
Abstract
Criteria to identify patients who are ready to be liberated from mechanical ventilation (MV) are imprecise, often resulting in prolonged MV or reintubation, both of which are associated with adverse outcomes. Daily protocol-driven assessment of the need for MV leads to earlier extubation but requires dedicated personnel. We sought to determine whether machine learning (ML) applied to the electronic health record could predict next-day extubation. We examined 37 clinical features aggregated from 12AM-8AM on each patient-ICU-day from a single-center prospective cohort study of patients in our quaternary care medical ICU who received MV. We also tested our models on an external test set from a community hospital ICU in our health care system. We used three data encoding/imputation strategies and built XGBoost, LightGBM, logistic regression, LSTM, and RNN models to predict next-day extubation. We compared model predictions and actual events to examine how model-driven care might have differed from actual care. Our internal cohort included 448 patients and 3,095 ICU days, and our external test cohort had 333 patients and 2,835 ICU days. The best model (LSTM) predicted next-day extubation with an AUROC of 0.870 (95% CI 0.834–0.902) on the internal test cohort and 0.870 (95% CI 0.848–0.885) on the external test cohort. Across multiple model types, measures previously demonstrated to be important in determining readiness for extubation were found to be most informative, including plateau pressure and Richmond Agitation Sedation Scale (RASS) score. Our model often predicted patients to be stable for extubation in the days preceding their actual extubation, with 63.8% of predicted extubations occurring within three days of true extubation. Our findings suggest that an ML model may serve as a useful clinical decision support tool rather than complete replacement of clinical judgement. However, any ML-based model should be compared with protocol-based practice in a prospective, randomized controlled trial to determine improvement in outcomes while maintaining safety as well as cost effectiveness.
Similar content being viewed by others


Introduction
Mechanical ventilation (MV) is a life-saving intervention to support patients with respiratory failure. However, MV is also an invasive therapy with substantial risks1. Hence, ICU physicians seek to extubate patients at the earliest point in their hospital course when they can sustain spontaneous breathing without an artificial airway.
Premature extubation can lead to reintubation, which is associated with a prolonged ICU stay and greater hospital mortality2. As a result, physicians often delay weaning, prolonging the duration of MV and its associated complications3. Implementation of protocolized daily screening by nurses or respiratory therapists followed by spontaneous breathing trials (SBTs), without needing explicit physician orders at each step, reduces the duration of MV and ICU stay4. Despite this, compliance with these protocols is highly variable and SBTs alone have poor operating characteristics in predicting successful extubation5,6,7,8. Furthermore, these protocols distract from other processes of care, increase costs, and are difficult to continue when ICU resources become limited9.
The success of protocol-driven weaning highlights the value of objective and data-driven approaches to assist healthcare providers identify candidates for liberation from MV. Electronic Health Records (EHRs) ingest continuous clinical data that report on patient physiology, including vital signs, laboratory results, medications, and ventilator parameters10. Machine learning (ML) uses computational techniques that identify complex non-linear relationships within disparate data, including those in the EHR, to improve the accuracy of clinical decisions11,12. We sought to determine whether ML approaches applied to EHR data could predict next-day extubations and therefore assist with clinical decision-making.
Methods
Study participants and setting
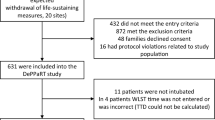
Clinical data was gathered from patients enrolled in the SCRIPT study (NU IRB # STU00204868)13,14,15 at Northwestern Memorial Hospital (NMH) for the training, validation, and internal test cohorts. SCRIPT is a single-site prospective cohort study of patients requiring mechanical ventilation, who underwent bronchoalveolar lavage for known or suspected pneumonia; patients or their legal authorized representative consented to participate in this study. Data from an external test cohort of MICU patients at a community hospital that provides advanced care within an academic health system, Central DuPage Hospital (CDH), were collected separately (NU IRB # STU00216678); this was a retrospective data-only protocol and received a waiver of informed consent. All research was performed in accordance with relevant guidelines/regulations. We included CDH patients who received MV, with ICD-9 or ICD-10 codes for pneumonia or from the top 10 ICD codes of SCRIPT patient admissions (Supplemental Table 1); we excluded patients admitted from an operating room to minimize surgical ICU patients. Our MICU has a standardized protocol for daily SAT/SBTs, though adherence to this protocol and associated documentation is variable and declined during the COVID-19 pandemic.
Data
EHR data from both hospitals were extracted from the Northwestern University Enterprise Data Warehouse16, and were manually reviewed and validated by ICU physicians who focused specifically on ventilation features and markers of intubation and extubation. Over two hundred charts were manually reviewed by physicians to ensure the accuracy of the extracted data, especially around intubation/extubation status. When the reviewing clinician was uncertain, a study adjudication committee meeting comprised of five critical care physicians made a consensus decision that was considered final. Our group is experienced in the annotation of clinical data in a rigorous, predefined process.17 Each patient chart was reviewed by the research study team to gather information including transition to comfort measures only (CMO). For patients who had multiple sequences of intubation and extubation, we used only the first intubation/extubation sequence. Because models trained on this kind of retrospective real-world data can only learn from previous clinical practice, we wanted to optimize the information provided to the model during training. Thus, from the training set, we excluded patients with tracheostomy and failed extubation (requiring reintubation within two days) and excluded ICU days with palliative extubation and extubation while on extracorporeal membrane oxygenation (ECMO) from our training data, so that the model would best learn how to predict sucessful extubation. Additional details are available in Supplemental Methods.
Missing data
Missing data is common in real-world EHR data. Some missing data in the EHR are not random, instead reflecting a change in clinical status that results in different patterns of monitoring and documentation. We reported the percent missing for each feature in Supplemental Table 2. Some ML models (such as XGBoost and LightGBM, detailed below and in Supplemental Methods) are designed to incorporate missing data. For other models, including RNN and LSTM, we tested several imputation strategies, including mean imputation and a binning strategy inspired by FIDDLE18. For binning, features were coded into a flag indicating missing/present, and flags indicating the quartile range into which the data point fell. For example, a day with a respiratory rate of 24 breaths per minute would have a 0 for the missing flag (indicating the data are present), a 0 for the first bin that encompasses range < 18 breaths per minute, a 0 for the second bin that encompasses range [18,22), a 1 for the third bin that encompasses range [22,27.4), and a 0 for the fourth bin that encompasses the highest range of 27.4. Details of each strategy are outlined in Supplemental Methods and in our code repository.
Labels
We labeled the patient’s intubation status on each day as intubated, extubated, failed extubation, comfort measures palliative extuation, or pre-intubation. After removing pre-intubation days, and sequences where there was failed extubation or palliative extubation, our dataset contained only intubated days for training. The label of interest that our models predicted was the next day’s intubation/extubation status. Additional details on labeling and filtering are available in Supplemental Methods.
Split
Our training dataset contains patients with hospital admission dates ranging from June 2018 to August 2023 (Fig. 1). We split patients into train and test sets based on a cutoff date of August 20, 2021. This split put 80% of patient hospitalizations before that date into the train set, and the 20% after into the test set. We further split the train data into smaller train and validation subsets based on an 80/20% random split.

(A) Data split for model development: schematic describing the data split used in our clinical ML study. The dataset was divided into three distinct subsets: the training set, validation set, and test set. The training set was used to train the MLmodels, the validation set for tuning and model selection, and the test set to assess the final model’s performance and generalization to unseen data. (B) Data processing pipeline; full details are available in Supplemental Methods. Individual days are labeled as intubated or extubated, with 12am–8am aggregated features used to predict next-day intubation/extubation status. Data are cleaned, detailed in Methods and Supplemental Methods, before ML models are trained and evaluated.
Modeling
Detailed explanations and comparisons of the models are available in Supplemental Methods.
Performance metrics
The primary metric for model evaluation was the Area Under the Receiver Operating Characteristic curve (AUROC). Additional metrics included Area Under the Precision-Recall Curve (AUPRC), Accuracy, F1-Score, Precision (PPV), Recall (Sensitivity), and Specificity. The threshold was set using the class imbalance in the train set. Specifically, the ratio of next-day intubated days to all days (0.91).
Feature importance
To understand and interpret the effect of the various features on the predictions made by our deep learning models, we used ablation techniques by masking individual features for 37 iterations (total features) and observing the decrease in AUC without that feature available. We also used XGBoost’s SHAP (Shapley Additive exPlanations) values19. For our logistic regression model, we plotted the top feature coefficients. More detailed explanations are available in Supplemental Methods.
Statistics
Descriptive statistics are reported for the train/validate/test cohorts using % and median [Q1,Q3]. Comparisons between nonparametric data were done using Mann–Whitney U tests.
Code and data availability
A detailed description of data extraction, processing, and modeling are available in our code repository at https://github.com/NUPulmonary/2024_Fenske_Peltekian. Programming was done in Python version 3.10. LLMs were used to help coding, with output reviewed and edited by authors. A deidentified version of our data is available on PhysioNet.20.
Reporting checklist
We followed the TRIPOD Checklist for predictive model development, which is available in Supplemental Materials.
Results
Cohort description
We examined data from patients enrolled in the Successful Clinical Response In Pneumonia Therapy (SCRIPT), a single-site prospective cohort study of patients requiring MV, who underwent bronchoalveolar lavage for known or suspected pneumonia at NMH from 2018 to 2023. 712 enrollments in SCRIPT occurred during the study period, with 940 separate ICU stays totaling 16,402 ICU days. After filtering days and stays for our next-day extubation task, we trained and evaluated using 448 unique patients, 478 ICU stays, and 3,095 ICU days. External testing was done using EHR data collected from patients in a mixed medical surgical ICU from a community hospital, Central DuPage Hospital (CDH), from 2018 to 2022. Our CDH dataset consisted of 459 unique patients, 518 ICU stays, and 5,814 ICU days. This was filtered down to 333 unique patients, 349 ICU stays, and 2,835 ICU days. The failed extubation rate, defined as requiring reintubation within two days was 23.1% and 15.8% in the SCRIPT and CDH cohorts, respectively. Patient demographics and outcomes are reported in Table 1 between the train/validate/test and external sets. In the SCRIPT cohort, the median [Q1,Q3] patient age was 64 [51, 72]; 44% of the patients were female; 25% patients had COVID-19. The percent of patients with unfavorable outcomes was 45% for the entire SCRIPT cohort and 42% for the external CDH cohort.
Features
Our features were inspired by the practice of daily multidisciplinary rounds in the ICU and built off a previously described dataset from our group13,20. As almost all extubations occurred after 8AM (Supplemental Fig. 1), we used only data from midnight to 8AM. This strategy is consistent with the protocol-driven weaning shown to reduce the duration of MV4 and can facilitate future deployment by presenting model predictions to the clinical team during morning rounds. For a given timestep, the model was fed with a dataset of 37 features pertaining to a specific patient, aggregated from the hours of 12–8am from a single day. Multiple measurements of the same feature within this time period were aggregated by taking the mean. Missing data handling is discussed in detail in Methods and Supplemental Methods, including our binning encoding process. Features included in the dataset span ventilator parameters, laboratory values, mental status assessments, and organ failure assessments. While the demographics and overall outcomes were similar among the different datasets, the features were markedly different (Table 2, Supplemental Table 2), likely reflecting changes in the cohort of patients requiring MV during the COVID-19 pandemic. A summary of the different types of intubation/extubation sequences and how often they occurred are presented in Supplemental Fig. 2.

(A) Performance metrics of different ML models. The receiver operating characteristic curve (ROC), precision-recall curve (PRC) plots of different ML models on same test set along with values of respective area under the curves, using each model’s best-performing imputation method, including extreme gradient boosting (XGBoost), Recurrent Neural Network (RNN), and long short-term memory (LSTM), on the test set, using different imputation strategies (raw and binning, detailed in Methods). Curves displayed are for a single pass through the test set. Full metrics and confidence intervals for the top optimized models shown are in Supplemental Table 4. (B) Model performance on external test cohort. We applied our top-performing binned LSTM model (based on AUROC) to a patient cohort from a different hospital system as an external test. ROC and curves show similar performance to the SCRIPT test set in Fig. 2. Curves displayed are for a single pass through the test set. Full metrics and confidence intervals for the top optimized models shown are in Supplemental Table 4.
Model results
Both traditional ML models and deep learning architectures were employed. We used traditional models, including logistic regression,21 random forest,22 LightGBM,23 and XGBoost,24 to make daily predictions. In contrast, deep learning models, specifically Recurrent Neural Networks (RNNs)25 and Long Short-Term Memory networks (LSTMs),26 used the entire patient sequence to make predictions. Predictions were generated for each ICU day, with the label of interest being the next-day intubation/extubation status. The performances of the predictive models using different processing strategies are summarized in Fig. 2. The performance of all the models in predicting extubation was similar. An LSTM classifier using binned data achieved the best performance with an area under the Receiver Operating Characteristic curve (AUROC) of 0.870 (95% CI 0.834–0.902) and an area under the Precision-Recall curve (AUPRC) of 0.382 (95% CI 0.269–0.492) on the temporally split test set (baseline rate of extubation/total days of 0.09, which would be the AUPRC for a no-skill model). Full metrics for all models before hyperparameter optimization are available in Supplemental Table 3 and full metrics for optimized models are available in Supplemental Table 4. In addition to the temporally split SCRIPT test set, we evaluated our top-performing model on data from an external hospital and found consistent performance across the two datasets (Fig. 2B).
Imputation/encoding strategies affect model performance
We compared the performance of different imputation strategies across models as well (additional details in Supplemental Methods). The best encoding strategy was binning, which encodes data presence or missingness, and then bins continuous variables into quartiles. The next was using raw data without any imputation, in models that could accommodate this such as XGBoost and LightGBM. Simpler but commonly employed strategies such as mean imputation performed consistently the worst across models all models (Supplemental Table 3).
Feature importance
We used an ablation technique to quantify LSTM feature importance and show the top 10 features (Fig. 3). They include markers of the patient’s mental status, as documented by Glascow Coma Scale (GCS), as well as markers of the patient’s lung physiology, as documented by presence of ventilator measurements such as plateau pressure. Different modeling approaches also show concordance in feature importance (Supplemental Fig. 3). Because RASS score and PEEP may be biased based on the clinician’s underlying adjustments to the ventilator or sedation, we performed additional sensitivity analysis on these features and report minimal effect on AUROC for LSTM models and similarly informative features (Supplemental Fig. 3).

Feature importance plot for LSTM model. Feature importance ablation plots for an LSTM model predicting next-day extubation provide insights in the significance of each feature. In these plots, each feature is a row, and the x axis represents how important that feature is. This feature importance is calculated by doing 37 iterations (number of features) while masking an individual feature each time and seeing the decline in AUC on the test set without that feature available.
Potentially missed opportunities and preventing failed extubations
Our model often predicted patients could be considered for extubation in the days preceding their actual extubation, suggesting opportunities to consider earlier extubation (Fig. 4). On a population level, we also observe the model to be more likely to predict extubation the closer it is to the true successful extubation event, suggesting that the model captures features associated with extubation readiness (Supplemental Fig. 4). We investigated model predictions on the days preceding failed extubation to see if it predicted the failed extubation. Our model predicted an ongoing need for mechanical ventilation through the extubation event in 35.4% (17/48) of these cases of failed extubation. A chart review of failed extubation cases revealed a diverse range of contributing factors, including airway protection (n = 8, 20.5%), altered mental status (n = 7, 17.9%), shock or hemodynamic instability (n = 7, 17.9%), secretions (n = 6, 15.4%), edema (n = 4, 10.3%), upper airway issues (n = 4, 10.3%), new pneumonia (n = 3, 7.7%), aspiration (n = 3, 7.7%), and respiratory distress (n = 2, 5.1%). Patients may have had more than one reason for extubation failure. These factors were identified from clinical notes; they are difficult to find using structured EHR data and thus not readily available for use as automatic model features.

Examining discrepancies between model prediction and time of extubation. (A) For each intubation sequence preceding extubation in the SCRIPT test cohort, we examined the first instance predicting next-day extubation (Supplemental Methods). Many model predictions, if not exactly one day before extubation as intended (29.3%), were within two days (50%) or three days (63.8%). (B) The same analysis as (A) performed on the external test cohort, where we report 37.3% of first next-day extubation predictions occurring within one day of successful extubation, 62.1% within two days, and 74.5% within three days.
Discussion
Identifying patients who are ready for extubation remains a challenging clinical problem in the ICU. Although ventilator-weaning protocols outperform routine physician-driven care,4,27 the adoption and standardization of these practices varies.5,28,29 Barriers to the adoption of some protocols include difficulty with coordination across nursing, respiratory therapy, and clinician roles,30 choice of sedation agent,31 and staff turnover.32 We built several ML models that incorporated features included in the electronic health record in most ICU settings. Several of these models performed well with the best model providing an AUROC above 0.85. These analyses suggest that EHR-based classifiers would have identified some patients who might have been considered for earlier spontaneous breathing trials (SBTs) and extubation. As SBTs have imperfect operating characteristics for predicting successful extubation,6,7,8 we propose that our model could provide an estimate of Bayesian pre-test (pre-SBT) probability to guide interpretation of the results of an SBT. For example, when the model predicts a high probability of extubation success, but the SBT result is borderline, the team may be more inclined to proceed with extubation. Conversely, a low predicted probability of success paired with an equivocal SBT result might lead the team to defer extubation and reassess readiness later. In this way, the model can support nuanced, probabilistic reasoning in situations where clinical indicators and protocolized assessments are ambiguous.
Other ML models in extubation decision support do not retrospectively evaluate failed extubation events or potentially missed opportunities, highlighting specific use cases where our model may improve patient outcomes by mitigating harms of premature extubation (e.g., traumatic re-intubation) or prolonged mechanical ventilation (e.g., VAP and upper airway injury).33 We recognize that when a model predicts extubation failure, it does not necessarily imply that the failed extubation could have been completely avoided. Outside of a study that randomizes patients to undergo extubation irrespective of the model’s output and clinical judgement, no counterfactual ground truth exists to show what would have happened if the patient had followed a different course. Nonetheless, we believe there are cases where a longer or shorter intubation period might have been beneficial, and a data-driven model can help identify those instances.
Extubation failure is a multifaceted issue that cannot be entirely predicted. In clinical practice, an adage suggests that if no extubations fail, clinicians may not be challenging patients early enough for extubation. With regards to false positives and false negatives, both are of concern as we aim to balance the risks of too-early extubation—which could lead to extubation failure and the need for reintubation—with the risks of complications associated with too-late extubation, such as ventilator-associated pneumonia (VAP) and delirium. On a day-to-day decision basis, clinicians in a medical ICU are likely to worry more about too-early extubation than about one additional day remaining intubated, as long as measures to optimize the patient for next-day extubation can be taken.
The models we used allow us to identify clinical features that drive their predictions. Protocol-driven weaning, which shortens the duration of MV, usually includes an assessment of mental status, oxygenation, hemodynamic stability, an absence of ongoing infection, and physiologic measures of lung mechanics.7,34 Our models were informed by clinical features that reflect these assessments, lending clinical plausibility to their predictions. Feature importance values reflect the weight of traditionally important parameters in extubation decision-making, suggesting that model predictions could have utility as an automated assessment of extubation readiness. Furthermore, models that treated each day independently performed similarly or just slightly inferior to sequential time series models that used information from multiple days, consistent with efficacy of protocols that assess readiness for spontaneous breathing on a daily basis irrespective of clinical context.3 Strong performance based on individual-day models compared with time-series models suggests that prior information of a patient’s clinical course may not be necessary for accurate extubation prediction.
We also examined the effect of different imputation strategies on model performance. Commonly used strategies, such as filling in missing values with the data’s mean value, performed significantly worse than maintaining missingness using either encoding strategies such as binning or working with models such as XGBoost that can inherently handle missing data. Binning effectively manages outliers by grouping extreme values into discrete intervals, thereby preventing them from skewing the model’s learning process. This approach not only naturally addresses data sparsity—ensuring a more consistent representation of missing values—but also aligns well with the sequential nature of time series models. Furthermore, binning discretizes features in a manner that can help the model capture nonlinear relationships in clinical time series data, without the need for an excessive number of parameters to model continuous distributions. This strategy can be particularly useful for complex models like deep learning algorithms where data in a medical context can have such extreme variance.
Compared with other ML models to predict extubation35 or shift off full ventilatory support,33 our work obtains good predictive performance when applied to a population of critically ill patients in both an internal test dataset and when applied to a distinct medical ICU setting. We employed a temporal training/validation/testing split, finding that models developed on data from 2018–2021 maintained solid performance when applied to test data from 2021 to 2023 and an external test cohort from 2018 to 2023. These results provide encouraging evidence that the models can adapt to varying data distributions, including those influenced by COVID-19 prevalence. Moreover, by identifying patterns and predicting outcomes in real time, the algorithm could help alleviate some of the burdens imposed by the limited availability of critical care expertise. Ensuring a sufficient time gap between data gathering and the prediction of interest is a crucial step in mitigating the risk of data leakage in a ML model. In contrast to studies that make predictions on the next time period without any gap for intervention,36 we specifically use only information from midnight to 8AM rather than the entire day so the model can offer this information to the multidisciplinary team on morning rounds to inform clinical decision-making.
There are several limitations. First, our model was trained using clinically adjudicated data from a quaternary care referral health system that cares for severely ill patients, reflected in the substantial mortality and long duration of MV, which might limit its relevance in other ICU settings. Nevertheless, the model performed well in a medical ICU from a community-based hospital, suggesting carefully curated data from relatively small populations can be used to train models for generalized use. Second, we limited the information used to train our models to physiological factors that are measured in most ICUs. Third, we acknowledge that high-risk extubation trials are sometimes clinically necessary, and such decision-making processes are difficult to capture in structured data alone. Future work incorporating clinical notes—potentially using large language models—may offer a promising approach to better understand and represent these nuanced judgments. The ICU used for the training dataset incorporates an evidence-based daily protocol for ventilator weaning. However, we were unable to determine from the EHR the levels of adherence to that protocol. It is possible that the levels of adherence to protocol-driven weaning may affect the incremental performance of the ML model. The incremental value of ML model over protocolized approach needs further studies before any conclusion can be drawn with confidence. Given we excluded cases of failed extubation from our training set, our model could possibly be biased towards predicting extubation, but we are reassured that, in the test set of failed extubation cases, the model suggested 35.4% of these cases remain intubated. Fourth, we trained our model using data from MICU patients with suspected pneumonia, which may limit its utility in different ICU settings, for example surgical or cardiac ICUs. While manual chart reviews were conducted on the SCRIPT cohort to validate our labeling strategy and model predictions, such manual review was not performed on the external test CDH cohort. Further validation through chart review would strengthen the case of the model’s generalizability. Finally, while our model supports the feasibility of an ML model to identify patients who might be considered for extubation, we have not yet deployed it in a clinical setting. Nevertheless, we designed our predictor with an eye towards deployment, only using data from midnight to 8AM, so that it might be able to provide outputs during clinical rounds. We emphasize that the model may serve as a clinical decision support tool rather than replacement of clinical judgement, and that it must be compared with protocol-based practice in a prospective, randomized controlled trial to determine improvement in outcomes while maintaining safety as well as cost effectiveness. We hope that this model predicting next-day extubation could help both shorten intubation duration and prevent failed extubations, to improve the care of critically ill patients.
Data availability
The data to reproduce our results has been deidentified and made publicly available to credentialed users who sign a DUA at PhysioNet: https://physionet.org/content/script-x2b8-dataset/1.0.0/. Code for processing and analysis are available at https://github.com/NUPulmonary/2024_Fenske_Peltekian.
References
Melsen, W. G. et al. Attributable mortality of ventilator-associated pneumonia: A meta-analysis of individual patient data from randomised prevention studies. Lancet Infect. Dis. 13(8), 665–671 (2013).
Epstein, S. K. & Ciubotaru, R. L. Independent effects of etiology of failure and time to reintubation on outcome for patients failing extubation. Am. J. Respir. Crit. Care Med. 158(2), 489–493 (1998).
Ely, E. W. et al. Effect on the duration of mechanical ventilation of identifying patients capable of breathing spontaneously. N. Engl. J. Med. New Engl. J. Med. (NEJM/MMS) 35(25), 1864–1869 (1996).
Girard, T. D. et al. Efficacy and safety of a paired sedation and ventilator weaning protocol for mechanically ventilated patients in intensive care (awakening and breathing controlled trial): A randomised controlled trial. Lancet 371(9607), 126–134 (2008).
Burns, K. E. A., Rizvi, L., Cook, D. J., Lebovic, G., Dodek, P., Villar, J., Slutsky, A. S., Jones, A., Kapadia, F. N., Gattas, D. J., Epstein, S. K., Pelosi, P., Kefala, K., Meade, M. O., Canadian Critical Care Trials Group. Ventilator weaning and discontinuation practices for critically ill patients. JAMA Am. Med. Assoc. (AMA) 325(12), 1173–1184 (2021).
Esteban, A. et al. A comparison of four methods of weaning patients from mechanical ventilation. Spanish Lung Failure Collaborative Group. N. Engl. J. Med. 332(6), 345–350 (1995).
Brochard, L. et al. Comparison of three methods of gradual withdrawal from ventilatory support during weaning from mechanical ventilation. Am. J. Respir. Crit. Care Med. Am. Thorac. Soc. 150(4), 896–903 (1994).
Perkins, G. D. et al. Effect of protocolized weaning with early extubation to noninvasive ventilation vs invasive weaning on time to liberation from mechanical ventilation among patients with respiratory failure: The breathe randomized clinical trial. JAMA Am. Med. Assoc. (AMA) 320(18), 1881–1888 (2018).
Dorado, J. H., Navarro, E., Plotnikow, G. A., Gogniat, E., Accoce, M., EpVAr Study Group. Epidemiology of weaning from invasive mechanical ventilation in subjects with COVID-19. Respir. Care 68(1), 101–109 (2023).
Cimino, J. J. Improving the electronic health record—are clinicians getting what they wished for?. JAMA 309(10), 991–992 (2013).
Wiens, J. & Shenoy, E. S. Machine learning for healthcare: On the verge of a major shift in healthcare epidemiology. Clin. Infect. Dis. 66(1), 149–153 (2018).
Ben-Israel, D. et al. The impact of machine learning on patient care: A systematic review. Artif. Intell. Med. 103, 101785 (2020).
Gao, C. A. et al. Machine learning links unresolving secondary pneumonia to mortality in patients with severe pneumonia, including COVID-19. J Clin. Invest. 133(12), e170682 (2023).
Grant, R. A. et al. Circuits between infected macrophages and T cells in SARS-CoV-2 pneumonia. Nature 590(7847), 635–641 (2021).
Super-SCRIPT (SCRIPT2) Systems Biology Center [Internet]. [cited 2025]. Available from: https://script.northwestern.edu/.
Starren, J. B., Winter, A. Q. & Lloyd-Jones, D. M. Enabling a learning health system through a unified enterprise data warehouse: The experience of the northwestern university clinical and translational sciences (NUCATS) institute. Clin. Transl. Sci. 8(4), 269–271 (2015).
Pickens, C. I., Gao, C. A., Bodner, J., Walter, J. M., Kruser, J. M., Donnelly, H. K., Donayre, A., Clepp, K., Borkowski, N., Wunderink, R. G., Singer, B. D., The NU SCRIPT Study Investigators. An adjudication protocol for severe pneumonia. Open Forum Infect. Dis. 10(7), 336 (2023).
Tang, S. et al. Democratizing EHR analyses with FIDDLE: A flexible data-driven preprocessing pipeline for structured clinical data. J. Am. Med. Inf. Assoc. 27(12), 1921–1934 (2020).
Lundberg, S., Lee, S. I. A unified approach to interpreting model predictions [Internet]. arXiv [cs.AI]. (2017). Available from: http://arxiv.org/abs/1705.07874.
Markov, N., Gao, C. A., Stoeger, T., Pawlowski, A., Kang, M., Nannapaneni, P., Grant, R., Rasmussen, L., Schneider, D., Starren, J., Wunderink, R., Budinger, G. R. S., Misharin, A., Singer, B., Study Investigators, NU SCRIPT. SCRIPT CarpeDiem Dataset: demographics, outcomes, and per-day clinical parameters for critically ill patients with suspected pneumonia. PhysioNet (2023) [cited 2023 Oct 16]. Available from: https://physionet.org/content/script-carpediem-dataset/1.1.0/
McCullagh, P. Generalized linear models. Eur. J. Oper. Res. 16(3), 285–292 (1984).
Breiman L. Mach Learn. Vol. 45(1), 5–32 (Springer Science and Business Media LLC, 2001).
Ke, G., Meng, Q., Finley, T., Wang, T., Chen, W., Ma, W., Ye, Q., Liu, T. Y., Research M, University P, Redmond M. LightGBM: A highly efficient gradient boosting decision tree [Internet]. [cited 2023 Oct 16]. Available from: https://proceedings.neurips.cc/paper_files/paper/2017/file/6449f44a102fde848669bdd9eb6b76fa-Paper.pdf.
Chen, T., Guestrin, C. XGBoost. in Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. (ACM, New York, NY, USA, 2016). https://doi.org/10.1145/2939672.2939785.
Medsker, L., & Jain, L. C. Recurrent Neural Networks: Design and applications. 1st edn (CRC Press, Boca Raton, FL, 1999).
Hochreiter, S. & Schmidhuber, J. Long short-term memory. Neural Comput. 9(8), 1735–1780 (1997).
Blackwood, B. et al. Use of weaning protocols for reducing duration of mechanical ventilation in critically ill adult patients: Cochrane systematic review and meta-analysis. BMJ 342(jan132), c7237 (2011).
Morandi A, Piva S, Ely EW, Myatra SN, Salluh JIF, Amare D, Azoulay E, Bellelli G, Csomos A, Fan E, Fagoni N, Girard TD, Heras La Calle G, Inoue S, Lim CM, Kaps R, Kotfis K, Koh Y, Misango D, Pandharipande PP, Permpikul C, Cheng Tan C, Wang DX, Sharshar T, Shehabi Y, Skrobik Y, Singh JM, Slooter A, Smith M, Tsuruta R, Latronico N. Worldwide survey of the “assessing pain, both spontaneous awakening and breathing trials, Choice of drugs, delirium monitoring/management, early exercise/mobility, and family empowerment” (ABCDEF) bundle. Crit Care Med. Ovid Technologies (Wolters Kluwer Health); 2017 Nov;45(11):e1111–e1122.
Balas, M. C., Tate, J., Tan, A., Pinion, B. & Exline, M. Evaluation of the perceived barriers and facilitators to timely extubation of critically ill adults: An interprofessional survey. Worldviews Evid. Based Nurs. 18(3), 201–209 (2021).
Olsen, G. H. et al. Awakening and breathing coordination: A mixed-methods analysis of determinants of implementation. Ann Am Thorac Soc. 20(10), 1483–1490 (2023).
Balas, M. C. et al. Factors associated with spontaneous awakening trial and spontaneous breathing trial performance in adults with critical illness: Analysis of a multicenter, nationwide, cohort study. Chest 162(3), 588–602 (2022).
Costa, D. K. et al. Identifying barriers to delivering the Awakening and Breathing Coordination, Delirium, and Early exercise/mobility bundle to minimize adverse outcomes for mechanically ventilated patients: A systematic review. Chest 152(2), 304–311 (2017).
Cheng, K. H. et al. The feasibility of a machine learning approach in predicting successful ventilator mode shifting for adult patients in the medical intensive care unit. Medicina (Kaunas) 58(3), 360 (2022).
Esteban, A. et al. A comparison of four methods of weaning patients from mechanical ventilation. N. Engl. J. Med. 332(6), 345–350 (1995).
Igarashi, Y. et al. Machine learning for predicting successful extubation in patients receiving mechanical ventilation. Front. Med. 9, 961252 (2022).
Yan, C. et al. Predicting brain function status changes in critically ill patients via machine learning. J. Am. Med. Inf. Assoc. 28(11), 2412–2422 (2021).
Acknowledgements
BioRender was used for figure generation.Funding: SCRIPT is supported by NIH/NIAID U19AI135964. Work in the Division of Pulmonary and Critical Care is also supported by Simpson Querrey Lung Institute for Translational Science (SQLIFTS) and the Canning Thoracic Institute. NSM is supported by AHA 24PRE1196998. GRSB is supported by the NIH (U19AI135964, P01AG049665, R01HL147575, P01HL071643, and R01HL154686); the US Department of Veterans Affairs (I01CX001777); a grant from the Chicago Biomedical Consortium; and a Northwestern University Dixon Translational Science Award. RGW is supported by NIH grants (U19AI135964, U01TR003528, P01HL154998, R01HL14988, and R01LM013337). AVM is supported by NIH grants (U19AI135964, P01AG049665, R21AG075423, R01HL158139, R01HL153312, and P01HL154998). BDS is supported by the NIH (R01HL149883, R01HL153122, P01HL154998, P01AG049665, and U19AI135964). AA is supported by NIH grants (U19AI135964 and R01HL158139). CAG is supported by NIH/NHLBI K23HL169815, a Parker B. Francis Opportunity Award, and an American Thoracic Society Unrestricted Grant.
Funding
SCRIPT is supported by NIH/NIAID U19AI135964. Work in the Division of Pulmonary and Critical Care is also supported by Simpson Querrey Lung Institute for Translational Science (SQLIFTS) and the Canning Thoracic Institute. NSM is supported by AHA 24PRE1196998. GRSB is supported by the NIH (U19AI135964, P01AG049665, R01HL147575, P01HL071643, and R01HL154686); the US Department of Veterans Affairs (I01CX001777); a grant from the Chicago Biomedical Consortium; and a Northwestern University Dixon Translational Science Award. RGW is supported by NIH grants (U19AI135964, U01TR003528, P01HL154998, R01HL14988, and R01LM013337). AVM is supported by NIH grants (U19AI135964, P01AG049665, R21AG075423, R01HL158139, R01HL153312, and P01HL154998). BDS is supported by the NIH (R01HL149883, R01HL153122, P01HL154998, P01AG049665, and U19AI135964). AA is supported by NIH grants (U19AI135964 and R01HL158139). CAG is supported by NIH/NHLBI K23HL169815, a Parker B. Francis Opportunity Award, and an American Thoracic Society Unrestricted Grant.
Author information
Authors and Affiliations
Consortia
Contributions
Conceptualization: C.A.G., A.A., A.V.M., G.R.S.B., R.G.W. Methodology: S.F., A.P., A.A., C.A.G. Data acquisition: M.K., A.P. Programming/analysis/visualization: S.F., A.P., N.S.M., A.A., C.A.G. Chart review: M.Z., K.G., M.B., C.A.G. Drafting: S.F., A.P., A.A., C.A.G. Editing: all authors.
Corresponding author
Ethics declarations
Competing interests
BDS holds US patent 10,905,706, “Compositions and methods to accelerate resolution of acute lung inflammation,” and serves on the scientific advisory board of Zoe Biosciences, in which he holds stock options. Other authors have no conflicts within the area of this work.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Fenske, S.W., Peltekian, A., Kang, M. et al. Developing and validating machine learning models to predict next-day extubation. Sci Rep 15, 27552 (2025). https://doi.org/10.1038/s41598-025-12264-4
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-025-12264-4
