
Abstract
We encounter issues with the huge number of useful features and the uneven target classes in the dataset when attempting to detect corruption reports in texts. We offer a novel approach that uses deep reinforcement learning techniques to identify corruption reports in texts in order to address these issues. Our suggested approach is broken down into four primary phases and integrates deep reinforcement learning, feature selection, and feature description techniques. In order to prepare the texts for the following steps, the first step is devoted to data preparation activities. The second step involves the feature extraction process, which is carried out employing three feature types: statistical features, which define the text’s attributes in terms of frequency and statistics; Term Frequency–Inverse Document Frequency (TF–IDF) features, which assign weights to terms based on their occurrence in all texts and throughout the dataset; and Word2Vec characteristics, which not only describe the importance of features but also model the concurrency and communication traits of phrases. Following the combination of these three feature sets, an ideal subset is chosen and the dataset’s dimensionality is decreased using the Singular Value Decomposition method. In the fourth and last stage, a Convolutional Neural Network (CNN) is utilized to carry out the detection process. The CNN model’s configuration is modified using the Q-learning model. Experiments on identifying corruption reports in texts have revealed that our suggested approach has an average accuracy of 90.04% and F-measure of 0.9. These findings demonstrate the method’s superior performance over other approaches already in use and validate its capacity to identify positive samples in texts pertaining to corruption with more accuracy.
Similar content being viewed by others
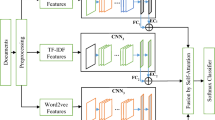

Introduction
Corruption is a widespread and destructive problem in the world, which is characterized as the misuse of the granted power to personal benefit1,2. It is cancerous in all areas, such as public procurement, healthcare, construction, energy, and transportation. The financial cost is overwhelming; the World Economic Forum calculates that the annual outflow of fraud, tax evasion, illicit financial flows, bribery, and corruption to developing countries alone is USD 1.26 trillion. And in addition, the Corruption Perceptions Index published by Transparency International shows that about 75 percent of the 180 countries assessed have a score of less than five, which means that there is a high level of perceived corruption in the public sector2. This rampant issue does not only undermine the trust in governmental and public systems but also increases inequality by distorting resource distribution, access to basic public services, including basic medicines, and acts as a major barrier to global development objectives, including the 2030 United Nations Sustainable Development Goals3,4,5,6,7,8.
The large amount of textual data that is produced every day, especially on social media sites such as Twitter, is an untapped, but very valuable, source of corruption detection and identification. The text classification methods play an important role in sorting, grouping, and interpreting this unstructured data and allow automatic detection of particular themes or events9. Nevertheless, the practical use of text classification to such complicated tasks as corruption reports is usually complicated by such factors as a high dimensionality of the textual characteristics and the imbalance of the real-world data. In order to deal with complexities related to features, feature selection methods are essential, which enables the determination of most salient and non-redundant features, thus saving computational load and enhancing model performance.
Recent developments in reinforcement learning (RL) provide new paradigms of optimizing complex systems. Deep reinforcement learning (DRL) is traditionally used to solve control problems by integrating the perceptual capacity of deep learning with the decision-making capacity of RL agents10. This is a strong synergy that enables models to acquire optimal strategies by interacting with an environment, which makes it especially suitable to dynamic optimization problems. Within the framework of deep learning model design, RL could be used to adaptively configure a model, where a model learns to choose the best architectural parameters to achieve the best performance on a task11.
The study suggests a new model of automatically detecting corruption reports in the text using deep reinforcement learning, feature selection, and a full description of features. The given approach solves the problem of a vast number of possible features and the uneven distribution of target classes in corruption-related data. We propose a hybrid deep reinforcement learning model in which Q-learning (QL) strategy is used to dynamically tune the convolutional layers in a Convolutional Neural Network (CNN) to optimize its performance. The combination of this novel model adaptation, a multi-faceted feature engineering pipeline (statistical, TF–IDF, and Word2Vec features) and Singular Value Decomposition (SVD) dimensionality reduction is a major contribution to the area of text processing in corruption detection. The contributions of this paper are as follows:
-
Presenting a new strategy for automatic detection of corruption reports in texts that has not been addressed in previous research.
-
Improving the performance of CNNs using a reinforcement learning strategy, in such a way that the convolution layers in CNN networks are tuned using the QL model.
-
Scalability is also a key feature; The proposed strategy can be applied to larger volumes of text data using relevant techniques.
This paper continues by having a review on the related works in Section “Related work”, followed by describing the proposed model in Section “Research method”. After that, implementation results are presented and discussed in Section “Experiments and results”; and finally, the conclusions are made in Section “Conclusion”.
Related work
In this section, an attempt has been made to address articles that have examined the issue of corruption in recent years. Lima et al.9 used machine learning for predicting corruption perception in modern societies and knew that the Random Forest algorithm was the most accurate. In their research they enumerated several factors that affect the level of corrupt practices. Liu12 developed an unsupervised method to detect corrupt textual data when used, shown to be superior to other methods. This study was helpful in the sphere of the approaches of detecting corrupt data and improving the text-based deep learning model.
Budsaratragoon et al.13 discussed important causal assumptions of the corruption perceptions index explaining that source level influences were not equal. They recommended that national policymakers use at least two forms of data and assured resource allocation for such enhancements. Spyromitros and Panagiotidis14 examined corruption in 83 nations of the developing world for the period 2012 to 2018 as having a signification negative effect on economic growth. It pointed out the importance of capital accumulation, human capital, economic growth and enhancing the quality of political economy institutions. Paulo et al.15 examined the effects of corruption of Latin American and Caribbean countries, adding that higher corruption level resulted in loss of 12.2% of the Gross Domestic Product (GDP) per capita and 3.05% of economic growth.
Bitterhout and Simo-Kengne16 discussed the effect of corruption in the economic growth of the member countries of the BRICS from 1996 to 2014. They established a negative relationship with output growth but noted a positive relationship when accounting for the heterogeneity and endogeneity. Belloumi and Alshehry17 compared the effect of corruption on growth and investment in the absolute member nation’s of Gulf Cooperation Council for Developing Nations & States through the period of 2003 to 2016. The authors established a long term one way causality indicating that corruption had a negative impact on growth but a positive impact on invest domestic investment.
Malanski and Póvoa18 investigated the influence of corruption on growth in Latin America and Pacific Asia with economic freedom as the conditional variable. From this study, they got to realise that corruption posed a negative impact on the Asian countries’ economic growth. Utomo et al.19 introduced a deep learning-based Anti-Corruption Disclosure (ACD) prediction from the firms listed in the Indonesia Stock Exchange. The proposed deep neural network yielded an average accuracy of 74.76%, thus serving as an alternative to logistic regression.
Li et al.20 employed unsupervised machine learning to analyses Twitter data to identify self-reports of corruption, including that in the health segment. The authors gathered Tweets from the Twitter public API and used biterm topic model to identify topics within the messages posted. Research about analyzing textual data for self-reported corruption is very limited. However, several studies about classification of textual data can be useful for this problem. For example, researchers in21, had a study on the influence of FastText model in combination with CNNs for text classification. This study, demonstrates the positive effect of this model of feature representation for analyzing text data which can be useful for self-reported corruption detection also. Also, researchers in22 introduced an ensemble-based model based on meta-classifier for categorization of textual data. This study shows the effectiveness of hybrid classifiers in improving the recognition accuracy; however, it leads to increased computational complexity which makes the unsuitable for large datasets.
Ash et al.23 applied a tree-based gradient-boosted classifier for anticipating corruption in municipalities of Brazil. Their findings indicated that machine learning techniques significantly improved the detection of corruption and identified nearly double the number of corrupt cases than previous methodologies. Li24 presented a deep learning method for analyzing financial fraud texts through neural network models. This method focused on regulatory announcements, enforcement bulletins, and MD&A reports while emphasizing effective sentence organization. The insights gained from this approach provided valuable guidance for both industry practitioners and researchers.
Djouadi et al.25 published the positive relationship between corruption, as well as economic growth in the East Asian and Middle Eastern countries and endorsed the rule of law with accountability, enhancement of transparency, and cutting the bureaucratic procedures. Muco26 proposed a new methodology of corruption assessment based on text data and methods of natural language processing, using human-coded data from a Brazilian anti-corruption program.
Although there are few studies that directly focus on the problem of corruption detection in the context of text classification, important progress in the area of text classification, especially using deep learning, provides helpful insights into the methodological progress. These methods give a background to the success of different methods in processing complex textual data.
Chen et al.27 have compared the automated legal text classification, and their results show the effectiveness of machine learning approaches. Their study showed that domain-specific concepts as features and Random Forests could be better than deep learning systems based on multiple pre-trained word embeddings and deep neural networks, particularly when fewer essential features were used. This publication highlights the importance of efficient feature engineering despite the emergence of deep learning.
Dogra et al.28 gave a detailed account of state-of-the-art NLP models of text classification. The paper was a systematic review of different machine and deep learning algorithms and their advantages and disadvantages in processing exponentially increasing online textual data in tasks such as news events, company reports, and social media analysis. Their publication is a good reference to the terrain of modern text classification methods and how they can be applied in various fields.
Mittal et al.29 proposed Deep Graph-Long Short-Term Memory (DG-LSTM), a new deep learning model that is used to classify multi-label texts. They solve the shortcomings of traditional Word2Vec by introducing graph databases to model logical and contextual connections between texts, to better represent semantic information in multi-label cases. The model uses document preprocessing to create classified dictionaries and subgraphs, which are very accurate in classifying legal cases.
The comparative study by Köksal and Akgul30 was devoted to deep learning algorithms of text classification. They explored and tuned different structures, such as Deep Neural Networks (DNN), CNN, LSTM and Gated Recurrent Units (GRU). Their results highlighted the significant gains of classification performance that can be obtained by carefully applying word embeddings and deep learning techniques along with hyperparameters fine tuning.
Within the scope of CNN-based text classification architecture, Soni et al.31 introduced TextConvoNet. The new model is an expansion of the one-dimensional convolutional filters because it uses a two-dimensional multi-scale convolutional operation. It enables TextConvoNet to learn not only intra-sentence n-gram features but also inter-sentence n-gram features resulting in improved performance on a variety of binary and multi-class classification datasets compared to existing machine learning, deep learning, and attention-based models.
Bangyal et al.32 demonstrated how deep learning could be applied in the real world to classify texts in their study on the detection of fake news about COVID-19 in social media, especially in Twitter. They conducted an in-depth study with a lot of preprocessing of data, semantic modeling with TF–IDF, and comparative study of various machine learning and deep learning models (CNN, LSTM, RNN, and GRU) to determine effective models of sentiment analysis on microblog data. This paper points out the usefulness of deep learning in public health emergencies in text classification.
In the case of a large number of labels, Xiong et al.33 proposed XRR, a two-stage framework of Extreme Multi-label Text Classification (XMTC). Their model overcomes the issues of computational efficiency and information loss by retrieving a small number of candidate labels with methods such as Point Mutual Information and Unified Label-Semantic Embedding and then ranking the most relevant labels through a deep ranking model (using pre-trained transformers). This new method outperforms complex multi-label dataset.
Lastly, Abarna et al.34 examined subtle details of language interpretation by creating an ensemble model to categorize idioms and literal text. They used a stacking ensemble to combine their work with baseline BERT and RoBERTa models based on Knowledge-enabled BERT (K-BERT) that injects knowledge graphs into sentences to improve domain knowledge. The study demonstrates that sophisticated transformer-based models may be used in complex semantic classification tasks in NLP. Table 1 provides a summarized overview of the studied works.
The literature review shows that there is a serious gap in the direct, multi-class classification of certain types of corruption on the basis of unstructured textual data, especially social media content such as tweets. Previous work tends to concentrate on macroeconomic effects, unsupervised approaches to general text detection12,20, or machine learning to fraud/corruption in other data settings19,23,24,26. Although overall deep learning-based text classification has progressed21,27,28,29,30,31,32,33,34, such models are generally configured with fixed or manually tuned architectures, and are not adaptive. The gaps are filled in our proposed model that provides a supervised deep reinforcement learning framework to perform accurate, multi-class corruption type classification directly on tweets. Distinctively, we combine Q-learning to tune the architectural hyperparameters of the CNN, and thus allow the model to discover the best hyperparameter values to use in this difficult task. The combination of this adaptive strategy with powerful feature engineering offers a new, precise, and automated solution that greatly promotes the use of AI in anti-corruption activities.
Research method
The research aims to develop a robust and precise method for the automatic detection of reported experiences of corruption in textual data. This research contributes to a better understanding of the dynamics of corruption, timely identification of potential networks of corruption, and supporting efforts to enhance transparency and accountability in various sectors. Therefore, this section first describes the data collection process and its characteristics, and then outlines the steps of the proposed approach to address the research issue.
Dataset
In this research, a dataset of 19,560 tweets has been used that has been extracted from the Twitter platform (X) between January 2020 to August 2022. This specific dataset was curated by the authors of this study. For this purpose, the dataset was collected using the Twitter API. By specifying keywords and hashtags related to corruption such as #corruption, #bribery, #embezzlement, #fraud, #graft, #nepotism, #patronage, #kickbacks, #moneylaundering, #whistleblower, #anticorruption, etc.… A preliminary sample of 22,548 tweets was obtained and pre-filtered to remove irrelevant samples that were unrelated to corruption reports, leaving the final sample of 19,560 relevant tweets. The tweets contained in this dataset are written in English, and no location data is provided. The tweets are between 108 to 257 characters which offers textual diversity to analyze.
Considering the objective of this research, the tweets were manually labeled into five categories that describe the type of reported corruption: Bribery, Embezzlement, Nepotism, Fraud, and Money Laundering. Table 2 provides samples tweets from each category in this dataset. This manual labeling procedure was carefully conducted by a team of three independent annotators, who all had knowledge in corruption, social dynamics, and pertinent legal issues. A strict annotation guideline was adhered to in order to guarantee quality and consistency and any discrepancies were settled by consensus. The tweets are distributed in the following categories: Bribery (4108 tweets), Embezzlement (3869 tweets), Nepotism (3731 tweets), Fraud (4151 tweets), and Money Laundering (3701 tweets). The size of the dataset at hand is adequate to offer enough samples to train and test machine learning models that will automatically identify reported cases of corruption in textual data. To this end, the text information of every sample tweet is fed to the model, and the aim is to predict the type of reported corruption based on this information.
Proposed method
This research proposes a novel approach to identify instances of reported experiences of corruption in textual data through a deep reinforcement learning (DRL) model. The proposed method includes the following key steps:
-
Preprocessing
-
Feature Extraction
-
Feature Combination and Dimensionality Reduction
-
Prediction Based on the Deep Reinforcement Learning Model.
Figure 1 illustrates the details of the proposed approach in the form of a diagram. According to this diagram, to prepare the textual data for analysis, the preprocessing process is first carried out. This step includes the removal of stop words, correction of spelling and grammatical errors, elimination of punctuation marks and special characters, and tokenization of the text into individual words or phrases. After preparing the text, three groups of features are used to describe the preprocessed tweets. First, a set of various statistical features along with the TF–IDF characteristics for each word in the tweets are calculated, where words can be weighted based on their frequency in a document and their rarity across the entire collection. As the other feature set, the Word2Vec model is used to learn distributed representations of words. The Word2Vec representations capture semantic relationships between words and can be used to understand the contextual meaning of the tweets.

Diagram of the steps of the proposed method.
In the third step of the proposed method, the extracted features are combined into a single feature vector for each tweet, and then Singular Value Decomposition (SVD) is applied to the merged feature set for dimensionality reduction and improved computational efficiency. After applying the process of feature dimensionality reduction, each sample is presented in a matrix form in order to form the required input for training the classification model. The last of the proposed method is to feed new feature vector through a CNN for modeling of the architecture. The proposed CNN uses hyperparameter tuning with the help of a reinforcement learning technique and QL. The DRL model of this study is trained on the labeled dataset based on the combined and reduced feature vectors as inputs and the labels as target outputs. Lastly, the model is tested on a new set of extracts by using a separate classifier for the detection of the experiences associated with corruption.
Preprocessing
In the first step of the proposed method, the input texts are preprocessed to prepare them for processing in subsequent steps. The text is broken down into its component paragraphs, phrases, and words during the preprocessing stage. Sentences are the objective for division in the suggested approach since they are the smallest appropriate unit for collecting structural information in a textual material. Each text content is first normalized in order to do this. Normalization means standardization of the text with regard to the spacing and punctuation rules. characters, new lines, and punctuation in the text are corrected during this process; two or more successive space characters are replaced with the single one. The Text Analytics Toolbox™ is employed for the texts preprocessing of the dataset. The preprocessing step concludes with the correction of specific entities in the texts. Specific entities refer to parts of the text whose presence can reflect a particular concept. These specific entities include numbers, time, email addresses, currency units, and web addresses. Accordingly, each of the above entities is replaced with a keyword in the texts. Specifically, numbers and time are replaced with the keywords NumberKey and TimeKey, respectively. Additionally, the email address, currency, and web address are replaced with the keywords emailKey, currencyKey, and webKey, respectively.
Feature extraction
In the second step of the proposed method, three different techniques are used to represent the features of preprocessed texts. These methods are: “statistical features”, “TF–IDF technique” and “word2vec technique”. The aim of using the combination of these methods is to achieve a more complete feature description model to cover the diversity of feature patterns related to corruption. Thus, each of the mentioned techniques separately describes the content features of the texts, which will be explained in the rest of this section.
Extracting statistical features from text
The first set of features used in the proposed method to describe the texts consists of statistical features which include engineered and TF–IDF features. To obtain the engineered statistical features, the identified sentences in the processed texts are analyzed, and the grammatical roles of the words in the text are determined. After stipulating the grammatical roles of the words in all developed sentences, one will get a labeled text document in which other necessary characteristics of the texts will be described at a statistical level. The set of engineered statistical features describing each text includes:
-
Mean Length of Each Sentence in Words: To calculate this feature for each text document, the total number of words in the document is counted and then divided by the total number of sentences in the text.
-
Mean Number of Stop Words in Each Sentence: To calculate this feature, the total number of stop words in the text document is divided by the number of sentences in that document.
-
Rate of Keyword Presence in the Text: To extract this feature, a list of keywords related to reporting corruption is utilized, and the total occurrences of these keywords in each text are counted. Finally, the obtained value is divided by the number of words in the text.
-
Frequency Rate of Each Grammatical Role in the Text: This feature is calculated separately for each possible grammatical role, such as noun phrases, verb phrases, adverbs, adjectives, etc. In this case, for each grammatical role, such as x, the number of phrases possessing grammatical role x in the text is calculated and divided by the total number of phrases in the text.
-
Rate of Punctuation Usage in the Text: For this feature, the number of punctuation characters present in the text is divided by the number of sentences in it.
-
Mean Length of Each Word: This feature indicates the average number of characters that make up each word in the input text.
Thus, extracting the above feature set, a numerical vector containing the statistic features of all text documents is constructed.
The second set of statistical features that describe the texts consists of TF–IDF vectors, which describe the importance of words in the text based on their frequency. This feature extraction strategy begins with identifying the keywords present in the text. To this end, the removal of stop words and the stemming of words in the text are performed initially. The removal of stop words involves identifying and filtering out words such as “as,” “from,” “because,” etc., which do not convey any specific meaning in the text. Additionally, the high frequency of these words in the texts may lead to errors in identifying keywords. For this reason, these words will be ignored in the input text. On the other hand, each word can take on different forms by receiving various prefixes and suffixes, resulting in two words with the same root having different forms, while both convey specific meanings. To address this issue, a stemming strategy is utilized. Thus, the obtained text is broken down into its constituent words, and stemming is applied.
Using stemmed words helps to limit the dimensionality of the word vector or, in other words, the feature vector. Accordingly, for each word in the input texts, prefixes and suffixes are disregarded. By counting the frequency of unique words in each text document, the K keywords with the highest frequency can be identified. In this way, K stem words with the highest occurrences are considered as the keywords of each document. After extracting keywords for each text, a list of unique keywords for the database is generated. This list includes the overall set of keywords in the database and is used to describe each text document. Let’s assume that by doing this, a vector like F = {w1, …, wn} is generated for the database. Each text document can be described by weighting into a feature vector like W = {t1, …,tn}, in which ti indicates the weight corresponding to the keyword wi in the vector F. The elements of a text document are described using the TF–IDF measure once the list of distinctive phrases found in the text has been extracted. This stage involves using the keywords found in each text document to go through its content. The TF–IDF criterion is then used to weight each keyword. The following formula is used to determine the weight of a term like w35:
N indicates the overall amount of collection records, and TF is the quantity of times the word “w” appears in the present text item. Additionally, Nw shows how many textual records in the database include the word “w.” Following the computation of each keyword’s weight, the weight value is saved in the feature vector W in the suggested fashion.
Word2vec feature extraction
The third category of features in describing the content characteristics of texts is Word2Vec. A language model, the so-called Word2Vec model, can learn the meaning of words in an automated way. The model is able to transform words into vectors that capture the semantic feature of text. Among different methods of text vectorization with the proposed method, Word2Vec uses the Skip-Gram technique. The Skip-Gram method predicts the surrounding words given a certain word. In this approach, the model assigns a vector to each word. This vector contains the semantic characteristics of the word. The steps for feature description using Word2Vec are as follows36:
-
Training the Word2Vec model
-
Converting text into vectors using the Word2Vec model
In the proposed method, the Text Analytics Toolbox™ and the pre-trained fastText model36 was used for Word2Vec feature extraction. The output of this model will be a vector for each text document.
Combination of features and dimensionality reduction
In the third step of the proposed technique, statistical features (engineered and TF–IDF), and Word2Vec features extracted previously in the second step will be combined into vector format. The result of this process describes each sample (text) in a vector of length F = S + T + W, where S represents the number of extracted statistical features, T denotes the length of the TF–IDF vector, and W indicates the length of the Word2Vec vector extracted for each sample. The length of this vector can be substantial for large datasets that contain a vast vocabulary. Furthermore, a significant portion of these features may be redundant and lack meaningful correlation with the target variable (the type of corruption reported in the text). For this reason, the proposed method employs the SVD strategy to reduce the dimensions of the obtained feature vectors. The aim of this algorithm is to decrease the dimensionality of the features to enhance processing speed and reduce error rates in detecting the type of reported corruption.
Consider that a database consists of P samples, each sample has a dimension equal to F. The SVD algorithm takes every record in the database as a vector in order to perform feature extraction. As a result, \({R}_{F\times P}\) can be used to describe the complete database. A square matrix such as R can be broken down into three matrix structures: an orthogonal structure U, a diagonal structure Σ, and a transposed orthogonal structure V, according to a linear algebra theory that forms the basis of the SVD algorithm. Reducing a square matrix to a smaller-dimensional space is the aim of the SVD algorithm. The feature matrix’s dimensions are decreased using this approach. After noise is eliminated, this method also uncovers hidden data. The matrix R is broken down into three matrices as part of the SVD computation37:
In the above equation, U is a matrix and its columns are the eigenvectors of the matrix \(\mathcal{R}{\mathcal{R}}^{T}\). This matrix is called the left eigenvectors. Also, ∑ is an orthogonal matrix whose diagonal elements are the singular values of \(\mathcal{R}\) and whose off-diagonal elements are zero. This matrix describes the relationships between the features. Finally, V is a matrix whose columns are the eigenvectors of the matrix \({\mathcal{R}}^{T}\mathcal{R}\). This matrix is referred to as the right singular vectors matrix. Moreover, VT represents the transpose of matrix V. In the proposed method, this matrix is used to rank the features of the database. Gong and Liu38 demonstrated that the order of rows in this matrix indicates the importance of features in the database, in such a way that the first row represents the most important feature, and so on. Moreover, it is critical to select an appropriate amount of features from the database in order to reduce its dimensions. The appropriate number of features can be identified based on the characteristics of the data. It has been empirically established that the suitable number of features for a data record is the number of features whose cumulative squared values account for 97 percent of the total squared values of the main diagonal. If we denote this number of features as N, the features extracted by the SVD method can be obtained through the following equation37:
The above equation indicates that the matrix of features extracted will be obtained by multiplying the coefficients corresponding to the top N features in the decomposition matrices. After extracting the descriptor features for each sample, each record will be transformed into a vector of length N. At the end of the feature description step, this vector will be converted into a matrix form to create the necessary input for the DRL model. In this case, each feature from the available records is first normalized using the max–min technique to map it to the range [0, 1]. Subsequently, each feature is encoded using a two-level strategy. At the first level, the range [0, 1] for each feature is divided into 100 intervals of size 0.01, and a numerical value is assigned to each interval. Then, each of these specified intervals is further divided into 10 intervals of size 0.001, with a numerical value between 1 and 10 assigned to each of these intervals. For example, a numerical value of 0.0241 for a feature will be converted into a vector of length 100 with values [0, 0, 5, 0,…, 0].
The non-zero entry in the third position of this vector indicates that the numerical value falls within the range (0.02, 0.03], and the value 5 for this entry indicates that it is within the interval [0.024, 0.025]. This process is repeated for all features of the samples so that each record of the dataset can be described as a matrix of dimensions N. The resulting matrix is used as the input for the proposed learning model to predict the type of reported corruption.
Prediction based on deep reinforcement learning
In the last step of the proposed method, a deep reinforcement learning strategy is used to predict the type of reported corruption.
Although transformer-based architectures are the best when it comes to NLP, particularly with long sequences, we chose a CNN as the fundamental learning model because it was part of our holistic approach. We are highly dependent on a multi-faceted feature engineering pipeline and SVD to reduce the dimension. This conversion converts text into information dense 2D matrix representations. CNNs are also good at working with such structured, engineered features and extracting hierarchical and local patterns. In contrast to transformers, which usually need huge volumes of raw text to pre-train, our method uses these polished features, and CNNs are a better and possibly less computationally demanding alternative to our particular dataset of shorter tweets.
The other important consideration was computational efficiency especially in the iterative Q-learning hyperparameter tuning. CNNs tend to perform well on fixed-size, engineered inputs than the complicated calculations of large-scale transformer architectures. In addition, CNNs are easier to integrate with Q-learning to optimize hyperparameters; the convolutional layers (filter sizes, number of filters) can be tuned by a Q-learning agent in a well-defined search space that is easier to explore than the larger and more complex state-action space of a general transformer architecture. Lastly, in classification problems involving feature-rich input, CNNs have been found to work very well in extracting pertinent patterns. Since tweets are short, CNNs are capable of extracting meaningful local patterns in our engineered feature representations, which is important in detecting corruption.
We recognize the progress of transformer models and we can envision their future application, maybe in the form of incorporating transformer-derived embeddings into our feature engineering pipeline, or in the form of hybrid architectures. Figure 2 depicts the structure of the learning model used in the proposed method.

Proposed DRL model for predicting the target variable.
Figure 2 presents the proposed architecture of DRL that expresses a model with the use of CNNs combined with QL for predicting the type of corruption based on textual feature representations in matrix format. The main components of this architecture are the feature extraction component, the classification component, and the reinforcement learning component. The feature extraction component is essentially the initial part of the convolutional network, which utilizes convolutional layers, the ReLU activation function, and max pooling for pattern compression. The layers of this component identify patterns and relationships within the feature sequences that are represented as two-dimensional matricesThe second component predicts the target value forecasted-the type of corruption reported in text-through a series of dense layers and the SoftMax function. The dense layers combine the extracted features and learn a nonlinear mapping to the target variable, allowing for the output to be predicted accordingly. The sequence of layers in the proposed prediction model is as follows:
-
Input Layer: This layer receives feature matrices describing text samples with dimensions \(N\times 100\).
-
Two-Dimensional Convolutional Layers: The model includes three convolutional layers. The first convolutional layer extracts local features from the input matrix using N1 filters of size L1 × W1. Then, the second convolutional layer extracts higher-level features from the output of the first layer using N2 filters of size L2 × W2. Finally, the third convolutional layer is responsible for extracting the deepest patterns of features from the input matrices using N3 filters of size L3 × W3.
-
Activation Layers: After each convolution layer in the proposed DRL model, an activation layer is placed. In this sequence of layers, ReLU activation introduces nonlinearity into the model and allows it to learn complex patterns.
-
Max Pooling Layers: After each level of feature extraction by the convolutional layers and their activation, two-dimensional pooling layers are used to compress the features. The max pooling layer reduces the dimensions of the feature maps while preserving important information. A 2 × 2 dimension causes the size of the feature maps to be halved in each dimension.
-
Dense Layer: The dense layer combines the extracted features and learns a nonlinear mapping to the target variable.
-
Output Layer: The output layer consists of a dense layer with five neurons (corresponding to the number of target categories) followed by a SoftMax layer, which determines the final predicted label for the target variable.
As shown in Fig. 2, in the proposed model, the hyperparameters of the first to third convolutional layers in the CNN component do not have specific values, and the tuning of these hyperparameters is performed by a QL model. This QL model first establishes the problem space by determining various strategies for the combinations of hyperparameters of the three convolutional layers. Then, by applying each configuration and evaluating the model’s performance based on it (using validation error), it assesses the effectiveness of each strategy and records the value of this action by updating its Q matrix. By repeating this cycle, the QL model is directed toward selecting more suitable configurations for the convolutional layers. It is worth noting that to increase the speed of the configuration process, during the hyperparameter tuning by QL, the model training is performed based on only 25% of the training samples.
QL is a reinforcement learning algorithm that does not require a model to learn the significance of an action in a given state. Since the algorithm doesn’t require an environment model, it can solve any problem involving random transitioning and reward without presuming the presence of a control strategy. The first step in the QL algorithm’s operation is to define a Q matrix with as many rows as states and as many columns as actions. It has zero values during initialization. Further, these Q values are updated whenever any action is taken and are stored in this matrix. This Q matrix behaves for the learning agent as a look-up table, which selects an action with respect to the value of Q.
A QL agent interacts with the environment in two ways: exploitation and exploration. These methods balance the rate of exploration versus exploitation using a threshold denoted as ε. Updates in the Q matrix are conducted at every step or after an action is taken and terminate at the end of a stage. The Q* values are learned by the learning agent through enough exploration over different stages and actions. Thereby, there are three major phases of learning for QL:
-
1.
The learning agent selects an action (a1) from a starting state (s1) and receives a reward (r1).
-
2.
The learning agent selects the action by referring to the Q table with the highest (maximum) value or randomly (ε).
-
3.
The Q values are updated.
The updating rule in the QL process can be described as the following equation39:
Gamma corresponds to the discount rate, while lr denotes the learning rate variable in the equation above. The suggested method’s QL model has to be able to identify the best values for the three convolutional layers’ dimensions and number of filters based on the problem’s circumstances (training samples). The search space for the hyperparameters of the filter length and width in the three convolutional layers is set to \(\{\text{2,3},\dots ,8\}\). Additionally, to maintain the simplicity of the model, it is assumed that each convolutional filter has equal length and width. In contrast, the search space for the hyperparameters of the number of filters in the convolutional layers is defined as \(\{\text{8,16,24},\dots ,128\}\).
All possible combinations for the different values of these two parameters create different states of the system. Then, by navigating through these states, the learning agent will be able to discover the optimal strategy for determining the values of the mentioned hyperparameters. In the given approach, the measures of the accuracy for the validation samples, specifically the prediction error rate, has been proposed as the reward r. To evaluate each state, the DRL model is first formed using the parameters specified in that state. Training is then conducted based on one-fourth of the training samples. Finally, the model is validated based on another one-fourth of the training samples to assess the quality of the configuration using the validation error metric.
After determining the suitable configuration for the convolutional layers using QL, the configured model is formed based on all the training samples in order to predict the target variable in unseen samples. It is worth noting that the SGDM optimizer is used with a minimum batch size of 64 for training this model, as this training configuration achieved the highest level of performance in various iterations.
Experiments and results
To implement this research, MATLAB version 2020a software was used and tenfold cross validation was employed in the experiments. In this section, after describing the evaluation metrics and experiments design, we will discuss the obtained results.
Experimental setup
The experiments were executed on a personal computer with Microsoft Windows 11 64-bit and Intel Core i7 13700H CPU and Nvidia RTX 4090 GPU. During implementation, Deep Learning and Statistics Toolboxes from MATLAB software was used. To assess the suggested deep reinforcement learning model, a strong tenfold cross-validation approach was used. In this experimental design, the whole data set was divided into ten subsets of equal size. On every fold, 80 percent of the data was used to train the model, 10 percent to validate, and the rest 10 percent was used to test. Such exact data partitioning will make sure that model training (with the 80% training set), hyperparameter tuning and early stopping (based on the 10% validation set, which is especially crucial in our Q-learning process), and unbiased performance measurement (on the 10% unseen test set) are done in a rigorous manner across data splits. This approach will help the results to be generalizable and reliable reducing the bias of using a single train/test split.
This study also focused on four key evaluation parameters to determine the efficiency of the proposed model. To study the influence of each technique employed in the proposed approach, our model was examined in three scenarios; the first scenario “Proposed”, is the case which both feature reduction and CNN tuning phases are employed for detection. The second scenario “Proposed (CNN)”, is the case which a CNN with static architecture is employed for detection. Finally, the third scenario shown as “Proposed (All Features)” is related to the case which feature reduction step is not applied on the concatenated feature sets.
When comparing the performance of our proposed model, we compared it with the current approaches in similar textual data analysis and classification problems. It is necessary to mention that, due to the originality of the direct classification of certain types of corruption using tweets, there were no works with exactly the same goal and data set that could be compared directly, end-to-end. As a result, we compared our strategy with those of the wider field of text classification and textual data mining, especially those that deal with fraud detection, which are methodologically similar in their processing of complex textual data using deep learning. As a result, the suggested method has been compared with the approaches introduced by Li24, Umer et al.21, and Mohammed and Kora22. All of these approaches were trained and evaluated using the same instances (Section “Research method”–“Introduction”).
Evaluation metrics
During the experiments and after each fold of cross-validation, metrics such as F-measure, Accuracy, Recall, and Precision were employed to describe the performance of each model.
Accuracy: By calculating the proportion of correctly categorized examples to all samples, the accuracy metric assesses how accurate the model’s predictions are overall.
Precision: This metric assesses how well a model can distinguish positive samples from real positive occurrences.
Recall: also known as sensitivity or the true positive rate, the recall measure assesses the model’s capacity to precisely identify positive samples within the real positive pool.
F-Measure: is the harmonic average of recall and precision.
In Eqs. (5) to (8), TP, FP, TN, FN, Acc, Pre, and Rec represent the true positive, false positive, true negative, false negative, accuracy, precision, and recall, respectively.
Results discussion
The experiments were executed based on the scenario explained in Section “Experimental setup” and the evaluation metrics from Section “Evaluation metrics” were used. Figure 3 shows the accuracy at different number of iterations. In this figure, the proposed model has achieved an accuracy of 90.04%, which is very good compared to other comparative methods. Also, the hybrid model suggested by Li24 also shows the closest performance and is next to the proposed method, but its accuracy is 6.01% lower than the proposed model. Overall, these results indicate the advantages of the proposed model in more accurate detection and its better efficiency compared to other methods studied. According to Fig. 6, the accuracy scored obtained by the proposed method in all folds of cross validation is higher and also show a more limited ranges of variations. This behavior could be a sign of higher reliability in the predictions made by our approach. Figure 4 can prove this claim by analyzing the box plots of the accuracy during folds.

The accuracy metric assessment in different folds.

The average accuracy metric assessment.
Figure 4 shows the average accuracy of each compared model, in addition to their box plots. As can be seen in this figure, the accuracy plot and the box plot are consistent with each other. In general, the box plot consists of four sections, each section showing the values of the accuracy changes in the first to fourth quartiles. Also, the median accuracy is indicated by a red line in the middle of the diagram. In the proposed model, the median accuracy and the average accuracy are equal, which indicates the success of this method in achieving results with a higher level of confidence. Additionally, the box plot of accuracy variation for the suggested model shows a uniform structure; which means the accuracy metric does not show a sudden change during folds. This consistency and equality of accuracies indicate that the proposed model has performed stably and effectively.
Figures 3 and 4 show that our suggested approach draws an edge over the compared models in terms of accuracy. This superiority can be related to two key techniques considered in this method. First, employing a diverse set of features and then reducing them by the SVD approach leads to significant gain in accuracy. As shown in these figures, compared to the “All Features” scenario, the suggested approach shows at least 6.26% higher accuracy. This is a sign of effectiveness of the feature reduction step in our model. Secondly, using Q-Learning agents to tune the CNN is significantly effective in obtaining a more accurate classifier. As these results show, in case of ignoring this mechanism, the accuracy will degrade to 82.02% which is 8.02% lower than the proposed method. According to these evidences, the effectiveness of the techniques in leveraging accuracy can be confirmed.
Figure 5 shows the Confusion Matrices (CMs) for each of the six comparison methods. The rows are the classes predicted by the model, while the columns represent the actual classes of the data. As shown, these CMs provide accuracy values for the classes individually, either as rows or columns. The outputs show that the predicted method can effectively predict and label the samples for each class.

The confusion matrix assessment.
The diagonal values of the CMs in Fig. 5 show the correct predictions made by the models. Comparing our model’s CM with other methods show that for each target category, our model produces a larger portion of correct predictions. In the proposed method, the biggest confusion has occurred between the “Bribery” and “Nepotism” categories (with 117 misclassifications). This is while the biggest confusion appeared in our method is still smaller than the least confusions appeared in the compared models. This can prove the efficiency of the proposed approach in providing more reliable predictions. As a result, the type I (False Positives) and type II (False Negative) errors of our model is significantly lower which leads to higher precision and recall for each category. Figure 5 demonstrated that our approach in addition to higher accuracy, shows potentials of higher generalizability (as a result of more accurate classification of unseen instances) and discrimination power (distinguishing the differences between various categories of corruption).
Figure 6 shows the precision, recall and f-measure metrics at different fold numbers. In the context of using deep reinforcement learning to automatically identify reported corruption experiences in text data, the evaluation of model performance is highly dependent on the metrics of Precision, Recall, and F-measure. Precision represents the ratio of correctly identified corruption cases to all cases that the model predicted as corruption, and thus characterizes the accuracy of the model’s positive predictions. Recall, on the other hand, measures the ability of the model to identify all real corruption cases in the dataset, indicating its efficiency in capturing relevant experiences. The F-measure acts as the harmonic mean of precision and recall, providing a single metric that balances both aspects and provides a comprehensive view of the model’s performance.

The classification quality assessment in different folds.
Figure 7 show the classification rates obtained for each of the target corruption categories in the datasets. It shows clearly that our proposed deep reinforcement learning model outperformed other models in multi-class corruption detection. In all the precision, recall and F-measure measures, and in all corruption classes, our approach scored the best (0.89–0.905). Such a strong performance confirms the success of our DRL-based adaptive CNN implementation and of the feature engineering in particular, as it outperforms the baseline versions by a large margin (“proposed (CNN)” and “proposed (All Features)”).

The classification quality assessment.
The fact that the model has shown high performance in all five different types of corruption (Bribery, Embezzlement, Nepotism, Fraud, Money Laundering) indicates that it is robust, which is an important feature in real-life implementation where the classes may be unbalanced. Moreover, our method significantly outperforms the current text classification and fraud detection baselines (Li24, Umer et al.21, Mohammed and Kora22) by a significant margin, which proves its targeted performance on such a challenging task on social media data.
The consequences of such findings are immense to anti-corruption campaigns. The accuracy of the model in categorizing the given types of corruption based on the textual data is high, which provides unprecedented opportunities in terms of efficient intelligence collection, early warning, and accurate resource distribution. Our automated system will help to reduce the number of misclassifications, which will allow anti-corruption bodies to become much more effective, as they will no longer be limited to manual reviews, but will be able to implement proactive and data-driven approaches to the global anti-corruption fight.
Figure 8 shows the Receiver Operating Characteristic (ROC) curves and Area Under the Curve (AUC) values that are key measures of how well a model can discriminate between positive and negative classes at different thresholds. The discriminative power of our suggested approach is clearly higher, with the AUC score of 0.9398. This much greater AUC, and the fact that its ROC curve is always higher than any of the others, means that our model is extremely good at distinguishing between texts related to each corruption type, reducing both false positives and false negatives at the same time.

The ROC curve assessment.
The figure also demonstrates the effects of our suggested approach. The AUC of the proposed model (0.9398) is significantly higher than the internal variants of the model, e.g., the AUC of the proposed model with all features (AUC = 0.9012) and the proposed model with CNN without tuning (AUC = 0.8901). Such a high internal validation confirms that the particular combination of deep reinforcement learning to dynamically configure CNNs, together with our tactical feature selection, is important in maximizing the discriminative power of the model. The sharp increase of the curve at the low False Positive Rates (FPR) of our method indicates the high sensitivity of our method in identifying the true positives without producing too many false alarms.
Compared to external benchmarks, the AUC of our proposed model is significantly higher than that of Li24 (AUC = 0.9047), Umer et al.21 (AUC = 0.8920) and Mohammed and Kora22 (AUC = 0.8848). This evident superiority in AUC values proves that our method not only provides a better overall classification result but also provides a more consistent and stable difference between the corruption types and non-corruption cases.
Table 3 presents results related to Precision, Recall, F-Measure, Total Accuracy and AUC for positive samples for different models. The proposed model with a precision of 0.9001, recall of 0.9004, and F-Measure of 0.9002 provides the best results, with a total accuracy of 90.0358 and an AUC of 0.9398. In contrast, models based on CNNs and other reference models clearly perform worse, with their accuracy and AUC being less than 0.9. These results indicate the superiority of the proposed model in identifying positive samples more accurately and its impact on analyzing corruption-related text data.
Limitations and future works
Although the given deep reinforcement learning method proves its great improvements in the area of corruption report detection, it is necessary to note that there are also some limitations that also open the path to the future research directions:
-
Language Dependency: The first weakness of this study is that it relies on one language. We only used English tweets to train and test our model. Therefore, when used in other languages, its performance might differ greatly. Future research will be aimed at the exploration of the model flexibility and effectiveness in various linguistic settings, possibly with multilingual data or cross-lingual transfer learning methods.
-
Contextual Interpretation of Subtle Language: The existing model, although powerful enough to recognize corruption by means of keywords and patterns, might prove ineffective in detecting more subtle linguistic features, like sarcasm, irony, figurative language, or highly specific jargon in corruption reports. Such contextual factors may cause misunderstanding. In our future research work we will strive to overcome this limitation by enhancing the structural capacity of the model, potentially by adding more complex contextual embeddings or higher-order attention layers to improve the semantic comprehension.
Conclusion
In the present paper, we introduced a new method of identifying corruption report in texts based on deep reinforcement learning. The given approach was specifically developed to deal with such issues as the high number of usable features and possible imbalance of target classes that are characteristic of textual data on corruption. The steps within our proposed methodology include: preprocessing of data, thorough feature extraction, selection of an optimal subset of features, and the last step, the usage of a Convolutional Neural Network (CNN) to detect the data precisely, which is adapted to the specific task by Q-learning.
Our method was proven to be effective with an impressive average accuracy of 90.04% and F-measure of 0.9 which was proved by the experimental results. These positive performance measures, particularly in comparison with other available approaches, validate the capability of our approach to better detect positive instances of corruption in texts. Such a high score of precision and recall highlights its great use potential in real areas of text analysis and community security. Resting on the solid results of the given research, one can make a conclusion that the suggested deep reinforcement learning framework can be used as one of the most effective and reliable tools in the fight against corruption and the further study of the textual data in this essential area.
Data availability
All data generated or analysed during this study are included in this published article.
References
Mackey, T. K. et al. The disease of corruption: views on how to fight corruption to advance 21st century global health goals. BMC Med. 14, 1–16 (2016).
Huisman, W. Corruption and Corruption Control in the Netherlands. Distinguishing criteria between petty and high-ranking corruption, 143 (2021).
Gupta, S., Davoodi, H. & Tiongson, E. Corruption and the provision of health care and education services. In The Political Economy of Corruption. 123–153 (Routledge, 2001)
Lalountas, D. A., Manolas, G. A. & Vavouras, I. S. Corruption, globalization and development: How are these three phenomena related?. J. Policy Model. 33(4), 636–648 (2011).
Tawiah, V. The impact of IPSAS adoption on corruption in developing countries. Finan. Account. Manag. 39(1), 103–124 (2023).
Kohler, J. C., Chang Pico, T., Vian, T. & Mackey, T. K. The global wicked problem of corruption and its risks for access to HIV/AIDS medicines. Clin. Pharmacol. Ther. 104(6), 1054–1056 (2018).
Mackey, T. K. & Liang, B. A. Combating healthcare corruption and fraud with improved global health governance. BMC Int. Health Hum. Rights 12, 1–7 (2012).
Vian, T. Review of corruption in the health sector: theory, methods and interventions. Health Policy Plan. 23(2), 83–94 (2008).
Lima, M. S. M. & Delen, D. Predicting and explaining corruption across countries: A machine learning approach. Gov. Inf. Q. 37(1), 101407 (2020).
Ribeiro, H. V., Alves, L. G., Martins, A. F., Lenzi, E. K. & Perc, M. The dynamical structure of political corruption networks. J. Complex Netw. 6(6), 989–1003 (2018).
Anders, G. & Nuijten, M. Corruption and the secret of law: An introduction. In Corruption and the Secret of Law 1–24 (Routledge, 2017).
Liu, P. Unsupervised corrupt data detection for text training. Expert Syst. Appl. 248, 123335 (2024).
Budsaratragoon, P. & Jitmaneeroj, B. A critique on the Corruption Perceptions Index: An interdisciplinary approach. Socioecon. Plann. Sci. 70, 100768 (2020).
Spyromitros, E. & Panagiotidis, M. The impact of corruption on economic growth in developing countries and a comparative analysis of corruption measurement indicators. Cogent Econ. Finan. 10(1), 2129368 (2022).
Paulo, L. D. D., Lima, R. C. D. A. & Tigre, R. Corruption and economic growth in Latin America and the Caribbean. Rev. Dev. Econ. 26(2), 756–773 (2022).
Bitterhout, S. & Simo-Kengne, B. D. The effect of corruption on economic growth in the BRICS Countries: A panel data analysis. In Economic and Well-being Research Group 66–78 (2020).
Belloumi, M. & Alshehry, A. S. The causal relationships between corruption, investments and economic growth in GCC countries. SAGE Open 11(4), 21582440211054424 (2021).
Malanski, L. K. & Póvoa, A. C. S. Economic growth and corruption in emerging markets: Does economic freedom matter?. Int. Econ. 166, 58–70 (2021).
Utomo, V. G., Kumkamdhani, T. Y. & Setiarso, G. Anti-corruption disclosure prediction using deep learning. J. Online Inf. 7(2), 168–176 (2022).
Li, J. et al. Detection of self-reported experiences with corruption on twitter using unsupervised machine learning. Soc. Sci. Human. Open 2(1), 100060 (2020).
Umer, M. et al. Impact of convolutional neural network and FastText embedding on text classification. Multimed. Tools Appl. 82(4), 5569–5585 (2023).
Mohammed, A. & Kora, R. An effective ensemble deep learning framework for text classification. J. King Saud Univ. Comput. Inf. Sci. 34(10), 8825–8837 (2022).
Ash, E., Galletta, S. & Giommoni, T. A machine learning approach to analyze and support anti-corruption policy. Available at SSRN 3589545 (2021).
Li, Q. Textual Data Mining for Financial Fraud Detection: A Deep Learning Approach. arXiv preprint arXiv:2308.03800 (2023).
Djouadi, I., Zakane, A. & Abdellaoui, O. Corruption and economic growth nexus: Empirical evidence from dynamic threshold panel data. Bus. Ethics Leadership 8(2), 49–62 (2024).
Muco, A. Measuring Corruption from Text Data. Available at SSRN 4852236 (2024).
Chen, H., Wu, L., Chen, J., Lu, W. & Ding, J. A comparative study of automated legal text classification using random forests and deep learning. Inf. Process. Manage. 59(2), 102798 (2022).
Dogra, V., Verma, S., Kavita, Chatterjee, P., Shafi, J., Choi, J. & Ijaz, M. F. A complete process of text classification system using state‐of‐the‐art NLP models. Comput. Intell. Neurosci. 2022(1), 1883698 (2022).
Mittal, V., Gangodkar, D. & Pant, B. Deep graph-long short-term memory: A deep learning based approach for text classification. Wireless Pers. Commun. 119, 2287–2301 (2021).
Köksal, Ö. & Akgül, Ö. A comparative text classification study with deep learning-based algorithms. In 2022 9th International Conference on Electrical and Electronics Engineering (ICEEE) 387–391 (IEEE, 2022).
Soni, S., Chouhan, S. S. & Rathore, S. S. TextConvoNet: A convolutional neural network based architecture for text classification. Appl. Intell. 53(11), 14249–14268 (2023).
Bangyal, W. H. et al. Detection of fake news text classification on COVID-19 using deep learning approaches. Comput. Math. Methods Med. 2021(1), 5514220 (2021).
Xiong, J., Yu, L., Niu, X. & Leng, Y. XRR: Extreme multi-label text classification with candidate retrieving and deep ranking. Inf. Sci. 622, 115–132 (2023).
Abarna, S., Sheeba, J. I. & Devaneyan, S. P. An ensemble model for idioms and literal text classification using knowledge-enabled BERT in deep learning. Meas. Sens. 24, 100434 (2022).
Setiawan, Y., Gunawan, D. & Efendi, R. Feature extraction TF–IDF to perform cyberbullying text classification: a literature review and future research direction. In 2022 International Conference on Information Technology Systems and Innovation (ICITSI) 283–288. (IEEE, 2022).
Dharma, E. M., Gaol, F. L., Warnars, H. L. H. S. & Soewito, B. E. N. F. A. N. O. The accuracy comparison among word2vec, glove, and fasttext towards convolution neural network (cnn) text classification. J. Theor. Appl. Inf. Technol. 100(2), 31 (2022).
He, Z. H., Ng, M. K. & Zeng, C. Generalized singular value decompositions for tensors and their applications. Numer. Math. Theory Methods Appl. 14(3), 692–713 (2021).
Gong, Y. & Liu, X. Video summarization and retrieval using singular value decomposition. Multimedia Syst. 9(2), 157–168 (2003).
Li, C., Ding, J., Lewis, F. L. & Chai, T. Model-free Q-learning for the tracking problem of linear discrete-time systems. IEEE Trans. Neural Netw. Learn. Syst. 35(3), 3191–3201 (2022).
Author information
Authors and Affiliations
Contributions
Qiushi Xiao wrote the main manuscript text. Qiushi Xiao reviewed the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Xiao, Q. Automated detection of corruption reports in text via deep reinforcement learning. Sci Rep 15, 36674 (2025). https://doi.org/10.1038/s41598-025-20330-0
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-20330-0
