
Abstract
This study aimed to develop and evaluate deep convolutional neural network (DCNN) models with Grad-CAM visualization for the automated classification with interpretability of tongue conditions—specifically glossitis and oral squamous cell carcinoma (OSCC)—using clinical tongue photographs, with a focus on their potential for early detection and telemedicine-based diagnostics. A total of 652 tongue images were categorized into normal control (n = 294), glossitis (n = 340), and OSCC (n = 17). Four pretrained DCNN architectures (VGG16, VGG19, ResNet50, ResNet152) were fine-tuned using transfer learning. Model interpretability was enhanced via Grad-CAM and sparsity analysis. Diagnostic performance was assessed using AUROC, with subgroup analysis by age, sex, and image segmentation strategy. For glossitis classification, VGG16 (AUROC = 0.8428, 95% CI 0.7757–0.9100) and VGG19 (AUROC = 0.8639, 95% CI 0.7988–0.9170) performed strongly, while the ensemble of VGG16 and VGG19 achieved the best result (AUROC = 0.8731, 95% CI 0.8072–0.9298). OSCC detection showed near-perfect performance across all models, with VGG19 and ResNet152 achieving AUROC = 1.0000 and VGG16 reaching AUROC = 0.9902 (95% CI 0.9707–1.0000). Diagnostic performance did not differ significantly by age (P = 0.3052) or sex (P = 0.4531), and whole-image classification outperformed patch-wise segmentation (P = 0.7440). DCNN models with Grad-CAM demonstrated robust performance in classifying glossitis and OSCC from tongue photographs with interpretability. The results highlight the potential of AI-driven tongue diagnosis as a valuable tool for remote healthcare, promoting early detection and expanding access to oral health services.
Similar content being viewed by others


Introduction
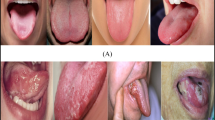
Tongue diagnosis is a simple, convenient, and noninvasive method for assessing oral and overall health. It involves the visual examination of the tongue in terms of its size, shape, color, moisture, texture, coating, fissures, and other conditions, and is a fundamental step in oral diagnosis and health assessment1,2. Owing to the ease with which it can be extended outside the oral cavity, the tongue offers distinct advantages for examination purposes compared with other oral structures (e.g., periodontium tissue, which often requires specialized probes). Additionally, the tongue can be assessed without specialized equipment and is less affected by external lighting variations, making it a practical and reliable diagnostic tool for conditions such as glossitis due to oral candidiasis, lichen planus, and oral cancer3,4,5. Since numerous oral and systemic medical conditions present oral manifestations, tongue diagnosis can be considered an essential component of comprehensive physical examinations6. However, traditional tongue examination depends largely on visual assessment by clinicians, making it prone to subjectivity and variability. Thus, routine tongue examinations are a standard part of health evaluation, and methods for performing tongue diagnosis more accurately, effectively, and easily should be developed.
The use of artificial intelligence (AI) and deep convolutional neural networks (DCNNs) hold great promise for transforming tongue image diagnosis and related medical and dental practices. DCNNs are a type of deep learning model specifically designed for image data processing and analysis7. These networks automatically extract features from input images and hierarchically learn abstract patterns to perform tasks, such as classification, prediction, or analysis8. Traditional clinical evaluations of the tongue rely heavily on the dentists’ and physicians’ subjective experience, underscoring the growing need for objective diagnostic methods. DCNN models are particularly effective in medical imaging research, excelling in handling complex, high-resolution data and identifying subtle patterns that may be challenging for human perception9. For example, Gomes et al. classified oral lesions into six categories using models like Residual Network 50 (ResNet50), VGG16, InceptionV3, and Xception with transfer learning10. Similarly, Tanriver et al. employed ResNet and RCNN to detect potentially malignant oral disorders11. Despite promising results from various studies utilizing different models/architectures, more comprehensive and comparative approaches must still be developed.
Glossitis, derived from the Greek words glossa (tongue) and the suffix -itis (inflammation). The clinical symptoms of glossitis include tongue swelling and edema, changes in surface color (e.g., reddish or smooth appearance), and burning or pain sensations12. Additionally, glossitis may also lead to taste perception alterations, loss of taste, and development of tongue cracks/fissures13. The global prevalence of glossitis is not precisely documented, but around 10–25% of those with nutritional deficiencies or certain systemic conditions have the condition14. Importantly, glossitis can manifest as localized conditions such as xerostomia, oral candidiasis, HIV infection, or allergic reactions, as well as serve as an indicator of systemic diseases, including anemia, immune deficiencies, and autoimmune disorders (e.g., oral lichen planus and Sjögren’s syndrome)15. Therefore, to ensure appropriate and timely management, glossitis should be carefully clinically evaluated and accurately diagnosed as quickly as possible.
In terms of the oral cavity, oral squamous cell carcinoma (OSCC) is the most common malignant tumor, accounting for approximately 90% of all oral cancers16. Globally, the sex-standardized incidence rates of OSCC are approximately 6.0 per 100,000 men and 2.3 per 100,000 women17. OSCC symptoms include the following: persistent mouth sores or ulcers that do not heal; cheek lumps or thickening; white/red patches on the tongue, gums, tonsils, or the lining of the mouth; difficulty chewing or swallowing; numbness of the tongue or other areas of the mouth; jaw swelling18. According to a recent study conducted with South Korean patients, the tongue is the most common site of OSCC19. Regarding prognosis, the overall five-year OSCC survival rate is approximately 50–60%, albeit this may vary by factors such as cancer stage at diagnosis, its location, and patient overall health20, and early detection is critical for effective treatment. Diagnostic methods typically include oral examination, biopsy of suspicious lesions, and imaging studies to determine the disease’s extent. Given that OSCC frequently occurs on the tongue, developing image-based diagnostic methods for tongue OSCC may play a significant role in the early detection and establishment of preventive strategies. DCNN can be useful here for development of automated, accurate prediction methods for OSCC in comparison with normal controls and glossitis.
Given the frequency with which clinicians encounter ambiguous tongue lesions, there is a compelling need to distinguish between benign and malignant conditions based on clinical appearance alone. Among various tongue lesions, glossitis and tongue cancer—specifically OSCC—merit direct comparison due to their distinct clinical implications, diagnostic ambiguity, and potential pathophysiological relationship5. Patients often present with symptoms such as tongue pain, redness, or surface irregularities, but the underlying condition can range from inflammation to early-stage cancer. Persistent inflammation in the oral cavity, including glossitis, has been linked to increased cancer risk through sustained epithelial damage, immune dysregulation, and pro-oncogenic signaling21. By contrasting benign glossitis and OSCC, emerging deep learning models may help support early detection of tongue cancer, reduce diagnostic uncertainty, and enhance clinical decision-making, particularly in telemedicine and remote care settings. Despite the clinical relevance of tongue image-based diagnosis, deep learning–based research in this area remains limited, underscoring the need for further investigation.
Accordingly, this study classified clinical tongue images into normal controls, glossitis, and OSCC using various DCNNs with transfer learning. The primary aim was to evaluate the diagnostic performance of these models in distinguishing glossitis from normal controls, and OSCC from both normal controls and glossitis. We hypothesized that DCNNs would achieve high diagnostic accuracy in differentiating glossitis, and even higher accuracy in identifying OSCC. Furthermore, we explored whether increasing the diversity of image inputs could enhance model performance, as prior studies suggest that diversity in training data improves generalizability of deep learning models22,23. To this end, we implemented a patch-wise ensemble approach by segmenting whole-tongue images into 3, 4, and 6 regions. This method aimed to enrich the representation of localized lesion features and increase variation in input patterns, thereby potentially improving classification accuracy. The study also examined whether diagnostic performance differences would be observed by sex and age (< 50 years, AGE1; ≥ 50 years, AGE2). Our evidence is expected to lay the foundation for advancing telemedicine, remote consultations, and innovative smart healthcare solutions using tongue images.
Materials and methods
The research protocol for this study was reviewed to ensure compliance with the principles of the Declaration of Helsinki, and approved by the Institutional Review Board of Kyung Hee University Dental Hospital in Seoul, South Korea (KHD IRB, IRB No-KH-23–015-001). Informed consent was obtained from all participants.
Study population
Figure 1 illustrates the study population, which comprised 652 participants (482 females and 170 males; mean age, 61.52 ± 17.27 years) who visited Kyung Hee University Dental Hospital between January 2021 and December 2024. These participants were divided into the following three classifications: (1) normal control (n = 294, mean age, 60.44 ± 15.46 years; female, 238; male, 56), (2) glossitis (n = 340, mean age, 62.77 ± 18.78 years; female, 241; male, 99), and (3) OSCC (n = 17, mean age, 56.65 ± 13.04 years; female, 2; male, 15). A specialist with over 10 years of experience in oral medicine, oral diagnosis of oral soft tissue diseases, and OSCC was the person responsible for caring for these patients who visited the aforementioned University Dental Hospital.

Study population for Tasks 1 and 2. OSCC, oral squamous cell carcinoma; N, number of samples in each class.
Dataset
This study developed and utilized a novel dataset for classifying tongue lesions, consisting of images collected from patients who visited the Department of Orofacial Pain and Oral Medicine at Kyung Hee University Dental Hospital for various dental conditions. This dataset has three classes, two which represent tongue lesions (glossitis and OSCC) and one which represents normal control images. These classes are briefly described as follows.
-
1.
Normal control: a healthy tongue appears pink, has medium thickness, lacks fissures, and exhibits a slightly whitish moist surface.
-
2.
Glossitis: this is a broad term denoting various forms of tongue inflammation, which often manifest clinically as tongue pain, surface appearance alterations (e.g., changes in texture/color), or a combination of both. Glossitis is frequently associated with tongue inflammation and swelling and arises from diverse etiologies, including allergic reactions, infections, and xerostomia.
-
3.
OSCC: this is the most common type of cancer in the oral cavity, originating from the squamous epithelium of the oral mucosa. It accounts for approximately 90% of all oral cancers worldwide and primarily arises in the tongue, palate, gingiva, floor of the mouth, and buccal mucosa. In this study, only patients with OSCC involving the tongue were included as representative OSCC cases. Furthermore, only patients with biopsy-confirmed OSCC were included.
In the dataset, all images were standardized using the JPEG format and resized according to the requirements of the specific DCNN architecture employed. Two oral medicine and diagnosis experts, each with over 10 years of clinical experience, engaged in independent annotation to label the high-quality tongue images according to the three classes (normal control, glossitis, and OSCC). The exclusion criteria for the images were as follows: patient under 18 years old; inadequate resolution; quality issues rendering them unsuitable for accurate tongue diagnosis; inaccuracies; ambiguous tongue diagnoses; the absence of the tongue in the image. Despite operators being exposed to standardized tongue-imaging training, abnormal tongue images remain frequent in clinical tongue-imaging, both from operators and participants. The criteria were considered during the construction of the new dataset with 652 tongue images.
The intra-examiner reproducibility measurements yielded intraclass correlation coefficients of 0.78 and 0.82, and these coefficients for tongue lesion diagnosis were 0.80 and 0.83. When disagreements occurred, the two experts engaged in multiple discussions to reach a consensus, and subsequently jointly labeled a small number of images with previously inconsistent labels. This collaborative process ensured consistent and accurate labeling across all images.
Study design
Figure 2 illustrates the flow of the study. This study used clinical images of the tongue to perform two tasks: Task 1, involving the diagnosis of glossitis compared with normal controls (i.e., for a total of 635 normal control and glossitis cases); Task 2, involving the diagnosis of OSCC compared with normal controls and those with glossitis (i.e., 17 OSCC cases were included, resulting in 652 cases). The ground truth for these tasks was determined by human experts in oral diagnosis who categorized the images into normal controls, glossitis, and OSCC based on clinical, oral, and histopathological examinations. In Task 1, all tongue images were classified into two categories (normal control and glossitis) using four fine-tuning strategies: VGG16, VGG19, ResNet50, and ResNet152. We ensembled the top two strategies (VGG16 and VGG19) and all four strategies (VGG16, VGG19, ResNet50, and ResNet152) to investigate whether the prediction accuracy improved. We also examined differences in prediction accuracy based on sex and age groups (< 50 years and ≥ 50 years).

Flow chart of the present study. OSCC, Oral squamous cell carcinoma; DCNN, Deep Convolutional Neural Network; VGG16, Visual Geometry Group 16-layer network; VGG19, Visual Geometry Group 19-layer network; ResNet50, Residual Network with 50 layers; ResNet152, Residual Network with 152 layers; Grad-CAM, Gradient-weighted Class Activation Mapping.
The study also probed into whether using the whole tongue image for prediction would yield improved accuracy than dividing the entire image into smaller segments. Tongue images were cropped into three, four, or six patch images, and fine-tuning was conducted using these patches. A patch-wise ensemble was applied to obtain the final tongue image classification and compare the results from these configurations. For Task 2, the models were trained by fine-tuning whole tongue images. We evaluated the results using the Area Under the Receiver Operating Characteristic curve (AUROC) values and interpreted the model outputs using Grad-CAM and sparsity to enhance explainability.
Tongue image classification
Data preparation: data splitting and preprocessing
The images were resized to 140 × 140 × 3 pixels, a size suitable for various DCNN-based models24, and divided into training, validation, and test sets in a 0.6:0.2:0.2 ratio while preserving the original label ratio across subsets. For data augmentation during training, we applied random rotation, random vertical flip, and random affine transformations, following methods previously used in effusion classification tasks25.
Training strategies for VGG19 with data augmentation
To determine the optimal training approach for classification with our limited number of tongue images, we tested three training strategies using the VGG19 model26:
-
From-scratch: training all layers from randomly initialized weights.
-
Freeze: training only the fully connected layers while keeping the pretrained convolutional layers fixed.
-
Fine-tuning: training the entire model, starting from pretrained weights.
The fine-tuning strategy, which is a specific technique used in transfer learning, outperformed the other strategies and achieved the highest AUROC scores, underpinning the effectiveness of fine-tuning the pretrained models in our scenario of a limited number of medical image data.
Performance of four DCNN-based models
Based on the superior performance of the fine-tuning strategy using VGG19, we used four DCNN-based architectures for tongue classification, namely VGG1627, VGG1928, ResNet5029, and ResNet15230. All models were fine-tuned using the same hyperparameters, which were determined through a grid-search process. Specifically, we explored a 3 × 3 grid of batch sizes (16, 32, 64) and learning rates (1e-4, 5e-4, 1e-3). Based on the validation loss observed during training with the VGG16 model, the optimal combination was found to be a batch size of 64 and a learning rate of 1e-4. Consequently, all models were trained using 20 epochs, batch size = 64, and learning rate = 1e-4.
Transfer learning leverages knowledge from one task to enhance the performance of a related task. In this study, we adapted pretrained DCNNs for tongue classification through fine-tuning. Given the moderate size of our dataset, this approach allowed us to effectively tailor the networks for our specific classification tasks, as well as helped us overcome the challenges associated with limited training data by utilizing models pretrained on large datasets. The DCNNs used in this study are briefly described below.
VGG16 The VGG16 architecture is a DCNN specifically designed for image-classification tasks known for its simplicity and depth, consisting of 16 layers (i.e., 13 convolutional layers and three fully connected layers), followed by a SoftMax output layer for classification. The number of filters in the convolutional layers progressively increases to enhance feature extraction (64, 128, 256, and 512).
VGG19 The VGG19 architecture is an extension of the VGG16 architecture, incorporating increased depth for improved image classification performance, comprising 16 convolutional layers, 3 fully connected layers, 1 SoftMax layer, and 5 MaxPooling layers. The convolutional layers use filters with sizes of 64, 128, and 256 to efficiently extract hierarchical features.
ResNet50 The ResNet50 is a 50-layer DCNN designed to overcome the vanishing gradient problem using residual connections. The architecture comprises five parts, each containing a convolution block and an identity block. Each block utilizes 3 × 3 and 1 × 1 filters for feature extraction and dimensionality adjustment.
ResNet152 The ResNet152 architecture is an extended version of ResNet50 consisting of 152 layers, and it is designed to enhance feature extraction and performance. It employs a skip connection strategy similar to that of ResNet50 with additional layers to increase depth. The network is divided into 33 blocks, 29 of which are identity blocks that directly use the output of the previous block, while four are convolutional blocks utilizing 1 × 1 filter for dimensionality adjustment.
Investigating whole image classification and patch-wise ensemble with cropped images
To address the potential influence of non-tongue elements (e.g., lips and background) in the dataset on model performance, we aimed to reduce these confounding variables by segmenting the tongue region from the images. Subsequently, we trained and evaluated the model using these patch images to determine whether this approach could mitigate the impact of non-tongue components and improve the overall performance.
Although the tongue images used in this study were relatively modest in size, with a maximum resolution of approximately 700 × 700 × 3 pixels, we evaluated the efficacy of a patch-based ensemble to determine its potential impact on medical image classification tasks and its broader applicability in the field. This approach was designed as an alternative to the traditional method of generating a single classification or diagnosis from an entire image, aiming to enhance model robustness and accuracy. We implemented a cut-and-vote approach by segmenting each image into smaller patches, as follows.
-
Three vertical splits (three crops, CROP_3): the image is divided into three equal vertical sections.
-
Two vertical and two horizontal splits (four crops, CROP_4): the image is divided into four equal sections by splitting it once vertically and once horizontally.
-
Three vertical and two horizontal splits (six crops, CROP_6): the image is divided into six equal sections by splitting it twice vertically and once horizontally.
Each patch was treated as an independent input during training. For each configuration, the probabilities obtained from the cropped images were integrated using a voting algorithm to obtain the final classification results (Fig. 3).

Cropping strategy for whole tongue images. VGG16, Visual Geometry Group 16; VGG19, Visual Geometry Group 19; ensemble, ensemble of VGG16 and VGG19; DIRECT, uses the whole tongue image without cropping; CROP_4, crops the image into four parts.
Grad-CAM visualization and locality characteristics of DCNNs
We utilized Grad-CAM to visualize image regions that contributed the most to model predictions and validate the locality characteristics of DCNNs31. Grad-CAM heatmaps were overlaid on input images and demonstrated that the models consistently focused on clinically-relevant tongue regions even when trained on whole images.
Fusion of classification decisions using patch-wise ensemble
In the fusion approach, the ensemble process is utilized to combine multiple classifier decisions and obtain a better classification performance. A common approach is to use a patch-wise ensemble by averaging the probabilities; that is, the mean value of the outputs obtained from multiple networks is assigned as the final probability of a particular sample.
In the patch-wise ensemble-based fusion step of this study, a label was assigned to a particular test sample prediction based on the probabilities obtained from multiple patches. For each patch, the classification probabilities were aggregated, and the final decision was made using a threshold determined by the Youden’s index, calculated from the validation dataset32. This threshold ensured an optimal balance between sensitivity and specificity for label assignment.
Experimental setup
All experimental procedures of this study are available at: https://github.com/SeonggwangJeon/Detection-of-Glossitis-and-OSCC-Lesions-on-the-tongue. The source codes were developed to run on Google Colaboratory for reproducibility and accessibility (Fig. 4).

Differentiation and diagnosis of OSCC compared to normal controls and glossitis. OSCC, oral squamous cell carcinoma; 0, normal control; 1, glossitis; 2, Grad-CAM, Gradient-weighted Class Activation Mapping.
Evaluations metrics
A Confusion matrix was used to measure the four DCNNs’ classification performance quality. This matrix defines the number of true positive (TP), false positive (FP), false negative (FN), and true negative (TN) tests. Based on the test results, accuracy, sensitivity, specificity, precision, Recall, and F1 score test metrics were obtained.
Statistical methods
Descriptive statistics are reported as means ± standard deviations or numbers with percentages, as appropriate. To analyze the distribution of categorical data, we used χ2 tests for equality of proportions, Fisher’s exact tests, and Bonferroni tests. All statistical analyses were performed using SPSS for Windows (version 24.0; IBM Corp.), R (version 4.0.2; R Foundation for Statistical Computing), and Python (version 3.9.7; Python Software Foundation). A ROC curve was plotted and the AUC was calculated for each model, in which an AUC = 0.5 indicated no discrimination, 0.6 ≥ AUC > 0.5 indicated poor discrimination, 0.7 ≥ AUC > 0.6 indicated acceptable discrimination, 0.8 ≥ AUC > 0.7 indicated excellent discrimination, and AUC > 0.9 indicated outstanding discrimination33. The AUROC represents the overall performance of a classification model, where a value of 0.5 indicates random guessing, and a value of 1.0 signifies perfect performance. Delong’s test was used to compare the AUROC values across the algorithms or models, primarily to evaluate and compare their performances. McNemar’s test, a non-parametric method used to statistically assess the differences in AUROC values between two or more ROC curves34, was used to compare the prediction accuracies of the DCNN models with those of the human experts. Statistical significance was set at a two-tailed P-value < 0.05.
Results
Task 1
Comparison of fine-tuning and extension strategies for DCNN
In diagnosing glossitis compared to normal controls using VGG16, we evaluated three DCNN training strategies: fine-tuning, which achieved an area under the curve (AUC) of 0.8468 (95% confidence interval [CI] 0.7757–0.9100); from-scratch training, which achieved an AUC of 0.7139 (95% CI 0.6203–0.7938); and freeze training, which achieved an AUC of 0.6731 (95% CI 0.5738–0.7577). Thus, the fine-tuning strategy outperformed the other methods in predicting glossitis (Figs. 3, 5).

Area under the receiver operating curves and confusion matrix of VGG19 models for classifying glossitis. Classification results of VGG19 upon three different learning strategies; green, from-scratch; orange, freeze; blue: fine-tuning; AUC, receiver operating characteristic curve.
Investigating the performance of four DCNNs and ensemble models
Considering the entire dataset, the results indicated no significant differences in AUROC performance among the four DCNNs (Table 1; Fig. 1). When considering an ensemble using the two top-performing models (i.e., VGG16 and VGG19; ensemble_2) and another with all four DCNNs (VGG16, VGG19, ResNet50, and ResNet152; ensemble_4), there were no significant differences in glossitis prediction accuracy. Notably, the accuracy results followed a similar trend to those of AUROC, reinforcing the consistency and reliability of AUROC as a performance metric in this context. These accuracy outcomes are presented in Fig. 6. For instance, ensemble_2 (AUROC = 0.8731, 95% CI 0.8072–0.9298) demonstrated significantly higher predictive performance for glossitis compared to ResNet50 alone (AUROC = 0.7771, 95% CI 0.6932–0.8559; P = 0.042352; Table 2). Therefore, the architectural variations of the four DCNNs had minimal impact on classification outcomes in our dataset.

Task 1 of the classification of glossitis using whole tongue images. Ensemble_2, an ensemble of the VGG16 and VGG19 models; Ensemble_4, an ensemble of the VGG16, VGG19, ResNet50, and ResNet152 models. TP, true positive; FP, false positive; FN, false negative; TN, true negative; PPV, positive predictive value; NPV, negative predictive value; sensitivity, TP/ FN + TP; specificity, TN/ TN + FP; PPV, TP/ TP + FP; NPV, TN/ TN + FN; Precision, TP/ TP + FP; Recall, TP/ TP + TN; F1 score, 2 ∗ Precision ∗ Recall / Precision + Recall.
Sensitivity was the highest in VGG19 (0.8060), specificity the highest in ensemble_2 (0.8000), positive predictive value was the highest in ensemble_2 (0.8125), negative predictive value was the highest in VGG19 (0.7636), and the F1 score was the highest in ensemble_2 (0.7939). However, there was no statistically significant difference in the diagnostic accuracy of glossitis compared with that of the normal controls among these models (P > 0.05; Fig. 6).
Prediction performance by sex and age using the VGG19 and ensemble models
Considering the entire dataset, both the VGG19 model (AUROC = 0.8639) and the ensemble_2 (AUROC = 0.8731) demonstrated excellent predictive performance (AUROC values exceeding 0.85). Regarding glossitis prediction accuracy by sex, the VGG19 strategy demonstrated a higher AUROC value in men than in women, albeit not to a statistically significant extent (0.9044 vs. 0.8430, P = 0.3052); ensemble_2 showed a similar trend of a non-significantly higher AUROC value among men than women (0.8978 vs. 0.8526, P = 0.453123). There was no significant performance difference between the VGG19 model and ensemble_2 (P > 0.05).
Regarding age groups, the AUROC values for the VGG19 model (AGE1 vs. AGE2: 0.8636 vs. 0.8668; P = 0.97006) and ensemble_2 (0.8977 vs. 0.8727, P = 0.744028) showed no statistically significant differences (all P > 0.05). Across all conditions, the prediction accuracy demonstrated excellent performance (i.e., AUROC exceeding 0.84), entailing that the models exhibited high predictive power without significant differences by sex or age (Fig. 7).

Comparison of model prediction performance by sex and age group. All, All subjects; AGE1, < 50 years; AGE2, ≥ 50 years; FEMALE, female participant; MALE, male participants; VGG19, Visual Geometry Group 19; Ensemble, Ensemble of VGG16 and VGG19.
Investigating whole image classification and patch-wise ensemble with cropped images
Considering whole tongue image data, both the VGG19 model (AUROC = 0.8731) and ensemble_2 (AUROC = 0.8731) demonstrated excellent predictive performance, with AUROC values exceeding 0.87. Interestingly, in the VGG19 model, cropping the tongue image into three (CROP_3, AUROC = 0.7704), four (CROP_4, AUROC = 0.7754), and six segments (CROP_6, AUROC = 0.7663) resulted in non–significantly lower AUROC values than those of the whole tongue images (AUROC = 0.8731). A similar pattern was observed in ensemble_2, where cropping the tongue image into three (CROP_3, AUROC = 0.7819), four (CROP_4, AUROC = 0.8254), and six segments (CROP_6, AUROC = 0.7672) also resulted in non–significantly lower AUROC values than those of whole tongue images (AUROC = 0.8731).
No model exhibited a consistent trend of a significant increase/decrease in AUROC values as the number of cropped segments increased from three to six. Ensemble_2 consistently showed slightly higher yet nonsignificant AUROC values than the VGG19 model across the three cropped segment conditions. Among the three configurations, the CROP_4 strategy achieved the highest AUROC score. However, compared to the whole image tongue classification approach, the CROP_4 strategy showed no significant improvement, suggesting that DCNNs effectively leverage their locality properties to capture important features, even without explicit image segmentation35. Overall, the findings suggest the efficiency, effectiveness, and timeliness of using whole tongue images with a straightforward VGG19 model, as this did not compromise predictive performance (Fig. 8).

The AUC for cropped tongue images compared to the whole tongue image. DIRECT, uses the whole tongue image without cropping; CROP_3, crops the image into three parts; CROP_4, crops the image into four parts; CROP_6, crops the image into six parts; VGG19, Visual Geometry Group 19; ensemble, ensemble of VGG16 and VGG19.
Visualization of tongue diagnosis using GRAD-CAM and sparsity
Heatmaps and sparsity were utilized to investigate which tongue regions are recognized as glossitis predictors (Fig. 6). We utilized gradient-weighted class activation mapping (Grad-CAM) to visualize the regions of tongue images that contributed the most to model predictions and validate the locality characteristics of the DCNNs31. By overlaying the heatmaps on the input images, we observed that the models consistently focused on clinically relevant tongue regions, even when trained on whole images.
Sparsity refers to the proportion of elements in a dataset/matrix with zero values, with a sparsity of 1.0 indicating that all elements are zero (completely sparse) and of 0.0 indicating that no elements are zero (completely dense). Considering whole tongue image data, sparsity was 0.7822. Regarding CROP_3, sparsity values for the posterior, middle, and anterior 1/3 were 0.7761, 0.7792, and 0.7870, respectively, and were non-significantly different from that of whole tongue image data. For CROP_4, sparsity values were 0.7852, 0.7774, and 0.7860 for the posterior right and left and anterior right 1/4, respectively. For CROP_6, sparsity values were 0.7846, 0.7756, and 0.7861 for the posterior, middle, and anterior right 1/3, respectively; the figures were 0.7882, 0.7777, and 0.7917 for the posterior, middle, and anterior left 1/3, respectively. The differences were nonsignificant between the sparsity values of the whole tongue image data (0.7822) and the smallest segments of CROP_6 (sparsity: 0.7756–0.7917).
A sparsity value in the range of 0.7–0.8 suggests that 70–80% of the dataset consists of zero elements and 20–30% of non-zeros. This implies that diagnostic information is concentrated within 20–30% of the data, narrowing the region of interest and often leading to relatively superior imaging-based predictive outcomes (Fig. 9).

Heatmaps with Grad-CAM and sparsity. Grad-CAM, Gradient-weighted class activation mapping. CROP_3, crops the image into three parts; CROP_4, crops the image into four parts; CROP_6, crops the image into six parts.
Task 2
{Normal controls and glossitis} vs. {OSCC}
In the binary classification, the DCNN’s ability to classify {normal controls and glossitis} vs. {OSCC} was exceptionally high, with the following AUROC values: VGG16 (0.9902, 95% CI 0.9707–1.000), VGG19 (1.0000, 95% CI 1.0000–1.0000), ResNet50 (0.9961, 95% CI 0.9840–1.0000), ResNet152 (1.0000, 95% CI 1.0000–1.0000), and ensemble (1.0000, 95% CI 1.0000–1.0000). These numbers demonstrated near-perfect prediction performance, and the performance differences between the models were nonsignificant (all P > 0.05).
{Normal controls} vs. {glossitis and OSCC}
The ability to perform the binary classification of {normal controls} vs. {glossitis and OSCC} was also high across all DCNNs, albeit lower than for the classification of {normal controls and glossitis} vs. {OSCC}. The AUROC values were as follows: VGG16 (0.8601, 95% CI 0.7924–0.9146), VGG19 (0.8312, 95% CI 0.7531–0.8941), ResNet50 (0.8174, 95% CI 0.7429–0.8824), ResNet152 (0.7768, 95% CI 0.6947–0.8558), and ensemble (0.8653, 95% CI 0.7994–0.9209). Among these, the ensemble and VGG16 models demonstrated relatively superior performance (i.e., AUROC > 0.86), and the performance of the VGG16 was significantly higher than that of the ResNet152 (P = 0.048673).
{Normal controls} vs. {glossitis} vs. {OSCC}
To investigate the classification performance for {normal controls}, {glossitis}, and {OSCC}, we used the DCNNs to perform a three-class classification. The results showed a rank for the macro AUROC values as described herein: ensemble (0.8841) > VGG16 (0.8731) > VGG19 (0.8545) > ResNet152 (0.849) > ResNet50 (0.8363). However, the differences in classification performance between the models were nonsignificant (all P > 0.05).
To enhance classification performance, we applied a tenfold augmentation incorporating random rotation, random vertical flip, and random affine transformations. After augmentation, the ranking of the macro AUROC values changed as follows: ResNet50 (0.9058) > Ensemble (0.8999) > VGG19 (0.8897) > VGG16 (0.8858) > ResNet152 (0.8848). Notably, the ResNet50 model exhibited a substantial improvement, with an increase of 6.95%. Despite these changes, the five models showed nonsignificant differences in prediction accuracy (P > 0.05; Fig. 10).

Diagnostic AUC for OSCC under different conditions and visualization. Class 0, normal control; Class 1, glossitis; Class 2, OSCC; VGG16, Visual Geometry Group 16; VGG19, Visual Geometry Group 19; RESNET50, Residual Network 50; RESNET152, Residual Network 152; Ensemble, Ensemble of VGG16 and VGG19.
Application of diagnostic tool
By uploading an image of the tongue—either from a patient in a clinical setting or an individual at home—into the provided diagnostic interface, the model generates a classification result, categorizing the input as normal control, glossitis, or OSCC.
The diagnostic process can be accessed at:
Discussion
This study confirmed our hypothesis that DCNNs can effectively distinguish glossitis from normal tongue conditions, and perform even more accurately in identifying OSCC. Among the evaluated models, VGG-based architectures, particularly VGG19 and its ensemble with VGG16, demonstrated the strongest diagnostic performance for glossitis. All models showed excellent classification capabilities for OSCC, with some achieving perfect separation between cancerous and non-cancerous cases. These findings validate our initial assumption and highlight the potential of DCNNs as reliable tools for differentiating both inflammatory and malignant tongue lesions. The models maintained consistent performance across different sex and age subgroups, and whole-image classification generally outperformed cropped or patch-wise approaches. Furthermore, Grad-CAM visualization confirmed that the models focused on clinically relevant regions of the tongue, while sparsity analysis suggested that diagnostic features were concentrated in specific localized areas. Together, these results support the clinical applicability of AI-based tongue image analysis, particularly for early cancer detection and telemedicine-supported decision-making.
Among the evaluated DCNNs, the VGG models and their ensemble outperformed, albeit to a reduced extent, the ResNet models. The fine-tuning strategy demonstrated superior performance compared with models trained from scratch or using frozen layers. Considering the hypothesis that image diversity or quantity increases would enhance model predictive capability, we augmented the OSCC images and hence achieved a classification performance improvement in the 1–10% range for each strategy. Furthermore, this study investigated whether diagnostic performance varied according to sex and age (< 50 years and ≥ 50 years). In the current AI-driven world, tongue image-based oral diagnosis is poised to become a vital healthcare component, particularly in telemedicine and virtual consultations36. Indeed, with the recent advancements in smart device technology, the ability to remotely capture and analyze tongue and oral cavity images or videos has become indispensable for non-face-to-face medical services37. Considering that AI-powered solutions have emerged as game-changers for diagnosis procedures, we anticipate that our findings mentioned in the prior paragraph may contribute to advancing telemedicine, remote consultations, and innovative smart healthcare solutions that utilize tongue images.
Regarding performance in glossitis classification using whole tongue images, the study found that both the VGG19 model and ensemble_2 exhibited superior diagnostic accuracy (AUROC > 0.85) in distinguishing glossitis from normal controls. VGG19 had several advantages over ResNet, particularly in medical imaging tasks. Its simpler and more uniform architecture makes it easier to implement and adapt to transfer learning, which is a critical factor when applying pretrained models to specific datasets such as tongue images. VGG19’s consistent use of 3 × 3 convolutional filters allows it to capture detailed and rich features essential for distinguishing subtle differences in medical images38. Additionally, VGG19 is well-suited for transfer learning and performs stably during training, especially when the dataset size is relatively small, as it avoids some of the potential instabilities associated with ResNet’s skip connections39.
In this study, when VGG16 and VGG19 were combined into an ensemble, their complementary strengths enhanced overall diagnostic performance. Although both models share a similar architecture, VGG19’s deeper structure captures finer and more complex features, while VGG16 excels at recognizing simpler, generalized patterns. By aggregating both models’ predictions, the ensemble reduces individual biases and errors, resulting in increased robustness and improved predictive accuracy40. This approach also enhances prediction confidence because the ensemble can average out the uncertainties that might arise from either model alone. Furthermore, because VGG16 and VGG19 belong to the same architectural family, their compatibility ensures a smooth integration, whereas their differences provide complementary benefits without conflicting outputs. The observed AUROC increase when using the ensemble highlights its effectiveness41. By leveraging the consistent feature extraction capabilities of the VGG family and mitigating individual model limitations42, the ensemble demonstrated improved diagnostic accuracy and robustness. This makes it an ideal approach for medical imaging tasks such as glossitis and OSCC classification, where reliable and precise predictions are critical.
This study also examined whether diagnostic accuracy varied by sex or age group in order to acknowledge the potential influence of these two variables. Still, the differences by age and sex were non-significant. Currently, comprehensive research addressing sex differences in tongue lesion prevalence is lacking. Meanwhile, OSCC is generally recognized to be more prevalent in men, with 90–93% of patients being men and 7–10% being women43,44. In this study, glossitis was more prevalent in women than in men (ratio, 2.43:1), whereas OSCC demonstrated a markedly higher prevalence in men (ratio, 1:7.5). Detailed data specifically focusing on age-related disparities in glossitis are limited. In contrast, OSCC is known to typically affect patients over 50 years old, 95% of cases are individuals aged over 40 years, and is extremely rare in those under 35 years of age45,46. These findings underscore the need for further in-depth studies to elucidate the sex- and age-related differences in tongue lesion diagnosis; larger datasets and multicenter designs may reveal clearer patterns of these differences. Advancing the field may require continued efforts to develop DCNN-based tongue diagnostic models that account for sex- and age-related disparities.
Regarding the hypothesis that increasing image diversity or quantity would improve predictive performance, it was not supported. The performance of deep learning models in medical image analysis is significantly affected by training data quantity and diversity47. However, obtaining sufficient medical imaging datasets is often challenging in real-world scenarios, often leading to data augmentation technique implementation to improve model performance. Furthermore, studies have shown that albeit increasing medical image volume and diversity can enhance performance in certain cases, this improvement is not universally guaranteed48,49,50. We also observed nonsignificant differences between whole tongue image use and the use of a cropping strategy in which the whole image is divided into smaller segments for voting. Interestingly, even without image cropping, the differentiation between OSCC, normal controls, and glossitis was exceptionally accurate (i.e., AUROC value range, 0.9–1.0). However, Zaridis et al. reported that appropriate cropping can enhance deep learning model performance by focusing on the relevant regions and reducing background noise51. Because the number of images in the OSCC class is smaller than that in the other two classes, establishing a model with a dataset that ensures a more balanced distribution across these classes is necessary to solidify our findings.
The primary strength of this study lies in its comprehensive methodology, which leveraged various DCNN models and strategies to develop a robust and interpretable diagnostic tool for distinguishing glossitis and OSCC in comparison to normal controls. By employing a range of DCNNs and exploring related techniques (e.g., ensemble modeling and transfer learning), this study provides a well-rounded evaluation of DCNN diagnostic performance. Another significant contribution of this research is the development of an online tool that integrates these findings, enabling real-time classification based on tongue images (https://github.com/SeonggwangJeon/Detection-of-Glossitis-and-OSCC-Lesions-on-the-tongue/blob/main/7.%20Diagnosis_process.ipynb). Notably, the use of whole tongue images as inputs allows for tool use to perform direct classifications into normal control, glossitis, and OSCC classes, making the process both efficient and user-friendly. The global experience of Severe Acute Respiratory Syndrome, Middle East Respiratory Syndrome, and COVID-19 evidence that pandemics and epidemics can recur, as well as the need for adaptable and robust diagnostic tools52,53. By leveraging DCNN-driven diagnostics and making possible a reduction in our current reliance on physical visits, this study paves the way for a new era of precision, accessibility, and efficiency in tongue diagnosis, thereby ensuring preparedness for future public health challenges.
This study used Grad-CAM and sparsity analysis as methods for AI interpretation. AI model reliability can be enhanced if the clinically significant regions overlap with the tongue lesion areas highlighted by Grad-CAM, as measured by simple metrics such as Intersection over Union and the Dice coefficient54. Grad-CAM provides visual interpretability and is considered one of the most comprehensive pixel attribution methods55. Furthermore, sparsity analysis is regarded as a method for interpreting AI in medical and dental images25,55,56. The sparsity values (approximately 0.7–0.8) indicated that diagnostic information was concentrated in about 20–30% of the whole tongue image, implying that learning efficiency can be improved by focusing on the region of interest and reducing noise. In this study, we used Grad-CAM and sparsity analysis to determine the tongue image regions to be analyzed, and then examined whether the locations and sizes of the highlighted regions aligned with the areas used by experts to diagnose glossitis and OSCC. In the near future, by automatically combining Grad-CAM and sparsity to identify regions of interest, or by investigating how these indicators vary according to sex and age, we can further refine and enhance the diagnostic process for tongue lesions.
This study had several limitations that should be addressed in future research. First, dataset imbalances (i.e., a smaller number of OSCC images compared with normal controls and glossitis images) may have influenced the findings, underscoring the need for more evenly-distributed datasets to validate model robustness. Although it is clinically challenging to obtain sufficient OSCC patient data, continued data collection and further research are warranted to strengthen the model’s validity. Second, although the study utilized clinical tongue images, the potential variability in image acquisition (e.g., lighting, angles, and patient positioning differences) may have introduced biases. Third, the lack of external validation by using data from diverse populations or multicenter sources limits result generalizability. Although this study explored the influence of sex and age on diagnostic performance, the limited scope of these demographic factors warrants further investigation in larger and more diverse cohorts.
Although this study explored the feasibility of using DCNNs to classify both glossitis and OSCC, the primary focus was on building and interpreting models that can accurately differentiate glossitis from normal tongue conditions. OSCC classification was included primarily as a proof-of-concept to assess the model’s ability to detect more severe pathological conditions. However, the tongue can manifest a wide spectrum of diseases beyond glossitis and OSCC—including geographic tongue, lichen planus, leukoplakia, traumatic ulcers, and various infectious or systemic conditions57,58. To further enhance clinical applicability, future research should aim to develop a more generalized diagnostic framework capable of recognizing a broader array of tongue pathologies. In particular, training a foundation model using large-scale, diverse datasets could enable fine-tuning for specific tasks and improve adaptability across clinical scenarios. Such a foundation model could significantly expand the utility of AI-assisted tongue diagnosis across diverse clinical settings, including real-world and resource-limited environments.
Conclusion
This study highlighted the potential of DCNNs, particularly VGG-based models and their ensembles, for glossitis and OSCC diagnosis using tongue images. The findings emphasize the utility of whole tongue images, effectiveness of transfer learning, and advantages of ensemble modeling. The efforts to increase image diversity and implement cropping strategies did not enhance performance, but the robustness of the current models demonstrates their promise for AI-driven tongue diagnosis. Future efforts to advance the field should focus on using balanced datasets, standardized imaging protocols, diverse populations, data augmentation techniques, and DCNN training strategies. Studies with these characteristics will strengthen the integration of AI diagnostics with telemedicine, reduce the need for in-person visits, and offer accessible, precise, and innovative healthcare solutions.
Data availability
The datasets used and analyzed in the current study are available from the corresponding author upon reasonable request.
References
Kim, J. et al. Availability of tongue diagnosis system for assessing tongue coating thickness in patients with functional dyspepsia. Evid. Based Complement. Altern. Med. 2013, 348272. https://doi.org/10.1155/2013/348272 (2013).
Xie, J. et al. Digital tongue image analyses for health assessment. Med. Rev. 2021(1), 172–198. https://doi.org/10.1515/mr-2021-0018 (2021).
Mollaoglu, N. Oral lichen planus: a review. Br. J. Oral Maxillofac. Surg. 38, 370–377. https://doi.org/10.1054/bjom.2000.0335 (2000).
R, A. N. & Rafiq, N. B. in StatPearls (StatPearls Publishing Copyright © 2025, StatPearls Publishing LLC., 2025).
Migueláñez-Medrán, B. C., Pozo-Kreilinger, J. J., Cebrián-Carretero, J. L., Martínez-García, M. A. & López-Sánchez, A. F. Oral squamous cell carcinoma of tongue: Histological risk assessment. A pilot study. Med. Oral Patol. Oral Cir. Bucal 24, e603–e609. https://doi.org/10.4317/medoral.23011 (2019).
Haber, J. et al. Putting the mouth back in the head: HEENT to HEENOT. Am. J. Public Health 105, 437–441. https://doi.org/10.2105/ajph.2014.302495 (2015).
Chan, H. P., Samala, R. K., Hadjiiski, L. M. & Zhou, C. Deep learning in medical image analysis. Adv. Exp. Med. Biol. 1213, 3–21. https://doi.org/10.1007/978-3-030-33128-3_1 (2020).
Dourado-Filho, L. A. & Calumby, R. T. An experimental assessment of deep convolutional features for plant species recognition. Eco. Inform. 65, 101411. https://doi.org/10.1016/j.ecoinf.2021.101411 (2021).
Li, M., Jiang, Y., Zhang, Y. & Zhu, H. Medical image analysis using deep learning algorithms. Front. Public Health 11, 1273253. https://doi.org/10.3389/fpubh.2023.1273253 (2023).
Gomes, R. F. T. et al. Use of artificial intelligence in the classification of elementary oral lesions from clinical images. Int. J. Environ. Res. Public Health. https://doi.org/10.3390/ijerph20053894 (2023).
Tanriver, G., Soluk Tekkesin, M. & Ergen, O. Automated detection and classification of oral lesions using deep learning to detect oral potentially malignant disorders. Cancers (Basel). https://doi.org/10.3390/cancers13112766 (2021).
Byrd, J. A., Bruce, A. J. & Rogers, R. S. 3rd. Glossitis and other tongue disorders. Dermatol. Clin. 21, 123–134. https://doi.org/10.1016/s0733-8635(02)00057-8 (2003).
Risso, D., Drayna, D. & Morini, G. Alteration, reduction and taste loss: main causes and potential implications on dietary habits. Nutrients https://doi.org/10.3390/nu12113284 (2020).
Kobayashi, A. & Iwasaki, H. Pernicious anemia presenting as glossitis. CMAJ 192, E434. https://doi.org/10.1503/cmaj.191331 (2020).
Chen, G.-Y., Tang, Z.-Q. & Bao, Z.-X. Vitamin B12 deficiency may play an etiological role in atrophic glossitis and its grading: A clinical case-control study. BMC Oral Health 22, 456. https://doi.org/10.1186/s12903-022-02464-z (2022).
Tan, Y. et al. Oral squamous cell carcinomas: state of the field and emerging directions. Int. J. Oral Sci. 15, 44. https://doi.org/10.1038/s41368-023-00249-w (2023).
Nethan, S. T., Ravi, P. & Gupta, P. C. in Microbes and Oral Squamous Cell Carcinoma: A Network Spanning Infection and Inflammation (ed Samapika Routray) 1–7 (Springer Nature Singapore, 2022).
Bagan, J., Sarrion, G. & Jimenez, Y. Oral cancer: Clinical features. Oral Oncol. 46, 414–417. https://doi.org/10.1016/j.oraloncology.2010.03.009 (2010).
Sim, Y. C., Hwang, J.-H. & Ahn, K.-M. Overall and disease-specific survival outcomes following primary surgery for oral squamous cell carcinoma: analysis of consecutive 67 patients. Jkaoms 45, 83–90. https://doi.org/10.5125/jkaoms.2019.45.2.83 (2019).
Kim, M. J. & Ahn, K. M. Prognostic factors of oral squamous cell carcinoma: the importance of recurrence and pTNM stage. Maxillofac. Plast. Reconstr. Surg. 46, 8. https://doi.org/10.1186/s40902-024-00410-3 (2024).
Tota, J. E. et al. Inflammatory tongue conditions and risk of oral tongue cancer among the US elderly individuals. J. Clin. Oncol. 42, 1745–1753. https://doi.org/10.1200/jco.23.00729 (2024).
Esteva, A. et al. Dermatologist-level classification of skin cancer with deep neural networks. Nature 542, 115–118. https://doi.org/10.1038/nature21056 (2017).
Kermany, D. S. et al. Identifying medical diagnoses and treatable diseases by image-based deep learning. Cell 172, 1122-1131.e1129. https://doi.org/10.1016/j.cell.2018.02.010 (2018).
Li, Z., Liu, F., Yang, W., Peng, S. & Zhou, J. A survey of convolutional neural networks: analysis, applications, and prospects. IEEE Trans. Neural Netw. Learn. Syst. 33, 6999–7019. https://doi.org/10.1109/TNNLS.2021.3084827 (2022).
Lee, Y.-H., Jeon, S., Won, J.-H., Auh, Q. S. & Noh, Y.-K. Automatic detection and visualization of temporomandibular joint effusion with deep neural network. Sci. Rep. 14, 18865. https://doi.org/10.1038/s41598-024-69848-9 (2024).
Kumaresan, S., Aultrin, K. S. J., Kumar, S. S. & Anand, M. D. Deep learning-based weld defect classification using VGG16 transfer learning adaptive fine-tuning. Int. J. Interact. Des. Manuf. (IJIDeM) 17, 2999–3010. https://doi.org/10.1007/s12008-023-01327-3 (2023).
Theckedath, D. & Sedamkar, R. R. Detecting affect states using VGG16, ResNet50 and SE-ResNet50 networks. SN Comput. Sci. 1, 79. https://doi.org/10.1007/s42979-020-0114-9 (2020).
Wen, L., Li, X., Li, X. & Gao, L. in 2019 IEEE 23rd International Conference on Computer Supported Cooperative Work in Design (CSCWD). 205–209.
Wen, L., Li, X. & Gao, L. A transfer convolutional neural network for fault diagnosis based on ResNet-50. Neural Comput. Appl. 32, 6111–6124. https://doi.org/10.1007/s00521-019-04097-w (2020).
Roy, P., Chisty, M. M. O. & Fattah, H. M. A. in 2021 5th International Conference on Electrical Information and Communication Technology (EICT). 1–6.
Selvaraju, R. R. et al. in Proceedings of the IEEE international conference on computer vision. 618–626.
Schisterman, E. F., Faraggi, D., Reiser, B. & Hu, J. Youden Index and the optimal threshold for markers with mass at zero. Stat. Med. 27, 297–315. https://doi.org/10.1002/sim.2993 (2008).
Metz, C. E. Basic principles of ROC analysis. Semin. Nucl. Med. 8, 283–298. https://doi.org/10.1016/s0001-2998(78)80014-2 (1978).
Vickers, A. J., Cronin, A. M. & Begg, C. B. One statistical test is sufficient for assessing new predictive markers. BMC Med. Res. Methodol. 11, 13. https://doi.org/10.1186/1471-2288-11-13 (2011).
Ku, W. L., Chou, H. C. & Peng, W. H. in 2015 Visual Communications and Image Processing (VCIP). 1–4.
Saber, A. F., Ahmed, S. K., Hussein, S. & Qurbani, K. Artificial intelligence-assisted nursing interventions in psychiatry for oral cancer patients: A concise narrative review. Oral Oncol. Rep. 10, 100343. https://doi.org/10.1016/j.oor.2024.100343 (2024).
Dos Santos, R. T. N. et al. Use of digital strategies in the diagnosis of oral squamous cell carcinoma: A scoping review. PeerJ 12, e17329. https://doi.org/10.7717/peerj.17329 (2024).
Haque, R., Hassan, M. M., Bairagi, A. K. & Shariful Islam, S. M. NeuroNet19: an explainable deep neural network model for the classification of brain tumors using magnetic resonance imaging data. Sci. Rep. 14, 1524. https://doi.org/10.1038/s41598-024-51867-1 (2024).
Khan, I. U. et al. An effective approach to address processing time and computational complexity employing modified CCT for lung disease classification. Intell. Syst. Appl. 16, 200147. https://doi.org/10.1016/j.iswa.2022.200147 (2022).
Pal, M., Parija, S. & Panda, G. An effective ensemble approach for classification of chest X-ray images having symptoms of COVID: A precautionary measure for the COVID-19 subvariants. e-Prime Adv. Electr. Eng. Electron. Energy 8, 100547. https://doi.org/10.1016/j.prime.2024.100547 (2024).
Celik, F., Celik, K. & Celik, A. Enhancing brain tumor classification through ensemble attention mechanism. Sci. Rep. 14, 22260. https://doi.org/10.1038/s41598-024-73803-z (2024).
Al-Thelaya, K. et al. Applications of discriminative and deep learning feature extraction methods for whole slide image analysis: A survey. J. Pathol. Inf. 14, 100335. https://doi.org/10.1016/j.jpi.2023.100335 (2023).
Liao, C. T. et al. Telomerase as an independent prognostic factor in head and neck squamous cell carcinoma. Head Neck 26, 504–512. https://doi.org/10.1002/hed.20007 (2004).
Liao, C. T. et al. Survival of second and multiple primary tumors in patients with oral cavity squamous cell carcinoma in the betel quid chewing area. Oral Oncol. 43, 811–819. https://doi.org/10.1016/j.oraloncology.2006.10.003 (2007).
Ferreira, E. C. R. et al. Oral squamous cell carcinoma frequency in young patients from referral centers around the world. Head Neck Pathol. 16, 755–762. https://doi.org/10.1007/s12105-022-01441-w (2022).
Müller, S., Pan, Y., Li, R. & Chi, A. C. Changing trends in oral squamous cell carcinoma with particular reference to young patients: 1971–2006. The Emory University experience. Head Neck Pathol. 2, 60–66. https://doi.org/10.1007/s12105-008-0054-5 (2008).
Tsuneki, M. Deep learning models in medical image analysis. J. Oral Biosci. 64, 312–320. https://doi.org/10.1016/j.job.2022.03.003 (2022).
Althnian, A. et al. Impact of dataset size on classification performance: An empirical evaluation in the medical domain. Appl. Sci. 11, 796 (2021).
Kebaili, A., Lapuyade-Lahorgue, J. & Ruan, S. Deep learning approaches for data augmentation in medical imaging: A review. J. Imaging 9, 81 (2023).
Davidian, M. et al. Exploring the interplay of dataset size and imbalance on CNN performance in healthcare: Using X-rays to identify COVID-19 patients. Diagnostics (Basel). https://doi.org/10.3390/diagnostics14161727 (2024).
Zaridis, D. G. et al. A new smart-cropping pipeline for prostate segmentation using deep learning networks. arxiv.abs/2107.02476 (2021).
Abdelghany, T. M. et al. SARS-CoV-2, the other face to SARS-CoV and MERS-CoV: Future predictions. Biomed. J. 44, 86–93. https://doi.org/10.1016/j.bj.2020.10.008 (2021).
Rosen, C. B., Joffe, S. & Kelz, R. R. COVID-19 moves medicine into a virtual space: A paradigm shift from touch to talk to establish trust. Ann. Surg. 272, e159–e160. https://doi.org/10.1097/sla.0000000000004098 (2020).
Wyatt, L. S., van Karnenbeek, L. M., Wijkhuizen, M., Geldof, F. & Dashtbozorg, B. Explainable artificial intelligence (XAI) for oncological ultrasound image analysis: A systematic review. Appl. Sci. 14, 8108 (2024).
Lee, Y.-H., Won, J. H., Kim, S., Auh, Q. S. & Noh, Y.-K. Advantages of deep learning with convolutional neural network in detecting disc displacement of the temporomandibular joint in magnetic resonance imaging. Sci. Rep. 12, 11352. https://doi.org/10.1038/s41598-022-15231-5 (2022).
van der Velden, B. H. M., Kuijf, H. J., Gilhuijs, K. G. A. & Viergever, M. A. Explainable artificial intelligence (XAI) in deep learning-based medical image analysis. Med. Image Anal. 79, 102470. https://doi.org/10.1016/j.media.2022.102470 (2022).
Straub, L., Schettini, P. & Myrex, P. Common tongue conditions in primary care. Am. Fam. Phys. 110, 467–475 (2024).
Zahid, E., Bhatti, O., Zahid, M. A. & Stubbs, M. Overview of common oral lesions. Malays. Fam. Phys. 17, 9–21. https://doi.org/10.51866/rv.37 (2022).
Acknowledgements
The authors extend their special thanks to Sung-Woo Lee of the Department of Oral Medicine and Oral Diagnosis at Seoul National University and to Jung-Pyo Hong of the Department of Orofacial Pain and Oral Medicine at Kyung Hee University Dental Hospital.
Funding
This work was supported by the National Research Foundation of Korea (NRF) grant funded by the Ministry of Science and ICT (MSIT) (No. RS-2024-00421203), the Institute of Information & Communications Technology Planning & Evaluation (IITP) grants funded by MSIT (IITP-2021-0-02068, RS-2020-II201373, RS-2023-00220628), and a research grant from Kyung Hee University in 2025 (KHU-20251299).
Author information
Authors and Affiliations
Contributions
Writing and original draft preparation: Y-HL and SJ; conceptualization: Y-HL and Y-KN; methodology: Y-HL, JSL and SJ; software: Y-HL, SJ, and Y-KN; validation and formal analysis: Y-HL, SJ, Q-SA, and AC; investigation: Y-HL and SJ; resources: Y-HL, JJ, and Q-SA; data curation: Y-HL and SJ; writing, review, and editing: Y-HL and SJ; visualization: Y-HL, SJ, and JJ; supervision: Y-KN and AC; project administration: Y-HL; funding acquisition: Y-HL and Y-KN. All authors contributed to and approved the submission of the manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Ethics approval
The research protocol complied with the Declaration of Helsinki and was approved by the Institutional Review Board of Kyung Hee University Dental Hospital in Seoul, South Korea (IRB No-KH-23-015-001).
Informed consent
Informed consent was obtained from all patients involved in the study.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Lee, YH., Jeon, S., Jung, J. et al. DCNN models with post-hoc interpretability for the automated detection of glossitis and OSCC on the tongue. Sci Rep 15, 31940 (2025). https://doi.org/10.1038/s41598-025-16760-5
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-025-16760-5
