
Abstract
Infrared images, rich in temperature information, have a broad range of applications. However, limitations in infrared imaging mechanisms and the manufacturing processes typically prevent uncooled infrared detector arrays from exceeding a resolution of one megapixel. Consequently, designing an efficient infrared image Super-Resolution (SR) algorithm is of significant importance. In this paper, we draw inspiration from the readout circuit structure prior to Uncooled Infrared Focal Plane Arrays (IRFPA), which scans infrared signals row by row and reads them out column by column. We propose an efficient Row-Column Transformer Block (RCTB) that splits features into rows and columns to effectively capture the spatio-temporal correlation between row-column pixels. Acknowledging the continuity of temperature information within the image and the correlation between adjacent pixel regions, we develop a Compact Convolution Block (CCB) that incorporates a U-shape Spatial Channel Attention Block (USCAB) to extract local features before the RCTB. During the training phase, we introduce a regularization control term into the loss function to enhance the reconstruction details of the infrared image. Building on these components, we propose a hybrid network named Efficient Infrared Image Super-Resolution (EIRSR), which achieves an excellent balance between performance and efficiency in terms of parameters and computational costs. Furthermore, we scale the model to create a family of variants, collectively known as EIRSRs. Extensive experiments demonstrate that EIRSR delivers competitive performance while maintaining a compact structure compared to superior methods.
Similar content being viewed by others


Introduction
The outstanding performance of infrared thermal imaging technology in non-contact temperature measurement during the COVID-19 pandemic has attracted significant attention in various fields, including autonomous driving, satellite remote sensing, video surveillance, biomedicine, and power inspection. Despite the widespread adoption of thermal imaging systems, several limitations persist: i) Existing infrared detectors rarely exceed megapixel resolution and often exhibit low spatial resolution. ii) Infrared images primarily capture the relative temperature information between objects and their backgrounds, lacking texture details compared to visible images. Consequently, improving the quality of infrared images through Super-Resolution (SR) algorithms is of great significance.
In recent years, deep learning-based methods have been successfully applied to infrared images, achieving promising performance. Learning rich infrared image detail features through skip connection to enhance reconstruction quality1. Feature distillation is employed to enhance the learning ability of network representation2. Design an effective network structure to enhance the quality of infrared images3. To address the issue of texture blur in infrared images, Generative Adversarial Networks (GAN)4 are employed to generate realistic texture features, effectively enhancing image visualization. Extracting texture details from visible images and fusing them into infrared images enhances the texture edge reconstruction of infrared images5. These deep-learning methods improve the quality of infrared images at the cost of increased model size and computational overhead. However, despite the introduction of larger models and increased computing power, the performance of infrared image SR has not improved as anticipated, suggesting that it may be encountering bottlenecks beyond just the model and computing power. Of course, these large models also limit the deployment of infrared imaging systems on edge devices, which prioritize high efficiency and require real-time performance in real-world scenarios. Numerous lightweight networks have been proposed to address the inefficiencies associated with SR tasks. However, the design paradigm of these models primarily emphasizes the network structure, which limits their ability to balance performance and efficiency simultaneously.
In addressing the challenges encountered in infrared image SR, we analyze the imaging process based on the operational principles of uncooled Infrared Focal Plane Arrays (IRFPA) readout circuit, as illustrated in Fig. 1. The small red square represents a single infrared pixel, with each column of pixels corresponding to a column readout channel. Collectively, these pixels form an IRFPA, which converts the infrared thermal radiation from an object into infrared image data. To illustrate the relationship between the readout circuit and the imaging process, we consider the green rectangular box (first row of IRFPA) as an example. When the IRFPA receives infrared thermal radiation from an object, the electrical characteristics of the infrared pixels change. The row selection circuit then selects all pixels in the row, followed by the column selection circuit, which sequentially selects each column pixel and reads it out as the first-row pixel of the image through the column readout channel. This process continues, scanning row by row and reading out column by column to form a complete frame of infrared image data. Consequently, this imaging process results in temporal correlation among row pixels and spatial correlation among column pixels in the infrared image data. At the circuit level of imaging principle, establishing dependencies between rows and columns will enhance the high-level semantic representation of features. This work is grounded in the imaging mechanism of uncooled IRFPAs, in which the row-by-row scanning and column-by-column readout process give rise to distinctive spatio-temporal priors, which are explicitly modeled and leveraged through a circuit-inspired network design.

Readout circuit level infrared imaging principle. From left to right are self-developed uncooled infrared focal plane detector, pixel readout array, imaging process.
Inspired by the readout circuit structure prior, we develop a Row-Column Transformer Block (RCTB) to capture the spatiotemporal correlations between pixel rows and columns within a lightweight mechanism. In RCTB, we forgo the window-based Multi-Head Self-Attention (MHSA) and instead split the features by rows or columns, applying the MHSA operation directly to the split features. This feature splitting enables EIRSR to effectively learn high-level semantic information from the infrared imaging mechanism while significantly reducing computational costs. The Transformer block exhibits a strong capacity to capture long-range dependencies among features, thereby providing global information. However, relevant studies6 have indicated that the Transformer block demonstrates a comparatively weaker ability to learn high-frequency features than the Convolutional Neural Network (CNN) block. This discrepancy may arise from the Transformer block’s methods of dividing the image into patches and flattening features into one-dimensional representations, which neglect the two-dimensional spatial local correlation. Furthermore, the Vision Transformers (ViT) architecture typically implemented in a cascading mode, results in high correlation across layers, leading to unnecessary computational overhead7. Considering the completeness of feature extraction and the lightweight network structure, we develop a Compact Convolution Block (CCB) that reduces feature channels in the middle layers to lower computational costs while enhancing feature representation through residual connections. Inspired by U-Net8, we design a U-shaped Spatial-Channel Attention Block (USCAB) within the CCB which couples the encoder-decoder pattern with local spatial attention mechanisms and channel attention mechanisms, significantly enhancing the representation capacity of local features. It is crucial to highlight that infrared signals are inherently faint, and the thermal radiation information from objects can easily be overwhelmed by background noise. To improve the performance of high-level vision tasks, including super-resolution, target recognition and tracking, and image fusion, applying filtering and detail enhancement to the raw infrared images before performing the tasks is essential. In image processing tasks, filtering and enhancement, and super-resolution, are treated as separate processing pipelines. This approach introduces additional latency and restricts its applicability in real-time applications. In the training phase, we define the \({{{L}}_{\text {1}}}\) norm distance between the reconstructed images and their filtered/enhanced counterparts as a regularization term, which is incorporated into the loss function using relaxation factors. This enables the network to learn both filtering/enhancement and super-resolution tasks simultaneously, thereby improving the detail preservation in reconstructed infrared images and minimizing latency, thus enhancing the model’s deployability in real-time systems. Based on this, we propose an Efficient Infrared Image Super-Resolution (EIRSR) network, a novel efficient hybrid network that combines CNN and Transformer. It is worth noting that the features split by RCTB are independent of each other, so we design both parallel and serial models. The serial model, which has lower network capacity, is suitable for scenarios with minimal real-time requirements. Conversely, the parallel model characterized by a broader network and greater capacity, can be deployed on resource-rich devices for parallel optimization, thereby significantly reducing inference latency. To the best of our knowledge, EIRSR is the first SR model based on circuit-level imaging principles.
In summary, our main contributions are as follows:
-
1)
Taking the imaging principle of uncooled IRFPA readout circuits as a prior, we design an efficient RCTB that splits the features into rows and columns to capture the spatio-temporal correlation between row-column pixels.
-
2)
Considering the local correlation of temperature information and the completeness of feature extraction in infrared images, we design a CCB that includes USCAB to extract local features before RCTB.
-
3)
In the training stage, we introduce a regularization control term into the loss function to enhance the reconstruction details of the infrared image. The proposed EIRSR, which integrates CCB and RCTB is an efficient hybrid network that demonstrates superior performance for infrared image SR.
Related works
Image SR is a fundamental task in machine vision that aims to reconstruct a high-resolution (HR) image from a low-resolution (LR) counterpart. However, it is essentially an ill-posed inverse problem since an LR image corresponds to countless potential HR images, which has attracted numerous researchers to this field of study over the past decade. With the development of deep learning, numerous excellent methods for image SR have emerged, outperforming traditional methods. In this section, we initially review and discuss research work relevant to ours.
Deep neural networks for super-resolution
Dong et al.9 were the first to employ CNN for SR vision tasks, making a pioneering advancement in the field. They proposed a three-layer network called SRCNN to learn the mapping between LR and HR, achieving superior performance compared to traditional methods. Subsequently, numerous methods have been proposed to enhance the performance of SR reconstruction. Various elaborate CNN architectures have been designed, including those based on Dual-branch structures10 and dense blocks11. These architectures address issues related to algorithm degradation and the challenges of training as model depth increases, further improving the performance of SR models. Additionally, several studies have explored alternative deep learning methods, such as Vision Mamba12,13, and Experts system14 for SR. To improve the visualization quality of images, the GAN4 method, has been introduced into SR tasks to generate texture information that appears more realistic to human perception. However, training the GAN model is complex and prone to collapse. In recent years, diffusion models15 have been applied to SR tasks, offering greater stability and controllability compared to GAN, albeit with lower operational efficiency. Recently, Transformers have garnered attention from the computer vision community due to their success in the field of natural language processing16. A series of Transformer-based visual models have been developed for high-level vision tasks. Liang et al.17 used the Swin Transformer to enhance the feature representation capability, achieving improved performance in image reconstruction. Zhang et al.18 proposed a group-wise multi-scale self-attention module to calculate the self-attention at different window sizes for the SR task. Chen et al.19 designed a novel Hybrid Transformer to activate more input pixels for better reconstruction. Chen et al.20 aggregated features and recursively extracted global information, effectively improving the reconstruction quality. Despite the substantial progress made by these deep learning models in SR performance, most still incur high computational costs and low efficiency, prompting researchers to develop more effective approaches for SR tasks.
Infrared readout circuit and infrared image super-resolution
The role of the readout circuit is to convert the thermal signal from the object into an electrical signal, a crucial factor for the imaging quality. Lv et al.21 proposed a model of the readout circuit for uncooled IRFPA detectors and conducted a detailed analysis of the relationship between the readout circuit and imaging quality. Subsequently, they introduced a novel and compact compensation architecture for uncooled microbolometers without substrate temperature stabilization. The investigation focused on substrate temperature-induced non-uniformity and the nonlinear resistance characteristics of the microbolometer array elements22. Que et al.23 integrated a 12-bit ADC compensation circuit into the readout circuit, which effectively reduces noise crosstalk in imaging and enhances image quality. Additionally, Lv et al.24 proposed a digital self-calibration implementation that incorporates discontinuity-error and gain-error corrections for a pipeline ADC, significantly improving the non-uniformity of infrared images.
To enhance the spatial resolution of infrared images, a series of deep learning-based infrared image processing algorithms have been proposed. Huang et al.12 employed a novel Mamba-based wavelet Transform feature modulation model, specifically designed for infrared image super-resolution. Hu et al.25 designed a transformer-based edge-enhanced infrared super-resolution model that improved texture details and achieved better reconstruction results. Zhang et al.26 proposed a novel closed-loop structure that fully leverages the learning capabilities of the channel attention module, maximizing the incorporation of information from infrared images. Huang et al.4 proposed a multistage transfer learning strategy for high-dimensional feature spaces, which enhances the reconstruction performance of infrared images, effectively overcoming the weak texture characteristic of infrared images. Mo et al.27 presented a lightweight multipath feature fusion network that reconstructs HR infrared images from their LR counterpart by refining multiple features. The fusion of visible light texture features into infrared images contributes to an improvement in the overall quality of infrared image reconstruction5.
Unlike most existing approaches that regard SR as a generic image processing task, our method explicitly models the underlying imaging process by incorporating prior knowledge derived from the readout circuitry of infrared detectors.
Efficient super-resolution models
Most existing SR models often entail substantial computational costs to enhance performance, which limits their applicability. Consequently, numerous methods have been proposed to design more efficient models for the SR task. Luo et al.28 proposed LatticeNet, which extracts contextual features for reverse fusion, reducing parameters and memory usage. Lu et al.29 proposed a hybrid structure network that can dynamically adjust the size of feature maps to extract features. Li et al.30 proposed a simplified network incorporating two effective attention modules, which secured first place in the model complexity track of the NTIRE 2022 Efficient SR Challenge. Luo et al.31 designed a novel lightweight Large Kernel Convolution Block that reduces the computational overhead. Lee et al.32 proposed novel approaches to employing large kernels, which can reduce latency and imitate instance-dependent weights. To address this issue, they proposed a skip-attention method that utilizes the self-attention calculations from the previous layer to approximate the attention in subsequent layers. Additionally, some researchers have examined the performance bottlenecks of deep neural networks and designed deep learning algorithms suitable for deployment on edge devices33,34,35.
The proposed method
In this section, first, we provide an overview of our method. Then, we describe the CCB and RCTB blocks in detail. Additionally, we provide the architectural specifications for different model sizes.
Overview
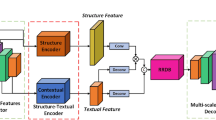
As illustrated in Fig. 2, EIRSR primarily comprises four components: shallow feature extraction, CCB, RCTB, and image reconstruction. To balance the extraction of local features and the modeling of global features, our framework integrates CCB and RCTB in a synergistic manner. This design ensures that the model remains lightweight while effectively capturing both local fine-grained textures and long-range dependencies. Let \(I_{L R}\) and \(I_{S R}\) represent the input and output of EIRSR, respectively. Initially, we extract the shallow features from \(I_{L R}\) using a depth-wise convolutional operation, which can be formulated as follows:

The architecture of EIRSR which mainly consists of CCB and RCTB. \(I_{L R}\) and \(I_{S R}\) represent the low resolution image and the reconstructed SR image, respectively.
where \(DWConv\left( \cdot \right)\) denotes the shallow feature extraction layer, and \({{f}_{0}}\) represents the extracted shallow features that are used as input to CCB. The cascaded CCB block can be formulated as follows:
where \({\Phi _{CCB}^{n}}\) denotes the mapping of \({{n}_{th}}\) CCB, and \(F_{CCB}^{n}\) represents the cascaded output of n CCBs. Before being input into RCTB, all outputs from CCBs must be fused, a process defined as:
where \(Concat\left( \cdot \right)\) denotes the aggregation of features by channel, \({{\psi }_{fusion}}\left( \cdot \right)\) represents the dimension reduction applied to the features along the channels, and \({{F}_{sf}}\) signifies the fused features. Subsequently, \({{F}_{sf}}\) is input into RCTB to establish long-range dependencies among the features, which can be formulated as follows:
where \({\Phi _{RCTB}^{n}}\) denotes the mapping of the \({{n}_{th}}\) RCTB and \(F_{RCTB}^{n}\) represents the output of n RCTBs. Finally, \(F_{RCTB}^{n}\) and \({{F}_{sf}}\) are simultaneously used to reconstruct the SR image \({{I}_{SR}}\), which can be expressed as follows:
where \(Conv\left( \cdot \right)\) denotes a series of convolution operations, and \({{\Phi }_{Rec}}\) represents infrared image reconstruction.
Inspired by perceptual loss36,37, we introduce a regularization control term to train the model based on minimizing the \({{{L}}_{\text {1}}}\) loss, which can be formulated as:
where \(\Theta\) denotes the updated parameters of EIRSR, \(\alpha\) represents the relaxation factor that decreases with the number of training iterations, \({I}_{S R}^{i}\) represents the \({{i}_{th}}\) reconstructed image, \({I}_{HR}^{i}\) represents the reference image of \({I}_{S R}^{i}\) and \({{\tau }_{prep}}\) refers to image preprocessing, including filtering and enhancement. The loss function is optimized using Adam38.
Compact Convolution Block (CCB)
We propose the CCB, whose primary role is to extract potential local features from LR images in advance, thereby equipping the model with a preliminary capacity for SR. The structure of the CCB is illustrated in Fig. 3. We incorporate residual connections to enhance the CCB’s capability to represent local features of LR images and to boost the efficiency of EIRSR training. A typical CCB consists of three stages: feature extraction, feature fusion, and feature enhancement. In the first stage, for the input features \({{f}_{in}}\), the feature extraction can be formulated as follows:

The architecture of the proposed Compact Convolution Block (CCB), which utilizes a compact cascade structure and includes a U-shape Spatial Channel Attention Block (USCAB).
where \(Con{{v}_{i}}(\cdot )\) represents a series of convolutions, \(DWCon{{v}_{i}}(\cdot )\) denotes depth-wise convolutions, and \(\oplus\) represents feature concatenation. In the feature fusion stage, the extracted features \({{f}_{extr\_\text {1}}}\), \({{f}_{extr\_\text {2}}}\), \({{f}_{extr\_\text {3}}}\), and \({{f}_{extr\_\text {4}}}\) are concatenated along the channel dimension. Subsequently, the dimensionality is reduced using a \(\text {1}\times \text {1}\) convolution, resulting in a dimension that matches the input features. This process can be expressed as equation 8. where \({{f}_{fusion}}\) is the fused feature, \(Con{{v}_{\text {1}\times \text {1}}}\left( \cdot \right)\) denotes \(\text {1}\times \text {1}\) convolution layer.
In the feature enhancement stage, we aim to improve the feature representation capability and model efficiency. To achieve this, we design the USCAB that integrates an enhanced spatial attention block and a contrast-aware channel attention block, as illustrated on the right side of Fig. 3. The input feature \({{f}_{fusion}}\) is represented as \(f_{fusion}^{w\times h\times c}\), where w, h and c denote its width, height and channels, respectively. Initially, we perform down-sampling on \(f_{fusion}^{w\times h\times c}\) to adjust its size and dimensions, which can be formulated as follows:
where \(f_{ds}^{i}\) denotes the result of downsampling, \(D{{S}^{i}}\left( \cdot \right)\) denotes down-sampling layer.
Many studies on feature down-sampling in vision tasks primarily focus on Pooling+Conv, especially in SR for visible images. In contrast, we introduce a Conv+PixelUnshuffle down-sampling method in this paper, motivated by several key reasons: i) Infrared images capture thermal radiation information from objects, which is particularly susceptible to noise interference. Avg-pooling and Max-pooling involve linear operations that directly couple features with noise, resulting in significant artifacts in the reconstructed images. Conversely, PixelUnshuffle solely entails pixel position shifting. While this approach does not eliminate image noise, it prevents the direct coupling noise with features. The subsequent image reconstruction still relies on separate learning of noise and features. ii) Taking Avg-pooling+Conv (Pooling: \(\text {2}\times \text {2}\), Conv: \(\text {3}\times \text {3}\)) as an example, the computation count for \(\text {4}wh{{c}_{i}}\left( \text {3Add}+\text {Div} \right)\) for AvgPooling and the number of parameters is \(\left( \text {9}{{c}_{i}}+\text {1} \right) {{c}_{o}}\) for Conv, \({{c}_{i}}\) and \({{c}_{o}}\) represent the number of input and output feature channels, respectively. For Conv+PixelUnshuffle, only pixel position movements in memory are involved, and the number of parameters is \({\left( \text {9}{{c}_{i}}+\text {1} \right) {{c}_{o}}}/{\text {4}}\). Therefore, the Conv+PixelUnshuffle design is more efficient. Up-sampling \(f_{ds}^{i}\) by three times, which can be formulated as follows:
where \(f_{up}^{\text {3}}\) denotes the result of three up-sampling, \(U{{S}^{i}}\left( \cdot \right)\) denotes up-sampling layer.
We propose using Conv+Pixelshuffle for up-sampling instead of Interpolation+Conv in this paper, primarily for the following reasons related to infrared image SR: i) Linearly interpolating features followed by Conv introduces a strong prior into the network, which assumes that feature up-sampling can be effectively achieved through linear interpolation. However, in many cases, this prior is inaccurate, leading to reduced edge quality in the reconstructed images, especially in infrared images. ii) Conv+Pixelshuffle essentially learns the feature up-sampling process, including linear interpolation. In other words, it can learn a more comprehensive up-sampling method. iii) Conv+Pixelshuffle and Interpolation+Conv have nearly identical parameters, but Interpolation involves pixel-by-pixel floating-point operation, which results in higher computational overhead, whereas Pixelshuffle only involves shifting pixel positions.
\(f_{fusion}^{h\times w\times c}\) is skip-connected to \(f_{up}^{\text {3}}\) after performing a convolution operation, then convolved again, and finally normalized, which can be formulated as follows:
where \({{f}_{weight}}\) denotes the spatial weight of features, and \(Norm\left( \cdot \right)\) denotes the normalized layer. The enhanced spatial features can be formulated as follows:
where \({{f}_{E}}\) denotes the enhanced features, \(\otimes\) represents the pixel-wise multiplication. To mitigate the homogenization of features in infrared images, we employ a skip connection for the standard deviation of \(f_{ds}^{\text {3}}\) and the AvgPooling of \({{f}_{E}}\), both in the channel dimension. Subsequently, \({{f}_{E}}\) is multiplied in the channel dimension, and the result is output through a convolutional layer. This process can be formulated as follows:
where \({{f}_{USCAB}}\) denotes the output of USCAB, and \(STD\left( \cdot \right)\) represents the standard deviation calculation. Therefore, the output of CCB can be formulated as follows:
Row-Column Transformer Block (RCTB)
Inspired by the uncooled IRFPA readout circuit structure prior that performs row-wise scanning and column-wise readout to generate infrared images, we propose a novel and efficient block RCTB for vision transformers. The RCTB is designed to capture long-range dependencies between row and column pixels in infrared images for HR reconstruction, based on local features extracted by CCB. The main structure of RCTB is illustrated in Fig. 4. It consists of several stages: first, the features are split by rows and then processed through MHSA; next, feature stitching occurs, followed by splitting the features by column and applying MHSA again. Specifically, in the first stage, the input feature is divided from a dimension of \(h\times w\times c\) into a series of feature sets with dimensions \({h}/{N}\;\times w\times c\), which can be formulated as follows:
where \(f_{r}^{i}\) denotes the \({{i}_{th}}\) feature in the feature set \({{F}_{r}}\) and N denotes the number of features. MHSA applies to \(f_{r}^{i}\) in \({{F}_{r}}\), formally, this attention mechanism can be expressed as:

The architecture of the proposed Row-Column Transformer Block (RCTB).
where \(\tilde{f}_{r}^{i}\) denotes the output of MHSA, \(\Phi _{r}^{Attn}\) represents MHSA operation applied to rows. The set of \(\left\{ \tilde{f}_{r}^{i} \right\}\) is aggregated into rows with a the dimension of \(h\times w\times c\), then transpose and split by rows. This entire process can be formulated as follows:
where \(f_{c}^{j}\) denotes the \({{j}_{th}}\) feature in the feature set \({{F}_{c}}\), M denotes the number of features. MHSA applied to \(f_{c}^{j}\) in \({{F}_{c}}\), formally, this attention mechanism can be formulated as:
where \(\tilde{f}_{c}^{j}\) denotes the column of MHSA, \(\Phi _{c}^{Attn}\) denotes MHSA operation applied to columns. The output of RCTB can be formulated as follows:
It is worth noting that we design two distinct types of RCTB: parallel and serial. In Fig. 4, the number of MHSA modules within the dashed box is represented as N for the parallel and 1 for the serial configuration. In parallel mode, N MHSAs are employed to process N features simultaneously, each with dimensions \({h}/{N}\;\times w\times c\). Conversely, in serial mode, a single MHSA computes N features sequentially. When comparing the computational complexity to the no-splitting mode16, the formula can be summarized as follows:
where N denotes the number of split features. Typically, it is clear that the computational complexity of transformer based on RCTB is significantly lower than that of the no-splitting mode.
EIRSR architectures
To achieve comprehensive feature extraction while maintaining a lightweight architecture, our framework integrates CCB and RCTB in a synergistic manner. The CCB block is specifically designed to efficiently extract high-frequency local features by leveraging its inherent spatial inductive bias. In contrast, RCTB captures long-range dependencies by modeling spatio-temporal correlations across rows and columns, effectively addressing the limitations of CNNs in global context modeling. By combining these two modules, our approach effectively retains both local sharpness and global consistency, making it particularly suitable for infrared image SR reconstruction. Furthermore, CCB is specifically optimized for computational efficiency by reducing intermediate feature channels while preserving strong representational power through residual connections. This design ensures that our backbone remains compact and lightweight, while further reduction of CNN components would compromise the ability to capture local features. Based on this fundamental architecture, we develop six typical variants(B: Base, S: Small, T: Tiny), namely EIRSR-parallel-B/S/T and EIRSR-serial-B/S/T. The architectural specifications are detailed in Table 1. The EIRSR-serial-B/S/T structure is more compact, allowing for a deeper design, and making it suitable for edge devices with lower real-time inference demands. EIRSR-parallel-B/S/T features a wider structure, which facilitates the learning of more abundant features in SR tasks. This variant accelerates the inference process through parallel processing and is suited to scenarios with real-time requirements. Suitable models can be selected from the six variants based on specific application scenarios.
Experiments
In this section, we first present the experimental settings of our study. Next, we evaluate our method by comparing it with state-of-the-art methods and report both quantitative and qualitative results. Finally, we explore the impact of basic blocks and various modes on SR performance. Additionally, we assess the effectiveness of our method on edge devices.
Experimental setup
Datasets and Metrics: The dataset contains 25,892 valid infrared image samples, all acquired using five self-developed infrared imaging systems equipped with a 640\(\times\)512 uncooled IRFPA. These 640\(\times\)512 images serves as Ground Truth HR references during the training phase. The corresponding LR images are generated using non-overlapping average pooling operations (e.g., a 2\(\times\)2 kernel for \(\times\)2 downsampling) instead of bicubic interpolation, motivated by our proposed readout circuit structure prior that models the physical infrared imaging process characterized by row-wise scanning and column-wise readout. Average pooling is more consistent with this mechanism and better preserves the spatio-temporal correlations in infrared images, effectively avoiding the artifacts and distortions commonly introduced by interpolation-based downsampling. Furthermore, due to the high cost and limited availability of megapixel-level infrared imaging systems, it is not feasible to obtain real infrared images at a resolution of 1280\(\times\)1024 that are perfectly aligned with the corresponding low-resolution counterparts. To evaluate SR performance at this scale, we generate pseudo HR references using the Upscayl, an image upscaling tool based on an open-source large-scale AI model. Although originally designed for natural image enhancement, Upscayl can reconstruct plausible high-frequency textures that serve as reasonable references for evaluating the quality of our reconstructions images. This approach facilitates the assessment of the performance of our method in the absence of true HR infrared image. The core infrared detectors of all imaging devices have the following key performance parameters: a pixel size of 17 µm, a 640\(\times\)512 focal plane array, a noise equivalent temperature difference (NETD) of 25 mK, a time constant of 8 ms, a frame rate of 50 Hz, and a response wavelength range of 8-14 µm. We utilize 2,500 images to evaluate the performance of different approaches. The supplementary file presents the infrared image datasets utilized in this work, including images acquired from a commercial cooled infrared imaging system, synthetically generated high-resolution infrared images, and validation data obtained from a self-developed uncooled infrared detector. Average peak signal-to-noise ratio (PSNR) and structural similarity index (SSIM) are employed as evaluation metrics.
Implementation Details: Different configurations of our proposed EIRSR are presented in Table 1. Data augmentation includes horizontal/vertical flips and random rotations of 90\(^\circ\), 180\(^\circ\), and 270\(^\circ\). The kernel sizes of all convolutions are limited to 3 and 1. The batch size is set to 32, and the size of each \({{I}_{LR}}\) is set to \(\text {48}\times \text {48}\) during the training phase. We employ Adam38 optimizer to train the model with \({{\beta }_{\text {1}}}=\text {0}\text {.9}\), \({{\beta }_{\text {2}}}=\text {0}\text {.999}\). The initial learning rate is set to \(\text {5}\times \text {1}{{\text {0}}^{\text {-4}}}\) and decays following a cosine learning rate. \({{{L}}_{SR}}\) is used to optimize the model over \(\text {5}\times \text {1}{{\text {0}}^{\text {5}}}\) iterations, with the initial relaxation factor \(\alpha\) set to 0.2 and is halved every \(\text {1}\times \text {1}{{\text {0}}^{\text {5}}}\) iterations. Our method is implemented in PyTorch, and all experiments are conducted on a single GeForce RTX 4090 GPU.

Visual comparison of EIRSR with state-of-the-art methods for \(\times \text {2/}\times \text {3/}\times \text {4}\) super-resolution. Based on the quantitative results in Table 2, the top six methods from the evaluation are selected, and their difference maps relative to the ground truth images are provided.
Comparison with state-of-the-art methods
To evaluate the effectiveness of EIRSR, we compare it with several advanced efficient SR methods, including RFDN2, LatticeNet28, SwinIR17, ELAN18, BSRN30, ESRT29, HAT19, LKDN31, RGT20, PLKSR32, and SeemoRe14. Table 2 presents the quantitative comparison results of PSNR and SSIM for \(\times \text {2/}\times \text {3/}\times \text {4}\) upscale factors, along with the number of parameters and Multi-Adds. At scale \(\times \text {2}\), the number of parameters and Multi-Adds for our method are 2.54\(\%\) and 2.9\(\%\) of those for the second-ranked method, and 2.77\(\%\) and 2.56\(\%\) of those for the third-ranked method. At scale \(\times \text {3}\), the number of parameters and Multi-Adds for our method are 2.74\(\%\) and 3.84\(\%\) of those for the second-ranked method, and 2.51\(\%\) and 3.72\(\%\) of those for the third-ranked method. At scale \(\times \text {4}\), the number of parameters and Multi-Adds for our method are 2.54\(\%\) and 3.15\(\%\) of those for the second-ranked method, and 2.77\(\%\) and 2.91\(\%\) of those for the third-ranked method. The results demonstrate that EIRSR, which utilizes a CNN-Transformer structure, surpasses previous leading models in PSNR and SSIM metrics. Comparison results reveal that, for infrared images, Transformer architecture like as HAT19, RGT20, SwinIR17, and ESRT29 outperform the convolutional architecture. This advantage may be attributed to the relationship between the infrared imaging process and the feature split of the Transformer.
In Fig. 5, we present a visual comparison of EIRSR and other efficient methods on \(\times \text {2/}\times \text {3/}\times \text {4}\). It is evident that the HR images reconstructed by EIRSR exhibit more accurate texture details, particularly along the edges. Compared to Ground Truth (GT) images at scale \(\times \text {2/}\times \text {3}\), our reconstructed images show overall smoothness with no obvious artifacts on the edges, which demonstrates superior visual quality and can be attributed to the incorporation of an image enhancement regularization control term in the loss function. The difference maps at scales \(\times \text {2}\) and \(\times \text {3}\) show that our method has the smallest discrepancy with the GT images in terms of both overall structure and fine details. The difference map at scale \(\times \text {4}\) shows that our method does not generate obvious artifacts. It is worth noting that at a scale of \(\times \text {4}\), most methods do not perform well due to the inherent lack of details in infrared images, as the algorithm cannot generate non-existent details. All comparative experiments demonstrate the effectiveness of our method. Furthermore, it is important to emphasize that Transformer-based methods outperform CNNs in infrared image SR, as demonstrated by HAT19 and RGT20. Although the ViT block in both methods employs window-based MHSA, it is essential to recognize that ViT is fundamentally linked to the mechanism of infrared imaging.

Qualitative and quantitative comparison of typical infrared image SR methods. The following sections present localized comparison views of the super-resolution results and their corresponding difference maps with ground truth images.
We present a comparison of the typical SR methods IRSRMamba12 and PSRGAN4 on infrared images, as illustrated in Fig. 6. Our method demonstrates superior performance compared to the current SR methods for infrared images, particularly in terms of image details and visual perception. Furthermore, the differential analysis through error mapping demonstrates that our reconstructed images maintain the closest structural fidelity to the ground truth references in terms of global feature consistency.
Ablation study
In this section, we perform ablation studies on important design elements in the proposed EIRSR to explore the impact of different blocks on infrared image reconstruction performance. Table 3 shows the results.
Effectiveness of CCB and its internal component USCAB. We conduct an ablation study to evaluate the effectiveness of CCB and its internal component USCAB, as shown in Table 3. By masking the CCB, EIRSR reduces to using only the RCTB component. In parallel model, PSNR decreases by 1.42\(\%\) and SSIM decreases by 1.44\(\%\) (see \(\#\)1 and \(\#\)5), while in serial mode, PSNR decreases by 1.65\(\%\) and SSIM decreases by 1.09\(\%\) (see \(\#\)7 and \(\#\)11). This finding confirms that, in the hybrid architecture, the local features extracted by CCB are crucial for establishing effective long-range dependencies between pixels using the RCTB, ultimately improving the network’s performance. Furthermore, we mask USCAB to assess its impact on performance. In parallel model, PSNR degrades by 0.73\(\%\) and SSIM degrades by 1.06% (see \(\#\)1 and \(\#\)2), whereas in the serial mode, PSNR degrades by 0.89\(\%\) and SSIM degrades by 0.25\(\%\) (see \(\#\)7 and \(\#\)8). The USCAB module operates interactively in both channel and spatial dimensions, facilitating the extraction of potential correlations between pixel locality and feature channels. This dual interaction significantly contributes to the improvement of performance in the SR task, especially when integrated with RCTB for global context modeling. These results validate that the CCB, especially when integrated with the USCAB, substantially improves the model’s capacity to extract local features and reinforce local contextual representations. Such localized enhancements are essential for facilitating the global dependency modeling in RCTB, thereby improving both reconstruction quality and overall SR performance in infrared imaging.

Based on the EIRSR-parallel in Table 3, visualize the cosine correlation between the rows and columns of the 128\(\times\)128 feature maps. (a) Corresponding to # 1 in Table 3, from top to bottom are row correlation in CCB, column correlation in CCB, row correlation in RCTB, and column correlation in RCTB. (b) Corresponding to # 2 in Table 3, from top to bottom are row correlation in CCB, column correlation in CCB, row correlation in RCTB, and column correlation in RCTB. (c) Corresponding to # 3 in Table 3, from top to bottom are row correlation in CCB, column correlation in CCB, row correlation in RCTB, and column correlation in RCTB. (d) Corresponding to # 4 in Table 3, from top to bottom are row correlation in CCB, column correlation in CCB, row correlation in RCTB, and column correlation in RCTB. (e) The red box corresponding to # 5 in Table 3, from top to bottom are the row correlations in RCTB and the column correlations in RCTB. The green box corresponding to # 6 in Table 3, from top to bottom are the row correlations in CCB and the column correlations in RCTB.
Effectiveness of RCTB. We compare the impact of RCTB on SR performance in three cases. When RCTB (\(\times\) rows) operates only in columns, in parallel model, the PSNR degrades by 0.78\(\%\) and the SSIM degrades by 1.1\(\%\) (see \(\#\)1 and \(\#\)3). In serial mode, PSNR degrades by 1.08\(\%\) and SSIM degrades by 0.44\(\%\) (see \(\#\)7 and \(\#\)9). Conversely, when RCTB (\(\times\) cols) operates solely in rows, the parallel model shows a PSNR degradation of 1.32\(\%\) and an SSIM degradation of 1.3\(\%\) (see \(\#\)1 and \(\#\)4), while in serial mode, the PSNR degrades by 1.56\(\%\) and the SSIM degrades by 1.09\(\%\) (see \(\#\)7 and \(\#\)10). In the absence of RCTB, the parallel model exhibits a PSNR degradation of 4.7\(\%\) and an SSIM degradation of 4.12\(\%\) (see \(\#\)1 and \(\#\)6), and in serial mode, the PSNR degrades by 5.0\(\%\) and the SSIM degrades by 3.24\(\%\) (see \(\#\)7 and \(\#\)12). These comparative results demonstrate that applying the transformer to either rows or columns alone is less effective than applying it to both.
The effectiveness of the RCTB is crucial for enhancing the performance of infrared image SR. RCTB is specifically designed to capture long-range dependencies by modeling correlations across rows and columns, a feature particularly important for infrared images where spatio-temporal relationships are critical for accurate reconstruction. Ablation experiments demonstrate that applying RCTB to both rows and columns yields superior performance compared to applying it to rows or columns individually. This indicates that fully applying RCTB enables it to capture interdependencies between pixels across both dimensions, thereby providing comprehensive image features and improving SR quality. Notably, masking RCTB results in significant performance degradation. For instance, in the parallel mode, the PSNR degrades by 4.7\(\%\) and SSIM by 4.12\(\%\), and in the serial mode, PSNR degrades by 5.0\(\%\) and SSIM by 3.24\(\%\). This sharp performance drop underscores the importance of RCTB in capturing global context, solidifying its role as an essential component of our framework. Furthermore, the combination of RCTB and CCB enables a comprehensive feature extraction approach. CCB is responsible for efficiently extracting high-frequency local details, while RCTB handles the long-range global dependencies. By integrating these two modules, our model harnesses their complementary strengths: the CCB enhances local feature representation, whereas the RCTB captures global spatio-temporal correlations grounded in the infrared imaging process. These results underscore the critical role of the RCTB design, which is inspired by the readout characteristics of IRFPA detectors, as essential for performance improvement and not substitutable by conventional designs relying solely on image content or network architecture. The synergy between CCB and RCTB allows the model to capture both fine textures and global coherence, which is critical for infrared image reconstruction. Another critical aspect of RCTB’s design is that it is based on the IRFPA readout circuit. The IRFPA circuit operates by scanning infrared images row-by-row and column-by-column, and RCTB is designed based on this prior knowledge. By incorporating this prior, RCTB effectively models spatio-temporal correlations between pixels across rows and columns, aligning with the structure of the IRFPA readout circuit. This design allows the network to capture semantically richer features from infrared images, significantly improving performance in infrared SR tasks.
In summary, the integration of RCTB with CCB significantly enhances the model’s ability to capture both local and global features. By leveraging the IRFPA readout circuit’s characteristics, RCTB further improves the model’s ability to handle complex dependencies in infrared images, establishing it as a crucial component for high-performance infrared super-resolution.
As illustrated in Fig. 7, we analyze the cosine correlation between rows and columns in features based on the EIRSR-parallel model in Table 3, revealing several noteworthy findings. First, a comparison between Fig. 7a and Fig. 7b demonstrates that integrating CCB enhances RCTB’s ability to capture high-level semantic information by preserving both row and column correlations. This enhancement is attributed to CCB’s efficient extraction of local features, which supports the long-range dependencies modeled by RCTB across rows and columns. In contrast, when CCB is used without USCAB, as shown in the feature correlation maps of Fig. 7b, the model’s ability to maintain row and column correlations within RCTB is significantly reduced, underscoring the critical role of USCAB in preserving these dependencies. Furthermore, as shown in Fig. 7a and Fig. 7c, the absence of row splitting in RCTB leads to a reduction in both row and column correlations, with row correlations being more significantly weakened. This highlights the importance of the row-splitting mechanism in RCTB, which is essential for preserving strong dependencies between pixels across different rows. Similarly, the comparison between Fig. 7a and Fig. 7d demonstrates that removing column splitting results in a reduction in both row and column correlations, with column correlations experiencing a more pronounced decline. This underscores the importance of column splitting in RCTB for capturing global dependencies between columns, a critical factor for accurately modeling pixel relationships in infrared images. Additionally, the comparison of the red and green boxes in Fig. 7e reveals that RCTB demonstrates a superior ability to model row and column correlations compared to CCB alone. This further emphasizes RCTB’s unique capacity to capture long-range dependencies and spatial-temporal correlations across rows and columns, a key factor in enhancing SR performance. Overall, the results shown in Fig. 7 indicate that column correlations are more prominent than row correlations. This phenomenon can be attributed to the architecture of the IRFPA readout circuit, where each column of pixels shares a single readout channel, resulting in stronger column-wise correlations. By leveraging this inherent structure, RCTB enhances the modeling of interdependencies across rows and columns, leading to significant improvements in infrared image SR performance.

The effect of the control term in the loss function on \(\times\)2 SR. (a) The top represents the local zoom of GT image, and the bottom represents the SR without control term. (b) Top represents GT image with guided filtering, and bottom represents image preprocessing in the control item is guided filtering. (c) The top represents GT image with guided filtering and image enhancement, the bottom represents image preprocessing in the control item are guided filtering and image enhancement.
Loss function. We introduce a regularization control term into the loss function and dynamically adjust this loss function using a relaxation factor \(\alpha\) during training, which yields interesting results, as illustrated in Fig. 8. Sub-image (a) shows that without the introduction of control terms, our method produces more noise than GT images, resulting in unsatisfactory outcomes. In sub-image (b), we observe that with the introduction of the control item, \({{\tau }_{prep}}\left( I_{HR}^{i} \right)\)represents \(I_{HR}^{i}\) processed by guided filtering and demonstrates superior performance compared to the GT image processed directly by guided filtering. Furthermore, in sub-image (c), where \({{\tau }_{prep}}\left( I_{HR}^{i} \right)\) refers to the application of guided filtering and detail enhancement (Laplacian sharpening) on \(I_{HR}^{i}\), our method outperforms the direct application of guided filtering and detail enhancement on GT images in the terms of image detail. The computational profiling conduct on the RK3588 Core Board reveals clear temporal characteristics: standalone guided filtering and Laplacian sharpening operations require 18.79 ms and 6.701 ms respectively under single-threaded mode. Our integrated architecture, which combines these preprocessing operators, demonstrated 37.815 ms processing latency. Compared to the conventional sequential approach (18.79 ms + 6.701 ms + 37.815 ms), the proposed end-to-end implementation achieves a 40.27\(\%\) reduction in total execution time. The experimental analysis of the loss function encourages us to investigate the integration of the infrared image preprocessing algorithm into the network in future research by incorporating the control term into the loss function, with the aim of reducing the computational cost associated with infrared imaging system preprocessing and minimizing overall processing latency.
SR comparison under different readout modes
To validate the effectiveness of the proposed spatio-temporal readout prior, we conduct a comparative experiment using infrared images acquired by a self-developed infrared imaging system and a commercial infrared imaging system, operating in rolling shutter and global shutter readout modes, respectively. The IRFPA in the self-developed system operates in a rolling shutter readout mode, which performs row-wise scanning and column-wise readout, in contrast to the commercial system that adopts a global shutter readout mode. The commercial system features a pixel size of 15 µm, a 640\(\times\)512 focal plane array, and a noise equivalent temperature difference (NETD) \(\le\) 17 mK. A total of 2,500 images are used for validation in both the rolling shutter and global shutter imaging systems. The average results of the quantitative comparison are summarized in Table 4. As shown in Table 4, the spatio-temporal readout prior-based method achieves PSNR improvements of 6.94\(\%\) and 9.65\(\%\), and SSIM improvements of 2.65\(\%\) and 6.68\(\%\) on the rolling shutter imaging system, compared to its performance on the global shutter system, under \(\times\)2 and \(\times\)4 upscaling factors, respectively.

Qualitative and Quantitative Comparison of Super-Resolution Performance in Infrared Imaging Systems with Different Readout Modes. (a) Self-developed imaging system (Rolling Shutter Readout Mode). (b) Commercial imaging system (Global Shutter Readout Mode).
Representative comparison images are selected from different imaging systems under \(\times\)2 and \(\times\)4 upscaling factors, and their corresponding PSNR, SSIM, and difference maps are computed, as illustrated in Fig. 9. As shown in Fig. 9, the proposed method achieves better performance on the self-developed imaging system that incorporates spatio-temporal readout priors, whereas its effectiveness is less pronounced on the global shutter imaging system, which lacks such priors. Specifically, under the \(\times\)4 SR scenario, it fails to reconstruct the vertical structural components of the glass curtain wall on the global shutter imaging system, leading to a reconstruction that retains only the horizontal stripe patterns, with the vertical features entirely absent. The comparative results across different imaging modes support the effectiveness of the proposed method that incorporates spatio-temporal readout priors. Moreover, these findings imply that accounting for hardware-level imaging characteristics can be beneficial to the performance of SR tasks. This further underscores the design specificity of our network design for row-wise scanning and column-wise readout IRFPAs, in which spatio-temporal readout priors play a crucial role in guiding the reconstruction process. While this specificity contributes to significant performance improvements on row-column scanned systems, it also underscores the need to adapt our framework for other imaging sensor architectures–such as global shutter or event-based imaging systems–where differing physical imaging process and spatio-temporal dynamics may necessitate alternative modeling approaches.
Edge device deployment
To validate the effectiveness of our model on edge devices, we optimized EIRSR-T as EIRSR-T-opt and evaluated it on an edge inference device: RK3588 Core Board, an embedded system-on-module (SoM) from Rockchip, which features three integrated NPU cores. We assessed the performance of models at a scale of \(\times \text {2}\) in single-process mode, utilizing 16-bit floating point precision during inference. For each input image size, we executed the models for two hours to avoid the warm-up effect, the results are presented in Table 5. As the size of the input image increases, there is a corresponding rise in power consumption, memory usage, memory read/write operations, and runtime for the model. In single-threaded mode, models with low power consumption can be deployed to edge devices. However, our optimized model cannot achieve real-time processing speeds in the single-threaded mode with an input size of 1280\(\times\)1024. In this case, real-time SR for large images can be achieved through multi-core and multi-threaded processing, but this approach significantly increases the resources consumption of edge devices. Table 5 illustrates that memory usage and memory read/write operations are significant bottlenecks that limit the model’s performance. To facilitate deployment on edge devices, we have summarized several guidelines for model optimization. Specifically, the following strategies are recommended: consider operator fusion whenever possible, implement weight sharing during model quantization, ensure that the number of feature channels is a multiple of four, adopt a general 3\(\times\)3 convolution kernel, reduce the number of heads in MHSA, maximize the split of row and column features, and utilize operators that are optimized for the specific hardware platform.
Motivation and applicability of the hardware prior
Our method is inspired by the row-wise scanning and column-wise readout mechanism of our self-developed uncooled IRFPA detectors. This readout mechanism introduces inherent temporal correlations among row pixels and spatial correlations among column pixels during the image formation process, both of which are explicitly exploited in our model design. To capture these correlations, we propose the RCTB, which applies self-attention separately along the row and column dimensions. This design aligns closely with the physical imaging mechanism and enables the network to effectively capture pixel-level dependencies introduced by the readout circuitry, thereby yielding improvements in SR performance, as demonstrated in our ablation studies. While our method is tailored to IRFPAs exhibiting such readout characteristics, this class of imaging sensors is widely deployed in low-power, cost-sensitive, and edge-oriented infrared imaging systems. Therefore, the proposed method has considerable potential for practical deployment.
We also acknowledge that the method is not directly applicable to global shutter mode imaging sensors, which lack the row-column spatio-temporal dependencies leveraged in our design. As demonstrated in the “SR Comparison under Different Readout Modes,” the method exhibits reduced effectiveness. Nonetheless, the principle of incorporating hardware-level priors into network design can be extended to other imaging architectures through appropriate modifications, which we aim to explore in future work. Compared with previous infrared SR methods that focus solely on images or networks, our approach is the first to integrate the imaging circuitry structure priors into the network architecture. This allows for more efficient modeling of spatio-temporal correlations that are consistent with the hardware, leading to enhanced reconstruction fidelity and robustness in the infrared SR task.
Conclusion
In this study, we propose a novel efficient hybrid network, named EIRSR, which is based on the IRFPA readout circuit structure prior, aimed at addressing the problem of infrared image SR. Specifically, leveraging this simple yet powerful prior, we meticulously designed RCTB to split features into rows and columns, thereby capturing the spatiotemporal correlation between row-column pixels and utilizing MHSA to establish long-range dependencies among pixel-level features. Furthermore, to address the issues of redundant computation and weak local feature extraction, we design CCB which incorporates USCAB to extract local features before RCTB. The integration of CCB and RCTB aims to significantly reduce the model’s parameters while enhancing network performance. In our proposed EIRSR, local features, spatiotemporal correlations between row-column pixels, and long-range dependencies are effectively captured and represented, thereby enriching the high-level semantic information. To improve the reconstruction details of infrared images, we incorporate enhancement and filtering in image processing as regularization control terms in the loss function. Extensive experiments demonstrate that EIRSR achieves an improved trade-off between model performance and computational cost. Additionally, we offer valuable insights into the design and deployment of an efficient SR model by analyzing the efficiency of our method on the edge device RK3588 core board.
Limitations: Our model is designed based on the imaging principles of infrared imagery. While it successfully balances between model performance and computational cost. However, the CCB and RCTB in EIRSR are constructed based on empirical criteria, leading to some redundancy in the model. In our future work, we plan to integrate adaptive model search techniques to further enhance our model’s efficiency.
Data availability
The data generated and analyzed during this study are publicly accessible via the following link: https://drive.google.com/file/d/1H6E9JQZNS3iOhHr7wjhCyQekEKKWqQB8/view?usp=sharing. Further data supporting the findings of this study are available from the corresponding author upon reasonable request.
Code availability
The code in this study is available at https://github.com/kaiche/Infrared-image-super-resolution. .
References
Zou, Y. et al. Super-resolution reconstruction of infrared images based on a convolutional neural network with skip connections. Opt. Lasers Eng. 146, (2021).
Liu, J., Tang, J. & Wu, G. Residual feature distillation network for lightweight image super-resolution. In Computer Vision–ECCV 2020 Workshops: Glasgow, UK, August 23–28, 2020, Proceedings, Part III 16, 41–55 (Springer, 2020).
Prajapati, K. et al. Channel split convolutional neural network (chasnet) for thermal image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 4368–4377 (2021).
Huang, Y., Jiang, Z., Lan, R., Zhang, S. & Pi, K. Infrared image super-resolution via transfer learning and psrgan. IEEE Signal Process. Lett. 28, 982–986 (2021).
Yang, X., Zhang, M., Li, W. & Tao, R. Visible-assisted infrared image super-resolution based on spatial attention residual network. IEEE Geosci. Remote. Sens. Lett. 19, 1–5 (2021).
Park, N. & Kim, S. How do vision transformers work? arXiv preprint arXiv:2202.06709 (2022).
Venkataramanan, S., Ghodrati, A., Asano, Y. M., Porikli, F. & Habibian, A. Skip-attention: Improving vision transformers by paying less attention. arXiv preprint arXiv:2301.02240 (2023).
Ronneberger, O., Fischer, P. & Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, October 5-9, 2015, Proceedings, Part III 18, 234–241 (Springer, 2015).
Dong, C., Loy, C. C., He, K. & Tang, X. Learning a deep convolutional network for image super-resolution. In Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part IV 13, 184–199 (Springer, 2014).
Zhang, Y., Zhou, P. & Chen, L. Dual-branch feature encoding framework for infrared images super-resolution reconstruction. Sci. Reports 14, 9379 (2024).
Anwar, S. & Barnes, N. Densely residual laplacian super-resolution. IEEE Transactions on Pattern Analysis and Mach. Intell. 44, 1192–1204 (2020).
Huang, Y., Miyazaki, T., Liu, X. & Omachi, S. Irsrmamba: Infrared image super-resolution via mamba-based wavelet transform feature modulation model (2024). arxiv:2405.09873.
Cheng, C., Wang, H. & Sun, H. Activating wider areas in image super-resolution. arXiv preprint arXiv:2403.08330 (2024).
Zamfir, E., Wu, Z., Mehta, N., Zhang, Y. & Timofte, R. See more details: Efficient image super-resolution by experts mining. In Forty-first International Conference on Machine Learning (2024).
Liu, Q., Zhuang, C., Gao, P. & Qin, J. Cdformer: When degradation prediction embraces diffusion model for blind image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 7455–7464 (2024).
Dosovitskiy, A. et al. An image is worth 16x16 words: Transformers for image recognition at scale. ICLR (2021).
Liang, J. et al. Swinir: Image restoration using swin transformer. In Proceedings of the IEEE/CVF international conference on computer vision, 1833–1844 (2021).
Zhang, X., Zeng, H., Guo, S. & Zhang, L. Efficient long-range attention network for image super-resolution. In European conference on computer vision, 649–667 (Springer, 2022).
Chen, X., Wang, X., Zhou, J., Qiao, Y. & Dong, C. Activating more pixels in image super-resolution transformer. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 22367–22377 (2023).
Chen, Z., Zhang, Y., Gu, J., Kong, L. & Yang, X. Recursive generalization transformer for image super-resolution. arXiv preprint arXiv:2303.06373 (2023).
Lv, J. et al. Model-based low-noise readout integrated circuit design for uncooled microbolometers. IEEE Sensors Journal 13, 1207–1215 (2013).
Lv, J. et al. Uncooled microbolometer infrared focal plane array without substrate temperature stabilization. IEEE Sensors Journal 14, 1533–1544 (2014).
Que, L., Wei, L., Lv, J. & Jiang, Y. A digital output readout circuit with substrate temperature and bias heating compensation for uncooled micro-bolometer infrared focal plane arrays. Infrared Phys. & Technol. 71, 252–262 (2015).
Lv, J., Que, L., Wei, L., Meng, Z. & Zhou, Y. A low power and small area digital self-calibration technique for pipeline adc. AEU-International J. Electron. Commun. 83, 52–57 (2018).
Hu, L., Hu, L. & Chen, M. Edge-enhanced infrared image super-resolution reconstruction model under transformer. Sci. Reports 14, 15585 (2024).
Zhang, H., Zhang, C., Xie, F. & Jiang, Z. A closed-loop network for single infrared remote sensing image super-resolution in real world. Remote. Sens. 15, 882 (2023).
Mo, F., Wu, H., Qu, S., Luo, S. & Cheng, L. Single infrared image super-resolution based on lightweight multi-path feature fusion network. IET Image Processing 16, 1880–1896 (2022).
Luo, X. et al. Latticenet: Towards lightweight image super-resolution with lattice block. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XXII 16, 272–289 (Springer, 2020).
Lu, Z. et al. Transformer for single image super-resolution. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 457–466 (2022).
Li, Z. et al. Blueprint separable residual network for efficient image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 833–843 (2022).
Luo, P., Xiao, G., Gao, X. & Wu, S. Lkd-net: Large kernel convolution network for single image dehazing. In 2023 IEEE International Conference on Multimedia and Expo (ICME), 1601–1606 (IEEE, 2023).
Lee, D., Yun, S. & Ro, Y. Partial large kernel cnns for efficient super-resolution. arXiv preprint arXiv:2404.11848 (2024).
Liu, X. et al. Efficientvit: Memory efficient vision transformer with cascaded group attention. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 14420–14430 (2023).
Li, Y. et al. Rethinking vision transformers for mobilenet size and speed. In Proceedings of the IEEE/CVF International Conference on Computer Vision, 16889–16900 (2023).
Pan, J. et al. Edgevits: Competing light-weight cnns on mobile devices with vision transformers. In European Conference on Computer Vision, 294–311 (Springer, 2022).
Li, Q. et al. Concealed attack for robust watermarking based on generative model and perceptual loss. IEEE Transactions on Circuits Syst. for Video Technol. 32, 5695–5706 (2021).
Johnson, J., Alahi, A. & Fei-Fei, L. Perceptual losses for real-time style transfer and super-resolution. In Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11-14, 2016, Proceedings, Part II 14, 694–711 (Springer, 2016).
Kingma, D. P. & Ba, J. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980 (2014).
Acknowledgements
This work was supported by Natural Science Foundation of Hubei Province of China (Grant No. 2024AFD116), Key Project of Science and Technology Research Plan of Hubei Provincial Department of Education (Grant NO. D20231805).
Funding
This work was supported by Natural Science Foundation of Hubei Province of China (Grant No. 2024AFD116), Key Project of Science and Technology Research Plan of Hubei Provincial Department of Education (Grant NO. D20231805).
Author information
Authors and Affiliations
Contributions
K.C. implemented the method and wrote the paper; J.L. and L.Q. built the method; Y.Z. analyzed the results; J.G. and J.W. contributed to the data collection and organization.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Che, K., Lv, J., Wei, J. et al. Infrared image super resolution with structure prior from uncooled infrared readout circuit. Sci Rep 15, 31047 (2025). https://doi.org/10.1038/s41598-025-16698-8
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-025-16698-8
