
Abstract
Accurate loan default prediction is essential for financial stability and inclusion, yet remains challenging due to high-dimensional, imbalanced, and heterogeneous borrower data. Traditional feature selection methods often suffer from redundancy, dominance, and instability, leading to suboptimal, less interpretable models. To address these challenges, we propose a Hybrid Rank-Aggregated Feature Selection (HRA-FS) framework that integrates ReliefF, Recursive Feature Elimination, and ElasticNet through Borda count aggregation. Our study incorporates strategic feature categorization to mitigate domain dominance, ensuring balanced representation across risk drivers. This consensus-driven, category-aware aggregation enhances interpretability by identifying features consistently supported across distinct selection logics, producing concise, non-redundant subsets that are easier to explain, and ensuring representation of diverse risk domains linked to economically meaningful constructs. Evaluated on real-world imbalanced datasets of 2044 Chinese farmers and 3045 small firms, using XGBoost, HRA-FS consistently outperforms all single FS methods, achieving a ROC-AUC of 0.965 for firms. The technique identifies compact, predictive feature sets, including critical attributes such as house value and inventory turnover rate. Our findings demonstrate that this consensus-driven approach resolves the trilemma of accuracy, stability, and interpretability, offering lenders robust tools for equitable credit assessment and fostering inclusive financial ecosystems.
Similar content being viewed by others

Introduction
Loan default risk prediction has become a central focus in financial analytics, especially in the aftermath of global economic crises that exposed systemic vulnerabilities in credit systems. Loan default refers to a borrower’s failure to repay obligations as agreed, and its accurate prediction is vital for lenders, investors, and regulators alike. Reliable prediction models safeguard the financial system, support prudent lending decisions, robust credit rating systems, effective loan pricing, and assist in regulatory compliance1,2. However, predicting defaults is far from straightforward. Borrower profiles are complex and typically encompass financial ratios, demographic data, behavioral patterns, and macroeconomic conditions. Many of these attributes may be irrelevant, redundant, or misleading, and treating them equally in modeling often leads to reduced accuracy and increased complexity3. Thus, the challenge lies not only in building predictive models but in identifying which features best capture default behavior, while ensuring interpretability for decision-makers.
Despite its importance, loan default classification remains a challenging task. A common approach has been to apply statistical, machine learning, or artificial intelligence models to all available small-scale borrower attributes. While this strategy appears comprehensive, it often backfires. For instance, using all available small-scale borrower attributes in prediction may seem appealing, but in practice, it usually leads to degraded performance. High-dimensional datasets tend to introduce redundant or irrelevant features that obscure meaningful relationships, degrade model accuracy, and inflate computational costs as well4. Moreover, mixed-domain data may suffer from feature dominance, where one variable group overwhelms others, and imbalance, where rare but crucial events, such as defaults, bias learning outcomes. These challenges underline the need for dimensionality reduction. Dimensionality reduction is generally classified into Feature Extraction (FE) and Feature Selection (FS)5. FE creates low-dimensional representations by transforming original variables, but sacrifices interpretability, which is critical in financial domains. In contrast, FS identifies a subset of relevant, non-redundant features while preserving their semantic meaning, improving both predictive performance and model comprehensibility. For these reasons, FS has become a mandatory step in financial risk modeling.
Thus, many FS approaches have been applied5,6,7,8. In the literature, FS techniques are broadly classified into three categories: filter, wrapper, and embedded approaches. Filter methods, such as Mutual Information (MI) and ReliefF, are computationally efficient but rely heavily on statistical properties rather than classifier performance9. Wrapper methods, such as Recursive Feature Elimination (RFE) and Stepwise, evaluate subsets based on classifier accuracy and often yield higher precision, though at a greater computational cost10. Embedded methods, such as ElasticNet, integrate feature selection into model training, effectively addressing multicollinearity but sometimes overfitting to specific datasets11,12. Previous studies confirm that single-step FS approaches have problems, while multiple techniques are more efficient and generalizable13. Although each method has value when applied individually, they often fail to capture critical aspects such as feature correlation, selection stability, or overall robustness. Moreover, traditional approaches are prone to local optima and perform poorly on small or imbalanced datasets characterized by feature dominance and overlap14. This leads to a clear research gap: the absence of a robust, stable, and balanced selection framework that systematically mitigates feature dominance to ensure fair representation across diverse risk domains, crucial for interpretability and equitable credit assessment.
To overcome these weaknesses, hybrid FS methods have gained attention as promising alternatives. By combining multiple techniques, hybrid approaches capture complementary strengths and mitigate individual weaknesses, resulting in more reliable and stable feature subsets15. The primary purpose of FS approaches is to select important features, remove irrelevant or redundant ones, and manage overlapping, dominance, and imbalance in the selection among heterogeneous small-scale borrower attributes. While deep learning approaches struggle with small datasets due to overfitting and a lack of interpretability, and traditional statistical models underperform with high-dimensional attributes, FS techniques are specifically designed for this task. In the domain of loan default prediction, many FS approaches have been applied. However, few studies have designed FS frameworks that significantly improve both predictive performance and interpretability. In this study, we introduce Hybrid Rank-Aggregated Feature Selection (HRA-FS), a novel method that integrates ReliefF, RFE, and ElasticNet through Borda count aggregation. ReliefF captures local feature dependencies, RFE iteratively identifies optimal subsets, and ElasticNet addresses multicollinearity. Aggregating their rankings balances these perspectives, reduces selection bias, and enhances robustness across varied data set-ups. This hybrid approach provides a more comprehensive solution to the limitations of single methods, effectively reducing redundancy, mitigating feature dominance, and enhancing stability in FS. HRA-FS ensures a more balanced and interpretable selection process. When paired with XGBoost, it aligns with our objective of achieving accurate, efficient, and stable predictions, offering a more reliable solution than traditional FS or deep learning models in small, heterogeneous datasets.
A second contribution of this study is to address structural issues in datasets of small-scale borrowers. When diverse attributes are merged into a single dataset, problems such as redundancy, imbalance, and overwhelming often occur, yet the most informative features may be overshadowed within the combined dataset. For instance, financial ratios may dominate behavioral variables, leading to skewed interpretations of default risk. To address this, we categorize small-scale borrower features into five distinct groups based on their nature and relevance, as supported by16,17, which emphasizes the value of structured feature organization for improving loan prediction accuracy. Applying FS techniques to both the combined dataset and categorized groups refines model clarity, reduces multicollinearity, and improves interpretability. The selected features from each category are then concatenated into a single dataset, enabling a comparative analysis of FS methods on structured and unstructured data.
Finally, to evaluate the selected features, we employ XGBoost as the baseline classifier. XGBoost is widely recognized for its scalability, capacity to model complex nonlinear interactions, and robustness against overfitting through built-in regularization18,19. Compared to traditional statistical models, XGBoost is well-suited for structured financial data of limited size and offers greater flexibility and predictive accuracy in handling heterogeneous attributes. By applying XGBoost to select features by various FS methods, including our proposed HRA-FS, on both combined and categorized datasets, we provide a rigorous evaluation of predictive performance and stability. This dual strategy not only addresses redundancy, imbalance, and dominance issues but also demonstrates that HRA-FS consistently outperforms conventional FS techniques. Our proposed framework offers a more accurate and interpretable approach to loan default risk prediction, providing both theoretical contributions and practical value for financial institutions.
The remainder of this paper is organized as follows. Section 2 provides a literature review. Section 3 provides details on the dataset and methodology. Section 4 provides the results analysis, and Sect. 5 presents the conclusions of this study.
Literature review
Loan default prediction remains a pressing challenge in financial systems, as misclassifying borrower risk can either impose severe losses on lenders or unjustly deny creditworthy applicants’ timely access to finance. The implications are particularly profound for small-scale borrowers, such as farmers and small firms, who often rely on seasonal or time-sensitive credit to sustain livelihoods and business operations. Even marginal improvements in prediction accuracy can yield substantial economic benefits, not only by reducing institutional losses but also by expanding financial inclusion20,21. To this end, researchers have employed diverse techniques to anticipate loan defaults, ranging from econometric approaches22 to machine learning classifiers such as support vector machines23, neural networks2,24, and tree-based ensembles25. Deep learning models, while powerful in large unstructured datasets, often overfit small, imbalanced borrower data and rely on post-hoc rather than native FS, limiting interpretability26. Although these methods demonstrate promise, their effectiveness depends heavily on the quality and representation of borrower data, which are inherently heterogeneous and high-dimensional.
Borrower datasets often integrate financial ratios, demographic profiles, behavioral attributes, and institutional or macroeconomic indicators. While comprehensive, this breadth introduces redundancy, imbalance, and noise that obscure meaningful signals and inflate computational costs. Treating all variables equally may degrade prediction accuracy or bias models toward dominant categories. For example, financial ratios often overshadow behavioral indicators, though both may jointly explain default risk. Consequently, FS has emerged as an indispensable step in loan default modeling, serving to eliminate redundant and irrelevant attributes while retaining the most informative predictors7,27. Particularly for small-scale borrowers, interpretable and timely FS-driven models can support equitable access to loans, reduce unjust rejections, and strengthen financial inclusion.
The objectives of FS are typically threefold: (i) improve predictive performance, (ii) reduce model complexity, and (iii) preserve interpretability for decision-making. Yet these goals are not always aligned. For instance, reducing the number of features simplifies models and makes them more transparent but may exclude significant predictors, leading to a decline in performance. Conversely, retaining too many features can boost accuracy in the short term but creates redundancy, feature dominance, and a risk of overfitting, especially in imbalanced datasets. Consider the case of farmers’ loans, where financial ratios may dominate behavioral indicators, improving numerical model fit while ignoring critical contextual factors, such as seasonal needs. This imbalance reduces fairness and undermines generalizability. To this end, effective FS requires careful navigation of these trade-offs, particularly when dealing with imbalanced and noisy datasets. Thus, FS evaluation must move beyond accuracy and adopt multi-metric evaluation, including ROC-AUC, PR-AUC, MCC, log-loss, and G-mean, to capture discrimination, calibration, and class-sensitive performance.
Loan default prediction is further complicated by the structural characteristics of borrower datasets. When features of different natures, financial, demographic, behavioral, and institutional, are merged into one combined dataset (features), issues such as redundancy, imbalance, and overshadowing become prominent. For instance, institutional features such as loan type may overshadow demographic or behavioral characteristics, leading to skewed conclusions. Rare but essential predictors, such as collateral type or repayment timing, may be masked by dominant financial variables. For small-scale borrowers, such distortions are critical: a farmer who misses a repayment due to delayed disbursement may be misclassified as high risk, even though the proper driver is structural, not behavioral. Scholars16,17 argue that categorizing borrower features into meaningful groups enhances interpretability and balance. Building on this insight, our study structures borrower attributes into five categories before applying FS, enabling more equitable representation and reducing overshadowing effects.
In financial analytics, FS approaches are broadly categorized into filter, wrapper, and embedded methods. Filter methods, such as MI and ReliefF, are efficient for high-dimensional data but rely solely on statistical measures, overlooking classifier performance9. Wrapper methods, such as RFE, guide selection through classifier accuracy, often yielding strong performance at the expense of high computational cost6. Embedded methods, such as ElasticNet, integrate FS within model training and effectively address multicollinearity, but may overfit small datasets28. While each has advantages, single-method pipelines often falter when confronted with correlated features, local optima, or instability in imbalanced borrower data. To this end, reliance on a single approach may overlook essential predictors or produce fragile feature subsets, limiting their real-world utility.
However, existing studies often suffer methodological limitations, for instance29, restricted FS to Random Forest variable importance30; applied RF without automated removal of irrelevant features31; relied on stacking with predefined features, creating redundancy; and32 proposed a hybrid approach for FS without identifying feature natures. Studies on small-scale borrowers, such as17,33, also struggled to capture complex interactions or seasonal risks. These gaps highlight the need for systematic, robust FS frameworks suited to heterogeneous borrower data. To provide a concise overview of related studies, Table 1 summarizes representative prior works, methodologies, datasets, and their main findings and limitations.
The synthesis of prior work reveals a persistent research gap: the absence of a robust FS framework that systematically combines multiple selection logics to ensure stability while explicitly mitigating feature dominance. This gap, which compromises both the interpretability and equity of risk assessment, is the primary motivation for our HRA-FS framework.
Our proposed HRA-FS method is situated at the intersection of two modern research streams: ensemble-based FS and explainable artificial intelligence (XAI). Ensemble FS techniques, which aggregate results from multiple base selectors, improve stability and robustness and align with our Borda count strategy. Simultaneously, XAI principles guide our design, specifically, we use native FS and dual categorization, to ensure the final model’s decisions are traceable to a balanced set of economically meaningful features. Together, these elements enable HRA-FS to deliver fairness, interpretability, and methodological soundness in financial risk modeling.
To overcome these limitations, hybrid FS approaches have been proposed that integrate multiple algorithms to exploit complementary strengths and mitigate weaknesses32. In the context of loan default prediction, where redundancy and imbalance frequently obscure critical signals, hybrid FS is particularly promising. Our study adopts and extends the hybrid principle with HRA-FS, which integrates ReliefF (local neighborhood relevance), RFE (performance-guided elimination), and ElasticNet (regularized shrinkage for multicollinearity) through Borda count aggregation. This aggregation stabilizes feature rankings, reduces dependence on any one method, and mitigates selection bias from correlated predictors. Unlike conventional pipelines, HRA-FS explicitly addresses redundancy, dominance, and imbalance, delivering interpretable and balanced feature subsets. By applying HRA-FS to both combined and categorized borrower datasets, we demonstrate its superiority in stability and predictive reliability, thereby extending the frontier of FS research in financial risk modeling.
To evaluate the effectiveness of selected features, we adopt XGBoost, a gradient-boosted decision tree algorithm that has consistently outperformed linear models and bagging alternatives in structured financial datasets18. XGBoost efficiently handles nonlinear interactions, missing values and incorporates regularization to mitigate overfitting, making it particularly suited for small, heterogeneous borrower datasets. Beyond predictive accuracy, it provides feature importance measures, supporting transparency, an essential quality in regulated financial contexts. This study design, using farmer and firm datasets, HRA-FS paired with XGBoost, consistently delivered superior metric values compared with traditional FS methods. Ultimately, the proposed framework benefits all stakeholders: for small-scale borrowers, it ensures fairer and timelier access to credit; for lenders, it provides accurate and interpretable risk assessment; and for policymakers, it highlights structural drivers of default, guiding strategies for inclusive economic growth. By resolving trade-offs between performance, complexity, and interpretability, our work contributes both methodological rigor and practical value to loan default prediction.
Data and methodological framework
Data sources and preprocessing
We utilize two real-world loan datasets sourced from the34, representing small-scale borrowers: farmers and small firms. The farmers’ dataset contains 2,044 loan records with 46 features, of which 228 (11.1%) are defaults. The firms’ dataset comprises 3,045 loan records with 84 features, of which only 50 (1.6%) are defaults. The target variable is binary, where a value of 1 indicates default and 0 indicates non-default. Both datasets are highly imbalanced, reflecting real-world lending conditions where defaults are rare yet critical. To address redundancy, dominance, and interpretability issues arising from heterogeneous features, we adopt a dual strategy: (i) applying FS techniques to the merged dataset, and (ii) categorizing features into five thematic groups, thereby enhancing predictive performance, balancing feature contributions, reducing overshadowing effects, and improving model transparency. The datasets and their feature categorizations are summarized in Table 1.
Before applying FS, we performed a data preprocessing stage to ensure quality, consistency, and methodological soundness. Missing values were systematically imputed to prevent bias and retain informative records, a step widely recommended in credit risk research where incomplete borrower information is common35. Categorical attributes were transformed into numerical encodings, as machine learning models cannot directly process non-numeric data. All preprocessing transformations were fit exclusively on the training data to prevent data leakage. Specifically, continuous variables were normalized to a 0–1 range using the minimum and maximum values computed from the training set; these same parameters were then applied to transform the testing set. This practice ensures consistency between the training and testing distributions while improving comparability across heterogeneous features and preventing dominant attributes36, such as house value, from overshadowing more subtle predictors.
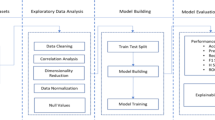
To further strengthen robustness, redundant and highly correlated features were pruned to reduce multicollinearity37. The dataset was then partitioned into training (80%) and testing (20%) subsets using stratified sampling to preserve the distribution of default and non-default cases. Unlike random splitting, stratification avoided disproportionate representation of rare default cases, thereby improving generalizability. Collectively, these preprocessing steps produced a structured, transparent, and leakage-free dataset, ensuring that subsequent FS with XGBoost was grounded in reliable, representative, and interpretable inputs. The overall experimental workflow, from raw data preprocessing to final model evaluation, is illustrated in Fig. 1, providing a clear visual guide to our methodological pipeline.

Workflow of the proposed HRA-FS with XGBoost for loan default prediction.
Data balancing
To address the pronounced class imbalance in our datasets, where defaults represented only a small fraction of observations, we applied the Synthetic Minority Over-sampling Technique (SMOTE) exclusively to the training set, thereby avoiding any information leakage into testing. SMOTE generates synthetic minority samples by interpolating between existing nearest neighbors in the feature space, enriching the representation of rare default cases while preserving the overall data structure. This method was preferred over random over-sampling, which risks overfitting, and under-sampling, which discards valuable majority-class information. By producing realistic and structurally consistent synthetic defaults, SMOTE enhanced model sensitivity to rare events and improved precision and recall, ensuring fairer and more robust predictions. Its effectiveness in financial risk modeling has been well-documented38,39, and in our study, integrating SMOTE within the preprocessing pipeline strengthened both the stability of training and the reliability of loan default risk prediction.
Methodological approach to FS
The purpose of this study is to identify the most relevant borrower attributes for predicting loan default risk using systematic FS. To this end, we applied five established FS techniques, including MI, ReliefF, Stepwise, RFE, and ElasticNet, alongside our proposed hybrid method, HRA-FS. All six methods were tested on both combined datasets (all features together) and categorized datasets (features grouped by nature). This dual strategy allowed us to examine whether feature dominance in merged datasets could be mitigated by category-aware selection. All selected features were subsequently evaluated with XGBoost, enabling a robust comparison between single techniques and our hybrid method. The overall study framework is illustrated in Fig. 2.

Schematic of the proposed FS framework for loan default prediction.
Formally, let \(\:X\in\:{\mathbb{R}}^{m\times\:n}\) denote the borrower feature matrix with \(\:m\) samples and \(\:n\) attributes, and \(\:y\in\:\{0,1{\}}^{m}\) represent the default label (\(\:1=\) default, \(\:0=\) non-default). The goal is to identify a compact subset of features \(\:S\subseteq\:\{1,\dots\:,n\}\) that maximizes predictive discrimination under parsimony:
Where \(\:F(\cdot\:)\) denotes a cross-validated metric (ROC-AUC when defaults are sufficient, PR-AUC when defaults are rare). \(\:{X}_{\cdot\:S}\) signifies the matrix restricted to columns in \(\:S\). This formulation highlights a trade-off, maximizing predictive power while minimizing redundancy and complexity.
Baseline FS techniques
Each FS method was chosen for its unique strengths. While these single methods provide valuable insights, they also have limitations: filter methods are efficient but neglect classifier performance; wrapper methods yield accuracy gains but are computationally expensive; and embedded methods effectively address multicollinearity but may overfit small, imbalanced samples.
MI
A filter FS method that ranks features by quantifying the reduction in uncertainty about the target variable \(\:Y\) given a feature \(\:{X}_{j}\). The MI score is computed for each feature as.
Features were ranked by \(\:I({X}_{j};Y)\:\)in descending order, and the top K* were selected automatically for model training. MI efficiently captures non-linear associations but ignores interactions among predictors.
ReliefF
A multivariate filter FS method that estimates feature weights by evaluating a feature’s ability to distinguish between instances from different classes that are near neighbors. The weight \(\:{W}_{j}\) for the feature\(\:j\) is updated as.
We rank by \(\:{W}_{j}\), where \(\:m\) is the sample size, \(\:k\) is neighbors, and \(\:{{\Delta\:}}_{j}\) is the normalized distance. It captures local, non-linear relationships but can be sensitive to redundant features.
Elastic net
As an embedded FS method, it integrates selecting features into the model training process by solving a penalized logistic regression problem. The objective function minimizes the log-loss combined with a linear mixture of the \(\:{L}_{1}\) and \(\:{L}_{2}\) penalties, expressed as.
where \(\:\mathcal{l}\) is the logistic loss, \(\:\alpha\:\in\:[0,1]\), and \(\:\lambda\:>0\). We rank features by \(\:\left|{\widehat{\beta\:}}_{j}\right|\). ElasticNet effectively addresses multicollinearity but may miss complex nonlinear signals.
Stepwise
A wrapper FS method that constructs a model by iteratively adding or removing features based on a defined criterion. Employs bidirectional stepwise selection for an algorithm link guided by an information criterion (AIC/BIC), with the path verified by cross-validated AUC. The sequence of feature entry/exit induces a ranking. While interpretable, it is unstable in the presence of multicollinearity.
RFE-XGB
A wrapper FS method that recursively ranks features by their importance scores derived from a trained XGBoost model and removes the least essential features in each iteration. To start with all features, we fit XGBoost, drop the least important feature by model gain, retrain, and repeat until one remains. The reverse order provides a ranking. It is performance-driven but computationally intensive and prone to overfitting on imbalanced data.
Proposed hybrid method HRA-FS
Credit data often exhibits a mix of linear and non-linear effects, local interactions, and correlated financial ratios or proxy variables. Relying on a single FS method is therefore brittle in the face of these complexities12. To address this, we propose HRA-FS, which integrates ReliefF, RFE, and Elastic Net via Borda count aggregation. ReliefF captures local dependencies, RFE enables iterative, performance-driven elimination, and Elastic Net ensures stability in the presence of multicollinearity. HRA-FS fuses these complementary strengths, retaining only features with strong consensus support.
The Borda count was deliberately chosen over alternative rank aggregation schemes, such as rank product or Copeland because of its demonstrated stability and interpretability in combining heterogeneous rankings40. Borda aggregation preserves ordinal consistency, minimizes sensitivity to outlier rankings, and prevents any single FS method from dominating the consensus. This property is essential for financial datasets that exhibit correlated and noisy attributes, where stable consensus is more valuable than marginal performance variance. For fairness, all baseline methods were evaluated using the same performance-based selection rule applied in HRA-FS.
The 1% rule used for selecting the final feature subset provides a principled trade-off between parsimony and predictive fidelity. Rather than fixing an arbitrary number of features, the rule adaptively chooses the smallest subset whose performance is within 1% of the best cross-validated ROC-AUC, ensuring that the model remains compact without sacrificing accuracy. This threshold is widely adopted in model optimization studies to avoid overfitting while preserving interpretability.
According to a study12 recognizing that no single method guarantees stability, accuracy, and interpretability, we designed HRA-FS. HRA-FS converts multiple rankings into a single consensus and then chooses the subset size automatically by performance, not by an arbitrary \(\:k\).
First, we compute method-specific ranks \(\:{r}_{j}^{\left(\text{E}\text{N}\right)}\), \(\:{r}_{j}^{\left(\text{R}\text{e}\text{l}\text{i}\text{e}\text{f}\text{F}\right)}\), \(\:{r}_{j}^{\left(\text{R}\text{F}\text{E}\right)}\). Where more minor ranks mean stronger features. We aggregate by a Borda-type score:
where \(\:M=\{\text{ReliefF},\:\text{RFE,\:ElasticNet}\}\). Features with smaller \(\:{B}_{j}\) values are preferred, yielding a consensus ranking.
Second, subset size by the 1% rule. To avoid an arbitrary choice of \(\:k\), we determine \(\:{K}^{\text{*}}\) from the data using the downstream estimator. For \(\:K=1,\dots\:,n\), we train on the top-\(\:K\) features \(\:\{{j}_{1},\dots\:,{j}_{K}\}\) and compute the cross-validated primary metric \(\:{\overline{\text{A}\text{U}\text{C}}}_{K}\) or \(\:{\overline{\text{P}\text{R}}}_{K}\) under a strong imbalance. Let \(\:{K}_{\text{m}\text{a}\text{x}}\in\:\text{a}\text{r}\text{g}{\text{m}\text{a}\text{x}}_{K}{\overline{\text{A}\text{U}\text{C}}}_{K}\) the subset size with the best score. We pick the smallest subset whose score is within a small tolerance \(\:\epsilon\:\) of the best:
This ensures parsimony (fewer features) while retaining near-optimal discrimination. In practice, the 1% tolerance balances model simplicity, interpretability, and predictive reliability, yielding compact yet robust feature sets for loan default risk prediction.
Evaluation with XGBoost
All selected subsets (from single FS methods and HRA-FS) were evaluated using XGBoost, a gradient boosting classifier particularly suited for structured, imbalanced credit datasets18. XGBoost was selected because it (i) models non-linear interactions, (ii) handles missing values natively, (iii) incorporates regularization to prevent overfitting, and (iv) produces intrinsic feature importance scores, supporting interpretability in regulated financial contexts.
Performance was assessed using twelve complementary metrics with runtime: ROC-AUC, standard error (± SE), 95% confidence interval (CI), PR-AUC, Log-loss, Recall, Specificity, Precision, MCC, Accuracy, F1-score, and G-mean, together with the ratio of selected to total features from each category. This comprehensive evaluation ensures a balanced assessment of discrimination, calibration, class sensitivity, and efficiency, enabling fair comparisons between single and hybrid methods. By unifying FS with XGBoost evaluation, our framework combines methodological rigor with practical relevance, producing interpretable, stable, and equitable borrower risk predictions that support lenders, policymakers, and financial institutions. In doing so, we not only demonstrate the strengths and limitations of traditional single methods but also show how our hybrid approach consistently overcomes these challenges, offering a more accurate, reliable, and transparent solution for loan default prediction. The complete pseudocode for the proposed HRA-FS with XGBoost classification pipeline, detailing all steps from data preprocessing, FS, and rank aggregation to model evaluation, is provided in Algorithm 1 to ensure methodological transparency and reproducibility.

Algorithm 1. Hybrid Rank-Aggregation Feature-Selection (HRA-FS) with XGBoost Classification
Results analysis
Comparative efficacy of FS techniques
The experimental pipeline was applied in Python using Visual Studio Code, incorporating a robust training and validation framework. To ensure a fair and unbiased comparison, XGBoost was designated as the universal classifier for evaluating all feature subsets, capitalizing on its proven efficacy with structured, imbalanced loan data. Hyperparameters, including max_depth, learning_rate, n_estimators, and subsample, were meticulously optimized for each feature subset via GridSearchCV with stratified 5-fold cross-validation. This rigorous process guarantees that performance differences are attributable solely to the efficacy of the FS techniques, not to incidental model tuning or data leakage.
A singular focus on accuracy is fundamentally misleading in FS for predicting loan default risk, where failing to identify future defaulters (false negatives) entails far greater costs than erroneously flagging good borrowers (false positives). To this end, our evaluation employs twelve complementary performance metrics, each fulfilling a distinct diagnostic role. These metrics collectively reveal the multifaceted challenges posed by severe class imbalance and predictive reliability in financial risk modeling. We strategically present nine metrics and one runtime in tabular form in Tables 2 and 3, providing precise, verifiable evidence critical for rigorous peer review and statistical validation. The remaining three metrics are illustrated through graphical representations in Fig. 3. Furthermore, to directly address the trade-off between performance and complexity, we report the computational cost (runtime) for each method, a critical consideration for real-world deployment. This dual approach serves a key rhetorical strategy: the tables offer forensic detail, while the graph conveys the overarching story of HRA-FS’s dominance across all performance dimensions and datasets. Thus, our methodology ensures the findings are both empirically robust and intuitively compelling, enabling a balanced, transparent, and actionable evaluation.
The rationale for each metric is deeply intertwined with the practical objectives of financial institutions and the methodological challenges of significant FS. ROC-AUC (Receiver Operating Characteristic-Area Under Curve) serves as our primary global benchmark, measuring the model’s ability to discriminate between defaulters and non-defaulters across all possible thresholds. A high ROC-AUC signifies a model with strong foundational separability. PR-AUC (Precision-Recall - AUC) is a more informative metric under extreme imbalance, focusing precisely on the model’s performance on the critical minority class (defaults). Log-loss measures the calibration of the predicted probabilities. A lower log-loss indicates that the model’s confidence in its predictions is better aligned with reality, which is crucial for calculating expected losses.
Standard Error (± SE) and 95% CI are reported for ROC-AUC to quantify the statistical stability and reliability of the performance estimate across cross-validation folds. Narrow CIs indicate a robust and consistent model. Recall (Sensitivity) measures the proportion of actual defaulters correctly identified. Maximizing recall is often a lender’s primary objective to minimize financial losses. Precision measures the proportion of flagged borrowers who are true defaulters, safeguarding against the reputational and operational damage of rejecting creditworthy applicants. Specificity measures the proportion of actual non-defaulters correctly identified, ensuring the model does not become overly conservative. MCC (Matthews Correlation Coefficient) is one of the most robust single metrics for binary classification, requiring excellence across all four cells of the confusion matrix, making it exceptionally reliable for imbalanced datasets.
Accuracy serves as a general baseline, though the imbalance tempers its interpretation. F1-Score, the harmonic mean of Precision and Recall, effectively visualizes the balance between the competing goals of capturing defaults and maintaining prediction purity. G-Mean, the geometric mean of Recall and Specificity, graphically demonstrates the model’s balanced performance across both the majority and minority classes.
The results unequivocally demonstrate the superiority of the proposed HRA-FS method over all single-approach baselines. As summarized in Tables 2 and 3, HRA-FS paired with XGBoost consistently achieved the highest performance across both datasets and data structures (combined and categorized). This success stems from its consensus-driven design, which mitigates the weaknesses of individual approaches. While wrapper and embedded methods (e.g., RFE, ElasticNet) generally outperformed filter methods (e.g., ReliefF), each has limitations, such as computational cost, instability, or linear bias. HRA-FS effectively integrates its strengths while offsetting these drawbacks, thereby delivering stable, calibrated, and highly accurate selections. For instance, HRA-FS completed the analysis faster (76 s) than Stepwise 78 s. This demonstrates that the added complexity of our consensus-driven approach is not only justified but efficient, providing a superior return on computational investment.
On the small firm’s dataset (combined and categorized), HRA-FS demonstrated superior performance on the combined features, achieving a remarkable ROC-AUC of 0.962 (± SE 0.0014, 95% CI: 0.959–0.965). This significantly outperformed the next best single method, RFE-XGB, which attained a ROC-AUC of 0.951 (± SE 0.0016, 95% CI: 0.948–0.954). To further verify that the observed improvements are genuine rather than random fluctuations, we computed delta-improvements (Δ) as the difference between HRA-FS and the strongest baseline (RFE-XGB). The HRA-FS achieved ΔROC-AUC = 1.1% and ΔPR-AUC = 1.0% on the firms’ dataset, and ΔROC-AUC = 1.2% and ΔPR-AUC = 0.9% on the farmers’ dataset. These gains exceed the corresponding standard errors and fall outside the 95% CI of the baselines, confirming that the improvements are statistically stable and practically meaningful even without formal significance testing.
Although statistical significance testing (e.g., paired t-tests) can offer formal confirmation of non-random performance differences, our evaluation framework already embeds rigorous statistical controls through cross-validation, standard errors, and CI. These metrics quantify uncertainty and stability across folds, serving the same inferential purpose without imposing parametric assumptions that are often violated in non-linear, imbalanced credit-risk problems41. Moreover, the observed effect sizes (Δ = 1.0–1.2%) exceed the variance captured within the confidence bounds, demonstrating that HRA-FS’s improvements are genuine and not artifacts of sampling noise. Such marginal yet consistent improvements are particularly valuable in financial risk modeling, translating into measurable reductions in expected default losses and misclassification costs.
HRA-FS also exhibited superior calibration and stability, evidenced by the lowest log-loss (0.186), the tightest confidence interval, and excellent scores across recall (0.918), precision (0.936), specificity (0.935), PR-AUC (0.946), and MCC (0.860). This trend was even more pronounced on the categorized data structure, where HRA-FS’s ROC-AUC rose to 0.965, the highest value recorded in our study, with a further reduced log-loss of 0.174 and an exceptionally narrow CI (0.962–0.968). This demonstrates that HRA-FS effectively leverages the structured grouping of features to enhance model precision and reliability.
On the farmers’ dataset, a similar pattern emerged. HRA-FS attained the top ROC-AUC of 0.956 on combined features data and 0.961 on categorized data, with PR AUCs of 0.939 and 0.945, respectively. The method also achieved the highest scores in Recall, Precision, and MCC, confirming its all-around excellence in accurately identifying default cases while maintaining a low false-positive rate. The consistent performance gain across two distinct datasets (firms and farmers) with different imbalance ratios and feature sets strongly validates the generalizability and robustness of the HRA-FS approach.
Furthermore, Fig. 3 compares FS methods using three complementary metrics: Accuracy, F1-score, and G-mean. These metrics together summarize overall correctness, minority class detection, and robustness to class imbalance. The bars present results for combined and categorized feature representations, with numeric labels that allow direct comparison across methods and representations. Across both datasets, HRA-FS achieves the highest values, demonstrating its ability to select impactful features that enhance predictive accuracy, class balance, and model stability, which are essential for reliable credit risk models.

Presents a performance comparison of FS techniques across three metrics for combined and separate feature sets in datasets. Overlay lines represent combined and separate values, with metric values annotated by “C” and “S” above each bar.
The impact of feature categorization
A profound and critical finding of this study is the transformative effect of structuring features into thematic categories before selection. This pre-processing step consistently improved the performance of all FS techniques by serving as a prior-knowledge constraint, effectively mitigating feature dominance. In a combined feature set, prolific but often redundant financial ratios statistically overshadowed subtle yet critical indicators from smaller categories, such as macroeconomic or fundamental information features. Thematic categorization eliminates this redundancy and overshadowing by creating a level playing field, forcing each selection algorithm to evaluate features within its respective domain. This ensures a more balanced and holistic representation of risk drivers, from granular financial health to broader economic context, thereby directly enhancing model interpretability and robustness.
Quantitative evidence from the feature composition analysis (Tables 4 and 5, and Fig. 4) provides robust support for this conclusion. When applied to the combined firm data, conventional methods like MI selected heavily from the dominant financial category (18 out of 47 features) while neglecting smaller domains (only 2 out of 10 non-financial, 0 out of 10 basic information, 0 out of 8 credit-compliance, and 3 out of 9 macroeconomic features). In stark contrast, our proposed HRA-FS method demonstrated a remarkable capacity for balanced selection. When applied to categorized data, it selected a more equitable portfolio: 8 financial, 3 non-financial, 2 basic information, 2 credit compliance, and 5 macroeconomic features. This equitable selection, coupled with the method’s Borda aggregation mechanism, yields compact, semantically meaningful, and stable feature sets that are both actionable and defensible. The enforced parsimony via the 1% rule further ensures the resulting models are computationally efficient, less prone to overfitting, and readily adoptable in operational credit risk environments.
Tables 4 and 5 present FS outcomes for combined and category-aware datasets: combined pooling exacerbates imbalance and overshadowing, whereas category-aware evaluation improves coverage. Across firms and farmers, HRA-FS yields parsimonious, balanced subsets (Selected/Total) that outperform single-method baselines.
Figure 4 presents a clear comparison of FS on combined versus categorized datasets across multiple methods. When applied to the combined feature set, all methods demonstrate a pronounced imbalance, with dominant categories such as financial information for firms and basic information for farmers overwhelmingly selected, while important categories like macroeconomic and willingness to repay features remain underrepresented. This imbalance limits the model’s ability to capture the full spectrum of risk factors. Conversely, categorizing features by their thematic domains before selection results in more balanced and equitable feature representation across all categories. Among the methods, the proposed HRA-FS consistently achieves the most stable and balanced selection in both combined and categorized settings, effectively reducing redundancy and overshadowing. The distinct trajectories of feature counts across categories in the figure underscore how hybrid consensus reduces methodological biases inherent in individual techniques, thereby enhancing model robustness and interpretability. This evidence highlights the critical importance of incorporating domain knowledge through feature categorization to produce parsimonious feature sets that comprehensively reflect multifaceted credit risk factors.

FS outcomes for combined and categorized datasets, showing that categorization improves balance across domains and HRA-FS yields the most compact and representative sets.
Bar plots in Fig. 5 show an aggregated ranking of selected features from categorically organized datasets, with the left panel showing farmers and the right panel showing firms using the hybrid FS method (HRA-FS) with the Borda count rule. Figure 5 elucidates that lower ranking values signify higher feature importance, as features consistently ranked highly across multiple selection methods achieve a stronger consensus. For firms, key predictors, such as the prominence of inventory turnover rate and sales scope, highlight operational efficiency and market reach as critical health indicators beyond simple profitability. The high importance of compliance status underscores the significance of managerial discipline and legal standing. Conversely, for farmers, house value serves as a key collateral and stability indicator, while the loan purpose differentiates between productive investments and consumption-led borrowing, which carries higher risk. The Engel coefficient (the proportion of income spent on food) is a remarkably insightful feature, serving as a proxy for financial fragility; a higher coefficient suggests less disposable income for debt servicing. These insights empower lenders to interpret credit decisions transparently, refine risk segmentation, and design fairer lending policies that reflect both financial capacity and socioeconomic resilience.
This visualization highlights the critical advantage of categorizing features before selection, as it allows for an equitable representation across domains and prevents the dominance of any one category. The comparisons made within the figure demonstrate that hybrid consensus-driven selection outperforms individual methods by effectively integrating complementary strengths, resulting in more parsimonious, interpretable, and stable feature sets. By prioritizing features that provide consistent, cross-methodological value, HRA-FS mitigates redundancy and imbalance, addressing core problems inherent in traditional single-method selection approaches. Furthermore, by explicitly balancing domain representation, HRA-FS promotes transparency, fairness, and alignment with domain knowledge, advancing responsible AI practices and ethical accountability in credit risk assessment.
Ultimately, this analysis reaffirms the core objectives of FS: optimizing predictive performance while safeguarding model interpretability and stability. Our study shows that a categorically informed, hybrid FS framework delivers on all three fronts: accuracy, stability, and interpretability, providing financial institutions with transparent and reliable risk indicators. The framework empowers lenders to trace credit decisions to a well-rounded set of borrower characteristics, from firm financial health to nuanced economic and behavioral factors, thereby facilitating regulatory compliance and operational auditability. Importantly, by unveiling balanced and domain-representative predictors, lower computational burden, the method supports more equitable credit access for vulnerable borrower groups such as farmers and small firms. This work transcends a methodological refinement, establishing a principled and practical foundation for advancing inclusive, interpretable, and high-performing credit risk models that resonate across both academic research and real-world applications.

Aggregated Borda ranks of the most predictive features selected by the HRA-FS method. A lower rank indicates higher importance.
Comparison with state-of-the-art models
To validate the competitiveness of the proposed framework, we compared HRA-FS plus XGBoost with several recently developed machine learning models widely applied in financial risk prediction, DT, RF, LR, ANN, and NB. These models were selected based on13, who combined a genetic algorithm with these classifiers for credit card fraud detection, an established benchmark in financial classification. The comparative results are summarized in Table 6.
Our proposed framework consistently outperforms all state-of-the-art models across both datasets. While ensemble and neural models such as RF and ANN achieve competitive accuracy, they depend on full feature sets and offer limited interpretability. In contrast, HRA-FS with XGBoost attains higher predictive accuracy with far fewer features, driven by its hybrid rank-aggregation mechanism that fuses local (ReliefF), global (RFE), and regularized (ElasticNet) perspectives. This integration yields more stable, compact, and interpretable feature subsets, ensuring both strong generalization and transparency in decision-making.
Although public benchmark datasets were not used, our real-world farmer and firm datasets present a more demanding and policy-relevant test environment, characterized by feature heterogeneity and class imbalance typical of real lending conditions. Therefore, outperforming benchmark models on such complex, real-world data demonstrates not only the methodological strength of the proposed approach but also its practical reliability and applicability for modern credit-risk prediction.
Conclusions
The study addresses the critical challenge of FS for loan default risk prediction models, particularly within the context of highly imbalanced small-scale borrower data. We propose a novel FS Hybrid framework (HRA FS), which integrates filter ReliefF, wrapper RFE, and embedded ElasticNet methods through a Borda count consensus mechanism. Empirical results on distinct datasets of firms and farmers demonstrate that our hybrid approach significantly outperforms individual FS methods. The consensus-based strategy effectively mitigates the inherent limitations of each constituent technique, such as redundancy sensitivity, computational expense, and linear assumption bias, to yield a robust, stable, and highly predictive feature subset. The superior performance of HRA FS is validated by its consistent attainment of the highest scores across a comprehensive set of evaluation metrics, including ROC AUC, PR AUC, and the Matthews Correlation Coefficient when paired with an XGBoost classifier.
A pivotal contribution of this study is the demonstration that structuring the initial feature space into meaningful thematic categories before selection. This methodology prevents feature dominance by ensuring a balanced representation of diverse risk drivers, which in turn enhances model interpretability and fairness. The final selected feature set provides financial institutions with a transparent, actionable, and parsimonious model for risk assessment. By advancing an FS framework that is simultaneously accurate, stable, and equitable, our study provides a practical tool that can enhance credit access for underserved borrowers while safeguarding lenders against losses. This work ultimately contributes to the development of more reliable and inclusive financial systems.
Limitations and future research directions
Although HRA-FS advances FS for small-scale borrower credit models, several limitations and future opportunities merit attention. The empirical evaluation was based on datasets from a single geographic and institutional context, which may limit external validity; thus, broader validation across different countries, loan products, and borrower groups is required to confirm generalizability. While XGBoost provided a strong and stable benchmark, dependence on a single classifier may limit interpretive diversity. In addition, although the Borda aggregation mechanism proved effective, exploring adaptive weighting schemes or alternative rank aggregation methods could further enhance robustness.
Future research should extend HRA-FS toward dynamic, time-varying FS, enabling models to adapt to evolving borrower behaviors and macroeconomic conditions. Integrating unstructured or alternative data sources, such as textual disclosures, mobile transaction records, and social network information, could enrich behavioral and contextual understanding of credit risk. As larger and more complex datasets emerge, examining the framework’s scalability, computational efficiency, and real-time deployment will be vital for practical adoption. These directions will strengthen the methodological versatility and real-world relevance of HRA-FS, advancing the development of transparent, adaptive, and inclusive credit risk assessment systems.
Data availability
The data that support the findings of this study are available from the Postal Savings Bank of China (PSBC) but restrictions apply. The data were used under license for the current study and so are not publicly available. Data are, however, available from the authors upon reasonable request and with permission from PSBC. These data were previously analyzed in Chi et al. (2017) [DOI: [https://doi.org/10.3846/16111699.2017.1280844](https:/doi.org/10.3846/16111699.2017.1280844)] and Bai et al. (2019) [DOI: [https://doi.org/10.1016/j.omega.2018.02.001](https:/doi.org/10.1016/j.omega.2018.02.001)].
References
Guo, Y. et al. Instance-based credit risk assessment for investment decisions in P2P lending. Eur. J. Oper. Res. 249 (2), 417–426 (2016).
Xu, J., Lu, Z. & Xie, Y. Loan default prediction of Chinese P2P market: a machine learning methodology. Sci. Rep. 11 (1), 18759 (2021).
Jiang, S. et al. Identifying predictors of analyst rating quality: an ensemble feature selection approach. Int. J. Forecast. 39 (4), 1853–1873 (2023).
Brahim Belhaouari, S. et al. Bird’s eye view feature selection for high-dimensional data. Sci. Rep. 13 (1), 13303 (2023).
Li, J. et al. Feature selection: A data perspective. ACM Comput. Surv. (CSUR). 50 (6), 1–45 (2017).
Mafarja, M. & Mirjalili, S. Whale optimization approaches for wrapper feature selection. Appl. Soft Comput. 62, 441–453 (2018).
Mafarja, M. et al. Binary grasshopper optimisation algorithm approaches for feature selection problems. Expert Syst. Appl. 117, 267–286 (2019).
Jović, A., Brkić, K. & Bogunović, N. A review of feature selection methods with applications, 2015 38th International Convention onInformation and Communication Technology, Electronics and Microelectronics (MIPRO), Opatija, Croatia, pp. 1200–1205 (2015). https://doi.org/10.1109/MIPRO.2015.7160458
Wang, D. et al. A hybrid system with filter approach and multiple population genetic algorithm for feature selection in credit scoring. J. Comput. Appl. Math. 329, 307–321 (2018).
Somol, P. et al. Filter-versus wrapper‐based feature selection for credit scoring. Int. J. Intell. Syst. 20 (10), 985–999 (2005).
Tran, B., Xue, B. & Zhang, M. Genetic programming for feature construction and selection in classification on high-dimensional data. Memetic Comput. 8 (1), 3–15 (2016).
Chen, C. W. et al. Ensemble feature selection in medical datasets: combining filter, wrapper, and embedded feature selection results. Expert Syst. 37 (5), e12553 (2020).
Ileberi, E., Sun, Y. & Wang, Z. A machine learning based credit card fraud detection using the GA algorithm for feature selection. J. Big Data. 9 (1), 24 (2022).
Kwakye, B. D. et al. Particle guided metaheuristic algorithm for global optimization and feature selection problems. Expert Syst. Appl. 248, 123362 (2024).
Khoirunnisa, A., Adytia, D. & Deris, M. M. Comprehensive Review of Hybrid Feature Selection Methods for Microarray-Based Cancer Detection (IEEE Access, 2025).
Lee, J. W., Lee, W. K. & Sohn, S. Y. Graph convolutional network-based credit default prediction utilizing three types of virtual distances among borrowers. Expert Syst. Appl. 168, 114411 (2021).
Zhao, Z., Colombage, S. & Chi, G. Key variables and characteristics of loan loss given default: empirical evidence from 28 provinces in China. Emerg. Markets Finance Trade. 56 (11), 2443–2460 (2020).
Chen, T. & Guestrin, C. Xgboost: A scalable tree boosting system. in Proceedings of the 22nd acm sigkdd international conference on knowledge discovery and data mining. (2016).
Deng, Y. & Lumley, T. Multiple imputation through Xgboost. J. Comput. Graphical Stat. 33 (2), 352–363 (2024).
Alonso-Robisco, A. & Carbó, J. M. Can machine learning models save capital for banks? Evidence from a Spanish credit portfolio. Int. Rev. Financial Anal. 84, 102372 (2022).
Bahrami, M. et al. Predicting merchant future performance using privacy-safe network-based features. Sci. Rep. 13 (1), 10073 (2023).
Panda, D. & Reddy, S. Predictors of microcredit default in Indian self-help groups. Ann. Public Cooper. Econ. 91 (2), 303–318 (2020).
Uddin, S. et al. A novel approach for assessing fairness in deployed machine learning algorithms. Sci. Rep. 14 (1), 17753 (2024).
Zandi, S. et al. Attention-based dynamic multilayer graph neural networks for loan default prediction. Eur. J. Oper. Res. 321 (2), 586–599 (2025).
Sigrist, F. & Leuenberger, N. Machine learning for corporate default risk: Multi-period prediction, frailty correlation, loan portfolios, and tail probabilities. Eur. J. Oper. Res. 305 (3), 1390–1406 (2023).
Shi, X., Tang, D. & Yu, Y. Credit Scoring Prediction Using Deep Learning Models in the Financial Sector (IEEE Access, 2025).
Robert Vincent, A. C. S. & Sengan, S. Effective clinical decision support implementation using a multi filter and wrapper optimisation model for internet of things based healthcare data. Sci. Rep. 14 (1), 21820 (2024).
Chamlal, H., Benzmane, A. & Ouaderhman, T. Elastic net-based high dimensional data selection for regression. Expert Syst. Appl. 244, 122958 (2024).
Uddin, M. S. et al. Leveraging random forest in micro-enterprises credit risk modelling for accuracy and interpretability. Int. J. Finance Econ. 27 (3), 3713–3729 (2022).
Zhou, Y., Shen, L. & Ballester, L. A two-stage credit scoring model based on random forest: evidence from Chinese small firms. Int. Rev. Financial Anal. 89, 102755 (2023).
Chi, G. et al. Discriminating the default risk of small enterprises: stacking model with different optimal feature combinations. Expert Syst. Appl. 229, 120494 (2023).
Gasmi, I., Neji, S., Smiti, S. et al. Features selection for credit risk prediction problem. Inform. Syst. Front. (2025). https://doi.org/10.1007/s10796-024-10559-x
Bai, C. et al. Banking credit worthiness: evaluating the complex relationships. Omega 83, 26–38 (2019).
Postal Savings Bank of China (PSBC), D.U.o.T. Credit Risk Lending Decision and Evaluation Report for Farmers (Postal Savings Bank of China Co., LTD, 2014).
Gupta, T., Bhatia, R. & Sharma, S. An ensemble-based enhanced short and medium term load forecasting using optimized missing value imputation. Sci. Rep. 15 (1), 21857 (2025).
Horng, H. et al. Improved generalized combat methods for harmonization of radiomic features. Sci. Rep. 12 (1), 19009 (2022).
Gottard, A., Vannucci, G. & Marchetti, G. M. A note on the interpretation of tree-based regression models. Biom. J. 62 (6), 1564–1573 (2020).
Azhar, N. A. et al. An investigation of Smote based methods for imbalanced datasets with data complexity analysis. IEEE Trans. Knowl. Data Eng. 35 (7), 6651–6672 (2022).
Sun, J. et al. Imbalanced enterprise credit evaluation with DTE-SBD: decision tree ensemble based on SMOTE and bagging with differentiated sampling rates. Inf. Sci. 425, 76–91 (2018).
Saari, D. G. Selecting a voting method: the case for the Borda count. Const. Polit. Econ. 34 (3), 357–366 (2023).
Dietterich, T. G. Approximate statistical tests for comparing supervised classification learning algorithms. Neural Comput. 10 (7), 1895–1923 (1998).
Acknowledgements
We gratefully acknowledge financial support from the National Natural Science Foundation of China (grant numbers 72071026 and 72271040). We also appreciate our research team, who fully cooperate with us.
Funding
We gratefully acknowledge financial support from the National Natural Science Foundation of China (grant numbers 72071026 and 72271040). We also appreciate our research team, who fully cooperate with us.
Author information
Authors and Affiliations
Contributions
Author Contribution statement: Ghazi Abbas led the conceptualization, methodology design, data analysis, and manuscript drafting. Professor Zhou Ying supervised the study, provided critical guidance, reviewed, and edited. Majid Ayoubi contributed to data preprocessing, validation, interpreting computational results, and manuscript revision. All authors reviewed and approved the final version of the manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Ethics approval and consent to publication
The authors declare no competing interests.
Consent to publish
This article does not contain any studies with human participants performed by any of the authors.
Ethical approval
This article does not contain any studies with human participants performed by any of the authors.
Informed consent
This article does not contain any studies with human participants performed by any of the authors.
Declaration of generative AI in scientific writing
During the preparation of this work, the author(s) used ChatGPT to improve the readability and language of the manuscript. After using this tool/service, the author(s) reviewed and edited the content as needed and take(s) full responsibility for the content of the published article.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Abbas, G., Ying, Z. & Ayoubi, M. Consensus-driven feature selection for transparent and robust loan default prediction. Sci Rep 16, 1496 (2026). https://doi.org/10.1038/s41598-025-31468-2
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-31468-2
