
Abstract
Accurate crop yield prediction is critical for informed agricultural planning, food distribution, and policy formulation. Traditional statistical models often fail to capture the nonlinear and temporal dynamics inherent in crop yield data. This Study introduces a novel hybrid Separate Evaluation of Regression models with Weighted Integration (SERWI) ensemble model, a novel hybrid ensemble model that integrates three machine learning algorithms: Long Short-Term Memory (LSTM) networks, Support Vector Regression (SVR), and Extreme Gradient Boosting (XGBoost). These base learners combine using a dynamic inverse RMSE-based weighting strategy that adaptively assigns higher weights to models exhibiting superior validation performance. The model is trained and evaluated using a comprehensive multi-decadal dataset sourced from the Season and Crop Report 2023–24 published by the Government of Tamil Nadu, which includes historical data on cultivated area, production, and yield of principal food grains, specifically focusing on foodgrains crop. Additionally, a detailed comparative analysis is performed against several individual models and ensemble combinations, including LSTM, SVR, XGBoost, Random Forest Regressor (RFR), Gaussian Process, and hybrid pairs such as LSTM plus SVR, SVR plus XGBoost, and LSTM plus RFR. SERWI outperformed the evaluated baseline models, achieving an RMSE of 70.16, MSE of 4923.07, MAE of 47.93, and R² of 0.9918 on the test set. These results indicate strong predictive performance and potential scalability for practical agricultural yield forecasting.
Similar content being viewed by others
Introduction
Agriculture remains a fundamental pillar of human civilization, particularly in agrarian economies where it plays a critical role in ensuring food security, sustaining livelihoods, and contributing to economic development1,2. Accurate crop yield prediction is crucial for informed decision-making in agricultural planning, resource allocation, and food supply management. With the increasing pressures of climate variability, population growth, and global food demand, reliable forecasting models have become essential to ensure both sustainable agricultural practices and economic stability3,4,5.
Traditional statistical methods and machine learning models have been widely employed for crop yield prediction. Techniques such as Support Vector Regression (SVR), Random Forest, and Gradient Boosting have demonstrated promising results by modeling nonlinear relationships between environmental factors and crop productivity. However, these approaches often struggle to capture complex temporal and spatial dependencies inherent in agricultural datasets6. Deep learning models, particularly Long Short-Term Memory (LSTM) networks and Convolutional Neural Networks (CNN), have shown superior capabilities in modeling such dependencies, effectively learning from sequential and high-dimensional data7,8. Despite their strengths, deep learning models are often sensitive to small datasets, noise, and feature redundancy, which can limit their predictive performance in real-world agricultural scenarios9. Similar hybrid intelligent frameworks that combine machine learning with fuzzy inference systems have demonstrated improved predictive accuracy, adaptability, and interpretability across diverse domains10,11.
Recent research has increasingly focused on ensemble and hybrid approaches to leverage the complementary strengths of multiple algorithms. By integrating machine learning and deep learning models, ensemble methods aim to improve prediction accuracy, reduce model variance, and enhance robustness against data variability12,13,14. Nevertheless, many of these models are either limited to specific crop types or constrained by regional applicability15,16, and few studies explicitly consider the weighting of individual model contributions based on predictive reliability17. Traditional statistical methods such as linear regression and ARIMA have offered interpretability but often fail to capture nonlinear patterns in complex agricultural systems18. Support Vector Regression with nonlinear kernels has been shown to significantly improve rice yield prediction19, while hybrid ML–DL approaches generalize more effectively across datasets20. Feature-selection frameworks have also been proposed to enhance forecasting performance while reducing computational costs21. Combining multiple algorithms can mitigate overfitting and seasonal variability22, and integrating meteorological and soil data into ensemble frameworks has been shown to outperform single-model baselines23. Deep learning methods have further advanced yield forecasting by effectively modeling temporal and spatiotemporal dependencies. Multistage DL models have been designed to capture crop growth stages24, and bi-directional LSTM networks have been applied for large-scale yield prediction with improved temporal accuracy25. LSTM combined with expectation maximization has shown improved accuracy in regional forecasting26. Remote sensing and IoT integration have also proven valuable, with DL applied to multi-temporal satellite imagery for corn yield prediction27, and multisensor fusion demonstrating benefits for wheat yield forecasting28. Despite these advances, recent studies note persistent challenges–DL models remain sensitive to small datasets, noise, and redundant features29, while ensemble frameworks often employ fixed or heuristic weights, limiting adaptability across crops and regions.
These findings suggest that while ML and DL approaches have significantly advanced crop yield prediction, there remains a gap in developing scalable, adaptive, and interpretable ensemble systems. Current agricultural forecasting models struggle with handling nonlinear relationships, temporal dependencies, and heterogeneous multi-decadal datasets, limiting their robustness and scalability across regions and crops. Reliance on single models like SVR, XGBoost, or LSTM often leads to under- or overfitting, while deep learning methods lack interpretability and fail to provide confidence intervals for policy relevance. Accurate forecasting is critical for food security, supply chain management, and agricultural risk mitigation, yet existing methods remain inadequate for capturing the dynamic, uncertain nature of climate variability. This motivates the need for intelligent systems capable of scalable, adaptive, and transparent modeling that fully exploit complex, high-dimensional data sources such as satellite imagery, sensors, and historical records.
To address these limitations, this work proposes the Separate Evaluation of Regression models with Weighted Integration (SERWI) framework, a novel hybrid ensemble approach for crop yield prediction. SERWI integrates LSTM, SVR, and XGBoost, leveraging their complementary strengths to effectively learn from both sequential and non-sequential agricultural data. A key innovation is the inverse RMSE-based dynamic weighting strategy, which adaptively adjusts model influence in real time, improving consistency and generalization across regions and years. The framework also incorporates uncertainty-aware forecasting with 95% confidence intervals and leverages multi-decadal, government verified datasets, enhancing robustness, scalability, and policy relevance. Empirical results suggest that SERWI performs favorably compared with baseline and recent ensemble approaches (RMSE = 70.16, R² = 0.9918), contributing toward improved modeling of nonlinearity, temporal dynamics, and adaptability.
The organization of this paper is as follows: “Proposed architecture” describes the proposed architecture, “Methodology” presents the methodology, “Results and discussion” discusses the results, and “Conclusion” concludes the study.
Proposed architecture
The proposed SERWI model introduces a robust hybrid framework that integrates traditional machine learning models with deep learning techniques for accurate and reliable crop yield prediction. The workflow begins with data preprocessing, where the input dataset is divided into two separate streams to meet the unique requirements of individual models. During the first stage of preprocessing, the data are reformatted by standardizing the features with the StandardScaler, which transforms them to have zero mean and unit variance, thereby improving the performance of scale-sensitive algorithms such as SVR and XGBoost. In the second stream, the data is reformatted into a three-dimensional structure to satisfy the input specifications of LSTM networks, enabling the capture of temporal dependencies that are essential for modeling agricultural outputs influenced by seasonal and climatic trends.
Each model SVR, XGBoost, and LSTM is trained independently to learn distinct patterns from the data.SVR models complex non-linear relationships through kernel-based methods, while XGBoost, a gradient boosting algorithm, efficiently handles large datasets with built-in regularization. LSTM networks retain long-term dependencies in sequential data, which is crucial for time-series forecasting in agriculture.
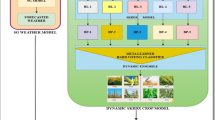
Following independent training, the outputs of all three models are combined using an error-driven weighting mechanism. Validation errors (e.g., RMSE) for each model are calculated, and the inverses of these errors are used as dynamic weights to determine the contribution of each model to the final ensemble prediction. This ensures that models with superior predictive performance have a proportionally higher impact, enhancing both accuracy and robustness. The combined output constitutes the SERWI model prediction. The overall workflow of the SERWI framework is illustrated in Fig. 1, which depicts the preprocessing pipelines, individual model training, and the error-weighted integration of predictions.

Architecture of the SERWI model.
To evaluate performance, the SERWI framework employs metrics such as RMSE, MAE, MSE, and R-squared on both training and testing datasets. For future forecasting, key features like area and production are extrapolated using linear regression, and the predicted feature sets are passed through the trained ensemble to forecast yields for the next ten years. Confidence intervals at 95% are calculated using residual standard deviation and z-scores, providing statistical bounds for predicted values. Visualizations of actual versus predicted yields, residual distributions, and future forecasts with confidence bands facilitate interpretability and analysis.
To maintain generalizability and prevent overfitting, a holdout validation strategy is used, partitioning the dataset into training and testing sets. Additional measures, such as regularization in SVR and XGBoost, dropout layers in LSTM, and early stopping based on validation loss, ensure the model learns generalizable patterns rather than memorizing training data. This combination of preprocessing, independent model training, dynamic weighting, and careful regularization makes SERWI a scalable, interpretable, and reliable framework for crop yield prediction across diverse crops and regions.
Methodology
The dataset, aggregated at the state level, consists of 68 yearly records (1966–2023). The features used for training are year, area, and production, with yield (production/area) as the target variable. Missing or inconsistent values were corrected or removed, and extreme values were treated using the Interquartile Range (IQR) method. A sample of the cleaned dataset and the normalized version is shown in Fig. 2(a–b).

Preprocessing of the dataset.
For numerical stability, StandardScaler (Z-score) is applied to area and production for SVR and XGBoost, while Min-Max normalization is used for LSTM due to its sensitivity to input ranges. LSTM inputs were further reshaped into a three-dimensional sequence format for time-series forecasting. Correlation analysis and Variance Inflation Factor (VIF) confirmed no multicollinearity issues: AREA and PRODUCTION show weak correlation (r = –0.17), and VIF values ( 1.03) are well below the threshold of 5. The correlation heatmap Fig. 3 illustrates these relationships and supports the stability of the feature set.

Correlation heatmap of AREA, PRODUCTION, and YIELD.
Model development
Three models were developed as base learners: Support Vector Regression (SVR), Extreme Gradient Boosting (XGBoost), and Long Short-Term Memory (LSTM) networks. SVR, equipped with a radial basis function (RBF) kernel, is used to capture nonlinear relationships between input features and yield outcomes. XGBoost, a tree-based gradient boosting method, is employed for its ability to model complex feature interactions with built-in regularization. LSTM networks were implemented to capture long-term sequential dependencies inherent in agricultural yield data. Each model is independently trained on the preprocessed dataset, with hyperparameters tuned through grid search and early stopping applied where appropriate to prevent overfitting.
Proposed SERWI framework
To combine the complementary strengths of the three base models, the SERWI framework is designed. SERWI integrates predictions from SVR, XGBoost, and LSTM using a dynamic, error-driven weighting mechanism. Validation errors, measured using RMSE, are computed for each model, and their inverses are used as weights. This approach ensures that models with lower prediction errors contribute more strongly to the final ensemble prediction. Mathematically, the hybrid yield forecast is expressed as:
where the weights are defined as:
These weights are normalized ( \(\alpha + \beta + \gamma = 1\)) to ensure proportional contribution. This dynamic weighting strategy allows the ensemble to adaptively prioritize models that perform better on the validation set, thereby improving robustness, accuracy, and generalizability.
Validation
To ensure reliable performance estimation, a hold-out validation strategy is adopted. The dataset, consisting of 68 records, is randomly partitioned into 80% training and 20% testing subsets using the train_test_split function in scikit-learn. This ensured a clear separation between data used for model training and unseen data reserved for evaluation. Given the limited dataset size (\(n=68\)), more complex resampling strategies such as k-fold cross-validation were avoided to prevent instability in performance estimates. However, the 57-year temporal span (1966–2023) captures multi-decadal climate variability critical for agricultural forecasting, while government-verified data quality minimizes noise. Similar studies19,26 achieved robust results with comparable sample sizes by leveraging temporal depth over instance volume. For the LSTM model, a portion of the training data is further split into a validation set to support early stopping and reduce overfitting.
The hold-out strategy, combined with standard regression metrics, enabled a rigorous and unbiased evaluation of model performance. The predictive performance of SERWI is evaluated using four standard regression metrics:
-
Mean squared error (MSE)—measures average squared error magnitude.
-
Root mean squared error (RMSE)—penalizes larger deviations more strongly.
-
Mean absolute error (MAE)—captures average absolute error for interpretability.
-
Coefficient of determination (\(R^2\))—indicates the proportion of variance explained by the model, with values closer to 1 reflecting stronger predictive power.
These metrics collectively provide a comprehensive evaluation of both accuracy and robustness.
Results and discussion
The SERWI framework is evaluated on the Foodgrains dataset as the primary case study. Table 1 and Fig. 4a–d report its performance across standard regression metrics. The model achieves RMSE, MAE, and \(R^2\) values of 64.56, 34.97, and 0.9892 on the training set, and 70.16, 47.93, and 0.9918 on the test set. These results demonstrate both strong accuracy and high explanatory power, with the minimal gap between training and testing errors confirming robust generalization. The small difference in RMSE (\(\approx 5.6\)) and \(R^{2}\) (\(\approx 0.0026\)) is consistent. with expected variability in limited datasets and indicates that the model is not overfitting.

Performance metric comparisons for the SERWI model on training and test sets.
Further evidence comes from residual analysis (Fig. 5), which shows symmetric error distributions centered near zero, with no skewness or systematic bias. The predicted vs. actual yield plots confirm close alignment across both training and test sets, highlighting the framework’s capacity to generalize while maintaining accuracy. Together, these results establish SERWI as a reliable and statistically robust predictor for foodgrain yields, consistent with prior findings in the literature that emphasize the importance of minimizing variance and bias in agricultural forecasting30.

Performance of the SERWI model (LSTM + SVR + XGBoost): (left) actual vs. predicted yield plot showing high correlation and minimal deviation for both train and test sets. (Right) residual error distribution illustrating symmetry and lack of bias, indicating low overfitting and good generalization.
Comparative evaluation with alternative models (Table 2, , Fig. 6a, b ) underscores SERWI’s consistent superiority. While individual learners such as SVR or XGBoost occasionally achieve lower errors on isolated metrics, they exhibit greater train–test discrepancies, suggesting reduced robustness. Hybrid two-model combinations improve stability but do not match the overall balance of accuracy and generalization achieved by SERWI. By dynamically weighting its base learners, SERWI effectively integrates their complementary strengths and achieves a balanced trade-off between precision and reliability, performing better than most comparative models. These results are consistent with hybrid frameworks reported by14,17, which also highlight the advantages of ensembles in improving resilience over single models.

Comparative evaluation of all models.
The framework is further extended to other major crop categories to test scalability (Table 3, Fig. 7). Results confirm that SERWI adapts effectively across cereals, pulses, and oilseeds, with \(R^2\) consistently above 0.96. Some crops, such as paddy and cotton, show relatively higher test errors, likely reflecting intrinsic yield volatility and limited data depth rather than deficiencies in the model31. By contrast, pulses and oilseeds achieve consistently low errors and high variance explanation, indicating strong adaptability where datasets are more stable. These findings highlight two key points: (1) the ensemble can adjust to different crop-specific noise levels, and (2) predictive performance is influenced by data quality32, echoing earlier work by23,28, who also noted the critical role of dataset robustness in yield forecasting.

Performance comparison across crops, highlighting strong prediction for Foodgrains and varying generalization to other crop types.
A comparative analysis with other existing models (Table 4) shows that the proposed SERWI model delivers better performance, particularly achieving the highest \(R^2\) value. This highlights its ability to capture complex yield patterns while maintaining competitive RMSE and MAE values.
Long-term forecasting further illustrates the utility of the model. Using the most recent inputs, a 10-year projection is generated with 95% confidence intervals (Fig. 8). The forecast shows a steady upward yield trajectory with narrow confidence bands, indicating stability under current assumptions. Importantly, the inclusion of confidence intervals enhances transparency and supports risk-aware planning, offering policymakers actionable bounds for procurement, storage, and subsidy strategies. This uncertainty-aware mechanism addresses a common gap in deep-learning-based forecasting, which often lacks explicit error quantification.

Predicted 10-year yield trend with 95% confidence intervals.
Applying traditional time series/statistical models, which suffered from weak autocorrelation, instability, and overfitting due to lack of seasonal patterns. These constraints also restricted robust validation methods like k-fold. Residual diagnostics (Fig. 9) confirmed low bias, normality, and no autocorrelation but also revealed the absence of seasonal information due to annual data granularity. Sequential sample indexing (Fig. 10) showed increasing variance in later samples, indicating possible heteroscedasticity and instability from the limited dataset. The SARIMA model’s forecasts (Fig. 11) appeared overly flat and stable, reflecting weak temporal autocorrelation and inability to capture seasonal or unexpected fluctuations. These issues underscored the dataset’s small size, temporal spread, and lack of seasonality.

Residual diagnostics using original chronological data.

Residual diagnostics using sequential sample index.

Actual vs. predicted vs. forecasted yield for foodgrains (SARIMA comparison).
SERWI demonstrates key strengths: high adaptability across crops
(R\(^{2}\) > 0.96), dynamic inverse-RMSE weighting, and policy-relevant uncertainty quantification, achieving superior accuracy (RMSE = 70.16, R\(^{2}\) = 0.9918). However, limitations include performance volatility in paddy (RMSE = 120.20) due to small samples (n=68) and annual data granularity, alongside reduced SVR/LSTM interpretability. Although this study primarily utilized three core features year, area, and production to demonstrate the performance of the SERWI framework, we acknowledge that crop yield is influenced by a wider range of agro-meteorological and biophysical variables. Parameters such as soil moisture, rainfall, solar radiation, crop health indices (e.g., NDVI), and temperature variations play significant roles in determining yield outcomes. However, these variables were not included in the present analysis due to limitations in consistent data availability across the study period. Future work will incorporate such features, potentially through remote sensing and IoT-based data sources, to enhance the model’s generalizability and its ability to capture the complex dynamics influencing agricultural productivity33.Future work should address these via data augmentation34, seasonal data integration, and explainability techniques like SHAP/LIME35. Overall, SERWI provides a robust foundation for agricultural forecasting under data constraints.
Conclusion
This study introduces the novel SERWI ensemble approach for crop yield prediction, effectively combining LSTM, SVR, and XGBoost through a dynamic inverse RMSE-based weighting strategy. Initially validated on foodgrain yield data from the Season and Crop Report 2023–24, the SERWI model demonstrates high predictive accuracy with no signs of overfitting and strong generalization capability. Beyond its initial application, the model is further evaluated across diverse crop types including pulses, cereals, oilseeds, and commercial crops to assess its scalability and robustness. Results indicate that the model demonstrates adaptability and reliable performance across varying agricultural contexts. The SERWI framework effectively captures complex, nonlinear, and temporal dynamics in crop yield data and shows improved performance over individual and simpler ensemble models. The rigorous use of standard evaluation metrics RMSE, MAE, R\(^{2}\) and hold-out validation underscores the robustness of the approach. The model’s strong generalization across crop types highlights its potential as a practical decision-support tool for agricultural planning, yield forecasting, and food security management. Future enhancements may include incorporating additional contextual variables such as soil health indicators, rainfall patterns, and remote sensing data to further improve predictive performance. The study’s current scope is limited to three primary features due to data constraints; however, future extensions will integrate additional environmental and remote-sensing parameters to improve yield prediction accuracy and scalability. Overall, the SERWI model establishes a promising foundation for intelligent, data driven agricultural systems and offers a meaningful contribution to advancing precision farming initiatives.
Data availability
All data are available within the manuscript.
References
van Klompenburg, T., Kassahun, A. & Catal, C. Crop yield prediction using machine learning: A systematic literature review. Comput. Electron. Agric. 177, 105709. https://doi.org/10.1016/j.compag.2020.105709 (2020).
Elavarasan, D. et al. Forecasting yield by integrating agrarian factors and machine learning models: A survey. Comput. Electron. Agric. 155, 257–282. https://doi.org/10.1016/j.compag.2018.10.024 (2018).
Saranyadevi, M. & Mohideen, A. K. Rice production in Tamilnadu using Bayesian predictive models. Bharathidasan Univ. https://doi.org/10.21203/rs.3.rs-3945299/v1 (2024).
Rashid, M. et al. A comprehensive review of crop yield prediction using machine learning approaches with special emphasis on palm oil yield prediction. IEEE Access 9, 63406–63439. https://doi.org/10.1109/ACCESS.2021.3075159 (2021).
Reddy, D. J. & Kumar, M. R. Crop yield prediction using machine learning algorithm. In Proceedings of the 2021 5th International Conference on Intelligent Computing and Control Systems (ICICCS). 1466–1470 (2021). https://doi.org/10.1109/ICICCS51141.2021.9432236
Shawon, S. M. et al. Crop yield prediction using machine learning: An extensive and systematic literature review. Smart Agric. Technol. 10, 100718. https://doi.org/10.1016/j.atech.2024.100718 (2025).
El-Kenawy, E. S. M. et al. Predicting potato crop yield with machine learning and deep learning for sustainable agriculture. Potato Res. 68, 759–792. https://doi.org/10.1007/s11540-024-09753-w (2025).
Srivastava, A. et al. Winter wheat yield prediction using convolutional neural networks from environmental and phenological data. Sci. Rep. 12(1), 1–12. https://doi.org/10.1038/s41598-022-06249-w (2022).
Gupta, R. et al. WB-CPI: Weather based crop prediction in India using big data analytics. IEEE Access 9, 137869–137885. https://doi.org/10.1109/ACCESS.2021.3117247 (2021).
Ordenshiya, K. M. & Revathi, G. K. Hybrid FCMG-OP-FIS model approach to convert regression into classification data for machine learning-based AQI prediction. Heliyon10(21) (2024).
Kulandhainadar Mariavalavan, O. & Govindasamy Krishnamoorthy, R. Enhanced air quality index prediction using fuzzy center merge labeling graph based fuzzy inference system model. Cybern. Syst. 1–43 (2025). https://doi.org/10.1080/01969722.2025.2522873
Srivallidevi, V. & Rama Rao, M. V. V. A robust crop yield forecasting model through machine learning ensemble techniques. In Proceedings of the 2024 International Conference Innovative Computing, Intelligent Communication and Smart Electrical Systems (ICSES). 1–6 (2024). https://doi.org/10.1109/ICSES63760.2024.10910450
Saravanan, K. S. & Bhagavathiappan, V. Prediction of crop yield in India using machine learning and hybrid deep learning models. Acta Geophys. 72, 4613–4632. https://doi.org/10.1007/s11600-024-01312-8 (2024).
Dhaliwal, H. S. & Williams, M. Sweet corn yield prediction using machine learning models and field-level data. Precis. Agric. 25(2), 345–360. https://doi.org/10.1007/s11119-023-10057-1 (2024).
Elavarasan, D. & Vincent, P. M. D. Crop yield prediction using deep reinforcement learning model for sustainable agrarian applications. IEEE Access 8, 86886–86901. https://doi.org/10.1109/ACCESS.2020.2992480 (2020).
Majumdar, S. & Chattopadhyay, S. An ensemble learning approach for rice yield prediction using meteorological and soil data. Comput. Electron. Agric. 201, 107394. https://doi.org/10.1016/j.compag.2023.107394 (2023).
Oikonomidis, A., Catal, C. & Kassahun, A. Hybrid deep learning-based models for crop yield prediction. Appl. Artif. Intell. https://doi.org/10.1080/08839514.2022.2031823 (2022).
Elbasi, E. et al. Crop prediction model using machine learning algorithms. Appl. Sci. 13(16), 9288. https://doi.org/10.3390/app13169288 (2023).
Paidipati, K. K. et al. Prediction of rice cultivation in India-Support vector regression approach with various kernels for non-linear patterns. AgriEngineering 3(2), 182–198. https://doi.org/10.3390/agriengineering3020012 (2021).
Sharma, P. et al. Predicting agriculture yields based on machine learning using regression and deep learning. IEEE Access 11, 111255–111264. https://doi.org/10.1109/ACCESS.2023.3321861 (2023).
Abdel-Salam, M. et al. A proposed framework for crop yield prediction using hybrid feature selection approach and optimized machine learning. Neural Comput. Appl. 36, 20723–20750. https://doi.org/10.1007/s00521-024-10226-x (2024).
Khandelwal, A. & Singh, N. Crop yield forecasting with multi-source remote sensing data using gradient boosting and deep learning. Remote Sens. Environ. 260, 112426. https://doi.org/10.1016/j.rse.2021.112426 (2021).
Al-Abadi, A. M. & Al-Mashhadani, A. K. Machine learning algorithms for crop yield prediction: A case study of Iraqi wheat. Int. J. Agric. Biol. Eng. 15(3), 40–51. https://doi.org/10.25165/j.ijabe.20221503.6132 (2022).
Aravind, K. S. et al. Development of multistage crop yield estimation model using machine learning and deep learning techniques. Int. J. Biometeorol. 69, 499–515. https://doi.org/10.1007/s00484-024-02829-9 (2025).
Chaudhary, Y. & Pathak, H. CYPBL: Crop yield prediction using bi-directional LSTM under PySpark interface. Multimed. Tools Appl. 83, 75781–75800. https://doi.org/10.1007/s11042-024-18638-6 (2024).
Mahale, Y. et al. Crop recommendation and forecasting system for Maharashtra using machine learning with LSTM: A novel expectation-maximization technique. Discov. Sustain. 5, 134. https://doi.org/10.1007/s43621-024-00292-5 (2024).
Zhao, X. et al. Deep learning based corn yield prediction from multi-temporal satellite images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 14, 6576–6585. https://doi.org/10.1109/JSTARS.2021.3093435 (2021).
Pantazi, X. E. et al. Wheat yield prediction using machine learning and advanced sensing techniques. Comput. Electron. Agric. 121, 57–65. https://doi.org/10.1016/j.compag.2015.11.018 (2016).
Iniyan, S. et al. Crop yield prediction using machine learning techniques. Adv. Eng. Softw. 175, 103326. https://doi.org/10.1016/j.advengsoft.2022.103326 (2023).
Wu, W. et al. Gaussian process modeling of nonstationary crop yield distributions with applications to crop insurance. Agric. Finance Rev. 81(5), 767–783. https://doi.org/10.1108/AFR-09-2020-0144 (2021).
Addey, K. A. & Jatoe, J. B. D. Implications of crop yield distributions for multiperil crop insurance rating in Ghana: A lasso model application. Agric. Finance Rev. 84(2/3), 246–265. https://doi.org/10.1108/AFR-05-2024-0078 (2024).
Nithya, V. et al. IoT-based crop yield prediction system in the Indian sub-continent using machine learning techniques. Remote Sens. Earth Syst. Sci. 6, 156–166. https://doi.org/10.1007/s41976-023-00097-6 (2023).
Durai, S. K. S. & Shamili, M. D. Smart farming using machine learning and deep learning techniques. Decis. Anal. J. 3, 100041. https://doi.org/10.1016/j.dajour.2022.100041 (2022).
Chu, Z. & Yu, J. An end-to-end model for rice yield prediction using deep learning fusion. Comput. Electron. Agric. 174, 105471. https://doi.org/10.1016/j.compag.2020.105471 (2020).
Sarkar, S. et al. Crop yield prediction using multimodal meta-transformer and temporal graph neural networks. IEEE Trans. AgriFood Electron. 2(2), 545–553. https://doi.org/10.1109/TAFE.2024.3438330 (2024).
Acknowledgements
The authors would like to thank the School of Computer Science and Engineering, and the School of Advanced Sciences, Vellore Institute of Technology, Chennai for their constant support and motivation to carry out this research.
Funding
Open access funding provided by Vellore Institute of Technology.
Author information
Authors and Affiliations
Contributions
Adhithi: Implemented the XGBoost model, developed the SERWI ensemble, and performed forecasting. Vishnusri: Designed and trained the LSTM model and conducted comparative and error analysis. Keerthanah: Handled data collection, preprocessing, and developed the SVR model. Ordenshiya: Supported model selection, parameter tuning, project coordination, and initial paper review. Revathi: Provided overall research direction, domain expertise, and final manuscript supervision
Corresponding author
Ethics declarations
Competing Interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Ravikumar, A., Periyasamy, V., Devi, K.M.K. et al. A hybrid SERWI ensemble model for crop yield prediction using an inverse RMSE weighting strategy. Sci Rep 15, 45085 (2025). https://doi.org/10.1038/s41598-025-31987-y
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-31987-y
