
Abstract
To address the challenges of low accuracy and limited real-time efficiency in detecting subsurface defects within concrete structures, this study proposes an enhanced YOLOv5 model integrated with an Efficient Channel Attention (ECA) mechanism for automated ground-penetrating radar (GPR) defect detection. A Deep Convolutional Generative Adversarial Network (DCGAN)-based augmentation strategy is introduced to mitigate class imbalance, synthesizing realistic minority-class defect samples while preserving wave scattering characteristics. A specialized dataset encompassing diverse defect types was constructed to reflect real-world concrete inspection scenarios. The proposed YOLOv5 + ECA model was rigorously evaluated against other attention-enhanced variants and the baseline YOLOv5. Experimental results demonstrate that ECA’s channel-specific feature recalibration significantly improves detection accuracy, achieving the highest mean average precision, while maintaining real-time inference speeds suitable for unmanned aerial vehicle (UAV)-mounted deployment. This work advances the precision and efficiency of infrastructure health monitoring, offering a robust solution for subsurface defect diagnosis in concrete structures such as tunnel linings and bridge decks.
Similar content being viewed by others

Introduction
As the backbone of modern infrastructure, concrete structures serve as critical load-bearing elements in bridges, dams, and high-rise buildings worldwide. However, these essential components are susceptible to progressive deterioration, with internal defects such as cracks, voids, and interfacial delamination developing over their service life. These hidden flaws significantly degrade structural performance and even lead to catastrophic structural failures.
Rapid and accurate detection of subsurface defects is crucial to ensuring the structural integrity and safe operation of concrete infrastructure1. Traditional detection methods, including visual inspection, ultrasonic testing, and core drilling techniques, typically exhibit inherent limitations such as inefficiency, subjectivity, and potential damage to structures2,3,4. Existing studies have demonstrated that manual inspection methods are prone to a misjudgment rate of 15%−20%, in addition to posing significant safety risks in overhead operations and confined spaces.
In recent years, non-destructive testing technologies, particularly ground-penetrating radar (GPR), have emerged as a prominent research focus for detecting concrete defects due to their superior detection capabilities, such as fast detection process, and high detection accuracy5,6. It has been widely applied to the detection for geological hazards7, bridge safety8,9, tunnel cavity10,11, and underground foreign objects.
However, original GPR radar images are often disturbed by noise, such as experimental noise and reflected waves from other materials on the ground surface12. Therefore, the current GPR image interpretation process remains heavily dependent on expert experience, which may lead problems of low detection efficiency, making it challenging to meet the automation requirements for large-scale infrastructure inspections13. Moreover, traditional GPR deployment often requires extensive scaffolding installation, which not only jeopardizes worker safety at heights but also causes substantial traffic disruptions. Although many researchers have developed robotic deployment platforms to mitigate these operational constraints, such as GPR system mounted on unmanned aerial vehicles (UAVs) or amphibious robots14,15, the GPR images still require manual interpretation.
Recent advancements of deep learning in computer vision have fundamentally revolutionized the field of pattern recognition and object detection methodologies, offering a promising alternative to traditional GPR data analysis. Convolutional Neural Networks (CNNs), with their hierarchical feature extraction capabilities, have demonstrated particular efficacy in identifying subsurface defects within complex noisy environments4. For example, Dinh et al.16 utilized CNN for automatic recognition of GPR images and achieved a promising accuracy, but the detecting speed did not fulfill the engineering demands of real-time outcome. The YOLO (you only look once) architecture has emerged as a promising solution to this speed-accuracy trade-off. Li et al.17 utilized a YOLOv3 model for GPR image recognition and exhibited an improvement in recognition speed. Compared to YOLOv3 and YOLOv4, YOLOv5 has also made significant progress in small data sets, and the model of YOLOv5 has better robustness and can better distinguish features in GPR images18. Wu et al.19 incorporated an attention mechanism into the YOLOv5, and achieved a high accuracy for bridge crack recognition. The existing studies have demonstrated the superior accuracy of deep learning model, but the computational efficiency remains insufficient for real-time field application.
This study addresses these limitations by proposing an optimized YOLOv5 architecture enhanced with an efficient channel attention (ECA) module, which simultaneously improves computational efficiency and detection accuracy. The ECA mechanism selectively emphasizes informative features while suppressing redundant ones, enabling real-time processing speeds without compromising the model’s precision.
The remainder of this paper is organized as follows: Sect. Methodology details the methodology, including GPR data acquisition, preprocessing techniques, and the architectural innovations of the enhanced YOLOv5 model. Section Performance presents a comprehensive evaluation of the model’s performance, comparing its accuracy, speed, and robustness against state-of-the-art alternatives. Finally, Sect. Conclusion concludes this study with key findings and outlines future directions to enhance GPR-based defect detection.
Methodology
Data generation and preprocessing
This study utilized a UAV-mounted GPR system for data generation, as illustrated in Fig. 1. The inspection platform employs a compact quadrotor UAV with an integrated wireless air-coupled radar system20,21, specifically designed to overcome the limitations of traditional ground-coupled antennas22,23. The UAV-mounted GPR system integrates a high-frequency antenna coupled with a 24-bit LTC2380-24 ADC for signal digitization, chosen for its ultra-low power (28 mW) and high dynamic range (145 dB at 30.5 SPS). During data collection, the system operates at a controlled flight speed of 1–3 m/s to maintain stable data acquisition. By eliminating the need for direct surface contact, this innovative radar design prevents antenna scraping against concrete surface while removing the constraints of wired transmission cables, enabling truly autonomous operation. The hybrid aerial-ground robot features a lightweight skeletal frame that minimizes structural weight while maintaining rigidity. Four cross-arranged rotors provide stable aerial maneuverability, complemented by four motorized wheels for optional terrestrial locomotion along tunnel walls. This amphibious design enables multimodal inspection capabilities, allowing seamless transition between flight and surface-crawling modes to accommodate complex structural geometries.

Photos of the UAV. Photographs taken by authors.
The collected dataset focuses on four critical defect types (as illustrated in Fig. 2), each exhibiting distinct GPR signatures: (1) Voids present continuous isotropic reflection waves with distinct diffraction but no multipath scattering; (2) Water-bearing voids show unidirectional reflection wave clusters accompanied by clear diffraction and multipath waves; (3) Hyperbolic defects are identified by characteristic hyperbolic signatures in radargram profiles; and (4) Looseness displays semi-continuous isotropic reflection waves with turbulent internal waveforms, lacking diffraction or multipath components. For clarity in presentation, the water-bearing void is denoted as Void 2, while the standard void (without liquid content) is denoted as Void 1.

Examples of (a) Void 1, (b) Void 2, (c) Hyperbola, and (d) Looseness.
A total of 780 PNG-format images were collected, split into 80% training and 20% testing sets. Each image was annotated in Pascal VOC format24, with XML files specifying bounding box coordinates and defect categories.
Field-acquired GPR B-scan images are inherently prone to noise contamination. Therefore, it necessitates rigorous preprocessing to enhance defect-related signals and suppress irrelevant noise. Following the methodologies for GPR analysis25, raw B-scans undergo a sequential refinement workflow. First, DC offset removal eliminates baseline drift by centering each A-scan signal around zero, ensuring amplitude consistency across scans26. Time-zero correction then aligns the direct wave (air-ground interface reflection) by truncating pre-peak data and shifting the peak to t = 0, which standardizes depth measurements and mitigates positional ambiguities. Subsequent bandpass filtering with a Butterworth filter27 attenuates high-frequency electromagnetic spikes and low-frequency drift. To suppress horizontal layer reflections from intact structural components, background removal subtracts the average of all A-scans within a B-scan, effectively isolating anomaly-specific signals. Finally, a time-varying gain (TVG) function compensates for depth-dependent signal attenuation, amplifying weak reflections from deep defects to match the intensity of shallow targets. The preprocessed B-scans are intensity-normalized to [0, 1] and resampled to a uniform resolution of 512 × 512 pixels, ensuring spatial and radiometric consistency for downstream model training.
To address class imbalance, a (Deep Convolutional Generative Adversarial Network) DCGAN-based augmentation28 was employed to synthesize minority-class samples while preserving defect-specific wave features. As illustrated in Fig. 3, the DCGAN framework consists of two adversarial networks: The generator (G) transforms latent noise vectors into synthetic B-scans using transposed convolutions, batch normalization29, and ReLU activations. To capture long-range wave interactions (e.g., rebar-induced scattering), we integrated dilated convolutional blocks with skip connections to retain high-frequency defect signatures. The discriminator (D) employs strided convolutions and LeakyReLU to hierarchically analyze inputs, enhanced by spectral normalization30 to enforce realistic material properties in synthetic samples. Unlike conventional data augmentation (e.g., rotation/flipping), the DCGAN learns the underlying data distribution, generating physically plausible variations that expand dataset diversity without distorting critical features31.

The structure of DCGAN.
To validate the progressive quality improvement of synthetic samples, the generator’s output at key training epochs (e.g., 50, 500, 1000, and 2000) was monitored. As shown in Fig. 4, early epochs yield noisy outputs with incoherent scattering patterns, while later epochs generate defects with physically consistent defect signatures that closely match characteristic GPR responses, demonstrating the method’s capability to learn authentic subsurface defect features. The distributions of different classes before and after data augmentation are summarized in Table 1. The original dataset exhibited significant class imbalance, with the Hyperbola class comprising only 10% of the data. While conventional data augmentation (DA) marginally increased Hyperbola to 12.1%, DCGAN augmentation expanded its proportion to 22.1%. The quantitative performance validation of DCGAN-augmented data will be presented in Sect. Performance.

Images generated by the generator.
Improved YOLOv5 model
YOLOv5 is an open-source object detection model widely adopted in industrial applications due to its high speed, accuracy, and ease of deployment. Designed as a single-stage detector, it processes images in one pass through a neural network, making it exceptionally efficient for real-time tasks like surface defect detection. Its architecture comprises three core components: Backbone, Neck, and Head, designed to balance speed, accuracy, and model size.
The backbone leverages a modified cross-stage partial network (CSP)32 structure, where feature maps are split into two branches. The first branch employs stride-1 convolutions with constrained receptive fields (3 × 3 kernels), ensuring the network retains high-frequency components. The second branch is a truncated residual pathway with gradient-optimized shortcuts, formulated as:
where the symbol ⋅ denotes the dot product, and F denotes a bottleneck convolution. The learnable weights αi dynamically balance shallow and deep feature, reducing computational redundancy while stabilizing gradients.
The neck integrates a modified PANet (Path Aggregation Network), in which a bidirectional feature pyramid layer aggregates high-resolution shallow features and deep semantic features via top-down and bottom-up paths:
where Conv denotes convolutional operation, \(\oplus\) denotes element-wise addition, Ci is the i-th backbone output and Pi is the fused pyramid layer.
The neck also introduces CSP blocks to reduce parameter count while maintaining feature fusion efficacy. The detection head generates bounding boxes, class probabilities, and objectness scores via three output branches.
While YOLOv5 excels in real-time object detection, its performance degrades in scenarios involving complex backgrounds and subtle defect features, such as GPR-based tunnel lining inspection. YOLOv5’s convolutional backbone treats all spatial regions equally, struggling to suppress interference from cluttered backgrounds. This leads to false positives when defect signals are obscured by noise. The model’s multi-scale fusion mechanism prioritizes dominant features but often overlooks low-contrast patterns characteristic of minor defects.
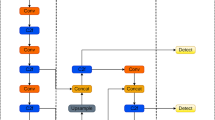
To address the challenges of defect detection in GPR images, including low signal-to-noise ratios (SNR), small target sizes, and complex background clutter, this study systematically evaluated four different models based on YOLOv5 architecture: the baseline YOLOv5 and three attention-integrated variants, each incorporating a distinct attention mechanism, as shown in Figs. 5 and 6.

The architecture of enhanced YOLOv5.

The architecture of CBAM, SENet, and ECA.
The baseline YOLOv5 model establishes fundamental performance metrics against which the attention-enhanced versions are compared. The first variant incorporates SENet (Squeeze-and-Excitation Network)33, which introduces channel-wise feature recalibration through a two-phase process that first compresses global spatial information via adaptive average pooling (Eq. 1), then models channel dependencies using a bottleneck architecture with two fully-connected layers (Eq. 2). The resulting attention weights s amplify defect-related channels.
where H and W denote the height and width of the input image, respectively, σ and δ denote sigmoid and ReLU activation function, respectively.
Building on this foundation, the second variant incorporates CBAM (Convolutional Block Attention Module)34 that combines the channel attention pathway of SENet with additional spatial attention processing through convolutions. The channel branch uses dual-pooling (average + max) followed by a shared Multilayer Layer Perceptron (MLP) enhances defect contrast:
Then the spatial branch applies a convolution on concatenated max/average features to locate defect boundaries:
The third variant employs ECA (Efficient Channel Attention)35, which optimizes SENet via Lightweight 1D convolution. It replaces FC layers with a kernel size k adaptively determined by channel dimension C:
with γ = 2, β = 1 in our implementation, which could capture cross-channel interactions without dimensionality reduction. This design achieves parameter efficiency while preserving channel-specific patterns critical for localized defects.
The model architecture and training process were carefully designed to address the unique challenges of GPR-based defect detection. The YOLOv5 framework served as our baseline, utilizing a CSPDarknet53 backbone with depth and width scaling factors of 0.33 and 0.50 respectively, optimized for efficient feature extraction from 512 × 512 pixel GPR images while maintaining critical aspect ratio information. The architecture incorporates SiLU (Swish-1) activation functions throughout the network, balancing computational efficiency with nonlinear representation capability. For attention-enhanced variants, we implemented three distinct configurations: SENet with channel reduction ratio r = 16, CBAM with 7 × 7 spatial attention kernels, and ECA using adaptive 1D convolution (base kernel size k = 3).
The hyperparameters of the training process are summarized in Table 2. Each model was trained for 1,000 epochs using a batch size of 5 to balance computational efficiency and gradient stability on our limited GPR dataset. The Nadam optimizer with an initial learning rate of 0.001 was adopted, which integrates Nesterov momentum into the Adam framework to accelerate convergence while maintaining gradient stability. The small batch size mitigates overfitting risks inherent in GPR data. Early stopping with a patience of 50 epochs was adopted. The loss function Weighted classification, objectness, and bounding box prediction at a 3:1:1 ratio, with additional focal loss (γ = 2.0) to address class imbalance. The models involved in this study were implemented using Python 3.8.11, PyTorch 1.12.136, and CUDA 11.3 on an NVIDIA GTX 1080Ti GPU.
Evaluation metrics
The performance of the proposed defect detection framework was rigorously evaluated using three standard metrics, balancing both accuracy and computational efficiency for real-world structural health monitoring applications.
-
(1)
Average precision (AP).
AP quantifies the precision-recall trade-off for a single defect class, calculated as the area under the precision-recall curve:
where P(r) denotes the precision at recall level r. In our implementation, AP is computed at an Intersection over Union (IoU) threshold of 0.5 (denoted as AP@0.5), following the standard Pascal VOC evaluation protocol24. A higher AP value (range: 0–1) indicates better detection performance, with precision and recall defined as:
where TP, FP, and FN represent true positives, false positives, and false negatives, respectively.
-
(2)
Mean average precision (mAP).
For multi-class defect scenarios, mAP generalizes AP by averaging across all N defect categories:
where APi represents the AP@0.5 for the i-th class. This mAP metric provides a unified assessment of the model’s overall detection accuracy under the IoU = 0.5 criterion.
-
(3)
Frames per second (FPS).
FPS quantifies inference speed as the number of images processed per second, evaluating practical deployment feasibility:
This metric is crucial for real-world applications, with ≥ 30 FPS generally considered the threshold for real-time processing in field conditions.
Performance
This section presents a systematic comparison of four detection model, i.e., the baseline YOLOv5 and three attention-enhanced variants (YOLOv5 + ECA, YOLOv5 + CBAM, and YOLOv5 + SENet). The test performance values are summarized in Table 3, and the predictive results are illustrated in Fig. 7.

Predictions of different methods.
The YOLOv5 + ECA configuration emerges as the superior architecture, achieving an exceptional balance between detection precision (85.4% mAP, + 2.7% over baseline) and processing efficiency (48.1 FPS), while demonstrating particular strength in identifying spectral signatures of subsurface anomalies with 87.5% AP for Void 1 and 86.6% AP for Void 2. This performance advantage stems from ECA’s dynamic channel Weighting mechanism, which effectively amplifies defect-sensitive frequency bands while suppressing noise-dominated channels through its parameter-efficient 1D convolutional implementation.
In contrast, while CBAM’s hybrid attention design shows competitive accuracy (83.9% mAP) through its combined channel and spatial processing, this comes at substantial computational cost - exhibiting an 18.6% reduction in inference speed (40.2 FPS) compared to the ECA variant, making it less suitable for power-constrained UAV deployment. Similarly, SENet’s fully-connected channel recalibration demonstrates more limited gains (83.5% mAP) while risking over-smoothing of high-frequency defect edges due to its aggressive dimensionality reduction, ultimately proving less effective than ECA’s targeted spectral weighting approach. These performance differentials become particularly pronounced in real-world operating conditions, where ECA’s 48.1 FPS processing enables < 25 ms latency for UAVs operating at 3–5 m/s while maintaining 5 cm GPR sampling intervals, coupled with superior power efficiency and compact memory footprint for edge deployment.
This result collectively demonstrated that for most GPR inspection scenarios requiring both spectral sensitivity and real-time processing, lightweight channel attention (ECA) is the preferred architecture for automated defect detection in resource-constrained UAV applications, while suggesting CBAM may retain value for specialized cases requiring enhanced spatial resolution of complex geometric features.
In this study, the potential of data augmentation (DA) using DCGAN are also investigated. Our experimental framework systematically evaluates three training scenarios: (1) baseline performance using the original dataset (780 images), (2) performance with conventional augmentation including rotation and flipping (2,340 images), and (3) performance with DCGAN-based augmentation (3,256 images).
The test performance is summarized in Table 4. The experimental results demonstrate that DCGAN-based data augmentation significantly enhances defect detection performance compared to both the original dataset and conventional augmentation methods. The DCGAN-augmented dataset achieves superior detection accuracy across all defect categories, with particularly notable improvements in void detection (87.5% AP for Void 1 and 86.6% for Void 2).
A quantitative comparison of data volume and AP gain is summarized in Table 5. It reveals that for void-type defects (Void 1/Void 2), DCGAN achieves + 7.3% and + 7.2% AP over conventional data augmentation, despite providing only + 117% more data. This 3 times higher marginal gain confirms that synthetic samples capture critical physical features. This performance advantage stems from DCGAN’s ability to learn and replicate the complex underlying distribution of GPR signals, generating synthetic yet realistic defect patterns that conventional geometric transformations cannot produce. This capability proves especially valuable for challenging detection tasks, while also effectively addresses class imbalance issues, as seen in the 71.1% AP for looseness defect detection. These results align with recent studies demonstrating GANs’ efficacy in addressing data scarcity in industrial inspection tasks37.
Conclusion
This study presents an enhanced YOLOv5 model for high-precision, real-time detection of subsurface defects in concrete structures using GPR data. By integrating the efficient channel attention (ECA) mechanism into the YOLOv5 architecture, and incorporating DCGAN-based data augmentation to address class imbalance, the proposed method achieves a mean average precision (mAP) of 85.4%, outperforming both the baseline YOLOv5 (82.7%) and its CBAM/SENet variants (83.9%/83.5%). The ECA module’s adaptive channel-wise feature recalibration proves particularly effective in distinguishing air-filled voids (87.5% AP) from water-filled voids (86.6% AP) by amplifying defect-specific spectral signatures while suppressing interference from aggregate noise. Furthermore, the model maintains a real-time inference speed of 48.1 FPS with minimal additional parameter, demonstrating its suitability for UAV-mounted deployment in large-scale infrastructure inspections.
While the current model achieves superior performance, its behavior in more challenging scenarios requires further investigation. For instance, the performance of the model could degrade in high-cluster environment due to GPR signal scattering, such as rebar-dense regions that are not fully represented in our training data. Such limitations highlight key directions for future work, including multi-modal data fusion (e.g., combining GPR with thermal imaging or hyperspectral camera), implementation of physics-informed deep learning architectures (e.g., incorporating physical constraints of wave propagation), and adaptive noise suppression algorithms for complex field conditions. Despite these challenges, this work provides a practical advancement in automated structural health monitoring, particularly for aging critical infrastructures such as tunnels, bridges, and dams.
Data availability
We sincerely appreciate the valuable feedback provided by the editor. We have fully complied with the journal’s code sharing policy by depositing our code in the Science Data Bank (DOI: https://doi.org/10.57760/sciencedb.27114.). The repository includes the custom code and pretrained models under the MIT License, enabling immediate public access without restrictions. The revised manuscript’s Code Availability section explicitly states this DOI and licensing terms, satisfying journal’s data availability requirements. We believe that our responses have addressed the concerns from the editor, and hope our revised manuscript will be accepted for publication.
Code availability
The custom code and pretrained models for this study have been deposited in the Science Data Bank under permanent DOI [https://doi.org/10.57760/sciencedb.27114]. This repository contains the implementation of the attention-enhanced YOLOv5 architecture, and model weights, released under the MIT License with no access restrictions for verification and reuse.
References
Hoang, N. D. Detection of surface crack in Building structures using image processing technique with an improved Otsu method for image thresholding. Adv. Civil Eng. 2018, 3924120 (2018).
Wang, Z. et al. Sui, 3D imaging and Temporal evolution recognition of concrete internal defects based on GPR. Meas. Sci. Technol. 35, 065407 (2024).
Yang, L. et al. Concrete defects inspection and 3D mapping using CityFlyer quadrotor robot. IEEE/CAA J. Automatica Sinica. 7, 991–1002 (2020).
Shaowei, W. et al. Concrete crack recognition and geometric parameter evaluation based on deep learning. Adv. Eng. Softw. 199, 103800 (2025).
Abu Dabous, S. & Feroz, S. Condition monitoring of bridges with non-contact testing technologies. Autom. Constr. 116, 103224 (2020).
Liu, P., Ding, Z., Zhang, W., Ren, Z. & Yang, X. Using ground-penetrating radar and deep learning to rapidly detect voids and rebar defects in linings, Sustainability, 15 11855. (2023).
Benson, A. K. Applications of ground penetrating radar in assessing some geological hazards: examples of groundwater contamination, faults, cavities. J. Appl. Geophys. 33, 177–193 (1995).
Alani, A. M., Aboutalebi, M. & Kilic, G. Applications of ground penetrating radar (GPR) in Bridge deck monitoring and assessment. J. Appl. Geophys. 97, 45–54 (2013).
Abouhamad, M., Dawood, T., Jabri, A., Alsharqawi, M. & Zayed, T. Corrosiveness mapping of Bridge decks using image-based analysis of GPR data. Autom. Constr. 80, 104–117 (2017).
Wei, L., Magee, D. R. & Cohn, A. G. An anomalous event detection and tracking method for a tunnel look-ahead ground prediction system. Autom. Constr. 91, 216–225 (2018).
Núñez-Nieto, X., Solla, M., Novo, A. & Lorenzo, H. Three-dimensional ground-penetrating radar methodologies for the characterization and volumetric reconstruction of underground tunneling. Constr. Build. Mater. 71, 551–560 (2014).
Li, S. et al. Enhanced automatic root recognition and localization in GPR images through a YOLOv4-Based deep learning approach. IEEE Trans. Geosci. Remote Sens. 60, 1–14 (2022).
Qiu, Z. et al. Application of an improved YOLOv5 algorithm in Real-Time detection of foreign objects by ground penetrating radar. Remote Sens. 14, 1895 (2022).
López, Y. Á., García-Fernández, M., Álvarez-Narciandi, G. & Andrés, F. L. H. Unmanned aerial Vehicle-Based Ground-Penetrating radar systems: A review. IEEE Geoscience Remote Sens. Magazine. 10, 66–86 (2022).
Noviello, C. et al. An overview on Down-Looking UAV-Based GPR systems. Remote Sens. 14, 3245 (2022).
Dinh, K., Gucunski, N. & Duong, T. H. An algorithm for automatic localization and detection of rebars from GPR data of concrete Bridge decks. Autom. Constr. 89, 292–298 (2018).
Li, Y., Zhao, Z., Luo, Y. & Qiu, Z. Real-Time Pattern-Recognition of GPR images with YOLO v3 implemented by tensorflow. Sensors 20, 6476 (2020).
Li, S. et al. Detection of concealed cracks from ground penetrating radar images based on deep learning algorithm. Constr. Build. Mater. 273, 121949 (2021).
Wu, Y., Shi, J., Ma, W. & Liu, B. Bridge crack recognition method based on Yolov5 neural network fused with attention mechanism. Int. J. Intell. Inf. Technol. 20, 1–25 (2024).
Yu, Q., Zhou, H., Wang, Y. & Duan, R. Quality monitoring of metro grouting behind segment using ground penetrating radar. Constr. Build. Mater. 110, 189–200 (2016).
Sudakova, M. S. & Vladov, M. L. Modern directions of application of ground-penetrating radar. Mosc. Univ. Geol. Bull. 73, 219–228 (2018).
Yang, G. et al. Autonomous navigation method for substation inspection robot based on travelling deviation. IOP Conf. Series: Earth Environ. Sci. 69, 012201 (2017).
Du, Y. et al. A wall climbing robot based on machine vision for automatic welding seam inspection. Ocean Eng. 310, 118825 (2024).
Everingham, M., Van Gool, L., Williams, C. K. I., Winn, J. & Zisserman, A. The Pascal visual object classes (VOC) challenge. Int. J. Comput. Vision. 88, 303–338 (2010).
Bianchini Ciampoli, L., Tosti, F., Economou, N. & Benedetto, F. Signal Processing of GPR Data for Road Surveys, Geosciences, 9 96. (2019).
Sun, M., Pan, J., Bastard, C. L., Wang, Y. & Li, J. Advanced signal processing methods for Ground-Penetrating radar: applications to civil engineering. IEEE. Signal. Process. Mag. 36, 74–84 (2019).
Oppenheim, A. V. & Schafer, R. W. Discrete-Time Signal Processing (Prentice Hall, 2009).
Radford, A., Metz, L. & Chintala, S. Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks, in, 2015, pp. arXiv:1511.06434.
Ioffe, S. & Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift, in: Proc. Proceedings of the 32nd International Conference on Machine Learning, PMLR, Proceedings of Machine Learning Research, 448–456. (2015).
Miyato, T., Kataoka, T., Koyama, M. & Yoshida, Y. Spectral Normalization for Generative Adversarial Networks, in, pp. arXiv:1802.05957. (2018).
Shorten, C. & Khoshgoftaar, T. M. A survey on image data augmentation for deep learning. J. Big Data. 6, 60 (2019).
Wang, C. Y. et al. CSPNet: A New Backbone that can Enhance Learning Capability of CNN, in: 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), pp. 1571–1580. (2020).
Hu, J., Shen, L. & Sun, G. Squeeze-and-Excitation Networks, in: 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 7132–7141. (2018).
Woo, S., Park, J., Lee, J. Y. & Kweon, I. S. CBAM: Convolutional Block Attention Module, in: Proc. Computer Vision – ECCV 2018: 15th European Conference, Munich, Germany, September 8–14, 2018, Proceedings, Part VII, Springer-Verlag, Munich, Germany, 3–19. (2018).
Wang, Q. et al. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks, in: 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 11531–11539. (2020).
Paszke, A. et al. PyTorch: an imperative style, high-performance deep learning library, in: Proceedings of the 33rd International Conference on Neural Information Processing Systems, Curran Associates Inc., pp. Article 721. (2019).
Jain, S., Seth, G., Paruthi, A., Soni, U. & Kumar, G. Synthetic data augmentation for surface defect detection and classification using deep learning. J. Intell. Manuf. 33, 1007–1020 (2022).
Funding
This research was supported by the Natural Science Foundation of China.
Award Number: 52479137.
Author information
Authors and Affiliations
Contributions
J.-Y.Z. and L.H. conceived the study and developed the methodology. J.-Y.Z. conducted the experiments and performed the data analysis. Y.-J.G. contributed to the dataset collection and GPR imaging setup. J.-Y.Z. wrote the initial draft of the manuscript. L.H. supervised the research and revised the manuscript critically for important intellectual content. All authors reviewed and approved the final manuscript.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Zhang, JY., Huang, L. & Guan, YJ. Real-time defect detection in concrete structures using attention-based deep learning and GPR imaging. Sci Rep 15, 35507 (2025). https://doi.org/10.1038/s41598-025-19596-1
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-025-19596-1
