
Abstract
Cardiovascular disease (CVD) remains one of the leading causes of morbidity and mortality worldwide, highlighting the urgent need for early-stage diagnosis to improve clinical outcomes. Machine learning (ML) approaches have demonstrated substantial potential in predictive modeling for CVD risk assessment. In this study, we propose an advanced predictive model based on the CatBoost algorithm to classify various stages of CVD using hospital records as the primary data source. The dataset, sourced from a publicly available repository, comprises 12 key predictor variables. The proposed methodology incorporates feature selection, rigorous validation processes, and data augmentation to enhance predictive performance and address the challenges associated with high-dimensional medical data. Among several ML algorithms evaluated, the fine-tuned CatBoost model achieved the highest performance, automating feature selection and facilitating the detection of early-stage heart disease. The model attained an impressive F1-score of 99% and an overall accuracy of 99.02%, outperforming existing ML-based approaches. These findings underscore the potential of the CatBoost algorithm for rapid and accurate CVD diagnosis, thereby supporting clinical decision-making. Future work will focus on external validation and testing on independent datasets to further assess the model’s generalizability and clinical applicability.
Similar content being viewed by others
Introduction
The heart, second only to the brain in physiological importance, plays a vital role in maintaining human health. Dysfunction of this organ can lead to serious complications, often culminating in life-threatening conditions. Cardiovascular disease remains one of the leading causes of morbidity and mortality worldwide and has shown a concerning upward trend over the past few decades. According to the World Health Organization (WHO), CVD is the primary cause of early death globally and is projected to claim approximately 24 million lives annually by 20301.
Recent studies highlight an alarming trend with significant public health implications: chronic diseases, historically more prevalent in older populations, are now increasingly impacting younger generations in Pakistan and globally. This is a critical concern, as these diseases, including cardiovascular conditions, diabetes, and certain cancers, are leading causes of mortality, often resulting in sudden and tragic fatalities, particularly when timely and appropriate medical intervention is lacking. Several interconnected factors contribute to this shift, including evolving dietary habits, increased sedentary lifestyles often linked to widespread electronic device use, and potentially other socio-economic influences. Acknowledging this challenge research is centered around the possibility of machine learning algorithms transforming healthcare by facilitating early detection in more accurate and ultimately more effective way of medical issues of patients, possibly preventing deaths preventable.
CVD comprises a group of disorders affecting the heart and blood vessels, primarily caused by atherosclerosis. These diseases often progress silently, without noticeable symptoms, making early detection crucial for effective intervention. CVD is recognized as the leading global killer, responsible for approximately 18 million deaths annually, with conditions such as heart attacks and strokes disproportionately affecting individuals under the age of 702,3,4,5. In this study, by employing a thorough approach to identify and utilize the most effective parameter settings for existing predictive models, the authors rigorously evaluate the resulting performance enhancements in comparison to previously established standards. The fundamental motivation and innovative aspect of this study lie in achieving a substantial improvement in diagnostic accuracy through the generation of timely and highly precise predictions, which holds paramount importance for informed and effective medical decision-making.
Risk factors of CVD are divided into modifiable (lifestyle-related) and non-modifiable (genetic and biological). Age, gender and genetics are preprogrammed aspects which cannot be changed, high blood pressure, poor dietary lifestyle, smoking and lack of physical exercise these are preventable and can be controlled by preventive measures. Research suggests that eliminating modifiable risk factors could significantly reduce the incidence of CVD6. Early symptoms of a potential heart attack, such as chest pain, arm pain, weakness, dizziness, and excessive sweating, often go unnoticed, further emphasizing the need for timely diagnosis. Given that CVD frequently has a latent symptomatology in its early stages, early intervention significantly improves treatment outcomes and enhances disease prevention strategies.
ML has an appealing answer to the issues of identifying vulnerable people and applying early diagnosis procedures. By leveraging large-scale patient data, ML models can enhance predictive capabilities, improving early screening and disease management. Machine learning, an offshoot of Artificial intelligence (AI), allows computers to go beyond handling large chunks of data, to identify patterns and use data to make predictions. In healthcare field, ML is possible to support CVD prevention through:
-
Identifying previously unrecognized correlations between risk factors and disease progression.
-
Developing predictive models for assessing an individual’s likelihood of developing CVD.
-
Enhancing clinical decision-making by generating tailored recommendations.
-
Optimizing healthcare resource utilization by reducing unnecessary tests and procedures.
ML based approaches may change the adverse outcomes of patients while reducing cost of healthcare by improving early screening, diagnosis and treatment. Despite the growing enthusiasm for ML driven medical predictions, existing research on using Electronic health records (EHRs) for predicting individual CVD survival rates in hypertensive patients remains limited. The integration of big data analytics and ML algorithms can significantly enhance patient care by enabling population health prediction, personalized intervention strategies, and efficient resource management in healthcare systems.
This study focuses on developing a highly effective ML model for early CVD detection. To achieve this, the authors proposed a gradient-boosting methodology and apply the Rough Set theory for feature selection and attribute reduction.
Key Contributions of This Study:
-
Model development: This study developed an efficient ML model using an 80/20 train-test split for performance evaluation.
-
Feature selection: A rigorous feature selection process was implemented to optimize model accuracy.
-
Early detection: The predictive model demonstrates the feasibility of early CVD screening, enabling timely intervention.
-
Dataset utilization: A large dataset containing diverse CVD cases was used for model training and validation. Utilizing a comprehensive CVD dataset, the researchers employed an 80:20 train-test ratio to train and evaluate the proposed model.
-
Clinical implications: This study gives ideas about the mechanism, risk factors and management of CVD as well as providing valuable input to clinical decision making. This study involves hybrid research, combining quantitative with qualitative data collection method. For instance, in the context of BP monitoring in cardiovascular disease patients, quantitative measurements are taken when a patient reports a BP-related symptom, and subsequently assessed by a physician. Similarly, the study investigates chest pain, where patients initially provide qualitative accounts of their experiences. Following this, physicians conduct examinations and may utilize quantitative data to diagnose and categorize the specific type of chest pain.
The rest of this study is organized as follows: Section “Related work” reviews related studies, Section “Methodology” describes the methodology, Section “Experimental evaluation” provides an experimental evaluation, Section “Discussion” discusses key results, and Section “Conclusion” summarizes the results of the study.
Related work
Many publications concern the application of data mining approaches for prediction of heart disease7,8,9,10,11. Researchers have applied a variety of datasets and algorithms and their outcomes have enhanced the development of this domain12,13,14,15,16,17. Here is a detailed literature discussed below:
Ashir Javeed et al.3 proposed a Neural Network model for heart disease diagnosis. Their model used ML to handle patient data and deliver clinical insights for patient management. With increased accuracy in providing diagnoses, their method can improve treatment results and, at the same time, cut costs. Feng Yuanchao et al.18 proposed an intelligent system with hypertension using machine learning for heart disease diagnosis. Their system collected data about the patient and provided helpful information for treatment planning purposes. Its use can enhance treatment output and decrease costs among patients.
According to Mohammad Ayoub Khan, it is essential to monitor the heart rate using the Israeli-developed MSSO-ANFIS19. Through tracking the heart rate, the cyclist can control their training levels and prevent incidents of heart failure. However, the conventional sensors for heart rate measures may not be reliable in collecting data at systematic periods. The absent data could be estimated using a fitted or prognostic equation. It was also possible to choose a variable and try to interpolate the missing values based on it. Singh et al.20 also pointed out that the AI algorithm is used increasingly in disease prediction. The skill of AI to replicate human tendencies suggested a great tool to enhance correct diagnoses, including coronary disease. With particular emphasis on the aspect of cardiac disease diagnosis, Khan et al.2 For this purpose, Machine Learning models were used to design a decision support system. Other authors, such as AD et al.4, pointed out that early disease detection is vital in diseases such as diabetes disease. Besides, Bansal5 analyzed the application of machine learning and patient history existing medical Data to forecast coronary CVD in situations such as COVID-19. Bhagawati et al.1 chronic diseases authors have presented measures for assessing disease severity and risk using deep learning (DL) methods. Further, Balakrishnan et al.21 have discussed the use of machine learning for diagnosing and predicting heart diseases. Learning methods may also be active and can improve performance, specifically in classification accuracy, when integrating expert advice. Furthermore, Taylan et al.22 explored using machine learning and statistical approaches for heart disease prediction. While traditional machine learning methods may struggle with high-dimensional textual data, their study investigated the development of robust algorithms to improve early prediction of CVD. This could enable timely intervention and enhance recovery outcomes.
Alkayyali et al.23 reviewed 37 articles on ML and DL algorithms for cardiovascular disease diagnosis, highlighting Convolutional Neural Networks (CNN), Recurrent Neural Networks (RNN), Support Vector Machine (SVM) and K-nearest Neighbor (KNN) as standard techniques. Following PRISMA guidelines, CNN and RNN achieved up to 97.89% accuracy. Limitations included small datasets and insufficient real-world clinical data, impacting generalizability. In addition, Alaa et al.24 used AutoPrognosis to develop CVD risk models for 423,604 UK Biobank participants. Through Bayesian optimization and cross-validation, it outperformed traditional models and identified new risk factors. However, limitations included missing cholesterol biomarkers and a lack of ethnic diversity in the cohort, affecting generalizability. Apart from that, Gurpreet Singh et al.25 investigated on machine learning for cardiovascular disease prediction, finding that models like deep learning and support vector machines outperformed traditional methods. Limitations included reliance on high-quality data, external validation and challenges in clinical integration due to algorithm complexity. As well, Nissa et al.26 classified six machine learning algorithms Logistic Regression, Decision Tree, Random Forest (RF), Naive Bayes, SVM and ANN for early cardiovascular disease detection using a dataset of the UCI data in a total of 1329 instances and 13 attributes available. The best-performing algorithm was the Random Forest at 97.29%. The research stressed the need to implement quality data and cross-checking, stating that the model requires the datasets to be more prominent to predict with higher reliability.
Jindal et al.27 looked at using K- Nearest Neighbors, Logistic Regression and Random Forest on 304 records from the UCI repository to predict heart disease. When undergoing feature extraction, KNN yielded the highest accuracy of 88.52% after the data went through pre-processing. This analysis proved that integrating the algorithm increased the number of effectively generated prognoses compared to prior models. Still, more significant data volumes and additional characteristics were required for enhanced prognosis. Further, Krittanawong et al.28 identified boost and SVM as the most accurate ML algorithms for predicting cardiovascular diseases. However, issues like heterogeneity, lack of validation and inconsistent metrics highlight the need for standardized methods. Furthermore, Baghdadi et al.29 address new approaches to enhancing machine learning techniques in the early diagnosis and forecasting of CVD through a Catboost model. This model emphasizes the importance of employing complete patient information stored in hospital data sources to raise the rate of timely diagnosis and clinical performance. The proposed Catboost model has good performance; it approximated an F1-score of 92.3% and an average accuracy of 90.94%; these results put the model among the best-performing techniques in classification.
Tompra et al.30 have compared several machine learning algorithms: logistic regression, decision trees, random forest, gradient boosting, XGBoost and CatBoost. CatBoost was the most accurate, considering that its combination with SMOTE-ENN resampling provided 88% recall. This speaks in favor of minimizing the false-negative rate in high-risk patient identification. As for future research suggestions, the authors propose combining different types of data, such as electronic health records and genetic data, the usage of deep learning technologies and explainable AI and the ways of improving the prediction models accuracy and applicability in the cardiovascular healthcare. Besides, Nissa, Jamwal, and Neshat31 cover different types of machine learning techniques used in cardiovascular disease, such as boosting algorithms like AdaBoost, CatBoost and Gradient Boosting for training models in predictive modeling. Their study also focused on the importance of diagnosis and detection at the early stage of cardiovascular disease. Employing data from the UCI machine learning library, this study provides valuable information on data choice and feature extraction. Moreover, it discusses the opportunities to develop the current state of the predictive frameworks and the ideas of deep learning that this study can consider as further directions for improving your research in CatBoost.
Ahmed et al.32 present a review of the effectiveness of machine-learning algorithms involved as a set tool for enhancing the prediction of cardiovascular diseases. The CatBoost is one of the most potent models, which revealed an accuracy of 87.93%; it is also far better than methods such as SVM and KNN. It shows the feature selection component and self-limiting data augmentation practice on improving the predictive power. Results show that machine learning can effectively contribute to the early diagnosis of the disease and predicting heart failure and the delivery of useful recommendations to clinicians and patients. This research serves as a good landing point for future research on superior predictive modeling techniques for cardiovascular health. Furthermore, Qiu et al.33 propose the CVD-OCSCatBoost—a machine learning framework that is supposed to enhance the recognition of cardiovascular diseases in an early form. Thus, theCatBoost model with the opposition-based learning cuckoo search (OCS) is being implemented in order to optimize the features to bring better predictive accuracy. It deals with the problem of risk estimation and applies Lasso regression for the purpose of feature selection in the CVD significant predictors estimation. A comparison with other dominating algorithms confirms the usefulness of the OCSCatBoost model because it has a higher level of accuracy, recall, and stability. Also, the study also looks forward to potential future developments that involve such techniques like genetic markers and modern computer science strategies designed to enhance the prediction of CVD. This delivers an idea of how the framework can enhance the possibilities solutions for early CVD diagnosis and promotion of health.
Methodology
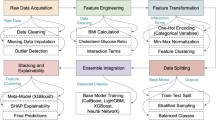
The following section discusses the classification model of the instances of heart diseases. There are three phases in the proposed model: preprocessing, training and classification (as depicted in Fig. 1). The next parts will describe every stage:

Proposed methodology for early detection of cardiovascular disease using CatBoost-based predictive modeling.
Preprocessing
All variables were initially utilized in the gradient boosting model for training. Categorical variables were converted into numerical values to ensure compatibility with the model. Features with importance values greater than 0.1 were selected for the final model. To address multicollinearity issues associated with interaction variables, several nonparametric tree-based techniques were evaluated to identify the most effective predictive model.
To compensate for overfitting, mean imputation was carried out to manage the missing values, and a number of feature selection methods were used to determine the most appropriate predictors. The dataset was however further refined using preprocessing techniques such as class balancing and feature selection so as to improved ability of the model to detect disease. This data pre-processing has a sound foundation which allows for advanced machine learning algorithms to be applied. Later on, various highly involved classification algorithm the cleaned dataset was analyzed in order to learn complex patterns leading to high accuracy, generalization and robustness of models, therefore leading to more effective disease detection and healthcare results.
Training process
After preprocessing and normalizing the dataset the machine learning model is trained. The data is then separated to train it and tested at an 80:20 ratio. In order to calculate the performance of the model, K-fold cross-validation is employed, which is the process of training and testing the model with various subsets of the data several times to measure its generalizability. Several machine learning algorithms are going to be tested during the present study, namely Extra Tree, Random Forest, Ada Boost, Gradient Boosting and CatBoost.
Classification
The proposed model is stable and represents a near-optimal machine learning solution with strong generalization capabilities. This research compares various ML algorithms to identify the most appropriate model for the problem at hand. One of the key objectives in machine learning is minimizing overfitting, which is a common challenge across many models. The regret-based model introduced in this study incorporates a risk minimization framework to address this issue effectively. Classification remains one of the most dominant and impactful areas in machine learning due to its ability to provide accurate solutions, particularly in high-dimensional feature spaces where separating hyperplanes yield optimal solutions efficiently. This process involves both data annotation and feature selection. Data labeling assigns categorical values to raw data, while feature extraction identifies the most relevant attributes that explain patterns within the dataset. Once trained, the model is capable of accurately labeling new data instances.
Experimental evaluation
In this study, the researchers used a Lenovo system with an Intel® Core™ i5-10210U CPU @ 1.60GHz (up to 2.10GHz) to implement machine learning algorithms and models. The experiments were conducted in a web-based application environment using Jupyter Notebook, which provides access to computing resources such as a GPU for deep learning training. The machine was equipped with 16 GB of RAM.
Data collection
The dataset on heart conditions analyzed in this research combines datasets from the Kaggle Repository34. This dataset includes twelve attributes, among which heart failure can be predicted as a serious risk factor for cardiovascular death.
The dependent binary classifier variable of the target is the presence or absence of heart failure. The summary of the target variable is presented in Table 1. Table 2 lists the features and their descriptions.
This data set comprises five originally separate heart datasets and is presently the most extensive heart disease data set available for research. The present heart disease dataset has a total observation of 918 and the total number of features is 1234. Table 3 summarizes the key statistics for the numerical features. The mean age is 53, with a maximum of 77.
Table 4 provides the statistics for categorical attributes. The ChestPainType attribute comprises four distinct categories: ASY, NAP, ATA and TA. “ASY” is the most prevalent category, representing 77.2% of the observations.
Table 5 summarizes the distribution of the Sex variable. The dataset includes male (90.2%) and female (9.8%) patients.
Exploratory data analysis
The dataset represents a balanced proportion of patients with and without heart disease. Out of the 918 patients; 508 out of the total 918 cases were found to have heart failure while 410 were healthy. Those with heart disease had the median age of 57 months, compared to a median age of 51 months among those who do not have heart disease. Figure 2 shows the distribution of patients with heart diseases in different groups according to their age. As shown in the Fig. 3 medians are split between the heart diseased and heart healthy patients. Figure 4 illustrates the distribution between patients with and without heart disease regarding age, systolic blood pressure, cholesterol, heart rate, and ST segment depression. Overall, those patients with a heart disease had higher values of these variables, while younger patients sometimes had outliers. For men and women, heart disease trends are compared in Fig. 5.

Age distributions of individuals with heart disease.

Median age of patients with and without heart disease.

Distribution of key values in patients with and without heart disease.

Prevalence of heart disease among men and women.
Figure 6 comprises two grouped bar charts illustrating the relationship between selected categorical clinical features and the diagnosed presence or absence of heart disease. The left panel, “ExerciseAngina vs Heart Disease,” depicts the distribution of heart disease based on the presence (Y) or absence (N) of exercise-induced angina. It clearly shows a substantially higher count of heart disease cases (n = 316) among individuals with exercise angina compared to those without (n = 192), while individuals without angina predominantly did not have heart disease (n = 355). The right panel, “ST_Slope vs Heart Disease,” visualizes heart disease incidence across different ST_Slope categories (Up, Flat, Down). This chart reveals a strong association of “Flat” (n = 381) and “Down” (n = 49) ST slopes with heart disease, whereas an “Up”sloping ST segment is predominantly observed in individuals without heart disease (n = 317). Collectively, these charts highlight a notable increased incidence of heart disease in patients presenting with exercise-induced angina or with Flat/Down ST segment slopes. Continuing with the analysis of categorical features, Fig. 6 further illustrates the distribution of heart disease cases based on patient sex and chest pain type. The left panel (“Sex vs Heart Disease”) reveals a markedly higher absolute count of heart disease diagnoses among males (M, n = 458) compared to females (F, n = 50), although males also represent a larger portion of the non-diseased group. The right panel (“ChestPainType vs Heart Disease”) indicates that Asymptomatic (ASY) chest pain is associated with the highest number of heart disease cases (n = 392), whereas Atypical Angina (ATA) is more prevalent in individuals without heart disease (n = 149), suggesting differing diagnostic implications for various chest pain presentations. Figure 6 also examines the association of Fasting Blood Sugar (FastingBS) and Resting Electrocardiogram (RestingECG) results with heart disease. The left panel (“FastingBS vs Heart Disease”) shows that elevated FastingBS (category 1) is linked to a considerably higher incidence of heart disease (n = 170) compared to individuals without heart disease in the same category (n = 44). The right panel (“RestingECG vs Heart Disease”) indicates that while ‘Normal’ ECG results are seen in both groups, ST-T wave abnormalities (‘ST’, n = 117) and Left Ventricular Hypertrophy (‘LVH’, n = 106) are more frequently observed in patients diagnosed with heart disease.

Distributions of heart disease across variables: exercise Angina, ST slope, sex, chest pain type, fasting blood sugar and resting ECG.
Figure 7, the “Correlation Matrix,” is a heatmap that visually displays the linear relationships between several numerical variables from a heart disease dataset, such as Age, Cholesterol, MaxHR, Oldpeak, and the target variable, Heart Disease. Each cell in the matrix shows a correlation coefficient, with the color intensity and hue indicating the strength and direction: dark red for strong positive correlations (values approaching + 1), dark blue for strong negative correlations (values approaching − 1), and lighter shades for weaker links. The matrix reveals that “Oldpeak” has the strongest positive correlation with ‘Heart Disease” (0.40), while “MaxHR” has the strongest negative correlation (− 0.40). Other features like Age (0.28) and FastingBS (0.27) show weaker positive associations with heart disease. Additionally, a notable inter-feature correlation is between “Age” and “MaxHR” (− 0.38), suggesting that maximum heart rate tends to decrease as age increases. This visualization is crucial for identifying which numerical features have more significant linear associations with each other and, importantly, with the presence of heart disease.

The correlation matrix for the heart disease dataset.
Figure 8 presents a collection of six pie charts, each visually summarizing the percentage distribution of different categorical variables within a dataset, likely related to cardiovascular health. The “Sex” chart indicates a significant male majority (90.2%). “Chest Pain Type” is predominantly Asymptomatic (ASY) at 77.2%, while “Fasting Blood Sugar” reveals that 33.5% of subjects have levels greater than 120 mg/dl. Furthermore, “Resting ECG” results are ‘Normal’ for 56.1% of the population. “Exercise Induced Angina” is present in 62.2% of individuals. Lastly, the “ST Slope” chart shows that a ‘Flat’ slope is the most common, occurring in 75.0% of cases. These charts collectively provide a baseline understanding of the prevalence of these characteristics in the sample.

Prevalence of heart disease with sex (a). (b) Prevalence of heart disease among patients with chest pain type; (c) Prevalence of heart disease for patients with fasting blood sugar; (d) Prevalence of heart disease for patients with resting ECG; (e) Prevalence of heart disease with resting exercise angina; (f) Prevalence of heart disease with ST slope.
The dataset shows slightly more individuals with heart disease than without, indicating a somewhat balanced distribution. The analysis identified moderate correlations for Oldpeak (0.40) and MaxHR (− 0.40) with heart disease, while others were weaker. Patients with asymptomatic chest pain are notably more likely (approx. 5.7 times) to have heart disease compared to those with atypical angina; respiratory disorders were not assessed. Men in this sample are over twice as likely (approx. 2.4 times) to have heart disease compared to women. Third, impaired ST-T waves (ST or LVH categories) in resting ECG are associated with a higher proportion of heart disease cases. Angina developed during exercise is a strong indicator, with a high proportion (approx. 85%) of such individuals having heart disease. The extent of ST segment depression (Oldpeak) is positively correlated with heart disease and shows a higher mean in affected patients.
Performance evaluation
As with any measure dealing with imbalanced datasets, using accuracy-based calibration of the classifier can be misleading. To deal with this problem, other performance measures are usually applied in organizations. The confusion matrix makes it easier to estimate a classifier’s performance. It shows the correct and incorrect classifications as true positives (TP), true negatives (TN), false positives (FP) and false negatives (FN). Standard performance metrics include accuracy, precision, recall (sensitivity), F1-score and the ROC curve. These metrics can be calculated using the formulas based on the TP, TN, FP and FN values in the test dataset.
Machine learning models
The gathered dataset (approximately 918 rows) was divided into training: 80% and testing 20%. The listed algorithms of machine learning were applied in the study: Extra Tree, Random Forest, Ada Boost, Gradient Boosting and CatBoost. Given these tendencies, a proper evaluation approach must be selected to achieve a more reliable and high-performing classifier. K-fold cross-validation is an example of partitioning a matrix into k equal portions that are equally divided and exclusive. On each iteration, one of the subsets is selected for testing while the rest is used for training. This is done for k times and goes through all the subsets. At each iteration, some metrics are computed from them. In particular, K-fold cross validation provides comparatively good measure of the model’s generalization ability and its ability to operate efficiently on small data amounts. It assists in avoiding overfitting by testing the ability of the model to work on unseen data sets as a s result of cross-validation. Positive or negative values of hyperparameters are crucial for optimizing the machine learning model. The other process of selecting the right algorithm requires identifying the correct parameters for each algorithm. One of the techniques used in hyperparameter optimization is grid search optimization. Table 6 presents the results of hyperparameter optimization for five machine learning models and one proposed model: Extra Trees, Random Forest, AdaBoost, Gradient Boosting, CatBoost, and fine-tuned CatBoost. These findings point to the critical importance of optimization of hyperparameters for development of better performance of the machine learning model.
Model performance on validation test
Figure 9 presents a Receiver Operating Characteristic (ROC) curve comparison for five distinct machine learning models: Random Forest, Gradient Boosting, Extra Trees, AdaBoost, and CatBoost, assessing their performance in classifying heart disease. The curves illustrate the trade-off between the True Positive Rate (TPR) and the False Positive Rate (FPR) at various classification thresholds. Notably, Gradient Boosting (orange line) and CatBoost (purple line) exhibit the highest discriminatory power, both achieving an Area Under the Curve (AUC) of 0.95. Random Forest (blue line) and Extra Trees (green line) also demonstrate strong performance with an AUC of 0.94 each. AdaBoost (red line) shows a slightly lower, yet still good, performance with an AUC of 0.90. These results suggest that Gradient Boosting and CatBoost provide the best balance between sensitivity and specificity among the evaluated models.

ROC curve comparison on the test set.
Table 7 shows the results for recall, precision and accuracy for the proposed CatBoost model. The presented classifier reveals a high accuracy in detecting heart disease. One should also note that CatBoost is also especially vulnerable to issues related to class imbalance. F1 score is an evaluation of precision and recall, meaning that it provides a balanced perspective on the performance of a model in categorization. The proposed model outstandingly improved heart disease classification with 0.9902 accuracy, 0.9904 precision, 0.992 recall, and 0.992 F1 score.
Discussion
Despite the abundance of data in healthcare, unique challenges hinder the widespread adoption of machine learning compared to other industries35,36,37. The Health Insurance Portability and Accountability Act (HIPAA) regulations, while crucial for patient privacy, have inadvertently created data silos. This limits the availability of large, diverse datasets for model development and validation. Consequently, much published healthcare machine learning models are based on locally obtained datasets without external validation. Based on the Tufts predictive analytics and comparative effectiveness cardiovascular prediction model, 58% of cardiovascular prediction models have not been externally verified38. Cardiovascular disorders remain a primary global health concern, contributing significantly to mortality and morbidity.
Many people living with heart disease do not know that they actually have heart disease. Early diagnosis makes a critical difference to outcomes, complications and global burden of heart disease3,4,5,20,39. Early detection and prediction of heart disorders can be achieved using machine learning models in a promising manner18,19,20,39,40. The effectiveness of the different machine learning techniques such as neural networks, Naive Bayes, Decision Trees and SVM for predicting cardiac illness has been shown in the past research24,25,26,27,28,29,30,31. The author draws attention as the hyperparameter tuning metrics applied in this study gave a great increase in accuracy compared to former studies. To this end, the researchers used a set of machine learning algorithms chosen on the basis of their specific advantages. Extra Trees accelerates training and enhances stability by using random split thresholds across trees, which reduces variance without significant computational overhead. Random Forest further mitigates overfitting by aggregating bootstrap‐sampled decision trees, delivering consistently high accuracy even in the presence of noisy data. AdaBoost adaptively concentrates on hard‐to‐classify instances by reweighting misclassified samples in successive iterations, thereby boosting overall ensemble performance. Finally, CatBoost was chosen for its ability to produce excellent results with default parameter settings being implemented with utilization of such techniques as ordered boosting and symmetric trees in order to prevent them from overfitting and obtaining state of art results. The proposed CatBoost model showed better performance in diagnosing heart disease compared to earlier approaches by producing an F1 score of 0.99 and a performance of 99.02% accuracy. One of the main strengths of this model is its capability to give high levels of prediction accuracy using few input features. This makes it very appropriate in clinical settings where efficient and straightforward diagnostics is necessary. Nevertheless, additional research is needed to determine whether the model generalizes well to heterogeneous populations. This is particularly important in clinical practice where timely and efficacious treatment depends on accurate and simplified diagnostic techniques. It is worth noting that the generalizability of the existing model may be limited. For it to be valid in the clinical practice, the proposed machine learning approach must be tested on the external datasets that reflect different populations. This would help to account for disease prevalence variability and evaluate its possible impact on physician decision-making and patient outcome.
Table 8 presents the measurement evaluation of the proposed model along with similar studies. It delineates the algorithms that were effective in the other earlier experiments and contrasts them with proposed out-competing CatBoost-based machine learning model. The training result of proposed model is shown to be good, giving a better accuracy of 99.02%.
Conclusion
The proposed machine learning model based on the CatBoost algorithm demonstrates high predictive performance in identifying various stages of cardiovascular disease, achieving an F1-score of 99% and an overall accuracy of 99.02%. By leveraging hospital records and incorporating effective feature selection techniques, the model outperforms several existing approaches, offering a more accurate and efficient method for CVD prediction. Hyperparameter optimization was applied to a selection of existing predictive models and their performance was evaluated against established benchmarks. Given the critical importance of timely and accurate prediction in improving diagnostic outcomes, multiple machine learning models were assessed in this study. Among them, the proposed CatBoost model consistently achieved the highest accuracy. These results highlight the potential of machine learning to enhance clinical decision-making and reduce dependence on costly and time-consuming diagnostic procedures.
Future work will focus on external validation to assess the model’s robustness across diverse populations and datasets. Furthermore, expanding the model to include a wider range of modifiable and non-modifiable risk factors will enhance its applicability in real-world clinical settings. In addition, future analyses will incorporate statistical tests such as ANOVA and the Wilcoxon signed-rank test to examine the significance of model performance. These advancements aim to ensure the model generalizability, reliability and practical utility in improving early detection and prevention strategies for CVD.
Data availability
All the relevant data is provided in the manuscript.
Abbreviations
- WHO:
-
World Health Organization
- BP:
-
Blood pressure
- CVD:
-
Cardiovascular
- HDPS:
-
Heart disease prediction system
- XAI:
-
Explainable artificial intelligence
- SVC:
-
Support vector classifier
References
Bhagawati, M. et al. Cardiovascular disease risk stratification using hybrid deep learning paradigm: First of its kind on Canadian trial data. Diagnostics 14(17), 1894. https://doi.org/10.3390/diagnostics14171894 (2024).
Khan, A., Qureshi, M., Daniyal, M. & Tawiah, K. A novel study on machine learning algorithm-based cardiovascular disease prediction. Health Soc. Care Commun. 2023(1), 1406060. https://doi.org/10.1155/2023/1406060 (2023).
Javeed, A. et al. Heart risk failure prediction using a novel feature selection method for feature refinement and neural network for classification. Mobile Inf. Syst. 2020(1), 8843115. https://doi.org/10.1155/2020/8843115 (2020).
American Diabetes Association. 10. Cardiovascular disease and risk management: Standards of medical care in diabetes—2021. Diabet. Care 44, S125–S150. https://doi.org/10.2337/dc21-S010 (2021).
Bansal, M. Cardiovascular disease and COVID-19. Diabet. Metab. Syndr. Clin. Res. Rev. 14(3), 247–250. https://doi.org/10.1016/j.dsx.2020.03.013 (2020).
Viji, D., Dhanka, S. & Thomas, M. Hybrid STO-IWGAN method based energy optimization in fuel cell electric vehicles. Energy Convers. Manag. 305, 118249. https://doi.org/10.1016/j.enconman.2024.118249 (2024).
Sharma, A., Dhanka, S., Kumar, A. & Maini, S. A comparative study of heterogeneous machine learning algorithms for arrhythmia classification using feature selection technique and multi-dimensional datasets. Eng. Res. Express 6(3), 035209. https://doi.org/10.1088/2631-8695/ad5d51 (2024).
Sanjay Dhanka, S. M. Random forest for heart disease detection: A classification approach. In IEEE 2nd International Conference On Electrical Power and Energy Systems (ICEPES) 1–3. https://doi.org/10.1109/ICEPES52894.2021.9699506 (2021).
Sanjay Dhanka, S. M. HyOPTXGBoost and HyOPTRF: Hybridized intelligent systems using optuna optimization framework for heart disease prediction with clinical interpretations. Multimed. Tools Appl. 83, 72889–72937. https://doi.org/10.1007/s11042-024-18312-x (2024).
Sanjay Dhanka, S. M. A hybridization of XGBoost machine learning model by Optuna hyperparameter tuning suite for cardiovascular disease classification with significant effect of outliers and heterogeneous training datasets. Int. J. Cardiol. 420, 132757. https://doi.org/10.1016/j.ijcard.2024.132757 (2025).
Sanjay Dhanka, V. K. B. & Maini, S. Comprehensive analysis of supervised algorithms for coronary artery heart disease detection. Expert. Syst. 40(7), e13300. https://doi.org/10.1111/exsy.13300 (2023).
Ahamed, M. F. et al. A review on brain tumor segmentation based on deep learning methods with federated learning techniques. Comput. Med. Imaging Graph. 110, 102313 (2023).
Ahamed, M. F. et al. Detection of various gastrointestinal tract diseases through a deep learning method with ensemble ELM and explainable AI. Expert Syst. Appl. 256, 124908 (2024).
Ahamed, M. F., Shafi, F. B., Nahiduzzaman, M., Ayari, M. A. & Khandakar, A. Interpretable deep learning architecture for gastrointestinal disease detection: A Tri-stage approach with PCA and XAI. Comput. Biol. Med. 185, 109503 (2025).
Ahamed, M. F. et al. Irv2-net: A deep learning framework for enhanced polyp segmentation performance integrating inceptionresnetv2 and unet architecture with test time augmentation techniques. Sensors 23, 7724 (2023).
Liu, W. et al. A simple weaning model based on interpretable machine learning algorithm for patients with sepsis: A research of MIMIC-IV and eICU databases. Front. Med. 8, 814566 (2022).
Li, F. et al. Prediction model of in-hospital mortality in intensive care unit patients with heart failure: Machine learning-based, retrospective analysis of the MIMIC-III database. BMJ Open 11, e044779 (2021).
Feng, Y. et al. Personalized prediction of incident hospitalization for cardiovascular disease in patients with hypertension using machine learning. BMC Med. Res. Methodol. 22(1), 325. https://doi.org/10.1186/s12874-022-01814-3 (2022).
Khan, M. A. & Algarni, F. A healthcare monitoring system for the diagnosis of heart disease in the IoMT cloud environment using MSSO-ANFIS. IEEE Access 8, 122259–122269. https://doi.org/10.1109/ACCESS.2020.3006424 (2020).
Singh, M. et al. Artificial intelligence for cardiovascular disease risk assessment in personalised framework A scoping review. EClinicalMedicine. https://doi.org/10.1016/j.eclinm.2024.102660 (2024).
Balakrishnan, M., Christopher, A. A. et al. Prediction of Cardiovascular Disease using Machine Learning. https://doi.org/10.1088/1742-6596/1767/1/012013 (2020).
Taylan, O., Alkabaa, A. S., Alqabbaa, H. S., Pamukçu, E. & Leiva, V. Early prediction in classification of cardiovascular diseases with machine learning, neuro-fuzzy and statistical methods. Biology 12(1), 117. https://doi.org/10.3390/biology12010117 (2023).
Vergaray, A. D. et al. Prediction of Heart Disease Using Machine Learning: A Systematic Literature Review. https://doi.org/10.1109/ICITACEE58587.2023.10277209 (2023).
Alaa, A. M. et al. Cardiovascular disease risk prediction using automated machine learning: A prospective study of 423604 UK Biobank participants. PloS One. 14(5), 0213653. https://doi.org/10.1371/journal.pone.0213653 (2019)
Al’Aref, S. J., Chang, H.-J., Narula, J., Bax, J. J., Guan, Y., Min, J. K. Clinical applications of machine learning in cardiovascular disease. Eur. Heart J. 40, 1975–1986 (2019).
Nissa, N., Jamwal, S. & Mohammad, S. Early detection of cardiovascular disease using machine learning techniques an experimental study. Int. J. Recent Technol. Eng 9(3), 635–641 (2020).
Jindal, H., Agrawal, S., Khera, R., Jain, R. & Nagrath, P. Heart disease prediction using machine learning algorithms. IOP Conf. Ser. Mater. Sci. Eng. 1022(1), 012072. https://doi.org/10.1088/1757-899X/1022/1/012072 (2021).
Krittanawong, C. et al. Machine learning prediction in cardiovascular diseases: A meta-analysis. Sci. Rep. 10(1), 16057. https://doi.org/10.1038/s41598-020-72685-1 (2020).
Baghdadi, N. A. et al. Advanced machine learning techniques for cardiovascular disease early detection and diagnosis. J. Big Data 10(1), 144. https://doi.org/10.1186/s40537-023-00817-1 (2023).
Tompra, K. V., Papageorgiou, G. & Tjortjis, C. Strategic machine learning optimization for cardiovascular disease prediction and high-risk patient identification. Algorithms 17(5), 178. https://doi.org/10.3390/a17050178 (2024).
Nissa, N., Jamwal, S. & Neshat, M. A technical comparative heart disease prediction framework using boosting ensemble techniques. Computation 12(1), 15. https://doi.org/10.3390/computation12010015 (2024).
Ahmed, S. et al. Prediction of cardiovascular disease on self-augmented datasets of heart patients using multiple machine learning models. J. Sens. 2022(1), 3730303. https://doi.org/10.1155/2022/3730303 (2022).
Qiu, Z., Qiao, Y., Shi, W. & Liu, X. A robust framework for enhancing cardiovascular disease risk prediction using an optimized category boosting model. Math. Biosci. Eng. 21(2), 2943–2969. https://doi.org/10.3934/mbe.2024131 (2024).
Heart Failure Prediction Dataset. https://www.kaggle.com/datasets/fedesoriano/heart-failure-prediction
Dhanka, S. & Maini, S. Multiple machine learning intelligent approaches for the heart disease diagnosis. In IEEE EUROCON 2023–20th International Conference on Smart Technologies 147–152 (IEEE, 2023)
Maini, S. & Dhanka, S. Hyper Tuned RBF SVM: A new approach for the prediction of the breast cancer. In 2024 1st International Conference on Smart Energy Systems and Artificial Intelligence (SESAI) 1–4 (IEEE, 2024).
Kumar, A., Dhanka, S., Singh, J., Ali Khan, A. & Maini, S. Hybrid machine learning techniques based on genetic algorithm for heart disease detection. Innov. Emerg. Technol. 11, 2450008 (2024).
Wessler, B. S. et al. Tufts PACE clinical predictive model registry: update 1990 through 2015. Diagn Progn Res 1, 1–8 (2017).
Visseren, F. L. et al. ESC Guidelines on cardiovascular disease prevention in clinical practice: Developed by the task force for cardiovascular disease prevention in clinical practice with representatives of the European society of cardiology and 12 medical societies With the special contribution of the European association of preventive cardiology (EAPC). Eur. Heart J. 42(34), 3227–3337. https://doi.org/10.1093/eurheartj/ehab484 (2021).
Nathan, D. et al. Atherosclerotic cardiovascular disease risk assessment: An American society for preventive cardiology clinical practice statement. Am. J. Prevent. Cardiol. 10, 100335. https://doi.org/10.1016/j.ajpc.2022.100335 (2022).
Saboor, A. et al. A method for improving prediction of human heart disease using machine learning algorithms. Mobile Inf. Syst. 2022(1), 1410169. https://doi.org/10.1155/2022/1410169 (2022).
Ahmad, G. N., Fatima, H., Ullah, S. & Saidi, A. S. Efficient medical diagnosis of human heart diseases using machine learning techniques with and without GridSearchCV. IEEE Access 10, 80151–80173. https://doi.org/10.1109/ACCESS.2022.3165792 (2022).
Bays, H. E. et al. Ten things to know about ten cardiovascular disease risk factors–2022. Am. J. Prevent. Cardiol. 10, 100342. https://doi.org/10.1016/j.ajpc.2022.100342 (2022).
Karthick, K. et al. Retracted: Implementation of a Heart Disease Risk Prediction Model Using Machine Learnin. https://doi.org/10.1155/2022/6517716 (2023).
Uddin, K. M. M. et al. Machine learning-based approach to the diagnosis of cardiovascular vascular disease using a combined dataset. Intell. Based Med. 7, 100100. https://doi.org/10.1016/j.ibmed.2023.100100 (2023).
Shaha, S. M. S. et al. Support vector machines-based heart disease diagnosis using feature subset. Wrap. Select. Extract. Methods. https://doi.org/10.1016/j.compeleceng.2020.106628 (2020).
Taminul Islam, A. V., Mahadi Hasan, Md. Masum Rana, Cardiovascular Disease Prediction Using Machine Learning Approaches. https://doi.org/10.1109/CISES58720.2023.10183490 (2023).
Acknowledgements
This research was funded by the Deanship of Scientific Research and Libraries at Princess Nourah bint Abdulrahman University, through the “Nafea” Program, Grant No. (NP-45-090)
Funding
This research was funded by the Deanship of Scientific Research and Libraries at Princess Nourah bint Abdulrahman University, through the “Nafea”Program, Grant No. (NP- 45-090).
Author information
Authors and Affiliations
Contributions
M.H. conceived the experiment(s), designed the methodology, and supervised the overall research process. M.H. and F.H. conducted the experiment(s), including data preprocessing, model development, and implementation of the CatBoost algorithm. M.H., F.H., A.S.A., and N.W.B.M. analyzed the results and performed statistical evaluations. M.H., A.S.A., and N.W.B.M. contributed to the interpretation of the findings and prepared visualizations. M.H. and F.H. drafted the manuscript, while A.S.A. and N.W.B.M. provided critical revisions to improve the content and presentation. All authors reviewed and approved the final manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Hamid, M., Hajjej, F., Alluhaidan, A.S. et al. Fine tuned CatBoost machine learning approach for early detection of cardiovascular disease through predictive modeling. Sci Rep 15, 31199 (2025). https://doi.org/10.1038/s41598-025-13790-x
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-025-13790-x
