UCI Machine Learning Repository were implemented by Lin et al. The range of minimum cases (M) for the leaf is 2–20, whereas the range of pruning confidence level (CF) is 0.01–0.35 (1–35%). Unfortunately, the M and CF are varied for different problems. Generally, the M is preferred to be a high value when data is noisy; on the other hand, the CF should be a lower value when the test error rate of pruned tree exceeds the estimated error rate19. John proposed that the parameter M depends heavily on the training set size18. As can be seen in Figs. 4 and 6, the sample size (N) has an impact on the selection of the optimal value of the hyperparameter M in mixed variable and continuous variable data sets.
In this paper, a fast-tuning method for C4.5 algorithm hyperparameter M based on data set characteristics is proposed. Through the verification on the training set and test set of the metadata of C4.5 algorithm hyperparameter optimization value, the accuracy rate of the hyperparameter optimization value judgment model obtained in this study can reach more than 80%, which proves the validity and feasibility of the constructed judgment model theoretically, thus realizing the rapid parameter adjustment optimization based on the characteristics of the data set. In medical research, data sets are often unbalanced due to different disease incidence rates, and predictive models need to be evaluated in combination with sensitivity and specificity. Previous studies on the optimization of algorithm parameters used base data sets less than 100, and most of them used a single index accuracy for prediction performance evaluation. In this paper, three evaluation values of accuracy, AUC and F1-measure and 293 basic data sets were used to build a meta-database of hyperparameter M optimization required by the study. Both sample size and metadata quality were improved. The clinical prediction model established based on the obtained knowledge of optimal value of C4.5 algorithm hyperparameter M could take into account sensitivity and specificity. That is to reduce the rate of misdiagnosis and missed diagnosis.
As mentioned above, the purpose of this article is to serve the personnel engaged in the integration of medicine and engineering. Currently, only the C4.5 decision tree and the dataset for classification tasks has been studied. More studies can be done in the future. First, as the proposed scheme framework is versatile, exploring the potential application of this approach to other data mining techniques to improve the classification result. Second, the proposed approach can be applied to other real-world problems to determine whether it can effectively solve such problems, such as numerical predictions.
Conclusion
By adjusting the hyperparameters of the model, the model can be optimized and improved. Because C4.5 algorithm has the advantages of high prediction accuracy, fast modeling speed and strong interpretability, it is suitable for popularization and application in medical data sets. In this paper, the important hyperparameter M of C4.5 algorithm, that is, the minimum sample number of each leaf node, is iteratively optimized to explore its optimal value. The optimal value of the hyperparameter M is associated with the quantization characteristics of the data sets, and the judgment model of the recommended value of the hyperparameter M on different characteristic data sets is obtained. The results of this study show that on more than 65% of the data sets, there is no need to tune the hyperparameter M, which can avoid the waste of time caused by unnecessary tuning. For the data set that needs to be tuned, the judgment model in this study can quickly determine the appropriate value range of hyperparameter M according to the characteristics of the corresponding data set, effectively shortening the time of parameter tuning. Further research will continue to explore the potential applications of this scheme framework in other data mining techniques and other research fields.
Data availability
Data is provided within the manuscript.
References
Wang, G. & Jiang, P. Survey of data mining. J. Tongji Univ. (Natural Science). 32 (2), 246–252 (2004).
Liu, H., Chen, J. & Chen, G. Review of classification algorithms for data mining. J. Tsinghua Univ. (Science Technology). 42 (6), 727–730 (2002).
Seal, H. L. Estimation of the probability of an event as a function of several independent variables. Biometrika 54 (1/2), 167–179 (1967).
Fisher, R. The use of multiple measurements in taxonomic problems. Annals Eugenics. 7 (2), 179–188 (1936).
Altman, N. An introduction to kernel and nearest-neighbor nonparametric regression. Am. Stat. 46 (3), 175–185 (1992).
Ding, S., Qi, B. & Tan, H. An overview on theory and algorithm of support vector machines. J. Univ. Electron. Sci. Technol. China. 40 (1), 2–10 (2011).
Wang, G., Yao, Y. & Yu, H. A survey on rough set theory and applications. Chin. J. Comput. 32 (7), 1229–1246 (2009).
Guo, M., Jia, X. & Shang, L. Decision-theoretic rough set attribute reduction and classification based on fuzzification. Pattern Recog. Artif. Intell. 27 (8), 701–707 (2014).
Li, M., Xu, B. & Kou, J. On the combination of genetic algorithms and neural networks. Syst. Engineering-Theory Pract. 19 (2), 1–7 (1999).
Zou, Q. et al. Multi-class classification algorithm based on ensemble learning and hierarchical structure. Pattern Recog. Artif. Intell. 28 (9), 781–787 (2015).
Quinlan, J. Induction of decision trees. Mach. Learn. 1 (1), 81–106 (1986).
Breiman, L. et al. Classification and regression trees (CART). Encyclopedia of Ecology, 40(3): 582–588. (1984).
Kass, G. An exploratory technique for investigating large quantities of categorical data. Appl. Stat. 29 (2), 119–127 (1980).
Ali, S. & Smith-Miles, K. A meta-learning approach to automatic kernel selection for support vector machines. Neurocomputing 70 (1–3), 173–186 (2006).
King, R., Feng, C. & Sutherland, A. Statlog: comparison of classification algorithms on large real-world problems. Appl. Artif. Intell. 9 (3), 289–333 (1995).
Quinlan, J. C4.5: Programs for Machine Learning [M] (Morgan Kaufmann Publishers Inc, 1992).
Biondi, G. & Prati, R. Setting parameters for support vector machines using transfer learning. J. Intell. Robotic Syst. 80 (1), 295–311 (2015).
John, G. H. Cross-validated C4.5: using error estimation for automatic parameter selection [C] // Proceedings of the AAAI Workshop on Statistical Methods in Machine Learning, (1994).
Lin, S. W. & Chen, S. C. Parameter determination and feature selection for C4.5 algorithm using scatter search approach. Soft. Comput. 16 (1), 63–75 (2012).
Aaboub, F., Chamlal, H. & Ouaderhman, T. Statistical analysis of various splitting criteria for decision trees. J. Algorithms Comput. Technol. 17, 1–12 (2023).
Zhang, Y., Li, Q. & Xin, Y. Research on eight machine learning algorithms applicability on different characteristics data sets in medical classification tasks. Front. Comput. Neurosci. 18, 1345575 (2024).
Acknowledgements
This work was funded by the Qingdao Huanghai University Doctoral Research Foundation Project 2023boshi02.
Author information
Authors and Affiliations
Contributions
Z.Y. wrote the main manuscript text and X.Y. and L.Q. proposed the conception. All authors reviewed the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Zhang, Y., Xin, Y. & Li, Q. Research on parameter selection and optimization of C4.5 algorithm based on algorithm applicability knowledge base. Sci Rep 15, 29418 (2025). https://doi.org/10.1038/s41598-025-11901-2
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-11901-2
