
Abstract
Ship radiated noise (SRN) recognition is challenging due to environmental noise and the broad frequency range of underwater signals. Existing deep learning models often include irrelevant frequencies and use red, green, and blue (RGB) channel configurations in convolutional networks, which are unsuitable for SRN data and computationally intensive. To address these limitations, we propose FCResNet5, a neural network optimized for SRN classification. FCResNet5 adopts a streamlined architecture that focuses on the critical frequency band and applies frequency channelization to enhance spectral representation. Its compact design achieves greater computational efficiency while maintaining comparable accuracy. Ablation studies confirm the contribution of each component, and comparative results demonstrate that FCResNet5 offers a more efficient alternative to existing models without compromising performance.
Similar content being viewed by others
Introduction
Background
Ship radiated noise (SRN), generated by various onboard sources such as the service diesel generator, main engine firing rate, and blade rate harmonics due to propeller cavitation1, is a key signal within the complex marine environment2. However, the intricate and dynamic nature of this environment introduces significant interference, making it challenging to effectively extract and identify SRN features2,3. In addition to its role in ship classification and identification, SRN is crucial for monitoring the health of structural components and onboard systems, including motors, gears, and pumps. Accurate SRN feature extraction and identification are therefore of paramount importance in hydro-acoustic research3. Moreover, understanding and mitigating SRN has far-reaching implications for marine detection and defense applications2,4,5, playing a pivotal role in ensuring the effectiveness of naval surveillance and acoustic monitoring systems.
Advancements in signal processing and machine learning greatly enhance SRN feature extraction and identification, surpassing traditional manual detection methods based on human auditory perception6. Modern signal processing techniques, such as spectral and time-frequency analysis, provide more accurate and efficient interpretations of acoustic signals by extracting key features such as frequency components, amplitude, and phase. Machine learning algorithms, including Support Vector Machines (SVM), Random Forests (RF), and K-Nearest Neighbors (KNN), further improve recognition accuracy and handle the complexity of SRN data7. While traditional machine learning relies on manual feature engineering and is more suited for small-scale datasets with limited features8,9, modern deep learning models automatically learn features and offer powerful non-linear representations, particularly beneficial for larger datasets, though they require more computational resources10,11.
Deep learning methods, such as Convolutional Neural Networks (CNNs)12,13 and Deep Belief Networks (DBNs)10, prove especially effective in recognizing SRN by automatically extracting and learning features from raw data, significantly improving performance. Additionally, models like Recurrent Neural Networks (RNNs)14,15 and Long Short-Term Memory (LSTM) networks16,17 are well-suited for processing sequential data, making them ideal for analyzing time-series acoustic signals. LSTMs, in particular, capture long-term dependencies in the data, which is critical for recognizing patterns in SRN that may span over extended periods. More recently, Transformer models gain attention for their effectiveness in handling sequential data and capturing long-range dependencies. Leveraging an attention mechanism, transformers show superior performance in natural language processing tasks18, and their ability to focus on informative features while suppressing noise makes them promising for SRN recognition as well19.
Motivation
Although deep learning models, particularly CNN-based approaches, improve SRN recognition by automating feature extraction and learning, several challenges remain when adapting them to the specific nature of underwater acoustic data.
The first challenge arises from the unique frequency characteristics of underwater signals. While these signals span a broad frequency range, only a narrow band around 2kHz typically contains critical information for ship classification20,21,22,23. Many current models process the entire bandwidth, decreasing the signal-to-noise ratio and the overall classification accuracy.
Second, CNN-based models, originally designed for image processing, often transform acoustic signals into formats resembling visual patterns, using channel configurations adapted from image data. This approach mismatches the frequency-based nature of SRN data, potentially distorting important signal characteristics and limiting the effectiveness of feature extraction.
Finally, underwater monitoring devices, especially those used in remote or deep-sea environments, face stringent constraints on power consumption and computational resources24,25. These devices have limited energy supply and processing capabilities, making it impractical to deploy large, resource-intensive models designed for high-performance land-based systems.
Given these limitations, there is a clear need for specialized neural network architectures tailored to SRN data. Efficient models must not only focus on the critical frequency band to exclude irrelevant information but also minimize computational load to be feasible for real-time deployment in resource-constrained underwater environments.
Our work
In this paper, we present a novel neural network architecture: Frequency Channelization ResNet5 (FCResNet5), specifically tailored for SRN data. Our approach focuses on three key contributions:
-
Targeting frequencies below 2kHz: By concentrating on the critical frequency band, we reduce the impact of irrelevant noise and interference, leading to improved recognition accuracy. This focus also reduces the overall input data volume, thereby lowering computational complexity.
-
Custom network architecture for SRN data: The proposed model is designed to align with the unique characteristics of SRN signals. By leveraging frequency channels as input, it efficiently captures fine-grained information across different frequency bands. Additionally, the model adjusts the number of channels in a descending manner as the network deepens, preserving high recognition performance while optimizing resource use.
-
Model compression design: To further enhance computational efficiency, we compress the model by reducing the number of ResNet layers and adjusting the kernel size, significantly decreasing parameter size and computational complexity without sacrificing performance. This compression also results in faster training time and lower resource demands, all while maintaining competitive accuracy.
We evaluate the effectiveness of these innovations through extensive experiments on the open-source Deepship dataset, demonstrating the superior performance and efficiency of FCResNet5 in SRN classification.
Related studies
In the field of underwater acoustic target recognition, SRN plays a critical role. However, environmental noise poses significant challenges in data collection and processing. To address these challenges, lots of studies propose various signal preprocessing, feature extraction, and deep learning methods. While these approaches make substantial progress in improving recognition accuracy, they often face limitations, such as neglecting the frequency characteristics of SRN, relying on complex models, or incurring high computational costs.
Preprocessing and feature extraction
Environmental noise, such as human activities, marine life, and multipath effects, makes data collection challenging32,38. Preprocessing is essential to reduce noise and interference, with common methods including FIR filtering26,27,30 to reduce noise and interference. However, these filters do not account for the primary frequency band of SRN. Similarly, down-sampling19,28,29 is often used to reduce data volume and computational complexity, but this is done without carefully considering the bandwidth characteristics of SRN. Additionally, pre-emphasis31,39, aiming at boosting high-frequency components, has an effect opposite to what is needed for SRN. In contrast, our approach focuses on a maximum frequency of 2kHz, which is sufficient for capturing the key features, allowing for more effective noise suppression and feature extraction. Several existing studies use CNNs to automatically extract features from underwater acoustic signals. Doan et al.13 propose UATC-DenseNet, a CNN that processes time-domain audio signals, demonstrating high classification accuracy on real-world passive sonar data. Yang et al.6 introduce an enhanced CNN with channel attention and feature fusion, achieving effective underwater signal recognition on the Shipsear and DeepShip datasets. Similarly, Li et al.27 develop FEM-ATNN, a feature extraction module integrating time-domain filters and time-frequency analysis with attention mechanisms to improve recognition accuracy. However the high dimensionality of time-series data can be burdensome for neural network models, making it challenging to efficiently capture key features. As a result, many studies shift towards using time-frequency to address these limitations. For example, Irfan et al.32 evaluate their network using time-frequency features like Mel-Frequency Cepstral Coefficients (MFCCs), wavelet packets, and Constant Q Transform (CQT), while Han et al.33 incorporate Mel-spectrograms, spectral contrast, and other features to enhance signal representation. Zhang et al.34 explore feature fusion, combining amplitude, phase, and bispectra after applying Short-Time Fourier Transform (STFT), yielding strong classification performance. Ren et al.35 use STFT spectrograms processed with parameterized Gabor filters, and Liu et al.36 employ a 3D feature set from Mel-spectrograms with delta and delta-delta features to capture the dynamics of underwater signals. Yang et al.24 propose a sub-band concatenated Mel (SC-Mel) spectrogram to improve feature extraction in low-frequency noise. However, these approaches primarily focus on methods derived from image processing or time-domain analysis, often overlooking the specific characteristics of acoustic signals across different frequency bands. In contrast, our approach emphasizes direct utilization of raw spectral data, specifically targeting the frequency domain aiming to provide a more effective solution for underwater acoustic signal recognition and demonstrating a unique perspective not addressed by existing methods.
Deep learning methods
Ren et al.35 propose a system UALF that uses parameterized Gabor filters in its learnable front-end to extract features from underwater acoustic signals. The backend classifier is a multi-channel ResNet50 structure. The system is tested on multiple datasets under different recording conditions and scenarios. The results show that UALF outperform baseline methods, verifying its intelligence and feasibility for practical applications. Xie et al.37 propose a Convolution-based Mixture of Experts (CMoE) model to enhance underwater acoustic target recognition by leveraging the adaptive learning capabilities of multiple expert layers and a routing layer. They conduct comprehensive experiments and visualization analyses on three underwater acoustic databases, demonstrating that the CMoE model consistently outperforms existing advanced methods in terms of recognition accuracy. Zhu et al.31 present a novel underwater acoustic target recognition network known as SNANet. The SNANet is structured to extract both auxiliary and primary features within specific frequency bands and then combines these features using the proposed adaptive weights. Comprehensive experiments and ablation studies validate the effectiveness of the proposed SNANet. The experiments compare SNANet’s performance with other state-of-the-art methods and demonstrated its superiority in terms of recognition accuracy. Huan et al.31 introduce a novel underwater acoustic target recognition method that leverages the WA-DS decision fusion algorithm. This method replaces anomalous evidence with weighted average evidence, thereby resolving issues related to synthesizing conflicting evidence. The proposed method demonstrate a remarkable recognition accuracy on the Shipsear dataset, marking a significant improvement over single-feature recognition methods. The network structures used by these researchers all employ ResNet as the backbone. In addition, some simpler network structures also achieve very good results. Liu et al.36 employ a Convolutional Recurrent Neural Network (CRNN) that combines CNN for local feature extraction and LSTM for capturing temporal dependencies, suitable for time-series signal processing. The CRNN-9 model, in particular, outperforms other models, including LSTM and CNN, across all tasks. Yang et al.24 introduce a method coupled with a multi-domain attention mechanism integrated into a lightweight CNN model named CFTANet and evaluate the system on two open datasets, DeepShip and Shipsear. While previous methods leverage complex architectures to improve the accuracy of underwater acoustic target recognition, they often rely on highly intricate models and complex feature extraction techniques. These two factors can lead to increased computational costs and challenges in real-time processing. our approach distinguishes itself by focusing on the raw spectral data, prioritizing frequency information. This focus allows our FCResNet5 model to efficiently extract relevant features, resulting in a lightweight yet powerful architecture that significantly reduces computational complexity while maintaining high classification accuracy.
The main differences between the existing literature and the proposed method are summarized in Table 1. The proposed approach introduces improvements in preprocessing, feature extraction, and model architecture, streamlining complexity and focusing on more targeted frequency processing and network design compared to prior methods.
Proposed method
Our proposed method, FCResNet5, is a neural network specifically designed for SRN data. The overall structure is illustrated in Fig. 1. In the following subsections, we will systematically elaborate on the complete process in Fig. 1, including data processing, feature extraction, and model construction. Throughout the explanation, we further highlight the three main innovations of this paper.

The overall processing structure of FCResNet5 method.
Preprocessing via effective bandwidth
Figure 2 illustrates the spectral characteristics of various SRN sources alongside typical marine environmental noise. It can be observed that the majority of SRN energy is concentrated below 2 kHz, covering the low to mid-frequency range. This includes contributions from mechanical noise (20–1000 Hz), propeller-induced tonal components (50–150 Hz), and low-frequency hydrodynamic noise (5–10 Hz), each associated with different operational conditions and physical mechanisms20,21,23,40. Notably, this SRN-dominant range also overlaps with background ocean noise, which poses challenges for accurate classification41.
Guided by this spectral distribution, we adopt the sub-2 kHz frequency band for feature extraction, which effectively captures the primary components of SRN while reducing computational cost without compromising classification accuracy. Furthermore, this design choice is supported by our ablation studies in the Effective Bandwidth section, where we experimentally evaluate the impact of different frequency bands on classification performance.

The distribution of ship and marine environmental noise23.
Feature extraction
For SRN classification, various feature extraction approaches have been proposed. In this study, we compare seven commonly used features, as summarized in Table 4 and discussed in Section Comparison Between Time-Frequency and Non-Time-Frequency Features. The results demonstrate that time-frequency features generally yield superior classification performance compared to non-time-frequency representations. Therefore, we focus on four widely adopted time-frequency features for further analysis and evaluation: STFT spectrogram, Mel spectrogram, CQT spectrogram, and Gamma-tone spectrogram. The extraction methods for these features are detailed below.
STFT spectrogram
The Short-Time Fourier Transform (STFT) decomposes a time-domain signal into short-time segments using a sliding window, then applies the Fourier transform to each segment to extract localized frequency information. The STFT is defined as:
where \(x(\tau )\) denotes the original signal, \(w(\tau - t)\) is the analysis window centered at time t, and f is the frequency. X(t, f) represents the complex-valued STFT of the signal, encoding its time-frequency energy distribution.
Mel spectrogram
The Mel spectrogram projects the STFT power spectrum onto a perceptually motivated Mel frequency scale, which models the nonlinear sensitivity of human hearing. The Mel frequency scale is defined by:
This mapping is approximately linear below 1 kHz and logarithmic above. The Mel spectrogram \(S_{\text {mel}}(t, m)\) is then computed by applying a bank of Mel filters to the STFT power spectrum:
where \(|X(t, f_k)|^2\) is the power spectrum at frequency bin \(f_k\), and \(H_m(f_k)\) is the response of the m-th Mel filter. The result \(S_{\text {mel}}(t, m)\) represents the energy distribution over Mel frequency bands at each time frame.
Gamma-tone spectrogram
The Gamma-tone spectrogram employs a filter bank composed of Gamma-tone filters, which are widely used to simulate the frequency selectivity of the human auditory system. The impulse response of a Gamma-tone filter is given by:
Here, \(t^{n-1}\) defines the envelope shape, \(e^{-2 \pi b t}\) controls the filter’s bandwidth, and \(\cos (2 \pi f_c t + \phi )\) is the sinusoidal carrier centered at frequency \(f_c\) with phase offset \(\phi\). The output of the Gamma-tone filter bank provides a biologically inspired time-frequency representation of the signal.
CQT Spectrogram
The Constant-Q Transform (CQT) performs frequency analysis using a logarithmically spaced set of frequency bins, providing high resolution for low frequencies and finer time resolution for high frequencies. It is formulated as:
where \(N_k\) is the window length for the k-th frequency bin, w[n] is the analysis window, and x[n] is the input signal. \(X_{\text {CQT}}(k, t)\) denotes the CQT coefficient, reflecting the spectral content of the signal with constant-Q bandwidths.
Tailored network architecture
In this work, we propose a network architecture specifically designed to align with the unique characteristics of SRN data. The design centers around two key strategies: leveraging frequency channels to align with the structure of time-frequency features and employing a descending channel structure to improve feature extraction performance.
Frequency channelization
In CNNs, the concept of channels is a fundamental design element, particularly suited for image processing tasks. For instance, in RGB images, the input is composed of three distinct channels: red, green, and blue, each representing different color components of the image. This multi-channel structure allows CNNs to effectively process and extract useful features from complex visual data.

The core concept of frequency channelization.
However, in signal processing, the input data, such as time-frequency representations, does not have the concept of channels similar to the RGB channels in images. Recognizing that signals can be decomposed into a series of sine waves at different frequencies, we propose an alternative approach: treating the frequency dimension as the channel dimension within CNNs. The core concept of this method, illustrated in Fig. 3, allows the network to process signals in a way that reflects their inherent frequency composition. Just as RGB channels represent distinct components of an image, frequency channels represent different frequency bands within the signal, enabling more efficient feature extraction from SRN data.
Descending channel structure
Building on the frequency channelization approach discussed in the previous subsection, we find that directly employing ResNet18 is not the most suitable option. Specifically, as illustrated in Fig. 4, the input feature maps have much more channels (132 for the CQT feature and 400 for others). In the original ResNet18 structure (left panel of Fig. 4), the number of channels initially decreases and then increases progressively, which does not align well with the frequency channelization setup.
To address this issue, we modify the channel configuration by adopting a descending structure, where the number of channels gradually decreases as the network deepens. This design reduces feature dimensionality in a more logical manner, as depicted in the right panel of Fig. 4. The importance of this descending channel structure in improving recognition accuracy will be validated by the experiments in Section 5, which highlight the significant impact of this adjustment on overall model performance.
Model compression design
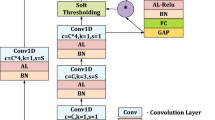
In addition to enhancing computational efficiency through bandwidth adjustment and aligning the network with signal characteristics, we further reduce complexity by compressing the network structure. Specifically, we propose compressing the ResNet18 architecture by reducing the number of layers and adjusting the kernel size, all while maintaining model performance. To evaluate the impact of these modifications, we conduct experiments to compare network performance under different configurations, specifically varying the number of ResBlock groups. Key metrics, including accuracy, parameters, MFLOPs, and average training time, are assessed for each configuration. Based on a comprehensive assessment of these factors, we find that using a single ResBlock group provides a good balance between computational efficiency and recognition performance. Consequently, our final model design incorporates only one ResBlock group, as depicted in Fig. 4, where the numbers represent the change in the number of feature channels. In FCResNet5, the initial convolution reduces the input channels, followed by a single ResBlock that further decreases the channels, creating a simplified architecture with fewer layers compared to ResNet18. This streamlined design reduces model complexity while still achieving competitive accuracy, making it more efficient for practical applications.

The comparison of the number of channels and layers between ResNet18 and FCResNet5.

Architecture diagram of FCResNet5.
Overall structure
Incorporating the settings discussed above, we present the overall structure of our FCResNet5, as shown in Fig. 5. It consists of one convolutional layer, one ResBlock, and one classification layer, with the number of channels decreasing sequentially. Detailed parameters are provided in Table 2.

Pseudocode for FCResNet5.
The pseudocode for the overall process of our FCResNet5 is provided in Algorithm 1. First, audio files are divided into 30-second segments, with a 15-second overlap between consecutive segments. Each segment undergoes min-max normalization to ensure consistency in value range. Time-frequency features are then extracted from each segment using multiple transformations, including STFT, Mel, Gamma-tone, and CQT. The resulting feature segments are further normalized using z-score normalization. Following feature extraction, the dataset is divided into training and test sets at a 3:1 ratio and we need to ensure that no segment from one audio file appears in both sets simultaneously. During training, 15% of the training set is reserved for validation. The model is trained using the cross-entropy loss function and the Adam optimizer. A learning rate scheduler, ReduceLROnPlateau, adjusts the learning rate based on validation accuracy. The model is trained for 50 epochs with a batch size of 256.
Experiment
Dataset
In our experiment, we use the open-source DeepShip dataset32, which is designed for marine vessel recognition. The data are collected using hydrophones deployed at the Strait of Georgia Delta node over a 29-month period, from May 2, 2016 to October 4, 2018. The recordings take place under realistic maritime conditions, with timestamps and vessel identities obtained through the Automatic Identification System (AIS). To ensure data clarity, only acoustic signals emitted by a single vessel within a 2 km radius of the hydrophone are retained, and data collection is paused when the vessel moves beyond this range.

Four classes of DeepShip and the four spectrograms.
The dataset encompasses recordings from four distinct classes of ships, namely oil tankers, tugboats, passenger ships, and cargo ships, as shown in the first row of Fig. 6. It contains 613 recordings from 265 individual vessels. The total recording duration is approximately 47 hours and 4 minutes, with individual clips ranging from 6 to 1530 seconds depending on vessel type, location, and motion. All signals are sampled at 32kHz, and the selected recordings ensure a relatively balanced duration across the four classes. Figure 6 also displays representative spectrograms of each class extracted using four typical time–frequency analysis methods: CQT, Gamma-tone, Mel, and STFT.
Dataset splitting
In this section, we detail the methodology used to preprocess the audio data and prepare the dataset for training and evaluation. This includes the process of audio track segmentation, as well as the strategy for splitting the data into training and test sets, both of which are crucial for ensuring the accuracy and consistency of our model’s performance.
Audio track splitting
In this study, we employ a segmentation method to process the audio tracks from the DeepShip dataset. Each audio track is divided into frames of 30 seconds in duration. To ensure continuity and capture sufficient contextual information, we implement an overlap of 15 seconds between consecutive frames. This approach allows each frame to retain part of the preceding and succeeding audio content, which is crucial for tasks such as classification or recognition. To avoid the introduction of artificial features, any segment shorter than 30 seconds is excluded from the analysis. This ensures that only sufficiently long segments, which can provide meaningful information, are considered. To formally describe the process, let the time series data be represented by x(t), where t is the time index, then the n-th frame \(f_n(t)\) can be expressed as \(f_n(t) = x(t + (n - 1) \times 15s)\) where n is the frame index.
After framing the time series data, each frame undergoes a normalization process. This normalization scales the data within each frame to fall within the range [-1, 1]. Let \(f_n\) denote the n-th frame and \(f_n^{norm}\) represent the normalized frame. The normalization is performed as follows:
where \(\max (f_n(t))\) and \(\min (f_n(t))\) are the maximum and minimum values of the frame \(f_n(t)\) respectively.
Training and test set splitting
In this study, we randomly divide the dataset with a training set comprising approximately 75% of the data and a test set comprising approximately 25% of the data. Additionally, we ensure that the proportion of each class in the training and test sets remain consistent with the overall class distribution across all groups. To maintain the integrity of the dataset and avoid introducing bias, audio tracks generated from the same audio file are kept exclusively in either the training or testing dataset, ensuring that correlated data does not appear in both sets.
Feature extraction through nnAudio
In our study, we utilize nnAudio for feature extraction, processing all relevant features. To ensure optimal frequency resolution, we set the FFT frame length and frame shift to 200 ms, resulting in no overlap between frames. The frequency range is restricted to 1 Hz to 2 kHz, and a Hamming window function is applied. The detailed parameters are provided in Table 3. Additionally, Fig. 6 provides visual examples of the four ship classes, each accompanied by corresponding time–frequency spectrograms generated using the adopted feature extraction methods.
Training parameters
During training, we utilize the Adam optimizer along with the ReduceLROnPlateau learning rate scheduler, starting with an initial learning rate of 0.001. The learning rate decay factor is set to 0.8 with a step size of 1 epoch, and the minimum learning rate is set to 1e-5. All experiments are conducted on a system equipped with an Intel i9-10900K CPU and an NVIDIA GeForce RTX 3060 GPU with 12 GB of VRAM.
The implementation is based on PyTorch 2.2.2 and nnAudio 0.3.3, running in a Python 3.12.2 environment. We do not apply fixed random seeds in order to simulate the average-case behavior, and all experiments are repeated ten times with different random splits. The final results are reported as the mean values across these ten runs.
Results
In this section, we conduct two experiments to validate the efficiency and superiority of our proposed method. The first is an ablation experiment to verify the impact of key model components. The second is a comparative experiment to evaluate our method against state-of-the-art approaches in terms of accuracy and efficiency.
Ablation experiment
In this section, we conduct a comprehensive ablation study to investigate the key design factors contributing to the performance of FCResNet5. Specifically, we compare time-frequency and non-time-frequency input features, assess the influence of frequency bandwidth selection, examine the effect of window overlap during feature extraction, evaluate the role of frequency channelization, and explore suitable network architectures. These analyses collectively demonstrate how FCResNet5 achieves a balance between accuracy and computational efficiency, making it well-suited for real-world ship-radiated noise classification.
Comparison Between Time-Frequency and Non-Time-Frequency Features
To evaluate the effectiveness of different input representations for ship-radiated noise classification, we conduct a comparative experiment using ResNet18 across seven feature types. These include four time-frequency features (STFT, Mel, CQT, and Gamma-tone) and three non-time-frequency features (MFCC, Wavelet, and Cepstrum). Each feature is evaluated using five randomly generated data splits, and the results are averaged over 10 repeated runs. The average classification accuracies are summarized in Table 4.
As shown in Table 4, the time-frequency representations consistently outperform the non-time-frequency counterparts. Among them, STFT achieves the highest average accuracy (72.38%), followed closely by Mel (71.20%), while Wavelet and Cepstrum exhibit the lowest performance. These findings suggest that time-frequency features preserve more discriminative information crucial for ship-radiated noise classification.

t-SNE visualizations of learned features using seven different feature types: Mel, CQT, Gamma-tone, STFT, MFCC, Wavelet, and Cepstrum.
To further evaluate feature separability, we visualize the t-SNE embeddings of the extracted features in Fig. 7. Subfigures (a) to (d), which correspond to the time-frequency representations, exhibit more distinct and compact clusters, reflecting stronger inter-class separability. In contrast, the non-time-frequency features in subfigures (e) to (g), particularly Wavelet and Cepstrum, show more diffuse and overlapping distributions, indicating limited discriminative capability. These qualitative observations are consistent with the classification accuracy results summarized in Table 4.
Based on this analysis, we adopt the four time-frequency features (STFT, Mel, CQT, and Gamma-tone) as the primary input representations for subsequent experiments.
Effective bandwidth
In this section, we validate the rationale behind selecting the 2kHz bandwidth. In our experiments, we use ResNet18 as the classification method to test the impact of different upper and lower frequency limits on the model’s performance.
The experimental results are illustrated in Fig. 8 and Table 5, which jointly present the classification accuracy (mean ± std over 10 trials) of ResNet18 under various frequency input configurations across four spectral features: CQT, Mel-spectrogram, STFT, and Gamma-tone. Figure 8 visualizes the accuracy trends for different maximum frequency cutoffs (green lines) and segmented frequency bands (orange lines), while Table 5 reports the detailed numerical values.
As shown by the green line, the model’s classification performance generally decreases as the bandwidth range increases, indicating that increasing the upper bandwidth limit does not improve the model’s performance but instead introduces interference. Furthermore, the yellow line also shows that higher bandwidth ranges correspond to lower classification accuracy, suggesting that these ranges likely do not contain useful signals for classification, but rather unwanted noise. Thus, this experiment confirms the rationale of our setting by limiting the data bandwidth to within 2 kHz.

Accuracy (mean ± std) of different frequency ranges on four different types of features. The green lines represent the results under different maximum frequency cutoffs, while the orange lines correspond to different frequency band segments.
Analyzing Window Overlap in Spectral Feature Extraction
To investigate the influence of windowing strategies on model performance and training efficiency, we conduct an ablation study on the use of overlapping windows during time-frequency feature extraction. In this experiment, we fix the window length at 200 ms and vary the overlap ratio between adjacent frames. Specifically, we consider four overlap settings: 0% (no overlap), 25%, 50%, and 75%, which correspond to hop sizes of 200 ms, 150 ms, 100 ms, and 50 ms, respectively. For each setting, the model is trained and evaluated 10 times using different random seeds. We report the average classification accuracy and standard deviation across ten repeated runs, as shown in Table 6.
The results indicate that applying overlap generally improves classification performance for most feature types. For example, STFT accuracy improves from 78.03% (±1.21) without overlap to 78.78% (±1.16) with 75% overlap. A similar pattern is observed for the Gamma-tone feature, which increases from 69.61% (±1.02) to 71.46% (±1.24). MEL features also show moderate gains with overlap, although the improvement is less consistent. In contrast, the CQT feature shows a decrease in accuracy when the overlap exceeds 25%.
However, the benefit of overlapping comes at the cost of increased training time. Due to the denser frame segmentation, total training time grows significantly as overlap increases. For instance, STFT training time increases from 364 s at 0% overlap to 1229 s at 75% overlap. This highlights a trade-off between performance and computational cost. While overlapping can marginally enhance performance, particularly for STFT and Gamma-tone, it also leads to substantially higher resource consumption. As such, the no-overlap setting is adopted in our default configuration to ensure a good balance between accuracy and efficiency.
Effectiveness of frequency channelization
In this section, we evaluate the effectiveness of Frequency Channelization (FC) by applying it to three representative models: ResNet18, RCMoE-balance, and CFTAnet. The “FC” suffix indicates that the model employs frequency channelization. A comprehensive comparison of model complexity (parameters and MFLOPs), average training time, and classification accuracy (mean ± std over 10 trials) before and after applying FC is presented in Table 7 and visualized in Fig. 9.

Figures of parameters (a-b), flops (c-d), training time (e-h), Accuracy (i-l) comparison on three methods with/without frequency channelization.
Table 7 and Fig. 9 demonstrate that introducing frequency channelization leads to a marginal increase in parameter count, ranging from approximately 0.4 to 1.25 million across all models and feature types. Despite this minor increase in model size, the reduction in computational cost is substantial. For example, the number of FLOPs drops by over 90% for ResNet18 and RCMoE-balance under all feature types, and by more than 50% for CFTAnet. These reductions translate into significantly lower training times. ResNet18 sees the largest improvement, with training time reduced by more than 660 seconds, while CFTAnet also benefits with reductions of over 230 seconds across most settings. These results confirm that FC enhances computational efficiency considerably, while introducing only a modest increase in model complexity.
In terms of classification accuracy, FC yields consistent performance improvements for CFTAnet across all spectral features. Notably, the gain is particularly pronounced for the Gamma-tone input, where the accuracy improves by 5.63%. In contrast, ResNet18 and RCMoE-balance exhibit slight drops in accuracy (generally less than 2–4%), suggesting that the standard ResNet18 backbone may not be optimally aligned with frequency-channelized inputs. Since RCMoE-balance also builds on ResNet18, this pattern reinforces the hypothesis that architectural compatibility plays a key role in leveraging the benefits of FC.
Overall, these results confirm that frequency channelization significantly enhances training efficiency while preserving, and in some cases improving, classification accuracy, particularly when paired with lightweight models such as CFTAnet. This highlights the importance of designing network architectures that are structurally adapted to frequency-segmented inputs.
Exploring optimal network architectures
In this section, we aim to explore network architectures that are better suited for frequency channelization. The network architecture of ResNet18 is given in Fig. 10, where the numbers 64, 128, 256, and 512 represent the feature channels generated at each layer. The diagram shows a progressive increase in the number of channels across the layers. However, after applying frequency channelization, the number of channels is 132 for CQT and 400 for other features, both significantly higher than the initial 64 channels after the first convolutional layer of ResNet18. This suggests that our input features undergo a rapid decrease in channel numbers before gradually increasing again, which we suspect may negatively impact the performance of frequency channelization. To further investigate, we conduct comparative experiments between descending and ascending channel configurations and evaluate different layer depths to assess their impact on performance.
In our experiments, the initial convolution layer is treated as the first layer, with the subsequent four groups of residual blocks treated as layers 2, 3, 4, and 5. The number of channels is adjusted uniformly for each group, and network depth is controlled by reducing the number of residual blocks. We use STFT as input features and set the maximum channel number to 256, since the final channel number in ResNet18 (512) exceeds our input’s channel number (400). Tables 8 and 9 compare accuracy (mean ± std over 10 trials), parameters, MFLOPs and average training time under descending and ascending channel configurations, respectively. In the table, the rows where the models achieved relatively higher accuracy are highlighted in bold to emphasize their performance.

The network architecture of ResNet18.
The results show that the descending channel configuration consistently achieves higher accuracy than the ascending configuration under the same conditions, with the difference becoming more pronounced as the number of layers increases. However, the descending configuration requires substantially more parameters and higher computational complexity, suggesting a trade-off between accuracy and efficiency.
From Table 9, we conclude that maximum channel numbers of 256 and 128 yield the best accuracy. Furthermore, when the number of layers exceeds 2, accuracy differences are minimal. Therefore, to balance accuracy and efficiency, we select the 128\(\rightarrow\)64 configuration for further experiments, considering that the CQT feature input has 132 channels.
In analyzing the initial convolution layer, we find that its kernel size has a significant impact on network performance. The original ResNet18 uses a kernel size of 7 with a stride of 2. We adjust the stride to 1 and compare the impact of different kernel sizes on network performance.
Figure 11 shows the comparison results of different kernel sizes for accuracy (mean over 10 trials), parameters, MFLOPs, and average training time. We can see that kernel size of 3 achieve the best performance with the lowest parameters and complexity.
Based on these results, we name our optimal network FCResNet5. This network includes 5 layers: an initial convolution layer and one residual block, with each residual block comprising two residual networks, and each residual network containing two convolutional layers. The name FCResNet5 reflects its simplified ResNet structure, lightweight design, and frequency channelization.

Comparison of different kernel sizes. (a) accuracy, (b) number of parameters, (c) computational complexity measured in MFLOPs, and (d) average training time.
Comparative experiment
To comprehensively assess the effectiveness of the proposed FCResNet5, we design two complementary comparative experiments. The first focuses on evaluating classification performance using four types of time-frequency spectral features: STFT, Mel, CQT, and Gamma-tone. The second assesses the robustness of different models under varying signal-to-noise ratio (SNR) levels, simulating real-world scenarios with degraded acoustic quality. These two perspectives jointly offer a holistic evaluation of both discriminative capacity and noise resilience.
Performance across spectral features
In the first part of the comparative study, we evaluate the classification performance of FCResNet5 against several representative methods, including RCMoE-balance37, CFTAnet24, and the widely used backbone network ResNet188,26,37,42. The dataset is divided into five distinct training and testing folds, as detailed in Table 10, ensuring that the evaluation covers diverse data distributions. We report the average classification accuracy along with standard deviation over ten independent runs, as well as model complexity metrics including parameter count, MFLOPs, and average training time. Furthermore, to support the reliability of the comparisons, we perform statistical significance tests using independent two-sample t-tests (\(n=50\)), with a Bonferroni-corrected threshold of \(p=0.0167\).
As shown in Tables 11 and 12, we present the classification performance of FCResNet5 compared to three representative baselines under 0% and 50% window overlap settings. Columns 3 to 7 report the accuracy (mean ± std over 10 trials) and training time for each of the five dataset folds using four types of spectral features. Column 8 summarizes the average accuracy across all folds, while Column 9 provides the p-values from two-sample t-tests between FCResNet5 and other competing methods under each feature. The last two columns display the model complexity in terms of MFLOPs and parameter count, offering a complete view of model efficiency and cost.
The results in Tables 11 and 12 reveal that ResNet18 performs best under STFT and Mel inputs, while FCResNet5 consistently ranks second. However, when using CQT and Gamma-tone features, FCResNet5 achieves the highest accuracy across both overlap settings, outperforming all baseline models. For instance, with no overlap, FCResNet5 achieves 66.38 on CQT and 66.98% on Gamma-tone, surpassing ResNet18 by 1.39% and 2.63%, respectively. Under 50% overlap, this advantage is maintained, with FCResNet5 reaching 66.98% and 66.90% on CQT and Gamma-tone, respectively.
While performance differences on STFT and Mel are relatively small, the consistent advantage of FCResNet5 on CQT and Gamma-tone demonstrates its adaptability across diverse input features. Given the limited performance gap and the consistent feature extraction settings, these variations are more likely attributed to statistical fluctuations rather than systematic feature dependence.
In addition to accuracy, FCResNet5 maintains significant efficiency benefits. It offers a substantial reduction in the number of parameters compared to ResNet18 and RCMoE-balance, with MFLOPs reduced by over 90% and shorter training times across all features. These results confirm that FCResNet5 achieves competitive performance while substantially reducing computational cost, making it a strong candidate for deployment in resource-constrained environments.
To assess performance differences, we conduct independent two-sample t-tests (Bonferroni-corrected, \(p < 0.0167\)) to compare FCResNet5 with baseline models under both non-overlap and 50% overlap conditions. Under the non-overlap setting, FCResNet5 shows significant advantages over ResNet18 and RCMoE-balance under the Gamma-tone feature (\(p < 0.001\)), while differences under STFT, Mel, and CQT are not statistically significant (\(p > 0.0167\)) despite variations in average accuracy. Under the 50% overlap setting, despite FCResNet5 showing a marginally lower average accuracy than ResNet18 under the Mel feature, the difference is statistically significant. For STFT, although ResNet18 again yields higher mean accuracy, the difference remains insignificant (\(p > 0.0167\)). These results indicate that while FCResNet5 offers competitive or superior performance across various scenarios, its improvements are feature-dependent and not always statistically significant. This underscores its practical value in resource-constrained environments, where balancing accuracy and efficiency is critical.
To further interpret the classification behavior, Fig. 12 presents the normalized confusion matrices of FCResNet5 using the four different spectral features. These matrices reflect the average performance over 10 repeated runs on the test set. Among the four target classes, Tug is generally recognized with the highest recall across all feature types. STFT provides the most balanced classification, yielding strong performance for Passengership (0.77), while Mel leads in accuracy for the Cargo class (0.74). In contrast, CQT and Gamma-tone representations result in relatively higher inter-class confusion, especially for Cargo and Tanker. For instance, under Gamma-tone, the recall for Cargo and Tanker drops to 0.58 and 0.66, respectively, reflecting a noticeable decline in discriminability.

Confusion matrices of FCResNet5 using: (a) STFT, (b) Mel, (c) CQT, and (d) Gamma-tone on the test set.
Robustness Evaluation under Different SNR Conditions
To evaluate the robustness of different models in noisy environments, we simulate additive Gaussian noise at various SNR levels: clean (no noise), 10 dB, 5 dB, 0 dB, \(-5\) dB, and \(-10\) dB. Noise is added directly to the raw audio signals before feature extraction. We compare our proposed model FCResNet5 with a standard ResNet18 baseline, as well as two competitive methods from the literature: RCMoE-balance and CFTAnet. Each setting is evaluated over 10 independent runs, and we report the average classification accuracy across these runs. Figure 13 illustrates the classification performance of different models under varying SNR conditions. As the noise level increases, all models exhibit a consistent decline in accuracy, indicating sensitivity to noise interference. FCResNet5 achieves the highest accuracy when the SNR is above 0 dB, suggesting its suitability for clean to moderately noisy environments. However, as the SNR drops below 0 dB, its performance deteriorates more noticeably, and CFTAnet slightly surpasses it in extreme noise conditions (e.g., −5 dB and −10 dB). These results indicate that while all models are vulnerable to severe noise, the overall robustness across models remains comparable. Enhancing low-SNR resilience without sacrificing model efficiency remains an important direction for future investigation.

Classification accuracy of four models under different SNR levels.
Conclusion
In this paper, we propose FCResNet5, a lightweight and efficient deep learning model tailored for SRN classification. The design of FCResNet5 is guided by three core principles: focusing on the dominant frequency band of SRN signals, leveraging frequency channelization to enhance spectral resolution, and adopting a compressed descending channel structure to reduce computational cost.
We first examine input representations and find that time-frequency features consistently offer better discriminative power than non-time-frequency ones. Ablation studies confirm the effectiveness of frequency band selection, channelization, and the descending structure. Further comparisons across spectral features and SNR conditions demonstrate that FCResNet5 achieves a favorable trade-off between accuracy and efficiency.
In future work, we plan to explore optimized architectures to improve classification while preserving simplicity, enhance performance under extremely low SNR conditions, and adopt automated compression strategies to better balance accuracy and efficiency.
Data availability
The datasets analyzed during the current study are available for download at https://github.com/irfankamboh/DeepShip repository. (Keeping in view the limitation of file size and space on github directory, only a part of dataset is uploaded on this repository. The complete dataset can be downloaded by following the information provided on the same repository web page).
References
Arveson, P. T. & Vendittis, D. J. Radiated noise characteristics of a modern cargo ship. J. Acoust. Soci. Am. 107, 118–129. https://doi.org/10.1121/1.428344 (2000).
Li, Y., Zhang, C. & Zhou, Y. A novel denoising method for ship-radiated noise. J. Marine Sci. Eng. 11, 1730. https://doi.org/10.3390/jmse11091730 (2023).
Li, G., Bu, W. & Yang, H. Research on noise reduction method for ship radiate noise based on secondary decomposition. Ocean Eng. 268, 113412. https://doi.org/10.1016/j.oceaneng.2022.113412 (2023).
Li, Y., Lou, Y., Liang, L. & Zhang, S. Research on feature extraction of ship-radiated noise based on multiscale fuzzy dispersion entropy. J. Marine Sci. Eng. 11, 997. https://doi.org/10.3390/jmse11050997 (2023).
Javier, R. F., Jaime, R., Pedro, P., Jesus, C. & Enrique, S. Analysis of the underwater radiated noise generated by hull vibrations of the ships. Sensors 23, 1035. https://doi.org/10.3390/s23021035 (2023).
Yang, J., Yan, S., Zeng, D. & Yang, B. Underwater time-domain signal recognition network with improved channel attention mechanism. J. Signal Process. 39, 1025–1035. https://doi.org/10.16798/j.issn.1003-0530.2023.06.008 (2023).
Liu, S. et al. A fine-grained ship-radiated noise recognition system using deep hybrid neural networks with multi-scale features. Remote Sens. 15, 2068. https://doi.org/10.3390/rs15082068 (2023).
Lin, X., Dong, R., Zhao, Y. & Wang, R. Efficient ship noise classification with positive incentive noise and fused features using a simple convolutional network. Sci. Rep. 13, 17905. https://doi.org/10.1038/s41598-023-45245-6 (2023).
Mumuni, A. & Mumuni, F. Automated data processing and feature engineering for deep learning and big data applications: A survey. J. Inform. Intell. 2949–7159, 2024. https://doi.org/10.1016/j.jiixd.2024.01.002 (2024).
Shiri, F. M., Perumal, T., Mustapha, N. & Mohamed, R. A Comprehensive Overview and Comparative Analysis on Deep Learning Models: CNN, RNN, LSTM, GRU. Computer Science (2023).
Yuan, F., Ke, X. & Cheng, E. Joint representation and recognition for ship-radiated noise based on multimodal deep learning. J. Marine Sci. Eng. 7, 380. https://doi.org/10.3390/jmse7110380 (2019).
Xie, Y., Ren, J. & Xu, J. Adaptive ship-radiated noise recognition with learnable fine-grained wavelet transform. Ocean Engineering265, 112626. https://doi.org/10.1016/j.oceaneng.2022.112626 (2022) arXiv:2306.01002.
Doan, V.-S., Huynh-The, T. & Kim, D.-S. Underwater acoustic target classification based on dense convolutional neural network. IEEE Geosci. Remote Sens. Lett. 19, 1–5. https://doi.org/10.1109/LGRS.2020.3029584 (2022).
Wang, Y., Zhang, H., Xu, L., Cao, C. & Gulliver, T. A. Adoption of hybrid time series neural network in the underwater acoustic signal modulation identification. J. Franklin Inst. 357, 13906–13922. https://doi.org/10.1016/j.jfranklin.2020.09.047 (2020).
Lipton, Z. C., Berkowitz, J. & Elkan, C. A Critical review of recurrent neural networks for sequence learning (2015). arXiv:1506.00019.
Xiaoping, S., Jinsheng, C. & Yuan, G. A new deep learning method for underwater target recognition based on one-dimensional time-domain signals. In 2021 OES China Ocean Acoustics (COA), 1048–1051, https://doi.org/10.1109/COA50123.2021.9520078 (IEEE, Harbin, China, 2021).
He, Q., Wang, H., Zeng, X. & Jin, A. Ship-radiated noise separation in underwater acoustic environments using a deep time-domain network. J. Marine Sci. Eng. 12, 885. https://doi.org/10.3390/jmse12060885 (2024).
Vaswani, A. et al. Attention is all you need (2023). arXiv:1706.03762.
Feng, S. & Zhu, X. A transformer-based deep learning network for underwater acoustic target recognition. IEEE Geosci. Remote Sens. Lett. 19, 1–5. https://doi.org/10.1109/LGRS.2022.3201396 (2022).
Wang, B. et al. Ship radiated noise recognition technology based on ML-DS decision fusion. Comput. Intell. Neurosci. 1–14, 2021. https://doi.org/10.1155/2021/8901565 (2021).
Liu, D., Zhao, X., Cao, W., Wang, W. & Lu, Y. Design and performance evaluation of a deep neural network for spectrum recognition of underwater targets. Comput. Intell. Neurosci. 1–11, 2020. https://doi.org/10.1155/2020/8848507 (2020).
Bach, N. H., Vu, L. H. & Nguyen, V. D. Classification of surface vehicle propeller cavitation noise using spectrogram processing in combination with convolution neural network. Sensors 21, 3353. https://doi.org/10.3390/s21103353 (2021).
Hummel, H. I., Van Der Mei, R. & Bhulai, S. A survey on machine learning in ship radiated noise. Ocean Eng. 298, 117252. https://doi.org/10.1016/j.oceaneng.2024.117252 (2024).
Yang, S. et al. Underwater acoustic target recognition based on sub-band concatenated Mel spectrogram and multidomain attention mechanism. Eng. Appl. Artif. Intell. 133, 107983. https://doi.org/10.1016/j.engappai.2024.107983 (2024).
Zhao, Y. et al. Towards battery-free machine learning and inference in underwater environments. in Proceedings of the 23rd Annual International Workshop on Mobile Computing Systems and Applications, 29–34, https://doi.org/10.1145/3508396.3512877 (2022). arXiv:2202.08174.
Feng, H. et al. Underwater acoustic target recognition method based on WA-DS decision fusion. Appl. Acoust. 217, 109851. https://doi.org/10.1016/j.apacoust.2024.109851 (2024).
Li, D. et al. Generalizable underwater acoustic target recognition using feature extraction module of neural network. Appl. Sci. 12, 10804. https://doi.org/10.3390/app122110804 (2022).
Shen, S. et al. Ship type classification by convolutional neural networks with auditory-like mechanisms. Sensors 20, 253. https://doi.org/10.3390/s20010253 (2020).
Liu, C., Hong, F., Feng, H. & Hu, M. Underwater Acoustic Target Recognition Based on Dual Attention Networks and Multiresolution Convolutional Neural Networks. In OCEANS 2021: San Diego – Porto, 1–5, https://doi.org/10.23919/OCEANS44145.2021.9706009 (IEEE, San Diego, CA, USA, 2021).
Lyu, C. et al. A light-weight neural network for marine acoustic signal recognition suitable for fiber-optic hydrophones. Expert Syst. Appl. 235, 121235. https://doi.org/10.1016/j.eswa.2023.121235 (2024).
Zhu, P. et al. Underwater acoustic target recognition based on spectrum component analysis of ship radiated noise. Appl. Acoust. 211, 109552. https://doi.org/10.1016/j.apacoust.2023.109552 (2023).
Irfan, M. et al. DeepShip: An underwater acoustic benchmark dataset and a separable convolution based autoencoder for classification. Expert Syst. Appl. 183, 115270. https://doi.org/10.1016/j.eswa.2021.115270 (2021).
Han, X. C., Ren, C., Wang, L. & Bai, Y. Underwater acoustic target recognition method based on a joint neural network. PLoS ONE 17, e0266425. https://doi.org/10.1371/journal.pone.0266425 (2022).
Zhang, Q., Da, L., Zhang, Y. & Hu, Y. Integrated neural networks based on feature fusion for underwater target recognition. Appl. Acoust. 182, 108261. https://doi.org/10.1016/j.apacoust.2021.108261 (2021).
Ren, J., Xie, Y., Zhang, X. & Xu, J. UALF: A learnable front-end for intelligent underwater acoustic classification system. Ocean Eng. 264, 112394. https://doi.org/10.1016/j.oceaneng.2022.112394 (2022).
Liu, F., Shen, T., Luo, Z., Zhao, D. & Guo, S. Underwater target recognition using convolutional recurrent neural networks with 3-D Mel-spectrogram and data augmentation. Appl. Acoust. 178, 107989. https://doi.org/10.1016/j.apacoust.2021.107989 (2021).
Xie, Y., Ren, J. & Xu, J. Unraveling complex data diversity in underwater acoustic target recognition through convolution-based mixture of experts. Expert Syst. Appl. 249, 123431. https://doi.org/10.1016/j.eswa.2024.123431 (2024).
Domingos, L. C. F., Santos, P. E., Skelton, P. S. M., Brinkworth, R. S. A. & Sammut, K. A survey of underwater acoustic data classification methods using deep learning for shoreline surveillance. Sensors 22, 2181. https://doi.org/10.3390/s22062181 (2022).
LI, L., LI, X. & YIN, J. Research on Classification Algorithm of Ship Radiated Noise Data Based on Generative Adversarial Network (2022).
Jun-Ping, Sun et al. Theoretical model and simulation of ship underwater radiated noise. Acta Physica Sinica 65, 124301. https://doi.org/10.7498/aps.65.124301 (2016).
Slamnoiu, G. et al. DEMON-type algorithms for determination of hydro-acoustic signatures of surface ships and of divers. IOP Conf. Series: Mater. Sci. Eng. 145, 082013. https://doi.org/10.1088/1757-899X/145/8/082013 (2016).
He, K., Zhang, X., Ren, S. & Sun, J. Deep residual learning for image recognition. in 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 770–778, https://doi.org/10.1109/CVPR.2016.90 (IEEE, Las Vegas, NV, USA, 2016).
Acknowledgements
This research is supported by the National Natural Science Foundation of China (Grant No. 62192711) and Goal-Oriented Project Independently Deployed by Institute of Acoustics, Chinese Academy of Sciences MBDX202104.
Author information
Authors and Affiliations
Contributions
Di Zeng: Model development, manuscript writing. Shefeng Yan: Manuscript review and revision. Jirui Yang: Experiments, result analysis. Xianli Pan: Supervision, manuscript revision.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Zeng, D., Yan, S., Yang, J. et al. An efficient deep learning approach with frequency and channel optimization for underwater acoustic target recognition. Sci Rep 15, 27369 (2025). https://doi.org/10.1038/s41598-025-12452-2
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-025-12452-2
Keywords
This article is cited by
-
Underwater acoustic target recognition based on multi-scale feature and CRDNet
The Journal of Supercomputing (2025)
