
Abstract
Dental diseases are the primary cause of oral health concerns around the world, affecting millions of people. Therefore, recent developments in imaging technologies have transformed the detection and treatment of oral problems. Applying three-dimensional (3D) reconstruction from two-dimensional (2D) dental images, such as X-rays, is a potential development field. 3D reconstruction technology converts real-world goals into mathematical models that are compatible with computer logic expressions. It’s been commonly used in dentistry. Particularly for patients with a vomiting reflex, 3D imaging techniques minimize patient discomfort and shorten the length of the examination or treatment. Therefore, this research paper proposes a new 3D reconstruction model from 2D multi-view dental images. The proposed framework consists of three stages. The first stage is the encoder stage, which extracts meaningful features from the 2D images. The second stage captures spatial and semantic information essential for the reconstruction task. The third stage is recurrence, which uses 3D long short-term memory (LSTM). It ensures that the information from various viewpoints is effectively integrated to produce a coherent representation of the 3D structure and decoder stage to translate the aggregated features from the LSTM into a fully reconstructed 3D model. When the proposed model was tested on the ShapeNet dataset, the suggested model achieved a maximum intersection over union (IoU) of 89.98% and an F1_score of 94.11%. A special case of 3D reconstruction, a dental dataset, has been created with the same structure as the ShapeNet dataset to evaluate our system. The proposed approach’s results show promising accomplishments compared to many state-of-the-art approaches, and they motivate the authors to make plans for further improvement.
Similar content being viewed by others
Introduction
Dentistry has rapidly changed over the previous several decades due to technological advancements in treatment and diagnosis1,2,3,4. Today, medical imaging is considered crucial for detecting and treating disorders in all medical professions5. Numerous medical imaging techniques are available for diagnosis, such as optical coherence tomography (OCT), laser-based pens for cavity detection, and X-ray radiography6,7. Dental diagnostic X-ray imaging is still one of the most widely used radiological modalities for oral examinations in dental clinics. It is essential for identifying and treating dental disorders, comprehending their nature, and anticipating them in their early stages. However, even the most experienced dentists may find that analyzing dental X-rays is a laborious and error-prone process that often leaves out important details. Therefore, using dental X-ray images to recreate 3D models will be beneficial8,9,10,11,12.
3D reconstruction has become one of the most popular areas of computer vision research, which accurately restores objects’ three-dimensional properties using their two-dimensional features. The human visual system is simulated via 3D reconstruction, which gives computers eyes representing transmitters and brains representing algorithms13,14,15. It also converts actual objectives into mathematical models compatible with computer logic expressions, and it has been used extensively in dentistry5,16,17. Researchers have worked intensively on advancing methodologies for 3D reconstruction from 2D X-ray images over the past decades18,19,20,21,22,23. In addition to reducing radiation exposure and patient expenses, these efforts seek to provide better details and greater precision24. Due to deep learning’s notable successes in fields connected to computer vision, scientists are now looking at how it may be used for 3D reconstruction from 2D X-rays.
The capability of 3D reconstruction to capture, replicate, process, analyze, and comprehend both static and dynamic images of dental procedures in real time. It offers the potential to more accurately describe or diagnose each disease and conduct a more in-depth analysis25. 3D images are a powerful tool for communication. A patient or physician can manipulate it to interactively view the scan target from any perspective. Furthermore, it improves the accuracy and efficiency of communication in remote situations using 3D images. 3D reconstruction technology is commonly employed in orthodontics, restorative dentistry, cranial bone, surgical navigation, and other areas of dentistry26,27. Even though 3D reconstruction technology has challenges, such as operator skill, inconsistent scanner quality, and high initial expenses, it has been crucial to dental care. The dental field has significantly transformed due to the digital revolution28.
Therefore, this research paper proposes a new method for 3D object reconstruction from 2D images using EfficientNetB0 deep convolutional neural network. As a result, the following are the primary contributions of the suggested method:
-
Developing a dental dataset for 3D reconstruction, namely TeethNet, with the same structure as the ShapeNet dataset.
-
Enhancing the 3D reconstruction performance by using the benefits of EfficientNetB0 within the encoder stage.
-
Different evaluation metrics have been applied to the developed TeethNet dataset, such as mean absolute error (MAE), mean square error (MSE), and root mean squared error (RMSE).
The remainder of this research is structured as follows. “Related work” shows the previous studies that discussed the 3D reconstruction, including their techniques. “The proposed framework” presents the proposed framework, including the description of each stage used to reconstruct the 3D model from the 2D dental image. The experimental results are shown in “Experimental results”, which explains the datasets and evaluation metrics used and then moves on to the obtained results and their analysis. Lastly, “Conclusion” presents the conclusion and future work.
Related work
The topic of 3D reconstruction from 2D images has been the subject of numerous studies, utilizing improvements in machine learning and computer vision techniques29,30,31,32,33. Traditional methods often relied on geometric approaches, such as structure-from-motion (SfM) and stereo vision, which utilized numerous views of the same scene to estimate depth and create 3D models. These methods demonstrated success in controlled environments but faced challenges in dealing with noise, textureless regions, and varying lighting conditions. More recently, deep learning techniques have revolutionized 3D reconstruction by enabling single-view and multi-view reconstructions using convolutional neural networks (CNNs) and transformer-based models. These methods have been employed in different fields, including cultural heritage preservation and robotics, demonstrating their ability to capture fine-grained features and complex geometries. Furthermore, hybrid methods that combine geometric and deep learning models have emerged to enhance reconstruction accuracy and robustness. Despite significant progress, challenges remain in achieving real-time performance, handling large-scale scenes, and generalizing to unseen environments. This section discusses some research for applying 3D construction from 2D images.
Liang et al.34 presented a method for applying 3D teeth reconstruction from X-rays, which was particularly important for diagnosing dental disorders and performing several clinical procedures. This method created 3D teeth from a single image using the ConvNet network, which divides the task into teeth localization and single-shape estimation. This method achieved the highest performance in computing the 3D structure of the cavity and reflected the tooth details with 68.1%. Chen et al.35 presented a method that reconstructs 3D teeth from five intra-oral images to help visualize the patients’ conditions in virtual consultations. This method used images to recreate upper and lower tooth shape, arrangement, and occlusion. The modified U-net network used an iterative process that alternated between finding point correspondences and optimizing a compound loss function to match the parametric teeth model to expected tooth outlines. Their dataset was split using five-fold cross-validation. This method achieved 76.72% for the Dice similarity coefficient.
Ali et al.36 proposed a method for producing a 3D teeth crown using a prototype intraoral custom design and public software. Several images of the unusual teeth were taken from various perspectives. Scale-invariant feature transform (SIFT) was used to extract key points from images. The RANSAC matching algorithm was applied, and then motion formed the structure. The camera posed and a 3D point cloud was computed. Finally, a 3D object was visualized and was created. The error was computed ranged from 0.003%: 0.13%. Farook et al.37 provided a method for producing 3D dental teeth for digital partial dental crown synthesis and validation. To construct partial dental crowns (PDC), this method utilized a 3D-CNN. This approach was 60% accurate.
Minhas et al.38 developed a 3D teeth reconstruction approach to assess the position of maxillary impacted canines using panoramic X-rays. The information was compiled from CBCT scans of 123 patients, including 74 with impacted canines and 49 without. Using 3D Convolution Neural Network (3D CNN), this method produced a mean structure similarity index measure (SSIM) of 0.71 and an accuracy of 55%. Song et al. 39 suggested an approach for reconstructing 3D teeth from 2D images. This solution relied on Oral-3Dv2 to handle the cross-dimensional translation challenge in dental healthcare by learning exclusively from projection data. By converting 2D coordinates into 3D voxel density values, this model was trained to depict 3D oral structures. It produced 86.04% performance in 3D reconstruction from a single panoramic X-ray image.
Li et al.40 developed a 3D oral image reconstruction method. It used a Multilayer Perceptron (MLP) CNN pyramid network (3DPX) to reconstruct oral PX from 2D to 3D. The 3DPX method combines CNNs and MLPs to capture long-range visual dependency. It achieved 15.84 % PSNR, 63.72% DSC, and 74.09% SSIM. Ma et al.41 offered a technique for converting a single panoramic X-ray into 3D point cloud teeth. Using a two-stage framework and a single PX image, PX2Tooth was utilized to reconstruct 3D teeth. First, permanent teeth were segmented from PX images using the PXSegNet, which provided morphological, positional, and categorical information for every tooth. Then, to convert random point clouds into 3D teeth, a unique tooth-generating network (TGNet) was created. In terms of intersection over union (IoU), this approach obtained 79.3%. Choy et al.42 suggested a 3D recurrent reconstruction neural network (3D-R2N2) model. One or more images of a dataset taken from different angles were used to teach this network. It produces the object reconstruction from these images and does not require object class labels or image annotations for training or testing. Their experimental research revealed that their reconstruction framework outperformed cutting-edge single-view reconstruction approaches.
This section reviews several studies on applying 3D reconstruction from 2D images for various objects, including teeth, chairs, pens, cars, and more. However, these studies face several limitations. A key challenge is their reliance on specific datasets, which restricts the generalizability of the methods to diverse real scenarios. Additionally, many approaches encounter issues such as operating with a limited number of images, handling low-contrast images, and achieving low accuracy. Moreover, one major obstacle to advancement in this discipline is the lack of publicly accessible datasets for 3D reconstruction from 2D images.
Using the ShapeNet public dataset, a technique for 3D reconstruction from 2D images taken from various perspectives has been implemented to overcome the aforementioned difficulties. This proposed methodology enhances the reconstruction process by leveraging a multi-stage framework. The first stage involves an encoder extracting meaningful features from the 2D images, capturing spatial and semantic information essential for the reconstruction task. In the second stage, a recurrent network utilizing 3D long short-term memory (LSTM) is employed to model the temporal and spatial dependencies between the multiple views. This stage ensures that the information from different perspectives is effectively integrated to produce a coherent representation of the 3D structure. Finally, the third stage consists of a decoder that translates the aggregated features from the LSTM into a fully reconstructed 3D model. This comprehensive pipeline not only improves the quality of the reconstructed 3D object but also addresses issues related to variability in object shape, viewing angles, and image consistency. Using a publicly available dataset like ShapeNet further enhances the reproducibility and comparability of the results, making this approach a significant step forward in 3D reconstruction. Table 1 discusses previous papers according to year, methodology, metrics, strengths, and limitations.
The proposed framework

The 3D reconstruction from 2D images based on EfficientNetB0 encoder, LSTM, and decoder.
The proposed work aims to design and train an advanced 3D object recognition model using a combination of multiview RGB images and voxel representations from the ShapeNet dataset as indicated in Fig. 1. The model’s architecture integrates state-of-the-art techniques in deep learning, combining EfficientNetB0 for 2D feature extraction, Conv3D LSTM cells for temporal learning of 3D structures, and 3D deconvolution for voxel reconstruction. Therefore, in this work, no explicit calibration has been performed in the traditional sense. Instead, we utilize a deep neural network trained on multiview images, where the network inherently learns spatial consistency and scale relationships from the training data42,43.
Encoder
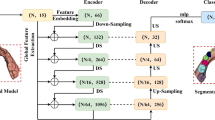
The proposed encoder leverages the EfficientNet-B0 architecture to extract robust 2D feature representations44,45. EfficientNet-B0, pre-trained on a large dataset, serves as the backbone, and its convolutional layers up to the penultimate stage are utilized for feature extraction. The classification head of the pre-trained model is excluded, ensuring that only spatially rich features are retained. These feature maps are flattened into a 1D vector during the forward pass to prepare for further processing.
To adapt to varying input dimensions, the encoder dynamically initializes a fully connected layer based on the flattened feature map’s size, determined during the first forward pass. This fully linked layer reduces dimensionality to a fixed 1024-dimensional latent space, assuring compatibility with subsequent tasks. A LeakyReLU activation function with a negative slope of 0.1 is used to introduce nonlinearity and reduce concerns with vanishing gradients. The encoder design combines EfficientNet-B0’s efficient feature extraction with a flexible and computationally efficient architecture, making it well-suited for diverse applications requiring compact yet powerful feature representations. Fig.2 presents the encoder architecture.

The encoder architecture based on the EfficientNetB0 model.
Recurrence: 3D LSTM
Our 3D-R2N2’s core component is a recurrence module, which allows the network to remember what it has already seen and update its memory whenever a new image is discovered. A three-dimensional convolutional LSTM (3D-LSTM) has been proposed. The network is composed of well-organized LSTM units with minimal connectivity. As depicted in Fig. 3, the 3D-LSTM units are dispersed in a grid pattern, each reproducing a fraction of the outcome. The 3D grid has \(N\) \(\times\) \(N\) \(\times\) N 3D-LSTM units, where N is the grid’s spatial resolution. Each 3D-LSTM unit (indexed \((i, j, k)\), has an independent hidden state \(h_t(i, j, k)\) \(\in\) \(R^{N_h}\). The equations that regulate the 3D-LSTM grid are the following:
where \(s_t\) is the state at time t, \(f_t\) is the forget gate, and \(s_{t-1}\) is the previous state, and \(i_t\) is the input gate.

The 3D LSTM architecture.
Decoder
After obtaining the input image sequence \(x_1\), \(x_2\),..... \(x_T\), the 3D-LSTM employs 3D convolutions, nonlinearities, and unspooling to enhance the resolution of the hidden state \(h_T\). As illustrated in Fig. 4, a basic decoder network with five convolutions and a deep residual version with four residual connections, followed by a final convolution, has been presented that is comparable to our encoders. After reaching the intended output resolution, a voxel-wise softmax was used to transform the final activation to the occupancy probability of the voxel cell.

The decoder architecture.
Experimental results
The performance of the proposed scheme for 3D construction from 2D images was evaluated using Python, a highly versatile and user-friendly programming language renowned for its extensive library support. Python is used extensively in domains like artificial intelligence and bioinformatics. For this study, we leveraged several libraries, including NumPy, Matplotlib, TensorFlow, Scikit-learn, Keras, and OpenCV, to develop and evaluate the models effectively. The computer configuration used in these experiments is as follows: CPU: Intel(R) Core(TM) i7-9750H @ 2.60 GHz (Lenovo, Beijing, China); Memory: 16 GB RAM; Operating System: Microsoft Windows 10 (Microsoft, Redmond, WA, USA); Programming Environment: Python. In the next section, we detail the metrics used for performance evaluation.
Dataset description
The ShapeNet dataset, which comprises 3D CAD models organized following the WordNet hierarchy, was used to evaluate the suggested approach. Thirteen main categories and 50 thousand models were used from a portion of the ShapeNet dataset42. Fig. 5 displays a selection of the ShapeNet dataset images.
The case study dataset
Due to a lack of teeth X-ray datasets online, the team started to create a graphical dataset simulation for the teeth dataset, namely TeethNet, to be used for initial testing. The generated multiview dataset has been loaded in GitHub repository46. The dataset contains the following as shown in Fig. 6:
-
Thirty-two folders (each folder is named after the corresponding tooth iso name) contain 18 images of different views generated by Unity 3D C# scripts.
-
Ground truth OBJ 3D format: 3D format for each tooth as Mesh OBJ files. It contains 32 models.
-
Ground truth Binvox 3D format: 3D voxel format for each tooth. It contains 32 models.
The last thumbnail in Fig. 6 shows a CSV (comma-separated values) file that contains the image names list and their relative positions during the generation of the dataset. The relative position is computed with respect to the first image in the dataset. Also, a few samples look like 2D while others look like 3D as all images are 2D projections based on the viewer’s location and angle. In some cases, the viewer’s angles have a visual appearance of 3D shades depending on light source reflection differences in the simulated environment. However, in other images, the angle of view has almost equal light reflections, giving a 2D-like visual appearance.
This dataset is developed using Unity 3D. Our custom dataset (TeethNet) has a metadata structure similar to the original ShapeNet dataset, as shown in Fig. 7.

The ShapeNet dataset images samples.

The generated image dataset sample contents.

The directory structure of generated TeethNet dataset.
Evaluation metrics
Various evaluation measures can be employed to evaluate the performance of the 3D reconstruction system, such as IoU, F1 score, MAE, MSE, and RMSE. The voxel IoU between a 3D voxel reconstruction and its ground truth voxelized model can be computed by Eq. 542.
where \((i,j,k)\) represents voxel coordinates, \(t\) is voxelization threshold and the corresponding ground truth occupancy is \((y_{(i,j,k)}\) \(\in\) \({0,1}\).
The F1 score is a prominent metric that measures the overall volume agreement between predicted and ground-truth 3D reconstructions47. MAE calculates the average magnitude of errors between expected and actual values, regardless of their direction48. It can be computed by Eq. 6.
where \(y_i\) represents the actual value, \(\hat{y}_i\) is the predicted value, and \(n\) is the total number of samples.
MSE evaluates the average squared difference between the predicted and actual values49,50, penalizing larger errors more significantly than MAE. The formula for MSE can computed by Eq. 7. RMSE, or the square root of MSE, is an interpretable error measure in the same units as the original data48,51. It can be computed by Eq. 8.
The Chamfer distance (CD) is used to quantify the difference between two point clouds by computing the squared distance between each point \(p\) in the predicted point cloud \(X_p\) and its closest neighbor in the true point cloud \(X\), and vice versa. It is formulated as follows:
The lower (denoted by \(\downarrow\)) the CD is, the better the reconstructed 3D shape is. The Earth Mover’s Distance (EMD) quantifies the dissimilarity between two multi-dimensional distributions in a given feature space by computing the point-to-point \(L_1\) distance between two point clouds. It is defined as:
The lower (denoted by \(\downarrow\)) the EMD value, the better the quality of the reconstructed 3D shape.
Results
This subsection presents and explains the results of the proposed system evaluated on the ShapeNet dataset.
A comparison of deep learning methods
Deep learning models such as EfficientNetB0, ResNet18, VGG16, and ResNet50 are well-known for their performance in various computer vision applications. EfficientNetB0 is notable for its revolutionary compound scaling method, allowing it to compromise accuracy and processing economy. ResNet18, with its lightweight architecture and residual learning framework, is particularly suited for tasks where computational resources are limited52. VGG16, characterized by its deep architecture with 16 layers, excels at capturing hierarchical features but requires higher computational power53. ResNet50, a deeper variant of the ResNet family, incorporates bottleneck blocks to efficiently learn complex representations, making it ideal for intricate tasks requiring detailed feature extraction54. These models collectively provide robust solutions for feature extraction and classification, each with unique strengths tailored to different application scenarios.
A comparison between the suggested system employing EfficientNet_B0 and other deep learning techniques, such as Resnet18, VGG19, and Resnet50, has been provided, as indicated in Table 2. This comparison demonstrates the superior outcome of the suggested work, which can be attributed to the parameter efficiency of EfficientNet_B0, which enables the model to achieve high accuracy without incurring excessive computational costs, and its compound scaling strategy, which optimally balances depth, width, and resolution. Furthermore, EfficientNet’s ability to extract rich features and effectively handle spatial information, combined with its training efficiency and generalization capabilities, make it ideal for complex tasks such as 3D reconstruction, where accuracy and computational efficiency are critical.
A comparison of different versions of EfficientNet
The comparison of different EfficientNet variants as encoders, as shown in Table 3, demonstrates the impact of model complexity on the reconstruction performance. EfficientNetB0 achieved the highest IoU of 89.98% and an F1-score of 94.11%, outperforming EfficientNetB1 and EfficientNetB2. This superior performance suggests that EfficientNetB0 balances capturing spatial-semantic features effectively and maintaining computational efficiency. Also, EfficientNet-B1 and B2 have a larger number of parameters, which may have led to overfitting, particularly given the dataset size. Reconstructing 3D structures from 2D images requires efficient feature extraction while maintaining fine-grained details. Our results suggest that B0’s lighter architecture is sufficient for capturing the necessary spatial features, while deeper architectures might introduce unnecessary complexity without significant benefits. These results highlight the effectiveness of EfficientNet_B0 as the encoder stage in the proposed framework.
A comparison with the state-of-the-art approaches
Table 4 presents a comparative analysis of recent state-of-the-art approaches for 3D reconstruction on the ShapeNet dataset. It includes studies from 2016 to 2025, listing the research authors, network architectures, and performance metrics such as Intersection over Union (IOU) and F1-score. The table effectively highlights the progression of methods, from early architectures like 3D-R2N2 Choy et al.42 to more advanced models such as Multi-Manifold Attention kalitsios et al.55. Notably, some entries have missing values, such as the IOU score for liu et al.56 and the F1-score for Choy et al. (2016), which may indicate either unreported metrics or inapplicability to those models. Additionally, the proposed methodology (EfficientNetB0, 2025) achieves the highest IOU (89.98) and F1-score (94.11), suggesting significant improvements over previous methods. However, the formatting of the table could be refined for better readability, particularly in aligning numerical values and handling long network names that span multiple lines. The highlighted title effectively draws attention but may need reformatting for consistency with academic standards. Overall, the table provides a clear comparison of different approaches, emphasizing the advancements in 3D reconstruction techniques over time.
Computing 3D Euler angle based on features descriptors
The provided code implements a pipeline for extracting Euler angles and reconstructing 3D structures from 2D image pairs58,59,60. Keypoint detection and matching are central to this process61,62,63,64, as they help establish correspondences between image pairs. The BRISK algorithm is utilized to detect and describe keypoints65,66, with the BFMatcher ensuring robust matching of descriptors. The fundamental matrix is computed using these correspondences, and the essential matrix is derived using the intrinsic camera matrix. The camera’s relative pose, including the rotation matrix R and translation vector t, is recovered from the essential matrix. Finally, the 3D points are triangulated, and their spatial arrangement is visualized in a point cloud67,68. This approach highlights the synergy of computer vision techniques and mathematical rigor to recover geometric transformations and compute Euler angles, which are essential for applications like robotics, augmented reality, and medical imaging.
Feature descriptors like binary robust independent elementary features like binary robust invariant scalable keypoints (BRISK), SIFT, oriented FAST and rotated brief (ORB), BRIEF, and AKAZE are essential components of computer vision and image processing. Each algorithm has distinct advantages depending on the application. For instance, SIFT excels in scale and rotation invariance, making it ideal for scenes with varying perspectives69,70. ORB offers a fast and efficient alternative with lower computational overhead, suitable for real-time tasks71,72. BRIEF emphasizes simplicity and speed by encoding binary descriptors73,74. Similarly, AKAZE focuses on nonlinear scale spaces, ensuring robustness against varying scales and affine transformations75,76. As used in the code, BRISK efficiently detects and describes features while ensuring robustness to rotation and scale changes65,66. These descriptors form the foundation of matching and reconstruction pipelines, enabling accurate spatial and geometric transformation recovery. Fig 8 indicates The matching results between dental images based on various descriptors.
To validate the accuracy of 3D reconstruction and pose estimation, the code computes key error metrics such as MAE, MSE, and RMSE. These metrics compare vectors, such as those derived from Euler angles or reconstructed 3D points, against ground truth values. MAE captures the average magnitude of errors, offering a straightforward measure of accuracy. MSE emphasizes larger errors due to its squared nature, providing insights into outlier behavior. RMSE, as the square root of MSE, presents the error in the same units as the original data, making it more interpretable. These metrics are crucial for assessing the precision and reliability of 3D reconstruction pipelines, particularly in applications like medical imaging, where even minor inaccuracies can lead to significant implications.
Table 5 presents the experimental results for various methods based on deep learning, focusing on keypoint detectors and descriptors, evaluated using three error metrics: MAE, MSE, and RMSE. Among the methods, the BRISK detector and descriptor achieved the lowest error rates, with an MAE of 0.087, MSE of 0.0083, and RMSE of 0.091, indicating superior accuracy and robustness. In contrast, SIFT, ORB, and BRIEF detectors and descriptors exhibit higher error rates, with identical MAE values of 0.37 and similar RMSE values of approximately 0.39, suggesting their performance is comparable but less precise than BRISK. AKAZE detector and descriptor performed better than SIFT, ORB, and BRIEF, with moderate error rates (MAE of 0.17, MSE of 0.044, and RMSE of 0.21), showcasing a balance between computational efficiency and accuracy. These results underline BRISK’s effectiveness in minimizing errors, making it a promising choice for deep learning-based applications requiring precise keypoint detection and description.

The matching results between dental images based on various descriptors.
Conclusion
3D reconstruction is crucial in advancing dental imaging by providing detailed and accurate representations of oral structures, enabling precise diagnostics and treatment planning. This technology enhances traditional 2D imaging methods by creating comprehensive models that improve visualization, reduce patient discomfort, and streamline clinical workflows. In conclusion, this research highlights the potential of advanced 3D reconstruction techniques to address challenges in dental imaging and diagnosis. By leveraging a robust framework comprising an encoder for feature extraction, a 3D LSTM for integrating multi-view information, and a decoder for generating the final 3D model, the proposed system demonstrates significant improvements in accuracy and coherence. The model’s performance, validated on both the ShapeNet dataset and a newly created dental dataset, underscores its effectiveness, achieving a maximum IOU of 89.98% and F1-Score of 94.11%. These results show the system’s potential for practical applications in dentistry, offering enhanced precision, reduced patient discomfort, and improved diagnostics and treatment planning efficiency. Future research will enhance the framework’s suitability for a wider range of dental and medical imaging scenarios, investigate the integration of extra modalities, and optimize it for clinical datasets.
References
Erdelyi, R.-A. et al. Dental diagnosis and treatment assessments: Between x-rays radiography and optical coherence tomography. Materials 13(21), 4825 (2020).
Javaid, M., Haleem, A. & Kumar, L. Current status and applications of 3D scanning in dentistry. Clin. Epidemiol. Glob. Health 7(2), 228–233 (2019).
Zhu, J. et al. Artificial intelligence in the diagnosis of dental diseases on panoramic radiographs: A preliminary study. BMC Oral Health 23(1), 358 (2023).
Sivari, E. et al. Deep learning in diagnosis of dental anomalies and diseases: A systematic review. Diagnostics 13(15), 2512 (2023).
Cen, Y. et al. Application of three-dimensional reconstruction technology in dentistry: A narrative review. BMC Oral Health 23(1), 630 (2023).
Huang, D. et al. Optical coherence tomography. Science 254(5035), 1178–1181 (1991).
Podoleanu, A. G. & Bradu, A. Master-slave interferometry for parallel spectral domain interferometry sensing and versatile 3D optical coherence tomography. Opt. Exp. 21(16), 19324–19338 (2013).
Hwang, S.-Y., Choi, E.-S., Kim, Y.-S., Gim, B.-E., Ha, M., & Kim, H.-Y. Health effects from exposure to dental diagnostic X-ray. Environ. Health Toxicol. 33(4) (2018).
Kim, H. J., Kim, H. N., Raza, H. S., Park, H. B. & Cho, S. O. An intraoral miniature X-ray tube based on carbon nanotubes for dental radiography. Nucl. Eng. Technol. 48(3), 799–804 (2016).
Chauhan, V. & Wilkins, R. C. A comprehensive review of the literature on the biological effects from dental X-ray exposures. Int. J. Radiat. Biol. 95(2), 107–119 (2019).
Asahara, T. et al. Helpfulness of effective atomic number image in forensic dental identification: Photon-counting computed tomography is suitable. Comput. Biol. Med. 184, 109333 (2025).
Ashame, L. A., Youssef, S. M., Elagamy, M. N., Othman, A. & El-Sheikh, S. M. A computer-aided model for dental image diagnosis utilizing convolutional neural networks. J. Adv. Res. Appl. Sci. Eng. Technol. 52(2), 15–25 (2025).
Mahanty, M., Kumar, P.H., Sushma, M., Chand, I.T., Abhishek, K. & Chowdary, C.S.R. A comparative study on construction of 3D objects from 2D images. In Smart Technologies in Data Science and Communication: Proceedings of SMART-DSC 2021. 205–222. (Springer, 2021).
Matthews, I., Xiao, J. & Baker, S. 2D vs. 3D deformable face models: Representational power, construction, and real-time fitting. Int. J. Comput. Vis. 75, 93–113 (2007).
Duta, N., Jain, A. K. & Dubuisson-Jolly, M.-P. Automatic construction of 2D shape models. IEEE Trans. Pattern Anal. Mach. Intell. 23(5), 433–446 (2001).
Karako, K., Wu, Q. & Gao, J. Three-dimensional imaging technology offers promise in medicine. Drug Discov. Ther. 8(2), 96–97 (2014).
Duhn, C., Thalji, G., Al-Tarwaneh, S. & Cooper, L. F. A digital approach to robust and esthetic implant overdenture construction. J. Esthetic Restor. Dent. 33(1), 118–126 (2021).
Rougée, A., Picard, C., Ponchut, C. & Trousset, Y. Geometrical calibration of X-ray imaging chains for three-dimensional reconstruction. Comput. Med. Imaging Graph. 17(4–5), 295–300 (1993).
Mu, Y., Zuo, X., Guo, C., Wang, Y., Lu, J., Wu, X., Xu, S., Dai, P., Yan, Y. & Cheng, L. GSD: View-guided Gaussian splatting diffusion for 3D reconstruction. In European Conference on Computer Vision. 55–72 (Springer, 2025).
Zhou, W., Shi, X., She, Y., Liu, K. & Zhang, Y. Semi-supervised single-view 3D reconstruction via multi shape prior fusion strategy and self-attention. Comput. Graph. 126, 104142 (2025).
Liu, A., Lin, C., Liu, Y., Long, X., Dou, Z., Guo, H.-X., Luo, P. & Wang, W. Part123: Part-aware 3D reconstruction from a single-view image. In ACM SIGGRAPH 2024 Conference Papers. 1–12 (2024).
Verma, P. & Srivastava, R. Three stage deep network for 3D human pose reconstruction by exploiting spatial and temporal data via its 2D pose. J. Vis. Commun. Image Represent. 71, 102866 (2020).
Verma, P. & Srivastava, R. Two-stage multi-view deep network for 3D human pose reconstruction using images and its 2D joint heatmaps through enhanced stack-hourglass approach. Vis. Comput. 38(7), 2417–2430 (2022).
Zhu, Z. & Li, G. Construction of 3D human distal femoral surface models using a 3D statistical deformable model. J. Biomech. 44(13), 2362–2368 (2011).
Olveres, J. et al. What is new in computer vision and artificial intelligence in medical image analysis applications. Quant. Imaging Med. Surg. 11(8), 3830 (2021).
Plooij, J. M. et al. Digital three-dimensional image fusion processes for planning and evaluating orthodontics and orthognathic surgery. A systematic review. Int. J. Oral Maxillofac. Surg. 40(4), 341–352 (2011).
Brosky, M., Major, R., DeLong, R. & Hodges, J. Evaluation of dental arch reproduction using three-dimensional optical digitization. J. Prosthet. Dent. 90(5), 434–440 (2003).
Aragón, M. L., Pontes, L. F., Bichara, L. M., Flores-Mir, C. & Normando, D. Validity and reliability of intraoral scanners compared to conventional gypsum models measurements: A systematic review. Eur. J. Orthodont. 38(4), 429–434 (2016).
Xu, Y., Tong, X. & Stilla, U. Voxel-based representation of 3D point clouds: Methods, applications, and its potential use in the construction industry. Autom. Construct. 126, 103675 (2021).
Yu, D., Ji, S., Liu, J. & Wei, S. Automatic 3D building reconstruction from multi-view aerial images with deep learning. ISPRS J. Photogramm. Remote Sens. 171, 155–170 (2021).
Mirzaei, K. et al. 3D point cloud data processing with machine learning for construction and infrastructure applications: A comprehensive review. Adv. Eng. Inform. 51, 101501 (2022).
Gao, J. et al. Get3D: A generative model of high quality 3D textured shapes learned from images. Adv. Neural Inf. Process. Syst. 35, 31841–31854 (2022).
Wang, D., Cui, X., Chen, X., Zou, Z., Shi, T., Salcudean, S., Wang, Z.J. & Ward, R. Multi-view 3D reconstruction with transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 5722–5731 (2021).
Liang, Y., Song, W., Yang, J., Qiu, L., Wang, K. & He, L. X2teeth: 3D teeth reconstruction from a single panoramic radiograph. In International Conference on Medical Image Computing and Computer-Assisted Intervention (2020).
Chen, Y., Gao, S., Tu, P. & Chen, X. Automatic 3D teeth reconstruction from five intra-oral photos using parametric teeth model. In IEEE Transactions on Visualization and Computer Graphics (2023).
Ali, F.I. & Al-dahan, Z.T. Teeth model reconstruction based on multiple view image capture. In IOP Conference Series: Materials Science and Engineering. Vol. 978. 012009 . (IOP Publishing, 2020).
Farook, T. H. et al. Computer-aided design and 3-dimensional artificial/convolutional neural network for digital partial dental crown synthesis and validation. Sci. Rep. 13(1), 1561 (2023).
Minhas, S. et al. Artificial intelligence for 3D reconstruction from 2D panoramic X-rays to assess maxillary impacted canines. Diagnostics 14(2), 196 (2024).
Song, W., Zheng, H., Yang, J., Liang, C. & He, L. Oral-nexf: 3D oral reconstruction with neural x-ray field from panoramic imaging. arXiv preprint arXiv:2303.12123 (2023).
Li, X., Meng, M., Huang, Z., Bi, L., Delamare, E., Feng, D., Sheng, B. & Kim, J. 3Dpx: Progressive 2D-to-3D oral image reconstruction with hybrid mlp-cnn networks. arXiv preprint arXiv:2408.01292 (2024).
Ma, W., Wu, H., Xiao, Z., Feng, Y., Wu, J. & Liu, Z. Px2tooth: Reconstructing the 3D point cloud teeth from a single panoramic x-ray. In International Conference on Medical Image Computing and Computer-Assisted Intervention. 411–421 (Springer, 2024).
Choy, C.B., Xu, D., Gwak, J., Chen, K. & Savarese, S. 3D-r2n2: A unified approach for single and multi-view 3D object reconstruction. In Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11–14, 2016, Proceedings, Part VIII 14. 628–644 (Springer, 2016).
Zhao, W., Yang, C., Ye, J., Zhang, R., Yan, Y., Yang, X., Dong, B., Hussain, A. & Huang, K. From 2D images to 3D model: weakly supervised multi-view face reconstruction with deep fusion. arXiv preprint arXiv:2204.03842 (2022).
Tan, M. & Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In International Conference on Machine Learning. 6105–6114 (PMLR, 2019).
Tadepalli, Y., Kollati, M., Kuraparthi, S. & Kora, P. Efficientnet-b0 based monocular dense-depth map estimation. Trait. Signal 38(5) (2021).
Mohamed, W. TeethNet Dataset. https://github.com/waleedmm/TeethNet-Dataset/tree/main. Accessed Jan 2025 (2025).
Jecklin, S., Shen, Y., Gout, A., Suter, D., Calvet, L., Zingg, L., Straub, J., Cavalcanti, N.A., Farshad, M. & Fürnstahl, P. et al. Domain adaptation strategies for 3D reconstruction of the lumbar spine using real fluoroscopy data. arXiv preprint arXiv:2401.16027 (2024).
Willmott, C. J. & Matsuura, K. Advantages of the mean absolute error (MAE) over the root mean square error (RMSE) in assessing average model performance. Clim. Res. 30(1), 79–82 (2005).
Köksoy, O. Multiresponse robust design: Mean square error (MSE) criterion. Appl. Math. Comput. 175(2), 1716–1729 (2006).
Schluchter, M.D. Mean square error. Encycl. Biostat. 5 (2005).
Chai, T. & Draxler, R. R. Root mean square error (RMSE) or mean absolute error (MAE). Geosci. Model Dev. Discuss. 7(1), 1525–1534 (2014).
Ou, X. et al. Moving object detection method via resnet-18 with encoder–decoder structure in complex scenes. IEEE Access 7, 108152–108160 (2019).
Karen, S. Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv: 1409.1556 (2014).
He, K., Zhang, X., Ren, S. & Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 770–778 (2016).
Kalitsios, G., Konstantinidis, D., Daras, P. & Dimitropoulos, K. Dynamic grouping with multi-manifold attention for multi-view 3D object reconstruction. IEEE Access (2024).
Liu, C., Zhu, M., Chen, Y., Wei, X. & Li, H. Paprec: 3D point cloud reconstruction based on prior-guided adaptive probabilistic network. Sensors 25(5), 1354 (2025).
Yang, S., Xu, M., Xie, H., Perry, S. & Xia, J. Single-view 3D object reconstruction from shape priors in memory. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 3152–3161 (2021).
Jebara, T., Azarbayejani, A. & Pentland, A. 3D structure from 2D motion. IEEE Signal Process. Mag. 16(3), 66–84 (1999).
Usta, U. Y. Comparison of quaternion and Euler angle methods for joint angle animation of human figure models (Naval Postgraduate School, 1999).
Nadimpalli, K.V., Chattopadhyay, A. & Rieck, B. Euler characteristic transform based topological loss for reconstructing 3D images from single 2D slices. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 571–579 (2023).
Liu, C., Xu, J. & Wang, F. A review of keypoints’ detection and feature description in image registration. Sci. Program. Wiley Online Lib. 2021(1), 8509164 (2021).
Hassaballah, M. & Awad, A.I. Detection and description of image features: An introduction. In Image Feature Detectors and Descriptors: Foundations and Applications. 1–8 (Springer, 2016).
Jakubović, A. & Velagić, J. Image feature matching and object detection using brute-force matchers. In 2018 International Symposium ELMAR. 83–86 (IEEE, 2018).
Antony, N. & Devassy, B.R. Implementation of image/video copy-move forgery detection using brute-force matching. In 2018 2nd International Conference on Trends in Electronics and Informatics (ICOEI). 1085–1090 (IEEE, 2018).
Liu, Y., Zhang, H., Guo, H. & Xiong, N. N. A fast-brisk feature detector with depth information. Sensors 18(11), 3908 (2018).
Leutenegger, S., Chli, M. & Siegwart, R.Y. Brisk: Binary robust invariant scalable keypoints. In 2011 International Conference on Computer Vision. 2548–2555 (IEEE, 2011).
Hartley, R. I. & Sturm, P. Triangulation. Comput. Vis. Image Underst. 68(2), 146–157 (1997).
Wei, D. et al. Clustering, triangulation, and evaluation of 3D lines in multiple images. ISPRS J. Photogramm. Remote Sens. 218, 678–692 (2024).
Vedaldi, A. An open implementation of the sift detector and descriptor. (UCLA CSD, 2007).
Mortensen, E.N., Deng, H. & Shapiro, L. A sift descriptor with global context. In 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05). Vol. 1. 184–190 (IEEE, 2005).
Rublee, E., Rabaud, V., Konolige, K. & Bradski, G. Orb: An efficient alternative to sift or surf. In 2011 International Conference on Computer Vision. 2564–2571 (IEEE, 2011).
Bansal, M., Kumar, M. & Kumar, M. 2D object recognition: A comparative analysis of sift, surf and orb feature descriptors. Multimed. Tools Appl. 80(12), 18839–18857 (2021).
Calonder, M. et al. Brief: Computing a local binary descriptor very fast. IEEE Trans. Pattern Anal. Mach. Intell. 34(7), 1281–1298 (2011).
Calonder, M., Lepetit, V., Strecha, C. & Fua, P. Brief: Binary robust independent elementary features. In Computer Vision–ECCV 2010: 11th European Conference on Computer Vision, Heraklion, Crete, Greece, September 5-11, 2010, Proceedings, Part IV. Vol. 11. 778–792 (Springer, 2010).
Sharma, S. K. & Jain, K. Image stitching using Akaze features. J. Indian Soc. Remote Sens. 48(10), 1389–1401 (2020).
Pieropan, A., Björkman, M., Bergström, N. & Kragic, D. Feature descriptors for tracking by detection: A benchmark. arXiv preprint arXiv:1607.06178 (2016).
Acknowledgements
This work is supported by the Information Technology Industry Development Agency (ITIDA) – Information Technology Academia Collaboration (ITAC) program under grant number CFP244.
Funding
Open access funding provided by The Science, Technology & Innovation Funding Authority (STDF) in cooperation with The Egyptian Knowledge Bank (EKB).
Author information
Authors and Affiliations
Contributions
Conceptualization, W.M., N.N., Y.M.A., N.E., M.E., and M.E.; methodology, W.M., N.N., Y.M.A., N.E., M.E., and M.E.; software, W.M., N.N., Y.M.A., N.E., M.E., and M.E.; validation, W.M., N.N., Y.M.A., N.E., M.E., and M.E.; formal analysis, W.M., N.N., Y.M.A., N.E., M.E., and M.E.; investigation, W.M., N.N., Y.M.A., N.E., M.E., and M.E.; resources, W.M., N.N., Y.M.A., N.E., M.E., and M.E.; data curation, W.M., and M.E.; writing original draft preparation, W.M., N.N., Y.M.A., N.E., and M.E.; writing review and editing, W.M., N.N., Y.M.A., N.E., and M.E.; visualization, M.E.; supervision, M.E.; project administration, M.E. All authors have read and agreed to the published version of the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Mohamed, W., Nader, N., Alsakar, Y.M. et al. 3D reconstruction from 2D multi-view dental 2D images based on EfficientNetB0 model. Sci Rep 15, 28775 (2025). https://doi.org/10.1038/s41598-025-12861-3
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-025-12861-3
