
Abstract
The accurate prediction of compressive strength (CS) in steel fiber reinforced concrete (SFRC) remains a critical challenge due to the material’s inherent complexity and the nonlinear interactions among its constituents. This study presents a robust machine learning framework to predict the CS of SFRC using a large-scale experimental dataset comprising 600 data points, encompassing key parameters such as fiber characteristics (type, content, length, diameter), water-to-cement (w/c) ratio, aggregate size, curing time, silica fume, and superplasticizer. Six advanced regression-based algorithms, including support vector regression (SVR), Gaussian process regression (GPR), random forest regression (RFR), extreme gradient boosting regression (XGBR), artificial neural networks (ANN), and K-nearest neighbors (KNN), were benchmarked through rigorous model validation processes including hold-out testing, K-fold cross-validation, sensitivity analysis, and external validation with unseen experimental data. Among the tested models, GPR consistently outperformed all others, achieving a maximum coefficient of determination (R²) of 0.93 and the lowest root mean square error (RMSE) of 16.54, thereby demonstrating superior capability in capturing the underlying nonlinear relationships within the data. The generalization performance of each model was examined by systematically altering input variables (fiber type, fiber content, w/c ratio, and aggregate size) while holding other parameters constant. GPR showed remarkable agreement with empirical trends across all validation cases, accurately identifying strength peaks and non-linear behavioral shifts, such as the parabolic relationship between w/c ratio and CS. Models like XGBR, SVR, and RFR provided reasonable estimates but lacked the precision of GPR under complex conditions. In contrast, ANN and KNN demonstrated weaker performance, frequently underpredicting or failing to capture key trends. By leveraging the predictive power and interpretability of advanced machine learning models, this research promotes a paradigm shift in structural engineering workflows.
Similar content being viewed by others


Introduction
Concrete still tops the list of go-to materials for global construction, regularly paired with steel to boost its strength and durability1. As infrastructure demands grow, there’s a pressing need to elevate concrete’s mechanical properties2. A proven strategy is the addition of steel fibers, which lock into the mix to shore up ductility, enhance toughness, and control crack propagation. As a result, steel fiber reinforced concrete, or SFRC, is winning favor across a broad range of engineering projects3.
Fiber-reinforced concrete (FRC) consists of randomly distributed fibers that create multiple micro-reinforced zones within the mix, bridging microcracks and thereby improving compressive, tensile, and flexural strengths. This mechanism also curbs crack propagation, producing heightened durability and greater toughness3. Of the fiber options available, steel fibers are particularly effective. Experiments reveal flexural strength gains of 3–81% in concrete that includes welded steel fibers4. When the fiber volume reaches up to 1.5%, not only is the mechanical strength noticeably heightened, but the material also shows greater resistance to freeze-thaw cycles and other environmental stresses5. These advantages have led to the adoption of steel fiber-reinforced concrete in a diverse array of critical infrastructure, such as tunnel linings, bridge decks, industrial flooring, pavement surfaces, airport runways, retaining walls, waterfront structures, precast components, utility tunnels, military bunkers, and the frame elements of high-rise buildings6.
Despite its advantages, predicting the mechanical behavior of SFRC remains challenging due to the complex interactions among variables such as fiber type, volume fraction, aspect ratio, curing conditions, and mix composition3,7,8. Conventional concrete’s mechanical properties have been extensively studied using machine learning approaches. However, the heterogeneity introduced by fiber reinforcement complicates modeling efforts9. Accurate prediction of compressive strength (CS) of SFRC is critical, especially for high-performance applications demanding superior tensile strength and crack control10.
Recent developments in the field have positioned artificial intelligence, notably machine learning, as a pivotal ally in the structural engineering toolbox for predicting the mechanical properties of concrete11,12. These algorithms thrive on extensive, intricate datasets that include variations in mix design, curing history, and ancillary conditions, permitting accurate forecasts of CS, tensile strength, and durability indices13,14,15,16. The nonlinear character of steel fibre-reinforced concrete coupled with its dependent variables leads traditional linear regression to undershoot accuracy, prompting the shift toward advanced data-centric models that can resolve the intricate interplay among competing factors17.
A growing body of research has successfully employed machine learning to forecast the mechanical and durability characteristics of SFRC. Zheng et al.18 illustrated that several machine learning techniques could reliably model flexural strength, underscoring their robustness with non-linear material behavior. Khan et al.19 further verified that AI-based formulations could estimate CS with minimal error, thereby reducing experimental time and costs in practical applications. Complementary efforts have leveraged feed-forward networks for CS17, tuned multilayer perceptrons to correlate shear strength with design variables20, and applied gene expression programming to forecast shear capacity21.
The latest strides in predictive accuracy stem from hybrid and optimized machine learning frameworks. In one case, Tipu et al.22 combined a backpropagation neural network (BPNN) and a conjugate gradient learning algorithm, yielding an R² of 0.91 for chloride ingress in marine environments. Tipu et al.23 then proposed a Newton-boosted model to predict the CS of concrete made with recycled aggregate. They later employed an extreme gradient-boosting algorithm alongside the non-dominated sorting genetic algorithm (NSGA-II) to design high-strength concrete mixtures that reached 98.5% accuracy while minimizing material waste24. Shafighfard et al.25 tested a suite of machine learning algorithms, including support vector machines, random forests, gradient boosting machines, extra trees, and K-nearest neighbours (KNN), reporting R² values that reached a peak of 0.92. Alyousef et al.26 discovered that gene expression programming surpassed ANN and adaptive neuro-fuzzy inference systems (ANFIS) in modeling the behavior of SFRC under dynamic high-temperature conditions. Preferentially, Li et al.5 combined support vector regression (SVR) with the AdaBoost ensemble, producing an R² of 0.96 for forecasting the 28-day CS of SFRC.
Expanding upon previously established work, the current investigation utilizes an extensive dataset of 600 experimental observations that investigate an array of parameters, including fiber type, volume fraction, aspect ratio, mix proportions, and curing conditions. A suite of machine learning algorithms is systematically evaluated concerning predictive accuracy, model interpretability, computational efficiency, and resiliency against overfitting. Standardized performance metrics allow for rigorous quantification and hierarchical ranking of the input variables, thereby enhancing the model’s transparency and its acceptance by end users. Additionally, cross-validation protocols and sensitivity studies rigorously assess the model’s generalizability across diverse and unseen experimental configurations.
The principal objective of this study is to deliver a dependable, data-centric framework that enables accurate prediction of CS in SFRC. This framework is intended to bolster performance-based design and rigorous quality-control procedures in real-world construction applications. By uniting cutting-edge machine-learning methodologies with a robust corpus of experimental results, the research actively supports the development of optimized SFRC mix designs that are finely tuned to the demands of specific structural applications and operating environments.
Research significance and novelty
Structural engineering has seen the adoption of SFRC because of its greater toughness, crack resistance, and post-cracking ductility when compared to conventional concrete. However, predicting its CS alongside multiple design variables, such as fiber type and content, w/c ratio, aggregate quality, and presence of admixture, along with their interactions, poses a challenge. Such multi-faceted dependencies require sophisticated modeling approaches, which are often lacking for enhanced material development and performance-focused designs.
The establishment and application of a detailed, high-quality experimental database consisting of 600 meticulously curated SFRC mix samples underscored the strength of this study. Unlike previous works, which relied on disparate datasets generated from different haphazard sources due to a lack of standardization and peer review scrutiny on measurement and material standards, as well as curing conditions, this database stems from carefully processed, peer-reviewed experimental studies and validated datasets. This database incorporates a wide variety of critical parameters like fiber types (hooked, straight, crimped), fiber volume fraction, w/c ratio, aggregate size, type of cement, and supplementary cementitious materials. Such diversification not only improves the validity of the machine learning models but also allows them to capture and learn intricate and high-order nonlinear relationships with great precision. This SFRC dataset, thus, provides a robust benchmark for subsequent modeling of SFRC data refinement and validation strategies while augmenting increasingly accessible resources on concrete informatics and AI-based structural materials design.
Machine learning approaches for predicting SFRC properties have recently emerged, but they have limitations in terms of coverage. Most works are not experimental and, without broader mixing scope considerations, utilize a narrow algorithmic focus restricted to an ANN or support vector regression (SVR) implementation. Furthermore, many prior models trained their predictions on non-representative datasets of SFRC, leading to overfitting and a lack of result validity for cross-condition applicability. This work aims to fill those knowledge gaps by providing experimentally grounded SFRC compressive strength predictions via a robust, transparent, and adaptable machine learning model.
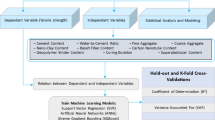
This research stands out for its application of six sophisticated machine learning algorithms. Each algorithm was chosen to offer diverse representations of model architectures, which include probabilistic, kernel, ensemble, and distance-based learners. The benchmarks of the evaluation framework conducted for this research were more rigorous than those in previous studies. Each model undergoes validation through multiple methods (the holdout and 5-fold cross-validation), as well as a generalization cross-validation test with new experimental data where one parameter is altered (fiber type, w/c ratio, or aggregate size) while the rest remain constant. This structure provides an assessment of model accuracy beyond estimation, as it tests the model with practical field-like variability.
This study presents and verifies Gaussian process regression (GPR), which applies Bayesian reasoning for uncertainty quantification, a crucial aspect for the safe implementation of machine learning in the context of structural engineering, where miscalculations could prove disastrous. Tracking peaking behaviors (such as the strength drop-off after an optimal w/c ratio or fiber dosage) is non-trivial, but GPR excels at capturing nonlinear relationships and interdependencies between parameters.
Another aspect of novelty is the focus on localized optimization. Much of the literature is based on the assumption that universal optimal mix designs exist. This study, with its experimental results and machine learning modeling, demonstrates that context design variables and interaction effects profoundly affect optimal parameter combinations. For instance, the optimal fiber content is influenced by the physical properties of the fibers, such as shape, length, and aspect ratio, because they affect dispersion and the efficacy of crack-bridging within the matrix. Also, the best performing w/c ratio is shown to shift as the aggregate size and admixture content change, which alters workability and hydration dynamics. These findings highlight the empirical system dependence of concrete mix design, refined by reductionist thinking that overlooks multi-parameter coupling.
Lastly, this study contributes to the methodologies of the domain by evaluating model criticisms and proposing better methods for data diversification, uncertainty processing, hybrid model creation, and online/transfer learning. It stands out as one of the few that constructs precise models yet penetrates their limits sharply and possibilities for practical use. With this, it situates machine learning in not only the role of a prediction apparatus, but rather a cornerstone in the evolution of materials engineering, where machine learning serves scalable, adaptive, and scientifically rational optimizations of concrete performance.
Methodology
The study developed six advanced machine learning models to predict the CS of SFRC, including KNN, GPR, ANN, support-vector regression (SVR), random forest regression (RFR), and extreme gradient boosting regression (XGBR). These models were selected based on their ability to account for complex, nonlinear interrelationships among the input variables, which is a hallmark of the CS across different mixtures of concrete and testing conditions.
ANNs are powerful data-driven models capable of approximating complex nonlinear functions, making them well-suited for predicting the CS of composite materials such as SFRC. Unlike traditional statistical methods, ANNs do not require prior assumptions about the functional form of the input–output relationships, allowing them to learn hidden patterns directly from the data.
Supervised SVR is particularly efficient for small to moderate-sized datasets because it takes the input data, puts it into a higher dimension, and creates an ideal hyperplane for regression analysis27. SVR can use different kernel functions such as linear, polynomial, or radial basis, which allows the SVR to depend on both linear and non-linear relationships effectively. SVR was used in this study to accurately predict the value of CS while controlling prediction limits to maintain the integrity of a wide range of concrete compositions28.
RFR employs an ensemble of decision trees constructed from randomly sampled data subsets. The averaged output from all the trees is used for the final prediction, which increases robustness while lessening overfitting. RFR’s strength is revealed when its feature importance is computed, in this case, interpreting which variables affect CS the most. Moreover, RFR’s performance is not significantly impacted by the presence of irrelevant or redundant features, which is beneficial for high-dimensional noisy data sets29.
XGBR expands on traditional boosting algorithms by adding regularization, automatic handling of missing values, and parallel processing. Its scalability and predictive power make it one of the most advanced models in the field of machine learning. For this research, XGBR was used due to its efficiency in capturing non-linear relationships, resistance to overfitting, low computational cost, and maintaining high generalizability and interpretability30.
Using the proximity of similar data points, KNN enables efficient predictions. The model estimates output by averaging outcomes from K closest neighbors in the training set. KNN was used in this study to evaluate how well local similarity measures could capture CS behavior. KNN does not need a training phase, making it easier to implement, but its speed and efficiency rely heavily on the distance metric and neighborhood size selected. Its performance is optimal in low-dimensional, well-clustered datasets but poor in high-dimensional ones, where the effectiveness of distance metrics diminishes31.
GPR is a non-parametric and fully probabilistic regression method that treats the target function as a Gaussian process. Instead of offering a single-point prediction, GPR provides a distribution over potential functions, allowing it to quantify uncertainty alongside predictions. Such abilities are helpful in small datasets where prediction confidence is crucial. Despite GPR having high computational costs because of needing to invert large covariance matrices, its flexibility and theoretical rigor made it a strong candidate for this study32.
Concrete sample Preparation and CS testing
To comprehensively assess and forecast the CS of SFRC, a precisely designed experimental database containing 600 records was developed. All the records in this database are original experimental results generated by this study. The data include numerous design constituents, confined to capture the critical mechanical and micro-structural drivers of the compressive behavior of concrete. These factors were chosen due to their importance in serviceability and structural performance, particularly in the context of high-end civil construction and geotechnical engineering. This dataset is used to build the empirical foundation for the sophisticated machine learning models, which require concrete science models for tuning and validation.
Sample Preparation
Figure 1 schematically shows how the samples were prepared. The mixes of concrete were designed with particular material selection criteria to maintain scientific accuracy and practical relevance. The primary binder used was Ordinary Portland Cement (OPC) as it is widely known to be compatible with structural reinforcement and to be durable in structurally bound applications. A highly reactive pozzolan, Silica fume, was added in small amounts (~ 0–15% by weight) to improve the interfacial transition zone and lower the porosity as well as refine the microstructure, resulting in improved long-term durability and strength. Natural fine and coarse aggregates were used to change the grading of the aggregates and reflect realistic field conditions for construction and simulated environments. Superplasticizers were also added (up to 5.0 kg/m3) to achieve optimal workability, particularly for low w/c ratio mixes and silica fume-containing mixes. The mix design focused on the following essential elements:
-
Exploring the hydration behavior and the interplay between strength increase and workability within w/c ratios of 0.30 to 0.60.
-
Fiber volume fractions from 0.51 to 2.00% to allow the investigation from under-reinforced to over-reinforced conditions.
-
Fibers with diameters of 0.02 mm to 1.00 mm and lengths between 6 mm and 30 mm to provide a range of aspect ratios to study crack-bridging and energy-absorption mechanisms.
-
The fiber types considered included different sorts of steel fibers, each having different tensile strengths and shapes.
Every parameter was adjusted based on an organized experimental design, which guaranteed statistically independent orthogonal combinations. This increased the confidence in the model training performed later and enabled one to factor in the influence of each parameter on CS behavior.
Concrete sample preparation adhered to the practices specified in ASTM C192, ensuring reproducibility, consistency, and industrial applicability. All contributing elements were measured and proportioned without error. The mixing procedures were tightly controlled to achieve even distribution of fibers and prevent balling or clustering, which would bias the mechanical testing. Concreting was carried out with standard cylindrical molds (normally 100 mm x 200 mm). After setting, the concrete was compacted within the cylindrical mold before curing. Specimens were transferred to a controlled environment set to 20 ± 2 °C and greater than 95% relative humidity after 24 h of demolding. To capture the development of both early-age and long-term strength, specimens were withdrawn after 7, 28, 56, and 90 days. The approach permits the study of hydration kinetics, progression of pozzolanic activity, and the evolution of bonds between the fibers and concrete matrix over time. The diverse curing regime provides a real-life scenario (from precast to in-situ applications) but, more importantly, adds another dimension to the data set. This improves the modeling of the time-dependent behavior surrounding concrete strength development.

Sample preparation and curing of concrete cylinders based on ASTM C192.
CS testing
The SFRC specimens were evaluated for CS using a calibrated universal testing machine by ASTM C39/C39M (Fig. 2). Specimens in the form of cylinders were subjected to axial loading with a constantly increasing load until failure occurred. Maximum load was captured automatically. Strength in MPa achieved after all parameters of influence: w/c ratio, binder type, fiber traits, curing time, and chemical admixtures. Measured values serve as a level of reality as a reference for training and validation of the predictive models. An experimental procedure was implemented to ensure that all data points captured under the condition were free of experimental noise, thereby enhancing the models. This dataset is of multi-dimensional scope, including but not limited to: material properties, geometry, and the factor of time, balanced for scaling to variations in other parameters, making it appropriate for an array of tasks encompassing but not limited to: machine learning regression and classification (strength thresholds) or sensitivity analysis. A complete summary is presented in Table 1 alongside bounds, means, and standard deviations of all dataset parameters.
The empirical basis for high-resolution, data-driven analyses of SFRC compressive performance is the dataset constructed with attention to detail. It unlocks the potential for:
-
Models of strength prediction with a wide range of age variation.
-
Refining the mixing formula to consider both performance and cost.
-
Quality control algorithms for use in automated systems in ready-mix manufacturing.
-
Generalization across other material systems, including hybrid or non-standard mixes, could offer insight into their behavior.
The intricacy and abundance of this dataset guarantee that it goes beyond capturing current engineering practices and involves advancing the fields of material science and artificial intelligence.

CS test of cylindrical SFRC Specimen using a universal testing machine under ASTM C39/C39M standards.
Procedure for normalizing data and modeling
When it comes to machine learning techniques, data normalization is one of the most crucial steps, particularly when there is variation in units and feature scales within the data. Normalization standardizes the scales of different features, which accelerates the model’s training and contributes to ensuring its reliability33.
Algorithms that learn based on gradient methods, like neural networks, SVM, and KNN algorithms, tend to be particularly sensitive to feature magnitude. Without normalization procedures, features with large values will dominate the learning, leading the model updates to become inefficient, converge more slowly, and undergo multiple inefficient training cycles. Normalization guarantees equal distribution of features and improves model training effectiveness, generalization, prediction capabilities, and all metrics of the model’s performance.
Among all normalization techniques, Min-Max scaling is one of the most commonly used. It adjusts all features to fit a specific range, which is usually [0, 1] or [−1, 1]. This adjustment is mathematically stated in Eq. (1):
Where, represents the original feature value, min and max are the minimum and maximum values of that feature, respectively, and ′ is the normalized value. In this study, the numerical parameters were normalized using this method. The outcome is a dataset where each covariate is scaled to equal importance during learning, improving model stability and interpretability while preserving the underlying concordance within the data. Nevertheless, Min-Max normalization is susceptible to outliers, as extreme values tend to shrink the range of the feature, making Min-Max best suited for datasets with few significant anomalies.
The implementation of the machine learning models was done under the Python environment and Anaconda version 2.3.1, which is a distribution of the Python programming language. Every task, ranging from coding, data cleaning, model training, and evaluation, was done in Jupyter Notebook 6.4.12, which is an interactive computational environment designed to make experimentation easier for users. In particular, Jupyter enables iteration through programming, debugging, and working with vital libraries like Scikit-learn, TensorFlow, NumPy, Pandas, and Matplotlib. Moreover, Jupyter was favored in this instance because of the complete support for dependencies, effortless control of data processing environments, and convenience in managing packages that are critical in dealing with big data—important for creating scalable and efficient models.
The Optuna framework was used to streamline hyperparameter tuning for the machine learning models. Optuna employs a cutting-edge Bayesian optimization strategy that flexibly weighs exploration against exploitation, allowing a more guided search of the hyperparameter landscape than older methods. By leveraging Tree-structured Parzen Estimators (TPE), Optuna builds probabilistic surrogates of the objective function and strategically selects hyperparameter samples that are statistically more likely to improve performance. For each algorithm, the target objective was set to reduce the validation mean squared error (MSE), and the tuning was executed over a series of trials to confirm consistent and reliable convergence. Adopting Optuna led to lower computational demands and enhanced the models’ generalization ability, yielding finely tuned hyperparameter sets that matched the requirements of the CS prediction problem. Table 2 presents the final optimized hyperparameters for each machine learning model.
The dataset consists predominantly of continuous numerical variables, except for the fiber type feature, which is categorical and includes four classes (Basalt, Glass, Steel, and Polypropylene). To integrate this feature into our machine learning pipelines, we employed one-hot encoding, thereby converting the single categorical column into four binary indicator columns. The one-hot encoded features were included consistently for each model’s training and prediction phases, maintaining uniform data representation and enabling fair performance comparisons.
A more structured approach to setting a model was adopted to improve generalization and performance. In the first step, the dataset was divided into a training set and a testing set using an 80/20 split. In this case, 80% of the dataset was allocated for training the models, while the remaining 20% was reserved for testing how well the models predict when presented with new data. To increase reliability, k-fold cross-validation was done, which entails repeatedly partitioning the data set into subsets and training the model on all but one subset to enable validation on a different portion. Afterward, hyperparameter tuning was performed with the help of Bayesian optimization. This type of optimization adjusts parameters in a probabilistic manner for the best possible outcome within a defined range.
Model performance evaluation was performed with a set of robust statistical measures, like root mean squared error (RMSE), coefficient of determination (R²), variance accounted for (VAF), and a10‒index (Eqs. 2–5)34. After that, a multivariate analysis was performed to assess the performance of various algorithms and discern those that provided reliable predictions alongside interpretability and robustness. The focus of the research was to identify whether all models accurately learned the training data’s patterns while still having excellent generalization performance on new data (samples).
Where, \(\:{Y}_{i}\), \(\:{\widehat{Y}}_{i}\), and \(\:\stackrel{-}{Y}\) represent the actual values, model predictions, and mean values of the actual values, respectively. \(\:n\) represents the number of samples.
Data analysis
Statistical dataset analyses must be done prior to applying machine learning, since they help in understanding the peculiar structure of data. Such analysis reveals hidden relationships, patterns, outliers, and even sets of anomalies that can affect the integrity of a model. Machine learning algorithms, regardless of how sophisticated they are, will always yield subpar performance results in the absence of a proper analytical framework. Scouting for pertinent features, assessing data variability, and checking for vital assumptions like normality or homoscedasticity are achievable through robust statistical evaluation. As part of the analysis step, descriptive statistics and correlation analyses are used, which in this case serve as primary components for hypothesis formulation driven by the data. Descriptive and correlational as well as other integrative means of statistics further augment the strength, interpretability, and even generalizability of machine learning models. For this study, we utilize extensive statistics to validate and refine the dataset features, ensuring that all inconsistencies are addressed and the data falls within meaningful intervals. Achieving this means preparing the model for accurate results, which significantly enhances the reliability and impact of the outcome.
Pair plots of the numerical parameters are displayed in Fig. 3. This plot shows many of the dataset’s features in a highly positive correlation with respect to their distribution. First, the quantitative variables such as fiber content, w/c, silica fume, and superplasticizer exhibit a good spread. This is indicative of significant variability. Such variability is critical when building accurate predictive models because it minimizes the impact of bias and overfitting. Furthermore, the histograms do not indicate that most of the variables are suffering from extreme skewness. Variables such as fiber length and aggregate size seem to possess ordinal characteristics with clear and distinct non-overlapping levels since they exhibit clear separation in the plot. The scatter plots with most pairs of features did not exhibit any linear correlation, suggesting low multicollinearity. This enhances the interpretability of the model while improving its numerical stability. In addition, the dataset contains strong predictive signals, as the dataset clearly shows a positive dependence of fiber content on CS, indicating the existence of meaningful relationships. Finally, parameters such as w/c, silica fume, and superplasticizer appear to be evenly stratified across their ranges, which guarantees all value levels are captured and prevents underrepresentation. All these characteristics are conducive to efficient exploratory data analysis, statistical analysis, and machine learning.

Pair plot matrix of numerical parameters.
Figure 4 shows Pearson correlation matrix for analyzed SFRC features and its CS. The overall weak correlation coefficients lie between − 0.10 and 0.32, indicating weak linear dependency of most input parameters on CS. It is important to note that the fiber content will increase this correlation the most as r = 0.32, while fiber length has a slightly negative correlation (r = −0.10). Other variables such as silica fume, superplasticizer, and aggregate size showcase almost zero correlation, suggesting no direct influence in a linear sense. The weak scope of inter-feature correlations also denotes low multicollinearity which is beneficial for modeling. On the other hand, the weak strength of inter-feature correlations propose the overwhelming reliance of classical statistical methods on these relationships is insufficient to explain the dependencies of traditional strategies due to the non-linear and possibly higher-order interactions that control CS. This emphasizes the idea that sophisticated machine learning tools are necessary to unmask these intricate relationships, manage complex interactions between various features, and improve the performance of predictive models designed to assess SFRC CS.

Heatmap of Pearson correlation matrix for the data-points.
Figure 5 shows the box plots of the numerical input parameters used to predict the CS of SFRC. This gives us an understanding of the data distribution, variability, and outliers if any are present. Almost all the features are quite symmetrical about their medians suggesting that there is no severe skewness to these distributions. The ranges of each parameter illustrate the diversity of data obtained from the samples. For example, fiber content has a range from roughly 0.51–2% while fiber length’s range is around 6 mm to 30 mm. Some features such as fiber diameter and superplasticizer, however, do have slightly larger interquartile ranges suggesting more variation within the middle 50% of data. The values plotted in the box plots also suggest that there are no extreme outliers which indicates that the dataset is free and good for modeling.
In spite of the insightful and informative summaries, these individual visualizations do not account the interactions between parameters and their joint effect on the result (CS). Box plots do not offer any explanation concerning nonlinear dependencies or complex relationships that are critical in governing the behavior of SFRC. So, even though the data seems well-behaved in terms of distributional properties, explaining how these variables jointly influence CS is far more sophisticated. This is yet another reason why advanced powerful machine learning methods that go far beyond those nontrivial visualization or statistical techniques need to be used in order to reveal the more complex hidden aspects of the data residing in its intricate, multi-dimensional space.

Box plots for numerical parameters.
Because of the step-wise impact of curing time on concrete properties, it is best considered a categorical rather than continuous parameter. Each of these curing ages corresponds to hydration milestones: 7, 14, 28, 56, and 90 days. Each curing time contributes to notable changes in microstructural development and, subsequently, concrete strength, durability, shrinkage, and other attributes. These transitions fundamentally differ from one another; they do not occur in a gradual manner or evolve continuously over time, but rather reveal profound shifts at specific concrete timelines. By treating curing age as a categorical variable, each developing stage of curing increments with age can distinctly be recognized, capturing the effects of each stage and modeling them accurately to the concrete’s behavior. Such an approach captures the real-world practice in concrete technology where concrete performance is evaluated against specific, rather than arbitrary, defined intervals.
Figure 6 displays count plots illustrating the distribution of two significant categorical parameters analyzed in this study including fiber type and curing time. These visualizations are helpful in understanding the nature of the dataset and the range of experimental conditions studied. The top panel demonstrates counts of each fiber type available in the dataset. The fiber materials are Basalt, Glass, Steel, and Polypropylene. Glass fibers dominate the dataset with around 175 occurrences. Almost 145 samples contain Basalt and Steel fibers, while Polypropylene is slightly less frequent, but still represented with around 140 samples. This broad and balanced distribution improves the comprehensiveness of the analysis by evaluating the individual and comparative impacts of different fiber types on fracture energy. The diversity captured here is crucial for identifying material-specific patterns and trends, especially when the relationships involve complexities and nonlinearity.
The lower part of Fig. 6 illustrates the distribution of a specific curing time which is a determining factor of the mechanical performance of concrete over time, which is a key parameter in the analysis of SFRC. The dataset encompasses standard curing periods of 7, 14, 28, 56, and 90 days with each segment having fairly equal representation. In addition to the distribution, a kernel density estimation (KDE) curve was added to the graph which demonstrates the distribution of frequencies with respect to the curing times. The addition of multiple curing periods surpasses the limits of literature which emphasizes on singular periods, often 28 days, so that the changes in CS over time can be studied.
The combination of these two graphs display the multi-faceted and non-homogenous components of the dataset that consists of a multitude of categorical and continuous data points. With this level of complexity, conventional statistics may be inadequate because of the intricate dependencies within fiber type, curing time, and numerous other factors. Models from an earlier time commonly assume interdepend reliance, which in most studies of materials with complex behavior does not hold true. Unlike traditional approaches, machine learning algorithms are particularly effective in examining such datasets. They are capable of acquiring complex interactions, identifying underlying structures, and managing high dimensional data. Through the use of SVR, GPR, ensemble methods, and neural networks, the study aims to reveal previously unknown relationships between the input variables and CS. Additionally, given the rather large dataset (600 samples), which is more extensive than datasets used in earlier studies, machine learning models can improve the accuracy and reliability of the results. Therefore, the distributional analysis depicted in Fig. 6 not only emphasizes the diversity of the dataset, but also serves as motivation for the application of effective predictive machine learning techniques that can meaningfully predict CS behavior in SFRC.

Count plots of categorical parameters.
Figure 7 shows the results of a Permutation Feature Importance (PFI) analysis which studies the impact of features on the performance of a predictive model (in this case, CS prediction in SFRC) and focus on the model’s most important features. PFI assesses the model’s accuracy metrics by calculating the prediction error’s increase when the feature in question’s values are randomly permuted and all other features are kept static. The greater the score, the more important it is for the model prediction accuracy.
As in Fig. 7, fiber content emerges as by far the most influential variable, with a mean importance value exceeding 1.5. This indicates that CS is mostly influenced by fiber content which means the fibers integrated within the concrete matrix highly augment its resistance to cracking as well as the energy dissipated during fracturing. The influence from traditional input features is captured in a broad ranging non linear effect model in contrast to what is expected from calibrated linear regression models. In contrast, all other parameters are of negligible importance value, almost zero. This does not mean that these parameters are inapplicable in every situation. Rather, their impacts in the current dataset is lesser in comparison to other parameters and that their interactions with other features are either subtle or complex. These sophisticated frameworks are difficult to interpret with classical statistical techniques and lie obscured within intricate data constructs, where traditional methods fall short.
The results of this analysis are of considerable importance. The first one is, as this proves that not all the mix design parameters are equal in contributing towards CS, and focusing and optimizing on the most significant one, which is the fiber content, is much more effective. The second one is that these results reinforce the necessity of employing machine learning models for predicting the material’s behavior. Unlike formal analytical criterion, machine learning models are designed to work with blended, nonlinear dependencies between factors, detect interactions from higher levels, and even adapt to big heterogeneous datasets as in this study.

Feature importance results obtained using the PFI method.
Figure 8 shows the Partial Dependence Plots (PDPs) corresponding to the input parameters associated with estimating the CS of SFRC. These plots are described as agnostic modelers that demonstrate each component’s contribution to the resultant output, taking into consideration all other components while averaging their influence. This is especially true for interpreting sophisticated and nonlinear machine learning models, where PDPs provide clarity on the contribution of specific features to model outcomes.
Indeed, one of the most important takeaways regarding the effect of fiber content on CS from the PDPs is that it has a significant nonlinear effect. The curve itself increases steeply, meaning that CS increases significantly as the volume fraction of fibers is increased. This is physically intuitive since with increase in fiber, the crack-bridging mechanisms increase which increases the resistance to fracture of the material. Fiber content is depicted as the most influential variable among all input variables. On the contrary, other parameters like fiber type, fiber length, and fiber diameter have PDPs that are mostly flat or gently arched, indicating a lack of strong direct influence on CS in and of themselves. These parameters may still have meaningful effects in conjunction with other parameters, but when considered alone, their impact is limited. Likewise, curing time and w/c ratio display a small positive value signifying some impact but not strong enough to indicate a positive change. Silica fume as well as aggregate size also show low sensitivity as demonstrated with almost flat PDPs.
These patterns support the previous conclusions that predict CS as being more sensitive to fiber content than any of the other factors. Yet the remaining unexplained factors, though weak, do not dilute the overall remaining signal which may be hidden beneath more intricate context specific relationships not exposed through less sophisticated univariate methods or linear analysis. This underscores the need to apply machine learning methods. The analysis CS behavior of SFRC involves the exercise of non-linear multi-dimensional relationships very difficult with classical statistical methods. In contrast, machine learning models actively manage to set higher order relationships, nonlinear dependencies, conditional dependencies of different variables alongside complex material science fundamentals where several factors interplay simultaneously to influence performance outcome.

PDP graphs for input parameters.
From the previous analyses, the necessity and sufficiency of the chosen input features were validated with the aid of PFI and PDP analyses amalgamation. That relevance was proven by the significant drop in model performance, specifically in terms of RMSE, when high-importance features like the w/c ratio, curing time, and cement dosage were permuted. These features had strong nonlinear relationships with the model’s output, as evidenced by their steep gradients in the PDPs, demonstrating that they dominated critical tensile behavior mechanisms.
To determine sufficiency, we employed ablation frameworks as iterative studies that gradually removed features, necessitating retraining the model. The group of ten features provided the greatest accuracy; even small reductions, such as removing moderately ranked features like the superplasticizer content, degraded the model’s performance. Moreover, each feature was verified to add unique and non-overlapping variance to the prediction, confirming the absence of multicollinearity-induced redundancy.
Therefore, the combination of PFI, PDP, and ablation-based performance degradation provides strong evidence that the features chosen in this study not only stand on their own (individually essential) but also in conjunction as the bare bones (sufficient) set needed for precise predictive ability regarding tensile strength. The approach used in the study adds rigor and validity to the model’s generalizability and scientific accuracy.
Results analysis and comparison
Evaluating machine learning models is important in finding a solution that achieves the best accuracy, reliability, and efficiency for a given task. With respect to the problem of predicting CS of SFRC, which is an intricate problem involving multiple input variables with nonlinear relationships, it is neither logically sound nor practical to assume that any specific algorithm will outperform all others without exhaustive benchmarking. Detailed benchmarking is necessary to explore the many algorithms available to determine which best estimates the CS.
By evaluating various algorithms, machine learning model researchers not only discover gaps in performance but also understand how to best optimize the model. Figure 9 shows a comparative graphic analysis on the prediction accuracy of the CS of SFRC using six machine learning models. Each subplot shows the measured versus predicted CS values for the 120-instance test dataset and the respective prediction errors, absolute (top) and signed (bottom) bar plots. This combination enables evaluating the prediction errors in all possible directions at the same time for all the models.
The KNN model has the most irregular prediction error values compared to the CS values meaning KNN predicted very poorly. The KNN model is capturing two temporal dependencies in the pattern embedded is strongly nonlinear which means the model is far from the truth especially for the mid and late parts of the data. These results indicates that KNN as a locally driven method is not effective for multi-dimensional interaction regression problems because it has poor generalization ability, thus the inability to complex high-dimensional problems.
Although KNN performed worse overall, SVR had a moderate predictive performance with lower error amplitudes. SVR did not perform as well in regions with sharp transitions in CS. With SVR, the predicted trendlines were smoother than the measured data, which shows an underfit SVR’s rigidity. Consequently, SVR offered limited capacity to accurately model the full response spectrum of SFRC compressive strength.
Among all the algorithms tested, GPR performed the best. GPR’s prediction line followed the measured values for the entire test set with low error bars and minimal deviation. GPR exhibited sharp trend peaks and valleys demonstrating good generalization. Its capture local and global variability enhances GPR’s probabilistic framework and kernel structure. Reliable for any task of SFRC prediction, the model’s strong performance across all examined test instances makes it the best candidate.
XGBR also performed admirably, showing a high degree of accuracy and error consistency across the dataset. Even though it was less precise than GPR, XGBR was still able to approximate the CS’s nonlinear behavior and fidelity graphically. There were some very small error spikes which most likely stemmed from local data overfitting along with overfitting tendencies, which is a common trait among boosting models. Overall, GPR is still better, but not by much, making XGBR a great alternative especially where computational cost is a concern.
The predictive accuracy of RFR was reasonable, but less accurate than GPR and XGBR in the center and outer ridges due to a greater spread of errors. The ensemble characteristic RFR model made stable but less accurate predictions, particularly in the quick shifts of the CS. It smoothed out too much crucial non-linear response region and would be costly in regimes with rapid fluctuations, thus it’s averaging, while useful in lowering variance, was counterproductive in regions where it is most needed.
ANN, in contrast, delivered the weakest performance among the tested models. The prediction line was often misaligned with measured values, and the associated error bars were highly erratic and pronounced. This suggests insufficient model training or suboptimal hyperparameter configuration. Additionally, the model’s inability to generalize to new, complex patterns in the test data reinforces concerns regarding its appropriateness in this context, particularly without extensive architecture tuning or data augmentation.

Prediction errors of CS for test data across machine learning algorithms.
Rigorously defined, quantifiable measures of performance such as RMSE, VAF, R², a10-index, and nanofeature delineate accurate performance assessment and generalization of the model. Such studies help in making sure that the model does not just perform well on a specific dataset, but also withstands any variations in its distribution, thus preventing overfitting or underfitting. Alongside other models, the interpretability and usefulness of machine learning results, as well as predictions, become significantly more precise when multiple models are analyzed together. This offers clearer, more trustworthy, and actionable insights that can be relied upon throughout various engineering problems.
For every model, the assessment starts by using the holdout cross-validation technique that is carried out in the first iteration especially for all models as a consistent uniform evaluation setup. In this technique, the dataset is randomly divided with 80% of the data set aside for training the models so they can learn intricate patterns, and the remainder 20% is used to test the models, giving an unbiased estimate of how well the models generalize to new unseen data. This approach minimizes overfitting, maximizes realistic evaluation of the model’s predictive capabilities, and validates the use of machine learning techniques and CS prediction tests.
Figure 10 offers a holistic comparison of the machine learning models for predicting the CS of SFRC subjects with the models evaluated graphically through a scatter plot of predicted vs. actual values (Fig. 10a) and through quantitate statistics(Fig. 10b). The score shown in Fig. 10(b) acts as an ordinal scale for the machine learning models to benchmark comparably within the framework of the a₁₀-index, RMSE, R², and VAF. Each of the six models received a ranked score based on their performance from 1 to 6, where 1 is the worst and 6 is the best, and their cumulative scores determine a relative ranking. This fosters a more straightforward evaluation of models by calculating their performance based on different aspects, such as absolute error (RMSE), relative fit (R²), and agreement within a prescribed margin of error (a10‒index). This modified scoring system is needed to clearly address cases when models fail to perform consistently across metrics; for example, one model might have a high R² but very high RMSE. The total score encompasses different measurements and therefore acts as a multi-criteria decision supporting framework to assess model performance while ensuring the evaluation is objective, reproducible, and independent of personal biases, thus enabling identification of the best iterative model.
Among the machine learning models, GPR seems to outperform all other models, as it possesses the best statistical parameters. It also seems to have the best score from the ranking matrix with 24 as benchmarked with a10‒index of 0.98, RMSE of 1.34 MPa, R² of 0.93, and VAF of 0.96. GPR outputs are not only precise, but consistent across the metrics, proving the models trustworthiness in data with complex non-linear SFRC datasets.
The results obtained with SVR which provided a10‒index of 0.96, an RMSE of 1.65, R² of 0.89, VAF value of 0.94, and overall a score of 20 making it the second-best model, demonstrate SVR’s performance is also remarkable. Its performance on XGBR and RFR was moderately accepted, with total scores of 15 and 13. Also, the scatter plot highlights an increased clustering around the 1:1 line which validates its high predictive capability strengthen. Even though both models are showing reasonable fit, having slightly higher RMSE values of 2.23 and 2.05 while also having lower correlation of R² at 0.84 and 0.81, these numbers do suggest sufficient but not optimal performance. Performance that does not trend towards optimally achieving the model’s potential nonlinearity.
In contrast, KNN and ANN showed insignificantly weaker performance metrics. The lowest R² score of 0.72 and a10-index of 0.78 for the KNN model suggests deviating from actual values and higher discrepancy in predictions. While ANN is a model that performs well in a variety of cases, in this instance it also underperformed, scoring the lowest overall score of 5. Its scatter plot is far from the ideal line, which corresponds to an a10‒index of 0.77 and RMSE of 2.77 MPa, meaning that it might have been overfitted, learnt inadequately from the data, or perhaps due to sub-optimal hyperparameter tuning, excess sensitivity to data preprocessing steps, or overfitting.
To conclude, for the purposes of this study, the algorithm which best predicts the SFRC CS is the GPR. It provides the lowest error and highest accuracy alongside a consistently outperforming generalization, demonstrating superiority to other algorithms throughout the analyzed metrics. It validates the selection of non-linear algorithms that deal with unrefined and intricate interactions of features in material science datasets.

Comparison of holdout results obtained from algorithms through statistical indices. (a) a10‒index; (b) Comprehensive ranking score.
To further segment the evaluation of the algorithm’s performance, a 5-fold cross-validation method is utilized to improve the accuracy and validity of the results. The dataset is randomly distributed into five equal parts or folds. Four out of five folds are used to build the model, while one fold is used to validate it. This cycling method ensures that all data points are incorporated during both training and validation stages. The reliability and precision of the model’s performance evaluation improves when averaging results over all folds as this is a more comprehensive, unbiased estimate. Unlike the K-fold method, the holdout method divides the dataset into two subsets and evaluates performance on an arbitrary single subset, which is prone to arbitrary results. The model’s accuracy and generalization capability are better assessed with repeated different data split exposures. Such resilience to data partition assumptions is especially beneficial when there is limited data, as it optimally utilizes data and reduces overfitting to provide accurate trustable evaluations of the algorithms.
Figure 11 visually depicts the evaluation of the performance of six machine learning algorithms through 5-fold cross-validation, utilizing three vital statistical parameters. Each metric receives a score for each fold and the total score determines the model’s dependability and consistency. Based on the listed results in Fig. 11, it can be noted that GPR scored the highest out of all algorithms with a total score of 81 proving its accuracy and stability across all folds. GPR demonstrates the best R2 value ranging from 0.87 to 0.91, lowest RMSE ranging from 14.5 to 18.6 and highest VAF of 0.94 to 0.97 which means GPR had the best accuracy and generalisation. SVR was the second scoring 65, followed by XGBR with 57, RFR with 44. KNN and ANN scored significantly lower with 15 and 34 showing lack of predictive competence.
The importance of these outcomes rests in the thorough validation process: 5-fold cross-validation alleviates the risk of overfitting by ensuring that a model’s accuracy is not tied to a particular split of data, thereby enhancing confidence in generalizability. GPR’s superiority in every fold illustrates the precision with which it captured intricate, nonlinear relationships subsumed within the dataset, with little error and substantial explanatory strength. There is no other algorithm more consistently accurate than GPR when predicting CS within this context, which justifies its use in practical engineering scenarios that require strong predictive reliability.

Comparison of the machine learning algorithms’ performance using 5-fold cross-validation: (a) tabulated results; and (b) graphical representation of the scores for each fold.
To interpret the predictions made by the trained GPR model, shapley additive explanations (SHAP) analysis was used. SHAP is a technique that analyzes model predictions from a game theory perspective, measuring the contribution of each feature to the prediction. It allows for both global and local analysis, which enhances understanding of the contribution of each feature. For predicting the CS of SFRC, this level of interpretability is important in rationalizing the influence of material properties and mix parameters and in justifying the reliance on the machine learning model seamlessly integrated with engineering.
The SHAP analysis for this study was conducted with the KernelExplainer, which approximates SHAP values through sampling from the training set. This reasoning is GPR specific, as it does not allow for tree-based explainers, thus requiring this agnostic approach. The analysis was performed with the trained GPR model on a dataset that included several mix design parameters like fiber content, fiber length, curing time, and silica fume content among others. For each test instance, SHAP values were computed, and the results were interpreted using multiple visualization methods including summary plots (beeswarm), mean absolute SHAP values bar plot, and dependence plots showing featured interactivity and interactions among features and parameters (see Fig. 12).
In Fig. 12(a), the distribution of SHAP values of all features with the test dataset is shown. Every observation is represented by a single dot, where the color reflects value of the feature (low to high) and the position on the x-axis shows the degree and polarity of the feature’s impact on the predicted CS. The plot rather unambiguously shows that fiber content is the dominant feature, with high values improving CS. Fiber length and curing time also impact the results significantly, although their contributions appear to be more mixed, suggesting some form of non-linear relationship. Other features, such as w/c ratio or fiber diameter, seem to be insignificant as evidence by their SHAP values tightly clustered around zero. The beeswarm plot provides insight into features that have potential interaction effects, which are important when analyzing SFRC behaviors due to complex dependencies.
In Fig. 12(b), a bar chart depicts features of the dataset with respect to their average absolute SHAP value. This illustrates global importance of each feature measurement without regard to the Global Importance Measurement Value deemed negative or positive. As in the beeswarm plot, fiber content emerges as the most dominant feature followed by fiber length, curing time, and content of silica fume. The rankings provide stronger corroboration towards the hypothesis that fiber parameters are central to the CS of SFRC. Of particular interest, superplasticizer, fiber diameter, and w/c ratio are also observed as features with relatively low importance that had a greater value in the presence of other more important features.
The SHAP dependence plot for fiber length shown in Fig. 12(c), coded by fiber type, illustrates pronounced non-linear relationships. Lengths in the middle range give a positive contribution to the composite stiffness, whereas fibers that are either very short or excessively long yield negative SHAP values. This behavior defines a preferred fiber length window where crack bridging and the redistribution of stress work most effectively. The plot also clearly demonstrates that different fiber materials alter the position and steepness of the response. Basalt and steel fibers, for example, maintain a narrower band of positive SHAP values throughout the mid-range, while polypropylene fibers scatter over a wider area, occasionally dipping into negative contribution. Consequently, the data indicate that fiber length alone cannot dictate the outcome; rather, its impact is shaped by the fiber type itself. It follows that practical optimization must simultaneously account for the fiber material and its geometry to ensure target mechanical properties are realized.
Figure 12(d) displays a SHAP dependence plot for fiber content with color mapping of fiber length. The plot reveals a distinct and positive linear correlation, indicating that higher fiber content consistently elevates CS forecasts. This primary trend, however, is magnified with longer fibers, suggesting a synergistic interplay between the amount of fiber and its geometry. The slope of the SHAP values varying with fiber length further confirms that the impact of larger fiber volume fractions becomes much more pronounced when fibers are elongate. This finding points to a synergistic mechanism wherein both volume fraction and aspect ratio together bolster the matrix’s capacity for energy dissipation and resistance to crack propagation. Such a non-linear interaction underlines that peak mechanical performance is unattainable if fiber content or length is optimized in isolation; rather, fine-tuning the interplay of both parameters is essential.
From an engineering standpoint, the observed interaction effects underscore key refinements for optimizing the material blend. First, they reinforce the argument for simultaneously adjusting multiple variables when designing performance-based SFRC, since univariate adjustments might miss beneficial synergies among variables. Second, the results show that the CS is particularly responsive to both the fiber dosage and the geometry, a response that varies distinctly among different fiber materials. Third, the documented interaction trends can be encoded into either rule-based heuristics or more formal optimization routines, paving the way for custom-tailored, high-performance FRC that precisely meets predefined mechanical performance metrics.

Shap analysis for GPR predictions. (a) SHAP beeswarm summary plot for CS predictions; (b) Mean absolute SHAP value ranking of features; (c) SHAP dependence plot for fiber length with interaction by fiber type; (d) SHAP dependence plot for fiber content with interaction by fiber length.
Evaluation of the generalization capability of the developed machine learning models will now be performed on new and unseen data points. For this puprose, four new test data points provided in Table 3 with different types of fiber characteristics (Basalt, Glass, Steel, and Polypropylene) and keeping all other input parameters constant to isolate the effect of fiber variation, are used to evaluate the trained machine learning models. These unique samples have not been encountered so far and present a significant challenge for the models, testing their ability to predict accurately by employing novel data and concepts. This step is essential for verifying whether the model has overfitted the training data, or rather, has learned the system’s fundamental behavior patterns. Those models which demonstrate an optimal response on this test are expected to permit valid claims regarding their generalization potential, dependability, and usefulness in engineering practice where material property variations are encountered. This methodology facilitates high confidence reliability in the models, CS predictions, and ensures diverse utility across various SFRC compositions.
In Table 4 and the associated graphs shown in Fig. 13, a comparison is made for each model’s predicted CS versus the laboratory values for all four fiber types. SVR performs satisfactorily too; it is in the proximity of the lab results and does not deviate from the trend concordance measure across all fibers. GPR also performs equally well as it does not deviate significantly from the actual values, suggesting good generalization. XGBR also provides strong predictions, particularly for Basalt and Polypropylene, showing no deviation from trends observed in the lab across the board. RFR opinionated but was slightly lower than expected stating the same pattern to the lab results. The KNN model did not provide acceptable performance. ANN provided the lowest performance of all samples analyzed; covering all, the values were steeply lower than expected leading to a response curve not capturing peak strength variation.

Comparison of CS results obtained from laboratory tests and machine learning models for different fiber type states
Among the models assessed, GPR exhibits the highest accuracy and consistency, reliably tracking with the laboratory data across all fiber types and intricacies of CS. XGBR and RFR are also quite strong and can be considered dependable options. The ANN, on the other hand, does not possess the ability to generalize to these new inputs, nor does KNN who struggles too with underprediction. Hence, GPR remains the strongest and most reliable model for predicting CS of SFRC of different fiber types.
The generalization ability of machine learning models is assessed further by adding a new set of seven test data points (Table 5) where fiber content is the only varying parameter. This analysis helps isolate the effect of fiber content (leading to a range of 0.5–2.0% by volume) on CS and evaluate how well the trained models are able to generalize this particular behavior of SFRC. From laboratory tests (Table 6), the actual CSs show a clear increasing trend with increasing fiber content, starting at 26.93 MPa for 0.5% and reaching 43.65 MPa for 2.0%. This observation clearly shows the reinforcing effect of fiber content on the mechanical performance of concrete.
The predictions for the CS from the six machine learning models are provided on Table 6. Figure 14 compares the predicted values against the measured results from laboratory. Each subgraph showcases how well the different models captured the increasing trend in CS with the rise in fiber content. Once again, GPR is the most accurate model because it aligns best with the experimentally obtained data over the entire span without any gaps. XGBR, SVR and RFR also perform well because they follow the linear increase. However, they tend to underpredict in most range. KNN follows the correct trend, but is understated on every other range. The ANN approach is by far the worst performer of all.
The insights graphically depicted in Fig. 14 highlight the heuristic of strong generalization in machine learning models when faced with physically plausible novel situations. The ability of a model to predict CS accurately in relation to fiber content, which is considered a crucial parameter in SFRC design and also varies, determines the model’s reality applicability. The sophisticated predictive capacity of GPR with respect to laboratory values suggests its effectiveness in predicting non-linear and complex phenomena associated with materials, even when evaluated outside the training distribution. GPR is not alone, as SVR, XGBR, and RFR exhibit strong general adaptability and generalization capabilities despite some systematic under-reporting. ANN’s persistent underperformance indicates a domain of shallow understanding structuring its learning.

Comparison of CS results obtained from laboratory tests and machine learning models for different fiber contents
The attention is directed towards the impact of change in the w/c ratio on the CS of SFRC using seven additional test data points in Table 7. To evaluate in a controlled manner, all other factors are considered constant. The w/c ratio is deliberately changed from 0.30 to 0.60, thereby defining a set of baseline parameters to analyze the extent to which different machine learning models can generalize and predict CS within this range. Laboratory results provided in Table 8 corroborate expectations regarding concrete behavior. CS rises with w/c ratio until an inflection point (approximately 0.50), and then tapers off, a well-documented phenomenon reflecting the compromise between workability and strength in cement-based materials.
Table 8 also features the estimated CS values of w/c ratios from the six trained machine learning models. Each of them is visually compared against the experimental results in Fig. 14. Again, GPR performed impressively, precisely matching the laboratory results and surpassing them on all fronts. It tracks the growing strength upward as w/c increases from 0.30 to 0.50, and the slight drop after 0.50, which is a truthful behavior of concrete, is also captured. SVR also does quite well, although it tends to overpredict during higher w/c ratios (0.55–0.60). This could be due to its reaction to minimal changes. XGBR performs fairly well in terms of trend following, however, also suffers from a drop in prediction accuracy at the end (w/c = 0.60) demonstrating a lack of ability to generalize to regions without linear predictability. RFR performs fairly well overall, but miscalculates mid-range values which results in smoothing out peaks in response curves. KNN demonstrates a reasonable level of accuracy as it follows the pattern fairly well, although it does tend to underpredict both the peak and post-peak values which could be due to its dependence on local smoothing. The weakest performer is ANN, as there is a significant difference between the predicted and actual results at all w/c ratios. This suggests the model did not capture the genuine non-linear relationship of strength relative to water content.
This continues to emphasize the importance of having effective data-driven predictive models, particularly for advanced mix design features like the w/c ratio. It is critical for structural applications that enduring, strong and cost-efficient materials are used to ascertain the almost parabolic function between the w/c ratio and CS is predicted accurately. Among the models, GPR once again proves to be the most accurate and reliable, capturing both the ascending and descending trends very well. SVR and XGBR are solid performers as well; however, they appear to be inaccurate in some regions. In contrast, ANN’s performance is too poor to warrant consideration, proving beyond any doubt the inadequacy of information capture on this relationship with ANNs. These results further alleviate doubts regarding GPR’s capability to model intricate physical phenomena and enhance its credibility for predictive simulations in design of SFRC.
Now, 11 additional data points found in Table 9 are applied to assess the effect of the aggregate size on the CS of SFRC while the other parameters are kept constant. According to Table 10, the empirically determined values of the CSs in the experiments are between 33.05 MPa and 35.68 MPa, indicating a non-linear relationship with maximum strength occurring at an aggregate size of 17 mm.
The CS values predicted using the six machine learning models are displayed in Table 10. These values are compared directly against laboratory results to evaluate how well the models are able to generalize and predict with fidelity. The graphs in Fig. 14 and 15 represent the comparison of the laboratory results and the predictions made by the machine learning algorithms. KNN has shown a fairly good compliant behavior when it comes to following trends; however, it underpredicts the CS values across all but the smallest sizes of aggregates. It also misses the 17 mm peak because of local data density effects. SVR showed the best results. Although it also fails at capturing the 17 mm peak, its closely monitoring the nonlinear trend of the test data shows good scope for capturing complex dependencies. GPR continues to demonstrate good results, deviating only slightly from the experimental results where its performance still remains strong. Because GPR is a probabilistic model, it can effectively model uncertainty and complex nonlinear trends. Also, GPR is capable of capturing the peak behavior. In contrast, XGBR and RFR appear to onset overfitting to the mean while maintaining a constant prediction of around 35 MPa for all aggregate sizes. This lack of variability indicates that these algorithms may have captured the dominant trends instead of the more delicate relationship between aggregate size and CS. ANN had the most difficulty out of all the models in replicating the trends seen in the laboratory results. It fails to capture the experimental peak and overall variation, assuming a monotonically flat or declining pattern after 14 mm. This might stem from a lack of diversity in training data or improper tuning.

Comparison of CS resultsobtained from laboratory tests and machine learning models for different w/c ratios
The nonlinear dependence of CS on aggregate size in the results indicates that aggregate size may have an aggregate effect on the internal packing density, interfacial transition zones, and load transfer efficiency of the concrete matrix. The further increase in strength with increase in aggregate size up to 17 mm may be attributed to more optimal packing and stress distribution, while the subsequent slight drop may be due to increased voids or weaker bonding interfaces. GPR model outperforms other models as it captures this peak behavior and trend nonlinearity, highlighting their appropriateness in complex material behavior modeling. As shown, GPR model is always able to learn nonlinear relationships and even subtle interactions that arise from a change in a single parameter, which is what this example demonstrates.
Figure 16 summarize, GPR performed best in all scenarios, showing the highest capacity propulsion in acquiring versatility with complex nonlinear interactions and subtle parameter interdependencies in SFRC’s behavior. SVR also performed quite well, particularly for smoother, less punctuated peaks. XGBR and RFR appeared to oversimplify the problem, while ANN was inaccurate with more complex and nonlinear solutions. These observations underline the effort to be made towards the selection of the appropriate machine learning models for material science case studies, especially when dealing with composite materials such as SFRC that are subjected to multi-factor influences.

Comparison of CS results obtained from laboratory tests and machine learning models for different aggregate sizes
It should be noted that, the maximum CS of SFRC studied in this research (based on the fiber type, fiber content, w/c ratio, and aggregate size), was achieved with the specified parameters. These particular parameters were dependent on the constant other parameters set in the laboratory test conditions. SFRC is a composit material where the constituents have mechanical interactions which creates more complex form of behavior. No parameter acts alone; the operators are part of a system and hence, every parameter has to rely on the others while at the same time become positively or negatively influenced by them. As an example, optimal fiber content calculated in this research together with glass fibers with specific shape dimensions assumes the use of glass fibers with specific physical characteristics (length, diameter, type). Changing the fiber from glass to steel or polypropylene alters interfacial bonding, crack-bridging, and dispersion behavior within the matrix. There is, thus, a shift in the ideal volumetric ratio needed to attain optimal performance. The best w/c ratio in this example depends on other ancillary traits of the aggregate, characteristics of the fibers, and even the amount of admixture which all influence workability and hydration, microstructure evolution. The nature of the aggregate size affects packing density and distribution causing it to interact with the other factors. Stress distribution is also partially affected by the aggregate size and zone of interfacial transition.
Consequently, the best values for the parameters attained in this work must be viewed as local optima for the given circumstances and are likely to change with differences in baseline conditions. Additionally, parameter predictions based on machine learning models are highly dependent on the specifics of the associated training dataset. This is because the models only derive relevant patterns and relationships from data they have been trained on, thus any change in range, distribution, or representativeness of the data may result in remarkably different predictions. For example, if a database does not sufficiently cover the interactions between fiber content and w/c ratio or does not capture some extreme or boundary cases, the models are very likely to mispredict values, which in this case would be suboptimal values. The latter case tends to occur most frequently for models such as KNN that rely strongly on local data density, or ANN, that require extensive training and tuning to deliver any non-robust results. On the other hand, models like GPR have been shown to capture non-linear trends and peak behaviors better because they use probabilistic reasoning which allows them to model features like the CS peak at 17 mm aggregate size more accurately. However, such models, regardless of their apparent advantages, are ultimately bounded by the data they are trained on.
Furthermore, it is important to note that the design parameters for SFRC obtained from machine learning model’s derived models are not final but rather flexible within the bounds of the data scope and its quality. Thus, further enhancement of the training dataset as well as increasing the scope of the parameters is required for the construction of effective, broad-based, and scientifically credible concrete technology models.
The trained models can be incorporated into intuitive design interfaces or as enhancements to existing software, enabling engineers to quickly estimate the CS of SFRC during the critical early phases of mix design or ongoing quality control. This embedding would streamline scenario evaluations, lessen dependence on lengthy lab tests, and promote a more performance-driven approach to concrete design. Moreover, the predictions can be merged with uncertainty quantification techniques (such as GPR) to generate confidence intervals that further refine decision-making for structural applications.
Key limitations and suggestions
Even with the fruitful results of this study, some factors must be addressed. First, while the training dataset provided enrichment with generalization test points, it also contained gaps in covering the entire parameter space. This could limit model prediction reliability under extreme or rare conditions. Moreover, the generalization evaluations for the model were conducted by varying one input parameter while keeping all others constant individually, providing a narrow perspective on model performance against more realistic multivariate variability encountered in practice. Some machine learning models, most notably ANN and KNN, demonstrated limited generalization capabilities and struggled to capture nonlinear trends accurately. This lack of accuracy may have come from insufficient availability of diverse training data or hyperparameter tuning. Furthermore, every model was trained in a static offline manner, rendering them incapable of real-time, adaptive learning as new data becomes accessible. Additional limitations stemmed from lacking predictive quantification of uncertainty for safety-sensitive applications across a majority of models excluding GPR, which could undermine their reliability. Lastly, the models have not undergone validation using data from real-world or large-scale experiments. This omission could undermine the models’ usefulness in practical engineering applications.
To address the gaps identified within the research, practical work in the future will require focus on several aspects. Amassing additional data of diverse material properties, mix designs, curing conditions, or, in general, expanding the data set would allow for greater model generalization. Furthermore, adjusting multiple input parameters at once would also be beneficial in representing field conditions accurately for testing the model’s reliability. More accurate and reliable predictions or trend tracking could result from the application of ensemble or hybrid methods in modeling like the combination of GPR and XGBR. Advanced hyperparameter optimization methods such as Bayesian optimization or thorough cross-validation, especially for underachieving models ANN or KNN, could offer better results if model set configurations were strategically changed. Additionally, the deployment of full-scale experiments using real-world data is crucial in evaluating the developed models’ practicality for transferability. Also, the broadening of uncertainty modeling across all algorithms using quantile regression, bootstrapped ensembles, or Monte Carlo dropout would optimize risk and uncertainty predictions. Lastly, developing a web-based application could be also an important path for future work and practical impact synthesizing this research. With such an application, engineers, designers, and researchers could specify key mix parameters (fiber content, length, curing time, and silica fume content) and immediately receive the predicted CS values derived from the trained machine learning models.
Conclusions
This research designed and validated sophisticated machine learning models to estimate the CS of SFRC using 600 data points from experiments. The main conclusions are stated below:
-
Model Performance.
-
Prediction performance was best for GPR as it achieved the highest R2 value of 0.93 and lowest RMSE of 16.54, with XGBR, SVR, and RFR following afterwards.
-
Two models that performed the worst consistently were ANN and KNN due to their inability to grasp important nonlinear relationships present in the data.
-
Cross-validation and generalization.
-
GPR was the best model in K-fold cross-validation and generalization to new experimental cases, predicting all instances best.
-
GPR made the best predictions for the effects of changing fiber type, fiber content, w/c ratio, and aggregate size.
-
Key experimental insights.
-
The highest CS was recorded using glass fibers, with GPR as the only model to predict all instances accurately.
-
GPR most accurately captured the upward trend in CS, rising sharply from 26.93 MPa at 0.5% fiber content to a peak of 43.65 MPa at 2.0% fiber content, precisely mirroring the experimental results.
-
GPR was the only model that successfully modeled the CS increase at w/c = 0.5 and subsequent decline after the peak value.
-
The nonlinear behavior of CS reached its peak with an aggregate size of roughly 17 mm and GPR showed the best agreement with experiments.
-
Practical implications.
-
In SFRC, optimal input values need not be fixed, but interdependently structured, which contradicts long-held beliefs in mix design principles.
-
Machine learning techniques, especially GPR, provide an effective means for the fast, precise, and general prediction of SFRC behavior which aids in performance-based design and optimization of materials.
-
More general impact.
-
The work highlights the advantages created by the application of AI tools into civil engineering workflows by streamlining material processes and promoting intelligent, automated, and data-centric designs for structures.
Data availability
The data and codes employed in this study not available due to restrictions imposed by research sponsors, ongoing analysis for future studies, and the necessity to maintain data confidentiality until further validation and publication. However, are available from the corresponding author on reasonable request.
References
Grytten, F., Sørensen, B. F., Goutianos, S., Joki, R. K. & Jørgensen, J. K. A micromechanical model of fiber bridging including effects of large deflections of the bridging fibers. Compos. Struct. 258, 113405. https://doi.org/10.1016/j.compstruct.2020.113405 (Feb. 2021).
Albaijan, I. et al. Predicting tensile strength of reinforced concrete composited with geopolymer using several machine learning algorithms. Steel Compos. Struct. 52 (3), 293–312. https://doi.org/10.12989/scs.2024.52.3.293 (2024).
Kashem, A. et al. Metaheuristic-based machine learning approaches of compressive strength forecasting of steel fiber reinforced concrete with SHapley additive explanations. Multiscale Multidisciplinary Model. Experiments Des. 8 (1), 61. https://doi.org/10.1007/s41939-024-00656-4 (Jan. 2025).
Yazıcı, Ş., İnan, G. & Tabak, V. Effect of aspect ratio and volume fraction of steel fiber on the mechanical properties of SFRC, Construction and Building Materials, vol. 21, no. 6, pp. 1250–1253, Jun. (2007). https://doi.org/10.1016/j.conbuildmat.2006.05.025
Li, Y. et al. Compressive strength of steel Fiber-Reinforced concrete employing supervised machine learning techniques. Materials 15 (12), 4209. https://doi.org/10.3390/ma15124209 (Jun. 2022).
Marcos-Meson, V. et al. Corrosion resistance of steel fibre reinforced concrete - A literature review. Cem. Concr. Res. 103, 1–20. https://doi.org/10.1016/j.cemconres.2017.05.016 (Jan. 2018).
Pakzad, S. S., Roshan, N. & Ghalehnovi, M. Comparison of various machine learning algorithms used for compressive strength prediction of steel fiber-reinforced concrete. Sci. Rep. 13 (1), 3646. https://doi.org/10.1038/s41598-023-30606-y (Mar. 2023).
Kang, M. C., Yoo, D. Y. & Gupta, R. Machine learning-based prediction for compressive and flexural strengths of steel fiber-reinforced concrete. Constr. Build. Mater. 266, 121117. https://doi.org/10.1016/j.conbuildmat.2020.121117 (Jan. 2021).
Albaijan, I. et al. Machine learning techniques for reinforced concret’s tensile strength assessment under different wetting and drying cycles. Steel Compos. Struct. 49 (3), 337–348. https://doi.org/10.12989/scs.2023.49.3.337 (2023).
Zhao, F., Liu, J., Wang, Y., Liu, Z. & Yao, Y. Experimental and numerical research on spalling behavior of steel fiber reinforced concrete (SFRC). Constr. Build. Mater. 463, 140021. https://doi.org/10.1016/j.conbuildmat.2025.140021 (Feb. 2025).
Fakhri, D. et al. Prediction of Mixed-mode I and II effective fracture toughness of several types of concrete using the extreme gradient boosting method and metaheuristic optimization algorithms. Eng. Fract. Mech. 276, 108916. https://doi.org/10.1016/j.engfracmech.2022.108916 (Dec. 2022).
Albaijan, I. et al. Estimating the initial fracture energy of concrete using various machine learning techniques. Eng. Fract. Mech. 295, 109776. https://doi.org/10.1016/j.engfracmech.2023.109776 (Jan. 2024).
Falah, M. W. et al. Compressive strength prediction using coupled deep learning model with extreme gradient boosting algorithm: environmentally friendly concrete incorporating recycled aggregate. Complexity 2022 (1). https://doi.org/10.1155/2022/5433474 (Jan. 2022).
Golafshani, E. M., Behnood, A. & Arashpour, M. Predicting the compressive strength of normal and High-Performance concretes using ANN and ANFIS hybridized with grey Wolf optimizer. Constr. Build. Mater. 232, 117266. https://doi.org/10.1016/j.conbuildmat.2019.117266 (Jan. 2020).
Feng, D. C. et al. Machine learning-based compressive strength prediction for concrete: an adaptive boosting approach. Constr. Build. Mater. 230, 117000. https://doi.org/10.1016/j.conbuildmat.2019.117000 (Jan. 2020).
Khan, M. A. et al. Geopolymer concrete compressive strength via artificial neural network, adaptive neuro fuzzy interface system, and gene expression programming with K-Fold cross validation. Front. Mater. 8 https://doi.org/10.3389/fmats.2021.621163 (May 2021).
Altun, F., Kişi, Ö. & Aydin, K. Predicting the compressive strength of steel fiber added lightweight concrete using neural network. Comput. Mater. Sci. 42 (2), 259–265. https://doi.org/10.1016/j.commatsci.2007.07.011 (Apr. 2008).
Zheng, D. et al. Flexural strength prediction of steel Fiber-Reinforced concrete using artificial intelligence. Materials 15 (15), 5194. https://doi.org/10.3390/ma15155194 (Jul. 2022).
Khan, K. et al. Compressive strength Estimation of Steel-Fiber-Reinforced concrete and Raw material interactions using advanced algorithms. Polymers 14 (15), 3065. https://doi.org/10.3390/polym14153065 (Jul. 2022).
Ben Chaabene, W. & Nehdi, M. L. Novel soft computing hybrid model for predicting shear strength and failure mode of SFRC beams with superior accuracy. Compos. Part. C: Open. Access. 3, 100070. https://doi.org/10.1016/j.jcomc.2020.100070 (Nov. 2020).
Sabetifar, H. & Nematzadeh, M. An evolutionary approach for formulation of ultimate shear strength of steel fiber-reinforced concrete beams using gene expression programming, Structures, vol. 34, pp. 4965–4976, Dec. (2021). https://doi.org/10.1016/j.istruc.2021.10.075
Tipu, R. K., Panchal, V. R. & Pandya, K. S. Enhancing chloride concentration prediction in marine concrete using conjugate gradient-optimized backpropagation neural network. Asian J. Civil Eng. 25 (1), 637–656. https://doi.org/10.1007/s42107-023-00801-3 (Jan. 2024).
Tipu, R. K., Batra, V., Suman, K. S., Pandya & Panchal, V. R. Efficient compressive strength prediction of concrete incorporating recycled coarse aggregate using Newton’s boosted backpropagation neural network (NB-BPNN), Structures, vol. 58, p. 105559, Dec. (2023). https://doi.org/10.1016/j.istruc.2023.105559
Tipu, R. K., Panchal, V. R. & Pandya, K. S. Multi-objective optimized high-strength concrete mix design using a hybrid machine learning and metaheuristic algorithm, Asian Journal of Civil Engineering, vol. 24, no. 3, pp. 849–867, Apr. (2023). https://doi.org/10.1007/s42107-022-00535-8
Shafighfard, T., Bagherzadeh, F., Rizi, R. A. & Yoo, D. Y. Data-driven compressive strength prediction of steel fiber reinforced concrete (SFRC) subjected to elevated temperatures using stacked machine learning algorithms, Journal of Materials Research and Technology, vol. 21, pp. 3777–3794, Nov. (2022). https://doi.org/10.1016/j.jmrt.2022.10.153
Alyousef, R. et al. Dec., Machine learning-driven predictive models for compressive strength of steel fiber reinforced concrete subjected to high temperatures, Case Studies in Construction Materials, vol. 19, p. e02418, doi: 10.1016/j.cscm.2023.e02418. R. Qamar and B. Ali Zardari, Artificial Neural Networks: An Overview, Mesopotamian Journal of Computer Science, pp. 130–139, Aug. 2023, (2023). https://doi.org/10.58496/MJCSC/2023/015
Cortes, C. & Vapnik, V. Support-vector networks. Mach. Learn. 20 (3), 273–297. https://doi.org/10.1007/BF00994018 (Sep. 1995).
Ho, T. K. The random subspace method for constructing decision forests. IEEE Trans. Pattern Anal. Mach. Intell. 20, 832–844. https://doi.org/10.1109/34.709601 (1998).
Dehestani, A., Kazemi, F., Abdi, R. & Nitka, M. Prediction of fracture toughness in fibre-reinforced concrete, mortar, and rocks using various machine learning techniques. Eng. Fract. Mech. 276, 108914. https://doi.org/10.1016/j.engfracmech.2022.108914 (Dec. 2022).
Cover, T. & Hart, P. Nearest neighbor pattern classification, IEEE Transactions on Information Theory, vol. 13, no. 1, pp. 21–27, Jan. (1967). https://doi.org/10.1109/TIT.1967.1053964
Rasmussen, C. E. Gaussian processes in machine learning, pp. 63–71. (2004). https://doi.org/10.1007/978-3-540-28650-9_4
Sun, Z. et al. Electrical resistivity prediction model for basalt fibre reinforced concrete: hybrid machine learning model and experimental validation. Mater. Struct. 58 (3, p. 89, ). https://doi.org/10.1617/s11527-025-02607-y (Apr. 2025).
Sun, Z., Li, Y., Yang, Y., Su, L. & Xie, S. Splitting tensile strength of basalt fiber reinforced coral aggregate concrete: optimized XGBoost models and experimental validation. Constr. Build. Mater. 416, 135133. https://doi.org/10.1016/j.conbuildmat.2024.135133 (Feb. 2024).
Sun, Z. et al. Apr., Pipeline deformation monitoring based on long-gauge FBG sensing system: missing data recovery and deformation calculation, Journal of Civil Structural Health Monitoring, (2025). https://doi.org/10.1007/s13349-025-00943-9
Acknowledgements
The author would like to thank Prince Sultan University for their support. Princess Nourah bint Abdulrahman University Researchers Supporting Project number (PNURSP2025R300). The authors extend their appreciation to Northern Border University, Saudi Arabia, for supporting this work through project number (NBU-CRP-2025-2225).
Funding
The author would like to thank Prince Sultan University for their support. Princess Nourah bint Abdulrahman University Researchers Supporting Project number (PNURSP2025R300). The authors extend their appreciation to Northern Border University, Saudi Arabia, for supporting this work through project number (NBU-CRP-2025-2225).
Author information
Authors and Affiliations
Contributions
Ala’a R. Al-Shamasneh, Arsalan Mahmoodzadeh: Data curation, Conceptualization, Investigation, Methodology, Resources, Writing – original draftFaten Khalid Karim: Investigation, Validation, Visualization, Writing - Review and EditingTaoufik Saidani, Abdulaziz Alghamdi: Visualization, Writing – original draftJasim Alnahas, Mohammed Sulaiman: Writing - Review and Editing.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Conflict of interest
The authors affirm that they have no identified conflicting financial interests or personal relationships that might be perceived to exert influence on the findings reported in this paper.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Al-Shamasneh, A.R., Mahmoodzadeh, A., Karim, F.K. et al. Application of machine learning techniques to predict the compressive strength of steel fiber reinforced concrete. Sci Rep 15, 30674 (2025). https://doi.org/10.1038/s41598-025-16516-1
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-16516-1
