
Abstract
In aerial imagery captured by drones, object detection tasks often face challenges such as a high proportion of small objects, complex background interference, and insufficient lighting conditions, all of which substantially affect feature representation and detection accuracy. To address these challenges, a novel object detection algorithm named channel attention and fine-grained enhancement YOLO (CAFE-YOLO) is proposed. This algorithm incorporates a channel attention mechanism into the backbone network to enhance the focus on critical features while suppressing redundant information. Furthermore, a fine-grained feature enhancement module is introduced to extract local detail features, improving the perception of small and occluded objects. In the detection head, a lightweight attention-guided feature fusion strategy is designed to further optimize object localization and classification performance. Experimental results on the VisDrone2019 dataset show that the proposed method achieves significantly better detection performance than most existing advanced algorithms in complex drone-captured imaging scenarios. While maintaining a lightweight architecture, it reaches a mean average precision at IoU threshold 0.5 of 44.6%, demonstrating substantial improvements in both overall detection accuracy and robustness.
Similar content being viewed by others

Introduction
With the widespread adoption of unmanned aerial vehicles (UAVs) and the rapid advancement of artificial intelligence, aerial image-based object detection is becoming an essential technique across various domains1. UAVs offer flexibility and a wide field of view, making them well-suited for applications such as urban security, environmental monitoring, traffic management, and emergency response2. However, images captured from UAV perspectives differ fundamentally from ground-level imagery3. Targets often appear small, exhibit varying viewing angles, and are embedded in complex scenes with rich and potentially distracting background information4. Furthermore, challenges such as densely distributed objects, occlusions, and low-light conditions significantly hinder the performance of vision-based detection algorithms5.
Traditional object detection methods rely on handcrafted features, which can extract target information to some extent but struggle to adapt to complex backgrounds and small-scale objects6. These limitations make them inadequate for the high-precision requirements of UAV image analysis7. In recent years, the emergence of deep learning, particularly convolutional neural networks, has brought transformative progress to object detection8. One-stage detectors such as YOLO9 and SSD10 have achieved notable improvements in detection accuracy while maintaining high inference speed, making them well-suited for UAV scenarios that demand real-time processing11. Nevertheless, the ability of these models to detect small-scale objects remains constrained, partly due to insufficient capture of fine-grained details during feature extraction and fusion12.
In response to these challenges, a novel object detection network, CAFE-YOLO, is proposed. This model integrates channel attention mechanisms with fine-grained feature enhancement. The channel attention module dynamically adjusts the importance of different channels, effectively suppressing irrelevant information and emphasizing salient features. Fine-grained enhancement further enables the network to capture local details of small objects, improving detection performance under occlusion and in complex backgrounds. The combination of these components not only enhances detection accuracy but also maintains low computational complexity, enabling efficient and precise visual perception for UAV-based applications.
The main contributions of this study are summarized as follows:
-
A feature enhancement module incorporating a channel attention mechanism is introduced. By dynamically adjusting the weights of different channels, the model’s responsiveness to critical features is improved, enhancing its ability to distinguish small targets from complex backgrounds.
-
A fine-grained feature enhancement strategy is designed to focus on local details of target objects. This approach significantly improves detection performance for occluded, small-scale, and low-illumination targets, addressing the challenges of scale variation and detail loss in UAV imagery.
-
Experimental results on the publicly available VisDrone2019 dataset demonstrate that CAFE-YOLO significantly outperforms the baseline model and mainstream algorithms, with notable improvements in detection accuracy and robustness. These results confirm the effectiveness and practical value of the proposed approach.
Related work
In recent years, with the rapid development of UAV technology and artificial intelligence, object detection in UAV aerial imagery has emerged as a key research focus in computer vision13. Challenges such as small target size14, complex background interference15, severe occlusion16, and high object density17 make detection tasks particularly difficult in terms of feature extraction and representation, target localization, and inference efficiency. To address these issues, various innovative detection approaches have been proposed from different perspectives18.
In the area of small object perception and feature modeling, Zhu et al.19 introduce a Transformer-based prediction head to enhance high-level semantic representation, significantly improving small object detection accuracy in dense scenes. Li et al.20 integrate a receptive field attention mechanism and semantic fusion strategy into the YOLOv8 framework, effectively boosting the network’s sensitivity to small-scale targets. Zhang et al.21 design DSNet, which incorporates a novel density-aware module that adaptively adjusts according to vehicle distribution density and leverages contextual information to generate weighted responses, thereby enhancing feature representation for small objects22.
For multi-scale feature fusion and fine-grained information preservation, Chen et al.23 propose the Info-FPN network. By introducing modules such as Pixel Shuffle-based lateral connection Module (PSM), Feature Alignment Module (FAM), and Semantic Encoder Module (SEM), the network addresses issues of channel information loss, feature misalignment, and computational redundancy, leading to improved accuracy and efficiency in cross-scale detection24. Zhang et al.25 develop the Fountain Fusion Network (FFN), in which the Fountain Feature Enhancement Module (FFEM) reconstructs underperforming detection units using a fountain-like structure, effectively enhancing the overall feature representation capability. Sathishkumar et al.26 proposed the HyMAT module, which enhances inter-feature correlations by exploring feature consistency. This module can be flexibly integrated into object detection frameworks.
To strengthen the modeling of complex semantics and contextual information, Zeng et al.27 present a hybrid architecture that integrates CNNs and Transformers, enabling collaborative fusion of features from both structures and improving the network’s perception of object details and spatial layouts. In addition, spatial attention and coordinate attention mechanisms are incorporated to further enhance the model’s responsiveness to fine-grained targets28.
In terms of inference efficiency and detection speed, Yang et al.29 propose QueryDet, which adopts a query-based mechanism to improve inference performance. This method first performs coarse object localization using low-resolution features and then refines predictions with high-resolution features, achieving a balance between accuracy and speed. Zhu et al.30 also introduce a deformable attention mechanism and construct an anchor-free Deformable DETR model, which demonstrates strong detection performance in UAV imagery and confirms that accurate object localization can be achieved without predefined anchors.
The overview of methods
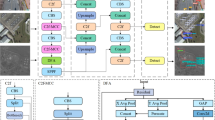
The overall architecture of the proposed CAFE-YOLO model is illustrated in Fig. 1. Built upon the YOLOv7 framework, the model is designed for object detection tasks involving small targets and complex backgrounds from UAV perspectives. It consists of three key modules:

CAFE-YOLO model.
1) Channel Attention Guided Module (CAG). A lightweight channel attention mechanism is integrated into the Neck structure to evaluate and reweight the importance of different feature map channels. This enhances the network’s response to semantically critical regions, improves the representation of target areas, suppresses redundant background noise, and increases overall detection robustness.
2) Fine-Grained Feature Enhancement Module (FGFE). Embedded in the backbone of YOLOv7, this module addresses the issue of small targets being weakened in high-level features. By improving shallow-layer local detail information, such as texture, edges, and shape, the perception and representation of small targets in low-level features are strengthened, thus improving detection performance.
3) Enhanced Feature Fusion Module (EFF). Based on the original FPN and PAN structures of YOLOv7, this module optimizes the feature fusion pathway to enable more compact and effective semantic information flow across multiple scales. The bottom-upm-up and top-down information interaction is employed to enhance feature consistenfurther improving the detection capability under complex scenarios.
The detection network retains the three core components of YOLOv7: Backbone, Neck (feature fusion structure), and Detection Head. To improve robustness in complex aerial imagery and enhance small object detection performance, customized modules are introduced for channel importance modeling and shallow feature preservation. Through a carefully designed integration strategy, the proposed architecture achieves significant accuracy improvements while maintaining high inference speed.
Detailed design principles and technical implementations of each module are presented in the following subsections.
Channel attention guided module
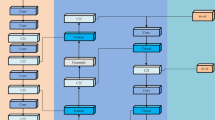
To enhance fine-grained perception in complex scenarios, a CAG module is introduced. This module aims to dynamically model inter-channel interactions through an adaptive mechanism, enabling the network to emphasize responses from critical channels for object detection. This improves recognition accuracy in small-object and background-cluttered scenes. Unlike conventional attention mechanisms that rely on fully connected mappings, CAG leverages lightweight convolutional operations to efficiently capture inter-channel dependencies, achieving more effective information selection and recalibration. The detailed content of this module is shown in Fig. 2.

The structure of CAG.
Channel descriptor construction
Given an input feature map \(\textbf{X} \in \mathbb {R}^{C \times H \times W}\), the spatial dimensions are compressed to obtain a global response vector for each channel using Global Average Pooling (GAP):
All channel responses are concatenated to form a channel descriptor vector \(\textbf{v} \in \mathbb {R}^C\), which serves as a statistical summary of the global context.
Local channel awareness mechanism
In contrast to traditional attention mechanisms that use fully connected layers across all channels, CAG employs a 1D convolution to construct a local channel-awareness mechanism. This avoids excessive parameterization and information compression. The 1D convolution $Conv1D$ captures local dependencies among adjacent channels while preserving relative positional information:
Here, \(\text {Conv1D}(\cdot , k)\) denotes a 1D convolution with kernel size $k$, and \(\sigma (\cdot )\) is the Sigmoid function that maps values to [0, 1], producing the channel attention weights \(\textbf{a} \in \mathbb {R}^C\). The kernel size k is adaptively determined based on the number of channels to match the receptive field appropriately:
where \(\gamma\) and b are tunable hyperparameters. In this study, \(\gamma = 2\) and \(b = 1\) are used. This design allows the receptive field to scale with channel count while maintaining an odd kernel size, which is favorable for feature alignment.
Channel recalibration and output fusion
The attention weights \(\textbf{a}\) are then mapped back to the original feature map to serve as channel importance scaling factors:
The final output feature map \(\textbf{X}' \in \mathbb {R}^{C \times H \times W}\) retains the spatial structure of the input while enhancing the semantic representation along the channel dimension.
Fine-grained feature enhancement module
To compensate for the limited spatial modeling capability of the CAG module, a FGFE module is proposed. This module adopts a direction-aware mechanism as its core design principle while preserving both spatial structure and channel representation. It significantly improves the network’s ability to detect small and edge-localized objects. The detailed content of this module is shown in Fig. 3.

The structure of FGFE.
Directional-aware pooling
Traditional attention mechanisms typically use global average pooling to derive channel weights, which captures global semantics but discards positional information–critical for small or edge-aligned objects. To address this, FGFE applies directional-aware pooling to capture contextual structures along both vertical and horizontal dimensions: Vertical pooling (along the width dimension):
Horizontal pooling (along the height dimension):
This process produces two single-directional feature tensors, \(\textbf{z}\_h \in \mathbb {R}^{C \times H \times 1}\) and \(\textbf{z}\_w \in \mathbb {R}^{C \times 1 \times W}\).
Joint encoding
To mitigate potential inconsistency between the two directional branches, the pooled features are concatenated and compressed using a shared \(1 \times 1\) convolution, enabling joint extraction of important semantics across directions:
Here, \(\delta (\cdot )\) denotes a nonlinear activation function. The resulting tensor \(\textbf{f} \in \mathbb {R}^{C/r \times (H + W)}\), where $r$ is a reduction ratio to decrease computational cost and enhance generalization.
Spatial recalibration
To further refine the spatial saliency of features, the joint tensor \(\textbf{f}\) is passed through two separate convolution branches to generate spatial attention maps:
The Sigmoid function \(\sigma (\cdot )\) ensures normalized outputs in the range [0, 1]. These directional attention maps encode the response strengths of channels along vertical and horizontal axes, respectively.
Finally, the original input feature map \(\textbf{X}\) is recalibrated through element-wise multiplication with \(\textbf{a}\_h\) and \(\textbf{a}\_w\), yielding the enhanced feature representation \(\textbf{Y}\):
The output feature map \(\textbf{Y} \in \mathbb {R}^{C \times H \times W}\) retains rich directional structural information and strengthens the network’s responsiveness to small objects.
Enhanced feature fusion module
To address issues such as semantic inconsistency across scales, insufficient shallow-layer detail, and redundant channel features, an EFF module is proposed, building upon the FGFE and CAG modules. EFF aims to achieve effective cross-layer information integration, semantic alignment, and lightweight structural expression, providing more discriminative fused features for the detection head. The detailed content of this module is shown in Fig. 4.

The structure of EFF.
Semantic-guided fusion
EFF employs a top-down semantic-guided fusion strategy, where features from deeper layers–rich in semantics but low in spatial resolution–progressively guide the integration of mid- and shallow-level features. The fusion process is defined as follows:
Here, \(\oplus\) denotes residual addition and Concat indicates channel-wise concatenation. This approach enhances object-level detail in shallow features while preserving semantic integrity.
Multi-strategy fusion with lightweight convolution
In the output stage, EFF integrates both anchor-based and anchor-free detection cues to refine candidate region localization and center point alignment, thereby improving adaptability to diverse object structures. The fused output is further compressed using depthwise separable convolution (DSConv):
The DSConv module consists of depthwise and pointwise convolutions, significantly reducing computational cost while maintaining feature expressiveness. The resulting fused representation is directly used for detection head prediction and optimized by the SimOTA strategy for positive-negative sample assignment.
Backbone detector
In this study, YOLOv731 was adopted as the backbone network for the object detection module. Recognized as one of the most balanced single-stage detectors in terms of accuracy and speed, YOLOv7 has been widely employed in real-time applications such as UAV vision and intelligent surveillance. Compared with its predecessors, the Extended Efficient Layer Aggregation Network (E-ELAN) was integrated into YOLOv7, by which gradient propagation paths and feature aggregation capability were enhanced, leading to improved multi-scale object modeling. During training, Dynamic Label Assignment (DLA) was introduced, through which the detection performance for objects of different scales was effectively improved. To further balance training and inference efficiency, Model Re-parameterization was incorporated, allowing complex training-time structures to be transformed into lightweight inference-time counterparts, thereby reducing computational complexity. With these designs, superior performance on small-object detection and real-time inference under complex environments has been demonstrated, making YOLOv7 the backbone network adopted in UAV-based object detection in this work.
Experiments and results
Datasets

VisDrone dataset and DroneVehicle dataset.
The VisDrone201932 dataset is a large-scale image dataset designed for UAV-based vision tasks, jointly released by research teams including Tianjin University. In this study, it is selected as the benchmark for object detection evaluation. The selected subset contains 6,471 training images, 548 validation images, and 3,190 test images, with over 2.6 million annotated objects. The data are collected from 14 cities across China, offering broad representativeness. A total of 11 object categories are defined in the dataset, including pedestrian, person, bicycle, car, van, truck, tricycle, awning-tricycle, bus, motor, and others. However, the “other” category is not considered a valid detection target and is excluded from both training and evaluation in this study. The dataset covers a wide range of weather conditions, lighting variations, and scene complexities, and presents significant challenges in terms of object density and scale variation, providing a rigorous setting for model performance assessment.
The DroneVehicle33 dataset was released in 2020 by a research team from Tianjin University, with the purpose of facilitating vehicle detection from UAV perspectives and advancing cross-modal learning studies. It has also been constructed to support the design and evaluation of subsequent RGB–infrared fusion detection models. A total of 56,878 aerial images are included in the dataset, in which RGB and infrared modalities are provided in equal proportion. The images cover a wide range of scenes, such as urban roads, residential areas, and parking lots, extending from daytime conditions to nighttime environments. The dataset samples are illustrated in the Fig. 5.
Implementation details
This study conducts experiments on a high-performance computing platform equipped with an Intel(R) Xeon(R) Processor (Icelake) CPU @ 2.59GHz and an NVIDIA A100 GPU (40GB). To enhance model robustness and enrich training sample diversity, we employ a multi-scale data augmentation strategy, including Mosaic (four-image stitching), Mixup (image blending), and spatial transformations such as random rotation and scaling. Performance is evaluated based on the MS COCO standard, with the primary metric being Average Precision (AP), calculated as the mean over IoU thresholds ranging from 0.5 to 0.95 with a step size of 0.05. Detailed parameters are shown in Table 1.
Evaluation metrics
To comprehensively evaluate the model’s performance across different datasets, several key evaluation metrics are introduced, including Precision, Recall, mean Average Precision (mAP0.5 and mAP0.5:0.95), Floating Point Operations (FLOPs), and the number of model parameters. These metrics offer a systematic assessment of the model from multiple perspectives, encompassing detection accuracy, computational efficiency, and model complexity. The formula is defined as follow:
Precision reflects the proportion of true positives among all instances predicted as positive, while Recall quantifies the model’s ability to correctly identify actual positive samples. The mAP0.5 metric evaluates the mean average precision at an Intersection over Union (IoU) threshold of 0.5, whereas mAP0.5:0.95 averages performance over multiple IoU thresholds ranging from 0.5 to 0.95 in increments of 0.05, offering a more stringent and comprehensive evaluation of detection accuracy.
FLOPs indicate the computational cost required for a single inference, thus reflecting the model’s efficiency in practical deployment. Meanwhile, the total number of parameters denotes the model’s scale and resource demands. Collectively, these evaluation criteria provide a robust foundation for performance comparison and model optimization across diverse application settings.
Ablation study
As shown in Table 2, the baseline model adopts the YOLOv7 architecture. Without incorporating any additional modules, it achieves a precision of 53.4%, recall of 44.8%, mAP50 of 43.5%, and mAP50:95 of 24.1%, demonstrating strong foundational performance among lightweight detection networks. Based on this, the CAG module is introduced. With a slight increase in parameters (from 18.8M to 19M), the recall improves to 45.1% and mAP50 rises to 43.8%, indicating that the module effectively enhances the inter-channel feature responses and improves the model’s discriminative capability in complex backgrounds.
The FGFE module is further integrated and used jointly with CAG. Although precision slightly decreases to 52.7%, the recall increases to 46.7% and mAP50 reaches 44.2%. This demonstrates the module’s effectiveness in preserving fine-grained features and improving small object perception, enabling more comprehensive capture of key regions. Notably, this combination significantly reduces model parameters (from 19M to 8.23M) while still achieving stable performance improvements, validating the effectiveness and lightweight advantages of the proposed design.

Training process curve variation.
To further analyze the trade-off between detection accuracy and computational cost, the proposed CAFE-YOLO was evaluated in terms of GFLOPs, parameter count, and inference speed (ms/image). As demonstrated in Table 2, compared with YOLOv7, CAFE-YOLO achieves a 1.1 percentage point improvement in mAP50 (from 43.5% to 44.6%) on the VisDrone2019 dataset, while the GFLOPs increase only marginally from 26.8 to 28.1 (a 4.9% increase). Notably, the parameter count is reduced significantly from 18.8M to 8.62M (a 54.2% reduction), with an inference time of merely 31.9ms per image, meeting real-time detection requirements. This favorable balance is attributed to three key design choices: (1) a lightweight channel attention mechanism, (2) selective integration of fine-grained enhancement modules in critical layers, and (3) an attention-guided fusion strategy in the detection head. These components collectively enhance feature representation while minimizing redundant computations, thereby maintaining high efficiency without compromising detection accuracy.
To achieve an optimal balance between computational cost and detection performance, two key strategies were employed in CAFE-YOLO: (1) Selective Module Deployment–the Channel Attention Guidance (CAG) module is introduced only in critical layers to avoid computational overhead from full-layer integration; and (2) Lightweight Design–the Fine-Grained Feature Enhancement (FGFE) module utilizes depthwise separable convolutions, reducing computational cost by approximately 70% compared to standard convolutions. From a cost-effectiveness perspective, CAFE-YOLO achieves a 2.5% improvement in mAP50 while reducing parameters by 54.2%, with only a 1.8% increase in GFLOPs per 1% mAP gain, demonstrating remarkable lightweight efficiency and well-optimized module design.
Finally, CAFE-YOLO integrates these modules with comprehensive architectural optimization, yielding state-of-the-art performance. As illustrated in Fig. 1, the ablation studies confirm that the model achieves an accuracy of 53.7%, a recall rate of 46.3%, an mAP50 of 44.6%, and an mAP50:95 of 24.5%, while maintaining a lightweight structure (8.62M parameters). These results indicate that the proposed module design not only enhances detection accuracy but also effectively controls model complexity, exhibiting strong potential for practical deployment and real-world applications.

Visual comparison of detection results at different stages of the ablation study.
The final model, CAFE-YOLO, integrates the aforementioned modules with overall architectural optimization, achieving the best performance. The overall effect of the ablation study is illustrated in Fig. 7. Additionally, the final model is compared with the baseline on the VisDrone2019 dataset through visualized training curves of precision, recall, and mAP, as shown in Fig. 6. The proposed approach consistently outperforms the YOLOv7 baseline across all metrics, with particularly notable improvements in recall and mAP. This indicates superior object recognition capabilities and enhanced robustness in complex scenarios, supporting stable and reliable performance in real-world UAV vision tasks.
Comparisons with SOTA models
To validate the trade-off capability between accuracy and complexity, CAFE-YOLO is systematically compared with several mainstream lightweight and high-performance object detection models. The comparison includes parameters (Params), computational complexity (GFLOPs), mAP50, and mAP50:95, as shown in the Table 3. In terms of detection accuracy, CAFE-YOLO achieves 44.6% mAP50 and 24.5% mAP50:95, outperforming all compared models, including EM-YOLO, CPAM-YOLO, and Dual-YOLO. This highlights the effectiveness of the proposed FGFE and CAG modules in enhancing feature representation for small objects and complex backgrounds.
Regarding model complexity, CAFE-YOLO maintains high accuracy with only 8.62M parameters, significantly fewer than CDYL, CPAM-YOLO, and YOLO-UAV. Its GFLOPs is 102.6, indicating lower computational cost compared to CDYL and CPAM-YOLO. These results suggest that CAFE-YOLO combines lightweight design with strong feature extraction and information fusion capabilities, making it suitable for deployment on resource-constrained edge devices or real-time inference tasks. Compared to other lightweight-focused models such as Dual-YOLO and EL-YOLO, CAFE-YOLO uses slightly more parameters but improves detection accuracy by 1.5% and 4.5%, respectively, and increases mAP50:95 by 1.5% and 1.7%, validating the effectiveness of the proposed accuracy–efficiency balance strategy. Although CAFE-YOLO exhibits slightly higher GFLOPs than some lightweight models, the integration of the FGFE module provides more detailed contextual information during feature fusion. Additionally, the CAG module strengthens spatial and channel-wise interaction awareness, leading to greater improvements in detection performance. This demonstrates the dual optimization of lightweight design and accuracy achieved by the proposed architecture.
For a more comprehensive evaluation of the computational efficiency of the proposed method, in addition to the GFLOPs metric, the processing time per image was further incorporated as an assessment criterion. As presented in Table 3, an inference time of 31.9 ms per image was achieved by CAFE-YOLO. When compared with other lightweight methods, superior detection accuracy was maintained by CAFE-YOLO while exhibiting competitive inference latency: a reduction of 6 ms in inference time was observed compared to EM-YOLO, accompanied by improvements of 1.1 and 1.3 percentage points in mAP50, respectively; while a marginal increase of 3.6 ms was required compared to EL-YOLO, significant enhancements of 4.5 and 8.8 percentage points in mAP50 were obtained.

Comparison of performance across various models on the test set.
In addition, Fig. 8 presents a comparative analysis with other models. It is worth noting that although CAFE-YOLO exhibits slightly higher GFLOPs than some lightweight models, the introduced FGFE module provides more detailed contextual information during the feature fusion stage. Combined with the CAG module, which enhances spatial and channel-wise interaction awareness, the overall network achieves a significant improvement in detection performance. This demonstrates the successful realization of both lightweight design and accuracy optimization.
Comparison under different scene conditions
To assess the adaptability and robustness of the proposed CAFE-YOLO model under various complex conditions, the test environments are divided into four representative scenarios: low illumination, complex background, occlusion, and densely populated targets. EL-YOLO and YOLOv7, two widely used lightweight detection models, are selected as baseline comparisons. Figures 9, 10, 11 and 12 present the detection performance across these scenarios. Superior detection stability and discriminative performance are exhibited by CAFE-YOLO in all cases, suggesting that its structural design effectively facilitates improvements in feature learning and spatial comprehension.
Low-light conditions

Under low-light conditions.
Under low-illumination or nighttime conditions, objects are often characterized by blurred edges, insufficient contrast, and degraded texture information, which lead to a significant reduction in detection performance for conventional models such as YOLOv7 and EL-YOLO. In such cases, a large proportion of small objects are frequently missed. With the introduction of the channel attention-guided module, shallow feature responses are strengthened and more discriminative texture cues are preserved. As a result, structural details of objects can still be maintained in weak-light environments, ensuring higher localization accuracy and recall. These improvements indicate that robust detection in UAV-based surveillance and night patrol scenarios can be better supported.
Complex scene conditions

Under complex scene conditions.
In environments where foreground and background share similar textures, false positives and confusion are prone to occur when conventional detectors attempt to distinguish them. Within DroneVehicle-like scenes such as urban streets or natural surroundings, this issue is particularly evident. Through the incorporation of the fine-grained feature enhancement module, local texture representations are reinforced, while orientation-aware modeling and a spatial re-calibration mechanism further improve sensitivity to semantic differences between objects and background. By this design, robustness and generalization capability under background interference are significantly improved, allowing vehicles or pedestrians to be accurately distinguished even when surrounded by distracting elements such as vegetation, billboards, or traffic signs.
Occlusion conditions

Under occlusion conditions.
Occlusion remains a common challenge in UAV- and ground-based monitoring, as partially hidden objects lack complete contour information, leading to frequent missed detections in conventional models. By means of the semantic enhancement guidance mechanism, contextual features from the surrounding environment are leveraged to compensate for and reconstruct the missing regions. In this manner, semantic integrity of occluded targets is effectively preserved. The reliance on contextual reasoning enables the reduction of missed detections, thereby yielding more complete object recognition. For instance, vehicles partially hidden by trees or pedestrians partially covered by crowds are detected with considerably improved integrity, which highlights the practical value of this approach in traffic monitoring and crowded environments.
Densely populated object conditions

Under densely populated object scenarios.
In scenarios with high object density, such as congested roads, parking lots, or pedestrian gatherings, issues including spatial overlap, boundary ambiguity, and large scale variations often result in inaccurate separation of adjacent objects. Consequently, bounding box overlap and classification confusion are frequently observed with conventional detectors. The adoption of an improved feature fusion structure, in combination with semantic guidance and lightweight convolutional operations, strengthens the decoupling and aggregation of features. In dense scenes, object boundaries are better delineated, while accuracy is preserved without a significant increase in computational burden. Experimental results have demonstrated that false positives and overlapping errors are substantially reduced in such scenarios, suggesting that more reliable detection performance can be achieved for UAV-based crowd monitoring and intelligent surveillance applications.
Conclusions
This study addresses the challenge of small object detection in UAV aerial imagery by proposing CAFE-YOLO, a model that integrates channel attention with fine-grained feature enhancement. By strengthening critical channel responses and improving detail extraction, the method significantly enhances detection accuracy and robustness under complex backgrounds and varying object scales. Experimental results show that the proposed approach outperforms existing mainstream algorithms across multiple public datasets, demonstrating its effectiveness and practical value.
Although CAFE-YOLO has achieved significant progress in complex backgrounds and multi-scale object detection, some limitations remain. The model’s performance still has room for improvement when dealing with heavily occluded or extremely small targets. Under extreme lighting conditions, such as strong backlight or low-light night scenarios, detection stability may be affected. Moreover, the generalization ability remains limited for object categories not covered in the training set or for objects with significant appearance variations. Future work will focus on enhancing the model’s adaptability to these challenging scenarios, exploring more lightweight network designs for deployment on edge devices, and incorporating cross-modal information to improve perceptual completeness and robustness.
Data availability
The VisDrone2019 datasets were obtained from https://github.com/VisDrone/VisDrone-Dataset.
Code availability
The datasets and source code used in this study are available from the corresponding author upon reasonable request.
References
Zhang, Y., Wu, C., Zhang, T., Liu, Y. & Zheng, Y. Self-Attention Guidance and Multiscale Feature Fusion-Based UAV Image Object Detection. IEEE Geosci. Remote Sens. Lett. 20, 1–5 (2023).
Wang, X., He, N., Hong, C., Wang, Q. & Chen, M. Improved YOLOXX Based UAV Aerial Photography Object Detection Algorithm. Image Vis. Comput. 135, 104697 (2023).
Zeng, S., Yang, W., Jiao, Y., Geng, L. & Chen, X. SCA-YOLO: A New Small Object Detection Model for UAV Images. Vis. Comput. 40, 1787–1803 (2023).
Gao, P. et al. “Double FCOS: A Two-Stage Model Utilizing FCOS for Vehicle Detection in Various Remote Sensing Scenes’’. IEEE J. Sel. Topics Appl. Earth Obs. Remote Sens 15, 4730–4743 (2022).
Huyan, N., Zhang, X., Quan, D., Chanussot, J. & Jiao, L. Cluster-Memory Augmented Deep Autoencoder via Optimal Transportation for Hyperspectral Anomaly Detection. IEEE Trans. Geosci. Remote Sens. 60, 5531916 (2022).
Li, W., Chen, Y., Hu, K. & Zhu, J. Oriented RepPoints for Aerial Object Detection. In Proc. CVPR 1819–1828 (2022).
Pawar, N. et al. Miniscule Object Detection in Aerial Images Using YOLOR: A Review. In Proc. Int. Conf. Commun. Comput. Technol. (ICCCT) Singapore: Springer 697–708 (2023).
Jiang, L. et al. MA-YOLO: A Method for Detecting Surface Defects of Aluminum Profiles with Attention Guidance. IEEE Access 11, 71269–71286 (2023).
Li, S., Tong, Q., Liu, X., Cui, Z. & Liu, X. MA2-FPN for Tiny Object Detection from Remote Sensing Images. In Proc. CISP-BMEI 1–8 (2022).
Gong, L., Huang, X., Chao, Y., Chen, J. & Lei, B. An Enhanced SSD with Feature Cross-Reinforcement for Small-Object Detection. Appl. Intell. 53, 19449–19465 (2023).
Jiang, C. et al. Object Detection from UAV Thermal Infrared Images and Videos Using YOLO Models. Int. J. Appl. Earth Obs. Geoinf. 112, 102912 (2022).
Zhang, L., Wang, M., Fu, Y. & Ding, Y. A Forest Fire Recognition Method Using UAV Images Based on Transfer Learning. Forests 13(7), 975 (2022).
Qian, J. et al. DACFusion: Dual Asymmetric Cross-Attention Guided Feature Fusion for Multispectral Object Detection. Neurocomputing 635, 129913 (2025).
Fan, Q. et al. LUD-YOLO: A Novel Lightweight Object Detection Network for Unmanned Aerial Vehicle. Inf. Sci. 686, 121366 (2025).
Chen, Y. et al. Global–Local Fusion With Semantic Information Guidance for Accurate Small Object Detection in UAV Aerial Images. IEEE Trans. Geosci. Remote Sens. 63, 1–15 (2025).
Khan, M. A. et al. On the Detection of Unauthorized Drones-Techniques and Future Perspectives: A Review. IEEE Sensors J. 22(12), 11439–11455 (2022).
Tan, L., Lv, X., Lian, X. & Wang, G. YOLOv4_Drone: UAV Image Target Detection Based on an Improved YOLOv4 Algorithm. Comput. Electr. Eng. 93, 107261 (2021).
Tian, Z., Shen, C., Chen, H. & He, T. FCOS: A Simple and Strong Anchor-Free Object Detector. IEEE Trans. Pattern Anal. Mach. Intell. 44(4), 1922–1933 (2022).
Zhu, X. et al. TPH-YOLOv5: Improved YOLOv5 Based on Transformer Prediction Head for Object Detection on Drone-captured Scenarios. arXiv:2108.11539 (2021).
Li, Y. et al. Sod-YOLO: Small-Object-Detection Algorithm Based on Improved YOLOv8 for UAV Images. Remote Sens. 16(16), 3057 (2024).
Zhang, Y. et al. DSNet: A Vehicle Density Estimation Network Based on Multi-Scale Sensing of Vehicle Density in Video Images. Expert Syst. Appl. 234, 121020 (2023).
Chen, G. et al. “A Survey of the Four Pillars for Small Object Detection: Multiscale Representation, Contextual Information, Super-Resolution, and Region Proposal’’. IEEE Trans. Syst., Man, Cybern.: Syst 52(2), 936–953 (2022).
Chen, S. et al. Info-FPN: An Informative Feature Pyramid Network for Object Detection in Remote Sensing Images. Expert Syst. Appl. 214, 119132 (2023).
Li, Q. et al. Edge-Guided Perceptual Network for Infrared Small Target Detection. IEEE Trans. Geosci. Remote Sens. 62, 5643510 (2024).
Zhang, T. et al. FFN: Fountain Fusion Net for Arbitrary-Oriented Object Detection. IEEE Trans. Geosci. Remote Sens. 61, 1–13 (2023).
Moorthy, S. et al. Hybrid multi-attention transformer for robust video object detection. Eng. Appl. Artif. Intell.139, 109606 (2025).
Zeng, B. et al. Detection of Military Targets on Ground and Sea by UAVs with Low-Altitude Oblique Perspective. Remote Sens. 16(7), 1288 (2024).
Zeng, S. et al. SCA-YOLO: A New Small Object Detection Model for UAV Images. Visual Comput. 40(3), 1787–1803 (2023).
Yang, C., Huang, Z. & Wang, N. QueryDet: Cascaded Sparse Query for Accelerating High-Resolution Small Object Detection. In Proc. CVPR 13668–13677 (2022).
Zhu, X. et al. Deformable DETR: Deformable Transformers for End-to-End Object Detection. arXiv:2010.04159 (2021).
Wang, C. Y., Bochkovskiy, A. & Liao, H. Y. M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 7464–7475 (2023).
Zhu, P. et al. Detection and Tracking Meet Drones Challenge. IEEE Trans. Pattern Anal. Mach. Intell. 44(11), 7380–7399 (2021).
Sun, Y. et al. Drone-based RGB-infrared cross-modality vehicle detection via uncertainty-aware learning. IEEE Trans. Circuits Syst. Video Technol. 32(10), 6700–6713 (2022).
Mu, A. et al. Small Target Detection in Drone Aerial Images Based on Feature Fusion. Signal Image Video Process. 18(Suppl 1), 585–598 (2024).
Wu, M. et al. Improved YOLOv5s Small Object Detection Algorithm in UAV View. J. Comput. Eng. Appl. 60(2), 191–199 (2024).
Wu, H., Zhu, Y. & Li, S. CDYL for Infrared and Visible Light Image Dense Small Object Detection. Sci. Rep. 14(1), 3510 (2024).
Liu, H., Tan, F. & Jin, Y. Dual-YOLO: Dual-Path UAV Aerial Image Target Detection Algorithm. J. Supercomput. 81(7), 809 (2025).
Wu, H., Zhu, Y. & Cao, M. An Algorithm for Detecting Dense Small Objects in Aerial Photography Based on Coordinate Position Attention Module. IET Image Process. 18(7), 1759–1767 (2024).
Wang, C., & Li, W. CM-YOLO: Small Object Detection Network Based on Contextual Feature Enhancement and Multi-Level Feature Fusion. In Proc. AANN. 2024 vol. 13416 SPIE 635–640 (2024).
Huang, T., Zhu, J., Liu, Y. & Tan, Y. UAV Aerial Image Target Detection Based on BLUR-YOLO. Remote Sens. Lett. 14(2), 186–196 (2023).
Shao, X. et al. A Small Object Detection Algorithm Based on Feature Interaction and Guided Learning. J. Vis. Commun. Image Represent. 98, 104011 (2024).
Wu, M. et al. Detection Algorithm for Dense Small Objects in High Altitude Image. Digit. Signal Process. 146, 104390 (2024).
Luo, X., Wu, Y. & Wang, F. Target Detection Method of UAV Aerial Imagery Based on Improved YOLOv5. Remote Sens. 14(19), 5063 (2022).
Li, X. et al. DM-YOLOX Aerial Object Detection Method with Intensive Attention Mechanism. J. Supercomput. 80(9), 12790–12812 (2024).
Xue, C. et al. EL-YOLO: An Efficient and Lightweight Low-Altitude Aerial Objects Detector for Onboard Applications. Expert Syst. Appl. 256, 124848 (2024).
Author information
Authors and Affiliations
Contributions
C.M. and Y.C. conceived the study. C.M. developed the methodology and implemented the software. Y.C. validated the results. C.M. conducted the formal analysis and curated the data. Y.C. carried out the investigation. C.M. provided the resources. C.M. and Y.C. prepared the original draft. L.Z., X.Y., J.S., and Q.L. revised and edited the manuscript. All authors reviewed the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Mi, C., Chen, Y., Zhu, L. et al. CAFE-YOLO: an object detection algorithm from UAV perspective fusing channel attention and fine-grained feature enhancement. Sci Rep 15, 35083 (2025). https://doi.org/10.1038/s41598-025-18881-3
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-18881-3
