
Abstract
Machine learning techniques for lithology prediction using wireline logs have gained prominence in petroleum reservoir characterization due to the cost and time constraints of traditional methods such as core sampling and manual log interpretation. This study evaluates and compares several machine learning algorithms, including Support Vector Machine (SVM), Decision Tree (DT), Random Forest (RF), Artificial Neural Network (ANN), K-Nearest Neighbor (KNN), and Logistic Regression (LR), for their effectiveness in predicting lithofacies using wireline logs within the Basal Sand of the Lower Goru Formation, Lower Indus Basin, Pakistan. The Basal Sand of Lower Goru Formation contains four typical lithologies: sandstone, shaly sandstone, sandy shale and shale. Wireline logs from six wells were analyzed, including gamma-ray, density, sonic, neutron porosity, and resistivity logs. Conventional methods, such as gamma-ray log interpretation and rock physics modeling, were employed to establish baseline lithological profiles, while core sample reports provided the necessary ground-truthing of the machine learning models. These traditional interpretations served as a benchmark for evaluating the performance of machine learning algorithms. The results revealed that Random Forest and Decision Tree models outperformed other algorithms, achieving accuracy, precision, recall, and F1 scores in the 96–98% range. Their robustness to noise, interpretability, and ability to handle complex, nonlinear data made them particularly suitable for the heterogeneous and multivariate nature of subsurface data. While SVM, ANN, KNN and LR required more tuning and were prone to overfitting, RF and DT proved efficient and reliable. The integration of traditional geological methods with machine learning provided a comprehensive approach to lithology prediction, enhancing reservoir characterization accuracy, while this study underscores the importance of combining domain expertise with computational models for optimizing petroleum exploration in complex geological environments.
Similar content being viewed by others

Introduction
Precise lithofacies predictions are critical for an adequate reservoir characterization and management in the petroleum industry. Classifying lithologies is challenging because different rocks have different porosity, permeability, and fluid saturation. Traditional methods for identifying lithology using wireline logs have long been recognized as labor-intensive, often hampered by subjective human interpretation, and reliant on core samples collected from drilled wells1,2. Moreover, nonlinear relationships observed amongst wireline logs and the diverse lithologies and petrophysical properties within geological formations add further complexity to manual interpretation techniques3. Nevertheless, recent advancements in computational methods, particularly machine learning algorithms, offer promising avenues for expediting and enhancing the lithology identification process.
In lithology prediction, researchers have traditionally relied on well-log data and empirical relationships to identify subsurface rock types. Wireline data such as gamma-ray, sonic, resistivity, neutron and density logs, are crucial for providing continuous downhole measurements that indicate the chemical composition and physical characteristics of rock layers. Historically, manual interpretation of well logs was the primary method for petrophysical characterization of reservoirs, with expert geologists analyzing log signatures based on established cutoffs and patterns; for example, gamma-ray logs distinguish between sandstones (low values) and shales (high values), as outlined by Asquith and Gibson4, with empirical cutoffs refined in subsequent studies. Advancements were made with rock physics models introduced by Avseth et al.5, linking log responses to the mechanical properties of rocks and enabling lithology prediction through the analysis of rock stiffness (e.g., Young’s modulus) and bulk properties. For instance, plotting Young’s modulus against Poisson’s ratio helps differentiate sand, shale, and intermediate lithologies like sandy shale and shaly sand. In the 1980s and 1990s, the rise of multivariate statistical methods allowed for more sophisticated lithology prediction techniques, including discriminant analysis and principal component analysis (PCA), which group rock types based on multiple log responses. Rider6 pioneered statistical techniques for automating lithology prediction, reducing the subjectivity of manual interpretations and providing a more data-driven approach to classification. Overall, various methods have been developed and refined over the past few decades to improve the accuracy and reliability of lithology prediction.
As industry embraces digital transformation, machine learning remains at the forefront of creative approaches to improving decision-making and operational efficiency in hydrocarbon exploration. These machine learning algorithms have been developed as useful tools for evaluating complex exploration and development data, allowing geoscientists to spot patterns and links that traditional techniques would miss. By processing vast volumes of seismic, well log, and core sample data, machine learning can accurately estimate lithofacies. This predictive capability deepens our understanding of subsurface formations and optimizes exploration and production strategies, reducing risks and costs associated with drilling and reservoir development. Leveraging machine learning facilitates the automated categorization and identification of lithologies, making it feasible to discern complex geological formations and their variations7,8,9,10,11. Notably, non-parametric approaches such as artificial neural networks (ANN), K-nearest neighbors (KNN), decision trees (DT), support vector machines (SVM), logistic regression (LR), and fuzzy logic have gained traction for their utility in lithology identification within petroleum reservoirs12,13,14. These increasingly explored methods represent a departure from traditional manual interpretation, offering potential solutions to the challenges posed by laborious and subjective lithology identification processes in the petroleum industry15,16.
While research in reservoir characterization predominantly focuses on deep-learning techniques, such as random forest (RF) and extreme gradient boosting, for forecasting porosity based on seismic and well-log characteristics, these methods have also proven to be equally effective for lithology prediction17,18,19,20. Notably, machine learning algorithms have become proficient in interpreting lithologies, mainly when applied to large well-log datasets21. This highlights the versatility and utility of machine learning algorithms in addressing various challenges within reservoir characterization, including lithology identification and prediction. By utilizing advanced computational techniques, researchers and industry professionals can achieve enhanced accuracy and efficiency in characterizing reservoirs and optimizing hydrocarbon recovery strategies.
Handling and processing extensive well-log datasets pose significant challenges that must be overcome before utilizing them for lithology prediction22. The application of various machine learning techniques generates a substantial quantity of data, further augmenting the volume available for lithology interpretation. To address the complexities of dataset management, Sircar et al. (2019)23 and Saporetti et al.24 explored the use of artificial neural networks (ANN), fuzzy logic, and genetic algorithms (GA). These methodologies offer promising avenues for efficiently handling and extracting valuable insights from large datasets, facilitating more accurate and robust lithology prediction processes.
In the context of lithology prediction in petroleum reservoir characterization, integrating geological descriptions and rock physics models is crucial in enhancing our understanding of reservoir quality25,26,27. By incorporating well-log data and geological characteristics, these models offer accurate insights into lithology distribution within a reservoir. Notably, lithological models are essential for capturing the complex relationships between lithologies and other properties of petroleum reservoirs (e.g., porosity), thus enabling effective lithology prediction28. Moreover, establishing a physical foundation for the relationships between porosity, lithology, and rock physics, including elastic properties, further improves lithology prediction accuracy29. By leveraging these models, both researchers and industry practitioners can deepen their understanding of reservoir characteristics and enhance the accuracy of lithology predictions, thereby facilitating improved reservoir management and more successful hydrocarbon exploration endeavours.
However, it is important to note that studies using seismic attributes operate at a significantly coarser resolution and often aim to characterize broader-scale heterogeneities, whereas well-log-based approaches, such as the present study, deal with high-resolution vertical data at the wellbore scale. As such, direct comparisons between the two must consider differences in data resolution, sampling density, and domain focus. In this context, the present study restricts its evaluation to well-log-based lithofacies classification, with references to seismic-based studies serving only to highlight broader methodological trends in machine learning applications across reservoir characterization.
This study applied six ensemble techniques, namely SVM, DT, RF, ANN, KNN, and LR, to forecast lithologies within the Basal Sand of the Lower Goru Formation in the Lower Indus Basin, Pakistan. While machine learning for lithofacies classification is not new, this study introduces a comparison of multiple algorithms (RF, SVM, ANN, etc.) on the Lower Goru Formation’s well logs, integrating traditional geological methods to enhance prediction accuracy. Additionally, the study explores insights into lithology distribution within the Basal Sand and how these insights can inform reservoir management strategies. By addressing these objectives, the research contributes to advancing machine learning applications in reservoir characterization and provides a roadmap for integrating computational techniques into petroleum exploration workflows.
Theoretical background
This section provides a theoretical overview of the machine learning algorithms utilized in this study, including Support Vector Machine (SVM), Decision Tree (DT), Random Forest (RF), Artificial Neural Network (ANN), K-Nearest Neighbor (KNN), and Logistic Regression (LR). Each algorithm offers unique approaches to handling classification tasks like lithology prediction, and their underlying principles are briefly outlined here.
-
1.
Support Vector Machine (SVM)
SVM is a supervised learning algorithm primarily used for tasks30. The main objective of SVM is to find an optimal hyperplane that separates data points of different classes with the maximum possible margin. The algorithm works well in high-dimensional spaces and is effective in cases where the relationship between the input data and the class labels is nonlinear. To handle non-linearity, SVM uses kernel functions (such as radial basis function or polynomial kernel) to map the input data into a higher-dimensional feature space, where a linear separation is possible31. SVM is especially suitable for binary classification problems but can be extended to multi-class tasks through methods like one-vs-one or one-vs-all approaches.
-
2.
Decision Tree (DT)
A Decision Tree is a non-parametric, tree-based learning model used for both classification and regression32. It splits the dataset into subsets based on feature values, recursively partitioning the data into nodes until a specific stopping criterion is met (e.g., all leaves contain homogeneous classes). DT aims to create a model that predicts the target variable by learning simple decision rules inferred from the data features. Each internal node represents a feature, each branch a decision rule, and each leaf a class label. Gini impurity or entropy are commonly used as measures of node splitting33,34. One key advantage of DTs is their interpretability, making them highly useful for geological data like well logs.
-
3.
Random Forest (RF)
Random Forest is an ensemble learning method built on the idea of combining multiple Decision Trees to improve accuracy and prevent overfitting35,36. It works by generating multiple DTs during training and averaging their predictions for classification tasks (or taking the majority vote). Each tree in the forest is trained on a random subset of the data (using bootstrapping), and a random subset of features is considered at each split, ensuring diversity among the trees. This bagging technique reduces the variance of the model, making Random Forest robust against overfitting and noise in the data34. RF is particularly effective in handling high-dimensional data and complex relationships, which are common in lithology prediction using well logs.
-
4.
Artificial Neural Network (ANN)
An Artificial Neural Network (ANN) is inspired by the structure and function of biological neural networks, designed by Marvin Minsky in 195137. ANNs consist of layers of interconnected nodes (neurons), where each node represents a feature in the dataset. ANNs are particularly powerful for capturing nonlinear relationships in data. The most common type of ANN is the feed-forward neural network, which consists of input, hidden, and output layers. Each neuron applies an activation function (e.g., ReLU, sigmoid) to the weighted sum of its inputs. The model learns by adjusting the weights during the training process using algorithms like backpropagation and gradient descent38. While ANNs are highly flexible and capable of modeling complex patterns, they often require large datasets and careful tuning of hyperparameters, which can make them prone to overfitting, especially with smaller datasets like those often used in lithology prediction.
-
5.
K-Nearest Neighbor (KNN)
K-Nearest Neighbor (KNN) is a simple, instance-based learning algorithm that classifies a data point based on the majority class of its k-nearest neighbors in the feature space39,40. KNN does not build an explicit model; instead, it stores the entire training dataset and makes predictions by calculating the distance (typically Euclidean distance) between the new data point and all training samples. The algorithm works well when there is a clear local structure in the data, making it useful for lithology prediction in cases where facies exhibit clear, local variations. However, KNN can be computationally expensive with large datasets since it requires calculating distances for every prediction38.
-
6.
Logistic Regression (LR)
Logistic regression is a widely used classification algorithm designed to predict categorical outcomes, particularly binary classification tasks41. Unlike linear regression, which predicts a continuous output, logistic regression models the probability of a data point belonging to a particular class using the logistic function (sigmoid). The model assumes a linear relationship between the input features and the log-odds of the target class, which makes it suitable for simple, linearly separable data42. In cases where lithology prediction involves more complex, nonlinear relationships, LR may underperform compared to nonlinear models like Decision Trees or SVM.
In addition to traditional supervised learning methods, recent studies have increasingly adopted deep learning architectures, such as convolutional neural networks (CNNs) for capturing spatial features in log images and recurrent neural networks (RNNs) for modeling sequential dependencies in well-log data (e.g., Mishra et al.11; Prajapati et al.38. These models, though data-intensive, have demonstrated improved performance in lithology classification and petrophysical property prediction tasks. Furthermore, there is growing interest in uncertainty-aware modeling and explainable AI (XAI) techniques, including SHAP (SHapley Additive exPlanations) and LIME (Local Interpretable Model-agnostic Explanations), which enhance model transparency and support geologically consistent interpretations.
Geological setting
The study area is located in the central part of the Lower Indus Basin (LIB) between the eastern boundary of the Indian Shield and the western boundary formed by the marginal zone of the Indian plate. To the south, it extends into the Sanghar field, supported by observations from the Offshore Murray Ridge (OMR) and Oven Fracture Plate (OFP)43. The Sanghar field is located within the Sinjhoro concession, covering an area of 180 square kilometers, as shown in Fig. 1a. Notably, significant discoveries of oil, gas, and condensate have been made from the Lower Goru Formation. The field produces 900 barrels per day of oil, with ongoing expansion efforts. This research focuses on the Lower Goru Formation, widespread in the Lower Indus Basin (LIB), Pakistan. These formations exhibit considerable lithological diversity, primarily due to fluctuations in sediment supply and environmental conditions44.

Sources: Esri, Maxar, Earthstar Geographics, and the GIS User Community. Map imagery © Google.; (b) Locations of the studied wells.
(a) Map of the study area in Sindh, Pakistan. The base image was extracted using Google Earth Pro (Version 7.3), Google LLC. (2025). (URL: https://www.google.com/earth/versions/#earth-pro). The background basemap is the World Imagery layer sourced from ArcGIS Online (URL: https://www.arcgis.com/apps/mapviewer/index.html? layers=10df2279f9684e4a9f6a7f08febac2a9).
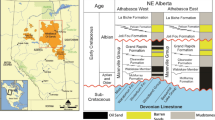
The stratigraphy of the Lower Indus Basin (LIB) is characterized by a thick sedimentary package ranging in age from the Triassic Wulagi Formation to Quaternary alluvium. The Lower Cretaceous Sembar Formation, mainly consisting of shale, is the primary source rock, whereas the late Early Cretaceous to Late Cretaceous Upper Shale acts as a seal, and the Lower Goru Formation is the reservoir rock45. This Sembar-Goru petroleum system in the LIB is notable for its efficiency and comprises several geological units.
The Early Cretaceous in the LIB is characterized by warmer latitude sedimentation of the Sembar and Goru over large erosional surfaces45. The Lower Goru Formation is a deltaic and shallow-marine sandstone characterized by different types of stratified sand representing a regressive stratum top sets prograding sequence. These intervals were deposited during rapid sea-level fluctuations, transitioning from high to low levels. This sequence exhibits aggradational patterns (Fig. 2). The uppermost portion of the Lower Goru Formation (LGF) comprises clastic sediments, primarily sandstone, which possess favorable reservoir characteristics and may indicate the presence of commercial hydrocarbons (oil and gas) in various parts of the LIB. The LGF was mainly deposited in deep marine settings, although some minor shallow benthic-rich fauna have been reported by researchers46. In the Lower Goru Formation, as in many other marine and deltaic basins, mixed lithologies are common, and the informal terms, such as, sandy shale and shaly sand help describe the gradational nature of the deposits. The use of such terminology allows for a more accurate and practical classification of lithofacies in this context, aligning with previous research in the study area (e.g., Khan et al.47; Hussain et al.43).
On a regional scale, sedimentary strata dip from east to west, with these structures serving as significant conduits for hydrocarbon accumulation. The Lower Indus Basin harbors numerous sandstone reservoirs spanning from the Cretaceous to the Paleogene units, including the Goru Formation, Pab Sandstone, and Ranikot Group, exhibiting substantial hydrocarbon potential. In the study area, the Lower Goru Formation of the middle Cretaceous serves as the primary confirmed reservoir. Shales of the Upper Goru Formation act as seal rocks for both the Goru and Sembar petroleum systems48. The reservoir quality generally reduces as Goru thickness increases westward45.

Methods
The workflow utilized in this study, as shown in Fig. 3, comprises several crucial steps tailored to predict lithology effectively.

Workflow for evaluating machine learning algorithms.
Data collection
The first step in this workflow was to gather well log data from six specific wells: Chak 7, Hakeem, Resham, Chak 63, Chak 66, and Chak 5, as shown in Fig. 1b, targeting the Basal Sand interval of the Lower Goru Formation (LGF). The logs available from these wells included gamma-ray (GR), bulk density (RHOB or ZDEN), sonic (compressional sonic travel time = DTP or DT), laterolog deep (RD or LLD), and neutron porosity (PHIN), with some logs (i.e., PHIN) missing for specific wells (Table 1). These available logs provide complementary data that are widely recognized for distinguishing lithologies in deltaic and shallow marine environments. The goal was to create a dataset that would support lithology prediction and reservoir characterization. The data for Chak 7 and Hakeem were reserved for model testing, while the rest were used for model training.
Data exploration and analysis
After data collection, exploratory data analysis (EDA) was performed to understand the characteristics of the dataset. EDA helped identify patterns and relationships between well logs and lithologies, which informed further data processing. Data visualization techniques, such as correlation matrices (Fig. 4), were employed to assess the relationships between key logs (GR, sonic, bulk density, resistivity) and lithologies. The scatter plots showed substantial overlap, complicating lithology interpretation, which emphasized the need for advanced data processing and machine learning models to better delineate lithological boundaries. While formal grain-size classifications (e.g., sand, silt, clay) are important for scientific accuracy, they sometimes fail to capture the real-world complexity of sedimentary facies, especially in transitional zones where both sand and shale co-exist. In these cases, informal terms like “sandy shale” and “shaly sand” provide a more accurate representation of the physical properties observed in the field and well logs.

Correlation matrix between gamma-ray (GR), sonic (DT), bulk density (RHOB or ZDEN) and deep-resistivity (RD) logs, illustrated for two test wells, Hakeem and Chak 7.
Data preprocessing
Preprocessing is a crucial step in machine learning workflows to ensure the data is clean and consistent. This involved the following tasks:
-
Data Cleaning: Missing values were addressed using domain-specific statistical methods, such as correlation-based imputation. Outliers were handled by applying standard deviation thresholds, and erroneous entries were corrected based on the physical limits of the logs.
-
Data Transformation: Categorical variables were encoded, numerical data was scaled, and skewness in the data was corrected. This transformation ensured the data was in a format suitable for machine learning models, allowing for consistent input across all algorithms.
After cleaning and transforming the data, the class distribution for each lithofacies type was assessed to ensure that the models’ performance metrics were contextualized with respect to class imbalance. Table 2 provides the distribution of samples for each lithofacies class used in this study. The codes used have been introduced as supplementary file, and Figs. S1 and S2.
Feature engineering
Feature engineering was applied to derive new informative variables from the available data. For instance, Young’s modulus was calculated using sonic logs and combined with quartz content to improve lithology classification. An additional sonic log, such as the shear sonic log (shear wave travel time, DTS), was available in the testing and training wells and was used along with DTP to calculate Young’s modulus. Detailed calculations can be found in Sohail et al.51. Cross-plots of these parameters helped identify distinct clusters, particularly for differentiating between sandstone, shale, and mixed lithologies like sandy shale and shaly sand (see Fig. 5 for the rock physics model of Chak 7 well). Sandy shale typically refers to rocks where shale is the dominant matrix with a significant sand fraction, while shaley sand involves a higher proportion of sand with some interspersed shaly components. To differentiate between shaly sand and sandy shale, the model considers not only gamma-ray and density logs but also advanced rock-physics modeling that incorporates Young’s modulus and other log-derived features. Both can be challenging to distinguish based solely on well-log data, and hence, advanced methods like machine learning are employed to model their characteristics.

Rock physics model for the classification of lithologies using well log data of Chak 7.
Data partitioning
Once the data was preprocessed and engineered, it was partitioned into training and testing sets. Chak 5, Resham, Chak 63, and Chak 66 wells were used for training, while Chak 7 and Hakeem were set aside for testing. This partitioning ensured the models were trained on a representative dataset and validated on unseen data for unbiased performance evaluation.
Data scaling
To ensure consistent input across all machine learning models, the numerical features (well logs) were scaled. Standardization was applied to ensure that all features had the same scale, which is particularly important for algorithms like Support Vector Machine (SVM) and K-Nearest Neighbor (KNN) that are sensitive to feature scaling.
Model training
Multiple machine learning algorithms were trained on the well log data, including:
-
1.
Logistic Regression (LR): Used for binary classification between lithologies.
-
2.
K-Nearest Neighbor (KNN): Employed for nonlinear relationships in the data.
-
3.
Random Forest (RF): A robust algorithm that handles non-linearity and missing values well.
-
4.
Decision Tree (DT): Used for interpretable model outputs.
-
5.
Artificial Neural Network (ANN): Applied to capture complex patterns and relationships between logs and lithologies.
-
6.
Support Vector Machine (SVM): Used with a radial basis function (RBF) kernel for nonlinear classification.
The models were trained using stratified k-fold cross-validation to avoid overfitting and ensure generalizability52,53,54. This technique was specifically chosen to address potential concerns related to the spatial dependency of facies variability within the Lower Goru Formation. Stratified k-fold cross-validation ensures that each well is represented in both the training and test sets, providing a more comprehensive evaluation of the model’s performance across diverse geological conditions.
Hyperparameter tuning
Hyperparameters for each model were optimized using grid search (e.g., GridSearchCV) to determine the best configuration for lithofacies prediction, as shown in Table 3, and their impact on model performance was evaluated using cross-validation techniques. This tuning process involved adjusting parameters such as the number of neighbors for KNN, the number of trees for the Random Forest, the learning rate for ANN, and the kernel type for SVM. The aim was to identify the configuration that would yield the best performance for each algorithm.
Model testing
The trained models were evaluated on the reserved test set (Chak 7 and Hakeem) to assess their performance on unseen data. The testing phase ensured that the models were not overfitted and generalized well beyond the training data.
Model evaluation and selection
Model performance was evaluated using several metrics:
-
Accuracy: To measure the proportion of correctly classified lithologies.
-
Precision: To assess the ability of the model to predict sand and shale.
-
Recall: To measure the model’s capability in identifying true positives (sand or shale).
-
F1 Score: To balance precision and recall in cases where data is imbalanced between lithologies.
Statistical tests, such as paired t-tests, were conducted to compare the performance of different models. The best-performing model was selected for lithology prediction based on the evaluation metrics.
Results
Manual interpretation of lithologies
The manual interpretation of lithologies involves a systematic examination of core samples and well logs to discern and classify various lithological units of the Basal Sands of the Lower Goru Formation, as illustrated in Fig. 6. This analysis relies on mineral composition, texture, and depositional environment specific to each lithology. Four main lithologies within the Basal Sands of the Lower Goru Formation—sand, shale, sandy shale, and shaly sand—have been identified based on a combination of geological knowledge of the Lower Goru Formation and analysis using the elbow method in the K-means clustering algorithm. The details of this manual interpretation fall beyond the scope of the present study and are therefore not delineated here. The lithologies interpreted within the Basal Sand intervals (2800–2845 m in Chak 7 well and 2955–2985 m in Hakeem well), as depicted in Fig. 6, serve as a benchmark and necessary input for the machine learning algorithms. These interpreted lithologies constrain the algorithms, ensuring accurate predictions by aligning them with the reference outputs obtained through this interpretation.

Shows well logs and manually interpreted lithologies of the Basal Sand interval of Lower Goru Formation encountered in Chak 7 (a) and Hakeem (b) wells.
The lithological correlation between Chak 63, Chak 66, and Resham wells provides critical insights into the subsurface geology of the Basal Sand within the Lower Goru Formation in the Lower Indus Basin, as illustrated in Fig. 7. In Chak 63 and Chak 66, the consistent sequence of sand overlying shale suggests relatively stable depositional conditions, with minor variations in sand thickness likely influenced by localized changes in sediment supply or energy regimes, post-depositional compaction, or slight variations in subsidence rates. In contrast, the more complex depth distribution of sand and shale in the Resham well indicates that geological factors such as faulting, folding, or variations in paleotopography may have played a role in controlling sediment deposition and preservation. This implies that Resham may be situated near a structural feature like an anticline or a fault zone, which could have influenced sedimentation patterns. Alternatively, these variations might reflect lateral shifts in the depositional environment, likely due to changes in shoreline position or sediment supply, which are common in fluvio-deltaic to shallow marine settings. In such settings, transgressive-regressive cycles play a key role in shaping sedimentary facies distributions55, as reflected in the distinct lithofacies observed across these wells.
The lithological profile of the Chak 5 well, as depicted in Fig. 8, is distinguished by a higher proportion of sandstone, thinner sandy shale units, and an overall dominance of sandstone compared to other wells in the area. Gamma-ray values above 80 API (e.g., 100 or 125 API) are attributed to glauconitic sands in the Lower Goru Formation, as noted by Khan et al.47, which explains the higher-than-expected readings for typical sandstones. Although Khan et al.47 also examine the Lower Goru Formation, their lithological interpretation differs due to regional variations in depositional environments, as well as differing methods of gamma-ray log calibration. This distinctive profile suggests a more energetic depositional environment, possibly driven by fluctuations in sea level or variations in sediment supply, which could reflect shifts in sedimentary facies or the influence of structural features, such as faulting, that have affected the distribution and thickness of the sedimentary layers. The clear predominance of sandstone in the upper and lower sections, along with the reduced thickness of the intervening sandy shale and shale units, may indicate proximity to a sediment source, such as a deltaic channel or shoreface system. Additionally, diagenetic processes like compaction and cementation may have influenced the porosity and permeability of the sandstone and shale units, further differentiating them from other wells in the region. Further analysis, such as biostratigraphic correlation, seismic interpretation, or advanced petrophysical studies, would help clarify the underlying factors driving this lithological variation, but these analyses are beyond the scope of the current study.

Shows well logs and manually interpreted lithologies of the Basal Sand interval of Lower Goru Formation encountered in (a) Chak 63, (b) Chak 66 and (c) Resham wells.

Shows well logs and manually interpreted lithologies of the Basal Sand interval of Lower Goru Formation encountered in Chak 5 well.
Lithology prediction using machine learning
The study employed a range of machine learning algorithms, including Support Vector Machine (SVM), Random Forest (RF), Conventional/Artificial Neural Network (ANN), K-Nearest Neighbor (KNN), Decision Tree (DT), and Logistic Regression (LR), to model and predict lithofacies within wells Chak 7 and Hakeem. The results obtained from these algorithms were compared both visually and mathematically with manually predicted lithologies, as illustrated in Figs. 9 and 10. The Chak 7 well exhibited two thick shale patches, contrasting with the thinner shale patches observed in the Hakeem well. This disparity suggests a gradual thinning of shale towards the southwest of the study area, a phenomenon supported by the depositional style of the Lower Goru Formation in this region. Moreover, the lithologies within the Basal Sands revealed several complexities, leading to the observation of sand-shale intercalations within the Hakeem well. Despite these complexities, all examined machine learning algorithms effectively captured the intricate lithological patterns in the study area. Figures 9 and 10 depict how these algorithms accurately delineate lithological boundaries and capture the variations and complexities inherent in the Basal Sands of the Lower Goru Formation. This highlights the robustness of machine learning techniques in handling and interpreting geological data, particularly in contexts marked by significant lithological heterogeneity.

Represents manually interpreted lithologies in the first column, followed by predicted lithologies by various machine learning algorithms for Chak 7 well, where (a) represents SVM, (b) for RF, (c) for NNC, (d) for KNN, (e) for DT and (f) for LR.

Represents manually interpreted lithologies in the first column, followed by predicted lithologies by various machine learning algorithms for Hakeem well, where (a) represents SVM, (b) for RF, (c) for NNC, (d) for KNN, (e) for DT and (f) for LR.
Performance of machine learning algorithms
The performance of the various machine learning algorithms was evaluated using key metrics, including accuracy, precision, recall, and F1 score. To provide a more granular comparison of model performance, Fig. 11 (a-f) present the F1 scores for individual lithofacies classes (Sand, Shale, Sandy Shale, and Shaly Sand) across six machine learning algorithms: Support Vector Machine (SVM), Decision Tree (DT), K-Nearest Neighbor (KNN), Artificial Neural Network (ANN), Logistic Regression (LR), and Random Forest (RF).

F1 Scores for Individual Lithofacies Classes (Sand, Shale, Sandy Shale, and Shaly Sand) across Different Machine Learning Algorithms (SVM, Decision Tree, KNN, ANN, Logistic Regression, and Random Forest). Each bar represents the F1 score for a specific lithofacies class, illustrating the comparative performance of the algorithms in predicting lithology types.
Table 4 shows high accuracy, certain lithologies, like sandy shale and shaly sand, were misclassified due to their overlapping physical characteristics. This is a common challenge in lithofacies classification and is particularly evident in models that struggle with distinguishing these two facies, as shown in Fig. 9. SVM showed challenges in correctly classifying the green cluster, which is likely due to its sensitivity to outliers and misclassifications in the overlapping data points. Further tuning of the SVM model or testing with different kernels could improve performance. Notably, among all algorithms, the random forest model achieved the highest scores for Chak 7, while the decision tree model performed exceptionally well for Hakeem. These results underscore the inherent strength of Decision Tree (DT) and Random Forest (RF) algorithms in extracting robust insights from well-log data. Random Forest demonstrated superior performance due to its adeptness at handling large datasets, resilience against overfitting, and feature importance ranking. Moreover, the dataset’s specific characteristics, such as lower lithological heterogeneity compared to the Hakeem well, likely contributed to RF’s success. Conversely, the DT exhibited effectiveness in scenarios with higher lithological heterogeneity, showcasing its simplicity and non-parametric nature. Despite other algorithms yielding satisfactory results in predicting lithological facies, their performance metrics were comparatively lower. Nevertheless, their contributions remain noteworthy as they offered valuable predictive outcomes, albeit with some limitations in accuracy and precision, indicating some limitations in handling overlapping lithologies like sandy shale and shaly sand.
Figure 12 presents the performance metrics with confidence intervals for six machine learning models (SVM, Decision Tree, KNN, ANN, Logistic Regression, and Random Forest) across four metrics: Accuracy, Precision, Recall, and F1 Score. The Accuracy metric shows that Random Forest achieves the highest accuracy at 96%, closely followed by Decision Tree at 93%. On the lower end, SVM and Logistic Regression have accuracy values of 89% and 88%, respectively. In terms of Precision, Decision Tree and Random Forest perform equally well, both achieving 95% and 94%, while SVM has the lowest precision at 86%. For Recall, Random Forest and Decision Tree again outperform the other models, both scoring 96%, while Logistic Regression has the lowest recall at 88%. The F1 Score follows a similar trend, with Random Forest leading at 95%, followed by Decision Tree at 93%. SVM and Logistic Regression show the lowest F1 Scores, at 86% and 84%, respectively. The confidence intervals (represented by the error bars) provide an estimate of uncertainty in these performance values. For example, SVM has an accuracy confidence interval of [87%, 91%], while Random Forest has a narrower interval of [94%, 98%]. The analysis includes micro and macro averaging techniques, which ensure that class imbalance is properly accounted for in the multi-class classification task, offering a more robust evaluation of model performance across different lithofacies classes.

Performance metric with confidence intervals for machine learning models.
The confusion matrices for both Random Forest (RF) and Decision Tree (DT) algorithms, as shown in Fig. 13, indicate that shale is the easiest lithology to predict, with a high number of correct classifications in all cases (e.g., 479 and 1031 correct predictions for shale in RF). This suggests that the models can quickly identify distinct lithologies like shale based on well log data, such as gamma-ray or density logs, which are often clear indicators. However, both algorithms struggle with more ambiguous lithologies such as sandy shale and shaly sand, where there are frequent misclassifications. This difficulty may be due to overlapping physical characteristics between these lithologies, making it hard for the models to distinguish them based on wireline log inputs. Although Random Forest outperforms Decision Tree—particularly in larger datasets (e.g., RF correctly predicts 1031 instances of shale vs. DT’s 1014)—both models demonstrate robustness in handling nonlinear data. Nevertheless, Random Forest’s ensemble learning framework provides an edge in dealing with noise and complex patterns, which explains its overall better performance in terms of accuracy and precision. These results emphasize the importance of algorithm selection and parameter tuning when predicting lithologies with well logs, especially when distinguishing between closely related rock types.

Confusion matrices demonstrating the classification performance of random forest and decision tree algorithms for lithology prediction, highlighting accuracy in predicting shale and challenges in distinguishing between Sandy Shale and Shaly Sand.
Feature importance for lithofacies prediction
Figure 14 compares the feature importance of different well logs in predicting lithofacies using two machine learning models: Random Forest and Decision Tree. Both models show that Gamma-Ray and Density are the most significant features, with Gamma-Ray having the highest importance in the Random Forest model (0.35) and both Gamma-Ray and Density being equally important in the Decision Tree model (0.30 each). Sonic log also contributes significantly, particularly to the Decision Tree model (0.20), but has a slightly lower importance in the Random Forest model (0.15). Neutron Porosity and Resistivity have the least impact in both models, with an importance score of 0.10 in Random Forest and Decision Tree. This indicates that Gamma-Ray and Density are the most critical logs for lithofacies classification, although their relative importance varies slightly between the two models. This figure enhances the transparency and interpretability of the Random Forest model by clearly showing which well logs have the greatest impact on lithofacies classification.

Comparison of feature importance for lithofacies prediction using random forest and decision tree models.
Receiver operating characteristic (ROC) curve
In addition to confusion matrix analysis, the accuracy of the predictive lithology type was also assessed through receiver operating characteristic (ROC) plot, as shown in Fig. 15. The ROC plots are obtained from the plots of true positive rate against false positive rate of the ML models for each lithology, wherein the area under the receiver operating characteristic curve (AUC) is one of the user-defined parameters to measure accuracy in the present analysis. AUC values obtained for lithologies from DT and RF vary from 0.84 to 0.93 and 0.97–0.99, respectively.
Additionally, the ROC and AUC values reinforce that, during the training phase, all ML models demonstrated over 80% accuracy, making them well-prepared for lithology prediction in testing. These findings highlight the importance of selecting algorithms with robust classification abilities and underscore the ROC curve’s role as a supplementary tool in evaluating and confirming model performance beyond conventional accuracy metrics. The ROC Curves for ML Algorithms are provided as Appendix in figures A1, A2, A3, and A4.

Receiver Operating Characteristic (ROC) curves of the (a) DT and (b) RF classifier for four lithology types, Sand, Shale, Sandy Shale and Shaly Sand.
Factors affecting prediction accuracy
Data quality and computational resources posed significant challenges, with noise and inconsistencies in well log measurements impacting model precision. While effective, models like RF require considerable computational power, especially in large datasets, underscoring the need for efficient optimization methods. Furthermore, missing or erroneous data necessitated robust imputation strategies to maintain prediction integrity. Incorporating these considerations into model selection processes remains crucial for optimizing lithology prediction in operational settings.
Comparison with literature
Table 5 compares RF and DT performance metrics across studies, showing close alignment with Banerjee et al.56 and Merembayev et al.57. Differences in F1 score and recall with Xie et al.7 highlight the influence of dataset quality and log sensitivity on model performance, reinforcing the importance of data quality and parameter tuning for lithology prediction. These findings align with the broader trend in the literature that supports ML models’ efficacy in managing complex, high-dimensional geological data, making them valuable tools for lithofacies classification in varied geological settings.
Moreover, this study aligns with broader trends in the literature, highlighting a growing preference for machine-learning models over traditional empirical methods for lithology prediction. These modern approaches excel at managing complex, high-dimensional datasets effectively, as supported by various researchers15,58,59. The evidence thus reinforces the need for continued exploration of machine learning applications in geosciences, as these techniques are proving to be instrumental in refining lithofacies classification.
In light of these challenges, this study underscores the transformative potential of machine learning algorithms in revolutionizing operational efficiency and decision-making within the oil and gas sector. By automating the lithology interpretation process, companies can significantly streamline operations, thereby curtailing the time and resources conventionally expended on manual log analysis and leading to substantial cost savings. Furthermore, the ability to swiftly and accurately predict lithologies across multiple wells empowers geoscientists and reservoir engineers to gain timely insights into subsurface geological properties, facilitating more informed decision-making throughout exploration and production activities. Through automated lithology prediction, companies can optimize well planning, refine reservoir characterization efforts, and enhance hydrocarbon recovery strategies, ultimately bolstering overall operational performance and maximizing asset value. Moreover, the integration of machine learning-based lithology prediction into existing workflows equips industry professionals with the tools to harness advanced analytics and data-driven insights, fostering a culture of continuous improvement and innovation within the oil and gas industry.
Suggestions for further study
Based on this study’s findings, several recommendations can guide future research and industry practices in lithology prediction within the oil and gas sector. Firstly, prioritize decision trees (DT) and random forests (RF) in modeling efforts due to their demonstrated effectiveness, robust performance, and interpretability for subsurface characterization. Further refinement of predictive models is crucial, involving ongoing research into optimization techniques to enhance accuracy and generalization capabilities. While Random Forest and Decision Tree showed the best results in this study, future work could explore hybrid models combining the strengths of various algorithms, such as ensemble methods or deep learning, to improve lithofacies classification. Additionally, integrating machine learning-based lithology prediction with other geophysical data sources, such as seismic surveys, can provide a more comprehensive understanding of reservoir properties and improve decision-making in exploration and production activities. Companies should invest in developing automated workflows and decision support systems based on machine learning algorithms to streamline lithology interpretation processes, reduce manual effort, and accelerate decision-making, thereby increasing productivity and cost-effectiveness for oil and gas companies. Lastly, thorough validation and benchmarking studies should be conducted across diverse datasets and geological settings to ensure the reliability and robustness of predictive models in real-world applications, facilitating their adoption by industry stakeholders. Implementing these recommendations can harness the full potential of machine learning in lithology prediction, driving innovation and efficiency in subsurface exploration and hydrocarbon recovery efforts within the oil and gas industry.
Conclusion
This study has used multiple machine learning techniques, including Support Vector Machine (SVM), Random Forest (RF), Decision Tree (DT), Artificial Neural Network (ANN), K-Nearest Neighbor (KNN), and Logistic Regression (LR), to predict lithofacies using wireline logs in the deltaic depositional system in the Lower Goru Formation, Lower Indus Basin, Pakistan. Each machine learning algorithm applied in this study offers distinct advantages and limitations depending on the characteristics of the data. While Support Vector Machines (SVM) excel at nonlinear classification, Decision Trees and Random Forests provide interpretability and robustness against noise. Artificial Neural Networks (ANN) are ideal for capturing complex patterns, whereas K-Nearest Neighbors (KNN) are more suited for localized variations. Logistic Regression serves as a useful baseline for simpler problems. In this study, Random Forest and Decision Tree models demonstrated superior performance, highlighting their strength in handling the complex, noisy, and multivariate nature of well log data for lithology prediction.
Among the evaluated models, Decision Tree (DT) and Random Forest (RF) demonstrated the highest classification accuracies, particularly in lithologically complex intervals. Specifically, DT achieved up to 98% accuracy, followed closely by RF at 97%, KNN and ANN at 96%, SVM at 96%, and LR at 94%, as applied to the Hakeem well. These results confirm the effectiveness of tree-based ensemble methods in handling the multivariate, nonlinear nature of well-log data. This performance ranking supports the recommendation of RF and DT as preferred models for lithofacies prediction in similar depositional settings.
Data availability
The authors used public domain data, where codes and data can be shared on request from the first author Ansar Saleem (ansar.saleem100@outlook.com), and first corresponding author Ghulam Mohyuddin Sohail (gmdsohail@uet.edu.pk).
References
Araya-Polo, M. et al. Automated fault detection without seismic processing. Lead. Edge 36, 208–214 (2017).
Underhill, J. R. An alternative origin for the ‘silverpit crater’. Nature 428, 1–2 (2004).
Guillen, P., Larrazabal, G., González, G., Boumber, D. & Vilalta, R. Supervised learning to detect salt body. Presented at the SEG International Exposition and Annual Meeting, SEG-2015. (2015).
Asquith, G. B. & Gibson, C. R. Basic Well Log Analysis for Geologists George B. Asquith; Charles R. Gibson (Vol. 3, Ser. ISBN Electronic: 9781629811710) (American Assoc. of Petroleum Geologists, 1982).
Avseth, P., Mukerji, T. & Mavko, G. Quantitative seismic interpretation. (Cambridge University Press, 2005).
Rider, M. The Geological Interpretation of Well Logs (Rider-French Consulting, 1996).
Xie, Y. et al. Evaluation of machine learning methods for formation lithology identification: A comparison of tuning processes and model performances. J. Petrol. Sci. Eng. 160, 182–193 (2018).
Bressan, T. S., de Souza, M. K., Girelli, T. J. & Junior, F. C. Evaluation of machine learning methods for lithology classification using geophysical data. Comput. Geosci. 139, 104475 (2020).
Mahmoud, A., Abdulhamid, S., Elkatatny & Al-AbdulJabbar, A. Application of machine learning models for real-time prediction of the formation lithology and tops from the drilling parameters. J. Petrol. Sci. Eng. 203, 108574 (2021).
Kumar, T., Seelam, N. K. & Rao, G. S. Lithology prediction from well log data using machine learning techniques: A case study from Talcher coalfield, Eastern India. J. Appl. Geophys. 199, 104605 (2022).
Mishra, A., Sharma, A. & Patidar, A. K. Evaluation and development of a predictive model for geophysical well log data analysis and reservoir characterization: Machine learning applications to lithology prediction. Nat. Resour. Res. 31 (6), 3195–3222 (2022).
Liu, R. et al. Application and comparison of machine learning methods for mud shale petrographic identification. Processes 11, 2042 (2023).
Asedegbega, J., Ayinde, O. & Nwakanma, A. Application of machine learning for reservoir facies classification in port field, Offshore Niger Delta. In Presented at the SPE Nigeria Annual International Conference and Exhibition, D021S003R008 (2021).
Hall, B. Facies classification using machine learning. Lead. Edge 35, 906–909 (2016).
Zhao, T., Jayaram, V., Roy, A. & Marfurt, K. J. A comparison of classification techniques for seismic facies recognition. Interpretation 3, SAE29–SAE58 (2015).
Kobrunov, A. & Priezzhev, I. Hybrid combination genetic algorithm and controlled gradient method to train a neural network. Geophysics 81, IM35–IM43 (2016).
Zou, C., Zhao, L., Xu, M., Chen, Y. & Geng, J. Porosity prediction with uncertainty quantification from multiple seismic attributes using random forest. J. Geophys. Res. Solid Earth 126, e2021JB021826 (2021).
Yasin, Q., Sohail, G. M., Khalid, P., Baklouti, S. & Du, Q. Application of machine learning tool to predict the porosity of clastic depositional system, Indus Basin, Pakistan. J. Petrol. Sci. Eng. 197, 107975 (2021).
Zhong, Z. & Carr, T. R. Application of a new hybrid particle swarm optimization-mixed kernels function-based support vector machine model for reservoir porosity prediction: A case study in jacksonburg-stringtown oil field. Interpretation 7, T97–T112 (2019).
Kim, Y., Hardisty, R., Torres, E. & Marfurt, K. J. Seismic facies classification using random forest algorithm. In Presented at the SEG International Exposition and Annual Meeting, SEG-2018 (2018).
Hall, M. & Hall, B. Distributed collaborative prediction: Results of the machine learning contest. Lead. Edge 36, 267–269 (2017).
Nguyen, T., Gosine, R. G. & Warrian, P. A systematic review of big data analytics for oil and gas industry 4.0. IEEE Access 8, 61183–61201 (2020).
Sircar, A., Yadav, K., Rayavarapu, K., Bist, N. & Oza, H. Application of machine learning and artificial intelligence in oil and gas industry. Petroleum Res. 6, 379–391 (2021).
Saporetti, C. M., da Fonseca, L. G., Pereira, E. & de Oliveira, L. C. Machine learning approaches for petrographic classification of carbonate-siliciclastic rocks using well logs and textural information. J. Appl. Geophys. 155, 217–225 (2018).
Shakir, U., Ali, A., Amjad, M. R. & Hussain, M. Improved gas sand facies classification and enhanced reservoir description based on calibrated rock physics modelling: A case study. Open. Geosci. 13, 1476–1493 (2021).
Tan, W., Ba, J., Müller, T., Fang, G. & Zhao, H. Rock physics model of tight oil siltstone for seismic prediction of brittleness. Geophys. Prospect. 68, 1554–1574 (2020).
Aleardi, M. Applying a probabilistic seismic-petrophysical inversion and two different rock-physics models for reservoir characterization in the offshore nile delta. J. Appl. Geophys. 148, 272–286 (2018).
Toqeer, M. et al. Application of model based post-stack inversion in the characterization of reservoir sands containing porous, tight and mixed facies: A case study from the Central Indus Basin, Pakistan. J. Earth Syst. Sci. 130, 1–21 (2021).
Chen, L. et al. Pore-scale modeling of complex transport phenomena in porous media. Prog. Energy Combust. Sci. 88, 100968 (2022).
Boser, B. E., Guyon, I. M. & Vapnik, V. N. A training algorithm for optimal margin classifiers. In Proceedings of the Fifth Annual Workshop on Computational Learning Theory (COLT ‘92) 144–152. (ACM Press, 1992). https://doi.org/10.1145/130385.130401
Hou, M. et al. Machine learning algorithms for lithofacies classification of the Gulong shale from the Songliao basin, China. Energies 16 (6), 2581. https://doi.org/10.3390/en16062581 (2023).
Breiman, L. Random forests. Mach. Learn. 45 (1), 5. https://doi.org/10.1023/A:1010933404324 (2001).
Breiman, L., Friedman, J., Olshen, R. & Stone, C. Classification and Regression Trees (Wadsworth Int. Group, 1984).
Ibrahim, A. F., Abdelaal, A. & Elkatatny, S. Formation resistivity prediction using decision tree and random forest. Arab. J. Sci. Eng. 47 (9), 12183–12191. https://doi.org/10.1007/s13369-022-06900-8 (2022).
Ho, T. K. Random decision forests. In Proceedings of the 3rd International Conference on Document Analysis and Recognition, 1 278–282. (IEEE Publications, 1995). https://doi.org/10.1109/ICDAR.1995.598994
Breiman, L. Bagging predictors. Mach. Learn. 24 (2), 123–140. https://doi.org/10.1007/BF00058655 (1996).
Mukherjee, B., Kar, S. & Sain, K. Machine learning assisted state-of-the-art-of petrographic classification from geophysical logs. Pure. Appl. Geophys. https://doi.org/10.1007/s00024-024-03563-4 (2024).
Prajapati, R., Mukherjee, B., Singh, U. K. & Sain, K. Machine learning assisted lithology prediction using geophysical logs: A case study from Cambay basin. J. Earth Syst. Sci. 133 (2). https://doi.org/10.1007/s12040-024-02326-y (2024).
Fix, E. & Hodges, J. L. Discriminatory analysis, non-parametric discrimination: consistency properties. Int. Stat. Rev. / Revue Int. De Stat. 57 (3). https://doi.org/10.2307/1403797 (1989). Technical Report 4.
Cover, T. M. & Hart, P. The nearest neighbor decision rule. Inf. Theory Italianist IEEE (trAns). 13, 21–27 (1967).
Cox, D. R. The regression analysis of binary sequences. J. Royal Stat. Soc. Ser. B: Stat. Methodol. 20 (2), 215–232. https://doi.org/10.1111/j.2517-6161.1958.tb00292.x (1958).
Zhang, J. et al. Identification of sedimentary facies with well logs: An indirect approach with multinomial logistic regression and artificial neural network. Arab. J. Geosci. 10 (11). https://doi.org/10.1007/s12517-017-3045-6 (2017).
Hussain, M. et al. Reservoir characterization of basal sand zone of lower Goru formation by petrophysical studies of geophysical logs. J. Geol. Soc. India 89, 331–338 (2017).
Baig, M. O., Harris, N. B., Ahmed, H. & Baig, M. O. A. Controls on reservoir diagenesis in the lower Goru sandstone formation, lower indus basin, Pakistan. J. Pet. Geol. 39, 29–47 (2016).
Wandrey, C. J. & Milici, R. and B. E. Law. Region Assessment summary South Asia geological survey. Digital Data Series 60 (2004).
Quadri, V. U. N. & Shuaib, S. M. Hydrocarbon prospects of southern Indus basin, Pakistan. AAPG Bull. 70, 730–747 (1986).
Khan, M. A., Khan, T., Ali, A., Bello, A. M. & Radwan, A. E. Role of depositional and diagenetic controls on reservoir quality of complex heterogenous tidal sandstone reservoirs: An example from the Lower Goru Formation, Middle Indus Basin. Marine Petrol. Geol. 154106337 (2023).
Raza, M., Khan, F., Khan, M. Y., Riaz, M. T. & Khan, U. Reservoir Characterization of the B-Interval of Lower Goru Formation, Miano 9 and 10, Miano area, Lower Indus Basin, Pakistan. Environ. Earth Sci. Res. J. 7, 1 (2020).
Krois, P., Mahmood, T. & Milan, G. Miano field, Pakistan, A case history of model driven exploration. In Presented at the Proceedings Pakistan petroleum convention, 98, 112–131, Pakistan Association of Petroleum Geoscientists (PAPG) Islamabad, Pakistan. (1998).
Azeem, T. et al. An application of seismic attributes analysis for mapping of gas bearing sand zones in the sawan gas field. Acta Geodaetica Geophys. 51723–744 (2016).
Sohail, G. M., Hawkes, C. D. & Yasin, Q. An integrated petrophysical and Geomechanical characterization of Sembar shale in the lower indus basin, pakistan, using well logs and seismic data. J. Nat. Gas Sci. Eng. 78, 103327. https://doi.org/10.1016/j.jngse.2020.103327 (2020).
Anguita, D., Ghelardoni, L., Ghio, A., Oneto, L. & Ridella, S. The’K’in K-fold Cross Validation. In Esann (Vol. 102), 441–446. (2012).
Wong, T. T. & Yeh, P. Y. Reliable accuracy estimates from k-fold cross validation. IEEE Trans. Knowl. Data Eng. 32 (8), 1586–1594 (2019).
Mukherjee, B., Gautam, P. K. & Sain, K. Machine learning assisted crustal velocity proxy: A case study over the Tibetan plateau and its surroundings. J. Asian Earth Sci. 263, 106004 (2024).
Kadri, I. B. Petroleum Geology of Pakistan (Pakistan Petroleum Limited, 1995).
Banerjee, A., Mukherjee, B. & Sain, K. Machine learning assisted model based petrographic classification: A case study from Bokaro coal field. Acta Geod. Geoph. https://doi.org/10.1007/s40328-024-00451-0 (2024).
Merembayev, T., Kurmangaliyev, D., Bekbauov, B. & Amanbek, Y. A comparison of machine learning algorithms in predicting lithofacies: Case studies from Norway and Kazakhstan. Energies 14 (7), 1896. https://doi.org/10.3390/en14071896 (2021).
Wang, K. & Zhang, L. Predicting formation lithology from log data by using a neural network. Pet. Sci., 5(3), 242–246. https://doi.org/10.1007/s12182-008-0038-9 (2008).
Bhatt, A. & Helle, H. B. Committee neural networks for porosity and permeability prediction from well logs. Geophys. Prospect. 50 (6), 645–660. https://doi.org/10.1046/j.1365-2478.2002.00346.x (2002).
Acknowledgements
The authors appreciate the suggestions from colleagues in the Department of Geological Engineering and Department of Computer Science, University of Engineering and Technology, Lahore, which have significantly enhanced the quality.The authors acknowledge the Directorate General of Petroleum Concession (DGPC) for providing data from the student domain. The publication has been supported by a grant from the Faculty Geography and Geology under the Strategic Programme Excellence Initiative at Jagiellonian University.
Author information
Authors and Affiliations
Contributions
A. S. Investigation, writing original draft, revision, G. S. Investigation, writing original draft, revision., S. R. Investigation, writing original draft, revision., Q. Y. Investigation, writing original draft, revision., A. R. writing original draft, revision.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Saleem, M.A., Sohail, G.M., Rehman, S.U. et al. Multiple machine learning algorithms for lithofacies prediction in the deltaic depositional system of the lower Goru Formation, Lower Indus Basin, Pakistan. Sci Rep 15, 34933 (2025). https://doi.org/10.1038/s41598-025-18670-y
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-18670-y
