
Abstract
Image style transfer is a key research area in computer vision. Despite significant progress, challenges such as mode collapse, over-stylization, and insufficient style transfer persist, impacting image quality and stability. To address these issues, we introduce StyDiff, a novel framework that combines diffusion models and Adaptive Instance Normalization (AdaIN) to achieve high-quality and flexible style transfer. Specifically, StyDiff uses the AdaIN module to precisely blend content and style features, mitigating problems of over-stylization and incomplete style transfer. The diffusion model optimizes image generation through a stepwise denoising process, ensuring consistency between content and style while significantly reducing artifacts. Additionally, a multi-component loss function is designed to further enhance the balance between content and style. Experimental results demonstrate that StyDiff outperforms existing methods across key metrics such as SSIM, GM, and LPIPS, producing images with superior style consistency, content retention, and detail preservation. This approach offers a more stable and efficient solution for style transfer tasks, with promising potential for widespread application.
Similar content being viewed by others

Introduction
Image style transfer has become an important research direction in the field of artificial intelligence-generated content (AIGC)1,2. Its goal is to modify the artistic appearance of an image while preserving its structural content, enabling seamless style transformation. This technology has broad applications in digital art, content creation, virtual reality, and film production, making it possible to automatically generate visually creative and artistic effects. Leveraging deep learning techniques, image style transfer not only enhances artistic expression but also automates tedious design processes, expanding the possibilities of visual storytelling3,4.
Traditionally, Generative Adversarial Networks (GANs) have been widely used for style transfer tasks5. GAN-based methods, such as StyleGAN and CycleGAN, have demonstrated excellent performance in generating high-quality stylized images. These models learn complex mappings between content and style images through adversarial training. However, GANs often face challenges such as unstable training, mode collapse, and difficulties in handling diverse style representations. Additionally, many GAN-based approaches still struggle to balance content preservation and style fidelity6.
The rapid development of diffusion models has brought significant advancements in image generation and transformation tasks. Unlike GANs, diffusion models operate through a stepwise denoising process, allowing better control over high-quality and diverse image generation7,8. In recent years, diffusion-based methods have achieved remarkable success in photorealistic image synthesis, texture manipulation, and high-resolution image translation9,10. Their ability to model complex data distributions makes them a promising alternative for style transfer applications.
However, diffusion model-based style transfer still encounters challenges such as mode collapse, excessive stylization, or insufficient style adaptation. Effectively transferring style attributes while maintaining the structural integrity of the content image remains a challenge. In many cases, existing approaches either distort important content details or fail to fully capture the stylistic essence of the reference image, limiting the quality of style transfer. Achieving a fine balance between content preservation and style consistency remains an urgent research problem.
To address these challenges, we propose StyDiff, a novel style transfer framework. This framework utilizes VDVAE (Variational Deep Latent Variable Autoencoder)11 to capture both low level attributes and the overall layout of images. Additionally, we incorporate adaptive instance normalization (AdaIN)12 as contextual guidance in the reverse diffusion process, enabling seamless style feature transfer from the reference image to the content image without introducing artifacts. To further optimize style transfer performance, we design a new loss function that integrates features from both the reference image and the style image, along with their compressed representations, ensuring better feature alignment between the generated images and the target styles. This innovative approach significantly improves the fidelity of style transfer and overcomes the shortcomings of existing diffusion models in style transfer tasks.
Figure 1 demonstrates the style transfer results of StyDiff. The three main contributions of this paper are as follows:
-
This paper introduces the StyDiff framework, which combines diffusion models and Adaptive Instance Normalization (AdaIN) to achieve high-quality and flexible image style transfer. The framework effectively preserves image content while accurately transferring the target style, addressing common issues such as over-stylization and insufficient style transfer in traditional methods.
-
A multi-component loss function is proposed, which includes content loss, style loss, element loss, and diffusion model loss. Through weighted optimization, this loss function further improves the balance between content and style during the image generation process, ensuring the preservation of image details and the consistent transfer of style.
-
Extensive experiments show that StyDiff outperforms existing state-of-the-art methods in key evaluation metrics such as SSIM, GM, and LPIPS. The generated images exhibit superior style consistency, content retention, and detail preservation, providing a more stable and efficient solution for image style transfer tasks.

StyleDiff style transfer examples showcase. All content images in this showcase are generated using DALL·E 313.
The structure of this paper is as follows: Section 2 reviews related work, covering classic methods and recent advances in the field of image style transfer; Section 3 describes the proposed StyDiff framework in detail, including the model architecture, core components, and key techniques; Section 4 presents the experimental setup and results, evaluating StyDiff’s performance on multiple benchmark datasets and comparing it with existing methods; Section 5 concludes the paper, summarizing the research findings and discussing future directions for further research.
Related works
Advancements and applications of neural style transfer technology
In recent years, the field of Neural Style Transfer (NST) has made significant progress, with much research focusing on improving transfer effectiveness and optimizing computational efficiency14. Gatys et al. proposed the initial neural style transfer method, which utilizes Convolutional Neural Networks (CNNs) to separate the content and style of an image and introduces a framework for style transfer by optimizing an objective function15. This method laid the foundation for subsequent style transfer research and demonstrated the potential of using deep learning for artistic style transformation of images. To improve efficiency, Johnson et al. introduced the perceptual loss function and proposed a real-time neural style transfer method. This method not only achieves efficient style transfer at a lower computational cost but also allows real-time style transfer on mobile devices, providing technical support for practical applications16. Later, Chen et al. proposed a universal style transfer method that transforms features, enabling the same model to handle multiple styles without the need to train separate models for each style17. This method enhances the flexibility of style transfer and overcomes the issue of needing to retrain for each style, as in traditional approaches. Li et al. further introduced a universal style transfer method based on deep feature reconstruction18. This method builds a shared feature space, allowing style transfer to be independent of specific style models, improving transfer effectiveness while boosting computational efficiency. Xie et al. proposed an interactive style transfer method that introduces a user interface, allowing users to adjust the details of the style transfer process in real time, making style transfer more personalized and flexible, and greatly enhancing creative freedom16. These methods have made significant contributions to improving the effectiveness of style transfer, enhancing computational efficiency, and increasing flexibility, driving the continuous development of neural style transfer technology, which has been widely applied in digital art, film production, and other fields.
Applications and advancements of generative adversarial networks in style transfer
Generative Adversarial Networks (GANs) have become a significant research direction in the field of NST. Traditional style transfer methods typically rely on explicit relationships between image content and style, whereas GANs, through adversarial training mechanisms, can generate more realistic and diverse stylized images19. CycleGAN introduced an image-to-image translation method that does not require paired data, solving the problem of unsupervised learning and enabling style transfer without paired image data, which is particularly useful in situations where paired images for style transfer are difficult to obtain20. To achieve more refined transformation with paired data, Pix2Pix proposed a style transfer method based on image pairs using Conditional Generative Adversarial Networks (cGANs). This method ensures style consistency while accurately preserving content information, making it suitable for tasks that require high-fidelity style transfer21. With technological advancements, StyleGAN proposed a generative model capable of independently controlling style and content. By adjusting multiple layers in the generation process, it makes style transfer more delicate and diverse, greatly reducing the occurrence of mode collapse, and excels at handling large-scale style transformations. To handle multiple style transfer tasks, StarGAN further expanded the application of GANs by introducing style labels, enabling the transformation of multiple styles within a single framework22. This not only improves the efficiency of style transfer but also adds flexibility, making it suitable for applications involving multi-style transformations. Finally, WCT combined wavelet transforms and convolutional neural networks to propose a method that captures style transfer through multi-scale features, allowing for finer control over style transformation details, making it suitable for scenarios that require precise style details23. GAN-based style transfer methods not only enhance the diversity and quality of image generation but also make significant breakthroughs in training efficiency and style flexibility, driving the application of style transfer technology in image processing and multimedia fields.
Applications and advancements of diffusion models in style transfer
In style transfer, diffusion models can better capture the complex relationship between image content and style by modeling the gradual noise process of images. Below are several style transfer methods based on diffusion models. First, the DDPM-based Style Transfer method proposes applying the classic Denoising Diffusion Probabilistic Model (DDPM) framework to the style transfer task24. By introducing a gradual noise addition and denoising process, this method can find a balance between style and content images, generating high-quality stylized images. DDPM achieves style transfer of content images through the reverse diffusion process, effectively avoiding the over-stylization or under-stylization issues seen in traditional methods, producing images that preserve content information while incorporating the target style. Next, Latent Diffusion Models propose a style transfer method based on diffusion in the latent space. By applying the diffusion process in the latent space, Latent Diffusion Models not only improve generation efficiency but also enhance the style transfer effect25. This method reduces computational resource consumption significantly while generating high-quality images. In style transfer applications, Latent Diffusion can flexibly adjust style transformation details and produce content-rich, style-accurate images by optimizing noise in the latent space. Furthermore, Conditional Diffusion for Style Transfer introduces conditional diffusion models for style transfer. By incorporating conditional information (such as style labels or content descriptions), this method controls the diffusion process, ensuring that the generated image meets specified style requirements26. Unlike traditional unconditional diffusion models, conditional diffusion models allow for more precise adjustment of style features in style transfer, making the process more controllable. This method offers greater flexibility in generating diverse style images and avoids style information loss. The Score-based Diffusion Model further enhances the application of diffusion models in style transfer by using score matching methods. By modeling the gradient information of the noise process, the Score-based diffusion model can more precisely combine style and content, improving the details and quality of generated images27. In style transfer tasks, this method adjusts the gradients of the style image, allowing the transferred image to maintain high-quality content while better incorporating the target style, thus avoiding style distortion seen in traditional methods. Lastly, Multi-Scale Diffusion Models propose a multi-scale diffusion model for handling fine details in style transfer tasks. By introducing multi-scale features for gradual denoising and style transformation, this method captures different levels of image features, ensuring that image details and textures are preserved during style transfer. In the multi-scale diffusion process, style information can be finely adjusted across different scales, producing images with rich high-frequency details while maintaining consistent style features. Overall, diffusion-based style transfer methods, by introducing gradual denoising and conditional control techniques, have significantly enhanced the effectiveness and controllability of style transfer. These methods not only generate high-quality, diverse style images but also achieve breakthroughs in the precision and efficiency of style transfer, driving further development in style transfer technology.
Methods
Preliminaries
Diffusion models (DM)28 are generative models based on probabilistic frameworks, advancing fields like image generation, inpainting, and style transfer. These models work by adding noise to data, turning its distribution into a Gaussian, and then reversing this process to recover the original data. Training involves two main steps: forward and reverse diffusion.
During the forward diffusion phase, starting with an image \(\textbf{x}_0\), noise is incrementally added until it becomes pure Gaussian noise. The aim is to transform the data distribution into a Gaussian distribution. The process is defined as follows:
where \(\textbf{x}_t\) represents the image at the \(t\)-th step, \(\beta _t\) represents the noise amount added at the \(t\)-th step, and \(\mathscr {N}\) denotes the Gaussian distribution. The diffusion process iteratively adds noise to the image from \(t = 1\) to \(t = T\), and at \(t = T\), the image \(\textbf{x}_T\) becomes approximately Gaussian distributed.
To facilitate modeling, the forward process is often assumed to be a Markov chain, allowing for the stepwise derivation of the conditional probability distribution for each step. Ultimately, the goal of the forward diffusion process is to estimate the distribution of the original image \(\textbf{x}_0\) given the noisy image \(\textbf{x}_T\).
In the reverse diffusion process, we start from a pure noise image and progressively remove the noise to recover the original data. The core of this process is learning how to gradually recover the data from noise, which is done by training a neural network model to predict the denoising process at each time step. The reverse diffusion process can be represented as:
where \(\hat{\mu }_\theta (\textbf{x}_t, t)\) is the denoised result predicted by the neural network, and \(\hat{\beta }_t\) is the noise control parameter learned by the model. The reverse process starts from \(\textbf{x}_T\) and gradually denoises the image to recover the original image \(\textbf{x}_0\).
The training objective of a diffusion model is to minimize the difference between the forward and reverse diffusion processes. Typically, the loss function is defined as the denoising error at each time step, which is given by:
One of the major advantages of diffusion models is their stability and generation quality. Unlike Generative Adversarial Networks (GANs), diffusion models do not rely on adversarial training, making them easier to train and yielding high-quality image generation. Due to their progressive denoising property, diffusion models can capture fine details and textures during image generation, producing more detailed and refined images.
Overview
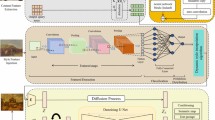
The proposed StyDiff framework, as shown in Figure 2, combines the diffusion model and Adaptive Instance Normalization (AdaIN) mechanism, aiming to achieve high-quality and flexible image style transfer.
First, the input images are passed through the AutoKL25,26,27,28,29,30 Encoder module, which encodes the image to extract content and style information. The image features are then further processed through quantization using the function \(Q()\). The processing of different style and content images is handled by the AutoKL Encoder module, which performs multi-scale feature extraction to capture fine-grained content and style information at different scales. After quantization and concatenation, the style information is passed to the subsequent processing modules.
Next, the fusion of style and content is achieved through the AdaIN module. AdaIN is designed to normalize the content features by aligning the channel-wise mean and variance to those of the style image, enabling the transfer of style characteristics while preserving the structural integrity of the content. The design of AdaIN allows for a flexible and adaptive style transfer process by dynamically adjusting the content image’s feature distribution to match that of the style image. This normalization process, based on the statistical moments (mean and variance), helps mitigate the problem of over-stylization seen in earlier methods, where content was often distorted during style transfer. The flexibility of AdaIN in controlling the balance between content and style is crucial in generating visually coherent results, as it allows for seamless fusion without compromising content details. This approach contributes to a more refined and accurate style transfer, producing images with high fidelity to both content and style.
In the image generation process, the Diffusion model is applied to gradually denoise the image. The generation process optimizes the combination of content and style through successive noise injection and denoising. This model adjusts the generated image based on the previously extracted feature information during the reverse diffusion process, ensuring precise style transfer and preserving image details. Furthermore, to enhance the generated results, the framework uses a multi-scale feature extractor to process image features at multiple levels. By extracting features at different scales, this method preserves rich textures and details in the generated image, thus enhancing its artistic expression. The multi-scale feature extraction combined with AdaIN ensures that style transfer across multiple levels remains distortion-free. Finally, the generated image is decoded by the AutoKL Decoder module, reconstructing the final style-transferred image. The overall process involves loss functions including image content loss (\(L_{Imagelatent}\)), style loss (\(L_{Stylelatent}\)), and element loss (\(L_{Element}\)), which are optimized through a weighted loss function to improve the style transfer results.

Overall network architecture of StyDiff. It includes content and style feature extraction, style-content fusion, and image generation through the diffusion model.
AdaIN feature extraction
In AdaIN extraction, a pre-trained VGG-16 CNN encoder is used to obtain content and style features from the image. The content image passes through the encoder to extract feature maps from layers like ’conv1_2’, ’conv2_2’, ’conv3_2’, and ’conv4_2’, capturing multi-scale content details.
During this process, we employ a multi-scale extractor that can handle these feature maps at different levels to ensure compatibility with the subsequent AdaIN module. For each extracted feature map, the feature fusion process can be expressed by the following formula:
where \(F_{c}\) represents the extracted content features, and \(F_{i}\) represents the feature maps extracted from different layers of the VGG encoder.
The AdaIN block merges content features from the content image with style features from the style image. It normalizes the content features and modifies them using the style image’s mean and variance. This process is expressed as:
where \(F_{c}\) denotes the content image’s feature map, \(F_{s}\) represents the style image’s feature map, \(\mu (F_{s})\) and \(\sigma (F_{s})\) are the mean and variance of the style’s features, and \(\gamma (F_{c})\) indicates the normalization applied to the content features.
Loss functions
In this paper, we define four primary loss functions that are used to optimize the style transfer process in the StyDiff framework. Each loss function is specifically designed to optimize content preservation, style consistency, the noise model in the generation process, and the structural fidelity of the generated image. The specific loss functions are described as follows:
Content loss ensures that the generated image accurately preserves the features of the original content image. To achieve this, we extract the latent representation of the content image using the VDVAE model, and compare it with the latent representation of the generated image. The loss function is computed by quantifying the difference between the latent variables of the content image and the generated image, as follows:
where\(\mathscr {X}_i\) denotes the content image, \(\mathscr {X}_{\text {output}}\) denotes the generated image, and \(\text {VDVAE}(\cdot )\) represents the feature extraction from the VDVAE model. This loss function calculates the Euclidean distance between the latent features of the content image and the generated image to ensure content preservation in the latent space.
Style loss ensures that the generated image accurately reflects the style features of the target style image. Similar to the content loss, we use the VDVAE model to extract the style features from the style image and compare them with the style features of the generated image. The style loss function is as follows:
where\(\mathscr {X}_s\) denotes the style image, \(\mathscr {X}_{\text {output}}\) denotes the generated image, and \(\text {VDVAE}(\cdot )\) represents the feature extraction from the VDVAE model. This loss function emphasizes the style consistency between the generated and style images by comparing their latent style features.
The diffusion model loss is used to optimize the noise alignment between the generated image and the target distribution in the diffusion process, promoting the accuracy of the image generation. The formula for this loss is given by:
where \(P_\theta (p(x_t | X_0), t, A(X_s, X_i))\) represents the probability distribution of the generated image at time step \(t\) with the noise transformation function \(A(X_s, X_i)\). This loss ensures that the noise process in the image generation aligns with the target distribution, thereby ensuring accurate style transfer.
The element loss is used to measure the fine-grained differences between the generated image and the original content image, ensuring that the generated image aligns with the style and content at the element level. The loss function is computed by quantifying the differences between the generated image and the style and content images at the element level:
where \(A(X_s, X_i)\) represents the style elements computed through the Adaptive Instance Normalization (AdaIN) module, and \(\text {VDVAE}(\mathscr {X}_{\text {output}})\) represents the latent features of the generated image. This loss function ensures that the generated image not only preserves high-level style and content features but also matches the fine-grained details of the style image.
In summary, these four loss functions optimize different aspects of the style transfer process, ensuring high-quality and consistent results by coordinating content preservation, style consistency, fine-grained details, and noise modeling of the generation process.
Experiments
Dataset
In this paper, multiple public datasets were selected for training, validation, and testing the model to ensure the diversity and generalization ability of style transfer.
First, we selected 100,000 images from the COCO dataset as content images. COCO (Common Objects in Context) is a widely used image dataset that contains a rich variety of everyday scenes and object categories. The dataset has been carefully curated to cover different scenes, objects, and environmental variations, ensuring the diversity of content in the generated images. These content images provide a broad range of background and object information, which offers strong support for training the style transfer model. Next, we selected 68,669 images from the WikiArt dataset as style images. The WikiArt dataset includes artwork from various artistic styles, covering a wide range of styles from classical art to modern art. To ensure the diversity and challenge of style transfer, we selected images from different art styles, including but not limited to Impressionism, Cubism, Abstract art, and more. The selected style images ensure significant stylistic differences between the images, allowing the style transfer model to learn a rich variety of style expressions.
For the dataset split, we randomly selected 100,000 pairs of content and style images for training, ensuring the diversity and representativeness of the training data. These image pairs were used in the model training phase, with each pair undergoing style transfer during training. To validate and evaluate the model’s performance, we further divided the dataset into two parts: 20,000 pairs for validation and 80,000 pairs for testing. The validation set was primarily used for hyperparameter tuning during the training process, while the test set was used for the final performance evaluation of the model.
Experimental settings
The experimental setup used in this paper is shown in Table 1. The environment was carefully configured to ensure optimal performance during model training and evaluation.
Evaluation metrics
To evaluate the performance of the style transfer model, we use a combination of four key metrics: GM for style fidelity, SSIM for image similarity, LPIPS for perceptual similarity, and PD for perceptual dissimilarity. These metrics offer a comprehensive and quantitative assessment of the style transfer results from different perspectives.
Given the inherent lack of ground truth in style transfer tasks, we use SSIM by comparing the source image (content image) and the target style image. Since style transfer is essentially an artistic transformation of content images, and there is no ”ground truth” image in this process, it is crucial to clarify how reference images are selected for SSIM. In this context, the source image and the target style image are compared to evaluate the similarity of content and style. Although the lack of a true ground truth makes SSIM less conventional in style transfer, it remains a useful metric to quantify content retention and style alignment. To enhance the evaluation of style transfer quality, we integrate related literature on image quality assessment, particularly no-reference methods, such as those by Zhou et al.31, Qu et al.32, and Xu et al.33, which provide valuable insights for assessing the quality of images in the absence of reference data. Additionally, Qu et al.34 introduced anglewise attention in no-reference quality assessment for light field images, and Qu et al.35 extended these concepts to evaluating images generated by neural radiance fields (NeRF), further supporting the validity of our evaluation framework.
The GM evaluates the fidelity of the generated image to the target style by calculating the Euclidean distance between the feature maps of the style and the generated images at specific layers. A lower GM value indicates a better alignment with the target style and superior style fidelity.
where \(\mathscr {F}_s\) and \(\mathscr {F}_\text {generated}\) represent the feature maps of the style and generated images, respectively.
The SSIM measures the structural similarity between two images by comparing their luminance, contrast, and structure. SSIM values range from -1 to 1, with 1 indicating maximum similarity. Given its ability to assess image structure, SSIM helps evaluate how well the content structure is preserved during style transfer.
where \(x\) and \(y\) are the pixel values, \(\mu _x\) and \(\mu _y\) are the means, \(\sigma _x^2\) and \(\sigma _y^2\) are the variances, \(\sigma _{xy}\) is the covariance, and \(c_1\) and \(c_2\) are constants to prevent division by zero.
The LPIPS (Learned Perceptual Image Patch Similarity) metric evaluates perceptual similarity by comparing image features extracted from a pre-trained deep network (e.g., VGG). It is particularly useful for capturing perceptual differences between images, especially for tasks like style transfer where pixel-level similarity may not fully reflect human perception.
where \(\mathscr {F}_i(x)\) and \(\mathscr {F}_i(y)\) represent the feature maps at the \(i\)-th layer for images \(x\) and \(y\), and \(N\) is the number of layers.
Lastly, the PD (Perceptual Dissimilarity) metric measures perceptual dissimilarity by comparing the style, structure, and texture features extracted from the images. A larger PD value indicates greater perceptual dissimilarity, while a smaller value suggests higher perceptual similarity.
where \(\mathscr {G}(\cdot )\) represents the high-level perceptual features extracted from the images.
By combining these four metrics, we provide a comprehensive evaluation of the style transfer process, capturing different aspects such as content preservation, style fidelity, perceptual quality, and dissimilarity. These metrics allow us to assess the performance of the proposed StyDiff framework from multiple perspectives and demonstrate its effectiveness in preserving content structure while accurately transferring the target style.
Quantitative results
In the comparative experiments shown in Table 2, our method demonstrates superior performance across multiple key evaluation metrics, highlighting its overall advantage in style transfer tasks. First, in terms of SSIM and GM, our method achieves the best results, indicating that the generated images maintain high structural integrity and accurately transfer the style. This can be attributed to the effective combination of the Adaptive Instance Normalization (AdaIN) mechanism and the diffusion model in our approach, which allows for more precise control over the fusion of content and style, avoiding both excessive stylization and insufficient style transfer, thus ensuring high-quality style transfer.
In terms of PD and LPIPS, our method also achieves the lowest scores, indicating that the generated images are perceptually closer to the target style, with a significant reduction in perceptual differences. This advantage stems from the fine-tuned operations in feature extraction and style transfer, particularly in preserving and optimizing high-level perceptual features, which results in more natural and consistent style characteristics in the generated images.
Although our model shows a slight increase in inference time compared to some existing methods, the improvements in image quality, style fidelity, and perceptual similarity make this small increase in time an acceptable trade-off. This indicates that our model effectively balances computational efficiency with high-quality results while ensuring superior style transfer performance.
Qualitative results
As shown in Fig. 3, our method significantly outperforms existing methods in terms of visual quality for style transfer. The qualitative results demonstrate that our method effectively preserves the structural integrity of the content image while accurately transferring the target style, avoiding common issues such as over-stylization, content distortion, and insufficient style transfer. Compared to StyleFlow and Cartoon-Flow, although these methods can produce stylized effects in certain cases, they often introduce artifacts and distort content details. In contrast, our method generates more natural and coherent style transfer results while maintaining content consistency. Furthermore, our method achieves a better balance between style and content fusion, preserving the richness of the style while avoiding unnatural color mapping, resulting in images that are both visually striking and semantically consistent.

Qualitative results. Comparison of StyDiff with different methods. All content images in this showcase are generated using DALL·E 313.
User study
This user study aims to evaluate the effectiveness of our proposed style transfer method compared to existing approaches. The study will recruit 100 non-expert participants to ensure diversity in participant backgrounds and avoid professional bias in image processing or computer vision. Each participant will be presented with 100 image pairs, each consisting of a content image, a style image, and a generated image. Participants will rate their satisfaction on a scale of 1 to 100. Figure 4 illustrates the results of the user study.

User study results. Participants evaluated the user satisfaction of each method on a scale from 1 to 100. We averaged the scores from all participants to obtain the overall satisfaction scores for each method.
Verification of AdaIN module’s effectiveness
To validate the effectiveness of the AdaIN module in the proposed StyDiff framework, we conducted a series of experiments comparing its performance with traditional style transfer methods, such as Gram Matrix-based style transfer. The evaluation was based on three metrics: SSIM, GM, and LPIPS. These metrics were used to assess content preservation, style consistency, and perceptual similarity.
The results of the comparison are shown in Table 3. The AdaIN group outperforms the Gram Matrix group in all metrics, demonstrating that the AdaIN module better preserves content structure and achieves more consistent style transfer. Specifically, the AdaIN group achieved higher SSIM and GM values, and lower LPIPS, indicating improved visual quality and perceptual similarity compared to the traditional method.
These findings confirm the effectiveness of the AdaIN module in improving both content retention and style consistency, validating its importance in the StyDiff framework for high-quality style transfer.
Verification of loss function weighting
In order to evaluate the influence of different loss function weights on the performance of the StyDiff framework, an ablation study was conducted. The study systematically varied the weights of each individual loss term (\(L_{\text {Imagelatent}}\), \(L_{\text {Stylelatent}}\), \(L_{\text {Element}}\), and \(L_{\text {diff}}\)) to assess their effect on the key evaluation metrics: SSIM, GM, and LPIPS. The total loss function is defined as follows:
where \(\alpha\), \(\beta\), \(\gamma\), and \(\delta\) denote the weight coefficients for each loss term, and they control the relative influence of each component on the final outcome.
In the experiments, we varied the weight parameters and measured the corresponding changes in performance. The results are summarized in Table 4, where the following weight configurations were evaluated:
-
Experiment 1 (Baseline): Equal weighting for all loss terms (\(\alpha = \beta = \gamma = \delta = 1.0\)).
-
Experiment 2: Increased emphasis on content loss (\(\alpha = 1.5, \beta = 0.7, \gamma = 0.5, \delta = 0.3\)).
-
Experiment 3: Increased emphasis on style loss (\(\alpha = 0.7, \beta = 1.5, \gamma = 0.5, \delta = 0.3\)).
-
Experiment 4: Increased emphasis on fine-grained element loss (\(\alpha = 0.7, \beta = 0.7, \gamma = 1.5, \delta = 0.3\)).
-
Experiment 5: Increased emphasis on diffusion model loss (\(\alpha = 0.7, \beta = 0.7, \gamma = 0.5, \delta = 1.5\)).
Table 4 summarizes the results of the ablation study, showing the impact of varying weightings on SSIM, GM, and LPIPS.
The results of the ablation study confirm that the weighting of loss functions plays a crucial role in balancing content retention and style transfer quality. In Experiment 1 (Baseline), where all loss terms were equally weighted, the model produced balanced results with SSIM = 0.7923, GM = 18.90, and LPIPS = 0.05. This setup effectively preserved content structure while transferring the target style. In Experiment 2 (Content Focus), when content loss (\(L_{\text {Imagelatent}}\)) was given higher weight, the model achieved improved content preservation with SSIM = 0.7981 and GM = 19.20, though the perceptual similarity (LPIPS) remained low, indicating minimal impact on style transfer. Experiment 3 (Style Focus), which increased the weight of style loss (\(L_{\text {Stylelatent}}\)), resulted in a noticeable decline in SSIM (0.7554) and GM (17.90), with a slight increase in LPIPS (0.09), highlighting the trade-off between content preservation and style fidelity when prioritizing style loss. In Experiment 4 (Element Focus), where element loss (\(L_{\text {Element}}\)) was emphasized, the results showed modest improvements in SSIM (0.7867) and GM (18.50), but the gains were less significant than those observed when content loss was prioritized, suggesting that while element loss refines fine-grained details, it does not significantly affect overall content or style transfer. Experiment 5 (Diffusion Focus), which focused on the diffusion model loss (\(L_{\text {diff}}\)), produced results comparable to the baseline with SSIM = 0.7832 and GM = 18.00, but LPIPS (0.07) was slightly higher. While the diffusion model loss contributes to smoother image generation, its effect on content preservation and style consistency is less pronounced compared to the other loss terms.
In conclusion, the experiments demonstrate that emphasizing content loss yields the best results for content preservation and style consistency. However, the combination of all loss terms with equal weighting provides the most balanced performance across all evaluation metrics. These findings highlight the importance of adjusting loss function weights to achieve optimal trade-offs between style fidelity, content preservation, and fine-grained detail transfer.
Ablation study
CNN encoder. As shown in Table 5, we focused on evaluating the performance of different CNN encoders in the style transfer task. Specifically, we compared the effects of various models (such as Resnet-32, EfficientNet-B0, ViT, PVT) with VGG-16 as the encoder. The experimental results demonstrate that the model using VGG-16 as the encoder outperforms all other models in terms of all evaluation metrics, especially achieving optimal results in SSIM, GM, and LPIPS. The VGG-16 model is better at capturing both content and style information compared to other models, with the generated images showing higher accuracy in structure preservation, style consistency, and detail transfer. Compared to models like Resnet-32 and EfficientNet-B0, VGG-16 not only better preserves the image content but also more effectively transfers the target style, avoiding issues of over-stylization or insufficient style transfer.
Loss functions As shown in Table 6, we analyze the impact of different combinations of loss functions on style transfer performance. Specifically, we compare the results of various combinations of loss functions, such as \(L_{stylelatent}\), \(L_{Imagelatent}\), and \(L_{Element}\), and compare them with the overall style transfer results.
First, using \(L_{stylelatent}\) or \(L_{Imagelatent}\) alone achieves reasonably good style transfer results, but there are still some issues with content distortion or incomplete style transfer. This is particularly evident in the preservation of fine details and the consistency of style, especially in balancing the fusion of content and style. Next, after combining \(L_{stylelatent} + L_{Imagelatent}\) and \(L_{stylelatent} + L_{Element}\), the model performs better in terms of style consistency and content preservation, with the generated images retaining more detailed features. However, compared to our final model, which combines \(L_{stylelatent} + L_{Imagelatent} + L_{Element}\), the results are still somewhat lacking. Through comparison, we find that the combination of all three loss functions (\(L_{stylelatent} + L_{Imagelatent} + L_{Element}\)) performs the best across all evaluation metrics. Specifically, the quality of the generated images is significantly higher in terms of SSIM, GM, and LPIPS scores. The combination of these three loss functions allows for a better balance between content, style, and elements, resulting in a more refined style transfer effect and avoiding over-stylization or insufficient style transfer issues.
Limitations and future work
Although the proposed StyDiff framework has achieved significant results in style transfer tasks, there are still some limitations. First, the evaluation of the framework was conducted on a limited set of datasets, which may restrict its generalization ability to more diverse or specialized image types. While the COCO and WikiArt datasets provide valuable perspectives for general content and artistic style transfer, the model’s performance may not be satisfactory under certain conditions, such as extreme lighting or complex visual content. Therefore, future work could consider expanding the dataset coverage by adding more challenging image categories, thus enhancing StyDiff’s robustness and applicability in different scenarios.
Second, the computational efficiency of the framework still needs improvement. Although StyDiff produces excellent style transfer results, the computational cost associated with the diffusion model and multi-scale feature extraction is high, resulting in longer inference times. This may limit its use in real-time or resource-constrained environments, such as on mobile devices or large-scale applications. Future research could focus on optimizing the model architecture, exploring more efficient neural network designs, or leveraging hardware accelerators to reduce computation time while maintaining the quality of style transfer.
In future work, we plan to further improve the efficiency of the StyDiff framework by employing techniques such as model pruning, knowledge distillation, or using lighter architectures, to reduce inference costs while maintaining high performance. Additionally, we plan to expand the dataset to include more complex and diverse image types, and fine-tune the model for specific use cases, such as video style transfer or domain-specific artistic applications. We may also consider incorporating interactive components, allowing users to control the style transfer process in real-time, which would open up new possibilities for creative applications in fields such as digital art and entertainment.
Conclusion and discussion
In this paper, we propose the StyDiff framework, which integrates the diffusion model with the Adaptive Instance Normalization (AdaIN) mechanism to achieve high-quality and flexible image style transfer. The extensive experimental evaluations demonstrate that StyDiff surpasses existing state-of-the-art methods across multiple key metrics, including SSIM, GM, and LPIPS. The framework effectively preserves the content of the image while accurately transferring the target style, addressing common challenges such as over-stylization and insufficient style transfer. These results validate the effectiveness of StyDiff in producing high-fidelity, visually consistent style transfer outputs.
Despite the strong performance of the proposed method, there remain significant opportunities for further improvement, particularly in the areas of video and image enhancement. One promising avenue for future work is the enhancement of temporal consistency and quality in low-light videos, which would substantially improve the applicability and performance of StyDiff. Recent advancements in this domain offer valuable insights. For instance, Zhu et al.49 introduced a method for achieving temporally consistent enhancement of low-light videos through spatial-temporal compatible learning, a technique that could be adapted to ensure the consistency of style transfer results across video frames. Furthermore, Zhu et al.50 explored controllable low-light video enhancement, which can be leveraged to generate dynamic style transfer effects in videos, thereby allowing for more interactive and refined control over the style transfer process.
Incorporating these advancements into the StyDiff framework would enable substantial improvements in temporal consistency and extend its potential to video processing. This would open new possibilities for high-quality, real-time, and controllable video style transfer, further expanding the versatility of StyDiff in creative applications within the digital media and entertainment industries.
In conclusion, the StyDiff framework provides a robust and effective solution for image style transfer, demonstrating superior performance while addressing critical challenges related to content preservation and style transfer fidelity. The integration of techniques for video enhancement would enhance the framework’s applicability, enabling dynamic and interactive style transfer for video content and paving the way for future research directions in creative industries.
Data availability
The data that support the findings of this study are available on request from the corresponding author. The data are not publicly available due to privacy or ethical restrictions.
References
Hamazaspyan, M. & Navasardyan, S. Diffusion-enhanced patchmatch: A framework for arbitrary style transfer with diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 797–805 (2023).
Chung, J., Hyun, S. & Heo, J.-P. Style injection in diffusion: A training-free approach for adapting large-scale diffusion models for style transfer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 8795–8805 (2024).
Pang, S. et al. Diff-tst: Diffusion model for one-shot text-image style transfer. Expert Syst. Appl. 263, 125747 (2025).
Yang, S., Hwang, H. & Ye, J. C. Zero-shot contrastive loss for text-guided diffusion image style transfer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, 22873–22882 (2023).
Li, S. Diffstyler: Diffusion-based localized image style transfer. arXiv preprint arXiv:2403.18461 (2024).
Austin, J. et al. Structured denoising diffusion models in discrete state-spaces. In NeurIPS 34, 17981–17993 (2021).
Chandramouli, P. & Gandikota, K. Ldeit: Towards generalized text guided image manipulation via latent diffusion models. In BMVC 1, 2 (2022).
Chang, H. et al. Muse: Text-to-image generation via masked generative transformers. In ICML, 4055–4075 (2023).
Devlin, J., Chang, M., Lee, K. & Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv: abs/1810.04805 (2019).
Ding, M. et al. Cogview: Mastering text-to-image generation via transformers. In NeurIPS 34, 19822–19835 (2021).
Nanaumi, T., Kawamoto, K. & Kera, H. Low-quality image detection by hierarchical vae. arXiv preprint arXiv:2408.10885 (2024).
Susladkar, O., Deshmukh, G., Mittal, S. & Shastri, P. \(\text{D}^2\) styler: Advancing arbitrary style transfer with discrete diffusion methods. In International Conference on Pattern Recognition, 63–82 Springer, (2025).
Betker, J. et al.(2023) Improving image generation with better captions. Computer Science. https://cdn openai. com/papers/dall-e-3. pdf 2, 8 .
Jing, Y. et al. Neural style transfer: A review. IEEE Trans. Visualization Comput. Graph. 26, 3365–3385 (2019).
Gatys, L., Ecker, A., Bethge, M., Hertzmann, A. & Shechtman, E. Controlling perceptual factors in neural style transfer. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 3985–3993 (2017).
Johnson, J., Alahi, A. & Fei-Fei, L. Perceptual losses for real-time style transfer and super-resolution. In Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11-14, 2016, Proceedings, Part II 14, 694–711 Springer, (2016).
Chen, D., Yuan, L., Liao, J., Yu, N. & Hua, G. Stylebank: An explicit representation for neural image style transfer. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 1897–1906 (2017).
Li, Y., Wang, N., Liu, J. & Hou, X. Demystifying neural style transfer. arXiv preprint arXiv:1701.01036 (2017).
Xu, W., Long, C., Wang, R. & Wang, G. Drb-gan: A dynamic resblock generative adversarial network for artistic style transfer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, 6383–6392 (2021).
Chu, C., Zhmoginov, A. & Sandler, M. Cyclegan, a master of steganography. arXiv preprint arXiv:1712.02950 (2017).
Henry, J., Natalie, T. & Madsen, D. Pix2pix gan for image-to-image translation. Research Gate Publication (2021).
Choi, Y. et al. Stargan: Unified generative adversarial networks for multi-domain image-to-image translation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 8789–8797 (2018).
Li, J. et al. Normally-off operation power algan/gan hfet. In 2004 Proceedings of the 16th International Symposium on Power Semiconductor Devices and ICs, 369–372 IEEE, (2004).
Yang, X., Zhou, D., Feng, J. & Wang, X. Diffusion probabilistic model made slim. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 22552–22562 (2023).
Rombach, R., Blattmann, A., Lorenz, D., Esser, P. & Ommer, B. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 10684–10695 (2022).
Yang, R. & Mandt, S. Lossy image compression with conditional diffusion models. In Advances in Neural Information Processing Systems, vol. 36 (2024).
Song, Y., Durkan, C., Murray, I. & Ermon, S. Maximum likelihood training of score-based diffusion models. Adv. Neural Inform. Process. Syst. 34, 1415–1428 (2021).
Rombach, R. et al. High-resolution image synthesis with latent diffusion models. In CVPR, 10684–10695 (2022).
Xu, X., Wang, Z., Zhang, G., Wang, K. & Shi, H. Versatile diffusion: Text, images and variations all in one diffusion model. In Proceedings of the IEEE/CVF International Conference on Computer Vision, 7754–7765 (2023).
Ozcelik, F. & VanRullen, R. Natural scene reconstruction from fmri signals using generative latent diffusion. Sci. Rep. 13, 15666 (2023).
Zhou, W., Chen, Z. & Li, W. Dual-stream interactive networks for no-reference stereoscopic image quality assessment. IEEE Trans. Image Process. 28, 3946–3958 (2019).
Qu, Q., Chen, X., Chung, V. & Chen, Z. Light field image quality assessment with auxiliary learning based on depthwise and anglewise separable convolutions. IEEE Trans. Broadcasting 67, 837–850 (2021).
Xu, J., Zhou, W. & Chen, Z. Blind omnidirectional image quality assessment with viewport oriented graph convolutional networks. IEEE Trans. Circ. Syst. Video Technol. 31, 1724–1737 (2020).
Qu, Q., Chen, X., Chung, Y. Y. & Cai, W. Lfacon: Introducing anglewise attention to no-reference quality assessment in light field space. IEEE Trans. Visualization Comput. Graph. 29, 2239–2248 (2023).
Qu, Q., Liang, H., Chen, X., Chung, Y. Y. & Shen, Y. Nerf-nqa: No-reference quality assessment for scenes generated by nerf and neural view synthesis methods. IEEE Trans. Visualization Comput. Graph. (2024).
Zhang, Y. et al. Inversion-based style transfer with diffusion models. In CVPR, 10146–10156 (2023).
Hu, Y., Zhuang, C. & Gao, P. Diffusest: Unleashing the capability of the diffusion model for style transfer. In Proceedings of the 6th ACM International Conference on Multimedia in Asia, 1–1 (2024).
Abdal, R., Zhu, P., Mitra, N. & Wonka, P. Styleflow: Attribute-conditioned exploration of stylegan-generated images using conditional continuous normalizing flows. ACM Trans. Graph. (ToG) 40, 1–21 (2021).
Hong, K. et al. Aespa-net: Aesthetic pattern-aware style transfer networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, 22758–22767 (2023).
Lee, J. et al. Cartoon-flow: A flow-based generative adversarial network for arbitrary-style photo cartoonization (In Int. Conf, Multimedia, 2022).
Deng, Y. et al. Stytr2: Image style transfer with transformers. In CVPR, 11326–11336 (2022).
Botti, F. et al. Mamba-st: State space model for efficient style transfer. arXiv preprint arXiv:2409.10385 (2024).
Zhang, Y. et al. Inversion-based style transfer with diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 10146–10156 (2023).
Liu, S. et al. Adaattn: Revisit attention mechanism in arbitrary neural style transfer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, 6649–6658 (2021).
An, J. et al. Artflow: Unbiased image style transfer via reversible neural flows. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 862–871 (2021).
Peebles, W. & Xie, S. Scalable diffusion models with transformers. In ICCV, 4195–4205 (2023).
Wang, Z., Zhao, L. & Xing, W. Stylediffusion: Controllable disentangled style transfer via diffusion models. In Proceedings of the IEEE/CVF International Conference on Computer Vision, 7677–7689 (2023).
Le, M.-H. & Carlsson, N. Styleid: Identity disentanglement for anonymizing faces. arXiv preprint arXiv:2212.13791 (2022).
Zhu, L. et al. Temporally consistent enhancement of low-light videos via spatial-temporal compatible learning. Int. J. Comput. Vision 132, 4703–4723 (2024).
Zhu, L. et al. Unrolled decomposed unpaired learning for controllable low-light video enhancement. In European Conference on Computer Vision, 329–347 Springer, (2024).
Funding
This work was sponsored in part by Research on Visual Cognitive Enhancement of Public Health Science Popularization in Jilin Province through Full Media Promotion (2021LY521W38).
Author information
Authors and Affiliations
Contributions
Yanming Sun: Responsible for the overall framework design and research in the methods section, led the implementation and analysis of experiments, wrote the main content of the paper, and conducted the literature review. He Meng: Provided theoretical guidance and suggestions for the methodological framework, participated in the structural optimization and revision of the paper, provided support for data analysis, and assisted in the final revision of the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Sun, Y., Meng, H. StyDiff: a refined style transfer method based on diffusion models. Sci Rep 15, 33521 (2025). https://doi.org/10.1038/s41598-025-17899-x
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-17899-x
