
Abstract
This paper investigates an optimal consensus control problem and proposes a policy iteration algorithm based on online integral reinforcement learning for nonlinear multi-agent systems with unknown dynamics. Introducing a critic-actor neural network into the traditional policy iteration avoids the identification of unknown dynamics. To address the issue of local optima in online learning, an experience-based weight-tuning law is introduced to ensure the persistence of excitation conditions during the training phase. The theoretical results show that the system is asymptotically stable, and the network weights converge. Finally, the effectiveness and correctness are verified by several simulation studies.
Similar content being viewed by others


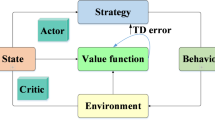
Introduction
The consensus optimal control problem of multi-agent systems (MASs) has been a highly active research area due to the multitude of applications in different areas, such as satellite scheduling1, wireless sensor networks2, multi-quadrotor formation flight3, robotics4, and vehicle formation control5. The primary objective of optimal control for MASs is to stabilize the system with the minimum tracking error and the energy consumed by a designed optimal controller6. Typically, the optimal controller is derived from the Hamilton-Jacobi-Bellman (HJB) equation, which is formulated based on a predefined performance index function7. However, solving the HJB equation is challenging due to its inherent nonlinearity and partial derivatives, making an analytical solution practically infeasible8,9. As an alternative, the policy iteration (PI) algorithm has been widely adopted as an effective method for approximating the solution to the HJB equation10. Instead of solving the equation directly, PI iteratively alternates between policy evaluation and improvement until convergence is achieved11. Nevertheless, most PI algorithms12,13,14 require that the dynamics of the controlled MASs are known. It should be pointed out that accurate dynamics of MASs are hard to obtain because of complex constructions and aging of components15,16. Therefore, developing a PI scheme that operates independently of system dynamics is a critical and meaningful research direction.
As the issue mentioned above, it is noted that neural networks are often introduced to design a controller for the controlled system with unknown or uncertain dynamics17,18,19,20. For example, Ferede et al.21 designed an end-to-end neural network controller for an aggressive high-speed quadcopter, Zishan et al.22 formulated an implementation of a densely connected neural network to detect arrhythmia on a low-compute device, and Hu et al.23 investigated a neural network-based robust tracking control algorithm for multi-motor driving servo systems. While these approaches effectively reduce control errors for systems with partially unknown dynamics, they often overlook the energy consumption of the designed controllers21,22,23. Motivated by this limitation, this paper aims to integrate a neural network-based approach into the PI framework to achieve optimal control while considering energy efficiency.
Recently, Modares et al.24 studied an integral reinforcement learning (IRL) method to address the challenges above, constructing an actor-critic neural network framework based on the PI algorithm. Building on this foundation, several advanced IRL approaches have been proposed. For example, Shen et al.25 studied an IRL method for nonlinear Markov jump singularly perturbed systems, Lin et al.26 designed a dynamic compensator-based IRL approach for unknown nonaffine nonlinear systems, and Yan et al.27 investigated a graphical game-based IRL bipartite containment scheme for high-order nonlinear MASs. However, most existing IRL methods28,29,30,31 face the risk of being trapped in local optima. While exploration and target strategies32,33,34 have been proposed to mitigate this issue, they are primarily suited for offline learning, which demands significant computational and storage resources. Consequently, a key motivation of this paper is to develop an online learning IRL approach that avoids local optima while maintaining computational efficiency by utilizing historical information over a specific period.
This paper investigates an optimal consensus control problem for MASs with unknown dynamics and proposes a PI algorithm based on online integral reinforcement learning with experience data. The main contributions of this article are listed as follows:
-
(1)
An actor-critic neural network-based PI algorithm is designed for nonlinear MASs. Unlike existing methods35,36, the proposed approach does not require prior knowledge of system dynamics or relies on a neural network-based identifier to approximate unknown dynamics, thereby avoiding additional cumulative errors.
-
(2)
An experience-based IRL method is formulated that bridges online and offline learning schemes for nonlinear MASs. Compared with existing methods37,38, the proposed approach selectively utilizes historical information over a specific period, effectively preventing convergence to local optima.
Notations: \(R^n\) and \(R^{n \times m}\) denote the set of n-dimensional real vectors and \(n \times m\) real matrices, respectively. \(\underline{1} \in R^n\) denotes the n-dimensional vector, where all elements are 1. ||a|| denotes the Euclidean norm of \(a \in R^n\), \({I_n}\) denotes an identity matrix with n dimensions, and \(\otimes\) denotes the Kronecker product.
Preliminaries and problem formulations
Here, we introduce fundamental knowledge and notations used in this article and describe the consensus issue of MASs.
Graph theory
Define a directed graph \(\mathscr {G} = \left( {\mathscr {V},\mathscr {E},\mathscr {A}} \right)\), which is composed of a finite nonempty node set \(\mathscr {V} = \{ 1,2,...,N\}\), an edge set \(\mathscr {E} \subseteq \mathscr {V} \times \mathscr {V}\), and a weighted adjacent matrix \(\mathscr {A} = \left[ {{a_{ij}}} \right] \in {\mathscr {R}^{N \times N}}\). If node j can send information to node i, it has \((j,i) \in \mathscr {E}\), \({a_{ij}}> 0\) (otherwise \({a_{ij}} = 0\)), and node j is one of the neighbors of node i. Define \({\mathscr {N}_i} = \left\{ {{j}:\left( {{j},{i}} \right) \in \mathscr {E}} \right\}\) as the set of all the neighbors of node i. Define the in-degree matrix \(\mathscr {D}\, = diag\left( {{d_1},...,{d_N}} \right)\), where \({d_i} = \sum \nolimits _{j \in {\mathscr {N}_i}} {{a_{ij}}}\), and the Laplacian matrix \(\mathscr {L}\) is defined as \(\mathscr {L} = \mathscr {D} - \mathscr {A} = [l_{ij}]\).
Consensus of MASs
Consider MASs in the form of a communication network \({\mathscr {G}}\) consisting of N agents, where the dynamics of agent i is given as
where \(f\left( {{x_i}} \right) \in {R^n}\) are partially unknown nonlinear smoothly function, and \(g\left( {{x_i}} \right) \in {R^{n \times m}}\) is partially unknown control effectiveness function with \(||g\left( {{x_i}} \right) ||<\bar{g}\). Moreover, \(f\left( {{x_i}} \right) \in {R^n}\) and \(g\left( {{x_i}} \right)\) are Lipschitz continuous. \({x_i} = {x_i}\left( t \right)\) is the state vector, and \({u_i} = {u_i}\left( t \right) \in {R^m}\) is the control input vector of agent i.
The global network dynamics is
where \(x = {\left[ {x_1^ \top , \hspace{5.0pt}x_2^ \top , \hspace{5.0pt}..., \hspace{5.0pt}x_N^ \top } \right] ^ \top } \in {R^{Nn}}\), \(f\left( x \right) = {\left[ {{f^ \top }\left( {{x_1}} \right) ,\hspace{5.0pt}{f^ \top }\left( {{x_2}} \right) ,\hspace{5.0pt}...,\hspace{5.0pt}{f^ \top }\left( {{x_N}} \right) } \right] ^ \top } \in {R^{Nn}}\), \(g\left( x \right) = diag\left( {g\left( {{x_i}} \right) } \right) \in {R^{Nn \times Nm}}\) with \(i = 1,2,...,N\), and \(u = {\left[ {u_1^ \top \hspace{5.0pt}u_2^ \top \hspace{5.0pt}...\hspace{5.0pt}u_N^ \top } \right] ^ \top } \in {R^{Nm}}\).
Assumption 1
39The system (2) is controllable on a set \(\Omega \in {R^{Nn}}\), which implies that there exists a control policy that can asymptotically stabilize the system.
Assumption 2
40A directed spanning tree is present in the communication network \({\mathscr {G}}\), and all agents have direct or indirect access to the leader agent’s information.
The leader state vector \({x_0} = {x_0}\left( t \right) \in {R^n}\) satisfies that
where \(k\left( {{x_0}} \right) \in {R^n}\). The tracking error of agent i is defined as
where \({\delta _i} = {\left[ {{\delta _{i1}}\hspace{5.0pt}{\delta _{i2}}\hspace{5.0pt}...\hspace{5.0pt}{\delta _{in}}} \right] ^ \top } \in {R^n}\). Note that \({b_i}> 0\) if and only if the leader agent can send information to agent i; otherwise, \({b_i} = 0\). The global error vector is given as
where \(\mathscr {L} = \left( {L + B} \right) \otimes {I_n}\), \(\delta = {\left[ {\delta _1^ \top \hspace{5.0pt}\delta _2^ \top \hspace{5.0pt}...\hspace{5.0pt}\delta _N^ \top } \right] ^ \top } \in {R^{Nn}}\) with \(\underline{I} = \underline{1} \otimes {I_n} \in {R^{Nn \times n}}\), and \(B = diag\left\{ {{b_1},{b_2},...,{b_N}} \right\} \in {R^{N \times N}}\)(\({b_{ii}} = {b_i}\) and \({b_{ij}} = 0,i \ne j\)).
By differentiating Eq. (4), the dynamics of \({\delta _i}\) is
where \({\mathscr {L}_i} = \left( {{L_i} + {B_i}} \right) \otimes {I_n}\). \({L_i} = \left[ {{l_{i1}}\hspace{5.0pt}...\hspace{5.0pt}{l_{ii}}\hspace{5.0pt}...\hspace{5.0pt}{l_{iN}}} \right]\) and \({B_i} = \left[ {{b_{i1}}\hspace{5.0pt}...\hspace{5.0pt}{b_{ii}}\hspace{5.0pt}...\hspace{5.0pt}{b_{iN}}} \right]\) are denoted as the ith row vector of L and B, respectively. Moreover, \({f_e}\left( x \right) = f\left( x \right) - \underline{k} \left( {{x_0}} \right)\) with \(\underline{k} \left( {{x_0}} \right) = \underline{I} k\left( {{x_0}} \right)\).
Problem statements
This paper aims to address the following problems and challenges.
-
(1)
How to solve the HJB equation for nonlinear MASs. To address this issue, we propose a PI scheme that is independent of system dynamics.
-
(2)
How to design a controller for MASs with unknown dynamics. To address this problem, we establish an actor-critic neutral network-based PI algorithm, where the dynamics are no longer needed.
-
(3)
How to avoid the designed IRL method from getting trapped in local optima. To address this drawback, we formulate an experience-based IRL method that selectively utilizes historical information to prevent getting trapped in local optima.
To sum up, the object of this study is to design a control strategy that ensures the uniform ultimate boundedness (UUB) of the system error \({\delta _i}\) for all \(i \in \left\{ 0,1,..., N \right\}\) without relying on the system model. Specifically, there exist positive constants \(\epsilon\) and \(\bar{t}\) such that, for all initial conditions and under Assumption 1, the tracking error \({\delta _i}\) satisfies the following condition:
In other words, \({\delta _i}\) will enter and remain within a bounded region after time \(\bar{t}\), thereby achieving the consensus control.
Controller design and convergence analysis
Discont fator-based optimal control policy
Here, a distributed performance function with a discount factor is proposed to guarantee that each agent minimizes their performance function.
Define the discounted local performance index function of agent i as
where \(r\left( {{\delta _i}\left( v \right) ,{u_i}\left( v \right) ,{u_{ - i}}\left( v \right) } \right) = {r_1}\left( {{\delta _i}} \right) + {r_2}\left( {{u_i},{u_{ - i}}} \right)\) denotes the cost function. \({r_1}\left( {{\delta _i}} \right) = \delta _i^ \top {Q_{ii}}{\delta _i}\) denotes the error cost, and \({r_2}\left( {{u_i},{u_{ - i}}} \right) = u_i^ \top {R_{ii}}{u_i} + \sum \nolimits _{j \in {\mathscr {N}_i}} {u_j^ \top {R_{ij}}{u_j}}\) denotes the control cost. \(\alpha> 0\) is the discount factor. \({Q_{ii}} \geqslant 0\), \({R_{ii}}> 0\), and \({R_{ij}}> 0\) are positive symmetric matrices. For brief, \(\sum \nolimits _{j \in {\mathscr {N}_i}} {u_j}\) is abbreviated to \({u_{ - i}}\).
We need to design a distributed optimal consensus method for each agent to ensure that all agents reach a consensus with the leader and reduce the local power function. In other words, this paper aims to minimize each agent’s local performance function with a designed control input set \(\{ u_1, u_2,..., u_N \}\).
Definition 1
(Global Nash Equilibrium) For all \(i = 1,2,...,N\), a set of control inputs \(\{u_1^ *,u_2^ *,...,u_N^ * \}\) is considered to establish a global Nash equilibrium if the following equation is satisfied:
The local discounted value function of each agent i is defined as
The optimal local discounted value function is defined as
The local coupled Hamiltonian function is constructed as
The gradient of the value function \({V_i}\) with respect to \({\delta _i}\left( t \right)\) is denoted by \(\nabla {V_i}\). \(V_i^ * \left( {{\delta _i}} \right)\) denotes the local optimal value function that satisfies
The optimal control policy can minimize Eq. (12), which can be expressed as
An IRL-based PI algorithm
Substituting Eq. (13) into Eq. (12), we have
It is noted that in solving Eq. (14), the optimal control policy of the agents is obtained. However, since Eq. (14) contains the information of the system’s dynamics, which is unknown, the solution of Eq. (14) is difficult to obtain. A common approach to solving this problem is using the PI algorithm, which approximates the solution through constant iteration. The PI algorithm consists of two steps: 1) Policy evaluation and 2) Policy improvement. In the policy evaluation step, according to Eq. (11) and Eq. (12), the given control policy \(u_i^{(k)}(t)\) is evaluated by
and updates it by
From Eqs. (15) and (16), it is found that they incorporate the dynamics of the controlled system. In order to release the need for the system’s dynamics, an IRL algorithm with an integration interval T is introduced into Eq. (9) that yields
where the controlled system’s dynamics are not contained.
Then, an IRL-based PI algorithm is designed as Algorithm 1.

IRL-Based Policy Iteration
Due to Algorithm 1 including an integral interval T, the update of control inputs is discontinuous. Thus, the designed IRL-based PI scheme can be regarded as a time-triggered control strategy, where T represents a special sampling period.
Remark 1
Compared with the common PI, the designed IRL-based PI eliminates the requirements for system dynamics. Moreover, according to the analysis in the work of Lewis et al.42, it is obtained that Eqs. (15) and (18) are equivalent. However, it also introduces a new problem: How to solve Eq. (19), presented below.
Model-free distributed consensus control algorithm
Here, we constructed a critic neural network and an actor neural network for Eqs. (18) and (19), respectively. Moreover, the weights tuning laws are designed, and the convergence is analyzed.
According to the universal approximation theorem43, it is obtained that neural networks can approximate smooth functions on a compact set. Thus, we construct neural networks to estimate the objective function, where the established neural networks consist of three layers: 1) the input layer, 2) the hidden layer, and 3) the output layer. The input-to-hidden weight is set to be 1 and no longer tuned. The hidden layer contains an activation function, and the weight connecting the hidden layer to the output can be tuned to minimize the approximation error. Eqs. (18) and (19) is expressed as
where \({\phi _{ci}}\left( {{z_{ci}}\left( t \right) } \right) \in {R^{{h_{vi}}}}\), and \({\psi _{ai}}\left( {{z_{ai}}\left( t \right) } \right) \in {R^{{h_{di}}}}\) denote the activation function vectors. \({h_{vi}}\) and \({h_{di}}\) are the numbers of neurons. \({\hat{W}}_{ci}^k\) and \({\hat{W}}_{ai}^k\) denote the weight vectors. \({z_{ci}}\left( t \right)\) is a vector of the information from \({\delta _i}\left( t \right)\), \(u_i^k\left( t \right)\), and \(u_{ - i}^k\left( t \right)\). \({z_{ai}}\left( t \right)\) denotes a vector of the information from \({\delta _i}\left( t \right)\).
Based on Eq. (18), the approximation error of the critic neural network is defined as
To make the square error \(E_{ci}^{(k)}\left( t \right) = \left( {1/2} \right) {\left( {e_{ci}^{(k)}\left( t \right) } \right) ^ \top }e_{ci}^{(k)}\left( t \right)\) minimal, a gradient-based update rule with history data for the critic neural network weights of agent i is derived as
where \({\beta _{ci}}> 0\) is the learning rate, and s denotes the time range of the history data, which could be used to update the weights.
The approximation error of the actor neural network is defined as
Define the square error as \(E_{ai}^{(k)} = \left( {1/2} \right) {\left( {e_{ai}^{(k)}} \right) ^ \top }e_{ai}^{(k)}\), and the update rule for the actor neural network weights of agent i is derived as
where \({\beta _{ai}}> 0\) is the learning rate, \({Z_i} = \partial {z_{ci}}\left( t \right) /\partial {\hat{u}}_i^{(k)}\left( t \right)\), and \({\phi '_{ci}}\left( {{z_{ci}}\left( t \right) } \right) = \partial {\phi _{ci}}\left( {{z_{ci}}\left( t \right) } \right) /\partial {z_{ci}}\left( t \right)\).
Combining the critic-actor neural network framework with Algorithm 1 yields the following algorithm, as shown in Algorithm 2.

Model-free Distributed Consensus Control Algorithm.
Remark 2
Notably, this weight update rule utilizes historical data, and a replay buffer is established to store this data, similar to references37,38. However, those update rules do not assign ratios to different periods of historical data. This paper introduces the exponential term for importance sampling, which allows the proportion of history data in the weight update to be inversely proportional to the time interval \(t-s^{\prime }\) between the historical moment \(s^{\prime }\) \((t-s<s^{\prime }<t)\) and the current moment t. The reason for importance sampling is that control inputs and states closer to the current moment have a more substantial influence on the state at the current moment. This weight update rule prevents the critic neural network from making inaccurate approximations of the past states of the agents, improves the control policy estimated by the actor neural network for real-time control processes, and accelerates the convergence of weights.
Convergence analysis
Theorem 1
Let the update rules for critic and actor neutral network weights be as in Eqs. (23) and (25). Define the weights estimation errors \({\tilde{W}}_{ci}^{(k)} = {\hat{W}}_{ci}^{(k)} - W_{ci}^ *\) and \({\tilde{W}}_{ai}^{(k)} = {\hat{W}}_{ai}^{(k)} - W_{ai}^ *\). Then, \({\tilde{W}}_{ci}^{(k)}\), \({\tilde{W}}_{ai}^{(k)}\), and \(\delta _i\) are UUB as \({k} \rightarrow \infty\), and there exists a scalar \(W> 0\), which satisfies
Proof
By Eqs. (23) and (25), \({\tilde{W}}_{ci}^{(k)}\) and \({\tilde{W}}_{ai}^{(k)}\) are rewritten as
where
Choose a Lyapunov function as
where \({L_{i,1}}\left( k \right) = {\left( {{\tilde{W}}_{ci}^{(k)}} \right) ^ \top }{\tilde{W}}_{ci}^{(k)}\), \({L_{i,2}}\left( k \right) = {\left( {{\tilde{W}}_{ai}^{(k)}} \right) ^ \top }{\tilde{W}}_{ai}^{(k)}\), and \({L_{i,3}}\left( k \right) = \delta _i^\top \delta _i + \Theta _iV_i(\delta _i(t))\).
The gradient of \({L_{i,1}}\left( k \right)\) is obtained as
where \({W_{ci}^{(k)}}\) satisfies
Because \(W_{ci}^{(k)}\) is bounded, there exists a scalar \({W_1}> 0\) which satisfies \(\left\| {W_{ci}^{(k)} - W_{ci}^ * } \right\| ^2 \leqslant {W_1}\). Substituting Eq. (31) into Eq. (22), one has
According to Eq. (32), Eq. (30) is rewritten as
where \({\eta _{ci}} = {{e^{ - \alpha T}}{\phi _{ci}}\left( {{z_{ci}}\left( {v + T} \right) } \right) - {\phi _{ci}}\left( {{z_{ci}}\left( v \right) } \right) }\), and \(\underline{W_1} = \underline{1}\otimes {W_1}\in R^{h_{vi}}\).
The gradient of \({L_{i,2}}\left( k \right)\) is given as
where \({W_{ai}^{(k)}}\) makes following equation hold
Since \({\hat{u}}_i^{(k)}\) is bounded, there exists a scalar \({W_2}> 0\) which satisfies \(\left\| {W_{ai}^{(k)} - W_{ai}^ * } \right\| ^2 \leqslant {W_2}\).
Combining Eqs. (22) and (35), one has
Substituting Eq. (36) into Eq. (34), one has
where \({\eta _{ai}}\left( v \right) = \int _t^{t + T} {{e^{ - \alpha \left( {v - t} \right) }}{{\left( {u_i^{(k)}} \right) }}{R_{ii}}\psi _{ai}\left( {{z_{ai}}\left( v \right) } \right) } dv\), and \(\underline{W_2} = \underline{1}\otimes {W_2}\in R^{h_{di}}\).
In addition, the gradient of \({L_{i,3}}\left( k \right)\) is derived as follows:
If \(\Theta _i\) satisfies
and the inequality \(||\delta _i||^2> \frac{||{\mathscr {L}_i}f_e(x)||^2}{2\Theta _i\lambda _{\text {min}}(Q_{ii})}\) holds, one has \(\nabla {L_{i,3}}\left( k \right) <0\).
Based on Eqs. (33), (37), and (38), one has
where \({\beta _i} = {\left[ {\beta _{ci}^\top \hspace{5.0pt}\beta _{ai}^\top } \right] ^\top }\), \(\rho _i \left( v \right) = diag \{ {\rho _{ci}^\top \left( v \right) , \rho _{ai}^\top \left( v \right) } \}\), \(\lambda _i \left( v \right) = [ ( e_{ci}^{(k)}\left( v \right) )^\top\) \(( e_{ai}^{(k)}( v ) )^\top ]^\top\), \(\eta _i \left( v \right) = {\left[ {\eta _{ci}^\top \left( v \right) \hspace{5.0pt}\eta _{ai}^\top \left( v \right) } \right] ^\top }\), \(W = \max \left\{ {{W_1},{W_2}} \right\}\), and \(\underline{W} = \underline{1} \otimes {W}\in R^{h_{vi+di}}\).
It’s clear that \(\nabla {L_i}\left( k \right) < 0\) if Eq. (26) holds, it is obtained that \({\tilde{W}}_{ci}^{(k)}\), \({\tilde{W}}_{ai}^{(k)}\), and \(\delta _i\) are UUB, that is, Algorithm 2 can approximate the optimal solution instead of finding the exact optimal solution. \(\square\)
Remark 3
According to the Lyapunov-based convergence analysis25,26,27, \({\tilde{W}}_{ci}^{(k)}\), \({\tilde{W}}_{ai}^{(k)}\), and \(\delta _i\) are UUB if the gradient of \(L_i(k)\) can be proved to be negative under certain conditions.
Remark 4
It is worthwhile to note that the selections of \(Q_{ii}\) and \(R_{ij}\) affect the size of the ultimate bounded region \(\frac{||{\mathscr {L}_i}f_e(x)||^2}{2\Theta _i\lambda _{\text {min}}(Q_{ii})}\). To minimize this region, it is recommended to select larger \(Q_{ii}\) and smaller \(R_{ij}\).
Remark 5
It should be pointed out that this study is focused on the issues of how to solve the HJB equation for nonlinear MASs, how to design an IRL controller, and how to avoid the designed IRL method from getting trapped in local optima. Meanwhile, it is noteworthy that the designed IRL method can be further optimized and extended to address more interesting issues44,45,46, such as limited communication resources, unknown disturbances, and constrained actuators.
Simulation studies
In this section, two simulation examples are given to demonstrate the effectiveness of the designed method. The simulation platform is PyCharm with Python, where the sampling period, T, is set to 0.001 seconds. The controlled MASs consist of five agents, which are connected as shown in Fig. 1.

The communication topology of MASs.
Example I
In this part, a nonlinear MASs47 is considered, where the communication topology of the MASs is set as shown in Fig. 1. \(f\left( {{x_i}} \right)\) and \(g\left( {{x_i}} \right)\) of each agent are given as \(f\left( {{x_i}} \right) = \left[ \begin{aligned} {x_{i2}} \\ 0.2{x_{i2}} - 5{x_{i1}} \\ \end{aligned} \right]\) and \(\left( {{x_i}} \right) = \left[ \begin{aligned} 0 \\ 5\cos {\left( {{x_{i2}}{x_{i1}}} \right) ^3} \\ \end{aligned} \right]\).
The system dynamics of the leader node is \(k\left( {{x_0}} \right) = \left[ {x_{02}}, - 5{x_{01}} \right] ^T\). Set \({Q_{11}} = {Q_{22}} = {Q_{33}} = {Q_{44}} = {Q_{55}} = 5\), \({R_{11}} = {R_{22}} = {R_{33}} = {R_{44}} = {R_{55}} = 0.5\), \({R_{ij}} = 0.2\) (note that \({R_{ij}} = 0.2\) only when \(j \in {\mathscr {N}_i}\), or \({R_{ij}} = 0\)), and the discount factor \(\alpha = 0.1\). Select the sigmoid functions as the activation functions \({\phi _{ci}}\left( \cdot \right)\) and \({\psi _{ai}}\left( \cdot \right)\) of critic network and actor network, respectively. Set \({h_{vi}} = 15\), \({h_{di}} = 18\), and \(s=5\). Set the learning rates \({\beta _{ci}} = 0.001\), and \(\beta _{ai} = 0.0005\). Set \({N_{c,\max }} = 150\) and \({N_{a,\max }} = 100\). The thresholds are set as \({E_{c,thr}} = {E_{a,thr}} = 0.001\), and the computation error is set as \(\varepsilon = 0.01\). The initial states of the leader and followers are selected as around (0, 0.5).

The local neighborhood tracking errors of five agents.

Evolutions of the control input of five agents.

States of five agents.
The local neighborhood tracking errors are shown in Fig. 2, where it can be observed that all errors converged at about 6 seconds. Fig. 3 shows the control inputs of all agents. The states are shown in Fig. 4, which shows that all agents reach a consensus on the leader within 6 seconds.

Weights of actor-critic framework.

Weights’ change trend of different update rules.
Fig. 5 shows the weight curves of each agent’s critic and actor neutral networks, demonstrating that the weights are convergent. To illustrate the merits of the proposed weight update rule, we compare it with the existing method28. The variables \(\bigtriangleup \hat{W}_{ci}(t) = {\textstyle \sum _{i\in N}^{}} || \hat{W}_{ci}(t+T) - \hat{W}_{ci}(t) ||\) and \(\bigtriangleup \hat{W}_{ai}(t) = {\textstyle \sum _{i\in N}^{}}|| \hat{W}_{ai}(t+T) - \hat{W}_{ai}(t) ||\) are introduced to express the total change of the weights value. The comparison results are shown in Fig. 6, where it’s apparent that the proposed weight update rule outperforms the existing method28.
Example II
In this section, a load frequency control simulation for a multi-area interconnected power system, shown in Fig. 7, is given to verify the effectiveness of the proposed scheme in practical systems.
The dynamics model48 of ith power system is described as
where \(x_i^\top = [ \Delta {F}_i, \Delta {P}_{\text{ tie-i } }, \Delta {P}_{m i}, \Delta {P}_{g i}]\) denotes the system states, \(w_i^\top =[\Delta P_{d i}, \sum _{j=1, j \ne i}^N T_{i j} \Delta F_j]\) denotes the external disturbances, \(f_i(x_i) =\left[ \begin{array}{cccc} -\frac{D_i}{M_i} & -\frac{1}{M_i} & \frac{1}{M_i} & 0 \\ 2 \pi \sum _{j=1, j \ne i}^N T_{i j} & 0 & 0 & 0 \\ 0 & 0 & -\frac{1}{T_{t i}} & \frac{1}{T_{t i}} \\ -\frac{1}{R_i T_{g i}} & 0 & 0 & -\frac{1}{T_{g i}} \end{array}\right] x_i\), \(g_i =\left[ \begin{array}{llll} 0&0&0&\frac{1}{T_{g i}} \end{array}\right] ^{\top }\), and \(h_i =\left[ \begin{array}{llll} \beta _i&1&0&0 \end{array}\right]\).

Moreover, \(\Delta F_i\), \(\Delta P_{\text{ tie }-i}\), \(\Delta P_{m i}\), \(\Delta P_{g i}\), and \(\Delta P_{d i}\) denote the frequency deviation, the tie line power deviation, the generator output power deviation, the load change, the governor valve position deviation, and the load disturbance, respectively. The system parameters are set as \(D_1 = 0.031\), \(D_2 = 0.035\), \(D_3 = 0.037\), \(M_1 = 0.076\), \(M_2 = 0.085\), \(M_3 = 0.083\), \(R_1 = 1.48\), \(R_2 = 1.53\), \(R_3 = 1.62\), \(T_{g1} = 0.071\), \(T_{g2} = 0.074\), \(T_{g3} = 0.076\), \(T_{t1} = 0.51, T_{t2} = 0.47 , T_{t3} = 0.46\), \(T_{12}=T_{21}=0.22\), \(T_{13}=T_{31}= 0.31\), and \(T_{23}=T_{32}=0.23\). The parameters of the controller are set as \({Q_{11}} = {Q_{22}} = {Q_{33}} = {Q_{44}} = {Q_{55}} = 5\), and \({R_{11}} = {R_{22}} = {R_{33}} = {R_{44}} = {R_{55}} = 0.5\). Select the sigmoid functions as the activation functions \({\phi _{ci}}\left( \cdot \right)\) and \({\psi _{ai}}\left( \cdot \right)\) of critic neutral network and actor neural network, respectively. Set \({h_{vi}} = 6\), \({h_{di}} = 3\), and \(s=10\). Set the discount factor \(\alpha = 0.1\), the learning rates \({\beta _{ci}} = 0.001\), and \(\beta _{ai} = 0.0005\). The weights of critic and actor neural networks are updated with \({N_{c,\max }} = 150\) and \({N_{a,\max }} = 100\), the thresholds are set as \({E_{c,thr}} = {E_{a,thr}} = 0.001\), and the computation error \(\varepsilon = 0.01\). The initial states of power systems are selected as 0, and the load disturbances are \(\Delta P_{di} = 0.03\) for all areas. The generation rate constraint is selected as \(|\Delta \dot{P}_{c i}|\le 0.01\).

Curves of \(\Delta F_i\) in three areas.

Curves of \(\Delta F_i\) in three areas with the existing data-driven method48.

Evolution of the control input for three areas.

Convergence of NNs weights.
Figure 8 illustrates the frequency deviation of three areas, indicating that the proposed algorithm stabilizes the system within 7 seconds. Fig. 9 presents the control results of the existing data-driven method48, which exhibit higher overshoot and slower convergence compared to the proposed method. Fig. 10 shows the control input curves for the three areas, which stabilize after approximately 5 seconds. Fig. 11 illustrates the convergence of the weight parameters of the actor-critic NNs, which stabilizes around 100 seconds, indicating the completion of the training process. Collectively, Figs. 8 to 11 demonstrates that the proposed method effectively achieves load frequency control in a multi-area power system, verifying its effectiveness and applicability.
Conclusions
This paper investigated an optimal consensus control issue for a nonlinear multi-agent system with unknown dynamics. By employing the integral reinforcement learning algorithm and policy iteration method, the control policy and value function solution have been approximated using an actor-critic neural network framework, and the historical data have been utilized in the update rule for the weights of the actor and critic neural networks. Compared to existing methods, the proposed method exhibits a faster convergence speed and effectively leverages historical information to prevent falling into local optima. Further study of limited communication resources, unknown disturbances, or constrained actuators is a meaningful endeavor in our efforts.
Data availability
All data generated or analysed during this study are included in this published article.
References
Erkeç, T. & Chingiz, H. Formation flight for close satellites with GPS-based state estimation method. IEEE Sensors Journal 22, 15457–15464 (2022).
Ren, Y., Liu, S., Li, D., Zhang, D., Lei, T., & Wang, L. Model-free adaptive consensus design for a class of unknown heterogeneous nonlinear multi-agent systems with packet dropouts. Scientific Reports 14(1), 23093 (2024).
Lee, H., Lee, C., Lee, J. & Kwon, C. Linear quadratic control and estimation synthesis for multi-agent systems with application to formation flight. IET Control Theory and Applications 18(18), 23093 (2024).
Yao, D., Li, H. & Shi, Y. Event-based average consensus of disturbed MASs via fully distributed sliding mode control. IEEE Transactions on Automatic Control 69(3), 2015–2022 (2023).
Dui, H., Zhang, S., Liu, M., Dong, X. & Bai, G. IoT-enabled real-time traffic monitoring and control management for intelligent transportation systems. IEEE Internet of Things Journal 11, 15842–15854 (2024).
Wei, Q., Jiao, S., Wang, F. & Dong, Q. Robust optimal parallel tracking control based on adaptive dynamic programming. IEEE Transactions on Cybernetics 54, 4308–4321 (2024).
Wang, D., Gao, N., Liu, D., Li, J. & Lewis, F. Recent progress in reinforcement learning and adaptive dynamic programming for advanced control applications. IEEE/CAA Journal of Automatica Sinica 11(1), 18–36 (2024).
Bianca, C. & Dogbe, C. Regularization and propagation in a Hamilton-Jacobi-Bellman-Type equation in infinite-simensional Hilbert apace. Symmetry 16(8), 1017 (2024).
Jimenez, C., Marigonda, A. & Quincampoix, M. Dynamical systems and Hamilton-Jacobi-Bellman equations on the Wasserstein space and their L-2 representations. Siam Journal on Mathematical Analysis 55, 5919–5966 (2024).
Luo, A., Zhou, Q., Ma, H. & Li, H. Event-Triggered optimal consensus control for mass with multiple constraints: a flexible performance approach. IEEE Transactions on Automation Science and Engineering 22, 13117–13127 (2025).
Jiang, H., Li, X., Zhou, B. & Cao, X. Bias-policy iteration-based adaptive dynamic programming for optimal control of discrete-time nonlinear systems. IEEE Transactions on Circuits and Systems I-Regular Papers 72(8), 4284–4296 (2025).
Lin, Z., Ma, J., Duan, J., Li, E., Ma, H., & Cheng, B., Policy iteration based approximate dynamic programming toward autonomous driving in constrained dynamic environment. IEEE Transactions on Intelligent Transportation Systems 24, 5003–5013 (2023).
Qasem, O., Davari, M., Gao, W., Kirk, D. & Chai, T. Hybrid iteration ADP algorithm to solve cooperative, optimal output regulation problem for continuous-time, linear, multiagent systems: theory and application in islanded modern microgrids with IBRs. IEEE Transactions on Industrial Electronics 71, 834–845 (2024).
Wang, X., Zhao, C., Huang, T., Chakrabarti, P. & Kurths, J. Cooperative learning of multi-agent systems via reinforcement learning. IEEE Transactions on Signal and Information Processing over Networks 9, 13–23 (2023).
Hong, X. et al. Adaptive average arterial pressure control by multi-agent on-policy reinforcement learning. Scientific Reports 15(1), 679 (2025).
Zhao, H., Peng, L., Xie, L. & Yu, H. Event-triggered bipartite consensus for multi-agent systems via model-free sliding-mode scheme. IEEE Transactions on Network Science and Engineering 12(2), 1137–1145 (2025).
Cao, H., Mao, Y., Sha, L. & Caccamo, M. Physics-regulated deep reinforcement learning: Invariant embeddings. arXiv preprint, 2023; arXiv:2305.16614.
Huo, W., Huang, L., Dey, S. & Shi, L. Neural-network-based distributed generalized nash equilibrium seeking for uncertain nonlinear multiagent systems. IEEE Transactions on Control of Netowrk Systems 11(3), 1323–1334 (2024).
Li, W., Yue, J., Shi, M., Lin, B. & Qin, K. Neural network-based dynamic target enclosing control for uncertain nonlinear multi-agent systems over signed networks. Neural Networks 184, 107057 (2025).
Zhang, Y., Wu, W., Lu, J. & Zhang, W. Neural predictor-based dynamic surface parallel control for MIMO uncertain nonlinear strict-feedback systems. IEEE Transactions on Circuits and Systems II-Express Briefs 70(8), 2909–2913 (2024).
Ferede, R., De Croon, G., De Wagter, C. & Izzo, D. End-to-end neural network based optimal quadcopter control. Robotics and Autonomous Systems 172, 104588 (2024).
Zishan, M. et al. Dense neural network based arrhythmia classification on low-cost and low-compute micro-controller. Expert Systems with Applications 239, 122560 (2024).
Hu, S., Ren, X., Zheng, D. & Chen, Q. Neural network-based robust adaptive synchronization and tracking control for multi-motor driving servo systems. IEEE Transactions on Transportation Electrification 10(4), 9618–9630 (2024).
Modares, H. & Lewis, F. L. Optimal tracking control of nonlinear partially-unknown constrained-input systems using integral reinforcement learning. Automatica 50, 1780–1792 (2014).
Shen, H., Wang, Y., Wang, J. & Park, J. A fuzzy-model-based approach to optimal control for nonlinear Markov jump singularly perturbed systems: A novel integral reinforcement learning scheme. IEEE Transactions on Fuzzy Systems 31, 3734–3740 (2023).
Lin, J., Zhao, B., Liu, D. & Wang, Y. Dynamic compensator-based near-optimal control for unknown nonaffine systems via integral reinforcement learning. Neurocomputing 564, 126973 (2024).
Yan, L. et al. Game-based adaptive fuzzy optimal bipartite containment of nonlinear multi-agent systems. IEEE Transactions on Fuzzy Systems 32, 1455–1465 (2024).
Li, H., Wu, Y., Chen, M. & Lu, R. Aaptive multigradient recursive reinforcement learning event-triggered tracking control for multiagent systems. IEEE Transactions on Neural Networks and Learning Systems 34, 144–156 (2023).
Zhao, H., Shan, J., Peng, L. & Yu, H. Adaptive event-triggered bipartite formation for multiagent systems via reinforcement learning. IEEE Transactions on Neural Networks and Learning Systems 35(12), 17817–17828 (2024).
Lv, Y., Chang, H. & Zhao, J. Online adaptive integral reinforcement learning for nonlinear multi-input system. IEEE Transactions on Circuits and Systems II: Express Briefs 70, 4176–4180 (2023).
Sun, Y., Xu, J., Chen, C., & Hu, W. Reinforcement learning-based optimal tracking control for levitation system of maglev vehicle with input time delay. IEEE Transactions on Instrumentation and Measurement 71, 1–13 (2022).
Li, C., Liu, Q., Zhou, Z., Buss, M. & Liu, F. Off-policy risk-sensitive reinforcement learning-based constrained robust optimal control. IEEE Transactions on Systems Man Cybernetics-Systems 53, 2478–2491 (2023).
Pang, B. & Jiang, Z. Reinforcement learning for adaptive optimal stationary control of linear stochastic systems. IEEE Transactions on Automatic Control 68, 2383–2390 (2023).
Zhang, H., Lin, Y., Han, S., Wang, S., & Lv, K. Off-policy conservative distributional reinforcement learning with safety constraints. IEEE Transactions on Systems, Man, and Cybernetics: Systems 55, 2033–2045 (2025).
Xia, Y., Zhang, Z., Xu, J., Ren, P., Wang, J., & Han, Z. Eye in the Sky: Energy efficient model-based reinforcement learning aided target tracking using UAVs. IEEE Transactions on Vehicular Technology 73, 19464-19479 (2024).
Zhu, Y., Lv, Y., Lin, S. & Xu, J. A stochastic traffic flow model-based reinforcement learning framework for advanced traffic signal control. IEEE Transactions on Intelligent Transportation Systems 26(1), 714–723 (2025).
Xue, S., Luo, B., Liu, D. & Gao, Y. Neural network-based event-triggered integral reinforcement learning for constrained \(H_\infty\) tracking control with experience replay. Neurocomputing 513, 25–35 (2022).
Modares, H. & Lewis, F. Linear quadratic tracking control of partially-unknown continuous-time systems using reinforcement learning. IEEE Transactions on Automatic Control 59, 3051–3056 (2014).
Wang, H. & Li, M. Model-free reinforcement learning for fully cooperative consensus problem of nonlinear multiagent systems. IEEE Transactions on Neural Networks and Learning Systems 33, 1482–1491 (2022).
Peng, Z. et al. A novel optimal bipartite consensus control scheme for unknown multi-agent systems via model-free reinforcement learning. Applied Mathematics and Computation 369, 124821 (2020).
Xue, S., Luo, B., Liu, D. & Gao, Y. Neural network-based event-triggered integral reinforcement learning for constrained \(H_\infty\) tracking control with experience replay. Neurocomputing 513, 25–35 (2022).
Lewis, F. & Vrabie, D. Reinforcement learning and adaptive dynamic programming for feedback control. IEEE circuits and systems magazine 9, 32–50 (2009).
Park, J. & Sandberg, I. Universal approximation using radial-basis-function networks. Neural computation 9, 246–257 (1991).
Tan, L. Distributed \(H_\infty\) optimal tracking control for strict-feedback nonlinear large-scale systems with disturbances and saturating actuators. IEEE Transactions on Systems, Man, and Cybernetics: Systems 50(11), 4719–4731 (2018).
Tan, L., Tran, H. & Tran, T. Event-triggered observers and distributed \(H_\infty\) control of physically interconnected nonholonomic mechanical agents in harsh conditions. IEEE Transactions on Systems, Man, and Cybernetics: Systems 52(12), 7871–7884 (2022).
Tan, L. Event-triggered observer-based \(H_\infty\) optimal tracking formation control for ITSs with longitudinal-lateral slips and disturbances. IEEE Transactions on Intelligent Transportation Systems https://doi.org/10.1109/TITS.2025.3566714 (2025).
Wang, D. & Mu, C. Adaptive-critic-based robust trajectory tracking of uncertain dynamics and its application to a spring–mass–damper system. IEEE Transactions on Industrial Electronics 65(1), 654–663 (2017).
Bu, X., Zhang, Y., Zeng, Y. & Hou, Z. Event-triggered data-driven distributed LFC using controller-dynamic-linearization method. IEEE Transactions on Signal and Information Processing over Networks 11, 85–96 (2025).
Chen, Y., Zhao, H., Peng, L. & Yu, H. Data-driven dynamic event-triggered load frequency control for multi-area interconnected power systems with random delays. International Journal of Robust and Nonlinear Control 35(8), 3358–3369 (2025).
Chen, Y., Zhao, H., Ogura, M., Yu, H. & Peng, L. Data-driven event-triggered fixed-time load frequency control for multi-area power systems with input delays. IEEE Transactions on Circuits and Systems I: Regular Papers https://doi.org/10.1109/TCSI.2025.3580122 (2025).
Funding
This work was supported in part by the National Natural Science Foundation of China (62403216), in part by the Basic Research Program of Jiangsu Province (BK20241608), in part by the Wuxi Young Science and Technology Talent Support Program (TJXD-2024-114), in part by the European Union (EU) iMARs project (HORIZON-MSCA-2023-101182996), and in part by the 111 project (B23008).
Author information
Authors and Affiliations
Contributions
Longquan Ma: Conceptualization, Methodology, Software, Writing - Original Draft. Huarong Zhao: Methodology, Investigation, Writing - Review & Editing, Funding acquisition, Supervision. Yuhao Chen: Visualization, Writing - Review & Editing. Yi Gao: Supervision, Validation. Hongnian Yu: Writing - Review & Editing
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Ma, L., Zhao, H., Chen, Y. et al. Experience-based integral reinforcement learning consensus for unknown multi-agent systems. Sci Rep 15, 32962 (2025). https://doi.org/10.1038/s41598-025-15573-w
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-025-15573-w
