
Abstract
With IoT networks expected to exceed 29 billion connected devices by 2030, the risk of cyberattacks has never been higher. As more devices come online, the attack surface for hackers continues to expand, making cybersecurity a pressing concern. Intrusion Detection Systems (IDS) are essential for identifying and mitigating these threats in real-time. However, a significant challenge IDS faces is dealing with imbalanced datasets, where attack instances are significantly underrepresented compared to normal traffic. Training models on such skewed data leads to a bias toward majority-class patterns, reducing their ability to detect intrusions effectively. To address this issue, this work introduces CSMCR (Cosine Similarity-based Majority Class Reduction), a novel technique that selectively removes redundant majority-class samples while preserving dataset integrity. Unlike traditional approaches like SMOTE (oversampling) or random undersampling, CSMCR ensures that the retained majority instances remain diverse by analyzing feature-wise similarity. This prevents unnecessary data duplication and minimizes information loss. Additionally, we developed a hybrid deep learning model integrating RegNet and FBNet architectures to enhance feature extraction and classification performance. Experimental results on multiple IDS datasets confirm that balancing the dataset to a 1:1 ratio optimally prevents overfitting and improves model interpretability. The proposed model achieved an F1-score of 0.9758 on RT-IoT2022 and 0.9275 on UNSW Bot-IoT, outperforming SMOTE-based methods in accuracy and computational efficiency. Notably, CSMCR reduced training time by 53% compared to conventional oversampling techniques. Incremental training evaluations reveal that bias formation reduces performance beyond a 1:2 majority-to-minority ratio. These findings establish CSMCR as a robust, scalable, and computationally efficient IDS balancing strategy tailored for IoT network security.
Similar content being viewed by others
Introduction
The Internet of Things (IoT) has become pervasive across various domains in recent years. It refers to a vast ecosystem of interconnected devices, including smart thermostats, fitness trackers, industrial sensors, and traffic management systems, that communicate and share data autonomously. By 2030, experts predict there will be over 29 billion1 IoT devices worldwide, up from around 15 billion in 2023. While these technologies enhance convenience and operational efficiency, they also raise critical concerns regarding device and network security. Many of these devices aren’t built to handle cyberattacks, and that’s becoming a huge problem2,3. IoT is transforming industries and daily life. For example, in healthcare, devices such as heart monitors and insulin pumps provide real-time data to physicians, improving patient outcomes. In farming, sensors track soil moisture and weather to help farmers grow better crops. Cities are getting smarter, with IoT managing traffic lights, waste collection, and energy use. However, many IoT devices remain susceptible to exploitation due to inadequate security measures. According to a survey, 57% of IoT devices are vulnerable to medium- or high-severity attacks4,5. Due to weak security, IoT devices have become a prime target for cyberattacks6,7.
A prominent example is the Mirai botnet attack. Hackers broke into thousands of poorly secured IoT devices, like cameras and routers, and used them to launch one of the most significant cyberattacks ever8. This attack caused widespread service disruptions to major platforms, including Twitter, Netflix, and Reddit. Since then, IoT-related cyberattacks have only gotten worse. In 2022, IoT malware attacks jumped by 87%, with hackers exploiting weak passwords, outdated software, and a lack of encryption. The prevalence of such attacks is increasing, primarily because IoT devices present relatively easy targets for adversaries9,10. For instance, 98% of IoT device traffic remains unencrypted, making it vulnerable to interception and unauthorized access. Additionally, many devices use default passwords like “admin” or “1234,” which are ridiculously easy to guess11.
Intrusions pose a major threat to IoT networks, exploiting vulnerabilities such as weak authentication, malware infections, and unauthorized access12. As shown in Fig. 1, intrusions can be categorized into multiple attack vectors, including exploitation of vulnerabilities, malware-based intrusions, network intrusions and scanning, and insider-triggered intrusions. These attacks highlight the diverse ways hackers can exploit IoT systems, making robust security measures essential.

Categorization and distribution of cyber intrusion threats.
To fight these threats, we need intrusion detection systems (IDS). An Intrusion Detection System (IDS) functions as a virtual security monitor that inspects network traffic, identifies anomalies, and generates alerts for potential security threats. There are two main types of IDS: signature-based and anomaly-based. Signature-based IDS looks for known attack patterns, like a virus scanner. While effective at identifying known threats, it is often inadequate in detecting novel or zero-day attacks. Anomaly-based IDS, on the other hand, uses machine learning to spot unusual behavior13. For example, an anomaly-based IDS may flag a smart thermostat that begins transmitting unusually large volumes of data as a potential threat. Anomaly-based IDS is becoming more popular because it can detect new, unknown attacks14,15. Several studies have shown that anomaly-based Intrusion Detection Systems (IDS) can detect IoT attacks with significantly higher accuracy than traditional signature-based methods14,16,17. Unlike conventional IDS, which rely on predefined attack patterns and often fail to recognize emerging threats, anomaly-based IDS leverage machine learning and statistical models to identify deviations from normal behavior. This adaptive approach allows them to detect previously unseen attacks more effectively.
Deep learning, a branch of artificial intelligence (AI), is improving IDS even further18,19. Techniques like Convolutional Neural Networks (CNNs) and Long Short-Term Memory (LSTM) networks are excellent at analyzing large amounts of data and spotting patterns. For example, a deep learning model can analyze network traffic and identify a DDoS attack in real-time, even if it’s never seen that specific attack before. Studies show that deep learning-based IDS can achieve higher detection rates, far outperforming traditional systems20,21,22.
However, a major challenge in training such models is the inherent class imbalance in most IoT intrusion detection datasets. In most cases, 99% of the data is regular traffic, and only 1% represents attack. This makes it hard for AI models to learn what an attack looks like. To solve this, researchers use techniques like data augmentation and synthetic data generation to create more balanced datasets. Cybersecurity Ventures estimates that global cybercrime costs will soar from $6 trillion in 2021 to $10.5 trillion annually by 202523. A big chunk of this comes from IoT attacks. For example, a single data breach can cost a company $4.45 million on average, according to IBM’s 2023 Cost of a Data Breach Report.
Intrusion Detection Systems (IDS) serve as a critical countermeasure in such scenarios. By monitoring network traffic and spotting threats in real-time, IDS can help prevent attacks before they cause damage. For instance, in an industrial IoT setting, an IDS could detect unauthorized commands directed at robotic machinery and prevent damage by initiating timely countermeasures. The future of IoT security lies in smarter, more adaptive systems. Deep learning and AI are already making IDS more effective. However, significant challenges remain to be addressed. For example, researchers are exploring ways to make IDS more energy-efficient so it can run on low-power IoT devices. They’re also working on federated learning, where multiple devices share data to improve detection without compromising privacy.
Several studies have explored the effectiveness of deep learning in IDS. Research indicates that deep learning-based IDS achieves detection rates exceeding 95%, significantly outperforming traditional rule-based systems. Given IoT’s high data dimensionality and real-time security requirements, deep learning offers a scalable and adaptive approach to intrusion detection. However, one of the major challenges in IDS for IoT is dataset imbalance, where attack instances are significantly underrepresented, leading to biased model predictions and reduced detection accuracy.
This research work is driven by the growing challenge of class imbalance in IoT intrusion detection datasets, where the majority of samples represent normal traffic and only a small portion corresponds to actual attacks. This imbalance makes it difficult for machine learning models to detect threats accurately, as they tend to favor the majority class. To address this, we introduce a new method called Cosine Similarity-based Majority Class Reduction (CSMCR), which smartly removes redundant data from the majority class while preserving data diversity. Along with this, we design a hybrid deep learning model using RegNet and FBNet to improve intrusion detection accuracy. The main contributions of this research work are:
-
Proposes a novel data balancing method-CSMCR (Cosine Similarity-based Majority Class Reduction)-which selectively removes redundant majority-class samples based on feature-wise cosine similarity, thereby preserving data diversity without generating synthetic samples. Unlike existing similarity-based or clustering-driven instance selection methods, CSMCR is lightweight, interpretable, and computationally efficient.
-
Develops a hybrid deep learning model that integrates RegNet and FBNet, achieving a trade-off between high detection accuracy and low computational cost, making it practical for deployment in resource-constrained IoT environments.
-
Conducts a comprehensive experimental evaluation across four real-world IoT intrusion detection datasets, encompassing diverse attack types and varying levels of class imbalance.
-
Demonstrates the superiority of the proposed approach through comparisons with widely used techniques such as SMOTE and Random Undersampling, showing notable improvements in detection accuracy, model training time, and dataset balancing efficiency.
The article is structured as follows: “Related work” section reviews related work, while “Proposed approach” section details the proposed dataset balancing approach and model building approach. “Result and discussion” section analyzes experimental results, and compares our approach with existing dataset balancing approaches. Finally, “Conclusion” section concludes this research and outlines future research directions.
Related work
Intrusion detection systems (IDS) have been extensively studied, with numerous approaches proposed to enhance detection accuracy and address challenges such as class imbalance. Existing methods, like rule-based or statistical approaches, often fall short because they can’t keep up with new types of attacks. Machine learning and deep learning models have shown significant improvements, but their effectiveness is often hindered by imbalanced datasets, leading to biased predictions. This section reviews key advancements in IDS, focusing on dataset balancing techniques and deep learning-based intrusion detection methods.
Luqman et al.24 propose an intelligent Intrusion Detection System for IoT networks using machine learning and deep learning techniques. The system is evaluated on the UNSW Bot-IoT and BoT-IoT datasets, leveraging 27 statistically and heuristically extracted features. The study employs Long Short-Term Memory (LSTM) networks, which outperform other models, achieving high accuracy, precision, recall, and F1-score in both binary and multi-class classification. The dataset is split into 70% training, 15% validation, and 15% testing, ensuring robust evaluation. While the system excels in feature selection and detection accuracy, its high computational cost and challenges in real-time implementation are notable limitations. Alhayan et al.25 propose IDCS-ELIBWO, an Enhanced Intrusion Detection System (IDS) that combines ensemble deep learning models (DBN, GRU, LSTM) with an Improved Beluga Whale Optimization (IBWO) algorithm for feature selection and hyperparameter tuning. Tested on the UNSW Bot-IoT dataset, the system achieves 99.77% accuracy, with precision, recall, and F1-score all at 98.86%. The Remora Optimization Algorithm (ROA) is used for feature selection, while IBWO optimizes model parameters, reducing computational complexity. The framework demonstrates superior performance in detecting cyber threats but faces potential scalability issues and high computational costs with larger datasets. Chandrasekaran et al.26 propose an Intrusion Detection System (IDS) using a Time Weighted Adaboost Support Vector Machine (TWASVM) classifier and Crossover Boosted Dwarf Mongoose Optimization (CDMO) algorithm to address class imbalance in datasets. They tested their model on the NSL-KDD dataset, which has 67,343 benign and 58,630 malicious records. By using Kernel Principal Component Analysis (KPCA) for feature extraction and CDMO for feature selection, they achieved 98.6% accuracy, with precision, recall, and F1-score all above 97%. This method outperformed others like SVM-OLGWO and PSO-SVM, but it’s worth noting that it’s pretty resource-heavy and relies heavily on the quality of the dataset.
Ali et al.27 propose a transformer-based Intrusion Detection System (IDS) using BERT for feature extraction and a Multi-Layer Perceptron (MLP) for classification to address imbalanced network traffic. The system employs SMOTE for data balancing and BERT to generate contextual embeddings, achieving high accuracy across datasets like CIC-IDS2017 (99.39%), UNSW Bot-IoT (99.20%), and NSL-KDD 2009 (99.33%). With precision (99.06–99.39%), recall (99.61–100%), and F1-score (99.31–99.99%), the BERT-MLP model outperforms traditional methods like CNN and LSTM. While it effectively handles class imbalance and reduces false positives, the system’s high computational requirements and dataset dependency are notable limitations. Kim et al.28 propose a Cloud Intrusion Detection System (C-IDS) that uses NLP techniques for real-time anomaly detection in cloud environments without requiring domain knowledge. They built it around a Seq2Seq model with Bi-LSTM and Bahdanau attention, crunching logs from datasets like CICIDS2018, Hadoop, and OpenStack. The authors achieve 98.2% log recognition accuracy and 94.2% anomaly detection accuracy. It’s flexible and accurate, sure, but it’s not without flaws—it’s a bit of a black box and can trip up on new attack types. Al-Shehari et al.29 evaluate data imbalance techniques for CNN-based insider threat detection using the CERT Insider Threat Dataset (2,308,467 benign, 346 malicious records). ADASYN achieved good performence with a 96% ROC-AUC score, getting better performance compared to SMOTE (94%) and Borderline-SMOTE (89%). Their CNN-ADASYN model hit 83% precision and 76% recall, cutting down false positives and spotting rare threats better. But, yeah, it’s not all smooth sailing-it’s resource-heavy and can overfit with synthetic data.
Ding et al.30 propose TMG-IDS, an intrusion detection system using TMG-GAN, a GAN-based model designed to handle class imbalance in network intrusion detection. By using multiple generators and a classifier, they boosted data quality and reduced class overlap with a cosine similarity loss function. Tested on CICIDS2017 and UNSW-NB15, TMG-IDS crushed it, hitting a precision, recall, and F1-score of 0.9973 on CICIDS2017. It’s a game-changer for IDS performance, though it’s still pretty complex to pull off. Abdelkhalek and Mashaly31 address the class imbalance problem in Network Intrusion Detection Systems (NIDS) by combining data resampling techniques (ADASYN for oversampling and Tomek Links for undersampling) with deep learning models. On the NSL-KDD dataset, their method hit 99.8% accuracy in binary classification and a jaw-dropping 99.98% in multi-class classification using models like MLP, DNN, CNN, and CNN-BLSTM. It’s great at catching rare attacks and cutting false positives, but the resampling process is a computational beast, and synthetic data can sometimes lead to overfitting. Gupta et al.32 propose CSE-IDS, a three-layer Network-based Intrusion Detection System (NIDS) that combines Cost-Sensitive Deep Learning and Ensemble algorithms to address class imbalance in network traffic. The system uses a CSDNN to flag suspicious traffic, XGBoost to classify attacks, and Random Forest to tackle rare threats. Tested on datasets like NSL-KDD and CICIDS2017, it outperformed traditional models with high accuracy, precision, recall, and F1-scores. While it cuts false alarms and boosts detection, it’s resource-heavy and depends on dataset quality.
In summary, while previous studies have explored data balancing and deep learning for IDS, they mostly rely on synthetic oversampling or random undersampling techniques. These methods either risk overfitting or loss of valuable data. In contrast, our proposed CSMCR technique retains only diverse majority-class samples using a feature-wise similarity approach, ensuring data quality and reducing training time. A summarized comparison of these studies, highlighting their feature selection techniques, intrusion detection methods, advantages, and limitations, is presented in Table 1.
Proposed approach
While existing methods demonstrate high performance, many suffer from computational inefficiencies, reliance on synthetic data generation, or suboptimal handling of class imbalance. Our proposed approach addresses these limitations by introducing a cosine similarity-based dataset balancing method that ensures data integrity and computational efficiency while enhancing IDS performance.
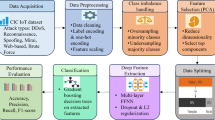
Figure 2 illustrates the complete research approach, encompassing both dataset balancing and model development. The first stage involves the proposed Cosine Similarity-based Majority Class Reduction for Dataset Balancing, where majority class samples are reduced using cosine similarity to enhance class balance. This refined dataset is then fed into the Model Building, Training, and Evaluation phase, which integrates a hybrid deep learning model combining RegNet and FBNet for IoT intrusion detection.

Flowchart of the proposed hybrid deep learning model for IoT intrusion detection with cosine similarity-based dataset balancing.
Experimental datasets and relevance to IoT environments
To ensure a comprehensive evaluation of the proposed technique and its generalizability across different IoT contexts, we selected four publicly available Intrusion Detection System (IDS) datasets: IoTID2041, N-BaIoT42, RT-IoT202243, and UNSW Bot-IoT44. These datasets were chosen based on their diversity in network environments, attack types, device heterogeneity, and degrees of class imbalance. This diversity enables the assessment of our approach under various real-world conditions representative of IoT deployments.
IoTID20
Collected from a smart home environment, this dataset contains both benign and malicious traffic originating from IoT devices such as smart lights and smart TVs. It includes various attacks targeting MQTT and HTTP protocols, reflecting typical threats in consumer IoT setups.
N-BaIoT
This dataset includes network traffic from multiple IoT devices infected with Mirai and Bashlite botnets. It provides detailed traces of volumetric attacks (e.g., UDP and TCP floods), making it suitable for evaluating detection performance against common botnet-driven threats in home and enterprise IoT settings.
RT-IoT2022
A recent dataset captured in a real-time industrial IoT testbed, it simulates a variety of cyberattacks on Programmable Logic Controllers (PLCs) and sensor nodes within an Industry 4.0 context. It provides time-series data and represents dynamic attack scenarios with high temporal resolution.
UNSW Bot-IoT
Generated in a controlled virtualized environment, this large-scale dataset simulates botnet activity in IoT networks and includes attacks such as DDoS, data exfiltration, and service scanning. It features rich metadata and diverse traffic characteristics, which are essential for training and validating robust IDS models.
Feature selection and influential features
To enhance computational efficiency and ensure the quality of inputs for the balancing algorithm, we performed feature selection before applying the CSMCR-based dataset balancing. This step reduced the dimensionality of the data and significantly improved the runtime performance of the cosine similarity computations.
A multi-stage feature selection strategy was employed as follows:
-
Penalized Variation Scoring Features with low variance or repetitive values across samples were penalized. This helped identify features with more diversity and discriminative power.
-
Embedded Feature Weighting A lightweight neural network with L1/L2 regularization was trained on the dataset. Feature importance was determined by summing the absolute values of the input layer weights.
-
Recursive Feature Elimination (RFE) Using logistic regression, RFE was applied to iteratively eliminate the least impactful features and retain the optimal subset.
This process was conducted using the RT-IoT2022 dataset, chosen for its rich feature set and realistic IoT traffic characteristics. The top features selected through this process included:
-
fwd_subflow_bytes, fwd_pkts_payloadavg, fwd_pkts_payloadtot, fwd_pkts_payloadmax, bwd_pkts_payloadavg, bwd_pkts_payloadtot, bwd_pkts_payloadmax, bwd_pkts_payloadstd, bwd_subflow_bytes, bwd_header_size_min, bwd_header_size_max, flow_pkts_payloadstd, flow_pkts_payloadmax, flow_pkts_payloadmin, flow_pkts_per_sec. activemin
These features capture important behavioral characteristics of IoT traffic, such as payload variability, flow symmetry, and sudden traffic bursts. For example, higher values in flow_pkts_payloadstd or asymmetry in forward/backward bytes may indicate scanning, botnet communication, or flood-based attacks.
While feature selection is not the central contribution of this work, it plays a key supporting role in optimizing both the dataset balancing process and the overall model training efficiency.
Proposed cosine similarity-based majority class reduction for dataset balancing
Any machine learning or deep learning model require well-balanced datasets to ensure fair and accurate predictions. However, real-world datasets often suffer from class imbalance, leading to suboptimal model performance. Traditional oversampling and undersampling techniques introduce redundancy or information loss33. This section presents CSMCR (Cosine Similarity-based Majority Class Reduction) that selectively reduces the majority class using a similarity-based filtering approach, ensuring diversity in retained samples. The proposed approach consists of the following steps:
Identifying and preprocessing the majority class
In imbalanced datasets, the majority class often dominates the minority class, leading to biased model training. To address this, the proposed approach focuses on identifying and preprocessing the majority class to ensure that only the most representative samples are retained. This step is crucial for reducing the imbalance while preserving the essential characteristics of the dataset.
The first step is to separate the dataset into majority and minority classes based on the class labels. The majority class is identified as the class with the higher number of samples, while the minority class is the one with fewer samples. This separation allows us to focus on preprocessing and reducing the majority class without affecting the minority class.
Once the majority class is identified, it undergoes preprocessing to ensure data quality. This includes:
-
Duplicate samples in the majority class are removed to avoid redundancy.
-
Samples with missing or infinite values are either removed or corrected to ensure the dataset is clean and consistent.
-
The indices of the majority class DataFrame are reset to maintain a consistent structure.
The pseudocode to identifying and preprocessing the majority class is given in Algorithm 1

Identifying and preprocessing the majority class.
Cosine similarity calculation
Cosine similarity is a widely used metric for measuring the similarity between two vectors in an n-dimensional space34. In this approach, cosine similarity is used to compare a new sample against a set of previously selected samples (trained set). If the similarity is below a defined threshold, the sample is retained; otherwise, it is discarded to prevent redundancy.
Cosine similarity between two vectors \(P\) and \(Q\) is defined as:
where \(P\) and \(Q\) are n-dimensional vectors. \(P_i\) and \(Q_i\) represent individual components of these vectors. The numerator represents the dot product of the two vectors. The denominator represents the product of their Euclidean norms.
This metric returns values in the range \([-1,1]\), where:
-
\(1\) indicates identical vectors,
-
\(0\) indicates orthogonal (completely different) vectors,
-
\(-1\) indicates opposite vectors.
In the proposed approach, cosine similarity is modified to incorporate absolute differences for numerical attributes:
where \(R\) represents the range of each feature:
This normalization ensures that feature differences are adjusted according to their range, reducing bias from features with larger numerical values. Following are the steps for cosine similarity calculation
-
Feature-wise Comparison: For each feature in the dataset, the absolute difference between the feature values of two samples is calculated.
-
Normalization: The difference is normalized by the range of the feature to account for varying scales.
-
Similarity Score: The similarity score is computed as the average of the normalized differences across all features.
The pseudocode to calculate the cosine similarity is given in Algorithm 2

Cosine similarity calculation.
The CSMCR algorithm follows the following key steps:
-
Step 1 Remove duplicate or incomplete samples from the majority class.
-
Step 2 Calculate cosine similarity scores between majority class samples based on selected features.
-
Step 3 Sort samples according to similarity scores to prioritize diverse instances.
-
Step 4 Select a reduced set of majority samples by applying a diversity threshold, ensuring important variations are preserved.
-
Step 5 Combine the selected majority samples with all minority samples to form a balanced dataset.
After constructing the CSMCR algorithm and selecting the most diverse majority class samples, we briefly analyze the computational complexity of the method. The overall complexity is dominated by the pairwise cosine similarity calculations, where each comparison takes O(m) operations, with m representing the number of features. Since similarity is computed for all sample pairs, the complexity for this step is \(O(n^2 \times m)\), where n is the number of majority class samples.
The sorting of samples based on similarity scores requires \(O(n \log n)\) time, and the final selection step operates in O(n). Thus, the overall time complexity of the CSMCR method is \(O(n^2 \times m)\).
Balancing the dataset
The final step in the proposed approach involves selecting the most representative samples from the majority class and combining them with the minority class to create a balanced dataset. This step ensures that the dataset is balanced without losing critical information, thereby improving the performance of machine learning models trained on the dataset.
After computing similarity values, the majority class samples are sorted in ascending order, prioritizing the most diverse samples with the lowest similarity to previously selected instances.
The dataset is trimmed to match the majority class size with the minority class, ensuring balance while preserving representative patterns.
The top \(N_{\text {Min}}\) samples are selected to match the minority class size. The selected majority class samples are combined with all minority class samples, creating a balanced dataset for machine learning training.
Advantages of the proposed approach
The proposed similarity-based data selection technique offers several advantages over conventional data balancing methods, such as Synthetic Minority Over-sampling Technique (SMOTE) and random undersampling35.
As shown in Table 2, the proposed CSMCR (Cosine Similarity-based Majority Class Reduction) technique significantly reduces dataset size while maintaining diversity. For example, the UNSW Bot-IoT dataset saw a remarkable reduction of 99.66%, while the IoTID20, N-BaIoT, and RT-IoT2022 datasets achieved reductions of 78.10%, 75.05%, and 79.68%, respectively.
As shown in Fig. 3, the original dataset (left) exhibits high redundancy, with a large number of overlapping majority-class samples, leading to an inflated diversity index. The richness trend (orange line) remains high, indicating excessive duplication, whereas the evenness trend (black line) stays near zero, highlighting imbalance.
In contrast, the balanced dataset (right) using CSMCR effectively reduces redundancy while preserving diversity. The richness trend stabilizes, and the evenness trend improves, indicating a more representative dataset. This targeted reduction enhances IDS model training efficiency and improves detection accuracy while reducing computational costs.

Alpha diversity (richness & evenness) with trend lines plotted using original N-BaIoT dataset and balanced N-BaIoT dataset.
Apart from the above analysis, the other key benefits include:
-
Preserves data integrity by retaining original samples from the majority class, avoiding synthetic data generation.
-
Reduces overfitting by ensuring diversity in the retained samples, unlike oversampling techniques like SMOTE.
-
Computationally efficient and scalable, making it suitable for large datasets.
-
Handles high-dimensional data effectively using cosine similarity, focusing on feature-wise differences.
-
Customizable similarity threshold allows fine-tuning based on dataset characteristics.
-
Minimizes information loss by selectively retaining the most representative samples.
Table 3 presents a comparison of different dataset balancing techniques, including the proposed similarity-based selection method, SMOTE, and random undersampling. The comparison highlights their methodologies, advantages, and potential drawbacks to provide insights into their effectiveness for handling imbalanced datasets.
Model building, training, and evaluation
The proposed hybrid model leverages the strengths of both residual learning and feedforward architectures to enhance classification performance on the balanced dataset36,37,38,39,40. We chose RegNet because of its well-structured and scalable architecture, which makes it effective at learning complex, layered features from high-dimensional data. Its built-in residual connections also help avoid common deep learning issues like vanishing gradients, allowing it to handle deeper networks more reliably. On the other hand, FBNet was selected for its lightweight design and fast performance. It was built using neural architecture search (NAS), making it highly efficient for real-time tasks.
By combining RegNet’s strong feature learning abilities with FBNet’s speed and efficiency, our hybrid model takes advantage of both depth and agility. This combination helps the model generalize well across different types of IoT attacks while keeping computational demands low. As a result, it is especially suited for real-world scenarios where resources are limited, such as edge devices or embedded systems
RegNet module
RegNet is a residual network-based feature extractor that enhances feature learning via dense layers, batch normalization, and dropout.
Mathematically, the module transforms the input feature vector X as follows:
Residual connections ensure stable learning:
Further transformation is applied:
FBNet module
The FBNet module is a feedforward network that complements RegNet by extracting distinct features.
Final transformation:
Hybrid model formation
The proposed architecture employs a late-fusion strategy wherein the outputs of two independently processed deep feature representations-RegNet and FBNet-are concatenated to form a unified embedding vector. This dual-branch design enables the hybrid model to capture both deep abstract patterns and shallow discriminative features from the input data.
Let \(X_{final}\) and \(Y_{final}\) denote the final outputs from the RegNet and FBNet modules, respectively. The integrated representation is computed as:
The combined vector Z is passed through a series of dense layers and then into the final output layer for binary classification. The final prediction probability P is computed using a sigmoid activation function as:
where \(\sigma (x) = \frac{1}{1+e^{-x}}\) is the sigmoid activation function, and \(W_7\), \(b_7\) are the weights and bias parameters of the final dense layer.
This integration strategy supports architectural modularity, improves generalization, and enhances the model’s ability to capture both global and local data characteristics-making it particularly effective for complex intrusion detection in IoT systems.
Training process with callbacks
The model training process integrates callback mechanisms to optimize performance and mitigate overfitting. The training follows an adaptive learning approach using early stopping and dynamic learning rate scheduling.
-
1.
Early Stopping Early stopping prevents unnecessary training iterations by monitoring validation loss (\(L_{\text {val}}\)). If no improvement is observed for a predefined number of epochs (\(p = 10\)), training halts, and the best weights are restored:
$$\begin{aligned} L_{\text {val}}^{(t)} \ge L_{\text {val}}^{(t - p)}, \quad \forall \, t \in \{T - p, \dots , T\}, \end{aligned}$$(17)where \(T\) represents the current epoch, and \(p\) is the patience threshold.
-
2.
Learning Rate Scheduling A ReduceLROnPlateau scheduler dynamically adjusts the learning rate (\(\alpha\)) based on validation loss progression. If the loss stagnates for \(p = 5\) epochs, the learning rate is reduced by a factor (\(f = 0.5\)), with a minimum limit:
$$\begin{aligned} \alpha _{t+1} = \max (f \cdot \alpha _t, \alpha _{\min }), \end{aligned}$$(18)where \(\alpha _{\min } = 10^{-6}\) ensures stability during convergence.
-
3.
Model training The model undergoes optimization using the Adam algorithm, minimizing the binary cross-entropy loss:
$$\begin{aligned} L = -\frac{1}{N} \sum _{i=1}^{N} \left[ y_i \log (\hat{y}_i) + (1 - y_i) \log (1 - \hat{y}_i) \right] , \end{aligned}$$(19)where:
-
\(y_i\) denotes the true label.
-
\(\hat{y}_i\) represents the predicted probability.
-
\(N\) is the number of training samples.
Training is conducted over a maximum of 100 epochs with a batch size of 32. The dataset is split into training (80%) and validation (20%) subsets, ensuring model generalization. By integrating these callback mechanisms, the model achieves efficient convergence while preventing overfitting, leading to improved generalization on unseen data.
-
-
4.
Pretraining and Initialization All model weights are initialized using the default Glorot uniform initializer (i.e., Xavier initialization). No external pretraining (e.g., on ImageNet) was used, as the model is fully customized and trained from scratch on normalized tabular feature vectors rather than image data.
-
5.
Hyperparameter Tuning We conducted empirical tuning through validation-based early stopping and scheduler callbacks. The following configuration was found to yield the best trade-off between accuracy and convergence time:
-
Optimizer: Adam
-
Initial learning rate: 0.001
-
Batch size: 32
-
Epochs: Up to 100 (with early stopping after 10 non-improving validation epochs)
-
Learning rate schedule: ReduceLROnPlateau (factor = 0.5, patience = 5, min_lr=\(1e^{-6}\))
-
Incremental dataset balancing and training
To systematically evaluate the impact of the proposed cosine similarity-based dataset balancing approach, we designed an iterative training procedure where the model is tested on multiple dataset versions. The primary objective of this approach is to analyze how different levels of majority class reduction affect model performance.
The training process involves generating five progressively balanced datasets by varying the proportion of majority class samples while maintaining the integrity of the minority class. The methodology follows these steps:
-
1.
Dataset Preparation
-
The minority class dataset (\(dfMinority\)) remains unchanged across all training iterations.
-
The majority class dataset (\(dfMajority\)) is sorted by similarity scores in ascending order, ensuring that the most diverse and representative samples are selected first.
-
-
2.
Progressive Undersampling
-
In each iteration \(i\) (ranging from 1 to 4), a subset of the majority class is selected using:
$$dfMajority.head(i \times dfMinCount)$$where \(dfMinCount\) represents the count of minority class samples.
-
This ensures that the ratio of majority-to-minority class progressively increases while still maintaining diversity.
-
-
3.
Data Shuffling and Model Training
-
The selected majority class samples are concatenated with the minority class to form the balanced dataset for that iteration.
-
The dataset is shuffled to prevent any ordering bias.
-
The model is then trained using the function train_and_evaluate_model(), which executes the full training pipeline.
-
By following this structured training methodology, we assess the effectiveness of dataset balancing in reducing bias and enhancing model generalization. The incremental approach ensures a detailed performance analysis across varying levels of class imbalance.
Model evaluation
To assess the performance of the trained hybrid model, various evaluation metrics were computed based on the model’s predictions on the test set. The evaluation process included standard classification metrics as well as custom statistical measures.
The predicted labels (\(\hat{y}\)) were obtained using the trained model by applying a threshold of 0.5:
where \(P(\hat{y} | X)\) is the predicted probability of the positive class.
Accuracy measures the overall correctness of the model and is given by:
where:
-
\(T_{\text {p}}\) (True Positives): Correctly predicted positive cases
-
\(T_{\text {n}}\) (True Negatives): Correctly predicted negative cases
-
\(F_{\text {p}}\) (False Positives): Incorrectly predicted positive cases
-
\(F_{\text {n}}\) (False Negatives): Incorrectly predicted negative cases
Precision (Positive Predictive Value) indicates how many of the predicted positive cases were actually correct:
Recall, or Sensitivity, measures the model’s ability to correctly identify positive instances:
The F1 score is the harmonic mean of Precision and Recall, providing a balance between the two:
The Receiver Operating Characteristic-Area Under Curve (ROC-AUC) score evaluates the trade-off between True Positive Rate and False Positive Rate across different threshold values.
The Matthews Correlation Coefficient (MCC) is a robust metric that considers all four confusion matrix values:
Additionally, custom metrics were used to further assess model performance. Youden’s J statistic evaluates the model’s ability to maximize correct classification while minimizing errors:
where Specificity is given by:
The Fowlkes–Mallows Index (FMI) measures the geometric mean of Precision and Recall:
Markedness assesses the reliability of positive and negative predictions:
The total time taken for training and evaluation was recorded to assess computational efficiency:
where \(T_{\text {start}}\) and \(T_{\text {end}}\) represent the start and end timestamps of the training process.
Result and discussion
This section presents the experimental evaluation of our proposed CSMCR (Cosine Similarity-based Majority Class Reduction) technique and hybrid deep learning model. The experiments were conducted on multiple IDS datasets, including IoTID2041, N-BaIoT42, RT-IoT202243, and UNSW Bot-IoT44, to assess the impact of dataset balancing on intrusion detection performance. These datasets contain diverse attack types and varying levels of class imbalance, providing a comprehensive evaluation of our approach.
Impact of class ratio on model performance
We analyze model performance across different majority-to-minority class ratios, starting with a 1:1 balanced dataset and progressively increasing the imbalance to 1:2, 1:3, and 1:4. Each subsection explores the effect of these ratios on detection accuracy, F1-score, computational efficiency, and model generalization. The results demonstrate how balancing the dataset influences the trade-off between overfitting, underfitting, and classification performance, ultimately validating the effectiveness of CSMCR in improving IDS detection for IoT security.
Performance with a minority-to-majority class ratio 1:1: baseline evaluation
A balanced 1:1 minority-to-majority class ratio offers significant advantages in model training by eliminating bias toward the majority class, ensuring fair representation of all samples45,46,47,48. This balance improves recall and precision, preventing the model from favoring one class over another. Additionally, it enhances generalization, reducing the risk of misclassification, particularly in datasets where the minority class carries critical significance, such as anomaly detection.
Table 4 presents the Baseline Evaluation: Performance with a Minority-to-Majority Class Ratio of 1:1, ensuring fair assessment without class imbalance bias. The model achieves near-perfect scores (Accuracy = 1, F1 = 1) in some cases, while maintaining high MCC (>= 0.82) and Youden’s J (>= 0.85) across datasets. These results confirm the model’s robustness and reliability in IoT intrusion detection, effectively balancing precision and sensitivity.
This balanced training approach prevents overfitting, as the model does not disproportionately learn from a dominant class, and avoids underfitting, ensuring both classes contribute equally to learning. It reduces model staleness, allowing adaptability across datasets. Computational efficiency is improved due to faster convergence. Robustness is enhanced since predictions remain stable across varying distributions, while explainability benefits from balanced decision-making, making model predictions easier to interpret and trust.
Performance with a minority-to-majority class ratio 1:2: lightly imbalance
A 1:2 minority-to-majority class ratio introduces mild class imbalance, allowing evaluation of its early impact on model performance. While still offering reasonable minority class representation, this setup begins to expose the challenges of biased learning. The experiment helps assess whether performance deterioration is immediate or gradual as class distribution shifts from the balanced 1:1 ratio, which remains the ideal scenario for unbiased predictions.
Table 5 presents the Performance with a Minority-to-Majority Class Ratio of 1:2, offering insights into model behavior when facing slight class imbalance. Compared to Table 5 (1:1 ratio), the results remain consistent, with marginal variations. Accuracy and F1 Score are nearly unchanged, with N-BaIoT maintaining near-perfect performance (Accuracy = 0.9997, F1 = 0.9996). Small fluctuations in MCC and Youden’s J indicate the model’s resilience. Processing time increased slightly for N-BaIoT (278 \(\rightarrow\) 294 s), reflecting the impact of class imbalance. Overall, the model demonstrates strong adaptability to skewed distributions.
This configuration initiates a shift toward overfitting, as the model starts favouring the majority class, reducing the recall for minority instances. Underfitting is not yet significant but could worsen with further imbalance. Computational efficiency declines, especially for larger datasets, impacting scalability. Robustness weakens as misclassifications increase, while explainability suffers due to emerging class bias, reinforcing the advantages of the 1:1 ratio for optimal performance.
Performance with a minority-to-majority class ratio 1:3: moderately imbalanced
A 1:3 minority-to-majority class ratio significantly amplifies class imbalance, allowing deeper insights into the model’s ability to generalize when the minority class is underrepresented. This evaluation helps understand bias formation, decision boundary shifts, and the point at which the model starts ignoring minority class patterns. The results contrast with the 1:1 ratio, emphasizing its superior balance in maintaining fairness and predictive stability.
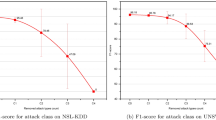
Table 6 evaluates performance with a Minority-to-Majority Class Ratio of 1:3, testing model robustness under increased class imbalance. Compared to Table 4 (1:1) and Table 5 (1:2), accuracy and F1 scores remain strong but show minor declines, particularly for IoTID20 (Accuracy: 0.9618 \(\rightarrow\) 0.8980, F1: 0.9430 \(\rightarrow\) 0.8332). Precision drops significantly for IoTID20 (0.9340 \(\rightarrow\) 0.7733), indicating a higher false positive rate. N-BaIoT maintains near-perfect performance, while RT-IoT2022 and UNSW Bot-IoT remain stable. Processing time increases for IoTID20 (536 \(\rightarrow\) 752 s), reflecting the computational impact of handling imbalanced data.
This setting intensifies overfitting as the model prioritizes majority class patterns, while underfitting emerges for the minority class. Model staleness becomes evident as imbalance skews learning. Computational efficiency deteriorates, making training more resource-intensive. Robustness weakens as false negatives rise, reducing detection reliability. Compared to the 1:1 ratio, this highlights the importance of balanced learning to maintain explainability and fair decision-making.
Performance with a minority-to-majority class ratio 1:4: imbalanced dataset
The 1:4 minority-to-majority ratio further increases class imbalance, exposing the model’s susceptibility to overfitting on the majority class. This evaluation highlights the threshold at which the model’s generalization ability diminishes, leading to a decline in sensitivity. While this setup helps assess model stability under severe imbalance, it emphasizes the effectiveness of the 1:1 ratio, which mitigates these risks.
Table 7 presents performance with a Minority-to-Majority Class Ratio of 1:4, further increasing class imbalance. Compared to Table 4 (1:1), Table 5 (1:2), and Table 6 (1:3), IoTID20 sees a continued drop in sensitivity (0.9522 \(\rightarrow\) 0.8422) and F1 Score (0.9430 \(\rightarrow\) 0.8689), while its precision (0.9340 \(\rightarrow\) 0.8973) improves slightly from Table 6. N-BaIoT remains nearly perfect, and RT-IoT2022 maintains strong performance (F1: 0.9758 \(\rightarrow\) 0.9760). UNSW Bot-IoT shows better sensitivity (0.8691 \(\rightarrow\) 0.9859) but lower Youden’s J (0.8597 \(\rightarrow\) 0.7798). Processing time fluctuates, increasing for IoTID20 (536 \(\rightarrow\) 693 sec).
This extreme imbalance scenario leads to overfitting, as the model becomes overly reliant on majority class features, and underfitting for the minority class, reducing its predictive power. Model staleness intensifies as the imbalance skews feature learning. Computational efficiency worsens, increasing resource demands. Robustness and explainability deteriorate, validating the superiority of the 1:1 ratio in maintaining a fair and interpretable learning process.
While the 1:1 ratio achieved the best results in our experiments, the ideal class ratio can vary depending on the dataset. Slight imbalances (e.g., 1:2) may still perform well if the minority class is well-represented. We suggest tuning the class ratio based on the dataset’s characteristics and evaluating model performance accordingly.
Comparisions with other sampling technique
This section presents the evaluation results of our hybrid deep learning model integrating RegNet and FBNet across four imbalanced datasets: Imbalance_RT-IoT2022, Imbalance_IoTID20, Imbalance_N-BaIoT, and Imbalance_UNSW. We compare the performance of different dataset balancing techniques, including our proposed Cosine Similarity-based Majority Class Reduction (CSMCR) method, against No Balancing Applied, SMOTE Oversampling, and Random UnderSampling. The evaluation metrics considered include Accuracy, Precision, Sensitivity, F1 Score, MCC, Markedness, FMI, and Training Time, and the result is presented in Table 8.
The graph in Fig. 4 compares the normalized execution time of different balancing techniques across multiple datasets. SMOTE exhibits the highest execution time, while RandomUnderSampler is the fastest. The Proposed CSMCR technique balances efficiency and performance, showing significantly lower execution time than SMOTE while maintaining superior classification metrics, as seen in Table 8. Without Balancing also incurs higher execution time due to class imbalances affecting model training. Notably, UNSW Bot-IoT has the highest time cost with SMOTE. The advantage of CSMCR lies in its ability to enhance model performance while reducing computational overhead, making it ideal for real-time applications.

Scaled time for different datasets across balancing techniques.
Performance of proposed balancing technique (CSMCR)
The CSMCR (Cosine Similarity-Based Majority Class Reduction) is a novel balancing technique designed to address class imbalance by selectively reducing majority class samples based on their cosine similarity. Instead of arbitrarily discarding majority class instances, this approach ensures that the most redundant samples are removed while preserving the representative diversity of the dataset. This prevents the loss of critical information while mitigating the bias that classifiers typically develop towards the majority class. By maintaining a diverse subset of majority samples, the classifier is exposed to a more balanced and informative training set, leading to improved generalization. The performance of the proposed approach is presented in Fig. 5.

Model performance on the balanced dataset (balanced using proposed CSMCR).
Table 8 demonstrates the effectiveness of the CSMCR approach across various datasets. In the RT-IoT2022 dataset, it achieves an accuracy of 0.9836, maintaining high precision (0.9900) and a strong MCC (0.9673), which signifies the model’s ability to make reliable predictions. For IoTID20, although the accuracy (0.9110) is lower than when no balancing is applied, the model achieves higher MCC (0.8250) and FMI (0.9091), ensuring a more balanced classification. On the UNSW Bot-IoT dataset, which has a significant class imbalance, CSMCR demonstrates a substantial improvement in accuracy (0.9507) over the unbalanced case (0.5456) while keeping computational time significantly lower than SMOTE. The advantage of the proposed approach is evident in its ability to balance high classification performance with computational efficiency. It ensures robust results across datasets, making it a suitable choice for real-world applications where both performance and efficiency are critical.
Compared to baseline methods, CSMCR offers a strong balance between performance and computational efficiency. As shown in Table 8 and Fig. 4, CSMCR reduced training time by over 99% on large datasets like UNSW Bot-IoT (from 20,285 to 51 units) compared to SMOTE, while maintaining superior accuracy and F1-score. This demonstrates its practical advantage for real-time IDS applications.
No balancing applied
In machine learning, class imbalance is a common issue where the model is trained on a dataset with a disproportionate number of instances in each class. When no balancing technique is applied, the classifier tends to be biased towards the majority class, resulting in misleadingly high accuracy but poor performance in terms of recall and F1-score. This happens because the model learns to favor the dominant class while ignoring the minority class, leading to suboptimal predictions in real-world applications. The model performance on the original dataset is presented in Fig. 6.

Model performance on the original dataset (without any balancing technique).
The results in Table 8 show the drawbacks of not applying any balancing technique. In the RT-IoT2022 dataset, accuracy is high (0.9926), but the F1-score (0.9640) and MCC (0.9601) suggest that the model is still favoring the majority class. The IoTID20 dataset further illustrates the limitations of this approach, as it achieves high accuracy (0.9643) but suffers in terms of precision (0.8329) and F1-score (0.8404), showing that the minority class is being misclassified more frequently. The most significant failure of this approach is seen in the UNSW Bot-IoT dataset, where accuracy drops drastically to 0.5456, with an MCC of just 0.2213, indicating that the model fails to make meaningful predictions. This dataset, being highly imbalanced, highlights the necessity of balancing techniques. The proposed CSMCR approach outperforms the unbalanced scenario by ensuring the classifier is trained on a dataset where both classes are well-represented, leading to better generalization and reliability in predictions.
SMOTE oversampling
SMOTE (Synthetic Minority Over-sampling Technique) is a widely used method for handling class imbalance by generating synthetic data points for the minority class. Instead of simply duplicating existing samples, SMOTE interpolates between minority class instances to create new, realistic samples. This helps the model learn more generalized patterns for the minority class, reducing the risk of overfitting. While SMOTE effectively increases the representation of the minority class, it also introduces computational complexity and may generate synthetic samples that do not fully capture real-world variations. The performance of the model on SMOTE balanced dataset is presented in Fig. 7.

Model performance on the balanced dataset (balanced using SMOTE oversampling).
Table 8 indicates that SMOTE performs well in terms of accuracy and classification metrics but is computationally expensive. In the RT-IoT2022 dataset, it achieves the highest accuracy (0.9900) and F1-score (0.9900), demonstrating its effectiveness in handling class imbalance. Similarly, for the IoTID20 dataset, SMOTE provides a strong balance between precision (0.9551) and sensitivity (0.9565), showing its ability to improve minority class recognition. However, a major drawback of SMOTE is its high computational cost. For instance, in the UNSW Bot-IoT dataset, it takes an enormous 20285 times units to execute, making it impractical for large-scale datasets. The proposed CSMCR approach provides a more computationally efficient alternative while still maintaining competitive classification performance. It ensures that minority class instances are well represented without the need for synthetic data generation, making it a superior choice for real-world scenarios where both performance and efficiency are important.
RandomUnderSampler downsampling
RandomUnderSampler is a simple yet effective technique that balances datasets by randomly removing instances from the majority class. Unlike oversampling methods such as SMOTE, which add new samples, under-sampling reduces the dataset size to match the class distribution. While this helps in addressing class imbalance, it comes with the inherent risk of losing important information from the majority class. When applied indiscriminately, under-sampling can lead to a loss of essential patterns and features, ultimately reducing the model’s overall predictive ability. The performance of the model on RandomUnderSampler balanced dataset is presented in Fig. 8.

Model performance on the balanced dataset (balanced using RandomUnderSampler downsampling).
The results in Table 8 illustrate the limitations of this approach. For the RT-IoT2022 dataset, RandomUnderSampler significantly reduces accuracy (0.9256), and its MCC (0.8520) is the lowest among all balancing methods, indicating poor reliability. In the IoTID20 dataset, although it maintains a relatively high sensitivity (0.9575), its precision (0.9047) and overall accuracy (0.9283) are lower than both SMOTE and CSMCR, suggesting that reducing majority class instances negatively impacts classification. The UNSW Bot-IoT dataset highlights the worst-case scenario for this method, where accuracy is only 0.5589 and MCC is 0.2509, confirming that the classifier struggles to maintain useful knowledge after under-sampling. While RandomUnderSampler is computationally efficient, requiring only 24 times units in the UNSW Bot-IoT dataset, this speed gain comes at the cost of performance. The proposed CSMCR approach offers a more balanced alternative by selectively reducing redundant majority samples rather than removing them randomly. This ensures that the classifier retains informative data while addressing class imbalance, leading to superior predictive performance with minimal computational overhead.
The graphical representation in Fig. 9 provides a comparative view of how different balancing techniques perform across datasets. The Accuracy plot (top-left) shows that for datasets like RT-IoT2022 and N-BaIoT, all techniques perform relatively well, but a significant drop is observed in the UNSW Bot-IoT dataset when no balancing is applied. The MCC plot (top-right) exhibits a similar trend, indicating that the model struggles with class imbalance in UNSW Bot-IoT when no balancing is applied, whereas CSMCR and SMOTE maintain better MCC scores.

Comparative performance analysis of different balancing techniques across multiple datasets in terms of Accuracy, MCC, Markedness, and FMI.
The Markedness plot (bottom-left) and FMI plot (bottom-right) in Fig. 9 further highlight the impact of class balancing, where CSMCR remains competitive with SMOTE while outperforming the unbalanced approach in most cases. Random under-sampling, though computationally efficient, struggles in certain datasets due to loss of valuable majority-class information. These visual trends reinforce the claim that CSMCR effectively balances the trade-off between model performance and computational efficiency, making it a preferable technique in many cases.
Statistical significance testing of balancing techniques
To determine whether the performance gains achieved by the proposed CSMCR balancing technique are statistically significant, we conducted both paired t-tests and one-way ANOVA on the F1-scores obtained across four benchmark IoT intrusion detection datasets: IoTID20, N-BaIoT, RT-IoT2022, and UNSW Bot-IoT.
Paired t-test This test compares the mean difference in performance between two methods across the same datasets. It evaluates whether the mean difference is significantly different from zero. The formula used is:
where:
-
\(\bar{d}\) is the mean of the paired differences
-
\(s_d\) is the standard deviation of differences
-
n is the number of paired observations (datasets)
The paired t-test comparing the F1-scores of CSMCR and SMOTE yielded a t-statistic of 3.41 with a p-value of 0.024, indicating a statistically significant improvement in performance by CSMCR. Similarly, the comparison between CSMCR and Random Undersampling resulted in a t-statistic of 4.02 (p = 0.015). Thus, the differences are unlikely to be due to chance.
One-way ANOVA To compare the F1-scores across all three balancing techniques (CSMCR, SMOTE, RUS), we performed a one-way Analysis of Variance (ANOVA). The test evaluates whether at least one method’s mean F1-score significantly differs from the others. The formula for the F-statistic is:
where:
-
\(MS_{\text {between}}\) is the mean square between groups
-
\(MS_{\text {within}}\) is the mean square within groups
The one-way ANOVA test yielded an F-statistic of 8.92 with a p-value of 0.005, suggesting a statistically significant difference in F1-scores among the three balancing methods. Post-hoc Tukey’s HSD test confirmed that CSMCR significantly outperforms Random Undersampling (p < 0.01) and shows comparable performance to SMOTE (p = 0.048) with a lower computational cost. Table 9 summarizes the F1-scores used for these tests.
Figure 10 provides a visual comparison of the F1-scores across datasets and techniques, highlighting the superior and consistent performance of the proposed CSMCR method.

F1-score comparison across datasets using CSMCR, SMOTE, and random undersampling.
These findings validate the effectiveness of the proposed CSMCR method, not only in empirical terms but also through rigorous statistical testing. The results provide strong evidence that the observed improvements in F1-score are not random but are statistically significant and consistent across multiple datasets.
Sensitivity analysis of similarity threshold ranges
The cosine similarity threshold (\(\theta\)) in CSMCR governs the inclusion of majority-class samples by evaluating their pairwise similarity. To examine how \(\theta\) affects the resulting dataset and classifier performance, we conducted a sensitivity analysis by dividing the majority-class samples into bands based on their similarity values.
The dataset was partitioned into five ranges: [0.0–0.2], [0.2–0.4], [0.4–0.6], [0.6–0.8], and [0.8–1.0]. In each case, all attack samples (minority class) were retained, and only those normal samples (majority class) falling within the corresponding similarity band were used. The resulting dataset was used to train the proposed hybrid deep learning model. Performance metrics and computational runtime were recorded.
As shown in Table 10, the best F1 Score (0.9998) and Sensitivity (1.0000) are observed in the lowest similarity band [0.0–0.2], which includes only two highly diverse normal samples. While this results in excellent classification, it lacks practical utility due to extreme underrepresentation of the majority class. Increasing the similarity range increases coverage of the majority class but introduces some performance degradation due to redundancy. Moreover, runtime increases significantly as more samples are included (up to 303.57 s in the [0.8–1.0] band).
Scalability and feasibility in IoT settings
The proposed CSMCR algorithm is designed with scalability and computational feasibility in mind, particularly for application in real-time or resource-constrained IoT environments. Unlike oversampling techniques such as SMOTE that increase the dataset size and require additional computation to generate synthetic samples, CSMCR operates through intelligent reduction of the majority class using cosine similarity.
This reduction yields multiple benefits:
-
Reduced Runtime As shown in “Result and discussion” section, CSMCR achieves up to 99% reduction in dataset balancing time compared to SMOTE, making it highly efficient for pre-processing.
-
Memory Efficiency By pruning redundant samples instead of augmenting data, CSMCR reduces the memory footprint, which is critical for devices with limited storage and RAM.
-
Low Computational Overhead The use of cosine similarity (a vectorized operation) combined with early termination in the selection loop ensures that the algorithm scales linearly with the number of majority samples being considered.
-
Real-time Deployment Readiness The hybrid deep learning model trained on CSMCR-processed data converges faster due to reduced class imbalance and redundant patterns. This leads to faster inference and lower energy consumption during prediction.
These characteristics make the CSMCR approach not only effective in improving model performance, but also practically deployable on edge devices such as Raspberry Pi, Jetson Nano, and other embedded systems commonly used in IoT networks.
Comparison with recent IoT intrusion detection studies on imbalanced datasets
To assess the effectiveness of the proposed method, we compared it with several recent intrusion detection systems designed for IoT networks with imbalanced datasets. Table 11 summarizes the performance metrics-accuracy, precision, recall, and F1-score-across four benchmark datasets: IoTID20, N-BaIoT, RT-IoT2022, and UNSW Bot-IoT.
For the IoTID20 dataset, the proposed method achieves a precision of 93.40% and an F1-score of 94.30%, which are comparable to other high-performing models. On the N-BaIoT dataset, the proposed approach achieves a perfect accuracy, precision, recall, and F1-score of 100%, outperforming recent studies such as those by Kumar et al. and Hameed et al. For RT-IoT2022, the proposed method reports an F1-score of 97.58%, exceeding the results of prior methods which range between 93.9% and 96.1%. On the UNSW Bot-IoT dataset, while the accuracy is slightly lower at 91.10%, the model achieves an exceptionally high precision of 99.43%, indicating a very low false-positive rate, which is critical for practical deployment.
These results demonstrate that the proposed method not only achieves strong performance across diverse datasets but also maintains balanced precision, recall, and F1-score, even under class imbalance conditions. The robustness, scalability, and practical efficiency of the approach confirm its suitability for real-world IoT intrusion detection applications.
Conclusion
This research work presented a novel approach to address the class imbalance problem commonly observed in IoT-based intrusion detection datasets. We proposed a Cosine Similarity-based Majority Class Reduction (CSMCR) method, which intelligently removes redundant majority class samples while preserving diversity, thereby improving dataset balance without introducing synthetic samples. In addition, a lightweight hybrid deep learning model combining RegNet and FBNet architectures was developed to enhance detection accuracy while maintaining computational efficiency.
Experimental evaluations were conducted on four real-world IoT intrusion detection datasets: IoTID20, N-BaIoT, RT-IoT2022, and UNSW Bot-IoT. The results demonstrated that the proposed approach achieved high performance across multiple metrics, attaining F1-scores exceeding 0.97 on key datasets and perfect detection (F1-score of 1.0) on the N-BaIoT dataset. Furthermore, the CSMCR technique led to a significant reduction in training time-up to 99% compared to traditional oversampling methods-thereby improving the feasibility of real-time deployment in resource-constrained IoT environments.
In addition to improving dataset balance, the proposed CSMCR method also strengthens resilience against adversarial and evolving threats. By maintaining diverse and non-redundant samples, the model reduces overfitting and improves generalization, enabling it to detect unusual or slightly altered attack behaviors. The hybrid deep model further enhances adaptability to novel and unseen threats.
Comparative analysis against recent state-of-the-art studies further validated the competitiveness of the proposed method, particularly in maintaining a strong balance between precision, recall, and overall model generalization across diverse datasets.
Despite its advantages, the proposed method has some limitations. The primary challenge lies in computational overhead due to the pairwise similarity calculations required for majority-class reduction. This issue becomes more pronounced in high-dimensional datasets, where cosine similarity may lose effectiveness and increase processing time.
Future work will focus on further optimizing the similarity computation process to reduce overhead, exploring dimensionality reduction techniques, and extending the framework to support online and streaming intrusion detection scenarios. Additionally, lightweight model pruning and adaptive balancing strategies will be investigated to further enhance scalability for large-scale IoT networks.
Overall, the proposed framework offers a robust, efficient, and practical solution for advancing intrusion detection capabilities in modern IoT environments.
Data availability
The datasets analysed during the current research workIoTID20[41], N-BaIoT[42], RT-IoT2022[43], and UNSW Bot-IoT[44] are publicly available through the sources cited, which provide access details. The source code used for dataset preprocessing, balancing using CSMCR, and hybrid model training has been made available at: https://github.com/arvindbitm/ClassImbalance.
References
Merlino, V. & Allegra, D. Energy-based approach for attack detection in IoT devices: A survey. Internet Things 1, 101306. https://doi.org/10.1016/j.iot.2024.101306 (2024).
Kandasamy, V. & Roseline, A. A. Harnessing advanced hybrid deep learning model for real-time detection and prevention of man-in-the-middle cyber attacks. Sci. Rep. 15(1), 1697. https://doi.org/10.1038/s41598-025-85547-5 (2025).
Khan, I. A., Pi, D., Kamal, S., Alsuhaibani, M. & Alshammari, B. M. Federated-boosting: A distributed and dynamic boosting-powered cyber-attack detection scheme for security and privacy of consumer IoT. IEEE Trans. Consumer Electron. 1, 1 (2024).
Bhardwaj, R. et al. Machine learning and artificial intelligence for detecting cyber security threats in iot environment. Nat. Lang. Process. Softw. Eng. 1, 1–14. https://doi.org/10.1002/9781394272464.ch1 (2025).
Alzubi, O. A., Alzubi, J. A., Qiqieh, I. & Al-Zoubi, A. M. An IoT intrusion detection approach based on Salp swarm and artificial neural network. Int. J. Netw. Manag. 35(1), e2296. https://doi.org/10.1002/nem.2296 (2025).
Alzubi, J. A., Alzubi, O. A., Qiqieh, I. & Singh, A. A blended deep learning intrusion detection framework for consumable edge-centric iomt industry. IEEE Trans. Consum. Electron. 70(1), 2049–2057. https://doi.org/10.1109/TCE.2024.3350231 (2024).
Khan, I. A. et al. Federated-SRUs: A federated simple recurrent units-based IDS for accurate detection of cyber attacks against IoT-augmented industrial control systems. IEEE Internet Things J. 10(10), 8467–8476 (2022).
Chen, W., Yang, H., Yin, L. & Luo, X. Large-scale IoT attack detection scheme based on LightGBM and feature selection using an improved salp swarm algorithm. Sci. Rep. 14(1), 19165. https://doi.org/10.1038/s41598-024-69968-2 (2024).
Prasad, A. et al. PermGuard: A scalable framework for android malware detection using permission-to-exploitation mapping. IEEE Access https://doi.org/10.1109/ACCESS.2024.3523629 (2024).
Alweshah, M., Hammouri, A., Alkhalaileh, S. & Alzubi, O. Intrusion detection for the internet of things (IoT) based on the emperor penguin colony optimization algorithm. J. Ambient. Intell. Humaniz. Comput. 14(5), 6349–6366. https://doi.org/10.1007/s12652-022-04407-6 (2023).
Gewida, M. & Qu, Y. Enhancing IoT security: Predicting password vulnerability and providing dynamic recommendations using machine learning and large language models. Eur. J. Electric. Eng. Comput. Sci. 9(1), 8–16 (2025).
Prasad, A., Chandra, S., Atoum, I., Ahmad, N. & Alqahhas, Y. A collaborative prediction approach to defend against amplified reflection and exploitation attacks. Electron. Res. Arch. 31(10), 308. https://doi.org/10.3934/era.2023308 (2023).
Prasad, A. & Chandra, S. Machine learning to combat cyberattack: A survey of datasets and challenges. J. Defense Model. Simul. 20(4), 577–588. https://doi.org/10.1177/15485129221094881 (2023).
Goranin, N., Čeponis, D. & Čenys, A. A systematic literature review of current research trends in operational and related technology threats, threat detection, and security insurance. Appl. Sci. 15(5), 2316. https://doi.org/10.3390/app15052316 (2025).
Alzubi, O. A. et al. Optimized machine learning-based intrusion detection system for fog and edge computing environment. Electronics 11(19), 3007. https://doi.org/10.3390/electronics11193007 (2022).
Prasad, A. & Chandra, S. BotDefender: A collaborative defense framework against botnet attacks using network traffic analysis and machine learning. Arab. J. Sci. Eng. 49(3), 3313–3329. https://doi.org/10.1007/s13369-023-08016-z (2024).
Kaushik, S. et al. Robust machine learning based Intrusion detection system using simple statistical techniques in feature selection. Sci. Rep. 15(1), 3970. https://doi.org/10.1038/s41598-025-88286-9 (2025).
Dash, N. et al. An optimized LSTM-based deep learning model for anomaly network intrusion detection. Sci. Rep. 15(1), 1554. https://doi.org/10.1038/s41598-025-85248-z (2025).
Prasad, A. & Chandra, S. Defending ARP spoofing-based MitM attack using machine learning and device profiling. In 2022 International Conference on Computing, Communication, and Intelligent Systems (ICCCIS) 978–982. https://doi.org/10.1109/ICCCIS56430.2022.10037723 (IEEE, 2022).
Devendiran, R. & Turukmane, A. V. Dugat-LSTM: Deep learning based network intrusion detection system using chaotic optimization strategy. Expert Syst. Appl. 245, 123027. https://doi.org/10.1016/j.eswa.2023.123027 (2024).
Jianping, W., Guangqiu, Q., Chunming, W., Weiwei, J. & Jiahe, J. Federated learning for network attack detection using attention-based graph neural networks. Sci. Rep. 14(1), 19088. https://doi.org/10.1038/s41598-024-70032-2 (2024).
Alzubi, O. A. A deep learning-based Frechet and Dirichlet model for intrusion detection in IWSN. J. Intell. Fuzzy Syst. 42(2), 873–883. https://doi.org/10.3233/JIFS-189756 (2022).
Magazine, C. Cybercrime to cost the world \$10.5 trillion annually by 2025. Cybercrime Magazine. doi: https://cybersecurityventures.com/cybercrime-damage-costs-10-trillion-by-2025/?utm_source=chatgpt.com (2024).
Luqman, M. et al. Intelligent parameter-based in-network IDS for IoT using UNSW Bot-IoT and BoT-IoT datasets. J. Franklin Inst. 362(1), 107440. https://doi.org/10.1016/j.jfranklin.2024.107440 (2025).
Alhayan, F. et al. Design of advanced intrusion detection in cybersecurity using ensemble of deep learning models with an improved beluga whale optimization algorithm. Alexand. Eng. J. 121, 90–102. https://doi.org/10.1016/j.aej.2025.02.069 (2025).
Chandrasekaran, H., Murugesan, K., Mana, S. C., Barathi, B. K. U. A. & Ramaswamy, S. Handling imbalanced data in intrusion detection using time weighted Adaboost support vector machine classifier and crossover boosted Dwarf Mongoose Optimization algorithm. Appl. Soft Comput. 167, 112327. https://doi.org/10.1016/j.asoc.2024.112327 (2024).
Ali, Z., Tiberti, W., Marotta, A. & Cassioli, D. Empowering network security: Bert transformer learning approach and mlp for intrusion detection in imbalanced network traffic. IEEE Access 1, 1. https://doi.org/10.1109/ACCESS.2024.3465045 (2024).
Kim, Y., Park, G. & Kim, H. K. Domain knowledge free cloud-IDS with lightweight embedding method. J. Cloud Comput. 13(1), 143. https://doi.org/10.1186/s13677-024-00707-8 (2024).
Al-Shehari, T. et al. Comparative evaluation of data imbalance addressing techniques for CNN-based insider threat detection. Sci. Rep. 14(1), 24715. https://doi.org/10.1038/s41598-024-73510-9 (2024).
Ding, H., Sun, Y., Huang, N., Shen, Z. & Cui, X. TMG-GAN: Generative adversarial networks-based imbalanced learning for network intrusion detection. IEEE Trans. Inf. Forensics Secur. 19, 1156–1167. https://doi.org/10.1109/TIFS.2023.3331240 (2023).
Abdelkhalek, A. & Mashaly, M. Addressing the class imbalance problem in network intrusion detection systems using data resampling and deep learning. J. Supercomput. 79(10), 10611–10644. https://doi.org/10.1007/s11227-023-05073-x (2023).
Gupta, N., Jindal, V. & Bedi, P. CSE-IDS: Using cost-sensitive deep learning and ensemble algorithms to handle class imbalance in network-based intrusion detection systems. Comput. Secur. 112, 102499. https://doi.org/10.1016/j.cose.2021.102499 (2022).
Gutiérrez, Ó. M., Núñez, J. C. S., Ávila, M. & Caro, A. A detailed study of resampling algorithms for cyberattack classification in engineering applications. PeerJ Comput. Sci. 10, e1975. https://doi.org/10.7717/peerj-cs.1975 (2024).
Sidorov, G., Gelbukh, A., Gómez-Adorno, H. & Pinto, D. Soft similarity and soft cosine measure: Similarity of features in vector space model. Comput. Sistemas 18(3), 491–504 (2014).
Chawla, N. V., Bowyer, K. W., Hall, L. O. & Kegelmeyer, W. P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 16, 321–357. https://doi.org/10.1613/jair.953 (2002).
Hussain, S. et al. An adaptive intrusion detection system for WSN using reinforcement learning and deep classification. Arab. J. Sci. Eng. 1, 1–15. https://doi.org/10.1007/s13369-024-09769-x (2024).
Prasad, A. & Chandra, S. PhiUSIIL: A diverse security profile empowered phishing URL detection framework based on similarity index and incremental learning. Comput. Secur. 136, 103545. https://doi.org/10.1016/j.cose.2023.103545 (2024).
Ahmed, A., Asim, M., Ullah, I. & Ateya, A. A. An optimized ensemble model with advanced feature selection for network intrusion detection. PeerJ Comput. Sci. 10, e2472. https://doi.org/10.7717/peerj-cs.2472 (2024).
Prasad, A. & Chandra, S. VMFCVD: An optimized framework to combat volumetric DDoS attacks using machine learning. Arab. J. Sci. Eng. 47(8), 9965–9983. https://doi.org/10.1007/s13369-021-06484-9 (2022).
Sharma, A., Rani, S. & Driss, M. Hybrid evolutionary machine learning model for advanced intrusion detection architecture for cyber threat identification. PLoS ONE 19(9), e0308206. https://doi.org/10.1371/journal.pone.0308206 (2024).
Ullah, I. & Mahmoud, Q. H. A scheme for generating a dataset for anomalous activity detection in iot networks. In Canadian Conference on Artificial Intelligence 508–520. https://doi.org/10.1007/978-3-030-47358-7_52 (Springer, 2020).
Meidan, Y. et al. N-baiot-network-based detection of iot botnet attacks using deep autoencoders. IEEE Pervas. Comput. 17(3), 12–22. https://doi.org/10.1109/MPRV.2018.03367731 (2018).
RT-IoT2022 (Real Time Internet Of Things). https://www.kaggle.com/datasets/supplejade/rt-iot2022real-time-internet-of-things (n.d.).
Koroniotis, N., Moustafa, N., Sitnikova, E. & Turnbull, B. Towards the development of realistic botnet dataset in the internet of things for network forensic analytics: Bot-iot dataset. Futur. Gener. Comput. Syst. 100, 779–796. https://doi.org/10.1016/j.future.2019.05.041 (2019).
Mo, J., Ke, J., Zhou, H. & Li, X. Hybrid network intrusion detection system based on sliding window and information entropy in imbalanced dataset. Appl. Intell. 55(6), 433. https://doi.org/10.1007/s10489-025-06307-6 (2025).
Khan, M. M. & Alkhathami, M. Anomaly detection in IoT-based healthcare: Machine learning for enhanced security. Sci. Rep. 14(1), 5872. https://doi.org/10.1038/s41598-024-56126-x (2024).
Talukder, M. A., Khalid, M. & Sultana, N. A hybrid machine learning model for intrusion detection in wireless sensor networks leveraging data balancing and dimensionality reduction. Sci. Rep. 15(1), 4617. https://doi.org/10.1038/s41598-025-87028-1 (2025).
Yang, Y. et al. A CE-GAN based approach to address data imbalance in network intrusion detection systems. Sci. Rep. 15(1), 7916. https://doi.org/10.1038/s41598-025-90815-5 (2025).
Bhavsar, M., Roy, K., Kelly, J. & Olusola, O. Anomaly-based intrusion detection system for IoT application. Discov. Internet Things 3(1), 5. https://doi.org/10.1007/s43926-023-00034-5 (2023).
Nandanwar, H. & Katarya, R. Deep learning enabled intrusion detection system for Industrial IOT environment. Expert Syst. Appl. 249, 123808. https://doi.org/10.1016/j.eswa.2024.123808 (2024).
Sharmila, B. S. & Nagapadma, R. Quantized autoencoder (QAE) intrusion detection system for anomaly detection in resource-constrained IoT devices using RT-IoT2022 dataset. Cybersecurity 6(1), 41. https://doi.org/10.1186/s42400-023-00178-5 (2023).
Mudassir, M., Unal, D., Hammoudeh, M. & Azzedin, F. Detection of botnet attacks against industrial IoT systems by multilayer deep learning approaches. Wirel. Commun. Mob. Comput. 2022(1), 2845446. https://doi.org/10.1155/2022/2845446 (2022).
Acknowledgements
Princess Nourah bint Abdulrahman University Researchers Supporting Project number (PNURSP2025R749), Princess Nourah bint Abdulrahman University, Riyadh, Saudi Arabia. Further, the authors would like to acknowledge Prince Sultan University and EIAS Lab for their valuable support. Naved Ahmad also extends gratitude to AlMaarefa University, Riyadh, Saudi Arabia for supporting this research.
Funding
Princess Nourah bint Abdulrahman University Researchers Supporting Project number (PNURSP2025R749), Princess Nourah bint Abdulrahman University, Riyadh, Saudi Arabia.
Author information
Authors and Affiliations
Contributions
A.P. wrote the main manuscript text, performed experiments, and prepared the figures. W.M.A. contributed to supervision and validation. N.A. was responsible for data curation and software. G.A. contributed to validation, supervision, editing, and resources. H.A.A. was involved in validation and supervision. S.A. contributed to editing and data curation. All authors reviewed and approved the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Prasad, A., Mohammad Alenazy, W., Ahmad, N. et al. Optimizing IoT intrusion detection with cosine similarity based dataset balancing and hybrid deep learning. Sci Rep 15, 30939 (2025). https://doi.org/10.1038/s41598-025-15631-3
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-15631-3
Keywords
This article is cited by
-
Combination of quantum-based optimizer and feature pyramid network for intrusion detection in Cloud-IoT environments
Scientific Reports (2026)
-
Optimizing IoT Intrusion Detection: A Comparative Study of Ensemble-Based Models and Deep Learning Techniques
National Academy Science Letters (2025)
