
Abstract
Prediction of small (SGA) and large for gestational age (LGA) using routinely collected antenatal data remains suboptimal, particularly among nulliparous women. In this study, models for SGA (< 10th percentile) and LGA (> 90th percentile) were developed by combining grandmaternal pregnancy-related information and maternal birth characteristics (“G0 predictors”) with maternal clinical factors available at 26 weeks’ gestation (“G1 predictors”). The study used a cohort of first-born, singleton births to nulliparous women in Nova Scotia, Canada (1981–2011), and their mothers, from the Nova Scotia Atlee Perinatal Database. Models using G0 predictors, G1 predictors, and their combination were developed with Super Learner, an ensemble machine learning algorithm, and internally validated using nested cross-validation. Discrimination was assessed via the area under the receiver operating characteristic curve (AUC-ROC) and the precision-recall curve (AUC-PR); calibration was also evaluated. Among 9,097 grandmother-mother-infant triads, 902 (9.9%) infants were SGA and 891 (9.8%) were LGA. Including G0 predictors improved discrimination compared to G1-only models (AUC-ROC 0.69 vs. 0.66 for SGA and 0.71 vs. 0.66 for LGA; AUC-PR: 0.21 vs. 0.18 for SGA and 0.22 vs. 0.18 for LGA). Models fitted using both sets of predictors were well calibrated. While incorporating intergenerational information modestly improved prediction, overall predictive performance remains poor.
Similar content being viewed by others

Introduction
Deviations from normal fetal growth are associated with adverse perinatal and long-term health outcomes. Infants born small for gestational age (SGA) have increased risks of perinatal morbidity and mortality, neurodevelopmental deficits, and cardiovascular disease in later in life1,2,3. Those born large for gestational age (LGA) are faced with increased risk of birth injury, asphyxia, polycythemia, and hypoglycemia, and are more likely to develop obesity, diabetes, and cardiovascular disease in adulthood1,4. Accurate identification of pregnancies at risk for fetal growth abnormalities may enhance preconception counselling, antenatal assessment, and intrapartum care.
Several prediction models for SGA and LGA have been developed using routinely collected antenatal data, including maternal sociodemographic characteristics, pregnancy risk factors, obstetric history, and clinical characteristics; however, predictive performance remains poor, particularly among nulliparous women. For example, one validation study of six prediction models for SGA and LGA using a cohort of 1,311 nulliparous women reported discriminative performance estimates, measured as the area under the receiver operating characteristic curve (AUC-ROC), of 0.50–0.66 for SGA and 0.58–0.67 for LGA5. Similarly, in a cohort of 14,923 nulliparous Nova Scotian women, prediction models resulted in AUC-ROC estimates of 0.63 for SGA and 0.70 for LGA6. Efforts to improve prediction models for early detection of SGA and LGA include adding ultrasound measurements, biochemical markers, and results of biophysical tests, but only modest improvements have been reported7,8,9,10,11,12,13,14 and measurement of some predictors may be costly, time-consuming, and inconvenient for pregnant women15.
Fetal growth is shaped by a complex combination of maternal, fetal, and environmental factors. Recent evidence has suggested that grandparental characteristics may also play a role, with studies reporting small to moderate associations between grandparental risk factors and child birthweight16, including grandparental birthweight17,18, body mass index (BMI)19,20, smoking in pregnancy21,22, socioeconomic status23, and diabetes24,25, with most research focusing on the maternal line. Despite the well-established relationship between maternal and offspring size-at-birth26, maternal birth characteristics and grandmaternal pregnancy-related information have not yet been incorporated into prediction models for SGA or LGA.
The application of machine learning algorithms to predict clinical outcomes is growing27,28, but remains relatively limited in the context of SGA and LGA6,15,29. Unlike traditional regression-based approaches to prediction, machine learning methods learn from existing data without explicit model specification, make fewer distributional assumptions, and can capture non-linear relationships and complex interactions among predictors. Given that grandmaternal factors may modify maternal-offspring associations and that these relationships may be non-linear, machine learning approaches may offer improved predictive performance in this setting.
Due to the difficulty in determining a priori which machine learning algorithm will perform best in a given dataset, predictive performance can be optimized by combining predictions from multiple algorithms using ensemble learning methods. Therefore, the objective of this study was to develop and validate prediction models for SGA and LGA by integrating grandmaternal pregnancy-related information and maternal birth characteristics (“G0 predictors”) with maternal clinical factors available at 26 weeks’ gestation (“G1 predictors”) using the ensemble machine learning algorithm Super Learner in a large sample of nulliparous women in Nova Scotia, Canada.
Methods
Study population and design
Data were derived from the 3G Multigenerational Cohort30, which includes women whose births and subsequent pregnancies were recorded in the Nova Scotia Atlee Perinatal Database (NSAPD). The NSAPD is a population-based database that contains extensive information on demographics, medical conditions, reproductive history, delivery events, and neonatal outcomes for each birth to mothers residing in Halifax County, Nova Scotia, Canada, since 1981, and to mothers residing anywhere in the province after 1988. Information is collected from standard forms completed prenatally and during the hospital stay associated with the delivery. Provincial health card numbers are assigned to all Nova Scotia residents at birth and remain with them throughout their lifetime, even if they leave and return to the province. Health card numbers of women and their offspring are recorded in the NSAPD thereby facilitating creation of the 3G Multigenerational Cohort by linking women’s birth information with information on their own pregnancies and deliveries. The Reproductive Care Program has assigned many health card numbers retroactively for those born before the introduction of health card numbers in 1993 based on name, date of birth, civic address, medical records, and later deliveries in the database.
As of April 30th, 2021, the 3G cohort consisted of 19,583 grandmothers (born 1939–1987), 22,307 mothers (born 1981–2006), and 38,922 infants (born 1996–2021). The present study restricted the cohort to singleton pregnancies and the first-born offspring in both the maternal and grandmaternal generations. In addition, only second-generation infants with complete information on gestational age and birthweight, gestational age \(\ge\) 26 weeks, and a plausible value of birthweight z-score (< 5 in absolute value) were included in the analysis.
Outcomes
The two primary outcomes of interest were infant birthweight for gestational age and sex: SGA (< 10th percentile) and LGA (> 90th percentile) relative to a Canadian reference population31. Secondary outcomes included more stringent definitions (< 3rd percentile (SGA3) and > 97th percentile (LGA97) for gestational age). Birthweight was recorded in grams on the birth record. Gestational age was available in days and was estimated using information from a dating ultrasound, the last menstrual period, and where applicable, embryo transfer; details of the algorithm can be found elsewhere32.
Predictors
Two sets of predictors were considered (Supplementary Table S1). “G1 predictors” included the mother’s demographic, pre-pregnancy, and pregnancy information that was available at 26 weeks’ gestation. “G0 predictors” included grandmaternal demographic, pregnancy, and delivery characteristics at the time of the mother’s birth and the mother’s birth characteristics and neonatal outcomes.
Area-level income quintile was used as a measure of socioeconomic status and was derived from linkage of the woman’s residence postal code to national census information33. Blood pressure was measured at each prenatal visit to screen for pre-existing hypertension (< 20 weeks’ gestation) and hypertensive disorders of pregnancy (onset \(\ge\) 20 weeks’ gestation, pre-existing hypertension with superimposed proteinuria, or eclampsia) based on the Society of Obstetricians and Gynaecologists of Canada Guidelines34. All women in Nova Scotia were eligible to undergo screening for gestational diabetes according to guidelines set by Diabetes Canada35. Any smoking reported during pregnancy (first prenatal visit, 20 weeks, or birth admission), or any alcohol use disorder reported at any point in the pregnancy, were used as proxy measures for smoking and alcohol use disorders at 26 weeks. Pre-pregnancy BMI was calculated by dividing pre-pregnancy weight (kg) by the square of height (m), which are recorded at the first prenatal visit. Gestational weight gain (kg) at 26- and 40-weeks’ gestation (denoted by \(X\) below) was estimated by
assuming a 2 kg weight gain in the first trimester (13 weeks) and a steady increase in weight thereafter36.
Statistical analysis
Descriptive statistics including means and standard deviation and percentages were used to describe the study sample overall and by SGA and LGA status. Absolute standardized mean differences (SMD)37 between groups defined by SGA and LGA status were computed for each predictor. Continuous predictors were standardized (rescaled to have a mean of 0 and a standard deviation of 1) prior to model building.
Prediction models were developed using G1 predictors only, G0 predictors only, and their combination. All models were developed using the Super Learner algorithm38, an ensemble method that combines predictions from multiple models into a single model that has been optimized for predictive accuracy. Optimization occurs by assigning weights based on each algorithms performance with respect to a user-specified loss function; in this study, the Brier score (equivalent to the mean squared error for predictions) was used. The resulting Super Learner model has been shown to perform as well as, or better than, the best algorithm in the ensemble in large samples39.
The library of candidate learners included a range of statistical and machine learning approaches: logistic regression (with and without interaction terms); generalized additive models (GAMs), an extension of generalized linear models that allow for flexible, non-linear relationships between predictors and the dependent variable; elastic net40, a regularized regression technique that performs well with highly correlated predictors; random forest41, an ensemble of decision trees; tree-based extreme gradient boosting (XGBoost)42, a more refined tree-based method that improves accuracy by correcting errors made by the previous trees built in the model (boosting); and kernel-based support vector machine (SVM)43, which classify observations by identifying optimal decision boundaries in the data. This set of learners was selected to provide a diverse set of modeling approaches while remaining computationally feasible.
For each imputed dataset, nested stratified cross-validation (tenfold inner and fivefold outer cross-validation) was used to develop and validate the prediction models. For learners requiring hyperparameter tuning, Super Learner (fitted using fivefold cross-validation) was used to create an optimally weighted combination of the learner fitted with different hyperparameter configurations (Supplementary Table S2), with weights optimized based on the Brier score. Predictions from the base learners (including the tuned learners) were then passed to the main Super Learner, which was fitted and evaluated using the nested cross-validation framework. Models were evaluated based on discrimination and calibration. Discrimination was assessed using the AUC-ROC and the area under the precision-recall curve (AUC-PR), which is a plot of precision (i.e., positive predictive value) vs. recall (i.e., sensitivity). A lack of discrimination is indicated by an AUC-PR value equal to the prevalence of the outcome. Predictive variable importance rankings in the two estimation algorithms with the largest mean weight in the Super Learner ensemble were measured by the increase in Brier score after permuting the values of each predictor and averaging across imputed datasets.
Calibration, the agreement between predicted and observed risk, was visually assessed using calibration curves fitted using thin plate splines and decile groups. Data for the calibration curves were created by stacking the Super Learner predictions from each imputed dataset when each observation served in the validation fold. Within each imputed dataset, deciles calculated using the stacked Super Learner predictions were used to group observations, within which the proportion of observations with the outcome was estimated. Pooled estimates were used to derive calibration point estimates with 95% confidence intervals (CI).
All analyses were performed in R (v4.2.1)44 using functions primarily from the mice,45 psfmi,46 PRROC,47,48 SuperLearner49, and ck37r50 packages and modified R source code developed by Chris Kennedy51. This study followed the Transparent Reporting of a Multivariable Prediction Model for Individual Prognosis or Diagnosis plus Artificial Intelligence (TRIPOD + AI) reporting guidelines52.
Missing data
Implausible values of maternal birthweight z-score (\(\ge\) 5 in absolute value) and grandmaternal and maternal pre-pregnancy weight (BMI < 13 kg/m2, or < 35 kg if height was missing) were set to missing. The proportion of missing values was below 32% for all predictors, except for grandmaternal pre-pregnancy height and consequently, BMI, where approximately 90% of values were missing due to height information not being routinely collected before 2003. Multiple imputation using chained equations was used to account for missingness in predictors45. Imputation models included G0 predictors, G1 predictors, and outcome variables. Ten imputed datasets (25 iterations) were generated where missing values for each variable with missingness were imputed using random forest (RF)41,53. Continuous derived variables, such as BMI and gestational weight gain, were passively imputed54. Analyses were performed on each imputed dataset and results were pooled using Rubin’s rules55. Traceplots suggested no issues with convergence of the multiple imputation procedure, and a comparison of imputed and observed values showed that the imputed values were all within reasonable ranges and did not differ substantially from the observed values.
Results
Study population
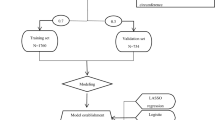
Between 1981 and 2021, a total of 9,165 pregnancies to first-born, nulliparous women resulted in singleton births. After removing second-generation infants with missing birthweight or gestational age (n = 42) or implausible birthweight z-scores (n = 7), and those born at less than 26 weeks’ gestation (n = 19), the final analytical sample included 9,097 grandmother-mother-infant triads (Fig. 1). During this period, 902 (9.9%) and 891 (9.8%) infants were born SGA and LGA, respectively. Characteristics of the sample are shown in Table 1. Small differences (absolute SMDs less than 0.2) in grandmaternal characteristics existed by outcome status. Mothers of infants born SGA had lower birthweight z-scores and, as adults, had lower pre-pregnancy BMIs and gained less weight in pregnancy than mothers of infants born non-SGA. Mothers of infants born LGA had higher birthweight z-scores and, as adults, had higher pre-pregnancy BMIs and gained more weight in pregnancy than mothers of infants born non-LGA.

Flow chart describing study cohort creation.
Discrimination
Cross-validated estimates of the AUC-ROC and AUC-PR for the Super Learner algorithm are shown in Table 2. For both SGA and LGA, AUC estimates from models fitted using the combined set of predictors were poor, with an AUC-ROC of 0.69 for SGA and 0.71 for LGA, and an AUC-PR of 0.21 for SGA and 0.22 for LGA. For reference, an AUC-ROC of 0.5 and an AUC-PR of approximately 0.1 (average prevalence of SGA and LGA in training samples) suggest no discrimination. These estimates were only marginally higher than those obtained from models fitted using either predictor set alone (AUC-ROC 0.63–0.66 for SGA and 0.64–0.66 for LGA; AUC-PR 0.15–0.18 for SGA and 0.17–0.18 for LGA). ROC and precision-recall curves can be found in Supplementary Figure S1 and Supplementary Figure S2. AUC estimates for the Super Learner algorithm and the individual learners are shown in Supplementary Table S3.
Calibration
The mean predicted risk of SGA and LGA from the Super Learner ensemble (approximately 10% for both) matched the overall risk in the sample. Calibration plots (Fig. 2) indicated good agreement between the predicted risk of SGA and LGA from the Super Learner and the smoothed actual risk estimated using thin plate splines. The Super Learner ensemble slightly overestimated the risk of SGA and LGA when the actual risk was small (< 5%) (Supplementary Table S4) but predicted risk estimates were within the 95% CIs for the actual risk in all decile groups.

Calibration plots showing the comparison of predicted risk from Super Learner algorithms fitted using the combined set of predictors (G0 + G1 predictors) and deciles of observed risk plotted on the logarithmic scale for A) small for gestational age (SGA) and B) large for gestational age (LGA). The red line indicates perfect calibration.
Super learner weights and variable importance
To assess the contribution of the individual learners to the final Super Learner predictions, coefficients (i.e., weights) of the Super Learner model were calculated and averaged across validation folds and imputed datasets (Supplementary Table S5). Most highly weighted in SGA prediction were XGBoost (mean weight 0.41), elastic net (mean weight 0.18), and GAM (mean weight 0.18). Most highly weighted in LGA prediction were GAM (mean weight 0.43), RF (mean weight 0.25), and XGBoost (mean weight 0.21). Similar key predictors were identified across outcomes and estimation methods (Supplementary Table S6); all were related to the maternal generation: birthweight z-score, gestational weight gain, and pre-pregnancy BMI.
Sensitivity analysis
The prevalence of SGA3 and LGA97 was 2.6% and 3.3%, respectively, which represented the value of no discrimination for AUC-PR. Super Learner predictions were best with the combined set of G0 and G1 predictors (Supplementary Table S7). Discriminative performance for SGA3 was similar to that for SGA defined by the 10th percentile, but slightly better for LGA97 than for LGA defined by the 90th percentile. Key predictors for SGA3 and LGA97 (Supplementary Table S8) were similar to those identified in the primary analyses.
Discussion
The current study used a large sample of prospectively collected data on three generations to assess the addition of grandmaternal pregnancy-related information and maternal birth characteristics to Super Learner models for SGA and LGA based on standard maternal factors in nulliparous women. Predictive performance measured using the AUC-ROC and AUC-PR increased with the inclusion of grandmaternal pregnancy-related factors and maternal birth characteristics to models fitted using only maternal characteristics, but discriminative performance remained poor. Predictors most influential on model performance included maternal clinical factors such as weight gain in pregnancy at 26 weeks and pre-pregnancy BMI, but also the mother’s birthweight z-score, a factor rarely considered in the prediction of SGA and LGA.
This study focused on using easily obtainable antenatal information to predict SGA and LGA. Other prediction models based on maternal characteristics alone have reported similar AUC-ROC estimates between 0.59 and 0.75 for SGA and LGA6,7,9,10,11,13,14,56,57,58,59, but few have been restricted to nulliparous women5,6,10,11 in whom prediction is poorer5,6. The AUC-PR estimates from the present study could not be compared to other studies in which this measure of discrimination was not reported.
Prediction of SGA and LGA was only slightly improved by the addition of grandmaternal factors and maternal birth characteristics. As several studies have shown an association between a mother’s own birthweight and the intrauterine growth of her offspring18,26,60, the observed increase in performance may be attributed to the addition of maternal birthweight z-score. For instance, a meta-analysis of three studies reported a 2.6 times increase in the odds of having a SGA birth in women who themselves were born SGA compared to women who were born non-SGA61. Moreover, a study using the Swedish Birth Register indicated that women who were born LGA had twice the odds of having an LGA infant in their own pregnancy62. In the current study, maternal SGA and LGA status was associated with a two and nearly two and a half times increased risk of having a (first-born) SGA and LGA birth, respectively, compared to mothers born non-SGA and non-LGA.
Only two studies have considered maternal birthweight in prediction models for SGA or LGA but model discrimination was poor (AUC-ROC 0.63 for SGA10, and 0.59 for LGA11). In the current study, maternal birthweight z-score was consistently identified as an important predictor of both outcomes. In an exploratory analysis, the Super Learner algorithm fitted using maternal predictors and maternal birthweight z-score (i.e., ignoring all other G0 predictors) performed as well as models that included all grandmaternal predictors. Thus, maternal birthweight z-score likely contributed to the increase in predictive performance seen with the addition of all G0 predictors as a set.
The primary outcomes in this study were defined using the 10th and 90th percentiles for birthweight-for-gestational age and sex, consistent with definitions used in other studies of fetal growth. However, there is growing concern that these thresholds do not adequately capture true fetal growth restriction or excessive fetal growth63,64. Although lower thresholds may better identify infants at highest risk of adverse outcomes, the aim of this study was not to detect pathologic growth, but to evaluate whether intergenerational pregnancy-related information provides additional predictive value beyond standard clinical factors. In sensitivity analyses, we found that model performance and variable importance were similar when using the 3rd and 97th percentiles, suggesting minimal impact of the specific thresholds used. Despite limitations in the definition of SGA and LGA, these classifications remain clinically relevant: they are associated with increased risk of adverse perinatal morbidity, and are easily operationalized, making them practical outcomes for prediction tools in clinical settings.
The use of data-adaptive algorithms to predict health outcomes is becoming more popular27,28. Many data-adaptive algorithms have the theoretical advantage over parametric models like logistic regression in that they require no distributional assumptions, no explicit model specification, and can capture non-linear relationships between the predictors and the outcome. However, in the present study and another study conducted in the same population6, AUC estimates from the Super Learner were approximately the same or only minimally higher than those derived from logistic regression models. With the inclusion of continuous predictors that could have non-linear associations with the outcomes, it was expected that the Super Learner algorithm would perform better than logistic regression. Prediction models developed using GAM performed nearly as well as the Super Learner algorithm, suggesting non-linear associations were likely accommodated by splines and relevant interactions among predictors did not exist. The Super Learner algorithm should still be considered in other datasets that may be more complex, contain a larger number of predictors, or when interactions among predictors are likely.
A main strength of this study is the use of a large sample with prospectively collected data on a diverse set of variables from three generations of Nova Scotians. A second strength is the flexible modeling approach used to predict SGA and LGA, which reduced the risk of bias due to model misspecification. This study also has several limitations worth discussing. First, approximately 90% missingness in grandmaternal pre-pregnancy height (required to calculate BMI) occurred because height has only been routinely collected in the NSAPD since 2003. However, analyses of multiply imputed BMI values were expected to be minimally biased since height was likely to be missing at random, and the imputation procedure included variables that were correlated with height. This study was also limited by the availability of predictors in the NSAPD, so other early-pregnancy factors such as paternal characteristics could not be included.
In conclusion, few studies have investigated the contribution of generational factors to predicting second-generation health outcomes. Adding grandmaternal risk factors and maternal birth characteristics modestly improved the prediction of SGA and LGA in nulliparous women as compared to models based on maternal clinical factors only. A novel finding of this study is that maternal birthweight z-score may be a useful predictor of abnormal fetal growth. However, predictive performance remained less than optimal, and more research is needed to identify predictors that are readily available early in pregnancy. Future research could build on this work by integrating maternal intergenerational data with grandpaternal and paternal information and other early-pregnancy predictors, including biomarkers and fetal biometric or ultrasound imaging data, which may offer added value when incorporated into an ensemble approach that uses machine learning algorithms.
Data availability
The data that support the findings of this study are available from the Reproductive Care Program of Nova Scotia, but restrictions apply to the availability of these data, which were used under license for the current study and are not publicly available. Further queries can be directed to the corresponding author.
References
Damhuis, S. E., Ganzevoort, W. & Gordijn, S. J. Abnormal fetal growth. Obstet. Gynecol. Clin. North Am. 48, 267–279 (2021).
Fung, C. & Zinkhan, E. Short- and Long-term implications of small for gestational age. Obstet. Gynecol. Clin. North Am. 48, 311–323 (2021).
Colella, M., Frérot, A., Novais, A. R. B. & Baud, O. Neonatal and long-term consequences of fetal growth restriction. Curr. Pediatr. Rev. 14, 212–218 (2018).
Scifres, C. M. Short- and long-term outcomes associated with large for gestational age birth weight. Obstet. Gynecol. Clin. North Am. 48, 325–337 (2021).
Meertens, L. et al. External validation and clinical usefulness of first-trimester prediction models for small- and large-for-gestational-age infants: A prospective cohort study. BJOG Int. J. Obstet. Gynaecol. 126, 472–484 (2019).
Kuhle, S. et al. Comparison of logistic regression with machine learning methods for the prediction of fetal growth abnormalities: A retrospective cohort study. BMC Pregnancy Childbirth 18, 333 (2018).
Boucoiran, I. et al. First-trimester prediction of birth weight. Am. J. Perinatol. 30, 665–672 (2013).
Frick, A. P., Syngelaki, A., Zheng, M., Poon, L. C. & Nicolaides, K. H. Prediction of large-for-gestational-age neonates: Screening by maternal factors and biomarkers in the three trimesters of pregnancy: Screening for LGA. Ultrasound Obstet. Gynecol. 47, 332–339 (2016).
González-González, N. L. et al. Value of placental volume and vascular flow indices as predictors of intrauterine growth retardation. Eur. J. Obstet. Gynecol. Reprod. Biol. 212, 13–19 (2017).
McCowan, L. M. E. et al. Prediction of small for gestational age infants in healthy nulliparous women using clinical and ultrasound risk factors combined with early pregnancy biomarkers. PLoS ONE 12, e0169311 (2017).
Vieira, M. C. et al. Clinical, ultrasound and molecular biomarkers for early prediction of large for gestational age infants in nulliparous women: An international prospective cohort study. PLoS ONE 12, e0178484 (2017).
Monari, F. et al. A first trimester prediction model for large for gestational age infants: A preliminary study. BMC Pregnancy Childbirth 21, 654 (2021).
Crovetto, F. et al. Differential performance of first-trimester screening in predicting small-for-gestational-age neonate or fetal growth restriction. Ultrasound Obstet. Gynecol. 49, 349–356 (2017).
Schneuer, F. J. et al. Angiopoietin 1 and 2 serum concentrations in first trimester of pregnancy as biomarkers of adverse pregnancy outcomes. Am. J. Obstet. Gynecol. 210(345), e1-345.e9 (2014).
Ewington, L., Black, N., Leeson, C., Al Wattar, B. H. & Quenby, S. Multivariable prediction models for fetal macrosomia and large for gestational age: A systematic review. BJOG Int. J. Obstet. Gynaecol. https://doi.org/10.1111/1471-0528.17802 (2024).
Harville, E. W., Kruse, A. N. & Zhao, Q. The impact of early-life exposures on women’s reproductive health in adulthood. Curr. Epidemiol. Rep. 8, 175–189 (2021).
De Stavola, B. L., Leon, D. A. & Koupil, I. Intergenerational correlations in size at birth and the contribution of environmental factors: The uppsala birth cohort multigenerational study, Sweden, 1915–2002. Am. J. Epidemiol. 174, 52–62 (2011).
Lahti-Pulkkinen, M. et al. Intergenerational transmission of birth weight across 3 generations. Am. J. Epidemiol. 187, 1165–1173 (2018).
Kelly, G. E., Murrin, C., Viljoen, K., O’Brien, J. & Kelleher, C. Body mass index is associated with the maternal lines but height is heritable across family lines in the Lifeways Cross-Generation Cohort Study. BMJ Open 4, e005732 (2014).
Brown, M. M. et al. Grandmaternal prepregnancy body mass index and infant birthweight: A mediation analysis of maternal prepregnancy body mass index. Am. J. Epidemiol. 194, 389–396 (2025).
Ding, M. et al. Smoking during pregnancy in relation to grandchild birth weight and BMI trajectories. PLoS ONE 12, e0179368 (2017).
Rumrich, I. K., Hänninen, O., Viluksela, M. & Vähäkangas, K. Effect of grandmaternal smoking on body size and proportions at birth. Int. J. Environ. Res. Public. Health 18, 4985 (2021).
Huang, J. Y. et al. Are early-life socioeconomic conditions directly related to birth outcomes? grandmaternal education, grandchild birth weight, and associated bias analyses. Am. J. Epidemiol. 182, 568–578 (2015).
McCarron, P. Type 2 diabetes in grandparents and birth weight in offspring and grandchildren in the ALSPAC study. J. Epidemiol. Community Health 58, 517–522 (2004).
Naess, O. et al. Cardiovascular mortality in relation to birth weight of children and grandchildren in 500 000 Norwegian families. Eur. Heart J. 34, 3427–3436 (2013).
Ramakrishnan, U., Martorell, R., Schroeder, D. G. & Flores, R. Role of intergenerational effects on linear growth. J. Nutr. 129, 544S-549S (1999).
Bertini, A., Salas, R., Chabert, S., Sobrevia, L. & Pardo, F. Using machine learning to predict complications in pregnancy: A systematic review. Front. Bioeng. Biotechnol. 9, 780389 (2022).
Sufriyana, H. et al. Comparison of multivariable logistic regression and other machine learning algorithms for prognostic prediction studies in pregnancy care: Systematic review and meta-analysis. JMIR Med. Inform. 8, e16503 (2020).
Perichart-Perera, O. et al. Vitamin D deficiency, excessive gestational weight gain, and oxidative stress predict small for gestational age newborns using an artificial neural network model. Antioxidants 11, 574 (2022).
Brown, M. M. et al. The 3G multigenerational cohort of nova scotian women and their mothers and offspring. Paediatr. Perinat. Epidemiol. 34, 214–221 (2020).
Kramer, M. S. et al. A new and improved population-based Canadian reference for birth weight for gestational age. Pediatrics 108, e35–e35 (2001).
Guideline for Assessment of the “Best Estimate” of Gestational Age. Reproductive Care Program of Nova Scotia. http://rcp.nshealth.ca/clinical-practice-guidelines/best-estimate-gestational-age-202006.
Wilkins, R. & Peters, P. A. PCCF + Version 5K* User’s Guide. Automated Geographic Coding Based on the Statistics Canada Postal Code Conversion Files, Including Postal Codes through May 2011. https://mdl.library.utoronto.ca/sites/default/public/mdldata/open/canada/national/statcan/postalcodes/pccfplus/2006/2011may/MSWORD.PCCF5K.pdf (2012).
Magee, L. A. et al. Diagnosis, evaluation, and management of the hypertensive disorders of pregnancy: Executive summary. J. Obstet. Gynaecol. Can. 36, 416–438 (2014).
Feig, D. S. et al. Diabetes and pregnancy. Can. J. Diabetes 42, S255–S282 (2018).
Rasmussen, K. M. et al. Recommendations for weight gain during pregnancy in the context of the obesity epidemic: Obstet. Gynecol. 116, 1191–1195 (2010).
Austin, P. C. An introduction to propensity score methods for reducing the effects of confounding in observational studies. Multivar. Behav. Res. 46, 399–424 (2011).
van der Laan, M. J., Polley, E. C. & Hubbard, A. E. Super learner. Stat. Appl. Genet. Mol. Biol. https://doi.org/10.2202/1544-6115.1309 (2007).
van der Laan, M. J. & Rose, S. Targeted Learning in Data Science: Causal Inference for Complex Longitudinal Studies. (Springer International Publishing : Imprint: Springer, Cham, 2018). https://doi.org/10.1007/978-3-319-65304-4.
Zou, H. & Hastie, T. Regularization and variable selection via the Elastic Net. J. R. Stat. Soc. Ser. B 67, 301–320 (2005).
Breiman, L. Random forests. Mach. Learn. 45, 5–32 (2001).
Chen, T. & Guestrin, C. XGBoost: A Scalable Tree Boosting System. in Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining 785–794 (ACM, San Francisco California USA, 2016). https://doi.org/10.1145/2939672.2939785.
Cortes, C. & Vapnik, V. Support-vector networks. Mach. Learn. 20, 273–297 (1995).
R Core Team. R: A Language and Environment for Statistical Computing. (R Foundation for Statistical Computing, Vienna, Austria, 2020).
van Buuren, S. & Groothuis-Oudshoorn, K. mice: Multivariate Imputation by Chained Equations in R. J. Stat. Softw. 45, 1–67 (2011).
Heymans, M. Psfmi: Prediction Model Pooling, Selection and Performance Evaluation Across Multiply Imputed Datasets. (2021).
Grau, J., Grosse, I. & Keilwagen, J. PRROC: Computing and visualizing precision-recall and receiver operating characteristic curves in R. Bioinformatics 31, 2595–2597 (2015).
Keilwagen, J., Grosse, I. & Grau, J. Area under precision-recall curves for weighted and unweighted data. PLoS ONE 9, e92209 (2014).
Polley, E., LeDell, E., Kennedy, C. & Laan, M. van der. SuperLearner: Super Learner Prediction. (2021).
Kennedy, C. Ck37r: Chris Kennedy’s R Toolkit. (2022).
Kennedy, C. Source code from ‘Development of an ensemble machine learning prognostic model for predicting 60-day risk of major adverse cardiac events in adults with chest pain’. https://github.com/ck37/chest-pain-risk-prediction (2021).
Collins, G. S. et al. TRIPOD+AI statement: updated guidance for reporting clinical prediction models that use regression or machine learning methods. BMJ https://doi.org/10.1136/bmj-2023-078378 (2024).
Doove, L. L., Van Buuren, S. & Dusseldorp, E. Recursive partitioning for missing data imputation in the presence of interaction effects. Comput. Stat. Data Anal. 72, 92–104 (2014).
Buuren, S. van. Flexible Imputation of Missing Data. (CRC Press, Taylor & Francis Group, Boca Raton London New York, 2018).
Rubin, D. B. Multiple Imputation for Nonresponse in Surveys (Wiley-Interscience, 2004).
Erkamp, J. S. et al. Second and third trimester fetal ultrasound population screening for risks of preterm birth and small-size and large-size for gestational age at birth: A population-based prospective cohort study: Fetal ultrasound screening for common adverse birth outcomes. BMC Med. 18, 63 (2020).
Macdonald-Wallis, C. et al. Antenatal blood pressure for prediction of pre-eclampsia, preterm birth, and small for gestational age babies: Development and validation in two general population cohorts. BMJ 351, h5948–h5948 (2015).
Onwudiwe, N., Yu, C. K. H., Poon, L. C. Y., Spiliopoulos, I. & Nicolaides, K. H. Prediction of pre-eclampsia by a combination of maternal history, uterine artery Doppler and mean arterial pressure. Ultrasound Obstet. Gynecol. 32, 877–883 (2008).
Poon, L. C. Y., Karagiannis, G., Stratieva, V., Syngelaki, A. & Nicolaides, K. H. First-Trimester prediction of macrosomia. Fetal Diagn. Ther. 29, 139–147 (2011).
Klebanoff, M. A., Graubard, B. I., Kessel, S. S. & Berendes, H. W. Low birth weight across generations. JAMA 252, 2423–2427 (1984).
Shah, P. S. & Shah, V. Influence of the maternal birth status on offspring: A systematic review and meta-analysis. Acta Obstet. Gynecol. Scand. 88, 1307–1318 (2009).
Ahlsson, F., Gustafsson, J., Tuvemo, T. & Lundgren, M. Females born large for gestational age have a doubled risk of giving birth to large for gestational age infants. Acta Paediatr. 96, 358–362 (2007).
Wilcox, A. J., Snowden, J. M., Ferguson, K., Hutcheon, J. & Basso, O. On the study of fetal growth restriction: Time to abandon SGA. Eur. J. Epidemiol. 39, 233–239 (2024).
Wilcox, A. J., Cortese, M., McConnaughey, D. R., Moster, D. & Basso, O. The limits of small-for-gestational-age as a high-risk category. Eur. J. Epidemiol. 36, 985–991 (2021).
Acknowledgements
The authors acknowledge the Reproductive Care Program of Nova Scotia for access to the data.
Funding
This work was supported by a Scotia Scholars Award from the Nova Scotia Health Research Foundation (NSHRF), a Nova Scotia Graduate Scholarship from Dalhousie University, and the New Brunswick Innovation Foundation (NBIF) to MB and by the IWK Health Centre to SK and CW.
Author information
Authors and Affiliations
Contributions
M.M.B. conceptualized and designed the study, performed the analysis, and wrote the initial manuscript draft. C.G.W., B.S., and S.K. contributed to the design of the study, and provided input regarding methodology and continuous feedback on the manuscript. J.P. and V.M.A provided content expertise and guidance for implications and design of the study. All authors reviewed and revised the manuscript, and approved the final manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Ethics approval
This study was approved by the IWK Health Centre Research Ethics Board (#1023071) and the Joint Data Access Committee of the Reproductive Care Program of Nova Scotia. All methods were carried out in accordance with relevant guidelines and regulations, including those outlined in the Tri-Council Policy Statement: Ethical Conduct for Research Involving Humans – TCPS 2 (2022). The need for informed consent for this database-based study was waived by the IWK Health Centre Research Ethics Board as per the Nova Scotia Personal Health Information Act.
Disclaimer
The Nova Scotia Atlee Perinatal Database (NSAPD) data used in this report were made available by the Reproductive Care Program of Nova Scotia, a program of IWK Health (IWK). Although this analysis is based on data obtained from IWK, and it was reviewed before publication to ensure compliance with NSAPD disclosure policies, and understanding of the variable definitions, the observations and opinions expressed are those of the authors and do not necessarily represent those of IWK.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Brown, M.M., Kuhle, S., Smith, B. et al. Development and validation of super learner models to predict small and large for gestational age in the second generation. Sci Rep 15, 33212 (2025). https://doi.org/10.1038/s41598-025-18466-0
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-18466-0
