
Abstract
Camouflaged object detection particularly is considered as challenging and crucial because these objects are designed to either mimic their environment or be completely hidden within it. The goal of camouflage patterns utilization is to help objects blend into their surroundings, making them harder to detect. One of the biggest hurdles is distinguishing the object from the background. Many efforts have been made to tackle this problem all around the globe, and this research builds on those advancements. The focus is on developing methods for detecting camouflaged targets in military settings, including materials, operations, and personnel using convolutional neural network. A key contribution of this work is the MSC1K dataset, which includes 1,000 images of camouflaged people with detailed annotations for object-level and bounding-box segmentation. This dataset can also support broader computer vision tasks like detection, classification, and segmentation. Additionally, this research introduces the Dynamic Feature Aggregation Network (DFAN), a method inspired by previous studies that uses multi-level feature fusion to detect camouflaged soldiers in various conditions. Extensive testing shows that DFAN and SINet-V2 (Search and identification network) achieved the highest accuracy with the least error, while SINet struggles the most. Notably, DFAN shines with its precision-recall balance, while SINET lags behind, potentially due to difficulties in handling intricate saliency patterns. The most intriguing contrast arises in the third setting (MSC1K + CPD), where DFAN remarkably excels, displaying superior structural similarity, strong human-perception alignment, and optimal precision-recall trade-offs. DFAN emerges as the top performer in terms of error minimization, achieving the lowest MAE values: 0.051 for MSC1K, 0.004 for CPD, and 0.028 for the combined dataset. In contrast, SINet shows the highest error rates, making it the Least reliable model, with MAE values of 0.079, 0.157, and 0.049 respectively. ZoomNet and SINetV2 delivered moderate performance; ZoomNet records MAEs of 0.056, 0.005, and 0.029, whereas SINetV2 reports 0.051, 0.005, and 0.027 in the same settings. These results indicated that DFAN and SINetV2 consistently produced more accurate predictions, while SINet has less precision. Overall, the comparative assessment sheds light on how each model adapts to varying datasets, revealing key insights into their performance robustness.
Similar content being viewed by others

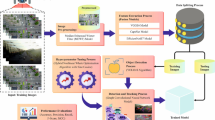
Introduction
Object detection is a technique used to identify and locate specific objects, like cars, people, or animals, in images and videos. It plays a key role in many fields, including surveillance, image search, and visual analysis. There are two main types of objects detected: generic objects, which commonly appear in images, and salient objects, which naturally draw human attention. Over time, various frameworks and algorithms have been developed to improve detection accuracy and efficiency, each designed to tackle different challenges in visual object detection. One major challenge in this field is camouflaged objects, which blend seamlessly into their surroundings, making detection more difficult. Camouflage is a natural adaptation seen in animals and insects, helping them hide from predators or stalk prey without being noticed. By matching their texture and color to the environment, they increase their chances of survival. Different animals have evolved unique camouflage strategies depending on their body coverings scaly creatures can change color quickly, while those with fur take longer to adapt1,2. Both predators and prey use camouflage as a survival tool: prey hide to avoid being caught, while predators use it to sneak up on their target. This fascinating adaptation has been observed across species and continues to be a key aspect of survival in nature. Some examples of natural and artificial camouflage are shown in Fig. 1. These animals are expertly embedded into their surroundings, making them difficult to identify at first glance. Considering the various concealment tactics employed by animals, four distinct types of camouflage can be identified.

Examples taken randomly, which reflect animals as camouflaged objects are completely ingrained in their surroundings, which make it difficult to identify them with the naked eye.
Figure 1 demonstrated the random examples that have been taken, it can also be observed in these images that it is complex to identify with respect to their surroundings. Concealing coloration is acknowledged as it is the most basic way to mask the identity in the respective surroundings. Concealing coloration deals with the similarity of the specie body colour with the background colour of the surrounding environment or habitat. For example, some animals (like Chameleons, and Snowshoe hares) are used to changing the colour of fur, hair, and scales according to the background colour. Disruptive Coloration deals with contrasting marks, that can be spots, stripes or some patterns present on the body surface, which disrupts the body outline. For example, the presence of the black and orange stripes on the tiger’s body finds it challenging for other animals to detect them in shady areas. Disguise can be defined as the ability to modify the appearance or colour which helps to blend completely in the surrounding environment with respect to shape colour and texture as it looks like another non-living object. As some insects like stick bugs, spiders, and leaf butterflies are examples of this type of camouflage. Moreover, militaries also utilized it with the help of camouflage materials to blend/conceal soldiers and assets with the environment so that they won’t be able to be seen by the adversary.
Mimicry: It refers to the adoption or mimicry of the physical appearance and characteristics of some objects to deceive an adversary. It may be either in behaviour, appearance, odour or in sound. For example, several species of viceroy butterflies mimic the toxic monarch butterflies which help to safeguard themselves from predators like birds. Because monarch butterflies are toxic and are not eaten by birds. Similarly, in the military the use of decoy is also an effective means of camouflage. Decoy is referred to as the installation of dummies which resemble the original targets. It is being used to create deception which draws an enemy’s attention away from the original assets and towards the decoy. Camouflage is also the most useful and worthwhile intend for military reconnaissance3,4. The military used camouflage mechanisms in war or battlefields to conceal war equipment or soldiers in the background’s texture for hiding themselves from enemies. They are applying the effect of camouflage (using dresses or applying colours to their bodies), which helps them to blend with their surrounding environment. It was first adopted in World War-I by the French army by applying paint on their sensitive post and artillery in the same pattern as a forest. The implementation of camouflage techniques on the battlefield can be classified as artificially camouflaged strategies. Soldiers employ various artificial camouflage methods5, such as artistic body painting, in order to conceal their identities and avoid potential engagements with hostile forces. However, the most optimal approach to achieve concealment involves the utilization of camouflage suits and accompanying accessories, which significantly diminishes their visibility to enemy observers.

Military personnel blend seamlessly with their surroundings by utilizing camouflage suits.
Figure 2 illustrated how military personnel skillfully use camouflage to blend into their surroundings, making it difficult to spot them in the image. Beyond just wearing camouflage, soldiers also adjust their movements and behavior to match the environment, further reducing their chances of being detected. By imitating natural elements like the colors and textures of foliage, they enhance their ability to remain unseen. These tactics are crucial in military operations, helping soldiers stay hidden, gather intelligence, and maintain the element of surprise. Effective camouflage not only improves their safety but also gives them a strategic edge on the battlefield. As technology advances, so do camouflage techniques, reinforcing their importance in modern warfare by allowing soldiers to operate covertly and outmaneuver their opponents. Existing deep learning algorithms for target detection are typically categorized into two groups. One group relies on identifying potential target regions to achieve detection, exemplified by methods like Faster R–CNN and SPP-Net. The other group is centered around regression concepts, as seen in approaches such as YOLO and SSD. However, these conventional algorithms encounter challenges when applied to detecting camouflaged targets within authentic battlefield settings, which can encompass diverse environments like desert, woodland, and snow. In such scenarios, the outlined traditional algorithms exhibit poor performance due to their susceptibility to mistaking the edges and background of camouflaged targets, hampering accurate detection. For this challenging task many substantial efforts had been taken to segment/detect the camouflaged object detection (COD) using different natural environments, which creates the urgency of an effective COD approach. Zhang et al.7 introduces a Bayesian framework that detects camouflaged objects which are not stationary. Deep learning advanced the remarkable accomplishments are achieved in COD and several deep based COD strategies had introduced. Le et al.8 introduced end-to-end network segmentation model for camouflaged objects. A largely collected COD dataset named COD10K with COD framework, named SINet was introduced by Fan et al.9, which boosts COD research to the next level. COD is also very useful in the applications of computer vision (e.g., search and rescue purposes or rare object discovery), agriculture (e.g., locust detection for prevention) image segmentation in the medical field (e.g., lung infection segmentation), in recreational art and can also be used for military reconnaissance in a combat operation. The availability of extensive datasets pertaining to military scenarios is notably limited. However, there is a published dataset comprising 1000 images specifically gathered for the purpose of camouflage people detection10. This dataset serves as a remarkable contribution, catering to the exigencies of identifying individuals seamlessly integrated into their environmental backdrop, a tactic often employed by soldiers with their equipment, but not cover specific scenarios or situations that are of particular interest. Therefore, contribution was provided by assembling the MSC1K dataset, specially designed for artificially camouflage soldiers, who are completely disguised with their equipment in the surroundings background, hence overcome the limitation and shortcomings of existing dataset10. The MSC1K dataset is different from the existing dataset in the following aspects, the dataset consists of 1,000 images that exclusively feature camouflaged soldiers in diverse environmental categories, including desert, snow, rocky terrain, and forests. Each camouflaged image has undergone meticulous annotation, surpassing real-world standards with matting-level labelling11. The precision in annotation, taking a minimum of 5 min per image, ensures the dataset provides accurate insights into the field of COD. Every image is annotated and categorized into two groups: bounding box and object-level annotation. These annotations accelerate computer vision tasks such as object localization, object proposal generation, and task transfer learning12. Furthermore, evaluation on four state-of-the-art (SOTA) frameworks9,13,14,15 using the collected dataset. Building upon the MSC1K dataset, obtained analysis has led to several significant conclusions and has identified potential areas for future exploration. One such area involves expanding the dataset in terms of size and classes, including the inclusion of military camouflage equipment. Moreover, further enhancement in the framework to better address this problem and contribute to advancements in this field. AlexNet introduced the concept of deep CNNs and demonstrated their effectiveness on large-scale image classification tasks16.
Literature review
Computer vision is a fast-growing field that focuses on teaching computers how to understand and make sense of visual data, such as images and videos. This involves creating algorithms and systems that can extract useful information from what they “see.” In recent years, machine learning especially deep learning has been a game changer in this area, making it possible to build highly accurate and efficient models. Deep learning, a specialized branch of machine learning, has transformed computer vision by enabling models to recognize patterns and details directly from raw data. Among the most powerful deep learning models for visual tasks are Convolutional Neural Networks (CNNs). CNNs are designed to process images and automatically learn key features, making them essential for tasks like identifying objects in photos, detecting specific items, and breaking down images into meaningful segments. Their structure is built on multiple layers, each responsible for refining the input data step by step. The core components of CNNs include convolutional layers, pooling layers, and fully connected layers. Convolutional layers are particularly important because they identify spatial patterns in images and extract crucial details. These layers use multiple filters that scan across the image, applying mathematical operations to highlight important features. This layered approach allows CNNs to effectively interpret complex visual information with impressive accuracy. These feature maps capture the presence of certain visual patterns or textures in the input. Pooling layers serve the purpose of decreasing the size of feature maps, making them smaller while preserving the essential information. They help in creating translation invariance of the input by summarizing the presence of certain features in different regions. Fully connected layers are accountable for computation of the final predictions from the extracted features. They take the high-level features from the previous layers and perform a series of matrix multiplications and non-linear activations to generate the desired output.

CNN architecture illustration16.
Figure 3 represented CNN architectures that can vary in depth, width, and connectivity patterns. Deep CNNs, such as VGGNet, ResNet, and Inception, consist of numerous layers, enabling them to learn complex hierarchical representations. These architectures often utilize skip connections, residual connections, or inception modules to improve gradient flow and capture diverse features. Several influential CNN architectures have emerged over the years, each with its unique design and performance characteristics. For example, AlexNet introduced the concept of deep CNNs and demonstrated their effectiveness on large-scale image classification tasks. VGGNet increased the network depth, showing that deeper architectures can improve performance. ResNet introduced residual connections which helps to tackle the vanishing gradient problem, enabling training of even deeper networks. InceptionNet utilized parallel convolutional operations to capture different scales of information. These seminal works have paved the way for numerous advancements in CNN architecture, and researchers continue to explore innovative designs to further improve performance and address specific challenges in computer vision tasks. The primary objective of the computer vision area centers around the identification and segmentation of salient or non-camouflage objects, categorizing them into predefined classes. Numerous research endeavors have been undertaken to advance the fields of general and salient object detection, yielding significant progress and valuable insights. However, it is important to note that research pertaining to camouflage object detection (COD) remains relatively unexplored within existing literature. Consequently, the focus of this section is twofold: firstly, to comprehensively review the prevailing research efforts related to general and salient object detection, encompassing their methodologies, techniques, and outcomes. Secondly, it was aimed to present a comprehensive summary of the existing body of work and datasets pertaining to camouflage object detection. By bridging this gap in knowledge, it was planned to contribute to the advancement and understanding of COD techniques and their practical applications. CNN architectures can be developed using popular deep learning frameworks such as TensorFlow, PyTorch, Keras, and Caffe. These frameworks provide high-level APIs and tools for building and training CNN models. TensorFlow and PyTorch offer flexible and intuitive interfaces, while Keras provides a user-friendly abstraction layer. Caffe is specifically designed for convolutional networks. These platforms support various programming languages and offer pre-trained models, extensive documentation, and community support. The choice of platform depends on factors like programming language preference and task requirements.
Object detection
Object detection in computer vision encompasses various approaches which are Semantic object detection, instance object detection, bounding box object detection, and segmentation object detection, each serving a distinct purpose. Semantic object detection refers to the classification and to locating objects in an image without distinguishing between individual instances. Object detection plays a crucial role in computer vision by identifying objects within an image and categorizing them. At a high level, it determines what objects are present and where they are located, typically providing bounding boxes along with class labels for each detected object. Building on standard object detection, instance object detection takes it a step further by distinguishing between multiple instances of the same object class. Instead of simply detecting an object type, this method ensures that each individual object is uniquely identified and labelled. The result includes bounding boxes and class labels for every detected instance. Another approach, bounding box object detection, focuses solely on locating objects by drawing rectangular boxes around them. Unlike instance detection, it does not classify objects or differentiate between multiple instances of the same type. Its main goal is to localize objects within an image without further segmentation. For a more detailed level of detection, segmentation object detection goes beyond bounding boxes by identifying the precise outlines of objects. This method assigns pixel-level masks to each object, segmenting the image into regions that correspond to different detected objects. This fine-grained approach provides detailed localization, making it useful for applications that require precise boundary information.
General object detection
General Object Detection (GOD) is one of the most widely studied areas in computer vision17,18,19. Its main objective is to accurately detect different types of objects within an image while classifying them into relevant categories. Unlike standard detection methods, general object detection needs to account for both clearly visible (salient) and hidden (camouflaged) objects, requiring a deep understanding of visual patterns. Advanced techniques like panoptic and semantic segmentation have greatly improved the accuracy of object detection by providing detailed categorization and localization. Researchers continue to refine these approaches to make object detection systems more robust and reliable, leading to improvements in various real-world applications.
Salient object detection
Salient Object Detection (SOD) is designed to identify objects that naturally grab human attention20,21. These objects stand out due to their color, shape, or contrast compared to their surroundings21. The method analyzes color variations both at a broad level (global) and within smaller regions (local). Locally, it compares a region’s color distribution to its neighboring areas to determine how visible or attention-grabbing an object is.
Camouflage object detection
Research on camouflage object detection had a tremendous impact on the computer vision field. Biologists conclude and examine the various instances and the principles of natural adaptation of camouflage. To read more, kindly refer to this survey paper22. With the help of deep learning remarkable accomplishments are achieved in COD and a number of deep based COD strategies have been proposed. In early work, detection of foreground region is localized, even with few similarities occurring between its texture and background23. Foreground and background are differentiated by its color, orientation, edge, and shape. Le et al.8 discovered end to end network, named ANet, which leads to Camouflaged object segmentation by converting classification data into segmentation. Zhang et al.7 proposed a Bayesian framework which detects moving camouflaged objects. Le et al.24 further proposed camouflaged instance segmentation by training Mask RCNN25 on CAMO dataset8. Furthermore, efforts have been contributed to this field using bio-inspired adversarial attack26 which helps to tackle the posed challenges of optical illusions, that can clearly deceive and generalize the deep models. Zheng et al.33, firstly purposed camouflage people detection dataset contains 1,000 images and introduce strong semantic dilation network (SSDN) to identify camouflaged personnels via end to end architecture. Another study by Deng et al.9 introduced a dataset named COD10K, which has 10,000 images of camouflaged objects in different natural scenes and categories. The key goal is to detect military personnel wearing camouflage in various environments, but COD10K has only a few relevant images.
Dataset: There are four existing datasets (CPD, CHAMELEON, CAMO and COD10K) related to COD. (1) CHAMELEON27 dataset has 76 images with object-level annotation (ground-truths). (2) CAMO8 comprises 2500 images, 500 for testing and 2000 for training with eight different categories. It also contains two sub datasets, named CAMO and MS-COCO, each containing 1250 images. (3) A dense deconvolution network (DDCN) was developed in literature10 by integrating short connections during the deconvolution phase after initially creating a dataset of camouflaged people (CPD) in various surroundings. (4) COD10K9 comprises 10,000 images categorized in 69 classes, densely annotated and the largest COD dataset so far.

Exemplary samples of MSC1K dataset, the original images, the bounding box, and the ground-truth. Figure 4 demonstrated that unlike existing datasets, MSC1K dataset highlights the camouflaged person or soldier, who is completely embedded in his surroundings as shown in Fig. 4 Previously dataset mostly discussed wildlife species and shows huge deficiency with this regard. Our dataset is densely annotated containing 700 images for training and 300 for testing.
Effectiveness of military camouflage uniforms
Camouflage techniques adopted on the battlefield come under the category of artificially camouflaged. Soldier uses artificial camouflage techniques like art or body painting to disguise themselves and avoid an encounter with hostile forces. But the most effective disguise is the use of camouflage suits and accessories to be less visible to enemy eyes. As you can see in Fig. 5, which reflects some examples related to military soldiers who artificially camouflage themselves and are hard to identify in the image. Camouflage uniforms possess specific characteristics that make them highly effective in providing concealment for military personnel. These uniforms are designed with visual disruption in mind, incorporating patterns that break up the human silhouette and make it challenging for the enemy to spot soldiers6. The patterns and colors on the uniforms are carefully chosen to mimic natural elements, enabling soldiers to blend seamlessly with their surroundings. Extensive research and development go into creating these patterns, ensuring optimal camouflage effectiveness in different environments. Additionally, modern camouflage uniforms utilize advanced materials that offer durability, comfort, and moisture-wicking properties. By understanding these characteristics, one can appreciate the level of detail and consideration put into designing camouflage uniforms for the purpose of enhancing soldiers’ concealment and overall mission effectiveness.
Digital vs. Analogue Camouflage: Traditional camouflage suits include analogue/amoeba style medium and large size patterns, which are smoothly curved and printed on the fabric of the uniform. It features a pattern of larger and smaller amoeba shapes of a specific colour and tone that makes a micro pattern for better effective concealing at closer distances. With the increase in the development of camouflage technology, traditional camouflage techniques are replaced by digital camouflage28. A computer program creates digital camouflage by analyzing images of the environment in which it will be used. Computer programs generate a colour scheme for the camouflage pattern by averaging the colours and percentage of colour density across numerous pictures of the concerned environment. This pattern is adjusted repeatedly until is aesthetically acceptable. Digital patterns are comprised of pixelated/clumps of square shapes which deceive the human eye by creating patterns more dithered that make it difficult to be noticed or identified. Instead of having a lot of large random squiggles, camouflage patterns are now more likely to include a lot of little random squares. Digital camouflage includes hundreds of different camo patterns for a single state and background5,6 only, which provide militant a tactical edge. Based on effectiveness analogue camouflage is further optimized w.r.t disruptive effect with the expected range at some particular distance. Large amoeba blobs have no concealing abilities at close distances. With the variation in the distance, these large blobs squeeze into smaller ones which enhances effectiveness, and the human eye can’t be able to distinguish the individual well enough. Similarly, digital camouflage is adequate at various scales. The small pixelated square blocks work at close range. The disruptive effect is still noticeable at the medium range because each small pixels blocks merge into larger shapes which are still highly erratic when viewed from a distance.
Digital and analogue camouflage approaches have distinct advantages and disadvantages29. Digital camouflage offers enhanced concealment through computer-generated patterns that closely match the background, making detection difficult for the human eye. This adaptability allows for a wider range of camouflage options, providing tactical advantages in different environments and combat scenarios. Additionally, digital patterns align well with the digital imaging technologies prevalent in today’s surveillance systems. However, digital camouflage may have drawbacks, including the lack of smooth curves, which can reduce effectiveness when viewed from a distance or in environments where smooth curves dominate. Moreover, its small pixelated square blocks may merge into larger shapes at close range, potentially compromising concealment in close-quarter combat. On the other hand, analogue camouflage employs smoothly curved amoeba-style patterns that effectively disrupt the human silhouette, making it harder for the enemy to detect military personnel. Distance optimization further enhances its effectiveness by squeezing larger amoeba shapes into smaller ones, making them challenging to distinguish. Nevertheless, analogue camouflage may lack adaptability to various terrains and combat scenarios, as it is designed for specific environments. Moreover, the smooth curves of analogue patterns may not blend well with the pixelated backgrounds displayed on digital screens, limiting their effectiveness in digitally monitored environments. Ultimately, the choice between digital and analogue camouflage depends on factors such as operational requirements, terrain characteristics, and available resources, with each approach offering distinct benefits and drawbacks. Nowadays, surveillance and observation methods are comprised of digital seeing30. Different visual targeting systems and night vision tools are dependent on digital electronics instead of analogue optics. As for the scanning purposes of prohibited locations, visualization is being monitored in a digital form (digital image/image based on pixel) on a screen. Accordingly, the squares of the digital camouflage will blend more effectively with the pixilated background terrain of the digital image rather than the smooth curves of conventional camouflage. The main concern of digital camouflage is to adopt the disruptive effect in a digitally imaged world, due to the lack of smooth curves.

A visual comparison illustrating the characteristics of digital and analogue camouflage patterns.
The primary aim of this research is to comprehensively examine and analyze the challenges presented by military-based camouflage in the context of visual object detection as depicted in Fig. 5. In order to achieve this, several specific objectives have been identified and pursued, which are outlined as follows:
-
1.
Examine the application of camouflage techniques in military reconnaissance and their significance in ensuring the safety and success of military operations.
-
2.
Propose a comprehensive dataset consisting of camouflaged soldiers in diverse environmental categories, including desert, snow, rocky terrain, and forests. This dataset will serve as a benchmark for evaluating camouflaged object detection (COD) algorithms.
-
3.
Annotate and categorize the dataset to provide precise and detailed labeling, facilitating computer vision tasks such as object localization, object proposal generation, and task transfer learning.
-
4.
Evaluate the performance of four SOTA frameworks on the proposed dataset and analyze their effectiveness in detecting camouflaged objects.
-
5.
Identify areas for future research and development in the field of camouflaged object detection.
Digital camouflage is characterized by its block-like, pixelated shapes, designed to break up the outline of an object and work effectively at multiple viewing distances, while analogue camouflage relies on smooth, organic patterns that replicate natural forms such as vegetation, rocks, or terrain features. To help readers easily recognise these differences, we have also included subtle annotations within the figure, such as arrows and labels pointing to key areas that illustrate variations in shape, colour blending, and edge definition. This ensures that the figure provides sufficient insight even when viewed without constant reference to the main text.
Dataset collection
In the rapidly evolving landscape of visual recognition, driven by the emergence of new tasks and datasets8,9,10,27, deep learning models have revolutionized the field. However, there remains a significant gap in the availability of datasets specifically focused on military-based camouflage. Recognizing this need, the MSC1K dataset is developed, which aims to address this gap and achieve the following objectives: (1) to promote research and exploration in camouflage object detection (COD) by providing a comprehensive dataset that encompasses new topics and ideas. (2) the MSC1K dataset.
serves a practical military-related application by enabling the detection of camouflaged objects. Table 1 provided the digital and analogue camouflaged patterns with attributes. It provides valuable insights for military operations such as reconnaissance and surveillance, where the ability to accurately identify and locate camouflaged objects is crucial. By facilitating the development and evaluation of advanced detection algorithms on realistic military camouflage scenarios, the dataset has the potential to enhance the effectiveness and efficiency of such operations. (3) to enhance the COD dataset for better insights which can facilitate the evaluation and comparison of different algorithms but also provide the research community with a valuable resource. As seen in Fig. 5, which reflects the capabilities of MSC1K dataset, showcasing the diversity and complexity of camouflaged individuals.
The lifespan and benchmark value of a dataset heavily rely on its size and the quality of annotations it encompasses. Recognizing this, the MSC1K dataset has been carefully curated to meet these criteria. It comprises a collection of 1000 images featuring fully camouflaged snipers or soldiers. To ensure the dataset’s authenticity and compliance with legal considerations, these images have been sourced from various photography websites that offer content free from royalties and copyright restrictions. To gather a diverse range of camouflaged images, extensive literature review was conducted using popular search engines such as Google, DuckDuckGo, YouTube and Bing, using relevant keywords such as “camouflaged sniper,” “camouflaged soldier,” and “hidden sniper.” In addition to these sources, some portions of images are collected from Pinterest. To mitigate any potential bias in the dataset, 200 salient messages were included, which were sourced independently. Furthermore, image collection was complemented by extracting frames from relevant YouTube videos, which augmenting the dataset with dynamic scenes.
The MSC1K dataset encompasses various environmental categories, including snow-covered landscapes, rocky terrains, mountainous regions, dense forests, and open moose habitats. By incorporating diverse backgrounds, which provide a comprehensive representation of real-world scenarios where camouflage plays a crucial role. It enables researchers to evaluate the performance of detection algorithms across different environmental contexts, thereby fostering the development of robust and versatile solutions. The future objective is to expand the MSC1K dataset by introducing additional classes and categories specifically related to military contexts. By including a broader range of military-related objects, equipment, and scenarios, which enhance the dataset’s applicability and versatility. This expansion will enable researchers to explore and address various challenges associated with camouflage detection in military settings comprehensively.
Annotation
The dataset is carefully labeled using two distinct methods: bounding box annotation and object-level annotation. In the first approach, clear and accurate bounding boxes are drawn around objects in the images, making it easier to identify and locate them for object detection tasks. This precise labelling improves the dataset’s effectiveness for various computer vision applications. In addition to bounding boxes, object-level annotations also known as masking is used to highlight and categorize camouflaged objects within the dataset. As shown in Fig. 5, this detailed labelling helps differentiate hidden objects, allowing researchers to gain deeper insights into the challenges of camouflaged object detection. By providing comprehensive annotations, the dataset enables thorough testing and evaluation of different algorithms, helping improve their accuracy and performance.

Correlation Variation in Object-Environment Relationship between MSC1K and CPD Datasets.
Dataset characteristics
This dataset has several key features that make it highly useful for research on camouflaged object detection. One of the most important aspects is the inclusion of high-resolution images, which allow for capturing even the smallest details of object boundaries. This Level of precision Helps in training models more effectively and improves their accuracy during testing. Another important factor is the balanced representation of object sizes. The dataset ensures that objects appear across different scales by normalizing their sizes relative to the overall image area. Additionally, around 60% of the dataset consists of images where the target object is deliberately hard to spot, providing a challenging test scenario that helps assess the performance and reliability of detection algorithms. To create a more realistic dataset, steps were taken to reduce center bias. Instead of placing objects mainly in the middle of the frame, they are distributed more naturally across different positions, better reflecting real-world situations. A strict quality control process is also in place to ensure that every object is labelled with high accuracy, as shown in Fig. 5. These precise annotations make the dataset more reliable for detailed analysis and evaluation. For a deeper understanding of different camouflage scenarios, the dataset is divided into three levels of complexity, as illustrated in Fig. 6. This classification makes it easier to study how different degrees of camouflage affect detection. To ensure a broad variety of camouflage styles, the dataset includes 52 carefully selected camouflage patterns sourced from various places on the internet. These patterns help in evaluating the effectiveness of different camouflage techniques, and Table 3 provides a complete list of them.

Three levels of camouflage are based on the complexity of concealment.
Additionally, Fig. 7 features a chart that compares how well objects blend into their backgrounds in two different datasets: MSC1K and CPD. The x-axis represents the number of images (ranging from 1 to 1000), while the y-axis measures the correlation between the colours of objects and their surroundings. The chart shows two curves—one in blue representing MSC1K and another in orange for CPD. The MSC1K curve is positioned higher, reaching a correlation value of about 3.0, while CPD peaks at around 2.0. This suggests that objects in the MSC1K dataset tend to merge more seamlessly with their environments than those in CPD. The gap between the two curves highlights how different datasets capture object-environment relationships in distinct ways.
Methodology
This study examines how well camouflage object detection algorithms perform using the MSC1K dataset, which was specifically created to help detect military personnel in camouflage settings. Identifying camouflaged objects is particularly challenging in computer vision because these objects are designed to blend seamlessly into their surroundings, making them difficult to distinguish. Researchers have explored various methods to address this issue, from traditional computer vision techniques to modern deep learning models. These advanced approaches rely on sophisticated algorithms and architectures to improve accuracy and efficiency in detecting camouflaged objects. To assess the effectiveness of the MSC1K dataset, we compare its performance with several state-of-the-art (SOTA) detection models9,13,14,15 that are widely recognized for their ability to handle complex camouflage scenarios. These models were selected based on their strong performance in benchmark evaluations and their ability to adapt to challenging detection tasks. By analyzing how the dataset performs across different SOTA frameworks.
Dynamic feature aggregation network (DFAN)
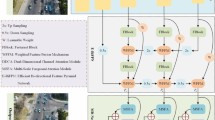
Motivated by the innovative approach of15, Dynamic Feature Aggregation Network (DFAN) methodology draws inspiration from their feature fusion concept. The design of the model architecture seeks to overcome the constraints of single-view salient object detection (SOD) models. It achieves this by capturing both boundary and regional semantic details from various angles and distances, offering a broader and more adaptable perspective. The model integrates a feature fusion module that utilizes a two-stage attention mechanism and a structure for mining local and overall context/cues. This integration enhances the representation of features, leading to improved performance.
The DFAN architecture consists of several key components. Firstly, the Multi-view Generation module, where input image \(\:{I}^{O}\in\:\:{R}^{H\:\times\:\:W\:\times\:\:3}\) is converted or generated into two different perspectives of views i.e., distance and angle views, to overcome the limitations of single-view models, where O represent the original input image. The distance views {\(\:{I}^{{C}_{1}}\in\:\:{R}^{H\:\times\:\:W\:\times\:\:3}\), \(\:{I}^{{C}_{2}}\in\:\:{R}^{H\:\times\:\:W\:\times\:\:3}\)} are obtained through the resize operation with a proportional interval larger than 0.5 to increase distinction, where \(\:{C}_{1}\:and\:{C}_{2}\) correspond to the two different distance views. The angle views are obtained through mirror transformations {\(\:{I}^{{D}_{M}}\in\:\:{R}^{H\:\times\:\:W\:\times\:\:3}\), \(\:{I}^{{V}_{M}}\in\:\:{R}^{H\:\times\:\:W\:\times\:\:3}\)}, including diagonal and vertical mirror transformations, where \(\:{D}_{M}\) represent Diagonal transformation and \(\:{V}_{M}\) represent vertical transformation. While combining all the dynamic-view inputs are defined as: { \(\:{I}^{D}\in\:\:{R}^{H\:\times\:\:W\:\times\:\:3}\),\(\:{I}^{V}\in\:\:{R}^{H\:\times\:\:W\:\times\:\:3}\),\(\:{I}^{O}\in\:\:{R}^{H\:\times\:\:W\:\times\:\:3}\),\(\:{I}^{C1}\in\:\:{R}^{H\:\times\:\:W\:\times\:\:3}\),\(\:{I}^{C2}\in\:\:{R}^{H\:\times\:\:W\:\times\:\:3}\)}. This multi-view strategy captures complementary information and enhances performance in salient object detection (SOD) tasks. DFAN’s overall architecture employs ResNet as the backbone network for feature extraction and leverages the Layered Feature Encoder (LFE) to gather feature insights from various levels and perspectives.
The model incorporates the Co-attention of Multi-view (CAMV) sub-module to combine diverse context details and capture supplementary information from encoded multi-view features. The inspiration behind the CAMV module stems from the notion that visual information originating from distinct viewing angles and distances can be interconnected and reinforcing. As there is the variance in scales among the feature sets for different viewing distances, denoted as \(\:{f}_{i}^{{C}_{1}}\in\:\:{R}^{{h}_{1}\:\times\:\:{w}_{2}\:\times\:\:c\:},\:{f}_{i}^{{C}_{2}}\in\:\:{R}^{{h}_{2}\:\times\:\:{w}_{2}\:\times\:\:c\:}\), therefore initialization of standardize scale to the distance’s feature sets, which can match the resolution (dimensions) of \(\:{f}_{i}^{O}\in\:\:{R}^{{h}_{1}\:\times\:\:{w}_{2}\:\times\:\:c\:}\) through a downsampling process. Subsequently, postprocessing is performed on \(\:{f}_{i}^{V},{f}_{i}^{D}{,f}_{i}^{O},{f}_{i}^{{C}_{1}},{f}_{i}^{{C}_{2}}\) mainly focusing on the features derived from distinct angles \(\:{f}_{i}^{V},{f}_{i}^{D}{,f}_{i}^{O}\), while maintaining their original resolution. Upon completing the postprocessing phase, the encoded multi-view feature tensors\(\:{f}_{i}^{V},{f}_{i}^{D}{,f}_{i}^{O},{f}_{i}^{{C}_{1}},{f}_{i}^{{C}_{2}}\) are then concatenated belonging to the same level i (mv-tensor). This fusion results in the creation of a single multi-view enhanced feature tensor (en-tensor).
This module is characterized by a two-stage attention mechanism, which harmonizes boundary data with features from varying viewing angles and enhances semantic insights through different viewing distances. The initial stage of attention gathers relevant clues related to viewing distance and viewing angle separately. As the feature tensor \(\:{f}_{i}^{V},{f}_{i}^{D}{,f}_{i}^{O}\) gathered from three different viewing angles. The initial step encompasses channel feature compression, achieved through a convolution layer to obtain a compact version \(\:{f}_{i}^{Ang}\in\:\:{R}^{h\:\times\:\:w\:\times\:\:c\:}\). This \(\:{f}_{i}^{Ang}\) is then directed into three separate parallel modules for attention calculation, using tensor multiple modulus multiplication. The formulation of this process is as follows:
Here, {\(\:{u}_{A}\), \(\:{u}_{B}\), \(\:{u}_{C}\)} denote attention factors, {\(\:{f}_{i}^{V},{f}_{i}^{D}{,f}_{i}^{O}\)} represent feature tensors from distinct viewing angles, and FAngi embodies the enhanced tensor from the first-stage attention. The sigmoid function, symbolized as σ, scales weight values within the (0, 1) range. The concatenation operation \(\:Cat\left(\right)\) operates across channels, and ReLU () signifies the activation function. {\(\:{U}_{{A}_{i}}\), \(\:{U}_{{B}_{i}}\), \(\:{U}_{{C}_{i}}\)} correspond to the parameter matrices of the attention factor calculation modules, employing tensor multiple modulus multiplication where \(\:{\:\times\:}_{1\:}\) signifies modular multiplication and \(\:\odot\:\) denotes element-wise multiplication. Seamlessly, the similar process can be applied to the feature tensor \(\:{F}_{i}^{Dist}\) of distance-based perspectives. This parallel attention approach aims to enhance the semantic features maps in both angle-based and distance-based scenarios. The second stage attention further interacts with features from discriminative viewing angles and distance views. This interaction enhances feature expression, separates boundaries, and improves the distinction between the object and the background. The features originating from specific different viewing angles, denoted as \(\:{F}_{i}^{{\prime\:}Ang}\) are derived using self-attention-based boundary separation. This \(\:{F}_{i}^{{\prime\:}Ang}\) serves as a complementary element to \(\:{F}_{i}^{Dist}\). The next step involves merging \(\:{F}_{i}^{{\prime\:}Ang}\) and \(\:{F}_{i}^{Dist}\) to construct the multi-view intermediate feature tensor \(\:{F}_{MV}\). After that \(\:{F}_{MV}\) is then fuse together to obtaining the final output of the CAMV module. The process can be summarized as follows:
The terms MaxPool() and AvgPool() refer to maximum and average pooling operations, while mean() signifies taking the average of elements and max() represents taking the maximum along the channel dimension. In essence, AvgPool() tends to preserve background information, whereas MaxPool() retains texture details. This distinction aids in capturing subtle differences like shape, color, and scale discrepancies between the object and its background. Additionally, the model employs the Channel Fusion Unit (CFU) module for channel-wise integration. The CFU module partitions the integrated feature map \(\:{f}_{i}\) obtained from the CAMV module into j segments or chunks {\(\:{f}_{i}^{1},\:{f}_{i}^{2},\:\dots\:{f}_{i}^{k},\dots\:,{f}_{i}^{j}\)}along the channel dimension, here k indicates the chunks number. It then conducts channel-wise local interactions (CLIP) between neighboring segments. This local interaction connects all channels and helps in capturing semantic relevance. The outputs of the local interaction are reassembled into one feature map, which is then used for overall progressive iteration (OPI). OPI explores potential semantic relevance and obtains a powerful feature representation. In addition, the DFAN architecture integrates an Overall Progressive Iteration (OPI) approach to systematically delve into the semantic significance of the context. This hybrid strategy, implemented iteratively, contributes to the creation of a more robust and potent feature representation. The feature maps of different levels are gradually restored to a consistent resolution using progressive up sampling. Lastly, the predicted outcomes are acquired by employing a fusion unit in conjunction with a sigmoid function. For training the DFAN, the model utilizes a loss function composed of binary cross-entropy loss (BCEL) and uncertainty perceived loss (UAL). The BCEL measures the discrepancy between the predicted values and the ground truth. The UAL functions as a supplementary loss, enhancing the model’s predictive capability for detecting camouflaged objects.

Illustration of the DFAN framework’s structure.
Figure 8 elaborated that DFAN architecture captures boundary and regional semantic information by incorporating a multi-view generation module, a feature fusion sub-module based on a two-stage attention mechanism, a channel fusion unit for channel-wise integration, and an overall progressive iteration strategy. The objective of the model is to elevate the performance of SOD by capitalizing on a wide spectrum of contextual insights derived from multi-view inputs and the multi-level outputs of the LFE.
Implementation details
The PyTorch framework is used to implement the entire model code. For feature extraction, a pre-trained ResNet-50 model was applied that has been trained on the ImageNet dataset. To ensure the model’s validity, similar hyperparameter settings as other comparable models are adopted. For optimization, SGD with a momentum of 0.9 and a weight decay of 0.0005 is employed, with training spanning 40 epochs and utilizing a batch size of 16. Activation was achieved using the Sigmoid function. The machine configuration consisted of an Intel Core i7 processor complemented by a Nvidia GeForce 1080Ti GPU.
SINet-V2
The proposed SINet-V213 architecture is specifically designed for concealed object detection and builds upon the previous version of SINet. Inspired by the hunting behavior of predators, the SINet-V2 model follows a similar approach of first searching for potential prey, then identifying it, and finally capturing it. The architecture comprises two main stages: the search phase and the identification phase. These stages are further supported by three key components: the Texture Enhanced Module (TEM), the Neighbour Connection Decoder (NCD), and the Group-Reversal Attention (GRA) blocks. The SINET-V2 has been explained in Fig. 9.

Illustration of the SINet-V2 framework’s structure [41].
In the search phase, the SINet-V2 architecture utilizes a set of features extracted from Res2Net50, a deep neural network model. These features are extracted at different resolutions, encompassing a spectrum of feature pyramids that span from high-resolution with low semantic cues to low-resolution with strong semantic characteristics. This allows the model to capture diverse and informative features from the input image. Features are extracted using the ResNet-50 architecture. The features are divided into different levels: low-level features (X0, X1), middle-level features (X2), and high-level features (X3, X4). The RF component consists of five branches (bk, k = 1, …, 5) with convolutional layers of different dimensions. These branches capture and process features at various scales and their outputs are concatenated to obtain the final feature representation (rfk). To enhance the model’s ability to capture fine-grained textures and local details during the search phase, a Texture Enhanced Module (TEM) was introduced. The TEM includes four parallel residual branches (bi, i = 1, 2, 3, 4) with different dilation rates, along with a shortcut branch. These branches incorporate convolutional operations to capture discriminative feature representations. The TEM helps to mimic the textural structure of receptive fields in the human visual system and enables the model to focus on small/local areas during the search for concealed objects. In the search phase, the Neighbor Connection Decoder (NCD) is used to locate concealed objects. The NCD aggregates the features from the TEMs and refines them to obtain a more efficient learning capability. It addresses the issues of maintaining semantic consistency within a layer and bridging context across layers. The NCD modifies the partial decoder component with a neighbor connection function to refine the features and generate a coarse location map. In the identification phase, the SINet architecture utilizes reverse guidance and group guidance operations to mine discriminative concealed regions. The reverse guidance operation erases existing estimated target regions from side-output features, while the group guidance operation splits candidate features into multiple groups and interpolates the guidance prior among them. This group-wise operation ensures effective utilization of the reverse guidance prior. Finally, the Group-Reversal Attention (GRA) blocks are introduced in the identification phase for multi-stage refinement. The GRA blocks utilize Reverse Guidance (RG) and Group Guidance Operations (GPO) to refine the features and generate more accurate predictions. By combining multiple GRA blocks, the model progressively improves its performance in identifying concealed objects. Overall, the SINet-V2 architecture consists of the Texture Enhanced Module (TEM), the Neighbor Connection Decoder (NCD), and the Group-Reversal Attention (GRA) blocks. These components work collaboratively to search for and identify concealed objects. The TEM enhances the model’s ability to capture fine-grained textures, while the NCD locates concealed objects and the GRA blocks refine the predictions. By incorporating these components, the SINet-V2 model achieves improved performance in concealed object detection.
Implementation details
The model architecture is implemented using the PyTorch framework and trained using the Adam optimizer [42]. For training, a batch size of 36 is utilized, and the initial Learning rate is set to 1e-4, with a division of 10 every 50 epochs. The training process completes in approximately 36 h for 100 epochs. The training and inference are performed on the machine configuration consisting of an Intel Core i7 processor complemented by a Nvidia GeForce 1080Ti GPU. During inference, each image is resized to 352 × 352 and directly inputted into the proposed pipeline for obtaining the final prediction, without the need for additional post-processing techniques.
ZoomNet
ZoomNet takes inspiration from the way humans instinctively adjust their focus when analyzing complex scenes. By incorporating multiple zoom levels, this model effectively gathers details at different scales, improving its ability to detect hidden objects in visually challenging environments. To accomplish this, an image pyramid is created using a single input image. This pyramid consists of three versions of the image: the original (main scale) and two resized versions that mimic zooming in and out. These images are processed through a shared triplet feature encoder, which extracts key details before passing them to the scale-merging layer. This merging process, guided by an attention mechanism, prioritizes the most relevant visual cues, allowing the model to identify even the most subtle patterns. Once the data is integrated, hierarchical mixed-scale units (HMUs) refine the features further by expanding the receptive field. These units apply a mix of group-wise interaction and channel-wise modulation to enhance feature recognition, making it easier to pinpoint camouflaged objects in cluttered scenes. To increase reliability, ZoomNet incorporates an uncertainty-aware loss (UAL), which works alongside binary cross-entropy loss (BCEL). The UAL specifically targets ambiguous regions, reducing uncertainty in predictions and improving overall accuracy. The model’s triplet feature encoder plays a key role in feature extraction. It consists of two sub-networks: E-Net, which is based on a modified ResNet50 architecture, and C-Net, which streamlines computation and optimizes feature compression. Together, these networks generate three sets of 64-channel feature maps for different zoom levels (0.5×, 1.0×, and 1.5×). Next, the scale-merging layer fuses these features using Scale Integration Units (SIUs), which selectively filter and integrate information based on an attention mechanism. This ensures that even fine details from different zoom levels are preserved, refining the overall representation of the image. The hierarchical mixed-scale decoder enhances feature clarity even further by facilitating structured interactions between different channels. Using a series of HMUs, the model iteratively refines feature maps. Group-wise iteration enables different feature groups to share insights, while channel-wise modulation applies weighted adjustments to emphasize critical details. During training, ZoomNet uses a combination of BCEL and UAL to fine-tune its learning process. BCEL measures the difference between predicted and actual values, while UAL helps reduce uncertainty, leading to more confident and reliable predictions.

Illustration of the ZoomNet framework’s structure [43].
Figure 10 demonstrated that ZoomNet’s desig built on an image pyramid, attention-based feature merging, and hierarchical refinement allows it to accurately detect hidden objects in complex backgrounds. By integrating uncertainty-aware loss mechanisms, the model enhances prediction reliability, making it highly effective for camouflage detection tasks.
Implementation details of sinet
The implementation of ZoomNet is carried out using the PyTorch framework. The encoder is initialized with the pre-trained parameters of ResNet-50 on the ImageNet dataset, while the remaining parts are randomly initialized. For optimization, Stochastic Gradient Descent SGD with a momentum of 0.9 and weight decay of 0.0005. The Learning rate is set to 0.05 initially and follows a linear warmup and decay strategy. with training spanning 40 epochs and utilizing a batch size of 16. Activation was achieved using the Sigmoid function. The machine configuration consisted of an Intel Core i7 processor complemented by a Nvidia GeForce 1080Ti GPU.
The Search Identification Network (SINet) model architecture proposed is motivated by biological studies on predator hunting behavior, which involve three stages: searching for potential prey, identifying the target animal, and capturing it. The SINet framework focuses on the first two stages of hunting, namely searching for a camouflaged object and precisely detecting it. The SINet architecture comprises two main modules, the Search Module (SM) and the Identification Module (IM). In the SM, the goal is to locate the camouflaged object by highlighting the area close to the retinal fovea, which is sensitive to small spatial shifts. This is achieved by incorporating a Receptive Field (RF)31 component that captures discriminative feature representations in a small/local space. For an input image, features are extracted using the ResNet-50 architecture32. These features are divided into different levels: low-level features (\(\:{X}_{0}\), \(\:{X}_{1}\)), middle-level features (\(\:{X}_{2}\)), and high-level features (\(\:{X}_{3}\), \(\:{X}_{4}\)). The features from different levels are combined through concatenation, up-sampling, and down-sampling operations to preserve spatial details for constructing object boundaries and retain semantic information for locating objects. The SINet employs a densely connected strategy to maintain information from different layers and enhance feature representations. The modified RF component is utilized to enlarge the receptive field and generate a set of enhanced features (\(\:{rf}_{1}^{s}\), \(\:{rf}_{2}^{s}\), \(\:{rf}_{3}^{s}\), \(\:{rf}_{4}^{s}\)) for learning robust cues. The RF component consists of five branches, each comprising convolutional layers with different dimensions. These branches capture and process the features at various scales, and their outputs are concatenated and further processed to obtain the final feature representation (\(\:rfk\)). In the IM, the candidate features obtained from the SM are used to precisely detect the camouflaged object. The Partial Decoder Component (PDC)33 is extended to integrate four levels of features from the SM. This integration enables the computation of a coarse camouflage map (\(\:{C}_{s}\)) by applying the PDC to the enhanced features (\(\:{rf}_{1}^{s}\), \(\:{rf}_{2}^{s}\), \(\:{rf}_{3}^{s}\), \(\:{rf}_{4}^{s}\)). Attention mechanisms, specifically the Search Attention (SA) module40, are introduced to eliminate interference from irrelevant features and enhance the middle-level features (\(\:{X}_{2}\)). The SA module applies a Gaussian filter and normalization operations to generate an enhanced camouflage map (\(\:{C}_{h}\)). To holistically capture high-level features, the PDC is further utilized to aggregate three layers of features enhanced by the RF function. This aggregation results in the final camouflage map (\(\:{C}_{i}\)). The difference between the PDC in the SM (\(\:{PD}_{s}\)) and the PDC in the IM (\(\:{PD}_{i}\)) lies in the number of input features they consider. The SINet model is trained using a cross-entropy loss function (LCE), which measures the discrepancy between the generated camouflaged object maps \(\:{C}_{csm}\) and \(\:{C}_{cim}\) (acquired form \(\:{C}_{s}\) and \(\:{C}_{i}\)) and the ground truth maps (G). The total loss function (L) is the sum of the cross-entropy losses for the SM and the IM. By incorporating these modules and techniques, the SINet architecture aims to mimic the process of searching for and identifying camouflaged objects, leveraging various levels of features and attention mechanisms to enhance the detection performance. The SINet model is built using PyTorch and optimized with the Adam algorithm34.

Illustration of the SINet framework’s structure11.
Figure 11. Showed that during training, it processed data in batches of 36, with an initial Learning rate of 1e-4. The model undergoes training for 30 epochs, incorporating an early stopping mechanism to prevent overfitting. The entire training process takes roughly 70 min. For experimentation, the model runs on a system equipped with an Intel Core i7 processor and an Nvidia GeForce 1080Ti GPU. When making predictions, it processes a 352 × 352 image in just 0.2 s, ensuring efficient real-time performance.
Experimentation analysis and challenges
To thoroughly evaluate the effectiveness of the detection approach, several key performance metrics were selected, each offering a unique perspective on accuracy and reliability. One of the primary measures used is the Mean Absolute Error (MAE), which calculates the average difference between the predicted saliency map and the actual ground-truth map. By focusing on the magnitude of these differences, MAE provides a clear understanding of overall accuracy. To refine the assessment at a more detailed level, the MAE (M) metric was introduced. This particular measure concentrates on pixel-level accuracy, ensuring that individual pixels in the predicted output align closely with the ground truth. This level of precision is critical for evaluating the fine details of object detection. While MAE helps determine the extent of errors, it does not reveal their exact locations within an image. To bridge this gap, the E-measure (E_∅) was incorporated. This metric accounts for how the human eye perceives visual differences by analyzing both overall image quality and localized details. By combining these perspectives, E-measure provides a more perceptually relevant evaluation of detection accuracy. Since camouflaged objects often blend seamlessly with their surroundings, assessing structural integrity is just as important as pixel-level precision. For this reason, the S-measure (S_α) was included 35,36. This metric evaluates how well the predicted output preserves the spatial layout and structural characteristics of the original object, ensuring that the detected shapes remain true to their real-world form37. Additionally, to achieve a more balanced evaluation, the F-measure (F_β^ω)38 was used. Another pproach combined the strengths of Vision Transformers with a DenseNet-based neural feature extractor to create a new and efficient technique. The design achieved performance on par with the latest Vision Transformer models, without relying on complex strategies such as knowledge distillation or model ensembles. It was also introduced a straightforward yet effective inference method that uses a voting scheme to handle cases where multiple faces appear in the same video frame. In testing, best-performing model achieved exceptional results, reaching an AUC of 99.99% and a mean F1-score of 99.0% on the DeepForensics 1.0 dataset. On the CelebDF dataset, the model maintained strong performance with an AUC of 97.4% and an F1-score of 95.1%, underscoring its robustness and accuracy39. The experimental findings confirmed that the DWT- and SWT-based denoising method effectively retains essential details in DEXI images while reducing unwanted noise. Its performance was evaluated using Peak Signal-to-Noise Ratio (PSNR) and Mean Squared Error (MSE) metrics. For DEXI images at a resolution of 256 × 256, the approach achieved an average PSNR of 35.23 and an MSE of 19.52, while for 512 × 512 images, it reached an average PSNR of 36.01 and an MSE of 16.29, indicating strong noise suppression with minimal loss of important visual information40.
Table 2 portrayed the dataset distribution for testing and training. Datasets are also mentioned in the table with training and testing split. This measure considers both precision and recall, meaning it not only checks how accurately objects are detected but also ensures that irrelevant elements are not mistakenly classified as targets. By balancing these two aspects, the F-measure helps gauge the reliability of the detection process. By combining these diverse evaluation methods, this study presents a well-rounded analysis of the detection system’s performance. The integration of overall accuracy, pixel-level precision, structural consistency, and perceptual relevance allows for a comprehensive and meaningful assessment of how well the methodology performs in real-world scenarios. A manual segmentation approach was employed using professional image annotation tools, where annotators carefully traced the precise object boundaries at the pixel level. In cases of highly complex camouflage, where the target blends almost seamlessly into the background, annotators used contextual cues such as subtle texture variations, shadow outlines, and shape continuity to differentiate the object from its surroundings. Each annotated image underwent a two-stage verification process: initial annotation by one annotator followed by independent review and correction by a second expert to minimize human error and subjectivity. The main challenges included differentiating partially occluded objects and accurately marking boundaries in low-contrast regions, which occasionally led to ambiguities. However, the rigorous verification protocol and the use of high-resolution source images helped ensure that the annotations remained consistent and reliable across the dataset.
Dataset distribution
In this experimental chapter, evaluations were conducted using two datasets: MSC1k and CPD. These datasets were preferred to ensure a comprehensive assessment of the proposed methodology. To evaluate the performance, the datasets were divided into three distinct training/testing settings. For the MSC1k dataset, 748 samples were allocated for training purposes, while 330 samples were reserved for testing. Similarly, for the CPD dataset, 650 samples were used for training and 350 samples for testing. This split allowed for a balanced representation of data for training and evaluation, enabling a robust examination of the proposed methodology’s effectiveness, generalization, and performance on unseen data. Moreover, both datasets were combined to create a merged dataset. From this merged dataset, 1398 samples were selected for training, encompassing images from both MSC1k and CPD, while 680 samples were allocated for testing. By merging the datasets, the aim was to enhance the diversity of the training data, enabling the methodology to learn from a wider range of visual characteristics. This careful partitioning of the datasets and allocation of samples for training and testing ensured a comprehensive evaluation of the classical models. It allowed for the assessment of the performance of datasets and varying sample sizes, contributing to a more robust analysis of its capabilities and potential applications.
Results and data analysis
A detailed analysis of Table 2 highlights some key differences in model performance across different dataset settings. In the first scenario (MSC1K), noticeable distinctions emerge between the models. Both ZoomNet and DFAN show strong capabilities in identifying prominent regions, as reflected in their low Mean Absolute Error (MAE) values and competitive F-measures. However, DFAN consistently edges out ZoomNet across all evaluation criteria, demonstrating its ability to capture intricate structural details (S-measure) while aligning closely with human visual perception (E-measure). Similarly, SINET and its enhanced version, SINET-v2, also perform well in this setting. Notably, SINET-v2 achieves the highest structural similarity and perceptual alignment, suggesting its refined ability to detect key features within complex environments. While each model exhibits slight variations in performance, their overall results remain strong, reinforcing their effectiveness in handling this dataset. Shifting focus to the second dataset setting (CPD), the differences between models become even more pronounced. ZoomNet, DFAN, and SINET-v2 demonstrate superior performance across multiple evaluation metrics. Notably, SINET-v2 excels in E-measure scores, emphasizing its ability to closely mirror human perception. DFAN, on the other hand, achieves the highest F-measure, indicating its efficiency in balancing precision and recall. In contrast, SINET appears to lag in most metrics, suggesting that it may struggle to capture more intricate saliency patterns. These findings highlight the critical role of dataset diversity in evaluating model performance. The combined dataset introduces more variability, testing the models’ adaptability across a range of conditions. This variation ultimately provides deeper insight into each model’s strengths and areas for improvement. Analysis suggested that the performance drop is largely dataset-related rather than solely an inherent limitation of the method. The CPD dataset contains highly subtle camouflage patterns with minimal texture and contrast differences between objects and their surroundings, often captured under uniform lighting conditions. These properties reduce the saliency cues that SINet relies on, making accurate segmentation more challenging. SINet’s architecture is less adept at capturing fine-grained structural cues in such low-contrast scenarios, which likely explains its lower scores on CPD. In contrast, our MSC1K dataset includes more diverse camouflage conditions such as varying backgrounds, lighting variations, and complex object boundaries which allow feature-learning models like SINet to leverage richer contextual information. This diversity appears to improve generalization and may explain why SINet performs relatively better on MSC1K than on CPD. Models like DFAN and SINetV2, which incorporate multi-level feature aggregation and stronger contextual reasoning, are better equipped to handle the subtle saliency challenges in CPD, hence their superior performance.

Qualitative results comparison on MSC1K dataset between SOTA frameworks.
and weaknesses. Figure 12 demonstrated the qualitive comparative analysis for MSC1K dataset between SOTA frameworks. In Dataset Setting 3 (MSC1K + CPD), DFAN emerges as a strong performer once again, outshining other models across various metrics. It demonstrates the highest S-measure, indicating its effectiveness in capturing structural similarities. DFAN ‘s consistently high E-measure signifies its strong alignment with human perception.
Moreover, DFAN ‘s ability to balance precision and recall is evident in its top F-measure scores. These strengths collectively contribute to DFAN ‘s superior performance in this combined dataset. While SINET-v2 holds its ground with competitive scores, it is intriguing to note that, in this specific setting, DFAN ‘s architecture seems to align better with the dataset’s challenges and complexities.
Table 3 presented a comprehensive comparison of model performance metrics, which includes F-measure E-measure, S-measure, and Mean Absolute Error (MAE), across three distinct dataset settings. MSC1K, CPD, and MSC1K + CPD. Table 3 compares four different methods SINet, ZoomNet, SINetV2, and DFAN under three test conditions: MSC1K, CPD, and a combination of both. The goal is to achieve higher scores for s_α, E_∅, and F_β^ω, while keeping MAE (Mean Absolute Error) as low as possible. Looking at the error values (MAE), DFAN performs the best, with the lowest errors: 0.051 in MSC1K, 0.004 in CPD, and 0.028 in the combined setting. On the other hand, SINet has the highest error values, making it the Least accurate, with 0.079 in MSC1K, 0.157 in CPD, and 0.049 in the combined setup. ZoomNet and SINetV2 fall somewhere in between ZoomNet has 0.056, 0.005, and 0.029, while SINetV2 shows 0.051, 0.005, and 0.027 across the three settings. From this, it can be observed that that DFAN and SINetV2 provide the most precise results, while SINet struggles with accuracy. The quantitative analysis of the models’ performances across the three dataset settings provides valuable insights into their strengths and adaptability. In the first dataset setting (MSC1K), all models demonstrate commendable results, with DFAN slightly outperforming others in capturing structural details and aligning with human perception. Transitioning to the second setting (CPD), the variations become more pronounced, showcasing the effectiveness of ZoomNet, DFAN, and SINET-v2 in different aspects. Notably, DFAN shines with its precision-recall balance, while SINET lags behind, potentially due to difficulties in handling intricate saliency patterns. The most intriguing contrast arises in the third setting (MSC1K + CPD), where DFAN remarkably excels, displaying superior structural similarity, strong human-perception alignment, and optimal precision-recall trade-offs. On the other hand, SINET-v2’s performance seems less aligned with the dataset’s challenges, suggesting potential limitations in this specific context. These variations underscore the critical role of diverse dataset compositions in highlighting models’ adaptability and revealing their strengths and weaknesses. The quantitative analysis facilitates a deeper understanding of each model’s behavior across different scenarios, enabling informed decisions for their utilization in real-world applications.

Qualitative results comparison on CPD dataset between SOTA frameworks.
Figure 13 presented compares visual outputs of various camouflage object detection models. It includes results from MFFN, ZoomNet, SINet-V2, and SINet, benchmarked against ground truth (GT) across diverse natural scenes. The highlighted regions represent the predicted camouflaged object locations. Each row corresponds to a different image input, illustrating how well each method reveals the hidden object.
Conclusion
This research introduced a novel dataset specifically designed for detecting camouflaged individuals, providing a valuable resource for advancing state-of-the-art techniques in this field. The dataset captures a diverse range of real-world scenarios, including complex camouflage conditions, which helps in developing and evaluating more effective detection algorithms. To assess the dataset’s effectiveness, four leading detection frameworks were tested, offering valuable insights into their performance. The results were promising, reinforcing the idea that camouflage detection remains a challenging yet evolving area of research. Each framework exhibited different strengths and weaknesses, highlighting the complexity of the task and the need for further improvements. Moving forward, the focus will be on refining and enhancing existing models to improve detection accuracy. Exploring ensemble methods and fostering collaborations with experts in military science and psychology could bring new perspectives to the field. Additionally, efforts will be directed toward developing practical applications for real-world scenarios and integrating interpretable AI techniques to create more transparent and reliable detection systems.
Data availability
Data can be provided on request. Corresponding author Talha Ahmed Khan can be contacted for the dataset if required.
References
Copeland, A. C. & Trivedi, M. M. Models and metrics for signature strength evaluation of camouflaged targets, AeroSense’. 97, 194–199 (1997).
Singh, S., Dhawale, C. & Misra, S. Survey of object detection methods in camouflaged image. J. IERI Procedia. 4, 351–357 (2013).
Talas, L., Baddeley, R. J. & Cuthill, I. C. Cultural evolution of military camouflage. Philos. Trans. R Soc. Lond. B Biol. Sci. 372, 20160351 (2017). [CrossRef].
Merilaita, S., Scott-Samuel, N. E. & Cuthill, I. C. How camouflage works. Philos. Trans. R Soc. Lond. B Biol. Sci. 372, 20160341 (2017). [CrossRef] [PubMed].
King, A. The digital revolution: camouflage in the twenty-first century. Millenn J. Int. Stud. 42, 397–424 (2014). [CrossRef].
Chu, M. & Tian, S. H. An Extraction Method for Digital Camouflage Texture Based on Human Visual Perception and Isoperimetric Theory. In Proceedings of the 2nd International Conference on Image, Vision and Computing, Chengdu, China, 2–4 June ; pp. 158–162. (2017).
Zhang, X., Zhu, C., Wang, S., Liu, Y. & Ye, M. A bayesian approach to camouflaged moving object detection. IEEE Trans. Circuits Syst. Video Technol. 27 (9), 2001–2013 (2016).
Le, T. N., Nguyen, T. V., Nie, Z., Tran, M. T. & Sugimoto, A. Anabranch network for camouflaged object segmentation. Comput. Vis. Image Underst. 184, 45–56 (2019).
Fan, D. P. et al. Camouflaged object detection, in: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, (2020).
Fang, Z., Zhang, X., Deng, X., Cao, T. & Zheng, C. Camouflage people detection via strong semantic dilation network. In Proceedings of the ACM Turing Celebration Conference-China (pp. 1–7). (2019), May.
Zhang, Y. et al. A late fusion Cnn for digital matting. IEEE CVPR, 1, 7469–7478 (2019).
Amir, R. et al. Taskonomy: Disentangling task transfer learning. In IEEE CVPR, pages 3712–3722, (2018).
Fan, D. P., Ji, G. P., Cheng, M. M. & Shao, L. Concealed object detection. IEEE Trans. Pattern Anal. Mach. Intell. 44 (10), 6024–6042 (2021).
Pang, Y., Zhao, X., Xiang, T. Z., Zhang, L. & Lu, H. Zoom in and out: A mixed-scale triplet network for camouflaged object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 2160–2170). (2022).
Zheng, D. et al. Mffn: Multi-view feature fusion network for camouflaged object detection. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (pp. 6232–6242). (2023).
Krizhevsky, A., Sutskever, I. & Hinton, G. E. ImageNet Classification with Deep Convolutional Neural Networks. In Advances in Neural Information Processing Systems (pp. 1097–1105). (2012).
Kirillov, A., He, K., Girshick, R., Rother, C. & Dollar, P. Panoptic ´ segmentation. IEEE Conf. Comput. Vis. Pattern Recog, vol. 3. pp. 9404–9413 (2019).
Le, T. N., Sugimoto, A., Ono, S. & Kawasaki, H. Attention r-cnn for accident detection, in IEEE Intelligent Vehicles Symposium, (2020).
Girshick, R., Donahue, J., Darrell, T. & Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation, in June 2014, pp. 580–587. (2014) CVPR.
Achanta, R., Hemami, S., Estrada, F. & Susstrunk, S. Frequency-tuned salient region detection. In Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, pages 1597–1604, (2009).
Cheng, M., Mitra, N., Huang, X., Torr, P. & Hu, S. Global contrast based salient region detection. In Proceedings of Conference on Computer Vision and Pattern Recognition, pages 409–416. (2011).
Martin Stevens and Sami Merilaita. Animal camouflage: current issues and new perspectives. Phil Trans. R Soc. B: Biol. Sci. 364 (1516), 423–427 (2008).
Song, L. & Geng, W. A new camouflage texture evaluation method based on wssim and nature image features, in International Conference on Multimedia Technology, Oct pp. 1–4. (2010).
Le, T. N. et al. Camoufinder: Finding camouflaged instances in images, in AAAI Conference on Artificial Intelligence, pp. 1–4. (2021).
He, K., Gkioxari, G., Dollar, P. & Girshick, R. Mask r-cnn, in ´ International Conference on Computer Vision, pp. 2980–2988. (2017).
Yan, J. et al. Mirrornet: Bio-inspired adversarial attack for camouflaged object segmentation, arXiv preprint arXiv:2007.12881 (2020).
Skurowski, P. et al. Animal Camouflage Analysis: Chameleon Database (Unpublished Manuscript, 2018).
Wang, J., Wang, G., Cheng, S. & Zhang, W. Research on Digital Camouflage Pattern Matching Method Based on Improved SURF Algorithm. In Proceedings of the 3rd International Conference on Artificial Intelligence and Security (pp. 303–309). ACM. (2018).
Deng, L., Zhang, S., Zhu, X. & Zhou, J. Comparative analysis of digital and analogue camouflage pattern recognition performance. In Proceedings of the 11th International Conference on Image Processing Theory, Tools and Applications (IPTA) (pp. 1–6). IEEE. (2019).
Wu, Y., Xu, J. & Liu, D. A comparative study on digital and analogue camouflage patterns based on visual perception. J. Ambient Intell. Humaniz. Comput. 12 (3), 2763–2773 (2021).
Songtao et al. Receptive field block net for accurate and fast object detection. In ECCV European Conference on Computer Vision (ECCV), pp. 385–400, (2018).
He, K., Zhang, X., Ren, S. & Sun, J. Deep residual learning for image recognition. IEEE CVPR, pp. 770–778, (2016).
Zhe Wu, L. & Huang, S. Cascaded partial decoder for fast and accurate salient object detection. IEEE CVPR, pp. 3907–3916, (2019).
Kingma, D. P. & Ba, J. Adam: A method for stochastic optimization. Int. Conf. Learn. Represent, (2015).
Federico & Perazzi Philipp Krahenb ¨ uhl, Yael pritch, and ¨ Alexander hornung. Saliency filters: contrast based filtering for salient region detection. IEEE CVPR, vol. 4 pages 733–740, (2012).
Deng-Ping, F. et al. Enhanced-alignment measure for binary foreground map evaluation. In IJCAI, International Joint Conference on Artificial Intelligence pages 698–704, (2018).
Deng-Ping, F., Cheng, M. M., Liu, Y., Li, T. & Borji, A. Structure-measure: A new way to evaluate foreground maps. IEEE ICCV IEEE International Conference on Computer Vision (ICCV), pages 4548–4557, (2017)., pages 4548–4557, (2017).
Ran & Margolin Lihi Zelnik-Manor, and Ayellet tal. How to evaluate foreground maps. IEEE CVPR, pages 248–255, (2014).
Fazeela Siddiqui, J., Yang, S. & Xiao Muhammad fahad,enhanced deepfake detection with densenet and Cross-ViT, expert systems with applications, 267, 126150, ISSN 0957–4174, (2025). https://doi.org/10.1016/j.eswa.2024.126150
Fahad, M. et al. Optimizing dual energy X-ray image enhancement using a novel hybrid fusion method. J. X-Ray Sci. Technol. 32 (6), 1553–1570. https://doi.org/10.3233/XST-240227 (2024).
Acknowledgements
Authors are thankful to the resourceful lab provided by the Universiti Kuala Lumpur, Malaysia.
Funding
Research is funded by Universiti Kuala Lumpur, Malaysia.
Author information
Authors and Affiliations
Contributions
A.H. and G.M. wrote the main manuscript text. T.A.K. and K.K. conducted the experiments and prepared Figures. M.N.H. handled data acquisition and analysis. H.M.N. contributed to the literature review and manuscript formatting. All authors reviewed and approved the final manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Haider, A., Muhammad, G., Khan, T.A. et al. Identification of camouflage military individuals with deep learning approaches DFAN and SINETV2. Sci Rep 15, 33271 (2025). https://doi.org/10.1038/s41598-025-18886-y
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-18886-y
