
Abstract
To address the over-reliance on sociological and structural balance theories in analysing directed signed networks, which inadequately describe the true relationships between nodes, this paper proposes the DADSGNN model. DADSGNN is a decoupled signed graph neural network that employs a dual attention mechanism to enhance the quality of node embedding representations. Firstly, DADSGNN decouples node features into multiple potential factors within its encoder, employing the concept of decoupled representation learning. This allows for a deeper exploration of potential factors influencing internodal relationships. Secondly, a dual attention mechanism, comprising local and structural attention, is applied. This enables the model to classify and aggregate diverse types of neighbour information and subsequently calculate the characteristics of each potential influence factor. Such an approach effectively improves the accuracy and interpretability of the model’s representation of complex internodal relationships. Thirdly, the decoder component of DADSGNN incorporates a novel decoder for the link sign prediction task. This decoder fully considers the correlation between different potential factors, thereby significantly improving prediction accuracy. Finally, the predictive capability and validity of DADSGNN are evaluated using directed network datasets of varying scales, thereby verifying the model’s performance on real-world signed network data.
Similar content being viewed by others

Introduction
A signed directed network is inherently more complex than its undirected counterpart owing to the inclusion of directional information. Consequently, it offers a richer representation of information, making the effective mining of this information a crucial issue. Currently, most researches on signed directed networks employs structural equilibrium theory and social status theory to describe internodal relationships. However, these theories often simplistically attribute these relationships to dichotomies such as hostility versus friendship, or high versus low status. In practice, numerous other potential factors influence internodal relationships, including habits, hobbies, and political inclinations, among others. Moreover, some links within signed directed networks do not conform to established sociological theories1,2,3. Therefore, sociological theory alone cannot adequately describe the true relationships between nodes, as shown in Table 1.
In many studies, when employing graph neural networks to aggregate neighbor information and update node features, the feature vectors are often merely summed or averaged. This computational approach not only overlooks the varying importance of different neighbors but also diminishes the model’s interpretability4,5. Furthermore, the coexistence of positive and negative labels alongside directional information in signed directed networks necessitates an undifferentiated aggregation of neighbour information. This makes it challenging to identify features that genuinely affect internodal relationships, significantly diminishing the model’s capacity to discern such relationships.
To address this limitation, this paper proposes DADSGNN, a directed, signed, decoupled graph neural network model based on a dual attention mechanism. The contributions are as follows:
Firstly, in the encoder component of the DADSGNN model, node features from the dataset are decoupled using the principles of decoupled representation learning, thereby decomposing them into potential influencing factors.
Secondly, based on the characteristics of directed signed networks, neighbours are categorised. Different types of neighbour information are then classified and aggregated. The characteristics of each potential influence factor are calculated post-aggregation, and a two-layer attention mechanism is proposed for this aggregation process.
Finally, within the DADSGNN decoder, a specialised component learns the correlation of different decoupled features between node pairs for the link sign prediction task. This enhances the accuracy of the model’s predictions.
Related work
A directed signed network is a network comprising signed and directional information on links. In comparison to an undirected signed network, a directed signed network contains a greater quantity of information and is more complex. The directional information inherent in a directed signed network facilitates understanding of the unidirectional relationship between nodes and the direction of information transmission. In the study of directed signed networks, the accuracy of link sign prediction has been significantly enhanced through the integration of sociological theories and the development of novel models.
Cui et al.6 addressed the challenge of achieving an optimal balance between prediction accuracy and algorithmic complexity in the symbolic prediction algorithm by incorporating a regulating factor to balance the similarity scores of the two sociological theories. Wang et al.7 devised four categories of features pertaining to negative links: node features, structural features, similarity features, and scoring features. A logistic regression algorithm was employed to predict negative links, thereby addressing the issue of low prediction performance. Yan et al.8 employed a multi-head attention mechanism to integrate the symbolic and structural information of first-order and second-order neighbours, thereby extracting low-dimensional features of users. This approach enhanced the efficacy of symbolic prediction and elevated the accuracy of predictions. Wang et al.9 devised a relational prediction model based on a three-layer perceptron to delineate the diverse types of contextual link relationships between nodes. By mining complex semantic information, semantic information from link signs containing positive and negative relationships is introduced into the learning process of network representation, thereby improving prediction performance. Kim et al.10 proposed the SIDE model, which generates a node sequence through a random walk and then randomly selects node pairs to extract structural information. Node similarity is calculated through the inner product of the node pair vector representation and the softmax function. Furthermore, the SIDE model considers the directionality of links within a network. Chen et al.11 concurrently considered structural balance theory and social status theory, defined their own loss functions for the two theories, and proposed 12 fundamental triangular relationships that satisfy the two theories to facilitate the learning of node representations. Chen et al.12 devised loss functions that incorporated “bridge edges” as an additional component to the triplet structure. They employed a multilayer perceptron to extract structural information, which was used to generate node representations. This approach yielded favourable outcomes in a range of downstream tasks. Yuan et al.13 classified the features in the signed network into three categories: node features, triplet features, and user similarity features. They extracted these features separately to obtain node representations, which proved to be an effective approach to the signed prediction problem.
Subsequent studies have employed more sophisticated models to enhance the efficacy of symbol prediction in directed signed networks and to bolster the model’s capacity to process intricate features. Xu et al.14 proposed two categories of symbolic latent factors, contemplated four distinct social relationships, and calculated the scores of nodes for varying types of social relationships through the SLF model. The accuracy of the model was validated through link prediction tasks. Xu et al.15 proposed a Skip-Gram model suitable for signed networks. This model employs a negative sampling method to learn the connection and trust propagation pattern features of nodes and latent factors. Additionally, it generates negative samples based on random walks to optimize node representations. Huang et al.16 constructed the SiGAT model by defining different types of motifs and introducing an attention mechanism to learn their weight coefficients. This was combined with structural balance theory and applied to a directed signed network. Huang et al.17 proposed the SDGNN model, which generates node representations by aggregating disparate types of neighbour information and devises three distinct loss functions to enhance the model’s capacity to capture features. Jung et al.18 proposed the SGDNET model for the integrated learning of node representations and link sign prediction in signed networks. This model considers the information of multi-hop neighbours and retains local information through the diffusion of symbol random walks and the injection of local features. In a further development of the field, Taewook et al.19 proposed a complex conjugate adjacency matrix, representing the direction and sign of edges by their phase and amplitude, and defined a magnetic Laplacian matrix based on this adjacency matrix. Chen et al.20 developed a method for learning a more representative node embedding representation by simultaneously capturing the first- and higher-order topology in a directed signed network. This method, which they called a decoupled variational embedding (DVE) method, was designed to address the challenge of representing nodes in networks with complex topologies. The efficacy of the algorithm was validated through the utilisation of link sign prediction tasks and node recommendation tasks, which served to corroborate the algorithm’s effectiveness. He et al.21 proposed a magnetic sign Laplacian matrix and employed this matrix to develop an efficient spectral graph neural network architecture. The model was validated through the successful execution of clustering and link prediction tasks, which demonstrated its capacity to effectively fuse sign and direction information. Song et al.22 developed a framework for learning node and edge vectors in signed networks. By postulating the existence of a global mapping between the node vector space and the edge vector space, the edge vector can be employed directly to represent edge attributes, thereby enhancing the precision of subsequent tasks. Cui et al.23 proposed a semi-supervised gated spectral convolution method for directed signed networks. By defining the sign propagation rule in a directed signed network, the network is transformed into a semi-supervised network. Concurrently, the structural balance theory is augmented to impose constraints on the sign propagation process, thereby facilitating the acquisition of more interpretable network embeddings. Moreover, the method introduces a gating mechanism to adaptively discard symbol information, thereby markedly reducing the time and space complexity of the symbol propagation process. In a separate contribution, Ko et al.24 proposed a method for learning a decoupled representation of nodes in a directed symbolic graph that does not rely on social theory assumptions. This approach has been designated DINES. The method employs factorisation of each embedding into multiple latent factors, along with a directed symbolic graph convolution that focuses on symbols and directions, thereby avoiding reliance on social theory.
The structure of DADSGNN encoder
The DADSGNN model structure proposed in this paper is shown in Fig. 1. To accurately describe true internodal relationships in a signed directed network and identify the factors that genuinely influence these relationships, this paper applies a decoupling framework. This framework decompose node features into multiple, unique latent influencing factors with defined semantics. Subsequently, a dual attention mechanism is incorporated into the graph neural network. This mechanism aggregates the latent influencing factors of neighboring nodes from diverse perspectives, thereby facilitating comprehensive feature aggregation and the generation of the final node embedding representation.

The structure of DADSGNN model.
Relative definitions
The related concepts and research questions for directed signed networks are described as follows:
-
(1)
Signed Directed Network: A signed directed network is defined as \(G=\left\{V, E, S\right\}\), where \(V=\{{v}_{1}, {v}_{2}, {v}_{3}, \dots , {v}_{n}\}\) represents the set of all nodes in graph G, and \(E=\{{e}_{ij} | {e}_{ij}\ne 0 \}\) is the set of all links in the network.
-
(2)
In a signed directed network, internodal relationships are not merely single-dimensional; they also encompass directionality and positive or negative attributes. This provides abundant information for comprehending and analysing the intricate dynamic within the network. Specifically, links in the network can be subdivided into four main categories based on their direction (out-degree or in-degree) and nature (positive or negative). These categories are: links with a positive sign in the out-degree direction (\({\to }^{+}\)), links with a negative sign in the out-degree direction (\({\to }^{-}\)), links with a positive sign in the in-degree direction (\({\leftarrow }^{+}\)), and links with a negative sign in the in-degree direction (\({\leftarrow }^{-}\)). These four link types reflect the intricate and multifaceted interactions and relationships between nodes.
Accordingly, the neighbours of a node are also classified into four types based on these four types of links:
\({N}_{u}^{{\to }^{+}}\): Represents neighbour nodes that are pointed to by node \(u\) and have a positive relationship with it. This type of neighbour reflects positive support or positive evaluation.
\({N}_{u}^{{\to }^{-}}\): Refers to neighbour nodes pointed to by the node \(u\) that have a negative relationship with it. This indicates a negative attitude or some form of opposition towards these neighbours.
\({N}_{u}^{{\leftarrow }^{+}}\): Includes neighbour nodes that point to the node \(u\) and have a positive relationship with it. This type of neighbour represents recognition or support.
\({N}_{u}^{{\leftarrow }^{-}}\): Includes neighbour nodes that point to the node \(u\) and have a negative relationship with it. This indicates that these neighbours hold a negative or hostile attitude.
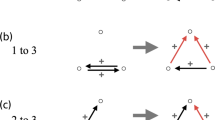
As show in Fig. 2, the classification of internodal relationships in a network, where each specific type of neighbour is assigned a clear semantic role, represents distinct social dynamics and interaction patterns within the network. This approach not only enhances our comprehension of network structure but also offers a novel lens through which to investigate and elucidate phenomena within the network. For example, positive in-degree neighbours (\({N}_{u}^{{\to }^{+}}\)) and negative out-degree neighbours (\({N}_{u}^{{\leftarrow }^{-}}\)) respectively reflect the positive influence originating from other nodes and the negative influence exerted by the external environment on the nodes \(u\). This detailed distinction offers significant insights and methodologies for a comprehensive investigation into the dynamics of influence, social structure, and group behaviour within the network.

Four types of directed signed neighbors.
Decoupled feature representation
To explore in depth the complex interactions and influences among nodes, this paper introduces a more detailed and multi-dimensional perspective for network analysis. The initial feature vector of each node is decoupled into K independent factors. Each factor represents an independent dimension of the node 's characteristics. Collectively, these dimensions provide a comprehensive description of node behaviour and internodal relationships, enabling each factor to capture underlying connections and differences between nodes more precisely. This decoupling strategy explores and explains the interactions between nodes from multiple perspectives, thereby revealing the hidden structures and patterns in the network. The core of the decoupling process is to map the feature vector of each node to \(K\) different subspaces using the fully connected layer, so as to obtain the feature representation corresponding to each potential factor. Therefore, for each node \(v \in V\), a fully connected layer transforms the initial feature vector \({h}_{v}\) into K distinct subspaces, yielding \({h}_{v}=\{{h}_{v,1},{h}_{v,2},\dots ,{h}_{v,k}\}\), as illustrated in formula (1).
where \({f}_{k}^{\left(l\right)}(v)\) denotes the feature representation of the \(k\)-th latent factor for node \(v\) at the \(l\)-th feature update . The function \(normalise(\cdot )\) is a normalisation function that avoids bias introduced by differences in feature scales. The function \(\sigma \left(\cdot \right)\) is a non-linear activation function that enhances the model’s ability to capture complex relationships. The function \(FC(\cdot )\) represents the fully-connected layer. The parameter matrix is represented by \({W}_{k}\), and the bias parameter of the \(k\)-th latent factor is represented by \({b}_{k}\). The parameters are optimised during the training phase. Formula (1) effectively represents a transformation from the original feature space to the latent factor space, enabling each latent factor to potentially capture a distinct aspect of the node’s features. Decoupling the initial feature vector into multiple underlying factors facilitates understanding internodal relationships from multiple dimensions, rather than relying solely on original, potentially entangled or mutually confusing feature representations.
Feature aggregation based on dual attention mechanism
As there are different types of neighbour nodes in the directed signed network, different neighbour information needs to be aggregated separately. Since the importance of different nodes within the same type of neighbours varies, different weights should be assigned during feature aggregation to better distinguish their respective importance. Different types of neighbours contain varying directional and signed information; consequently, different types of neighbours hold varying levels of importance to a node. The model needs to select the most important features for transmission during the feature update process to improve its overall accuracy. Therefore, a dual attention mechanism is designed to address the feature aggregation problem in directed signed networks, as illustrated in Fig. 3.

Dual attention mechanism.
Firstly, neighbour information for the target node is sampled from the network. The sampling process involves selecting a spectific number of neighbour nodes around the target node, achieved through random sampling or biased sampling based on defined criteria. The aim is to reduce computational complexity while preserving the most representative and informative connections in the network. Secondly, the sampled neighbours are divided into distinct sets according to the nature of the relationship(e.g., positive or negative) and the directionality of the connection (i.e., pointing to or from the target node) between the neighbour node and the target node. This approach allows for a better capture of the complex and diversified structure within the directed symbol network. Thirdly, a local attention mechanism is used to calculate the attention coefficients for different potential influencing factors within the same type of neighbours. The calculation of attention coefficient is typically based on the characteristics of neighbour nodes and their relationship with the target node, adaptively adjusting the influence weights of different neighbours on the target node. Finally, a structural attention mechanism is used to calculate the weights of different types of neighbours; these weights are then used to update the characteristics of the target node. The dual attention mechanism considers not only the characteristics of neighbour nodes and their potential impact on the target node but also the relative importance between different types of neighbours. The model synthesises information from different sources to update node features in a more comprehensive and accurate manner. The specific calculation process is as follows:
The local attention mechanism is defined as follows: In accordance with the definition of directed signed neighbours, the weights between nodes of the same type under different potential factors are calculated. This calculation is provided in formula (2).
where \({c}_{k}^{\Omega }(i,j)\) represents the importance of node \(j\) for node \(i\) in the calculation of the \(k\)-th latent factor among the \(\Omega\)-type neighbours. \(at{t}_{l}\) represents the neural network used to calculate local attention. \({h}_{i,k}\) and \({h}_{j,k}\) represent the feature vectors of nodes \(i\) and \(j\) respectively, under the k-th latent factor. The weight \({c}_{k}^{\Omega }(i,j)\ne {c}_{k}^{\Omega }(j,i)\), indicating that the significance of node \(i\) to node \(j\) is asymmetric. That is, the importance of node \(i\) to node \(j\) is differs from that of node \(j\) to node \(i\).
After calculating the degree of importance between nodes, dimensional differences in features are eliminated by normalisation, and the attention coefficient for aggregating features is obtained, as shown in formula (3).
where \({a}_{k}^{\Omega }(i,j)\) represents the attention coefficient of node \(j\) of type \(\Omega\) for node \(i\) under the \(k\)-th latent factor, \(\sigma\) represents the activation function, \({a}_{k}^{\Omega }\) represents the attention vector of nodes of type \(\Omega\) under the \(k\)-th latent factor, \(||\) denotes the concatenation operation; and \({N}_{i}^{\Omega }\) represents the set of neighbours of node \(i\) that belong to type \(\Omega\).
The vector representation of nodes obtained by aggregating neighbour information is shown in formula (4).
where \({h}_{i,k}^{\Omega }\) represents the node embedding representation of node \(i\) subsequent to the aggregation of neighbour information of type \(\Omega\) under the \(k\)-th latent factor.
The node embeddings learned by the local attention mechanism can only reflect information from nodes within the same type of neighbours. Since different types of neighbours reflect different paths linked to nodes, encompassing directions and positive and negative information on the paths, a structural attention mechanism is applied in this paper to learn the importance of different types of neighbours. This allows for more comprehensive and accurate feature aggregation for nodes.
The structural attention mechanism: if the node embeddings learned by the local attention mechanism are used as inputs, the importance of different types of neighbours is determined as shown in formula (5).
where \(\left\{ {\Omega_{1} ,\Omega_{2} ,\Omega_{3} ,\Omega_{4} } \right\}\) represent distinct neighbour types, \(C_{k}^{{\Omega }}\) represents the relative importance of neighbour type \(\Omega\) under the \(k\)-th latent factor, and \(at{t}_{s}\) represents the neural network used to compute structural attention.
The nodes embeddings learned by the local attention mechanism are transformed via a parameter matrix for non-linear changes. The degree of similarity with the attention vector q in the structural attention mechanism is then calculated to obtain the degree of importance for different types of neighbours, as shown in formula (6).
where \({\beta }_{k}^{\Omega }\) represents the attention coefficient of type \(\Omega\) neighbours in the \(k\)-th latent factor, \({W}_{k}\) and \({b}_{k}\) are the parameter matrix and bias matrix in the \(k\)-th latent factor, respectively.
After the weights for different types of neighbours are obtained, they are normalised, as shown in formula (7).
where \({A}_{k}^{\Omega }\) represents the normalised weight of different types of neighbours. The larger the value of \({A}_{k}^{\Omega }\), the more important the type of neighbour is in the \(k\)-th latent factor. Different weights for different types of neighbours can be obtained through learning, yielding the final target node embedding, as shown in formula (8).
DADSGNN model decoder
In this paper, the link sign prediction task is used to verify the encoding efficacy of the encoder. As the feature representation of nodes is decoupled into different potential factors, a factor fusion decoder is proposed. This decoder aims to identify the relationships between these potential factors and nodes, thereby improving the overall performance of the model. Given an encoded pair of nodes \((u,v)\) for which a prediction is required, their feature representations are denoted as \({Z}_{u}=\{{z}_{u,1},{z}_{u,2},\dots ,{z}_{u,K}\}\) and \({Z}_{v}=\{{z}_{v,1},{z}_{v,2},\dots ,{z}_{v,K}\}\), respectively. The decoder then predicts the probability of the link sign between the node pair \((u,v)\). The specific process is as follows:
Firstly, the potential features resulting from the decoupling of the two nodes are concatenated. This enables the correlation matrix \({H}_{uv}\) between the potential factors to be obtained, as demonstrated in formula (9).
where \(({z}_{u,i},{z}_{v,j})\) in the matrix represents the correlation between the \(i\)-th latent factor of node \(u\) and the \(j\)-th latent factor of node \(v\).
Then, the decoder uses \({H}_{uv}\) to compute the sign score \({s}_{uv}\) between nodes \((u,v)\), as shown in formula (10).
where \(sum(\cdot )\) is the function used to sum all elements of the input matrix; \({W}_{s}\) is a learnable weight matrix; \(\odot\) represents the Hadamard product operation; and \({w}_{ij}\) represents the weight corresponding to the \(i\)-th and \(j\)-th potential factors within \({W}_{s}\).
Finally, the link sign prediction probability between the nodes is calculated as \({\rho }_{uv}= sigmoid({s}_{uv})\).
In traditional prediction methods0,0,0, the approach for calculating link signs typically involves concatenate the final features of the node pairs and then calculate the sign probability. However, this calculation method has inherent limitations when applied to feature representations obtained through decoupling. Therefore, if the traditional method is used for concatenating node pair features, the resulting score \({s}_{uv}\) can be expressed as shown in formula (11).
where \({w}_{u,k}\) and \({w}_{v,k}\) represent the weights for different features of nodes u and v respectively, in the prediction process for the node pair \((u,v)\). Compared with traditional prediction methods, the factor fusion decoder designed in this paper not only considers all potential factors for each node but also learns the correlation weights of \(O({K}^{2})\) pairs of potential factors. The method fully leverages the advantages of decoupling representation learning and extends the \(O(2K)\) correlation weights (obtained by the simple concatenation) by an order of magnitude (to \(O({K}^{2})\)). This improves the model’s prediction accuracy and its ability to capture the potential interaction factors between node pairs more effectively.
The link sign prediction task is treated as a binary classification task. Consequently, the loss function is obtained by calculating the difference between the actual and predicted results, as shown in formula (12).
In formula (12), \(\epsilon\) represents the set of links in the training set, and \({y}_{uv}\) is the true sign. Thus, \({y}_{uv}=1\) represents a positive sign (“+”) and \({y}_{uv}=0\) represents a negative sign (“−”).
The pseudo-code for the DADSGNN model is presented in Algorithm 1.

DADSGNN Model
As complexity control plays an important role in the design of graph neural networks, this paper ensures rational time and space complexity through multiple optimisation strategies within the model architecture, as described below:
-
(1)
Optimal design for time complexity
The model reduces the linear transformation complexity in the feature update stage from the traditional \(O({d}^{2})\) to \(O(K\cdot {d}^{2}/{K}^{2})\) through the factorisation design of decoupled representation learning, where K is the number of factors. This design renders the total time complexity inversely proportional to K, thereby supporting a balance of computational efficiency achieved by adjusting K. In the dual attention mechanism, although the original complexity of the attention score calculation is \(O({E}^{2}\cdot {K}^{2}\cdot {d}^{2})\), by introducing the dimension decomposition \(d={d}_{out}/K\), the actual equivalent complexity is optimized to \(O({E}^{2}\cdot {\text{d}}_{\text{out}}^{2})\). This avoids direct amplification of the complexity by the number of factors K.
-
(2)
Controllability of space complexity
The storage requirement of the decoupled embedding matrix is \(O(N\cdot K\cdot d)\), consistent with the storage overhead of the traditional one-dimensional embeddings. The parameter size is optimised due to the factorisation design (e.g., the parameter size of the convolutional layer weights decreases as K increases). The parameter size of the dual attention mechanism is \(O({K}^{2}\cdot {M}^{2}\cdot {d}^{2})\), where M is the number of neighbour types (default M = 4). This design avoids the risk of parameter explosion by limiting the number of neighbour types and through the decomposition of factor dimensions. Furthermore, the intermediate attention coefficient matrix only needs to store the non-zero values, approximately \(O(E\cdot K)\) if E refers to edges with non-zero attention, thereby full utilising the sparsity of the graph data.
-
(3)
Balancing strategy of overall complexity
The overall time complexity of the model is \(O(L\cdot (N\cdot K+E\cdot {d}_{out}^{2}))\) and the space complexity is \(O(N\cdot K+L\cdot K\cdot {M}^{2}\cdot {d}^{2})\), where L is the number of network layers. Through hierarchical design and parameter sharing mechanisms, the complexity remains linearly controllable as the model depth increases.
In conclusion, the DADSGNN model comprehensively adopts factor parameter design, sparsity utilisation, and hierarchical optimization strategies for complexity control, ensuring a balance between computational efficiency and model performance. Therefore, this design approach avoids an unreasonable increase in complexity while ensuring expressive ability.
Experimental results and analysis
To validity the proposed DADSGNN model, five datasets of varying sizes were selected: Bitcoin-Alpha, Bitcoin-OTC, Wiki-Rfa, Slashdot, and Epinions. These datasets, which represent directed signed networks, were used for the experiments. The accuracy of the DADSGNN model was evaluated through experiments. By comparing DADSGNN with different baseline models, the superiority of its dual attention mechanism and the high efficiency of its coupling framework were verified.
Experimental dataset
The Bitcoin-Alpha and Bitcoin-OTC25 datasets comprise trust networks for transactions between users on the Bitcoin platform. In these datasets, platform members rate other members on a scale from -10 (indicating complete distrust) to + 10 (indicating complete trust). In the experiments, scores greater than 0 are considered positive, and scores below 0 are considered negative. The other experimental datasets used are Wiki-Rfa26, Slashdot and Epinions27. Comprehensive statistics for the five datasets are presented in Table 2.
Experimental results analysis
To ascertain the efficacy of DADSGNN, this paper presents a comparative analysis with selected benchmark models, including signed embedding method and signed graph neural network, as detailed below.
To verify the validity of DADSGNN model, it is compared with other models, including signed embedding method and signed graph neural network. The comparison models are: SiNE28, BESIDE12, SLF14, SiGAT16 and SDGNN17.
The link sign prediction task is used to evaluate the model’s accuracy. For this task, each dataset is randomly divided into training and test sets using an 8:2 ratio. AUC, Macro-F1, Binary-F1 and Micro-F1 scores are used as standard evaluation metrics. For all benchmark models, the dimension of the final node embedding was set to 64 to ensure comparable capacity for learning downstream tasks, and the number of training epochs was set to 100. For each metric, the experiment was repeated 10 times using different random seeds, and the average test results. were recorded. AUC and F1-scores (Macro-F1, Binary-F1, Micro-F1) are used as evaluation metrics. AUC provides a threshold-independent measure of the model’s ability to rank positive links higher than negative links. F1-scores offer a balance between precision and recall, making them suitable and robust choices for evaluating link prediction performance, particularly in potentially imbalanced signed network datasets.
Experiments were conducted for the link sign prediction task on all models using the directed signed network dataset, and the experimental results are presented in Table 3.
As shown in Table 3, the experimental results indicate that DADSGNN outperformers other baseline models across the five different datasets, demonstrating its superiority and wide applicability in link sign prediction tasks. The performance of the SiNE model is lower than that of DADSGNN on all data sets, as SiNE still has inherent limitations in signed network representation learning and cannot effectively learn complex internodal interactions. Although BESIDE and SLF perform well on some datasets, their overall performance is not comparable to that of DADSGNN. The reason is that these models solely utilise relevant sociological theories, and their deep learning architecture have limitations compared to graph neural network models, resulting in ab inability to adequately capture complex network relationships. SiGAT and SDGNN achieve better prediction performance by incorporating sociological theory and graph neural network architectures. However, DADSGNN decouples node features into a greater number of potential impact factors and achieves higher performance through its dual attention mechanism and graph neural network architecture, indicating its more advanced model design and implementation.
The Macro-F1, Binary-F1 and Micro-F1 scores evaluate the model’s performance from different perspectives. Figures 4, 5, 6, 7 and 8 show that the Macro-F1 scores for the DADSGNN model on all datasets are generally higher than those of other models. This indicates that when addressing classification problems, DADSGNN exhibits a more balanced performance evaluation across categories, particularly with uneven sample distributions. DADSGNN can effectively enhance the recognition of minority classes, which is particularly important for imbalanced datasets. On the Binari-F1 metric, DADSGNN also demonstrated outstanding performance, especially on the BC-Alpha, BC-OTC and Epinions datasets, where the performance was most significant. This indicates that DADSGNN possesses strong discriminative ability in binary classification problems and can effectively identify positive and negative classes. This is highly valuable for application scenarios requiring precise predictions. For the Micro-F1 score, DADSGNN performs equally well on all datasets, particularly on the BC-Alpha and BC-OTC datasets. DADSGNN can achieve better performance and is well-suited for complex scenarios with uneven sample distributions.

F1 scores of BC-alpha dataset.

F1 scores of BC-OTC dataset.

F1 scores of Wiki-Rfa dataset.

F1 scores of Slashdot dataset.

F1 scores of Epinions dataset.
In general, DADSGNN moves beyond treating internodal relationships as simple binary concepts such as “friendly” versus “hostile” or high versus low status. Instead, it decouples these relationships into distinct latent factors and applies a dual attention mechanism to capture interactions and relationships between nodes at both local and structural levels with greater precision. Consequently, this approach affords DADSGNN greater flexibility and accuracy when dealing with complex network structures, as reflected in the AUC results across all datasets. DADSGNN employs a graph neural network architecture to learn node feature representations. The deep learning methodology enables the model to capture more profound network structure information, thereby improving the prediction accuracy. DADSGNN has demonstrated excellent performance on many different types of networks, which attests to its robust generalization ability and broad applicability.
Parametric analysis
This section investigates the impact of varying DADSGNN hyperparameters K (number of latent factors), L (number of aggregation layers), and node embedding dimension on the BC-Alpha, BC-OTC, and Wiki-Rfa datasets. AUC values are used as the evaluating metric for the performance of the different configurations. The experimental results are presented in Figs. 9, 10, and 11. When modifying the value of one hyperparameter, the values of the remaining hyperparameters are maintained at their optimal configurations.

Analysis results of the latent factors number.

Analysis results of aggregation layer.

Analysis results of node embedding dimension.
In the experiment concerning the number of latent factors (K), as K increases, the model’s AUC value initially rises significantly, reaching a peak. Subsequently, as K continues to increase, the AUC value begins to decline gradual. This trend was observed across all three datasets: BC-Alpha, BC-OTC, and Wiki-Rfa. As shown in Fig. 10, with an increase of the number of aggregation layers (L), the model’s AUC value initially either remained unchanged or slightly increased to reach its optimal point. Thereafter, with a continued increase in the number of layers, the model’s performance began to decline.
In summary, when K is set to 8 and L is set to 2, the DADSGNN model exhibits optimal performance on the three datasets. This indicates that within this parameter configuration, DADSGNN can effectively learn potential feature representation, and effectively integrate neighbor information via the graph neural network’s aggregation mechanism, tthereby improving the overall performance. Employing fewer aggregation layers helps to avoid over-smoothing problems, allowing the model to retain more useful local information. Simultaneously, a moderate number of potential factors can balance the model’s expressiveness with its computational complexity, enabling better generalisation performance to be achieved on different datasets.
Across all three datasets, the model achieves its highest AUC value when the embedding dimension is 64. This implies that for these specific datasets and experimental settings, selecting 64 as the node embedding dimension yields the best classification performance. The is because an embedding dimension of 64 enables the model to capture sufficient information for effective classification, while avoiding overfitting problems that can arise from a dimension that is either too low (failing to capture enough information) or too high. A low dimension may not adequately represent complex internodal relationships, whereas a high dimension may cause the features learned by the model to be overly detailed, thereby affecting the model’s generalization ability.
Ablation experiment
The ablation experiment focused on the performance of the DADSGNN model and its two variants: DADsGNN-D (the model without the decoupling module) and DADsGNN-LS (the model without the dual attention mechanism module). These were evaluated on two datasets: BC-Alpha and BC-OTC. The details of there variants are as follows.
-
(1)
DADSGNN-D: This variant is equivalent to not decoupling the initial features (conceptually, where the number of latent factors K = 1). In its decoder component, the correlation matrix is not used; instead, node features are directly concatenated to calculate the link sign prediction probability.
-
(2)
DADSGNN-LS: This model replaces the dual attention mechanism. Instead, it uses a standard attention mechanism aggregator for neighbour information in the first layer, and a concatenation operation to combine information from different neighbor types in the second layer. Information from different neighbour types is concatenated, and a fully-connected layer is then used for aggregate.
In the ablation experiment, the link sign prediction task was retained as the downstream task, and the AUC value was used as the evaluation metric to assess the distinct effects of the decoupling framework and the dual attention mechanism module. The results of the ablation experiment are presented in Fig. 12.

Results of the ablation experiment.
On the BC-Alpha dataset, the AUC value for DADSGNN is 0.9102. When the decoupling module is removed (DADSGNN-D), the AUC value drops to 0.896. On the BC-OTC dataset, the AUC value for DADSGNN is 0.9422, and removing the decoupling module, this value drops to 0.9254. This demonstrates that the decoupling module has a significant positive effect on model performance. Decoupling modules typically function by separating different factors within the data, allowing the model to focus more effectively on task-related features. This separation can help to improve the model’s generalization ability and reduce the risk of overfitting, resulting in better performance across multiple datasets. For the DADSGNN-LS model (i.e., the model with the dual attention mechanism module removed), the AUC value on the BC-Alpha dataset was 0.9027, while on the BC-OTC dataset it was 0.9289. Compared to the original DADSGNN model, there is a performance decline on both datasets. Although this decline is relatively small, it indicates that the dual attention mechanism contributes to the model’s overall performance.
By assigning different attention weights, the dual attention mechanism captures relationships between different types of neighbour nodes and the correlations within information aggregated from the same type of neighbours, thereby enhancing the model’s ability to extract information. In summary, the DADSGNN model achieves high AUC values on both BC-Alpha and BC-OTC datasets by integrating the decoupling module and the dual attention mechanism module. This demonstrates the positive impact of these two modules on the overall model performance. By identifying and separating multi-dimensional feature relationships within the data, the decoupling module can independently model and analyze these relationships. This achieves a deeper understanding of complex data structures, enabling the model to be optimised separately for each feature relationship, thereby improving the prediction accuracy for novel or unseen data samples and effectively enhancing the model’s generalization ability. The dual attention mechanism module enhances the model’s ability to capture data structure through refine weight allocation. The combination of these two modules provides significant performance benefits to the DADSGNN model.
Application of DADSGNN model
With the rapid development of network and information technology, directed signed networks have found wide application in fields such as financial transactions, social media, and academic citations. In the financial domain, for instance, within the Bitcoin trading network, trust is foundamental for establishing cooperative relationships between parties. Analyzing the Bitcoin transaction network using the DADSGNN model can effectively identify and predict trust and distrust relationships within the network. Aided by the model’s decoupled feature representation and its two-layer attention mechanism, multiple factors influencing the trust relationship between transacting parties can be deeply understood. These factors include transaction frequency, transaction amount, historical transaction evaluation, among others. These insights are valuable for predicting future transaction relationships, identifying potential fraudulent behaviors and at-risk nodes, and providing decision support for financial regulatory authorities. In the domain of social networks, interaction relationships among users are complex and diverse, encoompassing activities such as following, commenting, and sharing. These interaction behaviors reflect users’ emotional tendencies and the flow of influence within social networks. Using the DADSGNN model, positive or negative interaction relationships among users can be accurately captured, enabling subsequent analysis of public opinion trends across the entire social network. The academic citation network constitues an important network structure within academic research. Citation relationships allow for the tracking of knowledge flow and the dissemination of academic influence. Applying the DADSGNN model to academic citation networks allows for the analysis of citation relationships among papers. It can distinguish between positive citations (recognition) and negative citations (criticism), and further explore multi-dimensional factors affecting academic influence, such as research fields, publication times, and author collaboration networks.
In conclusion, the DADSGNN model offers a novel perspective and an effective tool for in-depth analysis and understanding of complex relationships in directed signed networks, achieved through its unique decoupled feature representation and two-layer attention mechanism.
Conclusion
This paper proposed DADSGNN, a decoupled signed graph neural network model based on a two-layer attention mechanism. It aims to overcome the limitations of sociological theories in the research of directed signed networks and to improve the quality of node embedding representations. Firstly, within its encoder, DADSGNN decouples node features into multiple potential factors using the principles of decoupled representation learning. This allow for a deep exploration of potential factors influencing internodal relationships. Secondly, by employing a two-layer attention mechanism (comprising local and structural attention), the model classify and aggregate diverse types of neighbour information. It subsequently calculates the aggregated features for each potential influencing factor, thereby effectively improving the accuracy and interpretability of the model’s representation of complex internodal relationships. Finally, in its decoder section, DADSGNN incorporates a novel decoder specifically designed for the link signed prediction task. This decoder fully considers the correlation among different potential factors, thereby significantly improving prediction accuracy.
The experimental results demonstrate the following: for the AUC metric, the DADSGNN model can effectively improve the recognition of minority categories when addressing prediction problems with uneven sample distributions, achieving good performance on imbalanced datasets. Analysis of the ablation experiment reveals that the decoupling module identifies and separates multi-dimensional feature relationships within the data. It independently models and analyzes these feature relationships, enabling the DADSGNN model to be optimised separately for each. This thereby effectively improves the prediction accuracy for novel or unseen data samples and significantly enhances the model’s generalization ability. The tow-layer attention mechanism captures relationships between different types of neighbour nodes and correlations within the aggregated information from the same type of neighbours by allocating different attention weights, thereby enhancing the model’s ability to extract information. Therefore, the model’s capabilities were verified on real-world signed network datasets, and the predictive ability and effectiveness of DADSGNN were evaluated on directed network datasets of varying scales.
The research presented in this paper provides a new method for representing complex internodal relationships in signed networks. It effectively enhance the ability to represent these relationships and offers further possibilities for the practical application of signed networks in financial decision-making, social relationship analysis, and academic citation networks. Given the dynamics and complexity of signed networks, future work will involve identifying and predicting the evolutionary relationships among the K potential factors post-decoupling. This includes developing new theoretical frameworks and computational models to track the changing trends, network behaviours and states of the network over time.
Data availability
The data presented in this study are available on request from the corresponding author.
References
Yu, L., Tian, Y., Zhang, J. W. et al. Learning signed network embedding via graph attention. In Proceedings of the AAAI Conference on Artificial Intelligence Vol. 34 (2020).
Huang, J. J., Shen, H. W., Cao, Q. et al. Signed bipartite graph neural networks. In Proceedings of the 30th ACM International Conference on Information & Knowledge Management (2021).
Chen, J. W. et al. Learning embedding for signed network in social media with global information. IEEE Trans. Comput. Soc. Syst. 11(1), 871–879 (2022).
Liu, H. X., Zhang, Z. W., Cui, P. et al. Signed graph neural network with latent groups. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining (2021).
Wu, H. G., Guan, D. H., Han, G. J. et al. Signed network embedding with dynamic metric learning. In 2020 International Wireless Communications and Mobile Computing (IWCMC) (IEEE, 2020).
Cui, X. L., Xu, L. Y. & Zhang, P. Signed prediction algorithm based on structural balance theory and status theory. Complex Syst. Complex. Sci. 20(03), 68–73. https://doi.org/10.13306/j.1672-3813.2023.03.009 (2023).
Wang, W., Xue, M. M. & Liu, M. M. A negative link prediction method for signed social networks. J. Xi’an Polytechnic Univ. 35(03), 100–106 (2021).
Yan, S. X., Zhu, Y. & Li, C. P. Social network sign prediction based on multi-head attention mechanism. Appl. Res. Comput. 38(05), 1360–1364. https://doi.org/10.19734/j.issn.1001-3695.2020.07.0180 (2021).
Wang, K., Zhao, X. L. & Li, Y. L. Network representation learning algorithm incorporated with edge signed semantic information. Appl. Res. Comput. 37(07), 1946–1951. https://doi.org/10.19734/j.issn.1001-3695.2019.01.0012 (2020).
Kim, J., Park, H., Lee, J. E. et al. Side: Representation learning in signed directed networks. In Proceedings of the 2018 World Wide Web Conference. International World Wide Web Conferences Steering Committee 509–518 (2018).
Chen, Y., Qian, T., Zhong, M. et al. BASSI: Balance and status combined signed network embedding. In International Conference on Database Systems for Advanced Applications 55–63 (Springer, 2018).
Chen, Y. Q., Qian, T. Y., Liu, H. et al. “Bridge” enhanced signed directed network embedding. In Proceedings of the 27th ACM International Conference on Information and Knowledge Management (2018).
Yuan, W. W. et al. Negative sign prediction for signed social networks. Future Gener. Comput. Syst. 93, 962–970 (2019).
Xu, P. H., Hu, W. B., Wu, J. et al. Link prediction with signed latent factors in signed social networks. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining (2019).
Xu, P. H., Hu, W. B., Wu, J. et al. Social trust network embedding. In 2019 IEEE International Conference on Data Mining (ICDM) (IEEE, 2019).
Huang, J. J., Shen, H. W., Hou, L. et al. Signed graph attention networks. In Artificial Neural Networks and Machine Learning–ICANN 2019: Workshop and Special Sessions: 28th International Conference on Artificial Neural Networks, Munich, Germany, September 17–19, 2019, Proceedings 28 (Springer International Publishing, 2019).
Huang, J. J., Shen, H. W., Hou, L. et al. SDGNN: Learning node representation for signed directed networks. In Proceedings of the AAAI Conference on Artificial Intelligence Vol. 35 (2021).
Jung, J. H., Jaemin, Y. & Kang, U. Signed graph diffusion network. arXiv preprint arXiv:2012.14191 (2020).
Taewook, K. & Kim, C. K. A graph convolution for signed directed graphs. arXiv preprint arXiv:2208.11511 (2022).
Xu, C. et al. Decoupled variational embedding for signed directed networks. ACM Trans. Web TWEB 15(1), 1–31 (2020).
He,Y. X., Perlmutter, M., Reinert, J. et al. Msgnn: A spectral graph neural network based on a novel magnetic signed Laplacian. In Learning on Graphs Conference (PMLR, 2022).
Song, W. Z. et al. Learning node and edge embeddings for signed networks. Neurocomputing 319, 42–54 (2018).
Cui, J. C. et al. Semi-supervised gated spectral convolution on a directed signed network. IEEE Access 8, 49705–49716 (2020).
Geonwoo, K. & Jung, J. H. Learning disentangled representations in signed directed graphs without social assumptions. Inf. Sci. 665, 120373 (2024).
Kumar, S., Spezzano, F., Subrahmanian, V. S. et al. Edge weight prediction in weighted signed networks. In 2016 IEEE 16th International Conference on Data Mining (ICDM) 221–230 (IEEE, 2016).
West, R. et al. Exploiting social network structure for person-to-person sentiment analysis. Trans. the Assoc. Comput. Linguist. 2, 297–310 (2014).
Leskovec, J., Huttenlocher, D. & Kleinberg, J. Signed networks in social media. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems (2010).
Wang, S., Tang, J., Aggarwal, C. et al. Signed network embedding in social media. In Proceedings of the 2017 SIAM International Conference on Data Mining 327–335 (Society for Industrial and Applied Mathematics, 2017).
Acknowledgements
This research was supported by National Natural Science Foundation of China (No. 62172352, No. 62171143, No. 42306218); Guangdong Provincial Department of Education Ocean Ranch Equipment Information and Intelligent Innovation Team Project (No.2023KCXTD016); Guangdong Ocean University Research Fund Project (No. 060302102304); the Central Government Guides Local Science and Technology Development Fund Projects (Grant No. 226Z0102G, No. 226Z0305G).
Author information
Authors and Affiliations
Contributions
J.C. and X.Y. conducted the primary investigation and designed the DADSGNN model. Y.W. was responsible for writing and integrating the manuscript. Y.Z. performed the data preprocessing and initial analysis. M.L. contributed to the experimental setup and parameter optimization. X.C. assisted with the literature review and visualization of results. All authors reviewed and approved the final manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Chen, J., Yang, X., Wang, Y. et al. Research on signed directed network link prediction based on dual attention mechanism. Sci Rep 15, 35638 (2025). https://doi.org/10.1038/s41598-025-19502-9
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-025-19502-9
